Capítulo 4. Automatización de la Implementación de Bases de Datos en Kubernetes con Helm
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En el capítulo anterior, aprendiste a implementar bases de datos de nodo único y multinodo en Kubernetes de forma manual, creando un elemento cada vez. Hicimos las cosas de la "manera difícil" a propósito para ayudar a maximizar tu comprensión del uso de las primitivas de Kubernetes para configurar los recursos de computación, red y almacenamiento que requiere una base de datos. Por supuesto, esto no representa la experiencia de ejecutar bases de datos en producción en Kubernetes, por un par de razones.
En primer lugar, los equipos no suelen implementar las bases de datos a mano, un archivo YAML cada vez. Eso puede resultar bastante tedioso. E incluso combinar las configuraciones en un único archivo podría empezar a ser bastante complicado, especialmente para Implementaciones más sofisticadas. Considera el aumento de la cantidad de configuración necesaria en el Capítulo 3 para Cassandra como base de datos multinodo en comparación con la implementación MySQL de nodo único. Esto no será escalable para las grandes empresas.
En segundo lugar, aunque la implementación de una base de datos está muy bien, ¿qué pasa con su mantenimiento a lo largo del tiempo? Necesitas que tu infraestructura de datos siga siendo fiable y eficaz a largo plazo, y la infraestructura de datos es conocida por requerir mucho cuidado y alimentación. Dicho de otro modo, la tarea de hacer funcionar un sistema suele dividirse en "día uno" (el feliz día en que despliegas una aplicación en producción) y "día dos" (todos los días después del primero, cuando necesitas hacer funcionar y evolucionar tu aplicación manteniendo una alta disponibilidad).
Estas consideraciones en torno a la implementación y las operaciones de las bases de datos reflejan las tendencias más amplias de la industria hacia DevOps, un enfoque en el que los equipos de desarrollo asumen un papel más activo en el apoyo a las aplicaciones en producción. Las prácticas DevOps incluyen el uso de herramientas de automatización para CI/CD de aplicaciones, acortando el tiempo que tarda el código en pasar del escritorio de un desarrollador a la producción.
En este capítulo, veremos herramientas que ayudan a estandarizar la implementación de bases de datos y otras aplicaciones. Estas herramientas adoptan un enfoque de infraestructura como código (IaC), lo que te permite representar las opciones de instalación y configuración del software en un formato que puede ejecutarse automáticamente, reduciendo la cantidad total de código de configuración que tienes que escribir. También haremos hincapié en las operaciones de infraestructura de datos en estos dos próximos capítulos y mantendremos ese tema a lo largo del resto del libro.
Implementación de aplicaciones con gráficos de Helm
Empecemos echando un vistazo a una herramienta que te ayuda a gestionar la complejidad de la gestión de configuraciones: Helm. Este gestor de paquetes para Kubernetes es de código abierto y un proyecto graduado de la CNCF. El concepto de gestor de paquetes es común a múltiples lenguajes de programación, como pip para Python, el Node Package Manager (NPM) para JavaScript y la función Gems de Ruby. También existen gestores de paquetes para sistemas operativos específicos, como Apt para Linux, o Homebrew para macOS. Como se muestra en la Figura 4-1, los elementos esenciales de un sistema gestor de paquetes son los paquetes, los registros donde se almacenan los paquetes y la aplicación gestora de paquetes (o cliente), que ayuda a los desarrolladores de gráficos a registrarlos y permite a los usuarios de gráficos localizar, instalar y actualizar paquetes en sus sistemas locales.
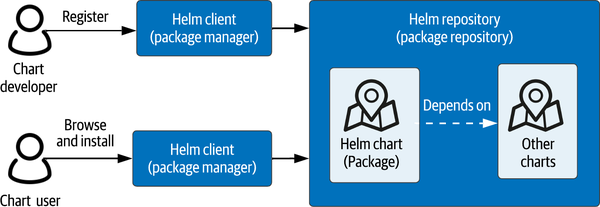
Figura 4-1. Helm, un gestor de paquetes para Kubernetes
Helm extiende el concepto de gestión de paquetes a Kubernetes, con algunas diferencias interesantes. Si has trabajado con alguno de los gestores de paquetes enumerados anteriormente, estarás familiarizado con la idea de que un paquete consta de un binario (código ejecutable), así como de metadatos que describen el binario, como su funcionalidad, API e instrucciones de instalación. En Helm, los paquetes se denominan gráficos. Los diagramas describen cómo construir una aplicación Kubernetes pieza a pieza utilizando los recursos Kubernetes para computación, redes y almacenamiento introducidos en capítulos anteriores, como Pods, Servicios y PersistentVolumeClaims. Para las cargas de trabajo de computación, las descripciones apuntan a imágenes de contenedores que residen en registros de contenedores públicos o privados.
Helm permite que los gráficos hagan referencia a otros gráficos como dependencias, lo que proporciona una forma estupenda de componer aplicaciones creando conjuntos de gráficos. Por ejemplo, podrías definir una aplicación como el ejemplo WordPress/MySQL del capítulo anterior definiendo un gráfico para tu implementación de WordPress que hiciera referencia a un gráfico que definiera una implementación de MySQL que quisieras reutilizar. O incluso podrías encontrar un gráfico de Helm que defina una aplicación WordPress completa, incluida la base de datos.
