Kapitel 4. Schutz der Routing Engine und DDoS-Prävention
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Dieses Kapitel baut auf dem letzten auf, indem es ein konkretes Beispiel für die Verwendung von zustandslosen Firewall-Filtern und Policern im Kontext eines Routing-Engine-Schutzfilters liefert und außerdem die neue Trio-spezifische DDoS-Präventionsfunktion demonstriert, die die bereits robuste Junos-Kontrollebene ohne explizite Konfiguration härtet.
Zu den besprochenen Themen zum Schutz von RE gehören:
Fallstudie: IPv4- und IPv6-Kontrollebene-Schutzfilter
Überblick über DDoS-Funktionen
Fallstudie zum DDoS-Schutz
Abschwächung von DDoS mit BGP-Flussspezifikation
BGP Flow-Specification Fallstudie
RE Schutz Fallstudie
In dieser Fallstudie wird ein aktuelles Beispiel für die bewährte Methode eines zustandslosen Filters zum Schutz der IPv4- und IPv6-Kontrollebene eines MX-Routers vorgestellt. Außerdem wird die DDoS-Erkennungsfunktion, die auf Trio-basierten MX-Routern ab Version v11.2 verfügbar ist, untersucht und dann mit der RE-Filterung kombiniert, um den Router gegen unbefugten Zugriff und Ressourcenerschöpfung zu schützen.
Da Netzwerke immer kritischer werden, werden Sicherheit und hohe Verfügbarkeit immer wichtiger. Die Notwendigkeit eines sicheren Zugriffs auf die Netzwerkinfrastruktur, sowohl im Hinblick auf die Authentifizierung und Autorisierung auf Benutzerebene als auch auf die Konfiguration und Verwendung von sicheren Zugriffsprotokollen wie SSH, ist eine Selbstverständlichkeit. So sehr, dass diese Themen bereits in vielen Büchern behandelt wurden. Um die gleichen Informationen nicht wieder aufzuwärmen, empfehlen wir Lesern, die sich für diese Themen interessieren, Junos Enterprise Routing, Second Edition, von O'Reilly Media.
Ziel dieses Abschnitts ist es, ein aktuelles Beispiel für einen starken RE-Schutzfilter sowohl für IPv4 als auch für IPv6 zu geben und zu erläutern, warum einfache Filter nicht vor Ressourcenverknappung schützen, die den Betrieb eines Routers genauso effektiv stoppen kann wie ein "Hacker", der sich in böser Absicht unbefugt Zugang zum System verschafft.
Das Thema Routersicherheit ist komplex und weit verbreitet. So sehr, dass der RFC 6192 erstellt wurde, um die bewährten Methoden zur IPv4- und IPv6-Filterung zusammen mit Beispielfiltern für IOS- und Junos OS-basierte Produkte zu beschreiben. Es gibt viele Überschneidungen zwischen den Beispielen in diesem Abschnitt und den Vorschlägen des RFC, was ein gutes Zeichen ist, denn man kann nie zu viele kluge Köpfe haben, die über Sicherheit nachdenken. Das ist ein gutes Zeichen, denn es gibt nie zu viele kluge Köpfe, die über Sicherheit nachdenken. Es ist gut, verschiedene Ansätze und Techniken zu sehen und eine Bestätigung dafür, dass es für viele komplexe Probleme gemeinsame Lösungen gibt, die gut getestet wurden.
IPv4 RE Schutzfilter
In diesem Abschnitt findest du ein Beispiel für die bewährte Methode eines RE-Schutzfilters für IPv4-Datenverkehr. Schutzfilter werden in der Eingangsrichtung eingesetzt, um den an den PFE- oder Management-Ports ankommenden Verkehr zu filtern, bevor er von der RE verarbeitet wird. Ausgangsfilter werden in der Regel für die CoS-Kennzeichnung des lokal erzeugten Control Plane-Verkehrs verwendet und nicht aus sicherheitsrelevanten Gründen, da du in der Regel deinen eigenen Routern und dem von ihnen erzeugten Verkehr vertraust. Abbildung 4-1 zeigt die Details der Topologie, die dieses Fallbeispiel umgibt.
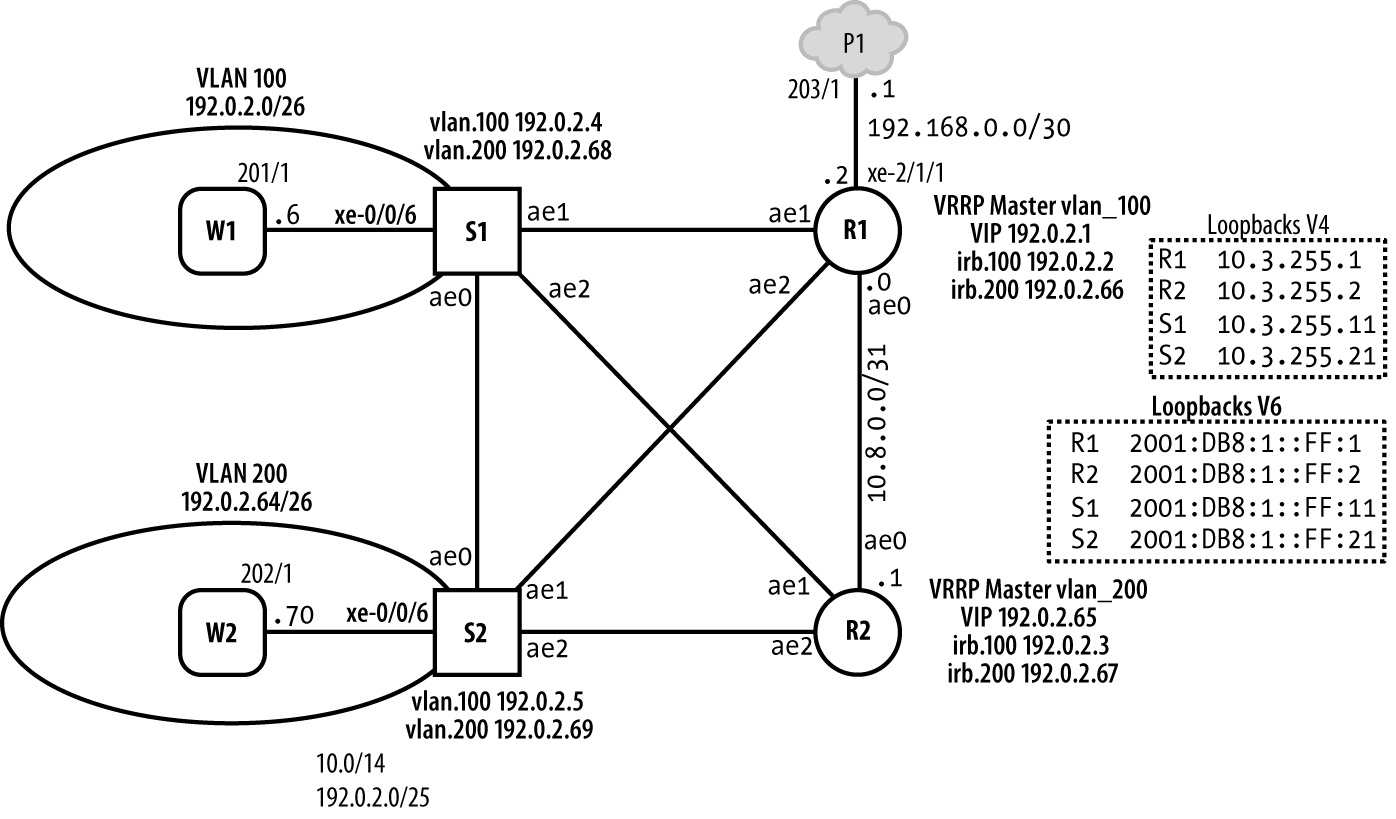
Abbildung 4-1. Topologie des DDoS-Schutzlabors
Das Beispiel, das mit Genehmigung von Juniper Networks Books verwendet wird, stammt aus dem Buch Day One: Securing the Routing Engine von Douglas Hanks, der auch Mitautor dieses Buches ist.
Warnung
Hinweis: Die Sicherheit von Routern ist keine Kleinigkeit. Wir empfehlen dem Leser, den Filter sorgfältig zu prüfen, bevor er ihn für sein eigenes Netzwerk anpasst.
Die Prinzipien, die der Funktionsweise des Filters zugrunde liegen, und die besonderen Überlegungen, die hinter seinem Design stehen, werden im Day One Buch erklärt und werden hier aus Gründen der Kürze nicht wiederholt. Der Filter wird hier aus mehreren Gründen als Beispiel für eine Fallstudie herangezogen:
RE-Schutz ist wichtig und notwendig, und dies ist ein wirklich guter Filter. Es macht keinen Sinn, ein bereits perfekt rundes Rad nachzubauen, und das Day One Buch ist kostenlos als PDF erhältlich.
Das Beispiel nutzt einige wichtige Junos-Funktionen, die nicht unbedingt MX-spezifisch sind und daher in diesem Kapitel nicht behandelt wurden, wie z. B. Filterverschachtelung (ein Filter ruft einen anderen Filter auf),
apply-pathundprefix-list. All dies sind leistungsstarke Tools, die die Verwaltung und das Verständnis eines komplexen Filters deutlich vereinfachen können. In den Beispielen wird auch die Anweisungapply-flags omitverwendet. Dieses Flag führt dazu, dass der zugehörige Konfigurationsblock nicht in einemshow configuration commandangezeigt wird, es sei denn, du leitest die Ergebnisse andisplay omitweiter. Auch wenn es sich hierbei nicht um eine filter-spezifische Funktion handelt, ist dies eine weitere coole Junos-Funktion, die das Leben mit langen Filtern sehr viel einfacher machen kann.Es ist ein guter Test für dieses Kapitel und für das Verständnis des Lesers. Dies ist ein reales Beispiel für einen komplexen Filter, der ein echtes Problem löst. Auch wenn bestimmte Protokollnuancen, wie z. B. die spezifischen Multicast-Adressen, die von OSPF verwendet werden, nicht bekannt sind, sollte der Leser, wenn er hier angekommen ist, in der Lage sein, die Funktionsweise des Filters und die Verwendung von Policing ohne große Anleitung zu verstehen.
Das Beispiel ist umfassend und bietet Unterstützung für praktisch alle bekannten legitimen Routing-Protokolle und -Dienste. Achte darauf, die Unterstützung für Protokolle oder Dienste zu entfernen, die derzeit nicht verwendet werden, indem du entweder den betreffenden Filter löschst oder ihn einfach nicht in die Liste der Filter aufnimmst, die du letztendlich auf die lo0-Schnittstelle anwendest. Da im aktuellen Praktikum zum Beispiel IS-IS verwendet wird, ist ein OSPF-spezifischer Filter nicht erforderlich. Vergewissere dich außerdem, dass die Präfixlisten alle Adressen enthalten, die den entsprechenden Dienst oder das entsprechende Protokoll erreichen können sollen.
Wenn du die Filterliste zum ersten Mal anwendest, solltest du den letzten Begriff discard-all durch einen Begriff ersetzen, der auf alle mit einer akzeptierenden und protokollierenden Aktion passt. Dies dient als Sicherheitsmaßnahme, um eine Unterbrechung des Dienstes zu verhindern, falls ein gültiger Dienst oder ein gültiges Protokoll von einem vorherigen Begriff nicht berücksichtigt wurde. Achte nach der Anwendung des Filters besonders auf Log-Treffer, die darauf hinweisen, dass der Datenverkehr bis zum letzten Catch-All-Term vorgedrungen ist, denn das könnte darauf hindeuten, dass du noch mehr Filterarbeit leisten musst.
Warnung
Bevor du einen RE-Filter anwendest, solltest du sowohl die Filter/Begriffe als auch ihre Anwendungsreihenfolge sorgfältig prüfen, um sicherzustellen, dass alle gültigen Dienste und Fernzugriffsmethoden erlaubt sind. Außerdem musst du die Beispiel-Präfixliste bearbeiten, um sicherzustellen, dass sie alle internen und externen Adressen, von denen aus die entsprechenden Dienste erreichbar sein sollen, korrekt wiedergibt. Bei jeder Änderung dieser Art sollte ein Konsolenzugang zur Verfügung stehen, falls eine Wiederherstellung erforderlich ist, und du solltest unbedingt den Befehl commit confirmed verwenden.
Wenn dein Filter korrekt auf die Besonderheiten deines Netzwerks abgestimmt ist, sollte nur noch der Datenverkehr durchgelassen werden, der nicht unterstützt wird und daher nicht benötigt wird und der sicher verworfen werden kann. Sobald dies bestätigt ist, solltest du den discard-all Filter zum letzten in der Kette machen - seine laufenden Zähl- und Protokollierungsaktionen vereinfachen die künftige Fehlersuche, wenn ein neuer Dienst hinzugefügt wird und niemand herausfinden kann, warum er nicht funktioniert. Ja, echte Sicherheit ist lästig, aber auf lange Sicht ist sie weit weniger lästig als das Fehlen oder - noch schlimmer - ein falsches Gefühl von Sicherheit!
Beginnen wir mit der richtlinienbezogenen Konfiguration, bei der die Präfixlisten so definiert werden, dass sie automatisch mit Adressen gefüllt werden, die dem System selbst zugewiesen sind, sowie mit bekannten Adressen, die mit gängigen Protokollen verbunden sind. Diese kleine Vorarbeit macht spätere adressbasierte Abgleiche zu einem Kinderspiel und stellt sicher, dass Änderungen an Adressen und Peer-Definitionen problemlos durchgeführt werden können, da der Filter automatisch mitzieht. Beachte, dass die Beispielausdrücke alle zugewiesenen Adressen erfassen, einschließlich derer im Verwaltungsnetzwerk und in GRE-Tunneln usw. Das Beispiel setzt die Verwendung von logischen Systemen voraus (eine Funktion, die früher als logische Router bekannt war). Wo dies nicht der Fall ist, kannst du die entsprechende Präfixliste getrost weglassen.
{master}[edit]
user1@R1-RE0# show policy-options | no-more
prefix-list router-ipv4 {
apply-path "interfaces <*> unit <*> family inet address <*>";
}
prefix-list bgp-neighbors {
apply-path "protocols bgp group <*> neighbor <*>";
}
prefix-list ospf {
224.0.0.5/32;
224.0.0.6/32;
}
prefix-list rfc1918 {
10.0.0.0/8;
172.16.0.0/12;
192.168.0.0/16;
}
prefix-list rip {
224.0.0.9/32;
}
prefix-list vrrp {
224.0.0.18/32;
}
prefix-list multicast-all-routers {
224.0.0.2/32;
}
prefix-list router-ipv4-logical-systems {
apply-path "logical-systems <*> interfaces <*> unit <*> family inet address
<*>";
}
prefix-list bgp-neighbors-logical-systems {
apply-path "logical-systems <*> protocols bgp group <*> neighbor <*>";
}
prefix-list radius-servers {
apply-path "system radius-server <*>";
}
prefix-list tacas-servers {
apply-path "system tacplus-server <*>";
}
prefix-list ntp-server {
apply-path "system ntp server <*>";
}
prefix-list snmp-client-lists {
apply-path "snmp client-list <*> <*>";
}
prefix-list snmp-community-clients {
apply-path "snmp community <*> clients <*>";
}
prefix-list localhost {
127.0.0.1/32;
}
prefix-list ntp-server-peers {
apply-path "system ntp peer <*>";
}
prefix-list dns-servers {
apply-path "system name-server <*>";
}
Du kannst überprüfen, ob deine apply-path- und Präfix-Listen das tun, was du erwartest, indem du die Liste anzeigst und die Ausgabe an display inheritance weiterleitest. Auch hier ist es wichtig, dass deine Präfixlisten alle erwarteten Adressen enthalten, von denen aus ein Dienst erreichbar sein sollte. Es lohnt sich also, hier etwas Zeit zu investieren, um sicherzustellen, dass die regulären Ausdrücke wie erwartet funktionieren. Hier werden die Ergebnisse des regulären Ausdrucks router-ipv4 apply-path untersucht.
{master}[edit]
jnpr@R1-RE0# show policy-options prefix-list router-ipv4
apply-path "interfaces <*> unit <*> family inet address <*>";
{master}[edit]
jnpr@R1-RE0# show policy-options prefix-list router-ipv4 | display inheritance
##
## apply-path was expanded to:
## 192.168.0.0/30;
## 10.8.0.0/31;
## 192.0.2.0/26;
## 192.0.2.64/26;
## 10.3.255.1/32;
## 172.19.90.0/23;
##
apply-path "interfaces <*> unit <*> family inet address <*>";
Wenn du ein oder mehrere kommentierte Präfixe nicht siehst, wie in diesem Beispiel, dann existiert entweder die entsprechende Konfiguration nicht oder es gibt ein Problem in deiner Pfadangabe. Als zusätzliche Bestätigung kannst du die BGP-Stanza auf R1 sehen, die aus drei BGP-Peergruppen besteht: zwei IPv6- und eine IPv4-Gruppe:
{master}[edit]
jnpr@R1-RE0# show protocols bgp
group int_v4 {
type internal;
local-address 10.3.255.1;
neighbor 10.3.255.2;
}
group ebgp_v6 {
type external;
peer-as 65010;
neighbor fd1e:63ba:e9dc:1::1;
}
group int_v6 {
type internal;
local-address 2001:db8:1::ff:1;
neighbor 2001:db8:1::ff:2;
}
Auch hier wird bestätigt, dass die entsprechenden Präfixlisten alle erwarteten Einträge enthalten:
{master}[edit]
jnpr@R1-RE0# show policy-options prefix-list bgp-neighbors_v4 | display
inheritance
##
## apply-path was expanded to:
## 10.3.255.2/32;
##
apply-path "protocols bgp group <*_v4> neighbor <*>";
{master}[edit]
jnpr@R1-RE0# show policy-options prefix-list bgp-neighbors_v6 | display
inheritance
##
## apply-path was expanded to:
## fd1e:63ba:e9dc:1::1/128;
## 2001:db8:1::ff:2/128;
##
apply-path "protocols bgp group <*_v6> neighbor <*>";
Und jetzt der eigentliche Filter. Er ist lang, aber Sicherheit ist nie einfach und sowieso eher ein fortlaufender Prozess als eine Ein-Punkt-Lösung. Immerhin bedeutet die umfassende Natur des Filters, dass es einfach ist, mit neuen Diensten oder Protokollen zu wachsen, da du einfach die entsprechenden Filter anwenden musst, wenn der neue Dienst eingeschaltet wird:
{master}[edit]
jnpr@R1-RE0# show firewall family inet | no-more
prefix-action management-police-set { /* OMITTED */ };
prefix-action management-high-police-set { /* OMITTED */ };
filter accept-bgp { /* OMITTED */ };
filter accept-ospf { /* OMITTED */ };
filter accept-rip { /* OMITTED */ };
filter accept-vrrp { /* OMITTED */ };
filter accept-ssh { /* OMITTED */ };
filter accept-snmp { /* OMITTED */ };
filter accept-ntp { /* OMITTED */ };
filter accept-web { /* OMITTED */ };
filter discard-all { /* OMITTED */ };
filter accept-traceroute { /* OMITTED */ };
filter accept-igp { /* OMITTED */ };
filter accept-common-services { /* OMITTED */ };
filter accept-sh-bfd { /* OMITTED */ };
filter accept-ldp { /* OMITTED */ };
filter accept-ftp { /* OMITTED */ };
filter accept-rsvp { /* OMITTED */ };
filter accept-radius { /* OMITTED */ };
filter accept-tacas { /* OMITTED */ };
filter accept-remote-auth { /* OMITTED */ };
filter accept-telnet { /* OMITTED */ };
filter accept-dns { /* OMITTED */ };
filter accept-ldp-rsvp { /* OMITTED */ };
filter accept-established { /* OMITTED */ };
filter accept-all { /* OMITTED */ };
filter accept-icmp { /* OMITTED */ };
filter discard-frags { /* OMITTED */ };
Es gibt nicht viel zu sehen, da die Auslassungsflagge im Spiel ist. Das ist leicht zu beheben:
{master}[edit]
jnpr@R1-RE0# show firewall family inet | no-more | display omit
prefix-action management-police-set {
apply-flags omit;
policer management-1m;
count;
filter-specific;
subnet-prefix-length 24;
destination-prefix-length 32;
}
prefix-action management-high-police-set {
apply-flags omit;
policer management-5m;
count;
filter-specific;
subnet-prefix-length 24;
destination-prefix-length 32;
}
filter accept-bgp {
apply-flags omit;
term accept-bgp {
from {
source-prefix-list {
bgp-neighbors_v4;
bgp-neighbors-logical-systems_v4;
}
protocol tcp;
port bgp;
}
then {
count accept-bgp;
accept;
}
}
}
filter accept-ospf {
apply-flags omit;
term accept-ospf {
from {
source-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
destination-prefix-list {
router-ipv4;
ospf;
router-ipv4-logical-systems ;
}
protocol ospf;
}
then {
count accept-ospf;
accept;
}
}
}
filter accept-rip {
apply-flags omit;
term accept-rip {
from {
source-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
destination-prefix-list {
rip;
}
protocol udp;
destination-port rip;
}
then {
count accept-rip;
accept;
}
}
term accept-rip-igmp {
from {
source-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
destination-prefix-list {
rip;
}
protocol igmp;
}
then {
count accept-rip-igmp;
accept;
}
}
}
filter accept-vrrp {
apply-flags omit;
term accept-vrrp {
from {
source-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
destination-prefix-list {
vrrp;
}
protocol [ vrrp ah ];
}
then {
count accept-vrrp;
accept;
}
}
}
filter accept-ssh {
apply-flags omit;
term accept-ssh {
from {
source-prefix-list {
rfc1918;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol tcp;
destination-port ssh;
}
then {
policer management-5m;
count accept-ssh;
accept;
}
}
}
filter accept-snmp {
apply-flags omit;
term accept-snmp {
from {
source-prefix-list {
snmp-client-lists;
snmp-community-clients;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol udp;
destination-port snmp;
}
then {
policer management-5m;
count accept-snmp;
accept;
}
}
}
filter accept-ntp {
apply-flags omit;
term accept-ntp {
from {
source-prefix-list {
ntp-server;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol udp;
port ntp;
}
then {
policer management-1m;
count accept-ntp;
accept;
}
}
term accept-ntp-peer {
from {
source-prefix-list {
ntp-server-peers;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol udp;
destination-port ntp;
}
then {
policer management-1m;
count accept-ntp-peer;
accept;
}
}
term accept-ntp-server {
from {
source-prefix-list {
rfc1918;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol udp;
destination-port ntp;
}
then {
policer management-1m;
count accept-ntp-server;
accept;
}
}
}
filter accept-web {
apply-flags omit;
term accept-web {
from {
source-prefix-list {
rfc1918;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol tcp;
destination-port [ http https ];
}
then {
policer management-5m;
count accept-web;
accept;
}
}
}
filter discard-all {
apply-flags omit;
term discard-ip-options {
from {
ip-options any;
}
then {
count discard-ip-options;
log;
syslog;
discard;
}
}
term discard-TTL_1-unknown {
from {
ttl 1;
}
then {
count discard-all-TTL_1-unknown;
log;
syslog;
discard;
}
}
term discard-tcp {
from {
protocol tcp;
}
then {
count discard-tcp;
log;
syslog;
discard;
}
}
term discard-netbios {
from {
protocol udp;
destination-port 137;
}
then {
count discard-netbios;
log;
syslog;
discard;
}
}
term discard-udp {
from {
protocol udp;
}
then {
count discard-udp;
log;
syslog;
discard;
}
}
term discard-icmp {
from {
protocol icmp;
}
then {
count discard-icmp;
log;
syslog;
discard;
}
}
term discard-unknown {
then {
count discard-unknown;
log;
syslog;
discard;
}
}
}
filter accept-traceroute {
apply-flags omit;
term accept-traceroute-udp {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol udp;
ttl 1;
destination-port 33435-33450;
}
then {
policer management-1m;
count accept-traceroute-udp;
accept;
}
}
term accept-traceroute-icmp {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol icmp;
ttl 1;
icmp-type [ echo-request timestamp time-exceeded ];
}
then {
policer management-1m;
count accept-traceroute-icmp;
accept;
}
}
term accept-traceroute-tcp {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol tcp;
ttl 1;
}
then {
policer management-1m;
count accept-traceroute-tcp;
accept;
}
}
}
filter accept-igp {
apply-flags omit;
term accept-ospf {
filter accept-ospf;
}
term accept-rip {
filter accept-rip;
}
}
filter accept-common-services {
apply-flags omit;
term accept-icmp {
filter accept-icmp;
}
term accept-traceroute {
filter accept-traceroute;
}
term accept-ssh {
filter accept-ssh;
}
term accept-snmp {
filter accept-snmp;
}
term accept-ntp {
filter accept-ntp;
}
term accept-web {
filter accept-web;
}
term accept-dns {
filter accept-dns;
}
}
filter accept-sh-bfd {
apply-flags omit;
term accept-sh-bfd {
from {
source-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol udp;
source-port 49152-65535;
destination-port 3784-3785;
}
then {
count accept-sh-bfd;
accept;
}
}
}
filter accept-ldp {
apply-flags omit;
term accept-ldp-discover {
from {
source-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
destination-prefix-list {
multicast-all-routers;
}
protocol udp;
destination-port ldp;
}
then {
count accept-ldp-discover;
accept;
}
}
term accept-ldp-unicast {
from {
source-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol tcp;
port ldp;
}
then {
count accept-ldp-unicast;
accept;
}
}
term accept-tldp-discover {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol udp;
destination-port ldp;
}
then {
count accept-tldp-discover;
accept;
}
}
term accept-ldp-igmp {
from {
source-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
destination-prefix-list {
multicast-all-routers;
}
protocol igmp;
}
then {
count accept-ldp-igmp;
accept;
}
}
}
filter accept-ftp {
apply-flags omit;
term accept-ftp {
from {
source-prefix-list {
rfc1918;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol tcp;
port [ ftp ftp-data ];
}
then {
policer management-5m;
count accept-ftp;
accept;
}
}
}
filter accept-rsvp {
apply-flags omit;
term accept-rsvp {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol rsvp;
}
then {
count accept-rsvp;
accept;
}
}
}
filter accept-radius {
apply-flags omit;
term accept-radius {
from {
source-prefix-list {
radius-servers;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol udp;
source-port [ radacct radius ];
tcp-established;
}
then {
policer management-1m;
count accept-radius;
accept;
}
}
}
filter accept-tacas {
apply-flags omit;
term accept-tacas {
from {
source-prefix-list {
tacas-servers;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol [ tcp udp ];
source-port [ tacacs tacacs-ds ];
tcp-established;
}
then {
policer management-1m;
count accept-tacas;
accept;
}
}
}
filter accept-remote-auth {
apply-flags omit;
term accept-radius {
filter accept-radius;
}
term accept-tacas {
filter accept-tacas;
}
}
filter accept-telnet {
apply-flags omit;
term accept-telnet {
from {
source-prefix-list {
rfc1918;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol tcp;
destination-port telnet;
}
then {
policer management-1m;
count accept-telnet;
accept;
}
}
}
filter accept-dns {
apply-flags omit;
term accept-dns {
from {
source-prefix-list {
dns-servers;
}
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol [ udp tcp ];
source-port 53;
}
then {
policer management-1m;
count accept-dns;
accept;
}
}
}
filter accept-ldp-rsvp {
apply-flags omit;
term accept-ldp {
filter accept-ldp;
}
term accept-rsvp {
filter accept-rsvp;
}
}
filter accept-established {
apply-flags omit;
term accept-established-tcp-ssh {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
source-port ssh;
tcp-established;
}
then {
policer management-5m;
count accept-established-tcp-ssh;
accept;
}
}
term accept-established-tcp-ftp {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
source-port ftp;
tcp-established;
}
then {
policer management-5m;
count accept-established-tcp-ftp;
accept;
}
}
term accept-established-tcp-ftp-data-syn {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
source-port ftp-data;
tcp-initial;
}
then {
policer management-5m;
count accept-established-tcp-ftp-data-syn;
accept;
}
}
term accept-established-tcp-ftp-data {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
source-port ftp-data;
tcp-established;
}
then {
policer management-5m;
count accept-established-tcp-ftp-data;
accept;
}
}
term accept-established-tcp-telnet {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
source-port telnet;
tcp-established;
}
then {
policer management-5m;
count accept-established-tcp-telnet;
accept;
}
}
term accept-established-tcp-fetch {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
source-port [ http https ];
tcp-established;
}
then {
policer management-5m;
count accept-established-tcp-fetch;
accept;
}
}
term accept-established-udp-ephemeral {
from {
destination-prefix-list {
router-ipv4;
router-ipv4-logical-systems ;
}
protocol udp;
destination-port 49152-65535;
}
then {
policer management-5m;
count accept-established-udp-ephemeral;
accept;
}
}
}
filter accept-all {
apply-flags omit;
term accept-all-tcp {
from {
protocol tcp;
}
then {
count accept-all-tcp;
log;
syslog;
accept;
}
}
term accept-all-udp {
from {
protocol udp;
}
then {
count accept-all-udp;
log;
syslog;
accept;
}
}
term accept-all-igmp {
from {
protocol igmp;
}
then {
count accept-all-igmp;
log;
syslog;
accept;
}
}
term accept-icmp {
from {
protocol icmp;
}
then {
count accept-all-icmp;
log;
syslog;
accept;
}
}
term accept-all-unknown {
then {
count accept-all-unknown;
log;
syslog;
accept;
}
}
}
filter accept-icmp {
apply-flags omit;
term no-icmp-fragments {
from {
is-fragment;
protocol icmp;
}
then {
count no-icmp-fragments;
log;
discard;
}
}
term accept-icmp {
from {
protocol icmp;
ttl-except 1;
icmp-type [ echo-reply echo-request time-exceeded unreachable
source-quench router-advertisement parameter-problem ];
}
then {
policer management-5m;
count accept-icmp;
accept;
}
}
}
filter discard-frags {
term 1 {
from {
first-fragment;
}
then {
count deny-first-frags;
discard;
}
}
term 2 {
from {
is-fragment;
}
then {
count deny-other-frags;
discard;
}
}
}
Vergiss nach all dieser Arbeit nicht, alle anwendbaren Filter als input-list unter Familie inet auf der lo0-Schnittstelle anzuwenden. Bevor du Änderungen vornimmst, solltest du jedoch die folgenden Vorschläge sorgfältig prüfen:
Bevor du die lo0-Anwendung des IPv4-Schutzfilters aktivierst, solltest du:
Vergewissere dich, dass alle Präfixlisten für deine Netzwerke korrekt sind und die erforderlichen Adressbereiche umfassen.
