Kapitel 4. Algorithmen für Kanten-KI
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Es gibt zwei Hauptkategorien von Algorithmen, die für Kanten-KI wichtig sind: Feature Engineering und künstliche Intelligenz. Beide Arten haben zahlreiche Unterkategorien; in diesem Kapitel werden wir einen Querschnitt davon untersuchen.
Ziel ist es, einen Überblick über jeden Algorithmus-Typ aus technischer Sicht zu geben und seine typische Verwendung, Stärken und Schwächen sowie seine Eignung für den Einsatz auf Kanten-Hardware hervorzuheben. Dies soll dir einen Ausgangspunkt für die Planung realer Projekte geben, die wir in den nächsten Kapiteln durchgehen werden.
Feature Engineering
In der Datenwissenschaft ist Feature Engineering der Prozess, bei dem Rohdaten in Inputs umgewandelt werden, die von den statistischen Werkzeugen genutzt werden können, mit denen wir Situationen und Prozesse beschreiben und modellieren. Beim Feature Engineering geht es darum, mithilfe deines Fachwissens zu verstehen, welche Teile der Rohdaten die relevanten Informationen enthalten, und dann dieses Signal aus dem umgebenden Rauschen zu extrahieren.
Aus Sicht der Kanten-KI geht es beim Feature Engineering darum, rohe Sensordaten in verwertbare Informationen umzuwandeln. Je besser dein Feature Engineering ist, desto einfacher ist das Leben für die KI-Algorithmen, die versuchen, sie zu interpretieren. Wenn du mit Sensordaten arbeitest, kommen beim Feature Engineering natürlich Algorithmen zur digitalen Signalverarbeitung zum Einsatz. Es kann auch bedeuten, dass die Daten in überschaubare Teile zerlegt werden.
Arbeiten mit Datenströmen
Wie wir gesehen haben, produzieren die meisten Sensoren Zeitreihendaten. Das Ziel einer Kanten-KI-Anwendung ist es, diese Zeitreihendatenströme zu nutzen und sie sinnvoll zu verarbeiten.
Die gängigste Art, Datenströme zu verwalten, besteht darin, eine Zeitreihe in Teile zu zerlegen, die oft Fenster genannt werden, und diese Teile dann einzeln zu analysieren.1 So entsteht eine Zeitreihe von Ergebnissen, die du interpretieren kannst, um zu verstehen, was vor sich geht. Abbildung 4-1 zeigt, wie ein Fenster aus einem Datenstrom genommen wird.
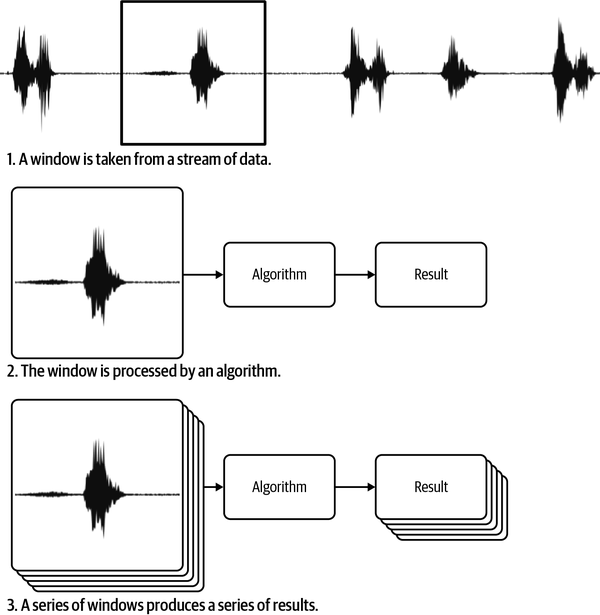
Abbildung 4-1. Eine Zeitreihe wird oft in Abschnitte, so genannte Fenster, unterteilt, die nacheinander analysiert werden
Es dauert eine gewisse Zeit, um ein einzelnes Datenpaket zu verarbeiten - wir können dies die Latenzzeit unseres Systems nennen. Dadurch wird begrenzt, wie oft wir ein Datenfenster erfassen und verarbeiten können. Die Geschwindigkeit, mit der wir Daten erfassen und verarbeiten können, wird als Framerate eines Systems bezeichnet und oft in der Anzahl der Fenster ausgedrückt, die pro Sekunde verarbeitet werden können. Die Frames können aufeinander folgen oder sich überschneiden, wie in Abbildung 4-2 dargestellt.
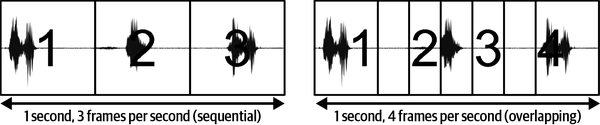
Abbildung 4-2. Abhängig von der Bildrate können sich die Fenster überlappen. Bei Daten, die Ereignisse enthalten, ist eine Überlappung wünschenswert, da sie die Wahrscheinlichkeit erhöht, dass ein ganzes Ereignis in ein Fenster fällt und nicht abgeschnitten wird.
Je geringer die Latenzzeit ist, desto mehr Datenfenster können in einem bestimmten Zeitraum analysiert werden. Je mehr Analysen du durchführen kannst, desto zuverlässiger sind die Ergebnisse. Stell dir zum Beispiel vor, wir verwenden ein maschinelles Lernmodell, um einen Befehl zu erkennen. Wenn die Fenster zu weit auseinander liegen, könnten wir wichtige Teile eines gesprochenen Befehls verpassen und ihn nicht erkennen (siehe Abbildung 4-3).
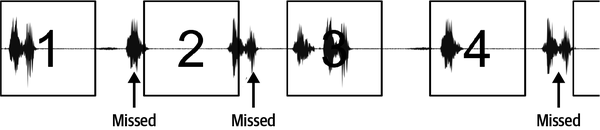
Abbildung 4-3. Wenn die Bildrate zu niedrig ist, werden einige Teile des Signals nicht verarbeitet; wenn du versuchst, kurzlebige Ereignisse zu erkennen, kann dies bedeuten, dass einige Ereignisse verpasst werden
Die Wahl der Fenstergröße ist sehr wichtig. Je größer das Fenster ist, desto länger dauert es, die Daten darin zu verarbeiten. Größere Fenster enthalten jedoch mehr Informationen über das Signal - das bedeutet, dass sie den verwendeten Signalverarbeitungs- und KI-Algorithmen das Leben leichter machen können. Der Kompromiss zwischen Fenstergröße und Bildrate ist ein wichtiger Punkt, den du bei der Entwicklung eines Systems untersuchen solltest.
Wie wir später sehen werden, gibt es viele verschiedene KI-Algorithmen - und einige von ihnen sind empfindlicher auf die Fenstergröße als andere. Einige Algorithmen (in der Regel solche, die einen internen Speicher für die Ereignisse in einem Signal haben) können gut mit sehr kleinen Fenstergrößen arbeiten, während andere große Fenstergrößen benötigen, um ein Signal richtig zu analysieren. Die Wahl des Algorithmus wirkt sich auch auf die Latenzzeit aus, die wiederum die Fenstergröße beeinflusst. Es ist ein komplexes System von Kompromissen zwischen Fenstergröße, Latenz und Algorithmuswahl.
Windowing gilt auch für Videostreams: In diesem Fall ist jedes "Fenster" des Videos eine bestimmte Anzahl von Standbildern - in der Regel ein einzelnes, aber einige KI-Algorithmen können potenziell mehrere Bilder gleichzeitig analysieren.
Anspruchsvollere Techniken für den Umgang mit Datenströmen fallen in die Kategorie der digitalen Signalverarbeitung. Diese Techniken können mit Windowing kombiniert werden, um Daten zu erzeugen, die KI-Algorithmen unterstützen.
Algorithmen der digitalen Signalverarbeitung
Es gibt Hunderte von verschiedenen Signalverarbeitungsalgorithmen, die dabei helfen können, die von Sensoren erzeugten Signale zu verarbeiten. In diesem Abschnitt stellen wir einige der DSP-Algorithmen vor, die für Kanten-KI am wichtigsten sind.
Neuabtastung
Alle Zeitreihensignale haben eine Abtastrate (auch als Frequenz bezeichnet), die oft als Anzahl der Datenabtastungen pro Sekunde (Hz) beschrieben wird. Oft ist es notwendig, die Abtastrate eines Signals zu ändern. Zum Beispiel kannst du die Rate eines Signals verringern ( Downsampling), wenn es schneller Daten produziert, als du sie verarbeiten kannst. Andererseits möchtest du vielleicht die Rate eines Signals erhöhen(Upsampling), damit es zusammen mit einem anderen Signal, das eine höhere Frequenz hat, bequem analysiert werden kann.
Beim Downsampling werden einige der Samples "weggeworfen", um die Zielfrequenz zu erreichen. Wenn du zum Beispiel jeden zweiten Frame eines 10-Hz-Signals (10 Samples pro Sekunde) wegwirfst, wird daraus ein 5-Hz-Signal. Aufgrund eines Phänomens, das Aliasing genannt wird, kann diese Art der Frequenzreduzierung jedoch zu Verzerrungen in der Ausgabe führen. Um dem entgegenzuwirken, müssen aus den Signalen einige hochfrequente Informationen entfernt werden, bevor sie heruntergetastet werden. Dies wird mit einem Tiefpassfilter erreicht, der im nächsten Abschnitt beschrieben wird.
Upsampling funktioniert auf die entgegengesetzte Weise - es werden neue Samples erstellt und eingefügt, um die Frequenz eines Signals zu erhöhen. Wenn zum Beispiel nach jedem Sample eines 10-Hz-Signals ein zusätzliches Sample eingefügt wird, wird daraus ein 20-Hz-Signal. Der schwierige Teil ist zu wissen, was eingefügt werden soll! Es gibt keine Möglichkeit, herauszufinden, was in der Zeit zwischen zwei Samples tatsächlich passiert ist, aber eine Technik von , die als Interpolation bekannt ist, kann verwendet werden, um die Lücken mit einer Annäherung zu füllen.
Neben Zeitreihen können Bilder auch hoch- oder heruntergetastet werden. In diesem Fall wird die räumliche Auflösung (Pixel pro Bild) erhöht oder verringert. Wie beim Resampling von Zeitreihen sind auch bei der Größenänderung von Bildern Anti-Aliasing- oder Interpolationstechniken erforderlich.
Sowohl Upsampling als auch Downsampling sind wichtig, aber Downsampling ist bei Kanten-KI häufiger anzutreffen. Typischerweise erzeugen Sensoren eine Ausgabe mit einer bestimmten Frequenz und überlassen es dem Entwickler, die Frequenz herunterzurechnen, die für den Rest der Signalverarbeitungspipeline am besten geeignet ist.
Für Kanten-KI-Anwendungen ist Upsampling vor allem dann sinnvoll, wenn du zwei Signale mit unterschiedlichen Frequenzen zu einer einzigen Zeitreihe kombinieren möchtest. Dies kann jedoch auch durch Downsampling des höherfrequenten Signals erreicht werden, wasrechnerisch günstiger sein kann.
Filtern
Ein digitaler Filter ist eine Funktion, die ein Zeitreihensignal auf eine bestimmte Art und Weise umwandelt. Es gibt viele verschiedene Arten von Filtern, die bei der Aufbereitung von Daten für Kanten-KI-Algorithmen sehr nützlich sein können.
Tiefpassfilter sind so konstruiert, dass sie niederfrequente Elemente eines Signals durchlassen, während sie hochfrequente Elemente entfernen. Die Grenzfrequenz des Filters beschreibt die Frequenz, ab der hochfrequente Signale beeinträchtigt werden, und der Frequenzgang beschreibt, wie stark diese Signale beeinträchtigt werden.
Hochpassfilter sind das Gleiche in umgekehrter Form: Sie lassen Frequenzen oberhalb einer Grenzfrequenz passieren und dämpfen die darunter liegenden. Ein Bandpassfilter kombiniert beides: Er lässt Frequenzen innerhalb eines bestimmten Bandes durch, dämpft aber die Frequenzen außerhalb dieses Bandes.
