Kapitel 1. Warum die Datenqualität Aufmerksamkeit verdient - jetzt
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Hebe deine Hand (oder spucke deinen Kaffee aus, seufze tief und schüttle den Kopf), wenn dir dieses Szenario bekannt vorkommt.
Für deinen CEO haben Daten Priorität, so wie es bei Unternehmen mit digitaler Ausrichtung oft der Fall ist, und er kennt sich mit den neuesten und besten Business Intelligence-Tools aus. Dein CTO ist begeistert von der Umstellung auf die Cloud und schickt deinem Team ständig Artikel, in denen er Leistungsmessungen mit den neuesten Technologien vorstellt. Deine nachgelagerten Datenkonsumenten wie Produktanalysten, Marketingleiter und Vertriebsteams verlassen sich auf datengesteuerte Tools wie Customer Relationship Management/Customer Experience-Plattformen (CRMs/CXPs), Content Management Systeme (CMSs) und alle anderen Abkürzungen, die es gibt, um ihre Arbeit schnell und effektiv zu erledigen.
Als Datenanalytiker oder -ingenieur, der für die Verwaltung dieser Daten und ihre Nutzbarkeit, Zugänglichkeit und Vertrauenswürdigkeit verantwortlich ist, vergeht kaum ein Tag, an dem du nicht eine Anfrage von deinen Stakeholdern beantworten musst. Aber was passiert, wenn die Daten falsch sind?
Warst du schon einmal kurz davor, dich nach einem langen Tag mit Abfragen oder dem Aufbau von Datenpipelines zu verabschieden, nur um dann von deinem Marketingleiter darauf hingewiesen zu werden, dass "Daten in einem wichtigen Bericht fehlen"? Wie wäre es mit einer verzweifelten E-Mail von deinem CTO über "doppelte Daten" in einem Business Intelligence Dashboard? Oder ein Memo deines CEOs, der so viel Wert auf Daten legt, über eine verwirrende oder ungenaue Zahl in seinem letzten Board Deck?
Wenn du dich in einer dieser Situationen wiederfindest, bist du nicht allein.
Dieses Problem, das oft als "Datenausfallzeit" bezeichnet wird, betrifft selbst die innovativsten und datenorientierten Unternehmen und ist unserer Meinung nach eine der größten Herausforderungen für Unternehmen im 21. Jahrhundert konfrontiert sind. Datenausfallzeiten sind Zeiträume, in denen Daten fehlen, ungenau oder anderweitig fehlerhaft sind, was sich in veralteten Dashboards, ungenauen Berichten und sogar schlechten Entscheidungen äußert.
Die Ursache für Datenausfälle? Unzuverlässige Daten, und zwar jede Menge davon.
Datenausfälle können Unternehmen jedes Jahr Millionen von Dollar kosten, ganz zu schweigen vom Vertrauen der Kunden. ZoomInfo fand 2019 heraus, dass jedes fünfte Unternehmen einen Kunden aufgrund eines Datenqualitätsproblems verloren hat.
Wie du wahrscheinlich weißt, ist der Gewinn deines Unternehmens nicht das Einzige, das unter den Ausfallzeiten der Daten leidet. Die Bearbeitung von Datenqualitätsproblemen beansprucht mehr als 40 % der Zeit deines Datenteams, die du sonst für interessantere Projekte oder Innovationen für dein Unternehmen verwenden könntest.
Diese Statistik ist für dich wahrscheinlich keine Überraschung. Für uns war sie es jedenfalls nicht.
In ihrem früheren Leben war Barr Moses VP of Operations bei einem Softwareunternehmen für Kundenerfolg. Ihr Team war für das Berichtswesen für das gesamte Unternehmen zuständig, von der Erstellung von Dashboards für den CEO, die er bei All-Hands-Meetings verwenden konnte, bis hin zur Festlegung von Strategien zur Verringerung der Kundenabwanderung auf der Grundlage von Benutzerkennzahlen. Sie war für die Datenverwaltung ihres Unternehmens zuständig und stellte sicher, dass die Beteiligten bei der Arbeit mit Daten erfolgreich sind.