Vergewissere dich, dass alle gültigen Dienste und Fernzugriffsprotokolle in einem Filter akzeptiert werden und dass der Filter in der Eingabeliste enthalten ist. In Day One: Securing the Routing Engine on M, MX, and T Series zum Beispiel wird der Filter
accept-telnetnicht angewendet, weil Telnet ein unsicheres Protokoll ist und offen gesagt niemals in einem Produktionsnetzwerk verwendet werden sollte. Telnet wird für den Zugriff auf das Testbed verwendet, das für die Entwicklung dieses Materials benötigt wird, so dass das Fehlen desaccept-telnetFilters zum Zeitpunkt der Übergabe ziemlich offensichtlich ist... Frag mich nicht, woher ich das weiß.Achte darauf, dass der Filter zunächst in einem Match-All-Term mit Akzeptanz- und Log-Aktionen endet, um sicherzustellen, dass keine gültigen Dienste verweigert werden.
Ziehe in Erwägung,
commit confirmedfür diese Art von Veränderung zu verwenden. Frag mich nicht, woher ich das weiß, aber es gibt einen Hinweis in den vorangegangenen Absätzen.
Die endgültigen RE-Schutzfilter, die in dieser Fallstudie verwendet wurden, wurden gegenüber dem Beispiel aus dem Day One Buch in folgender Weise verändert:
Der Filter
accept-telnetwird in der Liste angewendet; als Labor wird Telnet als akzeptabel angesehen. Die OSPF- und RIP-Filter werden weggelassen, da sie nicht verwendet werden oder für die nahe Zukunft geplant sind.Der Filter
accept-icmpwurde so geändert, dass er nicht mehr auf Fragmente passt; diese Funktion wurde durch einen globalen Filter "Fragmente verweigern" ersetzt, der am Anfang der Filterliste angewendet wird. Siehe die zugehörige Sidebar.
Die Liste der Filter, die in diesem Beispiel auf die lo0-Schnittstelle von R1 angewandt werden, ist abgebildet; beachte, dass die Liste jetzt mit dem discard-frags -Filter beginnt, den accept-telnet -Filter enthält und der endgültige discard-all -Filter in Kraft ist. Auch hier solltest du für die erste Anwendung in einem Produktionsnetzwerk einen abschließenden Match-All-Filter mit den Aktionen Akzeptieren und Protokollieren verwenden, um zunächst sicherzustellen, dass keine gültigen Dienste zum abschließenden Begriff durchgelassen werden, bevor du zu einer abschließenden Verwurfsaktion übergehst.
Der Filter umfasst nicht die Filter allow-ospf oder allow-rip, da der aktuelle Teststand IS-IS verwendet, das ohnehin nicht von einem Filter der Familie inet beeinflusst werden kann. Es ist erwähnenswert, dass der accept-sh-bfd Filter so genannt wird, da der angegebene Portbereich nur Single-Hop BFD-Sitzungen zulässt. Laut draft-ietf-bfd-multihop-09.txt, "BFD for Multihop Paths" (jetzt RFC 5883), müssen Multihop-BFD-Sitzungen den UDP-Zielport 4784 verwenden:
{master}[edit]
user@R1-RE0# show interfaces lo0
unit 0 {
family inet {
filter {
input-list [ discard-frags accept-sh-bfd accept-bgp
accept-ldp accept-rsvp accept-telnet accept-common-services
discard-all ];
}
address 10.3.255.1/32;
}
family iso {
address 49.0001.0100.0325.5001.00;
}
family inet6 {
address 2001:db8:1::ff:1/128;
}
}
Warnung
Achte auf die Reihenfolge der Filter in input-list, um Nebeneffekte zu vermeiden. Wenn du im obigen Fall den accept-common-services vor dem Filter accept-bgp platzierst, könntest du die eBGP-Sitzung tatsächlich beschränken. In accept-common-services begrenzen wir die Rate für den TCP-Traceroute (TTL=1) und erinnern uns daran, dass eBGP-Sitzungen (ohne Multihop) TCP-Pakete mit einer TTL von eins verwenden.
Ein Syslog wird hinzugefügt, um alle filterbezogenen Syslog-Aktionen aufzufangen und zu konsolidieren, damit sie später leichter zu debuggen sind. Erinnere dich daran, dass die Log-Aktion in einen Kernel-Cache schreibt, der bei einem Neustart überschrieben wird und verloren geht, während syslog die Archivierung von Dateien und die Fernprotokollierung unterstützen kann. Hier wird das lokale Syslog konfiguriert:
jnpr@R1-RE0# show system syslog
file re_filter {
firewall any;
archive size 10m;
}
Nachdem du den Filter bestätigt hast und erleichtert aufatmest, dass der Fernzugriff (dieses Mal) noch funktioniert, suchen wir schnell nach Problemen. Zunächst einmal wird die Anwendung des Filters bestätigt:
{master}[edit]
jnpr@R1-RE0# run show interfaces filters lo0
Interface Admin Link Proto Input Filter Output Filter
lo0 up up
lo0.0 up up inet lo0.0-i
iso
inet6
lo0.16384 up up inet
lo0.16385 up up inet
Als Nächstes untersuchst du das Syslog, um zu sehen, welcher Datenverkehr unangepasst verworfen wird:
{master}[edit]
jnpr@R1-RE0# run show log re_filter
Dec 12 12:58:09 R1-RE0 fpc2 PFE_FW_SYSLOG_IP: FW: irb.200
D vrrp 192.0.2.67 224.0.0.18 0 0 (1 packets)
Dec 12 12:58:15 R1-RE0 last message repeated 7 times
Dec 12 12:58:16 R1-RE0 fpc2 PFE_FW_SYSLOG_IP: FW: irb.200
D vrrp 192.0.2.67 224.0.0.18 0 0 (2 packets)
Dec 12 12:58:17 R1-RE0 fpc2 PFE_FW_SYSLOG_IP: FW: irb.200
D vrrp 192.0.2.67 224.0.0.18 0 0 (1 packets)
Dec 12 12:58:21 R1-RE0 last message repeated 4 times
Dec 12 12:58:22 R1-RE0 fpc2 PFE_FW_SYSLOG_IP: FW: irb.200
D vrrp 192.0.2.67 224.0.0.18 0 0 (2 packets)
Dec 12 12:58:23 R1-RE0 fpc2 PFE_FW_SYSLOG_IP: FW: irb.200
D vrrp 192.0.2.67 224.0.0.18 0 0 (1 packets)
Dec 12 12:58:26 R1-RE0 last message repeated 3 times
Dec 12 12:58:27 R1-RE0 fpc2 PFE_FW_SYSLOG_IP: FW: irb.200
D vrrp 192.0.2.67 224.0.0.18 0 0 (2 packets)
Dec 12 12:58:28 R1-RE0 fpc2 PFE_FW_SYSLOG_IP: FW: irb.200
D vrrp 192.0.2.67 224.0.0.18 0 0 (1 packets)
Do'h! Wie lautete noch einmal die Warnung, dass der angewandte Filter alle unterstützten Dienste unterstützt und dass im letzten Begriff ein accept-all verwendet werden sollte, bis der ordnungsgemäße Betrieb bestätigt ist? Die Syslog-Aktion im letzten discard-all Filter hat schnell gezeigt, dass VRRP durch den Filter verweigert wird, was erklärt, warum VRRP nicht funktioniert und die Telefone zu klingeln beginnen. Die Liste der angewandten Filter wird durch das Hinzufügen des accept-vrrp Filters geändert; beachte die Verwendung der Funktion insert, um die richtige Reihenfolge der Filter zu gewährleisten, indem sichergestellt wird, dass der discard-all Filter am Ende der Liste steht:
{master}[edit interfaces lo0 unit 0 family inet]
jnpr@R1-RE0# set filter input-list accept-vrrp
{master}[edit interfaces lo0 unit 0 family inet]
jnpr@R1-RE0# show
filter {
input-list [ discard-frags accept-sh-bfd accept-bgp
accept-ldp accept-rsvp accept-telnet accept-common-services discard-all
accept-vrrp ];
}
address 10.3.255.1/32;
{master}[edit interfaces lo0 unit 0 family inet]
jnpr@R1-RE0# insert filter input-list accept-vrrp before discard-all
{master}[edit interfaces lo0 unit 0 family inet]
jnpr@R1-RE0# show
filter {
input-list [ discard-frags accept-ospf accept-rip
accept-sh-bfd accept-bgp accept-ldp accept-rsvp accept-telnet accept-
common-services accept-
vrrp discard-all ];
}
address 10.3.255.1/32;
Nach der Änderung wird die Protokolldatei gelöscht und nach ein paar Augenblicken wieder angezeigt:
{master}[edit interfaces lo0 unit 0 family inet]
jnpr@R1-RE0# run clear log re_filter
. . .
{master}[edit interfaces lo0 unit 0 family inet]
jnpr@R1-RE0# run show log re_filter
Dec 12 13:09:59 R1-RE0 clear-log[21857]: logfile cleared
{master}[edit interfaces lo0 unit 0 family inet]
jnpr@R1-RE0#
Perfekt - das Fehlen von Syslog-Einträgen und der fortgesetzte Betrieb bestehender Dienste bestätigt den ordnungsgemäßen Betrieb des IPv4 RE-Schutzfilters.
IPv6 RE Schutzfilter
Während wir IPv4 nutzen, beginnen viele Netzwerke erst jetzt mit dem Einsatz von IPv6. Da IPv6 noch nicht so weit verbreitet ist, waren die IPv6-Kontrollebenen noch nicht das Ziel vieler Angriffe. Viele Betreiber haben es nicht für nötig gehalten, IPv6-RE-Schutz einzurichten, was zu einem allgemeinen Mangel an Erfahrung mit bewährten Methoden zur IPv6-Filterung führt.
Next-Header Verschachtelung, der Fluch der zustandslosen Filter
Ein wesentliches Problem bei allen IPv6-Filterschemata ist die Verwendung von Next-Header-Schachtelungen in IPv6, die einige zustandslose Filteraufgaben schwierig, wenn nicht sogar unmöglich machen. IPv6, wie in RFC 2460 definiert, besagt: "In IPv6 werden optionale Informationen der Internet-Schicht in separaten Headern kodiert, die zwischen dem IPv6-Header und dem Upper-Layer-Header in einem Paket platziert werden können. Ein IPv6-Paket kann null, einen oder mehrere Erweiterungs-Header enthalten, die jeweils durch das Next-Header-Feld des vorangehenden Headers identifiziert werden."
Das Ergebnis ist, dass zwischen dem IPv6-Header und dem Protokoll der oberen Schicht, das du abgleichen möchtest (TCP, UDP, OSPF3, ICMP6 usw.), mehrere Erweiterungsheader platziert sein können. Zustandslose Filter sind so konzipiert, dass sie Schlüssel für passende Paketfelder anhand von Bitpositionen innerhalb eines Pakets extrahieren, von denen angenommen wird, dass sie sich an derselben Stelle befinden. Die zustandslosen IPv6-Filter von Trio waren bisher nur in der Lage, das erste Protokoll (Next-Header) im Next-Header-Feld des IPv6-Pakets und/oder die Bits in der eigentlichen Nutzlast, d.h. die Ports des Transportprotokolls (TCP oder UDP), zu erkennen. In der Version 14.2 sind die Trio Linecards in der Lage, jeden beliebigen Erweiterungs-Header (unabhängig davon, ob er der erste in der Liste ist) sowie einen Payload-Port abzugleichen. Beachte, dass die Fähigkeit, auf jeden Extension Header zu passen, auf nicht fragmentiertes/erstes Fragment IPv6 beschränkt ist. Alle anderen Pakete, die nicht als erstes Fragment betrachtet werden, können nur auf den ersten Erweiterungs-Header nach dem IPv6-Header abgestimmt werden.
Hinweis
Sehr lange IPv6-Header (d.h. mit vielen Next-Headern) können von Junos nicht geparst werden. Erinnere dich daran, dass der Lookup-Chip einen Teil des Pakets (den PARCEL) erhält, der die ersten 256 Bytes enthält. Mit anderen Worten: Ein IPv6-Header, der größer als 256 Byte ist (was sehr selten vorkommt), wird nicht vollständig geparst.
Mit dem Schlüsselwort extension-header können sowohl ein Extension-Header als auch ein Payload-Port abgeglichen werden. Seit der Version 14.2 von Junos werden die folgenden Typen von Erweiterungs-Header-Matches unterstützt:
jnpr@R1-RE0# ...t6 filter foo term 1 from extension-header ? Possible completions: <range> Range of values [ Open a set of values ah Authentication header any Any extension header dstopts Destination options esp Encapsulating security payload fragment Fragment hop-by-hop Hop by hop options mobility Mobility routing Routing
Hinweis
Unabhängig davon, wie viele Erweiterungsheader vorhanden sind, können die Trio ASICs die ersten 32 Bits nach dem letzten Erweiterungsheader extrahieren, um portbasierte Layer 4 (TCP oder UDP) Matches zu ermöglichen, auch wenn ein oder mehrere Erweiterungsheader vorhanden sind. Bei einer unterstützten Version wird die Fähigkeit, auf ein Nutzdatenprotokoll zuzugreifen, wenn Erweiterungsheader vorhanden sind, durch die Angabe des Schlüsselworts payload-protocol in den Suchkriterien aktiviert.
Zunächst ist zu beachten, dass das Vorhandensein von Erweiterungsheadern zu einer unvorhersehbaren Filterfunktion führen kann, wenn der Filter eine next-header Übereinstimmungsbedingung verwendet, da diese Option die Übereinstimmung unmittelbar nach dem IPv6-Header erzwingt.
Um zu verdeutlichen, warum ein solcher Match-Typ problematisch sein kann, betrachten wir einen Benutzer, der Multicast Listener Discovery-Nachrichten (MLD) herausfiltern möchte. MLD macht für IPv6 das, was IGMP für IPv4 macht: nämlich Multicast-Hosts zu erlauben, ihr Interesse am Abhören einer Multicast-Gruppe zu bekunden. In diesem Fall weiß der Nutzer, dass MLD eine Erweiterung von ICMP6 ist, und erstellt (und bestätigt) den gezeigten Filter, nur um festzustellen, dass MLD-Nachrichten nicht erkannt werden und daher den Filter trotzdem passieren können:
{master}[edit firewall family inet6]
jnpr@R1-RE0# show
filter count_mld {
term 1 {
from {
next-header icmp;
icmp-type [ membership-query membership-report membership
-termination ];
}
then {
count mld_traffic;
discard;
}
}
term 2 {
then accept;
}
}
In diesem Fall macht ein kurzer Blick auf den RFC für MLD (RFC 3810) und die vorherige Einschränkung, nur einen einzigen Next-Header abgleichen zu können, den Grund für das Scheitern des Filters deutlich. MLD erfordert die Einbeziehung des Hop-by-Hop-Erweiterungsheaders (wie oben in der Paketaufzeichnung zu sehen), der dem ICMP6-Header, den der Filter abgleichen will, vorausgehen muss:
Internet Protocol Version 6, Src: fe80::6687:88ff:fe63:47c1 (fe80::6687:88ff:
fe63:47c1), Dst: ff02::1 (ff02::1)
0110 .... = Version: 6
.... 0000 0000 .... .... .... .... .... = Traffic class: 0x00000000
.... .... .... 0000 0000 0000 0000 0000 = Flowlabel: 0x00000000
Payload length: 32
Next header: IPv6 hop-by-hop option (0)
Hop limit: 1
Source: fe80::6687:88ff:fe63:47c1 (fe80::6687:88ff:fe63:47c1)
[Source SA MAC: JuniperN_63:47:c1 (64:87:88:63:47:c1)]
Destination: ff02::1 (ff02::1)
[Source GeoIP: Unknown]
[Destination GeoIP: Unknown]
Hop-by-Hop Option
Next header: ICMPv6 (58)
Length: 0 (8 bytes)
IPv6 Option (Router Alert)
IPv6 Option (PadN)
Internet Control Message Protocol v6
Type: Multicast Listener Query (130)
Code: 0
Checksum: 0x236c [correct]
Maximum Response Delay [ms]: 10000
Reserved: 0000
Multicast Address: :: (::)
Das bedeutet, wenn du MLD mit einem zustandslosen Filter filtern willst, musst du den Filter auf das Vorhandensein des Hop-by-Hop-Headers einstellen und nicht auf den Header, den du eigentlich haben willst. Das offensichtliche Problem dabei ist, dass auch andere Protokolle wie RSVP einen hop-by-hop-Header verwenden können (obwohl Junos derzeit keine IPv6-basierte MPLS-Signalisierung unterstützt), so dass eine umfassende Filterung auf Basis von hop-by-hop-Headern (oder anderen Erweiterungen) zu unerwarteten Filteraktionen führen kann.
Theoretisch könnte dieses Problem umgangen werden, indem der nächste Header-Match entfernt und durch einen Extension-Header-Match ersetzt wird. Letzteres würde wiederum einen Match des angegebenen Headers an beliebiger Stelle in der Liste ermöglichen, anstatt ihn unmittelbar hinter dem IPv6-Header zu erzwingen. Das Problem ist, dass die Junos-Version 14.2, wie oben gezeigt, ICMP nicht als Argument für den Extension-Header-Match unterstützt.
Da die Trio-Firmware derzeit nicht mit ICMP übereinstimmen kann, ist die nächstbeste Option hier die Verwendung eines Payload-Match-Typs. Hier wird die Nutzlast als der erste Teil des Pakets definiert, den die Firmware nicht erkennt, was in diesem Fall dem ICMP-Header entsprechen sollte. Ein geänderter Filter ist abgebildet:
{master}[edit firewall family inet6]
jnpr@R1-RE0# show
filter count_mld {
term 1 {
from {
payload-protocol icmp6;
icmp-type [ membership-query membership-report membership
-termination ];
}
then {
count mld_traffic;
discard;
}
}
term 2 {
then accept;
}
}
Der Beispiel-IPv6-Filter
Wie beim Beispiel des IPv4-Filters wird vorausgesetzt, dass der Leser mit der Syntax und der Funktionsweise des Junos-Firewall-Filters sowie mit den grundlegenden IPv6-Protokollfunktionen, Header-Feldern und Optionserweiterungs-Headern vertraut ist. Wie immer, wenn es um Filter geht, gibt es keine Einheitsgröße, die für alle passt, und der Leser sollte die Auswirkungen des Beispielfilters sorgfältig abwägen und seine Funktionsweise mit den spezifischen IPv6-Protokollen, die in seinen Netzwerken unterstützt werden, sorgfältig testen, damit alle notwendigen Anpassungen vorgenommen werden können, bevor er ihn in einem Produktionsnetzwerk einsetzt.
Weitere Details zum Filtern von IPv6-Protokollen, die sich auf die breite Palette möglicher ICMPv6-Meldungstypen beziehen, findest du in RFC 4890, "Recommendations for Filtering ICMPv6 Messages in Firewalls".
Zunächst werden die Definitionen der IPv6-Präfixlisten angezeigt; die bisherigen Listen, die für IPv4 verwendet wurden, bleiben bestehen, mit der im Folgenden genannten Ausnahme:
jnpr@R1-RE0# show policy-options
prefix-list router-ipv4 {
. . .
prefix-list bgp-neighbors_v4 {
apply-path "protocols bgp group <*_v4> neighbor <*>";
}
prefix-list router-ipv6 {
apply-path "interfaces <*> unit <*> family inet6 address <*>";
}
prefix-list bgp-neighbors_v6 {
apply-path "protocols bgp group <*_v6> neighbor <*>";
}
prefix-list link_local {
fe80::/64;
}
prefix-list rfc3849 {
2001:db8::/32;
}
Die IPv6-basierte Präfixliste erfüllt dieselbe Funktion wie ihre V4-Pendants. Da IPv6 die Link-Local-Adressierung für viele Routing-Protokolle verwendet, musst du diese ebenso unterstützen wie deine globalen IPv6-Schnittstellenrouten. Beachte, dass die bisherige bgp-neighbors Präfixliste, wie sie ursprünglich für IPv4 verwendet wurde, umbenannt und der apply-path reguläre Ausdruck geändert wurde, um nicht mit der gleichen Funktion in IPv6 in Konflikt zu geraten. Dieser Ansatz setzt voraus, dass du IPv4- und IPv6-Peers in getrennten Gruppen mit einem Gruppennamen platzierst, der entweder auf _v4 oder _v6 endet. Die IPv6 RE-Schutzfilter werden angezeigt:
{master}[edit firewall family inet6]
jnpr@R1-RE0#
filter discard-extension-headers {
apply-flags omit;
term discard-extension-headers {
from {
# Beware - VRRPv3 with authentication or OSPFv3 with Authentication
enabled may use AH/ESP!
next-header [ ah dstopts egp esp fragment gre icmp igmp ipip ipv6
no-next-header routing rsvp sctp ];
}
then {
count discard-ipv6-extension-headers;
log;
syslog;
discard;
}
}
}
filter deny-icmp6-undefined {
apply-flags omit;
term icmp6-unassigned-discard {
from {
next-header icmpv6;
icmp-type [ 102-106 155-199 202-254 ];
}
then discard;
}
term rfc4443-discard {
from {
next-header icmpv6;
icmp-type [ 100-101 200-201 ];
}
then discard;
}
}
filter accept-icmp6-misc {
apply-flags omit;
term neigbor-discovery-accept {
from {
next-header icmpv6;
icmp-type 133-136;
}
then accept;
}
term inverse-neigbor-discovery-accept {
from {
next-header icmpv6;
icmp-type 141-142;
}
then accept;
}
term icmp6-echo-request {
from {
next-header icmpv6;
icmp-type echo-request;
}
then accept;
}
term icmp6-echo-reply {
from {
next-header icmpv6;
icmp-type echo-reply;
}
then accept;
}
term icmp6-dest-unreachable-accept {
from {
next-header icmpv6;
icmp-type destination-unreachable;
}
then accept;
}
term icmp6-packet-too-big-accept {
from {
next-header icmpv6;
icmp-type packet-too-big;
}
then accept;
}
term icmp6-time-exceeded-accept {
from {
next-header icmpv6;
icmp-type time-exceeded;
icmp-code 0;
}
then accept;
}
term icmp6-parameter-problem-accept {
from {
next-header icmpv6;
icmp-type parameter-problem;
icmp-code [ 1 2 ];
}
then accept;
}
}
filter accept-shsh-bfd-v6 {
apply-flags omit;
term accept-sh-bfd-v6 {
from {
source-prefix-list {
router-ipv6;
}
destination-prefix-list {
router-ipv6;
}
source-port 49152-65535;
destination-port 3784-3785;
}
then accept;
}
}
filter accept-MLD-hop-by-hop_v6 {
apply-flags omit;
term bgp_v6 {
from {
next-header hop-by-hop;
}
then {
count hop-by-hop-extension-packets;
accept;
}
}
}
filter accept-bgp-v6 {
apply-flags omit;
term bgp_v6 {
from {
prefix-list {
rfc3849;
bgp-neighbors_v6;
}
next-header tcp;
destination-port bgp;
}
then accept;
}
}
filter accept-ospf3 {
apply-flags omit;
term ospfv3 {
from {
source-prefix-list {
link_local;
}
next-header ospf;
}
then accept;
}
}
filter accept-dns-v6 {
apply-flags omit;
term dnsv6 {
from {
source-prefix-list {
rfc3849;
}
next-header [ udp tcp ];
port domain;
}
then accept;
}
}
filter accept-ntp-v6 {
apply-flags omit;
term ntpv6 {
from {
source-prefix-list {
rfc3849;
}
next-header udp;
destination-port ntp;
}
then accept;
}
}
filter accept-ssh-v6 {
apply-flags omit;
term sshv6 {
from {
source-prefix-list {
rfc3849;
}
next-header tcp;
destination-port ssh;
}
then {
policer management-5m;
count accept-ssh;
accept;
}
}
}
filter accept-snmp-v6 {
apply-flags omit;
term snmpv6 {
from {
source-prefix-list {
rfc3849;
}
next-header udp;
destination-port snmp;
}
then accept;
}
}
filter accept-radius-v6 {
apply-flags omit;
term radiusv6 {
from {
source-prefix-list {
rfc3849;
}
next-header udp;
port [ 1812 1813 ];
}
then accept;
}
}
filter accept-telnet-v6 {
apply-flags omit;
term telnetv6 {
from {
source-prefix-list {
rfc3849;
}
next-header tcp;
port telnet;
}
then {
policer management-5m;
count accept-ssh;
accept;
}
}
}
filter accept-common-services-v6 {
apply-flags omit;
term accept-icmp6 {
filter accept-icmp6-misc;
}
term accept-traceroute-v6 {
filter accept-traceroute-v6;
}
term accept-ssh-v6 {
filter accept-ssh-v6;
}
term accept-snmp-v6 {
filter accept-snmp-v6;
}
term accept-ntp-v6 {
filter accept-ntp-v6;
}
term accept-dns-v6 {
filter accept-dns-v6;
}
}
filter accept-traceroute-v6 {
apply-flags omit;
term accept-traceroute-udp {
from {
destination-prefix-list {
router-ipv6;
}
next-header udp;
destination-port 33435-33450;
hop-limit 1;
}
then {
policer management-1m;
count accept-traceroute-udp-v6;
accept;
}
}
term accept-traceroute-icmp6 {
from {
destination-prefix-list {
router-ipv6;
}
next-header icmp;
icmp-type [ echo-request time-exceeded ];
hop-limit 1;
}
then {
policer management-1m;
count accept-traceroute-icmp6;
accept;
}
}
term accept-traceroute-tcp-v6 {
from {
destination-prefix-list {
router-ipv6;
}
next-header tcp;
hop-limit 1;
}
then {
policer management-1m;
count accept-traceroute-tcp-v6;
accept;
}
}
}
filter discard-all-v6 {
apply-flags omit;
term discard-HOPLIMIT_1-unknown {
from {
hop-limit 1;
}
then {
count discard-all-HOPLIMIT_1-unknown;
log;
syslog;
discard;
}
}
term discard-tcp-v6 {
from {
next-header tcp;
}
then {
count discard-tcp-v6;
log;
syslog;
discard;
}
}
term discard-netbios-v6 {
from {
next-header udp;
destination-port 137;
}
then {
count discard-netbios-v6;
log;
syslog;
discard;
}
}
term discard-udp {
from {
next-header udp;
}
then {
count discard-udp-v6;
log;
syslog;
discard;
}
}
term discard-icmp6 {
from {
next-header icmp;
}
then {
count discard-icmp;
log;
syslog;
discard;
}
}
term discard-unknown {
then {
count discard-unknown;
log;
syslog;
discard;
}
}
}
Hinweis
Wir haben die Option next-header im vorangegangenen Code verwendet, um die Nutzdaten zu filtern. Wie bereits erwähnt, enthalten Protokolle manchmal Erweiterungs-Header. In diesem Fall kannst du die Option payload match verwenden. Erinnere dich daran, dass next-header immer der erste Header nach dem IPv6-Header ist.
Die IPv6-Filter verwenden dieselben Policers, die zuvor für IPv4 definiert wurden, und folgen demselben allgemeinen modularen Ansatz, wenn auch mit weniger Zählaktionen in Begriffen, die Verkehr akzeptieren, deren Verwendung bereits für IPv4 demonstriert wurde. In diesem Fall verwirft der discard-extension-headers Filter alle ungenutzten Erweiterungsheader, einschließlich des Fragmentierungsheaders, wodurch sichergestellt wird, dass Fragmente keiner zusätzlichen Begriffsverarbeitung unterzogen werden, bei der unvorhersehbare Ergebnisse auftreten könnten, da ein Fragment keinen Transportheader hat. Wie im Kommentar des Filters angegeben, wird auch Datenverkehr mit AH- und/oder EH-Authentifizierungsheadern verworfen, die für legitimen Datenverkehr wie OSPF3 verwendet werden können. Wie immer musst du die Anforderungen deines Netzwerks sorgfältig mit einem Beispielfilter abgleichen und entsprechend anpassen.
Wie zuvor wird die entsprechende Liste der IPv6-Filter wieder als Eingabeliste auf die Schnittstelle lo0 angewendet. Jetzt unter Familie inet6:
{master}[edit]
jnpr@R1-RE0# show interfaces lo0 unit 0
family inet {
filter {
input-list [ discard-frags accept-sh-bfd accept-bgp
accept-ldp accept-rsvp accept-telnet accept-common-services
accept-vrrp discard-all ];
}
address 10.3.255.1/32;
}
family iso {
address 49.0001.0100.0325.5001.00;
}
family inet6 {
filter {
input-list [ discard-extension-headers accept-MLD-hop-by-hop_v6
deny-icmp6-undefined accept-sh-bfd-v6 accept-bgp-v6
accept-telnet-v6 accept-ospf3 accept-radius-v6 accept-common-services-
v6 discard-all-v6 ];
}
address 2001:db8:1::ff:1/128;
}
Nach der Anwendung des IPv6-Filters wird das Syslog geleert; nach einigen Augenblicken können neue Treffer angezeigt werden. Erinnere dich daran, dass zu diesem Zeitpunkt nur unzulässiger Datenverkehr die endgültige Discard-All-Aktion für die IPv4- und IPv6-Filterlisten erreichen sollte:
{master}[edit]
jnpr@R1-RE0# run show log re_filter
Dec 13 10:26:51 R1-RE0 clear-log[27090]: logfile cleared
Dec 13 10:26:52 R1-RE0 /kernel: FW: fxp0.0 D tcp 172.17.13.146 172.19.90.172
34788 21
Dec 13 10:26:55 R1-RE0 /kernel: FW: fxp0.0 D tcp 172.17.13.146 172.19.90.172
34788 21
Dec 13 10:26:55 R1-RE0 /kernel: FW: fxp0.0 D igmp 172.19.91.95 224.0.0.1 0 0
Dec 13 10:27:01 R1-RE0 /kernel: FW: fxp0.0 D tcp 172.17.13.146 172.19.90.172
34788 21
Dec 13 10:27:55 R1-RE0 /kernel: FW: fxp0.0 D igmp 172.19.91.95 224.0.0.1 0 0
. . .
