Chapter 1. Introduction to Kubeflow
Kubeflow is an open source Kubernetes-native platform for developing, orchestrating, deploying, and running scalable and portable machine learning (ML) workloads. It is a cloud native platform based on Google’s internal ML pipelines. The project is dedicated to making deployments of ML workflows on Kubernetes simple, portable, and scalable.
In this book we take a look at the evolution of machine learning in enterprise, how infrastructure has changed, and then how Kubeflow meets the needs of the modern enterprise.
Operating Kubeflow in an increasingly multicloud and hybrid-cloud world will be a key topic as the market grows and as Kubernetes adoption grows. A single workflow may have a life cycle that starts on-premise but quickly requires resources that are only available in the cloud. Building out machine learning tooling on the emergent platform Kubernetes is where life began for Kubeflow, so let’s start there.
Machine Learning on Kubernetes
Kubeflow began life as a basic way to get rudimentary machine learning infrastructure running on Kubernetes. The two driving forces in its development and adoption are the evolution of machine learning in enterprise and the emergence of Kubernetes as the de facto infrastructure management layer.
Let’s take a quick tour of the recent history of machine learning in enterprise to better understand how we got here.
The Evolution of Machine Learning in Enterprise
The past decade has seen the popularity and interest in machine learning rise considerably. This can be attributed to developments in the computer industry such as:
- Advances in self-driving cars
- Widespread adoption of computer vision (CV) applications
- Integration of tools such as Amazon Echo into daily life
Deep learning tends to get a lot of the credit for many tools these days, but fundamentally applied machine learning is foundational to all of the developments. Machine learning can be defined as:
In everyday parlance, when we say learning, we mean something like “gaining knowledge by studying, experience, or being taught.” Sharpening our focus a bit, we can think of machine learning as using algorithms for acquiring structural descriptions from data examples. A computer learns something about the structures that represent the information in the raw data.
Deep Learning by Josh Patterson and Adam Gibson (O’Reilly)
Some examples of machine learning algorithms are linear regression, decision trees, and neural networks. You should consider machine learning to be a subset of the broader domain of artificial intelligence (AI).
The mid-2000s saw the rise of deep learning research fueled by the availability of GPUs, better labeled datasets, and better tooling. This rise reignited interest in applied machine learning across all enterprises in the early 2010s, in their quest to leverage data and machine intelligence to be “more like Google and Amazon.”
Many early efforts in applied machine learning focused on the Apache Hadoop platform, as it had seen a meteoric rise in enterprise adoption in the first half of the 2010s. However, where Apache Hadoop was focused on leveraging commodity hardware with CPUs and distributed processing, deep learning practitioners were focused on single machines with one or more GPUs and the Python programming environment. Apache Spark on Apache Hadoop gave robust options for applied machine learning on the JVM, yet the graduate-level practitioner tended to be trained with the Python programming language.
Enterprises began hiring more graduate program–educated machine learning practitioners, which created a large influx of users demanding support for Python for their applied machine learning workflows.
In earlier years, Spark had been a key technology for running machine learning jobs, but in more recent years we see enterprises shifting toward GPU-based training in containers that may not live on a Hadoop cluster. The DevOps, IT, and platform teams working with these data scientists wanted to make sure they were setting the teams up for success, while also having a manageable infrastructure strategy.
The folks in charge of these platforms wanted to use the cloud in a way that did not cost too much, and took advantage of the transient nature of cloud-based workloads.
There is a growing need to make these worlds work together on data lakes—whether on-premise, in the cloud, or somewhere in between. Today, a few of the major challenges in the enterprise machine learning practitioner space are:
- Data scientists tend to prefer their own unique cluster of libraries and tools.
- These kinds of tools are generally heterogeneous, both inside teams and across organizations.
- Data scientists needs to interoperate with the rest of the enterprise for resources, data, and model deployment.
- Many of their tools are Python-based, where Python environments prove difficult to manage across a large organization.
- Many times, data scientists want to build containers and then just “move them around” to take advantage of more powerful resources beyond their laptop, either in the on-premise datacenter or in the cloud.
This makes operating a platform to support the different constituents using the system harder than ever.
It’s Harder Than Ever to Run Enterprise Infrastructure
We progressively live in an age where developers and data scientists feel empowered to spin up their own infrastructure in the cloud, so it has become antithetical for many organizations to enforce strict infrastructure rules for machine learning practitioners. We’ve seen this in the space where customers end up with three or four different machine learning pipeline systems because groups cannot agree (and simply run off to AWS or GCP to get what they want when they get told “no”).
Hadoop and Spark are still key tools for data storage and processing, but increasingly Kubernetes has come into the picture to manage the on-premise, cloud, and hybrid workloads. In the past two years we’ve seen Kubernetes adoption increase rapidly. Many enterprises have made infrastructure investments in previous technology cycles such as:
- RDBMs
- Parallel RDBMs
- Hadoop
- Key-value stores
- Spark
Just like the systems before them, these systems have a certain level of legacy inertia in their adoptive organizations. Therefore, it’s easy to predict that integration between Hadoop workloads and specialized Kubernetes-based machine learning workloads are on the horizon—as we see Cloudera using Kubernetes for their new data science tools as opposed to YARN, and Google changing out YARN for Kubernetes for Spark.
Other factors that make running infrastructure more complex than ever include how the evolution of open source acceptance in enterprise is using both on-premise and cloud infrastructure. On top of this, the security requirements are necessary to support the complexity of multiple platforms and multitenancy. Finally, we’re also seeing demands for specialized hardware such as GPUs and TPUs.
Some overall infrastructure trends we note as of interest as we go forward:
- Mixtures of on-premise, cloud, and hybrid deployments are becoming more popular with enterprises.
- The three major “big cloud” vendors continue to capture a number of workloads that move to the cloud; some of these workloads oscillate between cloud and on-premise.
- Docker is synonymous with the term container.
- Many enterprises are either using Kubernetes or strongly considering it as their container orchestration platform.
Beyond an on-premise cluster, Kubernetes clusters can be joined together with cluster federation within Kubernetes. In a truly hybrid world, we can potentially have a job scheduling policy that places certain workloads on the cloud because the on-premise resources are oversubscribed, or, conversely, restrain certain workloads to be executed on-premise only and never get executed in the cloud. Kubernetes also makes workloads more platform-agnostic, because it abstracts away the underlying platform specifics, making Kubernetes the key abstraction.
There are many factors to consider when dealing with cloud infrastructure, or a hybrid federated cluster infrastructure, including:
- Active Directory (AD) integration
- Security considerations
- Cost considerations for cloud instances
- Which users should have access to the cloud instances
We look at all of these topics in more depth in Chapter 2 and in the rest of this book.
Identifying Next-Generation Infrastructure (NGI) Core Principles
In the age of cloud infrastructure, what “big cloud” (AWS, Azure, Google Cloud Platform [GCP]) does tends to significantly impact how enterprises build their own infrastructure today. In 2018 we saw all three major cloud vendors offer managed Kubernetes as part of their infrastructure:
- Google Kubernetes Engine (GKE)
- Amazon Elastic Kubernetes Service (EKS)
- Azure Kubernetes Services (AKS)
In late 2017, after intially offering their own container service, Amazon joined the other two members of big cloud and offered Amazon EKS as a first-class supported citizen on AWS.
All three major cloud vendors are pushing Kubernetes, and these tailwinds should accelerate interest in Kubernetes and Kubeflow. Beyond that, we’ve seen how containers are a key part of how data scientists want to operate in managing containers from local execution, to on-premise infrastructure, to running on the cloud (easily and cleanly).
