Capítulo 4. Bases de datos Bases de datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
4.0 Introducción
Tienes un sinfín de opciones para utilizar bases de datos con AWS. Instalar y ejecutar una base de datos en EC2 te ofrece el mayor número de opciones de motores de bases de datos y configuraciones personalizadas, pero conlleva retos como la aplicación de parches, las copias de seguridad, la configuración de la alta disponibilidad, la replicación y el ajuste del rendimiento. Como se indica en su página de producto, AWS ofrece servicios administrados de bases de datos que ayudan a afrontar estos retos y cubren una amplia gama de tipos de bases de datos (relacionales, clave-valor/NoSQL, en memoria, de documentos, de columnas anchas, de gráficos, de series temporales, de libros mayores). Al elegir un tipo de base de datos y un modelo de datos, debes tener en cuenta la velocidad, el volumen y los patrones de acceso.
Los servicios administrados de bases de datos en AWS se integran con muchos servicios para proporcionarte funcionalidad adicional desde las perspectivas de la seguridad, las operaciones y el desarrollo. En este capítulo, explorarás Amazon Relational Database Service (RDS), el uso de NoSQL con Amazon DynamoDB y las formas de migrar, asegurar y operar estos tipos de bases de datos a escala. Por ejemplo, aprenderás a integrar Secrets Manager con una base de datos RDS para rotar automáticamente las contraseñas de los usuarios de la base de datos. También aprenderás a aprovechar la autenticación de IAM para reducir por completo la dependencia de la aplicación de las contraseñas de la base de datos, concediendo en su lugar acceso a RDS mediante permisos de IAM. Explorarás el autoescalado con DynamoDB y aprenderás por qué es importante desde el punto de vista del coste y el rendimiento.
Nota
Algunas personas piensan que la Ruta 53 es una base de datos, pero nosotros no estamos de acuerdo :-)
Nota
Algunos motores de bases de datos han utilizado en el pasado cierta terminología para las configuraciones de réplica, los nombres de usuario raíz por defecto, las tablas primarias, etc. Hemos procurado utilizar terminología inclusiva en este capítulo (y en todo el libro) siempre que ha sido posible. Apoyamos el movimiento para utilizar terminología inclusiva en estos motores de bases de datos comerciales y de código abierto.
Configuración del puesto de trabajo
Sigue los "Pasos generales de configuración de la estación de trabajo para las recetas CLI" para validar tu configuración y establecer las variables de entorno necesarias. A continuación, clona el repositorio de código del capítulo:
git clone https://github.com/AWSCookbook/Databases
Advertencia
Durante algunos de los pasos de este capítulo, crearás contraseñas y las guardarás temporalmente como variables de entorno para utilizarlas en pasos posteriores. Asegúrate de desactivar las variables de entorno siguiendo los pasos de limpieza cuando termines la receta. Utilizamos este enfoque para simplificar la comprensión. En entornos de producción debería utilizarse un método más seguro (como el método utilizado en la Receta 1.8).
4.1 Crear una base de datos PostgreSQL sin servidor de Amazon Aurora
Problema
Tienes una aplicación web que recibe peticiones impredecibles que requieren almacenamiento en una base de datos relacional. Necesitas una solución de base de datos que pueda escalar con el uso y sea rentable. Te gustaría construir una solución que tenga una baja sobrecarga operativa y debe ser compatible con tu aplicación existente respaldada por PostgreSQL.
Solución
Configura y crea un clúster de bases de datos sin servidor Aurora con una contraseña compleja. A continuación, aplica una configuración de escalado personalizada y activa la pausa automática tras la inactividad. La actividad de escalado en respuesta a la política se muestra en la Figura 4-1.
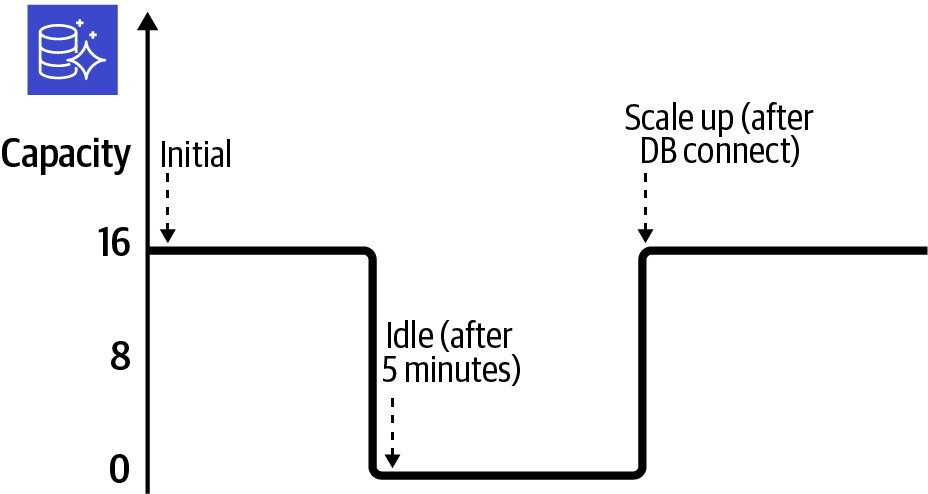
Figura 4-1. Clúster sin servidor Aurora escalando computación
Requisitos previos
-
VPC con subredes aisladas creadas en dos AZ y tablas de rutas asociadas.
-
Instancia EC2 implementada. Necesitarás poder conectarte a ella para realizar pruebas.
Preparación
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Pasos
-
Utiliza AWS Secrets Manager para generar una contraseña compleja:
ADMIN_PASSWORD=$(aws secretsmanager get-random-password \ --exclude-punctuation \ --password-length 41 --require-each-included-type \ --output text \ --query RandomPassword)Nota
Estamos excluyendo los caracteres de puntuación de la contraseña que estamos creando porque PostgreSQL no los admite. Consulta la tabla"Restricciones de nombres en Amazon RDS".
-
Crea un grupo de subredes de base de datos que especifique las subredes de la VPC que se utilizarán para el clúster. Los grupos de subredes de base de datos simplifican la colocación en de las interfaces de red elásticas (ENI) de RDS:
aws rds create-db-subnet-group \ --db-subnet-group-name awscookbook401subnetgroup \ --db-subnet-group-description "AWSCookbook401 subnet group" \ --subnet-ids $SUBNET_ID_1 $SUBNET_ID_2Deberías ver una salida similar a la siguiente:
{ "DBSubnetGroup": { "DBSubnetGroupName": "awscookbook402subnetgroup", "DBSubnetGroupDescription": "AWSCookbook401 subnet group", "VpcId": "vpc-<<VPCID>>", "SubnetGroupStatus": "Complete", "Subnets": [ { "SubnetIdentifier": "subnet-<<SUBNETID>>", "SubnetAvailabilityZone": { "Name": "us-east-1b" }, "SubnetOutpost": {}, "SubnetStatus": "Active" }, ... -
Crea un grupo de seguridad VPC para la base de datos:
DB_SECURITY_GROUP_ID=$(aws ec2 create-security-group \ --group-name AWSCookbook401sg \ --description "Aurora Serverless Security Group" \ --vpc-id $VPC_ID --output text --query GroupId) -
Crea un clúster de base de datos , especificando un
engine-modedeserverless:aws rds create-db-cluster \ --db-cluster-identifier awscookbook401dbcluster \ --engine aurora-postgresql \ --engine-mode serverless \ --engine-version 10.14 \ --master-username dbadmin \ --master-user-password $ADMIN_PASSWORD \ --db-subnet-group-name awscookbook401subnetgroup \ --vpc-security-group-ids $DB_SECURITY_GROUP_IDDeberías ver una salida similar a la siguiente:
{ "DBCluster": { "AllocatedStorage": 1, "AvailabilityZones": [ "us-east-1f", "us-east-1b", "us-east-1a" ], "BackupRetentionPeriod": 1, "DBClusterIdentifier": "awscookbook401dbcluster", "DBClusterParameterGroup": "default.aurora-postgresql10", "DBSubnetGroup": "awscookbook401subnetgroup", "Status": "creating", ... -
Espera a que el Estado indique disponible; esto tardará unos instantes:
aws rds describe-db-clusters \ --db-cluster-identifier awscookbook401dbcluster \ --output text --query DBClusters[0].Status -
Modifica la base de datos para que escale automáticamente con nuevos objetivos de capacidad de autoescalado (8 min, 16 max) y habilita
AutoPausetras cinco minutos de inactividad:aws rds modify-db-cluster \ --db-cluster-identifier awscookbook401dbcluster --scaling-configuration \ MinCapacity=8,MaxCapacity=16,SecondsUntilAutoPause=300,TimeoutAction='ForceApplyCapacityChange',AutoPause=trueDeberías ver una salida en similar a la que viste en el paso 4.
Nota
En la práctica, puede que quieras utilizar un valor diferente de
AutoPause. Para determinar cuál es el adecuado para tu uso, evalúa tus necesidades de rendimiento y los precios de Aurora.Espera al menos cinco minutos y observa que la capacidad de la base de datos se ha reducido a 0:
aws rds describe-db-clusters \ --db-cluster-identifier awscookbook401dbcluster \ --output text --query DBClusters[0].CapacityNota
La función
AutoPauseestablece automáticamente la capacidad del clúster en 0 tras la inactividad. Cuando se reanude la actividad de tu base de datos (por ejemplo, con una consulta o conexión), el valor de capacidad de se establecerá automáticamente en el valor de capacidad de escalado mínimo que hayas configurado. -
Concede al grupo de seguridad de tu instancia EC2 acceso al puerto PostgreSQL predeterminado:
aws ec2 authorize-security-group-ingress \ --protocol tcp --port 5432 \ --source-group $INSTANCE_SG \ --group-id $DB_SECURITY_GROUP_IDDeberías ver una salida similar a la siguiente:
{ "Return": true, "SecurityGroupRules": [ { "SecurityGroupRuleId": "sgr-<<ID>>", "GroupId": "sg-<<ID>>", "GroupOwnerId": "111111111111", "IsEgress": false, "IpProtocol": "tcp", "FromPort": 5432, "ToPort": 5432, "ReferencedGroupInfo": { "GroupId": "sg-<<ID>>" } } ] }
Comprobaciones de validación
Enumera el punto final del clúster RDS:
aws rds describe-db-clusters \
--db-cluster-identifier awscookbook401dbcluster \
--output text --query DBClusters[0].Endpoint
Deberías ver algo parecido a esto:
awscookbook401dbcluster.cluster-<<unique>>.us-east-1.rds.amazonaws.com
Recupera la contraseña de tu clúster RDS:
echo $ADMIN_PASSWORD
Conéctate a la instancia EC2 utilizando el Gestor de Sesiones SSM (ver Receta 1.6):
aws ssm start-session --target $INSTANCE_ID
Instala el paquete PostgreSQL para que puedas utilizar el comando psql para conectarte a la base de datos:
sudo yum -y install postgresql
Conéctate a la base de datos. Esto puede tardar un momento, ya que la capacidad de la base de datos está aumentando desde 0. Tendrás que copiar y pegar la contraseña (obtenida anteriormente):
psql -h $HOST_NAME -U dbadmin -W -d postgres
He aquí un ejemplo de conexión a una base de datos mediante el comando psql:
sh-4.2$ psql -h awscookbook401dbcluster.cluster-<<unique>>.us-east-1.rds.amazonaws.com -U dbadmin -W -d postgres Password for user dbadmin:(paste in the password)
Sal de psql:
\q
Sal de la sesión del Administrador de Sesiones:
exit
Comprueba de nuevo la capacidad del cluster para observar que la base de datos ha escalado hasta el valor mínimo que configuraste:
aws rds describe-db-clusters \
--db-cluster-identifier awscookbook401dbcluster \
--output text --query DBClusters[0].Capacity
Limpieza
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Consejo
El comportamiento por defecto al eliminar un clúster RDS es tomar una instantánea final como mecanismo de seguridad. Hemos optado por omitir este comportamiento añadiendo la opción --skip-final-snapshot para asegurarnos de que no incurres en ningún coste por almacenar la instantánea en tu cuenta de AWS. En un escenario del mundo real, probablemente querrías conservar la instantánea durante un periodo de tiempo por si necesitaras volver a crear la base de datos existente a partir de la instantánea.
