Kapitel 4. AutoML zur Vorhersage von Werbemittelverkäufen nutzen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
In diesem Kapitel erstellst du ein AutoML-Modell, um den Absatz von Werbemedienkanälen vorherzusagen. Zuerst erkundest du deine Daten mit Pandas. Dann lernst du, wie du mit AutoML ein ML-Modell zur Umsatzvorhersage erstellst, trainierst und einsetzt. Mithilfe von Leistungskennzahlen verschaffst du dir einen Überblick über die Leistung deines Modells und beantwortest gängige Geschäftsfragen. Ganz nebenbei lernst du die Regressionsanalyse kennen, eine gängige Technik für Vorhersageanwendungen.
Der Business Use Case: Verkaufsvorhersage für Medienkanäle
Unternehmen nutzen Werbemedienkanäle, um ihre Produkte, Dienstleistungen oder ihre Marke zu bewerben. Marketingfachleute und Medienplaner/innen erstellen Marketingkampagnen, die in digitalen Medien, im Fernsehen, im Radio oder in der Zeitung laufen. In diesem Szenario arbeitest du als Mediaplaner/in in der Marketingabteilung eines mittelständischen Solarenergieunternehmens. Dein Unternehmen verfügt über ein bescheidenes Medienbudget und muss herausfinden, welche Kanäle die meisten Vorteile für die geringsten Kosten bieten. Dies ist ein Problem der Ausgabenoptimierung.
Du wurdest gebeten, einen Marketingplan zu entwickeln, der die Produktverkäufe im nächsten Jahr steigern soll. Um dieses Ziel zu erreichen, musst du verstehen, wie sich die Werbebudgets der einzelnen Medienkanäle auf den Gesamtumsatz auswirken. Der Werbedatensatz erfasst die erzielten Umsätze im Verhältnis zu den Werbekosten in den Medienkanälen Digital, TV, Radio und Zeitung.
Normalerweise würde diese Art von Anfrage des Teamleiters an einen Datenwissenschaftler oder Datenanalysten gehen. Obwohl du keine Erfahrung im Programmieren hast, hat dich der Leiter des Marketingteams gebeten, mit AutoML ein Vorhersagemodell für den Verkauf zu erstellen, das sie zum ersten Mal im Team ausprobieren wollen. Das Ziel ist es, ein ML-Modell zu erstellen, das vorhersagt, wie viel Umsatz auf der Grundlage der in den einzelnen Medienkanälen ausgegebenen Gelder generiert wird.
Zu den geschäftlichen Fragen gehören:
-
Kann das Modell vorhersagen, wie viel Umsatz mit dem Geld, das in den einzelnen Medienkanälen ausgegeben wird, erzielt wird?
-
Gibt es einen Zusammenhang zwischen Werbebudget und Umsatz?
-
Welcher Medienkanal trägt am meisten zum Umsatz bei?
-
Kann das Modell verwendet werden, um zukünftige Verkäufe auf der Grundlage des vorgeschlagenen Budgets des Medienkanals vorherzusagen?
-
Wie genau kann das Modell zukünftige Verkäufe vorhersagen?
Der Anwendungsfall ist ein einfaches Regressionsproblem mit nur fünf Variablen, die du zur Beantwortung der vorangegangenen fünf Fragen verwenden kannst.
Projektablauf
Abbildung 4-1 zeigt den Überblick über den typischen AutoML-No-Code-Workflow aus Kapitel 3. Dieser Arbeitsablauf ist für deinen Anwendungsfall geeignet.
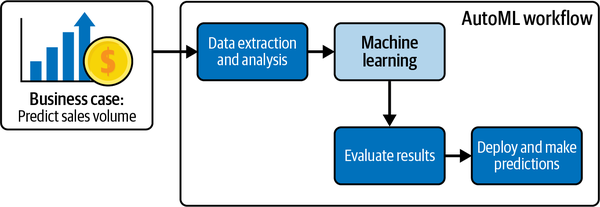
Abbildung 4-1. AutoML-Workflow für den Geschäftsfall.
Nachdem du nun den Anwendungsfall und das Ziel des Unternehmens verstanden hast, kannst du mit der Datenextraktion und -analyse fortfahren. Beachte, dass dieser Arbeitsablauf keinen Schritt der Datenvorverarbeitung beinhaltet. Du wirst in späteren Kapiteln viel praktische Erfahrung mit der Datenvorverarbeitung sammeln. Nach der Datenextraktion und -analyse lädst du den Datensatz in die AutoML-Plattform hoch. Die Werbebudgets der Digital-, TV-, Zeitungs- und Radiodaten werden dann in das Modell eingespeist. Anschließend wertest du die AutoML-Ergebnisse aus und setzt das Modell ein, um Vorhersagen zu treffen. Nach der praktischen Übung in diesem Kapitel wirst du in der Lage sein, einen strategischen Marketingplan für dein Team zu erstellen.
Projekt-Datensatz
Der Datensatz besteht aus historischen Marketingkanaldaten, die genutzt werden können, um Erkenntnisse für die Ausgabenverteilung zu gewinnen und Verkäufe vorherzusagen. Der Datensatz, der für dieses Kapitel verwendet wird, der advertising_2023-Datensatz, basiert auf Daten aus An Introduction to Statistical Learning with Applications in R von Daniela Witten, Gareth M. James, Trevor Hastie und Robert Tibshirani (Springer, 2021). Der Werbedatensatz erfasst die durch Werbung erzielten Umsätze (in Tausend Einheiten) für bestimmte Produktwerbebudgets (in Tausend Dollar) für die Medien Fernsehen, Radio und Zeitung.
Für dieses Buch wurde der Datensatz aktualisiert, um eine digitale Variable aufzunehmen und die Auswirkungen der digitalen Budgets auf die Verkäufe zu zeigen. Die Anzahl der Märkte wurde von 200 auf 1.200 erhöht. Somit bestehen die Daten aus den Werbebudgets für vier Medienkanäle (Digital, TV, Radio und Zeitungen) und dem Gesamtumsatz in 1.200 verschiedenen Märkten. Du solltest dich ermutigt fühlen, dir weitere Beispiele für die Arbeit mit diesem Datensatz anzusehen, um dein Wissen zu erweitern, nachdem du die Übungen in diesem Kapitel abgeschlossen hast.
Die Daten werden zunächst in einer CSV-Datei geliefert, sodass du einige Zeit damit verbringen musst, die Daten in Pandas zu laden, bevor du sie untersuchen kannst. Der Datensatz enthält nur numerische Variablen.
Der Datensatz besteht aus fünf Spalten. Tabelle 4-1 enthält die Spaltennamen, Datentypen und einige Informationen über die möglichen Werte für diese Spalten.
Erkunde den Datensatz mit Pandas, Matplotlib und Seaborn
Bevor du mit der Verwendung von AutoML beginnst, befolgst du den Arbeitsablauf, der in früheren Kapiteln zum Verständnis und zur Vorbereitung von Daten für ML besprochen wurde. Dieser Abschnitt zeigt dir, wie du Daten mit Pandas, einem Open-Source-Python-Paket, das in der Datenwissenschaft und Datenanalyse weit verbreitet ist, in ein Google Colab-Notebook lädst. Sobald die Daten in einen Datenrahmen geladen sind, wirst du die Daten untersuchen. Glücklicherweise wurden die Daten bereits bereinigt - es gibt keine fehlenden Werte oder seltsamen Zeichen im Datensatz. Deine explorative Datenanalyse soll dir dabei helfen, die Sauberkeit der Daten zu überprüfen und die Beziehungen zwischen den Variablen zu untersuchen, um die vom Team gestellten Fragen zu beantworten. Wie bereits in den vorangegangenen Kapiteln erwähnt, besteht ein Großteil der ML-Arbeit darin, die Trainingsdaten zu verstehen und vorzubereiten - und nicht darin, das Modell zu trainieren -, da du dich bei der Erstellung des Modells auf AutoML verlässt.
Der gesamte Code in diesem Abschnitt, einschließlich einiger zusätzlicher Beispiele, ist unter in einem Jupyter-Notebook mit dem Titel Chapter4_Media_Channel_Sales_Notebook im low-code-ai-Repository auf GitHub enthalten.
Daten in einen Pandas-Datenrahmen in einem Google Colab Notebook laden
Zuerst gehst du von zu https://colab.research.google.com und öffnest ein neues Notizbuch, indem du dem in Kapitel 2 beschriebenen Prozess folgst. Du kannst dieses Notizbuch in einen aussagekräftigeren Namen umbenennen, indem du auf den Namen klickst, wie in Abbildung 4-2 gezeigt, und den aktuellen Namen durch einen neuen Namen ersetzt, z.B. Advertising_Model.ipynb.
Abbildung 4-2. Umbenennung des Google Colab-Notizbuchs in einen aussagekräftigeren Namen.
Gib nun den folgenden Code in den ersten Codeblock ein, um die Pakete zu importieren, die für die Analyse und Visualisierung des Werbedatensatzes benötigt werden:
importpandasaspdimportnumpyasnpimportmatplotlib.pyplotaspltfromscipyimportstatsimportseabornassns%matplotlibinline
Du hast einige dieser Pakete bereits in Kapitel 2 gesehen, als du die Verwendung von Colab-Notizbüchern kennengelernt hast.
Führe nun die Zelle mit den Importanweisungen aus, um die Pakete zu importieren. Dazu klickst du auf die Schaltfläche Zelle ausführen auf der linken Seite der Zelle. Du kannst auch Shift + Enter drücken, um die Zelle auszuführen.