Der Zweck der Filterung in der Kanten-KI ist es, die nützlichen Teile eines Signals zu isolieren und die Teile zu entfernen, die nicht zur Lösung des Problems beitragen. Eine Spracherkennungsanwendung könnte zum Beispiel einen Bandpassfilter verwenden, um Frequenzen im normalen Bereich der menschlichen Sprache (125 Hz bis 8 kHz) zuzulassen, während Informationen in anderen Frequenzen zurückgewiesen werden. Dies könnte es einem maschinellen Lernmodell erleichtern, die Sprache zu interpretieren, ohne durch andere Informationen im Signal abgelenkt zu werden.
Filter können auf alle Arten von Daten angewendet werden. Wenn zum Beispiel ein Tiefpassfilter auf ein Bild angewendet wird, hat er einen verwischenden oder glättenden Effekt. Wird ein Hochpassfilter auf dasselbe Bild angewendet, werden Details "geschärft".
Eine Art von Tiefpassfilter ist der gleitende Durchschnittsfilter. Bei einer Zeitreihe berechnet er einen gleitenden Durchschnitt der Werte innerhalb eines bestimmten Fensters. Er glättet nicht nur die Daten, sondern bewirkt auch, dass ein einziger Wert Informationen aus einem großenZeitbereich repräsentiert.
Wenn mehrere gleitende Durchschnitte mit unterschiedlichen Fensterlängen berechnet und übereinander gestapelt werden, enthält eine Momentaufnahme des Signals (die mehrere verschiedene gleitende Durchschnitte enthält) Informationen über Veränderungen des Signals über ein Zeitfenster und eine Reihe verschiedener Frequenzen. Dies kann eine hilfreiche Technik bei der Merkmalstechnik sein, da ein KI-Algorithmus so mit relativ wenigen Datenpunkten ein breites Zeitfenster beobachten kann.
Die Filterung ist eine weit verbreitete Signalverarbeitungsoperation. Viele eingebettete Prozessoren bieten Hardware-Unterstützung für einige Arten der Filterung, was die Latenzzeit und den Energieverbrauch reduziert.
Spektralanalyse
Ein Zeitreihensignal befindet sich im Zeitbereich, d.h. es zeigt, wie sich eine Reihe von Variablen im Laufe der Zeit verändert. Mit einigen gängigen mathematischen Werkzeugen ist es möglich, ein Zeitreihensignal in den Frequenzbereich zu transformieren. Die durch die Transformation erhaltenen Werte beschreiben, wie viel des Signals in verschiedenen Frequenzbändern über einen Frequenzbereich liegt - ein Spektrum.
Wenn du ein Signal in mehrere dünne Fenster unterteilst und dann jedes Fenster in den Frequenzbereich transformierst (siehe Abbildung 4-5), kannst du eine Karte erstellen, die zeigt, wie sich die Frequenzen des Signals im Laufe der Zeit verändern. Diese Karte, das so genannte Spektrogramm, dient als sehr effektiver Input für maschinelle Lernmodelle.
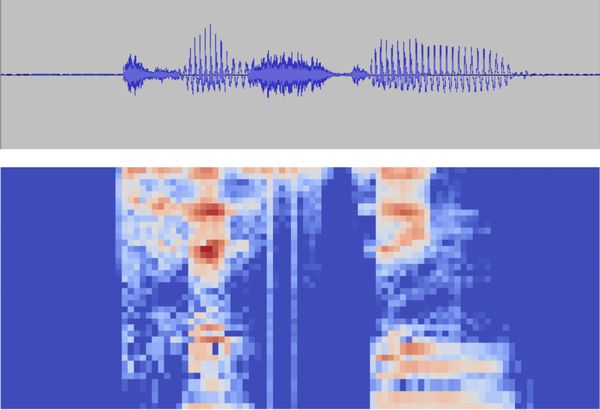
Abbildung 4-5. Derselbe Audioclip dargestellt als Wellenform im Zeitbereich (oben) und als Spektrogramm im Frequenzbereich (unten)
Spektrogramme werden häufig in realen Anwendungen eingesetzt, vor allem im Audiobereich. Die Aufteilung der Daten in gefensterte Frequenzbänder ermöglicht relativ kleine und einfache Modelle, um sie zu interpretieren.2 Außerdem können Menschen beim Betrachten von Spektrogrammen visuell ein Wort von einem anderen unterscheiden - manche haben sogar gelernt, sie zu lesen.
Es gibt viele Algorithmen, mit denen ein Signal vom Zeit- in den Frequenzbereich umgewandelt werden kann, aber der häufigste ist die Fourier-Transformation. Diese Operation ist weit verbreitet und oft gibt es Hardware-Unterstützung (oder zumindest optimierte Implementierungen) für die Durchführung von Fourier-Transformationen auf eingebetteten Geräten.
Es gibt eine Vielzahl von Algorithmen und Techniken für die digitale Signalverarbeitung und die Zeitreihenanalyse; sie sind wichtige Bereiche der Technik und des Studiums. Einige gute Quellen zu diesen Themen sind:
-
The Scientist and Engineer's Guide to Digital Signal Processing, von Steven W. Smith (California Technical, 1997)
-
Practical Time Series Analysis, von Aileen Nielsen (O'Reilly, 2019)
Erkennung von Bildmerkmalen
Eine ganze Reihe von Signalverarbeitungsalgorithmen befasst sich mit der Extraktion von nützlichen Merkmalen3 aus Bildern. Diese werden traditionell als Computer Vision Algorithmen bezeichnet. Einige gängige Beispiele sind:
- Kantenerkennung
-
Wird verwendet, um Grenzen in einem Bild zu identifizieren (siehe Abbildung 4-6)
- Eckenerkennung
-
Wird verwendet, um Punkte in einem Bild zu finden, die eine interessante zweidimensionale Struktur aufweisen
- Blob-Erkennung
-
Wird verwendet, um Regionen eines Bildes zu identifizieren, die etwas gemeinsam haben
- Ridge-Erkennung
-
Wird verwendet, um Kurven in einem Bild zu identifizieren

Abbildung 4-6. Algorithmen zur Kantenerkennung finden Grenzen zwischen Bereichen mit unterschiedlichen Farben oder Intensitäten
Die Erkennung von Bildmerkmalen reduziert ein großes, unübersichtliches Bild auf eine kompaktere Darstellung der visuellen Strukturen, die darin vorhanden sind. Das kann KI-Algorithmen, die nachgeschaltet sind, das Leben erleichtern.
Die Erkennung von Merkmalen ist bei der Arbeit mit Bildern nicht immer notwendig. Deep-Learning-Modelle sind in der Regel in der Lage, ihre eigenen Methoden zur Extraktion von Merkmalen zu erlernen, was den Nutzen der Vorverarbeitung verringert. Dennoch ist es üblich, bei der Interpretation von Bilddaten mit anderen Algorithmen der Kanten-KI eine Merkmalserkennung durchzuführen.
Das OpenCV-Projekt bietet eine Reihe von Bibliotheken für die Merkmalserkennung (und andere Bildverarbeitungsaufgaben), die auf den meisten SoC-Geräten laufen. Für Mikrocontroller bietet OpenMV eine quelloffene Bibliothek mit Algorithmen zur Merkmalserkennung und die dazugehörige Hardware.
Kombination von Funktionen und Sensoren
Nichts hält dich davon ab, mehrere verschiedene Merkmale und Signale als Input für deine KI-Algorithmen zu kombinieren. Du könntest zum Beispiel mehrere gleitende Durchschnitte einer Zeitreihe über verschiedene Zeitfenster berechnen und sie alle zusammen in ein maschinelles Lernmodell eingeben. Es gibt keine festen Regeln, also experimentiere ruhig und sei kreativ, wenn es darum geht, wie du deine Daten zerschneidest und würfelst. Die folgenden Kapitel bieten dir einen Rahmen für deine Experimente.
Bei der Sensorfusion werden nicht nur Merkmale desselben Signals kombiniert, sondern es werden auch Daten von mehreren Sensoren zusammengeführt. Ein Kanten-KI-Fitness-Tracker könnte zum Beispiel Informationen von einem Beschleunigungsmesser, einem Gyroskop und einem Herzfrequenzsensor kombinieren, um zu erkennen, welche Sportart der Träger gerade ausübt.
In einem komplexeren KI-Szenario müssen die Sensoren nicht einmal in dasselbe Gerät integriert sein. Stell dir ein intelligentes Klimatisierungssystem vor, das Temperatur- und Anwesenheitssensoren in einem Gebäude nutzt, um die Nutzung der Klimaanlage zu optimieren.
Es gibt drei Kategorien von Sensorfusionen:
- Ergänzend
-
Wenn mehrere Sensoren kombiniert werden, um ein umfassenderes Verständnis einer Situation zu erhalten, als es mit einem einzelnen Sensor möglich wäre - zum Beispiel die verschiedenen Sensoren an unserem hypothetischen Fitness-Tracker.
- Konkurrenzfähig
-
Mehrere Sensoren messen genau dasselbe, um die Wahrscheinlichkeit von Fehlmessungen zu verringern - zum Beispiel mehrere redundante Sensoren, die die Temperatur eines kritischen Geräts überwachen.
- Kooperativ
-
Wenn Informationen von mehreren Sensoren kombiniert werden, um ein Signal zu erzeugen, das sonst nicht verfügbar wäre - zum Beispiel wenn zwei Kameras ein Stereobild erzeugen, das Tiefeninformationen liefert.
Die Herausforderung bei der Sensorfusion besteht darin, mehrere Signale zu kombinieren, die sogar mit unterschiedlicher Geschwindigkeit auftreten können. Du solltest Folgendes bedenken:
-
Angleichung der Signale in der Zeit. Für viele Algorithmen ist es wichtig, dass alle Signale, die wir verschmelzen wollen, mit der gleichen Frequenz abgetastet werden und dass die Werte gleichzeitige Messungen widerspiegeln. Dies kann durch Resampling erreicht werden, z. B. durch Upsampling eines niederfrequenten Signals, damit es die gleiche Frequenz hat wie das hochfrequente Signal, mit dem es verschmolzen werden soll.
-
Skalierung der Signale. Es ist wichtig, dass die Werte der Signale auf der gleichen Skala liegen, damit ein Signal mit typischerweise großen Werten ein Signal mit typischerweise kleineren Werten nicht überdeckt.
-
Das numerische Kombinieren der Signale. Dies kann mit einfachen mathematischen Operationen (Addition, Multiplikation oder Mittelwertbildung) oder mit komplizierteren Algorithmen wie dem Kalman-Filter (dazu später mehr) geschehen - oder einfach durch die Verkettung der Daten und ihre Übergabe an den Algorithmus als eine einzige Matrix.
Du kannst die Sensorfusion vor oder nach anderen Phasen des Feature Engineering durchführen. Ein willkürliches Beispiel: Wenn du zwei Zeitreihen fusionieren willst, könntest du zunächst einen Tiefpass über eine der beiden Reihen laufen lassen, sie dann auf den gleichen Maßstab skalieren, die beiden durch Mittelwertbildung kombinieren und die kombinierten Werte in den Frequenzbereich transformieren. Hab keine Angst zu experimentieren!
Wir haben jetzt einige ernstzunehmende Werkzeuge, um Daten zu verarbeiten. Im nächsten Abschnitt werden wir die KI-Algorithmen erkunden, die uns helfen werden, sie zu verstehen.
Algorithmen der künstlichen Intelligenz
Es gibt zwei Möglichkeiten, über KI-Algorithmen nachzudenken. Die eine basiert auf der Funktionalität: Wozu sind sie da? Die andere basiert auf der Umsetzung: Wie funktionieren sie? Beide Aspekte sind wichtig. Die Funktionalität ist entscheidend für die Anwendung, die du entwickeln willst, und die Umsetzung ist wichtig, wenn du über deine Einschränkungen nachdenkst - das heißt in der Regel über deinen Datensatz und das Gerät, auf dem du ihn einsetzen willst.
