Chapter 1. Welcome to Differential Privacy
If you are new to the concept of differential privacy, you’ve found the right place. This chapter will present the historical background and conceptual intuition of differential privacy. This chapter is designed to achieve two main objectives:
-
Offer a brief history of data privatization, culminating in contemporary examples of differential privacy deployments
-
Provide a simple practical example of data privatization risks in a classroom setting that demonstrates basic key terms
This chapter is meant to be a soft introduction to differential privacy. You will learn about core DP concepts with less of a focus on math and code. The book will gradually mix in more formal mathematical language and implementations of algorithms as you progress through the chapters.
History
The idea that computing statistics on a data set can leak information about individual data points is not new. In fact, many of the fundamental differential privacy papers1,2 from the 21st century cite research from the 1970s and ’80s.
In 1977, Tore Dalenius sought to formalize the notion of statistical disclosure control.3 As part of this work, Dalenius contended that the goal should be disclosure control rather than elimination, adding that “elimination of disclosure is possible only by elimination of statistics.” This idea of controlling disclosure will be important throughout the book; the goal is to quantify and calibrate the risk of disclosure, rather than eliminate it altogether. In 1980, Dorothy E. Denning further raised the inference problem as the “deduction of confidential data by correlating the declassified statistical summaries and prior information.”4
These previous studies acknowledge challenges that are of widespread concern today. The problem of preserving privacy has gained increased attention, as data storage and computation are significantly more pervasive now than in 1980. In addition, “prior information” is more readily available for purchase and analysis, increasing the risk of privacy violations via inference. Denning’s paper also identifies a key concept in privacy: if you compute a statistic on a data set and then compute the same statistic on the data set minus one of the data points, you have learned something about that missing data point. In her words, “Comparing the mean salary of two groups differing only by a single record may reveal the salary of the individual whose record is in one group but not the other.”5
A variety of approaches were proposed to counter these vulnerabilities. Some early statistical disclosure control systems would add a fixed value to all queries or swap values within the data. Many approaches suffered from a significant reduction in utility, vulnerability to averaging attacks,6 and a lack of formal guarantees.
One promising approach, output perturbation, involves modifying (perturbing) the result of a query so that statistical inference is less likely to cause a privacy violation. Irit Dinur and Kobbi Nissim validated this approach by showing that output perturbation can be mathematically proven to provide immunity to data-set reconstruction attacks.7
The attack exploits what was later termed the Fundamental Law of Information Recovery:8 privacy can be destroyed by giving overly accurate answers to a sufficient number of questions.
In 2006, the paper “Calibrating Noise to Sensitivity in Private Data Analysis” was published by Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith to address the problem of scaling noise to satisfy a privacy guarantee. In this paper, the authors address “privacy-preserving statistical databases”9 and demonstrate privacy guarantees when adding noise to any statistical query. Let’s carefully look at the words in the previous sentence—you may have encountered these words before, but they have subtly different meanings in this context:
- Statistical database
-
A statistical database is a “system that enables its users to retrieve only aggregate statistics for a subset of the entities represented in the database.”10 You may already be familiar with databases like PostgreSQL or SQLite; with these databases, you can execute queries to search for individual rows based on certain conditions. By contrast, a statistical database only allows you to ask questions like, “What is the average age of the people in this database?” and prevents you from executing queries like:
SELECT * FROM users WHERE age = 32;
If this syntax looks unfamiliar to you, or you want a refresher on the type of database queries you will see throughout the book, check out Appendix D.
- Noise
-
In the context of privacy, noise refers to values sampled from a statistical distribution. You will encounter terms like Laplace noise and Gaussian noise that specify the kind of distribution that the values were sampled from.
- Privacy
-
Depending on context, the term privacy can mean the absence of surveillance, or the inability to be identified. In contrast to the previous two terms, which are technical in nature, the word privacy is used in philosophical and legal literature under various definitions. In fact, even the Stanford Encyclopedia of Philosophy admits that “there is no single definition or analysis or meaning of the term.”11
DP has enjoyed significant research and a gradual implementation in data releases since its establishment. Spurred by the work of Dinur and Nissim, the US Census Bureau conducted a data-set reconstruction attack against its own statistical releases to gauge the risk of violating its statutory obligations to protect confidentiality.
