Kapitel 4. So groß musst du sein
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Der Satz "Du musst so groß sein, um mitfahren zu können" steht häufig auf Schildern in Vergnügungsparks und auf Rummelplätzen, um die Menschen über die Mindestgröße für bestimmte Fahrgeschäfte zu informieren. Die Schilder dienen nicht der Kontrolle, sondern der Sicherheit. Martin Fowler hat diese Metapher in seinem Artikel über die Voraussetzungen für eine Microservices-Architektur verwendet. Genauso kannst du dir dieses Kapitel als das "Du musst so groß sein"-Schild vorstellen, das dir dabei helfen kann, herauszufinden, ob es für dein Team sicher ist, sich auf die rasante Fahrt der kontinuierlichen Bereitstellung einzulassen. Insbesondere beschreibe ich eine Liste von sicherheitsrelevanten Praktiken, die Teams umsetzen sollten, bevor sie zu einer vollständig automatisierten Pipeline wechseln.
Wenn jeder Commit ohne manuelles Eingreifen in die Produktion geschickt wird, kann das natürlich zu Problemen führen. Kritische Defekte, die durch unzureichende Qualitätssicherungen schlüpfen, können Unternehmen viel Geld kosten und die Stakeholder dazu verleiten, den Freigabeprozess übermäßig zu verkomplizieren (und die Produktion stark zu überwachen). Deshalb liegt es in unserer Verantwortung als Softwareexperten, sorgfältig zu prüfen, ob unsere Teams bereit sind, und wenn sie es nicht sind, Continuous Deployment in den Kontext einer größeren Reise zur Reife von Continuous Delivery zu stellen. Ziel dieser Reise sollte es sein, eine technische und organisatorische Grundlage zu schaffen, die es Menschen aller Erfahrungsstufen ermöglicht, an einem schnellen Bereitstellungslebenszyklus teilzunehmen.
In diesem Kapitel geht es nicht darum, zu erklären, wie man Entwicklerfehler verhindern kann. Wir sollten akzeptieren, dass Entwickler/innen Menschen sind, die schlechte Tage haben und dass Fehler passieren werden. Wir sollten uns darauf konzentrieren, Fehler frühzeitig zu erkennen und sie schnell zu beheben, anstatt zu versuchen, die absolute Perfektion der Entwickler zu erreichen, denn das ist ein unerreichbarer (und ungerechter) Standard. Stattdessen können wir uns bemühen, ein Sicherheitsnetz aus Praktiken und Automatisierung zu schaffen, das es erlaubt, fehlzuschlagen und sich leicht zu erholen. Deshalb werden wir über Werkzeuge für kontinuierliches Feedback wie häufige Integration, gründliche Tests, Code-Scanning und Beobachtbarkeit sprechen. An der Beherrschung dieser sicherheitsrelevanten Praktiken sollten wir die Leistung unserer Teams messen und nicht an gelegentlichen Fehlern.
Nachdem ich nun diesen Haftungsausschluss formuliert habe, wollen wir uns die Praktiken selbst genauer ansehen. Die meisten von ihnen sind etablierte Praktiken der kontinuierlichen Bereitstellung, die wir nur kurz auffrischen, während andere erst in jüngerer Zeit entstanden sind und für die kontinuierliche Bereitstellung besonders wichtig sind. Diese Liste wird unweigerlich unvollständig sein, und es kann sein, dass neue innovative Techniken auftauchen, nachdem dieses Buch veröffentlicht wurde. Nichtsdestotrotz wollen wir sie als Ausgangspunkt nehmen.
Funktionsübergreifende, autonome Teams
Silo-Teams sind in der Regel nach bestimmten Rollen oder Disziplinen organisiert, z. B. Entwicklung, Test oder Design. Ein funktionsübergreifendes Team hingegen besteht aus Mitgliedern mit unterschiedlichen Fähigkeiten und sollte alle Rollen umfassen, die für die Bereitstellung des Produkts als Ganzes erforderlich sind (siehe Abbildung 4-1). Dazu können Infrastruktur-, Frontend- und Backend-Fähigkeiten gehören, aber auch Tests, Sicherheit, Design und Projektmanagement.
Abbildung 4-1. Silo-Teams (links) versus funktionsübergreifende Teams (rechts)
Funktionsübergreifende Teams haben im Vergleich zu isolierten Teams mehrere Vorteile: engere Zusammenarbeit zwischen den Rollen, höhere Geschwindigkeit und weniger organisatorische Reibung sind die wichtigsten. Wenn ein Produktteam wirklich funktionsübergreifend ist, hat es auch mehrere Qualitäten, die kontinuierliche Bereitstellung ermöglichen.
Schnelle Entscheidungsfindung
Die größte Voraussetzung für eine schnelle Umsetzung ist, dass funktionsübergreifende Teams spontan und flexibel handeln können, ohne dass sie andere in ihre Entscheidungen einbeziehen müssen. Ihr Entscheidungsfindungsprozess ist in sich abgeschlossen, so dass sie sich schnell an veränderte Anforderungen anpassen können, ohne dass sie über die Teamgrenzen hinausgehen müssen, um eine Änderung umzusetzen.
Ein Team, das kontinuierlich kleine Inkremente für die Produktion bereitstellt, muss in der Lage sein, mit dem schnellen Tempo der Änderungen umzugehen, die mit einer sehr kurzen Feedbackschleife einhergehen. Beim Continuous Deployment werden täglich oder sogar mehrmals täglich neue Code-Updates für die Nutzer veröffentlicht. Das erfordert ein hohes Maß an Anpassungsfähigkeit, denn das Team muss in der Lage sein, schnell auf Richtungsänderungen und mögliche Fehlerbehebungen zu reagieren.
Ein Team, das auf Unterstützung oder Zustimmung von außen angewiesen ist, kann seine externen Mitarbeiter/innen schnell überfordern (oder verärgern), wenn es anfängt, viele Male am Tag zu veröffentlichen. Je mehr das Team sein Ziel erreicht, häufig zu veröffentlichen, desto mehr wird es die Außenstehenden verärgern, was nicht im Sinne des Teams ist.
Autonomie bei der Umsetzung
Ein wirklich funktionsübergreifendes Team ( ) sollte alle technischen Fähigkeiten besitzen, die für die Erstellung und Bereitstellung der Anwendung erforderlich sind. Continuous Deployment (oder sogar Continuous Delivery) funktioniert nicht gut mit reinen Backend-, Frontend- oder Infrastrukturteams, weil die Bereitstellung oft die komplexen Abhängigkeiten zwischen all diesen Softwarekomponenten aufdecken kann. Änderungen an einem Teil des Systems erfordern oft entsprechende Änderungen an einem anderen Teil, um sicher ausgerollt werden zu können, und andersherum. Und wenn kleine Änderungen einzeln in die Produktion übernommen werden, ist es wichtig, ständige Blockaden durch Teamgrenzen zu vermeiden, die dazu führen würden, dass große Mengen an laufender Arbeit stecken bleiben.
Feature Flags und Expand and Contract sind zum Beispiel besonders verbreitete Coding-Techniken beim Continuous Deployment. Sie erfordern, dass die Entwickler Provider- und Consumer-Systeme in schneller Folge aktualisieren, um die Stabilität der Produktionsumgebung zu gewährleisten. Wären die Teams nach Tech Stack oder bestimmten Teilen des Systems getrennt, wäre die Koordination dieser Änderungen schwierig: Die Teams haben naturgemäß unterschiedliche Backlogs mit unterschiedlichen Prioritäten und müssten oft aufeinander warten, anstatt an Features zu arbeiten.
Insgesamt ist das ideale Team, das Continuous Deployment praktiziert, eines, das alle Rollen und technischen Fähigkeiten enthält, die für die Betreuung eines vertikalen Teils des Unternehmens notwendig sind: ein Produktteam. Das funktioniert besonders gut in Microservices-orientierten Architekturen, in denen die Produkte sowohl technisch als auch organisatorisch voneinander getrennt sind.
Funktionsübergreifende Teams zu haben, bedeutet nicht, dass jedes Team gleich aussehen sollte oder dass es keinen Platz mehr für spezialisierte Teams gibt. In ihrem Buch Team Topologies,1 Matthew Skelton und Manuel Pais vier Kategorien von Teams, von denen einige hoch spezialisiert sind:
- Stream-aligned Team
Wie der Name schon sagt, ist ein Stream-aligned Team auf einen bestimmten Arbeitsstrom (oder Bereich) ausgerichtet. Diese Art von Team ist dafür verantwortlich, den Kunden durch neue benutzerorientierte Funktionen und Verbesserungen schnell einen Mehrwert zu bieten.
- Ermöglichungsteam
Ein "Enabling Team" unterstützt Teams, die auf einen Strom ausgerichtet sind, indem es Fachwissen und Werkzeuge zur Verfügung stellt. Es kann anderen Teams zum Beispiel helfen, neue Praktiken oder Technologien einzuführen oder komplexe Probleme zu lösen.
- Kompliziert-Subsystem-Team
Dieser Typ von Team arbeitet an komplexen Teilsystemen, die tiefes technisches Wissen erfordern, z.B. solche, die Fachwissen in Berechnung oder Mathematik erfordern.
- Plattform-Team
Ein Plattformteam erstellt und pflegt eine Reihe von internen Produkten und Tools, die andere Teams nutzen können, um ihre Arbeit zu beschleunigen, in der Regel solche, die im Selbstbedienungsmodus genutzt werden können.
Jedes dieser Teams hat ein bestimmtes Spezialgebiet, sei es ein Geschäftsfeld, eine bestimmte Technologie oder eine komplexe Problemstellung. Und jedes dieser Teams könnte auch seine eigenen Produkte pflegen, egal ob sie nach außen oder nach innen gerichtet sind. Diese Produkte sind alle potenzielle Kandidaten für eine kontinuierliche Bereitstellung. Voraussetzung für die kontinuierliche Bereitstellung dieser Produkte ist jedoch, dass das Team innerhalb seines Fachgebiets (welches auch immer das sein mag) über alle erforderlichen Fähigkeiten verfügt, um sie zu entwickeln und bereitzustellen. Das bedeutet volle Autonomie und Beherrschung des gewählten Software-Stacks, von Anfang bis Ende.
In einer der Fallstudien in diesem Buch beschreibt Tom Vollerthun von OTTO zum Beispiel ausführlich, wie sein Unternehmen die Rolle der Qualitätssicherung von einem Gatekeeping-Team auf einzelne QA-Ingenieure als Mitglieder von Produktteams übertragen hat. Dies war ein entscheidender Faktor für die Einführung von Continuous Deployment bei OTTO, und ich empfehle dir, seine Fallstudie zu lesen, um zu verstehen, wie das Unternehmen dies erreicht hat.
Häufige Integration
Wie ich in den Kapiteln 1 und 2 erläutert habe, ist die häufige Integration von Code das Rückgrat der kontinuierlichen Integration und auch die Grundlage für die kontinuierliche Bereitstellung und das Deployment. In der Praxis bedeutet das, dass wir unsere Code-Änderungen mindestens einmal am Tag (oder mehrmals am Tag) in den gemeinsamen Mainline-Zweig des Teams integrieren. Durch die häufige Integration bleiben die Änderungsdeltas klein und überschaubar - ein Prinzip, das unbedingt befolgt werden muss, wenn es in einer Vorproduktionsumgebung keine manuelle Überprüfung gibt.
Tausende von geänderten Zeilen auf unseren Entwicklungsmaschinen oder in einem Zweig zu horten, nur um sie dann auf einmal in die Produktion zu schicken, kann zu Chaos führen und Nutzer, Interessengruppen und den Rest des Teams stören. Deshalb ist es wichtig, dass sich alle Teammitglieder auf eine Code-Commit-Etikette einigen, die Änderungen klein hält und sie häufig in die Produktion einfließen lässt.
Zu einer guten Commit-Etikette mit Continuous Deployment sollten auch Werkzeuge gehören, die den Versionsverlauf leicht verständlich machen: Zusammenfassen von voneinander abhängigen Commits, häufiges Rebasing, um schnelle Merges zu ermöglichen, und aussagekräftige Commit-Nachrichten mit einer Aufgabenkennung und Co-Autoren. All diese kleinen Maßnahmen ermöglichen es dem Team, sich Klarheit darüber zu verschaffen, welche Code-Änderungen mit welchem Produktionseinsatz verbunden sind.
Das wichtigste Werkzeug, um unser Verständnis dessen, was eingesetzt wird, zu verbessern, ist jedoch in erster Linie die häufige Integration. Es gibt zwei Möglichkeiten, wie moderne Softwareteams dies erreichen: (sehr) kurzlebige Zweige und stammbasierte Entwicklung (TBD). Beide sind mit einer kontinuierlichen Bereitstellungsstrategie vereinbar, obwohl TBD aufgrund seiner Einfachheit definitiv der Favorit ist.
Kurzlebige Zweige
Mit kurzlebigen Zweigen kann ein Entwickler einfach einen neuen Zweig neben dem Hauptzweig erstellen, seine Änderungen vornehmen und dann einen Pull Request (PR) einreichen, um die Änderungen direkt wieder einzubinden, wenn er der Meinung ist, dass seine Arbeit in sich abgeschlossen genug ist. Sobald die Änderungen geprüft und genehmigt wurden, können sie in den Hauptzweig eingefügt und in Produktion gegeben werden. Dies bietet einen optionalen Kontrollpunkt für Codeüberprüfungen. Damit ein Zweig als "kurzlebig" bezeichnet werden kann, sollte die Entwicklung eines großen Features normalerweise die Lebensdauer eines offenen Zweigs überdauern, und die Entwickler müssen während der Entwicklung mehrmals in den Hauptzweig zurückkehren. Aus diesem Grund sollten kurzlebige Zweige zusammen mit anderen Techniken zum Verbergen von laufenden Arbeiten verwendet werden, die nicht auf Versionskontrolle beruhen, wie z. B. Feature Toggles.
