Chapter 4. Access Control
After the wide scope in the previous chapter on all things shell and scripting, we now focus on one specific and crucial security aspect in Linux. In this chapter, we discuss the topic of users and controlling access to resources in general and files in particular.
One question that immediately comes to mind in such a multiuser setup is ownership. A user may own, for example, a file. They are allowed to read from the file, write to the file, and also, say, delete it. Given that there are other users on the system as well, what are those users allowed to do, and how is this defined and enforced? There are also activities that you might not necessarily associate with files in the first place. For example, a user may (or may not) be allowed to change networking-related settings.
To get a handle on this topic, we’ll first take a look at the fundamental relationship between users, processes, and files, from an access perspective. We’ll also review sandboxing and access control types. Next, we’ll focus on the definition of a Linux user, what users can do, and how to manage users either locally or alternatively from a central place.
Then, we’ll move on to the topic of permissions, where we’ll look at how to control access to files and how processes are impacted by such restrictions.
We’ll wrap up this chapter covering a range of advanced Linux features in the access control space, including capabilities, seccomp profiles, and ACLs. To round things off, we’ll provide some security good practices around permissions and access control.
With that, let’s jump right into the topic of users and resource ownership, laying the basis for the rest of the chapter.
Basics
Before we get into access control mechanisms, let’s step back a little and take a bird’s-eye view on the topic. This will help us to establish some terminology and clarify relationships between the main concepts.
Resources and Ownership
Linux is a multiuser operating system and as such has inherited the concept of a user (see “Users”) from UNIX. Each user account is associated with a user ID that can be given access to executables, files, devices, and other Linux assets. A human user can log in with a user account, and a process can run as a user account. Then, there are resources (which we will simply refer to as files), which are any hardware or software components available to the user. In the general case, we will refer to resources as files, unless we explicitly talk about access to other kinds of resources, such as with syscalls. In Figure 4-1 and the passage that follows, you see the high-level relationships between users, processes, and files in Linux.
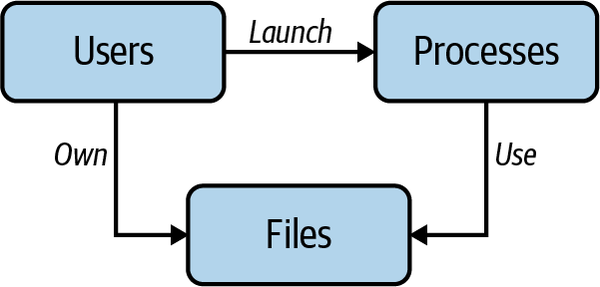
Figure 4-1. Users, processes, and files in Linux
- Users
-
Launch processes and own files. A process is a program (executable file) that the kernel has loaded into main memory and runs.
- Files
-
Have owners; by default, the user who creates the file owns it.
- Processes
-
Use files for communication and persistency. Of course, users indirectly also use files, but they need to do so via processes.
This depiction of the relationships between users, processes, and files is of course a very simplistic view, but it allows us to understand the actors and their relationships and will come in handy later on when we discuss the interaction between these different players in greater detail.
Let’s first look at the execution context of a process, addressing the question of how restricted the process is. A term that we often come across when talking about access to resources is sandboxing.
Sandboxing
Sandboxing is a vaguely defined term and can refer to a range of different methods, from jails to containers to virtual machines, which can be managed either in the kernel or in user land. Usually there is something that runs in the sandbox—typically some application—and the supervising mechanism enforces a certain degree of isolation between the sandboxed process and the hosting environment. If all of that sounds rather theoretical, I ask you for a little bit of patience. We will see sandboxing in action later in this chapter, in “seccomp Profiles”, and then again in Chapter 9 when we talk about VMs and containers.
With a basic understanding of resources, ownership, and access to said resources in your mind, let’s talk briefly about some conceptual ways to go about access control.
Types of Access Control
One aspect of access control is the nature of the access itself. Does a user or process directly access a resource, maybe in an unrestricted manner? Or maybe there is a clear set of rules about what kind of resources (files or syscalls) a process can access, under what circumstances. Or maybe the access itself is even recorded.
Conceptually, there are different access control types. The two most important and relevant to our discussion in the context of Linux are discretionary and mandatory access control:
- Discretionary access control
-
With discretionary access control (DAC), the idea is to restrict access to resources based on the identity of the user. It’s discretionary in the sense that a user with certain permissions can pass them on to other users.