Barr wird nie den Tag vergessen, an dem sie nach einer zermürbenden, stundenlangen Planungssitzung an ihren Schreibtisch zurückkam und einen Klebezettel mit den Worten "Die Daten sind falsch" auf ihrem Computerbildschirm fand. Diese Enthüllung war nicht nur peinlich, sondern leider auch keine Seltenheit. Immer wieder stießen sie und ihr Team auf diese stillen und kleinen, aber potenziell schädlichen Probleme mit ihren Daten.
Es musste doch einen besseren Weg geben.
Schlechte Datenqualität und unzuverlässige Daten sind schon seit Jahrzehnten ein Problem für Unternehmen, sei es durch schlechte Berichterstattung, falsche Informationen oder technische Fehler. Und da Unternehmen immer mehr Daten nutzen und immer komplexere Datenökosysteme und -infrastrukturen aufbauen, wird dieses Problem nur noch zunehmen.
Das Konzept der "schlechten Daten" und der schlechten Datenqualität gibt es schon fast so lange, wie es Menschen gibt, wenn auch in unterschiedlichen Formen. Bei Kapitän Robert Falcon Scott und anderen frühen Entdeckern der Antarktis führte schlechte Datenqualität (oder besser gesagt, datenlose Entscheidungsfindung) dazu, dass sie ungenau vorhersagten, wo und wie lange sie brauchen würden, um den Südpol, ihr Ziel, zu erreichen.
Auch in der jüngeren Vergangenheit sind einige Fälle bekannt. Zum Beispiel der berüchtigte Absturz des Mars Climate Orbiter im Jahr 1999. Der Mars Climate Orbiter, eine Raumsonde der NASA, stürzte aufgrund eines Dateneingabefehlers ab, der dazu führte, dass die Daten in Nicht-SI-Einheiten (Internationales System) und nicht in SI-Einheiten ausgegeben wurden, wodurch die Sonde dem Planeten zu nahe kam. Dieser Absturz kostete die NASA satte 125 Millionen Dollar. Wie Raumschiffe können auch Analysepipelines durch die harmlosesten Änderungen in jeder Phase des Prozesses extrem anfällig sein. Und das ist nur die Spitze des Eisbergs.
Barrs unglücklicher Klebezettel-Vorfall hat sie zum Nachdenken gebracht: "Ich kann nicht allein sein!" Zusammen mit Lior Gavish machte sich Barr daran, die Ursache für die "Datenausfallzeiten" zu finden. Gemeinsam befragten sie Hunderte von Datenteams zu ihren größten Problemen, und immer wieder stand die Datenqualität ganz oben auf der Liste. Von E-Commerce bis zum Gesundheitswesen hatten Unternehmen in allen Branchen mit ähnlichen Problemen zu kämpfen: Schemaänderungen führten dazu, dass Datenpipelines unterbrochen wurden, Zeilen- oder Spaltenduplikate in geschäftskritischen Berichten auftauchten und Daten in Dashboards fehlten, was viel Zeit, Geld und Ressourcen kostete, um sie zu beheben. Wir erkannten auch, dass es einen besseren Weg geben musste, um Probleme mit der Datenqualität zu kommunizieren und zu beheben, und zwar als Teil eines iterativen Zyklus zur Verbesserung der Datenzuverlässigkeit und zum Aufbau einer Kultur, die das Vertrauen in die Daten fördert.
Diese Gespräche haben uns dazu inspiriert, dieses Buch zu schreiben, um einige der bewährten Methoden zu vermitteln, die wir im Zusammenhang mit dem Management der Datenqualität in jeder Phase der Datenpipeline - von der Aufnahme bis zur Analyse - gelernt und entwickelt haben, und um mitzuteilen, wie Datenteams in ähnlichen Situationen in der Lage sein könnten, ihre eigenen Datenausfälle zu verhindern.
Für die Zwecke dieses Buches bezieht sich "Daten in der Produktion" auf Daten aus Quellsystemen (wie CRMs, CMSs und Datenbanken aus den zuvor erwähnten Analogien), die von deinem Warehouse, Data Lake oder anderen Datenspeicherungs- und -verarbeitungslösungen aufgenommen wurden und durch deine Datenpipeline (Extract-Transform-Load oder ETL) fließen, damit sie von der Analyseschicht für die Geschäftsanwender aufbereitet werden können. Datenpipelines können sowohl Batch- als auch Streaming-Daten verarbeiten, und die Methoden zur Messung der Datenqualität sind für beide Arten von Daten im Großen und Ganzen die gleichen.
