Capítulo 4. Persistencia de datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Casi todas las aplicaciones necesitan persistir datos de alguna forma, y las aplicaciones en la nube no son una excepción. Los datos pueden estar en una de las siguientes formas:
-
Archivos binarios o de texto, como imágenes, vídeos, música, formatos Apache Avro, CSV o JSON
-
Datos estructurados o semiestructurados almacenados en bases de datos relacionales o NoSQL
En el Capítulo 3, hablamos de Azure Storage, que puede almacenar datos no estructurados, como archivos blob (de texto, binarios, etc.). En este capítulo, hablaremos de las bases de datos que ofrece Azure para persistir datos relacionales y NoSQL.
La primera opción de es optar por las ofertas de bases de datos IaaS. Puedes aprovisionar una máquina virtual Azure e instalar el motor de base de datos que quieras, como Microsoft SQL Server, MySQL o incluso MongoDB. Esta opción te da una gran flexibilidad porque eres el propietario de la máquina virtual subyacente; sin embargo, requiere mucha sobrecarga administrativa. Eres responsable de mantener, proteger y parchear el sistema operativo de la máquina virtual y el motor de la base de datos.
Una segunda (y mejor) opción, y en la que nos centraremos en este capítulo, es optar por las bases de datos gestionadas de Azure. Se trata de ofertas PaaS (plataforma como servicio), también llamadas bases de datos gestionadas, que te permiten aprovisionaruna base de datoslista para usar en cuestión de minutos. Azure se encarga de los parches y la seguridad del sistema operativo de la máquina virtual subyacente y de muchas otras tareas administrativas, como el escalado.
Azure SQL, Azure Cosmos DB y Azure Database para PostgreSQL son algunas de las bases de datos PaaS de Azure que tienes a tu disposición. La integración nativa con otros servicios de Azure, como Azure Virtual Networks, Azure Key Vault y Azure Monitor, te permite integrar fácilmente estas bases de datos con tus soluciones Azure.
Este capítulo se centra en las dos principales bases de datos gestionadas de Azure: Azure Cosmos DB y Azure SQL. Los temas que aprenderás incluyen:
-
Habilitación de claves gestionadas por el cliente para el cifrado en reposo de Cosmos DB
-
Trabajar con Azure Cosmos DB y cortafuegos Azure SQL
-
Conceder acceso a Cosmos DB a otros servicios Azure utilizando identidades gestionadas y RBAC
-
Configurar el autoescalado para Azure Cosmos DB
Consejo
Azure mejora continuamente tanto Azure Cosmos DB como los servicios Azure SQL. Echa un vistazo a la página de actualizaciones de Azure para conocer las últimas y mejores funciones.
Configuración del puesto de trabajo
Tendrás que preparar tu estación de trabajo antes de empezar con las recetas de este capítulo. Sigue las instrucciones de "Lo que necesitarás" para configurar tu máquina para ejecutar los comandos de la CLI de Azure. Puedes clonar el repositorio GitHub del libro utilizando el siguiente comando:
git clone https://github.com/zaalion/AzureCookbook.git
Crear una cuenta API NoSQL de Cosmos DB
Solución
Crea una nueva cuenta Azure Cosmos DB NoSQL API, crea una base de datos y almacena tus datos JSON en los contenedores dentro de la base de datos, como se muestra en la Figura 4-1.
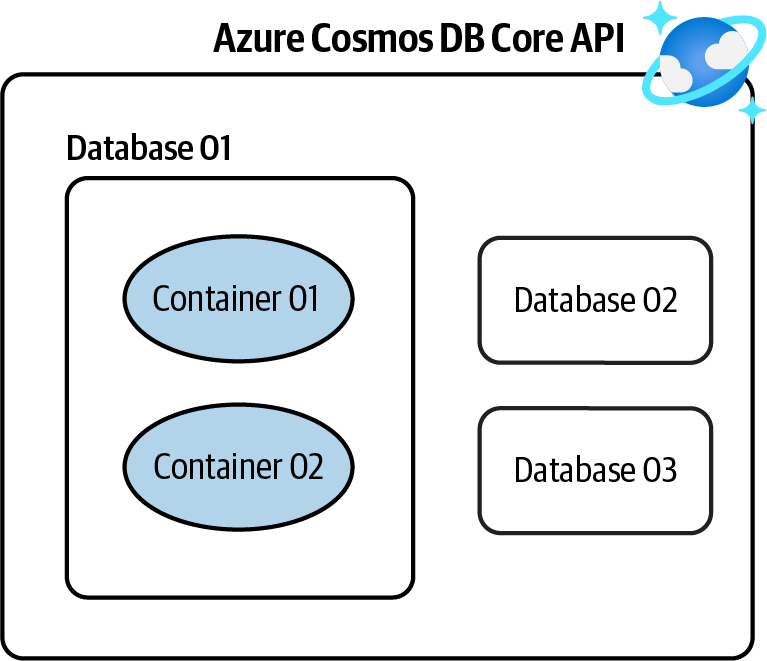
Figura 4-1. Almacenamiento de datos NoSQL en una cuenta Azure Cosmos DB NoSQL API
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
Crea una nueva cuenta Azure Cosmos DB NoSQL API. Sustituye <
cosmos-account-name> por el nombre de la cuenta de Cosmos DB deseada. Este script también configura las copias de seguridad periódicas para que se creen cada 240 minutos (4 horas) y se conserven durante 12 horas:cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName \ --backup-policy-type Periodic \ --backup-interval 240 \ --backup-retention 12
-
A continuación, tienes que crear una base de datos para alojar tus datos. Puedes asignar un rendimiento fijo (RU/s) a tu base de datos y/o asignar posteriormente el rendimiento deseado a nivel de contenedor (colección). Consulta la documentación de Azure para más detalles. Utiliza este comando para crear una base de datos llamada
MyCompanyDBen tu cuenta de Cosmos DB:az cosmosdb sql database create \ --account-name $cosmosAccountName \ --name MyCompanyDB \ --throughput 1000 \ --resource-group $rgName
Nota
Asignar un rendimiento fijo (provisionado) de a una base de datos no es obligatorio. Tienes la opción de asignar rendimiento a los contenedores hijos más adelante. Cosmos DB también ofrece las implementaciones de autoescala y sin servidor, que ajustan los recursos en función del tráfico y la carga. Consulta la documentación de Cosmos DB para más detalles.
-
Ahora el escenario está preparado para que crees tu primer contenedor (colección) en tu base de datos. Piensa en un contenedor como en una tabla de una base de datos relacional. Cada contenedor debe tener una clave de partición, que ayuda a distribuir los documentos del contenedor en particiones lógicas para mejorar el rendimiento. Utiliza el siguiente comando para crear una nueva colección llamada
Peoplecon un rendimiento fijo de 400 RU/s (unidades de solicitud):MSYS_NO_PATHCONV=1 az cosmosdb sql container create \ --name People \ --partition-key-path "/id" \ --throughput 400 \ --database-name MyCompanyDB \ --account-name $cosmosAccountName \ --resource-group $rgName
Consejo
Pon MSYS_NO_PATHCONV=1 antes del comando Bash para que /id no se convierta en una ruta Linux.
-
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
En esta receta, has creado una cuenta de la API Azure Cosmos DB NoSQL y una base de datos con un contenedor en ella. Ahora puedes persistir tus documentos NoSQL en esta base de datos.
Debate
Azure Cosmos DB es la principal oferta de base de datos NoSQL de Microsoft en la nube. Cosmos DB es una base de datos distribuida globalmente, segura y multimodelo. En el momento de escribir este libro, Cosmos DB ofrece las siguientes API (modelos):
- API SQL (núcleo)
-
Nosotros recomendamos esta API para todos los proyectos nuevos.
- API Gremlin (Gráfico)
-
Nosotros recomendamos esta API si necesitas persistir la estructura de datos del gráfico en tu base de datos. Por ejemplo, puedes querer hacerlo para una aplicación de redes sociales.
- API para MongoDB
-
Utiliza esta API si vas a migrar datos de MongoDB a Azure Cosmos DB y no quieres hacer cambios en el código de tu aplicación, o quieres que sean mínimos.