Requisitos previos del entorno Kubernetes
Los ejemplos de este capítulo suponen que tienes acceso a un clúster Kubernetes con un par de características:
El clúster debe tener al menos tres Nodos Trabajadores, con el fin de demostrar los mecanismos que proporciona Kubernetes para permitirte solicitar que los Pods se repartan por un clúster. Puedes crear un clúster sencillo en tu escritorio utilizando una distribución de código abierto llamada kind. Consulta la guía de inicio rápido de kind para obtener instrucciones sobre cómo instalar kind y crear un clúster multinodo. El código de este ejemplo también contiene un archivo de configuración que puede resultarte útil para crear un clúster simple de kind de tres nodos.
También necesitarás una StorageClass que admita el aprovisionamiento dinámico. Puedes seguir las instrucciones de "StorageClasses " para instalar una StorageClass sencilla y un aprovisionador que expongan el almacenamiento local.
Uso de Helm para la Implementación de MySQL
Para concretar un poco más, vamos a utilizar Helm para implementar las bases de datos con las que trabajaste en el Capítulo 3. En primer lugar, si aún no está en tu sistema, tendrás que instalar Helm utilizando la documentación del sitio web de Helm. A continuación, añade el repositorio Helm de Bitnami:
helm repo add bitnami https://charts.bitnami.com/bitnami
El repositorio Bitnami Helm contiene una variedad de gráficos de Helm para ayudarte a implementar infraestructuras como bases de datos, motores de análisis y sistemas de gestión de registros, así como aplicaciones como comercio electrónico, gestión de relaciones con los clientes (CRM) y, ya lo has adivinado: WordPress. Puedes encontrar el código fuente de los gráficos en el repositorio de Bitnami Charts en GitHub. El README de este repositorio proporciona instrucciones útiles para utilizar los gráficos en varias distribuciones de Kubernetes.
Ahora, vamos a utilizar el gráfico de Helm proporcionado en el repositorio bitnami para implementar MySQL. En la terminología de Helm, cada implementación se conoce como versión. La versión más sencilla que podrías crear utilizando este gráfico tendría este aspecto:
# don’t execute me yet! helm install mysql bitnami/mysql
Si ejecutas este comando, se creará una versión llamada mysql utilizando la tabla Bitnami MySQL Helm con su configuración predeterminada. Como resultado, tendrías un único nodo de MySQL. Puesto que ya has desplegado un único nodo de MySQL manualmente en el Capítulo 3, hagamos algo un poco más interesante esta vez y creemos un clúster MySQL. Para ello, crearás un archivo values.yaml con un contenido como el siguiente, o puedes reutilizar el ejemplo proporcionado en el código fuente:
architecture: replication secondary: replicaCount: 2
La configuración de este archivo values.yaml permite a Helm saber que quieres utilizar las opciones de la tabla Bitnami MySQL Helm para implementar MySQL en una arquitectura replicada en la que hay un nodo primario y dos secundarios.
Opciones de configuración de los gráficos de Helm de MySQL
Si examinas el archivovalues.yaml predeterminado que se proporciona con el gráfico Bitnami MySQL Helm, verás que hay bastantes opciones disponibles más allá de las simples selecciones que se muestran aquí. Los valores configurables incluyen los siguientes:
Imágenes a extraer y sus ubicaciones
La StorageClass de Kubernetes que se utilizará para generar PersistentVolumes
Credenciales de seguridad para cuentas de usuario y administrador
Ajustes de configuración de MySQL para las réplicas primaria y secundaria
Número de réplicas secundarias a crear
Detalles de las sondas de liveness, readiness
Ajustes de afinidad y antiafinidad
Gestionar la alta disponibilidad de la base de datos mediante presupuestos de interrupción Pod
Muchos de estos conceptos ya te resultarán familiares, y otros, como la afinidad y los presupuestos de interrupción de Pod, se tratan más adelante en el libro.
Una vez que hayas creado el archivo values.yaml, puedes iniciar el clúster utilizando este comando:
helm install mysql bitnami/mysql -f values.yaml
Tras ejecutar el comando, verás el estado de la instalación desde Helm, además de las instrucciones que se proporcionan con el gráfico en NOTES:
NAME: mysql LAST DEPLOYED: Thu Oct 21 20:39:19 2021 NAMESPACE: default STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: …
Hemos omitido aquí las notas porque son un poco largas. Describen los comandos sugeridos para monitorizar el estado de inicialización de MySQL, cómo pueden conectarse a la base de datos los clientes y los administradores, cómo actualizar la base de datos, etc.
Utiliza espacios de nombres para aislar los recursos
Como no hemos especificado un espacio de nombres, la versión de Helm se ha instalado en el espacio de nombres predeterminado de Kubernetes, a menos que hayas configurado por separado un espacio de nombres en tu kubeconfig. Si quieres instalar una versión de Helm en su propio Espacio de Nombres para trabajar con sus recursos de forma más eficaz, podrías ejecutar algo como lo siguiente:
helm install mysql bitnami/mysql \ --namespace mysql --create-namespace
Esto crea un espacio de nombres llamado mysql e instala en él la versión mysql.
