Chapter 1. Serverless and OpenWhisk Architecture
Welcome to the world of Apache OpenWhisk, an open source serverless platform designed to make it simple to develop applications in the cloud. The project was developed in the open by the Apache Software Foundation, so the correct name is “Apache OpenWhisk,” but for simplicity we’ll use “OpenWhisk” throughout.
Note that “serverless” does not mean “without a server”—it means “without managing the server.” Indeed, we will learn how to build complex applications without being concerned with installing and configuring the servers to run the code; we only have to deal with the servers when we first deploy the platform.
A serverless environment is most suitable for applications needing processing “in the cloud” because it allows you to split your application into multiple simpler services. This approach is often referred to as a “microservices” architecture.
To begin with, we will take a look at the architecture of OpenWhisk to understand its strengths and weaknesses. After that we’ll discuss the architecture itself, focusing on the serverless model to show you what it can and cannot do.
We’ll wrap up this chapter by comparing OpenWhisk with another widely used similar architecture, Java EE. The problems previously solved by Java EE application servers can now be solved by serverless environments, only at a greater scale (even hundreds of servers) and with more flexibility (not just with Java, but with many other programming languages).
Tip
Since the project is active, new features are added almost daily. Be sure to check the book’s website for important updates and corrections.
OpenWhisk Architecture
Apache OpenWhisk, as shown in Figure 1-1, is a serverless open source cloud platform. It works by executing functions (called actions) in response to events. Events can originate from multiple sources, including timers, databases, message queues, or websites like Slack or GitHub.
OpenWhisk accepts source code as input that provisions executing a single command with a command-line interface (CLI), and then delivers services through the web to multiple consumers, such as other websites, mobile applications, or services based on REST APIs.
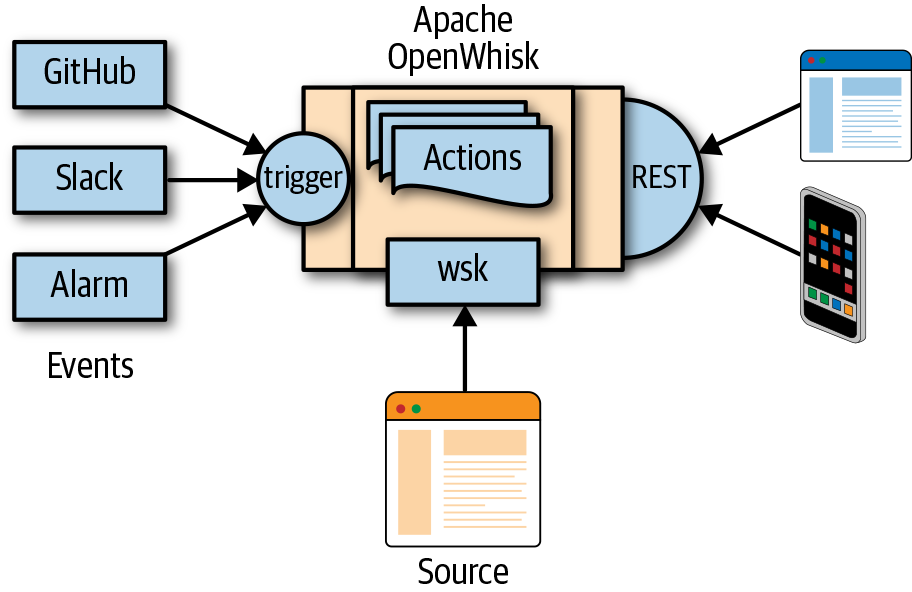
Figure 1-1. How Apache OpenWhisk works
Functions and Events
OpenWhisk completes its tasks using functions. A function is typically a piece of code that receives some input and provides an output in response. It is important to note that a function is generally expected to be stateless.
Backend web applications are stateful. Just think of a shopping cart application for e-commerce: while you navigate the website, you add your items to the basket to buy them at the end. You keep a state, which is the contents of the cart.
But being stateful is expensive; it limits scalability because you need a place to store your data. Most importantly, you will need something to synchronize the state between invocations. When your load increases, this “state-keeping” infrastructure will limit your ability to grow. If you are stateless, you can usually add more servers because you do not have the housekeeping of keeping the state in sync among the servers, which is complex, expensive, and has limits.
In OpenWhisk, and in serverless environments in general, the functions must be stateless. In a serverless environment you can keep state, but not at the level of a single function. You have to use some special storage that is designed for high scalability. As we will see later, you can use a NoSQL database for this.
The OpenWhisk environment manages the infrastructure, waiting for something important to occur. This something important is called an event. Only when an event happens a function is invoked.
Event processing is actually the most important operation the serverless environment manages. We will discuss in detail next how this happens. Developers want to write code that responds correctly when something happens—e.g., a request from the user or the arrival of new data—and processes the event quickly. The rest belongs to the cloud environment.
In conclusion, serverless environments allow you to build your application out of simple stateless functions, or actions as they are called in the context of OpenWhisk, that are triggered by events. We will see later in this chapter what other constraints those actions must satisfy.
Architecture Overview
Now that we know what OpenWhisk is and what it does, let’s take a look at how it works under the hood. Figure 1-2 provides a high-level overview.
