Chapter 1. MLOps: What Is It and Why Do We Need It?
At the root of inefficient systems is an interconnected web of incorrect decisions that compound over time. It is tempting to look for a silver bullet fix to a system that doesn’t perform well, but that strategy rarely, if ever, pays off. Consider the human body; there is no shortage of quick fixes sold to make you healthy, but the solution to health longevity requires a systematic approach.1
Similarly, there is no shortage of advice on “getting rich quick.” Here again, the data conflicts with what we want to hear. In Don’t Trust Your Gut (HarperCollins, 2022), Seth Stephens-Davidowitz shows that 84% of the top 0.1% of earners receive at least some money from owning a business. Further, the average age of a business founder is about 42, and some of the most successful companies are real estate or automobile dealerships. These are hardly get-rich-quick schemes but businesses that require significant skill, expertise, and wisdom through life experience.
Cities are another example of complex systems that don’t have silver bullet fixes. WalletHub created a list of best-run cities in America with San Francisco ranked 149 out of 150 despite having many theoretical advantages over other cities, like beautiful weather, being home to the top tech companies in the world, and a 2022-2023 budget of $14 billion for a population of 842,000 people. The budget is similar to the entire country of Panama, with a population of 4.4 million people. As the case of San Francisco shows, revenue or natural beauty alone isn’t enough to have a well-run city; there needs to be a comprehensive plan: execution and strategy matter. No single solution is going to make or break a city. The WalletHub survey points to extensive criteria for a well-run city, including infrastructure, economy, safety, health, education, and financial stability.
Similarly, with MLOps, searching for a single answer to getting models into production, perhaps by getting better data or using a specific deep learning framework, is tempting. Instead, just like these other domains, it is essential to have an evidence-based, comprehensive strategy.
What Is MLOps?
At the heart of MLOps is the continuous improvement of all business activity. The Japanese automobile industry refers to this concept as kaizen, meaning literally “improvement.” For building production machine learning systems, this manifests in both the noticeable aspects of improving the model’s accuracy as well the entire ecosystem supporting the model.
A great example of one of the nonobvious components of the machine learning system is the business requirements. If the company needs an accurate model to predict how much inventory to store in the warehouse, but the data science team creates a computer vision system to keep track of the inventory already in the warehouse, the wrong problem is solved. No matter how accurate the inventory tracking computer vision system is, the business asked for a different requirement, and the system cannot meet the goals of the organization as a result.
So what is MLOps? A compound of Machine Learning (ML) and Operations (Ops), MLOps is the processes and practices for designing, building, enabling, and supporting the efficient deployment of ML models in production, to continuously improve business activity. Similar to DevOps, MLOps is based on automation, agility, and collaboration to improve quality. If you’re thinking continuous integration/continuous delivery (CI/CD), you’re not wrong. MLOps supports CI/CD. According to Gartner, “MLOps aims to standardize the deployment and management of ML models alongside the operationalization of the ML pipeline. It supports the release, activation, monitoring, performance tracking, management, reuse, maintenance, and governance of ML artifacts“.
MLOps in the Enterprise
There are substantial differences between an enterprise company and a startup company. Entrepreneurship expert Scott Shane wrote in The Illusions of Entrepreneurship (Yale University Press, 2010) “only one percent of people work in companies less than two years old, while 60 percent work in companies more than ten years old.” Longevity is a characteristic of the enterprise company.
He also says, “it takes 43 startups to end up with just one company that employs anyone other than the founder after ten years.” In essence, the enterprise builds for scale and longevity. As a result, it is essential to consider technologies and services that support these attributes.
Note
Startups have technological advantages for users, but they also have different risk profiles for the investors versus the employees. Venture capitalists have a portfolio of many companies, diversifying their risk. According to FundersClub, a typical fund “contains 135 million” and is “spread between 30-85 startups.” Meanwhile, startup employees have their salary and equity invested in one company.
Using the expected value to generate the actual equity value at a probability of 1/43, an enterprise offering a yearly 50k bonus returns 200k at year four. A startup produces $4,651.16 in year four. For most people, on average, startups are a risky decision if judged on finance alone. However, they might offer an excellent reward via an accelerated chance to learn new technology or skills with the slight chance of a huge payout.
On the flip side, if a startup’s life is dynamic, it must pick very different technology solutions than the enterprise. If there is a 2.3% chance a startup will be around in 10 years, why care about vendor lock-in or multicloud deployment? Only the mathematically challenged startups build what they don’t yet need.
Likewise, if you are a profitable enterprise looking to build upon your existing success, consider looking beyond solutions that startups use. Other metrics like the ability to hire, enterprise support, business continuity, and price become critical key performance indicators (KPIs).
Understanding ROI in Enterprise Solutions
The appeal of a “free” solution is that you get something for nothing. In practice, this is rarely the case. Figure 1-1 presents three scenarios. In the first scenario, the solution costs nothing but delivers nothing, so the ROI is zero. In the second scenario, high value is at stake, but the cost exceeds the value, resulting in a negative ROI. In the third scenario, a value of one million with a cost of half a million delivers half a million in value.
The best choice isn’t free but is the solution that delivers the highest ROI since this ROI increases the velocity of the profitable enterprise. Let’s expand on the concept of ROI even more by digging into bespoke solutions, which in some sense are also “free” since an employee built the solution.
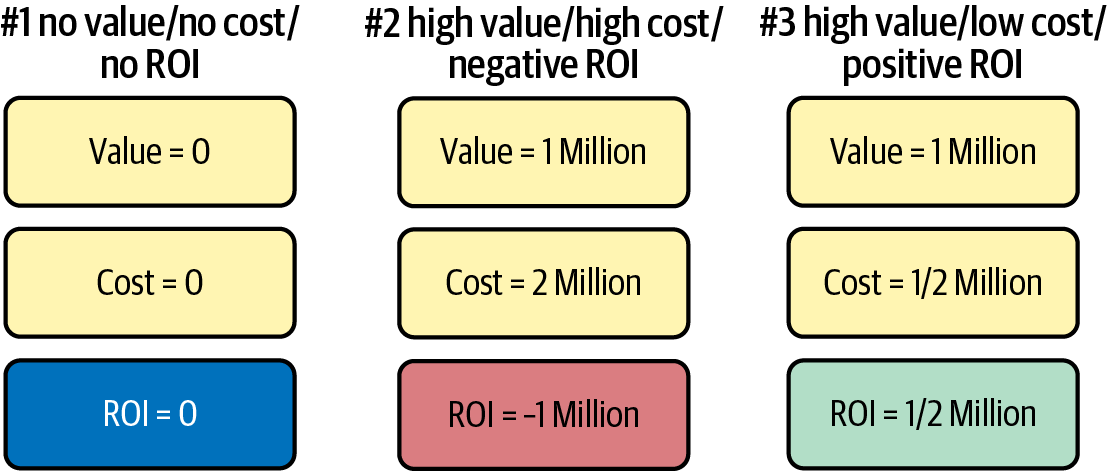
Figure 1-1. Evaluating ROI for technology platform solutions
In Figure 1-2, a genuinely brilliant engineer convinces management to allow them to build a bespoke system that solves a particular problem for the Fortune 100 company. The engineer not only delivers quickly, but the system exceeds expectations. It would be tempting to think this is a success story, but it is actually a story of failure. One year later, the brilliant engineer gets a job offer from a trillion-dollar company and leaves. About three months later, the system breaks, and no one is smart enough to fix it. The company reluctantly replaces the entire system and retrains the company on the new proprietary system.