Jetzt bist du bereit, deine Daten zu importieren. Mit Pandas kannst du eine CSV-Datei direkt von einem Ort im Internet in einen Datenrahmen importieren, ohne dass du die Datei erst herunterladen musst. Kopiere dazu den Code aus dem Lösungsheft oder gib den folgenden Code in eine neue Zelle ein und führe die Zelle aus:
url="https://github.com/maabel0712/low-code-ai/blob/main/advertising_2023.csv?raw=true"advertising_df=pd.read_csv(url,index_col=0)
Im Allgemeinen ist es eine gute Idee, sich die ersten Zeilen des Datenrahmens anzusehen. Verwende advertising_df.head() um die ersten paar Zeilen des Datenrahmens zu untersuchen. Mit der Pandas-Methode head können wir uns die ersten fünf Zeilen unserer Daten ansehen. So siehst du schnell die Merkmale, einige ihrer möglichen Werte und ob sie numerisch sind oder nicht.
Ein Beispiel für einige der Spalten findest du unter in Abbildung 4-3.
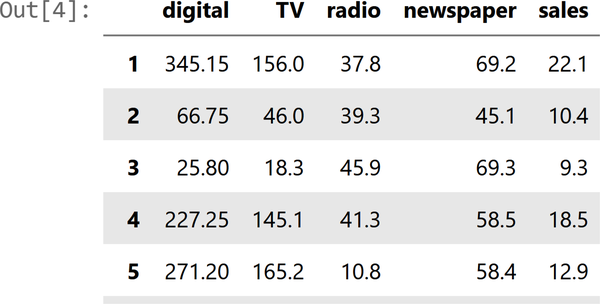
Erforsche den Datensatz zur Werbung
Nachdem die Daten in den Datenrahmen advertising_df geladen wurden, kannst du damit beginnen, sie zu untersuchen und zu verstehen. Das unmittelbare Ziel ist es, eine Vorstellung davon zu bekommen, wo es Probleme mit den Daten geben könnte, damit du diese Probleme lösen kannst, bevor du weitermachst.
Deskriptive Analyse: Überprüfe die Daten
Zuerst überprüfe die Daten mit den Standardmethoden von Python. Um die Datentypen deines Datenrahmens zu überprüfen, gibst du advertising_df.info() in eine neue Zelle ein und führe die Zelle aus. Die Informationen enthalten die Anzahl der Spalten, die Spaltenbezeichnungen, die Datentypen der Spalten, die Speichernutzung, den Bereichsindex und die Anzahl der Zellen in jeder Spalte (Nicht-Null-Werte).
Abbildung 4-4 zeigt ein Beispiel für die Ausgabe der Methode info() .
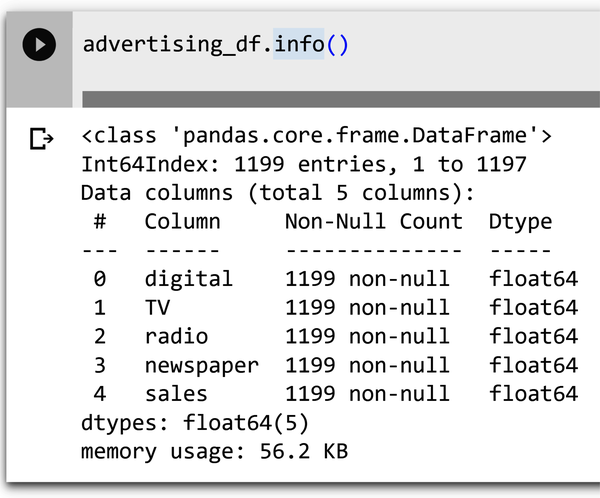
Abbildung 4-4. Informationen über den Datensatz mit der Methode info().
Mit den Informationen über den Datentyp kannst du überprüfen, ob die von Pandas abgeleiteten Typen mit den Erwartungen aus Tabelle 4-1 übereinstimmen.
In Abbildung 4-5 ist die Methode describe() zu sehen, die eine zusammenfassende Statistik für den Datensatz berechnet und anzeigt. Die Funktion describe zeigt Informationen über die numerischen Variablen unseres Datensatzes an. Du kannst den Mittelwert, den Höchst- und den Mindestwert jeder dieser Variablen sowie ihre Standardabweichung sehen. Gib advertising_df.describe() in eine neue Zelle ein und führe die Zelle aus.
In Abbildung 4-6 ist die Ausgabe der Methode .isnull() zu sehen. Gib advertising_df.isnull().sum() in eine neue Zelle ein und führe die Zelle aus. Die Ausgabe zeigt alle Spalten des Datenrahmens mit den zugehörigen Nullen an. Wenn es Nullwerte gibt, wird die Anzahl der Nullwerte für die Spalte unter angezeigt.
Abbildung 4-6. Ermittlung von Nullwerten mit der Methode isnull().
Erforsche die Daten
Die explorative Datenanalyse (EDA) ist der erste Schritt eines jeden ML-Projekts. Bevor du ein ML-Modell erstellst, musst du deine Daten untersuchen. Das Ziel ist es, einen Blick auf die Rohdaten zu werfen, sie zu untersuchen und aus den Informationen, die aus den Daten gewonnen werden, relevante Erkenntnisse zu gewinnen. Auf diese Weise kannst du auch die Modelle verbessern, da du "schmutzige Daten" wie fehlende Werte, seltsame Zeichen in einer Spalte usw. erkennen kannst, die die Leistung beeinträchtigen können.
Heatmaps (Korrelationen)
Eine Heatmap ist eine Möglichkeit, die Daten visuell darzustellen. Die Datenwerte werden in dem Diagramm als Farben dargestellt. Das Ziel der Heatmap ist es, eine farbige visuelle Zusammenfassung der Informationen zu erstellen. Heat Maps zeigen deine Beziehungen (Korrelationen) zwischen Variablen (Merkmalen). Die Korrelation ist ein statistisches Maß, das anzeigt, inwieweit sich zwei oder mehr Variablen zusammen bewegen. Abbildung 4-7 zeigt die Ausgabe einer Korrelationsmethode, die Korrelationswerte auf dem Raster aufträgt. Gib den folgenden Code in eine neue Zelle ein und führe die Zelle aus:
plt.figure(figsize=(10,5))sns.heatmap(advertising_df.corr(),annot=True,vmin=0,vmax=1,cmap='viridis')
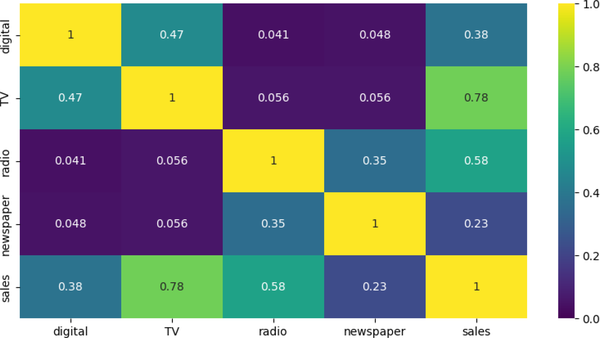
Abbildung 4-7. Korrelationsmatrix für Werbemedienkanäle.
Die Ergebnisse einer Korrelationsmatrix können auf verschiedene Weise genutzt werden, zum Beispiel:
- Beziehungen zwischen Variablen identifizieren
-
Der Korrelationskoeffizient zwischen zwei Variablen kann dir sagen, wie stark sie miteinander verbunden sind. Ein Korrelationskoeffizient von 0 bedeutet, dass es keinen Zusammenhang gibt, während ein Korrelationskoeffizient von 1 bedeutet, dass es einen perfekten positiven Zusammenhang gibt. Ein Korrelationskoeffizient von -1 bedeutet, dass es einen perfekten negativen Zusammenhang gibt. Die stärkste Beziehung besteht zwischen Umsatz und Fernsehen (0,78), gefolgt von Umsatz und Radio (0,58). Diese Informationen können genutzt werden, um gezielte Marketingkampagnen zu entwickeln, die den Absatz mit größerer Wahrscheinlichkeit steigern.
- Auswahl von Variablen für die Aufnahme in ein Modell
-
Wenn du ein Vorhersagemodell erstellst, musst du die Variablen auswählen, die das Ergebnis am ehesten vorhersagen können. Solltest du zum Beispiel Zeitungen (mit einer Korrelation von 0,23 zum Umsatz) als Merkmal in das Modell zur Umsatzvorhersage aufnehmen?
- Erkennen von Multikollinearität
-
Multikollinearität liegt vor, wenn zwei oder mehr Prädiktorvariablen in einem Regressionsmodell hoch korreliert sind. Wenn z. B. sowohl das Fernsehen als auch das Radio stark korreliert sind (d. h. beide haben einen Wert >0,7 statt 0,056 wie in Abbildung 4-7), würde dies auf Multikollinearität hindeuten. Da es schwieriger ist, Prädiktoren mit einer starken kollinearen Beziehung numerisch voneinander zu unterscheiden, ist es für einen Regressionsalgorithmus schwieriger, den Grad des Einflusses oder der Gewichtung zu bestimmen, den einer von ihnen auf den Umsatz haben sollte.
Streudiagramme
Streudiagramme werden verwendet, um Beziehungen zwischen zwei numerischen Variablen zu bestimmen. Sie helfen dir zu erkennen, ob es eine direkte Beziehung (z. B. eine positive lineare Beziehung oder eine negative lineare Beziehung) zwischen zwei Variablen gibt. Außerdem kannst du mit ihrer Hilfe feststellen, ob deine Daten Ausreißer enthalten oder nicht. Abbildung 4-8 zeigt eine Streuung zwischen dem digitalen Merkmal und dem Verkaufsziel. Gib den folgenden Code in eine neue Zelle ein und führe die Zelle aus:
advertising_df.plot(kind='scatter',x=['digital'],y='sales')
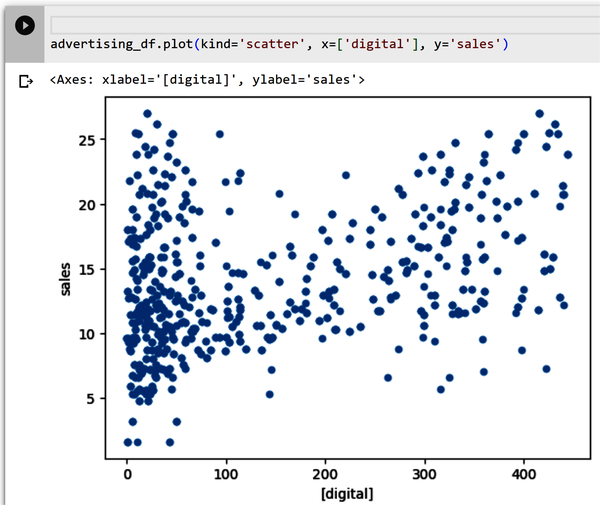
Abbildung 4-8. Streudiagramm von Digital und Umsatz.
