Chapter 4. Defining the Data Mesh Architecture
This chapter will discuss the core architecture components within a Data Mesh. The chapter is organized into two major sections. First, we discuss the data-product architecture, including the components required to support a wide-ranging set of artifacts and the components required for developing, running, and operating data products. Second, we focus on the broader Data Mesh architecture that binds all data products together into a unified whole.
Data Product Architecture
Each data product in a Data Mesh is designed to be discoverable, observable, and operable, ensuring that data can be efficiently shared and utilized across different parts of an organization. Figure 4-1 illustrates the data product architecture that we will elaborate on.
There are several key groups of capabilities within the data-product architecture: an architecture for artifacts as well as architectures for development, runtime, and operations capabilities.
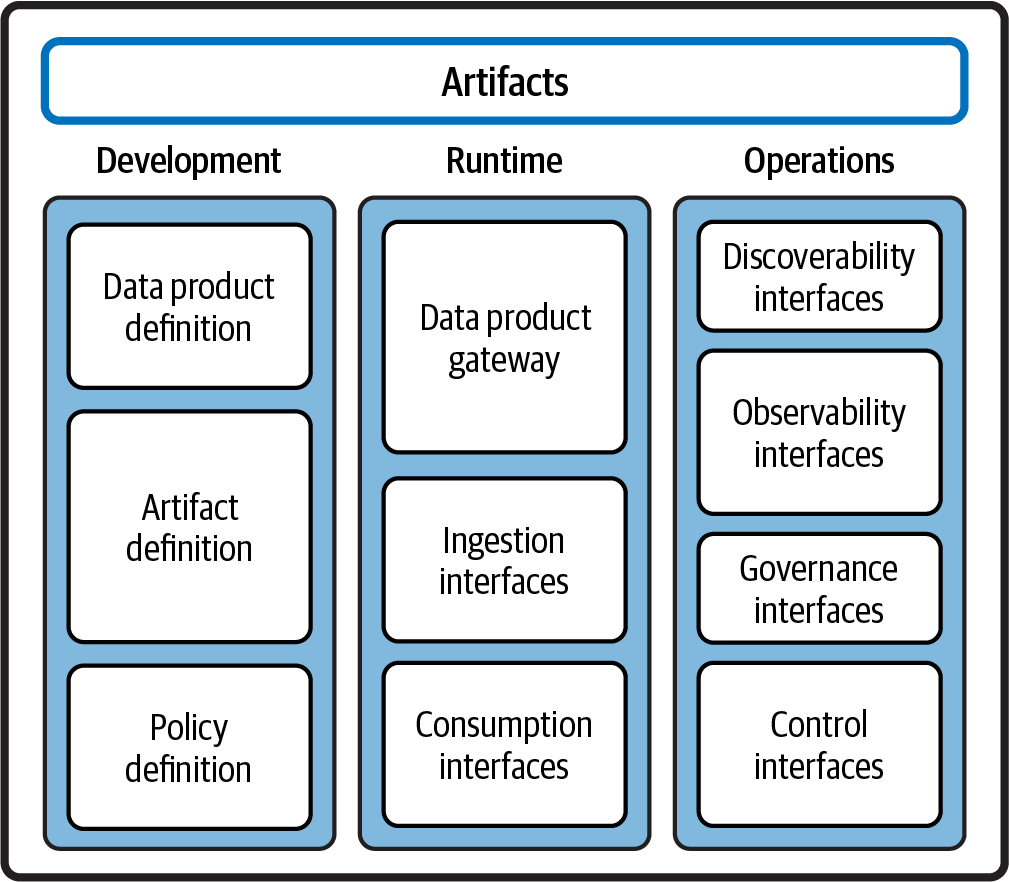
Figure 4-1. Data product architecture
Data Product Artifacts
The contents of a data product—the artifacts—are what make the data product valuable. Artifacts include not just data but also other objects that a DPO wants to make available for consumption.
Artifacts, as shown in Figure 4-2, range from basic datasets to complex programs and models. They add significant value to the data product, making it more than just a data store. They enable a more integrated and user-friendly approach to data management, where the focus is not just on providing data but also on delivering a complete, valuable, and ready-to-use data solution.
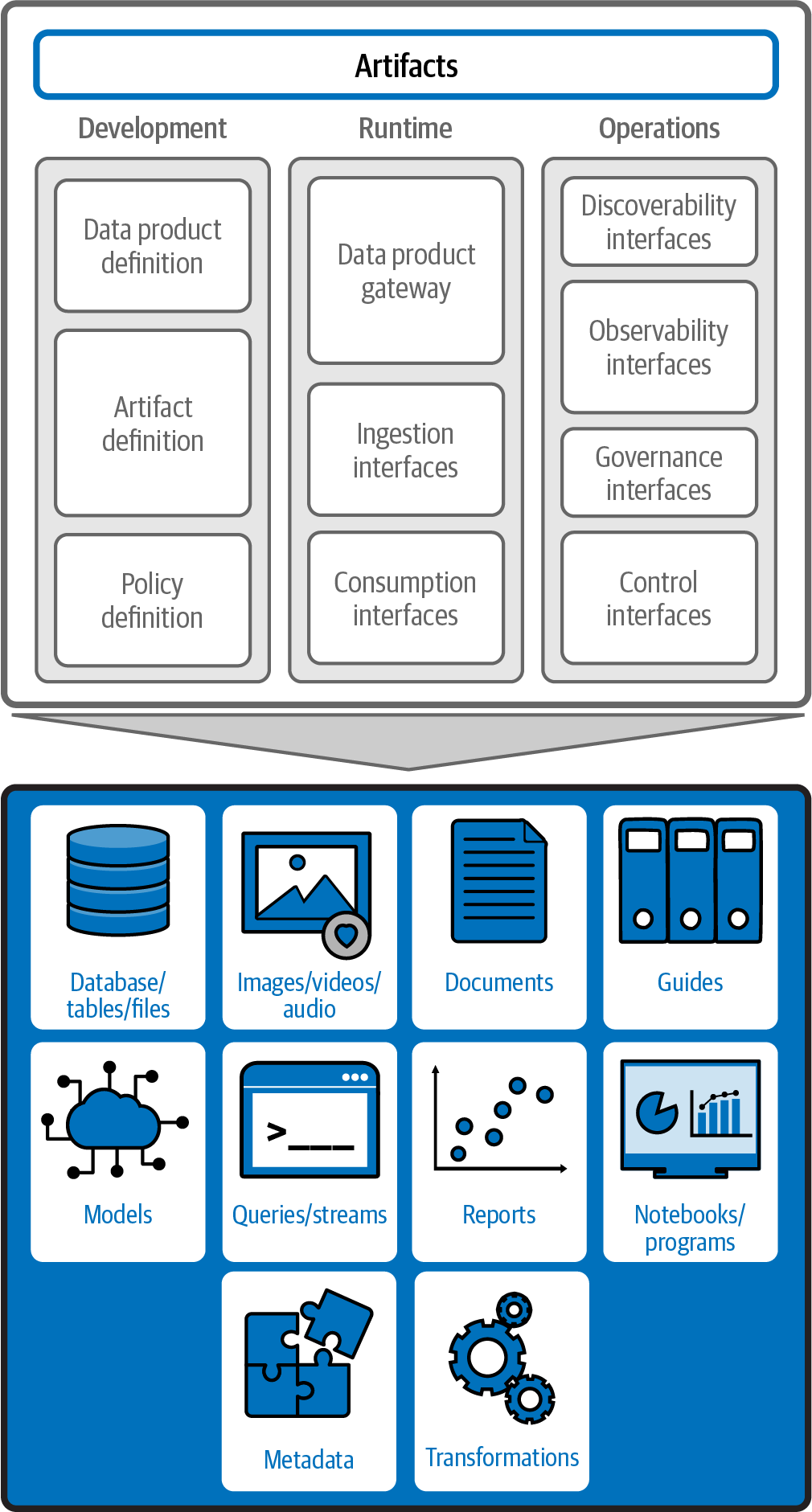
Figure 4-2. Data product artifacts
Let’s start with the most common type of artifact, and probably the one that is present in almost all data products today: databases, tables, and files. These fundamental components form the backbone of any data product, providing the core data that users seek for various applications. However, the scope of artifacts goes far beyond these basic elements, embracing a more holistic and integrated approach that is cognizant of the many forms of “data” today. As we discussed in Chapter 2, these artifacts may also include:
-
Images, videos, and audio, which are becoming commonplace in our modern multimodal data environment
-