Nicht alle Zweige sind gleich. Es ist wichtig, sich daran zu erinnern, dass kurzlebige Zweige für kleine, gezielte Aufgaben gedacht sind und nicht für langfristige Entwicklungsarbeiten oder ganze Funktionen verwendet werden sollten. Idealerweise sollten sie nicht länger als einen Tag bestehen. Kurzlebige Zweige stehen im direkten Gegensatz zu Feature-Zweigen, auch wenn die beiden in unseren Versionskontrollsystemen gleich aussehen mögen.
Kurzlebige Zweige versus Funktionszweige
Langlebige Feature-Zweige sind bei der kontinuierlichen Integration eher unüblich. Sie sind typisch für Entwicklungsworkflows wie Gitflow, die darauf abzielen, die Änderungen ganzer Initiativen bis zur Produktionsreife voneinander zu trennen. Solche Workflows führen zu einer engen Kopplung zwischen dem Freigabeprozess und der Funktionalität des Versionskontrollsystems und verhindern den Einsatz modernerer Techniken wie Feature Flags.
Es muss eingeräumt werden, dass Modelle wie Gitflow bemerkenswert gut für Open-Source-Projekte auf Kollaborationsplattformen wie GitHub funktionieren, wo Entwickler über längere Zeiträume zusammenarbeiten und die Kommunikation von Natur aus asynchron ist. In einem zusammenhängenden Team mit Echtzeit-Kommunikationskanälen bringen lange Funktionszweige jedoch mehr Aufwand als Nutzen. Im Gegenteil, sie sind sogar eher störend. Sie ermutigen dazu, dass der Code deutlich von der Produktion abweicht und sich zu großen, schmerzhaften Stapeln anhäuft, die zu chaotischen Merges und heiklen Releases führen.
Viele Teams nutzen erfolgreich kurzlebige Funktionszweige mit kontinuierlichem Deployment, aber das erfordert ein hohes Maß an Disziplin und kontinuierlicher Integrationsreife, um nicht in langlebige Funktionszweige auszuarten. Es genügt, wenn ein Entwickler der Trägheit verfällt und die Integration für ein oder zwei Tage vergisst, und schon sammelt ein Zweig so viele Änderungen an, dass er nicht mehr als "kurzlebig" bezeichnet werden kann.
Die Verwendung von Zweigen als Teil der alltäglichen Codierung im Team macht es leicht, das Falsche zu tun (versehentlich Änderungen zu horten), und erschwert es, das Richtige zu tun (bewusst oft zu integrieren). Deshalb verwenden viele Teams, die gute Praktiken fördern wollen, ein anderes Paradigma: Stamm-basierte Entwicklung.
Trunk-basierte Entwicklung
TBD ist eine Methode, bei der alle Entwickler an einem einzigen Zweig arbeiten, der üblicherweise als Stamm oder Hauptstamm bezeichnet wird. Dieser Ansatz steht im Gegensatz zu anderen Modellen, die auf getrennten Zweigen beruhen, bei denen die Entwickler ihre Änderungen vom Hauptzweig fernhalten und sie regelmäßig zusammenführen.
In TBD werden die Entwickler ermutigt, kleine, inkrementelle Änderungen einzubringen, damit die Codebasis immer grün und einsatzfähig bleibt. Dies ermöglicht eine noch kürzere Feedbackschleife, da die Änderungen allen anderen Entwicklern zur Verfügung stehen, sobald sie übertragen wurden. Durch die kontinuierliche Bereitstellung sind sie auch Minuten später für die Nutzer verfügbar.
Ein weiterer wichtiger Vorteil von TBD ist, dass es die Komplexität der Versionskontrolle im Team reduziert. Bei jeder Art von Zweig kann es aufgrund von Konflikten und Verzögerungen schwierig sein, Änderungen zu verfolgen und sie wieder in den Hauptzweig einzubringen. Durch die Arbeit an einem einzigen Zweig können die Entwickler diese Probleme vermeiden und sich auf die Entwicklung neuer Dinge konzentrieren.
TBD ist in einigen Gemeinden immer noch umstritten, wird aber von vielen Teams erfolgreich praktiziert, darunter auch von den meisten, mit denen ich das Glück hatte, zusammenzuarbeiten. Das haben die DORA-Forscher 2018 darüber berichtet:
Unsere Untersuchung ergab auch, dass die Entwicklung von Stamm/Master und nicht von langlebigen Feature-Zweigen mit einer höheren Lieferleistung korreliert. Teams, die gut abschnitten, hatten zu jeder Zeit weniger als drei aktive Zweige, ihre Zweige hatten eine sehr kurze Lebensdauer (weniger als einen Tag), bevor sie mit dem Stamm zusammengeführt wurden, und es gab keine "Code-Freeze"- oder Stabilisierungsphasen. Es ist wichtig zu betonen, dass diese Ergebnisse unabhängig von der Teamgröße, der Größe des Unternehmens oder der Branche sind.
Auch wenn wir festgestellt haben, dass trunk-basierte Entwicklungspraktiken zu einer besseren Leistung bei der Softwarebereitstellung beitragen, bleiben einige Entwickler, die an den "GitHub Flow"-Workflow gewöhnt sind, skeptisch. Dieser Arbeitsablauf beruht stark auf der Entwicklung mit Branches und dem regelmäßigen Zusammenführen mit Trunk.2
Nichtsdestotrotz gibt es einige Herausforderungen bei der Verwendung von TBD. Wenn das gesamte Team am selben Zweig arbeitet, kann es schwieriger werden, an mehreren Aufgaben gleichzeitig zu arbeiten und die Aktivitäten mehrerer Entwickler zu koordinieren. Außerdem muss bei der Planung der täglichen Arbeit darauf geachtet werden, dass sich die Entwickler/innen nicht gegenseitig auf die Füße treten (oder in die Codezeilen der anderen). Das ist aber nicht unbedingt ein Nachteil: Bei der Arbeit mit Zweigen besteht immer noch die Gefahr, dass die Entwickler/innen sich überschneidende Änderungen vornehmen; sie würden diese Änderungen nur erst beim Zusammenführen bemerken, wenn der Kontext veraltet ist und die umstrittenen Zeilen möglicherweise noch weiter auseinanderliegen. Man könnte sagen, dass TBD dazu beiträgt, dass Probleme beim Zusammenführen früher auftauchen, wenn sie leichter zu beheben sind.
Wenn TBD zusammen mit Continuous Deployment praktiziert wird, bedeutet das, dass jeder einzelne Code-Commit sofort in der Produktion eingesetzt wird. Dies ist die einfachste Umsetzung eines kontinuierlichen Änderungsflusses aus einem Guss. Wie in Kapitel 1 erläutert, ist es dieses Konzept aus der schlanken Produktion, das das Continuous Deployment so leistungsfähig macht: Es eliminiert Verschwendung und Stapelverarbeitung auf dem Weg zur Produktion. Aus diesem Grund würde ich sagen, dass die Kombination mit TBD die reinste Umsetzung von Continuous Deployment ist, obwohl die Verwendung von sehr kurzlebigen Zweigen ein guter Kompromiss ist, wenn dies keine Option ist.
In der Fallstudie über die Digitalbank N26 in Teil V kannst du über eine solche Situation lesen: Da TBD aufgrund von Vorschriften nicht möglich ist, verwenden die N26-Ingenieure Microbranches und PRs, um den Nachweis einer Peer Review zu erbringen und sicherzustellen, dass keine willkürlichen Änderungen am System durch einzelne Entwickler vorgenommen werden. Allerdings koppeln sie diesen Prozess mit Pair Programming und Mob Programming, so dass die Codeüberprüfung live stattfindet und die Integration in das Hauptsystem beschleunigt werden kann.
Das bringt uns zum nächsten Thema: die Überprüfung von Code.
Häufige Codeüberprüfungen
Codeüberprüfungen sind unverzichtbar, denn sie bieten einen entscheidenden Punkt für menschliches Feedback zum Design, zur Korrektheit und zur Vollständigkeit des Codes. Bei der kontinuierlichen Bereitstellung ist dieser menschliche Feedbackkanal auch die einzige menschliche Form des Feedbacks auf dem gesamten Weg zur Produktion. Das macht Codeüberprüfungen besonders sinnvoll, denn sie sind das einzige Instrument, das sicherstellt, dass jede Codezeile vor der Produktion von mehr als einem Paar Augen überprüft wird.
Egal, wie gut eine Funktion getestet ist, wenn der Entwickler, der sie geschrieben hat, die Anforderungen falsch verstanden hat, wird er falsche Tests schreiben, die mit einer ebenso falschen Implementierung einhergehen. Egal, wie viele ausgeklügelte Code-Scan-Tools wir haben, nur ein Mensch kann erkennen, ob der Code die funktionalen Anforderungen erfüllt und ob er die Vereinbarungen des Teams bezüglich Design und Struktur beachtet. Es gibt viele solcher Code-Entwurfsprinzipien, die über triviale Linting-Regeln hinausgehen und über die bereits unzählige Bücher geschrieben wurden. Zum Beispiel muss der Code gut aufgeteilt sein, nicht überraschend zu lesen sein, zur richtigen Abstraktionsebene gehören und konzeptionell auf die Architektur abgestimmt sein. Wenn wir Code nur schreiben würden, um von Maschinen und nicht von anderen Menschen verstanden zu werden, könnten wir genauso gut all unsere Designbücher und hoch abstrahierten Programmiersprachen wegschmeißen und zu den alten Assembler-Spaghetti zurückkehren, mit denen unsere Großmütter3 mit dem unsere Großmütter zurechtkommen mussten.
Die Betonung von Codeüberprüfungen mag im Widerspruch zu den anderen Botschaften in diesem Buch stehen. Wie wir in Kapitel 1 besprochen haben, sind wir bestrebt, manuelle Engpässe auf dem Weg zur Produktion vollständig zu beseitigen. Sind Codeüberprüfungen nicht ein Beispiel für einen manuellen Engpass, bei dem sich Änderungen anhäufen und stecken bleiben können? Und haben wir uns nicht gerade im vorigen Abschnitt die Vorteile von TBD gegenüber langen Feature-Zweigen und PRs angesehen? Wie sollen wir Codeüberprüfungen ohne PRs durchführen?
Pull-Anfragen
Es ist erwähnenswert ( ), dass viele Teams, die ihre Zweige klein halten, auch sehr kleine PRs erstellen, was zu schnellen Codeüberprüfungen führt, die den kontinuierlichen Fluss des Codes zur Produktion nicht allzu sehr stören. In diesen Teams müssen sich alle Entwickler/innen sehr stark in den Codeüberprüfungsprozess einbringen, damit sie die Wartezeit für ihre Kolleg/innen, die sich integrieren wollen, minimieren können. Viele Ingenieure arbeiten auf diese Weise und schaffen es, die Wartezeiten einigermaßen gering zu halten und einen einigermaßen reibungslosen Arbeitsablauf zu erreichen.
Trotzdem glaube ich, dass wir noch mehr erreichen können als das.
Mir ist aufgefallen, dass wir im Laufe der Jahre die Überprüfung einer offenen PR mit der einzigen Zeit und dem einzigen Ort, an dem Code überprüft werden kann, in Verbindung gebracht haben. Ich möchte dieses Konzept in Frage stellen. Es gibt noch eine andere Methode im Werkzeugkasten von eXtreme Programming, die eine Alternative zu PRs als Motor für Codeüberprüfungen bietet: Pair Programming.
Paarweise Programmierung
Paarweise Programmierung ist eine sehr alte Praxis; fast so alt wie das Programmieren selbst:
Betty Snyder und ich waren von Anfang an ein Paar. Und ich glaube, dass die besten Programme und Entwürfe von Paaren gemacht werden, weil man sich gegenseitig kritisieren, die Fehler des anderen finden und die besten Ideen nutzen kann.
Jean Bartik, einer der allerersten Programmierer4
Die Paarprogrammierung wurde in den frühen Tagen von Agile wieder populär, obwohl sie leider aus der Mode gekommen zu sein scheint, da viele Unternehmen vergessen haben, sie zu einem Teil ihrer "Agilen Transformation" zu machen. Aber da Praktiken wie TBD und Continuous Deployment immer beliebter werden, lohnt es sich, die Paarprogrammierung neu zu bewerten, denn sie kann mehr Sicherheit bieten als gewöhnliche Codeüberprüfungen durch PRs.
Bei der Paarprogrammierung wird der gesamte Produktionscode von zwei Entwicklern entwickelt, die sich eine Tastatur und einen Bildschirm teilen, im Falle von Remote Pairing auch einen virtuellen. Während das Paar an einer Aufgabe arbeitet, tauschen sie die Rollen zwischen der Eingabe und der Diskussion über den Codeentwurf. Da jedes Mitglied des Paares seine Annahmen und Designideen verbalisieren muss, diskutieren sie kontinuierlich über die Umsetzung und die Anforderungen und führen so eine kontinuierliche Codeüberprüfung durch.