Dec 13 10:34:41 R1-RE0 /kernel: FW: fxp0.0 D udp 172.19.91.43 172.19.91.255
138 138
Dec 13 10:34:55 R1-RE0 /kernel: FW: fxp0.0 D igmp 172.19.91.95 224.0.0.1 0 0
Dec 13 10:35:55 R1-RE0 /kernel: FW: fxp0.0 D igmp 172.19.91.95 224.0.0.1 0 0
Dec 13 10:36:55 R1-RE0 /kernel: FW: fxp0.0 D igmp 172.19.91.95 224.0.0.1 0 0
Das hier gezeigte Ergebnis ist gut. Der einzige Verkehr, der von anderen Begriffen nicht akzeptiert wird, kommt von nicht autorisierten Hosts unter 172.17.13.0/24, einer Adresse, die nicht in der offiziellen Labortopologie enthalten ist, was zeigt, dass der Filter die gewünschte Wirkung hat. Der gesamte verworfene Datenverkehr kommt über fxp0 im gemeinsamen OoB-Management-Netzwerk an und scheint eine Mischung aus IGMP, FTP und NetBIOS zu sein. Als letzte Bestätigung bestätigst du den BGP- und BFD-Sitzungsstatus auf R1:
{master}[edit]
jnpr@R1-RE0# run show bgp summary
Groups: 3 Peers: 3 Down peers: 1
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0 0 0 0 0 0 0
inet6.0 0 0 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|
#Active/Received/Accepted/Damped...
10.3.255.2 65000 2010 2009 0 0 15:09:23 0/0/0/0
2001:db8:1::ff:2 65000 298 296 0 2 2:13:16 Establ
inet6.0: 0/0/0/0
fd1e:63ba:e9dc:1::1 65010 0 0 0 0 17:52:23 Active
Zu diesem Zeitpunkt ist die EBGP-Sitzung zum externen BGP-Gerät P1 voraussichtlich ausgefallen, aber sowohl die IPv6- als auch die IPv4-IBGP-Sitzungen sind aufgebaut, ebenso wie die BFD-Sitzung zwischen R1 und R2. Diese BFD-Sitzung ist IPv4-basiert und läuft über die Schnittstelle ae0.1, um dem IS-IS-Protokoll eine schnelle Fehlererkennung zu ermöglichen:
{master}[edit]
jnpr@R1-RE0# show protocols isis
reference-bandwidth 100g;
level 1 disable;
interface ae0.1 {
point-to-point;
bfd-liveness-detection {
minimum-interval 1000;
multiplier 3;
}
}
interface lo0.0 {
passive;
}
{master}[edit]
jnpr@R1-RE0# run show bfd session
Detect Transmit
Address State Interface Time Interval Multiplier
10.8.0.1 Up ae0.1 3.000 1.000 3
1 sessions, 1 clients
Cumulative transmit rate 1.0 pps, cumulative receive rate 1.0 pps
Der fortgesetzte Betrieb zulässiger Dienste in Verbindung mit dem Fehlen unerwarteter Log-Einträge durch die "Discard-all"-Aktion beider RE-Schutzfilter bestätigt, dass sie wie vorgesehen funktionieren. schließt die RE-Schutz-Fallstudie ab.
Fallstudie zum DDoS-Schutz
Die MX Trio-Plattformen bieten seit der Version 11.2 einen integrierten DDoS-Schutz. Diese Funktion nutzt die umfangreichen Fähigkeiten des Trio-Chipsatzes zur Klassifizierung des hostgebundenen Datenverkehrs zusammen mit entsprechenden Policern, die auf verschiedenen Hierarchien innerhalb des Systems implementiert sind, um sicherzustellen, dass die RE bei übermäßigem Ausnahmeverkehr auf der Steuerebene reaktionsfähig bleibt, wie er beispielsweise durch Fehlkonfigurationen, übermäßige Skalierung oder absichtliche DDoS-Angriffe auf die Steuerebene eines Routers entstehen kann.
Der neue Low-Level-DDoS-Schutz bietet sozusagen direkt nach dem Auspacken große Vorteile, macht aber einen RE-Schutzfilter, der nicht erlaubten oder benötigten Datenverkehr zurückhält, nicht überflüssig. Wenn der neue DDoS-Schutz mit einem starken RE-Filter kombiniert wird, kannst du die Policing-Funktionen im Filter überflüssig machen, oder du kannst für zusätzlichen Schutz weiterhin RE-Filter-basiertes Policing als zusätzliche Schutzmaßnahme verwenden. In diesen Fällen solltest du jedoch sicherstellen, dass die RE-Filter-basierten Policer höhere Bandbreitenwerte haben als die entsprechenden PFE- und RE-DDoS-Policer, da die Policer im RE sonst nie eine Chance haben, aktiviert zu werden, da die DDoS-Policer alle Verwerfungsaktionen sehen. Das liegt daran, dass ein Policer, der von einem Eingangsfilter auf der Loopback-Schnittstelle aufgerufen wird, auf die Trio PFE heruntergeladen wird, wo er vor allen DDoS-Policern ausgeführt wird.
Das Problem der Erschöpfung der Kontrollebene
Da Router immer mehr Dienste für immer mehr Nutzer/innen bereitstellen, ist es nicht ungewöhnlich, dass sie an der Grenze ihrer Kapazität arbeiten, vor allem in Zeiten hoher Auslastung, wie z.B. bei Routenklappen, die durch Netzwerkausfälle verursacht werden. Jeder neue Dienst bringt nicht nur eine zusätzliche Belastung mit sich, sondern birgt auch die Gefahr einer unerwarteten Ressourcennutzung, die entweder absichtlich herbeigeführt wurde oder in vielen Fällen auf fehlerhafte Software oder Konfigurationsfehler zurückzuführen ist, die zu einem unerwarteten Betrieb führen.
Die Erschöpfung von Ressourcen kann an verschiedenen Stellen auftreten, die jeweils ihre eigenen betrieblichen Probleme haben. Wenn du zu wenig RIB/FIB hast, kann es sein, dass du Ziele ausblendest oder Standardrouten mit möglicherweise unerwünschten Pfaden verwendest. Zu wenig Arbeitsspeicher kann zu Abstürzen oder einer langsamen Rekonvergenz führen, da Prozesse auf die Festplatte ausgelagert werden. Wenn die CPU oder die internen Kommunikationspfade, die zum Senden und Empfangen von Keep-Alive-Nachrichten benötigt werden, knapp werden, kommt es zu noch mehr Problemen, da BFD-, BGP- und OSPF-Sitzungen zu flattern beginnen, was wiederum ein ohnehin schon überlastetes System noch weiter belastet.
In diesem Abschnitt liegt der Schwerpunkt auf dem Schutz des Verarbeitungspfads und damit der Ressourcen der Steuerebene. Diese Ressourcen der Steuerebene werden benötigt, um Fernzugriff, Routing-Protokolle und Netzwerkmanagement-Verkehr zu verarbeiten, der von einer Netzwerkschnittstelle über die PFE zur RE gelangt, wenn unerwarteter Steuerebenenverkehr auftritt. Ziel ist es, unterstützte Dienste in angemessenem Umfang zu ermöglichen, ohne dass ein einzelner Dienst oder ein Protokoll alle Ressourcen überlastet, was leicht zu einem Denial-of-Service für andere Protokolle und Nutzer führen kann. Ein solcher Dienstausfall kann sich leicht auf den Fernzugriff ausdehnen, der erforderlich ist, um auf einen Router zuzugreifen, um das Problem zu beheben. Kaum etwas im Leben ist so frustrierend wie die Tatsache, dass du weißt, wie du ein Problem beheben kannst, und dann feststellst, dass du aufgrund des Problems nicht auf das Gerät zugreifen kannst, um Korrekturmaßnahmen zu ergreifen.
DDoS Operative Übersicht
Die Juniper DDoS-Schutzfunktion basiert auf zwei Hauptkomponenten: der Klassifizierung des hostgebundenen Control-Plane-Verkehrs und einem hierarchischen Satz von Policern auf Einzel- und Aggregatebene, die das Volumen des Control-Plane-Verkehrs begrenzen, das jeder Protokolltyp zur Verarbeitung an die RE senden kann.
Diese Policers sind so organisiert, dass sie dem hierarchischen Fluss des Protokollkontrollverkehrs entsprechen. Der Kontrollverkehr, der von allen Ports einer Line Card ankommt, läuft in der Packet Forwarding Engine der Karte zusammen. Der Verkehr von allen PFEs läuft in der Line Card/FPC zusammen. Und schließlich konvergiert der Kontrollverkehr von allen Leitungskarten des Routers in der Routing Engine. Auch die DDoS-Policer werden hierarchisch entlang der Kontrollpfade platziert, damit überschüssige Pakete so früh wie möglich auf dem Pfad verworfen werden. Dieses Design schont die Systemressourcen, indem überschüssiger bösartiger Datenverkehr entfernt wird, so dass die Routing Engine nur so viel Datenverkehr erhält, wie sie tatsächlich verarbeiten kann. Insgesamt können zwischen dem Ingress an der Trio PFE und der Verarbeitung an der RE bis zu fünf Stufen der Überwachung liegen, und das ohne die zusätzliche lo0-basierte Filterung (mit entsprechender Überwachung), die ebenfalls in Kraft sein kann.
Im Betrieb wird der Kontrollverkehr unterbrochen, wenn er das Ratenlimit eines Policers überschreitet. Jede Verletzung erzeugt eine Meldung im Syslog, um den Betreiber über einen möglichen Angriff zu informieren. Jede Verletzung wird gezählt und die Startzeit notiert. Das System speichert außerdem einen Zeiger auf die Start- und Endzeit der letzten beobachteten Verletzung. Wenn die Verkehrsrate unter den Schwellenwert für die Bandbreitenverletzung fällt, bestimmt ein Recovery-Timer, wann der Verkehrsfluss wieder als normal angesehen wird. Tritt vor Ablauf des Timers keine weitere Verletzung mehr auf, wird der Verletzungsstatus aufgehoben und erneut eine Meldung über die Beseitigung des DDoS-Ereignisses erstellt.
Nach der Benachrichtigung liegt es in der Verantwortung des Betreibers, die Art des Ereignisses zu analysieren, um festzustellen, ob die Art und das Volumen des Datenverkehrs, der das DDoS-Ereignis ausgelöst hat, erwartet oder ungewöhnlich war. Hier gibt es keine einfache Antwort, denn jedes Netzwerk hat eine andere Skalierung und eine andere Mischung aus Protokollen und Abwanderungsrate. Wenn die Analyse ergibt, dass das Verkehrsaufkommen normal war, sollten die entsprechenden Policers erhöht werden, um Fehlalarme und potenzielle Serviceunterbrechungen in Zukunft zu vermeiden. Bei Protokollen, die nicht genutzt werden oder von denen bekannt ist, dass sie nur ein geringes Nachrichtenaufkommen erzeugen, können die Policers dagegen gesenkt werden.
Hinweis
Die Standard-Policer-Einstellungen sind absichtlich hoch angesetzt, um sicherzustellen, dass es keine unerwünschten Nebeneffekte für bereits bestehende Installationen gibt, wenn diese auf einen neueren Code mit DDoS-Schutz-Unterstützung aktualisiert werden, der standardmäßig aktiviert ist. In den meisten Fällen werden die Betreiber die zu erwartende Belastung ihres Netzwerks durch die Steuerebene ermitteln und dann die Standard-Policer-Werte senken wollen, um sicherzustellen, dass sie durch die Funktion einen robusten DDoS-Schutz erhalten.
Policer-Status und Statistiken von jeder Line Card werden an die Routing Engine weitergeleitet und aggregiert. Die Policer-Zustände werden bei einem Switchover beibehalten. Beachte, dass während eines GRES/NSR-Ereignisses die Leitungskartenstatistiken und die Anzahl der Verstöße erhalten bleiben, nicht aber die RE-Policer-Statistiken.
Warnung
Zurzeit ist der DDoS-Schutz eine reine Trio-Funktion. Du kannst sie auf einem System mit älteren Linecards im DPC-Stil konfigurieren und aktivieren, aber auf diesen Linecards gibt es keinen DDoS-Schutz. Eine Kette ist nur so stark wie das schwächste Glied; ein System mit einer einzelnen Linecard, die DDoS nicht unterstützt, ist immer noch anfällig für einen Angriff.
Sammle ein paar Figuren
Wie bereits erwähnt, sind die Standard-Policer absichtlich hoch eingestellt, um Nebenwirkungen in jeder Konfiguration zu vermeiden, von der kleinsten bis zur größten mit intensiven Protokollbenachrichtigungen. Die DDoS-Schutzfunktion liefert Echtzeitstatistiken auf jeder Ebene (PFE, Line Card und RE) und für jedes Protokoll. Nehmen wir das Beispiel des ICMP-Protokolls:
jnpr@R1-RE0> show ddos-protection protocols icmp statistics
Packet types: 1, Received traffic: 1, Currently violated: 0
Protocol Group: ICMP
Packet type: aggregate
System-wide information:
Aggregate bandwidth is never violated
Received: 285 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 1 pps
Routing Engine information:
Aggregate policer is never violated
Received: 285 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 1 pps
Dropped by individual policers: 0
FPC slot 0 information:
Aggregate policer is never violated
Received: 185 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 1 pps
Dropped by individual policers: 0
Dropped by flow suppression: 0
FPC slot 1 information:
Aggregate policer is never violated
Received: 100 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Dropped by individual policers: 0
Dropped by flow suppression: 0
FPC-Statistiken liefern Informationen für die gesamte Line Card, d.h. du hast keine Per-PFE-Statistiken, sondern nur aggregierte Informationen über durchgelassenen oder verworfenen Verkehr aus der Sicht des MPC. Die Per-PFE-Statistiken werden nur durch einen PFE-Befehl angezeigt, der auf ein paar weiteren Seiten vorgestellt wird. Die Routing-Engine-Informationen und die systemweiten Informationen, die in der Geräteausgabe angezeigt werden, sollten in einer Einzelchassis-Konfiguration identisch sein. Wie in diesem Beispiel zu sehen ist, wurde der gesamte ICMP-Verkehr ohne jegliche Kontrolle zugelassen: Die RE hat 285 ICMP-Pakete empfangen, das ist die Summe der 185 Pakete, die auf FPC 0 empfangen wurden, und der 100 Pakete, die auf FPC 1 empfangen wurden.
Diese Statistiken können pro Protokoll mit dem folgenden Befehl gelöscht werden:
jnpr@R1-RE0> clear ddos-protection protocols <protocol> statistics
Wenn du versuchst, die DDoS-Policer zu optimieren, ist es ein logischer erster Schritt, aktuelle Daten zu sammeln, die der Baseline deines aktuellen Netzwerks für alle unterstützten Protokolle entsprechen. Diese Daten sollten die PFE-, MPC- und RE-Gesamtstatistiken widerspiegeln, da eine optimale Abstimmung die Änderung von Policern auf all diesen Hierarchien beinhalten kann. Sobald du diese Daten hast, kannst du einen angemessenen Startwert für jeden Policer festlegen, indem du eine kleine Sicherheitsspanne zur beobachteten Basislinie hinzufügst.
Da DDoS standardmäßig für alle unterstützten Protokolle aktiviert ist, ist es ganz einfach, sich die resultierenden DDoS-Statistiken anzusehen, um eine Basisanalyse durchzuführen. Die wichtigste dieser Statistiken ist die Information "Maximale Ankunftsrate". Indem du die Spitzenrate jedes Protokolls analysierst (was du an mehreren Punkten deines Netzwerks und über ein angemessen großes Überwachungsfenster hinweg tun solltest, das natürlich auch Zeiten mit Spitzenaktivität einschließt), erhältst du einen genauen (und aktuellen) Überblick über die maximale Rate pro Protokoll für dein Netzwerk im normalen Betriebszustand. Da die wenigsten Netzwerke im Laufe der Zeit gleich bleiben, solltest du das DDoS-Tuning regelmäßig überprüfen, um sicherzustellen, dass deine Policers immer eine halbwegs aktuelle Momentaufnahme der erwarteten Protokolllast widerspiegeln. Falls dies nicht offensichtlich ist, solltest du die DDoS-Policers neu einstellen, wenn ein neues Protokoll oder ein neuer Dienst zu deinem Netzwerk hinzugefügt wird.
Sie können die Möglichkeiten der Junos-Skripterstellung nutzen, um die Überwachung eines bestimmten DDoS-Zählers auf einer bestimmten Hierarchieebene zu vereinfachen, z. B. auf der Routing-Engine oder auf der MPC-Ebene. Das hier gezeigte Beispielskript für den Betriebsmodus (op-Skript) wird verwendet, um die aktuellen und maximalen beobachteten Raten auf der Routing Engine auf Basis der einzelnen Protokolle/Pakettypen anzuzeigen:
version 1.0;
ns junos = "http://xml.juniper.net/junos/*/junos";
ns xnm = "http://xml.juniper.net/xnm/1.1/xnm";
ns jcs = "http://xml.juniper.net/junos/commit-scripts/1.0";
import "../import/junos.xsl";
match / {
<op-script-results> {
/* Take traces */
var $myrpc = <get-ddos-protocols-statistics> {};
var $myddos = jcs:invoke ($myrpc);
/* Now Display */
<output> "";
<output> "";
<output> "+----------------------------------------------------------------+";
<output> jcs:printf('|%-20s |%-20s |%-11s |%-10s\n',"Protocol","Packet Type",
"Current pps","Max pps Observed");
<output> "+----------------------------------------------------------------+";
for-each( $myddos/ddos-protocol-group/ddos-protocol/packet-type ) {
var $name = .;
if (../ddos-system-statistics/packet-arrival-rate-max != "0"){
<output> jcs:printf('|%-20s |%-20s |%-11s |%-10s\n',../../group-name,
$name,../ddos-system-statistics/packet-arrival-rate,../ddos-system-
statistics/packet-arrival-rate-max);
}
}
<output> "+----------------------------------------------------------------+";
}
}
Hinweis
Es werden nur Pakettypen mit einer "maximalen Ankunftsrate" größer als 0 angezeigt.
Dieser Code muss unter einem Dateinamen auf den Router kopiert werden - hier heißt die Datei checkddos.slax, die wiederum im Ordner /var/db/scripts/op gespeichert ist. Als nächstes muss das op-Skript in der Konfiguration deklariert und aktiviert werden:
jnpr@R1-RE0# set system scripts op file checkddos.slax
Als Nächstes werden alle DDOS-Statistiken auf den verschiedenen Routern gelöscht, die zur Bildung deiner Baseline verwendet werden. Wähle zum Beispiel mindestens deinen größten Knotenpunkt sowie mindestens einen P-Router, einen PE-Router, einen Zugangsknoten usw. Der Einfachheit halber konzentriert sich dieses Beispiel auf die Statistiken von nur einem Knoten. In einem realen Netzwerk musst du für einen optimalen Schutz jeden Knotenpunkt entsprechend seiner Rolle und der daraus resultierenden Verkehrslast dimensionieren und abstimmen:
jnpr@R1-RE0> clear ddos-protection protocols statistics
Bestimme deine Basislinie
Der Verkehr auf der Steuerungsebene kann je nach Tageszeit stark schwanken. Außerdem solltest du die Auswirkungen eines Netzwerkausfalls berücksichtigen, da der darauf folgende Zeitraum der Wiederherstellung für einige Arten von Datenverkehr auf der Steuerebene wahrscheinlich eine Spitze darstellt. Daher musst du die Statistiken über einen längeren Zeitraum, z. B. 24 Stunden oder vielleicht sogar eine ganze Woche lang, aufbauen lassen. Dein Ziel sollte es also sein, das Netzwerk "leben zu lassen", bevor du die Daten mit dem Op-Skript auf den Routern sammelst, die in deiner Baseline erfasst werden. Wie bereits erwähnt, ist es eine gute Idee, eine Art Stresstest einzuplanen (natürlich während eines Wartungsfensters), z. B. die Durchführung von Link Flaps, einen Neustart des Routings oder sogar einen Router-Neustart. Es ist wahrscheinlich, dass du bei Wiederherstellungsprotokollen wie BGP weitaus höhere pps-Raten und eine entsprechend höhere RE-Last feststellst, als dies im konvergenten Dauerbetrieb der Fall wäre.
Hinweis
Bei jeder Tuningmaßnahme gibt es keine allgemeingültige Regel. Du tauschst immer eine Sache gegen eine andere aus. Wenn dein Ziel z. B. die schnelle Konvergenz nach einem größeren Ausfall ist, wirst du wahrscheinlich einen relativ hohen DDoS-Policer-Wert einstellen wollen, um sicherzustellen, dass der legitime Protokollverkehr nicht unterbrochen wird, da dies die Konvergenz verlängern würde. Wenn du den Policer so einstellst, dass er eine absolute Worst-Case-Last für alle Protokolle widerspiegelt, verringert sich der Gesamtschutz des RE im Falle eines echten DDoS-Angriffs. Viele werden sich dafür entscheiden, die Differenz zwischen konvergierender (normaler) Last und konvergierender (anormaler, aber legitimer) Last als Kompromiss zu verwenden.
Ein Beispiel für die Ausgabe des Op-Skripts wird bereitgestellt:
jnpr@R1-RE0> op checkddos +-------------------------------------------------------------------------+ |Protocol |Packet Type |Current pps |Max pps Observed +-------------------------------------------------------------------------+ |resolve |aggregate |0 |67081 |resolve |mcast-v4 |0 |67081 |ICMP |aggregate |0 |1 |IGMP |aggregate |0 |30 |PIM |aggregate |1 |63 |RIP |aggregate |15 |116 |LDP |aggregate |10 |71 |BGP |aggregate |43 |7834 |VRRP |aggregate |7 |15 |SSH |aggregate |3 |564 |SNMP |aggregate |0 |145 |BGPv6 |aggregate |0 |22 |LACP |aggregate |21 |24 |ARP |aggregate |0 |10 |ISIS |aggregate |12 |643 |TCP-Flags |aggregate |2 |2 |TCP-Flags |established |2 |2 |TACACS |aggregate |0 |19 |Sample |aggregate |0 |3 |Sample |syslog |0 |1 |Sample |pfe |0 |1 +-------------------------------------------------------------------------+
Klassifizierung des Host-gebundenen Verkehrs
Ein moderner Multiservice-Router muss eine Vielzahl von Protokollen unterstützen, und die Unterstützung mehrerer Protokolle setzt eine Methode zur Erkennung jedes Protokolls voraus, damit es an den richtigen Verarbeitungsdämon weitergeleitet werden kann. Die DDoS-Schutzfunktion macht sich die umfangreichen Protokollklassifizierungsfunktionen des Trio-Chipsatzes zunutze, um eine Vielzahl von Teilnehmerzugangs-, Routing-, Netzwerkmanagement- und Fernzugriffsprotokollen korrekt zu erkennen und zu binden. Die aktuelle Liste ist bereits lang und wird voraussichtlich noch wachsen:
{master}[edit system ddos-protection global]
jnpr@R1-RE0# run show ddos-protection version
DDOS protection, Version 1.0
Total protocol groups = 98
Total tracked packet types = 220
Die Anzeige zeigt, dass es in v1.0 98 Protokollgruppen mit insgesamt 220 einzigartigen Pakettypen gibt, die individuell überwacht werden können. Die Funktion ? des Junos CLI wird hier verwendet, um die aktuelle Liste anzuzeigen:
{master}[edit system ddos-protection]
jnpr@R1-RE0# set protocols ?
Possible completions:
> amtv4 Configure AMT v4 control packets
> amtv6 Configure AMT v6 control packets
> ancp Configure ANCP traffic
> ancpv6 Configure ANCPv6 traffic
+ apply-groups Groups from which to inherit configuration data
+ apply-groups-except Don't inherit configuration data from these groups
> arp Configure ARP traffic
> atm Configure ATM traffic
> bfd Configure BFD traffic
> bfdv6 Configure BFDv6 traffic
> bgp Configure BGP traffic
> bgpv6 Configure BGPv6 traffic
> demux-autosense Configure demux autosense traffic
> dhcpv4 Configure DHCPv4 traffic
> dhcpv6 Configure DHCPv6 traffic
> diameter Configure Diameter/Gx+ traffic
> dns Configure DNS traffic
> dtcp Configure dtcp traffic
> dynamic-vlan Configure dynamic vlan exceptions
> egpv6 Configure EGPv6 traffic
> eoam Configure EOAM traffic
> esmc Configure ESMC traffic
> fab-probe Configure fab out probe packets
> filter-action Configure filter action traffic
> frame-relay Configure frame relay control packets
> ftp Configure FTP traffic
> ftpv6 Configure FTPv6 traffic
> gre Configure GRE traffic
> icmp Configure ICMP traffic
> icmpv6 Configure ICMPv6 traffic
> igmp Configure IGMP traffic
> igmpv4v6 Configure IGMPv4-v6 traffic
> igmpv6 Configure IGMPv6 traffic
> inline-ka Configure inline keepalive packets
> inline-svcs Configure inline services
> ip-fragments Configure IP-Fragments
> ip-options Configure ip options traffic
> isis Configure ISIS traffic
> jfm Configure JFM traffic
> l2pt Configure Layer 2 protocol tunneling
> l2tp Configure l2tp traffic
> lacp Configure LACP traffic
> ldp Configure LDP traffic
> ldpv6 Configure LDPv6 traffic
> lldp Configure LLDP traffic
> lmp Configure LMP traffic
> lmpv6 Configure LMPv6 traffic
> mac-host Configure L2-MAC configured 'send-to-host'
> mcast-snoop Configure snooped multicast control traffic
> mlp Configure MLP traffic
> msdp Configure MSDP traffic
> msdpv6 Configure MSDPv6 traffic
> mvrp Configure MVRP traffic
> ndpv6 Configure NDPv6 traffic
> ntp Configure NTP traffic
> oam-lfm Configure OAM-LFM traffic
> ospf Configure OSPF traffic
> ospfv3v6 Configure OSPFv3v6 traffic
> pfe-alive Configure pfe alive traffic
> pim Configure PIM traffic
> pimv6 Configure PIMv6 traffic
> pmvrp Configure PMVRP traffic
> pos Configure POS traffic
> ppp Configure PPP control traffic
> pppoe Configure PPPoE control traffic
> ptp Configure PTP traffic
> pvstp Configure PVSTP traffic
> radius Configure Radius traffic
> redirect Configure packets to trigger ICMP redirect
> reject Configure packets via 'reject' action
> rejectv6 Configure packets via 'rejectv6' action
> resolve Configure resolve traffic
> rip Configure RIP traffic
> ripv6 Configure RIPv6 traffic
> rsvp Configure RSVP traffic
> rsvpv6 Configure RSVPv6 traffic
> sample Configure sampled traffic
> services Configure services
> snmp Configure SNMP traffic
> snmpv6 Configure SNMPv6 traffic
> ssh Configure SSH traffic
> sshv6 Configure SSHv6 traffic
> stp Configure STP traffic
> syslog Configure syslog traffic
> tacacs Configure TACACS traffic
> tcp-flags Configure packets with tcp flags
> telnet Configure telnet traffic
> telnetv6 Configure telnet-v6 traffic
> ttl Configure ttl traffic
> tunnel-fragment Configure tunnel fragment
> tunnel-ka Configure tunnel keepalive packets
> unclassified Configure unclassified host-bound traffic
> virtual-chassis Configure virtual chassis traffic
> vrrp Configure VRRP traffic
> vrrpv6 Configure VRRPv6 traffic
So umfangreich die aktuelle Protokollliste auch ist, sie stellt nur die äußere Oberfläche der Protokollerkennungsfähigkeiten des MX-Routers dar; alle aufgeführten Protokollgruppen unterstützen Policing auf Aggregatsebene und viele bieten auch Policer für einzelne Pakettypen, die auf den einzelnen Nachrichtentypen innerhalb des Protokolls basieren. Die Protokollgruppe PPP over Ethernet (PPPoE) enthält zum Beispiel neben zahlreichen einzelnen Pakettyp-Policern auch einen Aggregat-Policer:
{master}[edit system ddos-protection]
jnpr@R1-RE0# set protocols pppoe ?
Possible completions:
> aggregate Configure aggregate for all PPPoE control traffic
+ apply-groups Groups from which to inherit configuration data
+ apply-groups-except Don't inherit configuration data from these groups
> padi Configure PPPoE PADI
> padm Configure PPPoE PADM
> padn Configure PPPoE PADN
> pado Configure PPPoE PADO
> padr Configure PPPoE PADR
> pads Configure PPPoE PADS
> padt Configure PPPoE PADT
{master}[edit system ddos-protection]
Im Gegensatz dazu wird ICMP derzeit nur auf der Aggregatebene unterstützt:
{master}[edit system ddos-protection protocols]
jnpr@R1-RE0# set icmp ?
Possible completions:
> aggregate Configure aggregate for all ICMP traffic
+ apply-groups Groups from which to inherit configuration data
+ apply-groups-except Don't inherit configuration data from these groups
{master}[edit system ddos-protection protocols]
jnpr@R1-RE0# set icmp
Die Möglichkeit, diese Vielfalt an Datenverkehr am Ingress zu erkennen, bedeutet, dass er an eine ebenso umfangreiche Reihe von Policing-Funktionen weitergeleitet werden kann, um sicherzustellen, dass die Belastung der Steuerebene innerhalb akzeptabler Grenzen bleibt. Da viele Protokollgruppen sowohl Policers für einzelne Pakettypen als auch Policing auf Aggregatsebene an mehreren Stellen im hostgebundenen Verarbeitungspfad unterstützen, bietet die DDoS-Schutzfunktion sowohl eine effektive als auch eine fein abgestufte Kontrolle über den Ressourcenschutz im Host-Verarbeitungspfad.
