Kapitel 1. Eine Fibel über Selen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Selenium ist eine Open-Source-Suite, die aus einer Reihe von Bibliotheken und Tools besteht, die die Automatisierung von Webbrowsern ermöglichen. Wir können Selenium als ein Dachprojekt mit drei Kernkomponenten sehen: WebDriver, Grid und IDE (Integrated Development Environment). Selenium WebDriver ist eine Bibliothek, mit der sich Browser programmatisch steuern lassen. So können wir mit Selenium WebDriver auf Websites navigieren und mit Webseiten interagieren (z. B. auf Links klicken, Formulare ausfüllen usw.), so wie es ein echter Benutzer tun würde, nur eben auf automatisierte Weise. Das Haupteinsatzgebiet von Selenium WebDriver ist das automatisierte Testen von Webanwendungen. Andere Einsatzgebiete von Selenium sind die Automatisierung von webbasierten Verwaltungsaufgaben oder Web Scraping (automatisierte Extraktion von Webdaten).
Dieses Kapitel bietet einen umfassenden Überblick über die Selenium-Kernkomponenten: WebDriver, Grid und IDE. Dann wird das Selenium-Ökosystem vorgestellt, d.h. andere Tools und Technologien, die Selenium umgeben. Schließlich werden die Grundlagen des Softwaretestens in Verbindung mit Selenium analysiert.
Selenium Kernkomponenten
Jason Huggins und Paul Hammant gründeten Selenium im Jahr 2004, als sie bei Thoughtworks arbeiteten. Sie wählten den Namen "Selenium" als Gegenstück zu Mercury, einem bestehenden, von Hewlett-Packard entwickelten Testframework. Der Name ist bezeichnend, weil die Chemikalie Selen dafür bekannt ist, die Toxizität von Quecksilber zu verringern.
Diese erste Version von Selenium (heute als Selenium Core bekannt) ist eine JavaScript-Bibliothek, die Benutzeraktionen in Webanwendungen nachahmt. Um diese Aufgabe zu erfüllen, interpretiert Selenium Core die sogenannten Selen-Befehle. Diese Befehle sind als HTML-Tabelle kodiert, die aus drei Teilen besteht: Befehl (Aktion, die in einem Webbrowser ausgeführt wird, z. B. das Öffnen einer URL oder das Anklicken eines Links), Ziel (Locator, der ein Webelement identifiziert, z. B. das Attribut einer bestimmten Komponente) und Wert (optionale Daten, z. B. der in ein Webformularfeld eingegebene Text).
Huggins und Hammant haben Selenium Core in einem neuen Projekt namens Selenium Remote Control (RC) um eine Skripting-Ebene erweitert. Selenium RC folgt einer Client-Server-Architektur. Clients verwenden eine Bindungssprache (z. B. Java oder JavaScript), um Selenium-Befehle über HTTP an einen zwischengeschalteten Proxy namens Selenium RC Server zu senden. Dieser Server startet bei Bedarf Webbrowser, injiziert die Selenium Core-Bibliothek in eine Website und leitet Anfragen von Clients an Selenium Core weiter. Darüber hinaus maskiert der Selenium RC Server die Zielwebseite auf die gleiche lokale URL wie die eingespeiste Selenium Core-Bibliothek, um Probleme mit der Same-Origin-Policy zu vermeiden. Dieser Ansatz war damals ein Durchbruch für die Browser-Automatisierung, hatte aber auch erhebliche Einschränkungen. Da JavaScript die zugrunde liegende Technologie zur Unterstützung der Automatisierung ist, sind einige Aktionen nicht erlaubt, da JavaScript sie nicht zulässt, z. B. das Hoch- und Herunterladen von Dateien oder der Umgang mit Pop-ups und Dialogen, um nur einige zu nennen. Außerdem führt Selenium RC einen erheblichen Overhead ein, der sich auf die Leistung des Programms auswirkt.
Parallel dazu gründete Simon Stewart im Jahr 2007 das Projekt WebDriver. WebDriver und Selenium RC waren aus funktionaler Sicht gleichwertig, d. h. beide Projekte ermöglichen es Programmierern, sich mithilfe einer Programmiersprache als Webbenutzer auszugeben. Dennoch nutzt WebDriver die native Unterstützung des jeweiligen Browsers, um die Automatisierung durchzuführen, und ist daher in seinen Möglichkeiten und seiner Leistung RC weit überlegen. 2009 beschlossen Jason Huggins und Simon Stewart nach einem Treffen auf der Google Test Automation Conference, Selenium und WebDriver in einem einzigen Projekt zu vereinen. Das neue Projekt wurde Selenium WebDriver oder Selenium 2 genannt. Dieses neue Projekt verwendet ein auf HTTP basierendes Kommunikationsprotokoll in Kombination mit der nativen Automatisierungsunterstützung des Browsers. Dieser Ansatz ist immer noch die Grundlage von Selenium 3 (veröffentlicht 2016) und Selenium 4 (veröffentlicht 2021). Heute bezeichnen wir Selenium RC und Core als "Selenium 1" und raten von seiner Verwendung zugunsten von Selenium WebDriver ab. Dieses Buch konzentriert sich auf die neueste Version von Selenium WebDriver, d.h. Version 4.
Tipp
Anhang A fasst die Neuerungen zusammen, die mit Selenium 4 ausgeliefert werden. Dieser Anhang enthält auch einen Migrationsleitfaden für den Umstieg von Selenium 3 auf 4.
Heute ist Selenium eine bekannte Automatisierungssuite, die aus drei Teilprojekten besteht: WebDriver, Grid und IDE. In den folgenden Unterkapiteln von werden die wichtigsten Merkmale der einzelnen Projekte vorgestellt.
Selenium WebDriver
Selenium WebDriver ist eine Bibliothek, die die automatische Steuerung von Webbrowsern ermöglicht. Zu diesem Zweck bietet sie eine plattformübergreifende API in verschiedenen Sprachbindungen. Die offiziellen von Selenium WebDriver unterstützten Programmiersprachen sind Java, JavaScript, Python, Ruby und C#. Intern nutzt Selenium WebDriver die native Unterstützung, die von jedem Browser implementiert wird, um den Automatisierungsprozess auszuführen. Aus diesem Grund müssen wir eine Komponente namens Treiber zwischen dem Skript, das die Selenium WebDriver API verwendet, und dem Browser platzieren. Tabelle 1-1 fasst die Browser und Treiber zusammen, die offiziell von Selenium WebDriver unterstützt werden.
Hinweis
Der Name Selenium wird häufig verwendet, um die Bibliothek für die Browser-Automatisierung zu bezeichnen. Da dieser Begriff auch der Name des Dachprojekts ist, verwende ich Selenium in diesem Buch, um die Browser-Automatisierungssuite zu bezeichnen, die aus drei Komponenten besteht: Selenium WebDriver (Bibliothek), Selenium Grid (Infrastruktur) und Selenium IDE (Werkzeug).
| Browser | Treiber | Operationssystem | Maintainer | Herunterladen |
|---|---|---|---|---|
Chrom/Chrom |
chromedriver |
Windows/macOS/Linux |
||
Kanten |
msedgedriver |
Windows/macOS/Linux |
Microsoft |
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver |
Firefox |
geckodriver |
Windows/macOS/Linux |
Mozilla |
|
Oper |
operadriver |
Windows/macOS/Linux |
Opera Software AS |
|
Internet Explorer |
IEDriverServer |
Windows |
Selenium Projekt |
|
Safari |
safaridriver |
macOS |
Apfel |
Eingebaut |
Treiber (z. B. Chromedriver, Geckodriver usw.) sind plattformabhängige Binärdateien, die Befehle von einem WebDriver-Skript empfangen und sie in eine browserspezifische Sprache übersetzen. In den ersten Versionen von Selenium WebDriver (d.h. in Selenium 2) waren diese Befehle (auch als Selenium-Protokoll bekannt) JSON-Nachrichten über HTTP (das sogenannte JSON Wire Protocol). Heutzutage folgt diese Kommunikation (immer noch JSON über HTTP) einer Standardspezifikation namens W3C WebDriver. Diese Spezifikation ist das bevorzugte Selenium-Protokoll ab Selenium 4.
Abbildung 1-1 fasst die Grundarchitektur von Selenium WebDriver zusammen, die wir bisher gesehen haben. Wie du sehen kannst, besteht diese Architektur aus drei Ebenen. Zuerst finden wir ein Skript, das die Selenium WebDriver API verwendet (Java, JavaScript, Python, Ruby oder C#). Dieses Skript sendet W3C WebDriver-Befehle an die zweite Schicht, in der wir die Treiber finden. Diese Abbildung zeigt den speziellen Fall der Verwendung von chromedriver (zur Steuerung von Chrome) und geckodriver (zur Steuerung von Firefox). Die dritte Schicht schließlich enthält die Webbrowser. Im Fall von Chrome folgt der native Browser dem DevTools-Protokoll. DevTools ist eine Reihe von Entwicklerwerkzeugen für Browser, die auf der Blink-Rendering-Engine basieren, wie Chrome, Chromium, Edge oder Opera. Das DevTools-Protokoll basiert auf JSON-RPC-Nachrichten und ermöglicht es, diese Browser zu untersuchen, zu debuggen und Profile zu erstellen. In Firefox verwendet die native Automatisierungsunterstützung das Marionette-Protokoll. Marionette ist ein auf JSON basierendes Remote-Protokoll, mit dem sich Webbrowser, die auf der Gecko-Engine basieren (wie Firefox), instrumentieren und steuern lassen.