Para obtener información sobre las versiones de Helm que has creado, utiliza el comando helm list, que produce una salida como ésta (formateada para facilitar su lectura):
helm list NAME NAMESPACE REVISION UPDATED mysql default 1 2021-10-21 20:39:19 STATUS CHART APP VERSION deployed mysql-8.8.8 8.0.26
Si no has instalado la versión en su propio espacio de nombres, sigue siendo sencillo ver los recursos informáticos que Helm ha creado en tu nombre ejecutando kubectl get all, porque todos han sido etiquetados con el nombre de tu versión. La inicialización de todos los recursos puede tardar varios minutos, pero una vez completada, tendrá un aspecto similar al siguiente:
kubectl get all NAME READY STATUS RESTARTS AGE pod/mysql-primary-0 1/1 Running 0 3h40m pod/mysql-secondary-0 1/1 Running 0 3h40m pod/mysql-secondary-1 1/1 Running 0 3h38m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT service/mysql-primary ClusterIP 10.96.107.156 <none> ... service/mysql-primary-headless ClusterIP None <none> ... service/mysql-secondary ClusterIP 10.96.250.52 <none> ... service/mysql-secondary-headless ClusterIP None <none> ... NAME READY AGE statefulset.apps/mysql-primary 1/1 3h40m statefulset.apps/mysql-secondary 2/2 3h40m
Como puedes ver, Helm ha creado dos StatefulSets, uno para las réplicas primarias y otro para las secundarias. El mysql-primary StatefulSet está gestionando un único Pod MySQL que contiene una réplica primaria, mientras que el mysql-secondary StatefulSet está gestionando dos Pods MySQL que contienen réplicas secundarias. Comprueba si puedes determinar en qué Nodo Trabajador de Kubernetes se está ejecutando cada réplica MySQL utilizando el comando kubectl describe pod.
En la salida anterior, también observarás que se han creado dos Servicios para cada StatefulSet, uno un servicio sin cabeza y otro que tiene una dirección IP dedicada. Puesto que kubectl get all sólo te informa sobre los recursos y servicios informáticos, es posible que también te preguntes por los recursos de almacenamiento. Para comprobarlos, ejecuta el comando kubectl get pv. Suponiendo que tengas instalada una StorageClass compatible con el aprovisionamiento dinámico, deberías ver los PersistentVolumes vinculados a los PersistentVolumeClaims denominados data-mysql-primary-0, data-mysql-secondary-0 y data-mysql-secondary-1.
Además de los recursos de los que hemos hablado, la instalación del gráfico también ha dado lugar a la creación de algunos recursos adicionales que exploraremos a continuación.
Espacios de nombres y ámbito de recursos de Kubernetes
Si has elegido instalar tu versión de Helm en un Namespace, tendrás que especificar el Namespace en la mayoría de tus comandos kubectl get para poder ver los recursos creados. La excepción es kubectl get pv, porque los PersistentVolumes son uno de los recursos de Kubernetes que no están Namespaced; es decir, pueden ser utilizados por Pods en cualquier Namespace. Para saber qué recursos Kubernetes de tu clúster tienen Namespaced y cuáles no, ejecuta el comando kubectl api-resources.
Cómo funciona Helm
¿Te has preguntado qué ocurre cuando ejecutas el comando helm install con un archivo de valores proporcionado? Para entender lo que ocurre, echemos un vistazo al contenido de un gráfico Helm, como se muestra en la Figura 4-2. Mientras analizamos estos contenidos, también te será útil echar un vistazo al código fuente del gráfico Helm de MySQL que acabas de instalar.
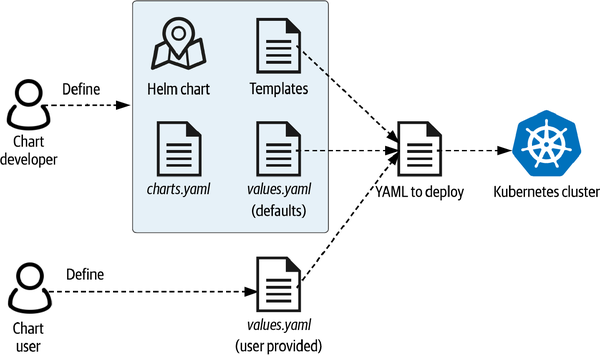
Figura 4-2. Personalización de una versión de Helm mediante un archivo values.yaml
Si observas el contenido de un gráfico de Helm, te darás cuenta de lo siguiente:
- Archivo README
- Aquí se explica cómo utilizar la tabla. Estas instrucciones se facilitan junto con el gráfico en los registros.
- Archivo Chart.yaml
- Contiene metadatos sobre el gráfico, como su nombre, editor, versión, palabras clave y cualquier dependencia de otros gráficos. Estas propiedades son útiles para buscar gráficos en los registros de Helm.