Ein Spießrutenlauf von Polizisten
Hierarchisches Policing ist die DDoS-Prävention, die hinter dem hostgebundenen Klassifizierungsgehirn steckt. Diese Art des hierarchischen Policings ähnelt eher kaskadierten Policern und sollte nicht mit den zuvor beschriebenen hierarchischen Policern verwechselt werden. Das Ziel ist es, übermäßigen Datenverkehr so nah wie möglich an der Quelle zu begrenzen, wobei jede untere Policer-Komponente in einen übergeordneten Policer einfließt, bis ein endgültiges policiertes Aggregat für diesen Protokolltyp zur Verarbeitung an die RE geliefert wird.
Abbildung 4-2 zeigt die verschiedenen DDoS-Policing-Hierarchien im Kontext der PPPoE-Protokollgruppe.
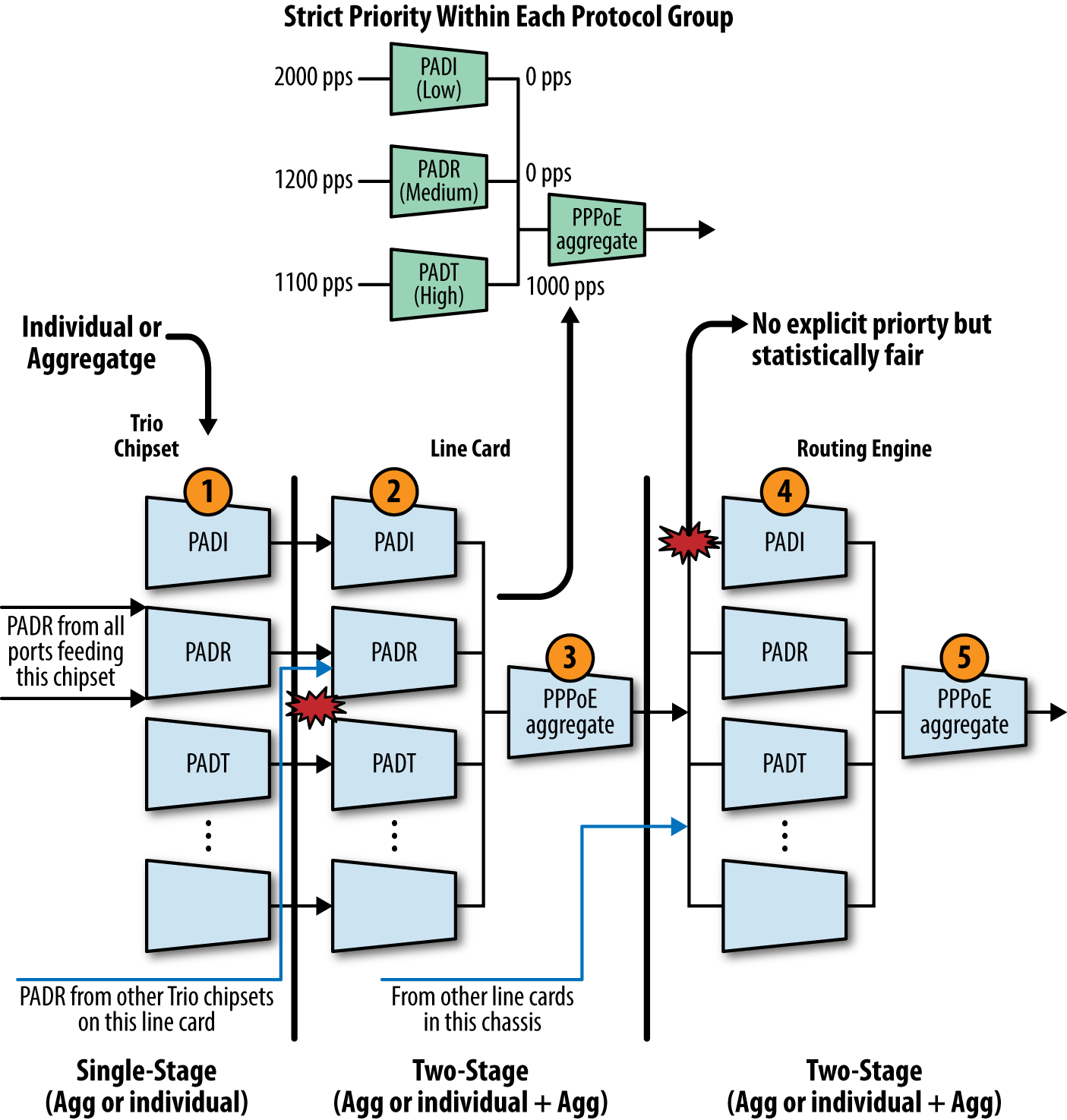
Abbildung 4-2. DDoS-Policing-Punkte für die PPPoE-Familie
Die erste Stufe der Überwachung erfolgt am Ingress des Trio-Chipsatzes (entweder der LU- oder der XL-Chip), wie in Schritt 1 dargestellt, wo jede Protokollgruppe einer einzelnen Überwachungsstufe unterzogen wird, die entweder auf dem Gesamtpaket oder auf dem einzelnen Pakettyp basiert.
Hinweis
Derzeit verwendet DHCP auf der PFE-Stufe nur einen aggregierten Policer, wie es auch auf allen Stufen für Protokolle der Fall ist, die kein Policing für einzelne Pakettypen unterstützen. In den PFE- und RE-Hierarchien wird DHCP für IPv4 und IPv6 mit einem zweistufigen Policing behandelt, das auf den einzelnen Nachrichtentypen basiert, zusätzlich zu einer aggregierten Rate für die Gruppe.
Die nächste Stufe des Policing findet auf der Ebene der Line Card (FPC) statt, da die aggregierten Datenströme aller PFEs, die sich auf der FPC befinden, um ihren Platz in der Warteschlange der Host-Verarbeitung kämpfen. In den meisten Fällen, so auch bei DHCP, besteht die zweite Stufe der Überwachung aus zwei Schritten: dem ersten für einzelne Nachrichtentypen und dem zweiten für das Protokollgruppenaggregat, das in den Schritten 2 und 3 dargestellt ist. Nur die Nachrichten, die im ersten Schritt akzeptiert wurden, werden in Schritt 2 angezeigt, und jedes Paket, das in den Schritten 1 und 2 akzeptiert wurde, kann in Schritt 3 vom Aggregat-Policer verworfen werden, wenn zu viel Aktivität in seiner Gruppe herrscht.
Innerhalb der einzelnen Nachrichten-Policer für eine bestimmte Protokollgruppe wird eine strikte Warteschlangenbildung durchgeführt, um den Wettbewerb um den aggregierten Policer der Gruppe auf der Grundlage einer konfigurierten Priorität von hoch, mittel oder niedrig zu steuern. Die strikte Prioritätsbehandlung ist oben in der Abbildung zu sehen, wo der PADT-Verkehr alle 1.000 pps des Gruppenaggregats beansprucht, obwohl andere PPPoE-Nachrichtentypen warten. Hier wird PPPoE Active Discovery Termination (PADT) als wichtiger angesehen als PPPoE Active Discovery Initiation (PADI), da sie die Freigabe von PPPoE-Ressourcen ermöglicht, was wiederum die Annahme neuer Verbindungen erleichtert. Aufgrund der strengen Priorität werden alle PADI-Pakete verworfen, wenn die PADT-Pakete alle Token des PPPoE-Aggregate-Policers verbrauchen.
Hinweis
Da Datenverkehr mit hoher Priorität den Datenverkehr mit niedrigerer Priorität innerhalb seiner Gruppe aushungern kann, solltest du gründlich darüber nachdenken, die Priorität für einen bestimmten Nachrichtentyp zu ändern, da die Standardwerte sorgfältig für eine optimale Leistung in den verschiedensten Anwendungsfällen entwickelt wurden.
Die letzte Ebene der Policing-Hierarchie findet in der RE selbst statt, mit einer weiteren Runde des zweistufigen, protokollgruppenbasierten Policing, wie in den Schritten 4 und 5 in Abbildung 4-2 dargestellt. Die Ausgabe dieser letzten Stufe besteht aus allen Pakettypen für diese Gruppe, die von allen Policing-Stufen im Pfad akzeptiert wurden, und wird dann an den zugehörigen Daemon zur Nachrichtenverarbeitung weitergegeben, vorausgesetzt, es befinden sich keine lo0-Filter oder Policer ebenfalls im Host-Verarbeitungspfad.
Das Ergebnis ist ein Minimum von drei Policing-Stufen für Protokolle, die keine individuellen Pakettyp-Policers haben, und fünf für solche, die es haben. Zu den reinen Aggregatgruppen gehören derzeit ANCP, dynamisches VLAN, FTP und IGMP-Verkehr. Zu den Gruppen, die beide Stufen des Policing unterstützen, gehören derzeit DHCPv4, MLP, PPP, PPPoE und virtueller Chassis-Verkehr. Wenn die Funktion ausgereift ist, können Gruppen, die derzeit nur die Aggregatebene unterstützen, bei Bedarf um die Überwachung einzelner Nachrichtentypen erweitert werden.
Standardmäßig haben alle drei Stufen des Policing (Trio-Chipsatz, Linecard und Routing Engine) die gleichen Bandbreiten- und Burst-Grenzen für einen bestimmten Pakettyp. Auf diese Weise kann der gesamte Kontrollverkehr von einem Chipsatz und einer Leitungskarte die RE erreichen, solange es keinen konkurrierenden Verkehr desselben Typs von anderen Chipsätzen oder Leitungskarten gibt. Wenn konkurrierender Verkehr vorhanden ist, werden überschüssige Pakete an den Konvergenzpunkten verworfen, d. h. an der Linecard für alle konkurrierenden Chipsätze und an der RE für alle konkurrierenden Linecards. Du kannst einen Skalierungsfaktor verwenden, um die ersten beiden Stufen unter die Standardwerte zu senken (100% des Wertes, der in der RE verwendet wird), um die Leistung fein abzustimmen.
Beachte, dass es an den Aggregate Policer Merge Points keinen Prioritätsmechanismus gibt, wie in Abbildung 4-2 dargestellt. Es gibt zwar keine explizite Priorisierung, aber die Bandbreite wird statistisch fair zugewiesen, d. h. Verkehrsströme mit höheren Raten erhalten proportional mehr Bandbreite als Verkehrsströme mit niedrigeren Raten, und bei Überlastung werden Streams mit höheren Raten auch häufiger verworfen.
Die Standard-Policer-Werte sind absichtlich hoch angesetzt, um sicherzustellen, dass gültige Dienste nicht gestört werden, da die DDoS-Funktion standardmäßig aktiviert ist und jedes Netzwerk unterschiedlich ist, was als normale Belastung der Steuerebene angesehen wird. Außerdem gibt es keine einheitliche Standardgröße für alle Protokollgruppen, da einige Nachrichtentypen lokal auf der Line Card verarbeitet werden und daher einen höheren Wert haben können, während die Verarbeitungslast für die an die RE gesendeten Nachrichten stark variieren kann. Um eine maximale DDoS-Prävention zu erreichen, wird erwartet, dass jeder Netzbetreiber die Policer-Werte von ihren großzügigen Standardwerten reduziert , nachdem er die tatsächliche Last in seinem Netz analysiert hat. Eine spezielle Methode, um DDOS auf die Besonderheiten deines Netzwerks abzustimmen, wurde in einem früheren Abschnitt beschrieben.
Warnung
Jedes Mal, wenn du einen Policer von seinem Standardwert heruntersetzt, solltest du besonders auf Warnmeldungen achten, die darauf hinweisen, dass der Wert für dein Netzwerk zu niedrig ist. Ein solcher Zustand kann zu einem unbeabsichtigten, selbst auferlegten DDoS-Angriff führen, wenn der aggressivere Policer beginnt, gültigen Protokollverkehr zu verwerfen.
DDoS-Konfiguration und Überprüfung der Funktionsfähigkeit
Die DDoS-Präventionsfunktion wird auf der Hierarchie [edit system ddos-protection] konfiguriert. Dort kannst du die Standard-Policer- und Prioritätswerte für eine lange Liste von Protokollen ändern, die Nachverfolgung konfigurieren oder globale Betriebseigenschaften wie die Deaktivierung von DDOS-Policern auf RE- oder FPC-Ebene und die Ereignisprotokollierung ändern.
{master}[edit system ddos-protection]
jnpr@R1-RE0# set ?
Possible completions:
+ apply-groups Groups from which to inherit configuration data
+ apply-groups-except Don't inherit configuration data from these groups
> global DDOS global configurations
> protocols DDOS protocol parameters
> traceoptions DDOS trace options
{master}[edit system ddos-protection]
Deaktivieren und Nachverfolgen
Du kannst das Policing auf der FPC-Ebene (CPU der Linecard + PFE) mit der Anweisung disable-fpc deaktivieren. Mit der Anweisung disable-routing-engine kannst du das Gleiche für die Policer der RE tun. Außerdem kannst du das Policing für ein bestimmtes Protokoll deaktivieren:
{master}[edit system ddos-protection protocol icmp aggregate]
jnpr@R1-RE0# show
disable-routing-engine;
disable-fpc;
Beide Optionen zusammen deaktivieren das Aggregate Policing auf allen drei Ebenen der Hierarchie, also auf der PFE-, FPC- und RE-Ebene. Beachte, dass du derzeit das Policing für einzelne Pakettypen auf der Ingress Trio PFE-Ebene nicht deaktivieren kannst und dass selbst wenn das aggregierte Policing deaktiviert ist, der zugehörige Daemon weiterläuft und die Statistiken weiterhin verfügbar sind: Nur die Policing-Funktion wird abgeschaltet.
Falls gewünscht, kannst du den DDoS-Daemon, der jddosd heißt, mit einer set system processes ddos-protection disable Konfigurationsanweisung vollständig deaktivieren.
Wenn du ein unerwartetes DDoS-Verhalten feststellst und nichts anderes zu helfen scheint, kannst du den jddosd Prozess mit einem restart ddos-protection Befehl im Betriebsmodus neu starten.
Hinweis
In der ersten Version entsprechen die Standard-DDoS-Policer-Werte den gleichen "höheren als der Host-Pfad unterstützen kann"-Raten, die verwendet werden, wenn die Funktion deaktiviert ist. Das bedeutet, dass die einzige wirkliche Auswirkung der Deaktivierung der Funktion bei den Standardwerten darin besteht, ob du Warnungen erhältst, wenn ein Policer verletzt wird oder nicht. Das bedeutet auch, dass du nicht annähernd so viel Schutz vor dem DDoS-Feature erhältst, wenn du die Last deines Netzwerks nicht modellierst und die Standard-Policer-Werte entsprechend reduzierst.
Die Entscheidung, Standardwerte zu verwenden, die höher sind als der Host-gebundene Pfad tatsächlich unterstützen kann, basiert darauf, dass die Funktion standardmäßig aktiviert ist und dass wir besonders vorsichtig sein wollen, wenn ein Kunde auf eine neuere Version mit DDoS-Unterstützung umsteigt.
Du kannst die Nachverfolgung aktivieren, um zusätzliche Informationen über DDoS-Operationen und -Ereignisse zu erhalten, indem du Trace-Flags einfügst - standardmäßig ist die Nachverfolgung deaktiviert. Falls gewünscht, kannst du einen Protokollnamen und Archivierungseinstellungen angeben, anstatt dich mit dem Standard /var/log/ddosd syslog zu begnügen, das standardmäßig 128 KByte groß sein darf, bevor es als eine von drei rollierenden Archivdateien mit den Namen ddosd.0 bis ddosd.2 gespeichert wird. Die derzeit unterstützten Trace-Flags werden angezeigt:
{master}[edit system ddos-protection]
jnpr@R1-RE0# set traceoptions flag ?
Possible completions:
all Trace all areas of code
config Trace configuration code
events Trace event code
gres Trace GRES code
init Trace initialization code
memory Trace memory management code
protocol Trace DDOS protocol processing code
rtsock Trace routing socket code
signal Trace signal handling code
state Trace state handling code
timer Trace timer code
ui Trace user interface code
{master}[edit system ddos-protection]
jnpr@R1-RE0# set traceoptions flag
In diesem Fall wird ein Syslog mit dem Namen ddos_trace und einer Dateigröße von 10 Mbyte erstellt, das Ereignisse und Vorgänge auf Protokollebene aufzeichnet. Die DDoS-Protokollierung erfolgt auf dem Schweregrad notice. Wenn du also einen weniger schweren Schweregrad angibst (z. B. info), wirst du keine Trace-Logs sehen:
{master}[edit system ddos-protection]
jnpr@R1-RE0# show traceoptions
file ddos_trace size 10m;
level notice;
flag protocol;
flag events;
Zugegeben, es gibt nicht viel zu sehen auf einem System, das nicht gerade in irgendeiner Form angegriffen wird:
{master}[edit system ddos-protection]
jnpr@R1-RE0# run show log ddos_trace
{master}[edit system ddos-protection]
jnpr@R1-RE0#
Konfiguriere die Eigenschaften der Protokollgruppe
Du kannst aggregierte (und individuelle Pakettyp-) Policing-Parameter konfigurieren, wenn dies von der Protokollgruppe in der [edit system ddos-protection protocols] Hierarchie unterstützt wird. In den meisten Fällen hat der aggregierte Policer einer Gruppe eine größere Bandbreite und Burst-Einstellung, die pro Paket berechnet wird, als jeder einzelne Pakettyp-Policer in der Gruppe; die Summe der einzelnen Policer kann jedoch die aggregierte Rate der Gruppe übersteigen. Standardmäßig übernehmen die FPC- und Trio-PFE-Policer die Bandbreiten- und Burstgrößen-Prozentsätze, die auf 100 % der aggregierten oder individuellen Paket-Policer-Rate auf RE-Ebene basieren. Von hier aus kannst du die FPC-Prozentsätze reduzieren oder herabsetzen, um sie auf einen Wert zu begrenzen, der unter den RE-Policer-Raten liegt, falls gewünscht. Die Standardeinstellung, die FPC-Rate an die RE-Rate anzupassen, stellt sicher, dass alle Nachrichten, die von den Trio-Polizisten akzeptiert werden, auch von den FPC-Polizisten akzeptiert werden, die wiederum auch von den RE-Polizisten akzeptiert werden, wenn kein überschüssiger Verkehr vorliegt.
Zusätzlich zu den Policer-Parametern kannst du auch konfigurieren, ob ein einzelner Policer-Typ den aggregierten Policer der Gruppe umgehen soll (während seine individuellen Pakettyp-Statistiken weiterhin verfolgt werden), ob Ausnahmen protokolliert werden sollen, die Zeitplanungspriorität für einzelne Pakettyp-Policer und die Wiederherstellungszeit. Außerdem kannst du das Policing auf RE- oder FPC-Ebene für jede Protokollgruppe/Nachrichtentyp deaktivieren.
Dieses Beispiel zeigt die aggregierten und individuellen Pakettyp-Policer-Einstellungen für die Gruppe ip-options:
protocols {
ip-options {
aggregate {
bandwidth 10000;
burst 500;
}
unclassified {
priority medium;
}
router-alert {
bandwidth 5000;
recover-time 150;
priority high;
}
}
}
Die Bandbreiten- und Burst-Einstellungen werden in Einheiten von Paketen pro Sekunde gemessen. Im gezeigten Beispiel werden die Bandbreiten- und Burst-Werte für den ICMP-Aggregat-Policer und den Router-Alarm-Policer für einzelne Nachrichten explizit festgelegt und der Typ des unklassifizierten ICMP-Pakets von der Standardpriorität niedrig auf mittel geändert. Der Router-Alarm-Paket-Typ hat standardmäßig eine hohe Priorität; in diesem Beispiel wird der Standardwert explizit eingestellt. Wenn die Burst-Größe für einen einzelnen Pakettyp nicht explizit konfiguriert ist, übernimmt er einen Wert, der auf der Vorgabe des Aggregats basiert. Dabei wird ein proprietärer Mechanismus verwendet, der die Burst-Größe entsprechend der zugewiesenen Priorität variiert, wobei eine hohe Priorität eine höhere Burst-Größe erhält.
In diesem Fall wurde die aggregierte Rate von 20 kpps auf 10 kpps mit einer Burstgröße von 500 Paketen reduziert. Die Bandbreite des individuellen Nachrichtentyps "Router-Alarm" wurde auf die Hälfte der Bandbreite des Aggregats (5 kpps) festgelegt. Außerdem wurde ihm eine Wiederherstellungszeit von 150 Sekunden zugewiesen, die festlegt, wie lange der Datenverkehr unter dem Schwellenwert liegen muss, bevor das DDoS-Ereignis gelöscht wird, und es wurde ihm eine hohe Priorität zugewiesen (die Standardeinstellung für diesen Nachrichtentyp). Die einzige Änderung, die am unklassifizierten Pakettyp vorgenommen wurde, ist, dass ihm eine mittlere Priorität zugewiesen wurde. Diese Änderung hat für dieses spezielle Beispiel einer Protokollgruppe keinen wirklichen Nutzen, da die Gruppe ip-option nur zwei Mitglieder hat, die sich um das Aggregat streiten. Schließlich ist die Einstellung einer mittleren Priorität nur dann von Bedeutung, wenn ein anderes Mitglied die niedrige Priorität verwendet, da die strenge Priorität gilt, wenn ein individueller Pakettyp-Policer mit anderen individuellen Paket-Policern um den Zugang zur Bandbreite des Aggregat-Policers konkurriert. Die Router-Alarmmeldungen mit hoher Priorität können die nicht klassifizierte Gruppe genauso leicht aushungern, unabhängig davon, ob sie eine mittlere oder niedrige Priorität verwendet. In diesem Beispiel ist eine Aushungerung nicht möglich, weil die Gesamtpaketrate der Gruppe die für IP-optionierte Pakete zulässige Einzelrate übersteigt. Die Aushungerung wird zu einem Problem, wenn die Gesamtpaketrate der Gruppe nur auf 5K gesetzt wurde, also achte auf die Prioritätseinstellungen in Bezug auf die Gesamtpaketrate für einen bestimmten Protokolltyp.
DDoS-Betrieb überprüfen
Du bestätigst nun die konfigurierten Einstellungen und den erwarteten Betrieb mit verschiedenen Formen des show ddos-protection operational mode Befehls:
{master}[edit]
jnpr@R1-RE0# run show ddos-protection ?
Possible completions:
protocols Show protocol information
statistics Show overall statistics
version Show version
{master}[edit]
jnpr@R1-RE0# run show ddos-protection
Das meiste Fleisch erhält man mit dem Schalter protocols, wie im Folgenden gezeigt wird. Die Option "Version" zeigt Informationen über die DDoS-Version und die Anzahl der klassifizierten Protokolle an:
{master}[edit]
jnpr@R1-RE0# run show ddos-protection version
DDOS protection, Version 1.0
Total protocol groups = 98
Total tracked packet types = 220
Die Option statistics bietet eine schnelle Zusammenfassung des aktuellen DDoS-Status:
{master}[edit]
jnpr@R1-RE0# run show ddos-protection statistics
Policing on routing engine: Yes
Policing on FPC: Yes
Flow detection: No
Logging: Yes
Policer violation report rate: 100
Flow report rate: 100
Currently violated packet types: 0
Packet types have seen violations: 3
Total violation counts: 290
Currently tracked flows: 0
Total detected flows: 0
Die Ausgabe zeigt, dass DDoS aktiviert ist und dass, obwohl keine aktuellen Verstöße vorliegen, in der Vergangenheit 290 Verstöße für drei verschiedene Pakettypen aufgetreten sind. In diesem Beispiel wollen wir uns auf die Gruppe ip-options konzentrieren und mit den Standardparametern für diese Gruppe beginnen:
{master}[edit]
jnpr@R1-RE0# run show ddos-protection protocols ip-options parameters brief
Packet types: 4, Modified: 0
* = User configured value
Protocol Packet Bandwidth Burst Priority Recover Policer Bypass FPC
group type (pps) (pkts) time(sec) enabled aggr. mod
ip-opt aggregate 20000 20000 -- 300 yes -- no
ip-opt unclass.. 10000 10000 Low 300 yes no no
ip-opt rt-alert 20000 20000 High 300 yes no no
ip-opt non-v4v6 10000 10000 Low 300 yes no no
Die Ausgabe bestätigt, dass die Gruppe aus einem Aggregat und drei einzelnen Nachrichtentypen besteht. Die Standardwerte für Bandbreite und Burst sind zugewiesen, ebenso wie die individuellen Prioritäten. Du siehst auch, dass keine einzelne Nachricht das Aggregat umgehen darf und dass die Policer aktiviert sind. Die Konfiguration wird geändert und die Änderungen werden bestätigt:
{master}[edit]
jnpr@R1-RE0# show | compare
[edit system]
+ ddos-protection {
+ traceoptions {
+ file ddos_trace size 10m;
+ level info;
+ flag protocol;
+ flag events;
+ }
+ protocols {
+ ip-options {
+ aggregate {
+ bandwidth 10000;
+ burst 500;
+ }
+ unclassified {
+ priority medium;
+ }
+ router-alert {
+ bandwidth 5000;
+ recover-time 150;
+ priority high;
+ }
+ }
+ }
+ }
{master}[edit]
jnpr@R1-RE0# run show ddos-protection protocols ip-options parameters brief
Packet types: 4, Modified: 3
* = User configured value
Protocol Packet Bandwidth Burst Priority Recover Policer Bypass FPC
group type (pps) (pkts) time(sec) enabled aggr. mod
ip-opt aggregate 10000* 500* -- 300 yes -- no
ip-opt unclass.. 10000 10000 Medium* 300 yes no no
ip-opt rt-alert 5000* 20000 High* 150 yes no no
ip-opt non-v4v6 10000 10000 Low 300 yes no no
Die Ausgabe bestätigt, dass die Änderungen wirksam geworden sind. Beachte, dass jeder vom Benutzer geänderte (nicht standardmäßige) Wert mit einem "*" angezeigt wird, um dich auf die geänderten Werte aufmerksam zu machen. Mit dem Befehl show ddos-protection protocols kannst du den aktuellen Verstoßstatus, Verkehrsstatistiken und Details zu den aggregierten und individuellen Pakettyp-Policer-Informationen für alle Protokolle oder nur für eine ausgewählte Protokollgruppe anzeigen:
{master}[edit system ddos-protection]
jnpr@R1-RE0# run show ddos-protection protocols ip-options ?
Possible completions:
<[Enter]> Execute this command
| Pipe through a command
parameters Show IP-Options protocol parameters
statistics Show IP-Options statistics and states
violations Show IP-Options traffic violations
flow-detection Show IP-Options flow detection parameters
culprit-flows Show IP-Options culprit flows
aggregate Show aggregate for all ip options traffic information
unclassified Show Unclassified options traffic information
router-alert Show Router alert options traffic information
non-v4v6 Show Non IPv4/v6 options traffic information
{master}[edit system ddos-protection]
jnpr@R1-RE0# run show ddos-protection protocols ip-options
Die System-Baseline wird nun untersucht, um zu bestätigen, dass es keine aktuellen Verstöße gibt und dass seit dem Hochfahren des Systems nur sehr wenig ICMP-Aktivität stattgefunden hat:
{master}[edit]
jnpr@R1-RE0# run show ddos-protection protocols ip-options violations
Number of packet types that are being violated: 0
{master}[edit]
jnpr@R1-RE0# run show ddos-protection protocols ip-options statistics brief
Packet types: 4, Received traffic: 0, Currently violated: 0
Protocol Packet Received Dropped Rate Violation State
group type (packets) (packets) (pps) counts
ip-opt aggregate 1 0 0 0 ok
ip-opt unclass.. 0 0 0 0 ok
ip-opt rt-alert 1 0 0 0 ok
ip-opt non-v4v6 0 0 0 0 ok
Nicht nur die aktuellen Zähler für die Verkehrsrate sind auf 0, sondern auch der kumulative Zähler ist sehr niedrig, da bisher nur ein einziges Router-Alarm-IP-Option-Paket entdeckt wurde. Um Details zu einzelnen Pakettypen zu sehen, gib das entsprechende Schlüsselwort ein:
{master}[edit]
jnpr@R1-RE0# run show ddos-protection protocols ip-options router-alert
Protocol Group: IP-Options
Packet type: router-alert (Router alert options traffic)
Individual policer configuration:
Bandwidth: 5000 pps
Burst: 20000 packets
Priority: high
Recover time: 150 seconds
Enabled: Yes
Bypass aggregate: No
System-wide information:
Bandwidth is never violated
Received: 1 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Routing Engine information:
Policer is never violated
Received: 1 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Dropped by aggregate policer: 0
FPC slot 1 information:
Bandwidth: 100% (5000 pps), Burst: 100% (20000 packets), enabled
Policer is never violated
Received: 0 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Dropped by aggregate policer: 0
FPC slot 2 information:
Bandwidth: 100% (5000 pps), Burst: 100% (20000 packets), enabled
Policer is never violated
Received: 1 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Dropped by aggregate policer: 0
Die Ausgabe für den individuellen Router-Alarm-Paket-Policer bestätigt die systemweiten Einstellungen und die Policer-Statistiken für die RE- und FPC-Hierarchien. Beachte, dass die Statistiken auf der ersten Stufe der Trio PFE-Ebene nicht in der CLI angezeigt werden, sondern Verstöße über das FPC-Gehäuse dieses Trio PFE gemeldet werden. Die PFE-Statistiken sind nur über den PFE-Befehl verfügbar. Hier bestätigst du, dass das Router-Alert-Paket tatsächlich von der PFE 0 des FPC 2 empfangen wurde:
jnpr@R1-RE0> start shell pfe network fpc2
NPC platform (1067Mhz MPC 8548 processor, 2048MB memory, 512KB flash)
NPC2(R1 vty)# show ddos policer ip-options stats
DDOS Policer Statistics:
idx prot group proto on loc pass drop rate rate flows
--- --- ------- ---------- -- ------ ------- ------- ------ ------ -----
132 3d00 ip-opt aggregate Y UKERN 0 0 0 0 0
PFE-0 0 0 0 0 0
PFE-1 0 0 0 0 0
133 3d01 ip-opt unclass.. Y UKERN 0 0 0 0 0
PFE-0 0 0 0 0 0
PFE-1 0 0 0 0 0
134 3d02 ip-opt rt-alert Y UKERN 1 0 0 0 0
PFE-0 1 0 0 0 0
PFE-1 0 0 0 0 0
135 3d03 ip-opt non-v4v6 Y UKERN 0 0 0 0 0
PFE-0 0 0 0 0 0
PFE-1 0 0 0 0 0
Anhand der bereitgestellten Informationen kannst du schnell erkennen, ob derzeit ein Übermaß an Router-Warndatenverkehr vorliegt, ob in der Vergangenheit ein Übermaß an Datenverkehr festgestellt wurde und wenn ja, wann der letzte Verstoß begann und endete. Die Anzeige pro FPC enthält alle Warnungen oder Verstöße, die entweder auf dem Trio-Chipsatz oder auf der FPC-Policing-Ebene festgestellt wurden. Diese Informationen ermöglichen es dir, schnell die Ingress-Punkte für anomalen Control Plane-Verkehr zu bestimmen.