Du möchtest die Streudiagramme für jede Variable mit der vorhergesagten Variable sales untersuchen. Du kannst jedes Merkmal einzeln als Streudiagramm darstellen (wie du es bereits getan hast), oder du kannst sie so darstellen, dass alle Beziehungen in einem Diagramm gezeigt werden. Gib den gesamten folgenden Code in eine neue Zelle ein und führe die Zelle aus(Abbildung 4-9 zeigt die Ausgabe):
plt.figure(figsize=(18,18))fori,colinenumerate(advertising_df.columns[0:13]):plt.subplot(5,3,i+1)# each row three figurex=advertising_df[col]#x-axisy=advertising_df['sales']#y-axisplt.plot(x,y,'o')# Create regression lineplt.plot(np.unique(x),np.poly1d(np.polyfit(x,y,1))(np.unique(x)),color='red')plt.xlabel(col)# x-labelplt.ylabel('sales')# y-label
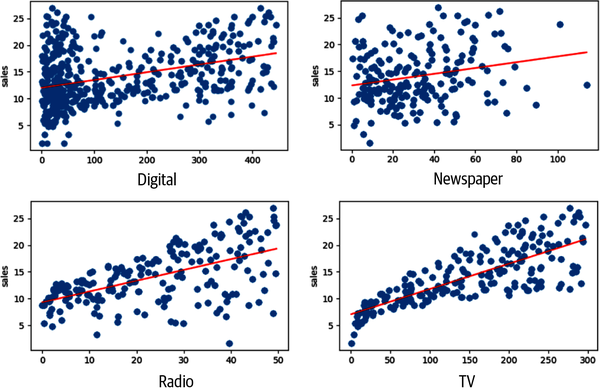
Abbildung 4-9. Streudiagramme für alle Merkmale und Verkaufsziele.
Beachte, dass zwischen Fernsehen und Umsatz ein starker linearer Zusammenhang besteht - es scheint zu zeigen, dass eine Erhöhung des Fernsehbudgets sich positiv auf die Verkaufszahlen auswirkt. Zwischen Zeitung und Umsatz scheint es keine starke Beziehung zu geben. Erinnere dich an die Korrelationswerte von 0,23 für diese Beziehung. Dies unterscheidet sich deutlich von der Beziehung zwischen TV und Umsatz (0,78).
Histogramm Verteilungsdiagramm
Ein gängiger Ansatz zur Visualisierung einer Verteilung ist das Histogramm. Ein Histogramm ist ein Balkendiagramm, bei dem die Achse, die die Zielvariable darstellt, in eine Reihe von diskreten Feldern unterteilt ist und die Anzahl der Beobachtungen, die in jedes Feld fallen, anhand der Höhe des entsprechenden Balkens angezeigt wird.
Gib diesen Code in eine neue Zelle ein und führe die Zelle aus:
sns.displot(advertising_df,x="sales")
Abbildung 4-10 zeigt die Datenwerte aus der Verkaufsspalte. Das Diagramm sieht aus wie eine Glockenkurve, die leicht nach links geneigt ist. Der häufigste Verkaufsbetrag ist 11.000 Dollar.
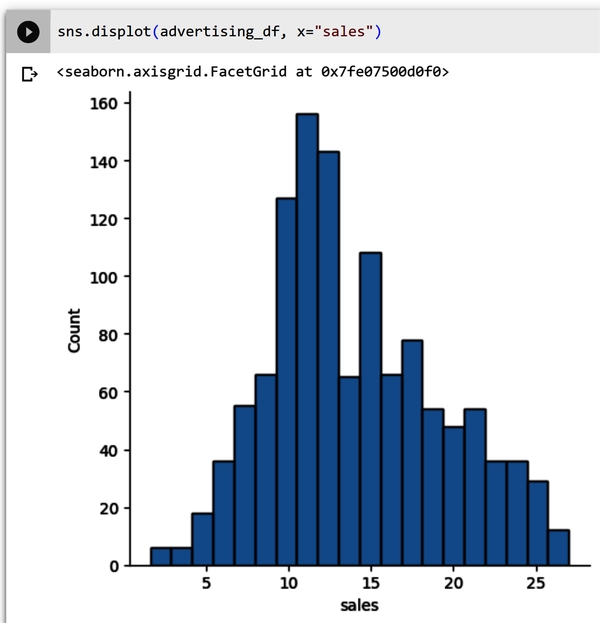
Abbildung 4-10. Verkaufs-Histogramm, das leicht nach links geneigt ist.
Was ist mit den anderen Merkmalen - sind sie links- oder rechtsschief oder haben sie eine "Normalverteilung", wie eine Glockenkurve? Du kannst den obigen Code für jedes einzelne Merkmal eingeben oder den folgenden Code verwenden, um alle Merkmale zusammen zu sehen. Gib den folgenden Code in eine neue Zelle ein und führe die Zelle aus(Abbildung 4-11 zeigt die Ausgabe):
lis=['digital','newspaper','radio','TV']plt.subplots(figsize=(15,8))index=1foriinlis:plt.subplot(2,2,index)sns.distplot(advertising_df[i])index+=1
Wie du in Abbildung 4-10 gesehen hast, sind die Umsätze einigermaßen normal verteilt. In Abbildung 4-11 scheint der digitale Bereich jedoch linksschief zu sein, und Fernsehen, Radio und Zeitungen sind nicht normal verteilt. Wenn du diese Merkmale so standardisierst, dass sie normalverteilt sind, bevor du sie in dein ML-Modell einspeist, würdest du bessere Ergebnisse erzielen.
Hinweis
Deine Rolle ist jedoch nicht die eines Datenwissenschaftlers. Mach dir keine Sorgen, diese Konzepte zu verstehen. Es würde den Rahmen dieses Kapitels sprengen, auf die einzelnen Transformationen einzugehen, die für die Funktionen erforderlich sind. In Kapitel 7 führst du Transformationen an einem Datensatz durch.
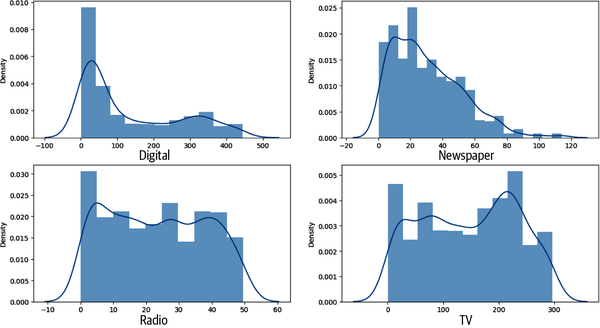
Abbildung 4-11. Verteilungsdiagramme für Digital, TV, Radio und Zeitung.
Exportiere den Werbedatensatz
Nachdem du den Datensatz überprüft und erkundet hast, ist es an der Zeit, die Datei zu exportieren, damit sie in dein AutoML-Framework hochgeladen werden kann. Gib den folgenden Code in eine neue Zelle ein und führe die Zelle aus. Die erste Zeile importiert das Betriebssystem, das es dir ermöglicht, ein Verzeichnis mit dem Namen data zu erstellen (Zeilen zwei und drei):
importosifnotos.path.isdir("/content/data"):os.makedirs("/content/data")
Nachdem das Verzeichnis erstellt wurde, gibst du den folgenden Code in eine neue Zelle ein und führst die Zelle aus. Die erste Codezeile erstellt eine CSV-Datei im Format des Werbedatenrahmens und legt sie in dem Verzeichnis für Inhalte/Daten ab, das du im vorherigen Schritt erstellt hast:
advertising_df.to_csv('/content/data/advertising.csv',encoding='utf-8',index=False)
Abbildung 4-12 zeigt das neu erstellte Verzeichnis namens data mit der Datei advertising.csv.

Abbildung 4-12. Neu erstelltes Datenverzeichnis mit der Datei advertising.csv.
Als bewährte Methode solltest du sicherstellen, dass du den Inhalt der neu exportierten Datei in dem neu erstellten Verzeichnis sehen kannst. Gib !head /content/data/advertising.csv in eine neue Zelle ein und führe die Zelle aus. Überprüfe, ob die in Abbildung 4-13 gezeigte Ausgabe mit der deinen identisch ist.
Abbildung 4-13. Ausgabe der Datei advertising.csv.
Nachdem du sichergestellt hast, dass die Datei richtig exportiert wurde, kannst du sie auf deinen Computer herunterladen.
Klicke mit der rechten Maustaste auf die Datei advertising.csv im neu erstellten Datenverzeichnis und wähle Download, wie in Abbildung 4-14 dargestellt. Die Datei wird auf deinen Desktop heruntergeladen. Jetzt kannst du die Datei zur Verwendung mit AutoML hochladen.
Abbildung 4-14. Validiere die Datei advertising.csv im Datenverzeichnis.
Im nächsten Abschnitt erstellst du ein codefreies Modell auf der Grundlage der Trainingsdatendatei, die du gerade exportiert hast.
