What is the Spark Streaming application data flow?
The following figure provides the data flow between the Spark driver, workers, streaming sources and targets:
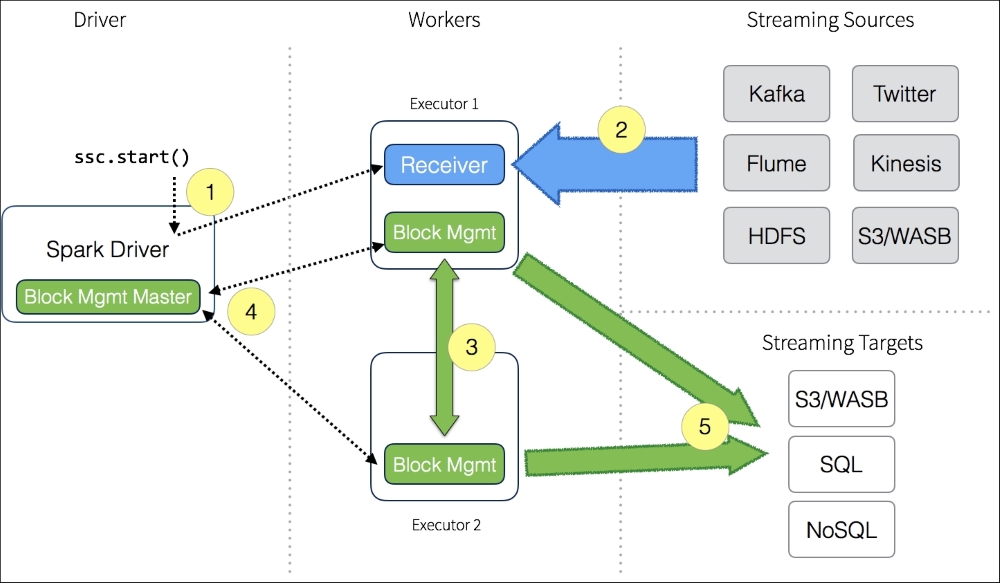
It all starts with the Spark Streaming Context, represented by ssc.start() in the preceding figure:
- When the Spark Streaming Context starts, the driver will execute a long-running task on the executors (that is, the Spark workers).
- The Receiver on the executors (Executor 1 in this diagram) receives a data stream from the Streaming Sources. With the incoming data stream, the receiver divides the stream into blocks and keeps these blocks in memory.
- These blocks are also replicated to another executor ...
Get Learning PySpark now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