Eine zweite Person sieht sich den Code vor und während des Schreibprozesses an, nicht erst im Nachhinein. Das kann hilfreicher sein als eine Überprüfung zur PR-Zeit, weil es ein viel größeres (und früheres) Zeitfenster bietet, um Designfehler zu korrigieren oder Missverständnisse bei den Anforderungen zu klären. Außerdem wird so die soziale Unbeholfenheit vermieden, große Änderungen zu verlangen, nachdem ein Kollege oder eine Kollegin bereits viel Arbeit an einem PR geleistet hat, was ein weiteres Hindernis für die Qualität des Codes ist (und was ich leider schon oft erlebt habe).
Paarweises Programmieren kann auch die Implementierung von Funktionen und die Behebung von Fehlern beschleunigen, weil mehr als ein Gehirn zur Verfügung steht, um Probleme zu lösen, wenn sie auftauchen. Außerdem wird die Integration beschleunigt, weil der Engpass beseitigt wird, verfügbare Reviewer zu finden, die möglicherweise den Kontext wechseln müssen, um ihre Kollegen freizugeben. Durch diesen kontinuierlichen und engagierten Codeüberprüfungsprozess ist der endgültige Entwurf des Codes in der Regel von höherer Qualität und erfordert weniger Nacharbeit, was viel Zeit spart.
Der Haupteinwand gegen Pair Programming lautet normalerweise: "Man braucht doppelt so viel Arbeitszeit, um das Gleiche umzusetzen!" Ich finde aber, dass das in den meisten Fällen nicht stimmt, weil es an der Zeitersparnis vorbeigeht, die dadurch entsteht. Selbst wenn dieser Einwand zuträfe und ein kontinuierlicher Codeüberprüfungsprozess wirklich so viel teurer wäre, würde ich behaupten, dass sich die Investition trotzdem lohnt. Schließlich bringen wir jeden Commit in die Produktion ein und wollen dabei ein hohes Maß an Sicherheit vor menschlichen Fehlern haben. Geschwindigkeit und Agilität erfordern immer eine Investition.
Ich persönlich habe in fast allen meinen Teams Pair Programming zur Codeüberprüfung eingesetzt und die meisten Entwicklerinnen und Entwickler, mit denen ich zusammengearbeitet habe, fanden, dass es eine große Hilfe bei der Auslieferung von Produkten, beim Onboarding neuer Teammitglieder und bei der Aufrechterhaltung eines gemeinsamen Gefühls der Codeverantwortung ist.
Psychologische Sicherheit
Unabhängig davon, ob dein Team PRs oder Pair Programming verwendet, solltest du sicherstellen, dass Codeüberprüfungen ein detaillierter und häufiger Prozess sind, wenn du eine kontinuierliche Bereitstellung planst. Es liegt in der Verantwortung aller leitenden Teammitglieder, einen Raum zu schaffen, in dem sich alle Kolleginnen und Kollegen, insbesondere die jüngeren, ermächtigt fühlen, ehrliches Feedback zu geben und schwierige Fragen zu stellen. Die Definition von "gutem Code" kann persönlich sein, aber das bedeutet nicht, dass sie nicht jeden Tag im Team diskutiert und ausgehandelt werden sollte. Jemandes Gefühle kurzzeitig zu verletzen ist nie angenehm, aber es ist besser als die Alternative: ein Kreislauf ruinöser Empathie, in dem sich alle gegenseitig auf Kosten der Stabilität des Produkts in der Produktion auf die Schulter klopfen.
Automatisierte Code-Analyse
Wir haben darüber gesprochen, wie wichtig es ist, dass mehr als ein Auge auf den Code schaut, aber das bedeutet nicht, dass häufige Fehler nicht automatisiert werden können. An dieser Stelle können Code-Analyse-Tools eine wichtige Rolle spielen und die Sicherheit der kontinuierlichen Bereitstellung erhöhen. Mit Hilfe der Automatisierung müssen sich Entwickler/innen und ihre Pairs (oder PR-Reviewer/innen) nicht mehr um die Suche nach kleinen Fehlern sorgen, die leicht übersehen werden können, sondern können sich auf das große Ganze konzentrieren: zum Beispiel darauf, wie die Änderungen in die bestehende Architektur passen, wie sie veröffentlicht werden sollten und ob sie den Anforderungen entsprechen.
Statische Code-Analyse-Tools können Code analysieren, ohne ihn tatsächlich auszuführen, und sie sind in der Regel recht schnell, so dass sie als früher Schritt in die Pipeline integriert werden können, um häufige Fehler zu erkennen, oder sogar in IDEs und Pre-Commit-Hooks. Sie können eingesetzt werden, um alle möglichen Probleme zu identifizieren, wie z. B. Bugs, Sicherheitsschwachstellen und Probleme mit der Ressourcennutzung, und sie können auch frühzeitig Codierungsstandards durchsetzen.
Es gibt viele Open-Source-Tools zur Codeanalyse, die eine Vielzahl von Programmiersprachen unterstützen. Es kann sein, dass du sie erst einmal einrichten und konfigurieren musst, aber die meisten von ihnen lassen sich danach ganz einfach weiterverwenden. Meiner Meinung nach überwiegen in den meisten Fällen die Gründe, die dafür sprechen, sie einzubeziehen, die Gründe, die dagegen sprechen.
Kurz gesagt, statische Code-Analyse-Tools sind hervorragend geeignet, um Fehler zu vermeiden, die durch Unachtsamkeit und gewöhnliche Programmierfehler entstehen. Es gibt jedoch zwei Funktionen, die ich in einem Continuous-Deployment-Szenario als besonders nützlich hervorheben möchte: das Scannen von Sicherheitslücken und die Leistungsanalyse.
Einige der menschlichen Fehler mit den schlimmsten Folgen für beliebte Anwendungen betreffen die Sicherheit und Leistung. Sie sind auch mit am schwersten zu erkennen, da automatisierte Tests in der Regel eher nach Regressionen im Verhalten als in den funktionsübergreifenden Eigenschaften der Software suchen. Da Entwickler/innen in kleinen Schritten arbeiten, ist es leicht möglich, dass man vergisst, ein Ressourcenleck einzubauen, das erst in einer stark belasteten Umgebung, wie der Produktion, Probleme verursacht. Genauso leicht vergessen wir, unsere Eingaben bei jedem Commit korrekt zu bereinigen, und öffnen das System damit für ein weiteres Problem, das erst dann auftritt, wenn es unbekannten, nicht vertrauenswürdigen Benutzern gegenübersteht. Automatisiertes Code-Scanning mindert diese Bedenken und gibt Entwicklern und Stakeholdern ein gutes Gefühl, wenn sie bedenken, was bei einem ständigen Strom von Änderungen alles schiefgehen kann.
Test Automatisierung
Da dies das 21. Jahrhundert ist, sollte es selbstverständlich sein, dass die Testautomatisierung den manuellen Regressionstests vor jeder Bereitstellung vorzuziehen ist. Sie ist schneller, effizienter, konsistenter und billiger. Automatisierte Tests können schnell und wiederholt durchgeführt werden, ohne dass ein menschliches Eingreifen erforderlich ist, so dass sie im Gegensatz zu manuellen Tests nicht von menschlichen Fehlern oder Abweichungen betroffen sind. Das Testen von Software ist das Paradebeispiel für eine sich wiederholende und exakte Aufgabe, die sich perfekt für die unendliche Geduld eines Computers eignet und nicht von Menschenhand durchgeführt werden sollte. Menschliche Kreativität und Aufmerksamkeit sollten dafür reserviert sein, Annahmen in Frage zu stellen und das System auf unerwartete Weise zu testen, und nicht dafür, dieselben Funktionen immer wieder zu überprüfen.
Die Automatisierung von Regressionstests, die früher manuell durchgeführt wurden, sollte in jedem Unternehmen ganz oben auf der To-Do-Liste stehen. Besonders ernst nehmen sollten es aber Teams, die eine kontinuierliche Bereitstellung anstreben.
Wir sollten nicht ständig Code einsetzen, der keine gute Testabdeckung hat. Wie Michael Feathers in Working Effectively with Legacy Code schreibt, ist Code ohne Tests genauso schlecht wie (und kann als) Legacy-Code betrachtet werden:
Für mich ist Legacy-Code einfach Code ohne Tests. [...] Code ohne Tests ist schlechter Code. Es spielt keine Rolle, wie gut er geschrieben ist; es spielt keine Rolle, wie hübsch oder objektorientiert oder gut gekapselt er ist. Mit Tests können wir das Verhalten unseres Codes schnell und nachprüfbar ändern. Ohne sie wissen wir wirklich nicht, ob unser Code besser oder schlechter wird.5
Es spielt keine Rolle, wie schön unser Code aussieht: Ohne eine Pipeline, die von gründlichen automatisierten Tests unterstützt wird, können wir nicht verhindern, dass Regressionen in die Produktion einfließen. Eine fehlende oder vernachlässigte Testabdeckung wäre vielleicht etwas erträglicher gewesen, wenn die Änderungen in der Vorproduktion angehalten und manuell überprüft worden wären, aber es wird rücksichtslos, wenn das Tor zur Produktion weit offen steht und keine manuelle Überprüfung möglich ist. Später in seinem Buch sagt Feathers weiter, dass es zwei Möglichkeiten gibt, Änderungen an einem Softwaresystem vorzunehmen: "Abdecken [mit Tests] und Ändern" oder "Bearbeiten und Beten". Wenn wir Continuous Deployment mit dem "Edit and Pray"-Ansatz verwenden, müssen wir besonders viel beten.
Jetzt, da wir diesen Disclaimer aus dem Weg geräumt haben, können wir darüber sprechen, welche Arten von Tests notwendig sind. Schließlich gibt es viele Arten von automatisierten Tests in der Werkzeugkiste eines Entwicklers, und es gibt sie auf allen möglichen Abstraktions- und Granularitätsebenen: Unit-Tests, Integrationstests, Akzeptanztests, Komponententests, visuelle Regressionstests, Vertragstests, Journey-Tests... um nur einige zu nennen (ich kann sie unmöglich alle in diesem Abschnitt behandeln, sonst würde es ein eigenes Buch werden). Abgesehen von den Unit-Tests, die im Allgemeinen gut verstanden werden, ist die Terminologie in der Branche seit jeher unscharf und es gibt konkurrierende Definitionen für verschiedene Arten von Tests. Wenn du zwei Entwickler in einen Raum sperrst und ihnen denselben Testcode zeigst, wirst du wahrscheinlich drei verschiedene Bezeichnungen dafür bekommen.
Nachdem ich jedoch in einigen Teams gearbeitet habe, wurde mir klar, dass die Terminologie keine Rolle spielt, solange sich das ganze Team auf dieselbe Definition einigt und daran festhält. Jedes Teammitglied sollte wissen, welche Arten von Tests in seinem Team verwendet werden, welchen Abstraktionsgrad sie haben, wann und wo sie angemessen sind und wo die Grenzen des zu testenden Systems liegen. Das Team sollte seine Teststrategie regelmäßig aktualisieren und neu aushandeln, welche Abdeckung benötigt wird, wenn das Produkt wächst.
Die zu verwendenden Testschichten variieren von Anwendung zu Anwendung und von Tech-Stack zu Tech-Stack. Welche und wie viele Tests hinzuzufügen sind, ist Ansichtssache und kann von Team zu Team unterschiedlich sein, aber ich finde, die hilfreichste Faustregel ist, dem bekannten Testpyramidenmodell zu folgen.
Das Pyramidenmodell der Prüfung
Die Testpyramide ist eine visuelle Metapher, die die verschiedenen Kategorien von Tests beschreibt, die für ein System durchgeführt werden sollten. Die Pyramide hat die Form einer Pyramide, weil die Idee dahinter ist, dass es viele Low-Level-Tests, wie z. B. Unit-Tests, und viel weniger High-Level-Tests, wie z. B. End-to-End-Tests, geben sollte. Die Tests am unteren Ende der Pyramide können zahlreich sein, da sie eine hohe Granularität haben (einzelne Klassen oder Funktionen), sehr schnell laufen und leicht zu schreiben sind. Die Tests an der Spitze der Pyramide sind dagegen umfangreich und wertvoll, aber sie laufen auch viel langsamer und erfordern aufwendige Einstellungen, so dass wir sie nur verwenden sollten, um das wertvollste Verhalten des Systems zu überprüfen und nicht alle Details.
In Abbildung 4-2 siehst du einige Beispiele dafür, wie eine Testpyramide für zwei verschiedene Arten von Anwendungen aussehen könnte: eine REST-API und ein einseitiges Anwendungs-Frontend.
