Kapitel 1. Kafka Connect kennenlernen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Systeme zur Datenverarbeitung gibt es schon seit den Anfängen der Computer. Die Menge der erzeugten und gesammelten Daten wächst jedoch exponentiell. Im Jahr 2018 wurden schätzungsweise 2,5 Quintillionen Bytes an Daten pro Tag erzeugt, und die International Data Corporation (IDC) geht davon aus, dass sich der Gesamtumfang aller vorhandenen Daten zwischen 2022 und 2025 verdoppeln wird.
Damit Unternehmen diese großen Datenmengen, die heute als "Big Data" bezeichnet werden, verarbeiten können, wurden neue Klassen von Systemen entwickelt. Inzwischen gibt es Hunderte von verschiedenen Datenbanken, Datenspeichern und Verarbeitungstools für jeden denkbaren Big-Data-Anwendungsfall. Heutzutage betreibt ein typisches Unternehmen mehrere dieser Systeme. Das kann daran liegen, dass verschiedene Systeme durch Übernahmen übernommen, für bestimmte Anwendungsfälle optimiert oder von verschiedenen Teams verwaltet wurden. Oder es kann sein, dass sich die bevorzugten Tools im Laufe der Zeit geändert haben und alte Anwendungen nicht aktualisiert wurden.
Für die meisten Unternehmen reicht es nicht aus, einfach nur Rohdaten zu sammeln und zu speichern, um einen Wettbewerbsvorteil zu erzielen oder neue Dienstleistungen anzubieten. Um neue Erkenntnisse zu gewinnen, müssen die Daten aus verschiedenen Quellen analysiert und kombiniert werden. So können zum Beispiel Daten aus dem Marketingteam zusammen mit Daten aus dem Vertrieb genutzt werden, um herauszufinden, welche Kampagnen am besten laufen. Verkaufs- und Kundenprofildaten können kombiniert werden, um personalisierte Belohnungsprogramme zu erstellen. Die Kombination von Tools, die für die Datenerfassung und -verdichtung verwendet wird, nennt man Datenpipeline.
In den letzten zehn Jahren hat sich Apache Kafka zum De-facto-Standard für die Aufnahme und Verarbeitung großer Datenmengen in Echtzeit entwickelt. Kafka ist eine Open-Source-Plattform für Daten-Streaming und wurde entwickelt, um als Daten-Backbone für Unternehmen zu dienen. Sie ist heute eine Schlüsselkomponente in vielen Datenanwendungen, da sie von über 80 % der Fortune 100 genutzt wird. Viele neue Anwendungen werden für die Zusammenarbeit mit Kafka entwickelt, damit ihre Daten sofort hochverfügbar sind und leicht wiederverwendet und effizient verarbeitet werden können, um Wissen in Echtzeit zu gewinnen.
Die meisten Unternehmen haben bereits eine Menge Daten in bestehenden Systemen. Auf den ersten Blick mag es relativ einfach erscheinen, eine Anwendung zu schreiben, die Daten aus diesen Systemen zusammenführt, da die meisten von ihnen über APIs verfügen. Doch je mehr externe Systeme du nutzt, desto schneller kann dies zu einer großen und kostspieligen Belastung für die Wartung und den Zeitaufwand der Entwickler werden. Die Systeme haben ihre eigenen Formate und APIs und werden oft von verschiedenen Teams oder Abteilungen verwaltet. Wenn du dann noch Überlegungen zur Sicherheit und zum Datenschutz anstellst, wie z. B. die Allgemeine Datenschutzverordnung der Europäischen Union (GDPR), kann das Schreiben einer Anwendung schnell zu einer Herausforderung werden.
Um diese Probleme zu lösen, wurde eine Reihe von Integrationssystemen entwickelt. Ein Integrationssystem ist so konzipiert, dass es sich mit verschiedenen Systemen verbinden und auf Daten zugreifen kann.
