Capítulo 1. Un camino hacia la producción
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
A lo largo de los años, el mundo ha experimentado una amplia adopción de Kubernetes en las organizaciones. Sin duda, su popularidad se ha visto acelerada por la proliferación de cargas de trabajo en contenedores y microservicios. A medida que los equipos de operaciones, infraestructura y desarrollo llegan a este punto de inflexión en el que necesitan construir, ejecutar y dar soporte a estas cargas de trabajo, varios están recurriendo a Kubernetes como parte de la solución. Kubernetes es un proyecto bastante joven en comparación con otros proyectos masivos de código abierto como Linux. Como demuestran muchos de los clientes con los que trabajamos, aún es pronto para la mayoría de los usuarios de Kubernetes. Aunque muchas organizaciones ya tienen una huella de Kubernetes, son muchas menos las que han llegado a la producción y aún menos las que operan a escala. En este capítulo, vamos a preparar el terreno para el viaje que muchos equipos de ingeniería están realizando con Kubernetes. En concreto, vamos a trazar algunas consideraciones clave que tenemos en cuenta a la hora de definir un camino hacia la producción.
Definición de Kubernetes
¿Es Kubernetes una plataforma? ¿una infraestructura? ¿Una aplicación? No faltan líderes de opinión que pueden ofrecerte su definición precisa de lo que es Kubernetes. En lugar de aumentar este montón de opiniones, pongamos nuestra energía en aclarar los problemas que Kubernetes resuelve. Una vez definidos, exploraremos cómo construir sobre este conjunto de características de forma que nos acerquemos a los resultados de producción. El estado ideal de "Kubernetes de producción" implica que hemos alcanzado un estado en el que las cargas de trabajo sirven con éxito al tráfico de producción.
El nombre Kubernetes puede ser un término un tanto general. Un rápido vistazo a GitHub revela que la organización kubernetes contiene (en el momento de escribir esto) 69 repositorios. También está kubernetes-sigs, que contiene unos 107 proyectos. Y no nos hagas hablar de los cientos de proyectos de la Cloud Native Compute Foundation (CNCF) que intervienen en este panorama. En este libro, Kubernetes se referirá exclusivamente al proyecto central. Entonces, ¿qué es el núcleo? El núcleo del proyecto se encuentra en el repositorio kubernetes/kubernetes. Esta es la ubicación de los componentes clave que encontramos en la mayoría de los clústeres de Kubernetes. Al ejecutar un clúster con estos componentes, podemos esperar la siguiente funcionalidad:
-
Programar cargas de trabajo en muchos hosts
-
Exponer una API declarativa y extensible para interactuar con el sistema
-
Proporcionar una CLI,
kubectl, para que los humanos interactúen con el servidor API -
Reconciliación del estado actual de los objetos con el estado deseado
-
Proporcionar una abstracción de servicio básica para ayudar a enrutar las peticiones hacia y desdelas cargas de trabajo
-
Exponer múltiples interfaces para soportar redes enchufables, almacenamiento y más
Estas capacidades crean lo que el propio proyecto afirma ser, un orquestador de contenedores de nivel de producción. En términos más sencillos, Kubernetes nos proporciona una forma de ejecutar y programar cargas de trabajo en contenedores en varios hosts. Ten en cuenta esta capacidad principal mientras profundizamos. Con el tiempo, esperamos demostrar que esta capacidad, aunque fundamental, es sólo una parte de nuestro camino hacia la producción.
Los componentes básicos
¿Cuáles son los componentes que proporcionan la funcionalidad que hemos cubierto? Como hemos mencionado, los componentes principales residen en el repositorio kubernetes/kubernetes. Muchos de nosotros consumimos estos componentes de diferentes maneras. Por ejemplo, quienes ejecutan servicios gestionados como Google Kubernetes Engine (GKE) probablemente encontrarán cada componente presente en los hosts. Otros pueden descargar binarios de repositorios u obtener versiones firmadas de un proveedor. En cualquier caso, cualquiera puede descargar una versión de Kubernetes del repositorio kubernetes/kubernetes. Tras descargar y desempaquetar una versión, los binarios pueden recuperarse utilizando el comando cluster/get-kube-binaries.sh. Esto detectará automáticamente tu arquitectura de destino y descargará los componentes del servidor y del cliente. Echemos un vistazo a esto en el siguiente código, y luego exploremos los componentes clave:
$./cluster/get-kube-binaries.sh Kubernetes release: v1.18.6 Server: linux/amd64(to override,setKUBERNETES_SERVER_ARCH)Client: linux/amd64(autodetected)Will download kubernetes-server-linux-amd64.tar.gz from https://dl.k8s.io/v1.18.6 Will download and extract kubernetes-client-linux-amd64.tar.gz Is this ok?[Y]/n
Dentro de los componentes del servidor descargados, probablemente guardados en server/kubernetes-server-${ARCH}.tar.gz, encontrarás los elementos clave que componen un clúster Kubernetes:
- Servidor API
-
El principal punto de interacción para todos los componentes y usuarios de Kubernetes. Aquí es donde obtenemos, añadimos, eliminamos y mutamos objetos. El servidor API delega el estado en un backend, que suele ser etcd.
- kubelet
-
El agente en el host que se comunica con el servidor API para informar del estado de un nodo y saber qué cargas de trabajo deben programarse en él. Se comunica con el tiempo de ejecución del contenedor del anfitrión, como Docker, para garantizar que las cargas de trabajo programadas para el nodo se inician y están en buen estado.
- Responsable de Control
-
Un conjunto de controladores, agrupados en un único binario, que gestionan la reconciliación de muchos objetos centrales de Kubernetes. Cuando se declara un estado deseado, por ejemplo, tres réplicas en una Implementación, un controlador interno gestiona la creación de nuevos Pods para satisfacer este estado.
- Programador
-
Determina dónde deben ejecutarse las cargas de trabajo basándose en lo que considera el nodo óptimo. Utiliza el filtrado y la puntuación para tomar esta decisión.
- Proxy Kube
-
Implementa servicios Kubernetes que proporcionen IPs virtuales que puedan enrutarse a Pods backend. Esto se consigue utilizando un mecanismo de filtrado de paquetes en un host como
iptablesoipvs.
Aunque no se trata de una lista exhaustiva, estos son los componentes principales que conforman la funcionalidad básica de la que hemos hablado. Desde el punto de vista de la arquitectura, la Figura 1-1 muestra cómo funcionan juntos estos componentes.
Nota
Las arquitecturas de Kubernetes tienen muchas variaciones. Por ejemplo, muchos clusters ejecutan kube-apiserver, kube-scheduler y kube-controller-manager como contenedores. Esto significa que el plano de control también puede ejecutar un container-runtime, un kubelet y un kube-proxy. Este tipo de consideraciones sobre la implementación se tratarán en el próximo capítulo.