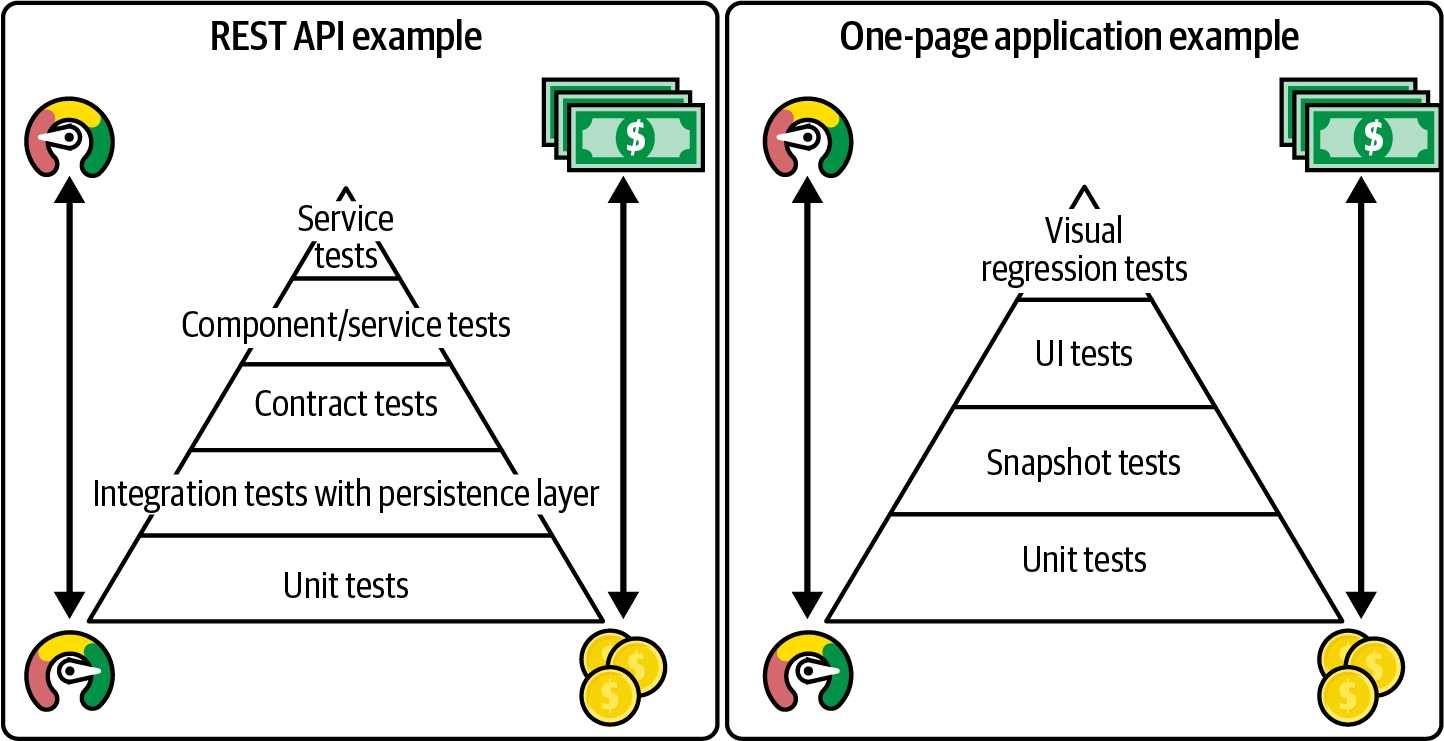
Abbildung 4-2. Zwei Beispiele für Prüfpyramiden
In der Vergangenheit wurden nur die Unit-Tests am unteren Ende der Pyramide während der Implementierungsphase von den Entwicklern selbst geschrieben. Die mühsame Aufgabe, die High-Level-Coverage zu schreiben, wurde in der Vergangenheit den QS-Mitarbeitern überlassen, um die Produktivität der manuellen Testarbeit zu optimieren, die sie sowieso gemacht hätten. Dies geschah normalerweise nach der Entwicklungsphase.
Wie wir in Kapitel 2 besprochen haben, ist dieser Ansatz der Testautomatisierung in modernen Teams, die kontinuierliches Deployment nutzen, nicht tragbar. Wenn der Code nie in einem Artefakt-Repository oder in der Vorproduktion wartet, geht das Zeitfenster für das Hinzufügen von High-Level-Tests "später" verloren. Daher ist es unerlässlich, dass das Team das Testen auf die linke Seite verlagert und jede Schicht der Testpyramide während der Entwicklungsphase selbst aktualisiert wird.
Die Arbeit mit automatisierten Tests auf jeder Ebene der Testpyramide ist etwas, mit dem sich jedes Teammitglied, das Code schreibt, wohlfühlen sollte, unabhängig von seinem Dienstgrad. Nur wenn dies der Fall ist, kann jede Änderung sicher in die Produktion gehen, unabhängig davon, wer sie erstellt hat. Wenn die Änderungen sofort in der Produktion eingesetzt werden, kann das Schreiben guter Tests sogar wichtiger sein als das Schreiben von gutem Code.
Das Schweizer Käse-Modell
Ein weiteres gutes Modell für die Testabdeckung, das die klassische Testpyramide ergänzen kann, ist das Schweizer Käse-Modell. Dieses Modell wurde erstmals von James T. Reason vorgeschlagen. Ursprünglich wurde es in Bereichen wie der Flugsicherheit, dem Maschinenbau und dem Gesundheitswesen angewandt, aber es eignet sich auch hervorragend für das Testen von Software.
In diesem Modell kann man sich alle Schichten der Prüfpyramide als verschiedene Scheiben Schweizer Käse vorstellen. Die Löcher in jeder Scheibe stehen für unterschiedliche Schwächen oder fehlende Abdeckung in den Prüfschichten. Ein Fehler kann durch eine oder zwei Schichten hindurchgehen, aber er kann später von einer anderen Schicht mit einer etwas anderen Abdeckung abgefangen werden, wie in Abbildung 4-3 dargestellt. Die Fehler, die den ganzen Weg durch die Käsescheiben schaffen, sind diejenigen, die die Nutzer in der Produktion zu Gesicht bekommen.
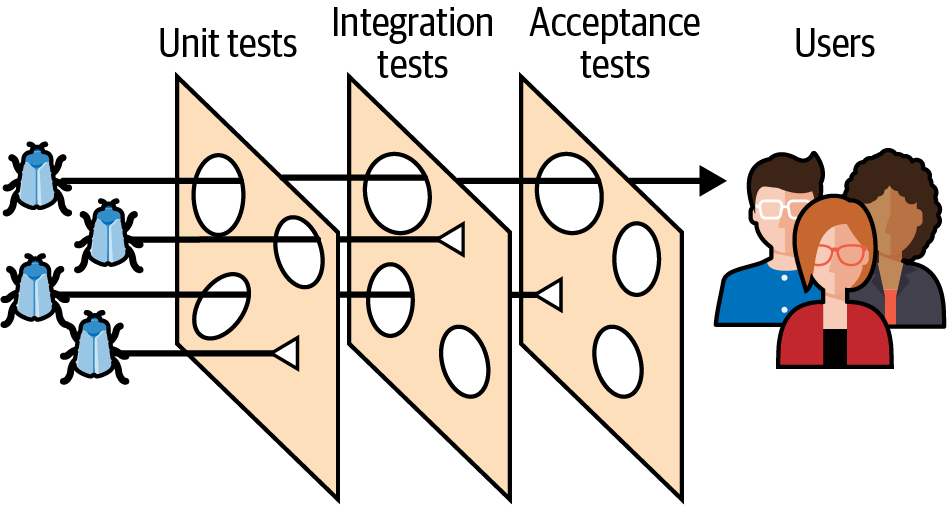
Abbildung 4-3. Das Schweizer Käse-Modell
Wenn wir die Eigenschaften der einzelnen Schichten untersuchen (z. B. Geschwindigkeit, Fehleranfälligkeit), können wir den angemessenen Umfang der Abdeckung bestimmen. Tests, die für die erste, detailliertere Schicht geeignet sind, könnten für langsamere und teurere Schichten viel zu detailliert sein und wären außerdem überflüssig.
Das Schweizer Käse-Modell kann auch hilfreich sein, wenn es darum geht, Entscheidungen über Bereiche zu treffen, in denen es unvermeidliche Überschneidungen zwischen den Schichten gibt. Mehr Überschneidungen bedeuten mehr Schutz für den Fall, dass die Abdeckung in einer der anderen Schichten falsch geändert wird, aber sie bedeuten auch höhere Wartungskosten, da eine Änderung der Funktionalität die Aktualisierung von mehr Schichten von Tests erfordert.
Test-first
Kontinuierliche Bereitstellung erfordert das Schreiben von Tests während der Implementierungsphase des Codes, aber das ist an sich kein neues Konzept. Unit-Tests werden schon seit einiger Zeit in den Entwicklungslebenszyklus integriert, vor allem mit der Einführung des "Test-First"-Prinzips und der testgetriebenen Entwicklung (TDD). Du kannst mehr über TDD in Test Driven Development lesen : By Example,6 aber jetzt fasse ich erst einmal zusammen, wie es funktioniert.
Wie in Abbildung 4-4 dargestellt, besteht TDD aus drei Phasen: dem Schreiben eines fehlgeschlagenen Tests, dem Schreiben der Mindestmenge an Code, die erforderlich ist, um den Test zu bestehen, und schließlich dem Refactoring des Codes, sobald du durch den Test geschützt bist.
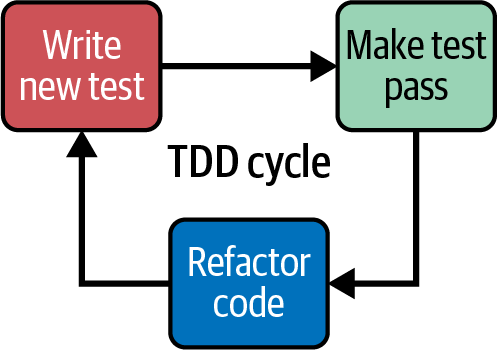
Abbildung 4-4. Der TDD-Lebenszyklus
TDD zu praktizieren ist eine weitere meiner Standardempfehlungen, wenn ein Team automatisierte Einsätze in Betracht zieht. Die Argumentation ist einfach. Wenn du fehlgeschlagene Tests schreibst, bevor du den Code schreibst, um sie grün zu machen, kannst du sicher sein, dass die Tests tatsächlich geschrieben werden und die Abdeckung stabil bleibt. Das mag aufgrund der Regeln, die es verbieten, Produktionscode ohne einen entsprechenden Test zu schreiben, offensichtlich erscheinen, aber es gibt noch einen weiteren, subtileren Vorteil von test-first gegenüber test-after, der sich positiv auf die Testabdeckung auswirkt.
Wenn du die Tests vor dem Code schreibst, fungieren die Tests als allererster Nutzer der API des Codes. Das zwingt die Entwickler dazu, sich über die Verträge ihrer Klassen und Funktionen und deren Interaktion untereinander Gedanken zu machen, noch bevor sie an ihre Implementierung denken. Folglich ist Code, der zuerst geschrieben wird, von Natur aus testbar und modular. Andererseits funktioniert das Schreiben von Tests nach der Implementierung nicht immer gut: Ein Entwickler könnte feststellen, dass es ihm schwerfällt, die notwendigen Mocks zu injizieren oder das System so einzurichten, dass der Test ausgeführt werden kann, wenn er seinen Code nicht mit Blick auf die Testbarkeit entworfen hat. Möglicherweise haben sie einen sehr dichten Code erstellt, der zu komplizierten Tests führt, die eine Menge Assertions oder Einstellungen benötigen. Diese zusätzliche Schwierigkeit kann Entwickler/innen davon abhalten, nachträglich Tests zu schreiben, oder sie kann dazu führen, dass die Funktionalität nicht so gründlich wie nötig abgedeckt wird. Auch wenn es kontraintuitiv erscheinen mag, ist es einfacher, die Tests zuerst zu schreiben, als sie nachträglich zu erstellen.
Beim kontinuierlichen Deployment sollten alle laufenden Arbeiten unter Feature-Toggles oder dem Expand-and-Contract-Muster versteckt werden, sodass wir sie jederzeit übertragen können, solange sie kompiliert werden und die Tests bestehen. Mit dem Zusatz der schnellen TDD-Schleife sollte die Codebasis höchstens einen fehlgeschlagenen Test davon entfernt sein, Commit-fähig zu sein, und daher in die Produktion deployt werden können.
Outside-in
TDD ist eine sehr nützliche Praxis für die Entwicklung von Software mit Unit-Tests an der Spitze, aber sie deckt nur die "Unit"-Schicht der Testpyramide ab, oder den Schweizer Käse. Du fragst dich vielleicht, wie die Tests auf höherer Ebene in diesen Prozess passen?
Es stellt sich heraus, dass es einfach ist, auch Tests auf höherer Ebene in einen Test-First-Workflow einzubinden. Dieser Prozess wurde in Growing Object-Oriented Software, Guided by Tests beschrieben:
Wenn wir eine Funktion implementieren, schreiben wir zunächst einen Akzeptanztest, der die Funktionalität, die wir entwickeln wollen, überprüft. Während er fehlschlägt, zeigt ein Akzeptanztest, dass das System die Funktion noch nicht implementiert; wenn er besteht, sind wir fertig. Wenn wir an einer Funktion arbeiten, orientieren wir uns am Akzeptanztest, um herauszufinden, ob wir den Code, den wir schreiben wollen, tatsächlich brauchen - wir schreiben nur Code, der direkt relevant ist. Unterhalb des Akzeptanztests folgen wir dem Zyklus aus Unit-Level-Test, Implementierung und Refactoring, um das Feature zu entwickeln.7
Abbildung 4-5 veranschaulicht den Prozess.