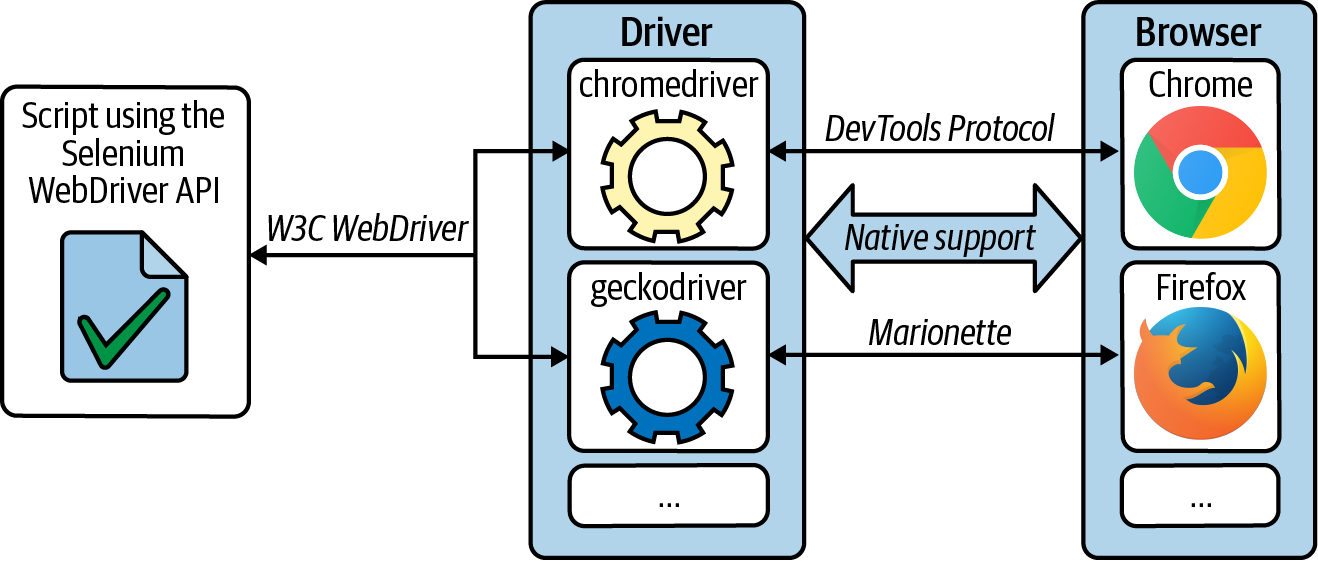
Abbildung 1-1. Selenium WebDriver Architektur
Insgesamt ermöglicht Selenium WebDriver die Steuerung von Webbrowsern wie ein Benutzer, allerdings programmatisch. Zu diesem Zweck bietet die Selenium WebDriver API eine Vielzahl von Funktionen, um durch Webseiten zu navigieren, mit Webelementen zu interagieren oder Benutzeraktionen zu imitieren, neben vielen anderen Möglichkeiten. Die Zielanwendung ist webbasiert, z. B. statische Webseiten, dynamische Webanwendungen, Single Page Applications (SPA), komplexe Unternehmenssysteme mit einer Weboberfläche, usw.
Selenium-Gitter
Das zweite Projekt der Selenium-Familie ist Selenium Grid. Philippe Hanrigou begann mit der Entwicklung dieses Projekts im Jahr 2008. Selenium Grid ist eine Gruppe von vernetzten Hosts, die eine Browser-Infrastruktur für Selenium WebDriver bereitstellt. Diese Infrastruktur ermöglicht die (parallele) Ausführung von Selenium WebDriver-Skripten mit entfernten Browsern unterschiedlicher Art (Typen und Versionen) auf mehreren Betriebssystemen.
Abbildung 1-2 zeigt die grundlegende Architektur von Selenium Grid. Wie du siehst, stellt eine Gruppe von Knoten die von den Selenium-Skripten verwendeten Browser bereit. Diese Knoten können verschiedene Betriebssysteme (wie wir in Tabelle 1-1 gesehen haben) mit verschiedenen installierten Browsern verwenden. Der zentrale Einstiegspunkt in dieses Grid ist der Hub (auch bekannt als Selenium Server). Diese serverseitige Komponente behält den Überblick über die Knoten und leitet die Anfragen der Selenium-Skripte weiter. Wie bei Selenium WebDriver ist die W3C WebDriver-Spezifikation das Standardprotokoll für die Kommunikation zwischen diesen Skripten und dem Hub.
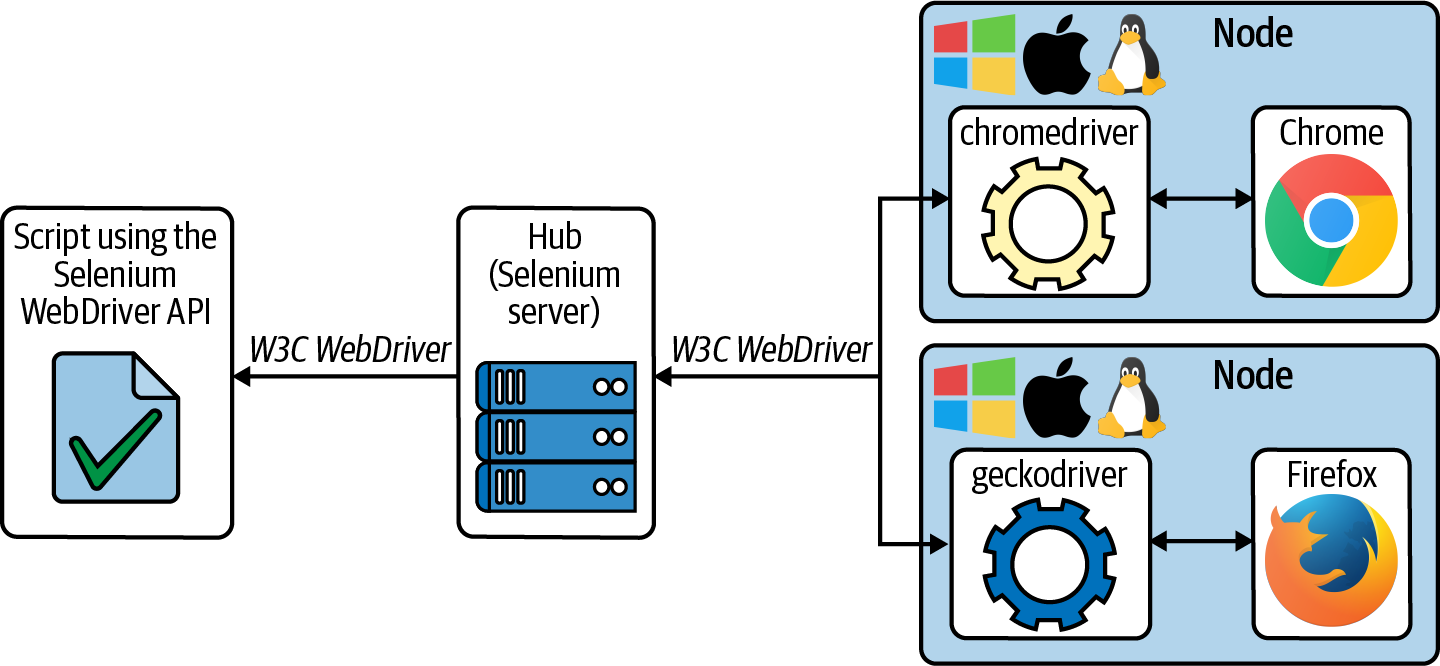
Abbildung 1-2. Selenium Grid Hub-Knoten Architektur
Die Hub-Nodes Architektur im Grid gibt es seit Selenium 2. Diese Architektur ist auch in Selenium 3 und 4 vorhanden. Allerdings kann diese zentralisierte Architektur zu Leistungsengpässen führen, wenn die Anzahl der Anfragen an den Hub hoch ist. Selenium 4 bietet eine vollständig verteilte Variante von Selenium Grid, um dieses Problem zu vermeiden. Diese Architektur implementiert fortschrittliche Lastausgleichsmechanismen, um eine Überlastung der einzelnen Komponenten zu vermeiden.
Tipp
In Kapitel 6 wird beschrieben, wie du Selenium Grid nach dem klassischen Ansatz einrichtest (basierend auf einem Hub und einer Reihe von Knotenpunkten). Dieses Kapitel behandelt auch den Standalone-Modus (d.h. Hub und Knoten werden auf demselben Rechner gehostet) und die vollständig verteilte Architektur.
Selenium IDE
Selenium IDE ist die letzte Kernkomponente der Selenium Suite. Shinya Kasatani hat dieses Projekt 2006 ins Leben gerufen. Selenium IDE ist ein Werkzeug, das die sogenannte Record and Playback (R&P) Automatisierungstechnik umsetzt. Wie der Name schon sagt, besteht diese Technik aus zwei Schritten. Erstens werden in Selenium IDE die Benutzerinteraktionen mit einem Browser aufgezeichnet und als Selenium-Befehle kodiert. Zweitens verwenden wir das generierte Selenium-Skript, um eine Browsersitzung automatisch auszuführen(Playback).
Diese frühe Version der Selenium IDE war ein Firefox-Plug-in, das Selenium Core einbettete, um Selenium-Skripte aufzuzeichnen, zu bearbeiten und abzuspielen. Diese frühen Versionen waren XPI-Module (d.h. eine Technologie, die zur Erstellung von Mozilla-Erweiterungen verwendet wird). Mit der Version 55 (2017 veröffentlicht) hat Firefox die Unterstützung für Add-ons auf die W3C-Spezifikation für Browsererweiterungen umgestellt. Infolgedessen wurde die Selenium IDE eingestellt und konnte eine Zeit lang nicht mehr verwendet werden. Um dieses Problem zu lösen, hat das Selenium-Team die Selenium IDE gemäß der Empfehlung für Browser-Erweiterungen neu geschrieben. Dadurch können wir Selenium IDE jetzt in mehreren Browsern wie Chrome, Kanten und Firefox verwenden.
Abbildung 1-3 zeigt die neue Selenium IDE GUI (Graphical User Interface).
Mit dieser GUI können Nutzer Interaktionen mit einem Browser aufzeichnen und das erzeugte Skript bearbeiten und ausführen. Die Selenium IDE kodiert jede Interaktion in verschiedene Teile: einen Befehl (d. h. die im Browser ausgeführte Aktion), ein Ziel (d. h. den Locator des Webelements) und einen Wert (d. h. die verarbeiteten Daten). Optional können wir auch eine Beschreibung des Befehls hinzufügen. Abbildung 1-3 zeigt ein aufgezeichnetes Beispiel für diese Schritte:
-
Website öffnen(https://bonigarcia.dev/selenium-webdriver-java). Wir werden diese Website im weiteren Verlauf des Buches als Übungsseite verwenden.