AutoML zum Trainieren eines linearen Regressionsmodells verwenden
Die AutoML-Projekte für dieses Buch werden mit Googles Vertex AI umgesetzt, dem GUI-basierten AutoML- und Custom Training-Framework, mit dem die Autoren am besten vertraut sind. Beachte, dass die drei größten Cloud-Anbieter (Google, Microsoft und AWS) alle AutoML-Tutorials anbieten. Die Anleitungen dieser drei großen Cloud-Anbieter findest du in ihrer Dokumentation. Viele Cloud-Anbieter bieten eine kostenlose Testphase an, um ihre Produkte zu testen.
Da Google ein Schritt-für-Schritt-Tutorial zu AutoML anbietet, sind einige einführende Schritte ausgeschlossen.
Abbildung 4-15 zeigt eine Übersicht über den AutoML-No-Code-Workflow für deinen Anwendungsfall.
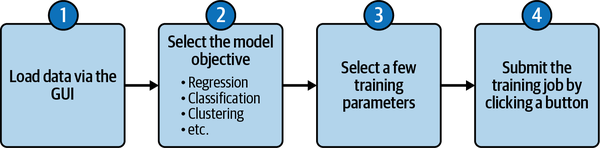
Abbildung 4-15. AutoML no-code Workflow für deinen Anwendungsfall.
No-Code mit Vertex AI
Abbildung 4-16 zeigt das Vertex AI Dashboard. Um ein AutoML-Modell zu erstellen, aktivierst du die Vertex AI API, indem du auf die Schaltfläche Alle empfohlenen APIs aktivieren klickst. Scrolle im linken Navigationsmenü von Dashboard nach unten und wähle Datasets.
Abbildung 4-16. Vertex AI Dashboard mit der Schaltfläche "Alle empfohlenen APIs aktivieren".
Einen verwalteten Datensatz in Vertex AI erstellen
Vertex AI bietet verschiedene AutoML-Modelle an, je nach Datentyp und dem Ziel, das du mit deinem Modell erreichen willst. Wenn du einen Datensatz erstellst, wählst du ein anfängliches Ziel aus, aber nachdem ein Datensatz erstellt wurde, kannst du ihn verwenden, um Modelle mit verschiedenen Zielen zu trainieren. Behalte die Standardregion (us-central1) bei, wie in Abbildung 4-17 dargestellt.
Wähle die Schaltfläche Erstellen am oberen Rand der Seite und gib dann einen Namen für den Datensatz ein. Du kannst den Datensatz zum Beispiel advertising_automl nennen.
Abbildung 4-17. Vertex AI Dataset Navigation, mit der du ein Dataset erstellen kannst.
Wähle das Modellziel
In Abbildung 4-18 ist Regression/Klassifizierung als Modellziel auf der Registerkarte Tabelle ausgewählt. Da du den Wert einer Zielspalte (Umsatz) vorhersagen willst, ist dies die richtige Wahl.
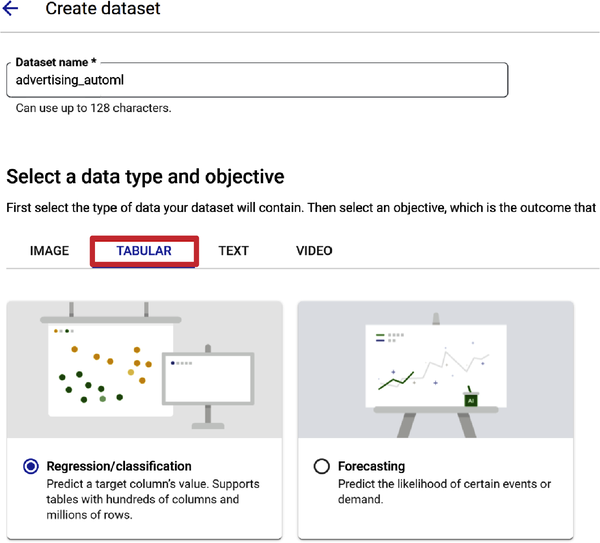
Abbildung 4-18. Auswahl der Regression/Klassifikation für das Modellziel.
Du hast Regression/Klassifizierung als dein Ziel ausgewählt. Lass uns einige grundlegende Konzepte besprechen, die dir bei zukünftigen Anwendungsfällen helfen. Regression ist ein überwachter ML-Prozess ( ). Es ähnelt der Klassifizierung, aber anstatt ein Label für eine Klassifizierung vorherzusagen, wie z. B. die Klassifizierung von Spam in deinem E-Mail-Posteingang, versuchst du, einen kontinuierlichen Wert vorherzusagen. Dielineare Regression definiert die Beziehung zwischen einer Zielvariablen(y) und einer Reihe von Vorhersagemerkmalen(x). Wenn du eine Zahl vorhersagen musst, dann verwende die Regression. In deinem Anwendungsfall sagt die lineare Regression einen realen Wert (Umsatz) anhand einiger unabhängiger Variablen aus dem Datensatz (Digital, TV, Radio und Zeitung) voraus.
Im Wesentlichen wird bei der linearen Regression eine lineare Beziehung zu jedem Merkmal angenommen. Die vorhergesagten Werte sind die Datenpunkte auf der Linie, und die wahren Werte sind im Streudiagramm zu sehen. Das Ziel ist es, die am besten passende Linie zu finden, damit das Modell bei der Eingabe neuer Daten vorhersagen kann, wo der neue Datenpunkt im Verhältnis zur Linie liegen wird. Die "Bewertung", wie gut diese Anpassung ist, beinhaltet ein Bewertungskriterium, das in "Modellleistung bewerten" behandelt wird .
Abbildung 4-19 zeigt eine "Best-Fit"-Linie auf der Grundlage deines Datensatzes, bei der das Modell versucht, die Linie an deine Datenpunkte anzupassen, die die dunklen Streuungen sind.
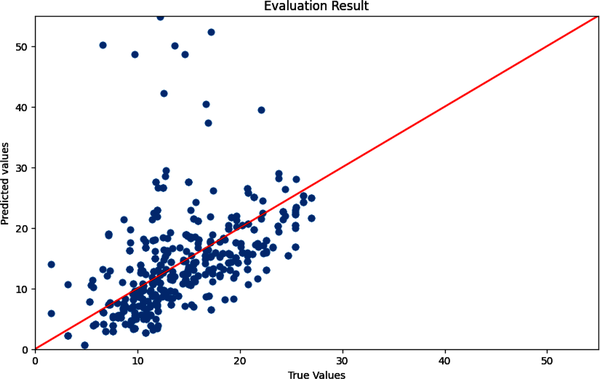
Abbildung 4-19. Wahre und vorhergesagte Werte mit einer Best-Fit-Linie.
Nachdem du die Regression/Klassifizierung ausgewählt hast, scrolle nach unten und klicke auf die Schaltfläche Erstellen. Jetzt kannst du Daten zu deinem Datensatz hinzufügen. Von Vertex AI verwaltete Datensätze sind für eine Vielzahl von Datentypen verfügbar, darunter Tabellen-, Bild-, Text- und Videodaten.
Abbildung 4-20 zeigt die Optionen zum Hochladen von Datenquellen: Lade CSV-Dateien von deinem Computer hoch, wähle CSV-Dateien aus der Cloud Speicherung oder wähle eine Tabelle oder Ansicht aus BigQuery (Googles Data Warehouse).
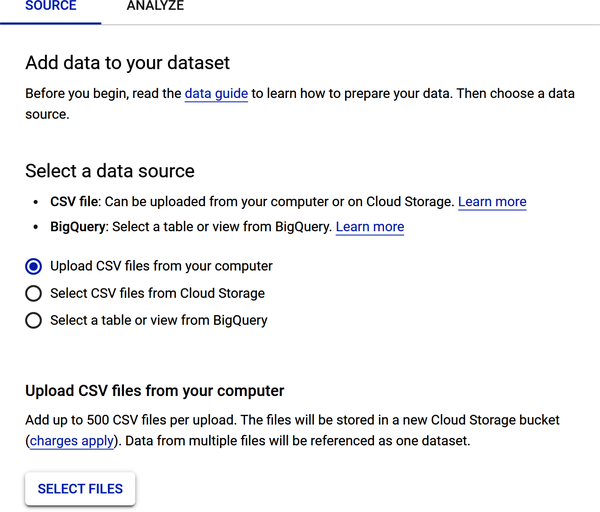
Abbildung 4-20. Optionen zum Hochladen der Datenquelle für deine Datensatzdatei.
Um deinen Werbedatensatz hochzuladen, wähle "CSV-Dateien von deinem Computer hochladen". Suche die Datei auf deinem lokalen Computer und lade sie hoch.
Scrolle auf der Seite nach unten und überprüfe den Abschnitt Wählen Sie einen Cloud-Speicherpfad, der verlangt, dass du die Datei in einem Cloud-Speicherbereich speicherst. Warum musst du die Datei in einem Cloud-Speicherkorb speichern? Dafür gibt es zwei Gründe: (1) Wenn du ein umfangreiches ML-Modell trainierst, musst du möglicherweise Terabytes oder sogar Petabytes an Daten speichern; und (2) Cloud-Speichersysteme sind skalierbar, zuverlässig und sicher.
Abbildung 4-21 zeigt, dass die Datei Advertising_automl.csv hochgeladen und ein Bucket für die Cloud Speicherung erstellt wurde, um die hochgeladene Datei zu speichern. Die schrittweise Erstellung der Speicherung und die gesamte Übung findest du in der PDF-Datei mit dem Titel Kapitel 4 AutoML Sales Prediction im Repository.