This attack validated confidentiality concerns, motivated the development of a differentially private statistical publication system, and led to a 2018 announcement that the US Census would privatize the results of the End-to-End (E2E) Census Test.12 This process was a practice run for future censuses and systems that passed validation in 2018 and were expected to be put into production for the 2020 census. The stakes were serious; the data in question is used to construct legislative districts and ensure that the 1965 Voting Rights Act is being followed.
The use of differential privacy in the census has not been without challenges. In 2021, the State of Alabama sued the US Census for its use of differential privacy, alleging that the census was providing “manipulated redistricting data to the States.”13 There is prior precedent of the US Census introducing techniques to protect individual privacy. For example, in 1930, census releases stopped including data from small areas to protect residents in sparsely populated regions from being re-identified. A panel of three judges ultimately rejected Alabama’s complaint, responding that the state had no claim of harm stemming from skewed results since they had yet to be released.14
Privatization Before Differential Privacy
Differential privacy is certainly not the first technique that has been developed to analyze data while protecting individuals in the data. Consider a situation where a researcher releases aggregate statistics about hospital patients over the past year. The researcher publishes a paper stating that there have been three cases of a particular type of cancer in that hospital this year. On the surface, you may assume this is safe; there were no names, addresses, Social Security numbers, or other sensitive, personally identifiable aspects released about these patients.
Previously, standard privatization techniques relied on anonymization to protect privacy—for example, removing or modifying the names of individuals. This is insufficient and can lead to privacy leakages. Consider the case of Dr. Latanya Sweeney who, while still a graduate student, purchased Massachusetts voter registration information and was able to identify the governor of Massachusetts within anonymized medical data.15 She was able to do this by isolating those individuals in the data with the same attributes as the governor, finding that “six people had [the governor’s] particular birthdate, only three of them were men, and, he was the only one in his 5-digit zip code.”16
This work led Sweeney to the discovery that many people are uniquely identifiable using only these three pieces of information: birthdate, government-recorded gender, and zip code.17 A 2006 study estimated that about 63% of the US population can be uniquely identified from these three attributes,18 while 44% of the population in the 2010 census is identifiable via census block, age, and sex.19
To protect against vulnerabilities like this, Sweeney introduced k-anonymity in 2002. K-anonymity is a generalized protection against this specific type of identification. The k in k-anonymity refers to its central principle—that an individual cannot be distinguished from at least k-1 other individuals in the data set. Using the Massachusetts scenario, this would mean a hypothetical scenario where Sweeney could not distinguish between the governor and k-1 other individuals in the voter roll, preventing her from re-identifying his medical records. Thus, k-anonymity has vulnerabilities to linking; if an attribute is considered non-identifying, but can be linked to another data set, it can become an identifying attribute and lead to privacy violations.
The two major attacks on k-anonymity are:
- Homogeneity attack
-
This attack takes advantage of a situation where the data has many identical values. Consider a situation where a hostile actor knows that someone has been admitted to the hospital on a certain date and looks at the admission logs. If everyone admitted to the hospital on that day had cancer, then the attacker has learned that this individual has cancer. Clearly, this attack relied on the homogeneity of the data—if everyone admitted on that date had a different disease, then the attacker would have learned nothing.
- Background knowledge attack
-
This attack relies on the attacker knowing things about the individual that are not present in the relevant data set. For example, if the attacker wants to know what type of cancer the individual has, and knows that the hospital admissions were all for prostate or cervical cancer, then the attacker simply needs to know whether the individual has a prostate or a cervix in order to learn their cancer diagnosis with certainty.20
As you can see, k-anonymity does not always prevent a bad actor from identifying individuals in a data set. Even if the data is sufficiently heterogeneous to not fall victim to a homogeneity attack, with the availability of third-party data for sale, the risk of a linkage attack is significant. Methods that suppress individual features in a data set are not sufficient to guarantee privacy.
Differential privacy gives a more general definition of privacy than techniques like k-anonymity. Instead of focusing on removing or anonymizing certain attributes from a data set, DP gives an analyst a quantitative guarantee about how distinguishable an individual’s information can be to a potential attacker.
Case Study: Applying DP in a Classroom
This section covers a simple case study that demonstrates the risks of nonprivate statistical releases. Though the stakes are relatively low (an exam score), the principles are the same for more sensitive types of data. This example highlights an important pattern when working with sensitive data: seemingly innocuous releases can lead to privacy violations.
By the end of this section, you should understand what makes two data sets adjacent and what the sensitivity of a function is.
