If we consider a simple model, here is what our network would look as follows:
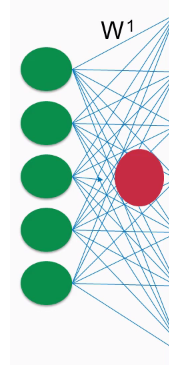
This just means that a simple model learns in one big step. This may work fine for simple tasks, but for a highly complex tasks such as computer vision or image recognition, this is not enough. Complex tasks require a lot of manual engineering to achieve good precision. To do this, we add a lot of other layers of neurons that enable the network to learn step by step, instead of taking one huge leap to the output. The network should look as follows:
The first layer may learn low-level features such as horizontal lines, vertical lines, ...

