Kapitel 4. gRPC: Unter der Haube
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Wie du in den vorangegangenen Kapiteln gelernt hast, kommunizieren gRPC-Anwendungen per RPC über das Netzwerk. Als gRPC-Anwendungsentwickler brauchst du dich nicht um die Details zu kümmern, wie RPC implementiert wird, welche Nachrichtenkodierungstechniken verwendet werden und wie RPC über das Netzwerk funktioniert. Du verwendest die Dienstdefinition, um entweder server- oder clientseitigen Code für die Sprache deiner Wahl zu erstellen. Alle Details der Low-Level-Kommunikation werden im generierten Code implementiert und du erhältst einige High-Level-Abstraktionen, mit denen du arbeiten kannst. Wenn du jedoch komplexe gRPC-basierte Systeme entwickelst und sie in der Produktion einsetzt, ist es wichtig zu wissen, wie gRPC im Detail funktioniert.
In diesem Kapitel werden wir untersuchen, wie der gRPC-Kommunikationsfluss implementiert wird, welche Kodierungstechniken verwendet werden, wie gRPC die zugrunde liegenden Netzwerkkommunikationstechniken nutzt und so weiter. Wir führen dich durch den Nachrichtenfluss, bei dem der Client eine bestimmte RPC aufruft. Dann besprechen wir, wie die Nachricht in einen gRPC-Aufruf umgewandelt wird, der über das Netzwerk läuft, wie das Netzwerkkommunikationsprotokoll verwendet wird, wie die Nachricht am Server entmarshaled wird, wie der entsprechende Dienst und die Remote-Funktion aufgerufen werden und so weiter.
Wir werden uns auch ansehen, wie wir Protokollpuffer als Kodierungstechnik und HTTP/2 als Kommunikationsprotokoll für gRPC verwenden. Schließlich werden wir uns mit der Implementierungsarchitektur von gRPC und dem Sprachunterstützungsstapel beschäftigen, der um sie herum aufgebaut ist. Obwohl die Low-Level-Details, die wir hier besprechen werden, für die meisten gRPC-Anwendungen nicht von großem Nutzen sind, ist ein gutes Verständnis der Low-Level-Kommunikationsdetails sehr hilfreich, wenn du eine komplexe gRPC-Anwendung entwickelst oder versuchst, bestehende Anwendungen zu debuggen.
RPC Fluss
In einem RPC-System implementiert der Server eine Reihe von Funktionen, die aus der Ferne aufgerufen werden können. Die Client-Anwendung kann einen Stub erstellen, der Abstraktionen für dieselben Funktionen bietet, die vom Server angeboten werden, sodass die Client-Anwendung direkt Stub-Funktionen aufrufen kann, die die Remote-Funktionen der Server-Anwendung aufrufen.
Schauen wir uns den Dienst ProductInfo an, den wir in Kapitel 2 besprochen haben, um zu verstehen, wie ein Remote Procedure Call über das Netzwerk funktioniert. Eine der Funktionen, die wir als Teil unseres ProductInfo Dienstes implementiert haben, ist getProduct, bei der der Kunde durch Angabe der Produkt-ID Produktdetails abrufen kann. Abbildung 4-1 veranschaulicht, was passiert, wenn der Kunde eine Remote-Funktion aufruft.
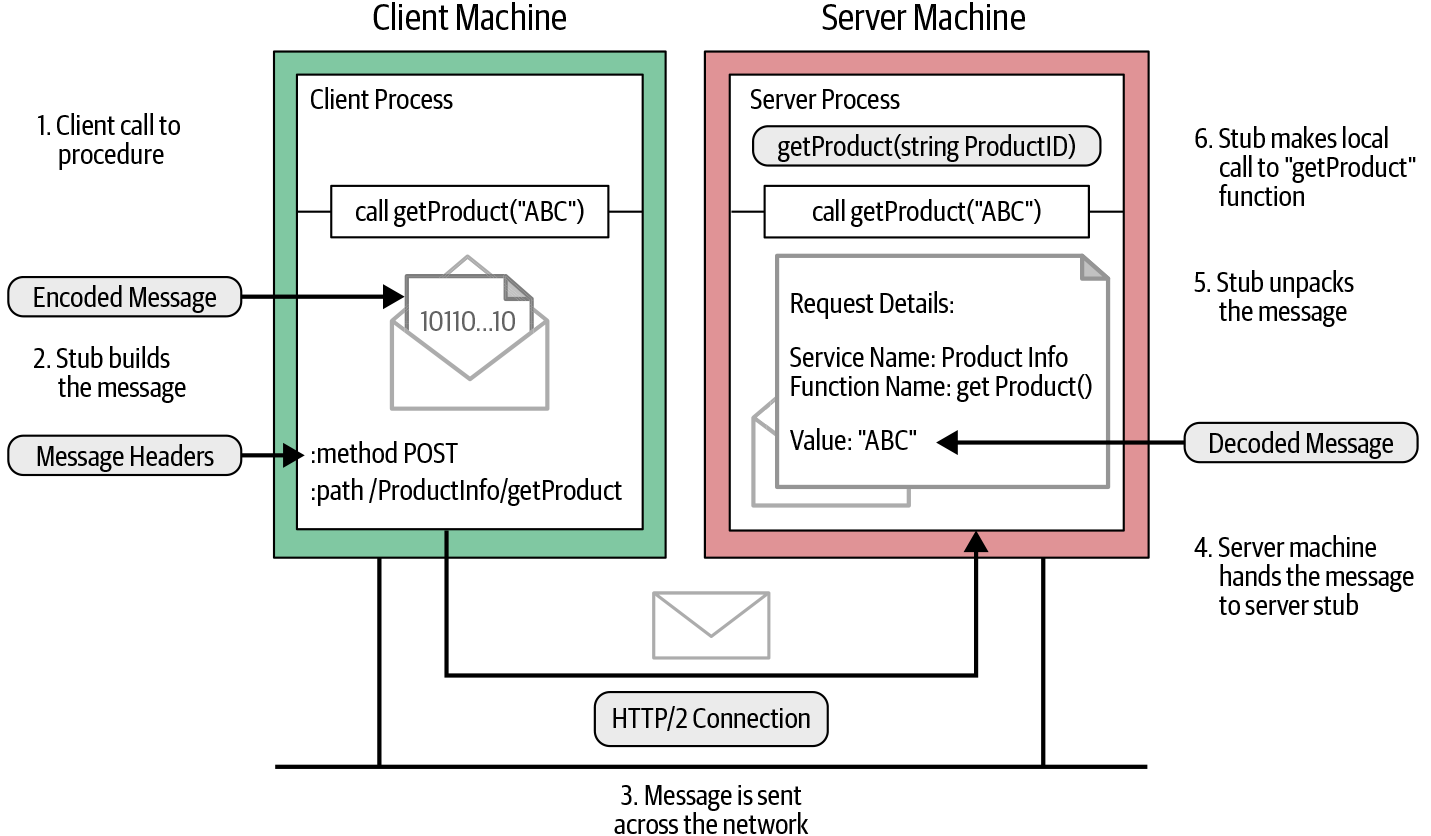
Abbildung 4-1. Wie ein Remote Procedure Call über das Netzwerk funktioniert
Wie in Abbildung 4-1 dargestellt, können wir die folgenden wichtigen Schritte erkennen, wenn der Client die Funktion getProduct im generierten Stub aufruft:
Der Client-Prozess ruft die Funktion
getProductim generierten Stub auf.
Der Client-Stub erstellt eine HTTP-POST-Anfrage mit der verschlüsselten Nachricht. In gRPC sind alle Anfragen HTTP-POST-Anfragen mit dem Content-Type
application/grpcvorangestellt. Die Remote-Funktion (/ProductInfo/getProduct), die er aufruft, wird als separater HTTP-Header gesendet.
Die HTTP-Anfrage wird über das Netzwerk an den Serverrechner gesendet.

Wenn die Nachricht beim Server eingeht, prüft der Server die Kopfzeilen der Nachricht, um festzustellen, welche Servicefunktion aufgerufen werden muss, und übergibt die Nachricht an den Service-Stub.

Der Service Stub parst die Nachrichtenbytes in sprachspezifische Datenstrukturen.

Mit der geparsten Nachricht ruft der Dienst dann lokal die Funktion
getProductauf.
Die Antwort der Servicefunktion wird kodiert und an den Kunden zurückgeschickt. Die Antwortnachricht folgt demselben Verfahren, das wir auf der Client-Seite beobachtet haben (response→encode→HTTP response on the wire); die Nachricht wird entpackt und ihr Wert an den wartenden Client-Prozess zurückgeschickt.
Diese Schritte sind den meisten RPC-Systemen wie CORBA, Java RMI usw. sehr ähnlich. Der Hauptunterschied zwischen gRPC und CORBA ist die Art und Weise, wie die Nachricht kodiert wird (siehe Abbildung 4-1). Für die Kodierung von Nachrichten verwendet gRPC Protokollpuffer. Protokollpuffer sind ein sprachunabhängiger, plattformneutraler und erweiterbarer Mechanismus zur Serialisierung strukturierter Daten. Du legst einmal fest, wie deine Daten strukturiert werden sollen, und kannst dann den speziell generierten Quellcode verwenden, um deine strukturierten Daten einfach in eine Vielzahl von Datenströmen zu schreiben und aus ihnen zu lesen.