-
Klicke auf den Link mit dem Text "GitHub". Daraufhin bewegt sich die Navigation zum Quellcode des Beispiel-Repositorys.
-
Stelle sicher, dass der Buchtitel(Hands-On Selenium WebDriver with Java) auf der Webseite vorhanden ist.
-
Schließe den Browser.
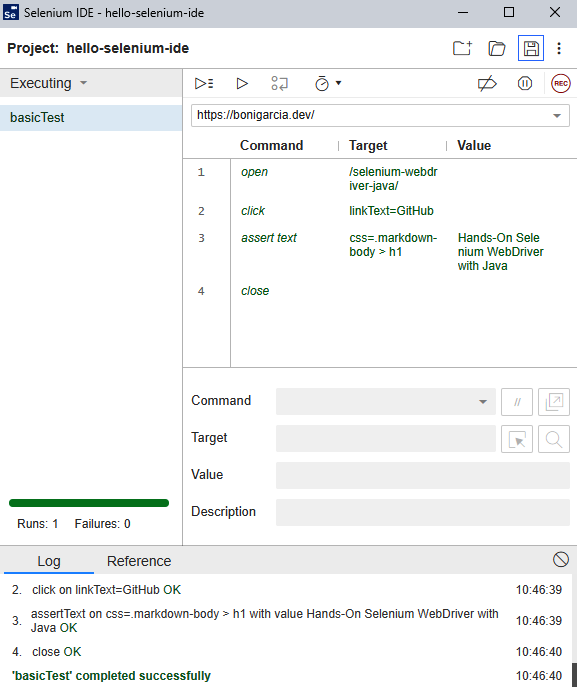
Abbildung 1-3. Selenium IDE zeigt ein Beispiel für ein aufgezeichnetes Skript
Sobald wir ein Skript in der Selenium IDE erstellt haben, können wir dieses Skript als Selenium WebDriver-Test exportieren. Abbildung 1-4 zeigt zum Beispiel, wie das Beispiel von in einen JUnit-Testfall umgewandelt wird. Schließlich können wir das Projekt auf unserem lokalen Rechner speichern. Das resultierende Projekt für dieses Beispiel ist im GitHub-Repository für Beispiele verfügbar.
Hinweis
Das Selenium-Projekt portiert die Selenium IDE auf Electron, wenn dieser Artikel geschrieben wird. Electron ist ein Open Source Framework, das auf Chromium und Node.js basiert und die Entwicklung von Desktop-Anwendungen ermöglicht.
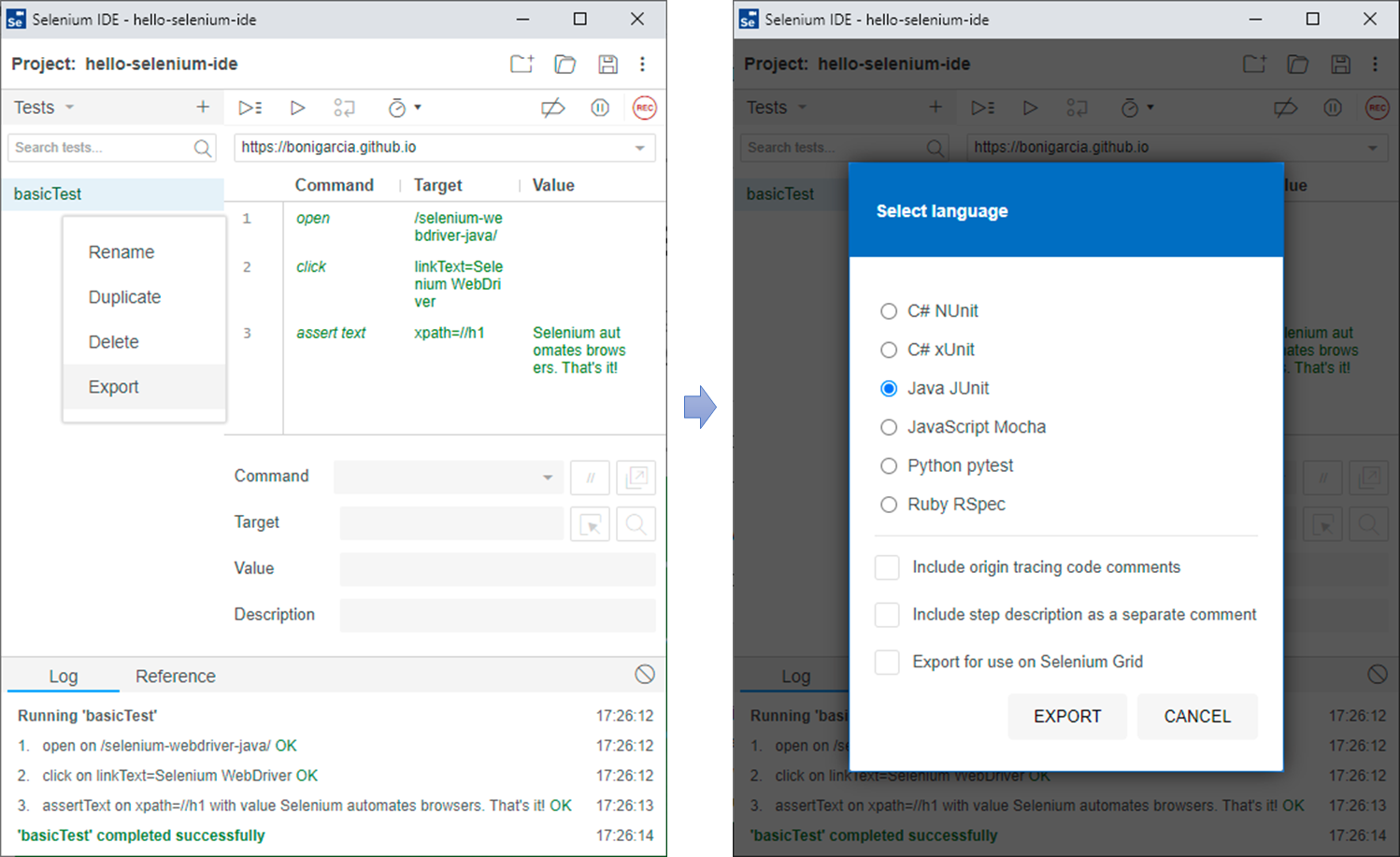
Abbildung 1-4. Exportieren eines Selenium IDE-Skripts in einen JUnit-Testfall
Selen-Ökosystem
Software-Ökosysteme sind Ansammlungen von Elementen, die auf einem gemeinsamen Markt interagieren und auf einem gemeinsamen technologischen Hintergrund basieren. Im Fall von Selenium umfasst das Ökosystem die offiziellen Kernprojekte und andere verwandte Projekte, Bibliotheken und Akteure. Dieser Abschnitt gibt einen Überblick über das Selenium-Ökosystem, das in die folgenden Kategorien unterteilt ist: Sprachbindungen, Treibermanager, Frameworks, Browser-Infrastruktur und Community.
Sprachbindungen
Wie wir bereits wissen, unterhält das Selenium Projekt verschiedene Sprachbindungen für Selenium WebDriver: Java, JavaScript, Python, Ruby und C#. Es sind aber auch andere Sprachen verfügbar. Tabelle 1-2 fasst diese Sprachbindungen für Selenium WebDriver zusammen, die von der Community gepflegt werden.
| Name | Sprache | Lizenz | Maintainer | Website |
|---|---|---|---|---|
hs-webdriver |
Haskell |
BSD-3-Klausel |
Adam Curtis |
|
php-webdriver |
PHP |
MIT |
Facebook, Gemeinschaft |
|
RSelenium |
R |
AGPLv3 |
rOpenSci |
|
Selen |
Geh |
MIT |
Miki Tebeka |
|
Selenium-Remote-Treiber |
Perl |
Apache 2.0 |
George S. Baugh |
|
webdriver.dart |
Dart |
Apache 2.0 |
||
wd |
JavaScript |
Apache 2.0 |
Adam Christian |
Fahrer-Manager
Treiber sind Pflichtkomponenten, um Webbrowser nativ mit Selenium WebDriver zu steuern (siehe Abbildung 1-1). Aus diesem Grund müssen wir, bevor wir die Selenium WebDriver API nutzen können, diese Treiber unter verwalten. Bei der Treiberverwaltung geht es darum, den richtigen Treiber für einen bestimmten Browser herunterzuladen, einzurichten und zu verwalten. Die üblichen Schritte bei der Treiberverwaltung sind:
- 1. Herunterladen
-
Jeder Browser hat seinen eigenen Treiber. Wir verwenden zum Beispiel chromedriver für die Steuerung von Chrome oder geckodriver für Firefox (siehe Tabelle 1-1). Der Treiber ist eine plattformspezifische Binärdatei. Deshalb müssen wir den richtigen Treiber für ein bestimmtes Betriebssystem (in der Regel Windows, macOS oder Linux) herunterladen. Außerdem müssen wir die Treiberversion berücksichtigen, da eine Treiberversion mit einer bestimmten Browserversion (oder -reihe) kompatibel ist. Um zum Beispiel Chrome 91.x zu verwenden, müssen wir chromedriver 91.0.4472.19 herunterladen. Die Browser-Treiber-Kompatibilität findest du normalerweise in der Treiberdokumentation oder in den Versionshinweisen.
- 2. Einrichtung
-
Sobald wir den richtigen Treiber haben, müssen wir ihn in unserem Selenium WebDriver-Skript verfügbar machen.
- 3. Wartung
-
Moderne Webbrowser (z. B. Chrome, Firefox oder Edge) aktualisieren sich automatisch und geräuschlos, ohne Eingabeaufforderung an den Benutzer. Aus diesem Grund und im Hinblick auf Selenium WebDriver müssen wir die Browser-Treiber-Versionskompatibilität rechtzeitig für diese sogenannten Evergreen-Browser aufrechterhalten.