- Mandatory access control
-
Mandatory access control is based on a hierarchical model representing security levels. Users are assigned a clearance level, and resources are assigned a security label. Users can only access resources corresponding to a clearance level equal to (or lower than) their own. In a mandatory access control model, an admin strictly and exclusively controls access, setting all permissions. In other words, users cannot set permissions themselves, even when they own the resource.
In addition, Linux traditionally has an all-or-nothing attitude—that is,
you are either a superuser who has the power to change everything or you are a normal user
with limited access. Initially, there was no easy and flexible way to assign a
user or process certain privileges. For example, in the general case, to enable
that “process X is allowed to change networking settings,” you
had to give it root access. This, naturally, has a concrete impact on a system
that is breached: an attacker can misuse these wide privileges easily.
Note
To qualify the “all-or-nothing attitude” in Linux a bit: the defaults in most Linux systems allow read access to almost every file and executable by “others”—that is, all users on the system. For example, with SELinux enabled, mandatory access control restricts access to only those assets that are explicitly given permission. So, for example, a web server can only use ports 80 and 443, only share files and scripts from specific directories, only write logs to specific places, and so on.
We’ll revisit this topic in “Advanced Permission Management” and see how modern Linux features can help overcome this binary worldview, allowing for more fine-grained management of privileges.
Probably the best-known implementation of mandatory access control for Linux is SELinux. It was developed to meet the high security requirements of government agencies and is usually used in these environments since the usability suffers from the strict rules. Another option for mandatory access control, included in the Linux kernel since version 2.6.36 and rather popular in the Ubuntu family of Linux distributions, is AppArmor.
Let’s now move on to the topic of users and how to manage them in Linux.
Users
In Linux we often distinguish between two types of user accounts, from a purpose or intended usage point of view:
- So-called system users, or system accounts
-
Typically, programs (sometimes called daemons) use these types of accounts to run background processes. The services provided by these programs can be part of the operating system, such as networking (
sshd, for example), or on the application layer (for example,mysql, in the case of a popular relational database). - Regular users
-
For example, a human user that interactively uses Linux via the shell.
The distinction between system and regular users is less of a technical one and more an organizational construct. To understand that, we first have to introduce the concept of a user ID (UID), a 32-bit numerical value managed by Linux.
Linux identifies users via a UID, with a user belonging to one or more groups
identified via a group ID (GID). There is a special kind of user with the UID 0,
usually called root. This “superuser” is allowed to do anything,
that is, no restriction apply. Usually, you want to avoid working as the
root user, because it’s just too much power to have. You can easily destroy
a system if you’re not careful (believe me, I’ve done this). We’ll get back to this
later in the chapter.
Different Linux distributions have their own ways to decide how to manage the
UID range. For example, systemd-powered distributions (see “systemd”),
have the following convention
(simplified here):
- UID 0
-
Is
root - UID 1 to 999
-
Are reserved for system users
- UID 65534
-
Is user
nobody—used, for example, for mapping remote users to some well-known ID, as is the case with “Network File System” - UID 1000 to 65533 and 65536 to 4294967294
-
Are regular users
To figure out your own UIDs, you can use the (surprise!) id command like so:
$id-u2016796723
Now that you know the basics about Linux users, let’s see how you can manage users.
Managing Users Locally
The first option, and traditionally the only one available, is managing users locally. That is, only information local to the machine is used, and user-related information is not shared across a network of machines.
For local user management, Linux uses a simple file-based interface with a somewhat confusing naming scheme that is a historic artifact we have to live with, unfortunately. Table 4-1 lists the four files that, together, implement user management.
| Purpose | File |
|---|---|
User database |
/etc/passwd |
Group database |
/etc/group |
User passwords |
/etc/shadow |
Group passwords |
/etc/gshadow |
Think of /etc/passwd as a kind of mini user database keeping track of user names, UIDs, group membership, and other data, such as home directory and login shell used, for regular users. Let’s have a look at a concrete example:
$cat/etc/passwdroot:x:0:0:root:/root:/bin/bashdaemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologinbin:x:2:2:bin:/bin:/usr/sbin/nologinsys:x:3:3:sys:/dev:/usr/sbin/nologinnobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologinsyslog:x:104:110::/home/syslog:/usr/sbin/nologinmh9:x:1000:1001::/home/mh9:/usr/bin/fish

The root user has UID 0.

