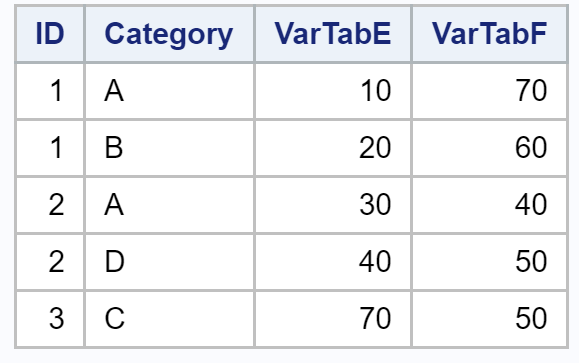
For a many-to-many join, we use the Y dataset and create a new dataset Z:
Data Z;Input ID Category $ VarTabE VarTabF;Datalines;1 A 10 701 B 20 602 A 30 402 D 40 503 C 70 50;
The dataset created is:
We will use the same code as above but just change the file names to Y and Z. We get the following output:
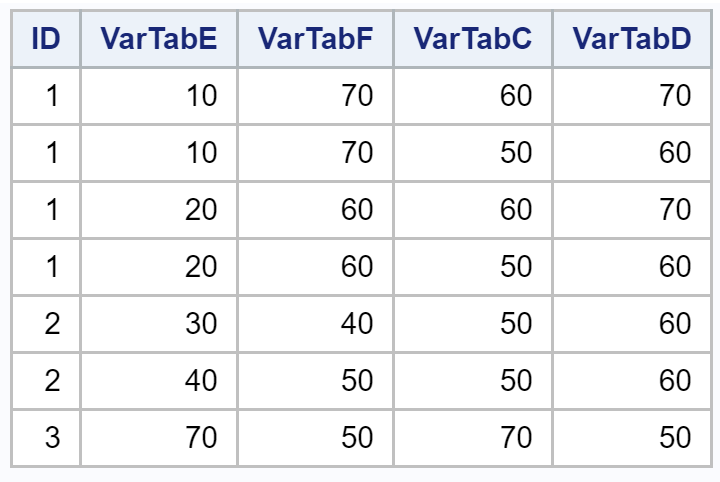
For ID 1, we get four rows of output. There were two ID rows each in both the datasets. So essentially for ID 1, what we have is a Cartesian product of the ID restricted to the particular ID.