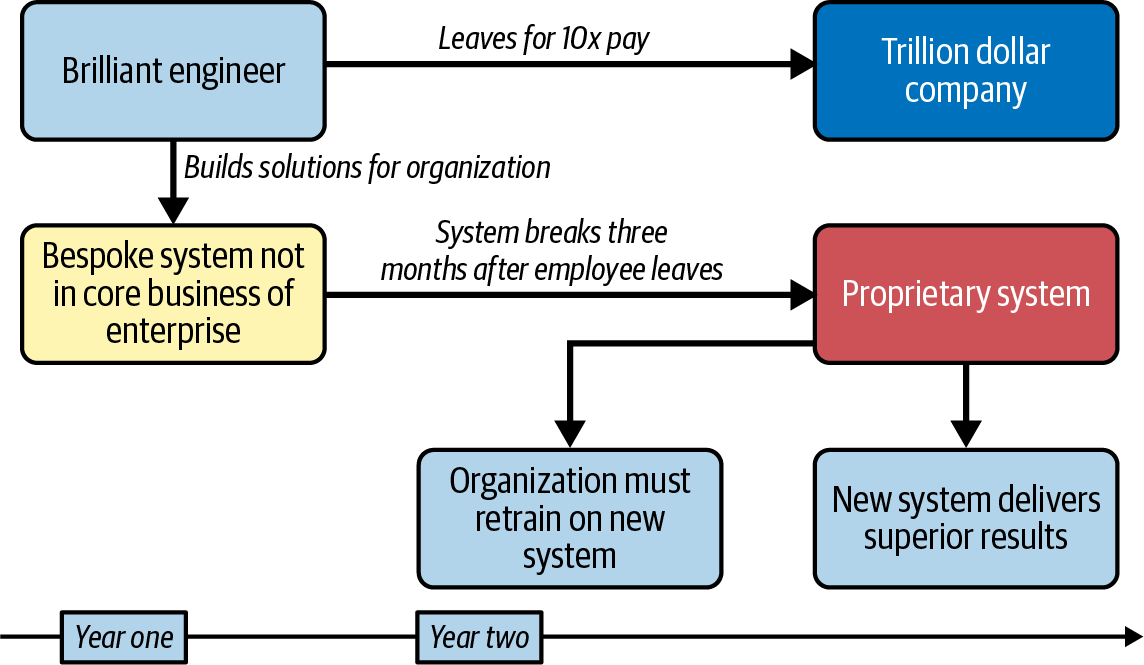
Figure 1-2. Bespoke system dilemma
The ultimate cost to the organization is the lack of momentum from using a superior system for a year, alongside the training time necessary to switch from the old system to the new system. Thus, a “free” solution with positive ROI can have long-term negative ROI for an organization. This scenario isn’t just hypothetical; you may have seen it yourself.2
In Fooled by Randomness: The Hidden Role of Chance in Life and the Markets (Random House, 2008), Nassim Taleb argues, “it does not matter how frequently something succeeds if failure is too costly to bear.” This statement directly applies to a successful enterprise that wants to implement MLOps. Taking the right kind of strategic risk is of critical importance. In the following section, we discuss the concept of risk in more detail.
Understanding Risk and Uncertainty in the Enterprise
Not all risk is the same, just as not all uncertainty is the same. Unlike a startup, an enterprise has made it to the survival phase. There are some risks that enterprises do not need to take. In his book about the enterprise, Good to Great (Harper Business, 2011), Jim Collins asks, “How do good-to-great organizations think differently about technology?” He found that in every case a “good-to-great” company found technological sophistication and became a pioneer in applying technology. Further, Collins states that technology is an accelerator, not a creator, of momentum.
Note
Mark Spitznagel makes a case for considering the geometric mean in financial investment in Safe Haven (Wiley, 2021). He states, “Profit is finite. Risk is infinite.” The percentage of your wealth you can lose is more important than the absolute value of the wealth you could lose when investing. This fact is well suited to the enterprise. Why take a risk with unbounded loss?
Collins’ key point about technology directly applies to MLOps in the enterprise. The purpose of machine learning is to accelerate the business value that is already there. The reason to use machine learning isn’t to pivot the organization to becoming machine learning researchers competing with companies that specialize in research; it is to accelerate the strategic advantages of the organization through technology.
The calculated risk of adopting machine learning as a business accelerator is acceptable if done in a manner that allows an organization to limit the downsides of technology change management. There is essentially unbounded risk in a company creating bespoke machine learning solutions and platforms when its core strength is in some other industry, such as manufacturing, hospitality, or financial services.
Many options exist to accelerate technological advancement in the enterprise, including using pretrained models like Hugging Face or TensorFlow Hub, computer vision APIs like AWS Rekognition, or open source AutoML solutions like Ludwig or MLOps orchestration frameworks like MLRun. Enterprises that adopt MLOps with an approach of using the right level of abstraction give themselves a “good-to-great” advantage over organizations that “hired 15 data scientists” who do “research.” In the latter example, it is often the case that after years of research, in the best case nothing is done, but in the worst case, a lousy solution creates a worse outcome than doing nothing.
Economist Frank Knight clearly articulates the difference between risk and uncertainty: the reward for taking a known risk is very different than a risk that is immeasurable and impossible to calculate. This form of risk, called Knightian uncertainty, was named after Knight. An enterprise doing machine learning should deeply consider which risk they are taking: a regular risk that is knowable, or are they embarking on a path with Knightian uncertainty? In almost all cases, it is better to take knowable risks in machine learning and AI since technology is not the creator of growth; instead, it is the accelerator.
Knowing that acceleration is the crucial insight into great companies that use technology, let’s look at some of the differences in technology acceleration between MLOps and DevOps.
MLOps Versus DevOps
Without DevOps, you cannot do MLOps. DevOps is a foundational building block for doing MLOps, and there is no substitute. DevOps is a methodology for releasing software in an agile manner while constantly improving the quality of both business outcomes and the software itself. A high-level DevOps practitioner has much in common with a gourmet chef. The chef has deep knowledge of ingredients and years of practical experience creating beautiful and delicious meals, and they can make these meals in an industrialized and repeatable manner. The repetition allows a restaurant to stay open and earn a profit.
Similarly, with DevOps, an expert in the domain has detailed knowledge of how to build software and deploy it in a high-quality and repeatable manner. One of the biggest challenges for experts in data science to transition to MLOps is a lack of experience doing DevOps. There is no substitute for experience; many data science practitioners and machine learning researchers should get experience building and deploying software with the DevOps methodology to get the foundational knowledge and experience necessary to be an expert at MLOps.
Note
You can learn more about DevOps from Python for DevOps (O’Reilly) by Noah Gift, Kennedy Behrman, Alfredo Deza, and Grig Gheorghiu.
There are apparent differences, though, between traditional DevOps and MLOps. One clear difference is the concept of data drift; when a model trains on data, it can gradually lose usefulness as the underlying data changes. A tremendous theoretical example of this concept comes from Nassim Taleb in Fooled by Randomness (Random House, 2021), where he describes how a “naughty child,” as shown in Figure 1-3, could disrupt the understanding of the underlying distribution of red versus black balls in a container.
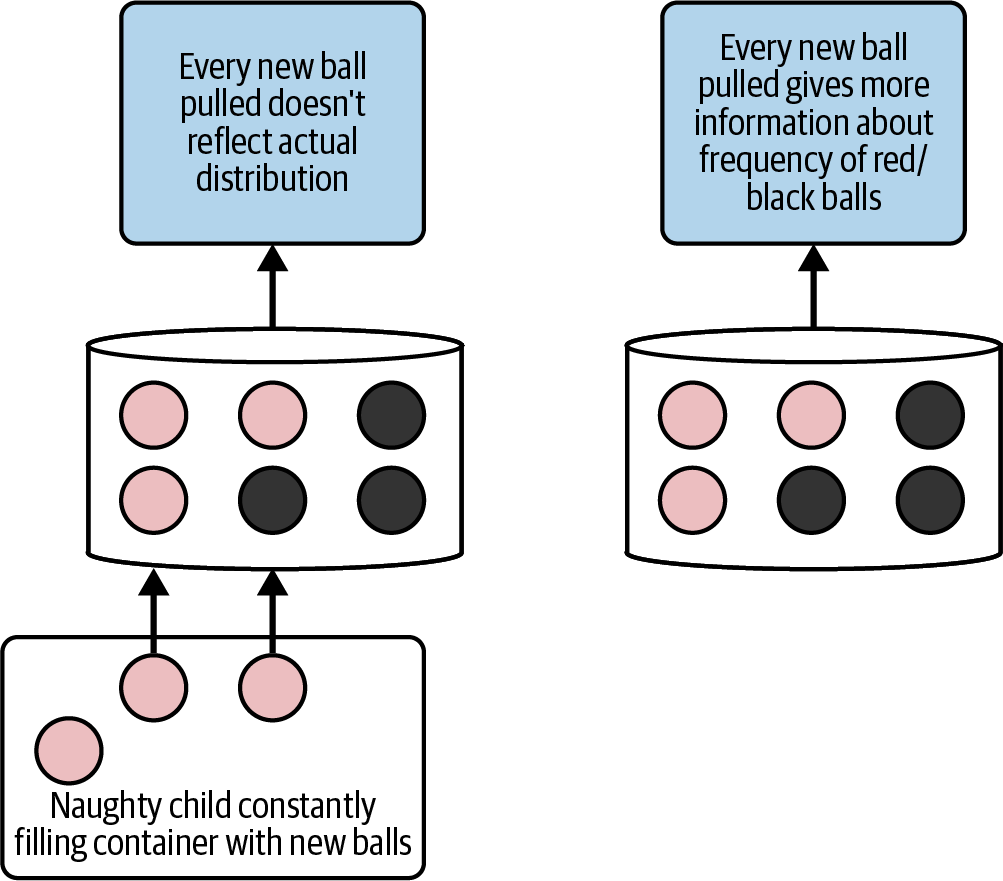
Figure 1-3. “Naughty child” data drift problem
In a static condition, the more balls pulled from a container, the more confident a person can be of the underlying distribution of red versus black balls. In a dynamic condition, if the balls are constantly changing, then a model trained on an older data version won’t be accurate. This example captures one of many unique elements specific to MLOps not found in DevOps.