Algorithmustypen nach Funktionalitäten
Schauen wir uns zunächst die wichtigsten Arten von Algorithmen aus funktionaler Sicht an. Das Problem, das du zu lösen versuchst, auf diese Algorithmentypen abzubilden, nennt man Framing. In Kapitel 6 werden wir uns eingehend mit Framing beschäftigen.
Klassifizierung
Klassifizierungsalgorithmen versuchen, das Problem der Unterscheidung zwischen verschiedenen Arten oder Klassen von Dingen zu lösen. Das kann bedeuten:
-
Ein Fitnessmonitor mit einem Beschleunigungsmesser, der zwischen Gehen und Laufen unterscheidet
-
Ein Sicherheitssystem mit einem Bildsensor, der einen leeren Raum von einem Raum mit einer anwesenden Person unterscheidet
-
Eine Wildtierkamera, die vier verschiedene Tierarten klassifiziert
Abbildung 4-7 zeigt einen Klassifikator, der anhand der von einem Beschleunigungssensor erfassten Daten feststellt, ob ein Gabelstapler im Leerlauf oder in Bewegung ist.
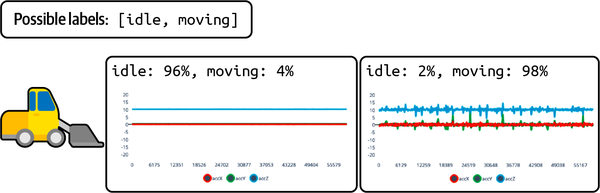
Abbildung 4-7. Ein Klassifikator gibt normalerweise eine Wahrscheinlichkeitsverteilung aus, die jede mögliche Klasse enthält
Die Klassifizierung kann auf verschiedene Arten erfolgen, je nach Aufgabe:
- Binäre Klassifizierung
-
Die Eingabe gehört zu einer von zwei Klassen.
- Multiklassen-Klassifizierung
-
Die Eingabe gehört zu einer von mehr als zwei Klassen.
- Multilabel-Klassifizierung
-
Die Eingabe gehört zu null oder mehr einer beliebigen Anzahl von Klassen.
Die gebräuchlichsten Formen der Klassifizierung sind die binäre und die Multiklassen-Klassifizierung. Bei diesen Formen der Klassifizierung brauchst du immer mindestens zwei Klassen. Selbst wenn es nur eine Sache gibt, die dich interessiert (z. B. eine Person im Raum), brauchst du auch eine Klasse, die alles repräsentiert, was dich nicht interessiert (z. B. Räume, in denen sich keine Personen befinden). Multilabel-Klassifizierung ist vergleichsweise selten.
Regression
Regressionsalgorithmen versuchen, Zahlen zu ermitteln. Das könnte bedeuten:
-
Ein intelligenter Thermostat, der die Temperatur in einer Stunde vorhersagt
-
Eine virtuelle Waage, die das Gewicht eines Lebensmittels mithilfe einer Kamera schätzt
-
Ein virtueller Sensor, der die Drehgeschwindigkeit eines Motors anhand seines Geräuschs schätzt
Virtuelle Sensoren, wie die letzten beiden Beispiele, sind ein besonders interessanter Fall von Regression. Sie können verfügbare Sensordaten nutzen, um Messungen von verschiedenen Sensortypen vorherzusagen - ohne dass diese Sensoren tatsächlich vorhanden sein müssen.
Objekterkennung und Segmentierung
Objekterkennungsalgorithmen nehmen ein Bild oder ein Video und identifizieren die Positionen bestimmter Objekte darin, indem sie oft Bounding Boxes um sie herum zeichnen. Sie kombinieren Klassifizierung und Regression, indem sie bestimmte Objekttypen identifizieren und ihre numerischen Koordinaten vorhersagen - wie in Abbildung 4-8 zu sehen.

Abbildung 4-8. Eine übliche Ausgabe von Objekterkennungsmodellen besteht aus Begrenzungsrahmen, die um erkannte Objekte herum gezeichnet werden, wobei jedes Objekt einen individuellen Konfidenzwert hat
Für bestimmte Arten von Objekten gibt es spezielle Algorithmen zur Objekterkennung. Modelle zur Schätzung der Körperhaltung wurden zum Beispiel entwickelt, um menschliche Körperteile zu erkennen und ihre Position in einem Bild zu bestimmen - wie in Abbildung 4-9 dargestellt.

Abbildung 4-9. Die Posenschätzung identifiziert Schlüsselpunkte am menschlichen Körper, deren Position als Input für andere Prozesse verwendet werden kann
Segmentierungsalgorithmen ähneln den Objekterkennungsalgorithmen, aber sie klassifizieren Bilder auf Pixelebene. Das Ergebnis ist eine Segmentierungskarte, wie in Abbildung 4-10 zu sehen, die versucht, Bereiche der Eingabe mit ihrem Inhalt zu kennzeichnen.

Abbildung 4-10. Diese Straßenszene wurde mit einer Segmentierungskarte beschriftet. Verschiedene Bereiche, wie Menschen und die Straßenoberfläche, sind in unterschiedlichen Farbtönen dargestellt. Ein Segmentierungsalgorithmus zielt darauf ab, vorherzusagen, welche Pixel zu welcher Art von Objekt gehören.
Hier sind einige Anwendungsbeispiele für die Erkennung und Segmentierung von Objekten:
Erkennung von Anomalien
Algorithmen zur Erkennung von Anomalien erkennen, wenn ein Signal von seinem normalen Verhalten abweicht. Sie sind in vielen Anwendungen nützlich:
-
Ein industrielles vorausschauendes Wartungssystem, das anhand der Stromaufnahme erkennen kann, wann ein Motor ausfällt
-
Ein Staubsaugerroboter, der mit Hilfe eines Beschleunigungssensors erkennen kann, wenn er auf einer ungewöhnlichen Oberfläche fährt
-
Eine Trail-Kamera, die weiß, wann ein unbekanntes Tier vorbeigegangen ist
Algorithmen zur Erkennung von Anomalien sind sehr nützlich für die vorausschauende Wartung. Sie sind auch sehr hilfreich, wenn sie mit maschinellen Lernmodellen kombiniert werden. Viele maschinelle Lernmodelle liefern falsche, zufällige Ergebnisse, wenn sie mit einer Eingabe konfrontiert werden, die nicht in ihrem Trainingssatz enthalten ist.
Um dies zu vermeiden, kann ein ML-Modell mit einem Algorithmus zur Erkennung von Anomalien gepaart werden, der ihm mitteilt, wenn etwas außerhalb der Verteilung liegt, damit seine falschen Ergebnisse verworfen werden können. Einige Modelle können auch so kalibriert werden, dass ihre Ausgabe eine echte Wahrscheinlichkeitsverteilung darstellt, die interpretiert werden kann, um zu erkennen, wann das Modell unsicher ist.
Clustering
Clustering-Algorithmen versuchen, Eingaben nach ihrer Ähnlichkeit zu gruppieren und können erkennen, wenn eine Eingabe nicht mit dem übereinstimmt, was sie zuvor gesehen hat. Sie werden häufig eingesetzt, wenn ein Kanten-KI-Gerät aus seiner Umgebung lernen muss, z. B. bei der Erkennung von Anomalien. Nehmen wir zum Beispiel an:
-
Ein Sprachassistent, der lernt, welche Stimme zu jedem seiner Nutzer gehört
-
Eine vorausschauende Wartungsanwendung, die einen "normalen" Betriebszustand erlernt und Abweichungen davon erkennen kann
-
Ein Verkaufsautomat, der Getränke auf der Grundlage der bisherigen Auswahl eines Benutzers empfehlen kann
Ein Clustering-Algorithmus kann seine Cluster entweder "on the fly" (nach dem Einsatz) lernen oder sie im Voraus konfigurieren.
Dimensionalitätsreduktion
Algorithmen zur Dimensionalitätsreduktion erzeugen aus einem Signal eine Darstellung, die die gleichen Informationen enthält, aber viel weniger Platz benötigt. Die Darstellungen von zwei Signalen können dann leicht miteinander verglichen werden. Hier sind einige Anwendungsbeispiele:
-
Komprimierung von Audiodaten, um die Übertragung von Tönen von einem entfernten Gerät billiger zu machen
-
Fingerabdruckerkennung, die sicherstellt, dass ein Fingerabdruck mit dem Besitzer eines Geräts übereinstimmt
-
Gesichtserkennung, Erkennung einzelner Gesichter in einem Videofeed
Die Dimensionalitätsreduktion wird in der Regel nicht allein, sondern zusammen mit anderen KI-Algorithmen eingesetzt. Sie kann zum Beispiel in Verbindung mit einem Clustering-Algorithmus verwendet werden, um ähnliche Signale in komplexen Datentypen wie Audio und Video zu identifizieren.
Transformation
Transformationsalgorithmen nehmen ein Signal und geben ein anderes aus. Hier sind einigeBeispiele:
-
Kopfhörer mit Rauschunterdrückung, die bestimmte Geräusche in einem Signal erkennen und entfernen
-
Eine Rückfahrkamera für Autos, die das Bild bei Dunkelheit oder Regen verbessert
-
Ein Spracherkennungsgerät, das ein Audiosignal aufnimmt und eineTranskription ausgibt
Die Eingabe und die Ausgabe von Transformationsalgorithmen können sehr unterschiedlich sein. Im Fall der Transkription ist die Eingabe ein Strom von Audiodaten und die Ausgabe eine Folge von Wörtern.
Algorithmen kombinieren
Es gibt keinen Grund, warum du nicht verschiedene Arten von Algorithmen in der gleichen Anwendung mischen kannst. Später in diesem Abschnitt werden wir Techniken zur Kombination von Algorithmen untersuchen (siehe "Algorithmen kombinieren").
Algorithmustypen nach Implementierung
Algorithmen nach ihrer Funktionalität zu untersuchen, hilft uns zu verstehen, wofür sie verwendet werden, aber aus technischer Sicht ist es wichtig, ein Gefühl für die verschiedenen Möglichkeiten zu bekommen, wie diese Funktionalitäten implementiert werden können. Es gibt Hunderte von verschiedenen Möglichkeiten, einen Klassifizierungsalgorithmus zu entwickeln, die das Ergebnis jahrzehntelanger Forschung in der Informatik sind. Jede Methode hat ihre eigenen Stärken und Schwächen, die durch die Beschränkungen der Kanten-KI-Hardware noch verstärkt werden.
Im folgenden Abschnitt werden wir die wichtigsten Arten der Implementierung von Kanten-KI-Algorithmen untersuchen. Beachte, dass diese Liste nicht vollständig ist - wir konzentrieren uns auf Kanten-KI und damit auf Technologien, die auf dem Gerät gut funktionieren.
Konditionale und Heuristiken
Die einfachste Art von KI-Algorithmen basiert auf bedingter Logik: einfache if Anweisungen, die zu Entscheidungen führen. Schauen wir uns noch einmal den Codeschnipsel an, den wir in "Künstliche Intelligenz" untersucht haben :
current_speed=10# In meters per seconddistance_from_wall=50# In metersseconds_to_stop=3# The minimum time in seconds required to stop the carsafety_buffer=1# The safety margin in seconds before hitting the brakes# Calculate how long we’ve got before we hit the wallseconds_until_crash=distance_from_wall/current_speed# Make sure we apply the brakes if we’re likely to crash soonifseconds_until_crash<seconds_to_stop+safety_buffer:applyBrakes()
Dieser einfache Algorithmus führt eine grundlegende Berechnung anhand einiger vom Menschen festgelegter Werte durch (seconds_to_stop, etc.) und entscheidet, ob die Bremsen eines Autos betätigt werden sollen. Gilt das als KI? Das ist eine Frage, die zu Diskussionen anregen könnte, aber die Antwort lautet eindeutig ja.4
Das gängige Verständnis von künstlicher Intelligenz ist, dass es darum geht, Maschinen zu schaffen, die wie Menschen denken können. Die technische Definition ist viel realistischer: KI ermöglicht es Computern, Aufgaben zu erledigen, die normalerweise menschliche Intelligenz erfordern. In diesem Fall ist die Steuerung der Bremsen eines Autos, um einen Zusammenstoß zu vermeiden, definitiv etwas, das normalerweise menschliche Intelligenz erfordert. Vor zwanzig Jahren wäre das noch sehr beeindruckend gewesen, aber automatische Bremsen sind inmodernen Fahrzeugen gang und gäbe.
