When selecting hyperparameters based on their validation score, be aware that this validation score is biased because of multiple tests, and is no longer a good estimate of the generalization error. For an unbiased estimate of the error rate, we have to estimate the score from a fresh dataset, as shown in the following diagram:
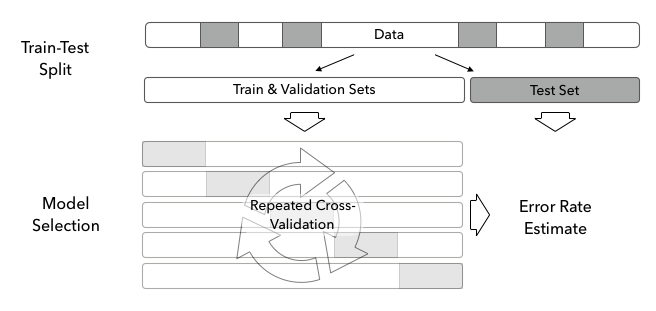
For this reason, we use a three-way split of the data, as illustrated in the preceding diagram: one part is used in cross-validation and is repeatedly split into a training and validation set. The remainder is set aside as a hold-out set that is only used once cross-validation is complete ...

