Another useful function in the SPSS modeler flow is the ability to easily divide data into training and testing sets. This can be accomplished using the Partition node. To train, test, and validate the stages of model building, the Partition nodes are used to produce a partition field that splits the data into separate subsets or samples.
Using a sample to generate the model and a separate sample to test it will get you a good hint of how well the model will generalize to larger datasets that are corresponding to the current data:
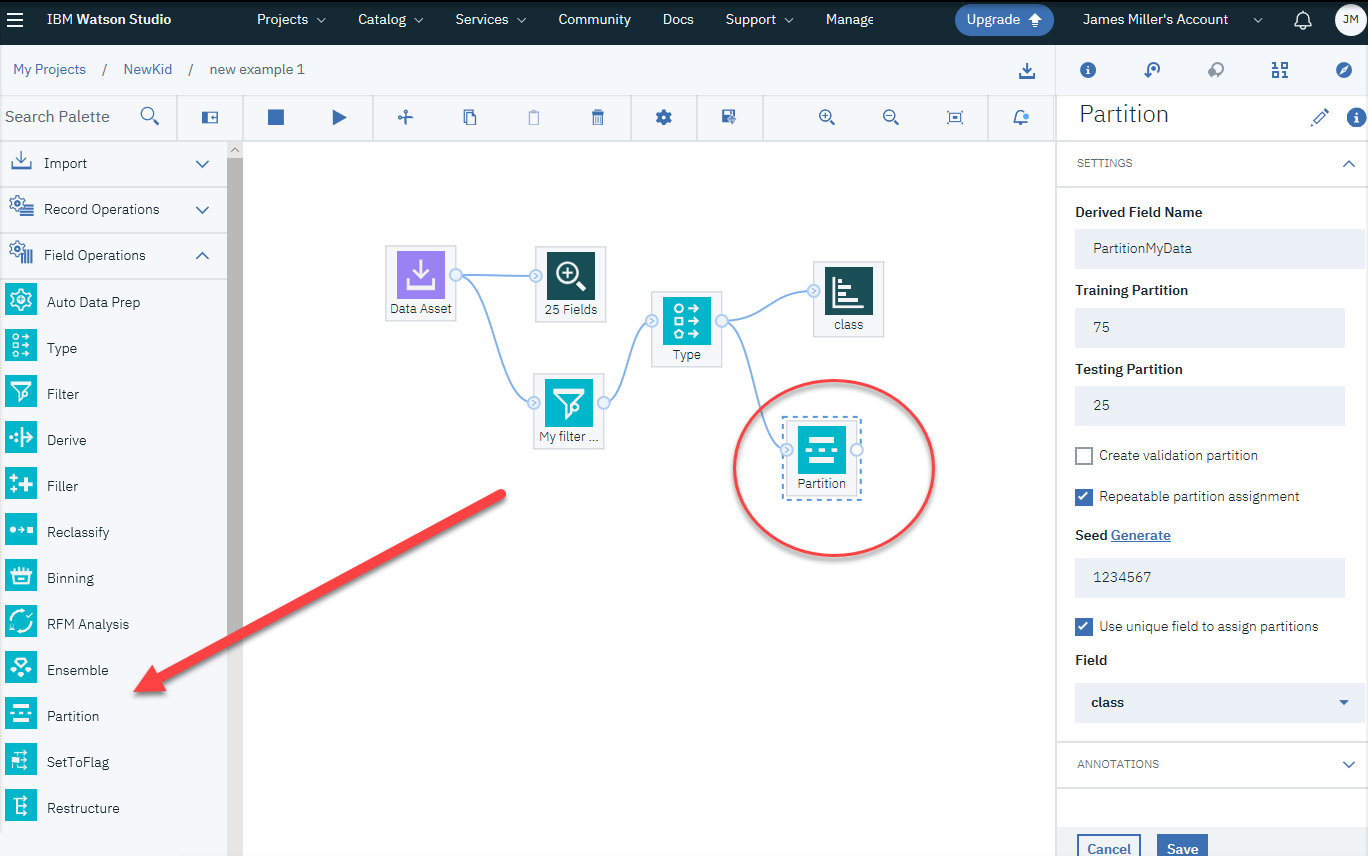
If we add a Partition node to our flow, open it and adjust the settings as shown in the preceding ...