The takeaway is that DevOps is a necessary foundation for MLOps, but MLOps’ additional requirements, like data drift, don’t appear in traditional DevOps.
Note
Microsoft notes, “Data drift is one of the top reasons model accuracy degrades over time.”
What Isn’t MLOps?
One way to understand more about MLOps is to define what it is not. Here are some common MLOps anti-patterns:
- Hiring a team of data scientists and hoping for the best
-
Perhaps the most common of the MLOps anti-patterns is hiring a team of data scientists and expecting an excellent solution to appear. Without organizational support that understands MLOps and technology infrastructure to support them, there will not be an ideal outcome.
- Building only bespoke machine learning solutions
-
A fundamental problem with building only customized solutions is that they may not be necessary for an organization’s business goals. Training a bespoke machine learning model on propriety data for a self-driving company is essential to a competitive advantage. Training a similar model for a Fortune 500 delivery company could be a costly experiment adding no real value to the business.
- Dismissing DevOps importance
-
Teams that work in silos are not following the best practices of DevOps. For example, it is impractical to have a data science team in Texas that builds models in R and then throws them over to the DevOps team in San Francisco’s financial district to put into the software stack in Python.
Ultimately, MLOps requires a business and production-first mindset. The purpose of machine learning is to accelerate business value. This means the teams building solutions must be agile in their approach to solving machine learning problems.
Mainstream Definitions of MLOps
A challenge in technology is separating marketing strategy from technology strategy. In the case of MLOps, it is not a marketing strategy; it is a specific solution to a severe problem in the enterprise. The bottom line is that models are not making it into production; if they do, they are brittle and fall apart when faced with the complexities of the actual world. Various surveys show that 50-70% of organizations have failed to deliver AI pilots or models to production.
With the condition identified, let’s find the cure. The cure needs to address the following key issues (among others):
-
Model deployment and development time
-
Collaboration between different teams
-
Operational excellence of ML systems
-
Data governance
-
Enhancing the ROI of the enterprise deploying the model
One minimalist way to define MLOps is that it supports ML development like DevOps supports software development.
What Is ML Engineering?
One way to define ML engineering is to look at popular certifications. Google’s Professional Machine Learning Engineer explains the following criteria for a professional ML engineer:
- Frame ML problems
-
Which model to choose depends on business constraints and the context. For example, a business may decide to classify damaged shipped boxes versus successfully delivered packages. In that context, a classification model would be more appropriate than a regression model.
- Architect ML solutions
-
An ML engineer develops a solution to solve the correctly framed problem using machine learning alongside other team members.
- Design data preparation and processing systems
-
Two critical steps in data preparation and processing are constructing the dataset and then transforming the data.
- Develop ML models
-
The detailed modeling process involves a team or individual that creates a model correctly suited to initial model framing.
- Automate and orchestrate ML pipelines
-
A pipeline serves to create a process for reproducible and maintainable ML.
- Monitor, optimize, and maintain
-
It is better to be proactive than reactive in building complex systems. Building monitoring allows for a proactive approach to maintaining ML systems.
ML engineering aims to build high-quality ML models that solve specific business problems while creating ROI.
Note
Several O’Reilly books discuss machine learning engineering, including Data Science on the Google Cloud Platform, Machine Learning Design Patterns, and Practical MLOps.
MLOps and Business Incentives
A classic problem in business school is incentives, often described as “who moved the cheese?” This scenario refers to a rat in a maze that moves depending on where the cheese is. Similarly, there are two common incentives worth discussing in MLOps: negative externalities and hiring data scientists without regard for ROI:
- Negative externalities
-
Negative externalities, like a company creating a profit dumping toxic waste into a river instead of the more expensive appropriate disposal, are classic examples of the fundamental problems in capitalism. In machine learning, the negative externalities could be biased algorithms that send an innocent person to jail or deny a person credit based on race, religion, national origin, and other categories. Even an unintentionally created bias in a model is still illegal (e.g., denying credit based on age). Enterprises that fail to look into the future could expose themselves to existential risk if system bias against elderly applications, for example, were accidentally baked into a machine learning model.
- Hiring data scientists without regard for ROI
-
It has recently been in vogue to hire data scientists without regard for the problem they are solving. As we discussed, this strategy ultimately doesn’t work because models are not in production at most organizations doing AI and ML.
MLOps in the Cloud
MLOps methodology leverages several critical advantages of cloud computing. First, the cloud is an elastic resource that enables both the efficient use of computing and storage and the ability to scale to meet almost any demand. This capability means that cloud computing has on-demand access to essentially infinite resources.
Second, the cloud has a network effect in that cloud technologies benefit from integrating other cloud technologies. A great example is AWS Lambda, a serverless technology. AWS Lambda is a valuable service to build applications with, not because of what it does alone, but because of the deep integration with other AWS services like AWS Step Functions, Amazon SageMaker, or AWS S3. For any active cloud platform, you can assume that the integrated network of services further strengthens its capabilities as the platform develops more features.
Third, all cloud vendors have MLOps platforms. AWS has SageMaker, Azure has Azure Machine Learning, and Google has Vertex AI. Even smaller niche clouds like Alibaba Cloud has their Machine Learning Platform for AI. By using a cloud platform, an organization will likely use some of the offerings of the native ML platform and potentially augment it with custom solutions and third-party solutions.
Fourth, all cloud vendors have Cloud Development Environments. A significant trend is the use of a combination of lightweight CloudShell environments like AWS CloudShell, heavier full interactive development environment (IDE) options like AWS Cloud9, and notebook environments, both free like SageMaker Studio Lab or Google Colab and those with rich IDE integration like SageMaker Studio.
Finally, depending on what a company is doing, it may have no option but to use cloud computing. Some cloud computing components are a hard requirement for organizations specializing in building bespoke deep learning solutions because deep learning requires extensive storage and compute capabilities.
In addition to the public cloud vendors, several additional players offer MLOps solutions in the cloud (see later in this section). These vendors can operate on the public cloud or on private clouds. The advantage of using a smaller vendor is the customization level that such a company provides its customers. In addition, an MLOps vendor will have more in-depth expertise in MLOps since that is its only focus. Integrated vendors often ensure more relevant features and many more integrations. Finally, by choosing a vendor that is agnostic to a specific cloud provider, you, as a customer, aren’t connected to it either. Instead, you can use the vendor across multiple clouds or on additional infrastructure that you may have (see later in this section).
Note
One helpful resource for machine learning vendor analysis is the AI Infrastructure Alliance (AIIA). This organization provides data scientists and engineers with clarity and information about AI/ML tools to build robust, scalable, end-to-end enterprise platforms. One resource is a comprehensive MLOps landscape that maps out all the players in the industry. This document includes an updated MLOps landscape that will map out open source and enterprise solutions for MLOps. The new landscape will encompass multiple categories and hundreds of companies while detailing the capabilities of each vendor solution.
In Figure 1-4, notice a typical pattern among all clouds in which there is a set of cloud development environments, flexible storage systems, elastic compute systems, serverless and containerized managed services, and third-party vendor integration.