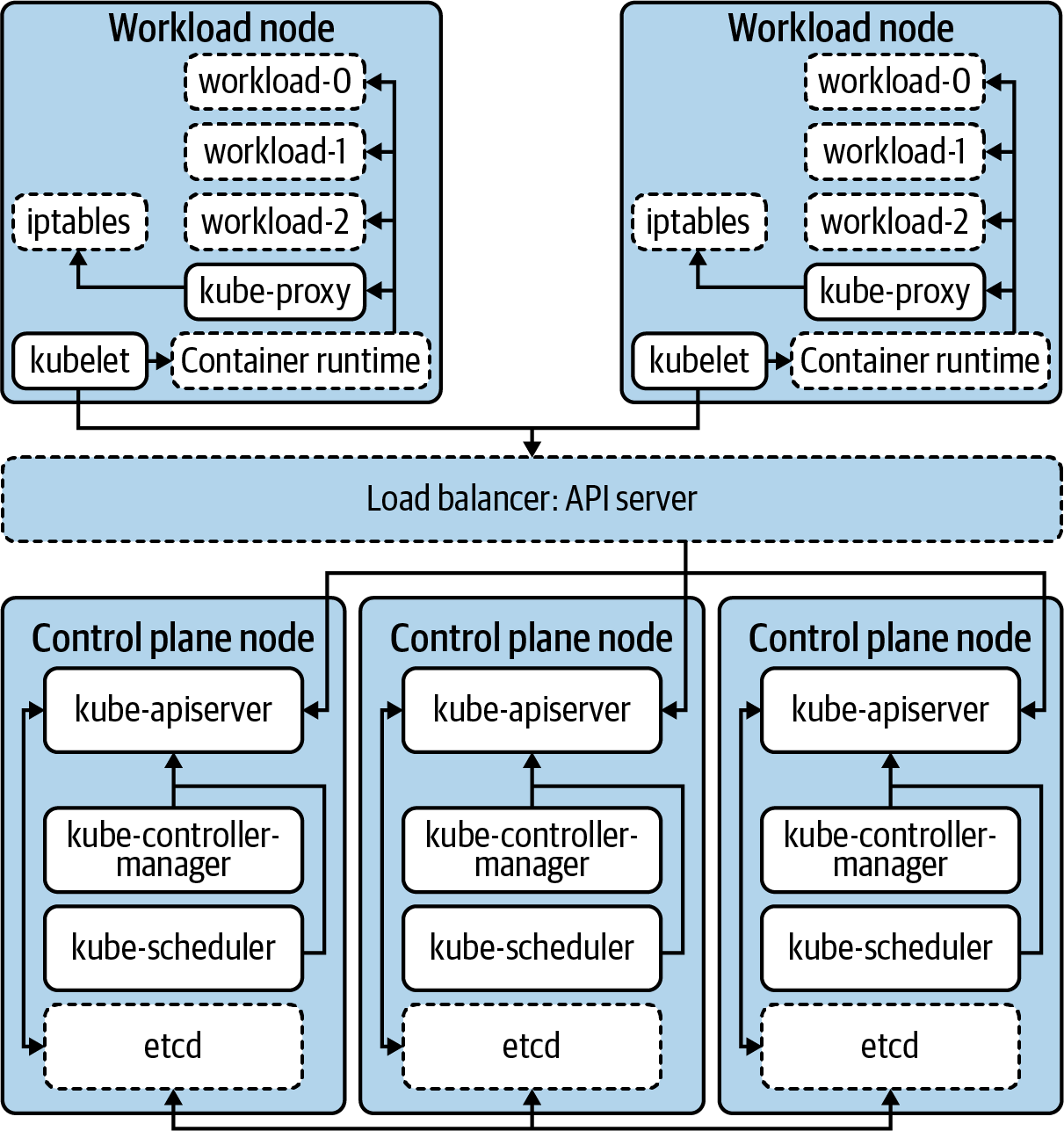
Figura 1-1. Los componentes principales que forman el clúster Kubernetes. Los bordes discontinuos representan componentes que no forman parte del núcleo de Kubernetes.
Más allá de la orquestación: funcionalidad ampliada
Hay áreas en las que Kubernetes hace algo más que orquestar cargas de trabajo. Como se ha mencionado, el componente kube-proxy programa hosts para proporcionar una experiencia de IP virtual (VIP) a las cargas de trabajo. Como resultado, se establecen direcciones IP internas que se dirigen a uno o varios Pods subyacentes. Ciertamente, esta preocupación va más allá de ejecutar y programar cargas de trabajo en contenedores. En teoría, en lugar de implementar esto como parte del núcleo de Kubernetes, el proyecto podría haber definido una API de Servicio y haber requerido un plug-in para implementar la abstracción de Servicio. Este enfoque obligaría a los usuarios a elegir entre diversos plug-ins del ecosistema, en lugar de incluirlo comofuncionalidad central.
Este es el modelo que adoptan muchas API de Kubernetes, como Ingress y NetworkPolicy. Por ejemplo, la creación de un objeto Ingress en un clúster de Kubernetes no garantiza que se realice ninguna acción. En otras palabras, aunque la API existe, no es una funcionalidad básica. Los equipos deben considerar qué tecnología les gustaría conectar para implementar esta API. Para Ingress, muchos utilizan un controlador como ingress-nginx, que se ejecuta en el clúster. Implementa la API leyendo objetos Ingress y creando configuraciones NGINX para instancias NGINX apuntadas a Pods. Sin embargo, ingress-nginx es una de las muchas opciones. El Proyecto Contour implementa la misma API Ingress, pero en su lugar programa instancias de envoy, el proxy que subyace a Contour. Gracias a este modelo enchufable, hay una gran variedad de opciones a disposición de los equipos.
Interfaces Kubernetes
Ampliando esta idea de añadir funcionalidad, ahora debemos explorar las interfaces. Las interfaces de Kubernetes nos permiten personalizar y construir sobre la funcionalidad central. Consideramos que una interfaz es una definición o contrato sobre cómo se puede interactuar con algo. En el desarrollo de software, esto es paralelo a la idea de definir la funcionalidad, que las clases o structs pueden implementar. En sistemas como Kubernetes, desplegamos complementos que satisfacen estas interfaces, proporcionando funcionalidades como la conexión en red.
Un ejemplo concreto de esta relación interfaz/plug-in es la Interfaz de Tiempo de Ejecución de Contenedores (IRC ). En los primeros tiempos de Kubernetes, sólo se admitía un único tiempo de ejecución de contenedores, Docker. Aunque hoy en día Docker sigue presente en muchos clústeres, cada vez hay más interés en utilizar alternativas como containerd o CRI-O. La Figura 1-2 muestra esta relación con estos dos tiempos de ejecución de contenedores.
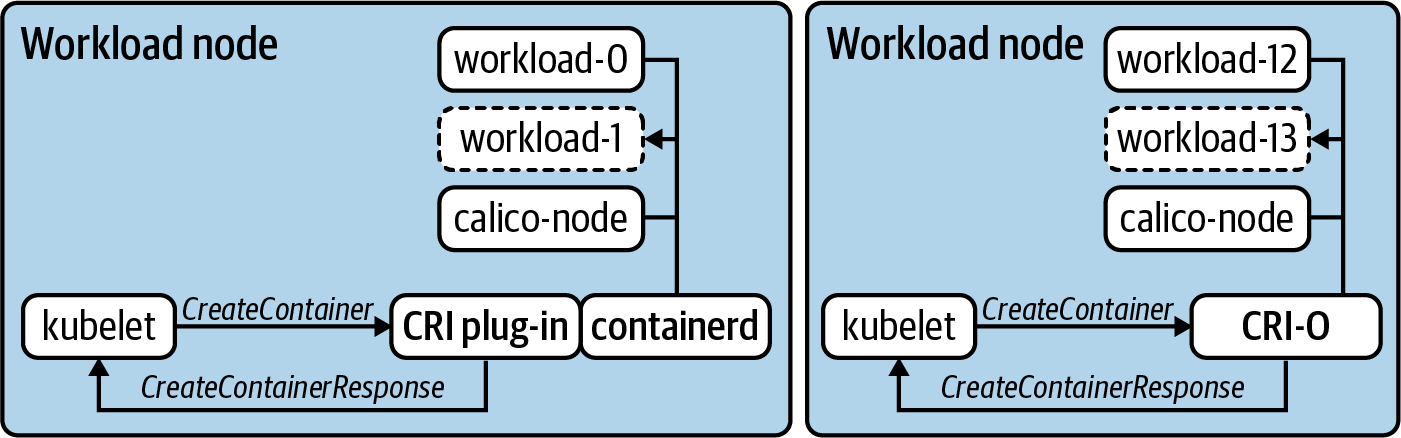
Figura 1-2. Dos nodos de carga de trabajo ejecutando dos tiempos de ejecución de contenedor diferentes. El kubelet envía comandos definidos en el CRI, como CreateContainer, y espera que el tiempo de ejecución satisfaga la petición y responda.
En muchas interfaces, los comandos, como CreateContainerRequest o PortForwardRequest, se emiten como llamadas a procedimientos remotos (RPC). En el caso de CRI, la comunicación se produce a través de GRPC y el kubelet espera respuestas como CreateContainerResponse y PortForwardResponse. En la Figura 1-2, también observarás dos modelos diferentes para satisfacer CRI. CRI-O se construyó desde cero como una implementación de CRI. Por tanto, el kubelet emite estos comandos directamente a él. containerd admite un complemento que actúa como un calce entre el kubelet y sus propias interfaces. Independientemente de la arquitectura exacta, la clave está en conseguir que el tiempo de ejecución del contenedor se ejecute, sin que el kubelet necesite tener conocimiento operativo de cómo ocurre esto para cada tiempo de ejecución posible. Este concepto es lo que hace que las interfaces sean tan potentes a la hora de diseñar, construir e implementar clusters de Kubernetes.