Documents, such as PDFs or other text-oriented, unstructured data
-
Guides, which may help consumers understand or consume a data product
-
Models, including AI and ML models as well as newer generative AI large language models
-
Queries and streams that have been vetted (safe, performant, etc.), which simplify consumption of the data product
-
Reports, which provide preformatted sets of output from a data product
-
Notebooks and programs that demonstrate how the data within the product can be used effectively or show the actual processing logic used within the data product
-
Metadata, or data about the data product, its contents, its fields, and its formats
-
Transformations, including pipelines and other workflow tooling that ingest the data and transform it into a form that is both usable and convenient for consumers
What architecture capabilities are required to support the varied forms of modern artifacts represented in a data product? We discuss these capabilities in the following three sections:
Development Architecture Components
The first considerations to address when creating a data product are the definition and development of the data product, as shown in Figure 4-3. This encompasses the detailed characterization of the data product, including who owns it, what it contains, and the rules governing its use. This clear and comprehensive definition is essential for ensuring that the data product is not only functional and accessible but also aligns with organizational policies and user needs. By thoroughly defining each data product, organizations can maximize their data’s value and utility, which makes this process a foundational aspect of modern strategies for data management.
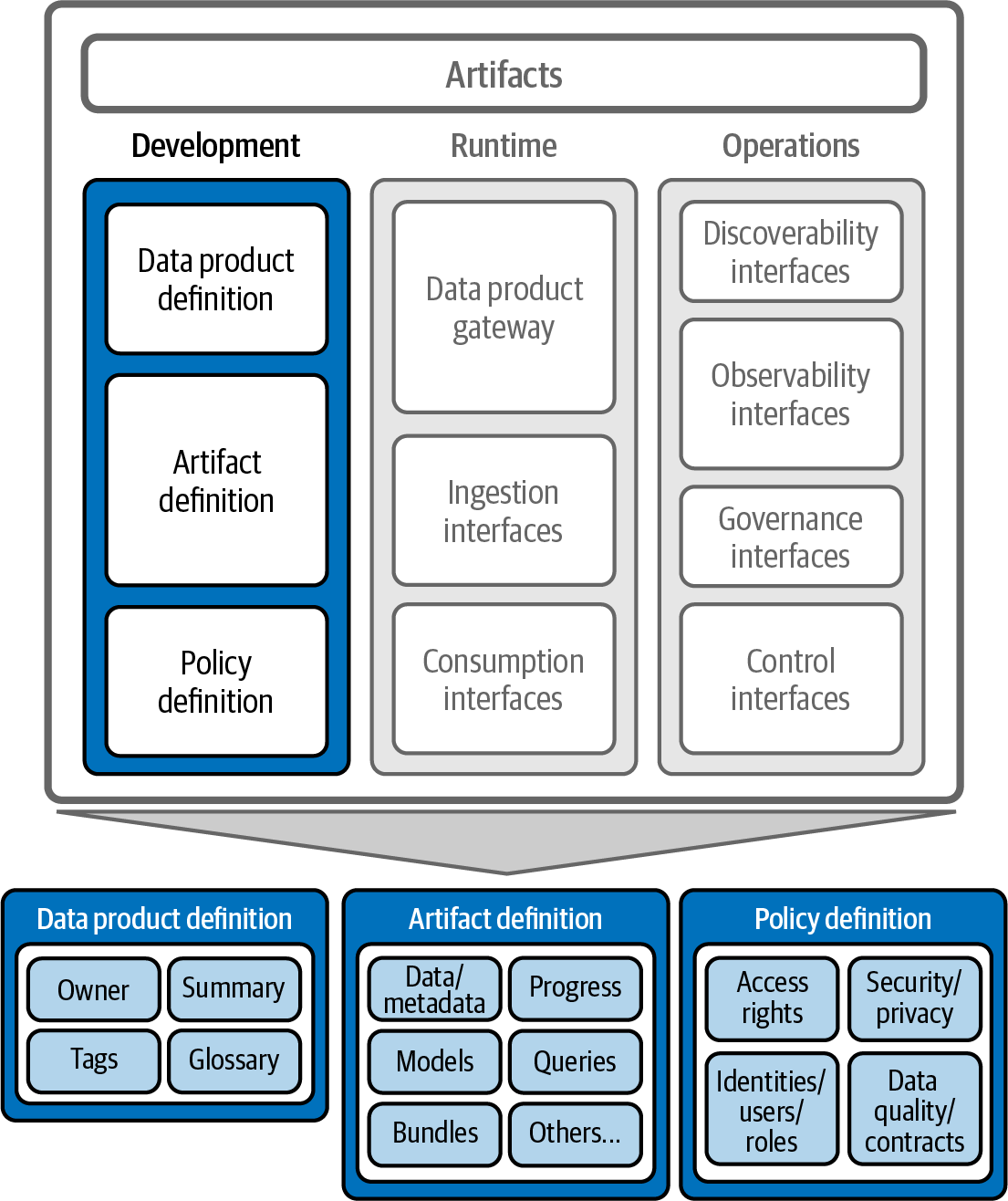
Figure 4-3. Data product definition and development
There are three groups of functionality in the data product development architecture:
- Data product definition
-
Describes the data product
- Artifact definition
-
Describes the artifacts within the data product
- Policy definition
-
Describes the rules and constraints for the data product and/or artifacts
Data product definition
The data product’s definition includes a minimum set of attributes:
- Namespace
-
The namespace (or domain) identifies the domain or category for the data product. Namespaces or domains are typically unique across a Data Mesh.