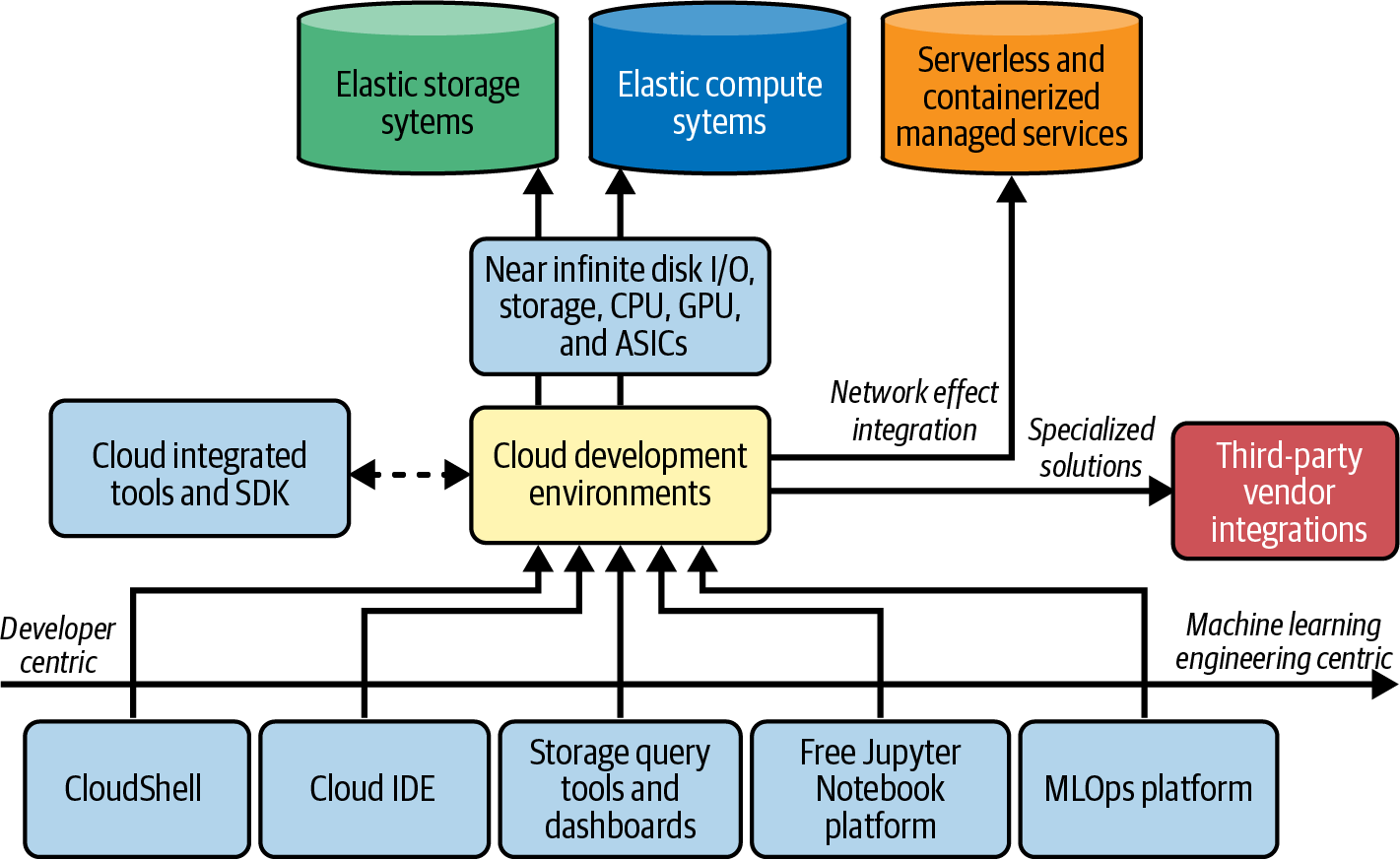
Figure 1-4. Cloud MLOps landscape
Here is more detail about these categories:
- Cloud development environments
-
Generally, developer-centric tools like cloud shells and IDEs are on one extreme and machine learning-centric tools on the other. Storage query tools like Google BigQuery, Amazon Athena, or Azure Databricks Integration are in the middle.
- MLOps platforms that operate in the cloud
-
MLOps platforms are built specifically for running MLOps for enterprises on the cloud or across any environment. Solutions like Iguazio, Valohai, DataRobot, Azure Databricks and Outerbounds, and many others offer a wide variety of MLOps solutions for the enterprise.
- Elastic storage systems and elastic computing systems
-
Deep learning systems thrive on big data, and flexible compute capabilities from GPUs, CPUs, and AI Accelerator application-specific integrated circuits (ASICs) like Tensor Processing Units (TPU). As a result, MLOps platforms, both native and third party, heavily use this elastic capability to provide managed solutions.
- Serverless and containerized managed services
-
Cloud platforms evolve toward more serverless solutions like AWS Lambda or Google Cloud functions and solutions with fully managed containerized solutions such as Google Cloud Run or AWS Fargate. These managed services, in turn, have deep platform integration, which enhances the value proposition of the cloud platform through a network effect.
- Third-party vendor integrations
-
A cloud platform can’t have the exact right mix of everything and at the right quality. A trip to a large warehouse store yields a wide variety of offerings at a reasonable price. However, they may not have the authentic gourmet food you like or the exact appliance features you need. Just like that large warehouse store, a cloud provider cannot go deep on everything. As a result, third-party integrations handle these specialized or advanced use cases.
With the common aspects of cloud computing for MLOps covered, let’s move on to discuss the cloud environments in more detail.
Key Cloud Development Environments
One of the best new products from Microsoft is GitHub Codespaces, a cloud-based development environment with many customizable features and a great place to practice MLOps. In particular, what is helpful about this environment is the deep integration with GitHub and the ability to customize it with a specialized runtime. Finally, the synergy with GitHub Actions allows for a great CI/CD story.
Note
Learn more about GitHub Codespaces with the following videos:
Three different flavors of cloud-based developments are available from Google: Colab notebooks, Google Cloud Shell, and Google Cloud Shell Editor.
Figure 1-5 shows a full editor available for Google Cloud Platform (GCP).
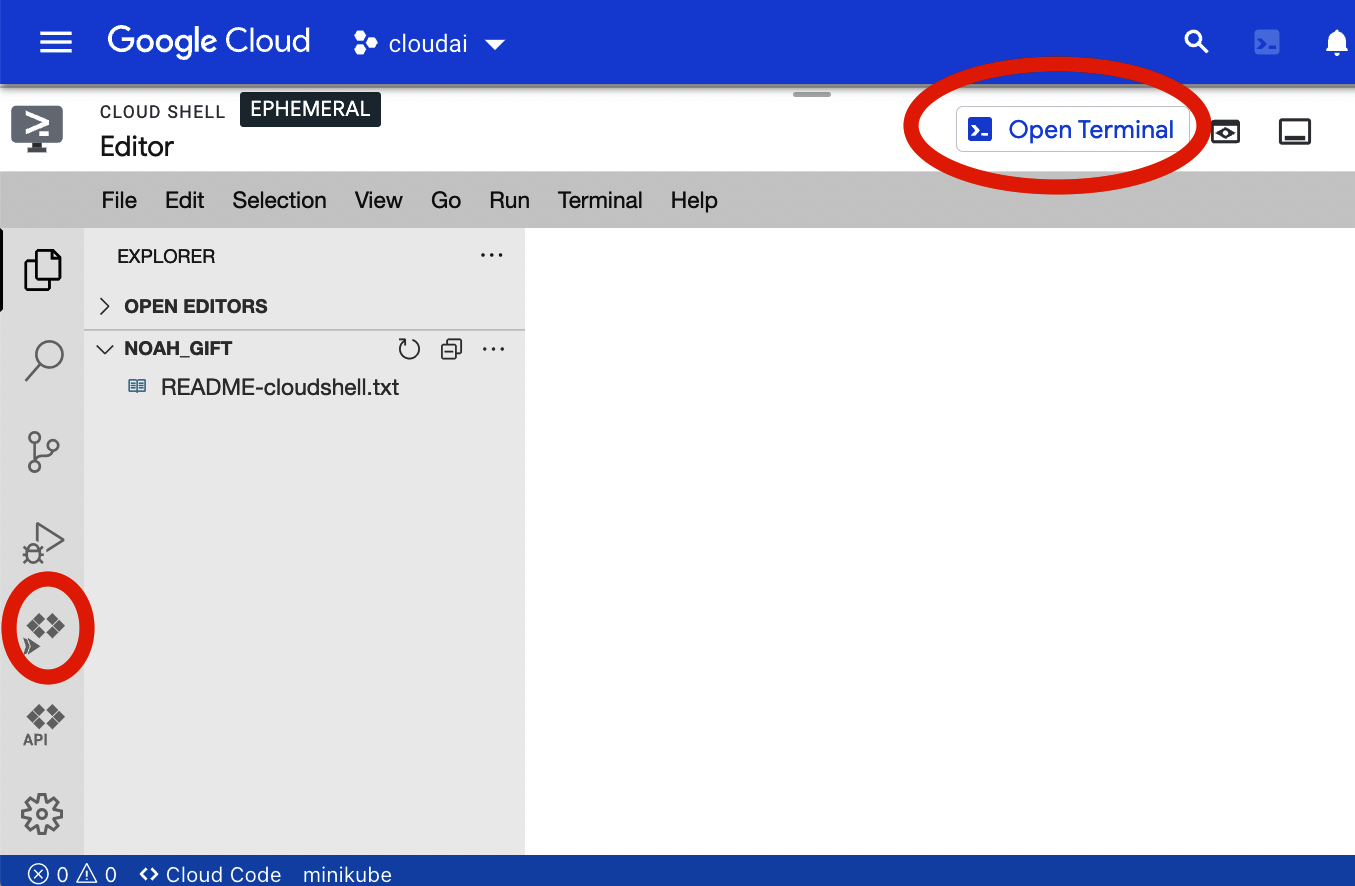
Figure 1-5. Google Cloud Shell Editor
In Figure 1-6, API docs integrate with the development environment.