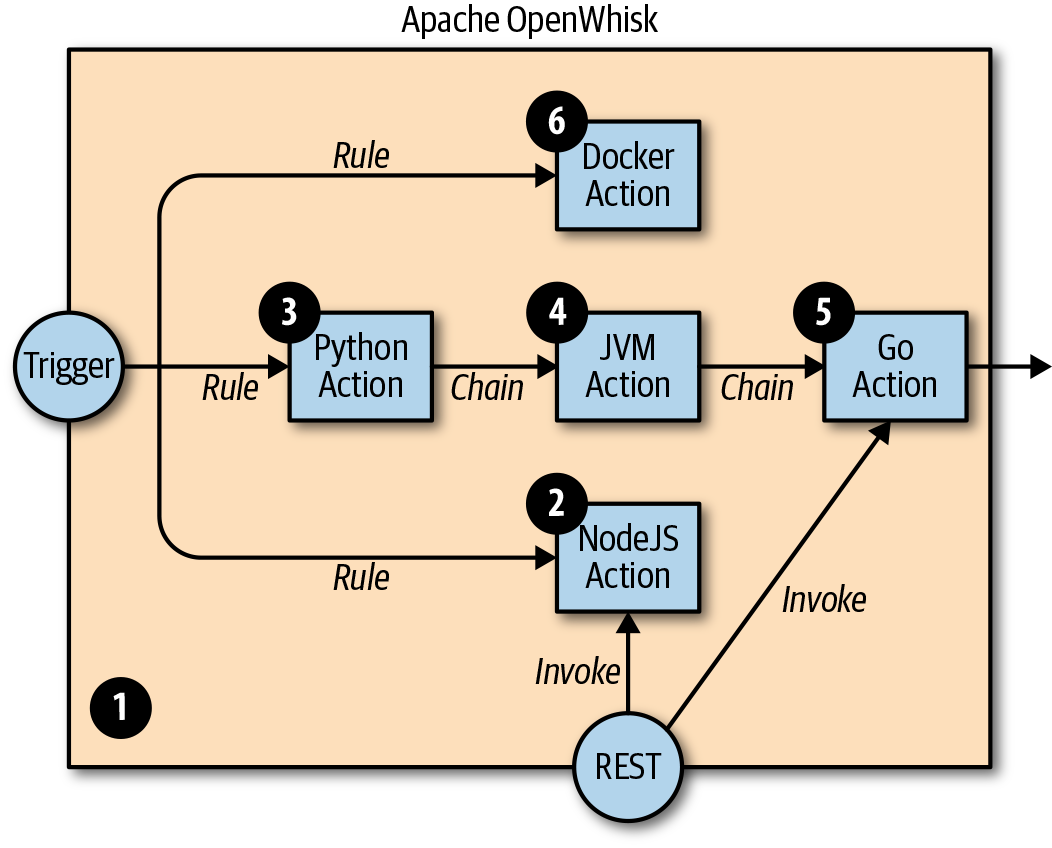
Figure 1-2. An example deployment with actions in multiple languages
In Figure 1-2, the big container in the center is OpenWhisk itself. It acts as a container of actions. We will learn more about the container and these actions shortly, but as you can see, actions can be developed in many programming languages. Next, we’ll discuss the various options available.
Note
The “container” schedules the actions, creating and destroying them as needed needed, and it will also scale them, creating duplicates in response to an increase in load.
Programming Languages for OpenWhisk
You can write actions in many programming languages. Typically, interpreted programming languages are used, such as JavaScript (actually, Node.js), Python, or PHP. These programming languages give immediate feedback because you can execute them without a compilation step. While these are higher-level languages and are easier to use, they are also slower than compiled languages. Since OpenWhisk is a highly responsive system (you can immediately run your code in the cloud), most developers prefer to use those interpreted languages as their use is more interactive.
Tip
While JavaScript is the most widely used language for OpenWhisk, other languages can also be used without issue.
In addition to purely interpreted (or more correctly, compiled-on-the-fly) languages, you can also use the precompiled interpreted languages in the Java family such as Java, Scala, and Kotlin. These languages run on the Java Virtual Machine (JVM) and are distributed in an intermediate form. This means you have to create a .jar file to run your action. This file includes the so-called “bytecode” OpenWhisk executes when it is deployed. A JVM actually executes the action.
Finally, in OpenWhisk you can use compiled languages. These languages use a binary executable that runs on “bare metal” without interpreters or virtual machines (VMs). These binary languages include Swift, Go, and the classic C/C++. Currently, OpenWhisk supports Go and Swift out of the box. However, you can use any other compiled programming language as long as you can compile the code in Linux elf format for the amd64 processor architecture. In fact, you can use any language or system that you can package as a Docker image and publish on Docker Hub: OpenWhisk is able to retrieve this type of image and run it, as long as you follow its conventions.
Note
Each release of OpenWhisk includes a set of runtimes for specific versions of programming languages. For the released combinations of programming languages and versions, you can deploy actions using the switch --kind on the command line (e.g., --kind nodejs:6 or --kind go:1.11). For single file actions, OpenWhisk will select a default runtime to use based on the extension of the file. You can find more runtimes for programming languages or versions not yet released on Docker Hub that can be used with the switch --docker followed by the image name.
Actions and Action Composition
OpenWhisk applications are collections of actions. Figure 1-3 shows how they are assembled to build applications.