Die Ausfallzeit von Daten zieht Konsequenzen für die Softwareentwicklung und den Betrieb von Entwicklern nach sich, eine Welt, in der die Betriebszeit oder Ausfallzeit von Anwendungen (d.h. wie oft deine Software oder dein Dienst "verfügbar" oder "up" oder "nicht verfügbar" oder "down" war) genau gemessen wird, um sicherzustellen, dass die Software zugänglich und leistungsfähig ist. Viele Techniker/innen, die sich mit der Zuverlässigkeit von Websites befassen, verwenden die "Uptime" als Messgröße, weil sie direkt mit den Auswirkungen einer schlechten Softwareleistung auf das Unternehmen korreliert. Wie können wir in einer Welt, in der "fünf Neunen" (mit anderen Worten: 99,999 % Betriebszeit) zum Industriestandard geworden sind, dies auf Daten anwenden?
In diesem Buch geht es darum, wie moderne Datenteams widerstandsfähigere Technologien, Teams und Prozesse aufbauen können, um eine hohe Datenqualität und -zuverlässigkeit in ihrem Unternehmen zu gewährleisten.
In diesem Kapitel werden wir zunächst definieren, was Datenqualität im Kontext dieses Buches bedeutet. Als Nächstes werden wir die aktuelle Situation beleuchten, um besser zu verstehen, warum Datenqualität für Datenverantwortliche wichtiger ist als je zuvor. Und schließlich schauen wir uns genauer an, wie Best-in-Class-Teams in jeder Phase der Datenpipeline eine hohe Datenqualität erreichen können und was nötig ist, um das Vertrauen in die Daten im großen Maßstab zu erhalten. Dieses Buch konzentriert sich in erster Linie auf die Datenqualität als Funktion der Datenanalyse-Pipelines für die Erstellung von Entscheidungs-Dashboards, Datenprodukten, Machine Learning (ML)-Modellen und anderen Data Science-Ergebnissen.
Was ist Datenqualität?
Das Konzept der Datenqualität ist nicht neu - "Datenqualität" gibt es schon so lange, wie Menschen Daten sammeln!
In den letzten Jahrzehnten hat sich jedoch die Definition von Datenqualität als eine Funktion der Messung der Zuverlässigkeit, Vollständigkeit und Genauigkeit von Daten in Bezug auf den Zustand dessen, worüber berichtet wird, herauskristallisiert. Wie man sagt, kann man nicht verwalten, was man nicht misst, und eine hohe Datenqualität ist die erste Stufe eines soliden Analyseprogramms. Die Datenqualität ist auch ein äußerst wirkungsvolles Mittel, um herauszufinden, ob deine Daten den Anforderungen deines Unternehmens entsprechen.
Für die Zwecke dieses Buches definieren wir Datenqualität als den Zustand der Daten in jeder Phase ihres Lebenszyklus. Die Datenqualität kann in jeder Phase der Datenpipeline beeinträchtigt werden, sei es vor dem Ingestion, in der Produktion oder sogar während der Analyse.
Unserer Meinung nach hat die Datenqualität häufig einen schlechten Ruf. Datenteams wissen, dass sie dem Thema Priorität einräumen müssen, aber es geht ihnen nicht so leicht von der Zunge wie "maschinelles Lernen", "Datenwissenschaft" oder sogar "Analytik", und viele Teams haben nicht die Bandbreite oder die Ressourcen, um einen Vollzeitmitarbeiter für diese Aufgabe einzustellen. Stattdessen verlassen sich Unternehmen mit knappen Ressourcen darauf, dass die Datenanalysten und -ingenieure sich selbst darum kümmern, und lenken sie von Projekten ab, die als interessanter oder innovativer gelten.
Aber wenn du den Daten und den Datenprodukten, die sie liefern, nicht trauen kannst, wie können dann die Datennutzer darauf vertrauen, dass dein Team einen Mehrwert liefert? Der Satz "Keine Daten sind besser als schlechte Daten" wird von Fachleuten in diesem Bereich oft in den Mund genommen, und obwohl er sicherlich seine Berechtigung hat, entspricht er oft nicht der Realität.