Con el tiempo, incluso hemos visto cómo se eliminaban algunas funciones del núcleo del proyecto en favor de este modelo de complementos. Se trata de cosas que históricamente existían "en el árbol", es decir, dentro de la base de código de kubernetes/kubernetes. Un ejemplo de ello son las integraciones de proveedores en la nube (IPC). Tradicionalmente, la mayoría de las CPI estaban integradas en componentes como el kube-controller-manager y el kubelet. Estas integraciones se ocupaban normalmente de cuestiones como el aprovisionamiento de equilibradores de carga o la exposición de metadatos del proveedor de la nube. A veces, especialmente antes de la creación de la Interfaz de Almacenamiento de Contenedores (CSI), estos proveedores aprovisionaban almacenamiento en bloque y lo ponían a disposición de las cargas de trabajo que se ejecutaban en Kubernetes. Eso es mucha funcionalidad para vivir en Kubernetes, ¡por no mencionar que hay que reimplementarla para cada proveedor posible! Como mejor solución, el soporte se trasladó a su propio modelo de interfaz, por ejemplo, kubernetes/cloud-provider, que puede ser implementado por múltiples proyectos o proveedores. Además de minimizar la dispersión en la base de código de Kubernetes, esto permite que la funcionalidad de la IPC se gestione fuera de la banda de los clústeres centrales de Kubernetes. Esto incluye procedimientos comunes como las actualizaciones o el parcheado de vulnerabilidades.
En la actualidad, existen varias interfaces que permiten la personalización y la funcionalidad adicional en Kubernetes. Lo que sigue es una lista de alto nivel, que iremos ampliando a lo largo de los capítulos de de este libro:
-
La Interfaz de Red de Contenedores (CNI) permite a los proveedores de red definir cómo hacen las cosas, desde el IPAM hasta el enrutamiento real de paquetes.
-
La Interfaz de Almacenamiento de Contenedores (CSI) permite a los proveedores de almacenamiento satisfacer las peticiones de carga de trabajo intra-clúster. Comúnmente implementada para tecnologías como ceph, vSAN y EBS.
-
La Interfaz de Tiempo de Ejecución de Contenedores (IRC) permite una variedad de tiempos de ejecución, entre los que se incluyen Docker, containerd y IRC-O. También ha permitido la proliferación de tiempos de ejecución menos tradicionales, como firecracker, que aprovecha KVM para proporcionar una máquina virtual mínima.
-
La Interfaz de Malla de Servicios (SMI) es una de las interfaces más recientes del ecosistema Kubernetes. Espera impulsar la coherencia a la hora de definir aspectos como la política de tráfico, la telemetría y la gestión.
-
La Interfaz de Proveedor de Nube (CPI) permite a proveedores como VMware, AWS, Azure y otros escribir puntos de integración para sus servicios en la nube con clústeres Kubernetes.
-
La Open Container Initiative Runtime Spec. (OCI) estandariza los formatos de imagen, garantizando que una imagen de contenedor creada a partir de una herramienta, cuando sea conforme, pueda ejecutarse en cualquier tiempo de ejecución de contenedor conforme con la OCI. Esto no está directamente relacionado con Kubernetes, pero ha sido una ayuda auxiliar para impulsar el deseo de tener tiempos de ejecución de contenedores conectables (CRI).
Resumiendo Kubernetes
Ahora nos hemos centrado en el ámbito de Kubernetes. Es un orquestador de contenedores, con un par de funciones adicionales aquí y allá. También tiene la capacidad de ampliarse y personalizarse aprovechando los complementos de las interfaces. Kubernetes puede ser fundamental para muchas organizaciones que buscan un medio elegante de ejecutar sus aplicaciones. Sin embargo, demos un paso atrás por un momento. Si tomáramos los sistemas actuales utilizados para ejecutar aplicaciones en tu organización y los sustituyéramos por Kubernetes, ¿sería suficiente? Para muchos de nosotros, hay mucho más implicado en los componentes y maquinaria que conforman nuestra actual "plataforma de aplicaciones".
Históricamente, hemos sido testigos de mucho dolor cuando las organizaciones tienen la visión de tener una estrategia de "Kubernetes", o cuando asumen que Kubernetes será una función de forzamiento adecuada para modernizar la forma en que construyen y ejecutan el software. Kubernetes es una tecnología, una gran tecnología, pero realmente no debería ser el punto central de hacia dónde te diriges en el ámbito de la infraestructura, la plataforma y/o el software modernos. Pedimos disculpas si esto parece obvio, pero te sorprendería saber con cuántos arquitectos ejecutivos o de alto nivel hablamos que creen que Kubernetes, por sí mismo, es la respuesta a los problemas, cuando en realidad sus problemas giran en torno a la entrega de aplicaciones, el desarrollo de software o cuestiones organizativas/personales. La mejor forma de concebir Kubernetes es como una pieza de tu puzzle, que te permite ofrecer plataformas para tus aplicaciones. Hemos estado danzando en torno a esta idea de una plataforma de aplicaciones, que exploraremos a continuación.
Definición de plataformas de aplicación
En nuestro camino hacia la producción, es clave que tengamos en cuenta la idea de una plataforma de aplicaciones. Definimos una plataforma de aplicaciones como un lugar viable para ejecutar cargas de trabajo. Como la mayoría de las definiciones de este libro, cómo se satisfaga eso variará de una organización a otra. Los resultados previstos serán amplios y deseables para distintas partes de la empresa: por ejemplo, desarrolladores contentos, reducción de costes operativos y ciclos de retroalimentación más rápidos en la entrega de software son algunos de ellos. La plataforma de aplicaciones es a menudo donde nos encontramos en la intersección de las aplicaciones y la infraestructura. Preocupaciones como la experiencia del desarrollador (devx) suelen ser un principio clave en esta área.
Las plataformas de aplicaciones tienen muchas formas y tamaños. Algunas abstraen en gran medida las preocupaciones subyacentes, como la IaaS (por ejemplo, AWS) o el orquestador (por ejemplo, Kubernetes). Heroku es un gran ejemplo de este modelo. Con él puedes tomar fácilmente un proyecto escrito en lenguajes como Java, PHP o Go y, con un solo comando, desplegarlo en producción. Junto a tu aplicación se ejecutan muchos servicios de plataforma que, de otro modo, tendrías que operar tú mismo. Cosas como la recopilación de métricas, los servicios de datos y la entrega continua (CD). También te proporciona primitivas para ejecutar cargas de trabajo de alta disponibilidad que pueden escalarse fácilmente. ¿Heroku utiliza Kubernetes? ¿Dispone de sus propios centros de datos o funciona sobre AWS? ¿A quién le importa? Para los usuarios de Heroku, estos detalles no son importantes. Lo importante es delegar estas preocupaciones en un proveedor o plataforma que permita a los desarrolladores dedicar más tiempo a resolver problemas empresariales. Este enfoque no es exclusivo de los servicios en la nube. OpenShift de RedHat sigue un modelo similar, en el que Kubernetes es más un detalle de implementación y los desarrolladores y operadores de la plataforma interactúan con un conjunto de abstracciones por encima.
¿Por qué no detenerse aquí? Si plataformas como Cloud Foundry, OpenShift y Heroku nos han resuelto estos problemas, ¿por qué molestarse con Kubernetes? Una de las principales desventajas de muchas plataformas de aplicaciones prefabricadas es la necesidad de ajustarse a su visión del mundo. Delegar la propiedad del sistema subyacente te quita un importante peso operativo de encima. Al mismo tiempo, si la forma en que la plataforma aborda cuestiones como el descubrimiento de servicios o la gestión de secretos no satisface tus requisitos organizativos, puede que no tengas el control necesario para solucionar ese problema. Además, existe la noción de bloqueo de proveedor u opinión. Con las abstracciones vienen las opiniones sobre cómo deben diseñarse, empaquetarse e implementarse tus aplicaciones. Esto significa que pasar a otro sistema puede no ser trivial. Por ejemplo, es mucho más fácil trasladar cargas de trabajo entre Google Kubernetes Engine (GKE) y Amazon Elastic Kubernetes Engine (EKS) que entre EKS y Cloud Foundry.