- archivo values.yaml
- Enumera los valores configurables que admite el gráfico y sus valores por defecto. Estos archivos suelen contener un buen número de comentarios que explican las opciones disponibles. Para el gráfico Bitnami MySQL Helm, hay muchas opciones disponibles, como hemos señalado.
- directorio de plantillas
- Contiene plantillas Go que definen el gráfico. Las plantillas incluyen un archivo Notes.txt utilizado para generar la salida que has visto anteriormente tras ejecutar el comando
helm install, y uno o varios archivos YAML que describen un patrón para un recurso de Kubernetes. Estos archivos YAML pueden organizarse en subdirectorios (por ejemplo, la plantilla que define un StatefulSet para las réplicas primarias de MySQL). Por último, un archivo _helpers.tpl describe cómo utilizar las plantillas. Algunas de las plantillas pueden utilizarse varias veces o no utilizarse en absoluto, dependiendo de los valores de configuración seleccionados.
Cuando ejecutas el comando helm install, el cliente Helm se asegura de que tiene una copia actualizada del gráfico que has nombrado consultando el repositorio de fuentes. A continuación, utiliza la plantilla para generar el código de configuración YAML, sustituyendo los valores por defecto del archivo values.yaml del gráfico por los valores que le hayas proporcionado. A continuación, utiliza el comando kubectl para aplicar esta configuración a tu clúster Kubernetes actualmente configurado.
Si quieres ver la configuración que producirá un gráfico Helm antes de aplicarlo, puedes utilizar el práctico comando template. Admite la misma sintaxis que el comando install:
helm template mysql bitnami/mysql -f values.yaml
Ejecutar este comando producirá bastante salida, así que quizá quieras redirigirla a un archivo (añade > values-template.yaml al comando) para poder echarle un vistazo más largo. También puedes consultar la copia que hemos guardado en el repositorio del código fuente.
Observarás que se crean varios tipos de recursos, como se resume en la Figura 4-3. Muchos de los recursos que se muestran ya se han comentado, incluidos los StatefulSets para gestionar las réplicas primaria y secundaria, cada uno con su propio servicio (el gráfico también crea servicios sin cabeza que no se muestran en la figura). Cada Pod tiene su propio PersistentVolumeClaim que se asigna a un único PersistentVolume.
La Figura 4-3 también incluye tipos de recursos que no hemos tratado anteriormente. Observa en primer lugar que cada StatefulSet tiene un ConfigMap asociado que se utiliza para proporcionar un conjunto común de ajustes de configuración a sus Pods. Después, fíjate en el Secreto llamado mysql, que almacena las contraseñas necesarias para acceder a varias interfaces expuestas por los nodos de la base de datos. Por último, se aplica un recurso ServiceAccount a cada Pod creado por esta versión de Helm.
Centrémonos en algunos aspectos interesantes de esta implementación, como el uso de etiquetas, ServiceAccounts, Secrets y ConfigMaps.
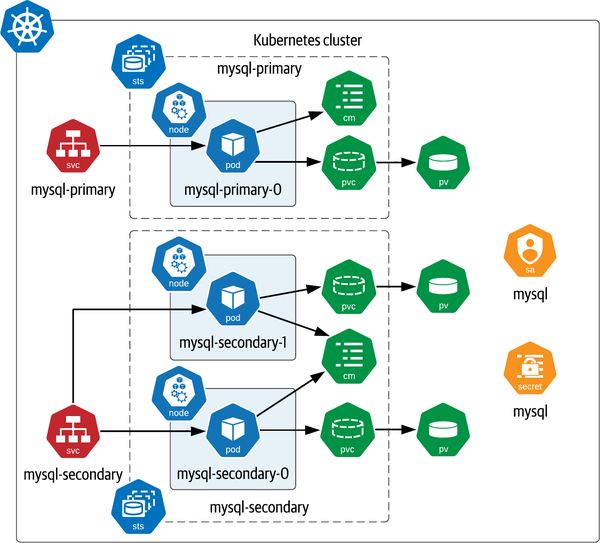
Figura 4-3. Implementación de MySQL mediante el gráfico Helm de Bitnami
Etiquetas
Si echas un vistazo a la salida de helm template, te darás cuenta de que los recursos tienen un conjunto común de etiquetas:
labels:
app.kubernetes.io/name: mysql
helm.sh/chart: mysql-8.8.8
app.kubernetes.io/instance: mysql
app.kubernetes.io/managed-by: Helm
Estas etiquetas ayudan a identificar los recursos como parte de la aplicación mysql e indican que están gestionados por Helm mediante una versión de carta específica. Las etiquetas son útiles para seleccionar recursos, lo que suele ser útil para definir configuraciones para otros recursos.
CuentasServicio
Los clústeres de Kubernetes distinguen entre usuarios humanos y aplicaciones a efectos de control de acceso. Una ServiceAccount es un recurso de Kubernetes que representa a una aplicación y a lo que se le permite acceder. Por ejemplo, una ServiceAccount puede tener acceso a algunas partes de la API de Kubernetes, o acceso a uno o más secretos que contengan información privilegiada, como credenciales de inicio de sesión. Esta última capacidad se utiliza en tu instalación Helm de MySQL para compartir credenciales entre Pods.