Hinweis
Bevor du über die Idee lachst, dass if Aussagen künstliche Intelligenz sein können, solltest du bedenken, dass Entscheidungsbäume - eineder beliebtesten und effektivsten Kategorien von Algorithmen für maschinelles Lernen - unter der Haube nur if Anweisungen sind. Heutzutage können sogar Deep-Learning-Modelle als binäre neuronale Netze implementiert werden, die im Wesentlichen aus bedingter Logik bestehen. Die Intelligenz kommt von der Anwendung, nicht von der Implementierung!
Die bedingte Logik in unserem Algorithmus zur Fahrzeugbremsung ist eigentlich eine Umsetzung der Klassifizierung. Anhand einer Eingabe (die Geschwindigkeit des Autos und der Abstand zu einer Wand) klassifiziert der Algorithmus die Situation in eine von zwei Arten: sicheres Fahren oder drohender Unfall. Die bedingte Logik wird natürlich für die Klassifizierung verwendet, da ihre Ausgabe kategorisch ist; eine if Aussage gibt uns entweder die eine oder die andere Ausgabe.
Die bedingte Logik ist mit der Idee der Heuristik verbunden. Eine Heuristik ist eine selbst erstellte Regel, die auf eine Situation angewendet werden kann, um sie zu verstehen oder auf sie zu reagieren. Unser Algorithmus zum Bremsen eines Autos verwendet zum Beispiel die Heuristik, dass wir bremsen sollten, wenn wir weniger als vier Sekunden Zeit haben, bevor wir gegen eine Wand fahren.
Heuristiken werden von Menschen mithilfe von Fachwissen entwickelt. Dieses Fachwissen kann auf Daten beruhen, die über eine reale Situation gesammelt wurden. In dieser Hinsicht könnte unser scheinbar einfacher Algorithmus zum Bremsen von Autos tatsächlich ein tiefes, gut erforschtes Verständnis der realen Welt darstellen. Vielleicht wurde der Wert von seconds_to_stop nach millionenschweren Crashtests ermittelt und stellt den idealen Wert für die Konstante dar. Vor diesem Hintergrund ist es leicht zu erkennen, dass selbst eine Anweisung von if eine beträchtliche Menge an menschlicher Intelligenz und Wissen repräsentieren kann, die in einem einfachen und eleganten Stück Code erfasst und destilliert wurde.
Unser Beispiel mit der Autobremse ist sehr einfach, aber in Verbindung mit der Signalverarbeitung kann die bedingte Logik ziemlich anspruchsvolle Entscheidungen treffen. Stell dir zum Beispiel vor, du baust ein vorausschauendes Wartungssystem, das Arbeiter/innen anhand der Geräusche einer Industriemaschine über deren Zustand informieren soll. Vielleicht gibt die Maschine ein charakteristisches hohes Heulen von sich, wenn sie kurz vor einem Ausfall steht. Wenn du den Ton aufnimmst und ihn mit einer Fourier-Transformation in den Frequenzbereich überträgst, kannst du mit einer einfachen Anweisung unter if feststellen, wann das Heulen auftritt, und es den Arbeitern mitteilen.
Über die if Anweisungen hinaus kannst du komplexere Logik verwenden, um Situationen auf der Grundlage bekannter Regeln zu interpretieren. Zum Beispiel kann eine Industriemaschine einen handcodierten Algorithmus verwenden, um Schäden zu vermeiden, indem sie ihre Drehzahl auf der Grundlage von Messungen der internen Temperatur und des Drucks verändert. Der Algorithmus könnte die Temperatur und den Druck nehmen und direkt eine Drehzahl berechnen, indem er menschliche Erkenntnisse nutzt, die im Code festgehalten sind.
Wenn es für deine Situation funktioniert, können bedingte Logik und andere handcodierte Algorithmen erstaunlich sein. Sie sind leicht zu verstehen, leicht zu debuggen und leicht zu testen. Es gibt kein Risiko von unbestimmtem Verhalten: Der Code verzweigt entweder in die eine oder in die andere Richtung, und alle Pfade können mit automatisierten Tests überprüft werden. Er läuft unglaublich schnell und funktioniert auf jedem erdenklichen Gerät.
Es gibt zwei große Nachteile von Heuristiken. Erstens kann ihre Entwicklung ein erhebliches Fachwissen und Programmierkenntnisse erfordern. Fachwissen ist nicht immer verfügbar - ein kleines Unternehmen hat vielleicht nicht die Ressourcen, um die teure Forschung durchzuführen, die notwendig ist, um die grundlegenden mathematischen Regeln eines Systems zu verstehen. Und selbst wenn das Fachwissen vorhanden ist, verfügt nicht jeder über das nötige Fachwissen, um einen heuristischen Algorithmus zu entwerfen und in effizienten Code umzusetzen.
Der zweite große Nachteil ist die Idee der kombinatorischen Explosion. Je mehr Variablen in einer Situation vorhanden sind, desto schwieriger ist es, sie mit herkömmlichen Computeralgorithmen zu modellieren. Ein gutes Beispiel dafür ist das Schachspiel: Es gibt so viele Figuren und so viele mögliche Züge, dass die Entscheidung, was als Nächstes zu tun ist, eine riesige Menge an Berechnungen erfordert. Selbst die fortschrittlichsten Schachcomputer, die mit bedingter Logik arbeiten, können von erfahrenen menschlichen Spielern leicht geschlagen werden.
Manche Kanten-KI-Probleme sind viel komplexer als Schachspiele. Stell dir zum Beispiel vor, du versuchst, von Hand eine bedingte Logik zu schreiben, mit der du bestimmen kannst, ob ein Kamerabild eine Orange oder eine Banane zeigt. Mit ein paar Tricks ("Gelb bedeutet Banane, Orange bedeutet Orange") könntest du es für einige Bildkategorien schaffen, aber es wäre unmöglich, es über die einfachsten Szenen hinaus zu verallgemeinern.
Eine gute Faustregel für handkodierte Logik lautet: Je mehr Datenwerte du verarbeiten musst, desto schwieriger wird es, eine zufriedenstellende Lösung zu finden. Zum Glück gibt es viele Algorithmen, die einspringen können, wenn ein handcodierter Ansatz fehlschlägt.
Klassisches maschinelles Lernen
Maschinelles Lernen ist ein spezieller Ansatz zur Erstellung von Algorithmen. Während heuristische Algorithmen durch manuelles Kodieren von Logik auf der Grundlage bekannter Regeln erstellt werden, entdecken maschinelle Lernalgorithmen ihre eigenen Regeln, indem sie große Datenmengen untersuchen.
Die folgende Beschreibung, die dem Buch TinyML entnommen ist, führt in die grundlegenden Ideen des maschinellen Lernens ein:
Um ein maschinelles Lernprogramm zu erstellen, füttert ein Programmierer Daten mit einer speziellen Art von Algorithmus und lässt den Algorithmus die Regeln entdecken. Das bedeutet, dass wir als Programmierer/innen Programme erstellen können, die auf der Grundlage komplexer Daten Vorhersagen treffen, ohne dass wir selbst die ganze Komplexität verstehen müssen. Der Algorithmus des maschinellen Lernens erstellt auf der Grundlage der von uns bereitgestellten Daten ein Modell des Systems, das wir Training nennen. Das Modell ist eine Art Computerprogramm. Wir lassen die Daten durch dieses Modell laufen, um Vorhersagen zu treffen, ein Prozess, der Inferenz genannt wird.
TinyML (O'Reilly, 2019)
Algorithmen des maschinellen Lernens können alle in diesem Kapitel beschriebenen funktionalen Aufgaben erfüllen, von der Klassifizierung bis zur Transformation. Die wichtigste Voraussetzung für den Einsatz von maschinellem Lernen ist, dass du einen Datensatz hast. Dabei handelt es sich um einen großen Datensatz, der in der Regel unter realen Bedingungen erhoben wird und zum Trainieren des Modells verwendet wird.
Normalerweise werden die Daten, die zum Trainieren eines maschinellen Lernmodells benötigt werden, während des Entwicklungsprozesses aus so vielen Quellen wie möglich zusammengetragen. Wie wir in späteren Kapiteln sehen werden, ist ein großer und vielfältiger Datensatz entscheidend für die Arbeit mit Kanten-KI - aber insbesondere für maschinelles Lernen.
Da maschinelles Lernen von großen Datensätzen abhängt und das Trainieren eines maschinellen Lernmodells sehr rechenintensiv ist, findet der Trainingsteil in der Regel vor dem Einsatz statt, während die Schlussfolgerungen am Rande des Geräts gezogen werden. Es ist sicherlich möglich, Machine-Learning-Modelle auf dem Gerät zu trainieren, aber der Mangel an Daten in Kombination mit der geringen Menge an Rechenleistung macht dies zu einer Herausforderung.
In der Kanten-KI gibt es zwei Hauptwege, um mit Machine-Learning-Datensätzen zu arbeiten:
- Überwachtes Lernen
-
Der Datensatz wurde von einem Experten beschriftet, um dem Algorithmus für maschinelles Lernen zu helfen, ihn zu verstehen.
- Unüberwachtes Lernen
-
Wenn der Algorithmus Strukturen in den Daten ohne menschliche Hilfe identifiziert
Maschinelles Lernen hat einen großen Nachteil in Bezug auf die Datenmenge. ML-Algorithmen hängen vollständig von ihren Trainingsdaten ab, um zu wissen, wie sie auf Eingaben reagieren sollen. Solange sie Eingaben erhalten, die ihren Trainingsdaten ähnlich sind, sollten sie gut funktionieren. Wenn sie jedoch eine Eingabe erhalten, die sich erheblich von ihren Trainingsdaten unterscheidet - eine so genannte "Out-of-Distribution"-Eingabe - werden sie eine völlig unbrauchbare Ausgabe produzieren.
Das Tückische daran ist, dass es keine offensichtliche Möglichkeit gibt, an der Ausgabe zu erkennen, dass eine Eingabe nicht richtig verteilt wurde. Das heißt, es besteht immer das Risiko, dass ein Modell unbrauchbare Vorhersagen macht. Dieses Problem zu vermeiden, ist ein zentrales Anliegen bei der Arbeit mit maschinellem Lernen.
Es gibt viele verschiedene Arten von Algorithmen für maschinelles Lernen. Das klassische maschinelle Lernen umfasst die überwiegende Mehrheit der Algorithmen, die in der Praxis verwendet werden, mit der großen Ausnahme des Deep Learning (das wir im nächsten Abschnitt untersuchen werden).
Hier sind einige der nützlichsten Arten von klassischen ML-Algorithmen für Kanten-KI. Der Titel gibt an, ob es sich um überwachte oder unüberwachte Algorithmen handelt:
- Regressionsanalyse (beaufsichtigt)
-
Lernt die mathematischen Beziehungen zwischen Eingabe und Ausgabe, um einen kontinuierlichen Wert vorherzusagen. Einfach zu trainieren, schnell auszuführen, geringe Datenanforderungen und hoch interpretierbar, kann aber nur einfache Systeme lernen.
- Logistische Regression (beaufsichtigt)
-
Die logistische Regression ist eine klassifikationsorientierte Art der Regressionsanalyse, die die Beziehung zwischen Eingabewerten und Ausgabekategorien lernt - und zwar für relativ einfache Systeme.
- Support-Vektor-Maschine (überwacht)
-
Nutzt ausgeklügelte Mathematik, um viel komplexere Zusammenhänge zu lernen als die einfache Regressionsanalyse. Geringe Datenanforderungen, schnelle Ausführung, kann komplexe Systeme lernen, aber schwierig zu trainieren und wenig interpretierbar.