Sehen wir uns an, wie gRPC Protokollpuffer verwendet, um Nachrichten zu kodieren.
Nachrichtenkodierung mit Protokollpuffern
Wie wir in den vorherigen Kapiteln besprochen haben, verwendet gRPC Protokollpuffer, um die Dienstdefinition für gRPC-Dienste zu schreiben. Die Definition des Dienstes mithilfe von Protokollpuffern umfasst die Definition von Remote-Methoden im Dienst und die Definition von Nachrichten, die wir über das Netzwerk senden wollen. Nehmen wir zum Beispiel die Methode getProduct im Dienst ProductInfo. Die Methode getProduct nimmt eine ProductID Nachricht als Eingabeparameter entgegen und gibt eine Product Nachricht zurück. Wir können diese Eingangs- und Ausgangsnachrichtenstrukturen mithilfe von Protokollpuffern definieren, wie in Beispiel 4-1 gezeigt.
Beispiel 4-1. Dienstdefinition des ProductInfo-Dienstes mit der Funktion getProduct
syntax="proto3";packageecommerce;serviceProductInfo{rpcgetProduct(ProductID)returns(Product);}messageProduct{stringid=1;stringname=2;stringdescription=3;floatprice=4;}messageProductID{stringvalue=1;}
Wie in Beispiel 4-1 dargestellt, enthält die Nachricht ProductID eine eindeutige Produkt-ID. Sie hat also nur ein Feld mit einem String-Typ. Die Nachricht Product hat die erforderliche Struktur, um das Produkt darzustellen. Es ist wichtig, eine Nachricht richtig zu definieren, denn wie du die Nachricht definierst, bestimmt, wie die Nachrichten kodiert werden. Wir werden später in diesem Abschnitt besprechen, wie die Nachrichtendefinitionen bei der Kodierung der Nachrichten verwendet werden.
Nachdem wir nun die Definition der Nachricht haben, wollen wir uns ansehen, wie wir die Nachricht kodieren und den entsprechenden Byte-Inhalt erzeugen. Normalerweise wird dies durch den generierten Quellcode für die Meldungsdefinition erledigt. Alle unterstützten Sprachen haben ihre eigenen Compiler, um Quellcode zu erzeugen. Als Anwendungsentwickler musst du die Meldungsdefinition übergeben und den Quellcode zum Lesen und Schreiben der Meldung erzeugen.
Nehmen wir an, wir brauchen die Produktdetails für die Produkt-ID 15; wir erstellen ein Nachrichtenobjekt mit dem Wert 15 und übergeben es an die Funktion getProduct. Der folgende Codeausschnitt zeigt, wie man eine ProductID Nachricht mit dem Wert 15 erstellt und sie an die Funktion getProduct weitergibt, um die Produktdetails abzurufen:
product, err := c.GetProduct(ctx, &pb.ProductID{Value: “15”})
Dieser Codeschnipsel ist in Go geschrieben. Hier befindet sich die Definition der Nachricht ProductID im generierten Quellcode. Wir erstellen eine Instanz von ProductID und setzen den Wert als 15. Auch in Java verwenden wir generierte Methoden, um eine Instanz von ProductID zu erstellen, wie im folgenden Code-Schnipsel gezeigt:
ProductInfoOuterClass.Product product = stub.getProduct(
ProductInfoOuterClass.ProductID.newBuilder()
.setValue("15").build());
In der folgenden ProductID Nachrichtenstruktur gibt es ein Feld namens value mit dem Feldindex 1. Wenn wir eine Nachrichteninstanz mit value gleich 15 erstellen, besteht der entsprechende Byte-Inhalt aus einer Feldkennung für das Feld value, gefolgt von seinem kodierten Wert. Dieser Feldbezeichner wird auch als Tag bezeichnet:
messageProductID{stringvalue=1;}
Diese Byte-Inhaltsstruktur sieht wie in Abbildung 4-2 aus, wobei jedes Nachrichtenfeld aus einem Feldbezeichner gefolgt von seinem kodierten Wert besteht.
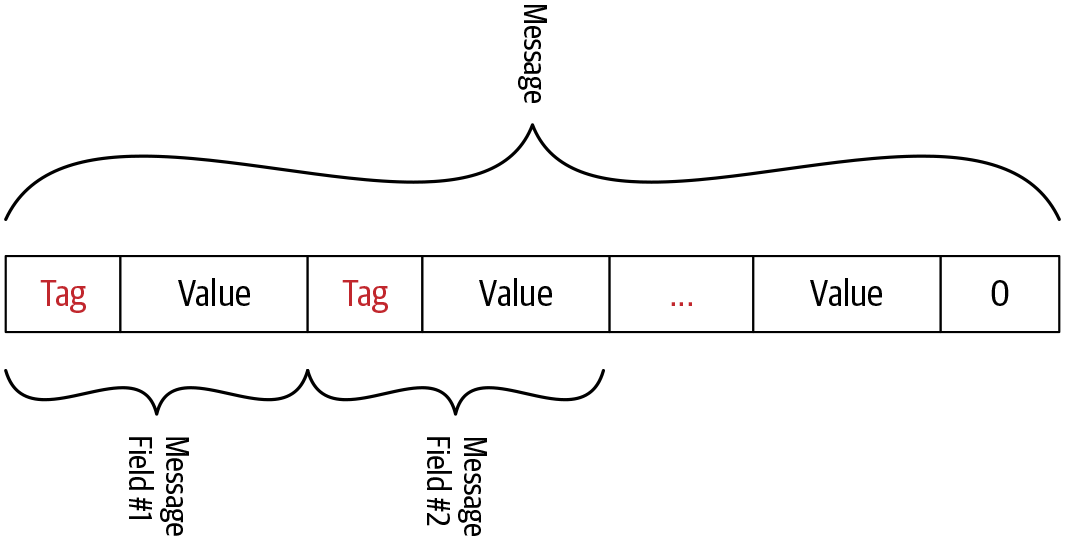
Abbildung 4-2. Protokollpuffer kodierter Bytestrom
Dieses Tag enthält zwei Werte: den Feldindex und den Kabeltyp. Der Feldindex ist die eindeutige Nummer, die wir jedem Nachrichtenfeld zugewiesen haben, als wir die Nachricht in der Proto-Datei definiert haben. Der Kabeltyp basiert auf dem Feldtyp, d. h. der Art der Daten, die in das Feld eingegeben werden können. Dieser Drahttyp liefert Informationen über die Länge des Wertes. Tabelle 4-1 zeigt, wie Drahttypen auf Feldtypen abgebildet werden. Dies ist die vordefinierte Zuordnung von Kabeltypen und Feldtypen. Weitere Informationen über die Zuordnung findest du im offiziellen Dokument zur Kodierung von Protokollpuffern.
| Drahttyp | Kategorie | Feldtypen |
|---|---|---|
0 |
Varint |
int32, int64, uint32, uint64, sint32, sint64, bool, enum |
1 |
64-Bit |
fixed64, sfixed64, double |
2 |
Längenbegrenzt |
String, Bytes, eingebettete Nachrichten, gepackte wiederholte Felder |
3 |
Gruppe starten |
Gruppen (veraltet) |
4 |
Gruppe beenden |
Gruppen (veraltet) |
5 |
32-Bit |
fixed32, sfixed32, float |
Sobald wir den Feldindex und den Kabeltyp eines bestimmten Feldes kennen, können wir den Tag-Wert des Feldes mit der folgenden Gleichung bestimmen. Hier verschieben wir die binäre Darstellung des Feldindexes um drei Stellen nach links und führen eine bitweise Vereinigung mit der binären Darstellung des Kabeltyps durch:
Tag value = (field_index << 3) | wire_type
Abbildung 4-3 zeigt, wie Feldindex und Drahttyp in einem Tag-Wert angeordnet sind.
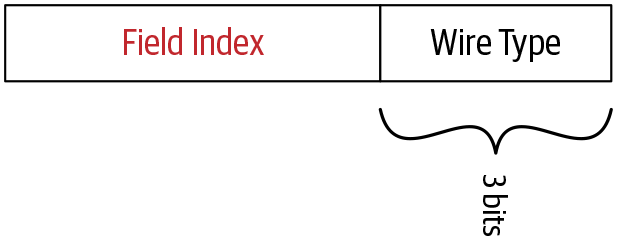
Abbildung 4-3. Struktur des Tag-Wertes
Versuchen wir, diese Terminologie anhand des Beispiels zu verstehen, das wir zuvor verwendet haben. Die Nachricht ProductID hat ein String-Feld mit dem Feldindex 1 und dem Drahttyp 2. Wenn wir sie in eine binäre Darstellung umwandeln, sieht der Feldindex wie 00000001 und der Drahttyp wie 00000010 aus. Wenn wir diese Werte in die obige Gleichung einsetzen, ergibt sich der Tag-Wert 10 wie folgt:
Tag value = (00000001 << 3) | 00000010
= 000 1010
Der nächste Schritt besteht darin, den Wert des Nachrichtenfeldes zu kodieren. Die Protokollpuffer verwenden unterschiedliche Kodierungstechniken, um die verschiedenen Datentypen zu kodieren. Wenn es sich zum Beispiel um einen String-Wert handelt, verwendet der Protokollpuffer UTF-8, um den Wert zu kodieren, und wenn es sich um einen Integer-Wert mit dem Feldtyp int32 handelt, verwendet er eine Kodierungstechnik namens varints. Wir werden die verschiedenen Kodierungstechniken und ihre Anwendung im nächsten Abschnitt im Detail besprechen. Um das Beispiel zu vervollständigen, besprechen wir jetzt, wie man einen String-Wert kodiert.