Cada Pod creado en Kubernetes tiene asignada una ServiceAccount. Si no especificas ninguna, se utiliza la ServiceAccount por defecto. Al instalar la carta Helm de MySQL se crea una ServiceAccount llamada mysql. Puedes ver la especificación de este recurso en la plantilla generada:
apiVersion: v1 kind: ServiceAccount metadata: name: mysql namespace: default labels: ... annotations: secrets: - name: mysql
Como puedes ver, esta ServiceAccount tiene acceso a un Secreto llamado mysql, del que hablaremos en breve. Una ServiceAccount también puede tener un tipo adicional de Secreto conocido como imagePullSecret. Estos Secretos se utilizan cuando una aplicación necesita utilizar imágenes de un registro privado.
Por defecto, una ServiceAccount no tiene ningún acceso a la API de Kubernetes. Para dar a esta ServiceAccount el acceso que necesita, el gráfico Helm de MySQL crea un Rol que especifica los recursos y operaciones de Kubernetes, y un RoleBinding para asociar la ServiceAccount al Rol. Hablaremos de las ServiceAccounts y del acceso basado en roles en el Capítulo 5.
Secretos
Como aprendiste en el Capítulo 2, un Secreto proporciona acceso seguro a la información que necesitas mantener en privado. Tu versión de mysql Helm contiene un Secreto llamado mysql que contiene las credenciales de acceso a las propias instancias de MySQL:
apiVersion: v1 kind: Secret metadata: name: mysql namespace: default labels: ... type: Opaque data: mysql-root-password: "VzhyNEhIcmdTTQ==" mysql-password: "R2ZtNkFHNDhpOQ==" mysql-replication-password: "bDBiTWVzVmVORA=="
Las tres contraseñas representan distintos tipos de acceso: la mysql-root-password proporciona acceso administrativo al nodo MySQL, mientras que la mysql-replication-password se utiliza para que los nodos se comuniquen con fines de replicación de datos entre nodos. La mysql-password la utilizan las aplicaciones cliente para acceder a la base de datos para escribir y leer datos.
ConfigMaps
El gráfico de Helm de Bitnami MySQL crea recursos ConfigMap de Kubernetes para representar los ajustes de configuración utilizados para los Pods que ejecutan los nodos de réplica primario y secundario de MySQL. Los ConfigMaps almacenan los datos de configuración como pares clave-valor. Por ejemplo, el ConfigMap creado por el gráfico Helm para las réplicas primarias tiene este aspecto:
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-primary
namespace: default
labels: ...
data:
my.cnf: |-
[mysqld]
default_authentication_plugin=mysql_native_password
...
En este caso, la clave es el nombre my.cnf, que representa un nombre de archivo, y el valor es un conjunto multilínea de ajustes de configuración que representan el contenido de un archivo de configuración (que aquí hemos abreviado). A continuación, observa la definición del StatefulSet para las réplicas primarias. Observa que el contenido del ConfigMap se monta como un archivo de sólo lectura dentro de cada plantilla, de acuerdo con la especificación Pod para el StatefulSet (de nuevo, hemos omitido algunos detalles para centrarnos en las áreas clave):
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql-primary
namespace: default
labels: ...
spec:
replicas: 1
selector:
matchLabels: ...
serviceName: mysql-primary
template:
metadata:
annotations: ...
labels: ...
spec:
...
serviceAccountName: mysql
containers:
- name: mysql
image: docker.io/bitnami/mysql:8.0.26-debian-10-r60
volumeMounts:
- name: data
mountPath: /bitnami/mysql
- name: config
mountPath: /opt/bitnami/mysql/conf/my.cnf
subPath: my.cnf
volumes:
- name: config
configMap:
name: mysql-primary
Al montar el ConfigMap como un volumen en un contenedor, se crea un archivo de sólo lectura en el directorio de montaje que se denomina según la clave y tiene el valor como contenido. En nuestro ejemplo, al montar el ConfigMap en el contenedor mysql del Pod, se crea el archivo /opt/bitnami/mysql/conf/my.cnf.
Esta es una de las varias formas en que pueden utilizarse los ConfigMaps en las aplicaciones Kubernetes:
Como se describe en la documentación de Kubernetes, puedes optar por almacenar los datos de configuración en pares clave-valor más granulares, lo que también facilita el acceso a valores individuales en tu aplicación.
También puedes hacer referencia a pares clave-valor individuales como variables de entorno que pasas a un contenedor.
Por último, las aplicaciones pueden acceder al contenido de ConfigMap a través de la API de Kubernetes.
Más opciones de configuración
Ahora que tienes una versión de Helm con un clúster MySQL operativo, puedes apuntar a él una aplicación, como WordPress. ¿Por qué no pruebas a ver si puedes adaptar la implementación de WordPress del Capítulo 3 para que apunte al clúster MySQL que has creado aquí?
Para aprender más, también podrías comparar tu configuración resultante con la producida por el gráfico Helm de Bitnami WordPress, que utiliza MariaDB en lugar de MySQL, pero que por lo demás es bastante similar.