El espectro de enfoques
Llegados a este punto, está claro que hay varios enfoques para establecer una plataforma de aplicación con éxito. Hagamos algunas grandes suposiciones en aras de la demostración y evaluemos las compensaciones teóricas entre enfoques. Para la empresa media con la que trabajamos, digamos una empresa mediana o grande, la Figura 1-3 muestra una evaluación arbitraria de enfoques.
En el cuadrante inferior izquierdo, vemos la implementación de clústeres de Kubernetes por sí mismos, que implica un esfuerzo de ingeniería relativamente bajo, especialmente cuando servicios gestionados como EKS manejan el plano de control por ti. La preparación para la producción es más baja, porque la mayoría de las organizaciones se darán cuenta de que hay que trabajar más sobre Kubernetes. Sin embargo, hay casos de uso, como los equipos que utilizan clústeres dedicados para sus cargas de trabajo, que pueden bastar sólo con Kubernetes.
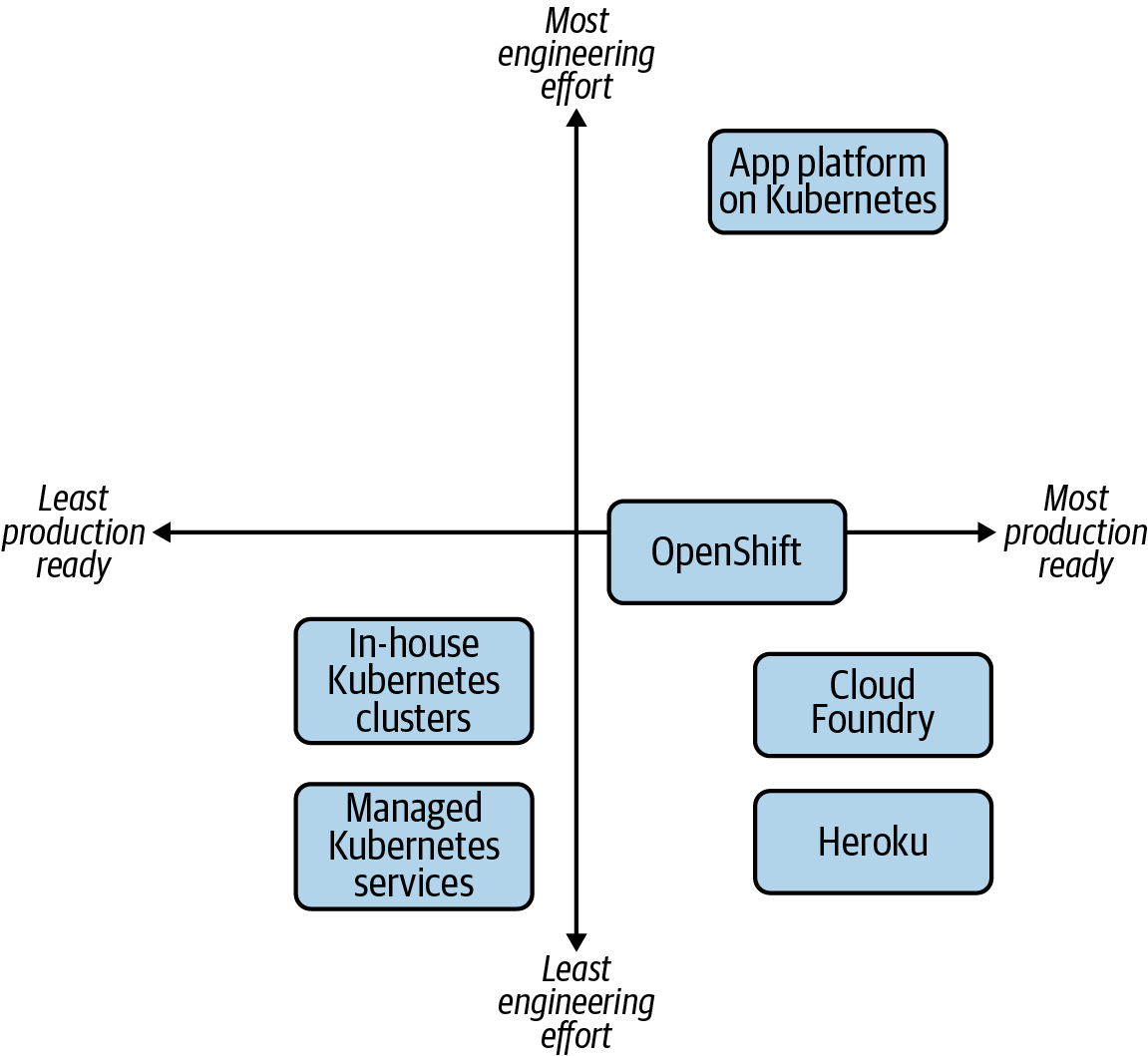
Figura 1-3. La multitud de opciones disponibles para proporcionar una plataforma de aplicaciones a los desarrolladores.
En la parte inferior derecha, tenemos las plataformas más consolidadas, las que proporcionan una experiencia integral al desarrollador desde el primer momento. Cloud Foundry es un gran ejemplo de proyecto que resuelve muchos de los problemas de las plataformas de aplicaciones. Ejecutar software en Cloud Foundry consiste más en asegurarse de que el software se ajusta a sus opiniones. OpenShift, por otro lado, que para la mayoría está mucho más preparado para la producción que Kubernetes, tiene más puntos de decisión y consideraciones sobre cómo configurarlo. ¿Es esta flexibilidad una ventaja o una molestia? Esa es una consideración clave para ti.
Por último, en la parte superior derecha, tenemos la construcción de una plataforma de aplicaciones sobre Kubernetes. En relación con las demás, ésta es sin duda la que requiere más esfuerzo de ingeniería, al menos desde la perspectiva de la plataforma. Sin embargo, aprovechar la extensibilidad de Kubernetes significa que puedes crear algo que se ajuste a tus necesidades de desarrollador, infraestructura y negocio.
Alinear tus necesidades organizativas
Lo que falta en el gráfico de la Figura 1-3 es una tercera dimensión, un eje z que demuestre lo alineado que está el enfoque con tus requisitos. Examinemos otra representación visual. La Figura 1-4 muestra el aspecto que podría tener cuando se considera la alineación de la plataforma con las necesidades de la organización.
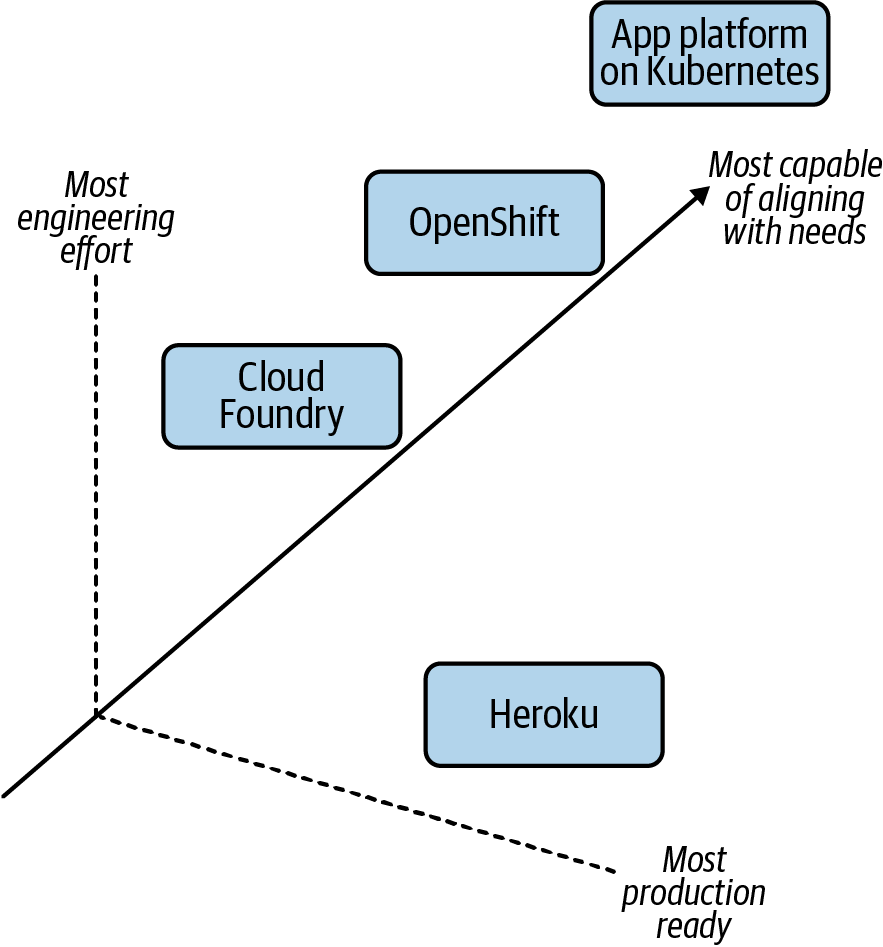
Figura 1-4. La complejidad añadida de la alineación de estas opciones con tus necesidades organizativas, el eje z.