Datenqualitätsprobleme (oder Datenausfallzeiten) sind angesichts des Wachstums und des Datenverbrauchs der meisten Unternehmen praktisch unvermeidlich. Aber wenn wir verstehen, wie wir Datenqualität definieren, wird es viel einfacher, sie zu messen und zu verhindern, dass sie Probleme verursacht.
Den aktuellen Moment einrahmen
Technische Teams verfolgen und verbessern die Datenqualität schon so lange, wie sie analytische Daten verfolgen, aber erst in den 2020er Jahren ist die Datenqualität für viele Unternehmen zur obersten Priorität geworden. Da Daten für viele Unternehmen nicht nur ein Output, sondern auch ein finanzielles Gut sind, ist es wichtig, dass man sich auf diese Informationen verlassen kann.
Infolgedessen behandeln Unternehmen ihre Daten zunehmend wie Code und wenden Frameworks und Paradigmen, die bei Softwareentwicklungsteams schon lange Standard sind, auf ihre Datenorganisationen und -architekturen an. Der Entwicklungsbetrieb (DevOps), ein technischer Bereich, der sich der Verkürzung des Lebenszyklus der Systementwicklung widmet, hat branchenweit bewährte Methoden wie Site Reliability Engineering (SRE), CI/CD (Continuous Integration / Continuous Deployment) und Microservices-basierte Architekturen hervorgebracht. Kurz gesagt, das Ziel von DevOps ist es, durch Automatisierung zuverlässigere und leistungsfähigere Software zu veröffentlichen .
In den letzten Jahren haben immer mehr Unternehmen diese Konzepte in Form von "DataOps" auf Daten angewandt. DataOps bezeichnet den Prozess, die Zuverlässigkeit und Leistung deiner Daten durch Automatisierung zu verbessern, Datensilos zu reduzieren und schnellere, fehlertolerantere Analysen zu fördern.
Seit 2019 haben Unternehmen wie Intuit, Airbnb, Uber und Netflix ausführlich darüber berichtet, wie sie durch die Anwendung bewährter Methoden im Bereich DataOps dafür sorgen, dass ihre Daten für alle Beteiligten zuverlässig und hochverfügbar sind. Die von diesen Unternehmen produzierten Daten dienen nicht nur der analytischen Entscheidungsfindung (z. B. Produktstrategie, Finanzmodelle, Wachstumsmarketing usw.), sondern auch als Grundlage für ihre Anwendungen und digitalen Dienste. Ungenaue, fehlende oder fehlerhafte Daten können sie Zeit, Geld und das Vertrauen ihrer Kunden kosten.
Da diese Tech-Giganten die Bedeutung und die Herausforderungen einer hohen Datenqualität immer deutlicher machen, beginnen andere Unternehmen aller Größen und Branchen, diese Bemühungen zu übernehmen und in bewährte Methoden des DataOps wie Monitoring und Datenbeobachtbarkeit zu investieren.
Aber was hat zu diesem Bedarf an höherer Datenqualität geführt? Was hat sich in der Datenlandschaft verändert, um den Aufstieg von DataOps und damit auch den Aufstieg der Datenqualität zu ermöglichen? Diesen Fragen gehen wir im Folgenden nach.
Den "Anstieg der Datenausfallzeiten" verstehen
Mit dem zunehmenden Fokus auf die Monetarisierung von Daten und dem ständigen Wunsch, die Datengenauigkeit zu erhöhen, müssen wir einige der Faktoren besser verstehen, die zu Datenausfällen führen können. Als Nächstes werfen wir einen genaueren Blick auf die Variablen, die deine Daten beeinflussen können.
Migration in die Cloud
Vor zwanzig Jahren hätte dein Data Warehouse (ein Ort, an dem du strukturierte Daten transformierst und speicherst) wahrscheinlich in einem Bürokeller gestanden und nicht auf AWS oder Azure. Mit dem Aufkommen von datengesteuerten Analysen, funktionsübergreifenden Datenteams und vor allem der Cloud sind Cloud-Data-Warehousing-Lösungen wie Amazon Redshift, Snowflake und Google BigQuery zu immer beliebteren Optionen für datenbegeisterte Unternehmen geworden. In vielerlei Hinsicht macht die Cloud Daten einfacher zu verwalten, für eine größere Anzahl von Nutzern zugänglich und viel schneller zu verarbeiten.