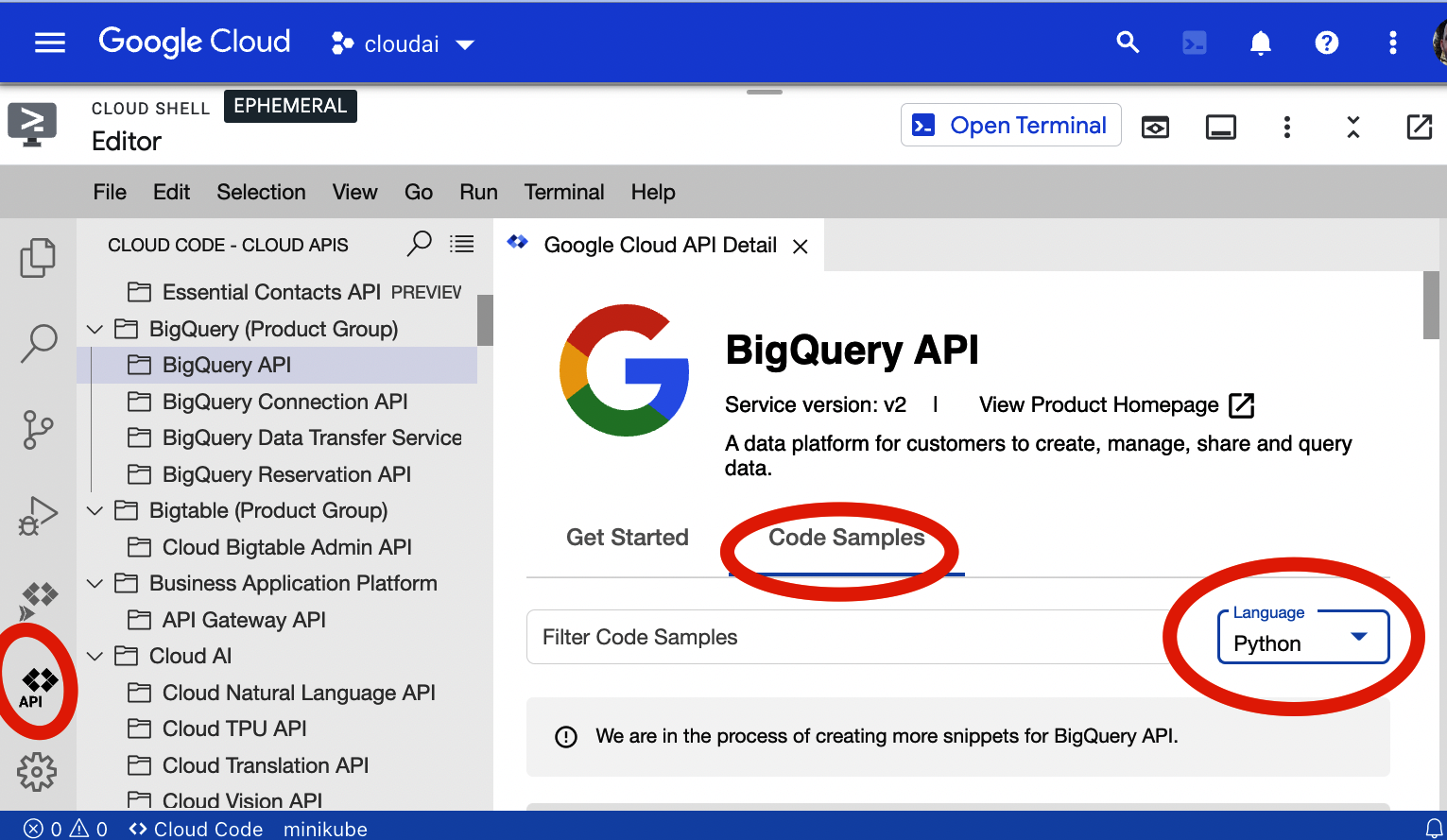
Figure 1-6. Google Cloud Shell Editor API
In Figure 1-7, the terminal shows a standard view of the experience using the cloud shell.
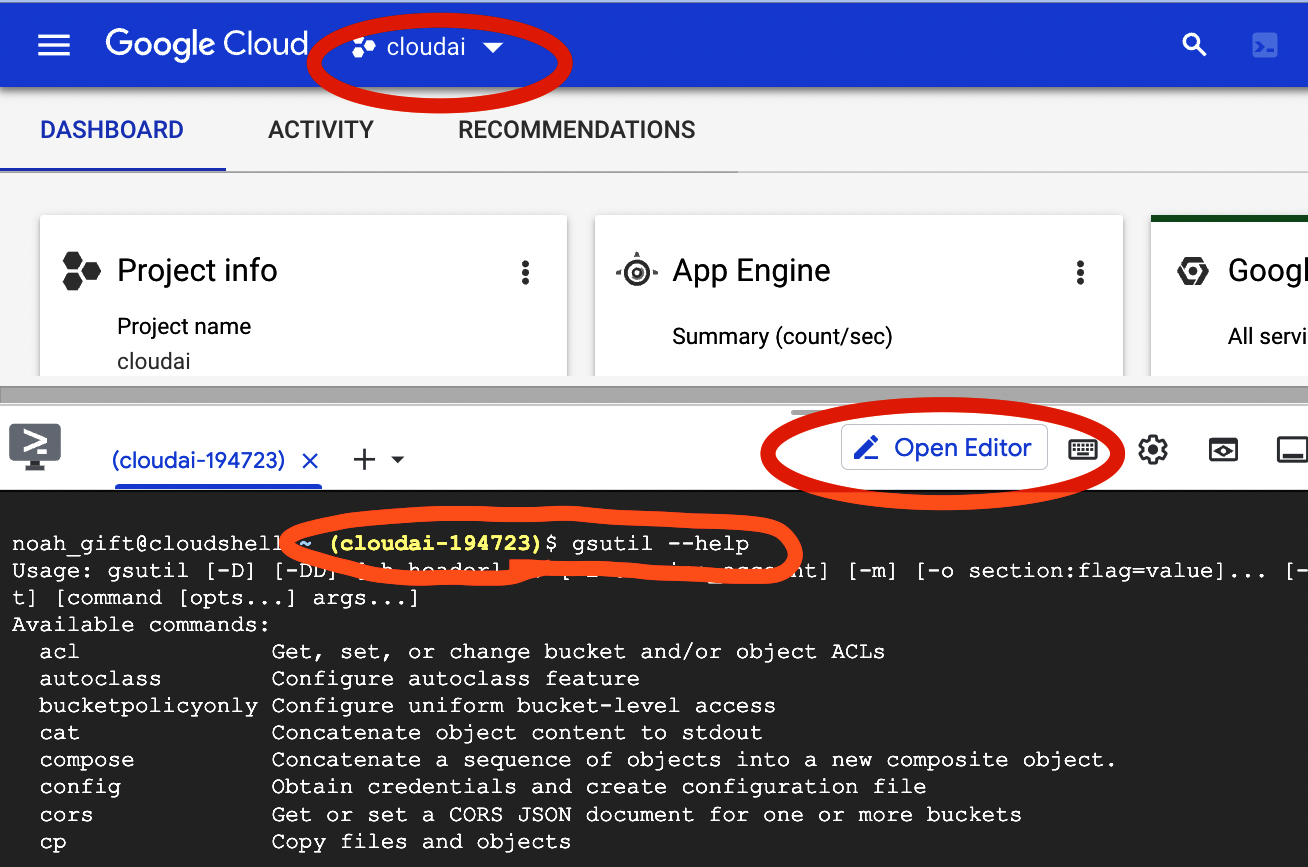
Figure 1-7. Google Cloud Shell terminal
Note
Learn more about Colab notebooks from the following videos:
Finally, the AWS platform has cloud shell environments, as shown in Figure 1-8.
Note
One quick way to learn about multiple clouds simultaneously is by setting up a multicloud continuous integration. You can learn how to set this up with the video “GitHub Actions Hello World All Cloud and Codespaces”.
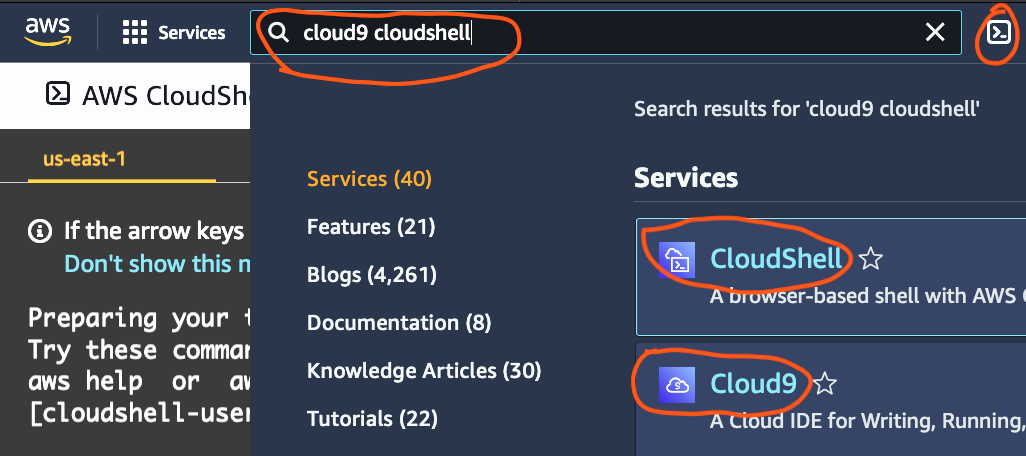
Figure 1-8. AWS Cloud Shell terminal
All of this leads to the concept of the cloud developer workspace advantage, as shown in Figure 1-9. A laptop or workstation is expensive and nondeterministic due to preinstalled software and, by definition, not the deploy target. When you look at a cloud-based workspace, it has many incredible advantages, including power, disposability, preloading, and deep integration with advanced tools.
