Capítulo 1. Curso acelerado de SQL
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Este breve capítulo pretende ponerte al día rápidamente sobre la terminología y los conceptos básicos de SQL.
¿Qué es una base de datos?
Empecemos por lo básico. Una base de datos es un lugar donde almacenar datos de forma organizada. Hay muchas formas de organizar los datos, y como resultado, hay muchas bases de datos entre las que elegir. Las dos categorías en las que se dividen las bases de datos son SQL y NoSQL.
SQL
SQL es la abreviatura de Lenguaje de Consulta Estructurado. Imagina que tienes una aplicación que recuerda todos los cumpleaños de tus amigos. SQL es el lenguaje más popular que utilizarías para hablar con esa aplicación.
- Inglés
-
"Hola app. ¿Cuándo es el cumpleaños de mi marido?"
- SQL
-
SELECT * FROM birthdays WHERE person = 'husband';
Las bases de datos SQL suelen denominarse bases de datos relacionales porque están formadas por relaciones, que más comúnmente se denominan tablas. Muchas tablas conectadas entre sí forman una base de datos. La Figura 1-1 muestra una imagen de una relación en una base de datos SQL.
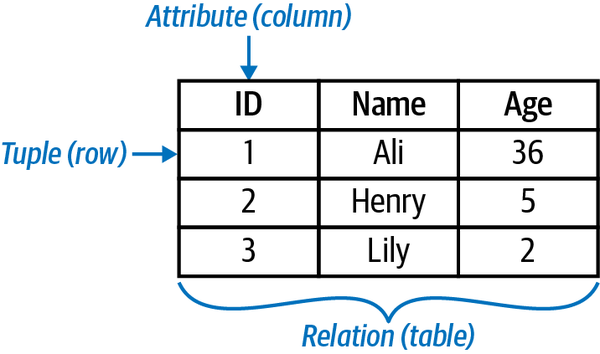
Figura 1-1. Una relación (también conocida como tabla) en una base de datos SQL
Lo principal a tener en cuenta sobre las bases de datos SQL es que requieren esquemas predefinidos. Puedes pensar en un esquema como la forma en que se organizan o estructuran los datos en una base de datos. Supongamos que quieres crear una tabla. Antes de cargar ningún dato en la tabla, primero hay que decidir la estructura de la tabla, incluyendo cosas como qué columnas hay en la tabla, si esas columnas contienen valores enteros o decimales, etc.
Sin embargo, llega un momento en que los datos no pueden organizarse de forma tan estructurada. Tus datos pueden tener campos variables o puedes necesitar una forma más eficaz de almacenar y acceder a una gran cantidad de datos. Ahí es donde entra NoSQL.
NoSQL
NoSQL no es sólo SQL. no se tratará en detalle en este libro, pero quería señalarlo porque el término ha crecido mucho en popularidad desde la década de 2010 y es importante entender que hay formas de almacenar datos más allá de las tablas.
Las bases de datos NoSQL suelen denominarse bases de datos no relacionales, y las hay de todos los tamaños y formas. Sus principales características son que tienen esquemas dinámicos (lo que significa que el esquema no tiene que estar fijado de antemano) y permiten el escalado horizontal (lo que significa que los datos pueden extenderse por varias máquinas).
La base de datos NoSQL más popular es MongoDB, que es más específicamente una base de datos de documentos. La Figura 1-2 muestra una imagen de cómo se almacenan los datos en MongoDB. Observarás que los datos ya no están en una tabla estructurada y que el número de campos (similar a una columna) varía para cada documento (similar a una fila).

Figura 1-2. Una colección (una variante de una tabla) en MongoDB, una base de datos NoSQL
Dicho todo esto, este libro se centra en las bases de datos SQL. Incluso con la introducción de NoSQL, la mayoría de las empresas siguen almacenando la mayor parte de sus datos en tablas de bases de datos relacionales.
Sistemas de Gestión de Bases de Datos (SGBD)
Puede que hayas oído términos como PostgreSQL o SQLite, y te estés preguntando en qué se diferencian de SQL. Son dos tipos de Sistemas de Gestión de Bases de Datos (SGBD ), que es el software utilizado para trabajar con una base de datos.
Esto incluye cosas como averiguar cómo importar datos y organizarlos, así como cosas como gestionar la forma en que los usuarios u otros programas acceden a los datos. Un Sistema de Gestión de Bases de Datos Relacionales (SGBDR ) es un software específico para bases de datos relacionales, o bases de datos formadas por tablas.