Nicht lange nach der Verlagerung von Data Warehouses in die Cloud wurden auch Data Lakes (ein Ort, an dem unstrukturierte Daten umgewandelt und gespeichert werden) eingeführt, was den Datenteams noch mehr Flexibilität bei der Verwaltung ihrer Daten gibt. Mit der Verlagerung der Unternehmen und ihrer Daten in die Cloud wurde die analytische Entscheidungsfindung (und der Bedarf an qualitativ hochwertigen Daten) für Unternehmen immer wichtiger.
Weitere Datenquellen
Heutzutage nutzen Unternehmen zwischen Dutzenden und Hunderten von internen und externen Datenquellen, um Analysen und ML-Modelle zu erstellen. Jede dieser Quellen kann sich auf unerwartete Weise und ohne Vorankündigung ändern und die Daten, die das Unternehmen für seine Entscheidungen nutzt, gefährden.
Zum Beispiel könnte ein Entwicklungsteam eine Änderung an der Website des Unternehmens vornehmen und dadurch die Ausgabe eines Datensatzes verändern, der für die Marketing-Analyse wichtig ist. Infolgedessen können wichtige Marketingkennzahlen falsch sein, was dazu führt, dass das Unternehmen schlechte Entscheidungen über Werbekampagnen, Verkaufsziele und andere wichtige, umsatzfördernde Projekte trifft.
Zunehmend komplexe Datenpipelines
Datenpipelines werden immer komplexer und umfassen mehrere Verarbeitungsstufen und nicht triviale Abhängigkeiten zwischen verschiedenen Datenbeständen. Dies ist das Ergebnis fortschrittlicherer (und uneinheitlicher) Tools, einer größeren Anzahl von Datenquellen und der zunehmenden Sorgfalt, die die Unternehmensleitung den Daten widmet. Ohne Einblick in diese Abhängigkeiten kann jedoch jede Änderung an einem Datensatz unbeabsichtigte Folgen haben, die sich auf die Korrektheit der abhängigen Datenbestände auswirken.
Kurz gesagt: In einer Datenpipeline passiert eine Menge. Quelldaten werden extrahiert, aufgenommen, umgewandelt, geladen, gespeichert, verarbeitet und geliefert, neben anderen möglichen Schritten, mit vielen APIs und Integrationen zwischen den verschiedenen Phasen der Pipeline. An jedem dieser Punkte kann es zu Datenausfällen kommen, genauso wie es bei der Zusammenführung von Code zu Anwendungsausfällen kommen kann. Außerdem kann auch dann etwas schiefgehen, wenn sich die Daten nicht an einem kritischen Punkt befinden, z. B. wenn Daten zwischen Lagern migriert oder manuell in ein Quellsystem eingegeben werden.
Mehr spezialisierte Datenteams
Da sich Unternehmen zunehmend auf Daten verlassen, um intelligente Entscheidungen zu treffen, stellen sie immer mehr Datenanalysten, Datenwissenschaftler und Dateningenieure ein, um die Datenpipelines, Analysen und ML-Modelle aufzubauen und zu pflegen, die ihre Dienstleistungen und Produkte sowie ihre Geschäftsabläufe antreiben.
Während Datenanalysten in erster Linie für das Sammeln, Bereinigen und Abfragen von Datensätzen zuständig sind, um den Stakeholdern in den Fachabteilungen dabei zu helfen, aussagekräftige und umsetzbare Erkenntnisse über das Unternehmen zu gewinnen, sind Dateningenieure dafür verantwortlich, dass die zugrunde liegenden Technologien und Systeme, die diesen Analysen zugrunde liegen, leistungsfähig, schnell und zuverlässig sind. In der Industrie sammeln Datenwissenschaftler/innen in der Regel unstrukturierte Daten, verarbeiten sie, erweitern sie und machen sie sinnvoll, um das Geschäft zu verbessern. Die Unterscheidung zwischen Datenanalysten und Datenwissenschaftlern kann etwas vage sein, und die Bezeichnungen und Aufgaben variieren oft je nach den Bedürfnissen des Unternehmens. So hat Uber Ende der 2010er Jahre nach einer organisatorischen Umstrukturierung alle Datenanalysten in Datenwissenschaftler umbenannt.