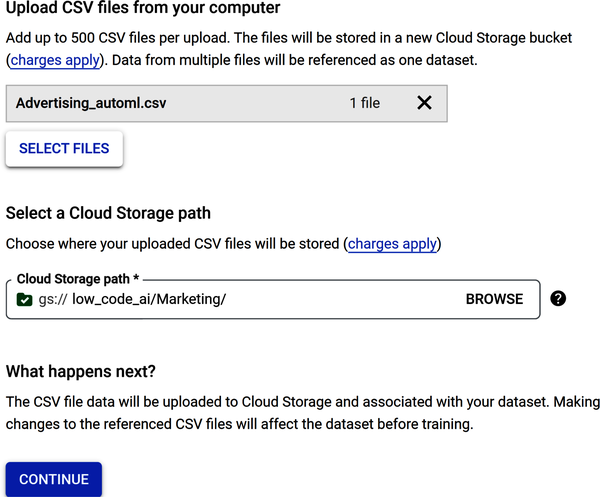
Abbildung 4-21. Datenquellenoptionen, um eine CSV-Datei zu laden und in einem Bucket der Cloud Speicherung zu speichern.
Einige Frameworks erstellen Statistiken, nachdem die Daten geladen wurden. Andere Frameworks helfen dabei, die Notwendigkeit der manuellen Datenbereinigung zu minimieren, indem sie fehlende Werte, anomale Werte und doppelte Zeilen und Spalten automatisch erkennen und bereinigen. Beachte, dass es einige zusätzliche Schritte gibt, die du durchführen kannst, z. B. die Daten nach dem Laden auf fehlende Werte zu überprüfen und die Datenstatistiken anzusehen.
Abbildung 4-22 zeigt die Ausgabe des Fensters Statistik generieren. Beachte, dass es keine fehlenden Werte gibt und die Anzahl der eindeutigen Werte für jede Spalte angezeigt wird.
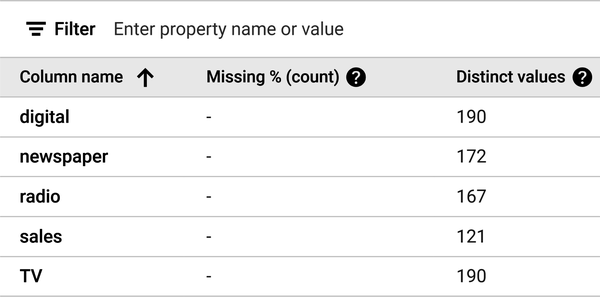
Abbildung 4-22. Die Ausgabe des Fensters Statistik generieren.
AutoML präsentiert ein Datenprofil für jedes Merkmal. Um ein Merkmal zu analysieren, klicke auf den Namen des Merkmals. Eine Seite zeigt die Histogramme der Merkmalsverteilung für das Merkmal an.
Abbildung 4-23 zeigt das Datenprofil für die Verkäufe. Beachte, dass der Mittelwert 14,014 beträgt, was dem numerischen Wert sehr nahe kommt, den du bei der Eingabe des Codes advertising_df.describe() erhalten hast, als du den Datensatz erkundet hast.
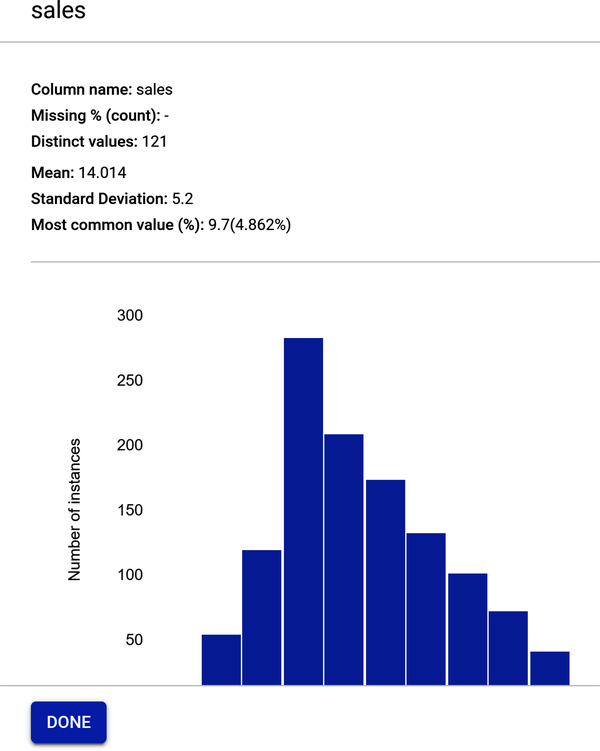
Abbildung 4-23. Merkmalsprofil für den Verkauf.
Das Ausbildungsmodell erstellen
Abbildung 4-24 zeigt, dass das Modell jetzt bereit für die Schulung ist. Wähle Neues Modell trainieren unter dem Abschnitt "Trainingsaufträge und Modelle". Wähle Andere und nicht AutoML on Pipelines. AutoML on Pipelines ist eine Funktion, mit der du die Art des ML-Modells, das du erstellen willst, und andere Parameter festlegen kannst. Dies würde den Rahmen dieses Buches sprengen.
Abbildung 4-24. Das Modell ist jetzt bereit für das Training.
Das Fenster "Neues Modell trainieren" erscheint. Es gibt vier Schritte:
-
Wähle die Trainingsmethode
-
Modelldetails konfigurieren
-
Ausbildungsmöglichkeiten festlegen
-
Rechenleistung und Preise auswählen
Wähle in Schritt 1 unter "Ziel" das Dropdown-Menü und wähle "Regression". Wähle unter "Modelltrainingsmethode" AutoML (wie in Abbildung 4-25 dargestellt). Klicke auf Weiter.
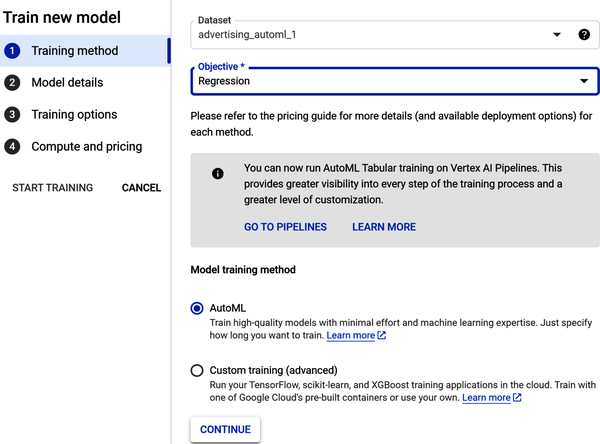
Abbildung 4-25. Konfiguriere die Trainingsmethode in Schritt 1.
Benenne in Schritt 2 unter "Modelldetails" dein Modell und gib ihm eine Beschreibung. Wähle unter "Zielspalte" den Eintrag "Umsatz" aus der Dropdown-Liste (siehe Abbildung 4-26). Klicke auf Weiter.
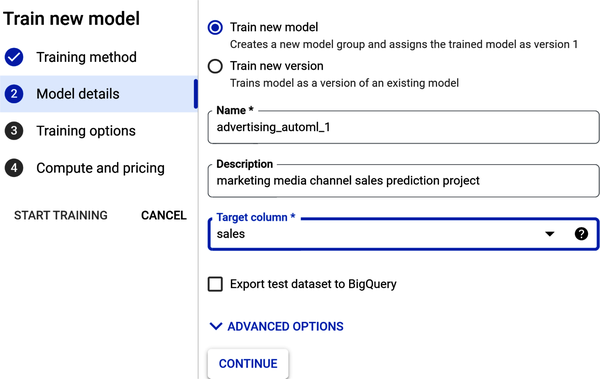
Abbildung 4-26. Füge die Modelldetails in Schritt 2 hinzu.
In Schritt 3 überprüfst du die Schulungsoptionen. Beachte, dass alle Datenumwandlungen (oder Datenverarbeitungen) wie z. B. die Standardisierung automatisch vorgenommen werden (siehe Abbildung 4-27). Klicke auf Weiter.
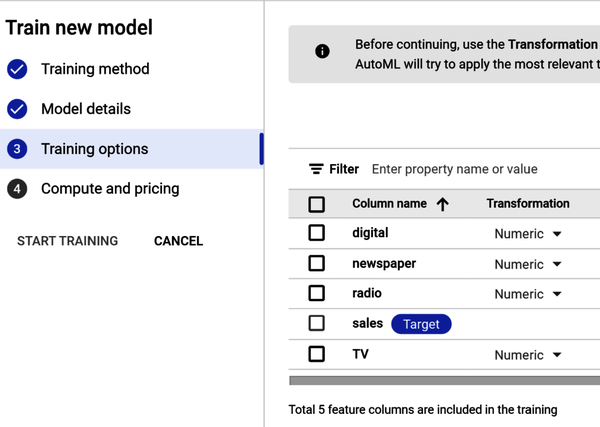
Abbildung 4-27. Füge in Schritt 3 Schulungsoptionen hinzu.
In Schritt 4 siehst du "Berechnen und Preisfindung" (wie in Abbildung 4-28 dargestellt). Die Zeit, die für das Training deines Modells benötigt wird, hängt von der Größe und Komplexität deiner Trainingsdaten ab. Eine Knotenstunde ist die Nutzung eines Knotens (einer virtuellen Maschine) in der Cloud für eine Stunde, verteilt auf alle Knoten. Gib den Wert 3 in das Feld Budget für die maximale Anzahl von Knotenstunden ein - dies ist nur eine Schätzung. Du zahlst nur für die genutzten Rechenstunden; wenn das Training aus einem anderen Grund als einer vom Nutzer veranlassten Stornierung fehlschlägt, wird dir die Zeit nicht in Rechnung gestellt. Die Schulungszeit wird dir in Rechnung gestellt, wenn du den Vorgang abbrichst.
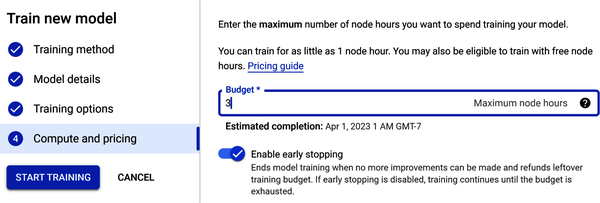
Abbildung 4-28. Wähle "Berechnen" und "Preise" in Schritt 4.