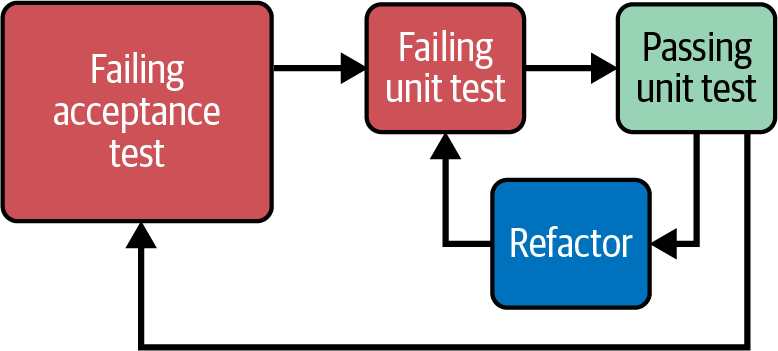
Abbildung 4-5. Outside-in TDD
Fehlgeschlagene High-Level-Tests, die vor der Implementierung geschrieben werden, können den Entwicklern als Leitfaden dienen, der ihnen Rückmeldung über die Vollständigkeit ihrer Funktion gibt und sie wissen lässt, wann der Code, den sie implementiert haben, ausreichend ist. High-Level-Tests können jedoch lange Zeit rot bleiben, manchmal viel länger als der wünschenswerte Abstand zwischen den Code-Commits. Es ist in Ordnung, sie als ignoriert zu markieren, bevor du einen Commit der laufenden Arbeit durchführst, damit sie nicht in der Pipeline fehlschlagen, sie lokal wieder zu aktivieren und sie erst einzuchecken, wenn sie grün sind. Das setzt natürlich voraus, dass der unvollständige Code gut versteckt ist und keine Auswirkungen auf bestehende Funktionen hat.
Ich habe die Erfahrung gemacht, dass die Kombination aus dem Test-First- und dem Outside-In-Prinzip bei der Arbeit mit Continuous Deployment wesentlich dazu beigetragen hat, dass sich unsere Teams bei der Testabdeckung unserer Anwendung sicher fühlen konnten. Jede neue Codezeile, die wir hinzufügten, hinterließ eine Spur von Unit- und High-Level-Tests. Ebenso wurde jeder Fehler, den wir behoben haben, zuerst durch einen fehlgeschlagenen automatisierten Test bewiesen, den wir grün färben konnten und der verhindern würde, dass der Fehler erneut auftritt. Dieser Ansatz machte unser Sicherheitsnetz für Regressionen immer stabiler, während sich unsere Produkte weiterentwickelten.
Was ist mit dem Erbe?
Nicht jedes Team hat den Luxus, auf der grünen Wiese an Codebases zu arbeiten, bei denen es die Testabdeckung schrittweise erhöhen kann, während es seinen Code aufbaut. Außerdem ist es eine schwierige Entscheidung, ob eine Legacy-Anwendung oder eine geerbte Anwendung für das Continuous Deployment geeignet ist, und wenn ja, zu welchem Zeitpunkt. Sich nur auf TDD zu verlassen, um die Testabdeckung opportunistisch zu erhöhen, könnte auch nicht ausreichen, da einige Legacy-Bereiche des Codes lange Zeit unangetastet bleiben oder schwer zu refaktorisieren sind. In solchen Fällen muss die Testabdeckung oft schon im Vorfeld verbessert werden, damit das System sicher geändert werden kann. Wenn der Anwendungscode sehr verworren ist, können selbst Öffnungen, die nur zum Zweck des Hinzufügens von Tests vorgenommen werden, Auswirkungen auf nicht verwandte Bereiche haben, die noch nicht abgedeckt wurden.
Meine Faustregel lautet, zuerst eine High-Level-Testsuite zu implementieren, mit der du das System von außen anfassen und wie eine Blackbox behandeln kannst, anstatt zu versuchen, den Code zu entwirren, um Tests auf Unit-Ebene hinzuzufügen. Das sollte ausreichen, um sicherzustellen, dass alle geschäftskritischen Funktionen gut geschützt sind, und ermöglicht es dir, später einige Öffnungen zu refaktorisieren.
Eine solche Testsuite kann auch dann erstellt werden, wenn wir nicht unbedingt alle Funktionen des Systems verstehen, die vielleicht unter einem Berg von verworrenem Code begraben sind, der das Ergebnis jahrelanger Änderungen der Anforderungen ist. Mit dem Ansatz, den Michael Feathers als "Charakterisierungstests" bezeichnet, können wir die Tests selbst nutzen, um das System zu testen und unsere Annahmen über seine Funktionsweise zu überprüfen.
Beim Charakterisierungstest können wir Tests schreiben, die ein Verhalten mit der zu prüfenden Eingabe auslösen, dann aber "Dummy"-Behauptungen aufstellen, von denen wir wissen, dass sie fehlschlagen werden, wie z. B. die Behauptung gegen Nullwerte. Die Fehlermeldung verrät uns das tatsächliche Ergebnis des Vorgangs, so dass wir unseren Test noch einmal überarbeiten können, um ihn grün zu machen. Dann können wir mit dem nächsten Test weitermachen, bis wir alle verschiedenen Arten von Eingaben, die das System in der realen Welt erhalten könnte, ausgeschöpft haben. Dieser Prozess hinterlässt eine ausführbare Spezifikation dessen, was das Produktionssystem derzeit tut, und kann es später vor unbeabsichtigten Änderungen schützen (selbst wenn sein Verhalten kontraintuitiv sein könnte).
Charakterisierungstests können bei der Vorbereitung einer Legacy-Anwendung hilfreich sein, wenn auch nicht für die kontinuierliche Bereitstellung, so doch zumindest für das sichere Refactoring und das Hinzufügen von Funktionen.
Zero-Downtime-Einsätze
Vielleicht einer der offensichtlichsten Punkte auf dieser Liste, aber dennoch erwähnenswert, ist die Zero-Downtime-Bereitstellung. Zero-Downtime-Deployments sind eine Voraussetzung für Teams, die sehr oft deployen wollen. Wir wollen auf keinen Fall, dass unsere Nutzerinnen und Nutzer mehrmals am Tag eine Wartungsmeldung sehen. Das passiert nämlich, wenn wir unsere Infrastruktur einfach abreißen und mit der neuen Version neu aufbauen, wie in Abbildung 4-6 gezeigt.
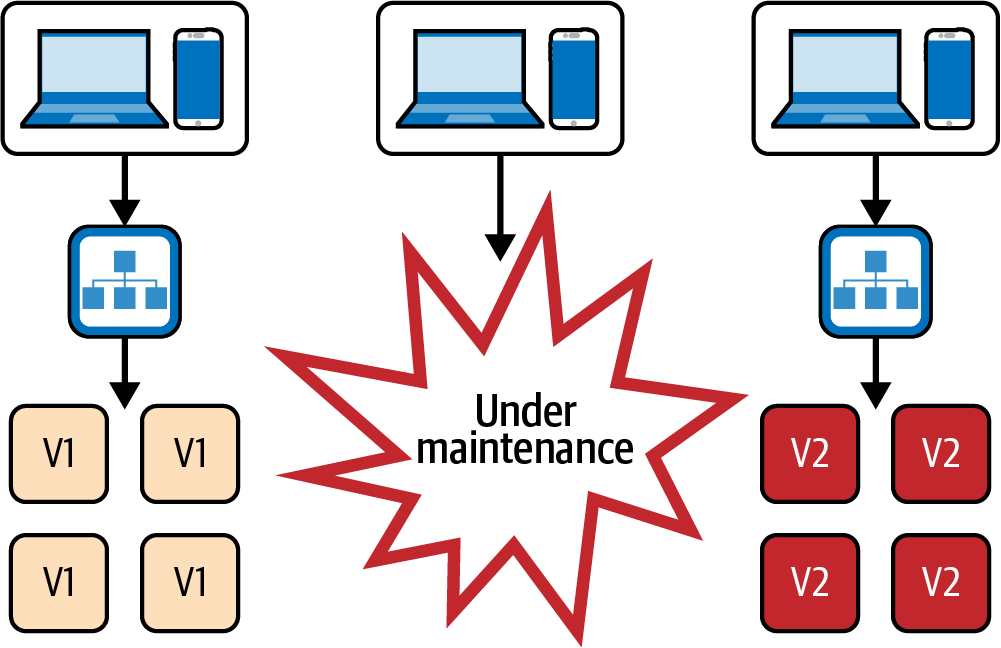
Abbildung 4-6. Einsatz mit Ausfallzeit
Es gibt verschiedene Techniken, um ein Bereitstellungsfenster zu vermeiden und keine Ausfallzeiten zu haben. Die bekanntesten sind Blue/Green Deployments und Rolling Deployments.
Blaue/grüne Einsätze
Blue/Green Deployment ist eine Technik, die auf zwei identischen Produktionsumgebungen basiert, die jeweils als "blau" und "grün" bezeichnet werden. Bei einer Bereitstellung wird die neue Version der Anwendung zunächst in der blauen Umgebung eingesetzt. Sobald die blaue Umgebung nachweislich wie erwartet funktioniert und bereit ist, live zu gehen, wird der eingehende Datenverkehr umgeleitet und die neue Version ist live. Während der Bereitstellung sind sowohl der blaue als auch der grüne Stack in Betrieb und der Traffic-Eingangspunkt schaltet einfach zwischen beiden um; siehe Abbildung 4-7.
Jedes Unternehmen setzt ein Blue/Green-Setup ein wenig anders um. Die meisten erstellen eine neue Umgebung direkt vor dem Einsatz, während andere aus Sicherheitsgründen immer beide Umgebungen laufen lassen, vor allem, um jederzeit einen Rollback durchführen zu können (obwohl die doppelte Infrastruktur ziemlich teuer werden kann). Welcher Stack als "blau" und welcher als "grün" bezeichnet wird, kann ebenfalls variieren. In einigen Fällen haben sie feste Namen, in anderen werden die Namen bei der Bereitstellung ausgetauscht. Für unsere Zwecke sind die Implementierungsdetails jedoch nicht von Bedeutung, und wir können uns einfach auf den blauen/grünen Einsatz als jede Einrichtung beziehen, die zwischen identischen Flotten von Produktionsservern wechselt.
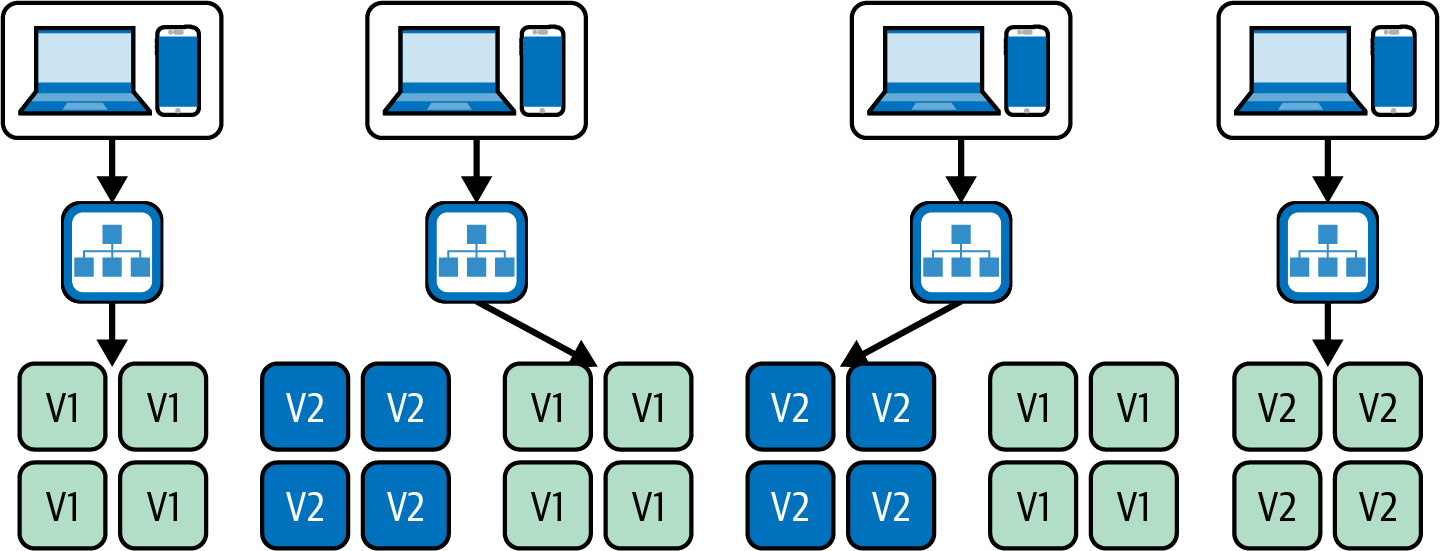
Abbildung 4-7. Blau/grüner Einsatz
Ein Vorteil der Blue/Green-Implementierung ist, dass sie ein schnelles Rollback ermöglicht, falls ein Problem mit der neuen Version der Anwendung auftritt. Wenn es Probleme mit der grünen Umgebung gibt, kann der Datenverkehr einfach auf die blaue Umgebung umgeleitet werden, wodurch die Ausfallzeit und die Auswirkungen auf die Nutzer/innen minimiert werden.
Ein Blue/Green Deployment beruht darauf, dass zwei verschiedene Versionen der Anwendung zumindest während eines kleinen Überlappungsfensters in Betrieb bleiben. So ist gewährleistet, dass immer mindestens eine Version der Anwendung für den Datenverkehr zur Verfügung steht und die Ausfallzeiten entfallen.
Es ist jedoch wichtig zu wissen, dass diese Überschneidung für die Entwickler einen gewissen Aufwand bedeutet. Wenn sie eine Änderung vornehmen, müssen sie dafür sorgen, dass die Codebasis für jede neue Version N der Anwendung immer neben der Version N - 1 laufen kann. Das gilt vor allem dann, wenn wir die Fähigkeit zum Rollback wirklich erhalten wollen.
