Chapter 1. Setting Up a Basic Service
This chapter describes the procedure for setting up a simple multitier application in Kubernetes. The example we’ll walk through consists of two tiers: a simple web application and a database. Though this might not be the most complicated application, it is a good place to start when learning to manage an application in Kubernetes.
Application Overview
The application that we will use for our example is fairly straightforward. It’s a simple journal service with the following details:
-
It has a separate static file server using NGINX.
-
It has a RESTful application programming interface (API) https://some-host-name.io/api on the /api path.
-
It has a file server on the main URL, https://some-host-name.io.
-
It uses the Let’s Encrypt service for managing Secure Sockets Layer (SSL).
Figure 1-1 presents a diagram of this application. Don’t be worried if you don’t understand all the pieces right away; they will be explained in greater detail throughout the chapter. We’ll walk through building this application step by step, first using YAML configuration files and then Helm charts.
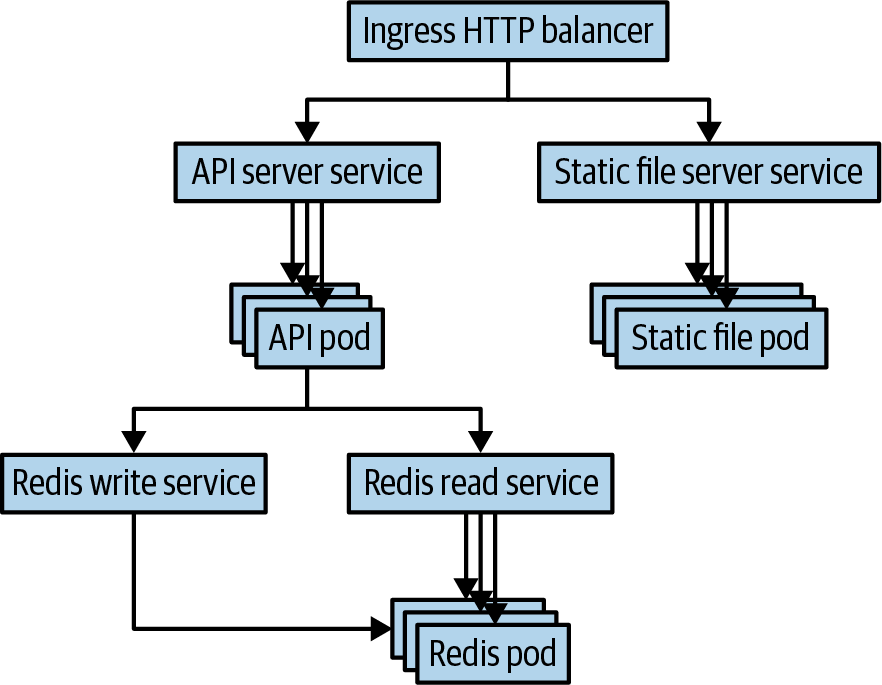
Figure 1-1. A diagram of our journal service as it is deployed in Kubernetes
Managing Configuration Files
Before we get into the details of how to construct this application in Kubernetes, it is worth discussing how we manage the configurations themselves. With Kubernetes, everything is represented declaratively. This means that you write down the desired state of the application in the cluster (generally in YAML or JSON files), and these declared desired states define all the pieces of your application. This declarative approach is far preferable to an imperative approach in which the state of your cluster is the sum of a series of changes to the cluster. If a cluster is configured imperatively, it is difficult to understand and replicate how the cluster came to be in that state, making it challenging to understand or recover from problems with your application.
When declaring the state of your application, people typically prefer YAML to JSON, though Kubernetes supports them both. This is because YAML is somewhat less verbose and more human editable than JSON. However, it’s worth noting that YAML is indentation sensitive; often errors in Kubernetes configurations can be traced to incorrect indentation in YAML. If things aren’t behaving as expected, checking your indentation is a good place to start troubleshooting. Most editors have syntax highlighting support for both JSON and YAML. When working with these files it is a good idea to install such tools to make it easier to find both author and file errors in your configurations. There is also an excellent extension for Visual Studio Code that supports richer error checking for Kubernetes files.