- Entscheidungsbäume und Zufallswälder (überwacht)
-
Verwendet einen iterativen Prozess, um eine Reihe von
ifAnweisungen zu konstruieren, die eine Ausgabekategorie oder einen Wert vorhersagen. Einfach zu trainieren, schnell auszuführen, hochgradig interpretierbar, kann komplexe Systeme erlernen, erfordert aber möglicherweise eine große Menge an Trainingsdaten. - Kalman-Filter (überwacht)
-
Sagt den nächsten Datenpunkt anhand einer Historie von Messungen voraus. Kann mehrere Variablen einbeziehen, um die Genauigkeit zu verbessern. Wird oft auf dem Gerät trainiert, benötigt nur wenige Daten, ist schnell ausgeführt und leicht zu interpretieren, kann aber nur relativ einfache Systeme modellieren.
- Nächste Nachbarn (unbeaufsichtigt)
-
Klassifiziert Daten danach, wie ähnlich sie bekannten Datenpunkten sind. Oft auf dem Gerät trainiert, geringe Datenanforderungen, leicht zu interpretieren, kann aber nur relativ einfache Systeme modellieren und kann bei vielen Datenpunkten langsam sein.
- Clustering (unüberwacht)
-
Lernt, Eingaben nach Ähnlichkeit zu gruppieren, benötigt aber keine Kennzeichnungen. Wird oft auf dem Gerät trainiert, benötigt wenig Daten, kann schnell ausgeführt werden, ist leicht zu interpretieren, kann aber nur relativ einfache Systeme modellieren.
Klassische ML-Algorithmen sind ein unglaubliches Instrumentarium, um die Ergebnisse deiner Feature-Engineering-Pipeline zu interpretieren und Entscheidungen anhand von Daten zu treffen. Sie decken das Spektrum von hocheffizient bis hochflexibel ab und können viele funktionale Aufgaben erfüllen. Ein weiterer großer Vorteil ist, dass sie in der Regel sehr gut erklärbar sind - es ist einfach zu verstehen, wie sie ihre Entscheidungen treffen. Und je nach Algorithmus können die Datenanforderungen recht gering sein (Deep Learning benötigt in der Regel sehr große Datensätze).
Die Vielfalt der klassischen ML-Algorithmen (es gibt buchstäblich Hunderte) ist für Kanten-KI sowohl ein Segen als auch ein Fluch. Einerseits gibt es Algorithmen, die für viele verschiedene Situationen gut geeignet sind, so dass es möglich ist, einen Algorithmus zu finden, der für einen bestimmten Anwendungsfall theoretisch ideal ist. Andererseits kann die große Konstellation von Algorithmen eine Herausforderung sein.
Bibliotheken wie scikit-learn machen es zwar einfach, viele verschiedene Algorithmen auszuprobieren, aber es ist eine Kunst und eine Wissenschaft, jeden Algorithmus so einzustellen, dass er optimal funktioniert, und seine Ergebnisse zu interpretieren. Wenn du einen Algorithmus auf einem Mikrocontroller einsetzen willst, musst du ihn möglicherweise selbst effizient implementieren - es gibt noch nicht viele Open-Source-Versionen.
Ein großer Nachteil der klassischen ML-Algorithmen ist, dass sie bei der Komplexität der Systeme, die sie modellieren können, an eine relativ niedrige Obergrenze stoßen. Das bedeutet, dass sie, um die besten Ergebnisse zu erzielen, oft mit einem umfangreichen Feature-Engineering gepaart werden müssen, das komplex und rechenintensiv sein kann. Selbst mit Feature-Engineering gibt es einige Aufgaben - wie z. B. die Klassifizierung von Bilddaten - bei denen klassische ML-Algorithmen einfach nicht gut abschneiden.
Klassische ML-Algorithmen sind also ein fantastisches Instrumentarium für Entscheidungen auf dem Gerät. Aber wenn du an ihre Grenzen stößt, kann Deep Learning helfen.
Deep Learning
Deep Learning ist eine Form des maschinellen Lernens, die sich auf neuronale Netze konzentriert. Diese haben sich als so effektives Werkzeug erwiesen, dass Deep Learning zu einem gigantischen Bereich geworden ist, in dem tiefe neuronale Netze für viele Arten von Anwendungen eingesetzt werden.
Hinweis
Dieses Buch konzentriert sich auf die wichtigen Eigenschaften von Deep-Learning-Algorithmen aus einer technischen Perspektive. Die zugrundeliegenden Mechanismen des Deep Learning sind interessant, aber sie sind keine Voraussetzung für die Entwicklung eines KI-Produkts. Mit modernen Werkzeugen kann jeder Ingenieur Deep-Learning-Modelle einsetzen, ohne einen formalen Hintergrund im maschinellen Lernen zu haben. Einige der Tools dafür werden wir später in den Kapiteln der Tutorials vorstellen.
Deep Learning beruht auf denselben Prinzipien wie klassisches ML. Ein Datensatz wird verwendet, um ein Modell zu trainieren, das auf einem Gerät implementiert werden kann, um Schlussfolgerungen zu ziehen. Ein Modell hat nichts Magisches an sich - es ist einfach eine Kombination aus einem Algorithmus und einer Sammlung von Zahlen, die zusammen mit den Eingaben des Modells eingegeben werden, um die gewünschte Ausgabe zu erzeugen.
Die Zahlen im Modell werden Gewichte oder Parameter genannt und werden während des Trainingsprozesses erzeugt. Der Begriff neuronales Netzwerk bezieht sich auf die Art und Weise, wie das Modell seine Eingaben mit seinen Parametern kombiniert.
Viele der verblüffendsten Leistungen der KI-Technik, die wir in den letzten zehn Jahren gesehen haben, wurden mit Deep-Learning-Modellen erzielt. Hier sind einige bekannte Highlights:
-
AlphaGo, ein Computerprogramm, das mit Hilfe von Deep Learning die besten Go-Spieler besiegt hat, ein uraltes Spiel, von dem man einst dachte, dass Computer es nicht meistern können
-
GPT-3, ein Modell, das geschriebene Sprache erzeugen kann, die von menschlicher Schrift nicht zu unterscheiden ist
-
Steuerung von Fusionsreaktoren, die mithilfe von Deep Learning die Form des Plasmas innerhalb eines Fusionsreaktors steuern
-
DALL-E, ein Modell, das auf der Grundlage von Eingabeaufforderungen realistische Bilder und abstrakte Kunst erzeugen kann
-
GitHub Copilot, eine Software, die Softwareentwicklern beim automatischen Schreiben von Code hilft
Abgesehen von den ausgefallenen Dingen, zeichnet sich Deep Learning durch alle Aufgaben aus, die in unseren Unterabschnitten der Algorithmustypen aufgeführt sind (siehe "Algorithmustypen nach Funktionalität"). Es hat sich als flexibel und anpassungsfähig erwiesen und ist ein unglaublich nützliches Werkzeug, das es Computern ermöglicht, die Welt zu verstehen und zu beeinflussen.
Deep Learning-Modelle sind effektiv, weil sie als universelle Funktionsannäherungen funktionieren. Es ist mathematisch bewiesen, dass ein Deep-Learning-Netzwerk eine kontinuierliche Funktion modellieren kann, solange man sie beschreiben kann. Das bedeutet, dass es für jeden Datensatz mit verschiedenen Eingaben und gewünschten Ausgaben ein Deep-Learning-Modell gibt, das das eine in das andere umwandeln kann.
Ein wirklich spannendes Ergebnis dieser Fähigkeit ist, dass Deep-Learning-Modelle während des Trainings herausfinden können, wie sie ihr eigenes Feature Engineering durchführen können. Wenn eine spezielle Transformation benötigt wird, um die Daten zu interpretieren, kann ein Deep-Learning-Modell möglicherweise lernen, wie man sie durchführt. Das macht das Feature Engineering nicht überflüssig, aber es verringert definitiv den Aufwand für den Entwickler, alles genau richtig zu machen.
Deep Learning-Modelle sind deshalb so gut darin, Funktionen zu approximieren, weil sie eine sehr große Anzahl von Parametern haben können. Mit jedem Parameter wird das Modell ein bisschen flexibler und kann so eine etwas komplexere Funktion beschreiben.
Diese Eigenschaft führt zu den zwei größten Nachteilen von Deep Learning-Modellen. Erstens ist es ein schwieriger Prozess, die idealen Werte für all diese Parameter zu finden. Dazu muss ein Modell mit vielen Daten trainiert werden. Daten sind oft eine seltene und kostbare Ressource, die schwer und teuer zu beschaffen ist, was ein großes Hindernis darstellen kann. Zum Glück gibt es viele Techniken, die dabei helfen können, das Beste aus den begrenzten Daten herauszuholen - wir werden sie später in diesem Buch behandeln.
Der zweite große Nachteil ist das Risiko der Überanpassung. Von Overfitting spricht man, wenn ein maschinelles Lernmodell einen Datensatz zu gut lernt. Anstatt die allgemeinen Regeln zu modellieren, die von den Ausgaben zu den Eingaben in seinem Datensatz führen, merkt es sich den Datensatz komplett. Das bedeutet, dass es bei Daten, die es noch nie gesehen hat, nicht gut abschneidet.
Überanpassung ist ein Risiko bei allen maschinellen Lernmodellen, aber es ist eine besondere Herausforderung für Deep-Learning-Modelle, weil sie so viele Parameter haben können. Jeder zusätzliche Parameter gibt dem Modell ein wenig mehr Fähigkeit, sich den Datensatz zu merken.
Es gibt viele verschiedene Arten von Deep Learning-Modellen. Hier sind einige der wichtigsten für Kanten-KI:
- Vollständig verbundene Modelle
-
Die einfachste Art von Deep Learning-Modellen, die voll verknüpften Modelle, bestehen aus übereinanderliegenden Schichten von Neuronen. Die Eingabe eines voll vernetzten Modells wird direkt als lange Zahlenreihe eingegeben. Vollständig verknüpfte Modelle können jede Funktion lernen, aber sie sind meist blind für räumliche Beziehungen in ihren Eingaben (zum Beispiel, welche Werte in einer Eingabe nebeneinander liegen).
In einem eingebetteten Kontext bedeutet das, dass sie gut für diskrete Werte funktionieren (z. B. wenn es sich bei den Eingangsmerkmalen um eine Reihe von Statistiken über eine Zeitreihe handelt), aber sie sind nicht so gut für rohe Zeitreihen oder Bilddaten geeignet.
Vollständig vernetzte Modelle werden auf eingebetteten Geräten sehr gut unterstützt, wobei Hardware- und Software-Optimierungen allgemein verfügbar sind.
- Faltungsmodelle
-
Faltungsmodelle sind darauf ausgelegt, die räumlichen Informationen in ihren Eingaben zu nutzen. Sie können z. B. lernen, Formen in Bildern oder die Struktur von Signalen in Zeitreihen von Sensordaten zu erkennen. Das macht sie besonders nützlich für eingebettete Anwendungen, da räumliche Informationen in vielen Signalen, mit denen wir zu tun haben, wichtig sind.
Wie vollverknüpfte Modelle werden auch Faltungsmodelle sehr gut von eingebetteten Geräten unterstützt.
- Sequenz-Modelle
-
Sequenzmodelle wurden ursprünglich für die Verwendung von Datenfolgen entwickelt, z. B. für Zeitreihensignale oder sogar für geschriebene Sprache. Damit sie langfristige Muster in Zeitreihen erkennen können, verfügen sie oft über einen internen "Speicher".
Es stellt sich heraus, dass Sequenzmodelle sehr flexibel sind, und es gibt immer mehr Beweise dafür, dass sie bei jedem Signal, bei dem räumliche Informationen wichtig sind, sehr effektiv sein können. Viele glauben, dass sie irgendwann die Faltungsmodelle ablösen werden.
Sequenzmodelle werden derzeit auf eingebetteten Geräten weniger gut unterstützt als Faltungsmodelle und vollständig verknüpfte Modelle; es gibt nur wenige Open-Source-Bibliotheken, die optimierte Implementierungen für sie bereitstellen. Dies ist eher auf Trägheit als auf technische Einschränkungen zurückzuführen, sodass sich die Situation in den nächsten Jahren wahrscheinlich ändern wird.