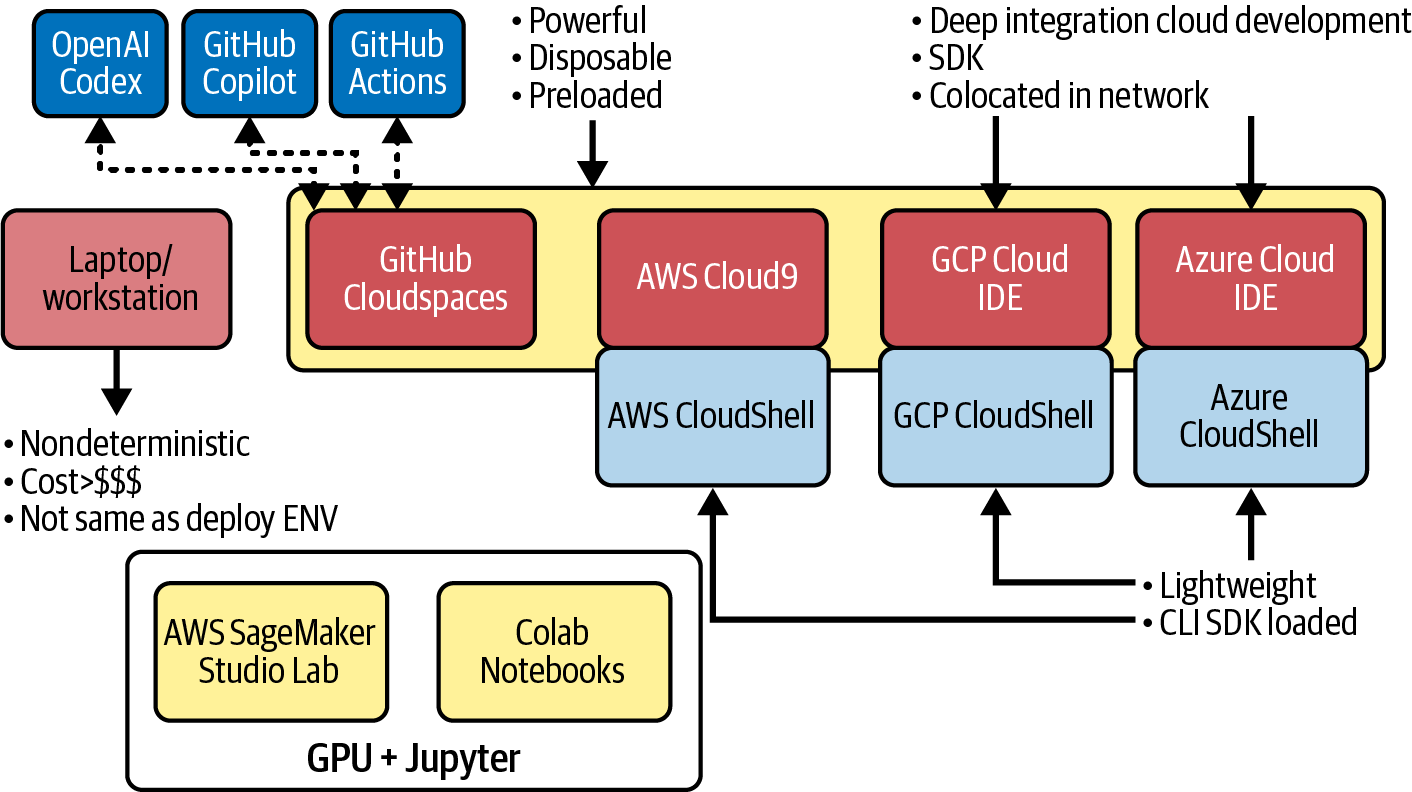
Figure 1-9. Cloud developer workspace advantages
Note
You can learn more about the cloud developer workspace advantage in the video “52 Weeks of AWS-The Complete Series” or on YouTube.
The Key Players in Cloud Computing
Know someone who wants to earn $200k or more a year? According to the 2022 Cloud Salary Survey by Mike Loukides (O’Reilly), the average salary for certified professionals on AWS, Azure, and GCP is over 200k.
Further backing this up is the data from Statista, as shown in Figure 1-10. As of Q2 2022, there were three key players in the worldwide market. AWS had about 33% of the market share, Azure had about 21%, and Google Cloud had about 10%. Combined, these three vendors controlled two-thirds of a market that generates almost $200 billion in revenue. Service revenue increased by 37% from the last year.
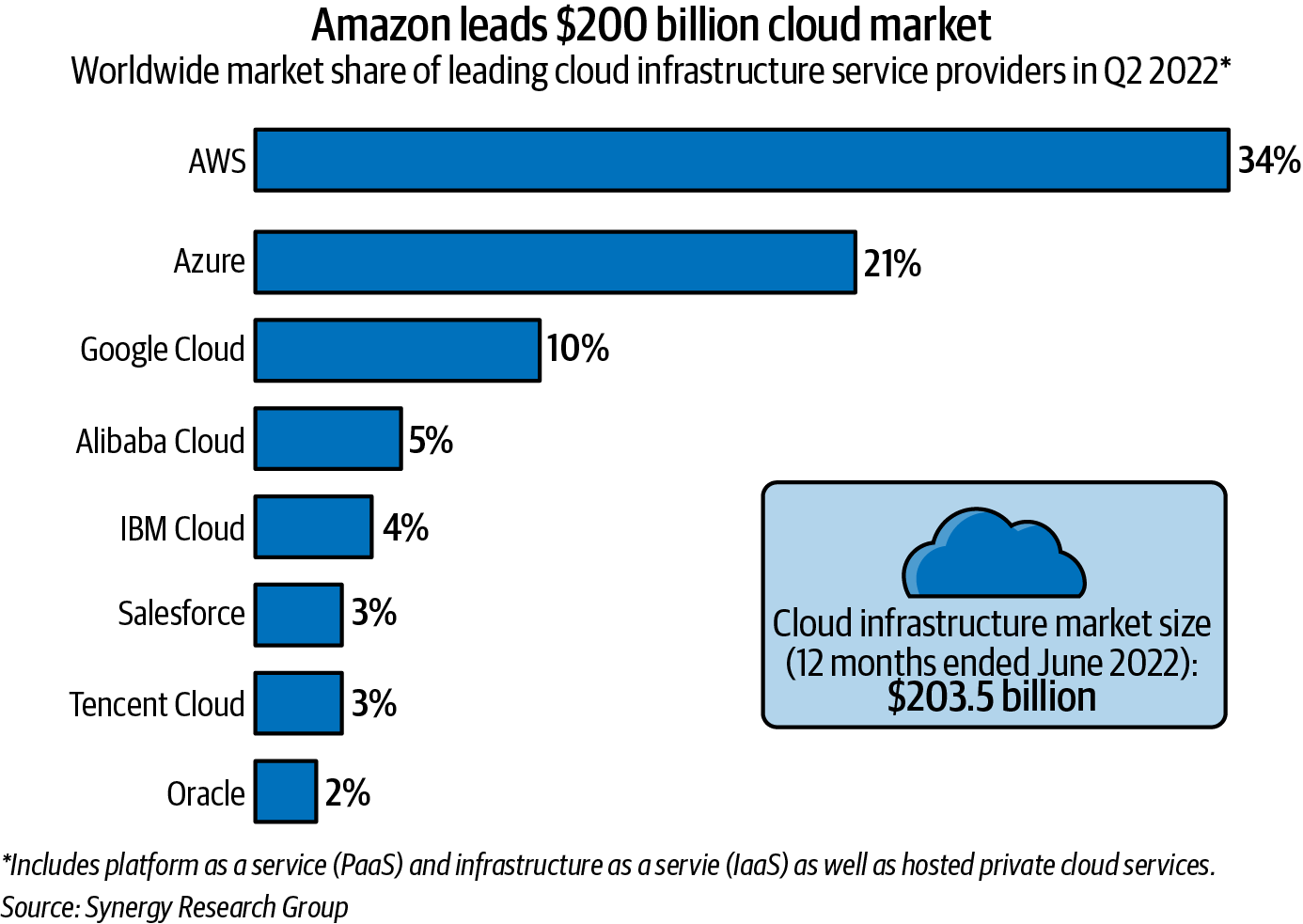
Figure 1-10. Cloud computing market
A reasonable strategy for an organization wishing to use cloud computing is to use the platform of the largest providers. The Matthew effect3 saying, “the rich get richer, and the poor get poorer,” applies to cloud computing for several reasons:
- Available employees and vendors to hire
-
Leveraging the most prominent cloud platforms makes hiring employees and finding vendors that work with the platform more accessible.