Du kannst den Verstoßverlauf nur bei einem Neustart des Systems löschen. Mit dem Befehl clear ddos-protection protocols kannst du die Statistiken einer bestimmten Gruppe oder einen aktuellen Verstoßstatus löschen:
{master}[edit]
jnpr@R1-RE0# run clear ddos-protection protocols ip-options ?
Possible completions:
statistics Clear IP-Options statistics
states Reset IP-Options states
culprit-flows Cleart all culprit flows for IP-Options
aggregate Clear aggregate for all ip options traffic information
unclassified Clear Unclassified options traffic information
router-alert Clear Router alert options traffic information
non-v4v6 Clear Non IPv4/v6 options traffic information
DDoS-Fallstudie
Diese Fallstudie soll die DDoS-Präventionsfunktion in Aktion zeigen. Sie beginnt mit der geänderten Konfiguration für die Gruppe ip-options, die im vorherigen Abschnitt beschrieben wurde. Bisher wurden auf R1 keine DDoS-Warnungen oder Trace-Aktivitäten festgestellt, wie das Fehlen von Warnungen in den Systemprotokollen beweist:
{master}
{master}
jnpr@R1-RE0> show log messages | match ddos
{master}
jnpr@R1-RE0> show log ddos_trace
{master}
jnpr@R1-RE0>
Das ist keine wirkliche Überraschung, wenn man bedenkt, dass das System im Labor eingesetzt wird und dass diejenigen, die das Vergnügen hatten, es zu benutzen, keine feindseligen Absichten hegen und eine gewisse Zuneigung zu dem kleinen Gehäuse entwickelt haben. Um die Sache voranzutreiben, hat sich der Autor bereit erklärt, einen Router-Tester zu benutzen, um R1 mit der sprichwörtlichen Ladung von IP-optierten Paketen zu attackieren. Schließlich gibt es einen DDoS-Schutz, so dass bei dem Experiment keine Router zu Schaden kommen sollten. In diesem Fall sind alle Pakete mit dem berüchtigten Router-Alarm verschlüsselt - denk daran, dass diese Option die Verarbeitung auf RE-Ebene erzwingt und damit als potenzieller Angriffsvektor für die zwielichtigen Gestalten dient, die unsere Zivilisation teilen.
Abbildung 4-3 zeigt die Details der Topologie für das DDoS-Schutzlabor.
Abbildung 4-3. DDoS-Schutz Labortopologie
Der Plan ist, zwei identische Ströme dieser Black-Hat-tragenden Pakete zu erzeugen, einen über die xe-0/0/6 Layer-2-Zugangsschnittstelle an S1 und den anderen über die xe-2/1/1 Layer-3-Schnittstelle, die R1 mit P1 verbindet. Beide Paketströme werden von der IP-Adresse 192.0.2.20 gesendet und sind für die 192.0.2.3-Adresse bestimmt, die der VLAN 100 IRB-Schnittstelle von R2 zugewiesen ist. Erinnere dich daran, dass die Option router-alert R1 dazu zwingt, diesen Transitverkehr zu untersuchen, auch wenn er nicht an eine seiner lokalen IP-Adressen gerichtet ist. Die Ziel-MAC-Adresse des Ethernet-Frames ist auf "all 1's broadcast" gesetzt, eine Einstellung, die sicherstellt, dass Kopien desselben Datenstroms auf der Layer-3-Schnittstelle von R1 zur Verarbeitung/Routing akzeptiert werden, während sie gleichzeitig von S1 in die Layer-2-Domäne VLAN 100 geflutet werden. Die Pakete sind auf Layer 2 128 Byte lang und werden mit 50.000 Paketen pro Sekunde generiert, was einer Gesamtlast von 100 kpps entspricht.
Das ist eine ziemliche Menge an Datenverkehr, die eine RE in jeder Sekunde verarbeiten muss. Das könnte gefährlich werden, wenn es keinen DDoS-Schutz gäbe!
Der Angriff hat begonnen!
Die Bühne ist bereitet, und der DDoS-Daemon steht bereit, um das Beste aus jedem Schuss herauszuholen, den du werfen kannst.
Oh, die Menschheit ... aber warte, der Router reagiert immer noch, es gibt keinen Zusammenbruch. Der einzige Hinweis darauf, dass etwas nicht in Ordnung ist, ist der Syslog-Eintrag von jddosd, der die Verletzung meldet:
jnpr@R1-RE0> show log messages | match ddos Dec 19 18:16:56 R1-RE0 jddosd[1541]: DDOS_PROTOCOL_VIOLATION_SET: Protocol IP-Options:router-alert is violated at fpc 2 for 1 times, started at 2011-12-19 18:16:56 PST, last seen at 2011-12-19 18:16:56 PST
Die Syslog-Informationen geben Aufschluss über die Art des Angriffsverkehrs und den betroffenen FPC, in diesem Fall FPC 2. Die gleichen Informationen werden auch in die DDoS-Trace-Datei geschrieben, was praktisch sein kann, wenn jemand die DDoS-Protokollierung global deaktiviert hat, da die globale Anweisung zum Deaktivieren der Protokollierung nur die Protokollierung in die Haupt-Syslog-Meldungsdatei steuert, nicht aber in eine DDoS-spezifische Trace-Datei:
{master}[edit]
jnpr@R1-RE0# run show log ddos_trace
Dec 19 18:16:56 Protocol IP-Options:router-alert is violated at fpc 2 for 1 times
started at 2011-12-19 18:16:56 PST, last seen at 2011-12-19 18:16:56 PST
Analysieren Sie die Art der DDoS-Bedrohung
Sobald du eine Warnung erhältst, dass ungewöhnlich viel Datenverkehr auf der Steuerebene festgestellt wurde, kannst du die Art und den Umfang der Anomalie mit dem folgenden Verfahren schnell eingrenzen.
Bestätige zunächst den Verstoßstatus mit einem show ddos-protection statistics Befehl:
{master}
jnpr@R1-RE0> show ddos-protection statistics
DDOS protection global statistics:
Currently violated packet types: 1
Packet types have seen violations: 1
Total violation counts: 1
Um den Umfang der aktuell beteiligten Protokolle anzuzeigen, füge das Schlüsselwort violations hinzu:
{master}
jnpr@R1-RE0> show ddos-protection protocols violations
Number of packet types that are being violated: 1
Protocol Packet Bandwidth Arrival Peak Policer bandwidth
group type (pps) rate(pps) rate(pps) violation detected at
ip-opt rt-alert 5000 100004 100054 2011-12-19 18:16:56 PST
Detected on: FPC-2
Wenn keine anderen Protokolle verletzt wurden und du weißt, dass nicht nur IP-Optionen, sondern auch Router-Warnungen für den Angriff verantwortlich sind, kannst du dir die Details für diesen Verkehrstyp anzeigen lassen:
{master}
jnpr@R1-RE0> show ddos-protection protocols ip-options router-alert
Protocol Group: IP-Options
Packet type: router-alert (Router alert options traffic)
Individual policer configuration:
Bandwidth: 5000 pps
Burst: 20000 packets
Priority: high
Recover time: 150 seconds
Enabled: Yes
Bypass aggregate: No
System-wide information:
Bandwidth is being violated!
No. of FPCs currently receiving excess traffic: 1
No. of FPCs that have received excess traffic: 1
Violation first detected at: 2011-12-19 18:16:56 PST
Violation last seen at: 2011-12-19 18:19:33 PST
Duration of violation: 00:02:37 Number of violations: 1
Received: 15927672 Arrival rate: 100024 pps
Dropped: 10402161 Max arrival rate: 100054 pps
Routing Engine information:
Policer is never violated
Received: 374395 Arrival rate: 2331 pps
Dropped: 0 Max arrival rate: 2388 pps
Dropped by aggregate policer: 0
FPC slot 1 information:
Bandwidth: 100% (5000 pps), Burst: 100% (20000 packets), enabled
Policer is never violated
Received: 0 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Dropped by aggregate policer: 0
FPC slot 2 information:
Bandwidth: 100% (5000 pps), Burst: 100% (20000 packets), enabled
Policer is currently being violated!
Violation first detected at: 2011-12-19 18:16:56 PST
Violation last seen at: 2011-12-19 18:19:33 PST
Duration of violation: 00:02:37 Number of violations: 1
Received: 15927672 Arrival rate: 100024 pps
Dropped: 10402161 Max arrival rate: 100054 pps
Dropped by this policer: 10402161
Dropped by aggregate policer: 0
Allein die Tatsache, dass dieses Ergebnis erzielt wurde, beweist, dass R1 während des gesamten Ereignisses reaktionsschnell war, und damit die Wirksamkeit des neuen Trio DDoS-Schutzes. Beachte, dass die Statistiken für das Policing auf RE-Ebene eine Spitzenlast von nur 2.388 pps zeigen, während die FPC 2-Statistiken eine Ankunftsrate von 100.000 pps bestätigen. Außerdem wird eine große Anzahl von Abbrüchen bestätigt, was den Unterschied zwischen der Trio/FPC-Überwachungslast und dem Verkehrsaufkommen, das tatsächlich in der RE ankommt, erklärt.
Die Anzeige bestätigt auch, dass der gesamte schädliche Datenverkehr über FPC 2 eindringt. Wenn du das weißt, kannst du Filter oder andere Methoden anwenden, um den Punkt zu finden, an dem der schädliche Datenverkehr in dein Netzwerk eindringt, damit du entweder die Peering-Schnittstelle deaktivieren oder einen Filter anwenden kannst, um den Datenverkehr zu blockieren, bevor er dein Netzwerk gefährdet.
Es ist oft hilfreich, Informationen auf Protokollebene anzuzeigen, die auch alle einzelnen Paket-Policer enthalten, selbst wenn du weißt, dass ein bestimmter Verstoß von einem einzelnen Paket-Policer erfasst wird, wie z.B. im Fall des hier besprochenen Router-Alarms. Auf der Gruppenebene werden die Informationen aller fünf Überwachungspunkte kombiniert angezeigt, auch wenn die Anzeige recht lang sein kann, was dir hilft, die Überwachungsmaßnahmen auf der Trio-Ebene der PFE von denen der FPC oder RE zu unterscheiden. Um zu verdeutlichen, wie die hierarchischen DDoS-Policer funktionieren, werden die Statistiken und der Status des letzten Experiments gelöscht:
{master}
jnpr@R1-RE0> clear ddos-protection protocols statistics
jnpr@R1-RE0> clear ddos-protection protocols state
Und der Traffic-Generator wird so verändert, dass er eine Million Router-Alarm-Pakete mit einer Rate von 100 kpps über eine einzige Schnittstelle sendet. Die runden Zahlen sollen die spätere Analyse erleichtern. Nachdem der Datenverkehr gesendet wurde, werden die DDoS-Policer-Informationen auf Protokollgruppenebene angezeigt:
{master}
jnpr@R1-RE0> show ddos-protection protocols ip-options
Protocol Group: IP-Options
Packet type: aggregate (Aggregate for all options traffic)
Aggregate policer configuration:
Bandwidth: 10000 pps
Burst: 500 packets
Priority: high
Recover time: 300 seconds
Enabled: Yes
System-wide information:
Aggregate bandwidth is never violated
Received: 71751 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 6894 pps
Routing Engine information:
Aggregate policer is never violated
Received: 40248 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 4262 pps
Dropped by individual policers: 0
FPC slot 1 information:
Bandwidth: 100% (10000 pps), Burst: 100% (500 packets), enabled
Aggregate policer is never violated
Received: 0 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Dropped by individual policers: 0
FPC slot 2 information:
Bandwidth: 100% (10000 pps), Burst: 100% (500 packets), enabled
Aggregate policer is never violated
Received: 71751 Arrival rate: 0 pps
Dropped: 31743 Max arrival rate: 6894 pps
Dropped by individual policers: 31743
Packet type: unclassified (Unclassified options traffic)
Individual policer configuration:
Bandwidth: 10000 pps
Burst: 10000 packets
Priority: medium
Recover time: 300 seconds
Enabled: Yes
Bypass aggregate: No
System-wide information:
Bandwidth is never violated
Received: 0 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Routing Engine information:
Policer is never violated
Received: 0 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Dropped by aggregate policer: 0
FPC slot 1 information:
Bandwidth: 100% (10000 pps), Burst: 100% (10000 packets), enabled
Policer is never violated
Received: 0 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Dropped by aggregate policer: 0
FPC slot 2 information:
Bandwidth: 100% (10000 pps), Burst: 100% (10000 packets), enabled
Policer is never violated
Received: 0 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Dropped by aggregate policer: 0
Packet type: router-alert (Router alert options traffic)
Individual policer configuration:
Bandwidth: 5000 pps
Burst: 20000 packets
Priority: high
Recover time: 150 seconds
Enabled: Yes
Bypass aggregate: No
System-wide information:
Bandwidth is being violated!
No. of FPCs currently receiving excess traffic: 1
No. of FPCs that have received excess traffic: 1
Violation first detected at: 2011-12-19 19:00:43 PST
Violation last seen at: 2011-12-19 19:00:53 PST
Duration of violation: 00:00:10 Number of violations: 2
Received: 1000000 Arrival rate: 0 pps
Dropped: 819878 Max arrival rate: 100039 pps
Routing Engine information:
Policer is never violated
Received: 40248 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 4262 pps
Dropped by aggregate policer: 0
FPC slot 1 information:
Bandwidth: 100% (5000 pps), Burst: 100% (20000 packets), enabled
Policer is never violated
Received: 0 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 0 pps
Dropped by aggregate policer: 0
FPC slot 2 information:
Bandwidth: 100% (5000 pps), Burst: 100% (20000 packets), enabled
Policer is currently being violated!
Violation first detected at: 2011-12-19 19:00:43 PST
Violation last seen at: 2011-12-19 19:00:53 PST
Duration of violation: 00:00:10 Number of violations: 2
Received: 1000000 Arrival rate: 0 pps
Dropped: 819878 Max arrival rate: 100039 pps
Dropped by this policer: 819878
Dropped by aggregate policer: 0
Es gibt hier viele Informationen; siehe Abbildung 4-2, um dich an die fünf möglichen Stufen der DDoS-Überwachung zu erinnern, und lass uns einen Schritt nach dem anderen machen.
Die erste Stufe des DDoS-Policing findet auf der Ebene des Trio FPC statt. Die Ingress Trio-Statistiken befinden sich am unteren Rand der Anzeige unter der Überschrift Packet type: router-alert (Router alert options traffic). Die maximale Ankunftsrate von 1.000.039 pps stimmt gut mit der Burst-Länge und den Ratenparametern des Verkehrs überein, ebenso wie die Anzahl der empfangenen Pakete von 1.000.000. Die Anzeige bestätigt, dass dieser Policer derzeit verletzt wird, und zeigt außerdem, dass 819.878 Pakete verworfen wurden.
Das Ziel des Junos-DDoS-Schutzes ist es, übermäßigen Datenverkehr auf der Steuerungsebene zu erkennen und ihn dann so nah wie möglich an der Quelle und so weit wie möglich von der RE abzuschneiden. Die Zahlen bestätigen, dass über 80 % des überschüssigen Datenverkehrs verworfen wurde, und das in der ersten von bis zu fünf Überwachungsstufen. Offensichtlich hat DDoS darauf hingewirkt, die Ressourcen der Steuerebene weiter oben in der Leitung zu schonen. Mit den in dieser Phase gezeigten Abbrüchen sollten noch etwa 180.122 Optionspakete ihren Weg nach Norden in das Land der RE finden.
Der nächste Schritt ist der FPC-Policer, der für diese Gruppe ein zweistufiger Policer mit individueller und aggregierter Überwachung ist. Einzelheiten dazu findest du auf FPC slot 2 information unter der Überschrift aggregate (Aggregate for all options traffic). An dieser Stelle musst du etwas Detektivarbeit leisten. Die Anzeige bestätigt, dass der Aggregate-Policer auf FPC-Ebene nie verletzt wurde, zeigt aber gleichzeitig 31.743 Drops an, die also von der individuellen Paket-Policer-Stufe stammen müssen. Die Anzeige zeigt auch, dass die FPC-Policing-Stufe nur 71.751 Pakete erhalten hat, was deutlich weniger ist als die 180.122 Pakete, die es durch den Trio-PFE-Policer geschafft haben.
Auf die Frage nach der Diskrepanz zwischen den DDoS-Stufen bestätigte ein Softwareentwickler das Vorhandensein von "Legacy-Policing-Funktionen, die auch überschüssigen Datenverkehr auf dem Host-Pfad verwerfen können", z. B. die eingebaute ICMP-Ratenbegrenzungsfunktion, die mit einem show system statistics icmp -Befehl eingesehen werden kann. Die Standardeinstellungen können über die Konfigurationsanweisung set system internet-options geändert werden:
[edit] jnpr@R4# set system internet-options icmpv? Possible completions: > icmpv4-rate-limit Rate-limiting parameters for ICMPv4 messages > icmpv6-rate-limit Rate-limiting parameters for ICMPv6 messages
Hier werden die V4-Optionen gezeigt:
[edit] jnpr@R4# set system internet-options icmpv4-rate-limit ? Possible completions: bucket-size ICMP rate-limiting maximum bucket size (seconds) packet-rate ICMP rate-limiting packets earned per second [edit] jnpr@R4# set system internet-options icmpv4-rate-limit
Die Moral von der Geschichte ist, dass du keine 100%ige Korrelation der in den verschiedenen Überwachungsstufen angezeigten Zähler erwarten solltest, da diese Daten nur die mit der DDoS-Verarbeitung verbundenen Aktionen widerspiegeln und nicht die anderer Host-Schutzmechanismen, die weiterhin nebeneinander bestehen können. Erinnere dich daran, dass das Ziel der Funktion darin besteht, die RE zu schützen und den Betreiber mit den Informationen zu versorgen, die er benötigt, um den Umfang und die Art eines Angriffs festzustellen, und nicht, um Statistiken zu erstellen, die für eine nutzungsbasierte Abrechnung geeignet sind.
Die Tatsache, dass der aggregierte Policer des FPC nie verletzt wurde, ist ein Beweis für die Wirksamkeit der Maßnahmen in der ersten Phase. Da der FPC den Empfang von 71.757 Paketen anzeigt und die 31.743 verworfenen Pakete berücksichtigt, sollten noch etwa 40.014 Pakete übrig sein, um die letzte Kontrollstufe in der RE selbst zu durchlaufen.
Die Policer-Statistiken der RE werden an mehreren Stellen angezeigt. Wenn du dir die Statistik unter dem Gruppenaggregat ansiehst, kannst du sehen, dass er insgesamt 40.248 Pakete empfangen hat. Die Anzeige bestätigt auch, dass der RE-Policer weder auf der Einzel- noch auf der Aggregatebene verworfen wurde. Die Zahl ist etwas höher als die 40.014 Pakete, von denen angenommen wurde, dass sie den FPC verlassen haben, was vielleicht auf eine andere Funktion des Altsystems zurückzuführen ist, aber die Zahlen passen immer noch relativ gut zu der bekannten Art dieses Angriffs. Die Tatsache, dass 1 Mio. dieser Welpen versendet wurden, während die RE nur 40.000 von ihnen bewältigen musste, und das alles aufgrund einer hardwarebasierten Funktion, die keine Auswirkungen auf die Weiterleitungsleistung hat, sollte die Vorteile dieser Trio-Only-Funktion deutlich machen.
Erkennung verdächtiger Kontrollflüsse
Wie bereits erwähnt hat, ist die Verwendung von ddos-protection ziemlich einfach, aber die Komplexität liegt in der Wahl der Policer-Werte. Das Policing eines bestimmten Protokolls oder eines bestimmten Pakettyps mag ausreichen, um die Routing Engine selbst zu schützen, aber was ist mit der Notwendigkeit, ein Protokoll selbst zu schützen? Die meisten Netzwerkbetreiber würden es zum Beispiel als inakzeptabel ansehen, wenn ein legitimes BGP durch einen TCP SYN Flood-Angriff auf den BGP-Port (179) unterbrochen würde.
Um den Bedarf an einer detaillierteren Überwachung von Datenströmen zu decken, hat Juniper die ursprüngliche DDoS-Schutzfunktion mit der Suspicious Control Flow Detection (SCFD) erweitert, um eine tiefere Analyse innerhalb eines bestimmten Protokolls oder Pakettyps zu ermöglichen. Im Gegensatz zur DDoS-Basisfunktion ist SCFD standardmäßig deaktiviert. Sobald die Funktion aktiviert ist, überwacht der Flussschutz die spezifischen Verursacher der verschiedenen aggregierten Flüsse und versucht dynamisch, diejenigen zu ermitteln, die "feindlich" sind, weil sie den Großteil der aggregierten Paketrate ausmachen. Verdächtige Flüsse werden über ein Zeitfenster hinweg verfolgt, um zu protokollieren, wann sie als verdächtig eingestuft werden und wann solche Flüsse wieder in akzeptable Grenzen zurückkehren. Ein verdächtiger Datenfluss, der seine konfigurierte Rate überschreitet, kann je nach Konfiguration fallen gelassen, überwacht oder weitergeleitet werden. Der letztere Fall bietet keinen inhärenten Schutz vor DDoS, aber die Identifizierung und Protokollierung von Flüssen, die gegen die Regeln verstoßen, kann für eine spätere Analyse und ein mögliches DDoS-Tuning nützlich sein.
Warnung
SCFD funktioniert nur auf der PFE-Ebene, also auf einem LU- oder XL-Chip. Der Lookup-Chip verwaltet die Flow-Hashtabelle mit den zugehörigen Policern. Durch die Überwachung von Mikroflüssen, die näher an ihrer Quelle liegen, soll die Gesamtrate auf FPC- und RE-Ebene für legitimen (unverdächtigen) Verkehr erhalten bleiben.
Es gibt drei Stufen der SCFD-Überwachung:
-
Subscriber Dies ist die feinkörnigste der drei Ebenen. Diese Ströme werden auf der untersten Aggregationsebene überwacht, um einzelne Teilnehmer zu überwachen, die durch eine Netzwerkschicht oder eine MAC-Adresse identifiziert werden.
-
Logicial-interface Die logische Schnittstellenebene kann die Aggregation mehrerer Teilnehmerströme darstellen, da einer einzelnen IFL mehrere Adressen zugewiesen werden können - zum Beispiel eine IPv4- sowie eine IPv6-Adresse.
-
Physical-interface Dieser Fluss stellt die physische Schnittstellenebene (IFD) dar und ist oft die Aggregation mehrerer IFLs mit ihren Teilnehmern.
SCFD Vokabular
Bevor wir eintauchen, sollten wir einige grundlegende Begriffe klären:
- Ein Fluss
Verschiedene Felder des Paketkopfes werden vom Lookup-Chip verwendet, um einen Hash zu erzeugen. Eine Folge von Paketen, die denselben Hash erzeugt, wird als ein Fluss bezeichnet.
- Ein normaler Fluss
Ein normaler Fluss hat eine Bandbreite, die unter der erlaubten Rate liegt. Diese Rate ist vom Benutzer konfigurierbar, hat aber einen Standardwert, der der Bandbreite des DDOS-Schutzes entspricht. Um Status zu sparen, werden normale Flüsse vom System nicht verfolgt, es sei denn, du konfigurierst den Überwachungsmodus explizit auf EIN.
- Eine verdächtige Strömung
Ein Datenfluss wird als verdächtig gekennzeichnet, wenn seine Rate über der zulässigen Bandbreite liegt. Die verdächtigen Flüsse werden vom System immer verfolgt.
- Ein Verursacherfluss
Dies ist ein verdächtiger Fluss, dessen Rate mindestens während einer konfigurierbaren Zeitspanne (
flow-detect-time; Standard ist 3 Sekunden) konstant über der zulässigen Bandbreite liegt.
Die SCFD-Überwachung kann auf jeder Ebene ein- oder ausgeschaltet oder auf automatisch (Standard) eingestellt werden. Im automatischen Standardmodus beginnt die Flow-Erkennung automatisch, wenn ein Verstoß gegen einen DDoS-Schutz-Policer festgestellt wird. Im EIN-Modus werden die Datenströme immer vom System verfolgt, auch wenn die Rate unter der zulässigen Bandbreite liegt. Dieser Modus benötigt mehr Speicherplatz und sollte nur zur Fehlersuche oder für andere gezielte Zwecke aktiviert werden.
Wenn ein Flow ankommt, prüft die Flow-Erkennung, ob der Flow bereits in einer Tabelle mit verdächtigen Flows aufgeführt ist. Ein verdächtiger Flow ist ein Flow, der die standardmäßig oder durch die Konfiguration erlaubte Bandbreite überschreitet. Wenn der Flow nicht in der Tabelle steht und der Flow-Erkennungsmodus auf Aggregationsebene aktiviert ist, listet die Flow-Erkennung den neuen Flow in der Tabelle auf. Wenn der Flow nicht in der Tabelle steht und der Flow-Erkennungsmodus automatisch ist, prüft die Flow-Erkennung, ob dieser Flow verdächtig ist.
Ein verdächtiger Datenfluss wird immer in die Datenflusstabelle aufgenommen. Diejenigen, die als unverdächtig eingestuft werden, werden auf der nächsthöheren Aggregationsebene, auf der die Flow-Erkennung aktiviert ist, auf ähnliche Weise neu bewertet. Wenn auf keiner der höheren Ebenen die Erkennung aktiviert ist, wird der Datenfluss an den DDoS Protection Packet Policer weitergeleitet, wo er entweder weitergeleitet oder verworfen werden kann.
Wenn die anfängliche Prüfung ergibt, dass der Fluss bereits in der Tabelle enthalten ist, wird er fallen gelassen, überwacht oder beibehalten, je nachdem, welcher Kontrollmodus für diese Aggregationsebene eingestellt ist.
Wie bereits erwähnt, sind unabhängig vom Modus oder der Ebene die folgenden drei Aktionen möglich, sobald ein Fluss als "culprit flow" markiert ist:
- Drop
Der gesamte Fluss wird unterbrochen, wenn er die Bandbreitengrenze erreicht.
- Polizei
Der Fluss wird basierend auf der konfigurierten Bandbreite auf dieser Ebene überwacht.
- Behalte
Es wird ein Protokoll erstellt, aber der Datenfluss wird an die nächste Schicht (d.h. die FPC- oder RE-Aggregationsebene) weitergeleitet.
Flow Detection konfigurieren
Wie bereits erwähnt, ist SCFD standardmäßig deaktiviert. Der erste Schritt besteht darin, die Flow Detection Funktion zu aktivieren:
[edit system ddos-protection] jnpr@R1# set global flow-detection
Sobald sie aktiviert ist, wird die Verkehrsflusserkennung für alle unterstützten Protokolle aktiviert. Erinnere dich daran, dass der Standardmodus für die Flusserkennung automatisch ist. Mit dem folgenden CLI-Befehl kannst du die Aktivität der Flusserkennung überprüfen:
jnpr@R1> show ddos-protection statistics | match flow Flow detection: Yes Flow report rate: 100 Currently tracked flows: 34 Total detected flows: 1564
In diesem Fall wurden 1564 Ströme durch den Mechanismus zur Erkennung von Strömen erkannt, von denen aber nur 34 Ströme als verdächtig verfolgt werden. Auch hier werden nur verdächtige Ströme verfolgt, und nur auf schuldige Ströme wird reagiert. Ein verdächtiger Datenfluss wird als verdächtig eingestuft und in die Verfolgungstabelle aufgenommen, wenn er die zulässige Bandbreite überschreitet. Ein verdächtiger Datenfluss wird als "culprit flow" eingestuft, wenn seine Rate für einen bestimmten Zeitraum (standardmäßig 3 Sekunden) konstant über der zulässigen Bandbreite liegt. Ein Datenfluss, der seine konfigurierte oder standardmäßige Datenflussrate während des Erkennungszeitraums nicht überschreitet, gilt als falsch positiv. Sobald die Rate eines verdächtigen (wenn der Überwachungsmodus eingeschaltet ist) oder schuldigen Datenflusses während des Erholungszeitraums (standardmäßig 60 Sekunden) unter seiner Bandbreite liegt, erklärt der SCFD den Datenfluss für normal und entfernt ihn aus der Tabelle der schuldigen Datenflüsse.