Bei der Kodierung von Protokollpuffern werden String-Werte mit der UTF-8-Kodierungstechnik kodiert. UTF (Unicode Transformation Format) verwendet 8-Bit-Blöcke, um ein Zeichen darzustellen. Es handelt sich um eine Technik zur Kodierung von Zeichen mit variabler Länge, die auch auf Webseiten und in E-Mails bevorzugt wird.
In unserem Beispiel ist der Wert des Feldes value in der Nachricht ProductID 15 und der UTF-8 kodierte Wert von 15 ist \x31 \x35. Bei der UTF-8 Kodierung ist die Länge des kodierten Wertes nicht festgelegt. Mit anderen Worten: Die Anzahl der 8-Bit-Blöcke, die zur Darstellung des kodierten Wertes erforderlich sind, ist nicht festgelegt. Sie variiert je nach dem Wert des Nachrichtenfeldes. In unserem Beispiel sind es zwei Blöcke. Daher müssen wir die Länge des verschlüsselten Werts (die Anzahl der Blöcke, über die sich der verschlüsselte Wert erstreckt) vor dem verschlüsselten Wert übergeben. Die hexadezimale Darstellung des verschlüsselten Wertes von 15 sieht wie folgt aus:
A 02 31 35
Die beiden rechten Bytes hier sind der UTF-8 kodierte Wert von 15. Der Wert 0x02 steht für die Länge des kodierten String-Wertes in 8-Bit-Blöcken.
Wenn eine Nachricht kodiert wird, werden ihre Tags und Werte zu einem Bytestrom verkettet. Abbildung 4-2 zeigt, wie die Feldwerte in einem Bytestrom angeordnet werden, wenn eine Nachricht mehrere Felder hat. Das Ende des Stroms wird durch das Senden eines Tags mit dem Wert 0 markiert.
Wir haben nun die Kodierung einer einfachen Nachricht mit einem String-Feld mithilfe von Protokollpuffern abgeschlossen. Die Protokollpuffer unterstützen verschiedene Feldtypen und einige Feldtypen haben unterschiedliche Kodierungsmechanismen. Gehen wir kurz die Kodierungstechniken durch, die von Protokollpuffern verwendet werden.
Kodierungstechniken
Es gibt viele Kodierungstechniken, die von Protokollpuffern unterstützt werden. Je nach Art der Daten werden unterschiedliche Kodierungstechniken angewendet. String-Werte werden zum Beispiel mit der UTF-8-Zeichencodierung codiert, während int32-Werte mit einer Technik namens varints codiert werden. Das Wissen darüber, wie die Daten in den einzelnen Datentypen kodiert werden, ist wichtig für die Gestaltung der Nachrichtendefinition, denn so können wir den am besten geeigneten Datentyp für jedes Nachrichtenfeld festlegen, damit die Nachrichten zur Laufzeit effizient kodiert werden.
In Protokollpuffern werden die unterstützten Feldtypen in verschiedene Gruppen eingeteilt und jede Gruppe verwendet eine andere Technik, um den Wert zu kodieren. Im nächsten Abschnitt sind einige häufig verwendete Kodierungstechniken in Protokollpuffern aufgeführt.
Varints
Varints (variable length integers) sind eine Methode zur Serialisierung von Ganzzahlen mit einem oder mehreren Bytes. Sie beruhen auf der Idee, dass die meisten Zahlen nicht gleichmäßig verteilt sind. Die Anzahl der Bytes, die für jeden Wert zugewiesen wird, ist also nicht fest. Sie hängt von dem Wert ab. Tabelle 4-1 zeigt, dass Feldtypen wie int32, int64, uint32, uint64, sint32, sint64, bool und enum in Varints gruppiert und als Varints kodiert werden. Tabelle 4-2 zeigt, welche Feldtypen unter Varints zusammengefasst werden und wofür jeder Typ verwendet wird.
| Feldtyp | Definition |
|---|---|
|
Ein Wertetyp, der ganze Zahlen mit Vorzeichen repräsentiert, deren Werte von negativen 2.147.483.648 bis zu positiven 2.147.483.647 reichen. Beachte, dass dieser Typ ineffizient für die Codierung negativer Zahlen ist. |
|
Ein Wertetyp, der ganze Zahlen mit Vorzeichen repräsentiert, deren Werte von negativ 9.223.372.036.854.775.808 bis positiv 9.223.372.036.854.775.807 reichen. Beachte, dass dieser Typ ineffizient für die Codierung negativer Zahlen ist. |
|
Ein Wertetyp, der ganze Zahlen ohne Vorzeichen mit Werten zwischen 0 und 4.294.967.295 darstellt. |
|
Ein Wertetyp, der ganze Zahlen ohne Vorzeichen mit Werten zwischen 0 und 18.446.744.073.709.551.615 darstellt. |
|
Ein Wertetyp, der ganze Zahlen mit Vorzeichen repräsentiert, deren Werte von negativen 2.147.483.648 bis zu positiven 2.147.483.647 reichen. Damit lassen sich negative Zahlen effizienter kodieren als normale int32s. |
|
Ein Wertetyp, der vorzeichenbehaftete Ganzzahlen mit Werten zwischen negativ 9.223.372.036.854.775.808 und positiv 9.223.372.036.854.775.807 darstellt. Damit lassen sich negative Zahlen effizienter kodieren als normale int64s. |
|
Ein Wertetyp, der zwei mögliche Werte darstellt, die normalerweise als wahr oder falsch bezeichnet werden. |
|
Ein Wertetyp, der eine Reihe von benannten Werten darstellt. |
In varints ist bei jedem Byte außer dem letzten Byte das höchstwertige Bit (MSB) gesetzt, um anzuzeigen, dass noch weitere Bytes folgen werden. Die unteren 7 Bits jedes Bytes werden verwendet, um die Zweierkomplement-Darstellung der Zahl zu speichern. Außerdem kommt die niederwertigste Gruppe zuerst, was bedeutet, dass wir ein Fortsetzungsbit zur niederwertigen Gruppe hinzufügen sollten.
Ganze Zahlen mit Vorzeichen
Ganzzahlen mit Vorzeichen sind Typen, die sowohl positive als auch negative Ganzzahlwerte darstellen. Feldtypen wie sint32 und sint64 werden als Ganzzahlen mit Vorzeichen betrachtet. Für vorzeichenbehaftete Typen wird die Zickzack-Kodierung verwendet, um vorzeichenbehaftete Ganzzahlen in vorzeichenlose umzuwandeln. Nicht vorzeichenbehaftete Ganzzahlen werden dann wie bereits erwähnt mit der Varints-Kodierung kodiert.
Bei der Zickzack-Kodierung werden ganze Zahlen mit Vorzeichen auf ganze Zahlen ohne Vorzeichen abgebildet, und zwar im Zickzack durch negative und positive ganze Zahlen. Tabelle 4-3 zeigt, wie das Mapping in der Zickzack-Kodierung funktioniert.
| Ursprünglicher Wert | Zugeordneter Wert |
|---|---|
0 |
0 |
-1 |
1 |
1 |
2 |
-2 |
3 |
2 |
4 |
Wie in Tabelle 4-3 dargestellt, wird der Wert Null dem ursprünglichen Wert Null zugeordnet und andere Werte werden im Zickzackkurs auf positive Zahlen abgebildet. Die negativen Originalwerte werden auf ungerade positive Zahlen abgebildet und die positiven Originalwerte auf gerade positive Zahlen. Nach der Zickzack-Kodierung erhalten wir eine positive Zahl, unabhängig vom Vorzeichen des Originalwerts. Sobald wir eine positive Zahl haben, führen wir Varints durch, um den Wert zu kodieren.
Für negative Integer-Werte wird empfohlen, vorzeichenbehaftete Integer-Typen wie sint32 und sint64 zu verwenden, denn wenn wir einen regulären Typ wie int32 oder int64 verwenden, werden negative Werte mithilfe der Varints-Kodierung in Binärwerte umgewandelt. Die Varints-Kodierung für einen negativen Ganzzahlwert benötigt mehr Bytes, um einen entsprechenden Binärwert darzustellen, als ein positiver Ganzzahlwert. Die effizienteste Art, einen negativen Wert zu kodieren, besteht also darin, den negativen Wert in eine positive Zahl umzuwandeln und dann den positiven Wert zu kodieren. Bei vorzeichenbehafteten Integer-Typen wie sint32 werden die negativen Werte zunächst mit Zickzack-Kodierung in positive Werte umgewandelt und dann mit varints kodiert.
Nicht-Varint-Zahlen
Nonvarint-Typen sind genau das Gegenteil des varint-Typs. Sie weisen eine feste Anzahl von Bytes zu, unabhängig von ihrem tatsächlichen Wert. Protokollpuffer verwenden zwei Drahttypen, die als Nonvarint-Zahlen kategorisiert werden. Der eine ist für die 64-Bit-Datentypen wie fixed64, sfixed64 und double. Der andere ist für 32-Bit-Datentypen wie fixed32, sfixed32 und float.
