Consider the finite MDP we developed in Chapter 1, Understanding Rewards Learning, that described your morning routine. Don't to worry if you didn't complete that exercise previously as we will consider a more specific example, as follows:
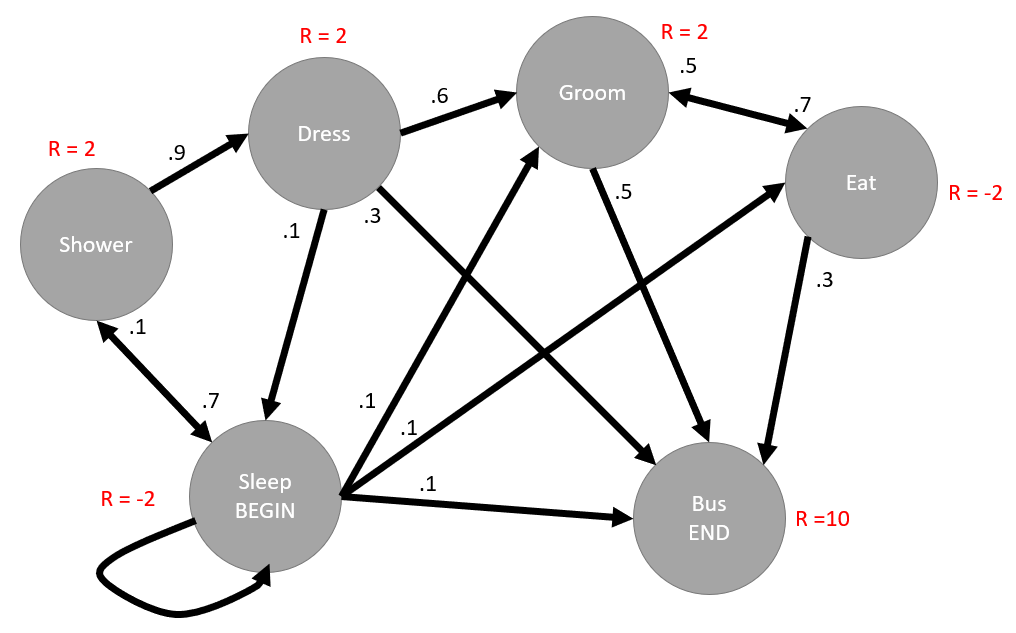 MDP for waking up and getting on the bus
MDP for waking up and getting on the busThe preceding finite MDP describes a possible routine for someone waking up and getting ready to get on a bus to go to school or work. In this MDP, we define a beginning state (BEGIN) and an ending state, that is, getting on the bus (END). The R = denotes the reward allotted when moving to that state and the number closest to the end of ...