Debate
El clúster escalará automáticamente la capacidad para satisfacer las necesidades de tu uso. Configurando MaxCapacity=16 limitas el límite superior de tu capacidad para evitar un uso desbocado y costes inesperados. El clúster pondrá su capacidad a 0 cuando no se detecte ninguna conexión o actividad. Esto se activa cuando se alcanza el valor SecondsUntilAutoPause.
Cuando activas AutoPause=true para tu clúster, sólo pagas por el almacenamiento subyacente durante los periodos de inactividad. El "periodo de inactividad" por defecto (y mínimo) es de cinco minutos. Conectarse a un clúster en pausa hará que la capacidad escale a MinCapacity.
Advertencia
No todos los motores y versiones de bases de datos están disponibles con el motor sin servidor. En el momento de escribir esto, las FAQ de Aurora afirman que Aurora Serverless está disponible actualmente para Aurora con compatibilidad MySQL 5.6 y para Aurora con compatibilidad PostgreSQL 10.7+.
La guía del usuario indica que el escalado sin servidor de Aurora es medido en unidades de capacidad (CU) que corresponden al cálculo y la memoria reservados para tu clúster. Esta capacidad se adapta bien a muchas cargas de trabajo y casos de uso, desde el desarrollo hasta las cargas de trabajo por lotes, pasando por las cargas de trabajo de producción en las que el tráfico es impredecible y los costes asociados a un posible sobreaprovisionamiento son motivo de preocupación. Al no necesitar calcular patrones de uso de referencia, puedes empezar a desarrollar rápidamente, y el clúster responderá automáticamente a la demanda que requiera tu aplicación.
Si actualmente utilizas un clúster de tipo de capacidad "provisionada" en Amazon RDS y te gustaría empezar a utilizar Aurora Serverless, puedes hacer un snapshot de tu base de datos actual y restaurarla desde la consola de AWS o desde la línea de comandos para realizar una migración. Si tu base de datos actual no está en RDS, puedes utilizar las funciones de volcado y restauración de tu motor de base de datos o utilizar el Servicio de Migración de Bases de Datos de AWS (AWS DMS) para migrar a RDS.
Nota
En el momento de escribir esto, Amazon Aurora Serverless v2 está en fase de previsualización.
La guía del usuario menciona que Aurora Serverless se basa en la plataforma Aurora existente, que replica el almacenamiento subyacente de tu base de datos de seis maneras a través de tres Zonas de Disponibilidad. Aunque esta replicación es una ventaja para la resiliencia, debes seguir utilizando copias de seguridad automatizadas de tu base de datos para protegerla de errores operativos. Aurora Serverless tiene las copias de seguridad automatizadas activadas por defecto, y la retención de la copia de seguridad puede aumentarse hasta 35 días si es necesario.
Nota
Según la documentación, si tu clúster de base de datos ha estado inactivo durante más de siete días, se realizará una copia de seguridad del clúster con una instantánea. Si esto ocurre, el clúster de base de datos se restaurará cuando haya una solicitud para conectarse a él.
4.2 Utilizar la autenticación de IAM con una base de datos RDS
Solución
Primero activarás la autenticación IAM para tu base de datos. A continuación, configurarás los permisos de IAM para que los utilice la instancia EC2. Por último, crearás un nuevo usuario en la base de datos, recuperarás el token de autenticación IAM y verificarás la conectividad (ver Figura 4-2).

Figura 4-2. Autenticación IAM desde una instancia EC2 a una base de datos RDS
Requisitos previos
-
VPC con subredes aisladas creadas en dos AZ y tablas de rutas asociadas.
-
Una instancia MySQL RDS.
-
Instancia EC2 implementada. Necesitarás poder conectarte a ella para configurar MySQL y realizar pruebas.
Preparación
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Pasos
-
Activa la autenticación de base de datos IAM en la instancia de base de datos RDS:
aws rds modify-db-instance \ --db-instance-identifier $RDS_DATABASE_ID \ --enable-iam-database-authentication \ --apply-immediatelyDeberías ver una salida similar a la siguiente:
{ "DBInstance": { "DBInstanceIdentifier": "awscookbookrecipe402", "DBInstanceClass": "db.m5.large", "Engine": "mysql", "DBInstanceStatus": "available", "MasterUsername": "admin", "DBName": "AWSCookbookRecipe402", "Endpoint": { "Address": "awscookbookrecipe402.<<ID>>.us-east-1.rds.amazonaws.com", "Port": 3306, "HostedZoneId": "<<ID>>" }, ...Advertencia
La autenticación de base de datos de IAM sólo está disponible para los motores de base de datos enumerados en este artículo de AWS.
-
Recupera el ID del recurso de instancia de base de datos RDS:
DB_RESOURCE_ID=$(aws rds describe-db-instances \ --query \ 'DBInstances[?DBName==`AWSCookbookRecipe402`].DbiResourceId' \ --output text) -
Crea un archivo llamado policy.json con el siguiente contenido (en el repositorio se proporciona un archivo policy-template.json ):
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "rds-db:connect" ], "Resource": [ "arn:aws:rds-db:AWS_REGION:AWS_ACCOUNT_ID:dbuser:DBResourceId/db_user" ] } ] }Nota
En el ejemplo anterior,
db_userdebe coincidir con el nombre del usuario de la base de datos al que queremos permitir conectarse. -
Sustituye los valores del archivo de plantilla utilizando el comando
sedpor las variables de entorno que hayas establecido:sed -e "s/AWS_ACCOUNT_ID/${AWS_ACCOUNT_ID}/g" \ -e "s|AWS_REGION|${AWS_REGION}|g" \ -e "s|DBResourceId|${DB_RESOURCE_ID}|g" \ policy-template.json > policy.json -
Crea una política IAM utilizando el archivo que acabas de crear:
aws iam create-policy --policy-name AWSCookbook402EC2RDSPolicy \ --policy-document file://policy.jsonDeberías ver una salida similar a la siguiente:
{ "Policy": { "PolicyName": "AWSCookbook402EC2RDSPolicy", "PolicyId": "<<ID>>", "Arn": "arn:aws:iam::111111111111:policy/AWSCookbook402EC2RDSPolicy", "Path": "/", "DefaultVersionId": "v1", "AttachmentCount": 0, "PermissionsBoundaryUsageCount": 0, "IsAttachable": true, "CreateDate": "2021-09-21T21:18:54+00:00", "UpdateDate": "2021-09-21T21:18:54+00:00" } } -
Adjunta la política IAM
AWSCookbook402EC2RDSPolicyal rol IAM que utiliza el EC2:aws iam attach-role-policy --role-name $INSTANCE_ROLE_NAME \ --policy-arn arn:aws:iam::$AWS_ACCOUNT_ID:policy/AWSCookbook402EC2RDSPolicy -
Recupera la contraseña de administrador del RDS del Gestor de Secretos:
RDS_ADMIN_PASSWORD=$(aws secretsmanager get-secret-value \ --secret-id $RDS_SECRET_ARN \ --query SecretString | jq -r | jq .password | tr -d '"') -
Texto de salida para que puedas utilizarlo más tarde cuando te conectes a la instancia EC2.
Enumera el punto final del clúster RDS:
echo $RDS_ENDPOINT
Deberías ver una salida similar a la siguiente:
awscookbookrecipe402.<<unique>>.us-east-1.rds.amazonaws.com
Lista la contraseña del clúster RDS:
echo $RDS_ADMIN_PASSWORD
-
Conéctate a la instancia EC2 utilizando el Gestor de Sesiones SSM (ver Receta 1.6):
aws ssm start-session --target $INSTANCE_ID
-
Instala MySQL:
sudo yum -y install mysql
-
Conéctate a la base de datos. Tendrás que copiar y pegar la contraseña y el nombre de host (obtenidos en los pasos 7 y 8):
mysql -u admin -p$DB_ADMIN_PASSWORD -h $RDS_ENDPOINT
Deberías ver una salida similar a la siguiente:
Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 18 Server version: 8.0.23 Source distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]>
Nota
En el comando
mysqldel paso 11, no hay ningún espacio entre la bandera-py el primer carácter de la contraseña. -
Crea un nuevo usuario de base de datos para asociarlo a la autenticación IAM:
CREATE USER db_user@'%' IDENTIFIED WITH AWSAuthenticationPlugin as 'RDS'; GRANT SELECT ON *.* TO 'db_user'@'%';
Para ambos comandos del paso 12, deberías ver una salida similar a la siguiente:
Query OK, 0 rows affected (0.01 sec)
-
Ahora, sal del indicador
mysql:quit
Comprobaciones de validación
Mientras aún estás en la instancia EC2, descarga el archivo RDS Root CA (autoridad de certificación) proporcionado por Amazon desde el bucket S3 rds-downloads:
sudo wget https://s3.amazonaws.com/rds-downloads/rds-ca-2019-root.pem
Establece la Región tomando el valor de los metadatos de la instancia:
export AWS_DEFAULT_REGION=$(curl --silent http://169.254.169.254/latest/dynamic/instance-identity/document \
| awk -F'"' ' /region/ {print $4}')
Genera el token de autenticación RDS y guárdalo como variable. Tendrás que copiar y pegar el nombre de host (obtenido en el paso 8):
TOKEN="$(aws rds generate-db-auth-token --hostname $RDS_ENDPOINT --port 3306 --username db_user)"
Conéctate a la base de datos utilizando el token de autenticación RDS con el nuevo db_user. Tendrás que copiar y pegar el nombre de host (obtenido en el paso 8):
mysql --host=$RDS_ENDPOINT --port=3306 \
--ssl-ca=rds-ca-2019-root.pem \
--user=db_user --password=$TOKEN
Ejecuta una consulta SELECT en el indicador mysql para verificar que este usuario tiene la concesión SELECT *.* que le has aplicado:
SELECT user FROM mysql.user;
Deberías ver una salida similar a la siguiente:
MySQL [(none)]> SELECT user FROM mysql.user; +------------------+ | user | +------------------+ | admin | | db_user | | mysql.infoschema | | mysql.session | | mysql.sys | | rdsadmin | +------------------+ 6 rows in set (0.00 sec)
Sal del indicador mysql:
quit
Sal de la sesión del Administrador de Sesiones:
exit
Limpieza
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Debate
En lugar de una contraseña en tu cadena de conexión MySQL, recuperaste y utilizaste un token asociado al rol IAM de la instancia EC2. La documentación de IAM indica que este token dura 15 minutos. Si instalas una aplicación en esta instancia EC2, el código puede actualizar regularmente este token utilizando el SDK de AWS. No es necesario rotar las contraseñas de tu usuario de base de datos porque el token antiguo se invalidará pasados 15 minutos.