Kafka Connect ist eines dieser Integrationssysteme. Es ist Teil von Apache Kafka und darauf spezialisiert, andere Systeme mit Kafka zu integrieren, damit Daten einfach verschoben, wiederverwendet, kombiniert oder verarbeitet werden können. Kafka Connect kann zum Beispiel verwendet werden, um Änderungen aus einer Datenbank in Kafka zu übertragen, so dass andere Dienste problemlos in Echtzeit reagieren können. Sobald die Daten in Kafka vollständig verarbeitet wurden, kann Kafka Connect sie in einen Datenspeicher verschieben, wo sie über einen längeren Zeitraum aufbewahrt werden können.
Kafka Connect Funktionen
Kafka Connect bietet eine Laufzeitumgebung und ein Framework, um robuste Datenpipelines mit Kafka aufzubauen und auszuführen. Es wurde erstmals in Kafka 0.10.0.0 im Jahr 2016 über KIP-26 eingeführt. Kafka Connect ist kampferprobt und bekannt dafür, dass es unter Last und in großem Maßstab stabil ist. Die Kafka-Connect-Laufzeitumgebung bietet außerdem eine einzige Steuerungsebene für die Verwaltung all deiner Pipelines und ermöglicht oft den Aufbau von Pipelines ohne das Schreiben von Code, damit sich die Ingenieure auf ihre Anwendungsfälle konzentrieren können, anstatt die Daten zu verschieben.
Kafka Connect unterscheidet zwischen Quell-Pipelines, bei denen die Daten von einem externen System zu Kafka gelangen, und Senken-Pipelines, bei denen die Daten von Kafka zu einem externen System fließen. Bei Kafka Connect muss eine Seite der Pipeline Kafka sein, du kannst also nicht zwei externe Systeme direkt miteinander verbinden. Dennoch ist es sehr üblich, dass Daten, die über eine Source-Pipeline in Kafka importiert werden, nach ihrer Verarbeitung über eine Sink-Pipeline in einem anderen externen System landen.
Abbildung 1-1 zeigt zum Beispiel eine Quellpipeline, die Daten aus einer Datenbank in Kafka importiert.

Abbildung 1-1. Eine grundlegende Quellpipeline mit Kafka Connect.
Werfen wir einen genaueren Blick auf die einzigartigen Funktionen und Merkmale, die Kafka Connect zu einer sehr beliebten Plattform für den Aufbau von Datenpipelines und die Integration von Systemen machen:
-
Steckbare Architektur
-
Skalierbar und zuverlässig
-
Deklarative Pipeline-Definition
-
Teil von Apache Kafka
Steckbare Architektur
Kafka Connect bietet eine gemeinsame Logik und klare APIs, um Daten in und aus Kafka auf eine belastbare Weise zu erhalten. Es verwendet Plug-ins, um die spezifische Logik für externe Systeme zu kapseln. Die Kafka-Community hat Hunderte von Plug-ins entwickelt, die mit Datenbanken, Speicherungen und verschiedenen gängigen Protokollen interagieren. Das macht den Einstieg in selbst komplexe Datenpipelines schnell und einfach. Wenn du eigene Systeme hast oder keines der vorhandenen Plug-ins deine Anforderungen erfüllt, bietet Kafka Connect APIs, mit denen du deine eigenen implementieren kannst.
Mit Kafka Connect kannst du komplexe Datenpipelines aufbauen, indem du Plug-ins kombinierst. Die Plug-ins, die zur Definition von Pipelines verwendet werden, heißen Connector-Plug-ins. Es gibt mehrere Arten von Connector-Plug-ins:
-
Quellkonnektoren, die Daten aus einem externen System in Kafka importieren
-
Sink-Konnektoren, die Daten aus Kafka in ein externes System exportieren
-
Konverter, die Daten zwischen Kafka Connect und externen Systemen umwandeln
-
Transformationen, die Daten umwandeln während sie durch Kafka Connect fließen
Eine Pipeline besteht aus einem einzelnen Konnektor und einem Konverter und enthält optionale Transformationen und Prädikate. Kafka Connect unterstützt sowohl Extract-Load-Transform (ELT)- als auch Extract-Transform-Load (ETL)-Pipelines. In ELT-Pipelines führt Kafka Connect die Extraktions- und Ladeschritte durch und ermöglicht es dir, ein anderes System zu verwenden, um Transformationen durchzuführen, sobald die Daten das Zielsystem erreichen. In ETL-Pipelines aktualisieren die Kafka Connect-Transformationen die Daten, während sie durch Kafka Connect fließen.