Because the declarative state contained in these YAML files serves as the source of truth for your application, correct management of this state is critical to the success of your application. When modifying your application’s desired state, you will want to be able to manage changes, validate that they are correct, audit who made changes, and possibly roll things back if they fail. Fortunately, in the context of software engineering, we have already developed the tools necessary to manage both changes to the declarative state as well as audit and rollback. Namely, the best practices around both version control and code review directly apply to the task of managing the declarative state of your application.
These days most people store their Kubernetes configurations in Git. Though the specific details of the version control system are unimportant, many tools in the Kubernetes ecosystem expect files in a Git repository. For code review there is much more heterogeneity; though clearly GitHub is quite popular, others use on-premises code review tools or services. Regardless of how you implement code review for your application configuration, you should treat it with the same diligence and focus that you apply to source control.
When it comes to laying out the filesystem for your application, it’s worthwhile to use the directory organization that comes with the filesystem to organize your components. Typically, a single directory is used to encompass an Application Service. The definition of what constitutes an Application Service can vary in size from team to team, but generally, it is a service developed by a team of 8–12 people. Within that directory, subdirectories are used for subcomponents of the application.
For our application, we lay out the files as follows:
journal/ frontend/ redis/ fileserver/
Within each directory are the concrete YAML files needed to define the service. As you’ll see later on, as we begin to deploy our application to multiple different regions or clusters, this file layout will become more complicated.
Creating a Replicated Service Using Deployments
To describe our application, we’ll begin at the frontend and work downward. The frontend application for the journal is a Node.js application implemented in TypeScript. The complete application is too large to include in the book, so we’ve hosted it on our GitHub. You’ll be able to find code for future examples there, too, so it’s worth bookmarking. The application exposes an HTTP service on port 8080 that serves requests to the /api/* path and uses the Redis backend to add, delete, or return the current journal entries. If you plan to work through the YAML examples that follow on your local machine, you’ll want to build this application into a container image using the Dockerfile and push it to your own image repository. Then, rather than using our example file name, you’ll want to include your container image name in your code.
Best Practices for Image Management
Though in general, building and maintaining container images is beyond the scope of this book, it’s worthwhile to identify some general best practices for building and naming images. In general, the image build process can be vulnerable to “supply-chain attacks.” In such attacks, a malicious user injects code or binaries into some dependency from a trusted source that is then built into your application. Because of the risk of such attacks, it is critical that when you build your images you base them on only well-known and trusted image providers. Alternatively, you can build all your images from scratch. Building from scratch is easy for some languages (e.g., Go) that can build static binaries, but it is significantly more complicated for interpreted languages like Python, JavaScript, or Ruby.
The other best practices for images relate to naming. Though the version of a container image in an image registry is theoretically mutable, you should treat the version tag as immutable. In particular, some combination of the semantic version and the SHA hash of the commit where the image was built is a good practice for naming images (e.g., v1.0.1-bfeda01f). If you don’t specify an image version, latest is used by default. Although this can be convenient in development, it is a bad idea for production usage because latest is clearly being mutated every time a new image is built.
Creating a Replicated Application
Our frontend application is stateless; it relies entirely on the Redis backend for its state. As a result, we can replicate it arbitrarily without affecting traffic. Though our application is unlikely to sustain large-scale usage, it’s still a good idea to run with at least two replicas so that you can handle an unexpected crash or roll out a new version of the application without downtime.
In Kubernetes, the ReplicaSet resource is the one that directly manages replicating a specific version of your containerized application. Since the version of all applications changes over time as you modify the code, it is not a best practice to use a ReplicaSet directly. Instead, you use the Deployment resource. A Deployment combines the replication capabilities of ReplicaSet with versioning and the ability to perform a staged rollout. By using a Deployment you can use Kubernetes’ built-in tooling to move from one version of the application to the next.