Du kannst die Parameter für die Flusserkennung pro Protokoll oder pro Pakettyp konfigurieren und die Flusserkennung auf Wunsch auch deaktivieren. Ein einfaches Beispiel zeigt, wie du die Flusserkennungsparameter für das ICMP-Protokoll änderst:
[edit system ddos-protection protocols icmp]
jnpr@R1# show
aggregate {
flow-level-bandwidth {
subscriber 10;
logical-interface 100;
}
flow-level-detection {
subscriber automatic;
logical-interface on;
physical-interface off;
}
flow-level-control {
subscriber police;
logical-interface police;
}
}
Der folgende CLI-Befehl fasst die Konfiguration zusammen:
jnpr@R1> show ddos-protection protocols icmp flow-detection
Packet types: 1, Modified: 1
* = User configured value
Protocol Group: ICMP
Packet type: aggregate
Flow detection configuration:
Detection mode: Automatic Detect time: 3 seconds
Log flows: Yes Recover time: 60 seconds
Timeout flows: No Timeout time: 300 seconds
Flow aggregation level configuration:
Aggregation level Detection mode Control mode Flow rate
Subscriber Automatic* Police* 10 pps*
Logical interface On* Police* 100 pps*
Physical interface Off* Drop 20000 pps
Die Ausgabe bestätigt, dass die Flusserkennungszeit und die Wiederherstellungszeit auf den Standardwerten von 3 bzw. 60 Sekunden belassen wurden (beachte, dass die Anzeige benutzerkonfigurierte Werte mit einem "*" kennzeichnet und für diese Parameter kein solcher Hinweis vorhanden ist). Der automatische Erkennungsmodus wird auch für ICMP-Flows bestätigt, die verfolgt werden, wenn sie 10 pps erreichen. Obwohl automatisch der Standardmodus ist, trägt dieses Feld immer noch das "*"-Flag, weil es in diesem Fall explizit durch die Konfiguration gesetzt wurde. In ähnlicher Weise wird der aggregierte Flow der IFL (logische Einheit) immer überwacht, was dazu führt, dass die IFL als permanent vom System verfolgt markiert und daher immer zur Tabelle der verfolgten Flows hinzugefügt wird.
Du kannst auch sehen, dass die Überwachung der physischen Schnittstelle deaktiviert ist (Aus) und dass sowohl auf der Teilnehmer- als auch auf der logischen Schnittstellenebene der Kontrollmodus von der Standardeinstellung (Drop) auf Polizei geändert wurde.
Wenn eine DDoS-Verletzung ausgelöst wird, kann jede IP-Adresse, die an die Schnittstelle angeschlossen ist, maximal 10 pps erzeugen. Gleichzeitig wird jede logische Einheit auf nicht mehr als 100 ICMP-Pakete pro Sekunde begrenzt. Eine höhere IFL-Rate ist sinnvoll, weil in Junos einer IFL mehrere Adressen zugewiesen werden können. In diesem Fall ist jede Adresse auf 10 pps begrenzt, während die Summe aller Adressen auf der IFL auf 100 pps begrenzt ist.)
Da die Flow Detection auf IFD-Ebene deaktiviert ist, werden die DDoS-Policer-Werte für ICMP verwendet, um den Verkehr über die Schnittstelle selbst zu begrenzen. Je nachdem, wie viele IFLs über die Schnittstelle bereitgestellt werden, kann dies eine gute Entscheidung sein oder auch nicht. Auf der einen Seite entfällt der Speicher-Overhead, der mit der Flow Detection auf einer der drei Ebenen verbunden ist, aber auf der anderen Seite kann es bei einer großen Anzahl von IFLs, von denen jede 100 pps senden kann, dazu kommen, dass die kombinierte Schnittstellenlast die faire Nutzung der gesamten ICMP-Bandbreite auf der FPC- oder RE-Ebene beeinträchtigt. Die Aktivierung der Flow Detection auf IFD-Ebene (wie in den Standardeinstellungen) würde diese Bedenken ausräumen, da die IFD dann auf einen Wert unterhalb der aggregierten DDoS-Policer-Rate begrenzt werden könnte, die von den Nutzern auf anderen IFDs, die an dieselbe PFE oder MPC angeschlossen sind, geteilt wird.
Fallstudie: Erkennung verdächtiger Ströme
Um die Leistungsfähigkeit von SCFD zu verdeutlichen, wollen wir einen einfachen Fall anhand des ARP-Protokolls untersuchen. In Rechenzentren (DCs) sind einige Router mit Switches verbunden und fungieren als Aggregationspunkte für eine große Anzahl von VLANs und die zugehörigen Abonnenten, wo sie als Gateways zwischen dem Layer-2-Switching im DC und dem Layer-3-Routing über WANs fungieren. Ein häufiger Fehlermodus in geswitchten Layer-2-Netzwerken wird als broadcast storm bezeichnet. Solche Stürme entstehen aus der grundlegenden Tatsache, dass Switches unbekannte Ziel-MACs fluten müssen, und Broadcast kann nie bekannt sein und wird daher immer geflutet. Wenn das Netzwerk die Bildung von Schleifen zulässt, kann sich ein einzelner gefluteter Broadcast-Frame schnell vervielfachen, bis er das Netzwerk aufgrund der Erschöpfung der Bandbreite buchstäblich zum Absturz bringt. Auf Layer 2 gibt es keinen Time to Live (TTL)-Mechanismus, was Schleifen in einem Layer-2-Netzwerk besonders schmerzhaft macht.
Die meisten Switches und L2-fokussierten Router unterstützen irgendeine Form von Storm Control-Mechanismus, der Broadcast-Stürme verhindern soll. Diese Mechanismen basieren jedoch auf der Deaktivierung eines L2-Ports, nachdem über einen bestimmten Zeitraum ein übermäßiger Broadcast festgestellt wurde. Nach einer Zeitüberschreitung wird der Port normalerweise wieder aktiviert, und wenn die Schleife bestehen bleibt, wird der Vorgang wiederholt. Das Problem ist, dass während der Zeit, in der der Sturm erkannt wird, und jedes Mal, wenn er wieder auftritt, der übermäßige Datenverkehr immer noch negative Auswirkungen auf die Layer-3-Bereiche deines Netzwerks haben kann.
Daher solltest du, selbst wenn du die Sturmkontrolle einsetzt, auch die Routing-Knoten gegen diese Überflutung schützen. Wir zeigen dir anhand einer Fallstudie zum ARP-Schutz, wie du das erreichen kannst.
Zunächst sei daran erinnert, dass ARP ein Layer-2-Protokoll ohne Netzwerkschicht ist. Als solches wird es nicht von einem lo0.0-Firewall-Filter verarbeitet, da ein solcher Filter auf einer Layer-3-Protokollfamilie basiert (d. h. inet oder inet6). Um den Bedarf an ARP-Kontrolle zu decken, bietet Junos drei Arten von ARP-Policern:
Standard-ARP-Policer pro PFE
Konfigurierbarer ARP-Policer pro IFL (logische Schnittstelle)
DDoS ARP-Polizist (hierarchisch)/SCFD
Der erste Policer-Typ ist nicht konfigurierbar und wird standardmäßig in der Eingangsrichtung auf Ethernet-Schnittstellen angewendet. Dieser Policer wird pro PFE angewendet und heißt __default_arp_ policer. Um zu überprüfen, ob auf eine bestimmte Schnittstelle dieser Policer angewendet wird, kannst du den folgenden CLI-Befehl verwenden:
jnpr@R1> show interfaces policers xe-11/0/0
Interface Admin Link Proto Input Policer Output Policer
xe-11/0/0 up up
xe-11/0/0.0 up up
inet
multiservice __default_arp_policer__
Es sollte beachtet werden, dass die Bandbreite des Standard-Policers absichtlich niedrig eingestellt ist. Wie du siehst, beträgt die Bandbreite nur 150 KBit/s in Kombination mit einer bescheidenen Burst-Größe von nur 15000 Bytes. Diese Werte spiegeln den Verwendungszweck des Standard-ARP-Policers auf gerouteten Schnittstellen wider, die in der Regel keine großen Mengen an ARP-Verkehr verarbeiten. Obwohl die Werte für Core-Schnittstellen völlig ausreichend sind, kann es durchaus vorkommen, dass die Standardwerte zu aggressiv sind, wenn man mit einem großen Layer-2-Netzwerk verbunden ist, was zu einer Leistungsverschlechterung führt, da legitimer ARP-Verkehr verworfen wird und die entsprechenden Anwendungen gezwungen sind, eine Zeitüberschreitung zu verursachen und die Übertragung zu wiederholen.
Ein kurzes Beispiel für den zweiten Ansatz, bei dem ein ARP-Policer pro IFL (logische Schnittstelle) mit benutzerdefinierten Durchsatzwerten konfiguriert wird, wird der Vollständigkeit halber ebenfalls gezeigt (interessierte Leser sollten sich den "Überblick über Firewall-Filter und -Policer" in Kapitel 3 ansehen, um mehr über diesen Ansatz zu erfahren):
[edit interfaces ae1]
jnpr@R1# show
vlan-tagging;
aggregated-ether-options {
link-speed 10g;
lacp {
active;
periodic fast;
}
}
unit 0 {
vlan-id 100;
family inet {
policer {
arp MY-POLICER-ARP;
}
}
}
jnpr@R1# show policer MY-POLICER-ARP
if-exceeding {
bandwidth-limit 10m;
burst-size-limit 64k;
}
then discard;
Der IFL-basierte ARP-Policer bietet ARP-Policing auf einer Pro-VLAN-Basis. Dieser Ansatz löst zwar den Bedarf an benutzerkonfigurierbaren Policing-Raten und das Problem, dass übermäßiger Datenverkehr in einem VLAN andere beeinträchtigen kann, aber er trägt nicht dazu bei, die Bandbreite zwischen den Benutzern, die sich dasselbe VLAN teilen, zu erhalten! Was ist, wenn du auch die Nutzer/innen innerhalb desselben VLANs vor übermäßigem Datenverkehr schützen musst? Die Antwort auf einen ARP-basierten DDoS-Angriff innerhalb eines VLANs ist SCFD!
Um besser zu veranschaulichen, wie DDoS-Policing und SCFD zusammenarbeiten, um sowohl das Problem des Intra-VLAN- als auch des Inter-VLAN-Schutzes zu lösen, behält die Konfiguration den spezifischen ARP-Policer pro IFL bei. Der Wert dieses Policers wird relativ hoch gehalten, um den Inter-VLAN-Schutz durch die SCFD-Funktion zu veranschaulichen.
Manchen mag es seltsam vorkommen, dass der Standard-Per-IFL-ARP-Policer beibehalten wird, wenn das Ziel der DDoS-Schutz ist. Der Grund dafür ist, dass der ARP-Policer pro PFE in der Eingangsverarbeitungskette vor dem DDoS-Feature steht. Indem wir ihn auf einen hohen Wert setzen, behalten wir die Standardverarbeitung bei und stellen gleichzeitig sicher, dass er die SCFD-Demonstration nicht beeinträchtigt.
Das Beispiel für eine SCFD-Topologie ist in Abbildung 4-4 dargestellt.
Abbildung 4-4. Topologie des SCFD-Studienfalls
Stell dir einen Router, R1, vor, der über die Schnittstelle ae1 mit einem Switch verbunden ist. Die Schnittstelle hat wiederum drei logische Einheiten, die als Layer-3-Endpunkte für jedes der drei VLANs (100, 200, 300) definiert sind. Innerhalb jedes VLANs gibt es fünf Endnutzer (Abonnenten).
Die Fallstudienanforderungen für ARP-Policing und -Schutz sind wie folgt:
Jeder Teilnehmer kann innerhalb eines VLANs maximal 50 pps ARP-Verkehr erzeugen.
Jedes VLAN ist auf 200 pps ARP-Verkehr beschränkt.
Ein physischer Port, der mehrere VLANs truncht, ist auf 1000 pps ARP begrenzt.
Überschüssiger ARP-Verkehr kann sich nicht auf Benutzer im selben oder in anderen VLANs auswirken.
SCFD und die anschließende Ratenbegrenzung sollten auf alle Flows wirken, unabhängig von ihrem DDoS-Verletzungsstatus. Mit anderen Worten: Der SCFD-Modus sollte auf EIN gesetzt werden.
Die Konfiguration für die Schnittstelle ae1 wird angezeigt:
[edit interfaces ae1]
jnpr@R1# show
vlan-tagging;
aggregated-ether-options {
link-speed 10g;
lacp {
active;
periodic fast;
}
}
unit 100 {
vlan-id 100;
family inet {
policer {
arp MY-POLICER-ARP;
}
address 172.16.39.9/28;
}
}
unit 200 {
vlan-id 200;
family inet {
policer {
arp MY-POLICER-ARP;
}
address 172.16.40.9/28;
}
}
unit 300 {
vlan-id 300;
family inet {
policer {
arp MY-POLICER-ARP;
}
address 172.16.41.9/28;
}
}
Der Verkehr wird für alle Kunden in allen VLANs erzeugt. In diesem Fall sendet jeder Kunde 200 pps ARP-Anfrageverkehr. Das Ergebnis ist, dass jedes VLAN 1.000 pps erhält, was wiederum zu einer Gesamt-ARP-Anfrage-Last von 3.000 pps auf der physischen Schnittstelle führt.
Beachte, dass zu diesem Zeitpunkt der Datenflussschutz deaktiviert ist und die Standardeinstellungen des DDoS-ARP-Policers gelten. Die standardmäßig hohen pps-Raten für den DDoS-Policer bedeuten, dass keine ARP-Ratenbegrenzung in Kraft ist; du erwartest also, dass du die vollen 3.000 pps an ARP-Anfrageverkehr erhältst. Wir bestätigen diese Theorie, indem wir uns zunächst die DDoS-ARP-Statistiken ansehen:
jnpr@R1> show ddos-protection protocols arp statistics terse Packet types: 1, Received traffic: 1, Currently violated: 0 Protocol Packet Received Dropped Rate Violation State group type (packets) (packets) (pps) counts arp aggregate 69705 0 3000 0 ok
Die Anzeige bestätigt die erwartete ARP-Last von 3.000 pps. Als Nächstes siehst du dir die Statistiken der physischen Schnittstelle an:
jnpr@R1> show interfaces ae1 | match rate Input rate : 1440752 bps (2999 pps) Output rate : 1250256 bps (3005 pps)
Wie erwartet ist die volle ARP-Last von 3.000 pps auf der Schnittstelle vorhanden. Ebenso wichtig ist, dass der Router auf alle ARP-Anfragen antwortet, wie die übereinstimmenden Eingangs- und Ausgangs-Paketraten zeigen. Wenn man bedenkt, dass jede ARP-Antwort interne Bandbreite und CPU-Leistung verbraucht, wird klar, dass eine Broadcast-Schleife mit ARP-Anfragen zu einem Ressourcenmangel führen kann, der andere Protokolle, die ebenfalls auf dem Router laufen, beeinträchtigen könnte.
Wie bereits gezeigt, können logische Schnittstellen-Policer verwendet werden, um die ARP-Belastung pro VLAN und damit pro Schnittstelle zu begrenzen, aber dieser Ansatz schützt nicht den fairen Anteil eines Nutzers am erlaubten ARP-Verkehr innerhalb seines VLANs, was in dieser Fallstudie eine Voraussetzung ist. Um exzessiven ARP-Verkehr zu verhindern und gleichzeitig den fairen Anteil eines Nutzers am ARP-Verkehr innerhalb eines einzelnen VLANs zu schützen, ist es am besten, die ARP-Flow-Detection zu aktivieren. Beachte, dass die Flow Detection die Nutzer innerhalb eines gemeinsamen VLANs schützt, während die DDoS-Funktion die ARP-Gesamtlast auf PFE-, MPC- und RE-Basis begrenzt. In diesem Beispiel werden die standardmäßigen hierarchischen ARP-DDoS-Policer beibehalten, wobei der Schwerpunkt auf dem Schutz der VLANs durch die Flow Detection liegt. Die geänderte DDoS-Stanza ist abgebildet:
edit system ddos-protection]
jnpr@R1# show
global {
flow-detection;
}
protocols {
arp {
aggregate {
flow-detection-mode on;
flow-level-bandwidth {
subscriber 50;
logical-interface 200;
physical-interface 1000;
}
flow-level-detection {
subscriber on;
logical-interface on;
physical-interface on;
}
flow-level-control {
subscriber police;
logical-interface police;
physical-interface police;
}
no-flow-logging;
}
}
}
Das bedeutet, dass ARP-Ströme immer in der Tabelle der verdächtigen Ströme aufgelistet werden und die Flusskontrolle (hier "Polizei") in jedem Fall funktioniert (auch wenn der DDoS-ARP-Policer keinen Verstoß auslöst). Erinnere dich daran, dass der ARP-DDoS-Policer eine Standardbandbreite von 20 kpps hat:
jnpr@R1# show ddos-protection protocols arp parameters
Packet types: 1, Modified: 0
* = User configured value
Protocol Group: ARP
Packet type: aggregate (Aggregate for all arp traffic)
Aggregate policer configuration:
Bandwidth: 20000 pps
Burst: 20000 packets
Recover time: 300 seconds
Enabled: Yes
Routing Engine information:
Bandwidth: 20000 pps, Burst: 20000 packets, enabled
FPC slot 0 information:
Bandwidth: 100% (20000 pps), Burst: 100% (20000 packets), enabled
Die Einstellungen für die Flussbandbreite werden auf jeder Ebene entsprechend der Fallstudie festgelegt und die individuelle ARP-Flow-Erkennung und -Überwachung wird auf allen Ebenen aktiviert. Nachdem die Änderung bestätigt wurde, wird die CLI verwendet, um zu bestätigen, dass die ARP-Flow-Erkennung aktiv ist:
jnpr@R1> show ddos-protection protocols arp flow-detection
Packet types: 1, Modified: 1
* = User configured value
Protocol Group: ARP
Packet type: aggregate
Flow detection configuration:
Detection mode: On* Detect time: 3 seconds
Log flows: No* Recover time: 60 seconds
Timeout flows: No Timeout time: 300 seconds
Flow aggregation level configuration:
Aggregation level Detection mode Control mode Flow rate
Subscriber On* Police* 50 pps*
Logical interface On* Police* 200 pps*
Physical interface On* Police* 1000 pps*
Werfen wir nun einen Blick auf die SCFD-Funktion in Aktion. Wir beginnen mit einem Blick auf die ae1-Statistiken, um einen Überblick über das Geschehen zu bekommen:
jnpr@R1> show interfaces ae100 | match rate Input rate : 1441408 bps (3000 pps) Output rate : 250208 bps (601 pps)
Wahnsinn! Die Ausgangsrate der Schnittstelle beträgt jetzt 600 pps. Das bestätigt, dass der Schwellenwert für die physische Schnittstelle (1 kpps) nicht mehr überschritten wird und die Ausgangsrate korrekt die zulässige Summe von 200 pps für jedes der 3 VLANs darstellt. Dies bestätigt indirekt, dass die empfangene ARP-Last von SCFD gemäß den angegebenen Anforderungen begrenzt wurde.
Als Nächstes schauen wir uns das SCFD genauer an, um zu sehen, ob irgendwelche "culprit flows" gemeldet werden. Erinnere dich daran, dass wir in diesem Beispiel davon ausgehen, dass jeder Kunde 200 pps Datenverkehr erzeugt, was weit über den erlaubten 50 pps liegt:
jnpr@R1> show ddos-protection protocols culprit-flows Currently tracked flows: 19, Total detected flows: 20 Protocol Packet Arriving Source Address group type Interface MAC or IP arp aggregate ae100.200 -- -- -- ifl:0013000000000000 2015-10-22 17:22:08 CEST pps:250 pkts:8257 arp aggregate ae100.300 -- -- -- ifl:0013000000000001 2015-10-22 17:22:08 CEST pps:250 pkts:8257 arp aggregate ae100.300 00:00:CC:CC:CC:C4 sub:0013000000000002 2015-10-22 17:22:08 CEST pps:199 pkts:5539 arp aggregate ae100.100 -- -- -- ifl:0013000000000003 2015-10-22 17:22:08 CEST pps:250 pkts:8257 arp aggregate ae100.200 00:00:BB:BB:BB:B5 sub:0013000000000005 2015-10-22 17:22:08 CEST pps:199 pkts:5539 arp aggregate ae100.200 00:00:BB:BB:BB:B4 sub:0013000000000006 2015-10-22 17:22:08 CEST pps:199 pkts:5539 arp aggregate ae100.300 00:00:CC:CC:CC:C5 sub:0013000000000007 2015-10-22 17:22:08 CEST pps:199 pkts:5539 arp aggregate ae100.100 00:00:AA:AA:AA:A6 sub:0013000000000008 2015-10-22 17:22:08 CEST pps:199 pkts:5539 arp aggregate ae100.100 00:00:AA:AA:AA:A5 sub:0013000000000009 2015-10-22 17:22:08 CEST pps:200 pkts:5540 arp aggregate ae100.100 00:00:AA:AA:AA:A0 sub:001300000000000a 2015-10-22 17:22:08 CEST pps:199 pkts:5539 arp aggregate ae100.300 00:00:CC:CC:CC:C7 sub:001300000000000b 2015-10-22 17:22:08 CEST pps:200 pkts:5540 arp aggregate ae100.200 00:00:BB:BB:BB:B6 sub:001300000000000c 2015-10-22 17:22:08 CEST pps:200 pkts:5540 arp aggregate ae100.200 00:00:BB:BB:BB:B0 sub:001300000000000d 2015-10-22 17:22:08 CEST pps:200 pkts:5540 arp aggregate ae100.100 00:00:AA:AA:AA:A7 sub:001300000000000e 2015-10-22 17:22:08 CEST pps:200 pkts:5539 arp aggregate ae100.200 00:00:BB:BB:BB:B7 sub:001300000000000f 2015-10-22 17:22:08 CEST pps:200 The display pkts:5540 arp aggregate ae100.300 00:00:CC:CC:CC:C6 sub:0013000000000010 2015-10-22 17:22:08 CEST pps:200 pkts:5540 arp aggregate ae100.300 00:00:CC:CC:CC:C0 sub:0013000000000011 2015-10-22 17:22:08 CEST pps:200 pkts:5540 arp aggregate ae100.100 00:00:AA:AA:AA:A4 sub:0013000000000012 2015-10-22 17:22:08 CEST pps:200 pkts:5540 arp aggregate ae61 -- -- -- ifd:0013000000000013 2015-10-22 17:23:11 CEST pps:597 pkts:1197
Die Ausgabe bestätigt, dass verdächtige Flows erkannt werden. Die für jede Ebene (Subscriber, IFL/VLAN und IFD) angezeigte Echtzeit-PS-Rate ist die tatsächliche Ankunftsrate vor dem Policing. Beachte, dass der Subscriber-Ebene das Schlüsselwort "sub", der IFL-Ebene das Präfix "ifl" und der Interface-Ebene das Präfix "ifd" vorangestellt ist.
Beachte, wie die Ströme auf Teilnehmerebene verfolgt werden. In diesem Fall erfordert die Layer-2-Natur von ARP, dass die Flussverfolgung anhand der MAC-Quelle erfolgt. Es gibt keine IP-Schicht/Quell-IP-Adresse in einer ARP-Anfrage, daher wird die MAC zur eindeutigen Identifizierung jedes Teilnehmers/Kunden verwendet:
arp aggregate ae100.200 00:00:BB:BB:BB:B5 sub:0013000000000005 2015-10-22 17:22:08 CEST pps:199 pkts:5539 arp aggregate ae100.200 -- -- -- ifl:0013000000000000 2015-10-22 17:22:08 CEST pps:250 pkts:8257 arp aggregate ae61 -- -- -- ifd:0013000000000013 2015-10-22 17:23:11 CEST pps:597 pkts:1197
Der aufmerksame Leser fragt sich vielleicht, warum die pps-Raten auf IFL- und IFD-Ebene nicht mit der Gesamtlast übereinstimmen, die von den zugehörigen Abonnenten erzeugt wird; denk daran, dass jede IFL fünf Nutzer hat, die jeweils 200 pps senden. Angesichts dieser Zahlen könnte man eine IFL-Last von 1.000 pps statt der angegebenen 250 pps erwarten. Das Gleiche gilt für die IFD-Ebene, bei der man eher 3.000 pps als die 597 angezeigten erwarten könnte; schließlich unterstützt sie drei IFLs mit jeweils theoretisch 1.000 pps, oder?
Die Antwort auf dieses Rätsel ist, dass die Teilnehmerströme bereits ratenbegrenzt wurden, bevor sie in der IFL-Last berücksichtigt wurden. Das Ergebnis ist, dass jedes IFL/VLAN eine Gesamtlast von nur 250 pps erfährt. In ähnlicher Weise werden auch die IFLs ratenbegrenzt, bevor sie in die IFD-Last einbezogen werden. Die drei ratenbegrenzten IFLs mit jeweils 200 pps werden am IFD zu einer Rate von 600 pps zusammengefasst.
Das Ergebnis ist, dass in diesem Beispiel kein ARP-Policing auf der IFD-Ebene erforderlich ist. Da die DDoS-Policer auf ihren Standardwerten belassen werden, ist keine zusätzliche Überwachung zu erwarten. Das bedeutet, dass die Line Card/Routing Engine 600 ARP-Anfragen pro Sekunde verarbeiten darf. Die maximale ARP-Antwortrate für diese Schnittstelle ist daher auf 600 pps begrenzt, wobei jeder IFL eine garantierte ARP-Kapazität von 200 pps erhält und jedem IFL-Nutzer wiederum 50 pps zugestanden werden.
Zusammenfassung der Erkennung verdächtiger Kontrollflüsse
Die SCFD-Funktion ist standardmäßig deaktiviert. Sie arbeitet mit der klassischen DDoS-Funktion zusammen, um einzelne Datenströme dynamisch zu identifizieren und bei Bedarf zu überwachen, damit ein fairer Zugang zu den gesamten Datenströmen gewährleistet ist. In Kombination mit DDoS-Policern, die Schutz auf Systemebene bieten, ergibt sich so eine stabile Plattform und ein fairer Zugang zu begrenzter Bandbreite, selbst bei DDoS-Angriffen.
DDoS-Angriffe entschärfen
Sobald du die Art eines DDoS-Verstoßes analysiert hast, weißt du, um welche Art von Datenverkehr es sich handelt und auf welchen PFEs und Linecards/FPCs der Datenverkehr ankommt. Mit diesen Informationen kannst du manuell zustandslose Filter auf den vorgelagerten Knotenpunkten einrichten, bis du die Grenze deines Netzwerks erreichst, wo du den angreifenden Peer deaktivieren oder einen Filter anwenden kannst, um den angreifenden Datenverkehr so nah wie möglich an der Quelle zu verwerfen oder zu begrenzen. Sobald das Feuer sozusagen gelöscht ist, kannst du dich mit den Administratoren des Peering-Netzwerks in Verbindung setzen und sie bitten, dich bei der Verfolgung des Angriffs bis zu den tatsächlichen Quellen/Ingress-Punkten zu unterstützen, wo dann Abhilfemaßnahmen ergriffen werden können.
BGP Flow-Specification als Retter in der Not
Die Junos-Funktion BGP Flow-Specification (Flow-Spec oder Flow-Route) nutzt MP-BGP, um schnell Filter- und Überwachungsfunktionen zwischen BGP-sprechenden Knoten sowohl innerhalb als auch zwischen autonomen Systemen einzusetzen. Diese Funktion eignet sich gut, um die Auswirkungen eines DDoS-Angriffs abzuschwächen, sowohl lokal als auch potenziell über das globale Internet, sobald die Art der Bedrohung bekannt ist. Eine Flow-Spezifikation ist eine n-Tupel-Filterdefinition, die aus verschiedenen IPv4-Übereinstimmungskriterien und einer Reihe damit verbundener Aktionen besteht und über MP-BGP verteilt wird, so dass entfernte BGP-Sprecher dynamisch zustandslose Filterung und Überwachung installieren oder den Verkehr zur weiteren Bearbeitung an ein anderes Gerät weiterleiten können. Ein bestimmtes IP-Paket entspricht dem definierten Fluss, wenn es alle festgelegten Kriterien erfüllt. Flow-Routen sind eine Zusammenfassung von Matching-Bedingungen und daraus resultierenden Aktionen für den passenden Datenverkehr, die Filterung, Ratenbegrenzung, Sampling und die Änderung von Community-Attributen umfassen. Mit flow-spec kannst du einen Filter einmal definieren und ihn dann in lokalen und entfernten Netzwerken verteilen - genau das richtige Mittel, um einen DDoS-Angriff im Keim zu ersticken.
Anders als bei den BGP-basierten Remote Triggered Black Holes (RTBH) kannst du mit flow-spec eine Vielzahl von Matching-Kriterien verwenden, anstatt richtlinienbasierte Matches, die auf der IP-Adresse des Ziels basieren. Und auch hier kannst du mit flow-spec die Abgleichs- und Filterbedingungen zentral definieren und dann BGP nutzen, um diese Informationen an interne und externe BGP-Sprecher weiterzuleiten.
Die BGP Flow-Specification Network-Layer Reachability Information (NLRI) und die damit verbundenen Vorgänge sind in RFC 5575, "Dissemination of Flow Specification Rules", definiert. In den Veröffentlichungen von Juniper wird immer noch auf den früheren Internet-Entwurf "draft-ietf-idr-flow-spec-09" verwiesen, der sich auf die gleiche Funktionalität bezieht. In der Praxis werden die Filterkriterien einer Flow-Spec in der NLRI der Flow-Spec kodiert, während die zugehörigen Aktionen in erweiterten Communities kodiert werden. Für IPv4 und Layer 3 VPN IPv4 werden unterschiedliche NLRI angegeben, um den zusätzlichen Route-Distinguisher und die Route-Targets zu berücksichtigen. Wieder einmal beweist das altehrwürdige Schlachtross BGP seine Anpassungsfähigkeit. Ein neuer Dienst wird durch undurchsichtige Erweiterungen von BGP ermöglicht, die es Betreibern erlauben, ein gut verstandenes und bewährtes Protokoll zu nutzen, um neue Dienste oder verbesserte Sicherheit und Netzwerkstabilität anzubieten, wie es bei Flow-Spec der Fall ist. Flow-Spec-Informationen gelten als undurchsichtig für BGP, weil es nicht die Aufgabe von BGP ist, die Flow-Spec-Nutzdaten zu analysieren oder zu interpretieren. Stattdessen werden die Flow-Spec-Informationen durch das Flow-Spec-Validierungsmodul geleitet und, wenn sie akzeptiert werden, an den Firewall-Daemon (dfwd) zur Installation in den PFEs als zustandsloser Filter und/oder Policer weitergegeben.