Wie du siehst, kann der Treiberwartungsprozess zeitaufwändig sein. Außerdem kann er Selenium WebDriver-Benutzern Probleme bereiten (z. B. fehlgeschlagene Tests aufgrund von Browser-Treiber-Inkompatibilität nach einem automatischen Browser-Upgrade). Aus diesem Grund zielen die sogenannten Treibermanager darauf ab, den Prozess der Treiberverwaltung bis zu einem gewissen Grad automatisiert auszuführen. Tabelle 1-3 fasst die verfügbaren Treibermanager für verschiedene Sprachbindungen zusammen.
| Name | Sprache | Lizenz | Maintainer | Website |
|---|---|---|---|---|
WebDriverManager |
Java |
Apache 2.0 |
Boni García |
|
webdriver-manager |
JavaScript |
MIT |
||
webdriver-manager |
Python |
Apache 2.0 |
Serhii Pirohov |
|
WebDriverManager.Net |
C# |
MIT |
Aliaksandr Rasolka |
|
webdrivers |
Ruby |
MIT |
Titus Fortner |
Tipp
In diesem Buch empfehle ich die Verwendung von WebDriverManager, weil er den gesamten Prozess der Treiberpflege (d.h. Download, Einrichtung und Wartung) automatisiert. In Anhang B findest du weitere Informationen über die automatisierte und manuelle Treiberverwaltung.
Locator Tools
Die Selenium WebDriver API bietet verschiedene Möglichkeiten, Webelemente zu finden (siehe Kapitel 3): nach Attribut (id, Name oder Klasse), nach Linktext (vollständig oder teilweise), nach Tag-Name, nach CSS-Selektor (Cascading Style Sheets) oder nach XML Path Language (XPath). Bestimmte Tools können dabei helfen, diese Locators zu identifizieren und zu erzeugen. Tabelle 1-4 zeigt einige dieser Tools.
| Name | Typ | Lizenz | Maintainer | Website |
|---|---|---|---|---|
Chrome DevTools |
Eingebautes Browser-Tool |
Proprietäre Freeware, basierend auf Open Source |
||
Firefox Entwickler-Tools |
Eingebautes Browser-Tool |
MPL 2.0 |
Mozilla |
|
Cropath |
Browser-Erweiterung |
Freeware |
AutonomIQ |
|
SelectorsHub |
Browser-Erweiterung |
Freeware |
Sanjay Kumar |
|
POM Builder |
Browser-Erweiterung |
Freeware |
LogiGear Corporation |
Rahmenwerke
In der Softwareentwicklung ist ein Framework eine Sammlung von Bibliotheken und Werkzeugen, die als konzeptionelle und technologische Grundlage und Unterstützung für die Softwareentwicklung dienen. Selenium ist die Grundlage für Frameworks, die die Standardfunktionen von Selenium umschließen, verbessern oder ergänzen. Tabelle 1-5 enthält einige dieser Frameworks und Bibliotheken, die auf Selenium basieren.
| Name | Sprache | Beschreibung | Lizenz | Maintainer | Website |
|---|---|---|---|---|---|
CodeceptJS |
JavaScript |
Multi-Backend-Testing-Framework, das Browser-Interaktionen als einfache Schritte aus der Nutzerperspektive modelliert |
MIT |
Michael Bodnarchuk |
|
FluentSelenium |
Java |
Fluent API für Selenium WebDriver |
Apache 2.0 |
Paul Hammant |
|
FluentLenium |
Java |
Website- und Mobile-Automatisierungsframework zur Erstellung lesbarer und wiederverwendbarer WebDriver-Tests |
Apache 2.0 |
FluentLenium Team |
|
Healenium |
Java |
Bibliothek zur Verbesserung der Stabilität von Selenium-Tests durch den Einsatz von Algorithmen für maschinelles Lernen zur Analyse von Web- und mobilen Webelementen |
Apache 2.0 |
Anna Chernyshova und Dmitriy Gumeniuk |
|
Helium |
Python |
High-Level-API basierend auf Selenium WebDriver |
MIT |
Michael Herrmann |
|
QAF (QMetry Automation Framework) |
Java |
Testautomatisierungsplattform für Web- und mobile Anwendungen |
MIT |
Chirag Jayswal |
|
Blitzschlag |
Java |
Leichtgewichtiger Selenium WebDriver Client für Java |
Apache 2.0 |
FluentLenium |
|
Nerodia |
Python |
Python Portierung des Watir Ruby Gems |
MIT |
Lucas Tierney |
|
Roboter Rahmen |
Python, Java, .NET, und andere |
Generisches Automatisierungsframework, das auf von Menschen lesbaren Testfällen basiert |
Apache 2.0 |
Robot Framework Foundation |
|
Selenid-Team |
Java |
Fließende, übersichtliche API für Selenium WebDriver |
MIT |
Selenid-Team |
|
SeleniumBase |
Python |
Browser-Automatisierungsframework basierend auf WebDriver und pytest |
MIT |
Michael Mintz |
|
Watir (Web Application Testing in Ruby) |
Ruby |
Gem-Bibliothek auf Basis von WebDriver für die Automatisierung von Webbrowsern |
MIT |
Titus Fortner |
|
WebDriverIO |
JavaScript |
Testautomatisierungs-Framework auf Basis von WebDriver und Appium |
MIT |
Christian Bromann |
|
Nachtwache.js |
JavaScript |
Integriertes End-to-End-Testing-Framework auf Basis des W3C WebDriver |
MIT |
Andrei Rusu |
|
Applitools |
Java, JavaScript, C#, Ruby, PHP, Python |
Testautomatisierungsframework für visuelle Benutzeroberflächenregression und A/B-Tests. Es bietet SDKs für Selenium, Appium und andere |
Kommerziell |
Applitools Team |
|
Katalon Studio |
Java, Groovy |
Testautomatisierungsplattform mit Selenium WebDriver, Appium und Cloud-Providern |
Kommerziell |
Katalon-Team |
|
TestProjekt |
Java, C#, Python |
Testautomatisierungsplattform für Web- und Mobilanwendungen, die auf Selenium und Appium aufbaut |
Kommerziell |
TestProjekt-Team |
Browser-Infrastruktur
Wir können Selenium WebDriver verwenden, um lokale Browser zu steuern, die auf dem Rechner installiert sind, auf dem das WebDriver-Skript ausgeführt wird. Selenium WebDriver kann auch entfernte Webbrowser steuern (d.h. solche, die auf anderen Rechnern ausgeführt werden). In diesem Fall können wir Selenium Grid verwenden, um die Infrastruktur für Remote-Browser zu unterstützen. Allerdings kann es schwierig sein, diese Infrastruktur zu erstellen und zu pflegen.
Alternativ können wir einen Cloud-Provider nutzen, um die Verantwortung für die Unterstützung der Browser-Infrastruktur auszulagern. Im Selenium-Ökosystem ist ein Cloud-Provider ein Unternehmen oder Produkt, das verwaltete Dienste für automatisierte Tests anbietet. Diese Unternehmen bieten in der Regel kommerzielle Lösungen für Web- und Mobile-Tests an. Die Nutzer eines Cloud-Providers fordern On-Demand-Browser verschiedener Typen, Versionen und Betriebssysteme an. Außerdem bieten diese Anbieter in der Regel zusätzliche Dienste zur Erleichterung der Test- und Überwachungsaktivitäten an, z. B. den Zugriff auf Sitzungsaufzeichnungen oder Analysefunktionen, um nur einige zu nennen. Einige der wichtigsten Cloud-Provider für Selenium sind heutzutage Sauce Labs, BrowserStack, LambdaTest, CrossBrowserTesting, Moon Cloud, TestingBot, Perfecto oder Testinium.
Eine weitere Lösung, die wir nutzen können, um die Browser-Infrastruktur für Selenium zu unterstützen, ist Docker. Docker ist eine Open-Source-Softwaretechnologie, die es Nutzern ermöglicht, Anwendungen als leichtgewichtige, portable Container zu packen und auszuführen. Die Docker-Plattform besteht aus zwei Hauptkomponenten: der Docker Engine, einem Werkzeug zum Erstellen und Ausführen von Containern, und dem Docker Hub, einem Cloud-Dienst zur Verteilung von Docker-Images. In der Selenium-Domäne können wir Docker zum Packen und Ausführen von containerisierten Browsern verwenden. Tabelle 1-6 enthält eine Zusammenfassung der relevanten Projekte, die Docker im Selenium-Ökosystem nutzen.
| Name | Beschreibung | Lizenz | Maintainer | Website |
|---|---|---|---|---|
docker-selenium |
Offizielle Docker-Images für Selenium Grid |
Apache 2.0 |
Selenium Projekt |
|
Selenoid |
Leichtgewichtige Golang-Implementierung von Selenium Hub, die in Browsern in Docker läuft (Images verfügbar auf Docker Hub) |
Apache 2.0 |
Aerokube |
|
Mond |
Enterprise Selenium-Cluster, die Docker und Kubernetes nutzen |
Kommerziell |
Aerokube |
|
Callisto |
Open Source Kubernetes-native Implementierung von Selenium Grid |
MIT |
Aerokube |
Gemeinschaft
Aufgrund ihrer gemeinschaftlichen Natur braucht die Softwareentwicklung die Organisation und Interaktion vieler Teilnehmer. Im Open-Source-Bereich können wir den Erfolg eines Projekts an der Bedeutung seiner Community messen. Selenium wird von einer großen Gemeinschaft mit vielen verschiedenen Teilnehmern weltweit unterstützt. Tabelle 1-7 enthält eine Zusammenfassung verschiedener Selenium-Ressourcen, die in folgende Kategorien eingeteilt sind: offizielle Dokumentation, Entwicklung, Support und Veranstaltungen.
| Kategorie | Beschreibung | Website |
|---|---|---|
Offizielle Dokumentation |
Benutzerhandbuch |
|
Blog |
||
Wiki |
||
Ökosystem |
||
Entwicklung |
Quellcode |
|
Themen |
||
Governance |
||
Unterstütze |
Benutzergruppe |
|
Slack |
||
IRC |
||
StackOverflow |
||
Veranstaltungen |
Konferenz |
|
Meetups |
Grundlagen der Softwareprüfung
Software Testen (oder einfach nur Testen) besteht aus der dynamischen Bewertung einer Software, die als System Under Test (SUT) bezeichnet wird, durch eine endliche Menge von Testfällen (oder einfach nur Tests), die ein Urteil über sie abgeben. Testen bedeutet, dass das SUT mit bestimmten Eingabewerten ausgeführt wird, um das Ergebnis oder das erwartete Verhalten zu beurteilen.