- Modelle einbetten
-
Ein Embedding-Modell ist ein vortrainiertes Deep-Learning-Modell, das für die Dimensionalitätsreduzierung entwickelt wurde - es nimmt eine große, unübersichtliche Eingabe und stellt sie als eine kleinere Menge von Zahlen dar, die sie in einem bestimmten Kontext beschreibt. Sie werden wie ein Signalverarbeitungsalgorithmus verwendet: Sie erzeugen Merkmale, die von einem anderen ML-Modell interpretiert werden können.
Einbettungsmodelle gibt es für viele Aufgaben, von der Bildverarbeitung (Umwandlung eines großen, unübersichtlichen Bildes in eine numerische Beschreibung seines Inhalts) bis hin zur Spracherkennung (Umwandlung von unbearbeiteten Audiodaten in eine numerische Beschreibung der darin enthaltenen Sprachlaute).
Die häufigste Anwendung für das Einbetten von Modellen ist das Transfer-Lernen, mit dem die Menge der Daten, die zum Trainieren eines Modells benötigt werden, reduziert werden kann. Darüber werden wir später noch mehr erfahren.
Bei den Einbettungsmodellen kann es sich um vollständig verknüpfte Modelle, Faltungsmodelle oder Sequenzmodelle handeln, so dass ihre Unterstützung auf eingebetteten Geräten unterschiedlich ist.
Erst in den letzten Jahren wurden Deep-Learning-Modelle auf Kanten-KI-Hardware übertragen. Da sie oft sehr groß sind und viele Berechnungen erfordern, haben High-End-MCUs und -SoCs mit relativ leistungsstarken Prozessoren und großen Mengen an ROM und RAM ihnen den Sprung ermöglicht.
Es ist möglich, ein kleines Deep-Learning-Modell mit nur ein paar Kilobyte Speicher auszuführen, aber für Modelle, die komplexere Dinge tun - von der Audioklassifizierung bis zur Objekterkennung - benötigen sie normalerweise mindestens Dutzende oder Hunderte von Kilobyte.
Das ist schon beeindruckend, denn herkömmliche serverseitige Modelle für maschinelles Lernen können zwischen einigen Dutzend Megabyte und mehreren Terabyte groß sein. Durch geschickte Optimierung und Begrenzung des Umfangs können eingebettete Modelle viel kleiner gemacht werden - einige dieser Techniken werden wir gleich vorstellen.
Es gibt verschiedene Möglichkeiten, ein Deep Learning-Modell auf einem eingebetteten Gerät laufen zu lassen. Hier ist eine kurze Zusammenfassung:
- Dolmetscher
-
Deep-Learning-Interpreter wie TensorFlow Lite für Mikrocontroller verwenden einen Interpreter, um ein Modell auszuführen, das in einer Datei gespeichert ist. Sie sind flexibel und einfach zu handhaben, aber sie verursachen einen gewissen Rechen- und Speicheraufwand und unterstützen nicht alle Arten von Modellen.
- Code-Erstellung
-
Codegenerierungstools wie EON übersetzen ein trainiertes Deep Learning-Modell in optimierten eingebetteten Quellcode. Das ist effizienter als ein interpreterbasierter Ansatz und der Code ist für Menschen lesbar, so dass er immer noch debuggt werden kann, aber er unterstützt immer noch nicht alle möglichen Modelltypen.
- Compiler
-
Deep Learning Compiler wie microTVM erzeugen aus einem trainierten Modell optimierten Bytecode, der in eingebettete Anwendungen integriert werden kann. Die erzeugte Implementierung kann sehr effizient sein, ist aber nicht so einfach zu debuggen und zu pflegen wie der eigentliche Quellcode. Sie können Modelltypen unterstützen, die von Interpretern und der Codegenerierung nicht explizit unterstützt werden. Es ist üblich, dass Anbieter von eingebetteter Hardware eigene Interpreter oder Compiler bereitstellen, um die Ausführung von Deep Learning-Modellen auf ihrer Hardware zu unterstützen.
- Handcodierung
-
Es ist möglich, ein Deep Learning-Netzwerk zu implementieren, indem du von Hand Code schreibst und die Parameterwerte eines trainierten Modells einbaust. Das ist ein schwieriger und zeitaufwändiger Prozess, aber er ermöglicht die volle Kontrolle über die Optimierung und erlaubt es dir, jeden Modelltyp zu unterstützen.
Die Umgebung für den Einsatz von Deep Learning-Modellen unterscheidet sich stark zwischen SoCs und Mikrocontrollern. Da auf SoCs vollständige, moderne Betriebssysteme laufen, unterstützen sie auch die meisten Tools, die zum Ausführen von Deep Learning-Modellen auf Servern verwendet werden. Das bedeutet, dass so ziemlich jede Art von Modell auf einem Linux-SoC läuft. Allerdings hängt die Latenz des Modells von der Architektur des Modells und dem Prozessor des SoCs ab.
Es gibt auch Interpreter, die speziell für SoC-Geräte entwickelt wurden. TensorFlow Lite zum Beispiel bietet Tools, mit denen Deep-Learning-Modelle effizienter auf SoCs ausgeführt werden können - in der Regel auf denen, die in Smartphones verwendet werden. Sie enthalten optimierte Implementierungen von Deep Learning-Operationen, die die Funktionen einiger SoCs, wie z. B. GPUs, nutzen.
SoCs mit integrierten Deep-Learning-Beschleunigern sind ein Sonderfall. In der Regel stellt der Hardwarehersteller einen speziellen Compiler oder Interpreter zur Verfügung, der es dem Modell ermöglicht, die Hardwarebeschleunigung zu nutzen. Beschleuniger beschleunigen in der Regel nur bestimmte Operationen, sodass der Grad der Beschleunigung von der Architektur des Modells abhängt.
Da auf Mikrocontrollern keine vollständigen Betriebssysteme laufen, gibt es keine Standardtools für die Ausführung von Deep Learning-Modellen. Stattdessen bieten Frameworks wie TensorFlow Lite für Mikrocontroller eine Grundausstattung an Modellunterstützung. Sie hinken den Standard-Tools in Bezug auf die Operator-Unterstützung etwas hinterher, was bedeutet, dass sie einige Modellarchitekturen nicht ausführen können.
Operatoren und Kerne
Beim maschinellen Lernen am Rande ist ein Operator oder Kernel eine Implementierung einer bestimmten mathematischen Operation, die zur Ausführung eines Deep-Learning-Modells verwendet wird. Dies sind überladene Begriffe mit unterschiedlichen Bedeutungen in anderen Bereichen, auch im Deep Learning.
Typische High-End-Mikrocontroller verfügen über Hardwarefunktionen wie SIMD-Befehle, die die Leistung von Deep-Learning-Modellen drastisch verbessern. TensorFlow Lite für Mikrocontroller enthält optimierte Implementierungen von Operatoren, die diese Befehle nutzen, für verschiedene Hersteller. Wie bei SoCs bieten die Hersteller von Mikrocontroller-basierten Hardware-Beschleunigern oft eigene Compiler oder Interpreter an, mit denen Modelle auf ihrer Hardware laufen können.
Die Hauptvorteile von Deep Learning sind seine Flexibilität, die geringeren Anforderungen an das Feature-Engineering und die Fähigkeit, große Datenmengen aufgrund der hohen Parameteranzahl der Modelle zu nutzen. Deep Learning zeichnet sich durch seine Fähigkeit aus, komplexe Systeme zu approximieren, die über einfache Vorhersagen hinausgehen und Aufgaben wie die Erzeugung von Kunst und die genaue Erkennung von Objekten in Bildern übernehmen. Deep Learning bietet viele Freiheiten, und die Forscher haben gerade erst begonnen, sein Potenzial zu erkunden.
Die Hauptnachteile sind der hohe Datenbedarf, die Neigung zur Überanpassung, die relativ große Größe und Rechenkomplexität von Deep-Learning-Modellen sowie die Komplexität des Trainingsprozesses. Außerdem können Deep Learning-Modelle schwer zu interpretieren sein - es kann schwierig sein zu erklären, warum sie eine bestimmte Vorhersage treffen und nicht eine andere. Es gibt jedoch Tools und Techniken, mit denen sich die meisten dieser Nachteile abmildern lassen.
Algorithmen kombinieren
Eine einzige Kanten-KI-Anwendung kann mehrere verschiedene Arten von Algorithmen nutzen. Hier sind einige typische Arten, wie das gemacht wird:
- Ensembles
-
Ein Ensemble ist eine Sammlung von maschinellen Lernmodellen, die mit demselben Input gefüttert werden. Ihre Ergebnisse werden mathematisch kombiniert, um eine Entscheidung zu treffen. Da jedes maschinelle Lernmodell seine eigenen Stärken und Schwächen hat, ist ein Ensemble von Modellen zusammen oft genauer als seine Einzelteile. Der Nachteil von Ensembles ist die zusätzliche Komplexität, der Speicher- und Rechenaufwand, der erforderlich ist, um mehrere Modelle zu speichern und auszuführen.
- Kaskaden
-
Eine Kaskade ist eine Reihe von ML-Modellen, die nacheinander ausgeführt werden. In einem Mobiltelefon mit eingebautem digitalen Assistenten wird zum Beispiel ein kleines, leichtes Modell ständig ausgeführt, um Anzeichen menschlicher Sprache zu erkennen. Sobald Sprache erkannt wird, wird ein größeres, rechenintensiveres Modell aktiviert, um zu bestimmen, was gesagt wurde.
Kaskaden sind eine großartige Möglichkeit, Energie zu sparen, da sie es dir ermöglichen, unnötige Berechnungen zu vermeiden. In einer heterogenen Rechenumgebung, in der mehrere Prozessortypen verfügbar sind, können die einzelnen Komponenten einer Kaskade sogar auf verschiedenen Prozessoren ausgeführt werden.
- Merkmalsextraktoren
-
Wie wir bereits gelernt haben, nehmen Einbettungsmodelle eine hochdimensionale Eingabe, wie z. B. ein Bild, und reduzieren sie auf eine Reihe von Zahlen, die ihren Inhalt beschreiben. Die Ergebnisse eines Einbettungsmodells können in ein anderes Modell eingespeist werden, das Vorhersagen auf der Grundlage dessen trifft, was das Einbettungsmodell über die ursprüngliche Eingabe beschreibt. In diesem Fall wird das Einbettungsmodell als Merkmalsextraktor verwendet.
Wenn ein vorab trainiertes Einbettungsmodell verwendet wird, kanndiese Technik - bekannt als Transferlernen -die Datenmenge, die zum Trainieren eines Modells benötigt wird, massiv reduzieren. Anstatt zu lernen, wie die ursprüngliche hochdimensionale Eingabe zu interpretieren ist, muss das Modell nur lernen, wie die einfache Ausgabe zu interpretieren ist, die der Feature Extractor zurückgibt.
Stell dir zum Beispiel vor, du möchtest ein Modell trainieren, um verschiedene Vogelarten auf Fotos zu identifizieren. Anstatt ein komplettes Modell von Grund auf zu trainieren, könntest du die Ausgabe eines vorab trainierten Merkmalsextraktors als Eingabe für dein Modell verwenden. So kannst du die Datenmenge und die Trainingszeit reduzieren, die du brauchst, um gute Ergebnisse zu erzielen.
Viele vortrainierte Deep-Learning-Merkmalextraktoren sind unter Open-Source-Lizenzen verfügbar. Sie werden häufig für bildbezogene Aufgaben verwendet, da große öffentliche Bilddatensätze zum Vortraining zur Verfügung stehen.
- Multimodale Modelle
-
Ein multimodales Modell ist ein einzelnes Modell, das Eingaben von mehreren Datentypen gleichzeitig annimmt. Ein multimodales Modell kann zum Beispiel sowohl Audio- als auch Beschleunigungssensor-Daten akzeptieren. Diese Technik kann als Mechanismus für die Sensorfusion genutzt werden, indem ein einziges Modell verwendet wird, um unterschiedliche Datentypen zu kombinieren.
Nachbearbeitungsalgorithmen
Auf Kanten-KI-Geräten arbeiten wir in der Regel mit Datenströmen - zum Beispiel mit einer kontinuierlichen Zeitreihe von Audiodaten. Wenn wir einen Kanten-KI-Algorithmus auf diesen Datenstrom anwenden, erzeugt er eine zweite Zeitreihe, die die Ergebnisse des Algorithmus im Laufe der Zeit darstellt.