Teams need to balance multitenancy with access to storage and compute options (NAS, HDFS, FlashBlade) and high-end GPUs (Nvidia DGX-1, etc.). Teams also need a flexible way to customize their applied machine learning full applications, from ETL, to modeling, to model deployment; yet in a manner that stays within the above tenants.
We see that cloud vendors have an increasing influence on how enterprises build their infrastructure, where the managed services they tend to advocate for are likely to get accelerated adoption. However, most organizations are separated from getting results from data science efforts in their organization by obstacles listed in the last section. We can break these obstacles down into the following key components:
- Composability
This component involves breaking down machine learning workflows into a number of components (or stages) in a sequence, and allowing us to put them together in different formations. Many times, these stages are each their own systems and we need to move the output of one system to another system as input.
- Portability
-
This component involves having a consistent way to run and test code:
- Development
- Staging
- Production
When we have deltas between those environments, we introduce opportunities to have outages in production. Having a machine learning stack that can run on your laptop, the same way it runs on a multi-GPU DGX-1 and then on a public cloud, would be considered desirable by most practitioners today.
- Scalability
-
Most organizations also desire scalability, and are constrained by:
- Access to machine-specific hardware (e.g., GPUs, TPUs)
- Limited compute
- Network
- Storage
- Heterogeneous hardware
Unfortunately scale is not about “adding more hardware,” in many cases it’s about the underlying distributed systems architecture. Kubernetes helps us with these constraints.
Kubernetes for Production Application Deployment
Kubernetes is an orchestration system for containers that is meant to coordinate clusters of nodes at scale, in production, in an efficient manner. Kubernetes works around the idea of pods which are scheduling units (each pod containing one or more containers) in the Kubernetes ecosystem. These pods are distributed across hosts in a cluster to provide high availability. Kubernetes itself is not a complete solution and is intended to integrate with other tools such as Docker, a popular container technology.
A container image is a lightweight, standalone, executable package of a piece of software that includes everything needed to run it (code, runtime, system tools, system libraries, settings). Colloquially, containers are referred to as “Docker,” but what the speaker typically means are containers in the general sense. Docker containers make it significantly easier for developers to enjoy parity between their local, testing, staging, and production environments. Containers allow teams to run the same artifact or image across all of those environments, including a developer’s laptop and on the cloud. This property of containers, especially when combined with container orchestration with a system like Kubernetes, is driving the concept of hybrid cloud in practice.
A major reason we see widespread container (e.g., Docker) and Kubernetes adoption today is because together they are an exceptional infrastructure solution for the issues inherent in composability, portability, and scalability. Kubernetes shines when we have a lot of containers that need to be managed across a lot of machines (on-premise, in the cloud, or a mixture of both).
What Are Containers?
A container image is a lightweight, standalone, executable software package that includes the code, runtime, system tools and libraries, and settings needed to run it. Containers and container platforms provide more advantages than traditional virtualization because:
- Isolation is done on the kernel level without the need for a guest operating system.
- Containers are much more efficient, fast, and lightweight.
This allows applications to become encapsulated in self-contained environments. Other advantages include quicker deployments, scalability, and closer parity between development environments.
Docker and Kubernetes are not direct competitors but complementing technologies. One way to think of it is Docker is for managing images and individual containers, while Kubernetes is for managing pods of containers. Docker provided an open standard for packaging, and distributing containerized applications, but it did not solve the container orchestration (inter-communication, scaling, etc.) issue. Competitors to Kubernetes in this space are Mesos and Docker Swarm, but we’re seeing the industry converge on Kubernetes as the standard for container orchestration.
With Kubernetes we also have the ability to dynamically scale applications on a cluster. With installable options such as Kubernetes Horizontal Pod Autoscaler, we also have the ability to scale clusters themselves.
Kubernetes allows applications to scale horizontally in the node and container (pod) scope, while providing fault tolerance and self-healing infrastructure improving reliability. Kubernetes also provides efficient use of resources for applications deployed on-premise or in the cloud. It also strives to make every deployed application available 24/7 while allowing developers to deploy applications or updates multiple times per day with no downtime.
Kubernetes is, further, a great fit for machine learning workloads because it already has support for GPUs and TPUs as resources, with FPGAs in development. In Figure 1-2 we can see how having key abstractions with containers and other layers is significant for running a machine learning training job on GPUs in a similar fashion to how you might run the same job on FPGAs.
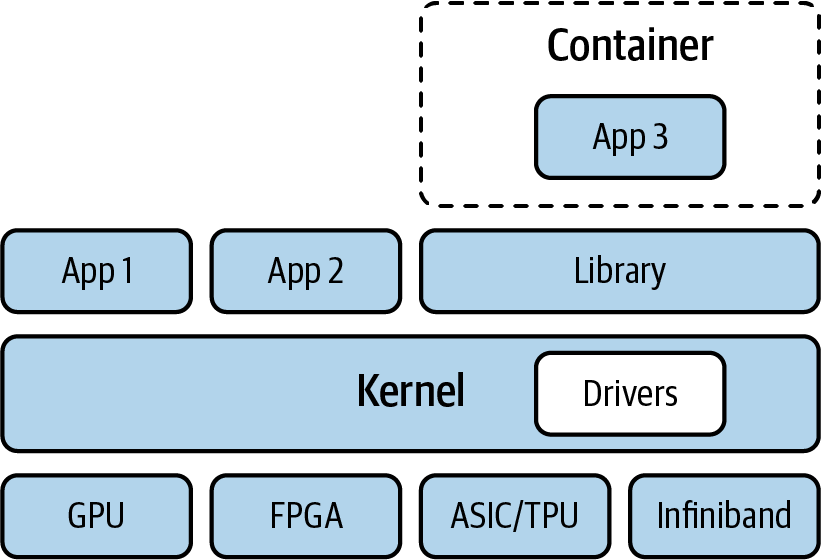
Figure 1-2. Containers and abstraction from hardware
We highlight the abstractions in Figure 1-2 because they are all components in the challenges involved with workflow portability. An example of this is how our code may work locally on our own laptop yet fail to run remotely on a Google Cloud virtual machine with GPUs.
Kubernetes also already has controllers for tasks such as batch jobs and deployment of long-lived services for model hosting, giving us many foundational components for our machine learning infrastructure. Further, as a resource manager, Kubernetes provides three primary benefits:
- Unified management
- Job isolation
- Resilient infrastructure
Unified management allows us to use a single-cluster management interface for multiple Kubernetes clusters. Job isolation in Kubernetes gives us the ability to move models and extract, transform, and load (ETL) pipelines from development to production with less dependency issues. Resilient infrastructure implies how Kubernetes manages the nodes in the cluster for us, and makes sure we have enough machines and resources to accomplish our tasks.
Kubernetes as a platform has been scaled in practice up into the thousands of nodes. While many organizations will not hit that order of magnitude of nodes, it highlights the fact that Kubernetes (the platform itself) will not have scale issues from a distributed system aspect as a platform.
Kubernetes Is Not Magic
Every distributed systems application requires thoughtful design. Don’t fall prey to the notion that Kubernetes will magically scale any application just because someone threw the application in a container and sent it to a cluster.
Although we can solve issues around moving containers and machine learning workflow stacks around, we’re not entirely home free. We still have other considerations such as:
- The cost of using the cloud versus the on-premises cost
- Organizational rules around where data can live
- Security considerations such as Active Directory and Kerberos integration
These are just to name a few. Modern datacenter infrastructure has a lot of variables in play, and it can make life hard for an IT or DevOps team. In this book we seek to at least arm you with a plan of attack on how to best plan and meet the needs of your data science constituents, all while keeping in line with organizational policies.
Kubernetes solves a lot of infrastructure problems in a progressively complex infrastructure world, but it wasn’t designed specifically for machine learning workflows.