A system account (the
nologingives it away; see more below).
My user account.
Let’s have a closer look at one of the lines in /etc/passwd to understand the structure of a user entry in detail:
root:x:0:0:root:/root:/bin/bash^^^^^^^||||||└──|||||└──||||└──|||└──||└──|└──└──
The login shell to use. To prevent interactive logins, use /sbin/nologin.
The user’s home directory; this defaults to /.
User information such as full name or contact data like phone number. Often also known as GECOS field. Note that GECOS formatting is not used, but rather the field itself is used typically for the full name of the person associated with the account.

The user’s primary group (GID); see also /etc/group.

The UID. Note that Linux reserves UIDs below 1000 for system usage.

The user’s password, with the
xcharacter meaning that the (encrypted) password is stored in /etc/shadow, which is the default these days.
The username, which must be 32 characters or fewer.
One thing we notice is absent in /etc/passwd is the one thing we would expect
to find there, based on its name: the password. Passwords are, for historic
reasons, stored in a file called /etc/shadow. While every user can read
/etc/passwd, you usually need root privileges to read for /etc/shadow.
To add a user, you can use the adduser
command as follows:
$sudoaddusermh9Addinguser`mh9' ... Adding new group `mh9'(1001)...Addingnewuser`mh9' (1000) with group `mh9'...Creatinghomedirectory`/home/mh9' ...Copying files from `/etc/skel'...Newpassword:Retypenewpassword:passwd:passwordupdatedsuccessfullyChangingtheuserinformationformh9Enterthenewvalue,orpressENTERforthedefaultFullName[]:MichaelHausenblasRoomNumber[]:WorkPhone[]:HomePhone[]:Other[]:Istheinformationcorrect?[Y/n]Y
The
addusercommand creates a home directory.It also copies a bunch of default config files into the home directory.
Need to define a password.
Provide optional GECOS information.
If you want to create a system account, pass in the -r option. This will
disable the ability to use a login shell and also avoid home directory creation.
For configuration details, see also /etc/adduser.conf, including options
such as the UID/GID range to be used.
In addition to users, Linux also has the concept of groups, which in a sense is just a collection of one or more users. Any regular user belongs to one default group but can be a member of additional groups. You can find out about groups and mappings via the /etc/group file:
$cat/etc/grouproot:x:0:daemon:x:1:bin:x:2:sys:x:3:adm:x:4:syslog...ssh:x:114:landscape:x:115:admin:x:116:netdev:x:117:lxd:x:118:systemd-coredump:x:999:mh9:x:1001:
Display the content of the group mapping file.
An example group of my user with the GID 1001. Note that you can add a comma-separated list of user names after the last colon to allow multiple users to have that group permission.
With this basic user concept and management under our belt, we move on to a potentially better way to manage users in a professional setup, allowing for scale.
Centralized User Management
If you have more than one machine or server for which you have to manage users—say, in a professional setup—then managing users locally quickly becomes old. You want a centralized way to manage users that you can apply locally, to one specific machine. There are a few approaches available to you, depending on your requirements and (time) budget:
- Directory based
-
Lightweight Directory Access Protocol (LDAP), a decades-old suite of protocols now formalized by IETF, defines how to access and maintain a distributed directory over Internet Protocol (IP). You can run an LDAP server yourself—for example, using projects like Keycloak—or outsource this to a cloud provider, such as Azure Active Directory.
- Via a network
-
Users can be authenticated in this manner with Kerberos. We’ll look at Kerberos in detail in “Kerberos”.
- Using config management systems
-
These systems, which include Ansible, Chef, Puppet, or SaltStack, can be used to consistently create users across machines.
The actual implementation is often dictated by the environment. That is, a company might already be using LDAP, and hence the choices might be limited. The details of the different approaches and pros and cons are, however, beyond the scope of this book.
Permissions
In this section, we first go into detail concerning Linux file permissions, which are central to how access control works, and then we look at permissions around processes. That is, we review runtime permissions and how they are derived from file permissions.
File Permissions
File permissions are core to Linux’s concept of access to resources, since everything is a file in Linux, more or less. Let’s first review some terminology and then discuss the representation of the metadata around file access and permissions in detail.
There are three types or scopes of permissions, from narrow to wide:
- User
-
The owner of the file
- Group
-
Has one or more members
- Other
-
The category for everyone else
Further, there are three types of access:
- Read (
r) -
For a normal file, this allows a user to view the contents of the file. For a directory, it allows a user to view the names of files in the directory.