- API Cassandra
-
Utiliza esta API si estás migrando de Cassandra a Azure Cosmos DB y quieres que tu aplicación funcione con Cosmos DB sin cambios en el código.
- Tabla API
-
Una alternativa premium de para los usuarios del almacenamiento Azure Table. Migra tus datos a Azure Cosmos DB Table API, y tu código funcionará sin ningún cambio necesario.
Consulta la documentación de la API Azure Cosmos DB SQL (Core) para obtener más detalles.
En esta receta, creamos una API SQL (Core). Esta API almacena datos en formato de documento JSON. Tienes control total sobre la interfaz, el servicio y las bibliotecas cliente del SDK.
Cosmos DB también ofrece las siguientes capacidades:
-
Distribución global y escrituras multirregión para que los datos de puedan servirse a clientes de todo el mundo con un gran rendimiento.
-
Nivel de coherencia ajustable para diferentesrequisitos de coherencia y rendimiento
-
Redundancia zonal para mejor protección contrafallos zonales
-
Funciones de seguridad como encriptación en reposo, encriptación en tránsito, un cortafuegos fácil de configurar y compatibilidad con la autenticación de Azure Active Directory
En este capítulo, repasaremos varias funciones y capacidades de Cosmos DB.
Crear una cuenta API Cosmos DB Apache Gremlin (Graph)
Solución
Crea una nueva cuenta Azure Cosmos DB Gremlin API, crea una base de datos y utilízala para almacenar tus objetos gráficos. Consulta la Figura 4-2.
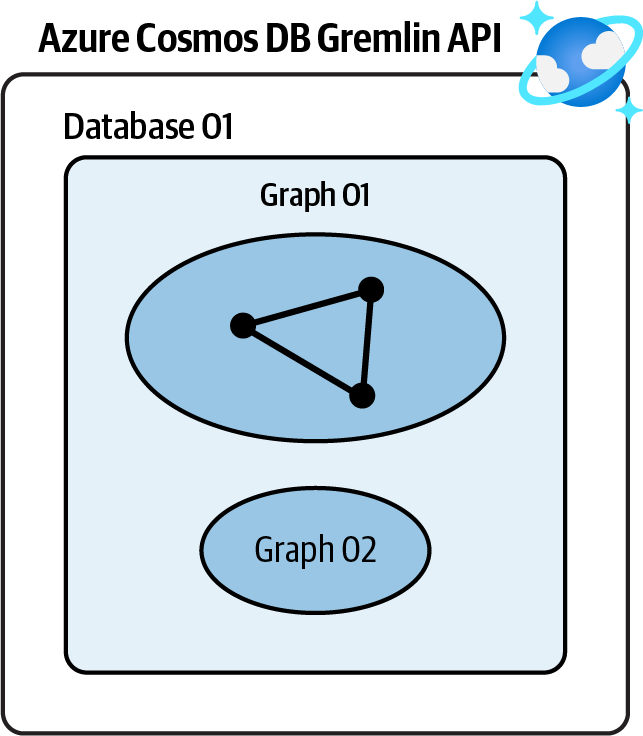
Figura 4-2. Almacenamiento de datos de gráficos en una cuenta Azure Cosmos DB Gremlin API
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
Crea una nueva cuenta Azure Cosmos DB Gremlin API. Sustituye <
cosmos-account-name> por el nombre de la cuenta de Cosmos DB deseada:cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName \ --capabilities EnableGremlin
-
Utiliza este comando para crear una base de datos llamada
MyGraphDBen tu cuenta de Cosmos DB:az cosmosdb gremlin database create \ --account-name $cosmosAccountName \ --resource-group $rgName \ --name MyGraphDB
-
Ahora puedes crear uno o más gráficos en
MyGraphDB. Al igual que con los contenedores, cada gráfico debe tener una clave de partición, que ayuda a distribuir los datos del gráfico en particiones lógicas para mejorar el rendimiento. Utiliza el siguiente comando para crear un nuevo gráfico llamadoPeople:MSYS_NO_PATHCONV=1 az cosmosdb gremlin graph create \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name MyGraphDB \ --name People \ --partition-key-path "/age"
Consejo
Pon MSYS_NO_PATHCONV=1 antes del comando Bash para que /id no se convierta en una ruta Linux.
-
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
Has creado correctamente una cuenta Azure Cosmos DB Gremlin API y una base de datos con un gráfico en ella.
Debate
Las bases de datos de grafos son almacenes de datos NoSQL, que están optimizados para persistir la estructura de datos de grafos y consultarla. Azure Cosmos DB Gremlin API es la principal oferta de bases de datos de grafos de Microsoft en la nube. Ofrece alta disponibilidad, niveles de consistencia flexibles, distribución global y SDK para muchos marcos de trabajo y lenguajes.
Las bases de datos gráficas son ideales para los siguientes escenarios
- Internet de las cosas
- Redes sociales
-
Modela la relación entre personas, lugares y otras entidades
- Motores de recomendación en el sector minorista
- Geoespacial
-
Encuentra rutas optimizadas en aplicaciones y productos con localización.
Consulta la documentación de Azure Cosmos DB Gremlin para obtener más detalles.
Configurar el cortafuegos de Azure Cosmos DB
Solución
Configura el cortafuegos del servicio Azure Cosmos DB para permitir el acceso de direcciones IP, redes virtuales y puntos finales privados de confianza, mientras deniega el resto del tráfico (consulta la Figura 4-3).
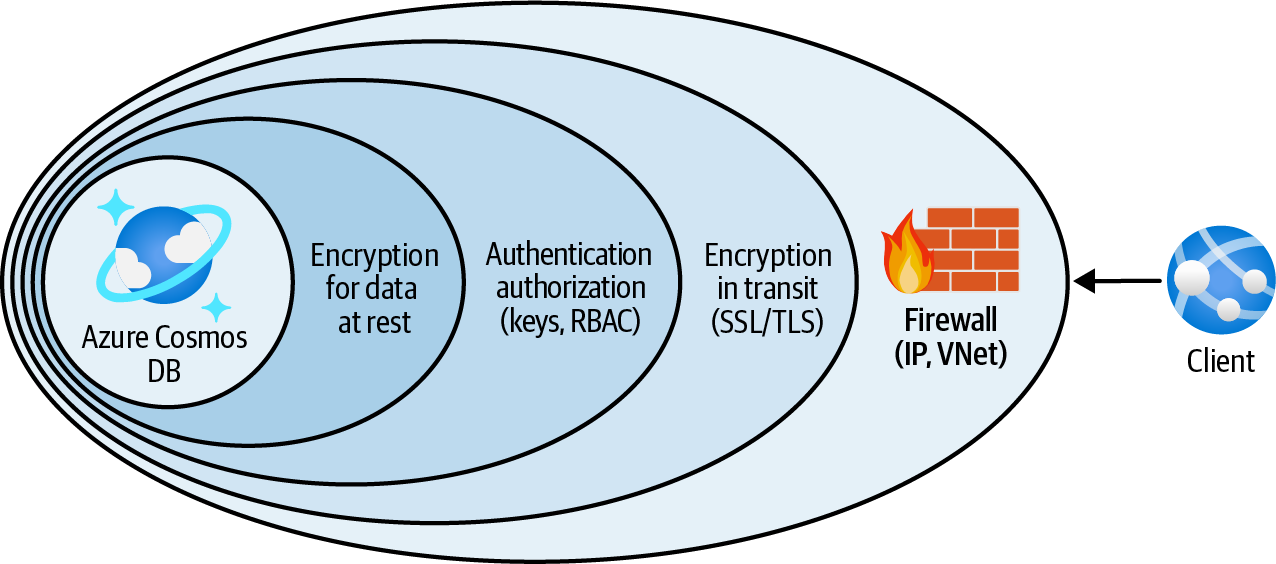
Figura 4-3. Proteger Azure Cosmos DB utilizando el cortafuegos de servicio
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
Crea una nueva cuenta de Azure Cosmos DB. El cortafuegos de servicios está disponible para todas las API de Cosmos DB. En esta receta, vamos a utilizar la API SQL (Core). Sustituye <
cosmos-account-name> por el nombre de la cuenta de Cosmos DB deseada:cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName
-
En primer lugar, vamos a añadir una nueva regla de filtro IP. Después de añadir esta regla, los clientes serán rechazados a menos que su dirección IP esté presente en la regla. Sustituye <
allowed-ip-range> por un rango de IP, una lista de IP separadas por comas o una única dirección IP:allowedIPRange="<allowed-ip-range>" az cosmosdb update \ --resource-group $rgName \ --name $cosmosAccountName \ --ip-range-filter $allowedIPRange
Nota
La actualización de Azure Cosmos DB puede tardar unos minutos. Espera a que se complete el comando.