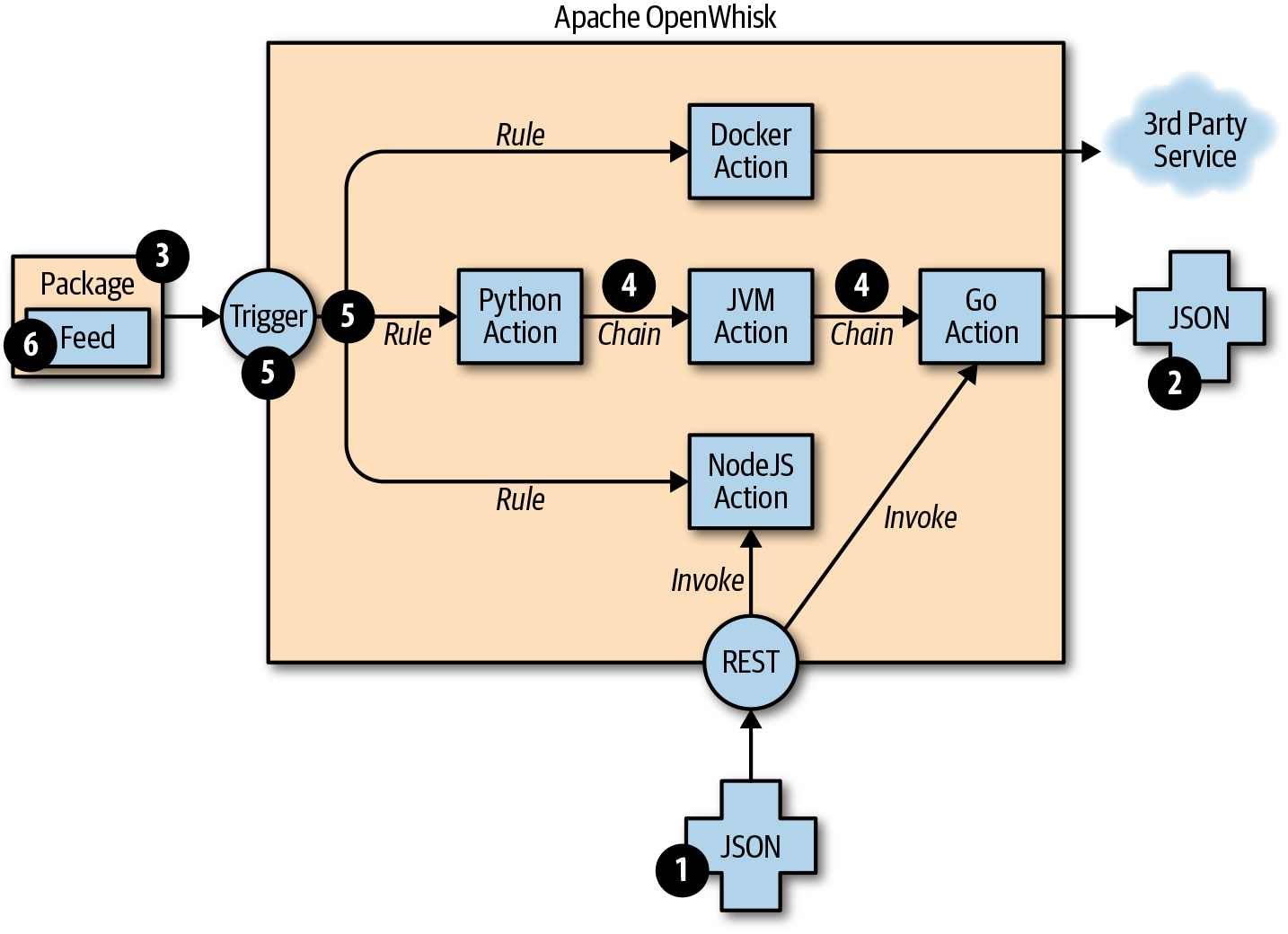
Figure 1-3. Overview of OpenWhisk action runtimes
An action is a piece of code, written in one of the supported programming languages (or even an unsupported language, as long as you can produce an executable and package it in a Docker image), that you can invoke. On invocation, the action will receive some information as input.
To standardize parameter passing among multiple programming languages, OpenWhisk uses the widely supported JavaScript Object Notation (JSON) format, because it’s pretty simple and there are libraries to encode and decode this format available for basically every programming language.
The parameters are passed to actions as JSON objects serialized as strings that the action receives when it starts and is expected to process. At the end of the processing, each action must produce a result, which is returned as a JSON object value.
You can group actions in packages. A package is a unit of distribution. You can share a package with others using bindings. You can also customize a package, providing parameters that are different for each binding.
Action Chaining
Actions can be combined in many ways. The simplest way is chaining them into sequences.
Chained actions use as input the output of the preceding actions. Of course, the first action of a sequence will receive the parameters (in JSON format), and the last action of the sequence will produce the final result as a JSON string. However, since not all the flows can be implemented as a linear pipeline of input and output, there is also a way to split the flows of an action into multiple directions. This feature is implemented using triggers and rules. A trigger is merely a named invocation. By itself a trigger does nothing. However, you can associate the trigger with one or more actions using rules. Once you have created the trigger and associated some action with it, you can fire the trigger by providing parameters.
Note
Triggers cannot be part of a package. but they can be part of a namespace, as we’ll see in Chapter 3.
The actions used to fire a trigger are called a feed and must follow an implementation pattern. In particular, as we will learn in “Observer”, actions must implement an Observer pattern and be able to activate a trigger when an event happens.
When you create an action that follows the Observer pattern (which can be implemented in many different ways), you can mark the action as a feed in a package. You can then combine a trigger and a feed when you deploy the application, to use a feed as a source of events for a trigger (and in turn activate other actions).
How OpenWhisk Works
Now that you know the different components of OpenWhisk, let’s look at how OpenWhisk executes an action.
The process is straightforward for the end user, but internally it executes several steps. We saw before the user visible components of OpenWhisk. We are now going to look under the hood and learn about the internal components. Those components are not visible by the user but the knowledge of how it works is critical to use OpenWhisk correctly. OpenWhisk is “built on the shoulders of giants,” and it uses some widely known and well-developed open source projects.
These include:
- Nginx
-
A high-performance web server and reverse proxy
- CouchDB
-
A scalable, document-oriented NoSQL database
- Kafka
-
A distributed, high-performing publish/subscribe messaging system
All the components are Docker containers, a format to package applications in an efficient but constrained, virtual machine–like environment. They can be run any environment supporting this format, like Kubernetes.
Furthermore, OpenWhisk can be split into some components of its own:
- Controller
-
Managing entities, handling trigger fires, and routing actions invocations
- Invoker
-
Launching the containers to execute the actions
- Action Containers
-
Actually executing the actions
In Figure 1-4 you can see how the processing happens. We are going to discuss it in detail, step by step.