For a Deeper Dive on Kubernetes
Check out Appendix B of this book, or one of the other O’Reilly books on Kubernetes such as Kubernetes: Up and Running, by Brendan Burns et al.
Let’s now take a look at how Kubeflow enters the picture to help enable machine learning workflows.
Enter: Kubeflow
Kubeflow was conceived of as a way to run machine learning workflows on Kubernetes and is typically used for the following reasons:
- You want to train/serve machine learning models in different environments (e.g., local, on-premise, and cloud).
- You want to use Jupyter Notebooks to manage machine learning training jobs (not just TensorFlow jobs).
- You want to launch training jobs that use resources (such as additional CPUs or GPUs, which aren’t available on your personal computer).
- You want to combine machine learning code from different libraries.
Sometimes, as the last example describes, we want to combine our TensorFlow code with other processes. In this example, we might want to use TensorFlow/agents to run simulations to generate data for training reinforcement-learning (RL) models. With Kubeflow Pipelines we could chain together these two distinct parts of a machine learning workflow.
With our machine learning platform, typically, we’d like an operational pattern similar to the “lab and the factory” pattern. In this way, we want our data scientists to be able to explore new data ideas in “the lab,” and once they find a setup they like, move it to “the factory” so that the modeling workflow can be run consistently and in a reproducible manner. In Figure 1-3 we can see a generalized representation of a common machine learning workflow.

Figure 1-3. The generalized machine learning workflow
Kubeflow was designed to operate machine learning workflows, such as the one represented in Figure 1-3, across the many different constraints we’ve called out so far in this chapter. Two key systems (covered in architectural detail in Chapter 2) that are great examples of the value Kubeflow provides beyond Kubernetes are the notebook system in Kubeflow, and Kubeflow Pipelines. We’ll refer back to this diagram several times in the book to contextualize how the parts of Kubeflow interact as a whole to achieve the goals of the DevOps and data science teams.
Kubeflow is a great option for Fortune 500 infrastructure, because it allows a notebook-based modeling system to easily integrate with the data lake ETL operations on a local data lake or in the cloud in a similar way. It also supports multitenancy across different hardware by managing the container orchestration aspect of the infrastructure. Kubeflow gives us great options for a multitenant “lab” environment while also providing infrastructure to schedule and maintain consistent machine learning production workflows in “the factory.”
While teams today can potentially share a server, when we attempt to manage 5 or 10 servers, each with multiple GPUs, we quickly create a situation where multitenancy can become messy. Users end up having to wait for resources, and may also be fighting dependencies or libraries that other users left behind from previous jobs. There is also the difficulty of isolating users from one another so users cannot see each other’s data.
If we have any hope of sustaining a robust data science practice across a cluster of heterogeneous hardware, we will need to use a system like Kubeflow and Kubernetes. Beyond just the obstacles we mention here, machine learning workflows tend to have much technical debt right under the visible surface.
What Problems Does Kubeflow Solve?
The goal of Kubeflow is to simplify the deployment of machine learning workflows to Kubernetes. The issue with using the Kubernetes API directly is that it is too low-level for most data scientists. A data scientist already has to know a number of techniques and technologies without the necessity of adding the complexities of the Kubernetes API to the list.
Wrapping Python machine learning models in containers is how many people start putting initial models into production. From that point, deploying the container on a pod on Kubernetes is a natural next step (as we can see from the market trends). As more machine learning applications are deployed on Kubernetes, this gravity effect tends to pull more of the machine learning work in as well. However, from a DevOps viewpoint, soon you’re implementing a full multitenant data science platform on Kubernetes from scratch.
There are many extra details to worry about, with all of the “glue” code involved in making things like notebook servers and pipelines work consistently and securely as a distributed system. Many times, data science work consists largely of scripts, as opposed to full-fledged applications, and this makes deploying them as a production workflow from scratch that much harder. Beyond just the Kubernetes API, you’d have to also write custom code to integrate different running components and also orchestrate the components for things like workflow orchestration.
Just adding nodes on Kubernetes and expecting them to operate as a cohesive platform doesn’t always go that easily. It is common for organizations to put together automation scripts that will quickly set up a user on a cloud environment, run the set of job or jobs, and then tear down the environment. However, this becomes cumbersome as there can be nontrivial integration issues around Active Directory (user management) or Kerberos, for example.
You want a data scientist to focus on the work of developing, training, testing, and deploying models and less on how to get the Kubernetes API to work in such a way that makes their primary work possible. The issues Kubeflow solves beyond just the core Kubernetes API are:
- Faster and more consistent deployment
- Better control over ports and component access for tighter security
- Protection against over-provisioning resources, saving costs
- Protection against tasks not being deallocated once complete, saving costs
- Workflow orchestration and metadata collection
- Centralized monitoring and logging
- Infrastructure to move models to production, securely and at scale
The name Kubeflow is a portmanteau of Kubernetes and TensorFlow. All three projects originated from teams at Google as open source projects. However, even though Kubeflow started as a way to put TensorFlow workflows and models into production, it has evolved beyond the initial state.
Kubeflow Doesn’t Lock You Into TensorFlow
Your users can choose the machine learning framework for their notebooks or workflows as they see fit.
Today, Kubeflow can orchestrate workflows for containers running many different types of machine learning frameworks (XGBoost, PyTorch, etc.). In some cases, a team may want to use Kubeflow to manage notebook servers for a multitenant environment that may not even focus on machine learning.
A job in Kubeflow can be a Jupyter Notebook or it can be a Python script in a series of pipeline-connected jobs. A job in Kubeflow can also be as simple as running a Python script in a container on a pod in Kubernetes via kubectl. We use notebooks, the CLI, or pipelines to set up machine learning workflows that run a job or a series of jobs to build machine learning models.
For any of these workflows, we use Kubeflow as the infrastructure beyond the low-level Kubernetes API to securely orchestrate heterogeneous machine learning workflows over heterogeneous hardware as managed and scheduled by Kubernetes. Kubeflow is the layer between the user and the Kubernetes API that makes it possible to operate this consistently as a scalable multitenant machine learning platform.
In Chapter 2 we’ll look more closely at the architecture of Kubeflow and its subsystems. We’ll see how the architecture solves specific problems in this space, and how the components fit together to form the machine learning platform solution that is Kubeflow.
Origin of Kubeflow
At Google Next in 2016, Google announced Cloud Machine Learning (Cloud ML) on the Google Cloud Platform (GCP). Cloud ML uses GKE, a precursor to what we know as Kubeflow today. In December 2017 at KubeCon, the initial version of Kubeflow was announced and demoed by David Aronchick and Jeremy Lewi. This version included:
- JupyterHub
- TFJob v1alpha1
- TFServing
- GPUs working on Kubernetes
In January 2018, the Kubeflow Governance Proposal was published to help direct how the community around the project would work. In June 2018, the 0.1 version of Kubeflow was introduced, containing an expanded set of components, including:
- JupyterHub
- TFJob with distributed training support
- TFServing
- Argo
- Seldon Core
- Ambassador
- Better Kubernetes support
Kubeflow version 0.2 was announced only two months later in August 2018, with such advancements as:
The project is still (as of the writing of this book) growing, and Kubeflow continues to evolve. Today the project has expanded such that over 100 engineers are working on it (compared to the 3 at the beginning), with 22 member organizations participating.
Who Uses Kubeflow?
Some of the key enterprise personnel that have the most interest in Kubeflow include:
- DevOps engineers
- Platform architects
- Data scientists
- Data engineers
DevOps and platform architects need to support everyone with the right infrastructure in the right places, cloud or on-premise, supporting the ingest, ETL, data warehouse, and modeling efforts of other teams. Data engineers use this infrastructure to set up data scientists with the best denormalized datasets for vectorization and machine learning modeling. All of these teams need to work together to operate in the modern data warehouse, and Kubernetes gives them a lot of flexibility in how that happens.