The Kubernetes Deployment resource for our application looks as follows:
apiVersion:apps/v1kind:Deploymentmetadata:labels:# All pods in the Deployment will have this labelapp:frontendname:frontendnamespace:defaultspec:# We should always have at least two replicas for reliabilityreplicas:2selector:matchLabels:app:frontendtemplate:metadata:labels:app:frontendspec:containers:-image:my-repo/journal-server:v1-abcdeimagePullPolicy:IfNotPresentname:frontend# TODO: Figure out what the actual resource needs areresources:request:cpu:"1.0"memory:"1G"limits:cpu:"1.0"memory:"1G"
There are several things to note in this Deployment. First is that we are using Labels
to identify the Deployment as well as the ReplicaSets and the pods that the Deployment
creates. We’ve added the app: frontend label to all these resources so that we can
examine all resources for a particular layer in a single request. You’ll see that as we
add other resources, we’ll follow the same practice.
Additionally, we’ve added comments in a number of places in the YAML. Although these comments don’t make it into the Kubernetes resource stored on the server, just like comments in code, they serve to guide people who are looking at this configuration for the first time.
You should also note that for the containers in the Deployment we have specified both Request and Limit resource requests, and we’ve set Request equal to Limit. When running an application, the Request is the reservation that is guaranteed on the host machine where it runs. The Limit is the maximum resource usage that the container will be allowed. When you are starting out, setting Request equal to Limit will lead to the most predictable behavior of your application. This predictability comes at the expense of resource utilization. Because setting Request equal to Limit prevents your applications from overscheduling or consuming excess idle resources, you will not be able to drive maximal utilization unless you tune Request and Limit very, very carefully. As you become more advanced in your understanding of the Kubernetes resource model, you might consider modifying Request and Limit for your application independently, but in general most users find that the stability from predictability is worth the reduced utilization.
Often times, as our comment suggests, it is difficult to know the right values for these resource limits. Starting by overestimating the estimates and then using monitoring to tune to the right values is a pretty good approach. However, if you are launching a new service, remember that the first time you see large-scale traffic, your resource needs will likely increase significantly. Additionally, there are some languages, especially garbage-collected languages, that will happily consume all available memory, which can make it difficult to determine the correct minimum for memory. In this case, some form of binary search may be necessary, but remember to do this in a test environment so that it doesn’t affect your production!
Now that we have the Deployment resource defined, we’ll check it into version control, and deploy it to Kubernetes:
gitaddfrontend/deployment.yamlgitcommit-m"Added deployment"frontend/deployment.yamlkubectlapply-ffrontend/deployment.yaml
It is also a best practice to ensure that the contents of your cluster exactly match the contents of your source control. The best pattern to ensure this is to adopt a GitOps approach and deploy to production only from a specific branch of your source control, using continuous integration/continuous delivery (CI/CD) automation. In this way you’re guaranteed that source control and production match. Though a full CI/CD pipeline might seem excessive for a simple application, the automation by itself, independent of the reliability it provides, is usually worth the time taken to set it up. And CI/CD is extremely difficult to retrofit into an existing, imperatively deployed application.
We’ll come back to this application description YAML in later sections to examine additional elements such as the ConfigMap and secret volumes as well as pod Quality of Service.
Setting Up an External Ingress for HTTP Traffic
The containers for our application are now deployed, but it’s not currently possible for anyone to access the application. By default, cluster resources are available only within the cluster itself. To expose our application to the world, we need to create a service and load balancer to provide an external IP address and to bring traffic to our containers. For the external exposure we are going to use two Kubernetes resources. The first is a service that load-balances Transmission Control Protocol (TCP) or User Datagram Protocol (UDP) traffic. In our case, we’re using the TCP protocol. And the second is an Ingress resource, which provides HTTP(S) load balancing with intelligent routing of requests based on HTTP paths and hosts. With a simple application like this, you might wonder why we choose to use the more complex Ingress, but as you’ll see in later sections, even this simple application will be serving HTTP requests from two different services. Furthermore, having an Ingress at the edge enables flexibility for future expansion of our service.
Note
The Ingress resource is one of the older resources in Kubernetes, and over the years numerous issues have been raised with the way that it models HTTP access to microservices. This has led to the development of the Gateway API for Kubernetes. The Gateway API has been designed as an extension to Kubernetes and requires additional components to be installed in your cluster. If you find that Ingress doesn’t meet your needs, consider moving to the Gateway API.