- Name
-
The name uniquely identifies the data product within its namespace/domain.
- Description
-
The description describes the data product’s purpose and contents.
- Links to endpoints
-
Links to endpoints are made available by the data product. These typically include references to discoverability, observability, administrative capabilities, and any other information the DPO wants to expose.
- Tags
-
Tags are keywords or labels that help categorize and organize data products within the larger ecosystem. Well-chosen tags can greatly simplify navigation and search processes within a Data Mesh (especially in the marketplace). Tags should ideally reference a broader business glossary, but note that this glossary does not need to start from a clean slate. Rather, many organizations leverage public and/or commercial business glossaries that have been created and vetted by experts.
- Owner
-
The owner (or publisher) plays a pivotal role, acting as the decision maker and primary source of knowledge for the data product. They are the key contact point for any questions, feedback, or problem resolution related to the data product. This information must be easily available and prominently displayed.
Artifact definition
Recall that a single data product can contain many artifacts, each with different and potentially unique form factors, attributes, and security and privacy needs. An artifact definition is more detailed than a data product definition and typically includes the following attributes:
- Name
-
The name uniquely identifies the artifact within the data product.
- Description
-
The description describes the artifact’s purpose and contents.
- Tags
-
Tags are keywords or labels that help categorize and organize artifacts within a Data Mesh.
- Policies
-
Policies reference the set of enterprise, regulatory, security, privacy, or operational rules and constraints that govern the data product’s use.
- Access rights
-
Access rights describe the permissions and roles required to access the artifact. Access rights should be verified before access to an artifact is granted.
- License
-
The license governs the terms of use for the artifact and should be agreed to when a consumer wants to access the data product.
- Links to endpoints
-
Links to endpoints made available by the data product typically include references to metadata, sample data, and links to the artifact’s data (as well as any other information the DPO wants to expose). Artifact links will probably have to be handled in a creative manner that explicitly recognizes their contents and may even require additional applications to access (for example, a link to a guide in PDF format would require a PDF reader).
Policy definition
