The architectural flow for running inference on the NMT (neural translation machine) is a little different than that of training the NMT. The following is the architectural flow for performing inference using the NMT:
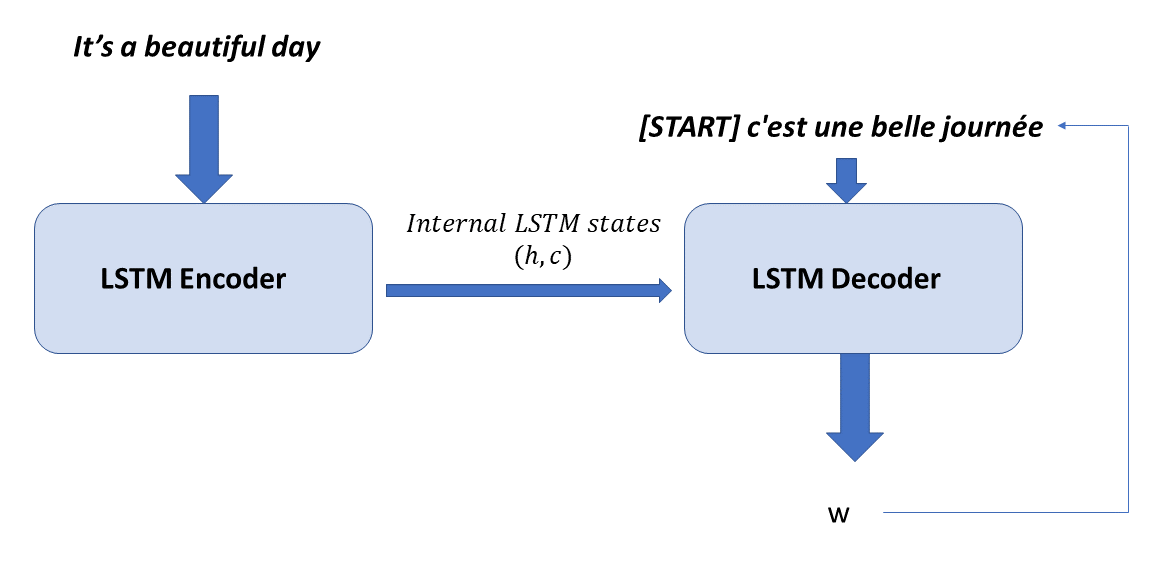
Figure 3.4: Inference from an encoder/decoder-based neural machine translation
During inference, the source language input sequence is fed to the encoder network and the final hidden and cell state produced, [hf, cf], is fed to the decoder hidden and cell states. The decoder is converted into a single time step, and the first input fed to the decoder is the dummy [START] word. So, based ...