Before the Ingress resource can be defined, there needs to be a Kubernetes Service for the Ingress to point to. We’ll use Labels to direct the Service to the pods that we created in the previous section. The Service is significantly simpler to define than the Deployment and looks as follows:
apiVersion:v1kind:Servicemetadata:labels:app:frontendname:frontendnamespace:defaultspec:ports:-port:8080protocol:TCPtargetPort:8080selector:app:frontendtype:ClusterIP
After you’ve defined the Service, you can define an Ingress resource. Unlike Service
resources, Ingress requires an Ingress controller container to be running in
the cluster. There are a number of different implementations you can choose from,
either offered by your cloud provider, or implemented using open source servers.
If you choose to install an open source Ingress provider, it’s a good idea to
use the Helm package manager to install and maintain it. The nginx or haproxy Ingress providers are popular choices:
apiVersion:networking.k8s.io/v1kind:Ingressmetadata:name:frontend-ingressspec:rules:-http:paths:-path:/testpathpathType:Prefixbackend:service:name:testport:number:8080
With our Ingress resource created, our application is ready to serve traffic from web browsers around the world. Next, we’ll look at how you can set up your application for easy configuration and customization.
Configuring an Application with ConfigMaps
Every application needs a degree of configuration. This could be the number of journal entries to display per page, the color of a particular background, a special holiday display, or many other types of configuration. Typically, separating such configuration information from the application itself is a best practice to follow.
There are several reasons for this separation. The first is that you might want to configure the same application binary with different configurations depending on the setting. In Europe you might want to light up an Easter special, whereas in China you might want to display a special for Chinese New Year. In addition to this environmental specialization, there are agility reasons for the separation. Usually a binary release contains multiple different new features; if you turn on these features via code, the only way to modify the active features is to build and release a new binary, which can be an expensive and slow process.
The use of configuration to activate a set of features means that you can quickly (and even dynamically) activate and deactivate features in response to user needs or application code failures. Features can be rolled out and rolled back on a per-feature basis. This flexibility ensures that you are continually making forward progress with most features even if some need to be rolled back to address performance or correctness problems.
In Kubernetes this sort of configuration is represented by a resource called a ConfigMap. A ConfigMap contains multiple key/value pairs representing configuration information or a file. This configuration information can be presented to a container in a pod via either files or environment variables. Imagine that you want to configure your online journal application to display a configurable number of journal entries per page. To achieve this, you can define a ConfigMap as follows:
kubectlcreateconfigmapfrontend-config--from-literal=journalEntries=10
To configure your application, you expose the configuration information as
an environment variable in the application itself. To do that, you can
add the following to the container resource in the Deployment that you defined earlier:
...# The containers array in the PodTemplate inside the Deploymentcontainers:-name:frontend...env:-name:JOURNAL_ENTRIESvalueFrom:configMapKeyRef:name:frontend-configkey:journalEntries...
Although this demonstrates how you can use a ConfigMap to configure your application, in the real world of Deployments, you’ll want to roll out regular changes to this configuration at least weekly. It might be tempting to roll this out by simply changing the ConfigMap itself, but this isn’t really a best practice, for reasons: the first is that changing the configuration doesn’t actually trigger an update to existing pods. The configuration is applied only when the pod is restarted. As a result, the rollout isn’t health based and can be ad hoc or random. Another reason is that the only versioning for the ConfigMap is in your version control, and it can be very difficult to perform a rollback.
A better approach is to put a version number in the name of the ConfigMap itself.
Instead of calling it frontend-config, call it frontend-config-v1. When you want
to make a change, instead of updating the ConfigMap in place, you create a new v2
ConfigMap, and then update the Deployment resource to use that configuration.
When you do this, a Deployment rollout is automatically triggered, using the appropriate
health checking and pauses between changes. Furthermore, if you ever need to roll back,
the v1 configuration is sitting in the cluster and rollback is as simple as updating
the Deployment again.
Managing Authentication with Secrets
So far, we haven’t really discussed the Redis service to which our frontend is connecting. But in any real application we need to secure connections between our services. In part, this is to ensure the security of users and their data, and in addition, it is essential to prevent mistakes like connecting a development frontend with a production database.