The definition of policies for a data product is a critical component that governs the data product’s usage and ensures the security and privacy of the data. Policies are enabled through data contracts (addressed in detail in Chapter 5) and delineate the acceptable ways in which the data can be accessed and utilized, taking into account various considerations like access rights, identity management, user authorization, service- and quality-level expectations, and compliance with security and privacy regulations. Establishing clear and comprehensive policies is essential for maintaining the integrity of the data product and for protecting it from unauthorized access or misuse.
Access rights are the primary consideration in policy definition. They determine who can access the data product and what level of access they are granted. This can range from read-only access for some users to full administrative rights for others. Defining access rights involves assessing the needs, purpose, and responsibilities of different users or user groups and assigning access levels accordingly. Effective management of access rights is crucial for ensuring that users can perform their roles efficiently while preventing unauthorized access to sensitive data.
Integration with identity books of record is another important aspect of policy definition. By linking the data product with an enterprise’s identity management systems, organizations can streamline the process of user authentication and authorization. This not only enhances security by ensuring that only authenticated users gain access but also simplifies the administrative process of managing user access across various data products and systems.
Runtime Architecture Components
The runtime architecture, as shown in Figure 4-4, describes the components in a data product.
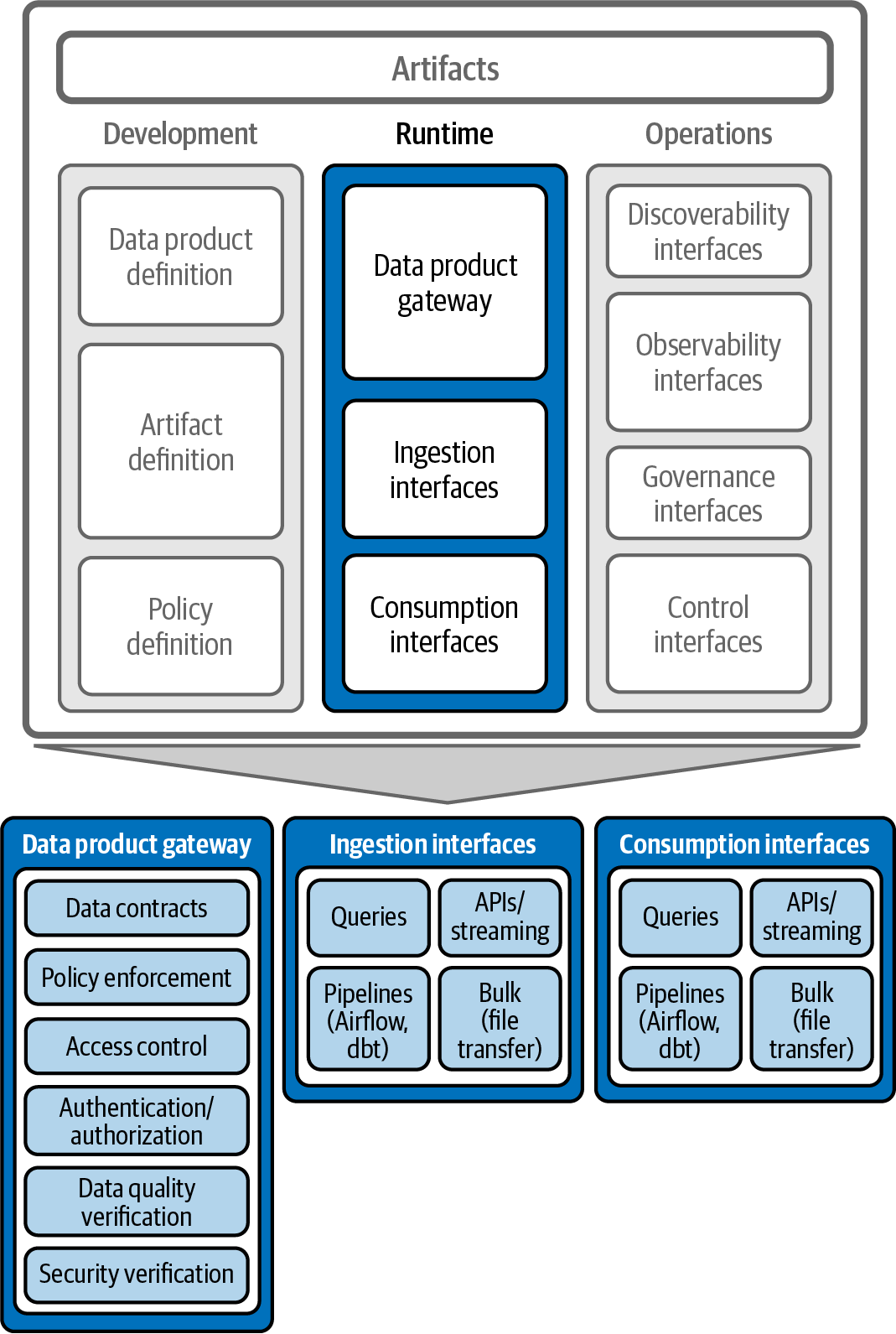
Figure 4-4. Data product runtime components
Data product gateway
All interactions with a data product—for consumers, publishers, and administrators—have interfaces that are implemented using a lightweight data product gateway, shown in Figure 4-5, which provides a consistent implementation for all interactions with the data product.
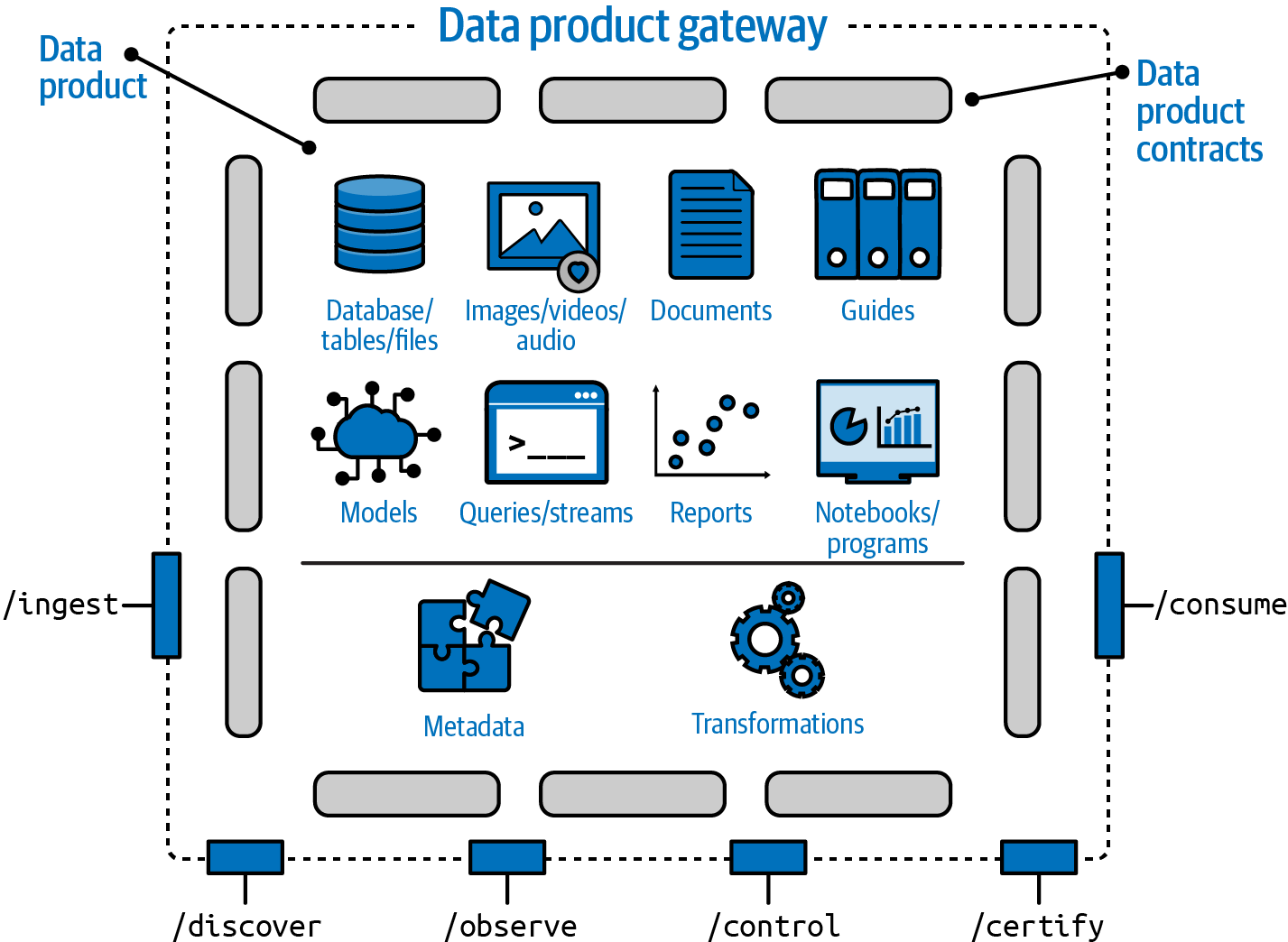
Figure 4-5. The data product gateway
The data product gateway is a lightweight framework and code that implements the various interfaces for a data product. While every data product is different and embodies unique capabilities, the mechanisms by which they interact and the signatures for their interactions can—and should—be made largely consistent.
This is true for ingestion (conceptually, an /ingest interface) and consumption (conceptually, a /consume interface). While these high-volume interfaces may be a simple passthru (passing requests through largely unchanged), the parameters and mechanisms for their interactions can be standardized.