- Write (
w) -
For a normal file, this allows a user to modify and delete the file. For a directory, it allows a user to create, rename, and delete files in the directory.
- Execute (
x) -
For a normal file, this allows a user to execute the file if the user also has read permissions on it. For a directory, it allows a user to access file information in the directory, effectively permitting them to change into it (
cd) or list its content (ls).
Let’s see file permissions in action (note that the spaces you see here in the output of the
ls command have been expanded for better readability):
$ls-altotal0-rw-r--r--1mh9devs9Apr1211:42test^^^^^^^||||||└──|||||└──||||└──|||└──||└──|└──└──
File name
Last modified time stamp
File size in bytes
Group the file belongs to
File owner
Number of hard links
File mode
When zooming in on the file mode—that is, the file type and permissions
referred to as ![]() in the preceding snippet—we have fields with the following
meaning:
in the preceding snippet—we have fields with the following
meaning:
.rwxrwxrwx^^^^|||└──||└──|└──└──
Permissions for others
Permissions for the group
Permissions for the file owner
The file type (Table 4-2)
The first field in the file mode represents the file type; see Table 4-2 for details. The remainder of the file mode encodes the permissions set for various targets, from owner to everyone, as listed in Table 4-3.
| Symbol | Semantics |
|---|---|
|
A regular file (such as when you do |
|
Block special file |
|
Character special file |
|
High-performance (contiguous data) file |
|
A directory |
|
A symbolic link |
|
A named pipe (create with |
|
A socket |
|
Some other (unknown) file type |
There are some other (older or obsolete) characters such as M or
P used in the position 0, which you can by and large ignore. If you’re
interested in what they mean, run info ls -n "What information is listed".
In combination, these permissions in the file mode define what is allowed for each element of the target set (user, group, everyone else), as shown in Table 4-3, checked and enforced through access.
| Pattern | Effective permission | Decimal representation |
|---|---|---|
|
None |
0 |
|
Execute |
1 |
|
Write |
2 |
|
Write and execute |
3 |
|
Read |
4 |
|
Read and execute |
5 |
|
Read and write |
6 |
|
Read, write, execute |
7 |
Let’s have a look at a few examples:
755-
Full access for its owner; read and execute for everyone else
700-
Full access by its owner; none for everyone else
664-
Read/write access for owner and group; read-only for others
644-
Read/write for owner; read-only for everyone else
400-
Read-only by its owner
The 664 has a special meaning on my system. When I create a file, that’s
the default permission it gets assigned. You can check that with the
umask command, which in my
case gives me 0002.
The setuid permissions are used to tell the system to run an executable as
the owner, with the owner’s permissions. If a file is owned by root, that can cause issues.
You can change the permissions of a file using chmod. Either you specify the
desired permission settings explicitly (such as 644) or you use shortcuts (for
example, +x to make it executable). But how does that look in practice?
Let’s make a file executable with chmod:
$ls-al/tmp/masktest-rw-r--r--1mh9dev0Aug2813:07/tmp/masktest$chmod+x/tmp/masktest$ls-al/tmp/masktest-rwxr-xr-x1mh9dev0Aug2813:07/tmp/masktest
Initially the file permissions are
r/wfor the owner and read-only for everyone else, aka644.Make the file executable.
Now the file permissions are
r/w/xfor the owner andr/xfor everyone else, aka755.
In Figure 4-2 you see what is going on under the hood. Note
that you might not want to give everyone the right to execute the file,
so a chmod 744 might have been better here, giving only the owner the
correct permissions while not changing it for the rest. We will
discuss this topic further in “Good Practices”.

Figure 4-2. Making a file executable and how the file permissions change with it
You can also change the ownership using chown (and chgrp for the group):
$touchmyfile$ls-almyfile-rw-rw-r--1mh9mh90Sep409:26myfile$sudochownrootmyfile-rw-rw-r--1rootmh90Sep409:26myfile
The file myfile, which I created and own.
After
chown,rootowns that file.
Having discussed basic permission management, let’s take a look at some more advanced techniques in this space.
Process Permissions
So far we’ve focused on how human users access files and what the respective permissions in play are. Now we shift the focus to processes. In “Resources and Ownership”, we talked about how users own files as well as how processes use files. This raises the question: what are the relevant permissions, from a process point of view?