Privacy and the Mean
Imagine you are in a class with 10 students total. You’ve just taken an exam and are eagerly awaiting the results. One day, the professor walks into the room and writes a number on the board: 85%. They announce that this was the average grade on the exam and that they will be passing back papers shortly. Suddenly, you get a text from your good friend Ari: “Big news! Just got a job with the circus and had to drop the class. See you this summer!” You mention to the professor that your friend is no longer enrolled in the class. With this information, they open their computer, type for a moment, then walk over to the board, erase the old average, and write 87%.
This scenario is innocent enough, right? After all, they didn’t write your friend’s score on the board.
“Well, in a way, they just did,” says a voice behind you.
Who said that? You turn around to find a demon sitting in the back row (yes, this connects to privacy—bear with us for a second). You are curious about his claim that the professor just essentially wrote your friend’s score on the board.
“What do you mean?” you ask.
He begins to explain that you know how to calculate an average in general. Suppose each student’s score is denoted by , the set of all such scores is , and the size of this set is . Then:
You know there were 10 people in the class before your friend dropped it:
where each is an exam score. Further, you know there were 9 people after he left and that the average score was 87:
Subtract the two equations from each other:
Let’s call your friend , then:
Simplify the subtraction term and use the definition of :
and simplify the fraction to its lowest common denominator:
Now you just need to isolate , your friend’s exam score:
You already know , it is simply the average written on the board:
Hold on—that’s your friend’s exam grade. What just happened? This demon just determined your friend’s grade using several pieces of information: the mean before he left, the mean after he left, and the number of students in the class. As you’ve just learned, releasing statistics about a data set can also release sensitive information about individuals in the data.
How Could This Be Prevented?
What could the professor have done? He could have instead written a possible range for the mean, like “80–90”, on the board. Unfortunately, this would be a poor trade-off for everyone, because it wouldn’t necessarily help privacy, and it would damage utility, because less information is being communicated to the students. The privacy of your friend could still be violated if dropping his score caused the range to shift, and the broad ranges don’t give the students very much specificity. All in all, this is suboptimal for the students and their privacy.
Randomized response
Another potential approach is randomized response, where the value is changed with a certain probability.21 In this case, the professor could have categorized every student as either “passed” (P) or “failed” (F). For each student, the professor flips a coin. If heads, they share the truth (either P or F) for that student. If tails, they flip again. They share P for heads or F for tails, regardless of the student’s true performance (see Figure 1-1). By building a histogram with the result of randomized response, the professor could present the students with a distribution that estimates the class’s overall performance on the exam.
- Randomized response
-
Randomized response is a method that modifies the value of each item in a data set according to certain probabilistic rules. For each item, if a coin flip returns tails (false), then the value recorded may not be the true value. This algorithm originated in the social sciences, where the goal was to prevent embarrassment to survey participants who were answering sensitive questions about their health or behavior.
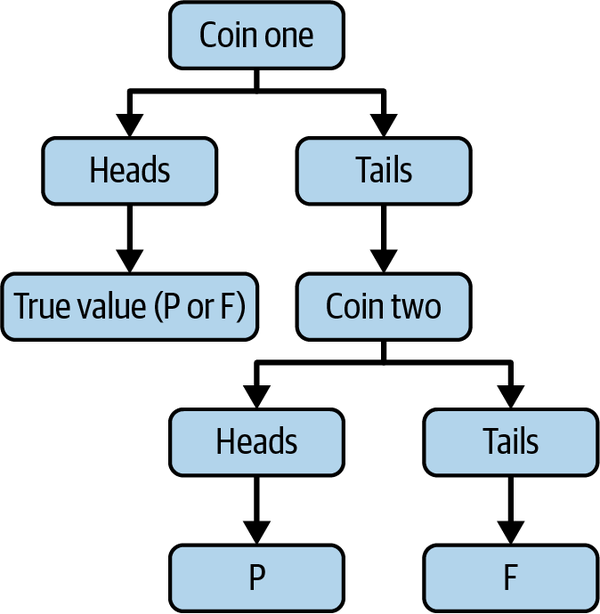
Figure 1-1. Randomized response via a coin flip
Randomized response certainly adds plausible deniability to the data set, since it is expected that 25% of the students will appear to be failing, even if none are (note that this just requires two flips of “tails” in a row). For this situation, randomized response may not be ideal; it places every student into one of two subsets and does not provide as accurate information about the overall class performance. This approach is preferable if the professor wants to share whether each student passed or failed in a way that gives each student plausible deniability. As written, it will also bias the pass/fail rate toward 0.5.