This is even more practical for other core and foundational interfaces for discovery (/discover interface), observability (/observe interface), and control or management capabilities (/control interface). By doing this, all interactions with data products become consistent and standardized—which means that templating and “factories” become a practical consideration for streamlining and speeding up the creation and management of data products.
Since all requests flow through the data product gateway, it becomes the vehicle for implementing cross-cutting concerns that affect or benefit all data products, including access verification, logging, lineage, exception notifications, and many more. The data product gateway also becomes the integration point for data contracts and associated policy-enforcement mechanisms. Data contracts in the data product gateway set policies that all aspects of the data product are expected to adhere to and provide the mechanism for a consistent policy enforcement point. These contracts define the structure and format of data access mechanisms as well as security and privacy needs, data quality and integrity requirements, data lineage and version needs, and any needs related to service expectations. Simply put, they define the policies—and even the enforcement mechanisms—that a data product is expected to meet.
That probably just whets your appetite regarding the power of data contracts—recognizing the importance of data contracts for establishing a Data Mesh that meets user expectations, we have included a full chapter (Chapter 5) to explain the nitty-gritty details of data contracts and their implementation in data products.
Ingestion interfaces
Ingesting data into a data product is a fundamental process that determines how data is collected, processed, and made available for use. The method chosen for data ingestion depends on various factors, such as the volume of data, the frequency of updates, and the specific requirements of the data product. Understanding and selecting the right ingestion method is crucial for ensuring the efficiency and effectiveness of the data product. From APIs to bulk ingestion and pipelines, each technique has its own advantages and ideal use cases.
Queries are a common method for ingesting data and are particularly useful when dealing with real-time or near-real-time data updates. They are ideal for situations where data needs to be pulled frequently and in small amounts. Queries allow for specific data to be selected and retrieved based on certain criteria, making them efficient for targeted data ingestion. This method is especially useful for data products that require up-to-date information and can handle frequent incremental updates.
APIs are another popular method for data ingestion and are especially effective for smaller datasets or when data needs to be integrated from external sources. APIs facilitate a controlled, secure way to import data, allowing for specific datasets to be accessed and transferred. They are particularly useful when the data source and the data product need to communicate in a standardized, consistent manner. APIs are also beneficial when dealing with structured data and when the integration needs to be scalable and maintainable over time.
Bulk ingestion methods, such as file transfers, are suited for scenarios where large volumes of data need to be imported into the data product. This method is typically used for initial data loads or periodic updates where a significant amount of data is transferred at once. Bulk ingestion is efficient in terms of resource usage and time, especially when dealing with large datasets that do not require frequent updates. It is often used in conjunction with data warehousing or when integrating historical data into a data product.
Data pipelines, using tools like Airflow or dbt (data build tool), are designed for more complex data-ingestion scenarios. These tools allow data workflows to be automated, enabling the ingestion, transformation, and loading of data in a more controlled, systematic manner. Pipelines are particularly useful when the data-ingestion process involves multiple steps, such as data cleansing, transformation, or integration from multiple sources. They provide a robust framework for managing complex data flows, ensuring consistency and reliability in the data-ingestion process.
Other ingestion methods include streaming data ingestion, used for real-time data processing, and web scraping, for extracting data from web sources. Streaming data ingestion is ideal for scenarios where data is continuously generated and needs to be processed in real time.
Consumption interfaces
Obviously, once the data has been ingested into the data product, it needs to be made easy to consume. While ingestion is about how data gets into the data product, consumption is about how that data, along with other artifacts created by the DPO, is made available and useful to end users. Consumption focuses on the output and user interaction rather than the input of data into the system. The methods of consumption are similar to ingestion methods, ranging from queries and APIs to bulk transfers and pipelines.
Queries, streaming, and APIs are methods of data consumption that allow users to retrieve specific subsets of data based on their requirements or, in the case of streaming, to be notified when a data event (for example, a new row is added to a database) takes place. These methods support a high level of flexibility, letting users extract precisely what they need when they need it.
Bulk consumption methods, such as file transfers, are used when large volumes of data need to be accessed, often for offline processing or analysis. This method is typical in scenarios where the entire dataset or large parts of it are required, such as for data warehousing or big data analytics. Bulk consumption is less about real-time interaction and more about comprehensive access, making it suitable for use cases where extensive data processing is necessary.
Operations Architecture Components
Within a Data Mesh framework, the operational considerations for data products, shown in Figure 4-6, encompass a spectrum of interfaces and capabilities to ensure that data products not only are functional but also align with an organization’s overarching operational standards and expectations. These considerations include discoverability, observability, governance, and control interfaces. Each plays a pivotal role in the lifecycle and utility of a data product.