-
En también puedes crear reglas de red de Cosmos DB para permitir el tráfico de determinadas VNets de Azure. En primer lugar, utiliza el siguiente comando para crear una nueva VNet de Azure. Sustituye <
vnet-name> por el nombre de la red que desees:vnetName="<vnet-name>" az network vnet create \ --resource-group $rgName \ --name $vnetName \ --address-prefix 10.0.0.0/16 \ --subnet-name Subnet01 \ --subnet-prefix 10.0.0.0/26
-
Tu objetivo es permitir que los clientes de la subred especificada vean y utilicen Azure Cosmos DB. Para conseguirlo, tienes que empezar por añadir el punto final del servicio
Microsoft.AzureCosmosDBa la subred:az network vnet subnet update \ --resource-group $rgName \ --name Subnet01 \ --vnet-name $vnetName \ --service-endpoints Microsoft.AzureCosmosDB
-
A continuación, activa el filtrado Azure VNet para tu cuenta Cosmos DB:
az cosmosdb update \ --resource-group $rgName \ --name $cosmosAccountName \ --enable-virtual-network true
-
En este punto, tu cuenta de Cosmos DB sólo acepta tráfico de las IP especificadas con
$allowedIPRange. Ahora el escenario está preparado para que permitas el tráfico procedente deSubnet01:az cosmosdb network-rule add \ --resource-group $rgName \ --virtual-network $vnetName \ --subnet Subnet01 \ --name $cosmosAccountName
Consejo
Este comando puede tardar unos minutos en completarse. Si aparece el mensaje "VirtualNetworkRules should be specified only if IsVirtualNetworkFilterEnabled is True", asegúrate de que el paso anterior se ha completado correctamente.
-
Utiliza el siguiente comando para confirmar que se hacreado la regla de red Cosmos DB:
az cosmosdb network-rule list \ --name $cosmosAccountName \ --resource-group $rgName
-
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
Has configurado correctamente el cortafuegos de Azure Cosmos DB para permitir el tráfico de clientes sólo desde las direcciones IP y VNets de Azure que desees.
Debate
Muchos servicios de Azure ofrecen cortafuegos a nivel de servicio que proporcionan defensa en profundidad para proteger tus datos. Azure SQL, Azure Storage y Azure Cosmos DB son algunos de estos servicios.
Es una buena práctica de seguridad configurar siempre cortafuegos a nivel de servicio además de otras protecciones de seguridad (como la autenticación de Azure Active Directory). Esto garantiza que ningún usuario no autorizado de Internet u otras redes pueda acceder a tus datos de Azure Cosmos DB.
El cortafuegos de Azure Cosmos DB te permite configurar las siguientes restricciones de forma individual o combinada:
-
Permitir el tráfico basado en la dirección IP del cliente mediante reglas IP
-
Permitir el tráfico en función de la red virtual del cliente
-
Permitir el tráfico privado a través de los puntos finales privados de Azure
Utiliza reglas IP para clientes que tengan direcciones IP estáticas, como máquinas virtuales públicas, o cuando necesites acceder a Cosmos DB desde tu propia máquina local. Utiliza reglas de red virtual para permitir servicios como las máquinas virtuales de Azure o los Entornos de Servicio de Aplicaciones, que se implementan en una subred VNet de Azure.
Configurar el acceso privado a Azure Cosmos DB
Solución
Crea un punto final privado para tu cuenta de Azure Cosmos DB y, a continuación, desactiva el acceso a la red pública para Azure Cosmos DB, como se muestra en la Figura 4-4.

Figura 4-4. Permitir sólo tráfico privado a Azure Cosmos DB utilizando puntos finales privados
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
Crea una nueva cuenta de Azure Cosmos DB. El cortafuegos de servicios está disponible para todas las API de Cosmos DB. En esta receta, vamos a utilizar la API SQL (Core). Sustituye <
cosmos-account-name> por el nombre de la cuenta de Cosmos DB deseada:cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName
-
Utiliza el siguiente comando para crear una nueva Azure VNet. Sustituye <
vnet-name> por el nombre de red que desees:vnetName="<vnet-name>" az network vnet create \ --resource-group $rgName \ --name $vnetName \ --address-prefix 10.0.0.0/20 \ --subnet-name PLSubnet \ --subnet-prefix 10.0.0.0/26
-
Ahora, coge el ID de cuenta de Cosmos DB y guárdalo en una variable. Utilizarás la variable en el siguiente paso:
cosmosAccountId=$(az cosmosdb show \ --name $cosmosAccountName \ --resource-group $rgName \ --query id --output tsv)
-
Ahora estás preparado para crear un endpoint privado para tu cuenta de Cosmos DB:
MSYS_NO_PATHCONV=1 az network private-endpoint create \ --name MyCosmosPrivateEndpoint \ --resource-group $rgName \ --vnet-name $vnetName \ --subnet PLSubnet \ --connection-name MyEndpointConnection \ --private-connection-resource-id $cosmosAccountId \ --group-id Sql
-
Tus clientes pueden utilizar el nuevo punto final privado en la subred PLSubnet para comunicarse con tu cuenta de Cosmos DB, pero esto no impide el acceso a la red pública. Utiliza el siguiente comando para desactivar explícitamente el acceso a la red pública para tu cuenta de base de datos Cosmos:
az cosmosdb update \ --resource-group $rgName \ --name $cosmosAccountName \ --enable-public-network false
-
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
En esta receta, has configurado el cortafuegos de Azure Cosmos DB para permitir el tráfico de clientes sólo desde un punto final privado.
Debate
En "Configuración del cortafuegos de Azure Cos mos DB" hablamos de las opciones de acceso a la red de Azure Cosmos DB. Hablamos de restringir el tráfico por dirección IP o por la VNet Azure del cliente. Ambas opciones siguen permitiendo que el tráfico pase por la red pública, lo que puede no ser deseable para muchas organizaciones.
En esta receta, has configurado Azure Cosmos DB para que desactive el acceso a la red pública y sólo acepte tráfico de red desde un punto final privado. Esta es, con diferencia, la opción más segura desde el punto de vista de la red. Echa un vistazo a la documentación de Azure Cosmos DB para obtener más detalles.
Microsoft define un punto final privado como "una interfaz de red que utiliza una dirección IP privada de tu red virtual". Esta interfaz de red te conecta de forma privada a un servicio que funciona con Azure Private Link. El tráfico de red del endpoint privado no va por la Internet pública, sino que utiliza únicamente la infraestructura de red privada de Azure. Puedes utilizar puntos finales privados para conectarte a muchos servicios, entre ellos:
-
Almacenamiento Azure
-
Azure Cosmos DB
-
Base de datos Azure SQL
-
Azure App Services
-
Aplicaciones Azure Function
Concedera las aplicaciones de funciones acceso a la base de datos Cosmosmediante RBAC
Solución
Crea una definición de función Cosmos DB personalizada con los permisos (acciones) deseados y asígnala a la identidad Function App para el ámbito de cuenta Cosmos DB, como se ilustra en la Figura 4-5.