Abbildung 1-2 zeigt eine einfache ETL-Pipeline, die aus einem Quellkonnektor, einer Transformation (einem Datensatzfilter) und einem Konverter besteht.

Abbildung 1-2. Kafka Connect-Plug-ins bilden eine Quell-Pipeline
Neben den Connector-Plug-ins gibt es eine weitere Gruppe von Plug-ins, mit denen Kafka Connect selbst angepasst werden kann. Diese sind genannt Worker-Plug-ins:
Skalierbarkeit und Verlässlichkeit
Kafka Connect läuft unabhängig von Kafka-Brokern und kann entweder auf einem einzelnen Host als eigenständige Anwendung oder auf mehreren Hosts zur Bildung eines verteilten Clusters eingesetzt werden. Ein Host, auf dem Kafka Connect läuft, wird Worker genannt.
Mit diesen beiden Bereitstellungsoptionen kann Kafka Connect ein breites Spektrum an Arbeitslasten bewältigen. Du kannst Arbeitslasten haben, die von einer einzelnen Pipeline, die nur ein paar Ereignisse verarbeitet, bis zu Dutzenden von Workern reichen, die Millionen von Ereignissen pro Sekunde verarbeiten. Außerdem kannst du einem Kafka-Connect-Cluster zur Laufzeit Worker hinzufügen oder aus ihm entfernen und so die Kapazität an den erforderlichen Durchsatz anpassen.
Beim Einsatz in einem Cluster arbeiten die Worker zusammen und jeder übernimmt einen Teil der Arbeitslast. Das macht Kafka Connect sehr zuverlässig und widerstandsfähig gegen Ausfälle, denn wenn ein Worker ausfällt, können die anderen seine Arbeitslast übernehmen.
Abbildung 1-3 zeigt einen Kafka-Connect-Cluster, der zwei Datenpipelines verarbeitet (von Datenbank 1 zu Kafka und von Datenbank 2 zu Kafka), wobei die Arbeitslast auf die verfügbaren Worker verteilt ist.
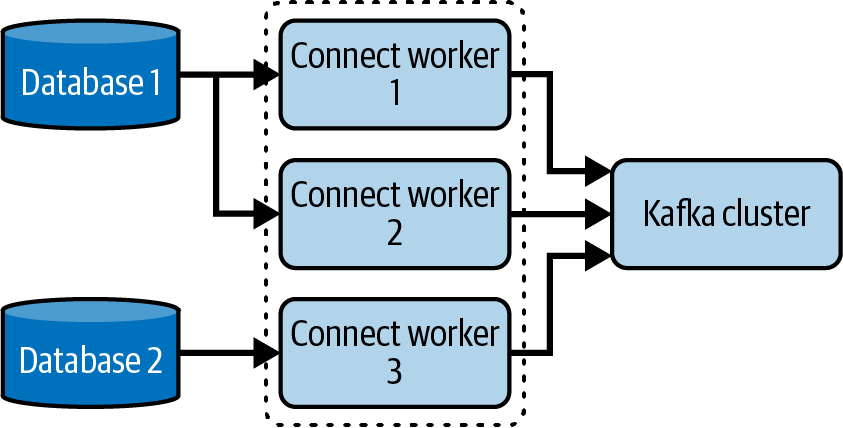
Abbildung 1-3. Ein Kafka-Connect-Cluster bestehend aus drei Workern, die zwei Pipelines bearbeiten
Deklarative Pipeline-Definition
Kafka Connect ermöglicht es dir, deklarativ deine Pipelines zu definieren. Das bedeutet, dass du durch die Kombination von Connector-Plug-ins leistungsstarke Datenpipelines aufbauen kannst, ohne Code schreiben zu müssen. Pipelines werden mithilfe von JSON (oder Eigenschaftsdateien in der Standalone-Konfiguration) definiert, die die zu verwendenden Plug-ins und ihre Konfigurationen beschreiben. So können sich Dateningenieure auf ihre Anwendungsfälle konzentrieren und die Feinheiten der Systeme, mit denen sie interagieren, abstrahieren.