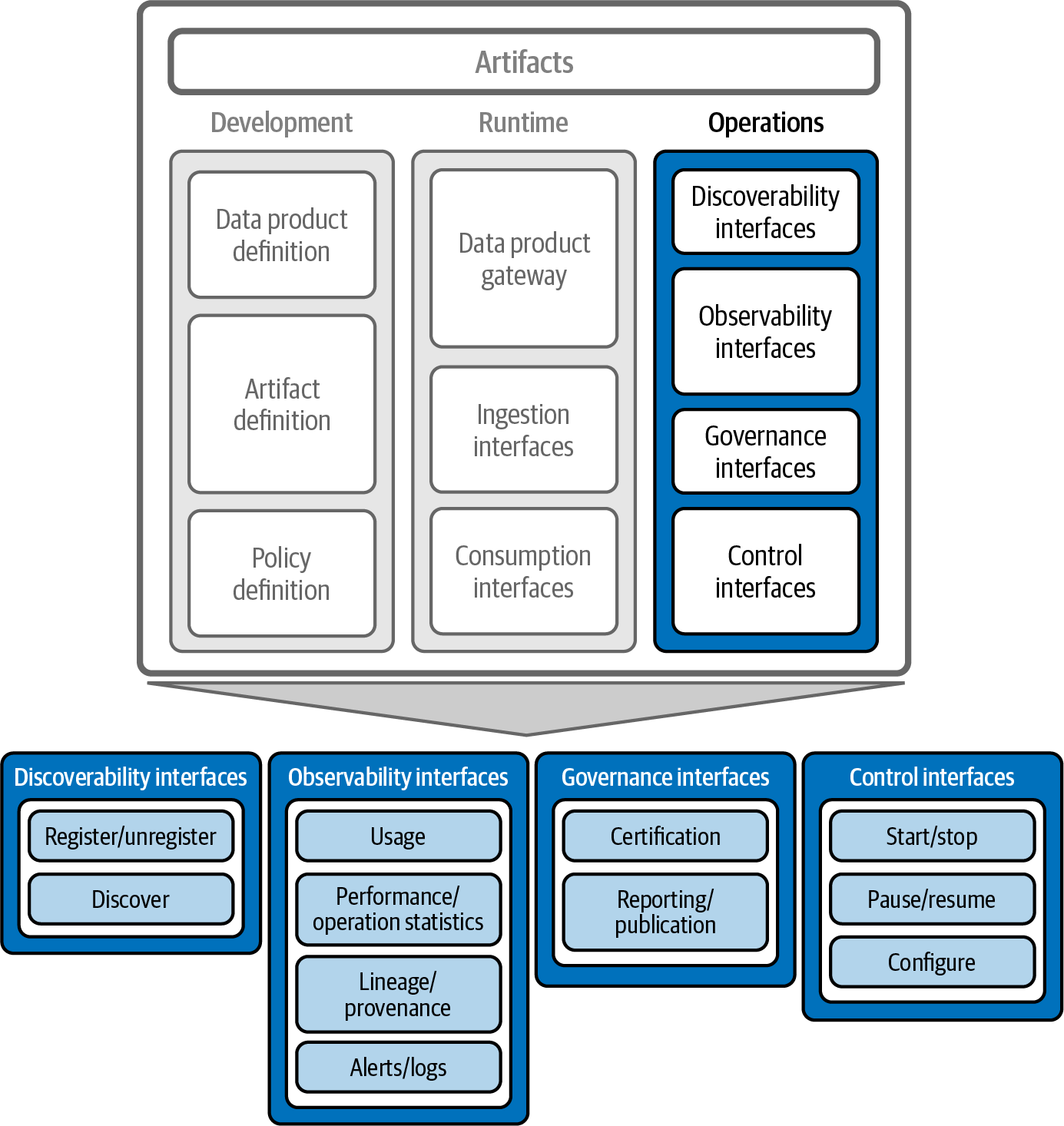
Figure 4-6. Data product operational components
Discoverability interfaces
Discoverability interfaces (conceptually, a /discover endpoint, as shown in Figure 4-5) enable data products to be first registered and then located within a Data Mesh, ensuring that the data products are visible and accessible to users.
Registration (conceptually, a /discover/registration endpoint) is akin to placing a pin on a digital map, marking the data product’s location and existence in the Data Mesh landscape. This registration is vital, as it ensures that the data product is not just a standalone entity but also a recognized part of the larger ecosystem of data products. The information provided during registration typically includes metadata from the data product and artifact definitions (namespace, name, etc.).
Once registered, a data product is made available in the Data Mesh Marketplace and can be found or “discovered” (conceptually, a /discover/metadata endpoint) in the ecosystem of data products. The metadata provided during the registration process can be viewed in the Data Mesh Marketplace, making data products and their artifacts easier to find, consume, and share.
Observability interfaces
Whereas data product metadata is relatively stable, the operational characteristics of a data product are constantly changing. Observability interfaces (conceptually, an /observe endpoint, as shown in Figure 4-5) monitor the continuously changing operating characteristics of a data product. These interfaces provide a comprehensive view into the various operational aspects of the data product, including usage statistics, performance metrics, and overall operating health. By offering real-time insights into how the data product is performing, observability interfaces allow data product owners and users to monitor and evaluate the product’s effectiveness.
One of the most significant benefits of observability interfaces is their ability to track and report on usage patterns. This includes how often the data product is accessed, which parts are most frequently used, and by whom. Such insights are invaluable for understanding user behavior and preferences, allowing for informed decisions on future enhancements or modifications to the data product. This data-driven approach ensures that the product evolves in line with user needs and remains relevant and useful over time while also aiding in resource allocation and scaling decisions, ensuring optimal performance even as demand fluctuates.
Observability interfaces also focus on performance and operating statistics. These encompass everything from load times and response rates to more complex metrics like data throughput and processing efficiency. Monitoring these aspects is crucial for maintaining a high level of service quality and for preemptively identifying potential bottlenecks or performance issues. Surfacing alerts and making logs accessible through observability interfaces are essential for problem diagnosis, enabling quick and effective troubleshooting. This not only minimizes downtime but also ensures that data quality and accuracy are maintained, which is critical for making informed decisions based on the data.
Lineage and provenance tracking exposed in observability interfaces offers traceability of processing within a data product. This feature provides detailed information about the origin and historical changes of the data, all of which are essential for maintaining data integrity and trust. It ensures transparency in how data has been collected, processed, and transformed over time.
Governance interfaces
Governance interfaces are critical for maintaining data integrity and compliance. These interfaces are designed to facilitate the process of certification or verification, whereby owners can assert that their data products meet specific standards of data quality, service-level expectations, regulatory compliance, and even lineage records (many of which can be defined in data contracts).
Viewing these interfaces is typically initiated by the user, who requests the governance or certification status of a data product and receives a report or checklist in response. The following set of interfaces is typically desired (note that the endpoints are conceptual; in practice, they are more verbose):
/certify-
Get the data product’s certification status or report.
/certify/subscribe-
Request to be notified when a governance threshold has been met or not met.
/certify/publish-
Proactively publish the data product’s governance or certification status on a regular basis.
These interfaces offer transparency into data management practices and standards adhered to by the data product. By providing clear insights into their governance practices, DPOs can build confidence among users, reassuring them that the data is managed responsibly and in accordance with best practices and regulatory requirements.
Control interfaces
Control interfaces in the context of data products are essential tools that give DPOs the ability to manage the operational state of their offerings. These interfaces encompass a range of functionalities, including the ability to start or stop the data product (conceptually, a /control/start or /control/stop interface) and to configure various settings and parameters (conceptually, a /control/configure interface).
This level of control is crucial for ensuring that data products can be managed effectively and can respond flexibly to different operational requirements or situations. In essence, control interfaces act as the command center for DPOs, offering them direct oversight and management capabilities for their products.
Moreover, the configuration aspect of control interfaces plays a significant role in tailoring the data product to specific needs or conditions. Owners can adjust settings to optimize performance, customize features according to user feedback, or dynamically adapt to changing data environments. In a landscape where users’ needs and technological environments are constantly evolving, the ability to configure and reconfigure data products swiftly ensures that the data products continue to deliver value and meet the expectations of their users.