En términos de requisitos, características y comportamientos que esperarías de una plataforma, construir una plataforma casi siempre va a ser lo más alineado. O al menos la más capaz de alinearse. Esto se debe a que ¡puedes construir cualquier cosa! Si quisieras reimplantar Heroku internamente, sobre Kubernetes, con pequeños ajustes en sus capacidades, es técnicamente posible. Sin embargo, el coste/recompensa debe sopesarse con los otros ejes (x e y). Concretemos más este ejercicio considerando las siguientes necesidades en una plataforma de nueva generación:
-
Las normativas te obligan a funcionar principalmente en las instalaciones
-
Necesitas dar soporte a tu flota baremetal junto con tucentro de datos habilitado para vSphere
-
Quieres apoyar la creciente demanda de desarrolladores para empaquetar aplicaciones encontenedores
-
Necesitas formas de crear mecanismos API de autoservicio que te alejen del aprovisionamiento de infraestructura "basado en tickets
-
Quieres asegurarte de que las API sobre las que construyes son independientes del proveedor y no te van a bloquear, porque migrar de este tipo desistemas te ha costado millones en el pasado.
-
Están abiertos a pagar soporte empresarial por una variedad de productos de la pila, pero no están dispuestos a comprometerse con modelos en los que toda la pila se licencia por nodo, núcleo o instancia de aplicación
Debemos comprender nuestra madurez de ingeniería, nuestro apetito por crear y potenciar equipos, y los recursos disponibles para determinar si crear una plataforma de aplicaciones es una empresa sensata.
Resumiendo las Plataformas de Aplicación
Hay que admitir que lo que constituye una plataforma de aplicaciones sigue siendo bastante gris. Nos hemos centrado en una variedad de plataformas que creemos que aportan una experiencia a los equipos que va mucho más allá de la mera orquestación de la carga de trabajo. También hemos articulado que Kubernetes puede personalizarse y ampliarse para lograr resultados similares. Avanzando en nuestro pensamiento más allá de "¿Cómo consigo un Kubernetes?" hacia preocupaciones como "¿Cuál es el flujo de trabajo, los puntos de dolor y los deseos actuales de los desarrolladores?", los equipos de plataforma e infraestructura tendrán más éxito con lo que construyan. Si se centran en esto último, diríamos que es mucho más probable que tracen un camino adecuado hacia la producción y logren una adopción no trivial. Al fin y al cabo, queremos cumplir los requisitos de infraestructura, seguridad y desarrolladores para garantizar que nuestros clientes -típicamente desarrolladores- reciban una solución que satisfaga sus necesidades. A menudo no queremos limitarnos a proporcionar un motor "potente" sobre el que cada desarrollador deba construir su propia plataforma, como se representa bromeando en la Figura 1-5.
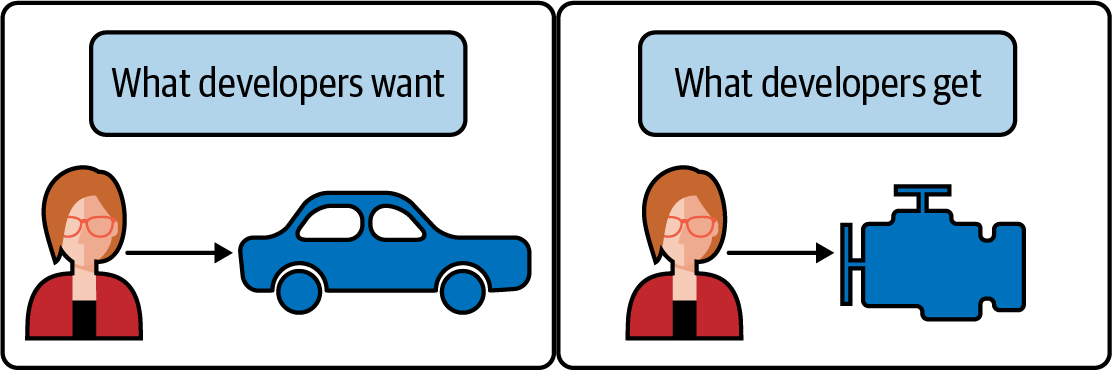
Figura 1-5. Cuando los desarrolladores deseen una experiencia integral (por ejemplo, un coche que se pueda conducir), no esperen que baste con un motor sin chasis, ruedas y demás.
Construir plataformas de aplicaciones en Kubernetes
Ahora hemos identificado Kubernetes como una pieza del puzzle en nuestro camino hacia la producción. Con esto, sería razonable preguntarse: "Entonces, ¿a Kubernetes no le faltan cosas?". El principio de la filosofía Unix de "haz que cada programa haga bien una cosa" es una aspiración convincente para el proyecto Kubernetes. Creemos que sus mejores características son en gran medida las que no tiene. Sobre todo después de quemarnos con plataformas de talla única que intentan resolver los problemas del mundo por ti. Kubernetes se ha centrado brillantemente en ser un gran orquestador, definiendo al mismo tiempo interfaces claras sobre las que se puede construir. Esto puede compararse a los cimientos de una casa.
Unos buenos cimientos deben ser estructuralmente sólidos, poder construirse sobre ellos y proporcionar interfaces adecuadas para llevar los servicios públicos a la casa. Aunque son importantes, los cimientos por sí solos rara vez son un lugar habitable para que vivan nuestras aplicaciones. Normalmente, necesitamos que exista algún tipo de hogar encima de los cimientos. Antes de hablar de construir sobre una base como Kubernetes, consideremos un apartamento preamueblado, como se muestra en la Figura 1-6.

Figura 1-6. Un apartamento listo para mudarse. Similar a las opciones de plataforma como servicio, como Heroku. Ilustración de Jessica Appelbaum.
Esta opción, similar a nuestros ejemplos como Heroku, es habitable sin trabajo adicional. Ciertamente, existen oportunidades para personalizar la experiencia en el interior; sin embargo, muchas preocupaciones están resueltas para nosotros. Mientras nos sintamos cómodos con el precio del alquiler y estemos dispuestos a ajustarnos a las opiniones no negociables del interior, podemos tener éxito el primer día.
Volviendo a Kubernetes, que hemos comparado con unos cimientos, ahora podemos intentar construir ese hogar habitable sobre ellos, como se muestra en la Figura 1-7.

Figura 1-7. Construir una casa. Similar al establecimiento de una plataforma de aplicaciones, para la que Kubernetes es fundamental. Ilustración de Jessica Appelbaum.
Al coste de planificación, ingeniería y mantenimiento, podemos construir plataformas extraordinarias para ejecutar cargas de trabajo en todas las organizaciones. Esto significa que tenemos el control total de cada elemento de la salida. La casa puede y debe adaptarse a las necesidades de los futuros inquilinos (nuestras aplicaciones). Desglosemos ahora las distintas capas y consideraciones que hacen esto posible.
Empezar desde abajo
Primero debemos empezar por la base, que incluye la tecnología que Kubernetes espera ejecutar. Normalmente se trata de un centro de datos o proveedor de nube, que ofrece computación, almacenamiento y redes. Una vez establecido, Kubernetes puede arrancar en la parte superior. En cuestión de minutos puedes tener clusters viviendo sobre la infraestructura subyacente. Hay varias formas de arrancar Kubernetes, y las trataremos en profundidad en el Capítulo 2.