Team alignment for the line of business, DevOps, data engineering, and data science
Another challenge for organizations in the space of machine learning infrastructure is how multifaceted the efforts are to build and support these pipelines. As we saw in Figure 1-4, there is a lot of “hidden technical debt” in most machine learning workflows, and the components in these workflows are owned by multiple teams. These teams include:
- Line of business
- The part of the company that intends to use the results of the machine learning model to produce revenue for the organization
- DevOps
- The group responsible for making sure the platform is operational and secure
- Data engineering
- The group responsible for getting data from the system of record (or data warehouse) and converting it into a form for the data science team to use
- Data science
- The team responsible for building and testing the machine learning model
Each of these teams has to work in concert or the business will likely find no value from their individual efforts. Let’s now take a look at some specific scenarios where we might see Kubeflow used for the above teams.
Common Kubeflow Use Cases
Specific scenarios for how we’d use a technology are always critical because otherwise it’s just “more infrastructure to manage.” In this section we’ll look at some specific use cases for how Kubeflow can be used, and how each of the teams from the previous section might be involved.
Running Notebooks on GPUs
Users commonly start out on local platforms such as Anaconda and design initial use cases. As their use cases need more data, more powerful processing, or data that cannot be copied onto their local laptop, they tend to hit roadblocks in terms of advancing their model activities.
We also note that running Jupyter locally gives the user the same experience of running it remotely on Kubeflow, because a local install is a server install just running on the desktop. From that perspective, users enjoy the same user experience from Jupyter Notebooks on their desktop as they do on the Kubeflow notebook platform.
Advantages of notebooks on GPUs
Given that many notebook users start locally on their laptop, this naturally leads us to the question: “why use Kubeflow for hosted notebook infrastructure?” Machine learning, and especially deep learning training algorithms, are notoriously hungry for processing power for their linear algebra routines. GPUs have become the industry standard for speeding up linear algebra processing in machine learning. Most laptops do not have GPUs onboard, so users go looking for places to eventually run their modeling code. A common platform stack on which users have converged is this:
- Jupyter Notebook
- Python code
- Dependency management with containers, typically Docker
These developers are good at getting this stack just how they want it on their laptop. However, operating like this in a Fortune 500 company has side effects such as:
- Security
- Data access
- Driver management
- Model integration
The IT organizations in most Fortune 500 companies take security and data access seriously. The idea of PhDs experimenting with sensitive corporate data on their local laptops conflicts directly with most IT information-security policies, and this creates natural contention in an organization. This contention revolves around the line of business’s need for more value from its data, versus the IT information security’s mandate in keeping key information safe.
Given that companies will not give up their security requirements, we need to find ways to better serve data scientists and how they want to operate, while keeping security policies intact. Kubeflow is a great option for this scenario because it allows a data scientist to keep their preferred working environment, built in a container, to execute in an environment blessed by IT corporate security.
This internal infrastructure can be secured with Active Directory and Kerberos, while providing GPUs (e.g., Nvidia’s DGX-1) and large storage arrays with object stores, proprietary storage (e.g., Pure’s FlashBlade, NetApp’s storage), or HDFS.
Team alignment for notebooks on GPUs
In this scenario, the DevOps team can enable the data scientists to build models faster with Kubeflow. This allows the data scientists to explore more concepts for the line of business faster, and this lets them eliminate poor candidate use cases faster.
If the line of business can validate use cases faster with the data science team, they can find the best fits for the business to make the most money from its data.
Shared Multitenant Machine Learning Environment
Many times, an organization will have either multiple data scientists who need to share a cluster of high-value resources (e.g., GPUs) or they will have multiple teams of data scientists who need the same access to shared resources. In this case, an organization needs to build a multitenant machine learning platform, and Kubeflow is a solid candidate for this scenario.
Often we’ll see organizations buy machines with one or more GPUs attached to specialized hardware such as an Nvidia DGX-1 or DGX-2 (e.g., eight GPUs per machine). This hardware is considerably more costly than a traditional server, so we want as many data scientists leveraging it for model training as possible.
Advantages of on-premise multitenant environment
Each data scientist will have their own model workflow and code dependencies, as described earlier in this chapter. We need a system such as Kubeflow that can execute each user’s workflow while keeping the workflow dependencies and data separate from other user’s work on the same set of resources (e.g., isolation).
Kubeflow and Kubernetes handle these requirements for us with their scheduling and container management functionality. A great example is how we may have three different data scientists all needing to each run their own notebook on a single GPU. Kubernetes with Kubeflow handles keeping track of who is running what code on what machine and which GPUs are currently in use. Kubernetes also keeps track of which jobs are waiting in the job queue, and will schedule the waiting jobs once an in-process job finishes.
Team alignment
Multitenant systems make DevOps teams’ lives far simpler, because they handle a lot of infrastructure complexity for us. DevOps can focus on keeping the Kubernetes cluster and the Kubeflow application operational, which lets us leverage all the benefits of scheduling, container scheduling, and resource management in Kubernetes.
When data scientists have more flexible access to the resources they need (e.g., GPUs), they can build models faster. This in turn allows the line of business to evaluate a data product faster to see if it can be effective enough to be viable for the organization.
Building a Transfer Learning Pipeline
Let’s use a computer vision scenario to better understand how Kubeflow might be deployed to solve a real problem. A realistic example would be a team wanting to get a computer vision transfer learning pipeline working for their team so they can build a custom computer vision model for detecting specific items in a retail store.
The team’s basic plan consists of:
- Getting a basic computer vision model working from the TensorFlow model zoo
- Updating the model with an example dataset to understand transfer learning
- Moving the model training code to Kubeflow to take advantage of on-premise GPUs
The team starts off by experimenting with the object detection example notebook provided in the TensorFlow object detection tutorial. Once they have this notebook running locally, they know they can produce inferences for objects in an image with a pre-built TensorFlow computer vision model.
Next, the team wants to customize a computer vision model from the model zoo with their own dataset, but first they need to get a feel for how transfer learning works in practice. The team checks out the TensorFlow documentation on transfer learning to learn more about building a custom computer vision model.
Once they get the transfer learning example running with the custom dataset, it should not be hard to label some of their own product data to build the annotations needed to further train their own custom computer vision model.
The original flower example shows how to use the notebook on Google Cloud as a Google Colab notebook, but the team wants to leverage a cluster of GPUs they have in their own datacenter. At this point, the team sets up Kubeflow on their internal on-premise Kubernetes cluster and runs the transfer learning notebook as a Jupyter Notebook on Kubeflow. The team had previously built their own custom annotated dataset that they can now use for building models on their own internal Kubeflow cluster.
Advantages of running computer vision pipeline on Kubeflow
The major reasons the team moves their pipeline to Kubeflow are:
- Secure access to sensitive data for multiple users (data that may not be allowed to live on users’ laptops)
- Cost savings by using on-premise GPUs
- Ability for multiple users to share the same cluster of GPUs
The team reasons that in some training scenarios, Kubeflow on-premise can be more cost-effective per GPU-hour than cloud GPUs. They also want to securely control where the core training dataset lives, and they want the ability to allow multiple data scientists to share the same consistent training dataset while trying different variations of models.
Team alignment for computer vision pipeline
This transfer learning scenario on Kubeflow allows the DevOps team to more tightly control who has a copy of the sensitive training data. The line of business has tasked the data science team with building a model that has a mAP score of a minimal level to be economically viable to the business unit.
To accomplish this modeling goal, the data science team needs to try many variations of hyperparameters and feature selection passes (in concert with the data engineering team) to drive up their model’s effectiveness. The faster the data science team can train models, the more variations of training runs the team can try. In the case of deep learning and computer vision, GPUs make training runs take significantly less time, so these are a key resource for the data science team.