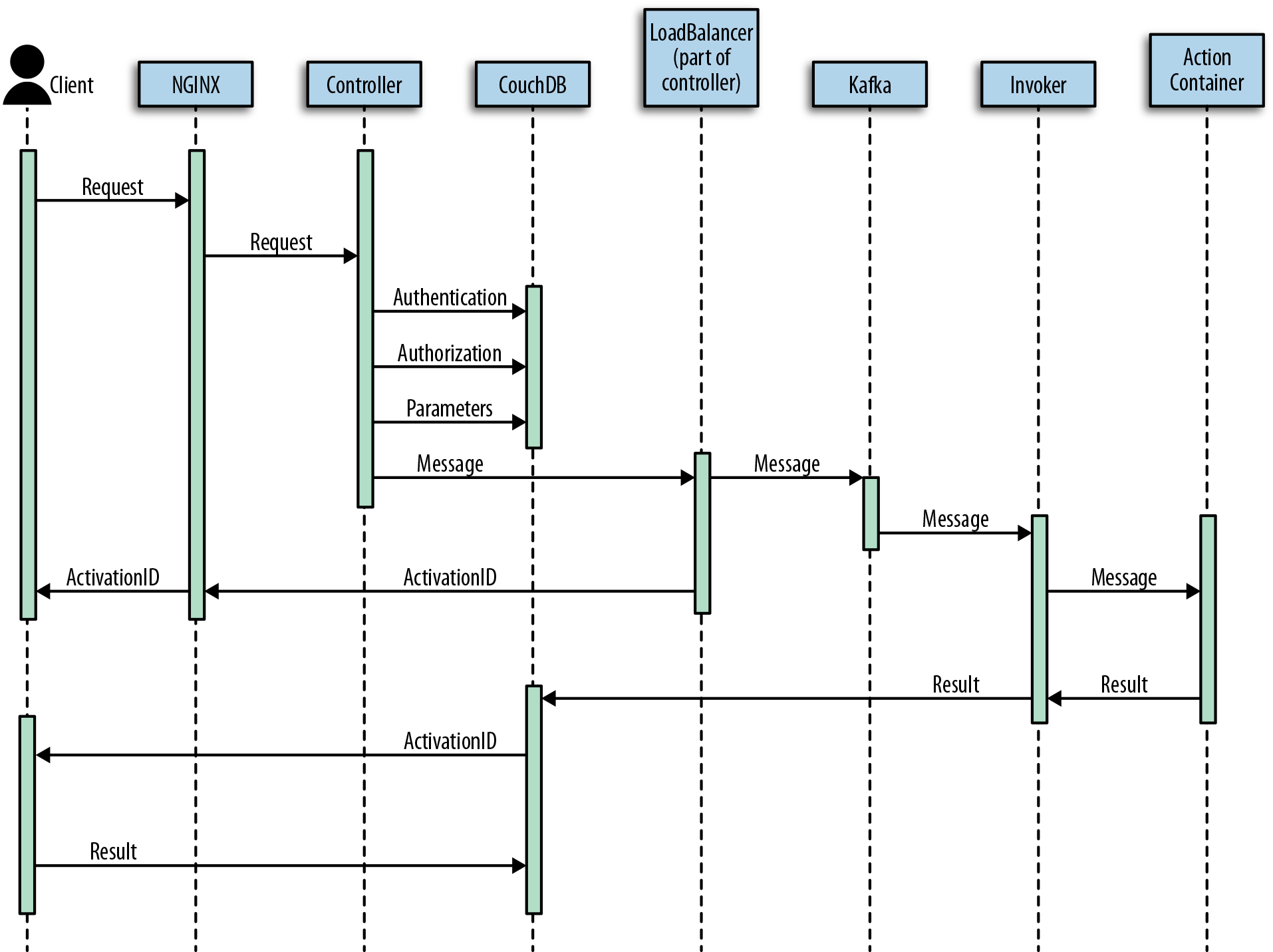
Figure 1-4. How OpenWhisk processes an action
Note
Basically, all the processing done in OpenWhisk is asynchronous, so we will go into the details of an asynchronous action invocation. Synchronous execution fires an asynchronous action and then waits for the result.
Nginx
Everything starts when an action is invoked. There are different ways to invoke an action:
-
From the web, when the action is exposed as a web action
-
When another action invokes it through the API
-
When a trigger is activated and there is a rule to invoke the action
-
From the CLI
Let’s call the client the subject who invokes the action. OpenWhisk is a RESTful system, so every invocation is translated to an HTTPS call and hits the so-called “edge” node. The edge is actually the web server and reverse proxy Nginx. The primary purpose of Nginx is to implement support for the HTTPS secure web protocol, so it deploys all the certificates required for secure processing. Nginx then forwards the requests to the actual internal service component, the controller.
Controller
Before executing the action, the controller checks whether it can execute the action and initialize it correctly:
-
It needs to be sure it can execute the action, so it must authenticate the request.
-
Once the origin of the request has been identified, it needs to be authorized, verifying that the subject has the appropriate permissions.
-
The request must be enriched with some additional parameters that, as we will see, are provided as part of action configuration.
To perform all those steps the controller consults the database, which in OpenWhisk is CouchDB. Once validated and enriched, the action is now ready to be executed, so it is sent to the next component of the processing, the load balancer.
Load Balancer
The job of the load balancer, as its name implies, is to balance the load among the various executors in the system, which are called invokers in OpenWhisk.
We already saw that OpenWhisk executes actions in runtimes. The load balancer keeps an eye on the available instances of the action runtime, reuses the existing ones if they are available, or creates new ones if they are needed.
We’ve arrived at the point where the system is ready to invoke the action. However, you cannot just send your action invocation to an invoker, because it may be busy serving another action. There is also the possibility that an invoker has crashed, or even that the whole system has crashed and is restarting.
So, because we are working in a massively parallel environment that is expected to scale, we have to consider the possibility that we will not have the resources we need to execute the action immediately. In cases like this, we have to buffer invocations. OpenWhisk uses Kafka to perform this action. Kafka is a high-performing “publish and subscribe” messaging system that can store your requests until they are ready to be executed. The request is turned into a message addressed to the invoker the load balancer chose for the execution. An action invocation is actually turned in an HTTPS request to Nginx; then it internally becomes a message to Kafka.