The Redis database is authenticated using a simple password. It might be convenient to think that you would store this password in the source code of your application, or in a file in your image, but these are both bad ideas for a variety of reasons. The first is that you have leaked your secret (the password) into an environment where you aren’t necessarily thinking about access control. If you put a password into your source control, you are aligning access to your source with access to all secrets. This isn’t the best course of action because you will probably have a broader set of users who can access your source code than should really have access to your Redis instance. Likewise, someone who has access to your container image shouldn’t necessarily have access to your production database.
In addition to concerns about access control, another reason to avoid binding secrets to source control and/or images is parameterization. You want to be able to use the same source code and images in a variety of environments (e.g., development, canary, and production). If the secrets are tightly bound in source code or an image, you need a different image (or different code) for each environment.
Having seen ConfigMaps in the previous section, you might immediately think that the password could be stored as a configuration and then populated into the application as an application-specific configuration. You’re absolutely correct to believe that the separation of configuration from application is the same as the separation of secrets from application. But the truth is that a secret is an important concept by itself. You likely want to handle access control, handling, and updates of secrets in a different way than a configuration. More important, you want your developers thinking differently when they are accessing secrets than when they are accessing configuration. For these reasons, Kubernetes has a built-in Secret resource for managing secret data.
You can create a secret password for your Redis database as follows:
kubectlcreatesecretgenericredis-passwd--from-literal=passwd=${RANDOM}
Obviously, you might want to use something other than a random number for your password. Additionally, you likely want to use a secret/key management service, either via your cloud provider, like Microsoft Azure Key Vault, or an open source project, like HashiCorp’s Vault. When you are using a key management service, they generally have tighter integration with Kubernetes secrets.
After you have stored the Redis password as a secret in Kubernetes, you then need to bind that secret to the running application when deployed to Kubernetes. To do this, you can use a Kubernetes Volume. A Volume is effectively a file or directory that can be mounted into a running container at a user-specified location. In the case of secrets, the Volume is created as a tmpfs RAM-backed filesystem and then mounted into the container. This ensures that even if the machine is physically compromised (quite unlikely in the cloud, but possible in the datacenter), the secrets are much more difficult for an attacker to obtain.
Note
Secrets in Kubernetes are stored unencrypted by default. If you want to store
secrets encrypted, you can integrate with a key provider to give you a key
that Kubernetes will use to encrypt all the secrets in the cluster.
Note that although this secures the keys against direct attacks to the etcd
database, you still need to ensure that access via the Kubernetes API server
is properly secured.
To add a secret Volume to a Deployment, you need to specify two new entries
in the YAML for the Deployment. The first is a volume entry for the pod
that adds the Volume to the pod:
...volumes:-name:passwd-volumesecret:secretName:redis-passwd
Container Storage Interface (CSI) drivers enable you to use key management systems (KMS) that are located outside of your Kubernetes cluster. This is often a requirement for compliance and security within large or regulated organizations. If you use one of these CSI drivers your Volume would instead look like:
...volumes:-name:passwd-volumecsi:driver:secrets-store.csi.k8s.ioreadOnly:truevolumeAttributes:secretProviderClass:"azure-sync"...
Regardless of which method you use, with the Volume defined in the pod, you need to mount it into a specific container.
You do this via the volumeMounts field in the container description:
...volumeMounts:-name:passwd-volumereadOnly:truemountPath:"/etc/redis-passwd"...
This mounts the secret Volume into the redis-passwd directory for access from the client code. Putting this all together, you have the complete Deployment as follows:
apiVersion:apps/v1kind:Deploymentmetadata:labels:app:frontendname:frontendnamespace:defaultspec:replicas:2selector:matchLabels:app:frontendtemplate:metadata:labels:app:frontendspec:containers:-image:my-repo/journal-server:v1-abcdeimagePullPolicy:IfNotPresentname:frontendvolumeMounts:-name:passwd-volumereadOnly:truemountPath:"/etc/redis-passwd"resources:requests:cpu:"1.0"memory:"1G"limits:cpu:"1.0"memory:"1G"volumes:-name:passwd-volumesecret:secretName:redis-passwd
At this point we have configured the client application to have a secret available to authenticate to the Redis service. Configuring Redis to use this password is similar; we mount it into the Redis pod and load the password from the file.