Die Aufrechterhaltung der N - 1 Kompatibilität bedeutet, dass die Entwickler besonders vorsichtig sein müssen, wenn sie z.B. Datenbankschema-Entwicklungen anwenden, den Vertrag zwischen Backend und Frontend ändern oder den Vertrag mit anderen externen Komponenten ändern.
Rollende Einsätze
Rolling Deployments (oder Rolling Updates) ist eine Technik zur Bereitstellung von Updates für den Anwendungscluster, bei der die aktuellen Instanzen durch neue Instanzen mit der neuesten Version ersetzt werden. Wenn die neuen Instanzen gesund sind, können die alten schrittweise entfernt werden, wie in Abbildung 4-8 dargestellt. Diese Technik wird häufig in Konfigurationen verwendet, bei denen die Anwendung in einem Container-Cluster wie ECS oder Kubernetes läuft.
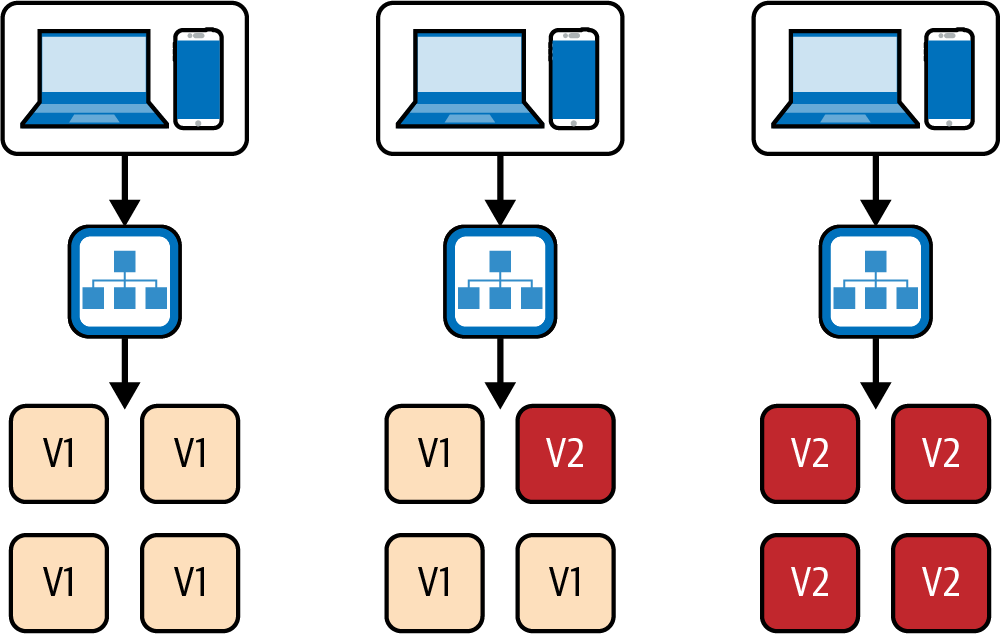
Abbildung 4-8. Ein rollendes Update
Dieser Ansatz ist weniger kostspielig als die Blue/Green-Bereitstellung, da er nur einen laufenden Stack der Produktionsinfrastruktur benötigt. Sie wird am häufigsten bei Container-basierten Einsätzen verwendet, obwohl sie auch mit herkömmlichen virtuellen Maschinen möglich ist.
Wie bei Blue/Green Deployments gibt es auch bei diesem Ansatz das N - 1 Kompatibilitätsproblem: Für eine kurze Zeit werden Instanzen der neuen Version neben der alten existieren, daher muss sichergestellt werden, dass der Vertrag mit externen Systemen mit beiden Versionen kompatibel bleibt.
Canary-Einsätze
Bevor wir mit der Beschreibung von Canary Deployments beginnen, ist es erwähnenswert, dass die Terminologie in diesem Bereich verwirrend sein kann: Canary Deployments werden manchmal als Canary Releases bezeichnet und umgekehrt. Deployments und Releases sind unterschiedliche Ereignisse, vor allem im Fall von Continuous Deployment, wo Teams Releases und Deployments routinemäßig durch Feature Toggles entkoppeln (wie ich in Kapitel 3 erklärt habe). In diesem Abschnitt spreche ich nur über Canary Deployments, d.h. das Ausrollen neuer Instanzen mit der neuesten Version des Codes und der Konfiguration. Über "Canary Releases" sprechen wir in Kapitel 12. Dort zeige ich dir, wie du ein sichtbares Feature schrittweise einführst (idealerweise zur Laufzeit und durch die Verwendung eines Feature Flags, das keine neue Bereitstellung erfordert).
Ein Canary Deployment kann als Erweiterung des Zero-Downtime Deployments betrachtet werden. Ihr Ziel geht sogar noch weiter: Sie ermöglicht es, die neue Version der Anwendung mit einer Teilmenge des Datenverkehrs zu validieren, bevor das Update für alle Nutzer/innen ausgerollt wird; siehe Abbildung 4-9.
Dies wird erreicht, indem eine Teilmenge der Instanzen mit der neuen Version (dem Kanarienvogel) bereitgestellt wird und der Rollout auf den Rest der Infrastruktur davon abhängig gemacht wird, wie gut die neue Version funktioniert. Dieser Vergleich wird automatisiert, indem Metriken für die neue und die alte Version gesammelt und miteinander verglichen werden. Diese Möglichkeit bieten Tools wie Spinnaker.

Abbildung 4-9. Ein Kanarienvogel-Einsatz
Diese Strategie gibt ein genaueres Feedback als ein einfacher Rolling oder Blue/Green Deployment, bei dem die automatisierten Prüfungen oft nur aus einem einfachen Health Check oder einem Smoke Test bestehen. Ein Canary-Einsatz kann viel interessantere Dinge aufdecken, wie z. B. einen signifikanten Unterschied in der Fehlerrate der Anwendung oder Leistungsprobleme.
Canary-Deployments, die anhand von Anwendungsmetriken automatisiert werden, können ein extrem leistungsfähiges Werkzeug sein, um zu überprüfen, ob neue Codeversionen keine unvorhergesehenen Auswirkungen auf die Produktion haben. Diese Art von gründlichem, umfassendem Feedback kann eine Voraussetzung für große Unternehmen sein, die Continuous Deployment einführen wollen, aber Angst vor den Auswirkungen auf die Leistung oder andere wichtige funktionsübergreifende Anforderungen haben.
Der Einsatz von Kanarienvögeln kann jedoch auch einige Nachteile haben. Die Einrichtung kann ziemlich kompliziert sein, und die Kennzahlen, auf die sie sich stützen, müssen aussagekräftig und stabil sein. Außerdem kann das Sammeln der Daten, die für eine statistische Analyse benötigt werden, um genaue Ergebnisse zu erzielen, viel Zeit in Anspruch nehmen, was den Einsatzprozess verlangsamt und zu einem Engpass führt.
In Anbetracht dieser Probleme würde ich Canary Deployments in den meisten kleinen bis mittelgroßen Organisationen nicht als "Muss" für Continuous Deployment ansehen. Ich persönlich habe in allen Teams, in denen wir Continuous Deployment praktiziert haben, einfachere Bereitstellungsstrategien verwendet. Wir sahen keine Notwendigkeit für ausgeklügelte Canary Deployments, da unsere Testabdeckung, Feature Toggles, Beobachtbarkeit und Alarme umfassend genug waren, um uns zu schützen.
Dennoch ist der Einsatz von Kanarienvögeln eine interessante Technik, die die Beteiligten beruhigen kann, wenn neue Einsätze als risikoreich angesehen werden. Ich bin gespannt, wie sich diese Technik weiterentwickelt und von immer mehr Unternehmen übernommen wird.
Einführungsstrategien und manuelle Schritte
Es ist erwähnenswert, dass einige Teams manuelle Schritte innerhalb von Blue/Green- oder Rolling Deployments als QA-Tool und/oder als Feature-Release-Tool durchführen - zum Beispiel, indem sie nur einen Teil des Deployments in die Produktion übertragen und dann einige manuelle Überprüfungsschritte durchführen, bevor sie es abschließen.
Diese Art von Workflow passt gut zu Continuous Delivery, ist aber nicht mit Continuous Deployment vereinbar. Wenn die Rate der Commits, die in der Produktion ankommen, viel höher ist, führt ein menschlicher Eingriff in der Mitte des Deployments zu einer riesigen Warteschlange von Änderungen, die es zu sortieren gilt. Manuelle Eingriffe führen außerdem dazu, dass sich die neue Version der Anwendung in der Produktion wie eine Vorproduktion verhält: Die Bereitstellung selbst wird zu einem Warteschlangenpunkt, an dem wir darauf warten, dass die Tests oder Experimente vor dem "endgültigen" Bereitstellungsschritt abgeschlossen sind. Teilweise Implementierungen mit manuellen Aktivitäten sind immer noch ein Tor zur Produktion.
Ich würde von einem solchen Ansatz abraten und bin der Meinung, dass Laufzeitmerkmalen und automatisierte Tests viel besser geeignet sind, um Änderungen zu überprüfen, ohne den Einsatz an die Qualitätssicherung und Produktexperimente zu koppeln.
Antipattern-Beispiel: Blau/Grün als QA-Tool
Ich habe Teams kennengelernt, die sich auf manuelle Blue/Green Deployments verlassen, um neue Versionen in der blauen Umgebung zu testen. Dazu greifen sie über eine private URL auf die temporäre Umgebung zu und führen Regressionstests durch, um sicherzustellen, dass alles wie erwartet funktioniert. Erst wenn das Team festgestellt hat, dass die neue Version gut aussieht, wechselt es in die grüne Umgebung. Dieser Prozess sollte jedoch automatisiert werden, wenn das Team zur kontinuierlichen Bereitstellung übergehen will, indem es ihn durch automatisierte Regressionstests in niedrigeren Umgebungen, automatisierte Smoke-Tests oder Canary Deployments ersetzt.
Beispiel für ein Antipattern: Partielle Einsätze als Canary-Release-Tool
In ähnlicher Weise können Teams versucht sein, Rolling Deployments als eine Art A/B-Test manuell zu steuern, um neue Funktionen zu validieren. Sie nehmen die neue Funktion in die nächste Version der Anwendung auf, rollen sie aber nur auf einige wenige Instanzen aus. Wenn die Funktion in dieser Teilmenge gut funktioniert, entscheiden die Verantwortlichen, sie auf den Rest der Infrastruktur auszuweiten.
Wie ich bereits erwähnt habe, ist diese Art des manuellen und teilweisen Rollouts von Änderungen nicht mit der kontinuierlichen Bereitstellung in der Produktion vereinbar. Der Einsatz sollte vollständig automatisiert werden, wobei die A/B-Tests für die Nutzer durch Feature-Flags ersetzt werden. Die Feature Flags für das Nutzerfeedback ermöglichen eine feinere Kontrolle darüber, welche Nutzer das Feature sehen sollen, als ein partieller Einsatz. Sie ermöglichen es zum Beispiel, eine Untergruppe von Nutzern nach dem prozentualen Anteil des Datenverkehrs oder sogar nach der Region auszuwählen, anstatt nach einer willkürlichen Anzahl von Anfragen, die bei bestimmten Instanzen eingehen. Und was noch wichtiger ist: Wenn eine Funktion nicht gut funktioniert, muss kein Rollback durchgeführt werden, und das Warten auf das Feedback der Nutzerinnen und Nutzer führt nicht dazu, dass andere Code-Änderungen nicht umgesetzt werden können.
Ich empfehle jedem Team, das über eine kontinuierliche Bereitstellung nachdenkt, die manuellen Bereitstellungsschritte durch eine Kombination aus Feature-Flags und automatisierten Tests zu ersetzen, bevor sie das Tor zur Produktion öffnen. In einer kontinuierlichen Bereitstellungspipeline sollte die Bereitstellung für die Produktion immer vollständig automatisiert sein.
Beobachtbarkeit und Überwachung
Wie ausgefeilt deine Codeüberprüfungen, Tests und Einsatzstrategien auch sein mögen, es können immer noch Probleme in der Produktion auftreten. Manchmal kann dies lange nach dem letzten Einsatz passieren, da die notwendigen Bedingungen für das Auftreten von Problemen zufällig auftreten können.
Deshalb ist es wichtig, dass die Entwickler/innen qualitativ hochwertige Informationen über den Stand der Produktion erhalten und dass diese Informationen gut sichtbar in Informationsradiatoren für das gesamte Team verfügbar sind.
Die Beobachtbarkeit bezieht sich auf die Fähigkeit, das Verhalten des eingesetzten Systems zu überwachen und zu verstehen, indem man seine Ausgaben wie Logs, Metriken und Traces untersucht. Sie stellt die grundlegende Fähigkeit dar, neue Fragen über das laufende System zu stellen, und bietet einen explorativen Weg, es zu verstehen. Außerdem können Teams so Probleme erkennen und diagnostizieren sowie Erkenntnisse darüber gewinnen, wie das System unter verschiedenen Bedingungen funktioniert (oder fehlschlägt).
Wenn du dir nicht sicher bist, was du überwachen solltest, zumindest was die technische Seite angeht, bietet Google in seinem SRE-Buch einen hervorragenden Ausgangspunkt, der vier goldene Signale beschreibt:
Latenz, oder die Zeit, die das System braucht, um eine Anfrage zu bearbeiten.
Traffic, ein Maß für die Nachfrage (z. B. HTTP-Anfragen, eingehende Nachrichten, Transaktionen pro Sekunde), die auf das System einwirkt.