Auf den ersten Blick unterscheiden wir zwei verschiedene Kategorien von Softwaretests: manuelle und automatisierte. Beim manuellen Testen bewertet eine Person (in der Regel ein Softwareentwickler oder der Endbenutzer) das SUT. Beim automatisierten Testen hingegen verwenden wir spezielle Softwaretools, um Tests zu entwickeln und ihre Ausführung gegen das SUT zu kontrollieren. Automatisierte Tests ermöglichen die frühzeitige Erkennung von Fehlern (in der Regel Bugs genannt) im SUT und bieten eine Vielzahl zusätzlicher Vorteile (z. B. Kosteneinsparungen, schnelles Feedback, Testabdeckung oder Wiederverwendbarkeit, um nur einige zu nennen). Manuelles Testen kann in manchen Fällen auch ein wertvoller Ansatz sein, z. B. beim explorativen Testen (d. h. menschliche Tester/innen untersuchen und bewerten das SUT frei).
Hinweis
Es gibt keine allgemeingültige Klassifizierung für die zahlreichen Formen des Testens, die in diesem Abschnitt vorgestellt werden. Diese Konzepte werden ständig weiterentwickelt und diskutiert, genau wie die Softwareentwicklung. Betrachte sie als einen Vorschlag, der in eine Vielzahl von Projekten passen kann.
Stufen der Prüfung
Abhängig von der Größe des SUT können wir verschiedene Teststufen definieren. Diese Ebenen definieren verschiedene Kategorien, in die Softwareteams ihre Testarbeit einteilen. In diesem Buch schlage ich ein gestapeltes Layout vor, um die verschiedenen Ebenen darzustellen (siehe Abbildung 1-5). Die unteren Ebenen dieser Struktur stellen die Tests dar, mit denen kleine Teile der Software (sogenannte Units) geprüft werden. Wenn wir im Stapel aufsteigen, finden wir andere Ebenen (z. B. Integration, System usw.), in denen das SUT mehr und mehr Komponenten integriert.
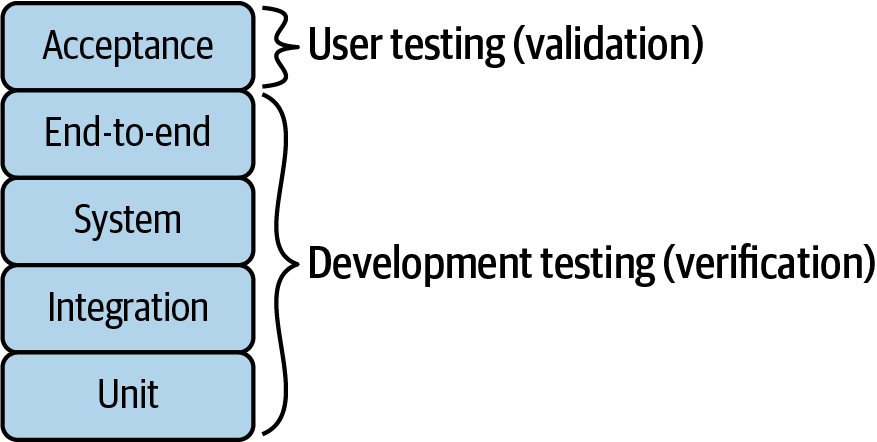
Abbildung 1-5. Stapeldarstellung der verschiedenen Prüfungsebenen
Die unterste Ebene dieses Stacks ist das Unit Testing. Auf dieser Ebene bewerten wir einzelne Einheiten der Software. Eine Einheit ist ein bestimmtes beobachtbares Element des Verhaltens. In der objektorientierten Programmierung sind das zum Beispiel Methoden oder Klassen, in der funktionalen Programmierung Funktionen. Unit-Tests zielen darauf ab, zu überprüfen, ob sich jede Einheit wie erwartet verhält. Automatisierte Unit-Tests laufen in der Regel sehr schnell, da jeder Test einen kleinen Teil des Codes isoliert ausführt. Um diese Isolierung zu erreichen, können wir Testdoubles verwenden, also Softwareteile, die die abhängigen Komponenten einer bestimmten Einheit ersetzen. Ein beliebter Typ von Testdoppelgängern in der objektorientierten Programmierung ist zum Beispiel das Mock-Objekt. Ein Mock-Objekt imitiert ein tatsächliches Objekt mit einem programmierten Verhalten.
Die nächste Ebene in Abbildung 1-5 ist die Integrationsprüfung. Auf dieser Ebene werden verschiedene Einheiten zu zusammengesetzten Komponenten zusammengesetzt. Ziel der Integrationstests ist es, die Interaktion zwischen den beteiligten Einheiten zu bewerten und Fehler in ihren Schnittstellen aufzudecken.
Dann, auf den Ebenen Systemtest und End-to-End (E2E), testen wir das Softwaresystem als Ganzes. Um diese Ebenen zu erreichen, müssen wir das SUT einsetzen und seine High-Level-Funktionen überprüfen. Der Unterschied zwischen System-/End-to-End- und Integrationstests besteht darin, dass bei ersteren alle Systemkomponenten und der Endnutzer (in der Regel in Gestalt einer Person) beteiligt sind. Mit anderen Worten: System- und End-to-End-Tests bewerten das SUT über die Benutzeroberfläche (UI). Diese Benutzeroberfläche kann grafisch (GUI) oder nicht-grafisch (z. B. textbasiert oder anders) sein.
Abbildung 1-6 veranschaulicht den Unterschied zwischen System- und End-to-End-Tests. Wie du siehst, umfassen End-to-End-Tests einerseits das Softwaresystem und seine abhängigen Subsysteme (z. B. die Datenbank oder externe Dienste). Andererseits umfasst die Systemprüfung nur das Softwaresystem, und die externen Abhängigkeiten werden in der Regel nur simuliert.
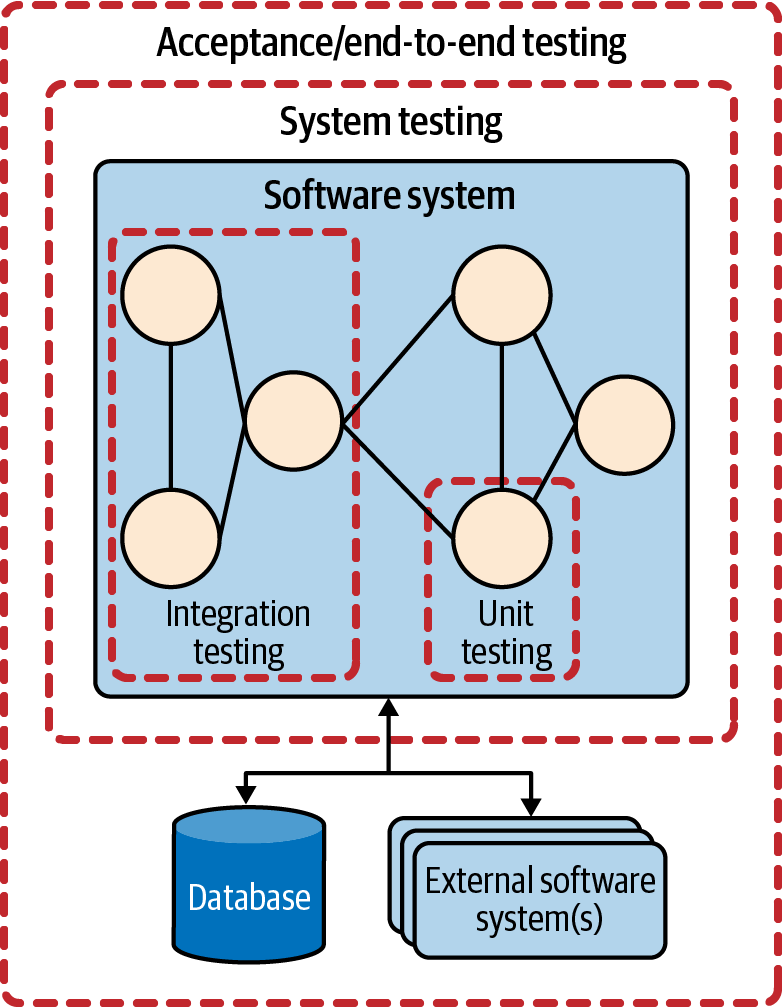
Abbildung 1-6. Komponentenbasierte Darstellung der verschiedenen Testebenen
Abnahmetests sind die oberste Ebene des vorgestellten Stacks. Auf dieser Ebene ist der Endnutzer am Testprozess beteiligt. Das Ziel der Akzeptanztests ist es, zu entscheiden, ob das Softwaresystem die Erwartungen der Endnutzer erfüllt. Wie in Abbildung 1-6 zu sehen ist, werden bei den Abnahmetests wie bei den End-to-End-Tests das gesamte System und seine Abhängigkeiten überprüft. Deshalb nutzen Akzeptanztests auch die Benutzeroberfläche, um die SUT-Validierung durchzuführen.
Tipp
Der primäre Zweck von Selenium WebDriver ist es, End-to-End-Tests zu implementieren. Wir können WebDriver aber auch für Systemtests verwenden, indem wir die Backend-Aufrufe der zu testenden Website nachbilden. Außerdem können wir Selenium WebDriver zusammen mit einem Tool für verhaltensorientierte Entwicklung (Behavior-Driven Development, BDD) verwenden, um Akzeptanztests durchzuführen (siehe Kapitel 9).
Arten von Prüfungen
Je nach Strategie für die Entwicklung von Testfällen können wir verschiedene Arten von Tests durchführen. Die beiden wichtigsten Arten von Tests sind:
- Funktionstests (auch bekannt als Verhaltenstests oder Closed-Box-Tests)
-
Bewertet die Übereinstimmung einer Software mit dem erwarteten Verhalten (d.h. mit den funktionalen Anforderungen).
- Strukturelle Tests (auch bekannt als Clear-Box-Tests)
-
Ermittelt, ob die Struktur des Programmcodes fehlerhaft ist. Zu diesem Zweck sollten Tester/innen die interne Logik einer Software kennen.