The business unit wants to hit their target minimum model effectiveness goal but they have to do so within a budget. Using Kubeflow on-premise with GPUs is a cheaper way to build models for the data science team, so costs end up being lower. The cost is forecasted as cheaper by the business unit because the data science team forecasts that they will need to model many times a week for a long period of time.
GPUs in the Cloud
GPUs in the cloud give us more flexibility than GPUs on-premise because we can spin them up ad hoc, on demand, making it more convenient to try new ideas.
However, this convenience may cost more than if we bought a GPU and used it locally all of the time.
The cost versus flexibility trade-off is something we should always keep in mind when deciding where to run our jobs.
Using Kubeflow on-premise with GPUs also allows the data science team to model faster, while running multiple computer vision jobs on the cluster at the same time, under the multitenant nature of the system.
Deploying Models to Production for Application Integration
Once a model is trained, it typically exists as a single file on a laptop or server host. We then need to do one of the following:
- Copy the file to the machine with the application for integration.
- Load the model into a server process that can accept network requests for model inference.
If we choose to copy the model file around to a single application host, then this is manageable. However, when we have many applications seeking to get model inference output from a model this becomes more complex.
One major issue involves updating the model once it has been deployed to production. This becomes more work as we need to track the model version on more machines and remember which ones need to be updated.
Another issue is rolling back a model once deployed. If we have deployed a model and then realize that we need to roll the version back to the previous model version, this is a lot of work when we have a lot of copies of the model floating around out there on different hosts. Let’s now take a look at some advantages if we use a model hosting pattern for deploying a model to production with Kubeflow.
Advantages of deploying models to production on Kubeflow
A major advantage of having a machine learning model loaded in a model server on Kubeflow is that we can do updates and rollbacks from a single point (e.g., the server process). This allows us to treat a model more like a database table, in that we can apply operations to the model, and then all of the consuming client applications get the updates as soon as the update transaction is complete and they make their next inference request.
Team alignment for model deployment
The model server pattern makes life for the DevOps team considerably easier as they don’t have to manually track many model copies. The application engineering team can focus on consuming the model as an internal REST resource on the network, and less on writing specific machine learning API code to integrate a model.
Once the data science team has developed models that the line of business wishes to put into production, the model server pattern allows them to hand the model to the DevOps team to put into production on the model server. This allows the data science team to get out of having to support individual models in production and focus on building the next round of models with the lines of business.
Components of Kubeflow
The logical component groupings of Kubeflow are:
- ML tools
- Applications and scaffolding
- Platforms/clouds
The relationships among the component groups can be seen in Figure 1-5.

Figure 1-5. Kubeflow platform overview (source: Kubeflow documentation)
These components work together to provide a scalable and secure system for running machine learning jobs (notebook-based jobs and also jobs outside of notebooks).
Given the rise of Kubernetes as an enterprise platform management system, it makes a lot of sense to have a way to manage our machine learning workloads in a similar manner. In the rest of this section we take a look at each of the component groups, some of their components, and how they are used within the Kubeflow platform.
Machine Learning Tools
Many machine learning frameworks are supported by Kubeflow. In theory, a user could just containerize an arbitrary framework and submit it to a Kubernetes cluster to execute. However, Kubeflow makes Kubernetes clusters aware of the execution nuances that each machine learning library expects or needs to do, such as parallel training on multiple Kubernetes nodes, or using GPUs on specific nodes.
The current training frameworks supported by Kubeflow are:
- TensorFlow
- XGBoost
- Keras
- scikit-learn
- PyTorch
- MXNet
- MPI
- Chainer
Next, we’ll give a brief overview about a few frameworks and how they’re used.
TensorFlow training and TFJob
TensorFlow is supported by Kubeflow and is the most popular machine learning library in the world today. Being that TensorFlow, Kubernetes, and Kubeflow were all created originally at Google, it makes sense that it was the original library supported by Kubeflow.
As we mentioned, TFJob is a custom component for Kubeflow which contains a Kubernetes custom resource descriptor (CRD) and an associated controller (tf-operator). The TFJob CRD is what enables Kubernetes to execute distributed TensorFlow jobs. The TFJob controller (tf-operator) is part of the supporting applications and scaffolding included in Kubeflow to enable machine learning libraries on Kubernetes.
Check out the Kubeflow documentation page on TensorFlow.
Keras
Keras is supported in the Kubeflow project and can be used in several ways:
- Single-process job run as a custom resource definition (CRD)
- Single-process GPU job run as a CRD
- TFJob as a single-worker job
- TFJob as a distributed-worker job (via the Estimator API)
- Jupyter Notebook (CPU or GPU)
- Kubeflow Pipelines–configured job
Many times, a user may just want to understand how to quickly get a job on the cluster. In Example 1-1, we show the simplest way to run a Keras job on Kubernetes as a job from the command line with kubectl.
Example 1-1. Job example YAML to run a Keras Python script
apiVersion: batch/v1 kind: Job metadata: name: keras-job spec: template: spec: containers: - name: tf-keras-gpu-job image: emsixteeen/basic_python_job:v1.0-gpu imagePullPolicy: Always volumes: - name: home persistentVolumeClaim: claimName: working-directory restartPolicy: Never backoffLimit: 1
In the preceding example, Kubernetes would pull the container image from the default container repository and then execute it as a pod on the Kubernetes cluster.
In this example, we’re skipping all the other more complex ways of using Kubeflow and running the Keras script as a simple and direct Kubernetes pod. However, when we do this, we lose the advantages of Kubeflow around workflow orchestration and metadata collection.
The Case for Kubeflow Over Just Kubernetes
Without workflow orchestration and metadata tracking, we lose the ability to reliably and consistently execute machine learning workflows and understand how they are performing as we change our training code.
Example 1-1 shows that while you can run simple machine learning scripts easily on Kubernetes, Kubeflow provides further value on top of Kubernetes that may not be immediately recognized.
Applications and Scaffolding
Managing machine learning infrastructure under all of the constraints and goals we’ve described in this chapter is a tall mountain to climb. Kubeflow provides many subapplications and scaffolding components to help support the full machine learning workflow experience.
Some of the “scaffolding” components that are “under the hood,” from the perspective of most users, include:
- Machine learning framework operators
- Metadata
- PyTorch serving
- Seldon Core
- TensorFlow Serving
- Istio
- Argo
- Prometheus
- Spartakus
Many of the above components are never used directly by a normal user, but instead support core functionality in Kubeflow. For example, Istio supports operations of the Kubeflow distributed microservice architecture by providing functionality such as role-based access control (RBAC) for network endpoints and resources. Argo provides continuous integration and deployment functionality for Kubeflow. Prometheus provides systems in Kubeflow with monitoring of components, and the ability to query for past events in monitoring data.
In the following subsections we’ll take a closer look at some of the key applications and components in Kubeflow.
Kubeflow UI
The Kubeflow UI is the central hub for a user’s activity on the Kubeflow platform. We can see the main screen of Kubeflow in Figure 1-6.