Um Pipelines zu definieren und zu betreiben, stellt Kafka Connect eine REST-API zur Verfügung. Das bedeutet, dass du alle deine Datenpipelines ganz einfach starten, stoppen, konfigurieren und deren Zustand und Status verfolgen kannst.
Sobald eine Pipeline über die REST-API erstellt wurde, instanziiert Kafka Connect automatisch die erforderlichen Plug-ins auf den verfügbaren Workern im Connect-Cluster.
Teil von Apache Kafka
Kafka Connect ist Teil des Apache Kafka-Projekts und wurde speziell für die Zusammenarbeit mit Kafka entwickelt. Apache Kafka ist ein Open-Source-Projekt, was bedeutet, dass Kafka Connect von einer großen und aktiven Community profitiert. Wie bereits erwähnt, gibt es Hunderte von Plug-ins für Kafka Connect, die von der Community entwickelt wurden. Kafka Connect erhält mit jeder Kafka-Version Verbesserungen und neue Funktionen. Diese Änderungen reichen von Aktualisierungen der Benutzerfreundlichkeit bis hin zu Änderungen, die es Kafka Connect ermöglichen, die neuesten Kafka-Funktionen zu nutzen.
Für Entwickler und Administratoren, die Kafka bereits nutzen und kennen, bietet Kafka Connect eine Integrationsoption, die kein neues System erfordert und viele der Kafka-Konzepte und -Verfahren wiederverwendet. Intern nutzt Kafka Connect reguläre Kafka-Clients und verfügt daher über viele ähnliche Konfigurationseinstellungen und Betriebsabläufe.
Es wird zwar empfohlen, immer die aktuellste Version von Kafka und Kafka Connect zu verwenden, aber du bist nicht dazu verpflichtet, dies zu tun. Die Kafka-Community setzt sich dafür ein, dass ältere Clients so lange wie möglich unterstützt werden. Das bedeutet, dass du deine Kafka- und Kafka Connect-Cluster jederzeit unabhängig voneinander aktualisieren kannst. Auch bei der Entwicklung der Kafka Connect APIs wurde auf Abwärtskompatibilität geachtet. Das bedeutet, dass du Plug-ins verwenden kannst, die für eine ältere oder neuere Version der Kafka Connect API entwickelt wurden als die, die du gerade verwendest.
Wenn Kafka Connect im verteilten Modus betrieben wird, muss es seine Konfiguration und seinen Status irgendwo speichern. Anstatt ein separates Speichersystem zu benötigen, speichert Kafka Connect alles, was es braucht, in Kafka.
Nachdem du nun weißt, was Kafka Connect ist, gehen wir auf einige Anwendungsfälle ein, in denen es sich auszeichnet.
Anwendungsfälle
Kafka Connect kann für eine Vielzahl von Anwendungsfällen genutzt werden, bei denen Daten in oder aus Kafka übertragen werden. In diesem Abschnitt gehen wir auf die häufigsten Anwendungsfälle von Kafka Connect ein und erklären, welche Vorteile sie für die Verwaltung und Verarbeitung von Daten bieten.
Die Anwendungsfälle sind:
-
Erfassen von Datenbankänderungen
-
Kafka-Cluster spiegeln
-
Aufbau von Data Lakes
-
Aggregieren von Baumstämmen
-
Altsysteme modernisieren
Erfassen von Datenbankänderungen
Eine häufige Anforderung an Datenpipelines ist, dass Anwendungen Änderungen in einer Datenbank in Echtzeit verfolgen können. Dieser Anwendungsfall wird als Änderungsdatenerfassung (CDC) bezeichnet.