If the professor modifies their first coin to only return heads with lower probability (say, in 1 out of 100 flips), then they give greater privacy/more plausible deniability to each student but less accurate information.
Adding noise
Alternatively, what if the professor samples a value from a distribution and adds it to the mean? For example, if the professor tells you that the mean has noise added to it, then reconstructing your friend’s score becomes impossible, since the equation has two unknowns: the exam score and the amount of noise added. In this case, the means from the previous section become:
where and are values drawn from some distribution and are not disclosed to the students. With this noise added, attempting to calculate your friend’s grade yields the following equation:
You now have three unknowns: and , so the equation can no longer be solved analytically. At best, if you know the distribution that and were drawn from, then you can estimate the probabilities of different scores, without knowing with perfect information the true score. The question becomes: how do you add noise in such a way that you strike a balance between protecting privacy and keeping the statistic as useful as possible? If you know that your friend is the only person who is leaving, you can choose the noise from a known distribution in such a way that you sufficiently protect his score.
Yet this raises an important point—you aren’t just protecting privacy for one scenario (your friend leaving) but for all such scenarios where one person joins or leaves the class. You can’t know who will leave the class or when, which means it is insufficient to look at only one outcome; you must instead prepare for all possible changes to the class roster.
Adjacent Data Sets: What If Someone Else Had Dropped the Class?
Back to this demon. He comes to you and says, “You will live this day over and over, but each time, a different person will drop the class. When this happens, I will use the definition of the mean to uncover their score.” Now, if you have put sufficient privacy protections in place, you would shrug this demon off, knowing he will be frustrated or simply think he has the true scores computed. However, if you have only protected against the scenario where your friend leaves the class, then that leaves everyone else vulnerable.
Now suddenly you are sitting in a room, exactly like the classroom in the previous example but with one major difference—your friend is sitting next to you. His application to the circus was tragically rejected, but he is still happy to be with you in class. Right before class starts, you get a text from another classmate, Bobby, who is going on tour with his band and has to drop the class. At least he promises you VIP passes next time they come through town. You are relieved that Ari’s score is private, but in the back row, you see the demon ready to calculate Bobby’s score, and understand that it will be leaked.
The professor comes in and writes the mean exam score on the board, and you point out that Bobby has dropped the class. Just like last time, they update the score based on this new information. But this time, they remove a different score, so the mean changes: 84. In this parallel universe, the exam average drops one point instead of increasing by two. Regardless of the change in the average, the demon still sits in the back row calculating the score of whoever dropped the class. There is nothing special about this particular parallel universe; in fact, you need to prepare for all of them. Obviously, we are more concerned with human actors, but the demon serves as a useful foil for what information someone might have about a data set and what they could do with it.
In a classroom of 10 students, there are 10 possible adjacent classrooms where exactly one person drops the class. These are the types of events that can cause privacy leakage, as was shown earlier in the chapter. This concept of adjacency is crucial to providing rigorous privacy guarantees.
Since the class enrollment is public information, it is not necessary to configure the differential privacy guarantee to conceal a student’s inclusion in the data set. It is only necessary to conceal the value of the individual’s data.
- Data set adjacency
-
Two data sets and are adjacent if they differ by changing a single individual. (This definition will be made more general in Chapter 3.)
Note
In the DP literature, and in common usage, neighboring is used interchangeably with adjacent.
There are many senses in which two data sets may differ by a single individual. In the classroom example, we consider two data sets to be adjacent if they differ by the change of a single individual. In Chapter 3, you will learn a generalization of the concept of adjacent data sets.
For example, rosters A and B are adjacent in this sense because they differ by exactly one student (Carol). Let’s examine these student rosters as tabular data, that is, data organized in rows and columns, as seen in Tables 1-1 and 1-2.
| ID | Name |
|---|---|
1 |
Alice |
2 |
Bob |
3 |
Carol |
| ID | Name |
|---|---|
1 |
Alice |
2 |
Bob |
3 |
Eustace |
Let’s recap what you know so far:
-
Releasing a statistic can “leak” private information about individuals in a data set.
In particular, if you know that one data point has been removed and you know how much a given statistic has changed, you can reconstruct the value of the missing data point. This means that you have to protect against all possible scenarios like this.