Puedes crear varios usuarios de base de datos asociados a concesiones específicas para permitir que tu aplicación mantenga distintos niveles de acceso a tu base de datos. Las concesiones se producen dentro de la base de datos, no dentro de los permisos de IAM. IAM controla la acción db-connect para el usuario específico. Esta acción de IAM permite recuperar el token de autenticación. Ese nombre de usuario se asigna desde IAM a la(s) CONCESIÓN(es) utilizando el mismo nombre de usuario dentro de la base de datos que en el archivo policy.json:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"rds-db:connect"
],
"Resource": [
"arn:aws:rds-db:AWS_REGION::dbuser:DBResourceId/db_user"
]
}
]
}
En esta receta, también has activado el cifrado en tránsito especificando el paquete de certificados SSL que has descargado en la instancia EC2 en tu comando de conexión a la base de datos. Esto encripta la conexión entre tu aplicación y tu base de datos. Se trata de una buena práctica de seguridad y a menudo es necesaria para muchas normas de cumplimiento. La cadena de conexión que utilizaste para conectarte con el token de autenticación IAM indicaba un certificado SSL como uno de los parámetros de conexión. El paquete de autoridad de certificación está disponible para descargarlo de AWS y utilizarlo en tu aplicación.
4.3 Aprovechar el proxy RDS para conexiones a bases de datos desde Lambda
Solución
Crea un Proxy RDS, asócialo a tu base de datos MySQL RDS y configura tu Lambda para que se conecte al proxy en lugar de acceder directamente a la base de datos (ver Figura 4-3).
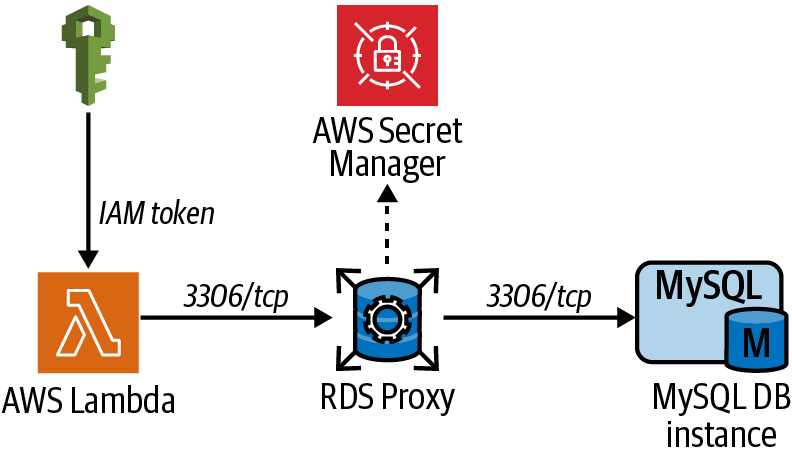
Figura 4-3. Ruta de conexión de Lambda a la base de datos a través del proxy RDS
Requisitos previos
-
VPC con subredes aisladas creadas en dos AZ y tablas de rutas asociadas
-
Una instancia RDS MySQL
-
Una función Lambda que quieras conectar a tu base de datos RDS
Preparación
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Pasos
-
Crea un archivo llamado assume-role-policy.json con el siguiente contenido (archivo proporcionado en el repositorio):
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } -
Crea un rol IAM para el Proxy RDS utilizando el archivo assume-role-policy.json:
aws iam create-role --assume-role-policy-document \ file://assume-role-policy.json --role-name AWSCookbook403RDSProxyDeberías ver una salida similar a la siguiente:
{ "Role": { "Path": "/", "RoleName": "AWSCookbook403RDSProxy", "RoleId": "<<ID>>", "Arn": "arn:aws:iam::111111111111:role/AWSCookbook403RDSProxy", "CreateDate": "2021-09-21T22:33:57+00:00", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } } } -
Crea un grupo de seguridad para que sea utilizado por el Proxy RDS:
RDS_PROXY_SG_ID=$(aws ec2 create-security-group \ --group-name AWSCookbook403RDSProxySG \ --description "Lambda Security Group" --vpc-id $VPC_ID \ --output text --query GroupId) -
Crea el Proxy RDS. Esto te llevará unos instantes:
RDS_PROXY_ENDPOINT_ARN=$(aws rds create-db-proxy \ --db-proxy-name $DB_NAME \ --engine-family MYSQL \ --auth '{ "AuthScheme": "SECRETS", "SecretArn": "'"$RDS_SECRET_ARN"'", "IAMAuth": "REQUIRED" }' \ --role-arn arn:aws:iam::$AWS_ACCOUNT_ID:role/AWSCookbook403RDSProxy \ --vpc-subnet-ids $ISOLATED_SUBNETS \ --vpc-security-group-ids $RDS_PROXY_SG_ID \ --require-tls --output text \ --query DBProxy.DBProxyArn)Espera a que el Proxy RDS esté disponible:
aws rds describe-db-proxies \ --db-proxy-name $DB_NAME \ --query DBProxies[0].Status \ --output text -
Recupera el
RDS_PROXY_ENDPOINT:RDS_PROXY_ENDPOINT=$(aws rds describe-db-proxies \ --db-proxy-name $DB_NAME \ --query DBProxies[0].Endpoint \ --output text) -
A continuación necesitas una política IAM que permita a la función Lambda generar tokens de autenticación IAM. Crea un archivo llamado template-policy.json con el siguiente contenido (archivo proporcionado en el repositorio):
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "rds-db:connect" ], "Resource": [ "arn:aws:rds-db:AWS_REGION:AWS_ACCOUNT_ID:dbuser:RDSProxyID/admin" ] } ] } -
Separa el ID de Proxy del ARN del punto final del Proxy RDS. El ID de Proxy es necesario para configurar las políticas de IAM en los pasos siguientes:
RDS_PROXY_ID=$(echo $RDS_PROXY_ENDPOINT_ARN | awk -F: '{ print $7} ') -
Sustituye los valores del archivo de plantilla utilizando el comando
sedpor las variables de entorno que hayas establecido:sed -e "s/AWS_ACCOUNT_ID/${AWS_ACCOUNT_ID}/g" \ -e "s|AWS_REGION|${AWS_REGION}|g" \ -e "s|RDSProxyID|${RDS_PROXY_ID}|g" \ policy-template.json > policy.json -
Crea una política IAM utilizando el archivo que acabas de crear:
aws iam create-policy --policy-name AWSCookbook403RdsIamPolicy \ --policy-document file://policy.jsonDeberías ver una salida similar a la siguiente:
{ "Policy": { "PolicyName": "AWSCookbook403RdsIamPolicy", "PolicyId": "<<Id>>", "Arn": "arn:aws:iam::111111111111:policy/AWSCookbook403RdsIamPolicy", "Path": "/", "DefaultVersionId": "v1", "AttachmentCount": 0, "PermissionsBoundaryUsageCount": 0, "IsAttachable": true, "CreateDate": "2021-09-21T22:50:24+00:00", "UpdateDate": "2021-09-21T22:50:24+00:00" } } -
Adjunta la política al rol de la función DBAppFunction Lambda:
aws iam attach-role-policy --role-name $DB_APP_FUNCTION_ROLE_NAME \ --policy-arn arn:aws:iam::$AWS_ACCOUNT_ID:policy/AWSCookbook403RdsIamPolicyUtiliza este comando para comprobar cuándo entra el proxy en el estado disponible y proceder a continuación:
aws rds describe-db-proxies --db-proxy-name $DB_NAME \ --query DBProxies[0].Status \ --output text -
Adjunta la política
SecretsManagerReadWriteal rol del Proxy RDS :aws iam attach-role-policy --role-name AWSCookbook403RDSProxy \ --policy-arn arn:aws:iam::aws:policy/SecretsManagerReadWriteConsejo
En un escenario de producción, querrás limitar este permiso a los recursos secretos mínimos a los que tu aplicación necesite acceder, en lugar de conceder
SecretsManagerReadWrite, que permite la lectura/escritura de todos los secretos. -
Añade una regla de entrada al grupo de seguridad de la instancia RDS que permita el acceso en el puerto TCP 3306 (el puerto TCP por defecto del motor MySQL) desde el grupo de seguridad Proxy RDS:
aws ec2 authorize-security-group-ingress \ --protocol tcp --port 3306 \ --source-group $RDS_PROXY_SG_ID \ --group-id $RDS_SECURITY_GROUPDeberías ver una salida similar a la siguiente:
{ "Return": true, "SecurityGroupRules": [ { "SecurityGroupRuleId": "sgr-<<ID>>", "GroupId": "sg-<<ID>>", "GroupOwnerId": "111111111111", "IsEgress": false, "IpProtocol": "tcp", "FromPort": 3306, "ToPort": 3306, "ReferencedGroupInfo": { "GroupId": "sg-<<ID>>" } } ] }Nota
Los grupos de seguridad pueden hacer referencia a otros grupos de seguridad. Debido a las direcciones IP dinámicas dentro de las VPC, ésta se considera la mejor forma de conceder acceso sin abrir demasiado tu grupo de seguridad. Para más información, consulta la Receta 2.5.