Es gibt eine Reihe von Konnektoren für Kafka Connect, die Änderungen aus Datenbanken in Echtzeit streamen können. Das bedeutet, dass du statt vieler Anwendungen, die die Datenbank abfragen, nur eine hast: Kafka Connect. Das verringert die Belastung der Datenbank und macht es viel einfacher, das Schema deiner Tabellen im Laufe der Zeit weiterzuentwickeln. Kafka Connect kann die Daten auch umwandeln, indem es ein Schema vorgibt, Daten validiert oder sensible Daten entfernt, bevor sie an Kafka gesendet werden. So hast du eine bessere Kontrolle über die Ansichten anderer Anwendungen auf die Daten.
Es gibt eine Untergruppe von Connector-Plug-ins, bei denen die Datenbank gar nicht abgefragt werden muss. Statt die Datenbank abzufragen, greifen sie auf die Änderungsprotokolldatei zu, in der die Aktualisierungen festgehalten werden, was eine zuverlässigere und weniger ressourcenintensive Methode ist, um Änderungen zu verfolgen.
Das Debezium-Projekt bietet unter Connector-Plug-ins für viele gängige Datenbanken an, die die Change Log-Datei nutzen, um Ereignisse zu erzeugen. In Kapitel 5 zeigen wir zwei verschiedene Möglichkeiten, um Änderungen in einer MySQL-Datenbank zu erfassen: mit einem Debezium-Konnektor und mit einem JDBC-Konnektor, der eine abfragebasierte CDC durchführt.
Kafka-Cluster spiegeln
Ein weiterer beliebter Anwendungsfall von Kafka Connect ist das Kopieren von Daten von einem Kafka-Cluster zu einem anderen. Dies wird als Spiegelung bezeichnet und ist eine wichtige Voraussetzung für viele Szenarien, z. B. für den Aufbau von Disaster-Recovery-Umgebungen, die Migration von Clustern oder die Georeplikation.
Obwohl Kafka über eine eingebaute Ausfallsicherheit verfügt, kann es bei produktionskritischen Einsätzen notwendig sein, einen Wiederherstellungsplan zu haben, falls deine Infrastruktur von einem größeren Ausfall betroffen ist. Mit Mirroring kannst du mehrere Cluster synchronisieren, um die Auswirkungen von Ausfällen zu minimieren.
Vielleicht möchtest du auch aus anderen Gründen, dass deine Daten in verschiedenen Clustern verfügbar sind. Du möchtest sie zum Beispiel Anwendungen zur Verfügung stellen, die in einem anderen Rechenzentrum oder einer anderen Region laufen, oder du möchtest eine Kopie haben, aus der die sensiblen Informationen entfernt wurden.
Das Kafka-Projekt bietet MirrorMaker an, um Daten und Metadaten zwischen Clustern zu spiegeln. MirrorMaker ist eine Reihe von Konnektoren, die in verschiedenen Kombinationen verwendet werden können, um deine Spiegelungsanforderungen zu erfüllen. Wie du sie richtig einsetzt und verwaltest, erfährst du in Kapitel 6.
Aufbau von Data Lakes
Du kannst Kafka Connect nutzen, um Daten in einen eigens dafür eingerichteten Data Lake zu kopieren oder sie in einer kostengünstigen Speicherung wie Amazon Simple Storage Service (Amazon S3) zu archivieren. Das ist besonders interessant, wenn du große Datenmengen oder Daten für eine lange Zeit aufbewahren musst (z. B. für Prüfungszwecke). Wenn die Daten in Zukunft wieder benötigt werden, kannst du sie jederzeit mit Kafka Connect wieder importieren.