In Version 14.2 unterstützt Junos flow-spec NLRI sowohl für IPv4-Unicast- als auch für Layer 3 VPN IPv4-Unicast-Datenverkehr der Hauptinstanz. Um flow-spec NLRI für die Hauptinstanz MP-BGP zu aktivieren, fügst du die Anweisung flow für die Adressfamilie inet in die Hierarchie [edit protocols bgp group group-name family inet] ein. Um Flow-Specification NLRI für die Adressfamilie inet-vpn zu aktivieren, fügst du die Anweisung flow auf der Hierarchieebene [edit protocols bgp group group-name family inet-vpn] ein. Beachte, dass die flow Familie nur für MP-BGP-Sitzungen der Hauptinstanz gültig ist; du kannst diese Familie nicht für eine BGP-Sitzung innerhalb einer VRF verwenden.
Lokale und empfangene Flow-Routen, die die Validierung bestehen, werden in die Flow-Routing-Tabelle instance-name.inetflow.0 aufgenommen, wo übereinstimmende Pakete dann den entsprechenden Flow-Spec-Aktionen unterzogen werden. Flow-Routen, die die Validierung nicht bestehen, werden in der entsprechenden Tabelle mit der Präferenz Null versteckt. Jede Änderung des Validierungsstatus führt zu einer sofortigen Aktualisierung der Flow-Route. Empfangene Layer 3 VPN-Flow-Routen werden in der Routing-Tabelle bgp.invpnflow.0 gespeichert und enthalten noch ihre Route Distinguished (RD). Sekundärrouten werden gemäß den vrf-import Richtlinien in eine oder mehrere spezifische VRF-Tabellen importiert. Im Gegensatz zur Flow-NLRI inet werden die Flow-Routen von inet-vpn nicht automatisch mit den Unicast-Routing-Informationen einer bestimmten VRF abgeglichen; dies liegt daran, dass ein solcher Vorgang innerhalb eines bestimmten VRF-Kontextes durchgeführt werden muss und dieselbe Flow-NLRI je nach Route-Target in mehrere VRFs importiert werden kann.
Lokale flow-spec Routen konfigurieren
Du konfigurierst eine lokale Flow-Specification für die Injektion in BGP auf der Hierarchie routing-options, entweder in der Hauptinstanz oder unter einem unterstützten Instanztyp (VRF oder VR). Während eine Form von IDS verwendet werden kann, um Warnungen über die Notwendigkeit einer Flow-Spec zu geben, werden Betreiber in vielen Fällen SNMP-Alarme, RE-Schutzfilter oder die neue DDoS-Funktion verwenden, um über abnormale Verkehrsmengen zu informieren. Anhand der von diesen Funktionen gelieferten Details kann der Betreiber eine oder mehrere Fluss-Spezifikationen erstellen, die auf den Angriffsvektor abgestimmt sind und je nach Bedarf entweder ganz herausgefiltert oder die Raten begrenzt werden.
Die Syntax der Ablaufspezifikation ähnelt der eines zustandslosen Filters. Der Hauptunterschied ist das Fehlen einer Termfunktion, da Ablaufspezifikationen aus einem einzigen Term bestehen. Ansonsten besteht die Ablaufspezifikation genau wie ein Filter aus einer Reihe von Übereinstimmungskriterien und zugehörigen Aktionen. Wie zuvor wird eine Übereinstimmung nur dann erklärt, wenn alle Kriterien in der Anweisung from wahr sind, andernfalls wird zur nächsten Ablaufspezifikation übergegangen. Die Optionen für die Flussdefinition werden angezeigt:
{master}[edit routing-options flow]
jnpr@R1-RE0# set ?
Possible completions:
+ apply-groups Groups from which to inherit configuration data
+ apply-groups-except Don't inherit configuration data from these groups
> route Flow route
term-order Term evaluation order for flow routes
> validation Flow route validation options
{master}[edit routing-options flow]
jnpr@R1-RE0# set
Das Schlüsselwort term-order wird verwendet, um zwischen der Version 6 und späteren Versionen der Flow-Spec-Spezifikation zu wählen, wie im nächsten Abschnitt beschrieben. Ein wichtiges Konzept ist die Validierung von Flussrouten, ein Prozess, der verhindern soll, dass eine Funktion, die Störungen minimieren soll, unerwünschte Störungen hervorruft. Auch sie wird in einem der folgenden Abschnitte näher erläutert. Derzeit wird das Schlüsselwort validation auf der Hierarchie [edit routing-options flow] verwendet, um das Tracing für den Validierungsprozess zu konfigurieren.
Zu den unterstützten Suchkriterien gehören:
{master}[edit routing-options flow]
jnpr@R1-RE0# set route test ?
Possible completions:
<[Enter]> Execute this command
+ apply-groups Groups from which to inherit configuration data
+ apply-groups-except Don't inherit configuration data from these groups
> match Flow definition
> then Actions to take for this flow
| Pipe through a command
{master}[edit routing-options flow]
jnpr@R1-RE0# set route test match ?
Possible completions:
+ apply-groups Groups from which to inherit configuration data
+ apply-groups-except Don't inherit configuration data from these groups
destination Destination prefix for this traffic flow
+ destination-port Destination TCP/UDP port
+ dscp Differentiated Services (DiffServ) code point (DSCP)
+ fragment
+ icmp-code ICMP message code
+ icmp-type ICMP message type
+ packet-length Packet length
+ port Source or destination TCP/UDP port
+ protocol IP protocol value
source Source prefix for this traffic flow
+ source-port Source TCP/UDP port
+ tcp-flags TCP flags
{master}[edit routing-options flow]
jnpr@R1-RE0# set route test match
Und die unterstützten Aktionen:
{master}[edit routing-options flow]
jnpr@R1-RE0# set route test then ?
Possible completions:
accept Allow traffic through
+ apply-groups Groups from which to inherit configuration data
+ apply-groups-except Don't inherit configuration data from these groups
community Name of BGP community
discard Discard all traffic for this flow
next-term Continue the filter evaluation after matching this flow
rate-limit Rate to limit traffic for this flow (9600..1000000000000)
routing-instance Redirect to instance identified via Route Target community
sample Sample traffic that matches this flow
{master}[edit routing-options flow]
jnpr@R1-RE0# set route test then
Es wird ein Beispiel für eine Fluss-Spezifikation gezeigt:
{master}[edit routing-options flow]
jnpr@R1-RE0# show
route flow_http_bad_source {
match {
source 10.0.69.0/25;
protocol tcp;
port http;
}
then {
rate-limit 10k;
sample;
}
}
Nach dem Kapitel über den Filter sollte der Zweck der flow_http_bad_source Flow-Spezifikation klar sein. Sobald sie an eine Gegenstelle gesendet wird, kannst du davon ausgehen, dass der entsprechende HTTP-Verkehr ratenbegrenzt und gesampelt wird (gemäß den Sampling-Parametern, die hier nicht gezeigt werden).
Version des Flow-Spec-Algorithmus
Bei der BGP-Fluss-Spezifikation ist es möglich, dass mehr als eine Regel auf einen bestimmten Verkehrsfluss passt. In diesen Fällen muss die Reihenfolge, in der die Regeln angepasst und auf einen bestimmten Verkehrsfluss angewandt werden, so festgelegt werden, dass die endgültige Reihenfolge nicht von der Ankunftsreihenfolge der Regeln in der Flussspezifikation abhängt und im Netzwerk konstant ist, um einen vorhersehbaren Betrieb zwischen allen Knotenpunkten zu gewährleisten.
Junos verwendet standardmäßig den Term-Ordering-Algorithmus, der in Version 6 des BGP-Flow-Spezifikationsentwurfs definiert ist. Ab Junos OS Release v10.0 kannst du den Router so konfigurieren, dass er dem Term-Ordering-Algorithmus entspricht, der erstmals in Version 7 der BGP-Flussspezifikation definiert und durch RFC 5575, "Dissemination of Flow Specification Routes", unterstützt wird. Die derzeit bewährte Methode ist die Konfiguration des Term-Ordering-Algorithmus der Version 7. Außerdem wird empfohlen, auf allen Routing-Instanzen, die auf einem bestimmten Router konfiguriert sind, dieselbe Term-Ordering-Version zu verwenden.
Im Standard-Algorithmus für die Termreihenfolge (Entwurf Version 6) wird ein Term mit weniger spezifischen Übereinstimmungsbedingungen immer vor einem Term mit spezifischeren Übereinstimmungsbedingungen ausgewertet. Das führt dazu, dass der Begriff mit den spezifischeren Bedingungen nie ausgewertet wird. In Entwurfsversion 7 wurde der Algorithmus überarbeitet, so dass die spezifischeren Bedingungen vor den weniger spezifischen Bedingungen ausgewertet werden. Aus Gründen der Abwärtskompatibilität wird das Standardverhalten in Junos nicht geändert, auch wenn der neue Algorithmus als besser angesehen wird. Um den neueren Algorithmus zu verwenden, füge die Anweisung term-order standard in die Konfiguration ein.
Validierung von Flussrouten
Junos installiert Flow-Routen nur dann in die Flow-Routing-Tabelle, wenn sie mit dem in draft-ietf-idr-flow-spec-09.txt, "Dissemination of Flow Specification Rules" beschriebenen Validierungsverfahren validiert wurden. Das Validierungsverfahren stellt sicher, dass die zugehörige Flow-Spec-NLRI gültig ist und verhindert darüber hinaus unbeabsichtigte DDoS-Filteraktionen, indem es gewährleistet, dass eine Flow-Specification für eine bestimmte Route nur dann akzeptiert wird, wenn sie von demselben Sprecher stammt, der der aktuell ausgewählte aktive Next-Hop für diese Route ist. Eine Flow-Specification-NLRI wird nur dann als durchführbar angesehen, wenn:
Der Absender der Fluss-Spezifikation stimmt mit dem Absender der besten Unicast-Route für das in der Fluss-Spezifikation enthaltene Ziel-Präfix überein.
Es gibt keine spezifischeren Unicast-Routen von einem anderen benachbarten AS als die beste Unicast-Route, die im ersten Schritt ermittelt wurde, verglichen mit dem Präfix des Flussziels.
Das zugrundeliegende Konzept ist, dass das Nachbar-AS, das die beste Unicast-Route für ein Ziel bekannt gibt, die Flow-Spec-Informationen für dieses Ziel-Präfix bekannt geben darf. Anders ausgedrückt: Dynamische Filterinformationen werden anhand von Unicast-Routing-Informationen validiert, so dass ein Flow-Spec-Filter nur dann akzeptiert wird, wenn er von dem Unicast-Nachbarn, der das Ziel-Präfix bekannt gibt, beworben wurde und es keine Unicast-Routen gibt, die spezifischer sind als das Flow-Ziel und eine andere Next-Hop-AS-Nummer haben. Indem sichergestellt wird, dass ein anderer benachbarter AS keine spezifischere Unicast-Route angekündigt hat, bevor eine empfangene Fluss-Spezifikation validiert wird, wird sichergestellt, dass eine Filterregel nur den Verkehr betrifft, der zur Quelle der Fluss-Spezifikation fließt, und verhindert unbeabsichtigte Filteraktionen, die sonst auftreten könnten. Das Konzept besteht darin, dass das System, wenn ein bestimmter Routing-Peer der Unicast Next-Hop für ein Präfix ist, eine spezifischere Filterregel, die zu diesem Aggregat gehört, sicher von demselben Peer akzeptieren kann.
Du kannst den Validierungsprozess umgehen und deine eigene Importrichtlinie verwenden, um zu entscheiden, welche Flow-Spec-Routen du mit dem Schalter no-validate akzeptierst:
[protocols bgp group <name>]
family inet {
flow {
no-validate <policy-name>;
}
}
Die Umgehung der normalen Validierungsschritte kann nützlich sein, wenn es im AS ein System gibt, das für die Bekanntgabe von Filterregeln zuständig ist, die lokal abgeleitet werden, vielleicht über ein Intrusion Detection System (IDS). In diesem Fall kann der Nutzer eine Richtlinie konfigurieren, die z. B. BGP-Routen mit einem leeren as-path akzeptiert, um die normalen Validierungsschritte zu umgehen.
Außerdem kannst du den Import und Export von Flow-Routen durch Import- bzw. Export-Richtlinienanweisungen steuern, die auf herkömmliche Weise auf die entsprechenden BGP-Peering-Sitzungen angewendet werden. Diese Richtlinien können auf verschiedene Kriterien abgestimmt werden, wie z. B. route-filter Anweisungen, um die Zieladresse einer Flow-Route abzugleichen, und die Möglichkeit, eine from rib inetflow.0 Anweisung zu verwenden, um sicherzustellen, dass nur Flow-spezifische Routen abgeglichen werden können. Du kannst eine Richtlinie für den Export von Weiterleitungstabellen anwenden, um den Export von Flow-Routen an den PFE zu beschränken. Standardmäßig werden alle lokal definierten Flow-Routen bekannt gegeben und alle empfangenen Flow-Routen zur Überprüfung akzeptiert.
Du kannst den Validierungsstatus einer Flow-Route mit einem show route detail Befehl bestätigen. Hier wird eine Layer 3 VPN-Flow-Route gezeigt:
. . .
vrf-a.inetflow.0: 2 destinations, 2 routes (2 active, 0 holddown, 0 hidden)
10.0.1/24,*,proto=6,port=80/88 (1 entry, 1 announced)
*BGP Preference: 170/-101
Next-hop reference count: 2
State: <Active Ext>
Peer AS: 65002
Age: 3:13:32
Task: BGP_65002.192.168.224.221+1401
Announcement bits (1): 1-BGP.0.0.0.0+179
AS path: 65002 I
Communities: traffic-rate:0:0
Validation state: Accept, Originator: 192.168.224.221
Via: 10.0.0.0/16, Active
Localpref: 100
Router ID: 201.0.0.6
In der Ausgabe bestätigt das Feld Validation state, dass die Flow-Route validiert (und nicht abgelehnt) wurde und dass der Absender der Flow-Route die IP-Adresse 192.168.224.221 ist. Das Feld via: zeigt an, welche Unicast-Route die Flow-Spec-Route validiert hat, in diesem Fall war es 10.0/16. Mit dem Befehl show route flow validation kannst du dir Informationen über Unicast-Routen anzeigen lassen, die zur Validierung von Flow-Spec-Routen verwendet werden.
Du kannst den Flow-Spec-Validierungsprozess nachverfolgen, indem du das validation Flag in der [edit routing-options flow] Hierarchie hinzufügst:
{master}[edit routing-options flow]
jnpr@R1-RE0# show
validation {
traceoptions {
file flow_trace size 10m;
flag all detail;
}
}
Begrenzung der Nutzung von Flow-Spec-Ressourcen
Flow-Spec-Routen sind im Wesentlichen Firewall-Filter, und wie bei jedem Filter gibt es einen gewissen Ressourcenverbrauch und Verarbeitungsaufwand, der je nach Komplexität des Filters variieren kann. Im Gegensatz zu einem konventionellen Filter, der eine lokale Definition erfordert, kann die Gegenstelle, sobald Flow-Spec in einer BGP-Sitzung aktiviert ist, die Instanziierung des lokalen Filters veranlassen, und zwar möglicherweise bis zur Erschöpfung der lokalen Ressourcen, was zu unangenehmen Folgen führen kann. Um eine übermäßige Ressourcennutzung im Falle von Fehlkonfigurationen oder böswilligen Absichten zu verhindern, können Sie mit Junos die Anzahl der Flow-Routen begrenzen, die in Kraft sein können.
Verwende die maximum-prefixes Anweisung, um die Anzahl der Flow-Routen zu begrenzen, die in der inetflow.0 RIB installiert werden können:
set routing-options rib inetflow.0 maximum-prefixes <number> set routing-options rib inetflow.0 maximum-prefixes threshold <percent>
Um die Anzahl der von einem bestimmten BGP-Peer zugelassenen Flow-Spec-Routen zu begrenzen, verwendest du die Anweisung prefix-limit für die Flow-Familie:
set protocols bgp group x neighbor <address> family inet flow prefix-limit maximum <number> set protocols bgp group x neighbor <address> family inet flow prefix-limit teardown <%>
Was gibt es Neues in der Welt von Flow-Spec?
Es wird erwartet, dass die Junos-Versionen 15.x und 16.x zusätzliche Flow-Spec-Funktionen hinzufügen werden. Zum Beispiel:
Hinzufügen der Möglichkeit, den Datenverkehr an einen IP Next-Hop umzuleiten. Dies kann für Flow-Spec-basiertes Routing oder für die Umleitung eines bestimmten Datenverkehrs zu einem IP-Tunnel nützlich sein. Diese neue "Aktion" wird derzeit in draft-ietf-idr-flowspec-redirect-ip.txt, "BGP Flow-Spec Redirect to IP Action", beschrieben. Derzeit unterstützt Junos die Redirect-Funktion nur in einem VRF-Kontext.
Hinzufügen von IPv6-Unterstützung, wie in draft-ietf-idr-flow-spec-v6.txt, "Dissemination of Flow Specifcation Tools for IPv6" beschrieben.
Bereitstellung von Schnittstellenindex- und Richtungsinformationen innerhalb der Ablaufspezifikation. So können Regeln zur Flowspecifizierung nur auf eine bestimmte Untergruppe von Schnittstellen und nur in eine bestimmte Richtung angewendet werden. Diese Erweiterung ist derzeit in draft-litkowski-idr-flowspec-interfaceset.txt, "Applying BGP Flowspec Rules on a Specific Interface Set" definiert.
Die BGP Flow-Specification-Funktion von Junos ist ein leistungsfähiges Werkzeug gegen DDoS-Angriffe, das gut mit den Schutzfiltern der Routing Engine und der DDoS-Präventionsfunktion von Trio zusammenarbeitet. Selbst eine gehärtete Steuerebene kann mit übermäßigem Datenverkehr überflutet werden, der an einen gültigen Dienst wie SSH gerichtet ist. Sobald du auf den anomalen Datenverkehr aufmerksam gemacht wirst, kannst du mithilfe von Flow-Spec schnell Filter für alle BGP-Sprecher einsetzen, um den Angriffsverkehr so nah wie möglich an der Quelle zu eliminieren. Dabei kannst du die Verbindung zum Router aufrechterhalten, um solche Mitigationsmaßnahmen durchzuführen, da du vorausschauend bewährte Methoden zum Schutz von REs zusammen mit dem integrierten DDoS-Schutz über Trio FPCs eingesetzt hast.
BGP Flow-Specification Fallstudie
Dieser Abschnitt enthält ein Anwendungsbeispiel für die BGP Flow-Spec-Funktion. Die Netzwerktopologie ist in Abbildung 4-5 dargestellt.
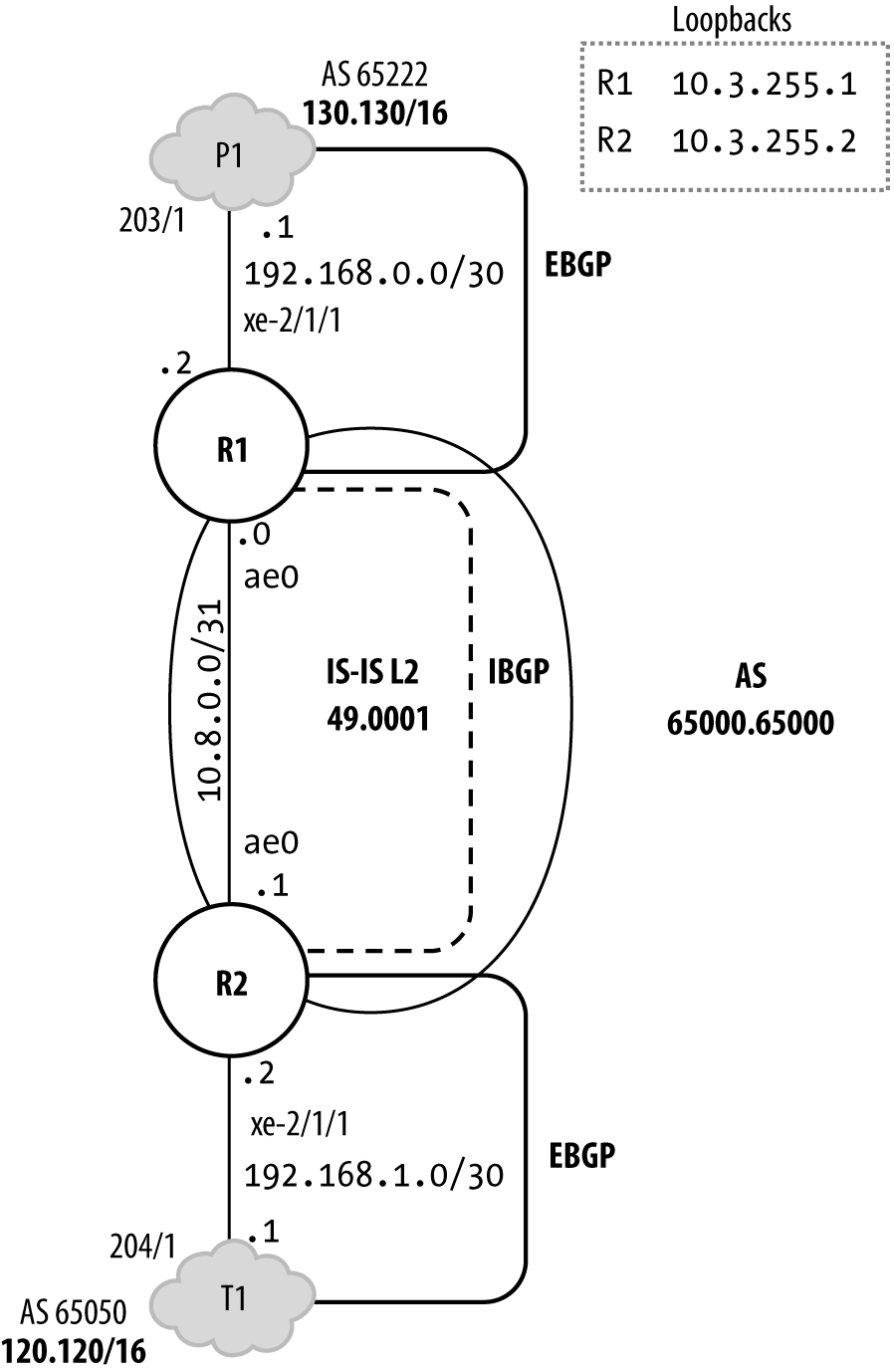
Abbildung 4-5. BGP-Flow-Spec-Topologie
Auf den Routern R1 und R2 ist der zuvor besprochene IPv4-RE-Schutzfilter nach bewährten Methoden auf ihren Loopback-Schnittstellen aktiviert. Die DDoS-Schutzfunktion ist aktiviert. Die einzige Änderung gegenüber der Standardeinstellung ist die skalierte FPC-Bandbreite für das ICMP-Aggregat. Die Peers arbeiten untereinander mit Loopback-basiertem MP-IBGP und mit den externen Peers P1 und T1 über EBGP. Das P1-Netzwerk ist die Quelle der Routen aus dem 130.130/16-Block, während T1 die Quelle der 120.120/16-Routen ist. IS-IS Level 2 wird als IGP verwendet. Er läuft passiv auf den externen Verbindungen, um sicherzustellen, dass die EBGP Next-Hops aufgelöst werden können. Er wird auch verwendet, um die Loopback-Adressen zu verteilen, die zur Unterstützung des IBGP-Peerings verwendet werden. Die protocols stanza auf R1 ist hier abgebildet:
{master}[edit]
jnpr@R1-RE0# show protocols
bgp {
log-updown;
group t1_v4 {
type external;
export bgp_export;
peer-as 65050;
neighbor 192.168.1.1;
}
group int_v4 {
type internal;
local-address 10.3.255.2;
family inet {
unicast;
flow;
}
bfd-liveness-detection {
minimum-interval 150;
multiplier 3;
}
neighbor 10.3.255.1;
}
}
isis {
reference-bandwidth 100g;
level 1 disable;
interface xe-2/1/1.0 {
passive;
}
interface ae0.1 {
point-to-point;
bfd-liveness-detection {
minimum-interval 150;
multiplier 3;
}
}
interface lo0.0 {
passive;
}
}
lacp {
traceoptions {
file lacp_trace size 10m;
flag process;
flag startup;
}
}
lldp {
interface all;
}
layer2-control {
nonstop-bridging;
}
vstp {
interface xe-0/0/6;
interface ae0;
interface ae1;
interface ae2;
vlan 100 {
bridge-priority 4k;
interface xe-0/0/6;
interface ae0;
interface ae1;
interface ae2;
}
vlan 200 {
bridge-priority 8k;
interface ae0;
interface ae1;
interface ae2;
}
}
Beachte, dass flow NLRI für die inet Familie für die interne Peering-Sitzung aktiviert wurde. Beachte auch, dass BGP flow-spec auch für EBGP-Peers unterstützt wird, was bedeutet, dass es über AS-Grenzen hinweg funktionieren kann, wenn beide Netzwerke bilateral vereinbart haben, diese Funktion zu unterstützen. Die DDoS-Stanza wird hier angezeigt:
{master}[edit]
jnpr@R2-RE0# show system ddos-protection
protocols {
icmp {
aggregate {
fpc 2 {
bandwidth-scale 30;
burst-scale 30;
}
}
}
}
Die DDoS-Einstellungen ändern den FPC-Slot 2 so, dass er 30% des Systemaggregats für ICMP zulässt. Aus dem vorangegangenen DDoS-Abschnitt wissen wir, dass alle FPCs standardmäßig 100 % des Systemaggregats nutzen. Das bedeutet, dass jeder FPC mit der vollen Maximallast senden kann, ohne dass es zu Ausfällen kommt, aber auch, dass ein DDoS-Angriff auf einen FPC zu Konflikten an den Aggregationspunkten für andere FPCs mit normaler Last führen kann. Hier wird erwartet, dass FPC 2 etwa 6.000 pps zulässt, bevor er DDoS-Aktionen bei 30 % des Systemaggregats durchsetzt, was in dieser Version standardmäßig 20.000 pps beträgt.
Als Nächstes überprüfst du die Anwendung der Filterkette auf die Schnittstelle lo0. Es wird zwar nur R1 gezeigt, aber auch R2 verfügt über die bewährten Methoden für den IPv4-RE-Schutzfilter; die Funktionsweise des RE-Schutzfilters wurde bereits in der Fallstudie zum RE-Schutz beschrieben:
{master}[edit]
jnpr@R1-RE0# show interfaces lo0
unit 0 {
family inet {
filter {
input-list [ discard-frags accept-sh-bfd accept-bgp accept-ldp
accept-rsvp accept-telnet
accept-common-services accept-vrrp discard-all ];
}
address 10.3.255.1/32;
}
family iso {
address 49.0001.0100.0325.5001.00;
}
family inet6 {
filter {
input-list [ discard-extension-headers accept-MLD-hop-by-hop_v6
deny-icmp6-undefined accept-sh-bfd-v6 accept-bgp-v6 accept-telnet-v6
accept-ospf3 accept-radius-v6
accept-common-services-v6 discard-all-v6 ];
}
address 2001:db8:1::ff:1/128;
}
}
Der IBGP- und EBGP-Sitzungsstatus wird bestätigt. Obwohl nicht angezeigt, hat R2 auch seine beiden Nachbarn im etablierten Status:
{master}[edit]
jnpr@R1-RE0# run show bgp summary
Groups: 2 Peers: 2 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0 200 200 0 0 0 0
inetflow.0 0 0 0 0 0 0
inet6.0 0 0 0 0 0 0
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|
10.3.255.2 65000.65000 12 12 0 0 3:14 Establ
inet.0: 100/100/100/0
inetflow.0: 0/0/0/0
192.168.0.1 65222 7 16 0 0 3:18 Establ
inet.0: 100/100/100/
Wie bei der erfolgreichen Aushandlung der Flow-NLRI während BGP wird der Austausch von Fähigkeiten durch die Anzeige des IBGP-Nachbarn bestätigt, um zu bestätigen, dass die inet-flow NLRI in Kraft ist:
{master}[edit]
jnpr@R1-RE0# run show bgp neighbor 10.3.255.2 | match nlri
NLRI for restart configured on peer: inet-unicast inet-flow
NLRI advertised by peer: inet-unicast inet-flow
NLRI for this session: inet-unicast inet-flow
NLRI that restart is negotiated for: inet-unicast inet-flow
NLRI of received end-of-rib markers: inet-unicast inet-flow
NLRI of all end-of-rib markers sent: inet-unicast inet-flow
Zum Schluss noch eine kurze Bestätigung des Routings zu den Loopback- und EBGP-Präfixen aus der Perspektive von R2:
{master}[edit]
jnpr@R2-RE0# run show route 10.3.255.1
inet.0: 219 destinations, 219 routes (219 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.3.255.1/32 *[IS-IS/18] 00:11:21, metric 5
> to 10.8.0.0 via ae0.1
{master}[edit]
jnpr@R2-RE0# run show route 130.130.1.0/24
inet.0: 219 destinations, 219 routes (219 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
130.130.1.0/24 *[BGP/170] 00:01:22, localpref 100, from 10.3.255.1
AS path: 65222 ?
> to 10.8.0.0 via ae0.1
Die Ausgabe bestätigt, dass IS-IS die IBGP-Sitzung unterstützt, indem es eine Route zur Loopback-Adresse des entfernten Routers bereitstellt, und dass R2 die Präfixe 130.130/16 von R1 lernt, der sie wiederum über sein EBGP-Peering zu P1 gelernt hat.