Each message sent to an invoker has an identifier called the activation ID. Once the message has been queued in Kafka, there are two possibilities: a nonblocking and a blocking invocation.
For a nonblocking invocation, the activation id is sent back as the final answer to the request to the client, and the request completes. In this case, the client is expected to come back later to check the result of the invocation.
For a blocking invocation, the connection stays open: the controller waits for the result from the action and sends the result to the client.
Invoker
In OpenWhisk the invoker is in charge of executing the actions. Actions are actually executed by the invoker in isolated environments provided by Docker containers. As already mentioned, Docker containers are execution environments that resemble an entire operating system, providing everything needed to run an application.
So, from the actions perspective, the environment provided by a Docker container looks like an entire computer (just like a VM). However, execution within containers is much more efficient than in VMs, so they are preferred.
Note
It would be safe to say that, without containers, serverless environments like OpenWhisk would not be possible.
Docker actually uses images to create the containers that execute actions. A runtime is really a Docker image. The invoker launches a new image for the chosen runtime and then initializes it with the code of the action. OpenWhisk provides a set of Docker images including support for various languages. The action runtimes also include the initialization logic. They support JavaScript, Python, Go, Java, and similar languages.
Once the runtime is up and running, the invoker passes the action requests that have been constructed in the processing so far. The invoker also manages and stores the logs needed to facilitate debugging.
After OpenWhisk completes the processing, it must store the result somewhere. This place is again CouchDB (where configuration data is also stored). Each result of the execution of an action is then associated with the activation ID, the one that was sent back to the client. Thus, the client can retrieve the result of its request by querying the database with the ID.
Client
The processing described so far is asynchronous. This means the client will start a request and forget about it, although it doesn’t leave it behind entirely, because it returns an activation ID as the result of an invocation. As we have seen already, the activation ID is used to store the result in the database after the processing. To retrieve the final result, the client will have to perform a request again later, passing the activation ID as a parameter. Once the action completes, the result, the logs, and other information will be available in the database and can be retrieved.
Synchronous processing is also available. It works the same way as asynchronous processing, except the client will block waiting for the action to complete and retrieve the result immediately.
Serverless Execution Constraints
Serverless applications come with a few constraints and limitations. We call those constraints the execution model. You can think of your application as a set of actions, collaborating with each other to meet the purpose of the application. Each action running in a serverless environment will be executed within certain limits, and those limits must be considered when designing the application.
Figure 1-5 shows the most important action execution constraints. All constraints have some value in terms of time or space, (timeout, frequency, memory, disk size, etc.). Some are configurable; others are hardcoded. Typical constraints (which can be different depending on the particular installation you are using) are:
-
Execution time: max 1 minute per action
-
Memory size: max 256 MB per action
-
Log size: max 10 MB per action
-
Code size: max 48 MB per action
-
Parameters: max 1 MB per action
-
Result: max 1 MB per action
Note that execution time and memory size can be configured by the developer of the action using annotations. Other constraints cannot be configured by the user, but they can be configured by the system administrator of OpenWhisk.
Furthermore, there are global constraints:
-
Concurrency: max 100 concurrent activations can be queued at the same time (configurable)
-
Frequency: max 120 activations per minute can be requested (configurable)
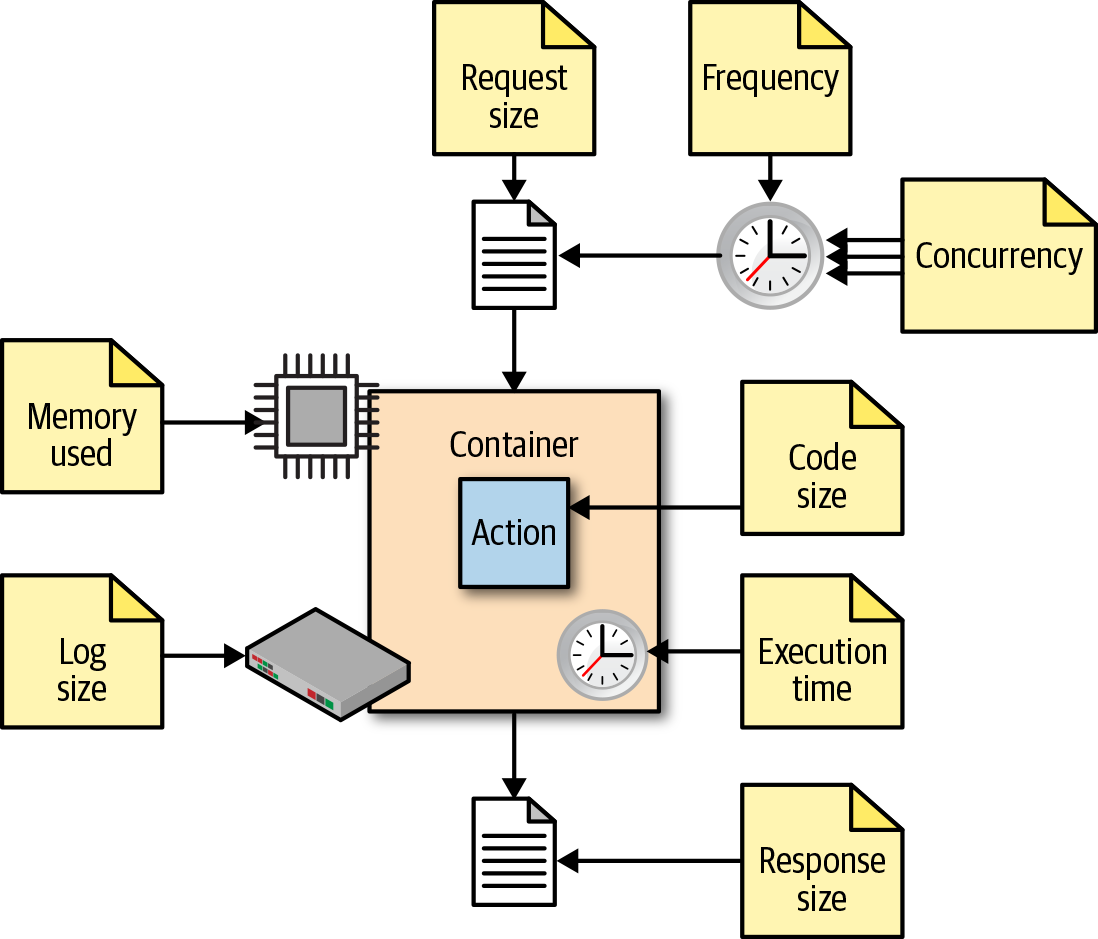
Figure 1-5. OpenWhisk action execution constraints
Note
Global constraints are actually per namespace. You can think of a namespace as a collection of OpenWhisk resources available under a URL prefix that can be accessed using the same API token (so they can invoke each other). In a sense, a namespace is the serverless equivalent of an application, split into multiple related entities.