-
Registra los objetivos con el Proxy RDS:
aws rds register-db-proxy-targets \ --db-proxy-name $DB_NAME \ --db-instance-identifiers $RDS_DATABASE_IDDeberías ver una salida similar a la siguiente:
{ "DBProxyTargets": [ { "Endpoint": "awscookbook403db.<<ID>>.us-east-1.rds.amazonaws.com", "RdsResourceId": "awscookbook403db", "Port": 3306, "Type": "RDS_INSTANCE", "TargetHealth": { "State": "REGISTERING" } } ] }Comprueba el estado del registro del objetivo con este comando. Espera hasta que el Estado llegue a DISPONIBLE:
aws rds describe-db-proxy-targets \ --db-proxy-name awscookbookrecipe403 \ --query Targets[0].TargetHealth.State \ --output text -
Añade una regla de entrada al grupo de seguridad Proxy RDS que permita el acceso en el puerto TCP 3306 desde el grupo de seguridad de la función Lambda App:
aws ec2 authorize-security-group-ingress \ --protocol tcp --port 3306 \ --source-group $DB_APP_FUNCTION_SG_ID \ --group-id $RDS_PROXY_SG_IDDeberías ver una salida similar a la siguiente:
{ "Return": true, "SecurityGroupRules": [ { "SecurityGroupRuleId": "sgr-<<ID>>", "GroupId": "sg-<<ID>>", "GroupOwnerId": "111111111111", "IsEgress": false, "IpProtocol": "tcp", "FromPort": 3306, "ToPort": 3306, "ReferencedGroupInfo": { "GroupId": "sg-<<ID>>" } } ] } -
Modifica la función Lambda para que ahora utilice el punto final del Proxy RDS como
DB_HOST, en lugar de conectarse directamente a la base de datos:aws lambda update-function-configuration \ --function-name $DB_APP_FUNCTION_NAME \ --environment Variables={DB_HOST=$RDS_PROXY_ENDPOINT}Deberías ver una salida similar a la siguiente:
{ "FunctionName": "cdk-aws-cookbook-403-LambdaApp<<ID>>", "FunctionArn": "arn:aws:lambda:us-east-1:111111111111:function:cdk-aws-cookbook-403-LambdaApp<<ID>>", "Runtime": "python3.8", "Role": "arn:aws:iam::111111111111:role/cdk-aws-cookbook-403-LambdaAppServiceRole<<ID>>", "Handler": "lambda_function.lambda_handler", "CodeSize": 665, "Description": "", "Timeout": 600, "MemorySize": 1024, ...
Comprobaciones de validación
Ejecuta la función Lambda con este comando para validar que la función puede conectarse a RDS utilizando tu Proxy RDS:
aws lambda invoke \
--function-name $DB_APP_FUNCTION_NAME \
response.json && cat response.json
Deberías ver una salida similar a la siguiente:
{
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
"Successfully connected to RDS via RDS Proxy!"
Limpieza
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Debate
Es importante tener en cuenta la agrupación de conexiones cuando utilices Lambda con RDS. Dado que la función podría ejecutarse con mucha concurrencia y frecuencia dependiendo de tu aplicación, el número de conexiones brutas a tu base de datos puede crecer e impactar en el rendimiento. Al utilizar el Proxy RDS para gestionar las conexiones a la base de datos, se necesitan menos conexiones a la base de datos real. Esta configuración aumenta el rendimiento y la eficiencia.
Sin el Proxy RDS, una función Lambda podría establecer una nueva conexión con la base de datos cada vez que se invoque a la función. Este comportamiento depende del entorno de ejecución, de los tiempos de ejecución (Python, NodeJS, Go, etc.) y de la forma en que instales las conexiones a la base de datos desde el código de la función. En casos con gran cantidad de concurrencia de funciones, esto podría dar lugar a grandes cantidades de conexiones TCP a tu base de datos, reduciendo el rendimiento de la base de datos y aumentando la latencia. Según la documentación, el Proxy RDS ayuda a gestionar las conexiones desde Lambda gestionándolas como un "pool", de modo que a medida que aumenta la concurrencia, el Proxy RDS aumenta las conexiones reales a la base de datos sólo cuando es necesario, descargando la sobrecarga TCP al Proxy RDS.
El Proxy RDS admite el cifrado SSL en tránsito cuando incluyes el paquete de certificados proporcionado por AWS en tu cadena de conexión a la base de datos. El Proxy RDS admite bases de datos RDS MySQL y PostgreSQL. Para obtener una lista completa de todos los motores y versiones de bases de datos compatibles, consulta este documento de soporte.
Consejo
También puedes architect para ser eficiente con conexiones a bases de datos de corta duración aprovechando la API de Datos RDS dentro de tu aplicación, que aprovecha una API REST expuesta por Amazon RDS. Para ver un ejemplo sobre la API de Datos RDS, consulta la Receta 4.8.
4.4 Cifrar el almacenamiento de una base de datos existente de Amazon RDS para MySQL
Solución
Crea una réplica de lectura de tu base de datos existente, haz una instantánea de la réplica de lectura, copia la instantánea en una instantánea encriptada y restaura la instantánea encriptada en una nueva base de datos encriptada, como se muestra en la Figura 4-4.
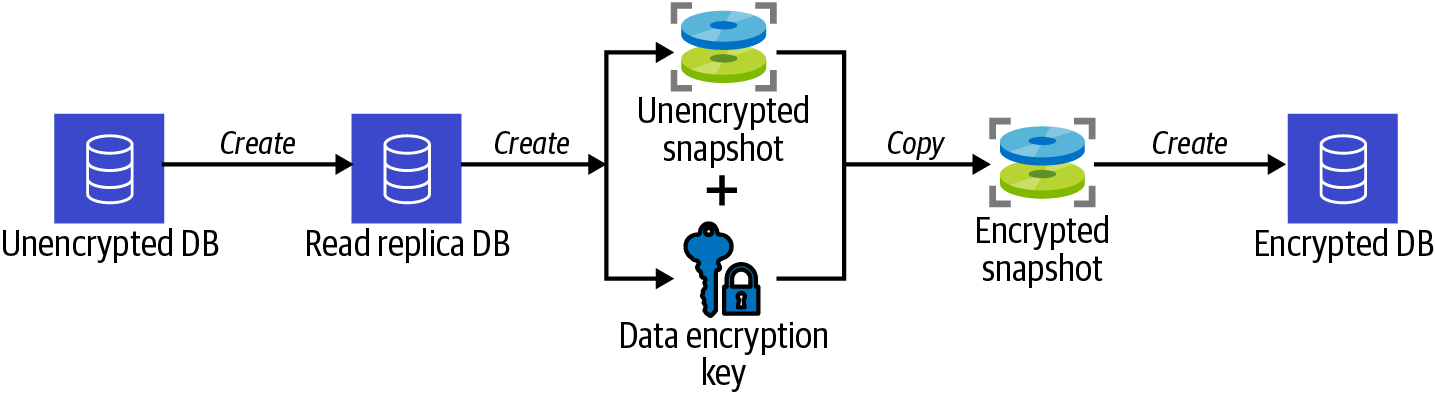
Figura 4-4. Proceso de encriptación de una base de datos RDS mediante una instantánea
Requisitos previos
-
VPC con subredes aisladas creadas en dos AZ y tablas de rutas asociadas
-
Una instancia MySQL RDS con un grupo de subred RDS
Preparación
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Pasos
-
Comprueba que el almacenamiento de la base de datos no está encriptado:
aws rds describe-db-instances \ --db-instance-identifier $RDS_DATABASE_ID \ --query DBInstances[0].StorageEncryptedDeberías ver la salida
false. -
Crea una clave KMS para utilizarla posteriormente para encriptar la instantánea de tu base de datos. Guarda el ID de la clave en una variable de entorno:
KEY_ID=$(aws kms create-key \ --tags TagKey=Name,TagValue=AWSCookbook404RDS \ --description "AWSCookbook RDS Key" \ --query KeyMetadata.KeyId \ --output text) -
Crea un alias para referenciar fácilmente la clave que has creado:
aws kms create-alias \ --alias-name alias/awscookbook404 \ --target-key-id $KEY_ID -
Crea una réplica de lectura de tu base de datos existente no encriptada:
aws rds create-db-instance-read-replica \ --db-instance-identifier awscookbook404db-rep \ --source-db-instance-identifier $RDS_DATABASE_ID \ --max-allocated-storage 10Deberías ver una salida similar a la siguiente:
{ "DBInstance": { "DBInstanceIdentifier": "awscookbook404db-rep", "DBInstanceClass": "db.m5.large", "Engine": "mysql", "DBInstanceStatus": "creating", "MasterUsername": "admin", "DBName": "AWSCookbookRecipe404", "AllocatedStorage": 8, "PreferredBackupWindow": "05:51-06:21", "BackupRetentionPeriod": 0, "DBSecurityGroups": [], ...Nota
Al crear una réplica de lectura, permites que la instantánea se cree a partir de ella y, por tanto, no afecta al rendimiento de la base de datos primaria.