Hinweis
Die Kafka-Gemeinschaft fügt derzeit Unterstützung für eine gestaffelte Speicherung zu Kafka hinzu. Das bedeutet, dass du in einer zukünftigen Version Kafka so konfigurieren kannst, dass es einen Teil seiner Daten in einem längerfristigen Speichersystem speichert, ohne die angeschlossenen Anwendungen zu beeinträchtigen. Um eine vollständige Kopie der Daten zu erstellen, wird jedoch weiterhin ein Tool wie Kafka Connect benötigt.
Das Kopieren deiner Ereignisdaten von Kafka in ein spezielles Speichersystem kann auch nützlich sein für maschinelles Lernen (ML) und künstliche Intelligenz (KI), die beide üblicherweise Trainingsdaten verwenden. Je realistischer die Trainingsdaten sind, desto besser wird dein System. Anstatt Scheindaten zu erstellen, kannst du mit Kafka Connect deine echten Ereignisse an einen Ort kopieren, auf den dein ML- oder KI-System zugreifen kann.
In Kapitel 5 zeigen wir, wie du mit einem Connector Daten aus Kafka-Themen in einen Bucket in Amazon S3 exportierst.
Logs aggregieren
Oft ist es sinnvoll, aggregierte Daten wie Logs, Metriken und Ereignisse aus allen deinen Anwendungen zu speichern und auf zu veröffentlichen. Es ist viel einfacher, die Daten zu analysieren, wenn sie sich an einem einzigen Ort befinden. Mit dem Aufkommen von Cloud, Containern und Kubernetes musst du außerdem damit rechnen, dass die Infrastruktur deine Workloads komplett entfernt und von Grund auf neu erstellt, wenn sie einen Fehler feststellt. Das bedeutet, dass es wichtig ist, Daten wie Logs an einem zentralen Ort zu speichern und nicht mit der Anwendung, um sie nicht zu verlieren. Kafka eignet sich hervorragend für die Datenaggregation, da es große Datenmengen mit sehr geringen Latenzzeiten verarbeiten kann.
Kafka kann als Appender von Logging-Bibliotheken wie Apache Log4j2 konfiguriert werden, um Logs direkt von Anwendungen an Kafka zu senden, anstatt sie in Log-Dateien auf der Speicherung zu schreiben. Dies funktioniert jedoch nur für Anwendungen, die diese Art von Bibliothek nutzen können. Ohne Kafka Connect müsstest du wahrscheinlich viele Anwendungen und Systeme mit Kafka-Clients ausstatten und alle deine Teams darauf vorbereiten, wie man diese Clients schreibt, einsetzt und betreibt. Wenn du diese anfängliche Hürde überwunden hast, hast du mehrere Stellen, die du aktualisieren kannst, wenn du deine Meinung über die Form der gesammelten Daten oder darüber, wohin sie gesendet werden sollen, änderst.
Wenn du Kafka Connect für diese Art von Anwendungsfällen einsetzt, verringert sich der Aufwand für das Sammeln der Daten. Ein einziges Team kann den Kafka-Connect-Cluster einrichten und verwalten, und angesichts der großen Anzahl von Konnektoren, die es bereits gibt, kann es dies oft tun, ohne Code zu schreiben. Da die Konnektoren und ihre Konfiguration alle über Kafka Connect abgewickelt werden, kannst du Datenformate und Zielthemen an einer Stelle ändern.
Modernisierung von Altsystemen
Moderne Architekturen tendieren dazu, viele kleine Anwendungen statt eines einzelnen Monolithen einzusetzen. Das kann zu Problemen bei bestehenden Systemen führen, die nicht dafür ausgelegt sind, mit so vielen Anwendungen zu kommunizieren. Außerdem sind sie oft nicht in der Lage, Echtzeitverarbeitung zu unterstützen. Da Kafka ein Publish/Subscribe-Messaging-System ist, trennt es zwischen den Anwendungen, die Daten an das System senden, und denjenigen, die Daten aus dem System lesen. Das macht es zu einem sehr nützlichen Werkzeug, das als Zwischenpuffer zwischen verschiedenen Systemen dient. Du kannst Kafka Connect nutzen, um die alten Daten in Kafka verfügbar zu machen und deine neuen Anwendungen stattdessen mit Kafka zu verbinden. Kafka-Anwendungen müssen nicht ständig mit Kafka verbunden sein oder die Daten in Echtzeit lesen. So können Legacy-Anwendungen Daten stapelweise verarbeiten, ohne dass sie neu geschrieben werden müssen.