Let’s discuss the qualitative constraints that impact the way you have to develop actions.
Actions Are Functional
As already mentioned, each action must be a function invoked with a single input and must produce a single output. The input is a string in JSON format. The action usually deserializes the string in a data structure specific to the programming language used for the implementation. The runtime generally performs the deserialization, so the developer receives an already-parsed data structure. If you use dynamic languages like JavaScript or Python, you will usually receive something like a JavaScript object or a Python dictionary, which can be efficiently processed using the programming language.
If you use a statically typed language like Java or Go, you may need to put more effort into decoding the input. Libraries for performing such decoding are readily available. However, some decoding work may be necessary to map the generally untyped arguments to the typed data structure of the language.
The same holds true for returning the output. It must be a single data structure appropriate for the programming language you are using, but it must also be serialized back into JSON format before being returned. Runtimes usually take care of serializing data structures back into strings.
Actions Are Event-Driven
Everything in the serverless environment is activated by events. Your code should execute quickly, do what is requested, and terminate. It is the system that will invoke your code when it is needed. An example of an event is when a user browses the web and invokes the URL of a web action deployed in OpenWhisk. This event triggers an action invocation.
But this is only one possible event. Another example is a request from another action that arrives in a message queue.
Database management is also event-driven. You can perform a query on a database, then wait until an event is triggered when the data arrives.
Websites can originate events, too. For example, you may receive an event:
-
When someone pushes a commit on GitHub
-
When a user interacts with Slack and sends a message
-
When a scheduled alarm is triggered
Actions Do Not Have Local State
Actions are executed in Docker containers. A container is created to execute a single action; it serves a number of requests, and then it is destroyed. As a consequence (by Docker design), the filesystem is ephemeral. Once a container terminates, all the data stored on the filesystem will be removed too. But this does not mean you cannot store anything in files when using a function. You can use files for temporary data storage while executing an application.
Indeed, a container can be used multiple times. For example, if your application needs some data downloaded from the web, an action can can perform the downloading and then save it and make it available to other actions executed in the same container.
What you cannot assume is that the data will stay in the container forever. At some point in time, either the container will be destroyed or another container will be created to execute the action. In a new container, the data you downloaded in a previous execution of the action will no longer be available.
In short, you can use local storage as a cache for speeding up further actions, but you cannot rely on the fact that the data you store in a file will persist forever. For long-term persistence, you need to use other means: typically a database or another form of cloud storage.
Actions Are Time-Bound
Actions must complete in the shortest time possible. As already mentioned, the execution environment imposes time limits on the execution time of an action. If the action does not terminate within that timeframe, it will be aborted. This is also true for background actions or threads you may have started.
So, ensure that your code will not keep going for an unlimited amount of time (e.g., when it gets larger input). Instead, you may want to split the processing into smaller chunks and ensure the execution time of your action will stay within the necessary limits.
Also remember that billing can be time-dependent. If your cloud provider supports OpenWhisk with a pay-per-use model, you will be charged for the time your actions take. Faster actions will result in lower costs. When you have millions of actions executing, a few milliseconds can make a difference.
Note
If you install OpenWhisk on your own servers, you are usually only billed for the VMs running them.
Actions Are Not Ordered
Note also that actions are not ordered. If you invoke action A at time X and action B at time Y, with X < Y, action B may be executed before A. As a consequence, if the actions have side effects—for example, writing to the database—the side effect of action A may be applied later than that of action B. Furthermore, there is no guarantee an action will be executed entirely before or after another action. They may overlap in time. For example, if you are writing to a database you must be aware that another action may start writing to it too before you are finished. So, you have to provide transaction support.
From Java EE to Serverless
While the serverless architecture may look brand new, it actually has quite a bit in common with existing architectures. In a sense, it is an evolution of those historical architectures.
To better understand the genesis and the advantages of the serverless architecture, it makes sense to compare the OpenWhisk architecture with one of its historical precedents: Java Enterprise Edition, or Java EE.
Note
Java EE itself was a specification. Some of the most prominent implementations of this specification still in broad use today are Oracle WebLogic and IBM WebSphere.
Classic Java EE Architecture
The core idea behind Java EE was to allow the development of large application out of small, manageable parts. It was a technology designed to help application development for large organizations, using the once new and revolutionary Java programming language—hence, the name Java Enterprise Edition.
Note
When the Java EE was created, everything was based on the Java programming language, leveraging the VM. At the time Java was considered to be a programming language suitable for building large, scalable applications (meant to replace C++). Scripting languages like Python were not yet largely used, and JavaScript was still in its infancy.
To facilitate the development of these vast and complex applications, Java EE provided a productive (and complicated) infrastructure of services offering many different types of components, each one deployable separately, with many ways for the various parts to communicate with each other. Those services were put together and made available through the use of software packages called application servers. Figure 1-6 gives an overview of the JavaEE architecture and its different tiers.