Actualización de los gráficos de Helm
Si estás ejecutando una versión de Helm en un entorno de producción, lo más probable es que necesites mantenerla a lo largo del tiempo. Puede que quieras actualizar una versión de Helm por varias razones:
Hay disponible una nueva versión de un gráfico.
Está disponible una nueva versión de una imagen utilizada por tu aplicación.
Quieres cambiar las opciones seleccionadas.
Para buscar una nueva versión de un gráfico, ejecuta el comando helm repo update. Ejecutar este comando sin opciones busca actualizaciones en todos los repositorios de gráficos que hayas configurado para tu cliente Helm:
helm repo update Hang tight while we grab the latest from your chart repositories... ...Successfully got an update from the "bitnami" chart repository Update Complete. ⎈Happy Helming!⎈
A continuación, deberás realizar las actualizaciones que desees en los valores configurados. Si vas a actualizar a una nueva versión de un gráfico, asegúrate de comprobar las notas de la versión y la documentación de los valores configurables. Es una buena idea probar una actualización antes de aplicarla. La opción --dry-run te permite hacerlo, produciendo valores similares a los del comando helm template:
helm upgrade mysql bitnami/mysql -f values.yaml --dry-run
Utilizar un archivo de configuración de superposición
Una opción útil que podrías utilizar para la actualización es especificar los valores que deseas anular en un nuevo archivo de configuración, y aplicar tanto el nuevo como el antiguo, algo así:
helm upgrade mysql bitnami/mysql \ -f values.yaml -f new-values.yaml
Los archivos de configuración se aplican en el orden en que aparecen en la línea de comandos, por lo que si utilizas este método, asegúrate de que tu archivo de valores anulados aparece después de tu archivo de valores original.
Una vez que has aplicado la actualización, Helm se pone manos a la obra, actualizando sólo aquellos recursos de la versión afectados por tus cambios de configuración. Si has especificado cambios en la plantilla Pod para un StatefulSet, los Pods se reiniciarán de acuerdo con la política de actualización especificada para el StatefulSet, tal y como comentamos en "Gestión del ciclo de vida de StatefulSet".
Desinstalar los gráficos de Helm
Cuando hayas terminado de utilizar tu versión de Helm, puedes desinstalarla por su nombre:
helm uninstall mysql
Observa que Helm no elimina ninguna de las PersistentVolumeClaims o PersistentVolumes que se crearon para este gráfico Helm, siguiendo el comportamiento de StatefulSets comentado en el Capítulo 3.
Uso de Helm para la Implementación de Apache Cassandra
Ahora cambiemos de marcha y veamos la implementación de Apache Cassandra utilizando Helm. En esta sección, utilizarás otro gráfico proporcionado por Bitnami, por lo que no es necesario añadir otro repositorio. Puedes encontrar la implementación de este gráfico en GitHub. Helm proporciona una forma rápida de ver los metadatos de este gráfico:
helm show chart bitnami/cassandra
Después de revisar los metadatos, también querrás conocer los valores configurables. Puedes examinar el archivovalues.yaml en el repositorio de GitHub, o utilizar otra opción del comando show:
helm show values bitnami/cassandra
La lista de opciones de este gráfico es más corta que la del gráfico de MySQL, porque Cassandra no tiene el concepto de réplicas primarias y secundarias. Sin embargo, seguro que verás opciones similares para imágenes, StorageClasses, seguridad, sondas de liveness y readiness, etc. Algunas opciones de configuración son exclusivas de Cassandra, como las que tienen que ver con la configuración de la JVM y los nodos semilla (como se explica en el Capítulo 3).
Una característica interesante de este gráfico es la posibilidad de exportar métricas desde nodos Cassandra. Si configuras metrics.enabled=true, el gráfico inyectará un contenedor sidecar en cada Pod de Cassandra que exponga un puerto que pueda ser rastreado por Prometheus. Otros valores en metrics configuran qué métricas se exportan, la frecuencia de recopilación, etc. Aunque no utilizaremos esta función aquí, los informes de métricas son una parte clave de la gestión de la infraestructura de datos que trataremos en el Capítulo 6.
Para una configuración sencilla de tres nodos Cassandra, podrías establecer el recuento de réplicas en 3 y establecer otros valores de configuración en sus valores predeterminados. Sin embargo, dado que sólo estás anulando un único valor de configuración, éste es un buen momento para aprovechar el soporte de Helm para establecer valores en la línea de comandos, en lugar de proporcionar un archivo values.yaml:
helm install cassandra bitnami/cassandra --set replicaCount=3
Como ya hemos comentado, puedes utilizar el comando helm template para comprobar la configuración antes de instalarla, o consultar el archivo que hemos guardado en GitHub. Sin embargo, como ya has creado la versión, también puedes utilizar este comando:
helm get manifest cassandra
Si echas un vistazo a los recursos en el YAML, verás que se ha establecido un conjunto similar de infraestructura, como se muestra en la Figura 4-4.