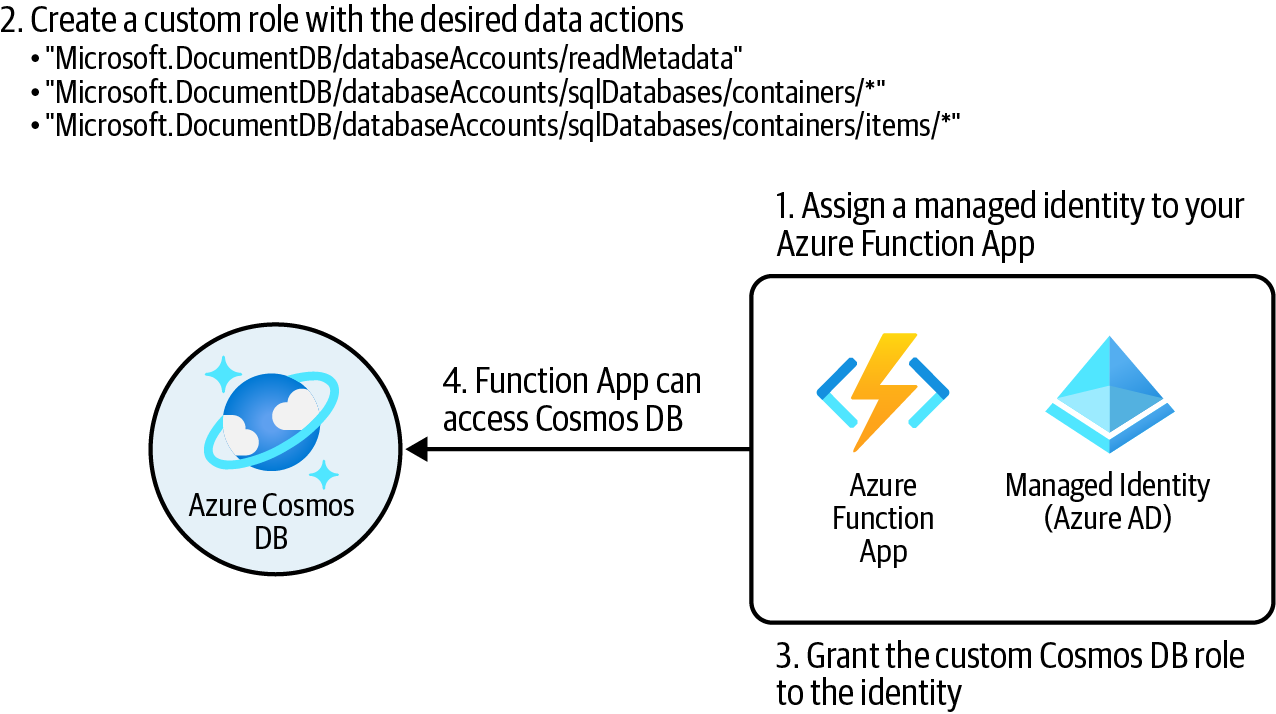
Figura 4-5. Conceder acceso a los datos de Cosmos DB a Azure Function App
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
Utiliza el siguiente comando CLI para crear una nueva cuenta Azure Cosmos DB:
cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName
-
Utiliza el siguiente comando para crear una nueva Azure Function App y asignarle una identidad gestionada asignada por el sistema:
funcStorageAccount="<func-storage-account-name>" planName="<appservice-plan-name>" funcAppName="<function-app-name>" az storage account create \ --name $funcStorageAccount \ --resource-group $rgName \ --location $region \ --sku Standard_LRS az appservice plan create \ --resource-group $rgName \ --name $planName \ --sku S1 \ --location $region az functionapp create \ --resource-group $rgName \ --name $funcAppName \ --storage-account $funcStorageAccount \ --assign-identity [system] \ --functions-version 3 \ --plan $planName -
Utiliza el siguiente comando para obtener el ID de identidad gestionada (GUID) de Function App y el ID de recurso de la cuenta de Cosmos DB. Los necesitarás más adelante:
cosmosAccountId=$(az cosmosdb show \ --name $cosmosAccountName \ --resource-group $rgName \ --query id \ --output tsv) funcObjectId=$(az functionapp show \ --name $funcAppName \ --resource-group $rgName \ --query identity.principalId \ --output tsv) -
En tienes que crear un rol RBAC personalizado con los permisos deseados para Cosmos DB. En primer lugar, crea un archivo JSON con el siguiente contenido y llámaloMyCosmosDBReadWriteRole.json:
{ "RoleName": "MyCosmosDBReadWriteRole", "Type": "CustomRole", "AssignableScopes": ["/"], "Permissions": [ { "DataActions": [ "Microsoft.DocumentDB/databaseAccounts/readMetadata", "Microsoft.DocumentDB/databaseAccounts/sqlDatabases /containers/*", "Microsoft.DocumentDB/databaseAccounts/sqlDatabases /containers/items/*" ] } ] } -
A continuación, crearás la definición del rol Cosmos DB. Sustituye <
path-to-MyCosmosDBReadWriteRole.json> por la ruta estilo Linux a tu archivo JSON, por ejemplo C:/Data/MyCosmosDBReadWriteRole.json:az cosmosdb sql role definition create \ --account-name $cosmosAccountName \ --resource-group $rgName \ --body <path-to-MyCosmosDBReadWriteRole.json>
-
Ahora puedes asignar el nuevo rol personalizado MyCosmosDBReadWriteRole a tu App Funcional:
MSYS_NO_PATHCONV=1 az cosmosdb sql role assignment create \ --account-name $cosmosAccountName \ --resource-group $rgName \ --role-definition-name MyCosmosDBReadWriteRole \ --principal-id $funcObjectId \ --scope "/dbs"
Consejo
Puedes limitar el ámbito a una sola base de datos o incluso a un contenedor de la cuenta de Cosmos DB, como /dbs/mydb/colls/mycontainer. En nuestro caso, /dbs, estás asignando el rol a todas las bases de datos de tu cuenta Cosmos DB.
-
Utiliza los siguientes comandos para obtener el ID de definición del rol y pasarlo a
azcosmosdbsql roledefinition show` para confirmar que tu rol se ha asignado correctamente:# Assuming there is only one role assignment in this Cosmos DB account roleDefinitionId=$(az cosmosdb sql role assignment list \ --account-name $cosmosAccountName \ --resource-group $rgName \ --query [0].roleDefinitionId --output tsv) # The last 36 characters will be the role definition ID (GUID) roleDefinitionGUID=${roleDefinitionId: -36} az cosmosdb sql role definition show \ --account-name $cosmosAccountName \ --resource-group $rgName \ --id $roleDefinitionGUID
Nota
En el momento de escribir este libro, ¡no puedes ver las asignaciones de roles personalizados de Cosmos DB en el portal de Azure!
-
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
Has concedido con éxito acceso a Azure Cosmos DB a una aplicación de función sin compartir ninguna clave de Cosmos DB. Cualquier código implementado en tu aplicación de función puede tener acceso de lectura/escritura a la base de datos de Cosmos sin proporcionar claves de cuenta de la base de datos de Cosmos.
Debate
De forma similar a Azure Storage, Azure Cosmos DB admite la autenticación de Azure Active Directory (Azure AD) mediante RBAC. Esto te permite conceder acceso a Cosmos DB a los principales de seguridad, como las identidades gestionadas por la aplicación Function o los Registros de aplicaciones, sin exponer las claves de cuenta de Cosmos DB. Se trata de una práctica de seguridad recomendada.
Azure Cosmos DB admite el acceso RBAC a los siguientes planos:
- Plano de gestión
-
Esto es así para que el cesionario pueda gestionar la cuenta Azure Cosmos DB, por ejemplo, configurando la copia de seguridad y la restauración. El cesionario no tiene acceso a los datos almacenados en la base de datos. Azure Cosmos DB proporciona roles integrados para trabajar con el plano de gestión. Si es necesario, tienes la opción de crear tus propios roles personalizados.
- Plano de datos
-
Esto es así para que el asignado pueda acceder a los datos de la base de datos. En esta receta, has creado un rol RBAC de plano de datos personalizado y lo has asignado a una entidad de seguridad principal (identidad de Azure Function). En el momento de escribir este libro, hay dos roles RBAC integrados disponibles para el acceso a los datos, Lector de datos integrado en Cosmos DB y Contribuidor de datos integrado en Cosmos DB, además de la opción de crear roles personalizados.
Te recomendamos que explores los roles RBAC incorporados en Cosmos DB para la gestión y los planos de datos antes de crear tu propio rol personalizado. Puedes crear roles personalizados si:
-
No hay ningún rol integrado para el acceso que necesitas conceder
-
Los roles incorporados dan demasiado acceso
Aunque el rol Cosmos DB Built-in Data Contributor concede los permisos necesarios para nuestra Function App, decidimos crear un rol RBAC personalizado con el fin de aprender en esta receta.