Unter "Berechnung und Preisgestaltung" findest du auch die Option "Frühzeitiges Beenden". Wenn du diese Option aktivierst, bedeutet das, dass das Training beendet wird, wenn AutoML feststellt, dass keine weiteren Modellverbesserungen mehr möglich sind. Wenn du die Option "Vorzeitiges Beenden" deaktivierst, trainiert AutoML das Modell, bis das Stundenbudget aufgebraucht ist.
Sobald alle Parameter eingegeben sind, startest du den Trainingsauftrag. Klicke auf Training starten.
Nach dem Modelltraining wird das Modell in der Modellregistrierung registriert (siehe Abbildung 4-29).
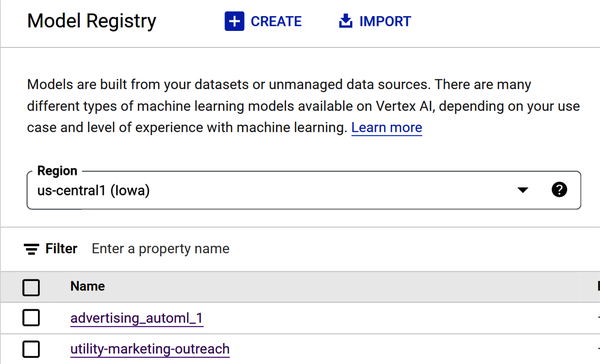
Abbildung 4-29. Das Modell Advertising_automl wird in der Modellregistrierung angezeigt.
Hinweis
Wie bereits erwähnt, kann das Training bis zu mehreren Stunden dauern, je nachdem, wie groß deine Daten sind und welche Art von Modellziel du gewählt hast. Die Verarbeitung von Bild- und Videodaten kann viel länger dauern als die von strukturierten Daten wie z. B. einer CSV-Datei. Auch die Anzahl der Trainingsproben wirkt sich auf die Trainingszeit aus.
Außerdem ist AutoML zeitintensiv. AutoML-Algorithmen müssen eine Vielzahl von Modellen trainieren, und dieser Trainingsprozess kann sehr rechenintensiv sein. Das liegt daran, dass AutoML-Algorithmen in der Regel eine große Anzahl verschiedener Modelle und Hyperparameter ausprobieren, und jedes Modell muss auf dem gesamten Datensatz trainiert werden. AutoML-Algorithmen müssen dann das beste Modell aus der Menge der trainierten Modelle auswählen, und auch dieser Auswahlprozess kann sehr zeitaufwändig sein. Das liegt daran, dass die AutoML-Algorithmen in der Regel die Leistung jedes Modells auf einem Holdout-Datensatz bewerten müssen, und dieser Bewertungsprozess kann rechenintensiv sein.
Bewertung der Modellleistung
Abbildung 4-30 zeigt die Trainingsergebnisse des Modells .
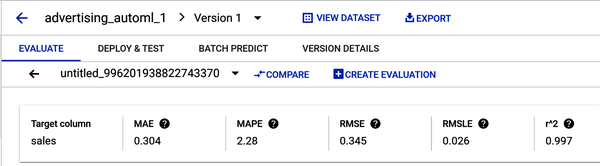
Abbildung 4-30. Ergebnisse der Modellschulung mit fünf Bewertungsmetriken.
Es gibt einige Faktoren, die ein/e Praktiker/in berücksichtigen sollte, wenn er/sie die Bedeutung der verschiedenen Bewertungskennzahlen der linearen Regression abwägt:
- Der Zweck des Modells
-
Der Zweck des Modells bestimmt, welche Bewertungskennzahlen am wichtigsten sind. Wenn das Modell zum Beispiel für Vorhersagen verwendet wird, sollte sich der Praktiker auf Kennzahlen wie den mittleren quadratischen Fehler (MSE) oder den mittleren quadratischen Fehler (RMSE) konzentrieren. Wenn das Modell jedoch dazu dient, die Beziehung zwischen den Variablen zu verstehen, sollte der Praktiker sich auf Kennzahlen wie R-Quadrat oder bereinigtes R-Quadrat konzentrieren.
- Die Merkmale der Daten
-
Auch die Eigenschaften der Daten wirken sich auf die Bedeutung der verschiedenen Bewertungskennzahlen aus. Wenn die Daten zum Beispiel verrauscht sind (d.h. unerwünschte Informationen oder Fehler enthalten), sollte sich der Praktiker auf Kennzahlen konzentrieren, die robust gegenüber Rauschen sind, wie z.B. den mittleren absoluten Fehler (MAE). Wenn die Daten jedoch nicht verrauscht sind, kann sich der/die Praktiker/in auf Kennzahlen konzentrieren, die empfindlicher auf Änderungen im Modell reagieren, wie z. B. MSE.
- Die Präferenzen des Praktikers
-
Letztendlich spielen auch die Präferenzen der Praktiker/innen eine Rolle bei der Bestimmung der Bedeutung der verschiedenen Bewertungsmaßstäbe. Manche Praktiker/innen bevorzugen leicht verständliche Kennzahlen, während andere genauere Kennzahlen bevorzugen. Es gibt keine richtige oder falsche Antwort, und der/die Auszubildende sollte die Kennzahlen wählen, die ihm/ihr am wichtigsten sind.
Hier sind gängige Bewertungsmaßstäbe für die lineare Regression:
- R-Quadrat
-
R-Quadrat ist ein Maß dafür, wie gut das Modell zu den Daten passt. Es ist das Quadrat des Pearson-Korrelationskoeffizienten zwischen den beobachteten und den vorhergesagten Werten. Er wird berechnet, indem die Summe der quadrierten Residuen (die Differenz zwischen den vorhergesagten und den tatsächlichen Werten) durch die Gesamtsumme der Quadrate geteilt wird. Ein höherer R-Quadrat-Wert zeigt eine bessere Übereinstimmung an. R-Quadrat reicht von 0 bis 1, wobei ein höherer Wert auf ein hochwertigeres Modell hinweist. DeinR2 sollte etwa 0,997 betragen.
- Bereinigtes R-Quadrat
-
Das bereinigte R-Quadrat ist eine modifizierte Version des R-Quadrats, bei der die Anzahl der unabhängigen Variablen im Modell berücksichtigt wird. Es wird berechnet, indem die Summe der quadrierten Residuen durch die Gesamtsumme der Quadrate abzüglich der Freiheitsgrade geteilt wird. Ein höherer bereinigter R-Quadrat-Wert weist auf eine bessere Anpassung hin, ist aber weniger empfindlich gegenüber der Anzahl der unabhängigen Variablen als R-Quadrat.
- Mittlerer quadratischer Fehler (MSE)
-
MSE ist ein Maß für den durchschnittlichen quadratischen Fehler zwischen den vorhergesagten Werten und den tatsächlichen Werten. Ein niedriger MSE-Wert bedeutet eine bessere Anpassung. In Abbildung 4-31 wird der Verlust in einer Tabelle und einem Diagramm dargestellt.
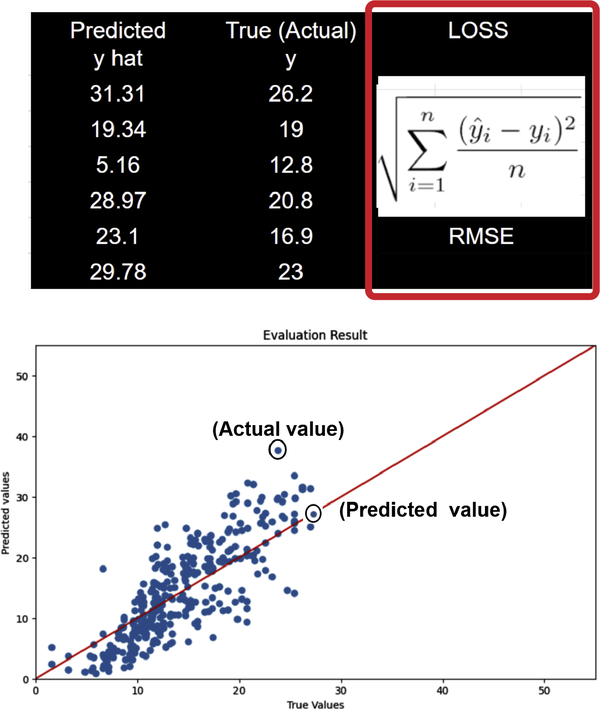
Abbildung 4-31. Verlustformel für RMSE von wahren und vorhergesagten Werten.
- Roter mittlerer quadratischer Fehler (RMSE)
-
RMSE ist die Quadratwurzel des MSE. Er ist eine besser interpretierbare Version des MSE. Ein niedrigerer RMSE-Wert deutet auf eine bessere Anpassung und eine höhere Qualität des Modells hin, während 0 bedeutet, dass das Modell keine Fehler gemacht hat. Die Interpretation des RMSE hängt von der Bandbreite der Werte in der Reihe ab. Dein RMSE sollte etwa 0,345 betragen.
- Root mean squared log error (RMSLE)
-
Die Interpretation von RMSLE hängt von der Bandbreite der Werte in der Reihe ab. Der RMSLE reagiert weniger auf Ausreißer als der RMSE und benachteiligt Unterschätzungen etwas stärker als Überschätzungen. Dein RMSLE sollte etwa 0,026 betragen.
- Mittlerer absoluter Fehler (MAE)
-
MAE ist ein Maß für den durchschnittlichen absoluten Fehler zwischen den vorhergesagten Werten und den tatsächlichen Werten. Ein niedriger MAE-Wert bedeutet eine bessere Anpassung. Dein MAE-Wert sollte bei 0,304 liegen.