As documented on the credentials(7) manual page,
there are different user IDs relevant in the context of runtime permissions:
- Real UID
-
The real UID is the UID of the user that launched the process. It represents process ownership in terms of human user. The process itself can obtain its real UID via
getuid(2), and you can query it via the shell usingstat -c "%u %g" /proc/$pid/. - Effective UID
-
The Linux kernel uses the effective UID to determine permissions the process has when accessing shared resources such as message queues. On traditional UNIX systems, they are also used for file access. Linux, however, previously used a dedicated filesystem UID (see the following discussion) for file access permissions. This is still supported for compatibility reasons. A process can obtain its effective UID via
geteuid(2). - Saved set-user-ID
-
Saved set-user-IDs are used in
suidcases where a process can assume privileges by switching its effective UID between the real UID and the saved set-user-ID. For example, in order for a process to be allowed to use certain network ports (see “Ports”), it needs elevated privileges, such as being run asroot. A process can get its saved set-user-IDs viagetresuid(2). - Filesystem UID
-
These Linux-specific IDs are used to determine permissions for file access. This UID was initially introduced to support use cases where a file server would act on behalf of a regular user while isolating the process from signals by said user. Programs don’t usually directly manipulate this UID. The kernel keeps track of when the effective UID is changed and automatically changes the filesystem UID with it. This means that usually the filesystem UID is the same as the effective UID but can be changed via
setfsuid(2). Note that technically this UID is no longer necessary since kernel v2.0 but is still supported, for compatibility.
Initially, when a child process is created via fork(2), it inherits copies of its
parent’s UIDs, and during an execve(2) syscall, the process’s real UID is preserved,
whereas the effective UID and saved set-user-ID may change.
For example, when you run the passwd command, your effective UID is your UID,
let’s say 1000. Now, passwd has suid set enabled, which means when you run it,
your effective UID is 0 (aka root). There are also other ways to influence
the effective UID—for example, using chroot and other sandboxing techniques.
Note
POSIX threads require that credentials are shared by all threads in a process. However, at the kernel level, Linux maintains separate user and group credentials for each thread.
In addition to file access permissions, the kernel uses process UIDs for other things, including but not limited to the following:
-
Establishing permissions for sending signals—for example, to determine what happens when you do a
kill -9for a certain process ID. We’ll get back to this in Chapter 6. -
Permission handling for scheduling and priorities (for example,
nice). -
Checking resource limits, which we’ll discuss in detail in the context of containers in Chapter 9.
While it can be straightforward to reason with effective UID in the
context of suid, once capabilities come into play it can be more challenging.
Advanced Permission Management
While so far we’ve focused on widely used mechanisms, the topics in this section are in a sense advanced and not necessarily something you would consider in a casual or hobby setup. For professional usage—that is, production use cases where business critical workloads are deployed—you should definitely be at least aware of the following advanced permission management approaches.
Capabilities
In Linux, as is traditionally the case in UNIX systems, the root user has
no restrictions when running processes. In other words, the kernel only
distinguishes between two cases:
-
Privileged processes, bypassing the kernel permission checks, with an effective UID of 0 (aka
root) -
Unprivileged processes, with a nonzero effective UID, for which the kernel does permission checks, as discussed in “Process Permissions”
With the introduction of the
capabilities syscall in
kernel v2.2, this binary worldview has changed: the privileges traditionally
associated with root are now broken down into distinct units that can be
independently assigned on a per-thread level.
In practice, the idea is that a normal process has zero capabilities, controlled by the permissions discussed in the previous section. You can assign capabilities to executables (binaries and shell scripts) as well as processes to gradually add privileges necessary to carry out a task (see the discussion in “Good Practices”).
Now, a word of caution: capabilities are generally relevant only for system-level tasks. In other words: most of the time you won’t necessarily depend on them.