Da Daten immer mehr zur Grundlage des Geschäfts werden, werden die Datenteams immer größer. Größere Unternehmen können sogar zusätzliche Rollen wie Data Stewards, Data Governance Leader, Operations Analysts und sogar Analytics Engineers (eine Mischform aus Data Engineer und Analyst, die bei Startups und mittelständischen Unternehmen beliebt ist, die nicht die Ressourcen für ein großes Datenteam haben) unterstützen.
Wenn all diese verschiedenen Nutzer/innen mit den Daten in Berührung kommen, sind Missverständnisse oder unzureichende Koordination unvermeidlich und führen dazu, dass diese komplexen Systeme bei Änderungen nicht funktionieren. Wenn zum Beispiel ein Team ein neues Feld zu einer Datentabelle hinzufügt, kann das dazu führen, dass die Pipeline eines anderen Teams fehlschlägt und Daten fehlen oder unvollständig sind. Die Folge sind fehlende oder unvollständige Daten. Diese fehlerhaften Daten können zu Umsatzeinbußen in Millionenhöhe führen, das Vertrauen der Kunden untergraben und sogar die Einhaltung von Vorschriften gefährden.
Dezentralisierte Datenteams
Da Daten in den Mittelpunkt des Geschäftsbetriebs rücken, sind immer mehr Funktionsteams im gesamten Unternehmen an der Datenverwaltung und -analyse beteiligt, um den Prozess der Gewinnung von Erkenntnissen zu rationalisieren und zu beschleunigen. Daher setzen immer mehr Datenteams auf ein verteiltes, dezentrales Modell, das die branchenweite Umstellung von monolithischen auf Microservice-Architekturen nachahmt, die Mitte der 2010er Jahre die Welt der Softwareentwicklung im Sturm eroberte.
Was ist eine dezentralisierte Datenarchitektur? Nicht zu verwechseln mit dem Data Mesh, einem Organisationsparadigma, das ein verteiltes, bereichsorientiertes Design nutzt. Eine dezentrale Datenarchitektur wird von einem zentralen Datenplattformteam verwaltet, wobei die analytischen und Data-Science-Teams über das gesamte Unternehmen verteilt sind. Wir stellen zunehmend fest, dass immer mehr Teams, die sich für das Modell des eingebetteten Datenanalysten entscheiden, auf diese Art von Architektur setzen.
Dein 200-Personen-Unternehmen könnte zum Beispiel ein Team von 3 Dateningenieuren und 10 Datenanalysten unterstützen, wobei die Analysten über funktionale Teams verteilt sind, um die Bedürfnisse des Unternehmens besser zu unterstützen. Diese Analysten unterstehen den operativen Teams oder zentralen Datenteams, sind aber für bestimmte Datensätze und Berichtsfunktionen zuständig. Mehrere Bereiche erzeugen und nutzen Daten, was zwangsläufig dazu führt, dass Datensätze, die von mehreren Teams genutzt werden, doppelt vorhanden sind, fehlen oder mit der Zeit veralten. Wenn du dieses Buch liest, kennst du wahrscheinlich auch die Erfahrung, dass du einen Datensatz verwendest, der nicht mehr relevant ist, ohne dass du es weißt!
Andere Branchentrends, die zur aktuellen Situation beitragen
Zusätzlich zu den oben genannten Faktoren, die häufig zu Datenausfällen führen, gibt es in der Branche auch einige Veränderungen, die auf technologische Innovationen zurückzuführen sind und die Datenlandschaft verändern. Diese Veränderungen tragen alle dazu bei, dass der Datenqualität mehr Aufmerksamkeit geschenkt wird.
Datengitter
Ähnlich wie Softwareentwicklungsteams von monolithischen Anwendungen zu Microservice-Architekturen übergegangen sind, ist das Data Mesh in vielerlei Hinsicht die Datenplattformversion der Microservices. Es ist wichtig zu erwähnen, dass das Konzept des Data Mesh erst im Entstehen begriffen ist und dass es in der Daten-Community viele Diskussionen darüber gibt, wie (oder ob es überhaupt Sinn macht), es auf kultureller und technischer Ebene umzusetzen.