Almacenar datos tabulares en tablas de Azure Storage
Solución
Crea una cuenta de almacenamiento v2 de uso general y almacena tus datos tabulares NoSQL en tablas de almacenamiento Azure, como se muestra en la Figura 4-6.
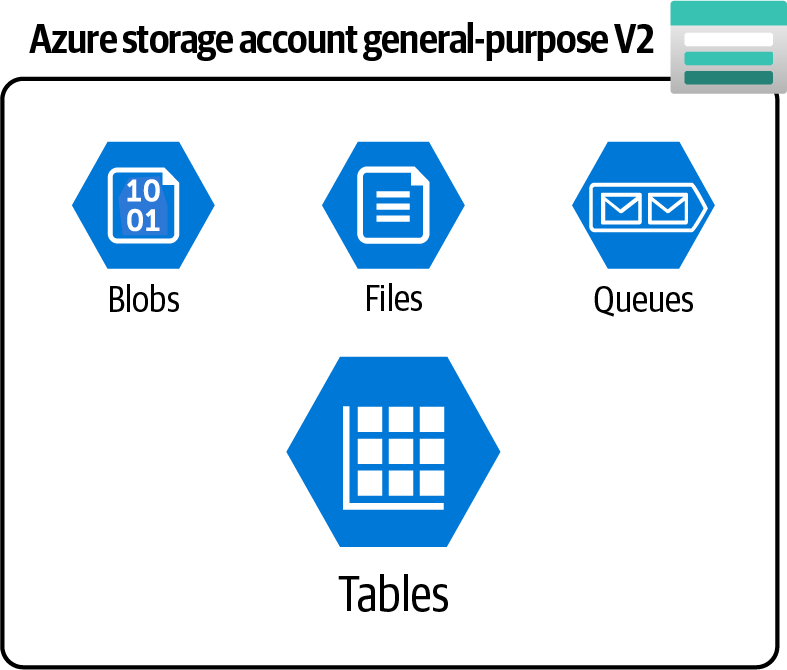
Figura 4-6. La cuenta de almacenamiento Azure de propósito general v2 ofrece servicio de tabla
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
Crea una nueva cuenta de almacenamiento Azure utilizando este comando. Este será el origen de nuestra migración. Sustituye <
storage-account-name> por el nombre único global deseado:storageName="<storage-account-name>" az storage account create \ --name $storageName \ --resource-group $rgName \ --location $region \ --sku Standard_LRS
-
Guarda una de las claves de la cuenta de almacenamiento en una variable:
storageKey1=$(az storage account keys list \ --resource-group $rgName \ --account-name $storageName \ --query [0].value \ --output tsv) -
Ahora, crea una tabla en tu cuenta de almacenamiento, llámala
People, y siémbrala con dos filas de datos:# creating a table az storage table create \ --account-name $storageName \ --account-key $storageKey1 \ --name People # inserting a new row az storage entity insert \ --account-name $storageName \ --account-key $storageKey1 \ --table-name People \ --entity PartitionKey=Canada RowKey=reza@contoso.com Name=Reza # inserting another new row az storage entity insert \ --account-name $storageName \ --account-key $storageKey1 \ --table-name People \ --entity PartitionKey=U.S.A. RowKey=john@contoso.com Name=John Last=Smith
Nota
Cada fila de datos de una tabla de almacenamiento Azure debe tener las propiedades PartitionKey y RowKey. Las filas con el mismo PartitionKey se colocarán en la misma partición para un mejor equilibrio de la carga. El RowKey debe ser único dentro de cada partición. Consulta la documentación del modelo de datos del servicio Azure Table para más detalles. Asegúrate de elegir las entidades adecuadas para evitar particiones frías o calientes. En esta receta, elegimos el nombre del país como PartitionKey y la dirección de correo electrónico como RowKey.
-
Utiliza el comando siguiente para confirmar que las dos filas se han insertado como se esperaba:
az storage entity query \ --table-name People \ --account-name $storageName \ --account-key $storageKey1
-
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
En esta receta de has almacenado datos tabulares en tablas de almacenamiento de Azure. Puedes utilizar los SDK de Azure Storage, las API REST y Azure Storage Explorer para gestionar tus tablas y manipular los datos.
Debate
En el momento de escribir este libro, Microsoft Azure ofrece dos servicios gestionados principales para almacenar datos tabulares NoSQL: Azure Cosmos DB para Table API y Azure Table storage. Mientras que Cosmos DB ofrece un rendimiento, latencia y SLA (acuerdos de nivel de servicio) de primera calidad, Azure Table es una opción más asequible para muchos proyectos.
Consulta la documentación de Azure para obtener una lista detallada de las diferencias entre estas dos ofertas de tablas. También puedes encontrar la introducción de Microsoft Azure sobre las ofertas de almacenamiento de tablas en la documentación de Azure.
Tienes unas cuantas opciones para migrar tus datos del almacenamiento Azure Table a Azure Cosmos DB para beneficiarte de la distribución global, el SLA y el rendimiento que ofrece Cosmos DB. Dependiendo del tamaño y la naturaleza de tu migración de datos, puedes utilizar la Herramienta de Migración de Datos de Cosmos DB, Azure Data Factory o incluso migraciones personalizadas. Consulta la documentación de Azure Cosmos DB para obtener más detalles.
Configuración de Autoescala para un Contenedor API NoSQL Azure Cosmos DB
Solución
Configura autoscale en la colección Cosmos DB (contenedor) y especifica el máximo de RU/s permitido.
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
Utiliza el siguiente comando para crear una nueva cuenta Azure Cosmos DB NoSQL API:
cosmosAccountName="<cosmos-account-name>" az cosmosdb create \ --name $cosmosAccountName \ --resource-group $rgName
-
Ahora, crea una nueva base de datos en tu cuenta de Cosmos DB. No vamos a añadir ningún caudal a nivel de base de datos:
az cosmosdb sql database create \ --account-name $cosmosAccountName \ --resource-group $rgName \ --name db01
-
A continuación, utiliza este comando para crear una nueva colección (contenedor) en esta base de datos y llámala
People. Vamos a crear este contenedor con un rendimiento aprovisionado fijo. Esto significa que el contenedor siempre tendrá 1000 RU/s para utilizar:MSYS_NO_PATHCONV=1 az cosmosdb sql container create \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name db01 \ --name People \ --partition-key-path "/id" \ --throughput "1000"
-
Utiliza este comando para ver los detalles de rendimiento del nuevo contenedor. La salida debería mostrar que el valor de la propiedad
throughputes 1000 RU/s:az cosmosdb sql container throughput show \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name db01 \ --name People
-
En el paso 4, podríamos haber pasado el parámetro
--max-throughputen lugar de--throughputpara activar el autoescalado del contenedor. Como no lo hicimos, en este paso migraremos el contenedor de rendimiento aprovisionado (fijo) a autoescalado utilizando el siguiente comando:az cosmosdb sql container throughput migrate \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name db01 \ --name People \ --throughput "autoscale"
-
Ejecuta de nuevo el comando
az cosmosdb sql container throughput showpara ver la configuración actualizada del rendimiento. Confirma que la propiedadmaxThroughputindica 1.000 RU/s:az cosmosdb sql container throughput show \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name db01 \ --name People
-
Por último, actualicemos el rendimiento máximo permitido del contenedor a 2.000 RU/s:
az cosmosdb sql container throughput update \ --resource-group $rgName \ --account-name $cosmosAccountName \ --database-name db01 \ --name People \ --max-throughput 2000
-
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
En esta receta, has creado un contenedor API SQL de Cosmos DB con un rendimiento fijo, has activado su autoescalado y, por último, has establecido su rendimiento máximo permitido.
Debate
Todas las API de Azure Cosmos DB, incluida la API SQL, te permiten establecer un rendimiento fijo provisionado tanto a nivel de base de datos como de contenedor. Se trata de un rendimiento respaldado por SLA que siempre se asignará a tus bases de datos y contenedores.
Establecer un rendimiento fijo en los contenedores (y/o bases de datos) te da una factura predecible a final de mes; sin embargo, los picos en las peticiones entrantes pueden dar lugar a un rendimiento deficiente, estrangulamiento de las peticiones o caídas. Para asegurarte de que tus bases de datos y contenedores Cosmos DB pueden escalar para acomodar más peticiones, puedes configurar el autoescalado en bases de datos, contenedores o ambos.