- Mittlerer absoluter Fehler in Prozent (MAPE)
-
MAPE reicht von 0 % bis 100 %, wobei ein niedrigerer Wert ein qualitativ hochwertigeres Modell anzeigt. MAPE ist der Durchschnitt der absoluten prozentualen Fehler. Dein MAPE sollte etwa 2,28 betragen.
Modellmerkmal Wichtigkeit (Attribution)
Das Modell zeigt dir, wie stark jedes Merkmal die Modellschulung beeinflusst hat. Abbildung 4-32 zeigt die Zuordnungswerte in Prozent. Je höher der Prozentsatz, desto stärker ist die Korrelation, d.h. desto stärker hat das Merkmal das Modelltraining beeinflusst. Anhand der Merkmalszuordnung kannst du sehen, welche Merkmale am stärksten zu dem in Abbildung 4-32 gezeigten Modelltraining beigetragen haben.
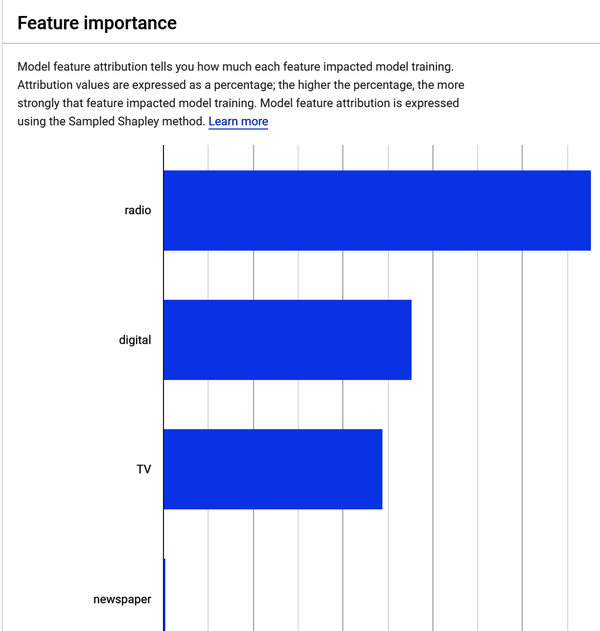
Abbildung 4-32. Ergebnisse der Merkmalsgewichtung im Datensatz Werbung.
Wenn du den Mauszeiger über das in Abbildung 4-32 gezeigte Zeitungsmerkmal bewegst, siehst du, dass sein Beitrag zum Modelltraining 0,2 % beträgt. Dies bestätigt, was du bereits in der EDA-Phase herausgefunden hast: Die Beziehung zwischen den Umsätzen und den Werbeausgaben für Zeitungen ist am geringsten. Diese Ergebnisse bedeuten, dass Radio-, Digital- und TV-Werbung den größten Beitrag zum Umsatz leisten und Zeitungsanzeigen nur einen geringen Einfluss auf denUmsatz von haben.
Erhalte Vorhersagen von deinem Modell
Um dein Modell einzusetzen, musst du es testen. Du kannst es in deiner Umgebung einsetzen, um dein Modell zu testen, ohne eine Anwendung zu erstellen, die du in der Cloud einsetzen müsstest. Nachdem du ein ML-Modell trainiert hast, musst du das Modell bereitstellen, damit andere es zum Inferencing nutzen können. Beim maschinellen Lernen wird ein trainiertes ML-Modell verwendet, um Vorhersagen für neue Daten zu treffen.
Es gibt vier Schritte, aber für dieses Kapitel brauchst du nur die ersten beiden. Für diese Übung ist es nicht notwendig, die Modellüberwachung oder die Modellziele zu konfigurieren. Bei der Modellüberwachung fallen zusätzliche Kosten für die Protokollierung an, während du bei den Modellzielen aus einer Vielzahl von Modellzielen auswählen musst, je nachdem, welche Art von Modell du trainierst und für welche Anwendung du es verwendest. Hier sind die vier Schritte:
-
Definiere deinen Endpunkt.
-
Konfiguriere die Modelleinstellungen.
-
Konfiguriere die Modellüberwachung.
-
Konfiguriere die Modellziele.
Hinweis
Was sind Endpunkte und Einsätze? In ML ist ein Endpunkt ein Dienst, der ein Modell für Online-Vorhersagen zur Verfügung stellt. Eine Bereitstellung ist der Prozess, bei dem ein Modell als Endpunkt verfügbar gemacht wird. Ein Endpunkt ist ein HTTPS-Pfad, über den Clients Anfragen (Eingabedaten) senden und die Ergebnisse eines trainierten Modells (Auswertung) empfangen können. Endpunkte werden in der Regel verwendet, um Vorhersagen in Echtzeit zu treffen. Du könntest zum Beispiel einen Endpunkt verwenden, um die Wahrscheinlichkeit vorherzusagen, dass ein Kunde auf eine Anzeige klickt, oder das Risiko, dass ein Kredit ausfällt.
Einsätze werden in der Regel verwendet, um ein Modell einem größeren Publikum zur Verfügung zu stellen. Du könntest zum Beispiel ein Modell in einer Produktionsumgebung einsetzen, damit es von deinen Kunden oder Mitarbeitern genutzt werden kann.
Abbildung 4-33 zeigt die Seite für die Bereitstellung und Prüfung. Um dein Modell einzusetzen, gehst du zu Model Registry, wählst Deploy and Test und wählst dein Modell aus.
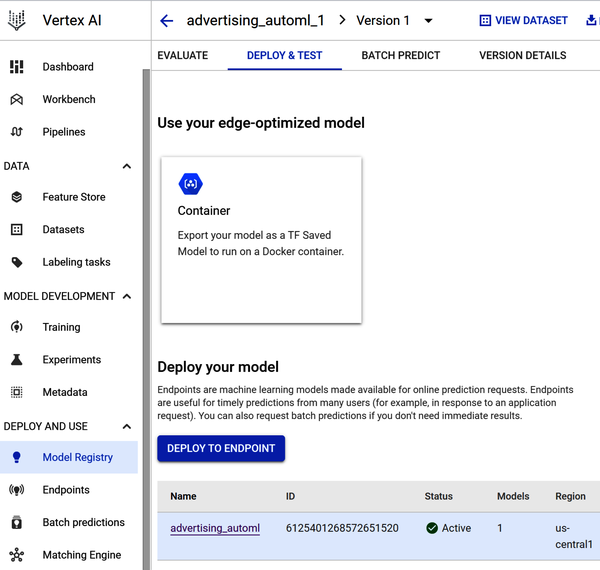
Abbildung 4-33. Setze dein Modell auf einer Endpunktseite ein.
In Schritt 1 definierst du deinen Endpunkt. Du wählst eine Region aus und bestimmst, wie auf deinen Endpunkt zugegriffen werden soll.
In Schritt 2 fügst du das Modell und die Verkehrsaufteilung hinzu. Ein Traffic-Split in Vertex AI ist eine Möglichkeit, den Datenverkehr auf mehrere Modelle zu verteilen, die für denselben Endpunkt eingesetzt werden. Dies kann für eine Vielzahl von Zwecken nützlich sein, z. B.:
- A/B-Tests
-
Mit dem Traffic-Splitting kann verschiedene A/B-Tests durchführen, um zu sehen, welches Modell besser abschneidet.
- Canary-Einsätze
-
Die Aufteilung des Verkehrs kann genutzt werden, um ein neues Modell bei einem kleinen Prozentsatz von Nutzern einzuführen, bevor es bei einer größeren Gruppe eingesetzt wird. So können Probleme mit dem neuen Modell erkannt werden, bevor sie zu viele Nutzer/innen betreffen.
- Rollouts
-
Das Traffic-Splitting kann genutzt werden, um ein neues Modell schrittweise bei den Nutzern einzuführen. Dies kann dazu beitragen, die Auswirkungen von Problemen mit dem neuen Modell abzumildern.
In Schritt 3 wählst du aus, wie die Rechenressourcen die Vorhersagen für dein Modell liefern sollen (siehe Abbildung 4-34). Für diese Übung verwendest du die Mindestanzahl an Rechenknoten (virtuelle Maschinenserver). Wähle unter "Maschinentyp" die Option Standard.
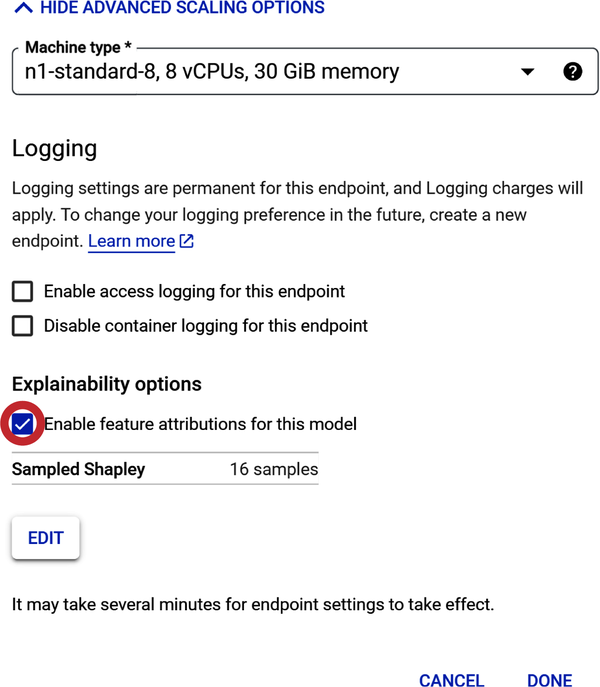
Abbildung 4-34. Wähle Rechenressourcen aus, um das Modell zu trainieren.
Hinweis: Die "Maschinentypen" unterscheiden sich in einigen Punkten: (1) Anzahl der virtuellen Zentraleinheiten (vCPUs) pro Knoten, (2) Menge des Speichers pro Knoten und (3) Preis.