Das wirft ein Problem auf. Wie interpretieren wir diese zweite Zeitreihe, um eine Entscheidung zu treffen? Stell dir zum Beispiel vor, wir analysieren Audiodaten, um zu erkennen, wann jemand ein Schlüsselwort sagt, damit wir eine Funktion für ein Produkt auslösen können. Was wir wirklich wissen wollen, ist: Wann haben wir das Schlüsselwort gehört?
Leider ist die Zeitreihe der Inferenzergebnisse für diesen Zweck nicht ideal. Erstens enthält sie viele Ereignisse, bei denen kein Schlüsselwort erkannt wurde. Um diese zu bereinigen, können wir alle ignorieren, bei denen die Wahrscheinlichkeit, dass ein Schlüsselwort entdeckt wurde, unter einem bestimmten Schwellenwert liegt.
Zweitens kann das Modell gelegentlich (und kurz) ein Schlüsselwort erkennen, obwohl es gar nicht gesprochen wurde. Wir müssen diese Ausreißer herausfiltern, um unser Ergebnis zu bereinigen. Dies ist gleichbedeutend mit der Anwendung eines Tiefpassfilters auf die Zeitreihe.
Anstatt uns jedes Mal zu sagen, wann das Schlüsselwort gesprochen wurde, sagt uns die rohe Zeitreihe in einem bestimmten Rhythmus, ob das Schlüsselwort gerade gesprochen wird. Das bedeutet, dass wir die Ausgabe steuern müssen, um die Informationen zu erhalten, die wir wirklich wollen.
Nachdem wir die Rohausgabe bereinigt haben, haben wir jetzt ein Signal, das uns sagt, wann ein Schlüsselwort tatsächlich entdeckt wurde. Dieses Signal können wir in unserer Anwendungslogik verwenden, um unser Gerät zu steuern.
Diese Art der Nachbearbeitung ist bei Kanten-KI-Anwendungen weit verbreitet. Der genaue Nachbearbeitungsalgorithmus und seine Parameter, z. B. der Schwellenwert, ab dem etwas als Treffer gewertet wird, können von Fall zu Fall festgelegt werden. Mit Tools wie der Performance Calibration von Edge Impulse (siehe "Performance Calibration") können Entwickler den idealen Nachbearbeitungsalgorithmus für ihre Anwendung automatisch ermitteln.
Fehlschlagsicheres Design
Es gibt viele Dinge, die bei einer Kanten-KI-Anwendung schiefgehen können. Deshalb ist es wichtig, dass es immer Sicherheitsvorkehrungen gibt, die vor unerwarteten Problemen schützen.
Stell dir zum Beispiel eine Wildtierkamera vor, die mithilfe eines Deep-Learning-Modells erkennt, wann ein interessantes Tier fotografiert wurde, und das Bild des Tieres über eine Satellitenverbindung hochlädt. Im Normalbetrieb sendet sie vielleicht ein paar Fotos pro Tag - das kostet nicht viel an Datengebühren.
Aber draußen im Feld kann ein physisches Problem mit der Kamerahardware - z. B. Schmutz oder Reflexionen auf dem Objektiv - dazu führen, dass Bilder aufgenommen werden, die sich stark von denen im ursprünglichen Trainingsdatensatz unterscheiden. Diese abweichenden Bilder könnten zu einem unbestimmten Verhalten des Deep-Learning-Modells führen - was bedeuten könnte, dass das Modell anfängt, ständig zu melden, dass das Tier von Interesse anwesend ist.
Diese Fehlalarme, die durch nicht verteilte Eingaben verursacht werden, könnten dazu führen, dass Hunderte von Bildern über die Satellitenverbindung hochgeladen werden. Das würde nicht nur die Kamera unbrauchbar machen, sondern könnte auch hohe Kosten für die Datenübertragung verursachen.
In der Praxis lassen sich Schäden an Sensoren oder unerwartetes Verhalten von Algorithmen nicht vermeiden. Stattdessen ist es wichtig, dass du deine Anwendung so gestaltest, dass sie fehlschlagsicher ist. Das heißt, wenn ein Teil des Systems fehlschlägt, wird der Schaden für die Anwendung so gering wie möglich gehalten.
Wie du das am besten machst, ist von Situation zu Situation unterschiedlich. Bei einer Wildtierkamera könnte es sinnvoll sein, eine Geschwindigkeitsbegrenzung einzubauen, die greift, wenn unangemessen viele Fotos hochgeladen werden. Bei einer anderen Anwendung könntest du das System lieber ganz abschalten, als zu riskieren, dass es Schaden anrichtet.
Die Entwicklung fehlschlagsicherer Anwendungen ist ein wichtiger Bestandteil verantwortungsvoller KI - und guter Technik im Allgemeinen. Daran sollte man schon zu Beginn eines Projekts denken.
Optimierung für Kantengeräte
Bei Modellen des maschinellen Lernens und insbesondere bei Deep-Learning-Modellen gibt es oft einen Kompromiss zwischen der Leistung eines Modells und dem Speicher- und Rechenaufwand, den das Modell benötigt.
Dieser Kompromiss ist für Kanten-KI extrem wichtig. Edge-Geräte sind in der Regel rechenschwach. Sie sind darauf ausgelegt, Kosten und Energieverbrauch zu minimieren, und nicht, die Rechenleistung zu maximieren. Gleichzeitig wird von ihnen erwartet, dass sie Sensordaten in Echtzeit verarbeiten, oft mit hoher Frequenz, und dass sie möglicherweise in Echtzeit auf Ereignisse im Datenstrom reagieren.
Größere Modelle für maschinelles Lernen sind in der Regel besser für komplexe Aufgaben geeignet, da sie mehr Kapazität haben - was für das Lernen komplizierter Beziehungen zwischen Eingaben und Ausgaben hilfreich ist. Diese zusätzliche Kapazität bedeutet, dass sie unter Umständen mehr ROM und RAM benötigen und dass sie länger für die Berechnung brauchen. Die zusätzliche Rechenzeit führt zu einem höheren Stromverbrauch, wie wir in "Einschaltdauer" erfahren werden .
Die richtige Balance zwischen Aufgaben- und Rechenleistung zu finden, ist für jede Anwendung wichtig. Es geht darum, mit den Zwängen zu jonglieren. Auf der einen Seite gibt es einen Mindeststandard für die Leistung bei einer bestimmten Aufgabe. Auf der anderen Seite setzt die Hardwareauswahl dem verfügbaren Speicher, der Latenzzeit und dem Energieverbrauch enge Grenzen.
Die Bewältigung dieses Kompromisses gehört zu den schwierigen, aber faszinierenden Aspekten der Entwicklung von Kanten-KI. Es ist ein Teil dessen, was das Feld so interessant macht und warum Tools wie AutoML (über die wir in "Automatisiertes maschinelles Lernen (AutoML)" mehr erfahren werden ) für Kanten-KI neu entwickelt werden müssen.
Hier sind einige der Faktoren, die uns dabei helfen können, den Rechenaufwand zu minimieren und gleichzeitig die Aufgabenleistung zu maximieren.
Wahl des Algorithmus
Jeder Kanten-KI-Algorithmus hat ein leicht unterschiedliches Profil in Bezug auf Speichernutzung und Rechenaufwand. Die Einschränkungen deiner Zielhardware sollten bei der Wahl deines Algorithmus berücksichtigt werden. In der Regel sind klassische ML-Algorithmen kleiner und effizienter als Deep-Learning-Algorithmen.
In der Regel verbrauchen Feature-Engineering-Algorithmen jedoch deutlich mehr Rechenleistung als die beiden anderen, sodass die Entscheidung zwischen klassischem ML und Deep Learning weniger wichtig ist. Eine Ausnahme von dieser Regel ist die Analyse von Bilddaten, die in der Regel wenig Feature Engineering, aber relativ große Deep Learning-Modelle erfordert.
Hier sind einige gängige Möglichkeiten, um die Latenzzeit und den Speicherbedarf deiner Algorithmen zu reduzieren:
-
Reduziere die Komplexität des Feature Engineering. Mehr Mathematik bedeutet höhere Latenz.
-
Verringere die Menge der Daten, die den KI-Algorithmus erreichen.
-
Verwende klassisches ML anstelle von Deep Learning.
-
Tausche die Komplexität zwischen Feature Engineering und maschinellem Lernen aus, je nachdem, was auf deinem Gerät effizienter läuft.
-
Reduziere die Größe (die Anzahl der Gewichte und Schichten) von Deep Learning-Modellen.
-
Wähle Modelle, die auf dem Gerät deiner Wahl einen Beschleuniger unterstützen.
Komprimierung und Optimierung
Es gibt viele Optimierungstechniken, die darauf abzielen, den Daten- und Rechenaufwand für einen bestimmten Algorithmus zu reduzieren. Hier sind einige derwichtigsten Arten:
- Quantisierung
-
Eine Möglichkeit, den Speicher- und Rechenaufwand eines Algorithmus oder Modells zu verringern, besteht darin, die Genauigkeit der Zahlendarstellungen zu reduzieren. Wie im Abschnitt "Wie werden Werte dargestellt?" erwähnt , gibt es viele verschiedene Möglichkeiten, Zahlen in Berechnungen darzustellen - einige haben eine höhere Genauigkeit als andere.
Unter Quantisierung versteht man den Prozess, bei dem eine Menge von Werten reduziert wird, während die wichtigen Informationen, die sie enthalten, erhalten bleiben. Dies kann sowohl bei Signalverarbeitungsalgorithmen als auch bei ML-Modellen geschehen. Sie ist besonders nützlich für Deep-Learning-Modelle, die standardmäßig 32-Bit-Gleitkomma-Gewichte haben. Wenn du die Gewichte auf 8-Bit-Ganzzahlen reduzierst, kannst du ein Modell auf ein Viertel seiner Größe verkleinern - in der Regel ohne große Einbußen bei der Genauigkeit.
Ein weiterer Vorteil der Quantisierung ist, dass der Code für die Durchführung von Ganzzahlberechnungen schneller und portabler ist als der Code für Fließkommaberechnungen. Das bedeutet, dass die Quantisierung auf vielen Geräten zu einer erheblichen Beschleunigung führt und dass quantisierte Algorithmen auch auf Geräten laufen, die keine Fließkommaeinheiten haben.
Die Quantisierung ist eine verlustbehaftete Optimierung, was bedeutet, dass sie die Aufgabenleistung des Algorithmus in der Regel verringert. Bei ML-Modellen kann dies durch Training mit einer geringeren Genauigkeit gemildert werden, damit das Modell lernt, dies zu kompensieren.
- Operator fusion
-
Bei der Operatorfusion wird ein rechenfähiger Algorithmus verwendet, um die Operatoren zu überprüfen, die bei der Ausführung eines Deep Learning-Modells verwendet werden. Wenn bestimmte Gruppen von Operatoren zusammen verwendet werden, ist es möglich, sie durch eine einzige fusionierte Implementierung zu ersetzen, die so geschrieben wurde, dass sie möglichst recheneffizient ist.
Die Fusion von Operatoren ist eine verlustfreie Technik: Sie verbessert die Rechenleistung, ohne die Leistung der Aufgaben zu beeinträchtigen. Der Nachteil ist, dass fusionierte Implementierungen nur für bestimmte Kombinationen von Operatoren zur Verfügung stehen, so dass ihre Auswirkungen stark von der Architektur eines Modells abhängen.
- Beschneiden
-
Pruning ist eine verlustbehaftete Technik, die während des Trainings eines Deep Learning-Modells angewendet wird. Es zwingt viele Gewichte des Modells, den Wert Null anzunehmen, wodurch ein sogenanntes spärliches Modell entsteht. Theoretisch sollte dies eine schnellere Berechnung ermöglichen, da jede Multiplikation mit einem Gewicht von Null unweigerlich zu einer Null führt.