Desde el punto de vista de la existencia de clústeres Kubernetes, a continuación tenemos que ver un flujo conceptual para determinar qué debemos construir encima. Las coyunturas clave se representan en la Figura 1-8.
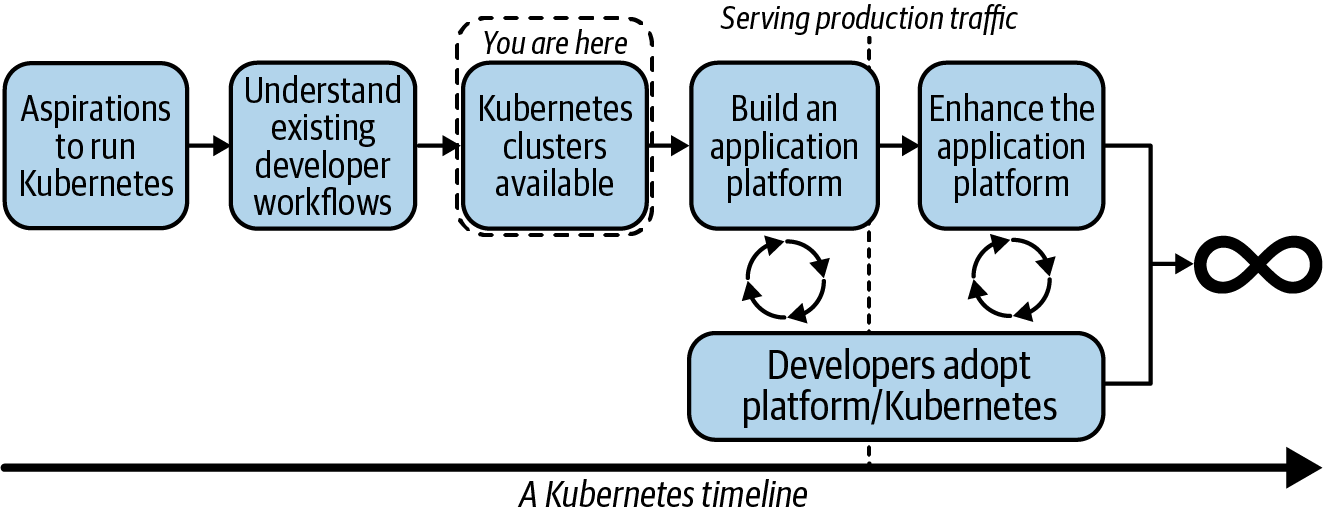
Figura 1-8. Un flujo por el que pueden pasar nuestros equipos en su camino hacia la producción conKubernetes.
Desde el punto de vista de la existencia de Kubernetes, puedes esperar recibir rápidamente preguntas como las siguientes:
-
"¿Cómo me aseguro de que el tráfico de carga de trabajo a carga de trabajo está totalmente encriptado?"
-
"¿Cómo me aseguro de que el tráfico de salida pasa por una pasarela que garantiza un CIDR de origen coherente?"
-
"¿Cómo proporciono rastreo y cuadros de mando de autoservicio a las aplicaciones?"
-
"¿Cómo dejo que los desarrolladores se incorporen sin preocuparme de que se conviertan en expertos en Kubernetes?"
Esta lista puede ser interminable. A menudo nos corresponde determinar qué requisitos resolver a nivel de plataforma y cuáles a nivel de aplicación. La clave aquí es comprender en profundidad los flujos de trabajo existentes para asegurarnos de que lo que construimos se ajusta a las expectativas actuales. Si no podemos cumplir ese conjunto de funciones, ¿qué impacto tendrá en los equipos de desarrollo? A continuación podemos empezar a construir una plataforma sobre Kubernetes. Al hacerlo, es clave que permanezcamos emparejados con equipos de desarrollo dispuestos a incorporarse pronto y a comprender la experiencia para tomar decisiones informadas basadas en una retroalimentación rápida. Una vez alcanzada la producción, este flujo no debe detenerse. Los equipos de plataforma no deben esperar que lo que se entregue sea un entorno estático que los desarrolladores utilizarán durante décadas. Para tener éxito, debemos estar constantemente en sintonía con nuestros grupos de desarrollo para comprender dónde hay problemas o posibles características que faltan y que podrían aumentar la velocidad de desarrollo. Un buen punto de partida es considerar qué nivel de interacción con Kubernetes debemos esperar de nuestros desarrolladores. Esta es la idea de cuánto, o cuán poco, debemos abstraer.
El espectro de la abstracción
En el pasado, hemos oído posturas como: "Si los desarrolladores de tus aplicaciones saben que están utilizando Kubernetes, ¡has fracasado!". Esta puede ser una forma decente de ver la interacción con Kubernetes, especialmente si estás construyendo productos o servicios en los que la tecnología de orquestación subyacente no tiene sentido para el usuario final. Tal vez estés construyendo un sistema de gestión de bases de datos (SGBD) que admita varias tecnologías de bases de datos. Que los fragmentos o instancias de una base de datos se ejecuten a través de Kubernetes, Bosh o Mesos probablemente no importe a tus desarrolladores. Sin embargo, trasladar esta filosofía al por mayor de un tuit a los criterios de éxito de tu equipo es algo peligroso. A medida que superpongamos piezas a Kubernetes y construyamos servicios de plataforma para servir mejor a nuestros clientes, nos enfrentaremos a muchos puntos de decisión para determinar qué aspecto tienen las abstracciones adecuadas. La Figura 1-9 ofrece una visualización de este espectro.
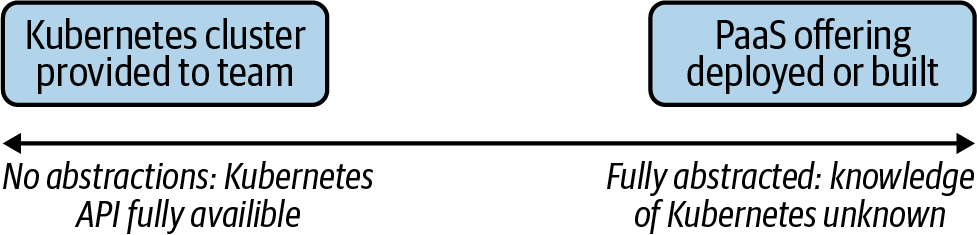
Figura 1-9. Los distintos extremos del espectro. Desde dar a cada equipo su propio clúster de Kubernetes hasta abstraer completamente Kubernetes de tus usuarios, mediante una oferta de plataforma como servicio (PaaS).
Esta puede ser una cuestión que quite el sueño a los equipos de plataforma. Ofrecer abstracciones tiene mucho mérito. Los proyectos como Cloud Foundry proporcionan una experiencia de desarrollo completa, por ejemplo, en el contexto de un único cf push podemos tomar una aplicación, crearla, implementarla y hacer que sirva al tráfico de producción. Con este objetivo y esta experiencia como objetivo principal, a medida que Cloud Foundry aumenta su compatibilidad con la ejecución sobre Kubernetes, esperamos ver esta transición más como un detalle de implementación que como un cambio en el conjunto de características. Otro patrón que vemos es el deseo de ofrecer más que Kubernetes en una empresa, pero sin hacer que los desarrolladores elijan explícitamente entre tecnologías. Por ejemplo, algunas empresas tienen una huella de Mesos junto a una huella de Kubernetes. Así construyen una abstracción que permite una selección transparente de dónde aterrizan las cargas de trabajo sin poner esa carga en los desarrolladores de aplicaciones. También les evita el bloqueo tecnológico. Una contrapartida de este enfoque es la creación de abstracciones sobre dos sistemas que funcionan de forma diferente. Esto requiere un esfuerzo y una madurez de ingeniería significativos. Además, mientras que a los desarrolladores se les libera de la carga de saber cómo interactuar con Kubernetes o Mesos, en su lugar tienen que entender cómo utilizar un sistema abstracto específico de la empresa. En la era moderna del código abierto, a los desarrolladores de toda la pila les entusiasma menos aprender sistemas que no se traducen entre organizaciones. Por último, un escollo que hemos visto es una obsesión con la abstracción que provoca una incapacidad para exponer las características clave de Kubernetes. Con el tiempo, esto puede convertirse en un juego del gato y el ratón de intentar seguir el ritmo del proyecto y, potencialmente, hacer que tu abstracción sea tan complicada como el sistema que está abstrayendo.