Data Mesh Architecture
As defined earlier, Data Mesh is an ecosystem composed of numerous data products, each functioning as a distinct unit with its own purpose and capabilities. However, what makes Data Mesh truly powerful are the components that bind data products into a cohesive and integrated whole. These components, shown in Figure 4-7, specifically address capabilities and components that are used by many, and perhaps all, data products, including the Data Mesh Marketplace, the Data Mesh Registry, and the Data Mesh backbone services. They are the connective tissue that binds all components into a Data Mesh.
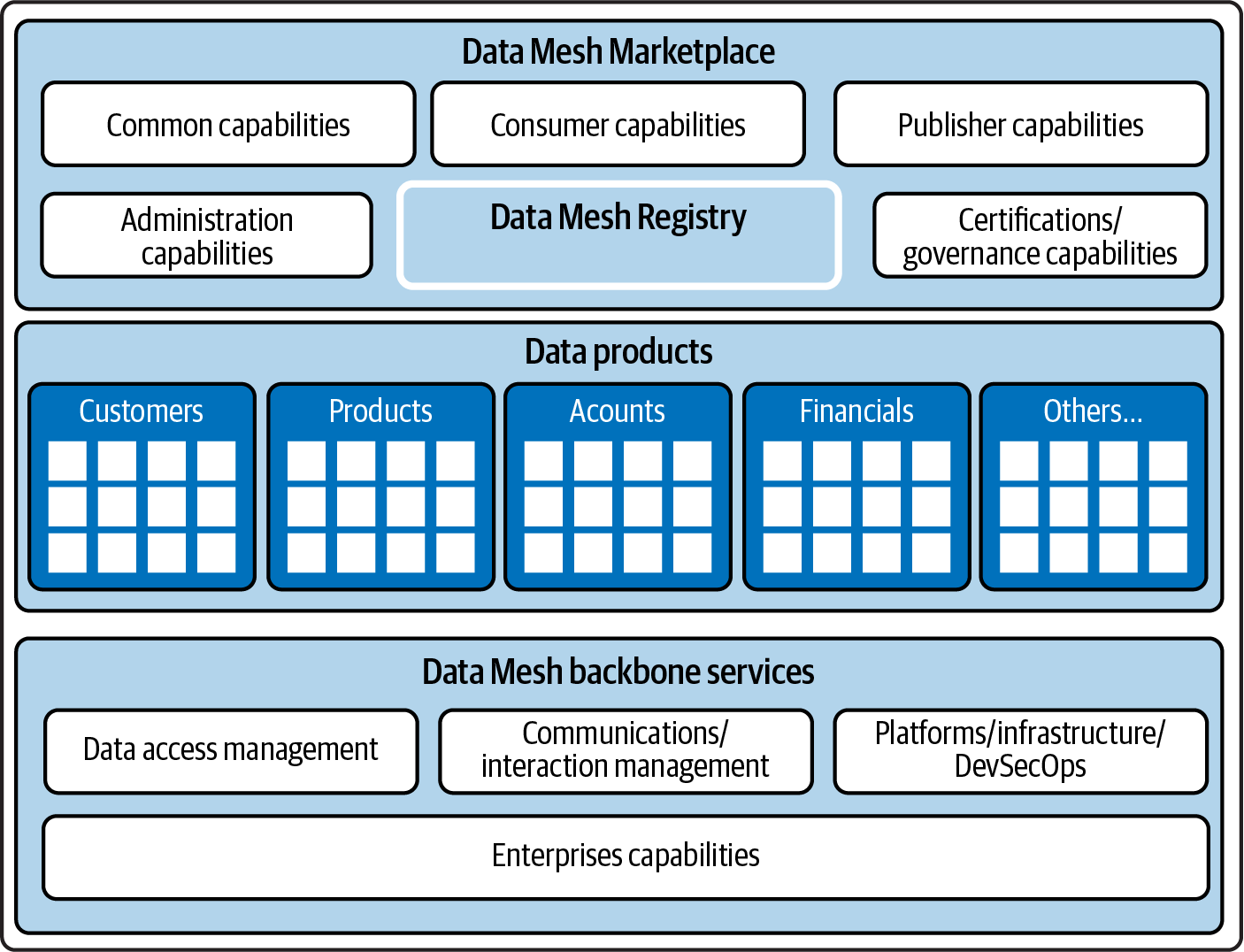
Figure 4-7. Data Mesh architecture
Data Mesh Marketplace and Registry
The Data Mesh Marketplace is a user interface that simplifies the process of finding, consuming, sharing, and establishing trust in data products. This marketplace is a window into a Data Mesh and an interactive space where data becomes more accessible and actionable for consumers, producers, governance professionals, and administrators.
The marketplace’s close cousin, the Data Mesh Registry, is a repository for information about a Data Mesh that acts as a phone book for it, much like DNS does for the internet. In many respects, the registry is the backend database for the marketplace, but it also maintains much more information.
We will leave it at that for now. Recognizing the importance of the marketplace and registry to Data Mesh, we have devoted a full chapter (Chapter 11) to these components.
Data Mesh Backbone Services
Data Mesh backbone services integrate Data Mesh components and data products into a cohesive whole, providing the necessary foundation for data products to communicate, interact, and deliver value.
Data access services include a set of common tools and technologies for federated query, data pipelines, and bulk data transfer. These services allow for efficient, flexible access to data across a Data Mesh and its data products, regardless of where they reside. Federated-query capabilities, for instance, enable users to retrieve and combine data from multiple sources without moving the data while pipelines and bulk transfer mechanisms provide efficient ways to move large volumes of data when necessary.
Communication and interaction services are another critical aspect of the Data Mesh backbone services. These services encompass APIs (RESTful and GraphQL APIs are common), streaming technologies (e.g., Kafka), and change data capture mechanisms (such as Debezium). They facilitate the interaction and exchange of information between different data products, enabling them to communicate and share data in real time. This interconnectedness is essential for creating a dynamic, responsive data ecosystem, where data can flow freely and securely between different data products (and other enterprise applications or external systems).
At the technical foundational layer of the Data Mesh fabric are the platform, infrastructure, and DevSecOps services. Platforms include a range of data management solutions like databases (e.g., PostgreSQL), data marts, data warehouses, data lakes, and data lakehouses (from vendors such as Snowflake and Databricks).
