Output from the batch and speed layers are stored in the serving layer, which responds to ad-hoc queries by returning precomputed views or building views from processed data.
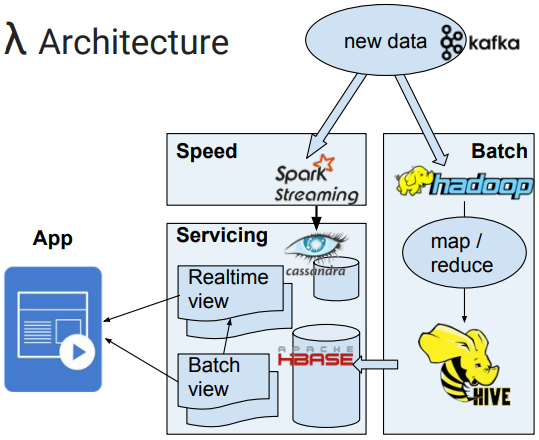
Some Lambda implementations have various storage and technology decisions, but they all have a batch and a real time components that both consume the same data and a real time view that can be updated by corrected data from batch processing.
The problem with this architecture is that the same data is ingested by both the Speed and by the Batch layer and typically stored in two separate databases, Cassandra and HBASE in the example above. Plus, extra processing ...