Alternativen zu Kafka Connect
Da es viele verschiedene Datensysteme gibt, ist es keine Überraschung, dass es auch viele verschiedene Integrationssysteme gibt. Kafka Connect ist nicht das einzige Tool, das für den Aufbau von Datenpipelines entwickelt wurde, und viele andere Tools unterstützen ebenfalls Kafka. Wir werden nicht auf alle Alternativen zu Kafka Connect eingehen, aber wir werden einige beliebte auflisten. Jedes Tool hat seine eigenen Besonderheiten und du solltest dich je nach deinen Anforderungen, deinem aktuellen Fachwissen und deinen Tools für eines entscheiden. Viele der verfügbaren Alternativen bieten eine Integration mit Kafka. Das Kafka-Projekt unterstützt mehrere Client-Versionen, sodass das von dir gewählte Tool nicht unbedingt den neuesten Kafka-Client verwendet. Wenn du jedoch diese Tools verwendest, kannst du neue Kafka-Funktionen möglicherweise nicht so schnell nutzen wie bei der Verwendung von Kafka Connect.
Hier sind einige Open-Source-Alternativen, die du in Betracht ziehen könntest:
- Apache Camel
- Ein Integrations-Framework. Es kann eigenständig oder als Teil eines Anwendungsservers implementiert werden. Apache Camel enthält eine Kafka-Komponente, die Daten in und aus Kafka holen kann.
- Apache NiFi
- Ein System zur Verarbeitung und Verteilung von Daten, das in einem Cluster eingesetzt werden kann. Apache NiFi bietet Prozessoren für das Senden von Daten zu und von Kafka.
- Apache Flume
- Ein System zum Sammeln, Aggregieren und Verschieben großer Mengen von Logdaten aus Anwendungen an einen zentralen Ort.
- LinkedIn Hoptimator
- Eine SQL-basierte Steuerungsebene für komplexe Datenpipelines. Hoptimator enthält einen Adapter für Kafka.
Hinweis
Eine Reihe von Anbietern bietet Unterstützung oder eigene Distributionen für die oben genannten Open-Source-Systeme an. Viele Unternehmen haben auch eigene Integrationssysteme und Plattformen entwickelt, die auf bestimmte Anwendungsfälle oder Branchen ausgerichtet sind.
Zusammenfassung
In diesem ersten Kapitel wurden die aktuelle Datenlandschaft und die Probleme vorgestellt, mit denen viele Unternehmen beim Umgang mit ihren Daten konfrontiert sind. Die Daten sind oft über viele verschiedene Systeme verteilt, was es für Unternehmen schwierig machen kann, sie zu nutzen, um Erkenntnisse zu gewinnen und ihren Kunden innovative Dienstleistungen anzubieten. Integrationssysteme wie Kafka Connect sollen diese Probleme lösen, indem sie einfache, skalierbare und zuverlässige Mechanismen zum Aufbau von Datenpipelines zwischen verschiedenen Systemen bereitstellen.
Kafka Connect hat einige wichtige Funktionen, die es so beliebt machen. Es verfügt über eine steckbare Architektur, die es einfach macht, komplexe Pipelines ohne Code aufzubauen. Es ist skalierbar und zuverlässig und verfügt über eine nützliche REST-Management-API, mit der sich Vorgänge automatisieren lassen. Und schließlich ist es Teil des Open-Source-Projekts Apache Kafka und profitiert von der florierenden Kafka-Community.
Get Kafka Verbinden now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