Der Unterschied zwischen diesen Testarten besteht darin, dass funktionale Tests auf Verantwortlichkeiten basieren, während strukturelle Tests implementierungsbasiert sind. Beide Arten können auf jeder Testebene durchgeführt werden (Unit, Integration, System, End-to-End oder Abnahme). Strukturelle Tests werden jedoch in der Regel auf der Unit- oder Integrationsebene durchgeführt, da diese Ebenen eine direktere Kontrolle über den Code-Ausführungsfluss ermöglichen.
Warnung
Black-Box- und White-Box-Tests sind andere Bezeichnungen für funktionale bzw. strukturelle Tests. Dennoch werden diese Bezeichnungen nicht empfohlen, da die Tech-Branche versucht, umfassendere Begriffe zu verwenden und neutrale Terminologie anstelle von potenziell schädlicher Sprache zu verwenden.
Es gibt verschiedene Arten von Funktionstests. Zum Beispiel:
- UI-Tests (bekannt als GUI-Tests, wenn die Benutzeroberfläche grafisch ist)
-
Bewertet, ob die visuellen Elemente einer Anwendung die erwartete Funktionalität erfüllen. Beachte, dass sich UI-Tests von den System- und End-to-End-Tests unterscheiden, da erstere die Benutzeroberfläche selbst testen, während letztere das gesamte System über die Benutzeroberfläche bewerten.
- Negative Prüfung
-
Bewertet das SUT unter unerwarteten Bedingungen (z. B. erwartete Ausnahmen). Dieser Begriff ist das Gegenstück zu den regulären Funktionstests (manchmal auch Positivtests genannt), bei denen wir prüfen, ob sich das SUT wie erwartet verhält (d. h. sein glücklicher Weg).
- Cross-Browser-Tests
-
Dies ist eine spezifische für Webanwendungen. Sie zielt darauf ab, die Kompatibilität von Websites und Anwendungen in verschiedenen Webbrowsern (Typen, Versionen oder Betriebssystemen) zu überprüfen.
Eine dritte Art von Tests ( ), das nichtfunktionale Testen, umfasst Teststrategien, die die Qualitätsmerkmale eines Softwaresystems (d.h. seine nichtfunktionalen Anforderungen) bewerten. Gängige Methoden für nicht-funktionale Tests sind unter anderem:
- Leistungstests
-
Bewertet verschiedene Metriken von Softwaresystemen, wie Reaktionszeit, Stabilität, Zuverlässigkeit oder Skalierbarkeit. Das Ziel von Leistungstests ist nicht das Auffinden von Fehlern, sondern das Aufspüren von Systemengpässen. Es gibt zwei gängige Unterarten von Leistungstests:
- Belastungstests
-
Erhöht die Nutzung des Systems, indem es mehrere gleichzeitige Nutzer simuliert, um zu überprüfen, ob es innerhalb der festgelegten Grenzen arbeiten kann.
- Stresstest
-
Überprüft ein System über seine Betriebskapazität hinaus, um die tatsächlichen Grenzen zu ermitteln, an denen das System zusammenbricht.
- Sicherheitstests
-
Versucht, Sicherheitsbelange zu bewerten, wie z.B. Vertraulichkeit (Schutz der Offenlegung von Informationen), Authentifizierung (Sicherstellung der Benutzeridentität) oder Autorisierung (Festlegung von Benutzerrechten und -privilegien).
- Usability-Tests
-
Bewertet, wie benutzerfreundlich eine Softwareanwendung ist. Diese Bewertung wird auch User eXperience (UX) Testing genannt. Eine Unterart von Usability-Tests ist:
- Zugänglichkeitsprüfung
-
Bewertet , ob ein System für Menschen mit Behinderungen nutzbar ist.
Tipp
Wir verwenden Selenium WebDriver in erster Linie für funktionale Tests (d. h. für die Interaktion mit der Benutzeroberfläche einer Webanwendung, um das Verhalten der Anwendung zu beurteilen). Es ist unwahrscheinlich, dass WebDriver für strukturelle Tests eingesetzt wird. Darüber hinaus kann WebDriver auch für nicht-funktionale Tests eingesetzt werden, z. B. für Last-, Sicherheits-, Barrierefreiheits- oder Lokalisierungstests (Bewertung spezifischer Gebietsschemaeinstellungen) (siehe Kapitel 9).
Testmethoden
Der Lebenszyklus der Softwareentwicklung ist die Reihe von Aktivitäten, Aktionen und Aufgaben, die zur Erstellung von Softwaresystemen in der Softwareentwicklung erforderlich sind. Der Zeitpunkt, an dem Softwareentwickler/innen im gesamten Entwicklungszyklus Testfälle entwerfen und implementieren, hängt vom jeweiligen Entwicklungsprozess ab (z. B. iterativ, Wasserfall oder agil, um nur einige zu nennen). Zwei der wichtigsten Testmethoden sind:
- Testgetriebene Entwicklung (TDD)
-
TDD ist eine Methode, bei der wir Tests entwerfen und implementieren, bevor wir die eigentliche Software entwerfen und implementieren. Zu Beginn des 21. Jahrhunderts wurde TDD mit dem Aufkommen von agilen Softwareentwicklungsmethoden wie Extreme Programming (XP) populär. Bei TDD schreibt ein Entwickler zunächst einen (zunächst fehlschlagenden) automatisierten Test für eine bestimmte Funktion. Dann erstellt der Entwickler ein Stück Code, das diesen Test besteht. Schließlich überarbeitet der Entwickler den Code, um die Lesbarkeit und Wartbarkeit zu verbessern.
- Test Last Development (TLD)
-
TLD ist eine Methodik, bei der wir Tests nach der Implementierung des SUT entwerfen und implementieren. Diese Praxis ist typisch für traditionelle Softwareentwicklungsprozesse wie Wasserfall (sequentiell), inkrementell (Multi-Wasserfall), spiralförmig (risikoorientiert Multi-Wasserfall) oder Rational Unified Process (RUP).
Eine weitere wichtige Testmethode ist die verhaltensorientierte Entwicklung (Behavior-Driven Development, BDD). BDD ist eine von TDD abgeleitete Testmethode, bei der wir die Tests in den frühen Phasen des Softwareentwicklungszyklus entwerfen. Zu diesem Zweck finden Gespräche zwischen dem Endnutzer und dem Entwicklungsteam statt (in der Regel mit dem Projektleiter, dem Manager oder den Analysten). In diesen Gesprächen wird ein gemeinsames Verständnis für das gewünschte Verhalten und das Softwaresystem formalisiert. Auf erstellen wir daher Akzeptanztests in Form von einem oder mehreren Szenarien, die einer Geben-Wenn-Dann-Struktur folgen:
- Gegeben
-
Ursprünglicher Kontext zu Beginn des Szenarios
- Wenn
-
Ereignis, das das Szenario auslöst
- Dann
-
Erwartetes Ergebnis
Tipp
TLD ist eine gängige Praxis bei der Implementierung von Selenium WebDriver. Mit anderen Worten: Entwickler/Tester implementieren einen WebDriver-Test erst, wenn das SUT verfügbar ist. Es sind jedoch auch andere Methoden möglich. BDD ist zum Beispiel ein gängiger Ansatz, wenn WebDriver mit Cucumber verwendet wird (siehe Kapitel 9).
Eng verwandt mit dem Bereich der Prüfmethoden ist das Konzept der Continuous Integration (CI) . CI ist eine Praxis der Softwareentwicklung, bei der die Mitglieder eines Softwareprojekts ihre Arbeit kontinuierlich erstellen, testen und integrieren. Grady Booch prägte den Begriff CI erstmals 1991. Heute ist es eine beliebte Strategie zur Erstellung von Software.
Wie Abbildung 1-7 zeigt, besteht KI aus drei verschiedenen Stufen. Zunächst verwenden wir ein Quellcode-Repository, eine Einrichtung, in der der Quellcode eines Softwareprojekts gespeichert und gemeinsam genutzt wird. Wir verwenden normalerweise ein Versionskontrollsystem (VCS), um dieses Repository zu verwalten. Ein VCS ist ein Werkzeug, das den Überblick über den Quellcode behält und festhält, wer wann welche Änderungen vorgenommen hat (manchmal auch Patch genannt).
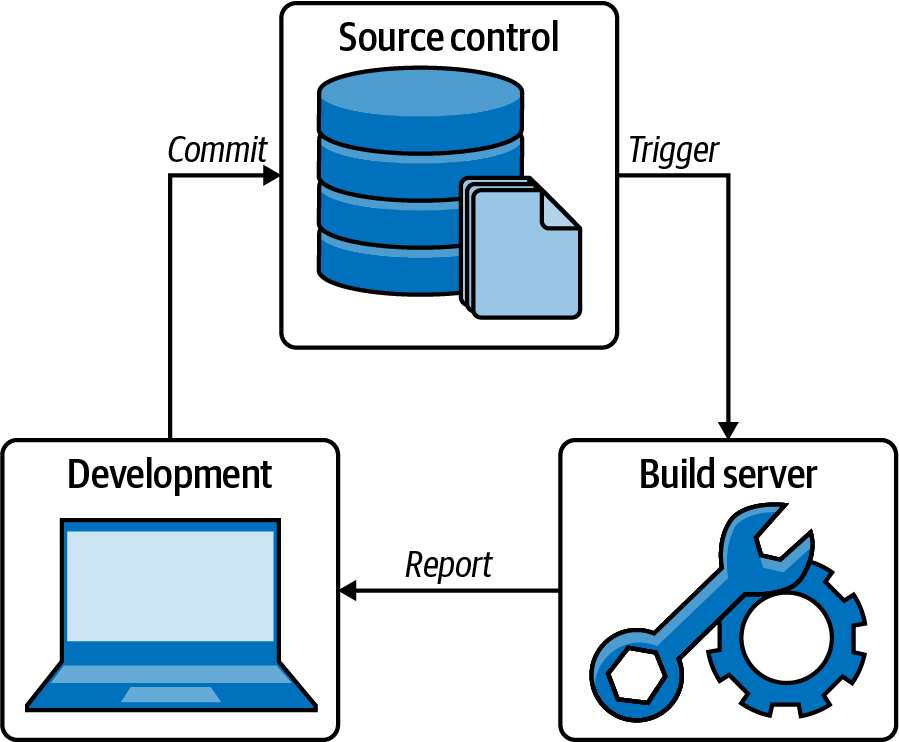
Abbildung 1-7. Allgemeiner CI-Prozess
Git, ursprünglich entwickelt von Linus Torvalds, ist heute das bevorzugte VCS. Andere Alternativen sind das Concurrent Versions System (CVS) oder Subversion (SVN). Zusätzlich zu Git bieten verschiedene Code-Hosting-Plattformen (wie GitHub, GitLab oder Bitbucket) kollaborative Cloud-Repository-Hosting-Dienste für die Entwicklung, den Austausch und die Pflege von Software an.