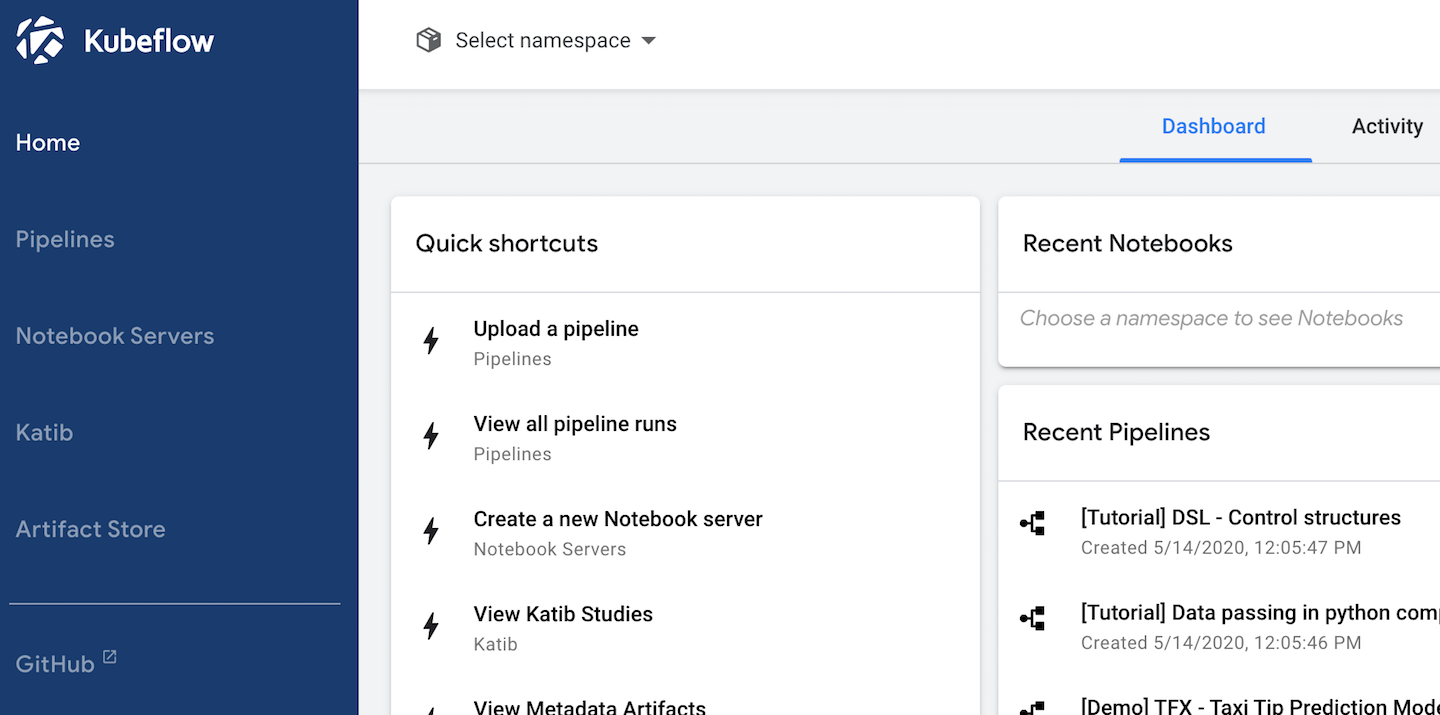
Figure 1-6. The Kubeflow UI
From the Kubeflow UI we can visually performs tasks such as creating Pipelines, running hyperparameter optimization jobs with Katib, and launching Jupyter Notebook servers.
Jupyter Notebooks
Jupyter Notebooks are included with the Kubeflow platform as a core component. These notebooks are popular due to their ease of use and are commonly associated (in machine learning especially) with the Python programming language. Notebooks typically contain code (e.g., Python, Java) and other visual rich-text elements that mimic a web page or textbook.
A novel aspect of notebooks is that they combine the concept of a computer program with the notes we typically associate with complex logic in our programs. This in-line documenting property allows a notebook user a better way to not only document what they’re doing but to communicate it better to other users that may want to run our code. Given the complexity of machine learning code, this property has been part of the reason we see their explosive popularity in the machine learning space.
Jupyter Notebook integration with Kubeflow
The Kubeflow application deployment includes support for spawning and operating Jupyter Notebooks. Advantages of having Jupyter Notebooks integrated into the Kubeflow platform include:
- Good integration with the rest of the Kubeflow infrastructure from the point of view of authentication and access control
- Ability to share notebooks between users
Notebooks and Fairing
Jupyter Notebooks in Kubeflow also have access to the Fairing library, enabling the notebooks to submit training jobs to Kubernetes from the notebook. This is compelling, because code in a Jupyter Notebook only uses the default single process execution mode. The ability to submit jobs to Kubernetes from the notebook allows us to leverage TFJob to run distributed training jobs.
Sometimes we want separate notebook servers for each user or for a team. Kubeflow allows us to set up multiple notebook servers for a given Kubeflow deployment. Each notebook server belongs to a namespace, and can serve and execute multiple notebooks. Namespaces in Kubeflow also give us multiuser isolation. This means we can have multiple sets of users who can’t see one another’s resources so that they don’t clutter one another’s workspaces on the shared multitenant infrastructure.
Kubeflow will launch a container image on Kubernetes for each notebook server. The notebook image containers dependencies such as the libraries for ML and CPU or GPU support in the notebook.
Operators for machine learning frameworks
Each supported machine learning framework on Kubeflow has an associated controller (e.g., tf-operator). For example, the TFJob CRD is what makes Kubernetes able to execute distributed TensorFlow jobs. The TFJob controller (tf-operator) is part of the supporting applications and scaffolding Kubeflow includes to enable machine learning libraries on Kubernetes.
Metadata and artifacts
The metadata component in Kubeflow helps users track and manage their ML workflows by collecting and storing the metadata produced by workflows. The information collected about a workflow by the metadata system in Kubeflow includes executions, models, datasets, and other artifacts. Kubeflow defines artifacts in this context as the objects and files that form the inputs and outputs of the components in a machine learning workflow, which we discuss further in Chapter 2.
Once code is run that has the kubeflow-metadata API collecting metadata for a workflow, you can go to the Artifacts tab in your Kubeflow UI and see the metadata collected per execution run, as seen in Figure 1-7.
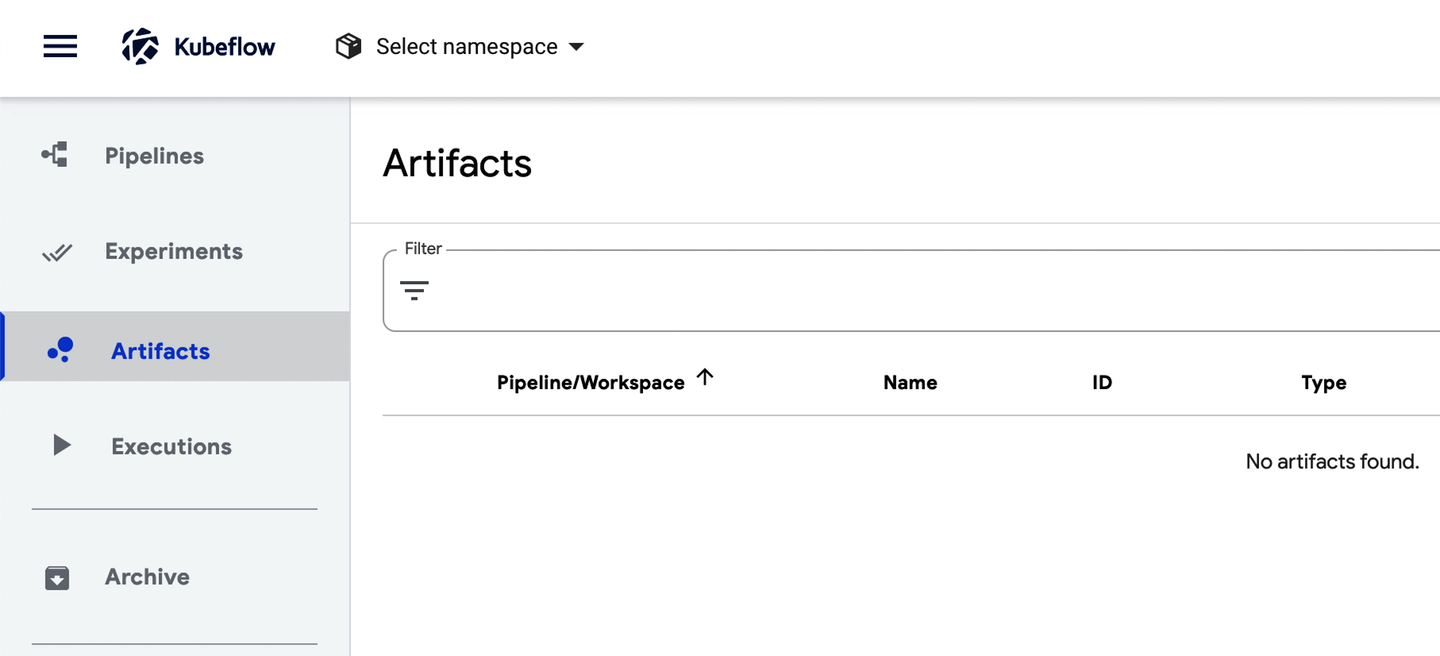
Figure 1-7. The Artifact tab page in the Kubeflow UI
Hyperparameter tuning
Hyperparameter tuning involves exploring the hyperparameter search space to find an optimal (or near optimal) set of hyperparameters for training a machine learning model. Data scientists spend a nontrivial amount of time trying combinations of hyperparameters, and seeing how much more accurate their model can be as a result.