String-Typ
In Protokollpuffern gehört der Stringtyp zum längenbegrenzten Kabeltyp, was bedeutet, dass der Wert eine varint-kodierte Länge ist, gefolgt von der angegebenen Anzahl von Datenbytes. String-Werte werden mit der Zeichenkodierung UTF-8 kodiert.
Wir haben gerade die Techniken zusammengefasst, die zur Kodierung häufig verwendeter Datentypen verwendet werden. Eine ausführliche Erklärung zur Protokollpufferkodierung findest du auf der offiziellen Seite.
Nachdem wir die Nachricht mit Hilfe von Protokollpuffern verschlüsselt haben, müssen wir sie im nächsten Schritt in einen Rahmen setzen, bevor wir sie über das Netzwerk an den Server senden.
Framing von Nachrichten mit Längenpräfix
Allgemein ausgedrückt: Der Ansatz des Message-Framing konstruiert Informationen und Kommunikation so, dass das Zielpublikum die Informationen leicht entnehmen kann. Das Gleiche gilt auch für die gRPC-Kommunikation. Wenn wir die verschlüsselten Daten an die andere Partei senden wollen, müssen wir sie so verpacken, dass die anderen Parteien die Informationen leicht entnehmen können. Um die Nachricht so zu verpacken, dass sie über das Netzwerk gesendet werden kann, verwendet gRPC eine Technik zum Framing von Nachrichten, das sogenannte Length-Prefix-Framing.
Length-prefix ist ein Ansatz für das Nachrichtenframing, bei dem die Größe jeder Nachricht vor der eigentlichen Nachricht angegeben wird. Wie du in Abbildung 4-4 sehen kannst, werden vor der kodierten Binärnachricht 4 Bytes zur Angabe der Größe der Nachricht zugewiesen. Bei der gRPC-Kommunikation werden jeder Nachricht 4 zusätzliche Bytes zugewiesen, um ihre Größe festzulegen. Die Größe der Nachricht ist eine endliche Zahl, und die Zuweisung von 4 Bytes für die Größe der Nachricht bedeutet, dass die gRPC-Kommunikation alle Nachrichten bis zu einer Größe von 4 GB verarbeiten kann.
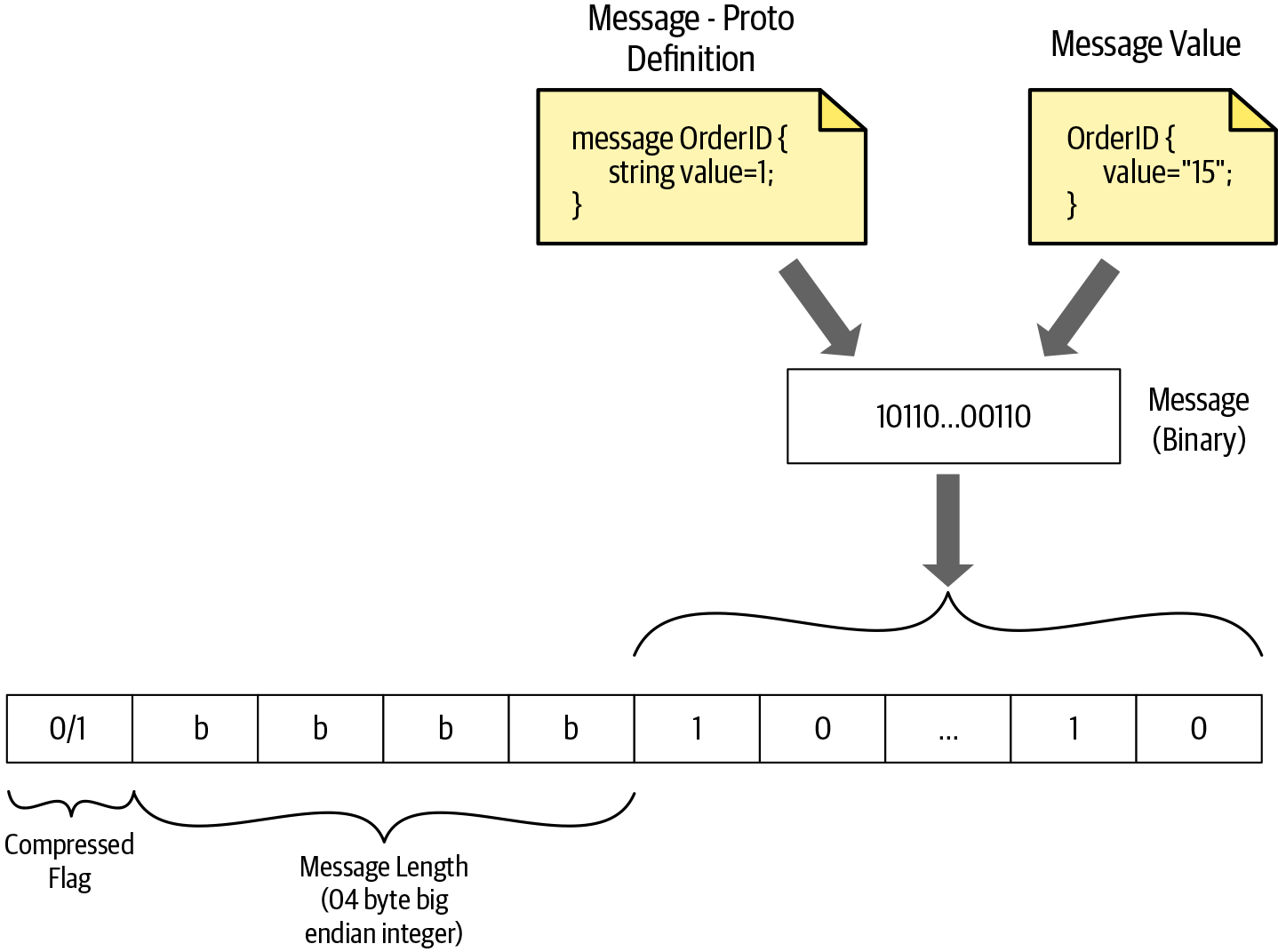
Abbildung 4-4. Wie ein gRPC-Nachrichtenrahmen das Längenpräfix-Framing verwendet
Wie in Abbildung 4-4 dargestellt, erhalten wir die Nachricht im Binärformat, wenn sie mit Protokollpuffern kodiert wird. Dann berechnen wir die Größe des binären Inhalts und fügen sie vor dem binären Inhalt im Big-Endian-Format hinzu.
Hinweis
Big-Endian ist eine Art, binäre Daten im System oder in der Nachricht zu ordnen. Im Big-Endian-Format wird der höchstwertige Wert (die größte Zweierpotenz) in der Folge an der niedrigsten Speicheradresse gespeichert.
Neben der Nachrichtengröße enthält der Frame auch eine vorzeichenlose 1-Byte-Ganzzahl, die angibt, ob die Daten komprimiert sind oder nicht. Ein Compressed-Flag-Wert von 1 zeigt an, dass die Binärdaten mit dem im Message-Encoding-Header deklarierten Mechanismus komprimiert wurden, der einer der im HTTP-Transport deklarierten Header ist. Der Wert 0 bedeutet, dass keine Kodierung der Nachrichtenbytes stattgefunden hat. Wir werden die HTTP-Header, die bei der gRPC-Kommunikation unterstützt werden, im nächsten Abschnitt im Detail besprechen.
Jetzt ist die Nachricht gerahmt und bereit, über das Netzwerk an den Empfänger gesendet zu werden. Bei einer Client-Request-Nachricht ist der Empfänger der Server. Bei einer Antwortnachricht ist der Empfänger der Client. Wenn der Empfänger eine Nachricht erhält, muss er zunächst das erste Byte lesen, um zu prüfen, ob die Nachricht komprimiert ist oder nicht. Dann liest der Empfänger die nächsten vier Bytes, um die Größe der kodierten Binärnachricht zu ermitteln. Sobald die Größe bekannt ist, kann die genaue Länge der Bytes aus dem Stream gelesen werden. Bei unären/einfachen Nachrichten haben wir nur eine Nachricht mit Längenangabe, bei Streaming-Nachrichten müssen wir mehrere Nachrichten mit Längenangabe verarbeiten.
Jetzt hast du ein gutes Verständnis dafür, wie Nachrichten für die Zustellung an den Empfänger über das Netzwerk vorbereitet werden. Im nächsten Abschnitt werden wir besprechen, wie gRPC diese Nachrichten mit Längenvorgabe über das Netzwerk sendet. Derzeit unterstützt der gRPC-Kern drei Transportimplementierungen: HTTP/2, Cronet und In-Process. Der häufigste Transport für das Versenden von Nachrichten ist dabei HTTP/2. Im Folgenden wird erläutert, wie gRPC das HTTP/2-Netzwerk nutzt, um Nachrichten effizient zu versenden.
gRPC über HTTP/2
HTTP/2 ist die zweite große Version des Internetprotokolls HTTP. Es wurde eingeführt, um einige der Probleme mit der Sicherheit, der Geschwindigkeit usw. der Vorgängerversion (HTTP/1.1) zu lösen. HTTP/2 unterstützt alle Kernfunktionen von HTTP/1.1, aber auf effizientere Weise. Daher sind Anwendungen, die mit HTTP/2 geschrieben wurden, schneller, einfacher und robuster.
gRPC verwendet HTTP/2 als Transportprotokoll, um Nachrichten über das Netzwerk zu senden. Das ist einer der Gründe, warum gRPC ein leistungsstarkes RPC-Framework ist. Lass uns die Beziehung zwischen gRPC und HTTP/2 untersuchen.