Fehler, oder die Fehlerquote, insbesondere im Vergleich zum Gesamtverkehr.
Sättigung, oder wie viel von der "Kapazität" deines Systems genutzt wird. Das kann sich auf die Speicher- und CPU-Auslastung, die aktuellen Instanzen im Vergleich zu deiner Skalierungsgrenze oder die Festplattenauslastung beziehen.
Auf der Frontend-Seite solltest du auch die Entwicklung der folgenden Core Web Vital-Kennzahlen im Laufe der Zeit im Auge behalten:
- Größte inhaltsreiche Farbe (LCP)
ist ein Maß dafür, wann das größte Element auf der Seite gerendert wird, was ein Indikator für die vom Nutzer wahrgenommene Gesamtladegeschwindigkeit ist.
- Kumulative Layout-Verschiebung (CLS)
-
Wenn ein Element seine Position von einem Frame zum nächsten ändert, ist das eine Layout-Verschiebung. Layoutverschiebungen sollten so gering wie möglich gehalten werden, da sie das Nutzererlebnis in vielerlei Hinsicht stören können.
- Interaktion zum nächsten Anstrich (INP)
ist ein Maß für die Latenzzeit für alle Klick-, Tipp- und Tastaturinteraktionen mit einer Seite und insbesondere für die längste Spanne. Dies ist ein Hinweis auf die wahrgenommene Reaktionsfähigkeit der Seite.
Neben den rein technischen Kennzahlen sollte das Team auch Daten für geschäftsrelevante Kennzahlen sammeln, die den Bereich der Anwendung widerspiegeln, z. B. die Anzahl der durchgeführten Suchen, Konversionsraten, Klickraten und Absprungraten.
Die Generierung von Outputs wie Protokollen, Metriken und Traces sollte in jede neue Funktion des Systems integriert werden, und zwar aus zwei Gründen: zum einen, um bereits beim ersten Einsatz Transparenz zu erhalten, und zum anderen, weil das nachträgliche Hinzufügen von Outputs ein Redesign des Codes erfordern kann, was zu unnötiger Nacharbeit führt.
Deshalb ist es wichtig, dass die wichtigsten Signale in übersichtlichen Dashboards zusammengefasst werden. Beispiele dafür findest du in den Abbildungen 4-10 und 4-11. Ein Entwickler, der mit dem System vertraut ist, sollte mit einem Blick feststellen können, ob das System normal funktioniert. Wenn Probleme festgestellt werden, sollten detailliertere Informationen wie einzelne Logs und Traces zur Verfügung stehen, die zu Debugging-Zwecken in separaten Bereichen durchsucht werden können.
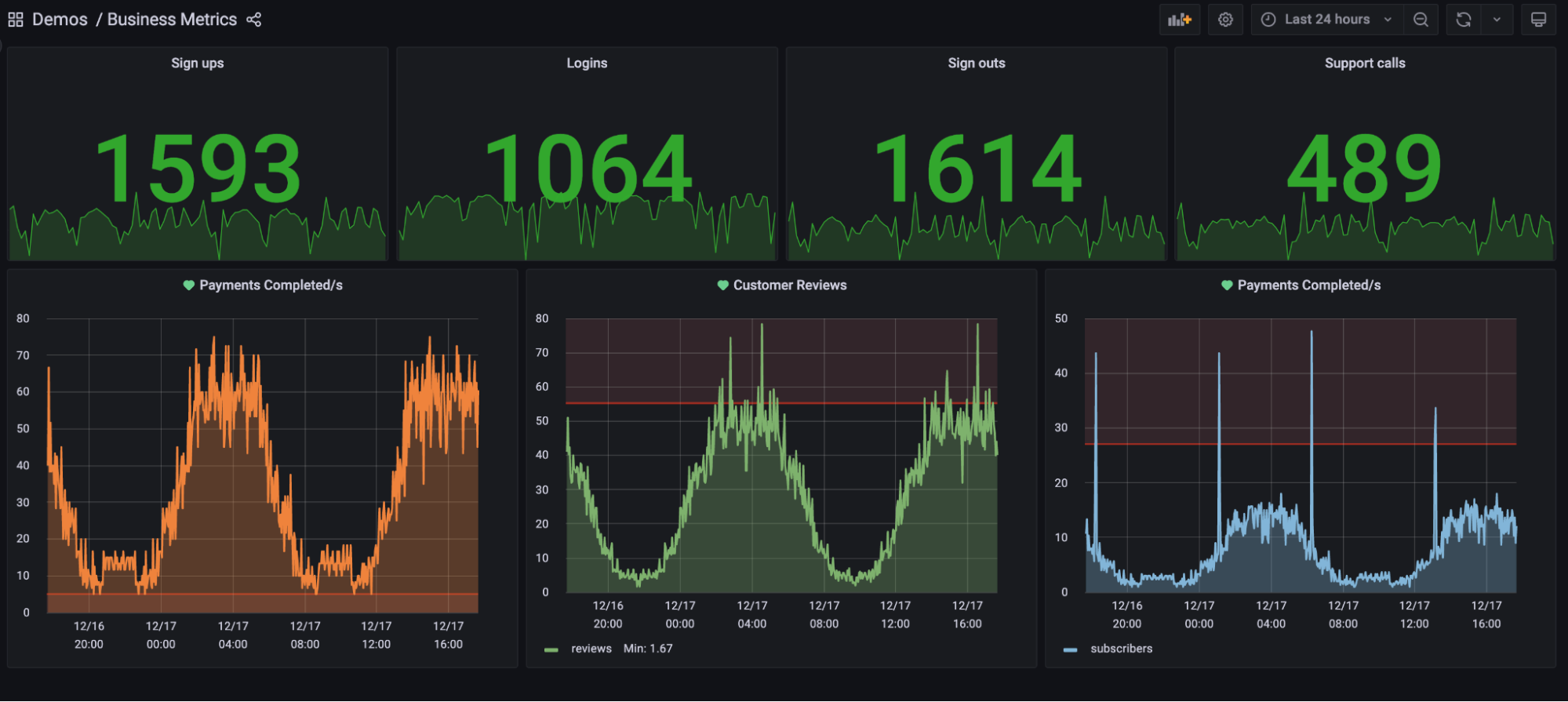
Abbildung 4-10. Ein Beispiel für ein Dashboard mit Geschäftsmetriken
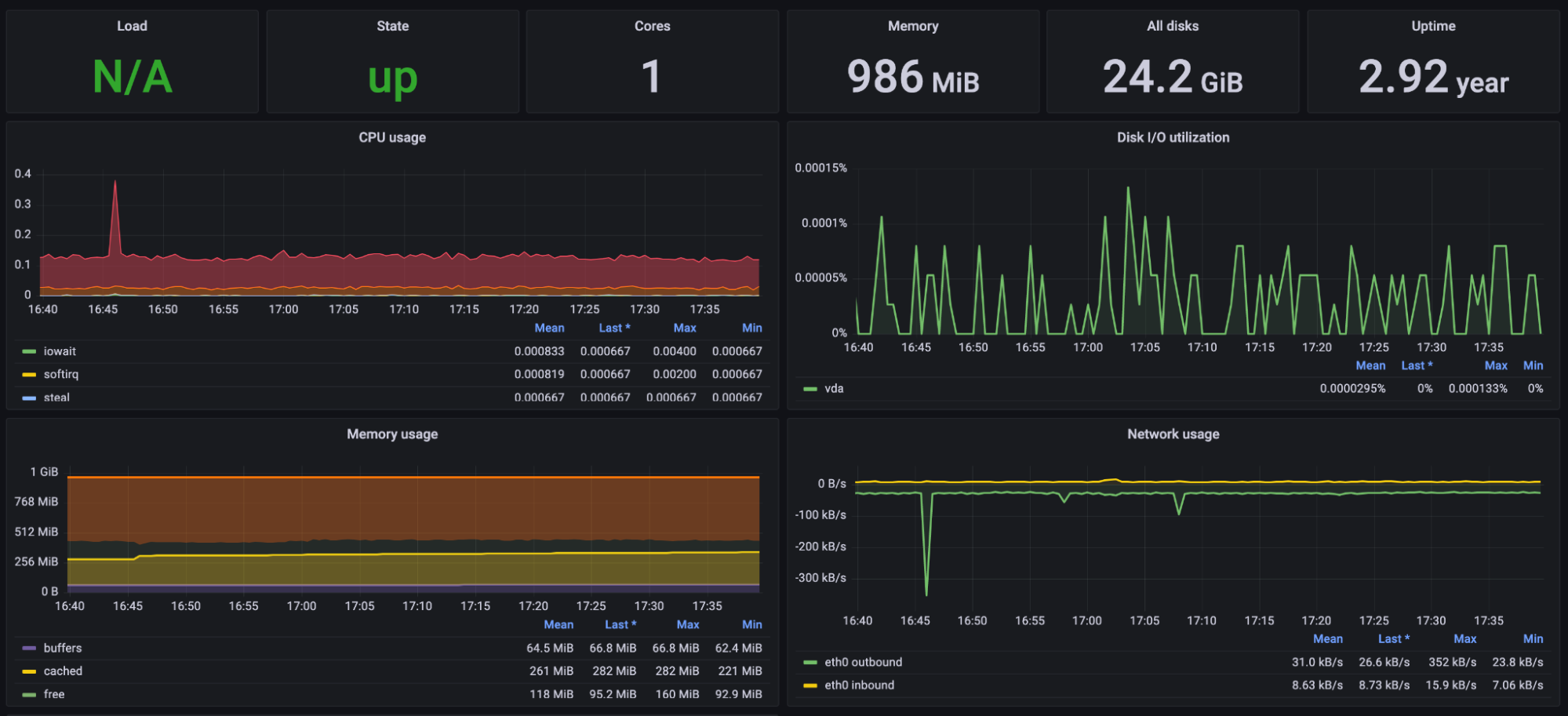
Abbildung 4-11. Ein Beispiel für ein Dashboard mit technischen Metriken
Im Bereich der Beobachtbarkeit gibt es viele Innovationen. Tools wie Datadog, Splunk, Prometheus, Grafana und NewRelic haben sich in den letzten Jahren immer weiter verbreitet und werden immer häufiger eingesetzt.
Warnungen
Ein Auge auf die Dashboards während der täglichen Arbeit zu haben, ist beim Continuous Deployment sehr wichtig, aber man kann von den Entwicklern nicht erwarten, dass sie 100% der Zeit auf ihren Datadog-Tab starren. Deshalb sollten Entwickler/innen proaktiv über Anomalien informiert werden, auch wenn sie ihr Bestes tun, um den Überwachungs-Tools Aufmerksamkeit zu schenken. Dies kann durch den Einsatz von Warnmeldungen erreicht werden.
Die meisten Observability-Tools bieten Warnmeldungen an, die Entwickler über verschiedene Kanäle benachrichtigen (z. B. per SMS, Telefonanruf oder Brieftaube), wenn sich bestimmte Metriken seltsam verhalten. Das ist ein Muss bei häufigen Einsätzen.
Warnungen können auf einer Vielzahl verschiedener Faktoren basieren, z. B. auf der Systemleistung, dem Nutzungsverhalten oder dem Auftreten bestimmter Protokollmeldungen oder Fehler. Indem sie auf Basis von Schlüsselindikatoren konfiguriert werden, können Teams über Probleme benachrichtigt werden, sobald sie auftreten, so dass sie proaktive Schritte unternehmen können, um das Problem zu lösen, bevor es kritisch wird.
Information versus Lärm
Viele Warnmeldungen und Überwachungen können überwältigend sein, wenn sie nicht richtig konfiguriert sind. Wenn es zu viele Monitore gibt oder wenn ständig Alarme ausgelöst werden, weil sie unzuverlässig sind, können Entwickler schnell lernen, sie auszublenden und das Interesse zu verlieren, wodurch sie möglicherweise kritische Probleme übersehen.
Es sollten nur wenige und aussagekräftige Warnmeldungen sein, nicht zu viele und überflüssige. Auf der technischen Seite solltest du zum Beispiel nur bei einigen wenigen Kennzahlen Alarm schlagen, z. B. bei Anwendungsfehlern, unkontrollierten Latenzzeiten oder zu wenig gesunden Instanzen. Aber vernachlässige nicht die geschäftsrelevanten Metriken. Das plötzliche Ausbleiben bestimmter Arten von Anfragen kann zum Beispiel darauf hindeuten, dass die Nutzer/innen Probleme haben, einen bestimmten Vorgang abzuschließen (z. B. wenn der letzte Commit den Checkout-Button irgendwie unsichtbar gemacht hat).
Manche Teams erstellen neue Alarme für jede neue Kennzahl und halten die Schwellenwerte niedrig, damit der Alarm häufiger ausgelöst wird. Das mag wie ein umfassender Ansatz erscheinen, ist aber nicht hilfreich. Warnmeldungen, die einen Wolf heulen, können sogar noch schlimmer sein, als gar keine Warnmeldungen zu haben. Wenn es keine Warnmeldungen gibt, bleibt das Team zumindest aufmerksam, weil es weiß, dass es eine Informationslücke gibt, während schlechte Warnmeldungen ein falsches Gefühl der Sicherheit vermitteln, obwohl sie die meiste Zeit ignoriert werden.
Schlechte Informationen sind schlimmer als keine Informationen. Deshalb sollte sich ein Team, das mit Continuous Deployment arbeitet, angewöhnen, die Beobachtbarkeit und die Warnmeldungen mit der gleichen Aufmerksamkeit zu überarbeiten, die es seinem Anwendungscode, seinen automatisierten Tests und seiner Pipeline widmet.