The included hyperparameter search application with Kubeflow is called Katib. Katib, originally inspired by an internal Google system named Vizier, was focused on being machine learning framework agnostic. It lets us create a number of experiments to test trials for hyperparameter evaluation. Currently, Katib supports exploration algorithms such as random search, grid search, and more.
Pipelines
Kubeflow Pipelines allows us to build machine learning workflows and deploy them as a logical unit on Kubeflow to be run as containers on Kubernetes. While many times we see machine learning examples in a single Jupyter Notebook or Python script, machine learning workflows are typically not a single script or job.
Previously in this chapter we introduced Figure 1-8, from “Hidden Technical Debt in Machine Learning.”
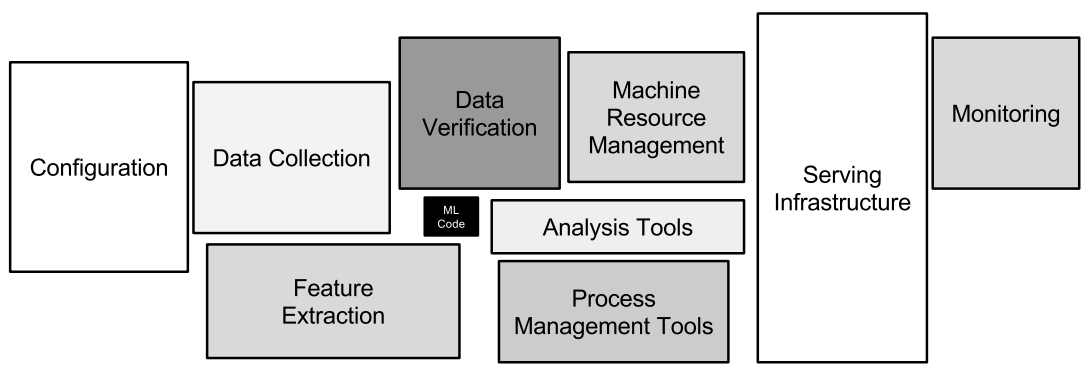
Many of the boxes in this diagram end up as their own subworkflows in practice in a production machine learning system. Examples of this can be seen in how data collection and feature engineering each may be their own workflows built by teams separate from the data science team. Model evaluation is another component we often see performed as its own workflow after the training phase is complete.
Kubeflow Pipelines (see Figure 1-9) simplify the orchestration of these pipelines as containers on Kubernetes infrastructure. This gives our teams the ability to reconfigure and deploy complex machine learning pipelines in a modular fashion to speed model deployment and time to production.
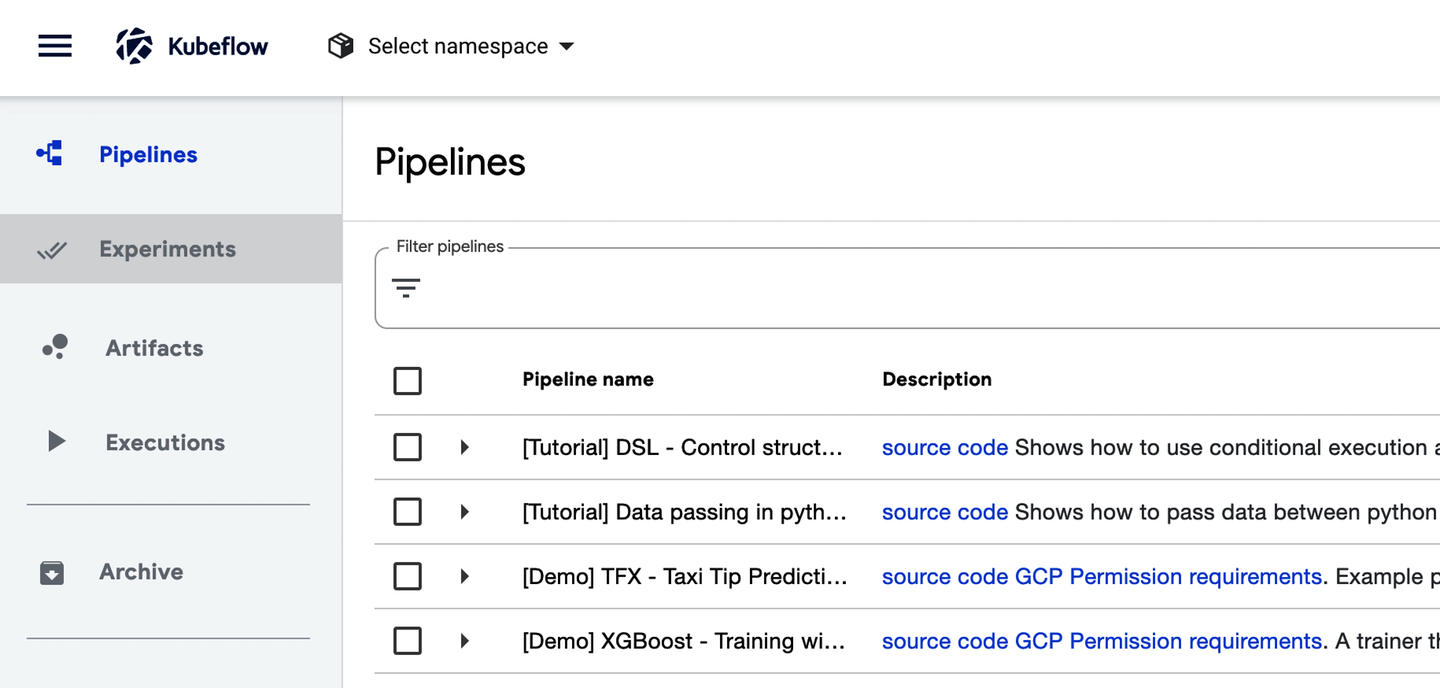
Figure 1-9. Pipeline user interface
Basic Kubeflow Pipeline concepts
A Kubeflow Pipeline is a directed acyclic graph (DAG) representing all of the components in the workflow. Pipelines define input parameter slots required to run the pipeline, and then how each component’s output is wired as input to the next stage in the graph.
A pipeline component is defined as a Docker image containing the user code and dependencies to run on Kubernetes. In Example 1-2 we can see a pipeline definition example in Python.