In Table 4-4 you can see some of the more widely used capabilities.
| Capability | Semantics |
|---|---|
|
Allows user to make arbitrary changes to files’ UIDs/GIDs |
|
Allows sending of signals to processes belonging to other users |
|
Allows changing the UID |
|
Allows setting the capabilities of a running process |
|
Allows various network-related actions, such as interface config |
|
Allows using RAW and PACKET sockets |
|
Allows calling |
|
Allows system admin operations, including mounting filesystems |
|
Allows using |
|
Allows loading kernel modules |
Let’s now see the capabilities in action. For starters, to view the capabilities, you can use commands as shown in the following (output edited to fit):
$capshCurrent:=Boundingset=cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,...$grepCap/proc/$$/statusCapInh:0000000000000000CapPrm:0000000000000000CapEff:0000000000000000CapBnd:000001ffffffffffCapAmb:0000000000000000
Overview of all capabilities on the system
Capabilities for the current process (the shell)
You can manage capabilities in a fine-grained manner—that is, on a per-file basis—with getcap and setcap (the details and good practices are beyond the scope of this chapter).
Capabilities help to transition from an all-or-nothing approach to finer-grained privileges on a file basis. Let’s now move on to a different advanced access control topic: the sandboxing technique of seccomp.
seccomp Profiles
Secure computing mode (seccomp)
is a Linux kernel feature available since 2005. The basic idea behind this
sandboxing technique is that, using a dedicated syscall called seccomp(2),
you can restrict the syscalls a process can use.
While you might find it inconvenient to manage seccomp yourself directly, there are ways to use it without too much hassle. For example, in the context of containers (see “Containers”), both Docker and Kubernetes support seccomp.
Let’s now have a look at an extension of the traditional, granular file permission.
Access Control Lists
With access control lists (ACLs), we have a flexible permission mechanism in Linux that you can use on top of or in addition to the more “traditional” permissions discussed in “File Permissions”. ACLs address a shortcoming of traditional permissions in that they allow you to grant permissions for a user or a group not in the group list of a user.
To check if your distribution supports ACLs, you can use
grep -i acl /boot/config* where you’d hope to find a POSIX_ACL=Y somewhere
in the output to confirm it. In order to use ACL for a filesystem, it must be enabled
at mount time, using the acl option. The docs reference on
acl has a lot of useful
details.
We won’t go into greater detail here on ACLs since they’re slightly outside the scope of this book; however, being aware of them and knowing where to start can be beneficial, should you come across them in the wild.
With that, let’s review some good practices for access control.
Good Practices
Here are some security “good practices” in the wider context of access control. While some of them might be more applicable in professional environments, everyone should at least be aware of them.
- Least privileges
-
The least privileges principle says, in a nutshell, that a person or process should only have the necessary permissions to achieve a given task. For example, if an app doesn’t write to a file, then it only needs read access. In the context of access control, you can practice least privileges in two ways:
-
In “File Permissions”, we saw what happens when using
chmod +x. In addition to the permissions you intended, it also assigns some additional permissions to other users. Using explicit permissions via the numeral mode is better than symbolic mode. In other words: while the latter is more convenient, it’s less strict. -
Avoid running as root as much as you can. For example, when you need to install something, you should be using
sudorather than logging in asroot.
Note that if you’re writing an application, you can use an SELinux policy to restrict access to only selected files, directories, and other features. In contrast, the default Linux model could potentially give the application access to any files left open on the system.
-
- Avoid setuid
-
Take advantage of capabilities rather than relying on
setuid, which is like a sledgehammer and offers attackers a great way to take over your system. - Auditing
-
Auditing is the idea that you record actions (along with who carried them out) in a way that the resulting log can’t be tampered with. You can then use this read-only log to verify who did what, when. We’ll dive into this topic in Chapter 8.
Conclusion
Now that you know how Linux manages users, files, and access to resources, you have everything at your disposal to carry out routine tasks safely and securely.
For any practical work with Linux, remember the relationship between users, processes, and files. This is crucial, in the context of the multiuser operating system that Linux is, for a safe and secure operation and to avoid damages.
We reviewed access control types, defined what users in Linux are, what they can do, and how to manage them both locally and centrally. The topic of file permissions and how to manage them can be tricky, and mastering it is mostly a matter of practice.
Advanced permissions techniques including capabilities and seccomp profiles are super relevant in the context of containers.
In the last section, we discussed good practices around access control–related security, especially applying least privileges.
If you want to dive deeper into the topics discussed in this chapter, here are some resources:
- General
-
-
“A Survey of Access Control Policies” by Amanda Crowell
-
Lynis, an auditing and compliance testing tool
-
- Capabilities
- seccomp
- Access Control Lists
Remember that security is an ongoing process, so you want to make sure to keep an eye on users and files, something we’ll go into greater detail on in Chapters 8 and 9, but for now let’s move on to the topic of filesystems.
Get Learning Modern Linux now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