Espera a que
DBInstanceStatusesté "disponible":aws rds describe-db-instances \ --db-instance-identifier awscookbook404db-rep \ --output text --query DBInstances[0].DBInstanceStatus -
Haz una instantánea no encriptada de tu réplica de lectura:
aws rds create-db-snapshot \ --db-instance-identifier awscookbook404db-rep \ --db-snapshot-identifier awscookbook404-snapshotDeberías ver una salida similar a la siguiente:
{ "DBSnapshot": { "DBSnapshotIdentifier": "awscookbook404-snapshot", "DBInstanceIdentifier": "awscookbook404db-rep", "Engine": "mysql", "AllocatedStorage": 8, "Status": "creating", "Port": 3306, "AvailabilityZone": "us-east-1b", "VpcId": "vpc-<<ID>>", "InstanceCreateTime": "2021-09-21T22:46:07.785000+00:00",Espera a que esté disponible la
Statusde la instantánea:aws rds describe-db-snapshots \ --db-snapshot-identifier awscookbook404-snapshot \ --output text --query DBSnapshots[0].Status -
Copia la instantánea sin encriptar a una nueva instantánea mientras la encriptas especificando tu clave KMS:
aws rds copy-db-snapshot \ --copy-tags \ --source-db-snapshot-identifier awscookbook404-snapshot \ --target-db-snapshot-identifier awscookbook404-snapshot-enc \ --kms-key-id alias/awscookbook404
Deberías ver una salida similar a la siguiente:
{ "DBSnapshot": { "DBSnapshotIdentifier": "awscookbook404-snapshot-enc", "DBInstanceIdentifier": "awscookbook404db-rep", "Engine": "mysql", "AllocatedStorage": 8, "Status": "creating", "Port": 3306, "AvailabilityZone": "us-east-1b", "VpcId": "vpc-<<ID>>", "InstanceCreateTime": "2021-09-21T22:46:07.785000+00:00", "MasterUsername": "admin", ...Consejo
Especificar una clave KMS con el comando
copy-snapshotencripta la instantánea copiada. Restaurar una instantánea encriptada en una nueva base de datos da como resultado una base de datos encriptada.Espera a que esté disponible el
Statusde la instantánea encriptada:aws rds describe-db-snapshots \ --db-snapshot-identifier awscookbook404-snapshot-enc \ --output text --query DBSnapshots[0].Status -
Restaura la instantánea encriptada en una nueva instancia RDS:
aws rds restore-db-instance-from-db-snapshot \ --db-subnet-group-name $RDS_SUBNET_GROUP \ --db-instance-identifier awscookbook404db-enc \ --db-snapshot-identifier awscookbook404-snapshot-encDeberías ver una salida similar a la siguiente:
{ "DBInstance": { "DBInstanceIdentifier": "awscookbook404db-enc", "DBInstanceClass": "db.m5.large", "Engine": "mysql", "DBInstanceStatus": "creating", "MasterUsername": "admin", "DBName": "AWSCookbookRecipe404", "AllocatedStorage": 8, ...
Comprobaciones de validación
Espera a que DBInstanceStatus esté disponible:
aws rds describe-db-instances \
--db-instance-identifier awscookbook404db-enc \
--output text --query DBInstances[0].DBInstanceStatus
Comprueba que el almacenamiento está ahora encriptado:
aws rds describe-db-instances \
--db-instance-identifier awscookbook404db-enc \
--query DBInstances[0].StorageEncrypted
Deberías ver la salida true.
Limpieza
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Debate
Cuando completes los pasos, deberás reconfigurar tu aplicación para que apunte al nuevo nombre de host del punto final de la base de datos. Para realizar esto con un tiempo de inactividad mínimo, puedes configurar un registro DNS de Route 53 que apunte al punto final de tu base de datos. Tu aplicación se configuraría para utilizar el registro DNS. A continuación, cambiarías el tráfico de tu base de datos a la nueva base de datos encriptada actualizando el registro DNS con el nuevo DNS del punto final de la base de datos.
El cifrado en reposo es un enfoque de seguridad que se deja en manos de los usuarios finales en el modelo de responsabilidad compartida de AWS, y a menudo es necesario para lograr o mantener la conformidad con las normas reguladoras. La instantánea cifrada que tomaste también podría copiarse automáticamente a otra Región, así como exportarse a S3 con fines de archivo/copia de seguridad.
Desafío
Crea una base de datos RDS desde cero que inicialmente tenga almacenamiento cifrado y migra tus datos de la base de datos existente a la nueva base de datos utilizando AWS DMS, como se muestra en la Receta 4.7.
4.5 Automatizar la rotación de contraseñas para bases de datos RDS
Solución
Crea una contraseña y colócala en AWS Secrets Manager. Configura un intervalo de rotación para el secreto que contiene la contraseña. Por último, crea una función Lambda utilizando el código proporcionado por AWS, y configura la función para que realice la rotación de la contraseña. Esta configuración permite que la automatización de la rotación de contraseñas se realice como se muestra en la Figura 4-5.
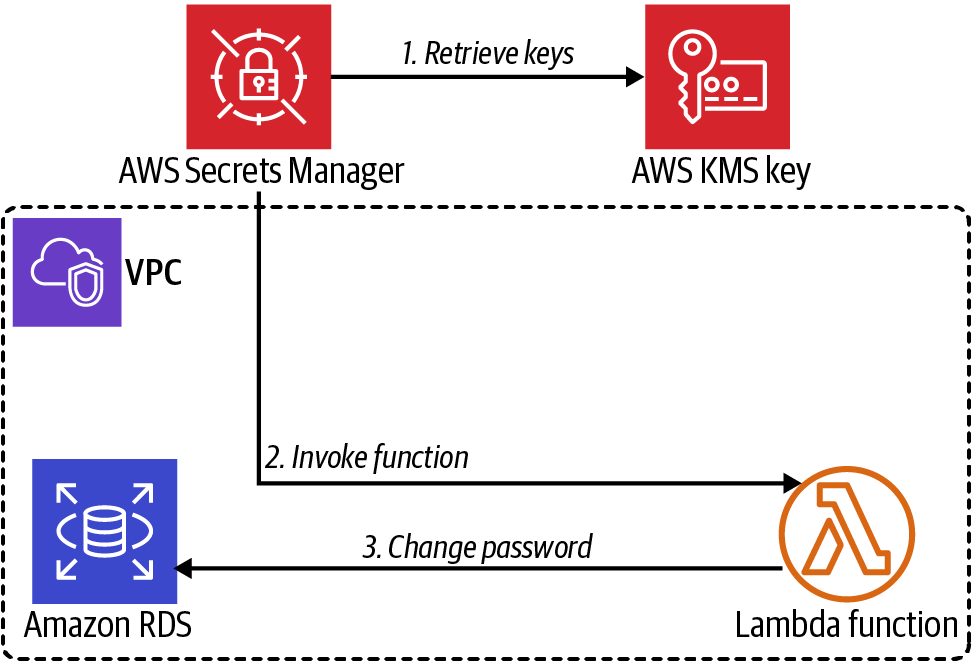
Figura 4-5. Integración de la función Lambda del Gestor de Secretos
Requisitos previos
-
VPC con subredes aisladas creadas en dos AZ y tablas de rutas asociadas.
-
Instancia RDS de MySQL e instancia EC2 desplegadas. Necesitarás poder conectarte a ellas para las pruebas.
Preparación
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Pasos
-
Utiliza AWS Secrets Manager para generar una contraseña que cumpla los requisitos de RDS:
RDS_ADMIN_PASSWORD=$(aws secretsmanager get-random-password \ --exclude-punctuation \ --password-length 41 --require-each-included-type \ --output text --query RandomPassword)Consejo
Puedes llamar al método de la API GetRandomPassword del Gestor de Secretos para generar cadenas aleatorias de caracteres para diversos usos más allá de la generación de contraseñas.
-
Cambia la contraseña de administrador de tu base de datos RDS por la que acabas de crear:
aws rds modify-db-instance \ --db-instance-identifier $RDS_DATABASE_ID \ --master-user-password $RDS_ADMIN_PASSWORD \ --apply-immediatelyDeberías ver una salida similar a la siguiente:
{ "DBInstance": { "DBInstanceIdentifier": "awscookbook405db", "DBInstanceClass": "db.m5.large", "Engine": "mysql", "DBInstanceStatus": "available", "MasterUsername": "admin", "DBName": "AWSCookbookRecipe405", ... -
Crea un archivo con el siguiente contenido llamado rdscreds-template.json (archivo proporcionado en el repositorio):
{ "username": "admin", "password": "PASSWORD", "engine": "mysql", "host": "HOST", "port": 3306, "dbname": "DBNAME", "dbInstanceIdentifier": "DBIDENTIFIER" } -
Utiliza
sedpara modificar los valores de rdscreds-template.json y crear rdscreds.json:sed -e "s/AWS_ACCOUNT_ID/${AWS_ACCOUNT_ID}/g" \ -e "s|PASSWORD|${RDS_ADMIN_PASSWORD}|g" \ -e "s|HOST|${RdsEndpoint}|g" \ -e "s|DBNAME|${DbName}|g" \ -e "s|DBIDENTIFIER|${RdsDatabaseId}|g" \ rdscreds-template.json > rdscreds.json -
Descarga el código del repositorio GitHub de AWS Samples para la función Lambda Rotación:
wget https://raw.githubusercontent.com/aws-samples/aws-secrets-manager-rotation- lambdas/master/SecretsManagerRDSMySQLRotationSingleUser/lambda_function.py
Nota
AWS proporciona información y plantillas para diferentes escenarios de rotación de bases de datos en este artículo.