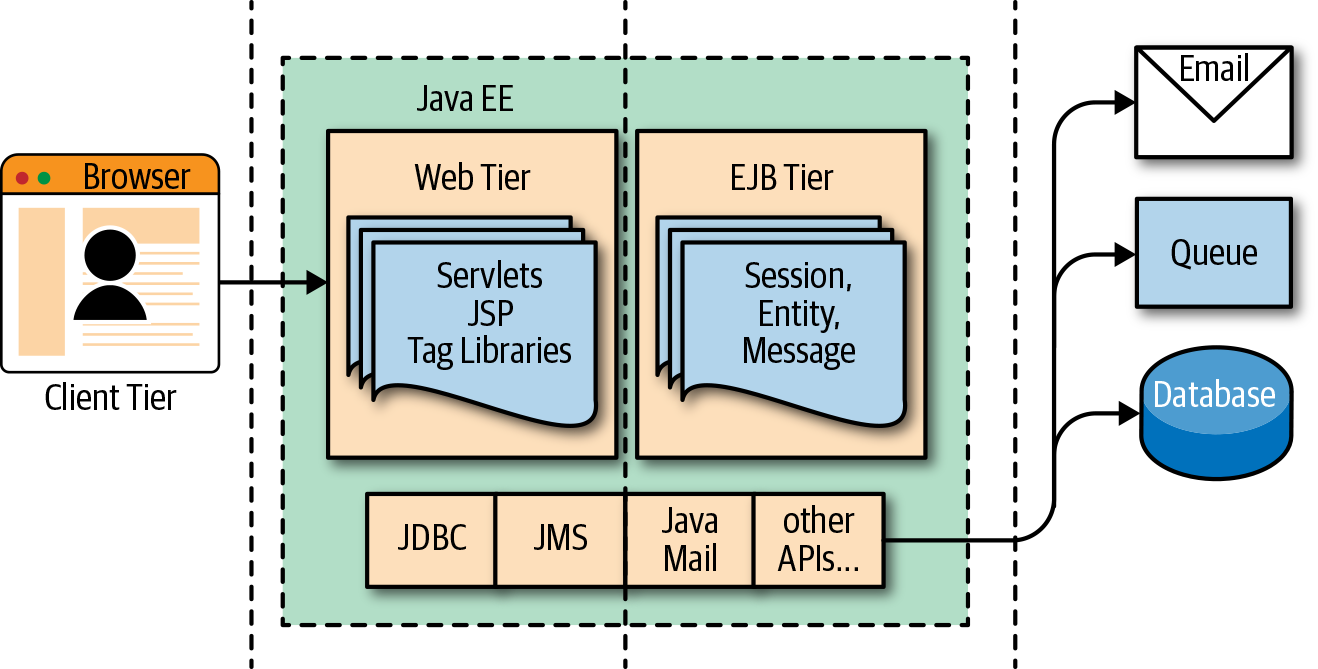
Figure 1-6. Java EE architecture
The client tier was expected to implement the application logic at the client level. Historically Java was used to implement applets, small Java components that were downloaded and run in browsers. JavaScript, CSS, and HTML replaced those web components.
In the web tier, the most crucial components were the servlets, further specialized in into JavaServer Pages (JSP), tag libraries, etc. Those components defined the web user interface at the server level.
The so-called business logic, managing data and connection to other enterprise systems, was expected to be implemented in the business or Enterprise Java Beans (EJB). There were many flavors of EJB, like Entity Beans, Session Beans, Message Beans, etc.
Each component in Java EE was a set of Java classes that implemented an API. The developer wrote those classes and then delivered them to the application server, which loaded the components and ran them in their containers.
The application servers also provided a set of connectors to interface the application with the external world, in the enterprise information system (EIS) tier. There were Java connectors allowing applications to interface with virtually any resource of interest, including:
-
Databases
-
Message queues
-
Email and other communication systems
In the Java EE world, application servers provided the implementation of the entire Java EE specification, including APIs and connectors, acting as a one-stop solution for all the development needs of enterprises.
Serverless Equivalent of Java EE
For many reasons, OpenWhisk can be seen as an evolution of Java EE. Both started from the same basic idea: split your application into many small, manageable parts, and provide a system to quickly put together all those pieces.
However, the technological landscape driving the development of serverless environments is different. In today’s world:
-
Applications are spread among multiple servers in the cloud, requiring virtually infinite scalability.
-
We have numerous programming languages, including scripting languages, that are used extensively.
-
VM and container technologies are available to wrap and control the execution of programs.
-
HTTP can be considered a standard transport protocol.
-
JSON is simple and widely used as a universal exchange format.
Figure 1-7 shows the OpenWhisk architecture in a way that is easy to compare with Java EE. It is intentionally similar to Figure 1-6, to make it easier to see the similarities and differences between the two architectures.
Tiers
As you can see, OpenWhisk also has a web tier and a business tier, in addition to a client and an integration tier. While there is no formal separation between the two tiers, in practice OpenWhisk has actions that are directly exposed to the web (web actions) and actions that are not.
Web actions can be considered to belong to the web tier. Other actions, meant to serve events either coming from web actions or triggered by other services in the infrastructure, can be considered business actions, defining a business tier.