La configuración incluye lo siguiente
Una ServiceAccount que hace referencia a un Secret, que contiene la contraseña de la cuenta de administrador
cassandra.Un único StatefulSet, con un Servicio headless utilizado para referenciar sus Pods. Los Pods están repartidos uniformemente entre los Nodos Trabajadores Kubernetes disponibles, de los que hablaremos en la siguiente sección. El Servicio expone los puertos de Cassandra utilizados para la comunicación intranodo (
7000, con7001utilizado para la comunicación segura a través de TLS), la administración a través de JMX (7199), y el acceso del cliente a través de CQL (9042).
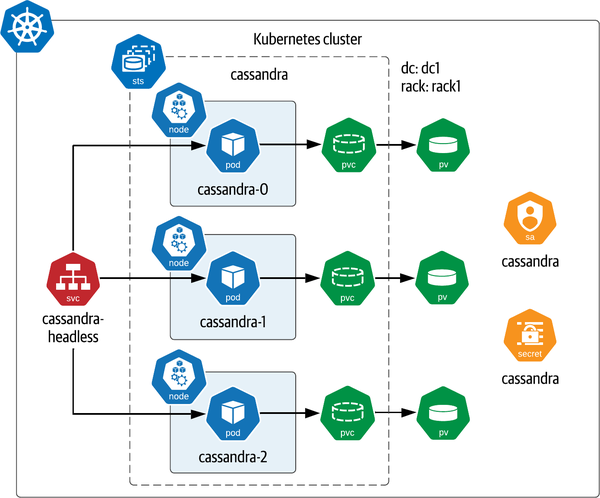
Figura 4-4. Implementación de Apache Cassandra mediante el gráfico Helm de Bitnami
Esta configuración representa una topología simple de Cassandra, con los tres nodos en un único Centro de Datos y bastidor. Esta topología sencilla refleja una de las limitaciones de este gráfico: no ofrece la posibilidad de crear un clúster Cassandra formado por varios Centros de Datos y racks. Para crear una implementación más compleja, tendrías que instalar varias versiones de Helm, utilizando el mismo clusterName (en este caso, estás utilizando el nombre predeterminado cassandra), pero un Centro de Datos y un bastidor diferentes para cada implementación. También tendrías que obtener la dirección IP de un par de nodos en el primer Centro de Datos para utilizarlos como additionalSeeds al configurar las versiones para los demás bastidores.
Afinidad y antiafinidad
Como se muestra en la Figura 4-4, los nodos Cassandra están repartidos uniformemente entre los Nodos Trabajadores de tu cluster. Para verificar esto en tu propia versión de Cassandra, podrías ejecutar algo como lo siguiente:
kubectl describe pods | grep "^Name:" -A 3 Name: cassandra-0 Namespace: default Priority: 0 Node: kind-worker/172.20.0.7 -- Name: cassandra-1 Namespace: default Priority: 0 Node: kind-worker2/172.20.0.6 -- Name: cassandra-2 Namespace: default Priority: 0 Node: kind-worker3/172.20.0.5
Como puedes ver, cada nodo Cassandra se ejecuta en un Nodo Trabajador diferente. Si tu clúster Kubernetes tiene al menos tres Nodos Trabajadores y ninguna otra carga de trabajo, es probable que observes un comportamiento similar. Si bien es cierto que esta asignación uniforme podría ocurrir de forma natural en un clúster que tenga una carga uniforme en todos los Nodos Trabajadores, probablemente no sea el caso en tu entorno de producción. Sin embargo, para promover la máxima disponibilidad de tus datos, queremos intentar honrar la intención de la arquitectura de Cassandra de ejecutar nodos en máquinas diferentes para promover la alta disponibilidad.
Para ayudar a garantizar este aislamiento, el gráfico de Bitnami Helm utiliza las capacidades de afinidad de Kubernetes, concretamente la antiafinidad. Si examinas la configuración generada para el StatefulSet de Cassandra, verás lo siguiente:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: cassandra
namespace: default
labels: ...
spec:
...
template:
metadata:
labels: ...
spec:
...
affinity:
podAffinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchLabels:
app.kubernetes.io/name: cassandra
app.kubernetes.io/instance: cassandra
namespaces:
- "default"
topologyKey: kubernetes.io/hostname
weight: 1
nodeAffinity:
Como se muestra aquí, la especificación de la plantilla Pod enumera tres posibles tipos de afinidad, y sólo se define la podAntiAffinity. ¿Qué significan estos conceptos?
- Afinidad de la vaina
- La preferencia de que un Pod se programe en un nodo donde se esté ejecutando otro Pod específico. Por ejemplo, la afinidad Pod podría utilizarse para colocar un servidor web con su caché.
- Vaina antiafinidad
- Lo contrario de la afinidad Pod, es decir, la preferencia de que un Pod no se programe en un nodo en el que se esté ejecutando otro Pod identificado. Esta es la restricción utilizada en este ejemplo, como veremos en breve.
- Afinidad de nodos
- La preferencia de que un Pod se ejecute en un nodo con características específicas.
Cada tipo de afinidad puede expresarse como restricciones duras o blandas. Se conocen como requiredDuringSchedulingIgnoredDuringExecution y preferredDuringSchedulingIgnoredDuringExecution. La primera restricción especifica reglas que deben cumplirse antes de programar un Pod en un nodo, mientras que la segunda especifica una preferencia que el programador intentará cumplir, pero que puede relajar si es necesario para programar el Pod.