-
Comprime el archivo que contiene el código:
zip lambda_function.zip lambda_function.py
Deberías ver una salida similar a la siguiente:
adding: lambda_function.py (deflated 76%)
-
Crea un nuevo grupo de seguridad para que lo utilice la función Lambda:
LAMBDA_SG_ID=$(aws ec2 create-security-group \ --group-name AWSCookbook405LambdaSG \ --description "Lambda Security Group" --vpc-id $VPC_ID \ --output text --query GroupId) -
Añade una regla de entrada al grupo de seguridad de las instancias RDS que permita el acceso en el puerto TCP 3306 desde el grupo de seguridad de Lambda:
aws ec2 authorize-security-group-ingress \ --protocol tcp --port 3306 \ --source-group $LAMBDA_SG_ID \ --group-id $RDS_SECURITY_GROUPDeberías ver una salida similar a la siguiente:
{ "Return": true, "SecurityGroupRules": [ { "SecurityGroupRuleId": "sgr-<<ID>>", "GroupId": "sg-<<ID>>", "GroupOwnerId": "111111111111", "IsEgress": false, "IpProtocol": "tcp", "FromPort": 3306, "ToPort": 3306, "ReferencedGroupInfo": { "GroupId": "sg-<<ID>>" } } ] } -
Crea un archivo llamado assume-role-policy.json con el siguiente contenido (archivo proporcionado en el repositorio):
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } -
Crea un rol IAM con la declaración del archivo assume-role-policy.json proporcionado utilizando este comando:
aws iam create-role --role-name AWSCookbook405Lambda \ --assume-role-policy-document file://assume-role-policy.jsonDeberías ver una salida similar a la siguiente:
{ "Role": { "Path": "/", "RoleName": "AWSCookbook405Lambda", "RoleId": "<<ID>>", "Arn": "arn:aws:iam::111111111111:role/AWSCookbook405Lambda", "CreateDate": "2021-09-21T23:01:57+00:00", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ ... -
Adjunta la política gestionada por IAM para
AWSLambdaVPCAccessal rol IAM:aws iam attach-role-policy --role-name AWSCookbook405Lambda \ --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole -
Adjunta la política gestionada por IAM para
SecretsManagerReadWriteal rol IAM:aws iam attach-role-policy --role-name AWSCookbook405Lambda \ --policy-arn arn:aws:iam::aws:policy/SecretsManagerReadWriteConsejo
El rol IAM que asociaste a la función Lambda para rotar la contraseña utilizó la política gestionada
SecretsManagerReadWrite. En un escenario de producción, te convendría reducirla para limitar los secretos con los que puede interactuar la función Lambda. -
Crea la función Lambda para realizar la rotación secreta utilizando el código:
LAMBDA_ROTATE_ARN=$(aws lambda create-function \ --function-name AWSCookbook405Lambda \ --runtime python3.8 \ --package-type "Zip" \ --zip-file fileb://lambda_function.zip \ --handler lambda_function.lambda_handler --publish \ --environment Variables={SECRETS_MANAGER_ENDPOINT=https://secretsmanager.$AWS_REGION.amazonaws.com} \ --layers $PyMysqlLambdaLayerArn \ --role \ arn:aws:iam::$AWS_ACCOUNT_ID:role/AWSCookbook405Lambda \ --output text --query FunctionArn \ --vpc-config SubnetIds=${ISOLATED_SUBNETS},SecurityGroupIds=$LAMBDA_SG_ID)Utiliza este comando para determinar cuándo la función Lambda ha entrado en estado Activo:
aws lambda get-function --function-name $LAMBDA_ROTATE_ARN \ --output text --query Configuration.State -
Añade un permiso a la función Lambda para que el Gestor de Secretos pueda invocarla:
aws lambda add-permission --function-name $LAMBDA_ROTATE_ARN \ --action lambda:InvokeFunction --statement-id secretsmanager \ --principal secretsmanager.amazonaws.comDeberías ver una salida similar a la siguiente:
{ "Statement": "{\"Sid\":\"secretsmanager\",\"Effect\":\"Allow\",\"Principal\":{\"Service\":\"secretsmanager.amazonaws.com\"},\"Action\":\"lambda:InvokeFunction\",\"Resource\":\"arn:aws:lambda:us-east-1:111111111111:function:AWSCookbook405Lambda\"}" } -
Establece un sufijo único para el nombre secreto, para asegurarte de que puedes reutilizar este patrón para rotaciones automáticas adicionales de la contraseña, si lo deseas:
AWSCookbook405SecretName=AWSCookbook405Secret-$(aws secretsmanager \ get-random-password \ --exclude-punctuation \ --password-length 6 --require-each-included-type \ --output text \ --query RandomPassword) -
Crea un secreto en el Gestor de Secretos para almacenar tu contraseña de administrador:
aws secretsmanager create-secret --name $AWSCookbook405SecretName \ --description "My database secret created with the CLI" \ --secret-string file://rdscreds.jsonDeberías ver una salida similar a la siguiente:
{ "ARN": "arn:aws:secretsmanager:us-east-1:1111111111111:secret:AWSCookbook405Secret-T4tErs-AlJcLn", "Name": "AWSCookbook405Secret-<<Random>>", "VersionId": "<<ID>>" } -
Configura la rotación automática cada 30 días y especifica la función Lambda para realizar la rotación del secreto que acabas de crear:
aws secretsmanager rotate-secret \ --secret-id $AWSCookbook405SecretName \ --rotation-rules AutomaticallyAfterDays=30 \ --rotation-lambda-arn $LAMBDA_ROTATE_ARNDeberías ver una salida similar a la siguiente:
{ "ARN": "arn:aws:secretsmanager:us-east-1:1111111111111:secret:AWSCookbook405Secret-<<unique>>", "Name": "AWSCookbook405Secret-<<unique>>", "VersionId": "<<ID>>" } -
Realiza otra rotación del secreto:
aws secretsmanager rotate-secret --secret-id $AWSCookbook405SecretName
Deberías ver una salida similar a la del paso 17. Observa que el
VersionIdserá diferente del último comando, lo que indica que el secreto se ha girado.
Comprobaciones de validación
Recupera la contraseña de administrador del RDS del Gestor de Secretos:
RDS_ADMIN_PASSWORD=$(aws secretsmanager get-secret-value --secret-id $AWSCookbook405SecretName --query SecretString | jq -r | jq .password | tr -d '"')
Enumera el punto final del clúster RDS:
echo $RDS_ENDPOINT
Recupera la contraseña de tu clúster RDS:
echo $RDS_ADMIN_PASSWORD
Conéctate a la instancia EC2 utilizando el Gestor de Sesiones SSM (ver Receta 1.6):
aws ssm start-session --target $INSTANCE_ID
Instala el cliente MySQL:
sudo yum -y install mysql
Conéctate a la base de datos para comprobar que la última contraseña rota funciona. Tendrás que copiar y pegar la contraseña (obtenida anteriormente):
mysql -u admin -p$password -h $hostname
Ejecuta una sentencia SELECT en la tabla mysql.user para validar los permisos de administrador:
SELECT user FROM mysql.user;
Deberías ver una salida similar a la siguiente:
+------------------+ | user | +------------------+ | admin | | mysql.infoschema | | mysql.session | | mysql.sys | | rdsadmin | +------------------+ 5 rows in set (0.00 sec)
Sal del indicador mysql:
quit
Sal de la sesión del Administrador de Sesiones:
exit
Limpieza
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Debate
La función Lambda proporcionada por AWS almacena la contraseña rotada en el Gestor de Secretos. A continuación, puedes configurar tu aplicación para recuperar secretos del Gestor de Secretos directamente; o la función Lambda que configuraste para actualizar los valores del Gestor de Secretos también podría almacenar la contraseña en una ubicación segura de tu elección. Tendrías que conceder a la función Lambda permisos adicionales para interactuar con la ubicación segura que elijas y añadir algo de código para almacenar allí el nuevo valor. Este método también podría aplicarse para rotar las contraseñas de las cuentas de usuario de la base de datos que no sean de administrador, siguiendo los mismos pasos después de haber creado el usuario o usuarios en tu base de datos.
La función Lambda que has implementado está basada en Python y se conecta a una base de datos compatible con el motor MySQL. El entorno de ejecución de Lambda no tiene incluida esta biblioteca por defecto, por lo que especificaste una capa Lambda con el comando aws lambda create-function. Esta capa es necesaria para que la biblioteca PyMySQL esté disponible para la función en el entorno de ejecución de Lambda, y se desplegó para ti como parte del paso de preparación cuando ejecutaste cdk deploy.
Ver también
4.6 Autoescalado de la capacidad aprovisionada de la tabla DynamoDB
Solución
Configura el escalado de lectura y escritura estableciendo un objetivo de escalado y una política de escalado para la capacidad de lectura y escritura de la tabla DynamoDB mediante el autoescalado de aplicaciones de AWS, como se muestra en la Figura 4-6.
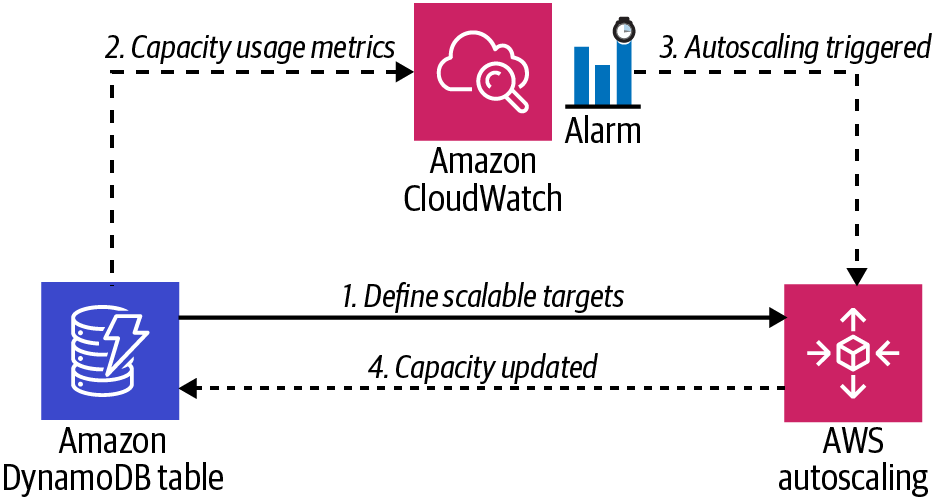
Figura 4-6. Configuración de autoescalado de DynamoDB
Requisito previo
-
Una tabla DynamoDB
Preparación
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Pasos
-
Navega hasta el directorio de esta receta en el repositorio de capítulos:
cd 406-Auto-Scaling-DynamoDB
-
Registra un objetivo de escalado
ReadCapacityUnitspara la tabla DynamoDB:aws application-autoscaling register-scalable-target \ --service-namespace dynamodb \ --resource-id "table/AWSCookbook406" \ --scalable-dimension "dynamodb:table:ReadCapacityUnits" \ --min-capacity 5 \ --max-capacity 10 -
Registra un objetivo de escalado
WriteCapacityUnitspara la tabla DynamoDB:aws application-autoscaling register-scalable-target \ --service-namespace dynamodb \ --resource-id "table/AWSCookbook406" \ --scalable-dimension "dynamodb:table:WriteCapacityUnits" \ --min-capacity 5 \ --max-capacity 10 -
Crea un archivo JSON de política de escalado para el escalado de capacidad de lectura(read-policy.json proporcionado en el repositorio):
{ "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBReadCapacityUtilization" }, "ScaleOutCooldown": 60, "ScaleInCooldown": 60, "TargetValue": 50.0 } -
Crea un archivo JSON de política de escalado para el escalado de la capacidad de escritura( archivowrite-policy.json proporcionado en el repositorio):
{ "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBWriteCapacityUtilization" }, "ScaleOutCooldown": 60, "ScaleInCooldown": 60, "TargetValue": 50.0 }Nota
La capacidad aprovisionada de DynamoDB utiliza unidades de capacidad para definir la capacidad de lectura y escritura de tus tablas. El valor objetivo que establezcas define cuándo escalar en función del uso actual. Los parámetros de enfriamiento del escalado definen, en segundos, cuánto tiempo hay que esperar para volver a escalar después de que se haya producido una operación de escalado. Para más información, consulta la referencia de la API para el autoescalado
TargetTrackingScalingPolicyConfiguration. -
Aplica la política de escalado de lectura a la tabla utilizando el archivo read-policy.json:
aws application-autoscaling put-scaling-policy \ --service-namespace dynamodb \ --resource-id "table/AWSCookbook406" \ --scalable-dimension "dynamodb:table:ReadCapacityUnits" \ --policy-name "AWSCookbookReadScaling" \ --policy-type "TargetTrackingScaling" \ --target-tracking-scaling-policy-configuration \ file://read-policy.json -
Aplica la política de escalado de escritura a la tabla utilizando el archivo write-policy.json:
aws application-autoscaling put-scaling-policy \ --service-namespace dynamodb \ --resource-id "table/AWSCookbook406" \ --scalable-dimension "dynamodb:table:WriteCapacityUnits" \ --policy-name "AWSCookbookWriteScaling" \ --policy-type "TargetTrackingScaling" \ --target-tracking-scaling-policy-configuration \ file://write-policy.json
Comprobaciones de validación
Puedes observar la configuración de autoescalado de tu tabla seleccionándola en la consola de DynamoDB y buscando en la pestaña "Configuración adicional".