Wie Zhamak Dehghani, ein Berater von Thoughtworks und der ursprüngliche Architekt des Begriffs, erstmals definierte, ist ein Datengeflecht, wie in Abbildung 1-1 dargestellt, ein soziotechnisches Paradigma, das die Interaktionen zwischen Menschen und der technischen Architektur und den Lösungen in komplexen Organisationen berücksichtigt. Das Datengeflecht macht sich die Allgegenwart von Daten im Unternehmen zunutze, indem es ein bereichsorientiertes, selbstverwaltendes Design einsetzt. Es nutzt die Theorie des domänenorientierten Designs von Eric Evans, ein flexibles, skalierbares Softwareentwicklungsparadigma, das die Struktur und Sprache deines Codes an die entsprechende Geschäftsdomäne anpasst.
Im Gegensatz zu herkömmlichen monolithischen Dateninfrastrukturen, die den Verbrauch, die Speicherung, die Umwandlung und die Ausgabe von Daten in einem zentralen Data Lake verwalten, unterstützt ein Data Mesh verteilte, domänenspezifische Datenkonsumenten und betrachtet "Daten als Produkt", wobei jede Domäne ihre eigenen Datenpipelines verwaltet. Das Gewebe, das diese Domänen und ihre zugehörigen Datenbestände verbindet, ist eine universelle Interoperabilitätsschicht, die dieselbe Syntax und dieselben Datenstandards verwendet.
Datenverflechtungen föderieren das Dateneigentum zwischen den Eigentümern der Domaindaten, die für die Bereitstellung ihrer Daten als Produkte verantwortlich gemacht werden, und erleichtern gleichzeitig die Kommunikation zwischen verteilten Daten an verschiedenen Standorten.
Während die Dateninfrastruktur dafür verantwortlich ist, jeder Domäne die Lösungen zur Verfügung zu stellen, mit denen sie die Daten verarbeiten kann, sind die Domänen dafür zuständig, die Daten aufzunehmen, zu bereinigen und zu aggregieren, um Assets zu erzeugen, die von Business Intelligence-Anwendungen genutzt werden können. Jede Domäne ist für ihre eigenen Pipelines verantwortlich, aber es gibt eine Reihe von Funktionen, die für alle Domänen gelten und die Rohdaten speichern, katalogisieren und die Zugriffskontrollen aufrechterhalten. Sobald die Daten an eine bestimmte Domäne geliefert und von ihr umgewandelt wurden, können die Domänenbesitzer die Daten für ihre Analysen oder betrieblichen Anforderungen nutzen.
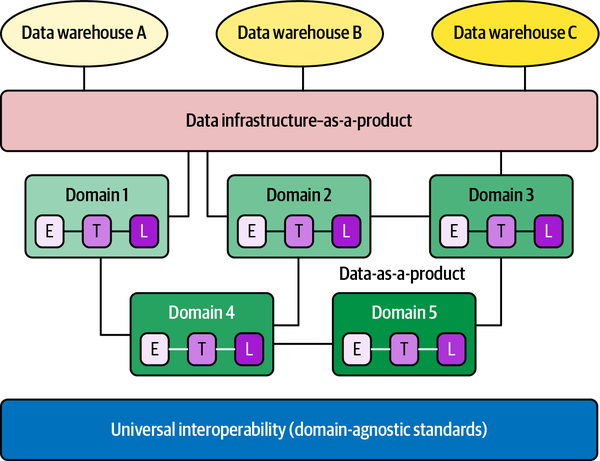
Abbildung 1-1. Das von Zhamak Dehghani entwickelte Datengeflecht setzt sich für eine dezentralisierte, domänenorientierte Datenarchitektur ein, die auf hochwertigen, zuverlässigen Daten und einer universellen Governance beruht
Das Paradigma der Datenverflechtung ist nur dann erfolgreich, wenn die Daten zuverlässig und vertrauenswürdig sind und wenn diese "universelle Interoperabilitätsebene" bereichsübergreifend angewendet wird. Der einzige Weg, wie Daten zuverlässig und vertrauenswürdig sein können? Indem man die Qualität der Daten durch Tests, Überwachung und Beobachtung genau kontrolliert.