Hinweis
Bei HTTP/2 wird die gesamte Kommunikation zwischen einem Client und einem Server über eine einzige TCP-Verbindung abgewickelt, die eine beliebige Anzahl von bidirektionalen Byteflüssen übertragen kann. Um den HTTP/2-Prozess zu verstehen, solltest du mit den folgenden wichtigen Begriffen vertraut sein:
-
Stream: Ein bidirektionaler Fluss von Bytes innerhalb einer bestehenden Verbindung. Ein Stream kann eine oder mehrere Nachrichten enthalten.
-
Frame: Die kleinste Einheit der Kommunikation in HTTP/2. Jeder Frame enthält einen Frame-Header, der mindestens den Stream identifiziert, zu dem der Frame gehört.
-
Nachricht: Eine vollständige Folge von Frames, die einer logischen HTTP-Nachricht entsprechen, die aus einem oder mehreren Frames besteht. So können die Nachrichten gemultiplext werden, indem Client und Server die Nachricht in unabhängige Frames aufteilen, sie verschachteln und dann auf der anderen Seite wieder zusammensetzen.
Wie du in Abbildung 4-5 sehen kannst, stellt der gRPC-Kanal eine Verbindung zu einem Endpunkt dar, der eine HTTP/2-Verbindung ist. Wenn die Client-Anwendung einen gRPC-Kanal erstellt, wird hinter den Kulissen eine HTTP/2-Verbindung zum Server aufgebaut. Sobald der Kanal erstellt ist, können wir ihn wiederverwenden, um mehrere Fernaufrufe an den Server zu senden. Diese Fernaufrufe werden in HTTP/2 auf Streams abgebildet. Die Nachrichten, die mit dem Fernaufruf gesendet werden, werden als HTTP/2-Frames gesendet. Ein Frame kann eine gRPC-Nachricht mit Längenangabe enthalten, oder wenn eine gRPC-Nachricht sehr groß ist, kann sie sich über mehrere Datenframes erstrecken.
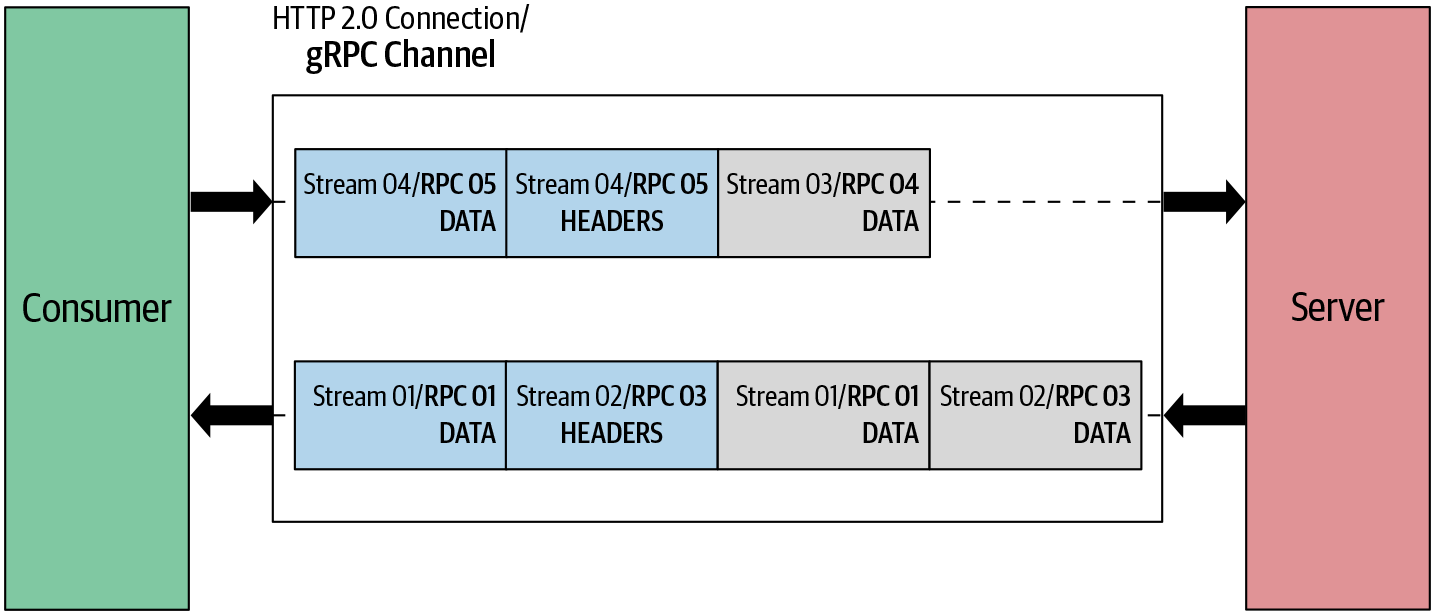
Abbildung 4-5. Wie sich die gRPC-Semantik auf HTTP/2 bezieht
Im vorigen Abschnitt haben wir besprochen, wie wir unsere Nachricht in eine Nachricht mit Längenangabe einrahmen. Wenn wir sie als Anfrage- oder Antwortnachricht über das Netzwerk senden, müssen wir zusätzliche Header mit der Nachricht mitschicken. In den nächsten Abschnitten werden wir besprechen, wie wir Anfrage- und Antwortnachrichten strukturieren und welche Header für jede Nachricht übermittelt werden müssen.
Nachricht anfordern
Die Anforderungsnachricht ist die Nachricht, die den Remote-Aufruf initiiert. In gRPC wird die Anforderungsnachricht immer von der Client-Anwendung ausgelöst und besteht aus drei Hauptkomponenten: den Anforderungs-Headern, der Nachricht mit Längenangabe und dem End-of-Stream-Flag, wie in Abbildung 4-6 dargestellt. Der Remote-Aufruf wird ausgelöst, sobald der Client die Request-Header sendet. Dann werden die Nachrichten mit Längenpräfix in dem Anruf gesendet. Zum Schluss wird das EOS-Flag (End of Stream) gesendet, um dem Empfänger mitzuteilen, dass der Versand der Anfrage abgeschlossen ist .

Abbildung 4-6. Abfolge der Nachrichtenelemente in der Anforderungsnachricht
Verwenden wir dieselbe getProduct Funktion im ProductInfo Dienst, um zu erklären, wie die Anforderungsnachricht in HTTP/2 Frames gesendet wird. Wenn wir die Funktion getProduct aufrufen, initiiert der Client einen Aufruf, indem er wie hier gezeigt Anfrage-Header sendet:
HEADERS (flags = END_HEADERS) :method = POSTauthorization = Bearer xxxxxx
Legt die HTTP-Methode fest. Für gRPC ist der
:methodHeader immerPOST.Legt das HTTP-Schema fest. Wenn TLS (Transport Level Security) aktiviert ist, wird das Schema auf "https" gesetzt, ansonsten auf "http".
Legt den Endpunktpfad fest. Für gRPC wird dieser Wert als "/" {Servicename} "/" {Methodenname} aufgebaut.
Legt den virtuellen Hostnamen des Ziel-URIs fest.
Definiert die Erkennung von inkompatiblen Proxys. Für gRPC muss der Wert "trailers" sein.
Legt die Anrufzeitüberschreitung fest. Wenn nicht angegeben, sollte der Server von einem unendlichen Timeout ausgehen .
Legt den Inhaltstyp fest. Für gRPC sollte der Content-Type mit
application/grpcbeginnen. Andernfalls antworten gRPC-Server mit dem HTTP-Status 415 (Unsupported Media Type).Legt die Art der Nachrichtenkomprimierung fest. Mögliche Werte sind
identity,gzip,deflate,snappy, und{custom}.
Dies sind optionale Metadaten.
authorizationMetadaten werden für den Zugriff auf den sicheren Endpunkt verwendet.
Hinweis
Einige weitere Anmerkungen zu diesem Beispiel:
-
Header-Namen, die mit ":" beginnen, werden als reservierte Header bezeichnet und HTTP/2 verlangt, dass reservierte Header vor anderen Headern erscheinen.
-
Header, die bei der gRPC-Kommunikation übergeben werden, werden in zwei Typen unterteilt: Call-Definition-Header und benutzerdefinierte Metadaten.
-
Call-Definition-Header sind vordefinierte Header, die von HTTP/2 unterstützt werden. Diese Header sollten vor den benutzerdefinierten Metadaten gesendet werden.
-
Benutzerdefinierte Metadaten sind ein beliebiger Satz von Schlüssel-Wert-Paaren, die von der Anwendungsschicht definiert werden. Wenn du benutzerdefinierte Metadaten definierst, musst du darauf achten, dass du keinen Header-Namen verwendest, der mit
grpc-beginnt. Dies ist im gRPC-Kern als reservierter Name aufgeführt.