Lasst die Attacke beginnen!
Nachdem die Weichen gestellt sind, beginnt alles mit einem DDoS-Log-Alarm bei R2:
{master}[edit]
jnpr@R2-RE0# run show log messages | match ddos
Mar 18 17:43:47 R2-RE0 jddosd[75147]: DDOS_PROTOCOL_VIOLATION_SET: Protocol
ICMP:aggregate is violated at fpc 2 for 4 times, started at 2012-03-18 17:43:47
PDT, last seen at 2012-03-18 17:43:47 PDT
In der Zwischenzeit werden bei R1 keine Verstöße gemeldet, wodurch klar wird, dass R2 das einzige Opfer des aktuellen DDoS-Bombardements ist:
{master}[edit]
jnpr@R1-RE0# run show ddos-protection protocols violations
Number of packet types that are being violated: 0
Der Syslog-Eintrag warnt vor übermäßigem ICMP-Verkehr bei FPC 2. Details über den aktuellen Verstoß erhältst du mit dem Befehl show ddos protocols:
jnpr@R2-RE0# run show ddos-protection protocols violations
Number of packet types that are being violated: 1
Protocol Packet Bandwidth Arrival Peak Policer bandwidth
group type (pps) rate(pps) rate(pps) violation detected at
icmp aggregate 20000 13587 13610 2012-03-18 17:43:47 PDT
Detected on: FPC-2
{master}[edit]
jnpr@R2-RE0# run show ddos-protection protocols icmp
Protocol Group: ICMP
Packet type: aggregate (Aggregate for all ICMP traffic)
Aggregate policer configuration:
Bandwidth: 20000 pps
Burst: 20000 packets
Priority: high
Recover time: 300 seconds
Enabled: Yes
System-wide information:
Aggregate bandwidth is being violated!
No. of FPCs currently receiving excess traffic: 1
No. of FPCs that have received excess traffic: 1
Violation first detected at: 2012-03-18 17:43:47 PDT
Violation last seen at: 2012-03-18 17:58:26 PDT
Duration of violation: 00:14:39 Number of violations: 4
Received: 22079830 Arrival rate: 13607 pps
Dropped: 566100 Max arrival rate: 13610 pps
Routing Engine information:
Aggregate policer is never violated
Received: 10260083 Arrival rate: 6001 pps
Dropped: 0 Max arrival rate: 6683 pps
Dropped by individual policers: 0
FPC slot 2 information:
Bandwidth: 30% (6000 pps), Burst: 30% (6000 packets), enabled
Aggregate policer is currently being violated!
Violation first detected at: 2012-03-18 17:43:47 PDT
Violation last seen at: 2012-03-18 17:58:26 PDT
Duration of violation: 00:14:39 Number of violations: 4
Received: 22079830 Arrival rate: 13607 pps
Dropped: 566100 Max arrival rate: 13610 pps
Dropped by individual policers: 0
Dropped by aggregate policer: 566100
Die Ausgabe bestätigt die ICMP-Aggregat-Verwerfungen auf der FPC-Ebene mit einer Spitzenlast von 13.600 pps, was weit über den derzeit zulässigen 6.000 pps liegt. Außerdem zeigt R2 zu deiner Zufriedenheit an, dass die erste Verteidigungslinie gegen DDoS ihre Arbeit macht. Abgesehen davon, dass du weißt, dass an FPC 2 für diesen Router eine Menge ICMP ankommt, gibt es noch nicht viele Anhaltspunkte, um den Angriff zu seiner Quelle zurückzuverfolgen, sei es durch Flow-Spec oder auf andere Weise. Du weißt, dass dieser ICMP-Verkehr für R2 bestimmt sein muss, entweder als Unicast oder als Broadcast, weil nur hostgebundener Verkehr der DDoS-Überwachung unterliegt.
Die Zähler des Loopback-Filters und die Policer-Statistiken werden bei R2 angezeigt:
{master}[edit]
jnpr@R2-RE0# run show firewall filter lo0.0-i
Filter: lo0.0-i
Counters:
Name Bytes Packets
accept-bfd-lo0.0-i 25948 499
accept-bgp-lo0.0-i 1744 29
accept-dns-lo0.0-i 0 0
accept-icmp-lo0.0-i 42252794 918539
accept-ldp-discover-lo0.0-i 0 0
accept-ldp-igmp-lo0.0-i 0 0
accept-ldp-unicast-lo0.0-i 0 0
accept-ntp-lo0.0-i 0 0
accept-ntp-server-lo0.0-i 0 0
accept-rsvp-lo0.0-i 0 0
accept-ssh-lo0.0-i 0 0
accept-telnet-lo0.0-i 7474 180
accept-tldp-discover-lo0.0-i 0 0
accept-traceroute-icmp-lo0.0-i 0 0
accept-traceroute-tcp-lo0.0-i 0 0
accept-traceroute-udp-lo0.0-i 0 0
accept-vrrp-lo0.0-i 3120 78
accept-web-lo0.0-i 0 0
discard-all-TTL_1-unknown-lo0.0-i 0 0
discard-icmp-lo0.0-i 0 0
discard-ip-options-lo0.0-i 32 1
discard-netbios-lo0.0-i 0 0
discard-tcp-lo0.0-i 0 0
discard-udp-lo0.0-i 0 0
discard-unknown-lo0.0-i 0 0
no-icmp-fragments-lo0.0-i 0 0
Policers:
Name Bytes Packets
management-1m-accept-dns-lo0.0-i 0 0
management-1m-accept-ntp-lo0.0-i 0 0
management-1m-accept-ntp-server-lo0.0-i 0 0
management-1m-accept-telnet-lo0.0-i 0 0
management-1m-accept-traceroute-icmp-lo0.0-i 0 0
management-1m-accept-traceroute-tcp-lo0.0-i 0 0
management-1m-accept-traceroute-udp-lo0.0-i 0 0
management-5m-accept-icmp-lo0.0-i 21870200808 475439148
management-5m-accept-ssh-lo0.0-i 0 0
management-5m-accept-web-lo0.0-i 0 0
Die Zähler für den management-5m-accept-icmp-lo0.0-I präfix-spezifischen Zähler und die Policer machen deutlich, dass eine große Menge an ICMP-Verkehr auf den Loopback-Filter trifft und durch den zugehörigen 5-M-Policer geregelt wird. Da der Loopback-Policer vor der DDoS-Verarbeitung ausgeführt wird, also genau dann, wenn der hostgebundene Verkehr an der Trio PFE ankommt, ist klar, dass die 5 Mbit/s ICMP, die der Policer zulässt, mehr als die 6.000 pps ausmachen; andernfalls gäbe es keine aktuelle DDoS-Warnung oder DDoS-Verwerfungsaktionen in der FPC.
Das Wissen, dass ein durch einen Loopback-Filter hervorgerufener Policer vor der DDoS-Verarbeitung ausgeführt wird, sollte bei der Dimensionierung deiner DDoS- und Loopback-Policer helfen, damit sie gut zusammenarbeiten. Wenn man bedenkt, dass ein durch einen Filter ausgelöster Policer die Bandbreite in Bits pro Sekunde misst, während die DDoS-Policer auf der Basis von Paketen pro Sekunde funktionieren, sollte klar sein, dass es bestenfalls schwierig ist, sie aufeinander abzustimmen, und dass es eigentlich gar nicht nötig ist.
Da ein Loopback-Policer ein Aggregat auf Systemebene darstellt, ist es sinnvoll, den Policer höher einzustellen als den eines einzelnen FPCs. Wenn das gesamte erwartete Aggregat auf einem einzelnen FPC ankommt, werden die niedrigeren DDoS-Einstellungen im FPC wirksam, um sicherzustellen, dass kein FPC die gesamte Bandbreite des Systems verbrauchen kann. Der Nachteil einer solchen Einstellung ist, dass du jetzt mit FPC-Drops rechnen musst, auch wenn nur ein FPC aktiv ist und die Gesamtlast des Systems unterschritten wird.
Angriffsdetails bestimmen und Flussroute festlegen
Um die Details zu erhalten, die für die Beschreibung des Angriffsflusses benötigt werden, kommen oft Stichproben oder filterbasierte Protokollierung ins Spiel. Der aktuelle RE-Schutzfilter verfügt sogar über eine Funktion zur Protokollierung:
{master}[edit]
jnpr@R2-RE0# show firewall family inet filter accept-icmp
apply-flags omit;
term no-icmp-fragments {
from {
is-fragment;
protocol icmp;
}
then {
count no-icmp-fragments;
log;
discard;
}
}
term accept-icmp {
from {
protocol icmp;
ttl-except 1;
icmp-type [ echo-reply echo-request time-exceeded unreachable source-
quench router-advertisement parameter-problem ];
}
then {
policer management-5m;
count accept-icmp;
log;
accept;
}
}
Das Vorhandensein der Aktionsmodifikatoren log und syslog im accept-icmp Filter bedeutet, dass du nur den Firewall-Cache oder das Syslog anzeigen musst, um die Details zu erhalten, die du brauchst, um den Angriffsfluss zu charakterisieren:
jnpr@R2-RE0# run show firewall log Log : Time Filter Action Interface Protocol Src Addr Dest Addr 18:47:47 pfe A ae0.1 ICMP 130.130.33.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.60.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.48.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.31.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.57.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.51.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.50.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.3.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.88.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.94.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.22.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.13.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.74.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.77.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.46.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.94.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.38.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.36.1 10.3.255.2 18:47:47 pfe A ae0.1 ICMP 130.130.47.1 10.3.255.2 . . .
Aus dem Firewall-Protokoll geht hervor, dass es sich um einen ICMP-Angriff handelt (wie bereits bekannt). Außerdem kannst du jetzt bestätigen, dass die Zieladresse mit dem Loopback von R2 übereinstimmt und dass die Quelle aus einem Bereich von 130.130.x/24 Subnetzen innerhalb des 130.130/16-Blocks von P1 zu stammen scheint. Mit diesen Informationen kannst du dich an den Administrator des P1-Netzwerks wenden und ihn bitten, sich um das Problem zu kümmern. Das kann aber warten, bis du den Datenverkehr am Ingress deines Netzwerks gefiltert hast, anstatt ihn erst dann zu untersuchen , wenn er die Möglichkeit hatte, Ressourcen in deinem Netzwerk und insbesondere bei R2 zu verbrauchen.
Auf R2 ist eine Flussroute definiert:
{master}[edit]
jnpr@R2-RE0# show routing-options flow
route block_icmp_p1 {
match {
destination 10.3.255.2/32;
source 130.130.0.0/16;
protocol icmp;
}
then discard;
}
Der Fluss passt auf den gesamten ICMP-Verkehr, der von einer beliebigen Quelle im Bereich 130.130/16 an die Loopback-Adresse von R2 gesendet wird, mit einer Verwerfungsaktion. Sobald die Flow-Spec lokal definiert ist, wird sie in Kraft gesetzt (es gibt keine Validierung für eine lokale Flow-Spec, so wie es auch keine Notwendigkeit gibt, einen lokal definierten Firewall-Filter zu validieren), was durch die aktuellen DDoS-Statistiken bestätigt wird, die nun eine Ankunftsrate von 0 pps melden:
{master}[edit]
jnpr@R2-RE0# run show ddos-protection protocols icmp
Protocol Group: ICMP
Packet type: aggregate (Aggregate for all ICMP traffic)
Aggregate policer configuration:
Bandwidth: 20000 pps
Burst: 20000 packets
Priority: high
Recover time: 300 seconds
Enabled: Yes
System-wide information:
Aggregate bandwidth is no longer being violated
No. of FPCs that have received excess traffic: 1
Last violation started at: 2012-03-18 18:47:28 PDT
Last violation ended at: 2012-03-18 18:52:59 PDT
Duration of last violation: 00:05:31 Number of violations: 5
Received: 58236794 Arrival rate: 0 pps
Dropped: 2300036 Max arrival rate: 13620 pps
Routing Engine information:
Aggregate policer is never violated
Received: 26237723 Arrival rate: 0 pps
Dropped: 0 Max arrival rate: 6683 pps
Dropped by individual policers: 0
FPC slot 2 information:
Bandwidth: 30% (6000 pps), Burst: 30% (6000 packets), enabled
Aggregate policer is no longer being violated
Last violation started at: 2012-03-18 18:47:28 PDT
Last violation ended at: 2012-03-18 18:52:59 PDT
Duration of last violation: 00:05:31 Number of violations: 5
Received: 58236794 Arrival rate: 0 pps
Dropped: 2300036 Max arrival rate: 13620 pps
Dropped by individual policers: 0
Dropped by aggregate policer: 2300036
Das Vorhandensein eines Flow-Spec-Filters wird mit einem show firewall Befehl bestätigt:
{master}[edit]
jnpr@R2-RE0# run show firewall | find flow
Filter: __flowspec_default_inet__
Counters:
Name Bytes Packets
10.3.255.2,130.130/16,proto=1 127072020948 2762435238
Das Vorhandensein des Flow-Spec-Filters ist gut, aber die Zähler, die nicht auf Null stehen, bestätigen, dass er immer noch eine Menge Datenverkehr an 10.3.255.2 von 130.130/16 Quellen für das Protokoll 1 (ICMP) anpasst, wie es seiner Definition entspricht. Das ist seltsam, denn theoretisch müsste R1 diesen Datenverkehr jetzt auch filtern, was aber nicht der Fall ist; dazu später mehr.
Es ist auch möglich, die Tabelle inetflow.0 direkt anzuzeigen, um sowohl die lokalen als auch die entfernten Einträge zu sehen; die Tabelle auf R2 hat derzeit nur eine lokal definierte Flow-Spec:
{master}[edit]
jnpr@R2-RE0# run show route table inetflow.0 detail
inetflow.0: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
10.3.255.2,130.130/16,proto=1/term:1 (1 entry, 1 announced)
*Flow Preference: 5
Next hop type: Fictitious
Address: 0x8df4664
Next-hop reference count: 1
State: <Active>
Local AS: 4259905000
Age: 8:34
Task: RT Flow
Announcement bits (2): 0-Flow 1-BGP_RT_Background
AS path: I
Communities: traffic-rate:0:0
Lass dich von dem fiktiven Next-Hop-Bit nicht beunruhigen. Es ist ein Artefakt der Verwendung von BGP, das eine Neigung zu Next-Hops hat, im Gegensatz zu einer Flow-Spec, die keinen solchen Bedarf hat. Beachte auch, dass die Aktion discard über eine Community übermittelt wird, die eine Aktion zur Ratenbegrenzung des entsprechenden Verkehrs auf 0 bps kodiert.
Da R2 gut aussieht, wollen wir nun herausfinden, warum R1 diesen Datenfluss offenbar noch nicht filtert. Wir beginnen mit der Bestätigung, dass die Route des Datenflusses an R1 bekannt gegeben wird:
{master}[edit]
jnpr@R2-RE0# run show route advertising-protocol bgp 10.3.255.1 table inetflow.0
inetflow.0: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
10.3.255.2,130.130/16,proto=1/term:1
* Self 100 I
Wie erwartet, bestätigt die Ausgabe, dass R2 die Flow-Spezifikation an R1 sendet, so dass du erwartest, einen passenden Eintrag in seiner inetflow.0 Tabelle zu finden, zusammen mit einem dynamisch erstellten Filter, der den Angriffsverkehr am Ingress von P1 verwerfen sollte, wenn er an der Schnittstelle xe-2/1/1 ankommt. Im Nachhinein wurde jedoch festgestellt, dass die lokale Flow-Route von R2 eine hohe Paketanzahl und Verwerfungsrate aufweist, was eindeutig darauf hindeutet, dass R1 diesen Datenverkehr noch durchlässt.
Neugierig geworden, gehst du zu R1 und stellst fest, dass die Flussroute versteckt ist:
{master}[edit]
jnpr@R1-RE0# run show route table inetflow.0 hidden detail
inetflow.0: 1 destinations, 1 routes (0 active, 0 holddown, 1 hidden)
10.3.255.2,130.130/16,proto=1/term:N/A (1 entry, 0 announced)
BGP /-101
Next hop type: Fictitious
Address: 0x8df4664
Next-hop reference count: 1
State: <Hidden Int Ext>
Local AS: 65000.65000 Peer AS: 65000.65000
Age: 16:19
Task: BGP_65000.65000.10.3.255.2+179
AS path: I
Communities: traffic-rate:0:0
Accepted
Validation state: Reject, Originator: 10.3.255.2
Via: 10.3.255.2/32, Active
Localpref: 100
Router ID: 10.3.255.2
Da die Flussroute versteckt ist, wurde in R1 kein Filter erstellt:
{master}[edit]
jnpr@R1-RE0# run show firewall | find flow
Pattern not found
{master}[edit]
Dadurch wird bestätigt, dass die Angriffsdaten die Schnittstelle ae0 von R1 auf dem Weg zu R2 verlassen:
Interface: ae0, Enabled, Link is Up Encapsulation: Ethernet, Speed: 20000mbps Traffic statistics: Current delta Input bytes: 158387545 (6624 bps) [0] Output bytes: 4967292549831 (2519104392 bps) [0] Input packets: 2335568 (12 pps) [0] Output packets: 52813462522 (6845389 pps) [0] Error statistics: Input errors: 0 [0] Input drops: 0 [0] Input framing errors: 0 [0] Carrier transitions: 0 [0] Output errors: 0 [0] Output drops: 0 [0]
Wenn du ein wenig über die versteckte Flow-Spec und ihren abgelehnten Status nachdenkst, findest du die Antwort: Es handelt sich um einen Validierungsfehler. Erinnere dich daran, dass standardmäßig nur die aktuell beste Quelle einer Route eine Flow-Spec generieren darf, die dazu dienen könnte, den entsprechenden Verkehr zu filtern. In diesem Fall ist R2 nicht die BGP-Quelle der Route 130.130/16, die mit der entsprechenden Flow-Spec gefiltert werden soll. Es handelt sich also um eine Flow-Spec eines Drittanbieters, die das Standard-Validierungsverfahren nicht besteht. Du kannst dieses Problem umgehen, indem du die Option no-validate zusammen mit einer Richtlinie auf R1 verwendest, die besagt, dass die Route akzeptiert werden soll. Zuerst die Richtlinie:
{master}[edit]
jnpr@R1-RE0# show policy-options policy-statement accept_icmp_flow_route
term 1 {
from {
route-filter 10.3.255.2/32 exact;
}
then accept;
}
Die Richtlinie wird unter der Flow-Familie mit dem Schlüsselwort no-validate angewendet:
{master}[edit]
jnpr@R1-RE0# show protocols bgp group int
type internal;
local-address 10.3.255.1;
family inet {
unicast;
flow {
no-validate accept_icmp_flow_route;
}
}
bfd-liveness-detection {
minimum-interval 2500;
multiplier 3;
}
neighbor 10.3.255.2
Nachdem die Änderung bestätigt wurde, wird die Flussroute in R1 bestätigt:
{master}[edit]
jnpr@R1-RE0# run show firewall | find flow
Filter: __flowspec_default_inet__
Counters:
Name Bytes Packets
10.3.255.2,130.130/16,proto=1 9066309970 197093695
Der 10.3.255.2,130.130/16,proto=1 Flow-Spec-Filter wurde auf R1 aktiviert, was ein gutes Zeichen dafür ist, dass die Flow-Spec-Route nicht mehr aufgrund eines Validierungsfehlers versteckt ist. Das Endergebnis, für das du so hart gearbeitet hast, ist, dass die Angriffsdaten nun nicht mehr über dein Netzwerk transportiert werden, nur um in R2 verworfen zu werden.
{master}[edit]
jnpr@R1-RE0# run monitor interface ae0
Next='n', Quit='q' or ESC, Freeze='f', Thaw='t', Clear='c', Interface='i'
R1-RE0 Seconds: 0 Time: 19:18:22
Delay: 16/16/16
Interface: ae0, Enabled, Link is Up
Encapsulation: Ethernet, Speed: 20000mbps
Traffic statistics: Current delta
Input bytes: 158643821 (6480 bps) [0]
Output bytes: 5052133735948 (5496 bps) [0]
Input packets: 2339427 (12 pps) [0]
Output packets: 54657835299 (10 pps) [0]
Error statistics:
Input errors: 0 [0]
Input drops: 0 [0]
Input framing errors: 0 [0]
Carrier transitions: 0 [0]
Output errors: 0 [0]
Output drops: 0 [0]
Damit ist die Fallstudie zur DDoS-Abwehr abgeschlossen.
Zusammenfassung
Das Junos-Betriebssystem in Kombination mit Trio-basierten PFEs bietet eine Vielzahl von zustandslosen Firewall-Filtern, eine Vielzahl von Policing-Optionen und einige wirklich coole integrierte DDoS-Funktionen. Alle Funktionen werden in Hardware ausgeführt, sodass du sie in einer skalierten Produktionsumgebung ohne nennenswerte Auswirkungen auf die Weiterleitungsraten aktivieren kannst.
Selbst wenn du deinen MX im Kern einsetzt, wo randbezogene Verkehrsbedingungen und die Durchsetzung von Verträgen in der Regel nicht erforderlich sind, benötigst du zustandslose Filter, Policer und/oder DDoS-Schutz, um die Steuerebene deines Routers vor nicht unterstützten Diensten zu schützen und übermäßigen Datenverkehr - ob gut oder schlecht - abzuwehren, um sicherzustellen, dass der Router sicher bleibt und auch in Zeiten abnormalen Verkehrsaufkommens auf der Steuerebene, sei es absichtlich oder aufgrund von Angriffen, wie vorgesehen funktioniert.
In diesem Kapitel wurden aktuelle Templates bewährter Methoden von starken RE-Schutzfiltern sowohl für die IPv4- als auch für die IPv6-Kontrollebene vorgestellt. Alle Leserinnen und Leser sollten ihre aktuellen RE-Schutzfilter mit den bereitgestellten Beispielen vergleichen, um zu entscheiden, ob Änderungen erforderlich sind, um die bewährten Methoden in diesem komplexen, aber allzu wichtigen Bereich aufrechtzuerhalten.
Die DDoS-Funktion, die nur von Trio Linecards unterstützt wird, arbeitet symbiotisch mit RE-Schutzfiltern zusammen oder kann eigenständig funktionieren und fungiert als robuste primäre, sekundäre und tertiäre Verteidigungslinie, um die Steuerebene vor der Erschöpfung von Ressourcen zu schützen, die von übermäßigem Datenverkehr herrührt, der andernfalls den Service beeinträchtigen oder, schlimmer noch, das Gerät funktionsunfähig und effektiv unerreichbar machen könnte, und zwar genau dann, wenn du den Zugang am dringendsten brauchst!
Die Kombination von DDoS-Policern mit der Erkennung verdächtiger Ströme bietet eine höhere Granularität, die es ermöglicht, schuldige Ströme auf der Ebene des einzelnen Teilnehmers, der IFL oder der IFD zu überwachen, um einen fairen Zugang auf einer bestimmten DDoS-Hierarchieebene zu gewährleisten.
Fragen zur Kapitelüberprüfung
- 1. Welche Aussage zur DDoS-Präventionsfunktion trifft zu?
Die Funktion ist standardmäßig deaktiviert
Die Funktion ist bei aggressiven Policern standardmäßig aktiviert
Die Funktion ist standardmäßig aktiviert, erfordert aber eine Policer-Konfiguration, bevor Warnungen oder Policing erfolgen können.
Die Funktion ist standardmäßig mit hohen Policer-Raten aktiviert, die in den meisten Fällen die Kapazität der Steuerebene des Systems übersteigen, um sicherzustellen, dass die bestehenden Funktionen nicht gestört werden.
- 2. Was trifft auf DDoS-Policer und RE-Schutz-Policer zu, die durch einen Filter hervorgerufen werden?
Der lo0-Policer ist deaktiviert, wenn DDoS in Kraft ist
Die DDoS-Policer laufen zuerst und der lo0-Policer wird zuletzt ausgeführt
Der lo0-Policer wird vor und nach den DDoS-Policern ausgeführt, einmal am Ingress und ein zweites Mal in der RE
Die Kombination von lo0- und DDoS-Policern ist nicht erlaubt und es wird ein Commit-Fehler zurückgegeben
- 3. Ein starker RE-Schutzfilter sollte mit welchem der folgenden Punkte enden?
Ein Akzeptanzsystem, das keine Unterbrechungen verursacht
A reject-all, um Fehlermeldungen an Quellen von nicht erlaubtem Verkehr zu senden
A discard-all, um nicht erlaubten Verkehr stillschweigend zu verwerfen
Eine Log-Aktion zur Fehlersuche bei der Filterung von gültigen/erlaubten Diensten
Sowohl C als auch D
- 4. Ein Filter wird auf die Hauptinstanz lo0.0 angewendet und eine VRF wird ohne eigene lo0.n IFL definiert. Was ist richtig?
Der Verkehr von der Instanz zur lokalen Kontrollebene wird durch den Filter lo0.0 gefiltert
Der Verkehr von der Instanz zu entfernten VRF-Zielen wird durch den Filter lo0.0 gefiltert
Der Verkehr von der Instanz zur lokalen Kontrollebene wird nicht gefiltert
Keine der oben genannten Möglichkeiten. VRFs benötigen ein lo0.n, damit ihre Routing-Protokolle funktionieren
- 5. Welche Junos-Funktion vereinfacht die Filterverwaltung, wenn adressbasierte Match-Kriterien verwendet werden, um nur explizit definierte BGP-Peers zuzulassen?
Dynamische Filterlisten
Präfixlisten und die Anweisung
apply-pathDie Möglichkeit, eine 0/0 als Match-All in einer adressbasierten Match-Bedingung anzugeben
Alle oben genannten Punkte
Ein srTCM-Policer, der auf Einheitsebene für alle Layer-2-Familien mit der Anweisung
layer2-policerangewendet wird
- 6. Was ist der typische Anwendungsfall für einen RE-Filter, der in der Ausgangsrichtung angewendet wird?
So stellen Sie sicher, dass Ihr Router keinen Angriffsverkehr erzeugt
Zur Verfolgung des vom Router gesendeten Datenverkehrs zu Abrechnungszwecken
Eine Fangfrage; Ausgangsfilter werden nicht unterstützt
So ändern Sie die CoS/ToS-Kennzeichnung und die Warteschlangenbildung für lokal erzeugten Verkehr auf der Steuerungsebene
- 7. Welches der folgenden Systeme eignet sich am besten für die Überwachung einzelner Teilnehmerströme?
Erkennung verdächtiger Kontrollflüsse
Hierarchische DDoS-Polizisten
Standard-ARP-Polizist
Logische Schnittstelle (IFL) policer
Kapitel Wiederholung Antworten
- 1. Antwort: D.
- Da DDoS standardmäßig aktiviert ist, sind die Policer auf die gleichen hohen Werte eingestellt wie bei deaktivierter Funktion, was bedeutet, dass der hostgebundene Datenverkehr von einer einzelnen PFE durch die Kapazitäten des Verarbeitungspfads und nicht durch den DDoS-Schutz begrenzt wird. Du musst die Standardwerte an die Bedürfnisse deines Netzwerks anpassen, um einen zusätzlichen DDoS-Schutz zu erhalten, der über die Alarmierung und das Policing an den Aggregationspunkten für Angriffe auf mehrere PFEs hinausgeht.
- 2. Antwort: C.
- Wenn ein lo0-Policer vorhanden ist, wird er zuerst ausgeführt, wenn der Verkehr an der Line Card ankommt, bevor DDoS (auch auf Trio PFE-Ebene) ausgeführt wird. Außerdem wird eine Kopie des RE-Policers im Kernel gespeichert, wo er nach der DDoS-Policer-Stufe auf die Gesamtlast einwirkt, die an die RE geht.
- 3. Antwort: E.
- Ein starker Sicherheitsfilter verwendet immer ein "Discard-all" als letzten Begriff. Die Verwendung von Ablehnungen kann zu Ressourcenverbrauch in Form von Fehlermeldungen führen, was bei einem Angriff eine schlechte Idee ist. Es ist eine gute Idee, die Log-Aktion zum letzten Begriff hinzuzufügen, denn so kannst du schnell feststellen, welcher Datenverkehr auf den endgültigen Verwerfungsbegriff trifft. Solange du nicht angegriffen wirst, sollte nur sehr wenig Verkehr auf den letzten Begriff treffen, sodass die Log-Aktion keine große Belastung darstellt. Der Firewall-Cache wird im Kernel aufbewahrt und nur angezeigt, wenn der Betreiber die Informationen anfordert, im Gegensatz zu einer Syslog-Filteraktion, bei der der PFE-zu-RE-Verkehr laufend nach Datenverkehr durchsucht wird, der dem endgültigen Verwerfungsbegriff entspricht.
- 4. Antwort: A.
- Wenn eine Routing-Instanz einen Filter auf eine lo0-Einheit in dieser Instanz angewendet hat, wird dieser Filter verwendet; andernfalls wird der Verkehr der Steuerebene von der Instanz zur RE durch den lo0.0-Filter der Hauptinstanz gefiltert.
- 5. Antwort: B.
- Verwende
prefix-listsund die Funktionapply-path, um eine dynamische Liste von Präfixen zu erstellen, die an anderer Stelle auf dem Router definiert sind (z. B. solche, die Schnittstellen zugewiesen sind oder in BGP-Peer-Definitionen verwendet werden), und verwende dann die dynamische Liste als Übereinstimmungsbedingung in einem Filter, um die Filterverwaltung angesichts neuer Schnittstellen- oder Peer-Definitionen zu vereinfachen. - 6. Antwort: D.
- Ausgangsfilter werden am häufigsten verwendet, um die Standard-CoS/ToS-Kennzeichnung für lokal erzeugten Verkehr zu ändern.
- 7. Antwort: A.
- Der SCFD-Prozess kann Ströme auf Teilnehmer-, IFL- oder IFD-Ebene anhand von vordefinierten Schwellenwerten kontrollieren. Die anderen Optionen sind zu granular, um auf individueller Nutzer-/Teilnehmerebene zu funktionieren.
Get Juniper MX-Serie, 2. Auflage now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