En esta receta, creamos un contenedor con un rendimiento fijo y después lo migramos al modelo de autoescala. Puedes cambiar las RU/s mínimas y máximas para adaptarlas a las necesidades de tu proyecto.
Nota
Azure Cosmos DB también tiene una oferta sin servidor (basada en el consumo). Al seleccionar esta opción, ya no tienes que preocuparte de establecer un mínimo y un máximo de RU/s. Azure Cosmos DB escalará hacia arriba y hacia abajo en función del tráfico de tu base de datos/contenedor. Consulta la documentación de Azure Cosmos DB para obtener más detalles.
Ahorrar costes en varias bases de datos Azure SQL Single con demandas de uso variables e impredecibles
Solución
Coloca tus bases de datos individuales de en un pool elástico de Azure SQL Database. Las bases de datos agrupadas son una alternativa rentable a las múltiples bases de datos individuales con demandas de recursos impredecibles, como se ilustra en la Figura 4-7.

Figura 4-7. Uso de pools elásticos de Azure SQL Database para ahorrar costes
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
En primer lugar, necesitas aprovisionar un servidor lógico Azure SQL utilizando el siguiente comando. Sustituye <
logical-sql-server-name> por el nombre del servidor deseado, <admin-user> por el nombre de usuario de administrador y <admin-pass> con la contraseña de administrador:logicalServerName="<logical-sql-server-name>" sqlAdminUser="<admin-user>" # Use a complex password with numbers, upper case characters and symbols. sqlAdminPass="<admin-pass>" az sql server create \ --resource-group $rgName \ --name $logicalServerName \ --admin-user $sqlAdminUser \ --admin-password $sqlAdminPass
-
Ahora, vamos a crear un nuevo pool elástico. Los recursos, como la memoria y la CPU, se asignan al pool. Utiliza el siguiente comando para asignar dos vCores (núcleos virtuales de CPU) a tu nuevo pool:
sqlPoolName="MyPool01" az sql elastic-pool create \ --resource-group $rgName \ --server $logicalServerName \ --name $sqlPoolName \ --edition GeneralPurpose \ --family Gen5 \ --capacity 2
-
Vamos a añadir dos bases de datos individuales a tu nuevo pool. Estas bases de datos compartirán los recursos asignados al pool padre:
az sql db create \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --elastic-pool $sqlPoolName az sql db create \ --resource-group $rgName \ --server $logicalServerName \ --name db02 \ --elastic-pool $sqlPoolName
-
Puedes ver todas las bases de datos de un pool determinado ejecutando el siguientecomando:
az sql elastic-pool list-dbs \ --resource-group $rgName \ --name $sqlPoolName \ --server $logicalServerName \ --query [].name
-
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
En esta receta, aprovisionaste un pool elástico de Azure SQL Database y le añadiste dos bases de datos.
Advertencia
Los recursos de Azure SQL pueden llegar a ser caros. Asegúrate de limpiar los recursos aprovisionados, incluido el pool elástico, después de concluir esta receta. Consulta la sección de limpieza en el repositorio del capítulo para más detalles.
Debate
Azure SQL ofrece los siguientes tipos:
-
Base de datos única Azure SQL
-
Grupos elásticos de Azure SQL Database
-
Instancia gestionada de Azure SQL
Azure SQL Managed Instance es la oferta de Azure SQL más compatible con Microsoft SQL Server y está fuera del alcance de esta receta.
Como su nombre indica, la base de datos única Azure SQL es una base de datos independiente con los recursos, como CPU y memoria, directamente asignados a ella. Esto funciona perfectamente para muchos escenarios, como una base de datos con un patrón de uso predecible. Sólo tienes que elegir el nivel correcto(unidad de transacción de base de datos (DTU) o vCore) y la base de datos funcionará como se espera.
Ahora imagina que tienes tres bases de datos individuales para clientes de Japón, la UE y el este de EEUU. Cada base de datos necesita 50 DTU en su pico de uso. Debido a la diferencia horaria, ninguna de las bases de datos alcanza su pico de uso al mismo tiempo, pero estás pagando por 150 DTUs 24x7 que no utilizarás en su totalidad. El pool elástico de Azure SQL Database es una forma de solucionar este problema. (La otra forma es optar por la capa sin servidor, de la que hablaremos en "Configuración de la capa informática sin servidor para bases de datos únicas Azure SQL") .
Si eliges pools elásticos, sólo tienes que crear un nuevo pool elástico, asignarle 100 DTU y, a continuación, añadir las tres bases de datos al pool. Esta configuración funcionará bien suponiendo que las tres bases de datos nunca alcancen su pico de uso al mismo tiempo.
Configuración de la capa de computación sin servidor para bases de datos individuales Azure SQL
Solución
Aprovisiona tus bases de datos Azure SQL single en el nivel de computación sin servidor. Azure se encargará de asignar los recursos necesarios a tu base de datos en función de la carga, como se ilustra en la Figura 4-8.
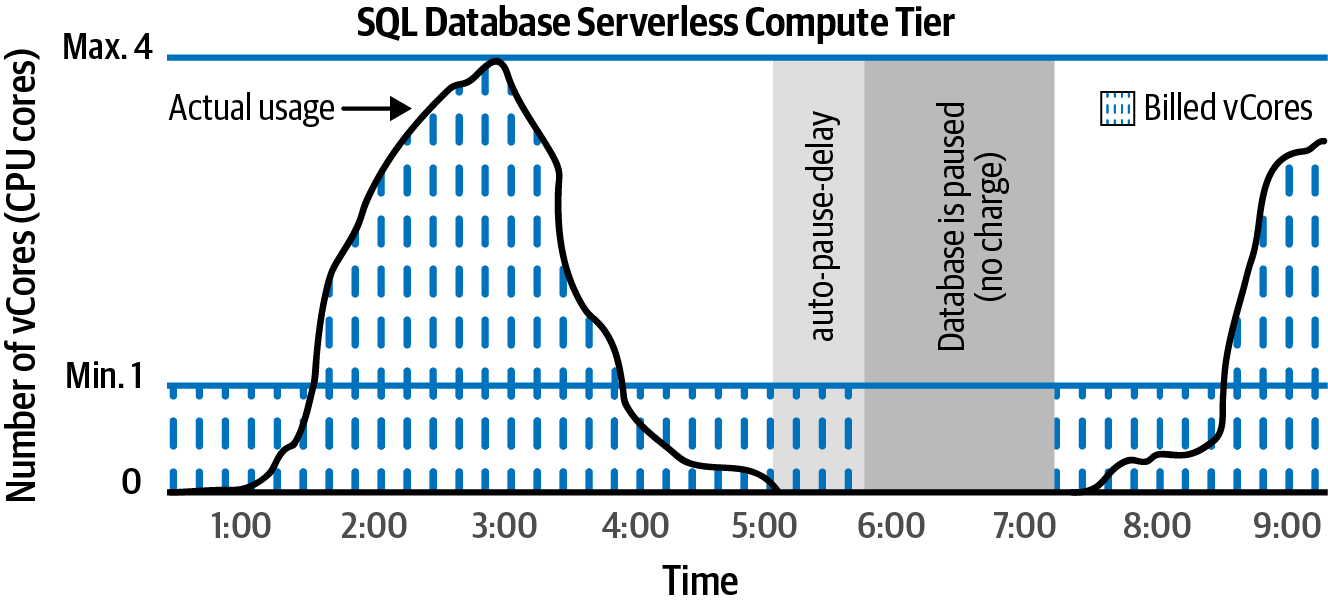
Figura 4-8. Nivel de computación sin servidor de base de datos única Azure SQL
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
Primero aprovisiona un servidor lógico Azure SQL. Sustituye <
logical-sql-server-name>, <admin-user> y <admin-pass> con los valores deseados:logicalServerName="<logical-sql-server-name>" sqlAdminUser="<admin-user>" sqlAdminPass="<admin-pass>" az sql server create \ --resource-group $rgName \ --name $logicalServerName \ --admin-user $sqlAdminUser \ --admin-password $sqlAdminPass
-
Ahora, vamos a crear una nueva base de datos única. El siguiente comando establece los límites mínimo y máximo del número de vCores (núcleos de CPU) asignados a tu base de datos y configurará la base de datos para que se ponga en pausa tras dos horas (120 minutos) de inactividad. La base de datos se reducirá y aumentará automáticamente cuando sea necesario:
# The minimum vCore limit is 1 and the maximum is 4. az sql db create \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --compute-model Serverless \ --edition GeneralPurpose \ --family Gen5 \ --auto-pause-delay 120 \ --min-capacity 1 \ --capacity 4
Consejo
En el momento de escribir este libro, el nivel de computación sin servidor sólo está disponible para la familia de hardware Gen5. Consulta la documentación de la base de datos única Azure SQL para obtener más información sobre los vCores mínimos y máximos admitidos.