Deploying a Simple Stateful Database
Although conceptually deploying a stateful application is similar to deploying a client like our frontend, state brings with it more complications. The first is that in Kubernetes a pod can be rescheduled for a number of reasons, such as node health, an upgrade, or rebalancing. When this happens, the pod might move to a different machine. If the data associated with the Redis instance is located on any particular machine or within the container itself, that data will be lost when the container migrates or restarts. To prevent this, when running stateful workloads in Kubernetes it’s important to use remote PersistentVolumes to manage the state associated with the application.
There are a wide variety of implementations of PersistentVolumes in Kubernetes, but they all share common characteristics. Like secret Volumes described earlier, they are associated with a pod and mounted into a container at a particular location. Unlike secrets, PersistentVolumes are generally remote storage mounted through some sort of network protocol, either file based, such as Network File System (NFS) or Server Message Block (SMB), or block based (iSCSI, cloud-based disks, etc.). Generally, for applications such as databases, block-based disks are preferable because they offer better performance, but if performance is less of a consideration, file-based disks sometimes offer greater flexibility.
Note
Managing state in general is complicated, and Kubernetes is no exception. If you are running in an environment that supports stateful services (e.g., MySQL as a service, Redis as a service), it is generally a good idea to use those stateful services. Initially, the cost premium of a stateful software as a service (SaaS) might seem expensive, but when you factor in all the operational requirements of state (backup, data locality, redundancy, etc.), and the fact that the presence of state in a Kubernetes cluster makes it difficult to move applications between clusters, it becomes clear that, in most cases, storage SaaS is worth the price premium. In on-premises environments where storage SaaS isn’t available, having a dedicated team provide storage as a service to the entire organization is definitely a better practice than allowing each team to build it themselves.
To deploy our Redis service, we use a StatefulSet resource. Added after the initial Kubernetes release as a complement to ReplicaSet resources, a StatefulSet gives slightly stronger guarantees such as consistent names (no random hashes!) and a defined order for scale-up and scale-down. When you are deploying a singleton, this is somewhat less important, but when you want to deploy replicated state, these attributes are very convenient.
To obtain a PersistentVolume for our Redis, we use a PersistentVolumeClaim. You can think of a claim as a “request for resources.” Our Redis declares abstractly that it wants 50 GB of storage, and the Kubernetes cluster determines how to provision an appropriate PersistentVolume. There are two reasons for this. The first is so we can write a StatefulSet that is portable between different clouds and on premises, where the details of disks might be different. The other reason is that although many PersistentVolume types can be mounted to only a single pod, we can use Volume claims to write a template that can be replicated and still have each pod assigned its own specific PersistentVolume.
The following example shows a Redis StatefulSet with PersistentVolumes:
apiVersion:apps/v1kind:StatefulSetmetadata:name:redisspec:serviceName:"redis"replicas:1selector:matchLabels:app:redistemplate:metadata:labels:app:redisspec:containers:-name:redisimage:redis:5-alpineports:-containerPort:6379name:redisvolumeMounts:-name:datamountPath:/datavolumeClaimTemplates:-metadata:name:dataspec:accessModes:["ReadWriteOnce"]resources:requests:storage:10Gi
This deploys a single instance of your Redis service, but suppose you want to replicate the Redis cluster for scale-out of reads and resiliency to failures. To do this you obviously need to increase the number of replicas to three, but you also need to ensure that the two new replicas connect to the write master for Redis. We’ll see how to make this connection in the following section.
When you create the headless Service for the Redis StatefulSet, it creates a DNS entry
redis-0.redis; this is the IP address of the first replica. You can use this to create
a simple script that can launch in all the containers:
#!/bin/shPASSWORD=$(cat/etc/redis-passwd/passwd)if[["${HOSTNAME}"=="redis-0"]];thenredis-server--requirepass${PASSWORD}elseredis-server--slaveofredis-0.redis6379--masterauth${PASSWORD}--requirepass${PASSWORD}fi
You can create this script as a ConfigMap:
kubectlcreateconfigmapredis-config--from-file=./launch.sh
You then add this ConfigMap to your StatefulSet and use it as the command for the container. Let’s also add in the password for authentication that we created earlier in the chapter.