-
Adding noise to a statistic can prevent this type of reconstruction from learning anything with perfect certainty. However, you don’t yet know how much noise to add.
Sensitivity: How Much Can the Statistic Change?
How do you define the possible changes in the exam score mean over these possible classes? To determine this, you need to understand sensitivity. You know that the mean can change when a person’s score changes: in one case, it increased by two points, and in the other, it decreased by one point. First, think about the largest change possible that can occur when any one person leaves the class.
This is the local sensitivity.
- Local sensitivity of the mean
-
The local sensitivity of the mean for a data set is the greatest possible value of over every adjacent data set .
Notice that the local sensitivity varies depending on your own data. If the class mean is around 50, then the mean computed on adjacent data sets could differ by less than a situation where the class mean was 100. Unfortunately, this means that the local sensitivity itself can reveal information about the structure of data in the data set. Because of this, the local sensitivity is not actually strong enough to defend against the demon.
You instead need the global sensitivity.
- Global sensitivity of the mean
-
The global sensitivity of the mean is the greatest possible value of over every pair of adjacent data sets , .
You can think of the global sensitivity as the greatest possible local sensitivity, for any initial data set. The sensitivities can be understood by thinking about pairs of neighboring data sets that maximize the difference between outputs of a function. Based on this intuition, in the most extreme case, let’s say your friend got a 0 and everyone else in the class got a 100—how embarrassing! In this situation, how much can changing his answer change the mean?
and after changing the exam score to 100:
which means the change in the mean is:
Alternatively, examine another extreme case: what if everyone else in the class got a 0 and your friend got a 100?
and after:
and again the change is:
Plugging in any values for the class, you will find that the maximum change in the mean is 10. For the mean of this data set, this number is special: it is the global sensitivity.
The global sensitivity tells us how much the statistic can change for any possible pair of initial data sets. Often, people refer only to the sensitivity without qualifying it as local or global.
Note
In this book, and in popular use, assume global when the kind of sensitivity is not specified.
For the classroom mean, our sensitivity is 10, since in the most distinguishable case, the exam score average changes by 10 points. Note that the justification given earlier is somewhat ad hoc: it relies on correctly identifying the choice of and for which the difference is the greatest. This kind of justification is prone to human error, which is why this kind of analysis is better handled by a mathematical proof. Throughout this book, you will encounter examples of proofs of important DP concepts.
Now that you’ve seen this scenario from the perspective of the students, let’s look at the professor’s role as the only person with access to the full data set. Since the students don’t have access to the full data set, the change in a statistic value is the only signal they can use to learn anything about the underlying data. On the other hand, those with access to the complete data set don’t need to infer anything because they can look directly at each individual row.
Adding Noise
As you’ve now seen, adding random noise can help obscure your friend’s exam grade—but from which distribution should you sample noise? The Laplace distribution is a particularly useful distribution, as it tends to minimize the amount of noise added while maximizing the privacy afforded (see Figure 1-2) The Laplace distribution has two tunable parameters: its center () and its width (). The probability density function shows how the tails decrease exponentially, meaning the likelihood of sampling a value further from the center decreases exponentially:
![Samples from the Laplace distribution are exponentially more likely nearer the origin/center, latexmath:[\mu].](/api/v2/epubs/9781492097730/files/assets/hodp_0102.png)
Figure 1-2. Samples from the Laplace distribution are exponentially more likely nearer the center
Let’s apply this method to the classroom example, where represents the mean. Notice that perturbed by a sample from a zero-centered Laplace distribution is identically distributed to sampling from a Laplace distribution centered at . Therefore, Laplacian output perturbation is the same as sampling from a Laplace distribution centered at (where ).
Imagine the professor wants to choose a noise scale of either or . As shown in the figure, since is smaller, the distribution is more tightly concentrated around , likely resulting in an estimate with greater utility (less error) than . On the other hand, adding noise scaled based on will result in better privacy protection because more noise is likely to be added. Choosing a parameter that balances the trade-off between privacy and utility is a common motif in differential privacy. Chapter 2 will provide you with tools to numerically quantify both the privacy and utility, which will help eliminate the guesswork when addressing this tension.
What Is a Trusted Curator?
Let’s examine this example from the professor’s point of view. In this scenario, the professor has total access to all the student data, while the students are only given access to aggregate statistics. This means that the professor is a trusted curator.