Die Entwickler synchronisieren eine Kopie des lokalen Projektarchivs( ) in ihrer lokalen Umgebung. Dann arbeiten sie an der Programmierung mit dieser lokalen Kopie und übertragen neue Änderungen in das entfernte Repository (in der Regel täglich). Der Grundgedanke von CI ist, dass jeder Commit den Build und Test der Software mit den neuen Änderungen auslöst. Die Testsuite, die durchgeführt wird, um sicherzustellen, dass ein Patch den Build nicht beschädigt, wird Regressionstest genannt. Eine Regressionssuite kann verschiedene Arten von Tests enthalten, z. B. Einheitstests, Integrationstests, End-to-End-Tests usw.
Wenn die Anzahl der Tests für Regressionstests zu groß ist, wählen wir normalerweise nur einen Teil der relevanten Tests aus der gesamten Suite aus. Es gibt verschiedene Strategien, um diese Tests auszuwählen, z. B. Smoke-Tests (d. h. Tests, die die kritische Funktionalität sicherstellen) oder Sanity-Tests (d. h. Tests, die die grundlegende Funktionalität überprüfen). Schließlich können wir die gesamte Suite als geplante Aufgabe ausführen (normalerweise nachts).
Um eine CI-Pipeline zu implementieren, müssen wir eine serverseitige Infrastruktur, einen sogenannten Build-Server, verwenden. Der Build-Server meldet dem ursprünglichen Entwickler normalerweise ein Problem, wenn die Regressionstests fehlschlagen. Tabelle 1-8 gibt einen Überblick über verschiedene Build-Server.
| Name | Beschreibung | Lizenz | Maintainer | Website |
|---|---|---|---|---|
Bamboo |
Einfache Nutzung mit Jira (Issue Tracker) und Bitbucket |
Kommerziell |
Atlassian |
|
GitHub-Aktionen |
Integrierter Build-Server in GitHub |
Kostenlos für öffentliche Repositorien |
Microsoft |
|
GitLab CI/CD |
Integrierter Build-Server in GitLab |
Kostenlos für öffentliche Repositorien |
GitLab |
|
Jenkins |
Open Source Automatisierungsserver |
MIT |
Jenkins-Team |
Tipp
Ich verwende ein GitHub-Repository(https://github.com/bonigarcia/selenium-webdriver-java), um die in diesem Buch vorgestellten Testbeispiele zu veröffentlichen und zu pflegen. GitHub Actions ist der Build-Server für dieses Repository (siehe Kapitel 2).
Wir können eine typische CI-Pipeline auf zwei Arten erweitern (siehe Abbildung 1-8):
- Kontinuierliche Lieferung (CD)
-
Nach dem CI stellt der Build-Server das Release in eine Staging-Umgebung (d.h. ein Replikat einer Produktionsumgebung für Testzwecke) bereit und führt die automatisierten Akzeptanztests (falls vorhanden) aus.
- Kontinuierliche Bereitstellung
-
Der Build-Server stellt die Softwareversion im letzten Schritt in der Produktionsumgebung bereit.
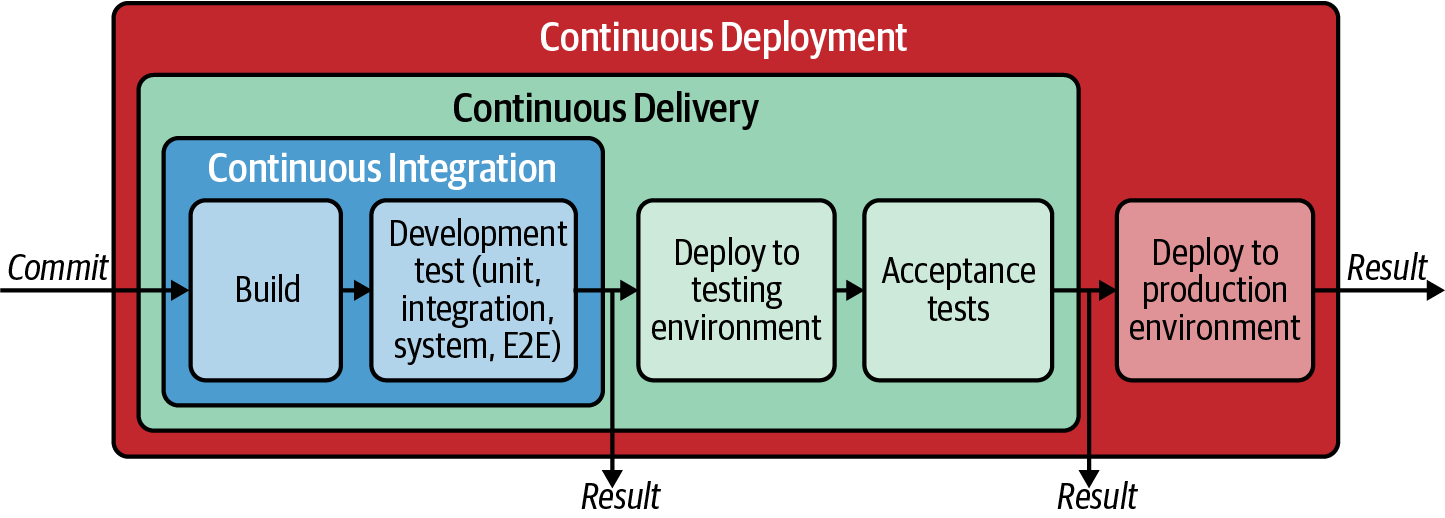
Abbildung 1-8. Continuous Integration, Delivery und Deployment Pipeline
In der Nähe von CI hat der Begriff DevOps (Entwicklung und Betrieb) an Bedeutung gewonnen. DevOps ist eine Software-Methodik, die die Kommunikation und Zusammenarbeit zwischen verschiedenen Teams in einem Softwareprojekt fördert, um Software effizient zu entwickeln und zu liefern. Zu diesen Teams gehören Entwickler/innen, Tester/innen, QA (Qualitätssicherung), Operations (Infrastruktur), usw.
Testautomatisierungs-Tools
Um automatisierte Tests effektiv zu implementieren, auszuführen und zu kontrollieren, müssen wir einige Werkzeuge verwenden. Eine der wichtigsten Kategorien für Testwerkzeuge ist das Unit Testing Framework. Das ursprüngliche Framework in der Unit-Test-Familie (auch bekannt als xUnit) ist SmalltalkUnit (oder SUnit). SUnit ist ein Unit-Test-Framework für die Smalltalk-Sprache und wurde 1999 von Kent Beck entwickelt. Erich Gamma portierte SUnit nach Java und schuf JUnit. Seitdem ist JUnit sehr beliebt und hat andere Unit-Test-Frameworks inspiriert. Tabelle 1-9 fasst die wichtigsten Unit-Testing-Frameworks in verschiedenen Sprachen zusammen.
| Name | Sprache | Beschreibung | Lizenz | Maintainer | Website |
|---|---|---|---|---|---|
JUnit |
Java |
Referenzimplementierung der xUnit-Familie |
EPL |
JUnit-Team |
|
TestNG |
Java |
Inspiriert von JUnit und NUnit, mit zusätzlichen Funktionen |
Apache 2.0 |
Cedric Beust |
|
Mokka |
JavaScript |
Test-Framework für Node.js und den Browser |
MIT |
OpenJS Stiftung |
|
Jest |
JavaScript |
Fokussiert auf Einfachheit mit Schwerpunkt auf Webanwendungen |
MIT |
Facebiij |
|
Karma |
JavaScript |
Ermöglicht es dir, JavaScript-Tests in Webbrowsern auszuführen |
MIT |
Karma-Team |
|
NUnit |
.Net |
Unit Testing Framework für alle .Net-Sprachen (C#, Visual Basic und F#) |
MIT |
.NET Stiftung |
|
unittest |
Python |
Unit-Testing-Framework, das seit Python 2.1 als Standardbibliothek enthalten ist |
PSF-Lizenz |
Python Software Foundation |
|
Minitest |
Ruby |
Komplette Suite von Testprogrammen für Ruby |
MIT |
Seattle Ruby Brigade |
Ein wichtiges gemeinsames Merkmal der xUnit-Familie ist die Teststruktur, die aus vier Phasen besteht (siehe Abbildung 1-9):
- Einrichtung
-
Der Testfall initialisiert das SUT so, dass es das erwartete Verhalten zeigt.
- Übung
-
Der Testfall interagiert mit dem SUT. Als Ergebnis erhält der Test ein Ergebnis aus dem SUT.
- Überprüfe
-
Der Test entscheidet, ob das Ergebnis der SUT den Erwartungen entspricht. Zu diesem Zweck enthält der Test eine oder mehrere Behauptungen. Eine Behauptung (oder ein Prädikat) ist eine boolesche Funktion, die überprüft, ob eine erwartete Bedingung wahr ist. Die Ausführung der Behauptungen führt zu einem Testurteil (in der Regel "bestanden" oder "fehlgeschlagen").
- Teardown
-
Der Test Fall versetzt das SUT zurück in den Ausgangszustand.