Cada RDBMS tiene una implementación diferente de SQL, lo que significa que la sintaxis varía ligeramente de un software a otro. Por ejemplo, así es como se daría salida a 10 filas de datos en 5 RDBMS diferentes:
- MySQL, PostgreSQL y SQLite
-
SELECT * FROM birthdays LIMIT 10; - Microsoft SQL Server
-
SELECT TOP 10 * FROM birthdays; - Base de datos Oracle
-
SELECT * FROM birthdays WHERE ROWNUM <= 10;
Este libro cubre los fundamentos de SQL junto con los matices de cinco populares sistemas de gestión de bases de datos: Microsoft SQL Server, MySQL, Oracle Database, PostgreSQL y SQLite.
Algunos son propietarios, es decir, son propiedad de una empresa y cuesta dinero utilizarlos, y otros son de código abierto, es decir, son gratuitos para que cualquiera pueda utilizarlos. La Tabla 1-1 detalla las diferencias entre los RDBMS.
| RDBMS | Propietario | Destacados |
|---|---|---|
Microsoft SQL Server |
Microsoft |
- RDBMS propietarios populares - A menudo se utiliza junto con otros productos de Microsoft, como Microsoft Azure y el marco .NET - Común en la plataforma Windows - También llamado MSSQL o SQL Server |
MySQL |
Código abierto |
- RDBMS populares de código abierto - A menudo se utiliza junto con lenguajes de desarrollo web como HTML/CSS/Javascript - Adquirido por Oracle, aunque sigue siendo de código abierto |
Base de datos Oracle |
Oracle |
- RDBMS propietarios populares - A menudo se utiliza en grandes empresas dada la cantidad de funciones, herramientas y soporte disponibles - También llamado simplemente Oracle |
PostgreSQL |
Código abierto |
- Crece rápidamente su popularidad - A menudo se utiliza junto con tecnologías de código abierto como Docker y Kubernetes - Eficaz y excelente para grandes conjuntos de datos |
SQLite |
Código abierto |
- El motor de base de datos más utilizado del mundo - Común en plataformas iOS y Android - Ligero y estupendo para una base de datos pequeña |
Nota
Avanzando en este libro:
Puedes encontrar instrucciones de instalación y fragmentos de código para cada RDBMS en Software RDBMS, en el Capítulo 2.
Una consulta SQL
Un acrónimo común en el mundo SQL es CRUD, que significa "Crear, Leer, Actualizar y Eliminar". Éstas son las cuatro operaciones principales que están disponibles en una base de datos.
Declaraciones SQL
Las personas que tienen acceso de lectura y escritura a una base de datos pueden realizar las cuatro operaciones. Pueden crear y eliminar tablas, actualizar datos de las tablas y leer datos de las tablas. En otras palabras, tienen todo el poder.
Escriben sentencias SQL, que es código SQL general que puede escribirse para realizar cualquiera de las operaciones CRUD. Estas personas suelen tener títulos como administrador de bases de datos (DBA) o ingeniero de bases de datos.
Consultas SQL
Las personas que tienen acceso de lectura a una base de datos sólo pueden realizar la operación de lectura, es decir, pueden consultar los datos de las tablas.
Escriben consultas SQL, que son un tipo más específico de sentencia SQL. Las consultas se utilizan para buscar y mostrar datos, lo que también se conoce como "leer" datos. Esta acción se denomina a veces consulta de tablas. Estas personas suelen tener títulos como analista de datos o científico de datos.
Las dos secciones siguientes son una guía rápida para escribir consultas SQL, ya que es el tipo de código SQL más común que verás. En el Capítulo 5 encontrarás más detalles sobre la creación y actualización de tablas.
La sentencia SELECT
La consulta SQL más básica de (que funcionará en cualquier software SQL) es:
SELECT * FROM my_table;
que dice: muéstrame todos los datos de la tabla my_table: todas las columnas y todas las filas.
Aunque SQL no distingue entre mayúsculas y minúsculas (SELECT y select son equivalentes), te darás cuenta de que algunas palabras están en mayúsculas y otras no.
-
Las palabras en mayúsculas de la consulta se llaman palabras clave, lo que significa que SQL las ha reservado para realizar algún tipo de operación con los datos.
-
Todas las demás palabras se escriben en minúsculas. Esto incluye nombres de tablas, nombres de columnas, etc.
Los formatos de mayúsculas y minúsculas no son obligatorios, pero es una buena convención de estilo para facilitar la lectura.