- Trusted curator
-
An individual or organization with complete access to a sensitive data set.
The students are the individuals in the data set, and the school staff and students represent the public that will receive the data analysis.
Suppose the professor has the student scores in a data set:
exam_scores ----------- 85 84 85 89 92 95 100 83 70 67
The professor then queries the student database using a mean function to get the mean test score for the class:
exam_scores.mean()>>>85.0
As before, student 0 joins the circus and drops the class. The professor computes a new mean and updates the score on the board:
exam_scores[:-1].mean()>>>87.0
You now know that anyone who knows how many students the school has could easily calculate the student’s grade, which is 67.
To protect the student’s privacy, the professor needs a function; let’s call it dp_mean. Under the hood, this function is calculating the mean and adding noise sampled from a Laplace distribution. With this function, the scenario looks like the following:
dp_mean(exam_scores)>>>83.84393665240519
dp_mean(exam_scores[:-1])>>>84.49003889353587
Now when the professor releases these statistics, the students cannot calculate their friend’s grade, even if they know the type of noise and scale parameters used!
As you’ve just seen, disclosing statistics about a data set leaks information about individuals in the data set. The professor certainly wasn’t trying to disclose sensitive information to their students, but the combination of a statistic and information about how the data set had changed was enough to isolate an individual. This will be a common theme throughout the book: how can you responsibly release statistics about sensitive data without disclosing data about individuals in the data set?
Available Tools
In data privacy, implementation is key to guaranteeing protection—a flawed implementation can leak information and cause privacy violations. Luckily, there are already high-quality open source tools available for working with data in a differentially private manner.
The majority of the code examples you will see in this book are written under the OpenDP Framework. Code examples that use libraries will typically use the OpenDP Library or SmartNoise, which contains higher-level abstractions over the OpenDP Library:
- The OpenDP Library
-
The OpenDP Library is a “modular collection of statistical algorithms” written under the OpenDP Framework. It can be used to build differentially private data analysis pipelines using a number of different models of privacy. The architecture of the OpenDP Library is based on a conceptual framework for expressing privacy-aware computations.22
The following OpenDP Library sample, taken from the documentation, creates a chain of three operations and applies them to a data set:
importopendp.preludeasdpcontext=dp.Context.compositor(data=exam_scores,privacy_unit=dp.unit_of(contributions=2),privacy_loss=dp.loss_of(epsilon=1.),split_evenly_over=1,domain=dp.vector_domain(dp.atom_domain(T=float),size=10))query=context.query().clamp((50.,100.)).sum().laplace()print(query.release())The OpenDP Library is part of the larger OpenDP Project, a community effort to build trustworthy, open source software tools for analysis of private data. The full documentation for OpenDP can be found at the OpenDP website.
- SmartNoise
-
SmartNoise is a collaboration between Microsoft, Harvard’s Institute for Quantitative Social Science (IQSS), and the OpenDP Project. The project aims to connect solutions from the research community with the lessons learned from real-world deployments to make differential privacy broadly accessible. Building upon the foundation of the OpenDP Library, the SmartNoise SDK includes two Python packages:
smartnoise-sql-
Allows data owners to run differentially private SQL queries. This package is useful when generating reports or data cubes over tabular data stored in SQL databases or Spark, or when the data set is very large.
smartnoise-synth-
Provides utilities for generating differentially private synthetic data sets. This is useful when you can’t predict the workload in advance and want to be able to share data that is structurally similar to the real data with collaborators.
- Tumult Labs
-
Tumult Core is a set of components for building differentially private computations. Tumult Analytics is a Python library, built on top of Tumult Core, that allows the user to perform differentially private queries on tabular data. Tumult also has an online platform for both batch and interactive data analysis. In May 2023, Tumult and Google announced a strategic partnership integrating Tumult’s differential privacy techniques into Google’s BigQuery platform. This allows BigQuery users to make differentially private queries on the platform by adding a differential privacy clause to their query. That is, you only have to add
WITH DIFFERENTIAL PRIVACYto yourSELECTstatement along with several options in order to make the query differentially private:
SELECTWITHDIFFERENTIAL_PRIVACYOPTIONS(epsilon=1.0,delta=.01,privacy_unit_column=id)item,AVG(quantity)average_salesFROMinventoryGROUPBYitem;
- Opacus
-
Opacus is a library for training differentially private PyTorch models. Training a DP model with Opacus requires minimal code changes, and in many cases does not have a significant impact on training performance. The library also supports online tracking of the privacy budget.