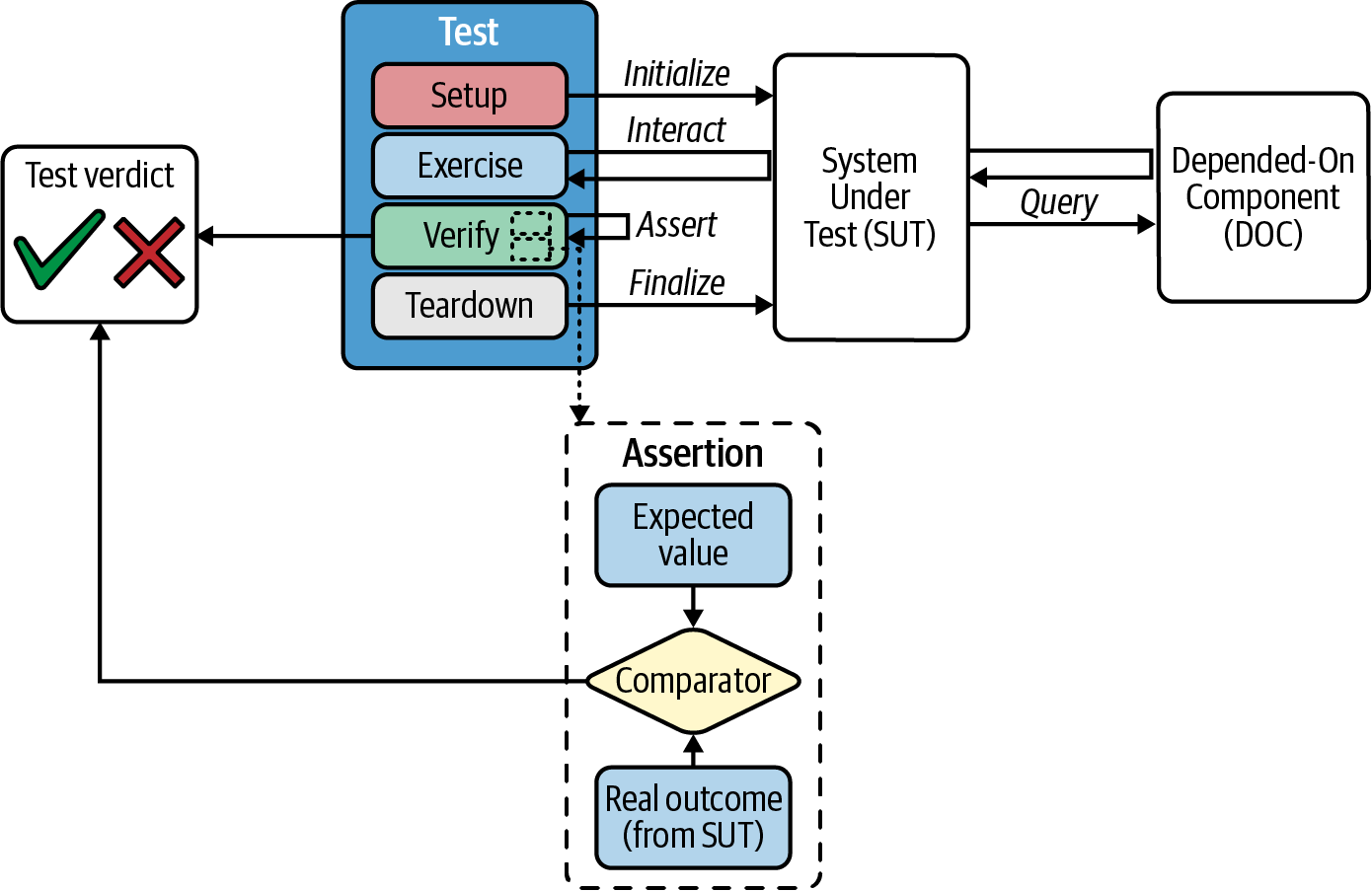
Abbildung 1-9. Generische Struktur des Einheitstests
Tipp
Wir können Unit-Testing-Frameworks in Verbindung mit anderen Bibliotheken oder Dienstprogrammen verwenden, um jeden Testtyp zu implementieren. Wie in Kapitel 2 erläutert, verwenden wir zum Beispiel JUnit und TestNG, um den Aufruf der Selenium WebDriver API einzubetten und so End-to-End-Tests für Webanwendungen zu implementieren.
Die Phasen des Auf- und Abbaus sind in einem Unit-Testfall optional. Obwohl es nicht zwingend erforderlich ist, wird die Überprüfung dringend empfohlen. Auch wenn Unit-Test-Frameworks Funktionen zur Implementierung von Assertions enthalten, ist es üblich, Assertions-Bibliotheken von Drittanbietern einzubinden. Diese Bibliotheken sollen die Lesbarkeit des Testcodes verbessern, indem sie einen umfangreichen Satz an flüssigen Assertions bereitstellen. Darüber hinaus bieten diese Bibliotheken erweiterte Fehlermeldungen, die den Prüfern helfen, die Ursache eines Fehlers zu verstehen. Tabelle 1-10 enthält eine Übersicht über einige der wichtigsten Assertion-Bibliotheken für Java.
| Name | Beschreibung | Lizenz | Maintainer | Website |
|---|---|---|---|---|
AssertJ |
Fluent Assertions Java Bibliothek |
Apache 2.0 |
AssertJ-Team |
|
Hamcrest |
Java-Bibliothek mit Matchern zur Erstellung flexibler Assertions |
BSD |
Hamcrest-Team |
|
Die Wahrheit |
Fließende Assertions für Java und Android |
Apache 2.0 |
Wie du in Abbildung 1-9 sehen kannst, kann das SUT normalerweise eine andere Komponente, die Depended-On Component (DOC), abfragen. In manchen Fällen (z. B. bei Unit- oder Systemtests) möchten wir das SUT von der/den DOC(s) isolieren. Unter findest du eine Vielzahl von Mock-Bibliotheken, um diese Isolierung zu erreichen.
Tabelle 1-11 zeigt eine umfassende Übersicht über einige dieser Mock-Bibliotheken für Java.
| Name | Level | Beschreibung | Lizenz | Maintainer | Website |
|---|---|---|---|---|---|
EasyMock |
Einheit |
Es ermöglicht das Mocking von Objekten für Unit-Tests mithilfe von Java-Annotationen |
Apache |
EasyMock-Team |
|
Mockito |
Einheit |
Mocking Java-Bibliothek für die Erstellung und Überprüfung von Mocks |
MIT |
Mockito-Team |
|
JMockit |
Integration |
Es ermöglicht Out-of-Container-Integrationstests für Java EE- und Spring-basierte Anwendungen |
Öffnen Sie |
JMockit-Team |
|
MockServer |
System |
Mocking-Bibliothek für jedes System, das über HTTP oder HTTPS mit Java-Clients verbunden ist |
Apache 2.0 |
James Bloom |
|
WireMock |
System |
Werkzeug zur Simulation von HTTP-basierten Diensten |
Apache 2.0 |
Tom Akehurst |
Die letzte Kategorie von Testwerkzeugen, die wir in diesem Abschnitt analysieren, ist BDD, ein Entwicklungsprozess, der Akzeptanztests erstellt. Es gibt viele Alternativen, um diesen Ansatz umzusetzen. Tabelle 1-12 zeigt zum Beispiel eine komprimierte Zusammenfassung von relevanten BDD-Frameworks.
| Name | Sprache | Beschreibung | Lizenz | Maintainer | Website |
|---|---|---|---|---|---|
Gurke |
Ruby, Java, JavaScript, Python |
Testframework zur Erstellung automatisierter Akzeptanztests nach einem BDD-Ansatz |
MIT |
SmartBear Software |
|
FitNesse |
Java |
Eigenständiges kollaboratives Wiki und Abnahmetest-Framework |
CPL |
FitNesse Team |
|
JBehave |
Java, Groovy, Kotlin, Ruby, Scala |
BDD-Framework für alle JVM-Sprachen |
BSD-3-Klausel |
JBehave Team |
|
Jasmine |
JavaScript |
BDD-Framework für JavaScript |
MIT |
Jasmine Team |
|
Capybara |
Ruby |
Webbasiertes Akzeptanztest-Framework, das Szenarien für User Stories simuliert |
MIT |
Thomas Walpole |
|
Serenity BDD |
Java, Javascript |
Bibliothek für automatisierte Abnahmeprüfungen |
Apache 2.0 |
Serenity BDD-Team |
Zusammenfassung und Ausblick
Selenium hat seit seiner Einführung im Jahr 2004 einen langen Weg zurückgelegt . Viele Praktiker halten es für die De-facto-Standardlösung zur Entwicklung von End-to-End-Tests für Webanwendungen und es wird von Tausenden von Projekten weltweit eingesetzt. In diesem Kapitel hast du die Grundlagen des Selenium-Projekts (bestehend aus WebDriver, Grid und IDE) kennengelernt. Darüber hinaus verfügt Selenium über ein reichhaltiges Ökosystem und eine aktive Community. WebDriver ist das Herzstück des Selenium-Projekts und eine Bibliothek, die eine API zur programmatischen Steuerung verschiedener Webbrowser (z. B. Chrome, Firefox, Edge usw.) bereitstellt. Tabelle 1-13 enthält einen umfassenden Überblick über die primären und sekundären Einsatzmöglichkeiten von Selenium WebDriver.
| Primäre | Sekundär (andere Verwendungen) | |
|---|---|---|
Zweck |
Automatisiertes Testen |
Web Scraping, webbasierte Verwaltungsaufgaben |
Test Level |
End-to-End-Tests |
Systemtests (Mocking von Backend-Aufrufen) |
Test Typ |
Funktionstests (Sicherstellung des erwarteten Verhaltens) |
Nichtfunktionale Tests (z. B. Last, Sicherheit, Zugänglichkeit oder Lokalisierung) |
Prüfmethodik |
TLD (Durchführung von Tests, wenn SUT verfügbar ist) |
BDD (Definition von Benutzerszenarien in frühen Entwicklungsphasen) |
Im nächsten Kapitel erfährst du, wie du ein Java-Projekt mit Maven oder Gradle als Build-Tools einrichtest. Dieses Projekt enthält End-to-End-Tests für Webanwendungen mit JUnit und TestNG als Unit-Testing-Frameworks und Aufrufen der Selenium WebDriver API. Außerdem lernst du, wie du verschiedene Webbrowser (z. B. Chrome, Firefox oder Edge) mit einem einfachen Testfall (der Selenium WebDriver-Version des klassischen Hallo Welt) steuern kannst.
Get Hands-On Selenium WebDriver mit Java now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