Sobald der Client den Anruf mit dem Server initiiert hat, sendet er Nachrichten mit Längenvorgabe als HTTP/2-Datenrahmen. Wenn die längenpräfixierte Nachricht nicht in einen Datenrahmen passt, kann sie sich auf mehrere Datenrahmen erstrecken. Das Ende der Anforderungsnachricht wird durch das Hinzufügen eines END_STREAM -Flags im letzten DATA -Frame angezeigt. Wenn keine Daten mehr zu senden sind, wir aber den Anfragestrom schließen müssen, muss die Implementierung einen leeren Datenrahmen mit dem END_STREAM Flag senden:
DATA (flags = END_STREAM) <Length-Prefixed Message>
Dies ist nur ein Überblick über die Struktur der gRPC-Anfragenachricht. Weitere Details findest du im offiziellen gRPC GitHub Repository.
Ähnlich wie die Anforderungsnachricht hat auch die Antwortnachricht ihre eigene Struktur. Schauen wir uns die Struktur der Antwortnachricht und die zugehörigen Kopfzeilen an.
Antwortnachricht
Die Antwortnachricht wird vom Server als Antwort auf die Anfrage des Clients erstellt. Ähnlich wie die Anforderungsnachricht besteht auch die Antwortnachricht in den meisten Fällen aus drei Hauptkomponenten: Antwortkopfzeilen, Nachrichten mit Längenvorgabe und Trailer. Wenn es keine Nachricht mit Längenvorgabe gibt, die als Antwort an den Client gesendet wird, besteht die Antwortnachricht nur aus Headern und Trailern, wie in Abbildung 4-7 dargestellt.
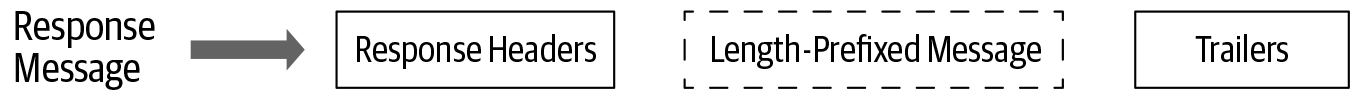
Abbildung 4-7. Abfolge der Nachrichtenelemente in einer Antwortnachricht
Schauen wir uns das gleiche Beispiel an, um die HTTP/2-Rahmensequenz der Antwortnachricht zu erklären. Wenn der Server eine Antwort an den Client sendet, sendet er zunächst Antwort-Header, wie hier gezeigt:
HEADERS (flags = END_HEADERS) :status = 200
Gibt den Status der HTTP-Anfrage an.
Legt die Art der Nachrichtenkomprimierung fest. Mögliche Werte sind
identity,gzip,deflate,snappy, und{custom}.Definiert die
content-type. Für gRPC sollte diecontent-typemitapplication/grpcbeginnen.
Hinweis
Ähnlich wie bei den Anfrage-Headern können auch in den Antwort-Headern benutzerdefinierte Metadaten festgelegt werden, die eine beliebige Menge von Schlüssel-Wert-Paaren enthalten, die von der Anwendungsschicht definiert wurden.
Sobald der Server die Antwort-Header sendet, werden die längenpräfixierten Nachrichten als HTTP/2-Datenrahmen im Aufruf gesendet. Ähnlich wie bei der Anforderungsnachricht kann sich die längenpräfixierte Nachricht, wenn sie nicht in einen Datenrahmen passt, auf mehrere Datenrahmen erstrecken. Wie im Folgenden gezeigt wird, wird das END_STREAM Flag nicht mit den Datenframes gesendet. Es wird als separater Header, der sogenannte Trailer, gesendet:
DATA <Length-Prefixed Message>
Am Ende werden Trailer gesendet, um dem Kunden mitzuteilen, dass wir den Versand der Antwortnachricht abgeschlossen haben. In den Trailern stehen auch der Statuscode und die Statusmeldung der Anfrage:
HEADERS (flags = END_STREAM, END_HEADERS) grpc-status = 0 # OK
Legt den gRPC-Statuscode fest. gRPC verwendet eine Reihe von genau definierten Statuscodes. Du kannst die Definition der Statuscodes in der offiziellen gRPC-Dokumentation finden.
Legt die Beschreibung des Fehlers fest. Dies ist optional. Sie wird nur gesetzt, wenn ein Fehler bei der Bearbeitung der Anfrage aufgetreten ist.
Hinweis
Trailer werden auch als HTTP/2-Header-Frames geliefert, allerdings am Ende der Antwortnachricht. Das Ende des Antwortstreams wird durch das Setzen des Flags END_STREAM in den Trailer-Headern angezeigt. Außerdem enthält er die Header grpc-status und grpc-message.
In bestimmten Szenarien kann es zu einem sofortigen Ausfall des Anfrageaufrufs kommen. In solchen Fällen muss der Server eine Antwort ohne die Datenrahmen zurücksenden. Daher sendet der Server nur Trailer als Antwort. Diese Trailer werden ebenfalls als HTTP/2 Header Frame geliefert und enthalten auch das END_STREAM Flag. Außerdem sind die folgenden Header in den Trailern enthalten:
-
HTTP-Status →.
:status -
Inhalt-Typ →.
content-type -
Status →
grpc-status -
Status-Meldung →
grpc-message
Da wir nun wissen, wie eine gRPC-Nachricht über eine HTTP/2-Verbindung fließt, wollen wir versuchen, den Nachrichtenfluss der verschiedenen Kommunikationsmuster in gRPC zu verstehen.
Verstehen des Nachrichtenflusses in gRPC-Kommunikationsmustern
Im vorherigen Kapitel haben wir vier Kommunikationsmuster besprochen, die von gRPC unterstützt werden. Das sind die einfache RPC, die Server-Streaming-RPC, die Client-Streaming-RPC und die bidirektionale Streaming-RPC. Wir haben auch besprochen, wie diese Kommunikationsmuster anhand von realen Anwendungsfällen funktionieren. In diesem Abschnitt werden wir diese Muster noch einmal aus einem anderen Blickwinkel betrachten. Mit dem Wissen, das wir in diesem Kapitel gesammelt haben, wollen wir besprechen, wie jedes Muster auf der Transportebene funktioniert.
Einfacher RPC
Beim einfachen RPC gibt es in der Kommunikation zwischen dem gRPC-Server und dem gRPC-Client immer nur eine Anfrage und eine Antwort. Wie in Abbildung 4-8 dargestellt, enthält die Anforderungsnachricht Header, gefolgt von einer Nachricht mit Längenvorgabe, die sich über einen oder mehrere Datenrahmen erstrecken kann. Am Ende der Nachricht wird ein EOS-Flag (End of Stream) hinzugefügt, um die Verbindung auf der Client-Seite halb zu schließen und das Ende der Anforderungsnachricht zu markieren. Hier bedeutet "die Verbindung halb schließen", dass der Client die Verbindung auf seiner Seite schließt, so dass er nicht mehr in der Lage ist, Nachrichten an den Server zu senden, aber immer noch die eingehenden Nachrichten des Servers hören kann. Der Server erstellt die Antwortnachricht erst, nachdem er die vollständige Nachricht auf der Serverseite erhalten hat. Die Antwortnachricht enthält einen Header-Frame, gefolgt von einer Nachricht mit Längenvorgabe. Die Kommunikation endet, sobald der Server den abschließenden Header mit Statusangaben sendet.
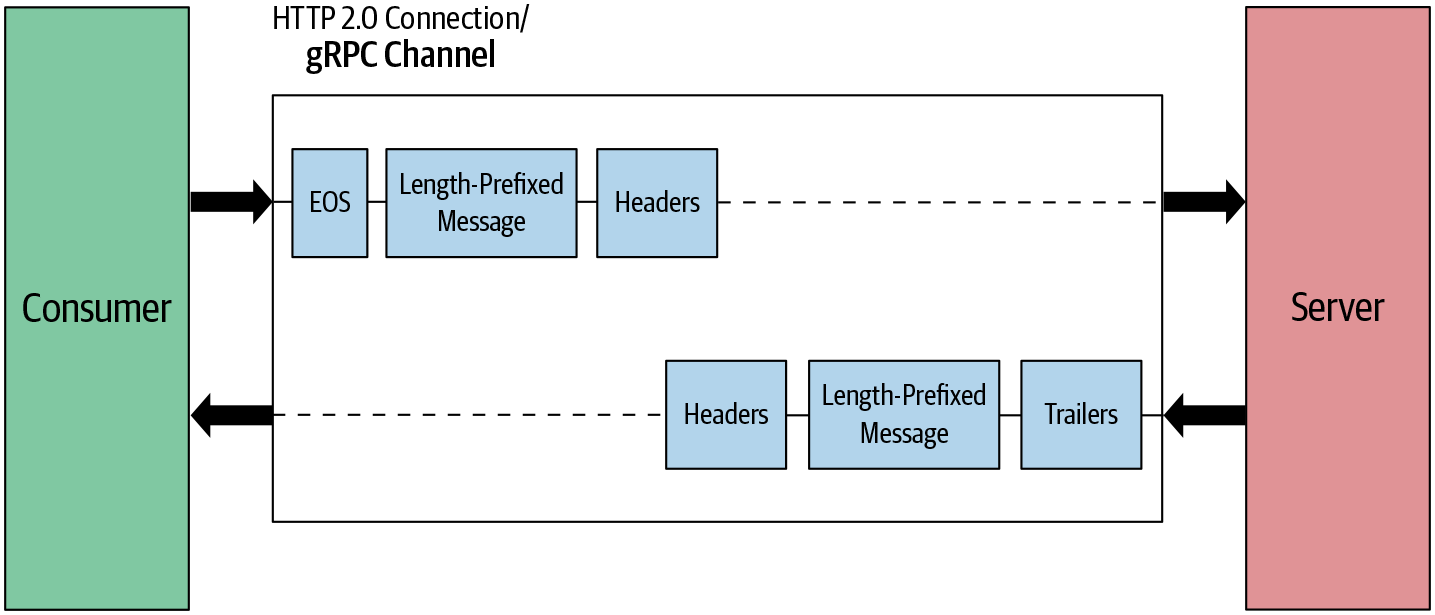
Abbildung 4-8. Einfacher RPC: Nachrichtenfluss
Dies ist das einfachste Kommunikationsmuster. Kommen wir nun zu einem etwas komplexeren Server-Streaming-RPC-Szenario.