Volvamos a esta consulta:
SELECT * FROM my_table;
Digamos que en lugar de devolver todos los datos en su estado actual, quiero
-
Filtra los datos
-
Ordena los datos
Aquí es donde modificaría la declaración SELECT para incluir algunas cláusulas más, y el resultado sería algo parecido a esto:
SELECT * FROM my_table WHERE column1 > 100 ORDER BY column2;
Encontrarás más detalles sobre todas las cláusulas en el Capítulo 4, pero lo principal que debes tener en cuenta es lo siguiente: las cláusulas deben enumerarse siempre en el mismo orden.
Nota
El -- es el inicio de un comentario en SQL, lo que significa que el texto que viene después es sólo para documentación y el código no se ejecutará.
En la mayoría de los casos, las cláusulas SELECT y FROM son obligatorias y todas las demás son opcionales. La excepción es si estás seleccionando una función concreta de la base de datos, entonces sólo es necesaria la SELECT.
La mnemotecnia clásica para recordar el orden de las cláusulas es:
Los pies sudorosos desprenden olores horribles.
Si no quieres pensar en pies sudorosos cada vez que escribas una consulta, aquí tienes una que me he inventado:
Empieza los viernes con la avena casera de la abuela.
Orden de ejecución
El orden en que se ejecuta el código SQL no es algo que se enseñe normalmente en un curso de SQL para principiantes, pero lo incluyo aquí porque es una pregunta habitual que recibí cuando enseñaba SQL a estudiantes que venían de una formación de codificación en Python.
Una suposición sensata sería que el orden en que escribes las cláusulas es el mismo orden en que el ordenador las ejecuta, pero no es así. Después de ejecutar una consulta, éste es el orden en que el ordenador trabaja con los datos:
-
FROM -
WHERE -
GROUP BY -
HAVING -
SELECT -
ORDER BY
Comparado con el orden en que escribes realmente las cláusulas, observarás que la SELECT se ha desplazado a la quinta posición. Lo más importante es que SQL funciona en este orden:
-
Reúne todos los datos con el
FROM -
Filtra filas de datos con la función
WHERE -
Agrupa las filas con el
GROUP BY -
Filtra las filas agrupadas con el
HAVING -
Especifica las columnas que se mostrarán con el
SELECT -
Reordena los resultados con la
ORDER BY
Un modelo de datos
Me gustaría dedicar la sección final de del curso intensivo a repasar un modelo de datos sencillo y señalar algunos términos que oirás a menudo en divertidas conversaciones sobre SQL en la oficina.
Un modelo de datos es una visualización que resume cómo se relacionan entre sí todas las tablas de una base de datos, junto con algunos detalles sobre cada tabla. La Figura 1-3 es un modelo de datos sencillo de una base de datos de calificaciones de alumnos.
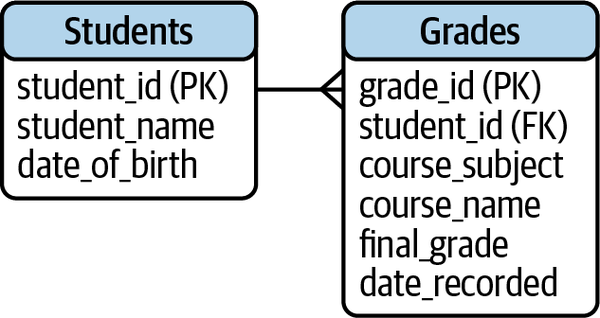
Figura 1-3. Un modelo de datos de las calificaciones de los alumnos
La Tabla 1-2 enumera los términos técnicos que describen lo que ocurre en el modelo de datos.
Encontrarás más detalles sobre estos términos en "Creación de tablas", en el capítulo 5.
Quizá te preguntes por qué pasamos tanto tiempo leyendo un modelo de datos en lugar de escribir ya código SQL. La razón es que a menudo escribirás consultas que vinculen varias tablas, por lo que es una buena idea familiarizarse primero con el modelo de datos para saber cómo se conectan todas ellas.
Los modelos de datos suelen encontrarse en un repositorio de documentación de una empresa. Tal vez quieras imprimir los modelos de datos con los que trabajas a menudo, tanto para consultarlos fácilmente como para decorar tu escritorio.
También puedes escribir consultas dentro de un RDBMS para buscar información contenida en un modelo de datos, como las tablas de una base de datos, las columnas de una tabla o las restricciones de una tabla.
Get Guía SQL de Bolsillo, 4ª Edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