Zum jetzigen Zeitpunkt gibt es jedoch nur sehr wenig KI-Hardware und -Software, die die Vorteile von spärlichen Gewichten nutzen kann. Das wird sich in den nächsten Jahren ändern, aber im Moment liegt der Hauptvorteil des Pruning darin, dass spärliche Modelle aufgrund ihrer großen Blöcke identischer Werte leichter zu komprimieren sind. Das ist hilfreich, wenn die Modelle per Funk verschickt werden müssen.
- Wissen destillieren
-
Die Wissensdestillation ist eine weitere verlustbehaftete Deep Learning-Trainingstechnik, bei der ein großes "Lehrermodell" dabei hilft, ein kleineres "Schülermodell" so zu trainieren, dass es seine Funktionalität reproduziert. Sie macht sich die Tatsache zunutze, dass die Gewichte eines Deep-Learning-Modells in der Regel sehr redundant sind, so dass es möglich ist, ein gleichwertiges Modell zu finden, das kleiner ist, aber fast genauso gut funktioniert.
Die Wissensdestillation ist etwas umständlich und daher noch nicht weit verbreitet, aber sie wird sich in den nächsten Jahren wahrscheinlich zu einer bewährten Methode entwickeln.
- Binäre neuronale Netze (BNNs)
-
BNNs sind Deep Learning-Modelle, bei denen jedes Gewicht eine einzelne Binärzahl ist. Da binäre Arithmetik auf Computern extrem schnell ist, können binäre neuronale Netze sehr effizient ausgeführt werden. Sie sind jedoch eine relativ neue Technologie, und die Werkzeuge zum Trainieren und Ausführen von Schlussfolgerungen mit ihnen sind noch nicht weit verbreitet. Die Binarisierung ist ähnlich wie die Quantisierung und daher eine verlustbehaftete Technik.
- Spiking neuronale Netze (SNNs)
-
Ein Spiking Neural Network ist ein künstliches neuronales Netz, bei dem die durch das Netz übertragenen Signale eine Zeitkomponente haben. Als "neuromorphe" Systeme sind sie so konzipiert, dass sie der Funktionsweise biologischer Neuronen näher kommen. Sie haben andere Kompromisse als herkömmliche Deep-Learning-Modelle und bieten bei einigen Aufgaben eine bessere Leistung und Effizienz. Allerdings benötigen sie spezielle Hardware (in Form eines Beschleunigers), um einen Vorteil zu bieten.
SNNs können entweder direkt trainiert oder in einem Konvertierungsprozess aus einem traditionellen Deep Learning-Modell erstellt werden. Dieser Prozess kann verlustbehaftet sein.
Die Modellkomprimierung hat zwei große Nachteile. Der erste ist, dass für die Ausführung komprimierter Modelle oft spezielle Software, Hardware oder eine Kombination aus beidem erforderlich ist. Dies kann die Anzahl der Geräte, auf denen ein komprimiertes Modell eingesetzt werden kann, einschränken.
Der zweite Nachteil ist gefährlicher. Die verlustbehaftete Art der Komprimierung führt oft zu einer subtilen Verschlechterung der Vorhersageleistung eines Modells, die nur schwer zu erkennen ist. Die geringere Genauigkeit kann dazu führen, dass ein Modell in häufigen Fällen gut abschneidet, aber im "Long Tail" der selteneren Eingaben an Leistung verliert.
Dieses Problem kann die inhärenten Verzerrungen in Datensätzen und Algorithmen verstärken. Wenn zum Beispiel ein Datensatz, der für das Training eines ML-gestützten Gesundheits-Wearables gesammelt wurde, weniger Beispiele von Menschen aus Minderheitengruppen enthält, kann die Modellkomprimierung zu einer schlechteren Leistung für Menschen aus diesen Gruppen führen. Da es sich um eine Minderheit handelt, sind die Auswirkungen auf die Gesamtgenauigkeit des Modells möglicherweise nur schwer zu erkennen. Deshalb ist es äußerst wichtig, die Leistung deines Systems für jede Untergruppe deines Datensatzes zu bewerten (siehe "Sammeln von Metadaten").
Es gibt zwei hervorragende wissenschaftliche Arbeiten zu diesem Thema von der Forscherin Sara Hooker et al. Die eine heißt "What Do Compressed Deep Neural Networks Forget?", die andere "Characterising Bias in Compressed Models".
Schulung auf dem Gerät
In den allermeisten Fällen werden die in der Kanten-KI verwendeten Machine-Learning-Modelle trainiert, bevor sie auf einem Gerät eingesetzt werden. Für das Training werden große Datenmengen benötigt, die in der Regel mit Labels versehen sind, und es sind umfangreiche Berechnungen erforderlich - das entspricht Hunderten oder Tausenden von Schlussfolgerungen pro Datenpunkt. Dies schränkt den Nutzen des Trainings auf dem Gerät ein, da Edge-KI-Anwendungen von Natur aus starken Einschränkungen in Bezug auf Speicher, Rechenleistung, Energie und Konnektivität unterliegen.
Dennoch gibt es einige Szenarien, in denen ein Training auf dem Gerät sinnvoll ist. Hier istein Überblick:
- Vorausschauende Wartung
-
Ein gängiges Beispiel für On-Device-Training ist die vorausschauende Wartung, bei der eine Maschine überwacht wird, um festzustellen, ob sie normal funktioniert. Ein kleines geräteinternes Modell kann mit Daten trainiert werden, die einen "normalen" Zustand darstellen. Wenn die Signale der Maschine von dieser Basislinie abweichen, kann die Anwendung dies erkennen und Maßnahmen ergreifen.
Dieser Anwendungsfall ist nur möglich, wenn davon ausgegangen werden kann, dass abnormale Signale selten sind und die Maschine zu einem bestimmten Zeitpunkt wahrscheinlich normal arbeitet. Dadurch kann das Gerät die gesammelten Daten als "normal" betrachten. Wenn abnormale Zustände üblich wären, wäre es unmöglich, Annahmen über den Zustand zu einem bestimmten Zeitpunkt zu treffen.
- Personalisierung
-
Ein weiteres Beispiel, bei dem ein Training auf dem Gerät sinnvoll ist, ist, wenn ein Nutzer aufgefordert wird, absichtlich Kennzeichnungen vorzunehmen. Einige Smartphones nutzen zum Beispiel die Gesichtserkennung als Sicherheitsmethode. Wenn der Nutzer das Gerät einrichtet, wird er gebeten, Bilder seines Gesichts zu registrieren. Eine numerische Darstellung dieser Gesichtsbilder wird gespeichert.
Für diese Art von Anwendungen werden in der Regel sorgfältig entwickelte Einbettungsmodelle verwendet, die Rohdaten in kompakte numerische Darstellungen ihres Inhalts umwandeln. Die Einbettungen sind so gestaltet, dass der euklidische Abstand zwischen zwei Einbettungen5 der Ähnlichkeit zwischen ihnen entspricht. In unserem Beispiel der Gesichtserkennung lässt sich so leicht feststellen, ob ein neues Gesicht mit den gespeicherten Repräsentationen übereinstimmt: Der Abstand zwischen dem neuen Gesicht und dem registrierten Gesicht wird berechnet, und wenn er ausreichend groß ist, werden die Gesichter als gleich angesehen.
Diese Form der Personalisierung funktioniert gut, weil der Algorithmus zur Bestimmung der Ähnlichkeit der Einbettung in der Regel sehr einfach ist: entweder eine Abstandsberechnung oder ein Algorithmus für die nächsten Nachbarn. Das Einbettungsmodell hat die ganze harte Arbeit erledigt.
- Implizite Assoziation
-
Ein weiteres Beispiel für On-Device-Training ist, wenn Labels durch Assoziation verfügbar sind. So werden z. B. für Batteriemanagement-Funktionen wie die optimierte Batterieladung von Apple Modelle auf dem Gerät trainiert, um vorherzusagen, zu welcher Zeit ein Nutzer sein Gerät wahrscheinlich benutzen wird. Eine Möglichkeit wäre, ein Prognosemodell so zu trainieren, dass es anhand eines Protokolls der letzten Stunden eine Wahrscheinlichkeit für die Nutzung zu einer bestimmten Zeit ausgibt.
In diesem Fall ist es einfach, Trainingsdaten auf einem einzigen Gerät zu sammeln und zu kennzeichnen. Die Nutzungsprotokolle werden im Hintergrund gesammelt und nach einer bestimmten Kennzahl (z. B. ob der Bildschirm aktiviert war) gekennzeichnet. Die implizite Verbindung zwischen der Zeit und dem Inhalt des Protokolls ermöglicht es, die Daten zu kennzeichnen. Anschließend kann ein einfaches Modell trainiert werden.
- Föderiertes Lernen
-
Eines der Hindernisse beim Training auf dem Gerät ist der Mangel an Trainingsdaten. Außerdem sind die Daten auf den Geräten oft privat und die Nutzer/innen wollen nicht, dass sie übertragen werden. Föderiertes Lernen ist eine Möglichkeit, Modelle verteilt auf vielen Geräten zu trainieren und dabei die Privatsphäre zu wahren. Anstatt Rohdaten zu übertragen, werden teilweise trainierte Modelle zwischen den Geräten (oder zwischen jedem Gerät und einem zentralen Server) weitergegeben. Die teilweise trainierten Modelle können kombiniert und wieder an die Geräte verteilt werden, sobald sie fertig sind.
Föderiertes Lernen scheint oft attraktiv zu sein, da es den Modellen die Möglichkeit gibt, zu lernen und sich zu verbessern, während sie in der Praxis eingesetzt werden. Es hat jedoch einige ernsthafte Einschränkungen. Es ist rechenintensiv und erfordert große Datenmengen, was den Hauptvorteilen der Kanten-KI zuwiderläuft. Der Trainingsprozess ist sehr komplex und erfordert sowohl geräteseitige als auch serverseitige Komponenten, was das Projektrisiko erhöht.
Da die Daten nicht global gespeichert werden, gibt es keine Möglichkeit zu überprüfen, ob das trainierte Modell im gesamten Einsatz gut funktioniert. Die Tatsache, dass die Modelle von lokalen Geräten hochgeladen werden, stellt einen Vektor für Sicherheitsangriffe dar. Und schließlich, und das ist das Wichtigste, wird das Problem der Kennzeichnung nicht gelöst. Wenn keine beschrifteten Daten zur Verfügung stehen, ist das föderierte Lernen nutzlos.
- Over-the-Air-Updates
-
Obwohl es sich eigentlich nicht um eine Trainingsmethode auf dem Gerät handelt, ist die gängigste Art, Modelle im Feld zu aktualisieren, ein Over-the-Air-Update. Ein neues Modell kann im Labor anhand der im Feld gesammelten Daten trainiert und über Firmware-Updates an die Geräte verteilt werden.
Dies hängt von der Netzwerkkommunikation ab und löst nicht das Problem, beschriftete Daten zu erhalten, aber es ist die gängigste Methode, um Modelle im Laufe der Zeit auf dem neuesten Stand zu halten .
1 Die Chunks können getrennt oder überlappend sein oder sogar Lücken zwischen ihnen haben.
2 Ein Grund dafür ist, dass das in Abbildung 4-5 gezeigte Rohmaterial aus 44.100 Samples besteht, während das entsprechende Spektrogramm nur 3.960 Elemente hat. Die kleinere Eingabe bedeutet ein kleineres Modell.
3 In der Bildverarbeitung ist ein Feature eine bestimmte Information über ein Bild, z. B. die Position bestimmter visueller Strukturen. Die Wikipedia-Seite mit dem Titel "Feature (Computer Vision)" listet viele gängige Bildmerkmale auf.
4 Es gibt ein gut dokumentiertes Phänomen, das als "KI-Effekt" bekannt ist: In dem Moment, in dem KI-Forscher/innen herausfinden, wie sie einen Computer dazu bringen können, eine Aufgabe zu erledigen, halten Kritiker/innen diese Aufgabe nicht mehr für repräsentativ für Intelligenz.
5 Eine Einbettung kann man sich als Koordinate in einem mehrdimensionalen Raum vorstellen. Der euklidische Abstand zwischen zwei Einbettungen ist der Abstand zwischen den beiden Koordinaten.
Get KI am Rande now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