En el otro extremo del espectro están los grupos de plataformas que desean ofrecer clusters de autoservicio a los equipos de desarrollo. Éste también puede ser un gran modelo. Pero hace recaer la responsabilidad de la madurez de Kubernetes en los equipos de desarrollo. ¿Comprenden cómo funcionan las Implementaciones, los ReplicaSets, los Pods, los Servicios y las APIs de Ingress? ¿Saben configurar milicpus y cómo funciona el sobrecompromiso de recursos? ¿Saben cómo garantizar que las cargas de trabajo configuradas con más de una réplica se programen siempre en nodos diferentes? Si la respuesta es afirmativa, ésta es una oportunidad perfecta para evitar la sobreingeniería de una plataforma de aplicaciones y, en su lugar, dejar que los equipos de aplicaciones la tomen desde la capa de Kubernetes hacia arriba.
Este modelo de equipos de desarrollo que poseen sus propios clústeres es un poco menos común. Incluso con un equipo de humanos con experiencia en Kubernetes, es poco probable que quieran dedicar tiempo al envío de funciones para determinar cómo gestionar el ciclo de vida de su clúster de Kubernetes cuando llegue el momento de actualizarlo. Hay mucho poder en todos los mandos que Kubernetes expone, pero para muchos equipos de desarrollo, esperar que se conviertan en expertos en Kubernetes además de distribuir software es poco realista. Como descubrirás en los próximos capítulos, la abstracción no tiene por qué ser una decisión binaria. En varios puntos podremos tomar decisiones informadas sobre dónde tienen sentido las abstracciones. Determinaremos dónde podemos proporcionar a los desarrolladores la cantidad adecuada de flexibilidad y, al mismo tiempo, agilizar su capacidad para hacer las cosas.
Determinar los servicios de la plataforma
Al construir sobre Kubernetes, una determinación clave es qué características deben incorporarse a la plataforma en relación con las resueltas a nivel de aplicación. Generalmente, esto es algo que debe evaluarse caso por caso. Por ejemplo, supongamos que cada microservicio Java implementa una biblioteca que facilita TLS mutuo (mTLS) entre servicios. Esto proporciona a las aplicaciones un constructo para la identidad de las cargas de trabajo y el cifrado de datos en la red. Como equipo de plataforma, necesitamos comprender en profundidad este uso para determinar si es algo que debemos ofrecer o implementar a nivel de plataforma. Muchos equipos intentan resolver esto implementando potencialmente una tecnología llamada malla de servicios en el clúster. Un ejercicio de compensación revelaría las siguientes consideraciones.
Ventajas de introducir una malla de servicios:
-
Las aplicaciones Java ya no necesitan agrupar bibliotecas para facilitar mTLS.
-
Las aplicaciones que no son Java pueden participar en el mismo sistema de cifrado/mTLS.
-
Menor complejidad de solución para los equipos de aplicación.
Contras de introducir una malla de servicios:
-
Gestionar una malla de servicios no es una tarea trivial. Es otro sistema distribuido con complejidad operativa.
-
Las mallas de servicios suelen introducir características que van mucho más allá de la identidad y la encriptación.
-
La API de identidad de la malla podría no integrarse con el mismo sistema backend que utilizan las aplicaciones existentes.
Sopesando estos pros y contras, podemos llegar a la conclusión de si merece la pena resolver este problema a nivel de plataforma. La clave es que no necesitamos, ni debemos esforzarnos, por resolver todos los problemas de las aplicaciones en nuestra nueva plataforma. Este es otro acto de equilibrio que debes considerar a medida que avanzas por los numerosos capítulos de este libro. Se compartirán varias recomendaciones, buenas prácticas y orientaciones, pero como en todo, debes evaluar cada una de ellas en función de las prioridades de las necesidades de tu empresa.
Los bloques de construcción
Concluyamos este capítulo identificando concretamente los componentes clave que tendrás a tu disposición cuando construyas una plataforma. Esto incluye todo, desde los componentes fundacionales hasta los servicios de plataforma opcionales que puedas desear implementar.
Los componentes de la Figura 1-10 tienen distinta importancia para distintos públicos.
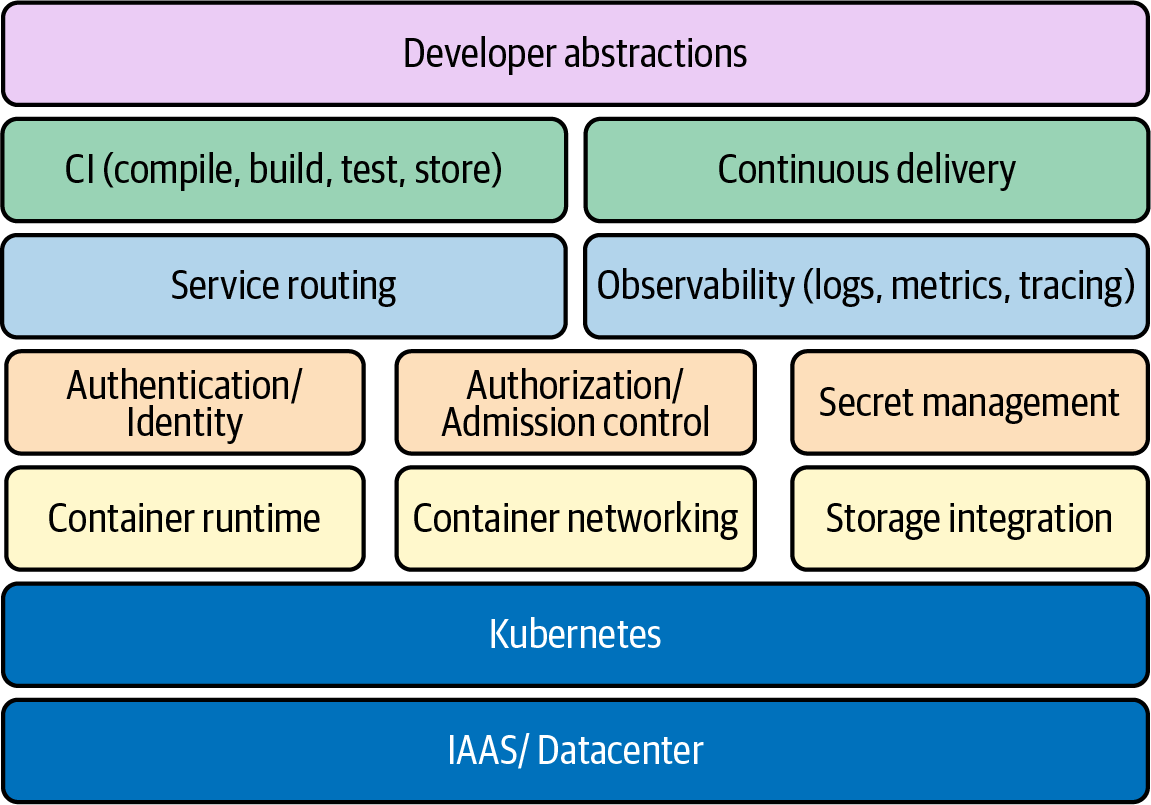
Figura 1-10. Muchos de los elementos clave que intervienen en el establecimiento de unaplataforma de aplicaciones.
Algunos componentes, como la red de contenedores y el tiempo de ejecución de contenedores, son necesarios para todos los clústeres, teniendo en cuenta que un clúster Kubernetes que no pueda ejecutar cargas de trabajo o permitir que se comuniquen no tendría mucho éxito. Es probable que algunos componentes varíen en cuanto a si deben implementarse o no. Por ejemplo, la gestión de secretos podría no ser un servicio de plataforma que pretendas implementar si las aplicaciones ya obtienen sus secretos de unasolución externa de gestión de secretos.
En la Figura 1-10 faltan claramente algunas áreas, como la seguridad. Esto se debe a que la seguridad no es una característica, sino más bien el resultado de cómo implementas todo desde la capa IAAS hacia arriba. Exploremos estas áreas clave a alto nivel, sabiendo que profundizaremos mucho más en ellas a lo largo de este libro.