Server-streaming RPC
Aus der Sicht des Clients haben sowohl die einfache RPC als auch die Server-Streaming-RPC denselben Nachrichtenfluss. In beiden Fällen senden wir eine Anforderungsnachricht. Der Hauptunterschied liegt auf der Serverseite. Anstatt eine Antwortnachricht an den Client zu senden, sendet der Server mehrere Nachrichten. Der Server wartet, bis er die vollständige Anforderungsnachricht erhält, und sendet die Antwort-Header und mehrere Nachrichten mit Längenpräfix, wie in Abbildung 4-9 dargestellt. Die Kommunikation endet, sobald der Server den abschließenden Header mit den Statusangaben sendet.
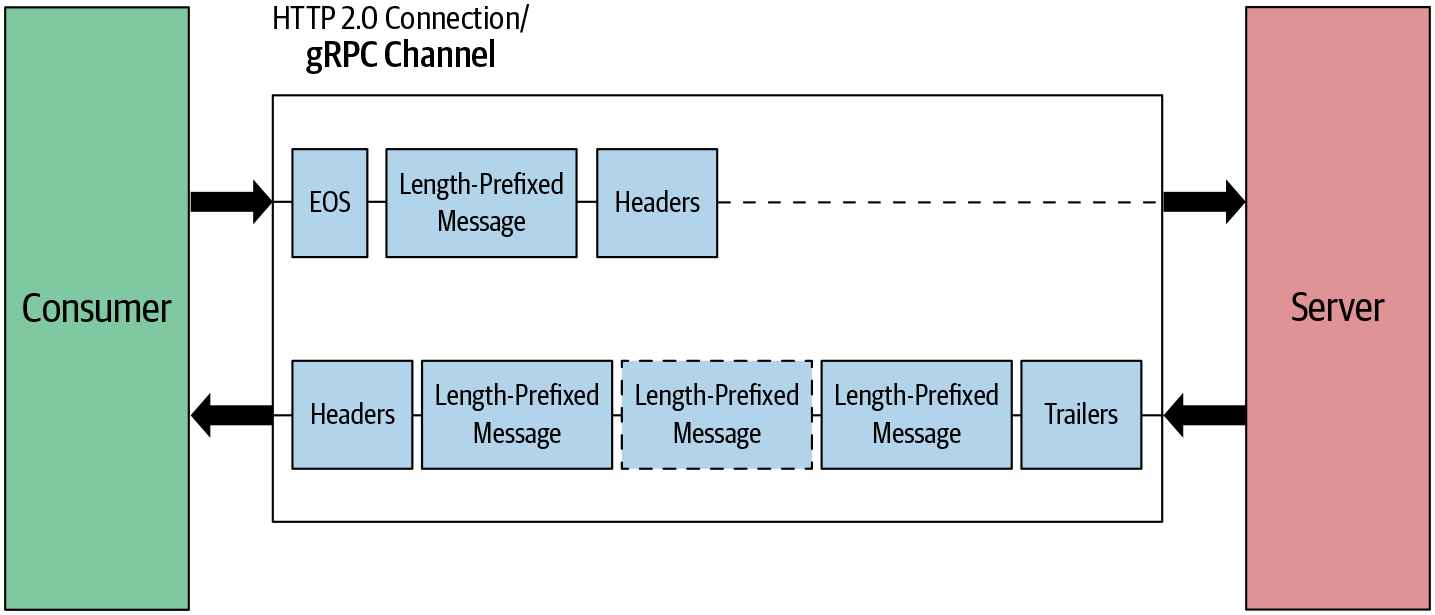
Abbildung 4-9. Server-streaming RPC: Nachrichtenfluss
Sehen wir uns nun die Client-Streaming-RPC an, die so ziemlich das Gegenteil der Server-Streaming-RPC ist.
Client-streaming RPC
Beim Client-Streaming RPC sendet der Client mehrere Nachrichten an den Server und der Server sendet eine Antwortnachricht als Antwort. Der Client stellt zunächst die Verbindung zum Server her, indem er die Header-Frames sendet. Sobald die Verbindung hergestellt ist, sendet der Client mehrere längenpräfixierte Nachrichten als Datenframes an den Server, wie in Abbildung 4-10 dargestellt. Am Ende schließt der Client die Verbindung halb, indem er im letzten Datenrahmen ein EOS-Flag sendet. In der Zwischenzeit liest der Server die vom Client empfangenen Nachrichten. Sobald er alle Nachrichten erhalten hat, sendet der Server eine Antwortnachricht zusammen mit dem Trailing-Header und schließt die Verbindung.
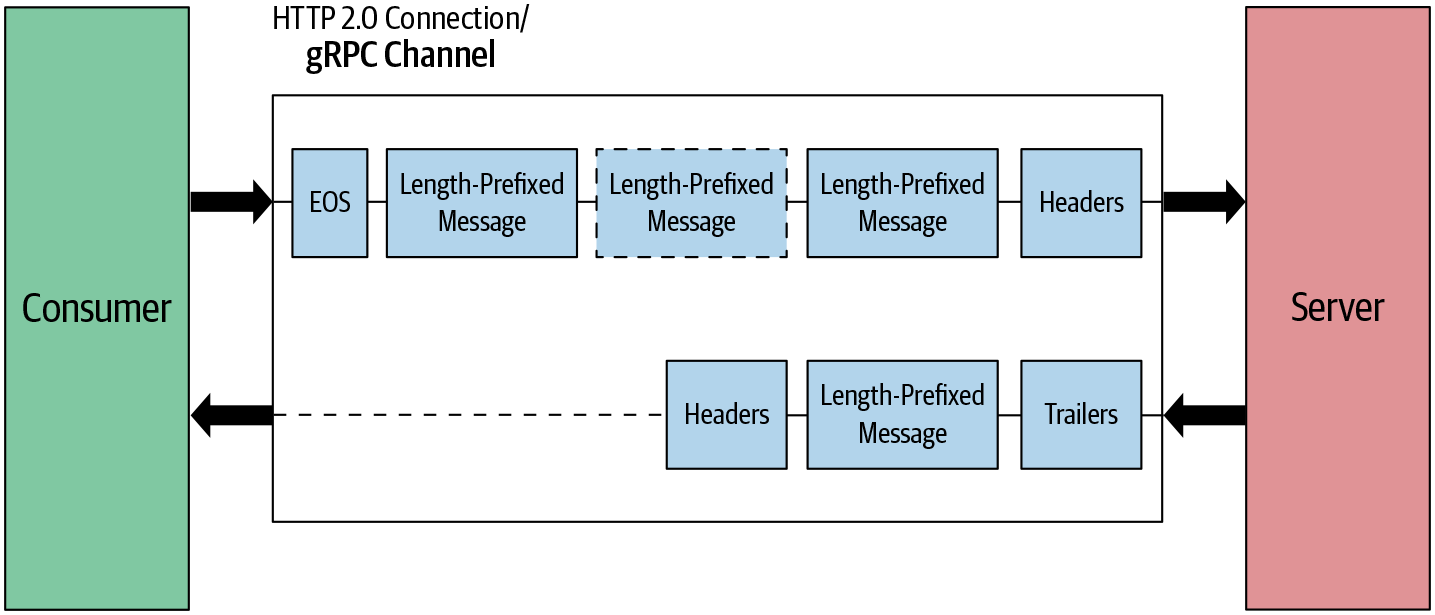
Abbildung 4-10. Client-streaming RPC: Nachrichtenfluss
Kommen wir nun zum letzten Kommunikationsmuster, dem bidirektionalen RPC, bei dem sowohl der Client als auch der Server mehrere Nachrichten aneinander senden, bis sie die Verbindung schließen.
Bidirektional-streaming RPC
Bei diesem Muster stellt der Client die Verbindung her, indem er Header-Frames sendet. Sobald die Verbindung aufgebaut ist, senden sowohl der Client als auch der Server Nachrichten mit Längenpräfix, ohne zu warten, bis der andere fertig ist. Wie in Abbildung 4-11 dargestellt, senden sowohl der Client als auch der Server gleichzeitig Nachrichten. Beide können die Verbindung auf ihrer Seite beenden, das heißt, sie können keine weiteren Nachrichten mehr senden.