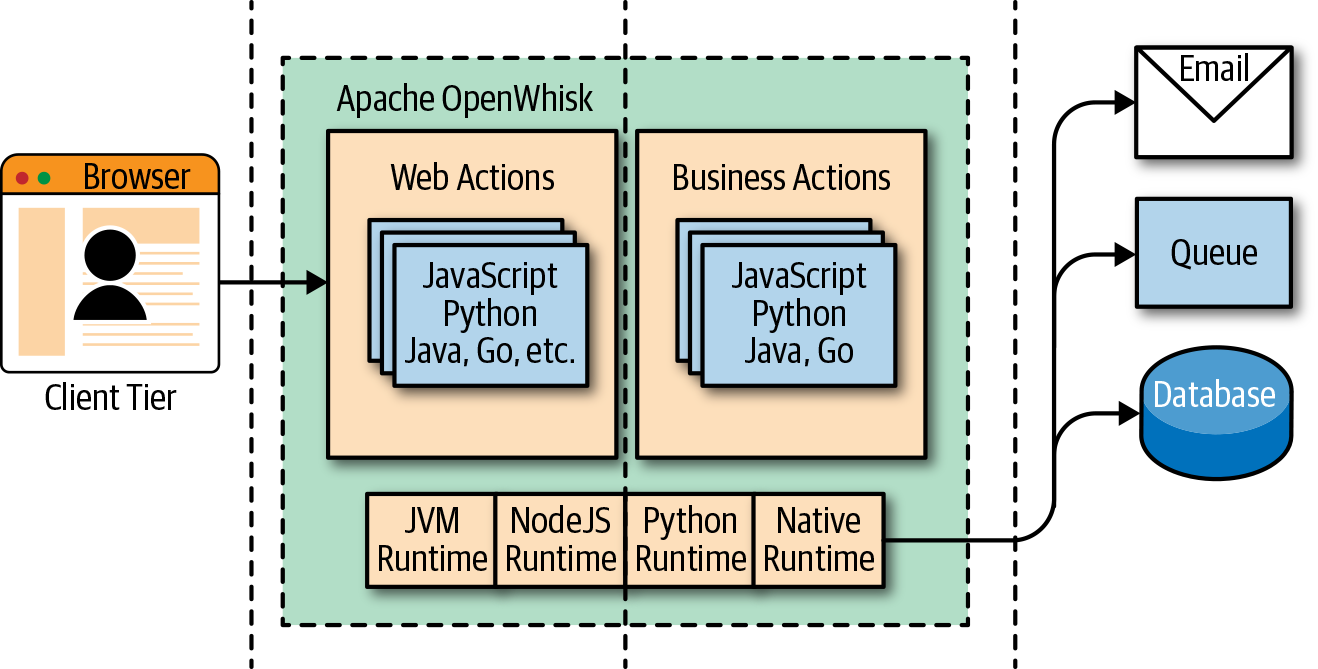
Figure 1-7. OpenWhisk architecture
Components
In Java EE, everything runs in the Java Virtual Machine, and everything must be coded in Java (or at least a programming language that can generate JVM-compatible bytecode). In OpenWhisk, you can code applications in multiple programming languages. We use their runtimes as equivalents of the JVM. Furthermore, those runtimes are wrapped in Docker containers to provide isolation and control over resource usage. This means you can write your components in any (supported) language you like. You are no longer confined to writing your application solely for the JVM. However, a JVM runtime is available, so you can still use Java and its family of languages if you like.
You can now write your code for the JavaScript Virtual Machine, more commonly referred to as Node.js.
Note
Under the hood, Node.js is an adaptation of the V8 JavaScript interpreter that powers the Chrome browser. It is a fast executor of the JavaScript language, which also has advanced functions like compiling on the fly to native code to speed up execution.
Instead of using VMs, you can also use language-producing native executables like Swift or Go. Go is becoming a popular choice in the serverless world. As long as you compile your application for Linux and AMD64, you can deploy it in OpenWhisk.
APIs
In JavaEE, you have APIs available to interact with the rest of the world, written in Java itself. Basically, in the Java EE model, every interesting resource for writing applications has been adapted to be used by Java.
In OpenWhisk, you have only one API for all the supported programming languages. This is the OpenWhisk API, and it is a RESTful API. You can invoke it over HTTPS using JSON as an interchange format.
This API can even be invoked directly using any HTTP library that can read and write JSON objects as strings. The OpenWhisk API acts as glue for the various components of the platform. All the communications among the different parts in OpenWhisk are performed in JSON over HTTP.
Connectors
In JavaEE, you have connectors for each external system you want to communicate with. For example, if you’re going to interact with an Oracle database, you need an Oracle JDBC connector; to communicate with IBM DB2, you need a DB2 JDBC driver, etc. The same holds true for messaging queues, email, and so on.
In OpenWhisk, interactions with other systems are wrapped in packages, collections of actions explicitly written to interact with a particular system. You can use any programming language and available APIs and drivers to communicate with packages. For example, if you have a Java driver for a database, you can write a package to interact with it. Packages act as connectors.
In the IBM Cloud, there are packages available to communicate with essential services such as:
-
The cloud database Cloudant
-
The Kafka messaging system
-
The enterprise chat Slack
-
Many others, some specific to IBM services
You use the feed mechanism provided by OpenWhisk to hook into those systems.
Application servers
In Java EE, everything is managed by application servers. They are the containers where enterprise applications are meant to be deployed.
In a sense, OpenWhisk itself takes on this role by providing a cloud-based, multinode, language-agnostic execution service. Using a serverless engine like OpenWhisk, the cloud becomes a transparent entity where you deploy your code. The environment manages the distribution of applications in the cloud.
Note
The problem then becomes not to install your code, but to install OpenWhisk. Each component of OpenWhisk must be appropriately deployed according to the available resources of the cloud. The installation of OpenWhisk in the cloud is a complex subject, and we will devote Chapter 12 to it.
We know that OpenWhisk runs in Docker containers. However, scaling Docker in a cloud requires you to manage those Docker containers under supervisory systems called orchestrators.
There are many orchestrators, but at the moment OpenWhisk supports the following:
Summary
Apache OpenWhisk is a serverless application platform. In this chapter, we learned how the serverless approach to software development makes it easy to take advantage of the cloud while keeping programming simple for developers.
We also took a good look at the OpenWhisk architecture and its components. Since constraints are critical to developing serverless applications, we also covered those in this chapter.
We wrapped up the chapter by comparing Apache OpenWhisk with Java EE to illustrate how serverless architecture has evolved.
Get Learning Apache OpenWhisk now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