-
Por último, utiliza el siguiente comando para obtener los detalles de tu nueva base de datos:
az sql db show \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --query \ "{Name: name, Sku: currentSku, Edition: edition, MinCapacity: minCapacity}" -
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
En esta receta, has aprovisionado una base de datos única Azure SQL utilizando la capa de cálculo sin servidor. Si es necesario, también puedes mover bases de datos individuales Azure SQL existentes de la capa aprovisionada a la capa sin servidor. Consulta la documentación de Azure SQL para conocer los detalles del comando.
Debate
Cuando elijas el modelo de compra vCore para tu base de datos única Azure SQL (en lugar de basado en DTU), tendrás dos opciones para el nivel informático: provisionado y sin servidor.
El nivel aprovisionado de requiere que asignes una cantidad fija de recursos (vCores, memoria, etc.) a tu base de datos. Se te cobrará por estos recursos 24 horas al día, 7 días a la semana. El coste no cambia si tu base de datos está infrautilizada o sobreutilizada. Esto podría dar lugar a problemas de rendimiento cuando tu base de datos reciba más peticiones de las esperadas. También seguirás pagando la factura completa cuando tu base de datos no esté en su pico de uso o incluso cuando esté completamente inactiva. Sin embargo, el nivel de cálculo aprovisionado es una gran opción si conoces el patrón de uso exacto de tu base de datos, o cuando esperas que la base de datos esté a plena carga la mayor parte del tiempo.
Elige el nivel de computación sin servidor cuando quieras que Azure se responsabilice de la asignación de recursos. Establecerás los vCores mínimo y máximo que se asignarán a tu única base de datos y dejarás el resto a Azure. También puedes configurar el retardo de pausa automática, para que tu base de datos se ponga en pausa si está inactiva durante un periodo especificado. Al elegir el nivel sin servidor, sólo se te facturará cuando se utilice la base de datos. Consulta la documentación de Azure para obtener más información sobre el nivel de computación sin servidor.
Configurar las reglas IP del cortafuegos de Azure SQL
Solución
Configura el cortafuegos del servicio Azure SQL para que sólo permita clientes con direcciones IP de confianza, como se muestra en la Figura 4-9.

Figura 4-9. Protección de una base de datos Azure SQL mediante reglas IP de cortafuegos
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
En primer lugar, vamos a aprovisionar un servidor Azure SQL lógico y una base de datos Azure SQL única. Sustituye <
logical-sql-server-name>, <admin-user> y <admin-pass> por los valores deseados:logicalServerName="<logical-sql-server-name>" sqlAdminUser="<admin-user>" sqlAdminPass="<admin-pass>" az sql server create \ --resource-group $rgName \ --name $logicalServerName \ --admin-user $sqlAdminUser \ --admin-password $sqlAdminPass az sql db create \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --compute-model Serverless \ --edition GeneralPurpose \ --family Gen5 \ --auto-pause-delay 60 \ --min-capacity 1 \ --capacity 2
-
Tu objetivo es permitir que los clientes dentro de un rango de IP accedan a Azure SQL. Las demás solicitudes deben ser rechazadas. Utiliza el siguiente comando para crear la regla del servidor cortafuegos:
az sql server firewall-rule create \ --resource-group $rgName \ --server $logicalServerName \ --name allowTrustedClients \ --start-ip-address 99.0.0.0 \ --end-ip-address 99.0.0.255
Consejo
Esta regla de cortafuegos se asigna al servidor lógico Azure SQL, y se aplica a todas las bases de datos hijas bajo este servidor. También puedes crear reglas de cortafuegos IP sólo a nivel de base de datos utilizando sentencias Transact-SQL una vez configurado el cortafuegos a nivel de servidor. Consulta la documentación de Azure para obtener más detalles.
-
Hasta ahora has permitido un rango de IP de confianza. ¿Y si necesitas permitir que todos los servicios de Azure accedan a tus bases de datos Azure SQL? Puedes conseguirlo con la dirección IP especial 0.0.0.0. Vamos a añadir esta regla utilizando Azure CLI:
az sql server firewall-rule create \ --resource-group $rgName \ --server $logicalServerName \ --name allowAzureServices \ --start-ip-address 0.0.0.0 \ --end-ip-address 0.0.0.0
-
Puedes ver las reglas del cortafuegos asignadas a tu servidor lógico Azure SQL utilizando el siguiente comando:
az sql server firewall-rule list \ --resource-group $rgName \ --server $logicalServerName
-
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
En esta receta, has configurado el cortafuegos Azure SQL para permitir clientes de un rango de IP de confianza, así como conexiones desde direcciones IP asignadas a cualquier servicio o activo de Azure.
Debate
Varios servicios de datos de Azure, como Azure Storage, Azure Cosmos DB, Azure Synapse Analytics y Azure SQL, ofrecen un cortafuegos a nivel de servicio. Utiliza este cortafuegos para mejorar la postura de seguridad de tus servicios de datos de Azure. El cortafuegos de Azure SQL es una potente herramienta para evitar que clientes no deseados accedan a tus datos.
Cuando asignes una regla de cortafuegos al servidor lógico Azure SQL, también se protegerán todas las bases de datos hijas. Ten en cuenta que también puedes crear reglas de cortafuegos a nivel de base de datos, de forma que sólo se proteja la base de datos para la que se haya creado la regla. Consulta la documentación de Azure SQL para más detalles.
Nota
También puedes permitir el tráfico de las redes virtuales de Azure mediante reglas VNet. Hablaremos de esta opción en "Configuración de las reglas VNet del cortafuegos de Azure SQL".
Configuración de las reglas VNet del cortafuegos Azure SQL
Solución
Configura el cortafuegos del servicio Azure SQL para permitir clientes dentro de una subred Azure VNet de confianza, como se ilustra en la Figura 4-10.
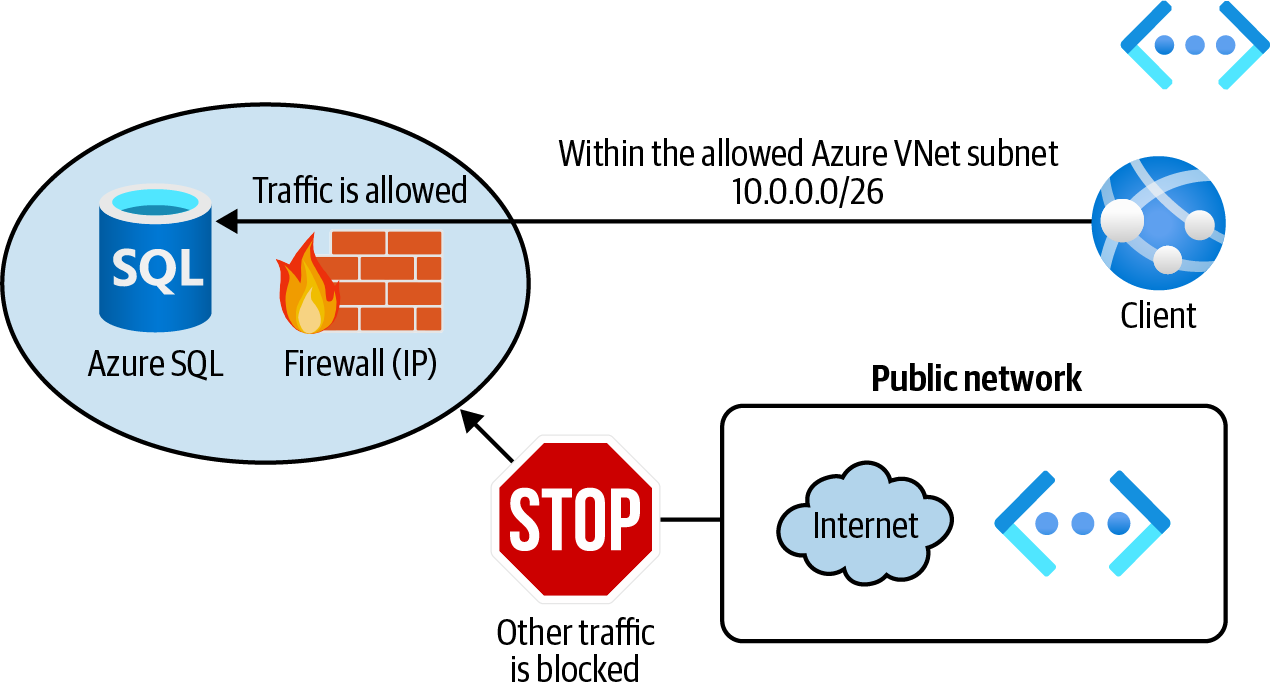
Figura 4-10. Proteger una base de datos Azure SQL utilizando las reglas VNet del cortafuegos
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
Sigue el paso 1 de "Configuración de las reglas IP del cortafuegos de Azure SQL" para crear un nuevo servidor lógico Azure SQL y una única base de datos.
