Leaky ReLU is a modification of the ReLU function that we saw in the previous section and it not only enables the network to learn faster but it is also more balanced as it helps deal with vanishing gradients.
The leaky ReLU function is as follows:
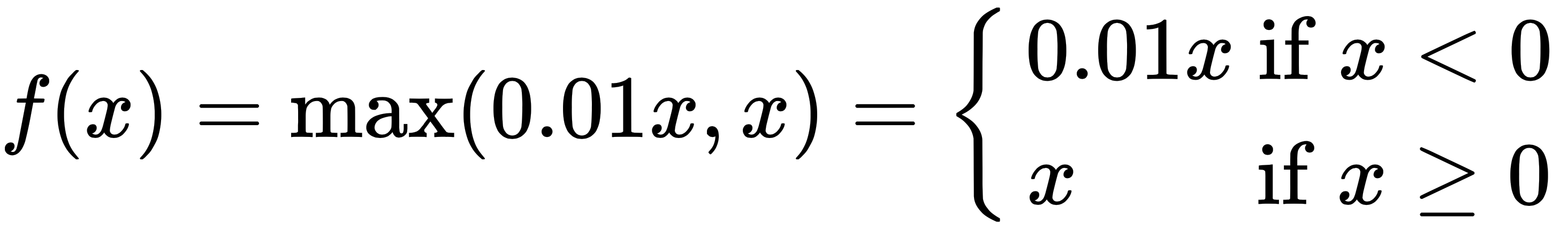
The function looks as follows:
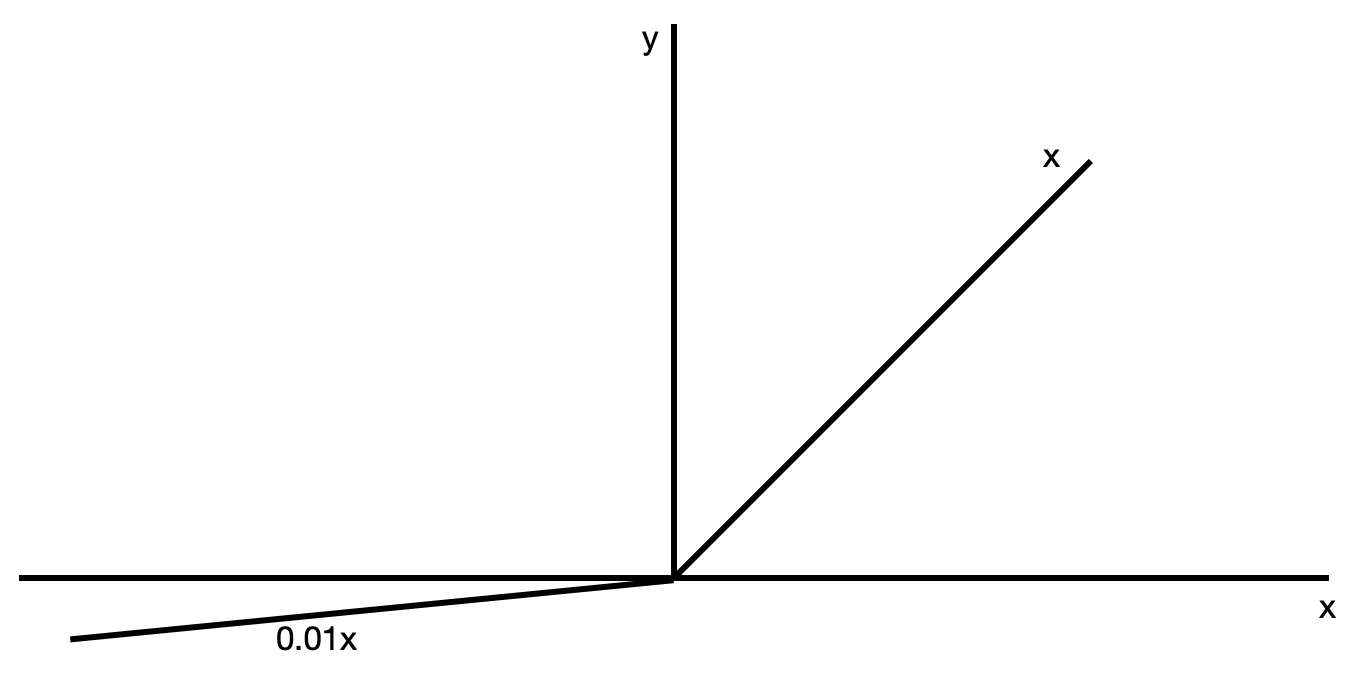
As you can see, the difference here is that the negative values of x that were clipped off before are now rescaled to 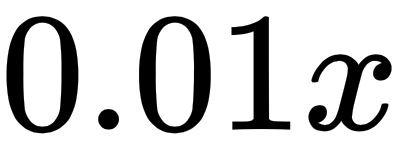 , which overcomes the dying ReLU problem. ...
, which overcomes the dying ReLU problem. ...