Bei der Auswahl der Rechenressourcen für ein Prognosemodell gibt es einige Faktoren zu beachten:
- Größe und Komplexität des Modells
-
Je größer und komplexer das Modell ist, desto mehr Rechenressourcen benötigt es. (Das gilt vor allem für die benutzerdefinierte Kodierung neuronaler Netze).
- Anzahl der Vorhersagen, die gemacht werden
-
Wenn du mit einer großen Anzahl von Vorhersagen rechnest, musst du eine Rechenressource wählen, die diese Last bewältigen kann.
- Anforderungen an die Latenzzeit
-
Wenn du Vorhersagen in Echtzeit oder mit sehr geringer Latenzzeit machen musst, brauchst du eine Rechenressource, die die nötige Leistung erbringt. Hinweis: Niedrige Latenzzeiten beim maschinellen Lernen beziehen sich auf die Zeit, die ein ML-Modell benötigt, um eine Vorhersage zu treffen, sobald es einen neuen Datenpunkt erhält.
- Kosten
-
Rechenressourcen können unterschiedlich teuer sein, also musst du eine auswählen, die in dein Budget passt.
Sobald du diese Faktoren berücksichtigt hast, kannst du deine Auswahl eingrenzen. Hier sind einige Beispiele für Rechenressourcen, die für Vorhersagemodelle genutzt werden können:
- CPUs
-
Zentraleinheiten (CPUs) sind die gängigste Art von Rechenressource und eine gute Wahl für Modelle, die nicht zu groß oder komplex sind.
- GPUs
-
Grafikprozessoren (GPUs) sind leistungsfähiger als CPUs und können eingesetzt werden, um das Training und die Inferenz von großen und komplexen Modellen zu beschleunigen.
- TPUs
-
Tensor Processing Units (TPUs) sind spezielle Hardwarebeschleuniger, die für ML-Workloads entwickelt wurden. Sie sind die leistungsstärkste Option und können zum Trainieren und Bedienen der anspruchsvollsten Modelle verwendet werden.
In Schritt 2 unter "Modelleinstellungen" gibt es eine Einstellung für die Protokollierung. Wenn du die Endpunktprotokollierung aktivierst, werden Gebühren fällig. Daher solltest du sie für diese Übung nicht aktivieren.
Die nächste Einstellung sind die Erklärbarkeitsoptionen, die nicht kostenpflichtig sind. Setze ein Häkchen bei "Merkmalszuschreibungen für dieses Modell aktivieren".
Schritt 3 ist "Modellüberwachung". Aktiviere sie für dieses Projekt nicht (wie in Abbildung 4-35 gezeigt ).
Abbildung 4-35. Konfigurationsfenster "Modellüberwachung".
Nachdem alle Konfigurationen vorgenommen wurden, sollte die Schaltfläche Bereitstellen hervorgehoben sein. Klicke auf Bereitstellen, um dein Modell auf dem Endpunkt zu verteilen (siehe Abbildung 4-36).

Nachdem der Endpunkt erstellt und das Modell auf den Endpunkt übertragen wurde, solltest du eine E-Mail mit dem Status der Endpunktübertragung erhalten. Wenn der Einsatz erfolgreich war, kannst du anfangen, Vorhersagen zu treffen. Es gibt vier Schritte:
-
Gehe zur Modellregistrierung.
-
Wähle dein Modell aus.
-
Wähle die Version des Modells aus.
-
Scrolle nach unten, bis du die Seite "Teste dein Modell" siehst.
Abbildung 4-37 zeigt die Seite "Teste dein Modell". Diese Seite könnte eine App oder eine Webseite sein, die so aussieht - auf der du und dein Team die Werte für die Medienkanäle eingeben und die Verkaufszahlen vorhersagen.
Klicke auf die Schaltfläche Vorhersage.
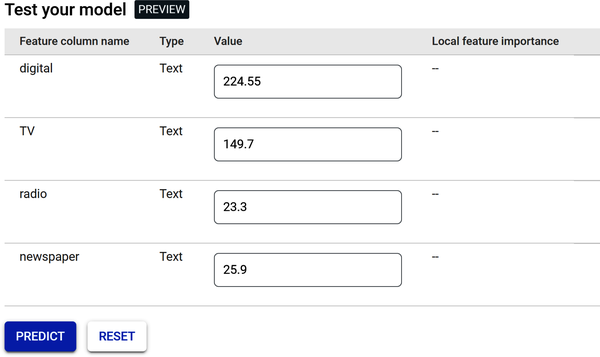
Abbildung 4-37. Testseite für Online-Vorhersagen.
Nachdem du auf die Schaltfläche Vorhersage geklickt hast, erhältst du eine Vorhersage für dein Label (Umsatz), wie in Abbildung 4-38 dargestellt.
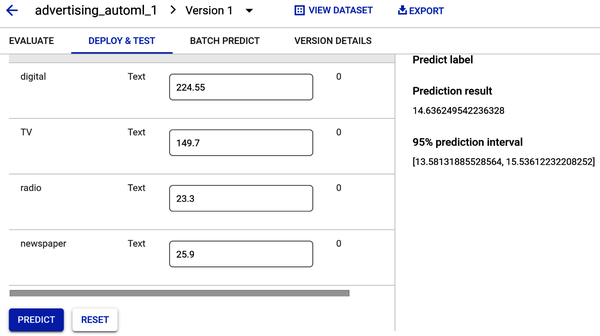
Abbildung 4-38. Vorhersage des Verkaufsvolumens auf Basis der Anfangswerte.
Regressionsmodelle liefern einen Vorhersagewert. Abbildung 4-38 zeigt einen Umsatzvorhersagewert von 14,63, der sehr nahe am Mittelwert aus dem Umsatzhistogramm liegt (siehe Abbildungen 4-10 und 4-23). Das Vorhersageintervall gibt einen Wertebereich an, in dem das Modell mit einer Wahrscheinlichkeit von 95% das tatsächliche Ergebnis findet. Da das Ergebnis der Umsatzvorhersage also 14,63 ist und das Vorhersageintervall einen Bereich zwischen 13,58 und 15,53 umfasst, kannst du zu 95 % sicher sein, dass jedes Vorhersageergebnis in diesen Bereich fällt.
Beantworten wir nun die geschäftlichen Fragen.
Das Ziel war es, ein ML-Modell zu erstellen, das vorhersagt, wie viel Umsatz auf der Grundlage der in den einzelnen Medienkanälen ausgegebenen Gelder erzielt wird.
- Kann das Modell vorhersagen, wie viel Umsatz mit dem Geld, das in den einzelnen Medienkanälen ausgegeben wird, erzielt wird?
-
Ja. Da du mit Vertex AI Werte für jeden Medienkanal eingeben kannst, kannst du jetzt Entscheidungen über die künftige Budgetverteilung treffen. Zum Beispiel kann der strategische Medienplan deines Unternehmens jetzt eine Erhöhung des Budgets für den digitalen Kanal auf der Grundlage der Ergebnisse einer Vorhersage vorsehen.
- Gibt es einen Zusammenhang zwischen Werbeausgaben und Umsatz?
-
Ja. Es besteht ein positiver linearer Zusammenhang zwischen den Werbeausgaben und dem Umsatz in den Bereichen Digital, TV und Radio. Die Ausgaben für Zeitungen stehen in einem schwachen Verhältnis zum Umsatz.
- Welcher Medienkanal trägt am meisten zum Umsatz bei?
-
Das Fernsehen trägt mehr zum Umsatz bei als die anderen Medienkanäle. Wie das? Das Streudiagramm, das du während des EDA-Teils erstellt hast, und dein Blick auf das Balkendiagramm der Vertex-KI-Funktion, nachdem das Modell trainiert wurde, zeigen den Beitrag des Fernsehens zum Umsatz.
- Wie genau kann das Modell zukünftige Verkäufe vorhersagen?
-
Das Regressionsmodell liefert einen Vorhersagewert, wenn die Werte für die Medienkanäle in das Fenster Vorhersage eingegeben werden, um die Verkaufsmenge vorherzusagen. Die Vorhersageergebnisse zeigen einen Umsatzvorhersagewert und ein Vorhersageintervall. Vorhersageintervalle können verwendet werden, um Entscheidungen über künftige Beobachtungen zu treffen. So kannst du dir zu 95% sicher sein, dass jedes künftige Ergebnis der Umsatzvorhersage innerhalb dieses Bereichs liegen wird.
Warnung
Vergiss nicht, dein Modell wieder abzuschalten, wenn du mit diesem Kapitel fertig bist. Eingesetzte Modelle verursachen auch dann Kosten, wenn sie nicht verwendet werden, damit sie immer verfügbar sind und schnelle Vorhersagen liefern. Um die Bereitstellung des Modells rückgängig zu machen, gehst du zu Vertex AI Endpoints, klickst auf den Namen des Endpunkts, dann auf das Drei-Punkte-Menü "Weitere Aktionen" und schließlich auf "Modell vom Endpunkt rückgängig machen".
Zusammenfassung
In diesem Kapitel hast du ein AutoML-Modell zur Vorhersage des Absatzes von Werbemedienkanälen erstellt. Du hast deine Daten mit Pandas untersucht und Heatmaps, Scatterplots und Histogramme erstellt. Nachdem du die Datendatei exportiert hast, hast du sie in Googles Vertex AI Framework hochgeladen. Dann hast du gelernt, wie du mit Google Cloud AutoML ein ML-Modell zur Vorhersage von Verkaufszahlen erstellst, trainierst und einsetzt. Du hast dir anhand von Leistungskennzahlen einen Überblick über die Leistung deines Modells verschafft und allgemeine Geschäftsfragen beantwortet. Du hast das Modell genutzt, um Online-Vorhersagen zu treffen und eine kleine Budgetprognose zu erstellen. Jetzt bist du bereit, es deinem Team zu präsentieren!
Get Low-Code AI now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