-
Tu objetivo es permitir que los clientes de una subred Azure VNet de confianza accedan a Azure SQL. Vamos a crear una nueva Azure VNet y una subred hija:
vnetName="<vnet-name>" az network vnet create \ --resource-group $rgName \ --name $vnetName \ --address-prefix 10.0.0.0/16 \ --subnet-name Subnet01 \ --subnet-prefix 10.0.0.0/26
-
Para que los clientes de esta subred puedan acceder a la base de datos Azure SQL, tenemos que añadir el punto final del servicio
Microsoft.Sqla la subred:az network vnet subnet update \ --resource-group $rgName \ --name Subnet01 \ --vnet-name $vnetName \ --service-endpoints Microsoft.Sql
-
Por último, utiliza el siguiente comando para crear una nueva regla de VNet para
Subnet01:az sql server vnet-rule create \ --resource-group $rgName \ --server $logicalServerName \ --name allowTrustedSubnet \ --vnet-name $vnetName \ --subnet Subnet01
-
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
Has configurado correctamente el cortafuegos de Azure SQL para permitir que los clientes de Subnet01 trabajen con tu base de datos Azure SQL. Consulta la documentación del cortafuegos del servicio Azure SQL para obtener más detalles.
Debate
Utiliza las reglas VNet del cortafuegos de Azure SQL con reglas IP para proporcionar protección frente a las solicitudes entrantes en función de la dirección IP del cliente y de la red virtual.
En las Recetas 4.10 y 4.11, hablamos de las reglas IP y VNet del cortafuegos de Azure SQL. Estas reglas protegen tus bases de datos Azure SQL contra las peticiones entrantes. El cortafuegos Azure SQL también ofrece reglas de salida para limitar el tráfico de salida de tu base de datos. Consulta la documentación del cortafuegos de Azure para conocer los detalles de implementación.
Copia de seguridad de bases de datos Azure SQL Single en Azure Storage Blobs
Solución
Almacena las copias de seguridad de Azure SQL en blobs de Azure Storage utilizando Azure CLI, como se muestra en la Figura 4-11.

Figura 4-11. Copia de seguridad de una base de datos SQL de Azure en blobs de Azure Storage
Pasos
-
Accede a tu suscripción de Azure con el rol de Propietario y crea un nuevo grupo de recursos para esta receta. Consulta "Instrucciones generales de configuración de la estación de trabajo" para más detalles.
-
En primer lugar, vamos a aprovisionar una nueva base de datos Azure SQL single y a sembrarla con la base de datos de ejemplo AdventureWorks. Sustituye <
logical-sql-server-name>, <admin-user> y <admin-pass> por los valores deseados:logicalServerName="<logical-sql-server-name>" sqlAdminUser="<admin-user>" sqlAdminPass="<admin-pass>" az sql server create \ --resource-group $rgName \ --name $logicalServerName \ --admin-user $sqlAdminUser \ --admin-password $sqlAdminPass az sql db create \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --compute-model Serverless \ --edition GeneralPurpose \ --family Gen5 \ --auto-pause-delay 60 \ --min-capacity 0.5 \ --capacity 2 \ --sample-name AdventureWorksLT
-
Tienes que permitir que los servicios de Azure accedan a las nuevas bases de datos Azure SQL para que se cree y guarde la copia de seguridad. Utiliza el siguiente comando para configurar el cortafuegos de Azure SQL:
az sql server firewall-rule create \ --resource-group $rgName \ --server $logicalServerName \ --name allowAzureServices \ --start-ip-address 0.0.0.0 \ --end-ip-address 0.0.0.0
-
Ahora tienes que crear una nueva cuenta de almacenamiento Azure y un contenedor hijo:
storageName="<storage-account-name>" bakContainerName="sqlbackups" # we chose the locally redundant storage (LRS) sku but you may need # to choose a better redundancy for your Azure SQL backups. az storage account create \ --name $storageName \ --resource-group $rgName \ --sku Standard_LRS storageKey1=$(az storage account keys list \ --resource-group $rgName \ --account-name $storageName \ --query [0].value \ --output tsv) MSYS_NO_PATHCONV=1 az storage container create \ --name $bakContainerName \ --account-name $storageName \ --account-key $storageKey1 -
Necesitas permiso de escritura en tu contenedor Azure Storage. Aquí utilizaremos la clave de la cuenta de almacenamiento para la autenticación. También puedes utilizar tokens SAS de cuenta de almacenamiento como método de autenticación. Consulta la documentación de la CLI de Azure para obtener más detalles. Utiliza el siguiente comando para crear la copia de seguridad de la base de datos:
storageURL= \ "https://$storageName.blob.core.windows.net/\$bakContainerName /sqlbackup01.bacpac" MSYS_NO_PATHCONV=1 az sql db export \ --resource-group $rgName \ --server $logicalServerName \ --name db01 \ --admin-user $sqlAdminUser \ --admin-password $sqlAdminPass \ --storage-key $storageKey1 \ --storage-key-type StorageAccessKey \ --storage-uri $storageURL -
Puedes confirmar que se ha creado el archivo de copia de seguridad enumerando todos los archivos y sus tamaños en el contenedor de almacenamiento:
MSYS_NO_PATHCONV=1 az storage blob list \ --container-name $bakContainerName \ --account-key $storageKey1 \ --account-name $storageName \ --query "[].{Name: name, Length: properties.contentLength}"
Consejo
Como la clave de nuestra cuenta de almacenamiento contiene una barra oblicua (/), se convertirá en una ruta Linux en el entorno Bash, lo que hace que falle el comando CLI. Por eso utilizamos MSYS_NO_PATHCONV=1 antes de los scripts CLI para evitar este problema. Alternativamente, puedes anteponer a tus comandos dos barras inclinadas (//).
-
Ejecuta el siguiente comando para eliminar los recursos que has creado en esta receta:
az group delete --name $rgName
En esta receta, has realizado con éxito una copia de seguridad de una base de datos Azure SQL single en un contenedor Azure Storage.
Debate
Azure Storage ofrece un servicio de almacenamiento asequible, escalable y seguro en la nube. Como viste en el Capítulo 3, puedes proteger tus archivos contra el borrado accidental activando la protección contra el borrado suave.
Los archivos de copia de seguridad pueden almacenarse en los niveles de acceso caliente, frío o incluso de archivo para ahorrar costes.
En esta receta de , utilizamos la opción de redundancia más barata de Azure Storage, que es el almacenamiento redundante local (LRS). Si planeas hacer copias de seguridad de bases de datos SQL de producción, se recomienda que elijas una opción con mejor redundancia, como el almacenamiento redundante por zonas (ZRS), el almacenamiento georredundante (GRS) o el almacenamiento georredundante por zonas (GZRS). Consulta el Capítulo 3 o la documentación de Azure Storage para más detalles.
Get Libro de cocina Azure now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