IAAS/centro de datos y Kubernetes
IAAS/datacenter y Kubernetes forman la capa fundacional que hemos mencionado muchas veces en este capítulo. No pretendemos trivializar esta capa, porque su estabilidad estará directamente correlacionada con la de nuestra plataforma. Sin embargo, en los entornos modernos, pasamos mucho menos tiempo determinando la arquitectura de nuestros bastidores para soportar Kubernetes y mucho más tiempo decidiendo entre una variedad de opciones de implementación y topologías. Esencialmente, tenemos que evaluar cómo vamos a aprovisionar y poner a disposición clústeres Kubernetes.
Tiempo de ejecución del contenedor
El tiempo de ejecución del contenedor facilitará la gestión del ciclo de vida de nuestras cargas de trabajo en cada host. Esto se implementa habitualmente utilizando una tecnología que pueda gestionar contenedores, como CRI-O, containerd y Docker. La posibilidad de elegir entre estas diferentes implementaciones se debe a la Interfaz de Tiempo de Ejecución de Contenedores (IRC). Junto a estos ejemplos comunes, existen tiempos de ejecución especializados que soportan requisitos únicos, como el deseo de ejecutar una carga de trabajo en una micro-vm.
Red de contenedores
Nuestra elección de la red de contenedores abordará habitualmente la gestión de direcciones IP (IPAM) de las cargas de trabajo y los protocolos de enrutamiento para facilitar la comunicación. Las opciones tecnológicas habituales son Calico o Cilium, gracias a la Interfaz de Redes de Contenedores (CNI). Al conectar una tecnología de red de contenedores al clúster, el kubelet puede solicitar direcciones IP para las cargas de trabajo que inicie. Algunos plug-ins llegan incluso a implementar abstracciones de servicio sobre la red Pod.
Integración del almacenamiento
La integración de almacenamiento abarca lo que hacemos cuando el almacenamiento en disco en el host no es suficiente. En los Kubernetes modernos, cada vez más organizaciones envían cargas de trabajo con estado a sus clústeres. Estas cargas de trabajo requieren cierto grado de certeza de que el estado será resistente a los fallos de la aplicación o a los eventos de reprogramación. El almacenamiento puede ser suministrado por sistemas comunes como vSAN, EBS, Ceph y muchos más. La posibilidad de elegir entre varios backends se ve facilitada por la Interfaz de Almacenamiento de Contenedores (ICN). Al igual que CNI y CRI, podemos desplegar un complemento en nuestro clúster que entienda cómo satisfacer las necesidades de almacenamiento solicitadas por la aplicación.
Enrutamiento de servicios
El enrutamiento de servicios es la facilitación del tráfico hacia y desde las cargas de trabajo que ejecutamos en Kubernetes. Kubernetes ofrece una API de Servicios, pero suele ser un paso previo para la compatibilidad con funciones de enrutamiento más ricas en funciones. El enrutamiento de servicios se basa en las redes de contenedores y crea funciones de nivel superior, como el enrutamiento de capa 7, los patrones de tráfico y mucho más. Muchas veces se implementan utilizando una tecnología llamada controlador de entrada. En el lado más profundo del enrutamiento de servicios se encuentra una variedad de mallas de servicios. Esta tecnología está totalmente equipada con mecanismos como mTLS de servicio a servicio, observabilidad y compatibilidad con mecanismos de aplicaciones comola ruptura de circuitos.
Gestión secreta
La gestión de secretos abarca la gestión y distribución de los datos sensibles que necesitan las cargas de trabajo. Kubernetes ofrece una API de Secretos con la que se puede interactuar con los datos sensibles. Sin embargo, fuera de la caja, muchos clústeres no tienen una gestión de secretos lo suficientemente robusta ni las capacidades de encriptación que exigen varias empresas. Se trata en gran medida de una conversación en torno a la defensa en profundidad. A un nivel sencillo, podemos garantizar que los datos se cifran antes de almacenarse (cifrado en reposo). A un nivel más avanzado, podemos proporcionar integración con diversas tecnologías centradas en la gestión de secretos, como Vault o Cyberark.
Identidad
La identidad abarca la autenticación de personas y cargas de trabajo. Una pregunta inicial habitual de los administradores de clústeres es cómo autenticar a los usuarios en un sistema como LDAP o el sistema IAM de un proveedor de nube. Más allá de los humanos, las cargas de trabajo pueden querer identificarse para soportar modelos de red de confianza cero, en los que la suplantación de las cargas de trabajo es mucho más difícil. Esto puede facilitarse integrando un proveedor de identidad y utilizando mecanismos como mTLS para verificar una carga de trabajo.
Autorización/control de admisión
La autorización es el siguiente paso después de que podamos verificar la identidad de un ser humano o de una carga de trabajo. Cuando los usuarios o las cargas de trabajo interactúan con el servidor API, ¿cómo concedemos o denegamos su acceso a los recursos? Kubernetes ofrece una función RBAC con controles a nivel de recurso/verbo, pero ¿qué pasa con la lógica personalizada específica para la autorización dentro de nuestra organización? En el control de admisión es donde podemos dar un paso más construyendo una lógica de validación que puede ser tan sencilla como consultar una lista estática de reglas o llamar dinámicamente a otros sistemas para determinar la respuesta de autorización correcta.
Cadena de suministro de software
La cadena de suministro del software abarca todo el ciclo de vida de conseguir que el software llegue del código fuente al tiempo de ejecución. Esto implica las preocupaciones comunes en torno a la integración continua (IC) y la entrega continua (EC). Muchas veces, el principal punto de interacción de los desarrolladores son las canalizaciones que establecen en estos sistemas. Conseguir que los sistemas CI/CD funcionen bien con Kubernetes puede ser primordial para el éxito de tu plataforma. Más allá de CI/CD están las preocupaciones en torno al almacenamiento de artefactos, su seguridad desde el punto de vista de la vulnerabilidad, y garantizar la integridad de las imágenes que se ejecutarán en tu clúster.
Observabilidad
La observabilidad es el término general que engloba todas las cosas que nos ayudan a comprender lo que ocurre con nuestros clusters. Esto incluye las capas del sistema y de la aplicación. Normalmente, pensamos que la observabilidad abarca tres áreas clave. Son los registros, las métricas y el rastreo. El registro suele implicar el reenvío de datos de registro desde las cargas de trabajo del host a un sistema backend de destino. Desde este sistema podemos agregar y analizar los registros de forma consumible. Las métricas implican la captura de datos que representan algún estado en un momento dado. A menudo agregamos, o raspamos, estos datos en algún sistema para su análisis. El rastreo ha ganado popularidad en gran medida por la necesidad de comprender las interacciones entre los distintos servicios que componen nuestra pila de aplicaciones. A medida que se recogen los datos de rastreo, se pueden llevar a un sistema agregado donde se muestra la vida de una solicitud o respuesta mediante alguna forma de contexto o ID de correlación.
Abstracciones del desarrollador
Las abstracciones del desarrollador son las herramientas y servicios de plataforma que ponemos en marcha para que los desarrolladores tengan éxito en nuestra plataforma. Como ya se ha comentado, los enfoques de abstracción viven en un espectro. Algunas organizaciones optarán por hacer que el uso de Kubernetes sea completamente transparente para los equipos de desarrollo. Otras optarán por exponer muchos de los potentes mandos que ofrece Kubernetes y dar una flexibilidad significativa a cada desarrollador. Las soluciones también tienden a centrarse en la experiencia de incorporación de los desarrolladores, garantizando que se les pueda dar acceso y control seguro de un entorno que puedan utilizar en la plataforma.
Resumen
En este capítulo, hemos explorado ideas que abarcan Kubernetes, plataformas de aplicaciones e incluso la construcción de plataformas de aplicaciones sobre Kubernetes. Esperemos que esto te haya hecho pensar en la variedad de áreas a las que puedes lanzarte para comprender mejor cómo construir sobre este gran orquestador de cargas de trabajo. Durante el resto del libro vamos a sumergirnos en estas áreas clave y a proporcionar información, anécdotas y recomendaciones que te ayudarán a construir tu perspectiva sobre la construcción de plataformas. ¡Pongámonos manos a la obra y comencemos a recorrer este camino hacia la producción!
Get Kubernetes de producción now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