- Training material available
-
The availability of training material for the most prominent platforms makes it easier to train employees.
- Services available
-
Larger platforms can hire more software engineers and product managers, meaning you can count on a continuation of new features and maintenance in their platform.
- Cost of service
-
Economies of scale mean that the most significant providers benefit the most from economies of scale. They can leverage pricing advantages by buying in bulk and then passing them on to the customer.
Note
You can study for the AWS Cloud Certifications by viewing “AWS Solutions Architect Professional Course” and “AWS Certified Cloud Practitioner Video Course” by Noah Gift.
Now that you know the top providers in cloud computing, let’s discuss how each vendor views the world of cloud computing as it relates to MLOps.
AWS view of cloud computing as it relates to MLOps
The best place to get a high-level summary of AWS cloud computing is the Overview of Amazon Web Services AWS Whitepaper. In particular, they mention six advantages of cloud computing:
- Trade fixed expense for variable expense
-
Avoiding large capital expenditures encourages agility and efficiency.
- Benefit from massive economies of scale
-
As prices decrease for the supplier, they fall for the customer, allowing for lower pricing than if the customer bought the same product. Similarly, managed services on the platform will have a steady schedule of new features.
- Stop guessing capacity
-
There isn’t a need to preprovision resources since systems get built with an elastic ability to scale as needed.
- Increase speed and agility
-
Focusing on an organization’s comparative advantage and not building nonessential-to-business IT allows an organization to move faster.
- Stop spending money running and maintaining data centers
-
Cost savings accumulate from outsourcing this component of IT.
- Go global in minutes
-
Going global is a highly challenging problem that goes away with AWS due to its comprehensive offerings.
Note
You can learn more about AWS in Developing on AWS with C# (O’Reilly) by Noah Gift and James Charlesworth.
These features ultimately drive into the core MLOps offering of Amazon SageMaker in Figure 1-11 as the project’s lifecycle goes from preparation to building to training, to finally deploying and managing the solution. At the center of the workflow is tight integration with developer tools from Studio and RStudio.
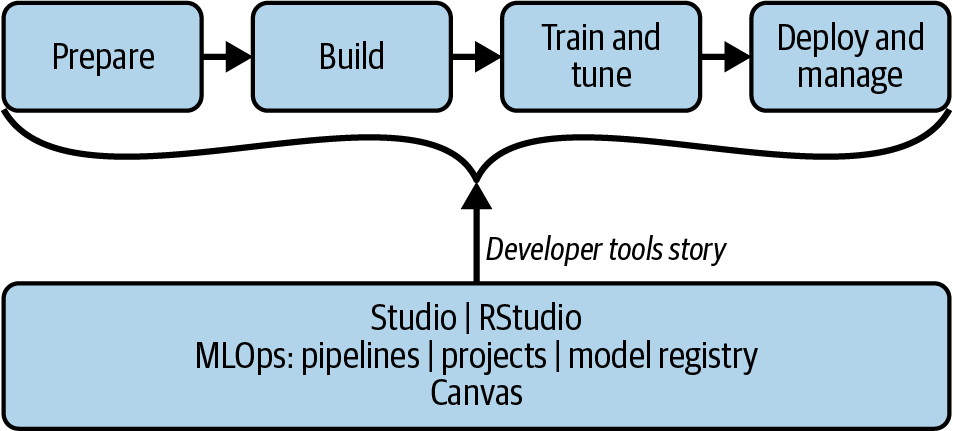
Figure 1-11. Amazon SageMaker MLOps workflow
Note
In the video “Amazon SageMaker Studio Labs: First Thoughts”, you can see a complete walkthrough of SageMaker Studio Lab.
With the AWS view of the MLOps complete, let’s look at Azure next.
Azure view of cloud computing as it relates to MLOps
Microsoft Azure sees the world of MLOps as a way to “efficiently scale from a proof of concept or pilot project to a machine learning workload in production.” As shown in Figure 1-12, the model’s lifecycle includes training, packaging, validating, deploying, monitoring, and retraining.

Figure 1-12. Azure MLOps
Next, let’s next look at how Google views MLOps.
GCP view of cloud computing as it relates to MLOps
An ideal place to look at how Google sees the world is by looking through the Production ML Systems crash course. One of the items the company points out is how tiny the modeling part of the problem is, as shown in Figure 1-13. Instead, the combination of other tasks, including data collection, serving infrastructure, and monitoring, take up much more of the problem space.
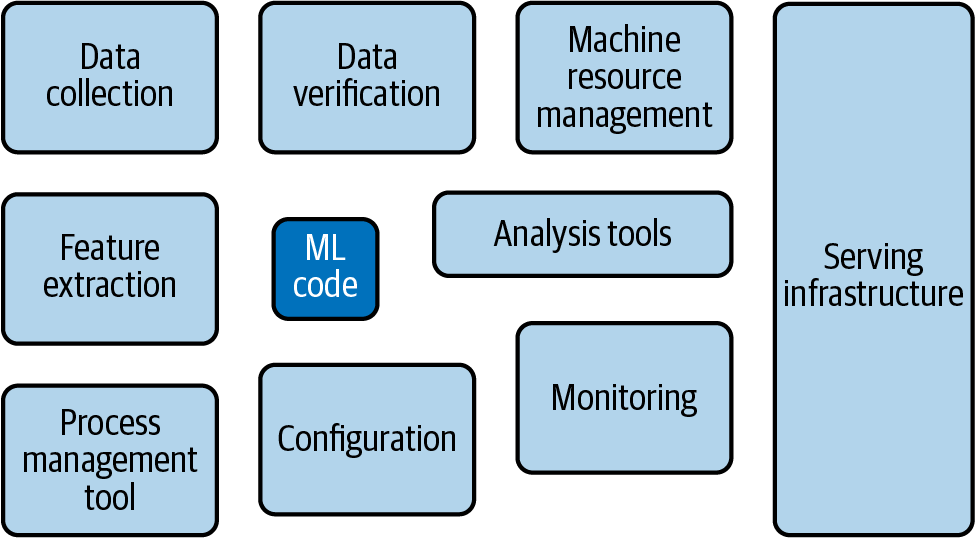
Figure 1-13. Google’s view of MLOps
Ultimately this leads to how Google’s Vertex AI platform handles the MLOps workflow, shown in Figure 1-14. The ML development process occurs, including model framing for the business problem. The data processing phase leads to an operationalized training process that can scale up as needed. Then the model deployment occurs along with a workflow orchestration alongside artifact organization. The model has monitoring baked into the deployment process.
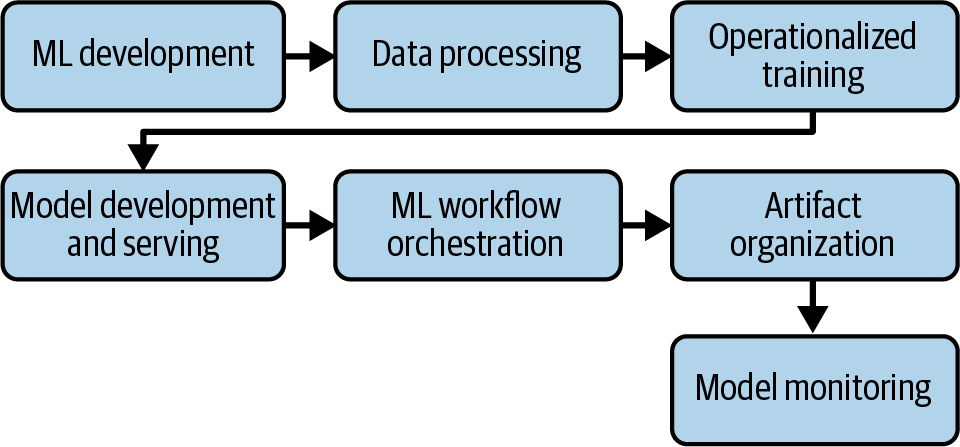
Figure 1-14. Google’s view of MLOps
While public cloud providers offer their own solutions, sometimes enterprises might need a solution that is more tailored to their specific needs. Let’s look at two more deployment options: on-premises deployment and hybrid cloud deployment.