Limpieza
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Debate
Consejo
Estos pasos autoescalarán las capacidades de lectura y escritura de forma independiente para tu tabla DynamoDB, lo que te ayudará a conseguir el modelo de coste operativo más bajo para los requisitos específicos de tu aplicación.
DynamoDB permite dos modos de capacidad: aprovisionada y bajo demanda. Cuando utilizas el modo de capacidad provisionada, puedes seleccionar el número de lecturas y escrituras de datos por segundo. La guía de precios indica que se te cobra en función de las unidades de capacidad que especifiques. Por el contrario, con el modo de capacidad bajo demanda, pagas por petición por las lecturas y escrituras de datos que tu aplicación realiza en tus tablas. En general, utilizar el modo bajo demanda puede suponer costes más elevados que el modo aprovisionado para aplicaciones especialmente intensivas en transacciones.
Debes comprender tu aplicación y tus patrones de uso cuando selecciones una capacidad provisionada para tus tablas. Si estableces una capacidad demasiado baja, experimentarás un rendimiento lento de la base de datos y tu aplicación podría entrar en estados de error y espera, ya que la API de DynamoDB devolverá respuestas ThrottlingException y ProvisionedThroughputExceededException a tu aplicación cuando se alcancen estos límites. Si estableces una capacidad demasiado alta, estarás pagando por una capacidad innecesaria. Activar el autoescalado te permite definir valores objetivo mínimos y máximos estableciendo un objetivo de escalado, al tiempo que te permite definir cuándo debe entrar en vigor el activador de autoescalado para escalar hacia arriba, y cuándo debe empezar a escalar hacia abajo tu capacidad. Esto te permite optimizar tanto el coste como el rendimiento mientras aprovechas el servicio DynamoDB. Para ver una lista de los objetivos escalables que configuraste para tu tabla, puedes utilizar el siguiente comando:
aws application-autoscaling describe-scalable-targets \
--service-namespace dynamodb \
--resource-id "table/AWSCookbook406"
Para obtener más información sobre las capacidades de DynamoDB y cómo se miden, consulta este documento de soporte.
4.7 Migrar bases de datos a Amazon RDS utilizando AWS DMS
Solución
Configura los grupos de seguridad de la VPC y los permisos IAM para permitir la conectividad del Servicio de Migración de Bases de Datos (DMS) de AWS a las bases de datos. A continuación, configura los puntos finales de DMS para las bases de datos de origen y de destino. A continuación, configura una tarea de replicación DMS. Por último, inicia la tarea de replicación. En la Figura 4-7 se muestra un diagrama de arquitectura de la solución.

Figura 4-7. Esquema de la red DMS
Preparación
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Pasos
-
Crea un grupo de seguridad para la instancia de replicación:
DMS_SG_ID=$(aws ec2 create-security-group \ --group-name AWSCookbook407DMSSG \ --description "DMS Security Group" --vpc-id $VPC_ID \ --output text --query GroupId) -
Concede al grupo de seguridad DMS acceso a las bases de datos de origen y destino en el puerto TCP 3306:
aws ec2 authorize-security-group-ingress \ --protocol tcp --port 3306 \ --source-group $DMS_SG_ID \ --group-id $SOURCE_RDS_SECURITY_GROUP aws ec2 authorize-security-group-ingress \ --protocol tcp --port 3306 \ --source-group $DMS_SG_ID \ --group-id $TARGET_RDS_SECURITY_GROUP -
Crea un rol para DMS utilizando el archivo assume-role-policy.json proporcionado:
aws iam create-role --role-name dms-vpc-role \ --assume-role-policy-document file://assume-role-policy.jsonAdvertencia
El servicio DMS requiere un rol IAM con un nombre y una política específicos. El comando que has ejecutado anteriormente satisface este requisito. También es posible que ya tengas este rol en tu cuenta si has utilizado DMS anteriormente. Este comando daría lugar a un error si ese fuera el caso, y puedes continuar con los siguientes pasos sin preocuparte.
-
Adjunta la política DMS gestionada al rol:
aws iam attach-role-policy --role-name dms-vpc-role --policy-arn \ arn:aws:iam::aws:policy/service-role/AmazonDMSVPCManagementRole
-
Crea un grupo de subred de replicación para la instancia de replicación:
REP_SUBNET_GROUP=$(aws dms create-replication-subnet-group \ --replication-subnet-group-identifier awscookbook407 \ --replication-subnet-group-description "AWSCookbook407" \ --subnet-ids $ISOLATED_SUBNETS \ --query ReplicationSubnetGroup.ReplicationSubnetGroupIdentifier \ --output text) -
Crea una instancia de replicación y guarda el ARN en una variable:
REP_INSTANCE_ARN=$(aws dms create-replication-instance \ --replication-instance-identifier awscookbook407 \ --no-publicly-accessible \ --replication-instance-class dms.t2.medium \ --vpc-security-group-ids $DMS_SG_ID \ --replication-subnet-group-identifier $REP_SUBNET_GROUP \ --allocated-storage 8 \ --query ReplicationInstance.ReplicationInstanceArn \ --output text)Espera hasta que el
ReplicationInstanceStatusesté disponible; comprueba el estado utilizando este comando:aws dms describe-replication-instances \ --filter=Name=replication-instance-id,Values=awscookbook407 \ --query ReplicationInstances[0].ReplicationInstanceStatusAdvertencia
En este ejemplo has utilizado el tamaño de instancia de replicación
dms.t2.medium. Debes elegir un tamaño de instancia apropiado para manejar la cantidad de datos que vas a migrar. DMS transfiere tablas en paralelo, por lo que necesitarás un tamaño de instancia mayor para cantidades de datos mayores. Para más información, consulta este documento de la guía del usuario sobre buenas prácticas para DMS. -
Recupera las contraseñas de administrador de la BD de origen y destino del Gestor de Secretos y guárdalas en variables de entorno:
RDS_SOURCE_PASSWORD=$(aws secretsmanager get-secret-value --secret-id $RDS_SOURCE_SECRET_NAME --query SecretString --output text | jq .password | tr -d '"') RDS_TARGET_PASSWORD=$(aws secretsmanager get-secret-value --secret-id $RDS_TARGET_SECRET_NAME --query SecretString --output text | jq .password | tr -d '"')
-
Crea un punto final de origen para DMS y guarda el ARN en una variable:
SOURCE_ENDPOINT_ARN=$(aws dms create-endpoint \ --endpoint-identifier awscookbook407source \ --endpoint-type source --engine-name mysql \ --username admin --password $RDS_SOURCE_PASSWORD \ --server-name $SOURCE_RDS_ENDPOINT --port 3306 \ --query Endpoint.EndpointArn --output text) -
Crea un punto final de destino para DMS y guarda el ARN en una variable:
TARGET_ENDPOINT_ARN=$(aws dms create-endpoint \ --endpoint-identifier awscookbook407target \ --endpoint-type target --engine-name mysql \ --username admin --password $RDS_TARGET_PASSWORD \ --server-name $TARGET_RDS_ENDPOINT --port 3306 \ --query Endpoint.EndpointArn --output text) -
Crea tu tarea de replicación:
REPLICATION_TASK_ARN=$(aws dms create-replication-task \ --replication-task-identifier awscookbook-task \ --source-endpoint-arn $SOURCE_ENDPOINT_ARN \ --target-endpoint-arn $TARGET_ENDPOINT_ARN \ --replication-instance-arn $REP_INSTANCE_ARN \ --migration-type full-load \ --table-mappings file://table-mapping-all.json \ --query ReplicationTask.ReplicationTaskArn --output text)Espera a que el estado llegue a listo. Para comprobar el estado de la tarea de replicación, utiliza lo siguiente:
aws dms describe-replication-tasks \ --filters "Name=replication-task-arn,Values=$REPLICATION_TASK_ARN" \ --query "ReplicationTasks[0].Status" -
Inicia la tarea de replicación:
aws dms start-replication-task \ --replication-task-arn $REPLICATION_TASK_ARN \ --start-replication-task-type start-replication
Comprobaciones de validación
Monitorea el progreso de la tarea de replicación:
aws dms describe-replication-tasks
Utiliza la consola de AWS o la operación aws dms describe-replication-tasks para validar que se han migrado tus tablas:
aws dms describe-replication-tasks \
--query ReplicationTasks[0].ReplicationTaskStats
También puedes ver el estado de la tarea de replicación en la consola DMS.
Limpieza
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Debate
Consejo
También podrías ejecutar full-load-and-cdc para replicar continuamente los cambios en el origen al destino y minimizar el tiempo de inactividad de tu aplicación cuando pases a la nueva base de datos.
DMS viene con una funcionalidad para probar los puntos finales de origen y destino desde la instancia de replicación. Se trata de una función muy útil que puedes utilizar cuando trabajes con DMS para validar que tienes la configuración correcta antes de empezar a ejecutar tareas de replicación. Probar la conectividad desde la instancia de replicación a los dos puntos finales que configuraste puede hacerse a través de la consola DMS o de la línea de comandos con los siguientes comandos:
aws dms test-connection \
--replication-instance-arn $rep_instance_arn \
--endpoint-arn $source_endpoint_arn
aws dms test-connection \
--replication-instance-arn $rep_instance_arn \
--endpoint-arn $target_endpoint_arn
La operación test-connection tarda unos instantes en completarse. Puedes comprobar el estado y los resultados de la operación utilizando este comando:
aws dms describe-connections --filter \ "Name=endpoint-arn,Values=$source_endpoint_arn,$target_endpoint_arn"
El servicio DMS admite muchos tipos de bases de datos de origen y destino dentro de tu VPC, otra cuenta de AWS o bases de datos alojadas en un entorno que no sea AWS. El servicio también puede transformar los datos por ti si tu origen y destino son diferentes tipos de bases de datos utilizando una configuración adicional en el archivo table-mappings.json. Por ejemplo, el tipo de datos de una columna en una base de datos Oracle puede tener un formato diferente al tipo equivalente en una base de datos PostgreSQL. La Herramienta de Conversión de Esquemas (SCT) de AWS puede ayudar a identificar estas transformaciones necesarias, y también a generar archivos de configuración para utilizarlos con DMS.