The complete three-replica Redis looks as follows:
apiVersion:apps/v1kind:StatefulSetmetadata:name:redisspec:serviceName:"redis"replicas:3selector:matchLabels:app:redistemplate:metadata:labels:app:redisspec:containers:-name:redisimage:redis:5-alpineports:-containerPort:6379name:redisvolumeMounts:-name:datamountPath:/data-name:scriptmountPath:/script/launch.shsubPath:launch.sh-name:passwd-volumemountPath:/etc/redis-passwdcommand:-sh--c-/script/launch.shvolumes:-name:scriptconfigMap:name:redis-configdefaultMode:0777-name:passwd-volumesecret:secretName:redis-passwdvolumeClaimTemplates:-metadata:name:dataspec:accessModes:["ReadWriteOnce"]resources:requests:storage:10Gi
Now your Redis is clustered for fault tolerance. If any one of the three Redis replicas fails for any reason, your application can keep running with the two remaining replicas until the third replica is restored.
Creating a TCP Load Balancer by Using Services
Now that we’ve deployed the stateful Redis service, we need to make it available to our frontend. To do this, we create two different Kubernetes Services. The first is the Service for reading data from Redis. Because Redis is replicating the data to all three members of the StatefulSet, we don’t care which read our request goes to. Consequently, we use a basic Service for the reads:
apiVersion:v1kind:Servicemetadata:labels:app:redisname:redisnamespace:defaultspec:ports:-port:6379protocol:TCPtargetPort:6379selector:app:redissessionAffinity:Nonetype:ClusterIP
To enable writes, you need to target the Redis master (replica #0). To do this, create a headless Service. A headless Service doesn’t have a cluster IP address; instead, it programs a DNS entry for every pod in the StatefulSet. This means that we can access our master via the redis-0.redis DNS name:
apiVersion:v1kind:Servicemetadata:labels:app:redis-writename:redis-writespec:clusterIP:Noneports:-port:6379selector:app:redis
Thus, when we want to connect to Redis for writes or transactional read/write pairs, we can build a separate write client connected to the redis-0.redis-write server.
Using Ingress to Route Traffic to a Static File Server
The final component in our application is a static file server. The static file server is responsible for serving HTML, CSS, JavaScript, and image files. It’s both more efficient and more focused for us to separate static file serving from our API serving frontend described earlier. We can easily use a high-performance static off-the-shelf file server like NGINX to serve files while we allow our development teams to focus on the code needed to implement our API.
Fortunately, the Ingress resource makes this sort of mini-microservice architecture very easy. Just like the frontend, we can use a Deployment resource to describe a replicated NGINX server. Let’s build the static images into the NGINX container and deploy them to each replica. The Deployment resource looks as follows:
apiVersion:apps/v1kind:Deploymentmetadata:labels:app:fileservername:fileservernamespace:defaultspec:replicas:2selector:matchLabels:app:fileservertemplate:metadata:labels:app:fileserverspec:containers:# This image is intended as an example, replace it with your own# static files image.-image:my-repo/static-files:v1-abcdeimagePullPolicy:Alwaysname:fileserverterminationMessagePath:/dev/termination-logterminationMessagePolicy:Fileresources:requests:cpu:"1.0"memory:"1G"limits:cpu:"1.0"memory:"1G"dnsPolicy:ClusterFirstrestartPolicy:Always
Now that there is a replicated static web server up and running, you will likewise create a Service resource to act as a load balancer:
apiVersion:v1kind:Servicemetadata:labels:app:fileservername:fileservernamespace:defaultspec:ports:-port:80protocol:TCPtargetPort:80selector:app:fileserversessionAffinity:Nonetype:ClusterIP
Now that you have a Service for your static file server, extend
the Ingress resource to contain the new path. It’s important to note
that you must place the / path after the /api path, or else it would
subsume /api and direct API requests to the static file server. The
new Ingress looks like this:
apiVersion:networking.k8s.io/v1kind:Ingressmetadata:name:frontend-ingressspec:rules:-http:paths:-path:/apipathType:Prefixbackend:service:name:fileserverport:number:8080# NOTE: this should come after /api or else it will hijack requests-path:/pathType:Prefixbackend:service:name:fileserverport:number:80
Now that you have set up an Ingress resource for your file server, in addition to the Ingress for the API you set up earlier, the application’s user interface is ready to use. Most modern applications combine static files, typically HTML and JavaScript, with a dynamic API server implemented in a server-side programming language like Java, .NET, or Go.