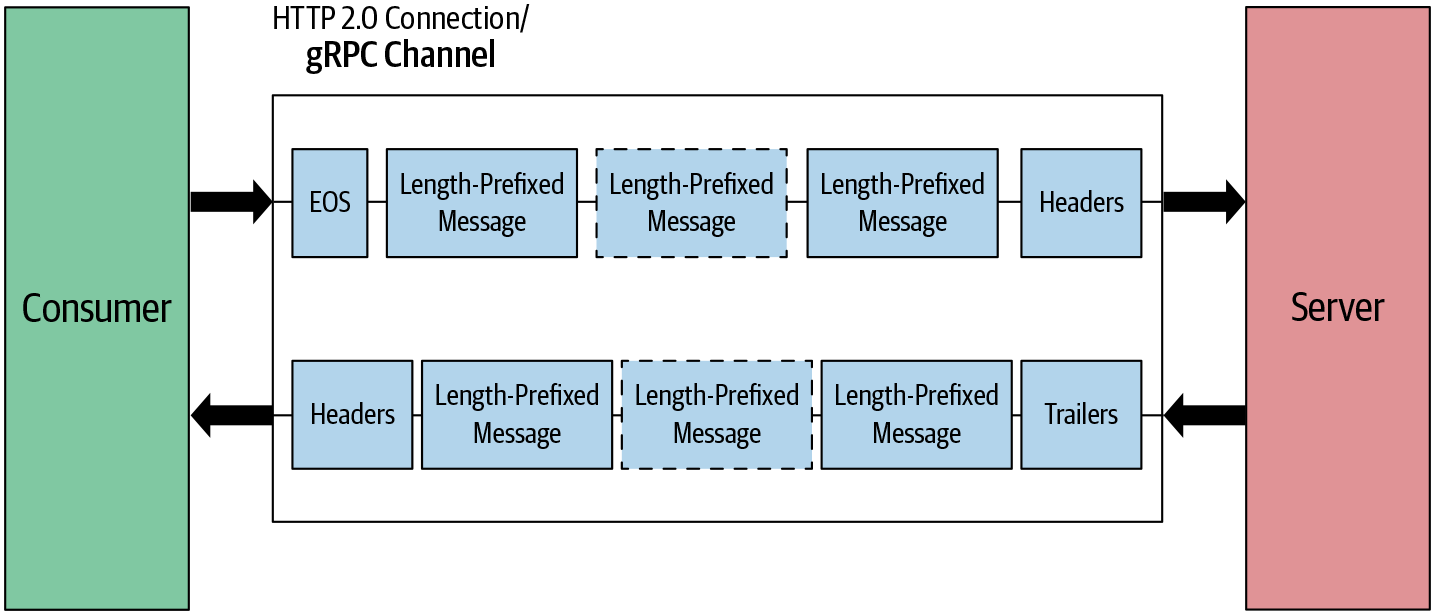
Abbildung 4-11. Bidirektionales Streaming RPC: Nachrichtenfluss
Damit sind wir am Ende unserer ausführlichen Tour durch die gRPC-Kommunikation angelangt. Netzwerk- und transportbezogene Vorgänge in der Kommunikation werden normalerweise in der gRPC-Kernschicht abgewickelt und du musst dich als gRPC-Anwendungsentwickler nicht mit den Details befassen.
Bevor wir dieses Kapitel abschließen, werfen wir einen Blick auf die gRPC-Implementierungsarchitektur und den Sprachstapel.
gRPC-Implementierungsarchitektur
Wie in Abbildung 4-12 dargestellt, kann die gRPC-Implementierung in mehrere Schichten unterteilt werden. Die Basisschicht ist die gRPC-Kernschicht. Sie ist eine dünne Schicht und abstrahiert alle Netzwerkoperationen von den oberen Schichten, so dass Anwendungsentwickler RPC-Aufrufe über das Netzwerk einfach durchführen können. Die Kernschicht bietet auch Erweiterungen für die Kernfunktionalität. Einige dieser Erweiterungen sind Authentifizierungsfilter, um die Sicherheit der Anrufe zu gewährleisten, und ein Deadline-Filter, um Anruffristen zu implementieren, usw.
gRPC wird nativ von den Sprachen C/C++, Go und Java unterstützt. gRPC bietet außerdem Sprachbindungen für viele beliebte Sprachen wie Python, Ruby, PHP usw. Diese Sprachbindungen sind Wrapper für die Low-Level-C-API.
Schließlich kommt der Anwendungscode über die Sprachbindungen. Diese Anwendungsschicht kümmert sich um die Anwendungslogik und die Datenkodierungslogik. Normalerweise erstellen Entwickler den Quellcode für die Datenverschlüsselungslogik mit Compilern, die von verschiedenen Sprachen bereitgestellt werden. Wenn wir zum Beispiel Protokollpuffer für die Datenkodierung verwenden, kann der Protokollpuffer-Compiler verwendet werden, um den Quellcode zu erstellen. So können Entwickler ihre Anwendungslogik schreiben, indem sie die Methoden des erzeugten Quellcodes aufrufen.
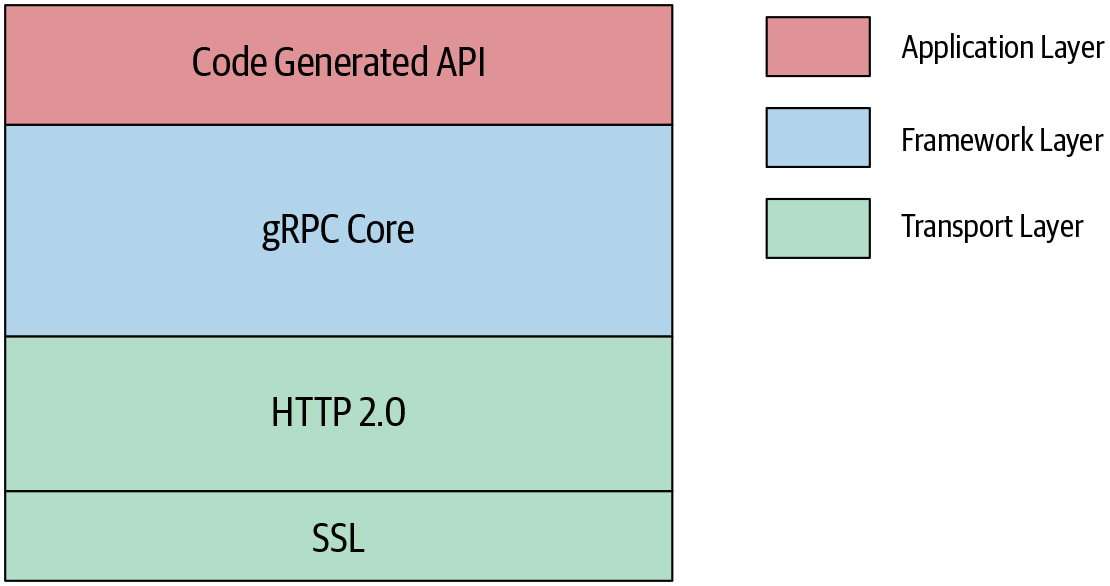
Abbildung 4-12. Architektur der nativen gRPC-Implementierung
Damit haben wir die meisten der Low-Level-Implementierungs- und Ausführungsdetails von gRPC-basierten Anwendungen behandelt. Als Anwendungsentwickler ist es immer besser, die Low-Level-Details der Techniken zu kennen, die du in deiner Anwendung einsetzen willst. Das hilft nicht nur dabei, robuste Anwendungen zu entwerfen, sondern auch bei der Fehlersuche in der Anwendung.
Zusammenfassung
gRPC baut auf zwei schnellen und effizienten Protokollen auf, den Protokollpuffern und HTTP/2. Protokollpuffer sind ein Daten-Serialisierungsprotokoll, das ein sprachunabhängiger, plattformneutraler und erweiterbarer Mechanismus zur Serialisierung strukturierter Daten ist. Nach der Serialisierung erzeugt dieses Protokoll eine binäre Nutzlast, die kleiner ist als eine normale JSON-Nutzlast und stark typisiert ist. Diese serialisierte binäre Nutzlast wird dann über das binäre Transportprotokoll HTTP/2 übertragen.
HTTP/2 ist die nächste große Version des Internetprotokolls HTTP. HTTP/2 ist voll multiplexfähig, das heißt, dass HTTP/2 mehrere Datenanfragen parallel über eine einzige TCP-Verbindung senden kann. Das macht Anwendungen, die mit HTTP/2 geschrieben wurden, schneller, einfacher und robuster als andere.
All diese Faktoren machen gRPC zu einem leistungsstarken RPC-Framework.
In diesem Kapitel haben wir die Low-Level-Details der gRPC-Kommunikation behandelt. Diese Details sind für die Entwicklung einer gRPC-Anwendung vielleicht nicht so wichtig, da sie bereits von der Bibliothek gehandhabt werden, aber das Verständnis des Low-Level gRPC-Nachrichtenflusses ist absolut unerlässlich, wenn es darum geht, Probleme bei der gRPC-Kommunikation zu beheben, wenn du gRPC in der Produktion einsetzt. Im nächsten Kapitel werden wir einige fortgeschrittene Funktionen von gRPC besprechen, um den Anforderungen der Praxis gerecht zu werden.
Get gRPC: Auf und davon now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