Example 1-2. Kubeflow Pipeline defined in Python
@dsl.pipeline(
name='XGBoost Trainer',
description='A trainer that does end-to-end distributed training for XGBoost models.'
)
def xgb_train_pipeline(
output,
project,
region='us-central1',
train_data='gs://ml-pipeline-playground/sfpd/train.csv',
eval_data='gs://ml-pipeline-playground/sfpd/eval.csv',
schema='gs://ml-pipeline-playground/sfpd/schema.json',
target='resolution',
rounds=200,
workers=2,
true_label='ACTION',
):
delete_cluster_op = DeleteClusterOp('delete-cluster',
project, region).apply(gcp.use_gcp_secret('user-gcp-sa'))
with dsl.ExitHandler(exit_op=delete_cluster_op):
create_cluster_op = CreateClusterOp('create-cluster', project, region,
output).apply(gcp.use_gcp_secret('user-gcp-sa'))
analyze_op = AnalyzeOp('analyze', project, region, create_cluster_op.output, \
schema,
train_data, '%s/{{workflow.name}}/analysis' % \
output).apply(gcp.use_gcp_secret('user-gcp-sa'))
transform_op = TransformOp('transform', project, region, create_cluster_op.output,
train_data, eval_data, target, analyze_op.output,
'%s/{{workflow.name}}/transform' % \
output).apply(gcp.use_gcp_secret('user-gcp-sa'))
train_op = TrainerOp('train', project, region, create_cluster_op.output, \
transform_op.outputs['train'],
transform_op.outputs['eval'], target, analyze_op.output, workers,
rounds, '%s/{{workflow.name}}/model' % \
output).apply(gcp.use_gcp_secret('user-gcp-sa'))
...
If we look at this graph in the Pipelines UI in Kubeflow, it would look similar to Figure 1-10.
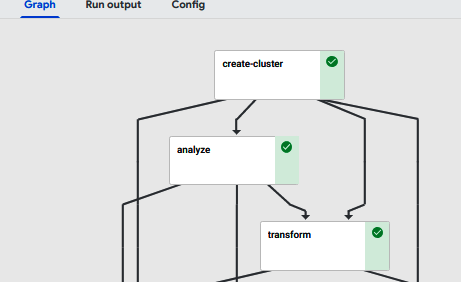
Figure 1-10. Visualization in Kubeflow of a pipeline
The Kubeflow Pipelines UI further allows us to define input parameters per run and then launch the job. The saved outputs from the pipeline include graphs such as a confusion matrix and receiver operating characteristics (ROC) curves.
Kubeflow Pipelines produce and store both metadata and artifacts from each run. Metadata from pipeline runs are stored in a MySQL database, and artifacts are stored in an artifact store such as MinIO server or a cloud storage system. Both MinIO and MySQL are both backed by PersistentVolumes (PV) in Kubernetes.
The metadata saved allows Kubeflow to track specific experiments and jobs run on the cluster. The artifacts save information so that we can investigate an individual job’s run performance.
Machine Learning Model Inference Serving with KFServing
Once we’ve constructed a model, we need to integrate the saved model with our applications. Kubeflow offers multiple ways to load saved models into a process for serving live model inference to external applications. These options include:
- KFServing
- Seldon Core Serving
- BentoML
- Nvidia Triton Inference Server
- TensorFlow Serving
- TensorFlow Batch Prediction
The preceding different options support different machine learning libraries, and have their own sets of specific features. Typically, each has a Docker image that you can run as a Kubernetes resource and then load a saved model from a repository of models.
KFServing was designed so that model serving could be operated in a standardized way across frameworks right out of the box. There was a need for a model serving system that could easily run on existing Kubernetes and Istio stacks, and also provide model explainability, inference graph operations, and other model management functions. Kubeflow needed to allow both data scientists and DevOps/MLOps teams to collaborate from model production to modern production model deployment.
KFServing’s core value can be expressed as:
- Helping to standardize model serving across orgs with unified data-plane and pre-built model servers
- A single way to deploy, monitor inference services/server, and scale inference workload
- Dramatically shortens time for the data scientist to deploy model to production
In some cases, a framework-specific inference server (e.g., TensorFlow Serving) may have specialized features for an associated framework.
Many teams, however, will use different frameworks and will need more flexibility for their model inference serving infrastructure. In this case you should consider KFServing or Seldon Core, as described earlier. In Chapter 8 we cover KFServing in detail, from the core concepts involved in deploying a basic model on KFServing, to building custom model servers for model deployment on KFServing.
Platforms and Clouds
Kubeflow has the flexibility to be deployed anywhere that Kubernetes can be deployed, from a major public cloud, to an on-premise Kubernetes cluster, and also a local single-node Kubernetes deployment on a single machine.
Public clouds
Given that all three major cloud vendors support both managed Kubernetes and then the ability to deploy Kubernetes manually on VMs, Kubeflow can be deployed on any of the major clouds, including:
- Google Cloud Platform (GCP)
- Amazon Web Services (AWS)
- Azure Cloud Platform
Later chapters dig into the specifics of the installation and configurations of each of these clouds. We’ll also inform you about what each major cloud offers and how it integrates with the managed Kubernetes offering for the cloud. This will give you a solid view of how appropriate your preferred cloud is for running their Kubernetes and Kubeflow infrastructure.
Installing Kubeflow on a public cloud requires a few things, including:
- Understanding how the cloud vendor integrates with your own infrastructure
- Making sure it’s the right version of Kubernetes (and other subcomponents) for your organization
- Security integration themes
Beyond vendor dogmatic themes, a dominant narrative in infrastructure is how a system can be integrated as legacy momentum in enterprise infrastructure. When executed well, this narrative produces consistent value for any enterprise.
Managed Kubernetes in the cloud
As mentioned previously in this chapter, all three major clouds offer an open source-compatible version of managed Kubernetes:
- Google Kubernetes Engine (GKE)
- Azure Kubernetes Services (AKS)
- Amazon Kubernetes Engine (AKE)
Each system has similarities and differences in how we install and integrate Kubeflow. There are, of course, variations in how to do a Kubeflow installation for every cloud, such as:
- Storage types and strategies
- Identity setup and management
- Container management strategies
- ETL pipeline integration
- Planning infrastructure and modeling cost
Over the course of this book we will introduce you to the core concepts for each cloud offering, and then show how to install Kubeflow specifically for each of the cloud platforms.
On-premise
Kubeflow is supported as deployed on an on-premise Kubernetes cluster. The major differences between Kubeflow on an on-premise cluster and Kubeflow on a major cloud is that an on-premise cluster will have more limitations on how much you can scale resources dynamically. However, an on-premise cluster is not billable by the hour, so there is certainly a trade-off every organization must make.
As we’ll see throughout this book, there are also different strategies for identity integration for on-premise Kubernetes versus cloud Kubernetes.
Local
In some cases—mainly testing, development, and evaluation—a user may want to run Kubeflow on a local machine or VM. In this case you can either use VMs to set up a small Kubernetes cluster locally, or you could try a pre-built single-node Kubernetes system such as Minikube.
Running Kubeflow Locally Can Take a Lot of Resources
Typically, a Kubeflow on Minikube deployment needs at least 12 GB of memory and 4 CPUs allocated for Minikube. You should also consider how many resources your computer will need, in addition to these requirements, to normally operate.
In Chapter 8 we take you through an exercise in deploying KFServing standalone on Minikube locally to test out model deployment.
Summary
In this introductory chapter we covered the impetus for Kubeflow as a machine learning platform. As we move forward through this book, we’ll come to understand how to plan, install, maintain, and develop on the Kubeflow platform as a key cornerstone in our machine learning infrastructure. In the next chapter, we’ll take you through the security fundamentals and architecture of Kubeflow to set up the operations content for the rest of the book.
Get Kubeflow Operations Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