- Tensorflow Privacy
-
Tensorflow Privacy (also known as TF Privacy) was created by Google Research. The library includes DP implementations of TensorFlow optimizers for training ML. TF Privacy was designed so that users can train DP models with TensorFlow by changing a minimal amount of code. Differentially private implementations of some Keras models are available as well.
- Diffprivlib
-
Diffprivlib, from IBM, is a “general-purpose library for experimenting with” differential privacy. The library has Python bindings that can be used to compare DP and non-DP ML models and to build DP-preserving applications. It includes a variety of mechanisms, including differentially private implementations of common scikit-learn machine learning models.
If you have a background with scikit-learn, this code sample from the diffprivlib documentation will likely seem familiar:
fromdiffprivlib.modelsimportGaussianNBclf=GaussianNB()clf.fit(X_train,y_train)
Summary
Differential privacy, though a relatively recent development, has led to the creation of powerful tools for analyzing sensitive data. It is not enough to simply remove sensitive attributes from data, nor is it sufficient to anonymize data in order to protect privacy. Relatively simple methods can be used to re-identify individuals in a data set, for example, cross-referencing demographic information with voter rolls in order to identify patients in a medical data set. With the weaknesses of previous privatization techniques in mind, you can begin to weigh your options so that you will be able to safely work with sensitive data in the future. The goal of this book is that, upon completing it, you will have a firm grasp of the concepts behind differential privacy and also feel confident and prepared to work with sensitive data without falling into common traps.
Each chapter has a set of exercises at the end. These exercises are divided between conceptual, theoretical, and programming:
-
A conceptual question will ask you to answer a “why” question in sentences. These questions will probe whether you understand the fundamentals that have been covered in the chapter.
-
Theoretical questions will rely on mathematical reasoning; sometimes answering them will involve solving a problem, other times proving a theorem.
-
Programming questions will challenge you to implement concepts in Python with the OpenDP Library.
All exercises are answered in the book’s repository, with explanations and further comments.
Now that you have become familiar with some introductory material in differential privacy, you may have started to think more about how data is shared (or not shared) around you. While differential privacy can give fantastic privacy guarantees about data releases you make, you haven’t yet seen why differential privacy can make these guarantees.
The next chapter will provide a slightly more technical look into the same concepts, more formally define what the differential privacy guarantee means, and expand on the implications of the definition.
Exercises
-
Assuming an individual can contribute at most one record, which of the following database pairs are adjacent?
-
X = [1,2,3] Y=[1,2,3]
-
X = [A,B,C] Y=[C,A,D]
-
X = [A,B] Y=[B,A,C]
-
X = [D,E,F] Y=[E,F,D,G]
-
X = [A,B] Y=[A,A,A,B]
-
X = [A,B] Y=[A,B]
-
-
Consider a
COUNT(x)function that takes as input a database and returns the number of rows in the database. Instead of saying two data sets are neighboring by counting the number of edits needed to turn one data set into another, instead consider two data sets to be neighboring if adding or removing an individual can add or remove one row.-
Given ], calculate
COUNT(x). -
Calculate
COUNT(x')for each possible adjacent data-set where one record is removed. Can the distance between counts ever be more than 1? -
What is the global sensitivity of
COUNT(x)?
-
-
Imagine the exam from the previous example had an extra-credit question, and the maximum score is actually 110.
-
What is the sensitivity of the mean exam score?
-
Now do the same for several max scores {120, 130, 140,…}
-
What is the relationship between sensitivity and the max exam score?
-
If there is no limit to the exam score, is the sensitivity still well-defined?
-
-
Consider the mean for data bounded on ]. What is the global sensitivity when the data set size is known?
-
Now consider the more general case where the data is bounded on ]. What is the global sensitivity when the data set size is known?
1 Cynthia Dwork et al., “Calibrating Noise to Sensitivity in Private Data Analysis,” in Theory of Cryptography, ed. S. Halevi and T. Rabin. Lecture Notes in Computer Science. (Berlin: Springer, 2006): 265–84, https://doi.org/10.1007/11681878_14.
2 Cynthia Dwork, “Differential Privacy,” in Automata, Languages and Programming, ed. M. Bugliesi et al. Lecture Notes in Computer Science. (Berlin: Springer, 2006): 1–12, https://doi.org/10.1007/11787006_1.