Infrastructure services provide the foundational compute, network, and storage capabilities that form the core platform supporting almost all components of a Data Mesh. They provide the essential resources required for data processing, storage, and orchestration, ensuring that data products have the necessary computational power and space to operate effectively.
DevSecOps (development, security, and operations) ensures that all services within a Data Mesh are managed—from development through deployment and management in a production environment—in an automated, safe, and reliable fashion. Applying DevSecOps to Data Mesh and data products provides the process and automation that will speed up the development as well as the deployment of data products.
Climate Quantum Use Case Considerations
At this point, we understand the architecture of a data product, how it defines its data and artifacts, its ingestion and consumption capabilities, and its core operational interfaces. We have also seen the constituent components of Data Mesh and how it binds data products into a broader ecosystem.
Now, let’s see how we can put the pieces together for a high-level architecture for Climate Quantum, our use case. As you recall, Climate Quantum’s mission is to make climate data easy to find, consume, share, and trust using data products and a broader Data Mesh ecosystem. Climate Quantum addresses many domains of climate data; a snapshot of Climate Quantum’s Data Mesh addressing specific data domains is shown in Figure 4-8.
Climate Quantum ingests data from raw climate data sources and creates several distinct domains:
- Flood data domain
-
Captures raw climate data (e.g., from weather stations, sensors, gauges, and satellite images) into more usable forms (e.g., identifying areas subject to flooding from a very large satellite image)
- Physical risk domain
-
Answers the question “Which of my assets, buildings, and population centers are affected by climate change?”
- Disclosure reporting domain
-
Responds to the need to disclose physical risks to regulators and stakeholders
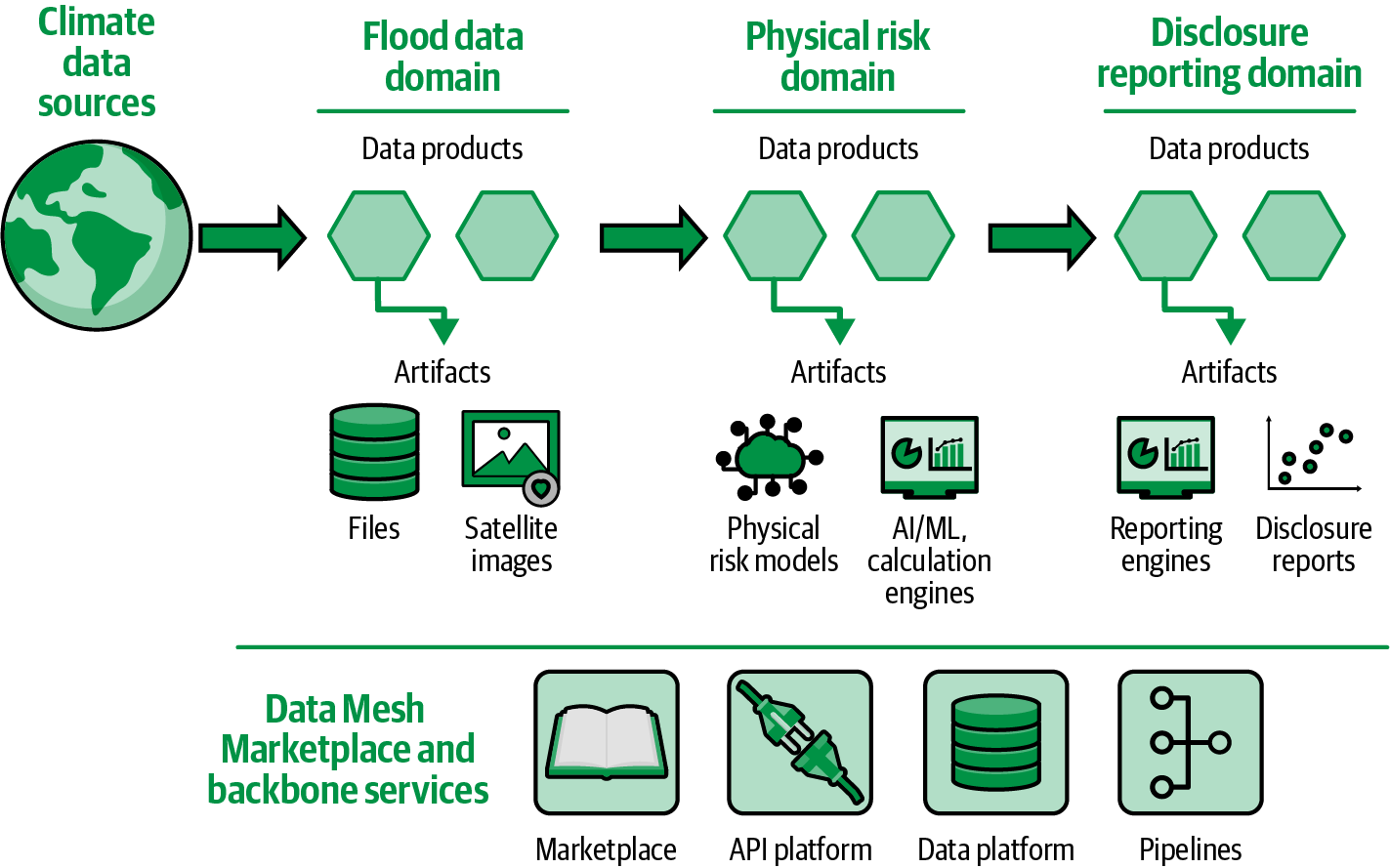
Figure 4-8. Climate Quantum Data Mesh snapshot
Each data product has a consistent definition (namespace, names, and other attributes mentioned previously). And each is both discoverable and observable using a lightweight data product gateway with published APIs. Each artifact is defined in a consistent way (using previously mentioned artifact attributes), making it easy to consume. All of this processing is supported using several core Data Mesh architecture components:
- Data Mesh Marketplace
-
All data products and their artifacts are published to the Data Mesh Marketplace, making them easy to find and consume by users as well as by other data products.
- Data Mesh backbone services
-
All data products interact via pipelines built on a number of common products, including Airflow and dbt, with data stored in a data platform and accessed via APIs made available through an API platform.
Hopefully, you can see that even in a data landscape as complex and diverse as climate data, Data Mesh can make the data agile.
Summary
Previous chapters described the essentials of a data product. In this chapter, we discussed the various architecture components that make up a Data Mesh, its data products, and the data product’s artifacts.
In the next chapter, we will elaborate on data contracts and then apply this architecture to show how to implement data products.
Get Implementing Data Mesh now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