Das Datadog-Team liefert in seinem Blog eine gute Heuristik dafür, was "sinnvolle" Alarme sind, und hilft dabei, diese Alarme von Rauschwarnungen zu unterscheiden, die sich auf Symptome statt auf Ursachen beziehen, was auch in Googles SRE-Buch behandelt wird:
Seiten [wie in "jemanden ausrufen"] sind sehr effektiv, um Informationen zu übermitteln, aber sie können ziemlich störend sein, wenn sie übermäßig genutzt werden oder wenn sie mit schlecht gestalteten Warnungen verbunden sind. Im Allgemeinen ist eine Meldung am besten geeignet, wenn das System, für das du verantwortlich bist, nicht mehr mit einem akzeptablen Durchsatz, einer akzeptablen Latenzzeit oder einer akzeptablen Fehlerquote arbeitet. Das sind die Art von Problemen, über die du sofort Bescheid wissen willst.
Die Tatsache, dass dein System keine nützliche Arbeit mehr leistet, ist ein Symptom, d.h. es ist ein Ausdruck eines Problems, das viele verschiedene Ursachen haben kann. Ein Beispiel: Wenn deine Website in den letzten drei Minuten sehr langsam reagiert hat, ist das ein Symptom. Mögliche Ursachen sind eine hohe Datenbanklatenz, fehlgeschlagene Anwendungsserver, ein Ausfall von Memcached, eine hohe Auslastung und so weiter. Wann immer möglich, solltest du deine Seiten nach den Symptomen und nicht nach den Ursachen aufbauen. [...]
Die Suche nach Symptomen zeigt reale, oft nutzerorientierte Probleme auf und nicht hypothetische oder interne Probleme. Ein Symptom, wie z. B. eine langsame Reaktion auf die Website, sollte nicht mit den möglichen Ursachen des Symptoms verglichen werden, wie z. B. eine hohe Auslastung der Webserver. Deine Nutzer/innen werden die Serverauslastung nicht bemerken oder sich nicht darum kümmern, wenn die Website immer noch schnell reagiert, und deine Techniker/innen werden es nicht mögen, wenn sie für etwas belästigt werden, das nur intern auffällt und das sich ohne Eingreifen wieder normalisieren kann .8
Vertrauen der Stakeholder
In diesem Kapitel haben wir viel über die technischen Voraussetzungen für ein sicheres Arbeiten im Rahmen der kontinuierlichen Bereitstellung gesprochen. Ich denke, es ist notwendig, das Kapitel mit einer Reflexion über den Einfluss des menschlichen Faktors abzuschließen.
Das Tor zur Produktion für alle Commits zu öffnen, ist eine Vertrauensübung zwischen den Beteiligten und ihrem Team. Als Entwickler, die täglich am System arbeiten, kennen wir alle Sicherheitsmaßnahmen, die wir ergreifen, um zu verhindern, dass Bad Things™ in der Produktion passieren. Bei der kontinuierlichen Bereitstellung sind wir diejenigen, die die Kontrolle über die Quality Gates behalten: Schließlich implementieren und konfigurieren wir die Automatisierung, die in unserem Namen handelt. Aber unsere Stakeholder können nicht dasselbe behaupten. Alles, was sie aus ihrer Sicht sehen können, ist, dass sie keine Möglichkeit mehr haben, sich einzubringen und gefährliche Änderungen zu verhindern, bevor es zu spät ist. Sie haben keinen Einblick in die Akribie der vielen Automatisierungsschichten, die ihre Zustimmung überflüssig machen, und müssen auf unser Wort als Ingenieure vertrauen. Wir verlangen von ihnen, dass sie ihre einzige Macht über den Weg zur Produktion aufgeben. Angesichts dieser großen Forderung sollten wir uns bemühen, für alle Bedenken, die sie äußern, Verständnis aufzubringen. Selbst wenn wir eine perfekte technische Grundlage geschaffen haben, ist die kulturelle Grundlage vielleicht doch die schwierigste.
Eine kontinuierliche Bereitstellung ist jedoch eine Teamleistung, und unsere Stakeholder müssen mit an Bord sein, damit sie das Beste aus dieser Praxis machen können. Wenn die Stakeholder zuversichtlich sind, werden sie auch geduldiger mit eventuellen Kinderkrankheiten umgehen, während sich das Team an die neue Arbeitsweise gewöhnt. Lasst uns also darüber reden, wie wir sie für automatisierte Einsätze begeistern können (statt sie zu fürchten).
Wie können wir den Chef überzeugen?
Als Berater musste ich in den Teams, in denen wir kurz vor der kontinuierlichen Bereitstellung standen, aber noch nicht ganz so weit waren, einiges an Überzeugungsarbeit leisten. Meiner Erfahrung nach lässt sich diese Überzeugungsarbeit am besten leisten, wenn nur noch wenig Überzeugungsarbeit zu leisten ist.
Keine der in diesem Kapitel besprochenen Praktiken wird ausschließlich für das Continuous Deployment benötigt: Jede von ihnen kann unabhängig umgesetzt werden und ist für sich genommen eine mehr als vertretbare Investition. Sie werden die Qualität der Anwendung zweifellos auch dann verbessern, wenn noch ein manuelles Tor zur Produktion besteht.
Deshalb möchte ich meine Kolleginnen und Kollegen ermutigen, sie einzuführen, unabhängig davon, ob Continuous Deployment das endgültige Ziel ist, denn sie werden trotzdem zu einer robusteren Umsetzung von Continuous Delivery führen.
Wenn das Team einen hohen Reifegrad bei der kontinuierlichen Bereitstellung erreicht hat, wird sich das mühsame manuelle Testen jedes Details eher überflüssig als notwendig anfühlen. Wenn das Team diesen Punkt erreicht hat, werden meiner Erfahrung nach sogar die Stakeholder lernen, manuelle Tests als lästig zu empfinden. Dann ist es am einfachsten, einen weiteren Schritt vorzuschlagen, ohne starke Reaktionen hervorzurufen. Vielleicht wird der Vorschlag dann sogar begrüßt, da er nur dazu führt, dass überflüssige Arbeit wegfällt.
Meiner Erfahrung nach nimmt dieser Ansatz nicht nur den Großteil der "Verhandlungen" aus diesen Gesprächen heraus, sondern hilft dem Team auch sicherzustellen, dass es tatsächlich bereit ist, da es bewertet hat, wie sehr es sich immer noch auf menschliche Augen statt auf Automatisierung verlässt. Dein Chef weiß es vielleicht sogar zu schätzen, dass die Bereitschaft zur kontinuierlichen Bereitstellung ein klares und konkretes Ziel ist, an dem sich das Team orientieren kann, um sich kontinuierlich zu verbessern.
Das wirft die Frage auf: "Woher wissen wir, wann wir bereit sind?"
Wie du in den Fallstudien in Teil V sehen wirst, treffen einige mutige Unternehmen wie AutoScout24 die Entscheidung, Continuous Deployment vom ersten Tag an einzuführen, sobald sie auf ein modernes Produktionsökosystem mit Microservices, Feature Flags und so weiter umstellen. Wenn dein Unternehmen jedoch etwas zögerlicher ist, könnte dir der nächste Abschnitt einige nützliche Hinweise geben.
Wann sind wir bereit?
Wir haben hier eine Menge Praktiken behandelt, und es könnte verlockend sein zu denken, dass jede von ihnen bis zur Perfektion vergoldet werden muss, bevor wir überhaupt daran denken, menschliche Schritte aus unseren Pipelines zu entfernen. Davon möchte ich meinen Lesern abraten. Wie wir in Kapitel 2 besprochen haben, besteht einer der Vorteile des Continuous Deployment darin, dass es, sobald es aktiviert ist, alle Qualitätskontrollen auf den Prüfstand stellt. Da der Code immer häufiger in die Produktion geht, werden Lücken in unseren Prozessen schnell sichtbar und können vom Team sofort behoben werden, wenn sie auftauchen. Wenn wir darauf warten, dass unsere Sicherheitsnetze absolut perfekt sind, werden wir den Schritt vielleicht nie wagen. Wenn wir die schmerzhaften Dinge früher und öfter tun, können sich die Praktiken auf natürliche Weise verfeinern.
Ob der richtige Zeitpunkt gekommen ist oder nicht, ist eine schwierige Frage, die jedes Team anhand der Umstände, in denen es sich befindet, selbst beantworten muss. Deshalb werde ich diese Frage mit einer weiteren Frage beantworten - genauer gesagt mit mehreren. Das sind einige Dinge, die ich dir vorschlagen würde, damit du deine eigenen Schlüsse ziehen kannst:
Kennt mein Team alle Praktiken, die in diesem Kapitel besprochen werden?
-
Haben wir alle Praktiken aus diesem Kapitel umgesetzt? Wenn ja, bis zu welchem Grad der Ausgereiftheit? Und wenn nicht, haben wir einen guten Grund, warum wir sie nicht brauchen?
Arbeitet jedes Teammitglied bei jeder von uns eingeführten Praxis vertrauensvoll damit, anstatt sie zu ignorieren oder zu umgehen?
Wenn wir morgen Continuous Deployment einführen würden, welche Art von Code-Fehler würde mich am meisten beunruhigen (z. B. Auswirkungen auf die Leistung, Sicherheitslücken, Regression bei einer bestimmten Funktion)? Welche Art von Fehler würde meine Stakeholder am meisten beunruhigen? Ist der Schutz vor diesen Fehlern heute manuell oder automatisiert?
Wenn wir morgen Continuous Deployment einführen würden, gibt es ein bestimmtes Signal aus dem Produktionssystem, das ich besonders im Auge behalten würde? Haben wir leicht zugängliche Metriken, die uns das heute schon zeigen? Gibt es bereits Warnmeldungen für den Fall, dass eine Verschlechterung eintritt?
Gibt es eine große Anzahl von Fehlern, die derzeit nur durch die manuelle Überprüfung von Änderungen entdeckt werden? Wenn ja, was haben sie gemeinsam? Welche Art von Automatisierung wäre notwendig, um sie früher zu erkennen?
Fühlt sich das manuelle Tor zur Produktion angesichts unserer technischen Praktiken heute wie ein Lebensretter an, oder fühlt es sich überflüssig und lästig an? Fühlen sich alle Teammitglieder gleich? Empfinden unsere Stakeholder das Gleiche?
Dies sind nur einige der Fragen, die ich gerne stelle, wenn ich prüfe, ob Continuous Deployment zu einem bestimmten Zeitpunkt die richtige Wahl ist. Selbst für diejenigen, die nicht vorhaben, es in nächster Zeit einzuführen, kann der Prozess der Beantwortung dieser Fragen zu einem tieferen Verständnis der Qualitätsstrategie des Teams und der Robustheit seines Systems führen.
Zusammenfassung
In diesem Kapitel haben wir über einige Praktiken gesprochen, die unsere Teams umsetzen sollten, bevor sie zur kontinuierlichen Bereitstellung übergehen. Einige Anforderungen sind kultureller und organisatorischer Natur, wie z. B. das Vertrauen der Stakeholder und funktionsübergreifende, autonome Teams mit der Gewohnheit häufiger Integration und Codeüberprüfungen. Die meisten anderen Anforderungen sind technischer Natur: Zero-Downtime-Deployments, eine Pipeline mit mehreren Schichten automatisierter Tests, Beobachtbarkeit und Warnmeldungen.
Dies sind keine Investitionen, die nur für die kontinuierliche Bereitstellung wertvoll sind. Es handelt sich vielmehr um gute Praktiken, die für sich alleine stehen. Das bedeutet, dass sie als isolierte Verbesserungen implementiert werden können und trotzdem großartige Ergebnisse für den Lebenszyklus der Softwarebereitstellung im Team bringen. Die Entscheidung, auf Continuous Deployment umzusteigen, kann später getroffen (oder rückgängig gemacht) werden, ohne dass dadurch Verluste entstehen.
Diese Grundlage von Praktiken kann sicherstellen, dass die Beseitigung des letzten Tores zur Produktion so schmerzlos wie möglich ist.
1 Matthew Skelton und Manuel Pais, Team Topologies: Organizing Business and Technology Teams for Fast Flow (Portland, OR: IT Revolution Press, 2019).
2 Nicole Forsgren et al., Accelerate: Building and Scaling High Performing Technology Organizations (Portland, OR: IT Revolution Press, 2018), S. 91.
3 Obwohl das nicht bekannt ist, war Programmieren früher ein Beruf, der von Frauen ausgeübt wurde. Die ersten Programmierer im frühen 19. Jahrhundert waren weiblich. Um mehr zu erfahren, besuche https://oreil.ly/cQb11.
4 "Jean Bartik, ENIAC's Programmers", Computer History Museum, 2011, Video, https://oreil.ly/4S38P.
5 Michael Feathers, Working Effectively with Legacy Code (Boston: Pearson, 2004), S. 16.
6 Kent Beck, Testgetriebene Entwicklung: By Example (Boston: Addison-Wesley, 2002).
7 Steve Freeman und Nat Pryce, Growing Object-Oriented Software, Guided by Tests (Boston: Addison-Wesley, 2009), S. 7.
8 Alexis Lê-Quôc, "Monitoring 101: Alerting on what matters", Datadog, 2016, https://oreil.ly/M3Wzn.
Get Kontinuierliche Bereitstellung now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