3 Tore Dalenius, “Towards a Methodology for Statistical Disclosure Control,” accessed June 21, 2023, https://ecommons.cornell.edu/handle/1813/111303.
4 Dorothy E. Denning, “Secure Statistical Databases with Random Sample Queries,” ACM Transactions on Database Systems 5, no. 3 (September 1980): 291–315, https://doi.org/10.1145/320613.320616.
5 Denning, “Secure Statistical Databases.”
6 An averaging attack is a process where an attacker executes a large number of queries and averages the results to de-noise the outputs. You will learn more about privacy attacks in Chapter 11.
7 Irit Dinur and Kobbi Nissim, “Revealing Information While Preserving Privacy,” in Proceedings of the Twenty-Second ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems. PODS ’03. (New York, NY, USA: Association for Computing Machinery, (2003): 202–10, https://doi.org/10.1145/773153.773173.
8 Cynthia Dwork and Aaron Roth, “The Algorithmic Foundations of Differential Privacy,” FNT in Theoretical Computer Science 9, nos. 3–4, (2013): 211–407, https://doi.org/10.1561/0400000042.
9 Cynthia Dwork et al., “Calibrating Noise to Sensitivity in Private Data Analysis,” in Theory of Cryptography, ed. S. Halevi and T. Rabin. Lecture Notes in Computer Science. (Berlin: Springer, 2006): 265–84, https://doi.org/10.1007/11681878_14.
10 Nabil Adam et al., “Statistical Databases,” in Encyclopedia of Cryptography and Security, ed. H. C. A. van Tilborg and S. Jajodia. (Berlin: Springer, 2011): 1256–60, https://link.springer.com/referencework/10.1007/978-1-4419-5906-5.
11 For further demonstrations of many concepts that will be centrally important in this book, see Chapters 1–3, 7, and 13 in Cynthia Dwork and Aaron Roth, “The Algorithmic Foundations of Differential Privacy,” FNT in Theoretical Computer Science 9, nos. 3–4, (2013): 211–407, https://doi.org/10.1561/0400000042.
12 John M. Abowd, “The U.S. Census Bureau Adopts Differential Privacy,” in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. (New York: ACM, 2018): 2867, https://doi.org/10.1145/3219819.3226070.
13 The State of Alabama v. United States Department of Commerce & United States Census Bureau, United States District Court for the Middle District of Alabama.
14 The full case is called “Memorandum Opinion and Order, The State of Alabama v. United States Department of Commerce & United States Census Bureau, United States District Court for the Middle District of Alabama.” A brief of amicus curae was filed by the Electronic Privacy Information Center (EPIC) in support of the US Census.
15 Latanya Sweeney, “Simple Demographics Often Identify People Uniquely.” (Carnegie Mellon University, 2000).
16 Latanya Sweeney, “Recommendations to Identify and Combat Privacy Problems in the Commonwealth,” October 2005. Testimony before the Pennsylvania House Select Committee on Information Security (House Resolution 351), Pittsburgh, PA.
17 Latanya Sweeney, “Simple Demographics Often Identify People Uniquely.” (Carnegie Mellon University, 2000)
18 Philippe Golle, “Revisiting the Uniqueness of Simple Demographics in the US Population,” in Proceedings of the 5th ACM Workshop on Privacy in Electronic Society (New York: 2006): 77–80.
19 John M. Abowd. Supplemental Declaration, 2021. State of Alabama v. US Department of Commerce.
20 Abou-el-ela Abdou Hussien, Nermin Hamza, and Hesham A. Hefny, “Attacks on Anonymization-Based Privacy-Preserving: A Survey for Data Mining and Data Publishing,” Journal of Information Security 4, no. 2 (2013): 101–12, https://doi.org/10.4236/jis.2013.42012.
21 Stanley L. Warner, “Randomized Response: A Survey Technique for Eliminating Evasive Answer Bias,” Journal of the American Statistical Association 60, no. 309, (1965): 63–69, https://doi.org/10.2307/2283137.
22 Michael Hay, Marco Gaboardi, and Salil Vadhan, “A Programming Framework for OpenDP,” 6th Workshop on the Theory and Practice of Differential Privacy (2020). https://salil.seas.harvard.edu/publications/programming-framework-opendp.
Get Hands-On Differential Privacy now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