Viele Unternehmen übernehmen das Paradigma der Datenverflechtung, insbesondere größere Organisationen, die mehrere Datendomänen benötigen. In einem Blogartikel von Mammad Zadeh, dem ehemaligen VP of Data Engineering von Intuit, und Raji Arasu, dem SVP of Core Services & Experiences von Intuit, vom Januar 2021 positioniert sich Intuit als "KI-gesteuertes Expertenplattformunternehmen", dessen Plattform "einen stetigen Datenstrom sammelt, verarbeitet und in ein zusammenhängendes Netz hochwertiger Daten umwandelt". Ein weiteres Beispiel ist JPMorgan Chase, das eine Data-Mesh-Architektur aufgebaut hat, um die Datenverantwortung zwischen den einzelnen Analysefunktionen abzugrenzen und die Transparenz der gemeinsamen Datennutzung im Unternehmen zu verbessern.
Unabhängig davon, wie du zum Data Mesh stehst, hat es die Daten-Community im Sturm erobert und für viel Gesprächsstoff - und Blogartikel - überdie Zukunft unserer verteilten Datenarchitekturen und Teamstrukturen gesorgt.
Daten streamen
Streaming Data bezeichnet den Prozess der Übertragung eines kontinuierlichen Datenstroms in deine Pipeline, um schnell Erkenntnisse in Echtzeit zu gewinnen. Früher wurde die Datenqualität durch das Testen von Batch-Daten sichergestellt, bevor sie in die Produktionspipelines eingespeist wurden, aber immer mehr Unternehmen wollen Analysen in Echtzeit durchführen. Das hat zwar das Potenzial, die Erkenntnisse zu beschleunigen, wirft aber auch mehr Fragen und Herausforderungen in Bezug auf die Datenqualität auf, da Streaming-Daten Daten "in Bewegung" sind.
Immer mehr Unternehmen setzen sowohl auf Stapelverarbeitung als auch auf Stream Processing, was die Datenteams zwingt, ihre Herangehensweise an die Prüfung und Beobachtung ihrer Daten zu überdenken.
Der Aufstieg des Data Lakehouse
Data Warehouse oder Data Lake? Das ist die Frage - zumindest, wenn du einen Dateningenieur fragst. Sowohl Data Warehouses, ein strukturierter Datenspeicher, als auch Data Lakes, ein Pool unstrukturierter Rohdaten, sind auf qualitativ hochwertige Daten für die Verarbeitung und Umwandlung angewiesen. Immer mehr Datenteams entscheiden sich dafür, sowohl Data Warehouses als auch Data Lakes zu nutzen, um den wachsenden Datenbedarf ihres Unternehmens zu decken. Darf ich vorstellen: das Data Lakehouse.
Data Lakehouses kamen zum ersten Mal auf den Plan, als Cloud-Provider begannen, Funktionen wie Redshift Spectrum oder Databricks Lakehouse einzuführen, die Vorteile im Stil eines Data Lakes bieten. In ähnlicher Weise haben Data Lakes Technologien hinzugefügt, die Warehouse-ähnliche Funktionen bieten, z. B. SQL-Funktionen und Schemata. Heute werden die historischen Unterschiede zwischen Warehouses und Lakes immer geringer, sodass du das Beste aus beiden Welten in einem Paket nutzen kannst.
Diese Umstellung auf das Lakehouse-Modell deutet darauf hin, dass die Pipelines immer komplexer werden, und während einige sich für einen einzigen Anbieter entscheiden, um beides zu bewältigen, migrieren andere die Daten auf mehrere Speicher- und Verarbeitungsebenen, was zu mehr Möglichkeiten für Pipeline-Daten führt, um mit ausreichenden Tests zu bestehen.
Zusammenfassung
Das Aufkommen der Cloud, verteilte Datenarchitekturen und -teams sowie die Entwicklung hin zur Datenproduktion haben die Verantwortlichen für die Datenverarbeitung in die Pflicht genommen, ihren Unternehmen zu vertrauenswürdigeren Daten zu verhelfen (was zu vertrauenswürdigeren Analysen führt). Das Erreichen zuverlässiger Daten ist ein Marathon, kein Sprint, und umfasst viele Stufen deiner Datenpipeline. Außerdem ist die Verbesserung der Datenqualität nicht nur eine technische, sondern auch eine organisatorische und kulturelle Herausforderung. Im nächsten Kapitel werden wir einige Technologien besprechen, die dein Team nutzen kann, um fehlerhafte Pipelines zu vermeiden und wiederholbare, iterative Prozesse und Frameworks zu entwickeln, mit denen du Datenausfälle besser kommunizieren, angehen und sogar verhindern kannst.
Get Grundlagen der Datenqualität now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