Desafío
Activa la carga completa y la replicación continua para replicar continuamente de una base de datos a otra.
4.8 Habilitar el acceso REST a Aurora sin servidor mediante la API de datos RDS
Solución
Primero, habilita la API de Datos para tu base de datos y configura los permisos IAM para tu instancia EC2. A continuación, haz una prueba tanto desde la CLI como desde la consola RDS. Esto permite que tu aplicación se conecte a tu base de datos Aurora Serverless, como se muestra en la Figura 4-8.

Figura 4-8. Una aplicación que utiliza la API de Datos RDS
Requisitos previos
-
VPC con subredes aisladas creadas en dos AZ y tablas de rutas asociadas.
-
Instancia PostgreSQL RDS e instancia EC2 implementadas. Necesitarás poder conectarte a ellas para las pruebas.
Preparación
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Pasos
-
Activa la API de Datos en tu clúster Aurora sin Servidor:
aws rds modify-db-cluster \ --db-cluster-identifier $CLUSTER_IDENTIFIER \ --enable-http-endpoint \ --apply-immediately -
Asegúrate de que
HttpEndpointEnabledestá ajustado atrue:aws rds describe-db-clusters \ --db-cluster-identifier $CLUSTER_IDENTIFIER \ --query DBClusters[0].HttpEndpointEnabled -
Prueba un comando de tu CLI:
aws rds-data execute-statement \ --secret-arn "$SECRET_ARN" \ --resource-arn "$CLUSTER_ARN" \ --database "$DATABASE_NAME" \ --sql "select * from pg_user" \ --output json(Opcional) También puedes probar el acceso a través de la consola de AWS utilizando el Editor de consultas de Amazon RDS. Primero ejecuta estos dos comandos desde tu terminal para poder copiar y pegar los valores:
echo $SECRET_ARN echo $DATABASE_NAME
-
Accede a la consola de AWS con permisos de administrador y ve a la consola RDS. En el menú de la barra lateral izquierda, haz clic en Editor de consultas. Rellena los valores y selecciona "Conectar a base de datos", como se muestra en la Figura 4-9.

Figura 4-9. Configuración de la conexión a la base de datos
-
Ejecuta la misma consulta y visualiza los resultados debajo del Editor de consultas (ver Figura 4-10):
SELECT * from pg_user;
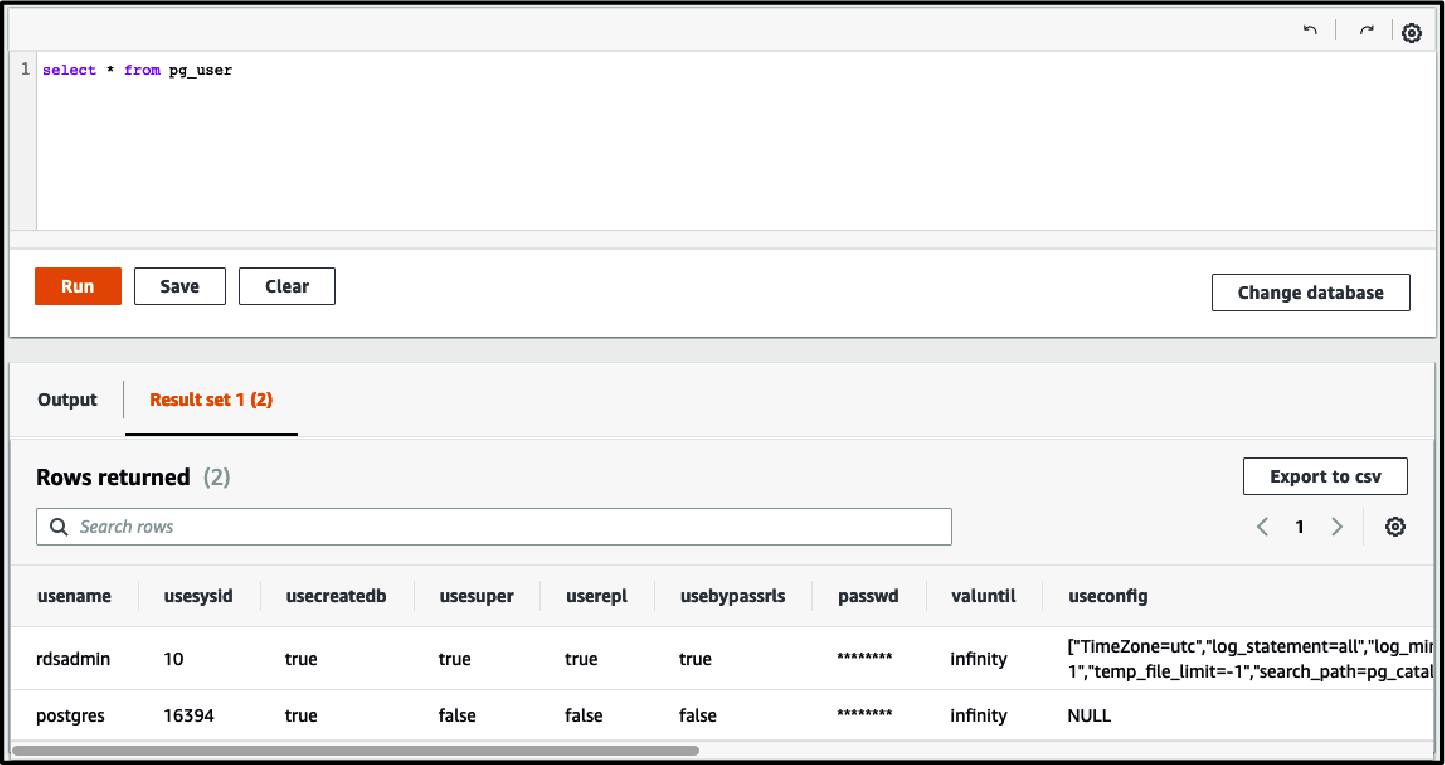
Figura 4-10. Editor de consultas RDS
-
Configura tu instancia EC2 para utilizar la API de Datos con tu clúster de bases de datos. Crea un archivo llamado policy-template.json con el siguiente contenido (archivo proporcionado en el repositorio):
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "rds-data:BatchExecuteStatement", "rds-data:BeginTransaction", "rds-data:CommitTransaction", "rds-data:ExecuteStatement", "rds-data:RollbackTransaction" ], "Resource": "*", "Effect": "Allow" }, { "Action": [ "secretsmanager:GetSecretValue", "secretsmanager:DescribeSecret" ], "Resource": "SecretArn", "Effect": "Allow" } ] } -
Sustituye los valores del archivo de plantilla utilizando el comando
sedpor las variables de entorno que hayas establecido:sed -e "s/SecretArn/${SECRET_ARN}/g" \ policy-template.json > policy.json -
Crea una política IAM utilizando el archivo que acabas de crear:
aws iam create-policy --policy-name AWSCookbook408RDSDataPolicy \ --policy-document file://policy.json -
Adjunta la política IAM para
AWSCookbook408RDSDataPolicyal rol IAM de tu instancia EC2:aws iam attach-role-policy --role-name $INSTANCE_ROLE_NAME \ --policy-arn arn:aws:iam::$AWS_ACCOUNT_ID:policy/AWSCookbook408RDSDataPolicy
Comprobaciones de validación
Crea y rellena algunos parámetros SSM para almacenar valores y poder recuperarlos de tu instancia EC2:
aws ssm put-parameter \
--name "Cookbook408DatabaseName" \
--type "String" \
--value $DATABASE_NAME
aws ssm put-parameter \
--name "Cookbook408ClusterArn" \
--type "String" \
--value $CLUSTER_ARN
aws ssm put-parameter \
--name "Cookbook408SecretArn" \
--type "String" \
--value $SECRET_ARN
Conéctate a la instancia EC2 utilizando el Gestor de Sesiones SSM (ver Receta 1.6):
aws ssm start-session --target $INSTANCE_ID
Establece la Región:
export AWS_DEFAULT_REGION=us-east-1
Recupera los valores de los parámetros SSM y ajústalos a los valores del entorno:
DatabaseName=$(aws ssm get-parameters \
--names "Cookbook408DatabaseName" \
--query "Parameters[*].Value" --output text)
SecretArn=$(aws ssm get-parameters \
--names "Cookbook408SecretArn" \
--query "Parameters[*].Value" --output text)
ClusterArn=$(aws ssm get-parameters \
--names "Cookbook408ClusterArn" \
--query "Parameters[*].Value" --output text)
Ejecuta una consulta en la base de datos:
aws rds-data execute-statement \
--secret-arn "$SecretArn" \
--resource-arn "$ClusterArn" \
--database "$DatabaseName" \
--sql "select * from pg_user" \
--output json
Sal de la sesión del Administrador de Sesiones:
exit
Limpieza
Sigue los pasos de la carpeta de esta receta en el repositorio de código del capítulo.
Debate
La API de Datos expone un punto final HTTPS para su uso con Aurora y utiliza la autenticación IAM para permitir que tu aplicación ejecute sentencias SQL en tu base de datos a través de HTTPS en lugar de utilizar la clásica conectividad TCP con la base de datos.
Consejo
Según la guía del usuario de Aurora, todas las llamadas a la API de Datos son síncronas, y el tiempo de espera por defecto para una consulta es de 45 segundos. Si tus consultas tardan más de 45 segundos, puedes utilizar el parámetro continueAfterTimeout para facilitar las consultas de larga duración.
Como ocurre con otras API de servicios de AWS que utilizan la autenticación de IAM, todas las actividades realizadas con la API de datos se capturan en CloudTrail para garantizar la existencia de un registro de auditoría, que puede ayudarte a satisfacer tus requisitos de seguridad y auditoría. Puedes controlar y delegar el acceso al punto final de la API de Datos utilizando las políticas de IAM asociadas a los roles de tu aplicación. Por ejemplo, si quisieras conceder a tu aplicación la capacidad de leer únicamente desde tu base de datos utilizando la API de Datos, podrías escribir una política que omitiera los permisos rds-data:CommitTransaction y rds-data:RollbackTransaction.
El Editor de consultas de la consola RDS proporciona a un medio de acceso basado en web para ejecutar consultas SQL contra tu base de datos. Se trata de un mecanismo cómodo para que los desarrolladores y los DBA realicen rápidamente tareas a medida. Los mismos privilegios que asignaste a tu instancia EC2 en esta receta tendrían que concederse a tu desarrollador y DBA a través de roles IAM.
Get Libro de cocina AWS now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