MLOps On-Premises
In some use cases, enterprises cannot use the public cloud. Business restrictions like the need to secure sensitive data or having to adhere to strict regulations (e.g., data localization privacy regulations) require an MLOps solution that can operate on-premises. Many MLOps solutions offer the ability to deploy them either in the cloud or on-premises. The only down side to this approach is that on-premises solutions require the enterprise to provide the servers and equipment that will support the intense computing power needed to run ML algorithms at scale. They will also need to update and maintain the infrastructure.
On the other hand, an on-premises deployment will almost certainly require some sort of customization. This installation gives enterprises more control over the product, and they can make specific requests to tailor it to their needs. More specifically, if the deployed solution is a startup solution, they will be attentive and work hard to ensure satisfaction and adoption. If it’s an open source product, then enterprises not only can leverage the community’s development power but also go inside with their own developers and tinker with the product to ensure it suits their needs.
MLOps in Hybrid Environments
Similar to on-premises deployment, some enterprises might prefer a hybrid cloud deployment. This involves deploying on the public cloud(s), on-premises, and perhaps even on a private cloud or on edge devices. Naturally, this makes things a lot more complex, since the MLOps solution must enable total separation of the data path from the control path and must be delivered by a highly available, scalable entity that orchestrates, tracks, and manages ML pipelines across types of infrastructure deployments. Lest we forget, this has to occur at high speed and with optimal performance. Finally, the solution ideally provides a single development and deployment stack for engineers across all infrastructure types.
Finding a vendor or open source solution that meets all these requirements might not be simple, but as mentioned before, your best bet is with startups or mature OSS solutions that can be customized to the specific needs of your infrastructure.
Enterprise MLOps Strategy
With a high-level overview of the critical issues involved in MLOps completed, it is time to turn to strategy, as shown in Figure 1-15. There are four key categories to consider when implementing an MLOps strategy: cloud, training and talent, vendor, and executive focus on ROI.
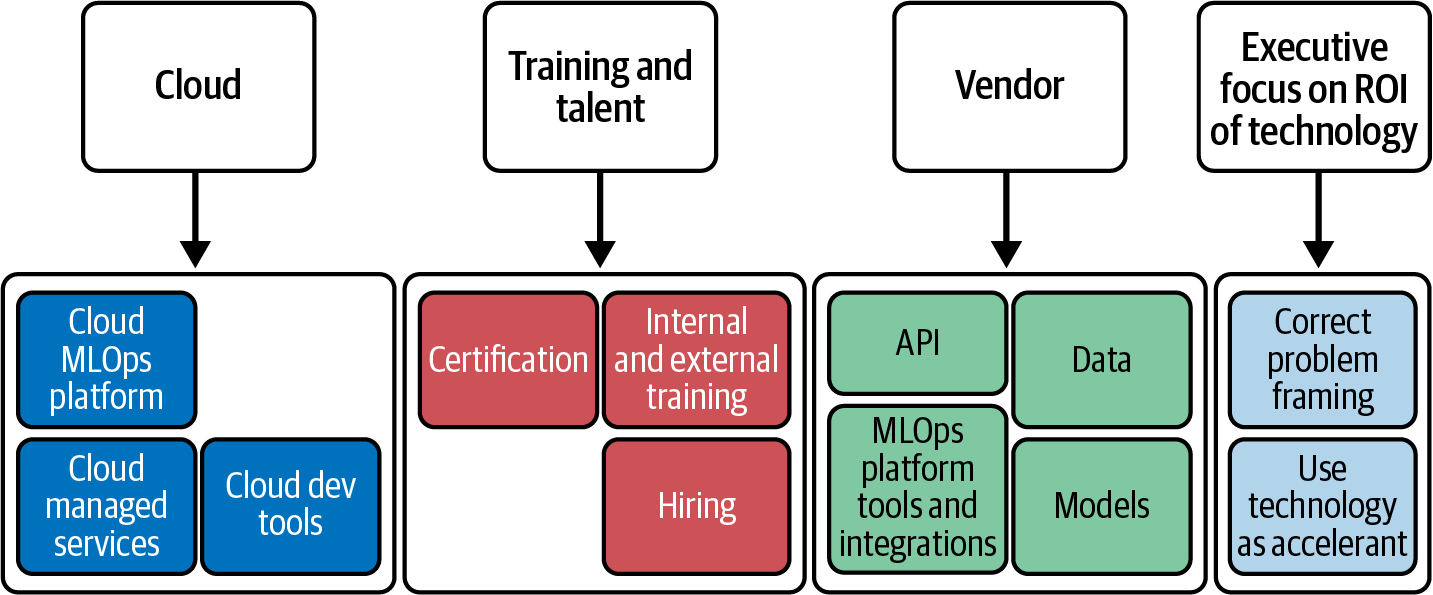
Figure 1-15. Enterprise MLOps strategy
Let’s discuss each of these four categories:
- Cloud
-
There is no perfect answer for which cloud platform to use. Any central platform will offer the advantages of economies of scale. What is essential in an MLOps strategy is to be aware of how a cloud platform fits into the unique goals of each organization and how it aligns with other strategic components like hiring or third-party vendor integration.
- Training and talent
-
Often, organizations look only at the power of new technology and don’t consider the training and talent component of using the technology. In almost all cases, an organization should use a less powerful technology if hiring and training are better with a less powerful solution. This fact means widespread technology is crucial when implementing new technology. Ultimately, the latest technology is dead on arrival if you cannot hire or train your staff.
- Vendor
-
An often overlooked issue with using cloud computing is that it usually needs to be augmented by specialized vendors to help an organization reach its goals with the technology. These strategic choices can lead to better ROI for both the cloud and the business strategies. Examples include using vendor technology specializing in Hadoop, Kubernetes, or pretrained models. The vendors will be unique to each organization and its business goals.
Note
In “Enterprise MLOps Interviews”, CEO of Outerbounds and author of Metaflow, Ville Tuulos, mentions that while all companies use the base layer of the cloud, say storage and databases, they often need to augment with vendors at higher layers.
Conclusion
This chapter sets the stage for understanding the crisis in enterprises getting machine learning and AI into production. From a common sense approach, the idea of “just hiring more data scientists” to increase ROI is as sensible as “just hiring more software engineers” to make a traditional software project go faster. In the case of the conventional software company, if there is no product, no goal, and no oversight, then hiring more developers increases the capital expenditure of the organization without any added value.
Instead of this scenario, MLOps aims to add a methodology that builds on the successful lessons of DevOps while handling the unique characteristics of machine learning. Finally, at the enterprise level, ultimately data science comes down to ROI. Technology is an accelerant of value for most organizations, not the value. Organizations that create a hunger for ROI can quickly adopt the MLOps mindset.
Critical Thinking Discussion Questions
-
There are many methods for deploying machine learning models to production, including pretrained models, APIs, AutoML, and bespoke training. What are the pros and cons of each of these approaches?
-
What strategies could an enterprise implement to attract new machine learning engineering talent and train and retrain current talent?
-
If your organization currently doesn’t do any DevOps, a foundational component necessary for MLOps, how could they start a first DevOps project to test concepts like CI/CD and infrastructure as code (IaC)?
-
If your organization doesn’t have large quantities of proprietary data, how can it use machine learning to gain a competitive advantage anyway?
-
What is your organization’s cloud strategy: single cloud, multicloud, hybrid cloud, private cloud, or something else? How does this help your organization reach your MLOps goals?
Exercises
-
Go to a popular model hosting site like TensorFlow Hub or Hugging Face and deploy one of their models to your favorite cloud platform.
-
Pick a cloud-based development environment like GitHub Codespaces, Amazon SageMaker Studio Lab, or Google Colab and explore the interface with an eye for building a machine learning engineering project.
-
Use a machine learning app framework like Gradio or Streamlit to build a simple machine learning application.
-
Brainstorm several organizational problems that may benefit from using machine learning and build a simple prototype using an MLOps technology.
-
Convert a Kaggle project to an MLOps project by downloading the dataset and coding an MLOps technology to serve predictions.
1 Dr. Luks summarizes the systematic evidence-based strategy: “Create a caloric deficit, then stay lean. Get sleep. Eat real food. Move often, throughout the day. Push and pull heavy things. Socialize. Have a sense of purpose.”
2 In Principles of Macroeconomics (McGraw Hill, 2009), Ben S. Bernanke shares the story of how a talented chef could extract all of the profit from restaurants in a scenario of perfect competition since they would continuously leave for a higher salary at a competing restaurant, ultimately removing all profit for the owner.
3 Sociologists Robert K. Merton and Harriet Zuckerman first coined this term.
Get Implementing MLOps in the Enterprise now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