Parameterizing Your Application by Using Helm
Everything that we have discussed so far focuses on deploying a single instance of our service to a single cluster. However, in reality, nearly every service and every service team is going to need to deploy to multiple environments (even if they share a cluster). Even if you are a single developer working on a single application, you likely want to have at least a development version and a production version of your application so that you can iterate and develop without breaking production users. After you factor in integration testing and CI/CD, it’s likely that even with a single service and a handful of developers, you’ll want to deploy to at least three different environments, and possibly more if you consider handling datacenter-level failures. Let’s explore a few options for deployment.
An initial failure mode for many teams is to simply copy the files from one cluster to another. Instead of having a single frontend/ directory, have a frontend-production/ and frontend-development/ pair of directories. While this is a viable option, it’s also dangerous because you are now in charge of ensuring that these files remain synchronized with one another. If they were intended to be entirely identical, this might be easy, but some skew between development and production is expected because you will be developing new features. It’s critical that the skew is both intentional and easily managed.
Another option to achieve this would be to use branches and version control, with the production and development branches leading off from a central repository and the differences between the branches clearly visible. This can be a viable option for some teams, but the mechanics of moving between branches are challenging when you want to simultaneously deploy software to different environments (e.g., a CI/CD system that deploys to a number of different cloud regions).
Consequently, most people end up with a templating system. A templating system combines templates, which form the centralized backbone of the application configuration, with parameters that specialize the template to a specific environment configuration. In this way, you can have a generally shared configuration, with intentional (and easily understood) customization as needed. There are a variety of template systems for Kubernetes, but the most popular by far is Helm.
In Helm, an application is packaged in a collection of files called a chart (nautical jokes abound in the world of containers and Kubernetes).
A chart begins with a chart.yaml file, which defines the metadata for the chart itself:
apiVersion:v1appVersion:"1.0"description:A Helm chart for our frontend journal server.name:frontendversion:0.1.0
This file is placed in the root of the chart directory (e.g., frontend/). Within this directory, there is a templates directory, which is where the templates are placed. A template is basically a YAML file from the previous examples, with some of the values in the file replaced with parameter references. For example, imagine that you want to parameterize the number of replicas in your frontend. Previously, here’s what the Deployment had:
...spec:replicas:2...
In the template file (frontend-deployment.tmpl), it instead looks like the following:
...spec:replicas:{{.replicaCount}}...
This means that when you deploy the chart, you’ll substitute the value for replicas with the appropriate parameter. The parameters themselves are defined in a values.yaml file. There will be one values file per environment where the application should be deployed. The values file for this simple chart would look like this:
replicaCount:2
Putting this all together, you can deploy this chart using the helm tool,
as follows:
helminstallpath/to/chart--valuespath/to/environment/values.yaml
This parameterizes your application and deploys it to Kubernetes. Over time these parameterizations will grow to encompass the variety of environments for your application.
Deploying Services Best Practices
Kubernetes is a powerful system that can seem complex. But setting up a basic application for success can be straightforward if you use the following best practices:
-
Most services should be deployed as Deployment resources. Deployments create identical replicas for redundancy and scale.
-
Deployments can be exposed using a Service, which is effectively a load balancer. A Service can be exposed either within a cluster (the default) or externally. If you want to expose an HTTP application, you can use an Ingress controller to add things like request routing and SSL.
-
Eventually you will want to parameterize your application to make its configuration more reusable in different environments. Packaging tools like Helm are the best choice for this kind of parameterization.
Summary
The application built in this chapter is a simple one, but it contains nearly all the concepts you’ll need to build larger, more complicated applications. Understanding how the pieces fit together and how to use foundational Kubernetes components is key to successfully working with Kubernetes.
Laying the correct foundation via version control, code review, and continuous delivery of your service ensures that no matter what you build, it is built solidly. As we go through the more advanced topics in subsequent chapters, keep this foundational information in mind.
Get Kubernetes Best Practices, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