IgnoredDuringExcecution implica que las restricciones sólo se aplican cuando los Pods se programan por primera vez. En el futuro, se añadirán nuevas opciones a RequiredDuringExecution denominadas requiredDuringSchedulingRequiredDuringExecution y requiredDuringSchedulingRequiredDuringExecution. Éstas pedirán a Kubernetes que desaloje los Pods (es decir, que los traslade a otro nodo) que ya no cumplan los criterios, por ejemplo, por un cambio en sus etiquetas.
Si nos fijamos en el ejemplo anterior, la especificación de la plantilla Pod para el StatefulSet de Cassandra especifica una regla antiafinidad utilizando las etiquetas que se aplican a cada Pod de Cassandra. El efecto neto es que Kubernetes intentará repartir los Pods entre los Nodos Trabajadores disponibles.
Éstos son los aspectos más destacados al mirar el gráfico de Bitnami Helm para Cassandra. Para limpiar las cosas, desinstala la versión de Cassandra:
helm uninstall cassandra
Si no quieres seguir trabajando con los gráficos de Helm de Bitnami, también puedes eliminar el repositorio de tu cliente Helm:
helm repo remove bitnami
Más restricciones de programación de Kubernetes
Kubernetes admite mecanismos adicionales para proporcionar pistas a su programador sobre la colocación de Pods. Uno de los más sencillos es NodeSelectors, que es muy similar a la afinidad de nodos, pero con una sintaxis menos expresiva que puede coincidir en una o más etiquetas utilizando la lógica AND. Dado que puedes tener o no los privilegios necesarios para adjuntar etiquetas a los Nodos Trabajadores de tu clúster, la afinidad de nodos suele ser una opción mejor. Las contaminaciones y tolerancias son otro mecanismo que puede utilizarse para configurar los Nodos Trabajadores para que repelan la programación de determinados Pods en esos nodos.
En general, debes tener cuidado de comprender todas las restricciones que estás imponiendo al programador de Kubernetes a partir de diversas cargas de trabajo, para no limitar en exceso su capacidad de colocar Pods. Consulta la documentación de Kubernetes para obtener más información sobre las restricciones de programación. También veremos cómo Kubernetes te permite conectar diferentes planificadores en "Planificadores alternativos para Kubernetes".
Helm, CI/CD y Operaciones
Helm es una potente herramienta centrada en una tarea principal: la implementación de aplicaciones complejas en clusters de Kubernetes. Para obtener el máximo beneficio de Helm, deberás considerar cómo encaja en tu conjunto más amplio de herramientas CI/CD:
Los servidores de automatización, como Jenkins, crean, prueban e implementan automáticamente el software según secuencias de comandos conocidas como trabajos. Estos trabajos suelen ejecutarse en función de desencadenantes predefinidos, como una confirmación en un repositorio de fuentes. Se puede hacer referencia a los gráficos de Helm en los trabajos para instalar una aplicación bajo prueba y su infraestructura de apoyo en un clúster de Kubernetes.
Las herramientas de automatización de IaC, como Terraform, te permiten definir plantillas y scripts que describen cómo crear infraestructura en diversos entornos de nube. Por ejemplo, podrías escribir un script Terraform que automatice la creación de una nueva VPC dentro de un proveedor de nube específico y la creación de un nuevo clúster Kubernetes dentro de esa VPC. A continuación, el script podría utilizar Helm para instalar aplicaciones dentro del clúster de Kubernetes.
Aunque ciertamente se producen solapamientos en las capacidades que proporcionan estas herramientas, querrás tener en cuenta los puntos fuertes y las limitaciones de cada una a medida que construyas tu conjunto de herramientas. Por esta razón, queremos asegurarnos de señalar que Helm tiene limitaciones cuando se trata de gestionar las operaciones de las aplicaciones que implementa. Para hacernos una idea de los retos que esto supone, hablamos con un profesional que ha construido conjuntos de gráficos de Helm para gestionar la implementación de una base de datos compleja. Esta discusión comienza a introducir conceptos como las Definiciones Personalizadas de Recursos (CRD) de Kubernetes y el patrón de operador, que trataremos en profundidad en el Capítulo 5.
Como señala John Sanda en su comentario, Helm es una potente herramienta para programar la implementación de aplicaciones compuestas por múltiples recursos de Kubernetes, pero puede ser menos eficaz a la hora de gestionar tareas operativas más complejas. Como verás en los próximos capítulos, un patrón común utilizado para la infraestructura de datos y otras aplicaciones complejas es utilizar un gráfico de Helm para desplegar un operador, que a su vez puede gestionar tanto la implementación como el ciclo de vida de la aplicación.
Resumen
En este capítulo, has aprendido cómo una herramienta de gestión de paquetes como Helm puede ayudarte a gestionar la implementación de aplicaciones en Kubernetes, incluida tu infraestructura de base de datos. Por el camino, también has aprendido a utilizar algunos recursos adicionales de Kubernetes como ServiceAccounts, Secrets y ConfigMaps. Ha llegado el momento de completar nuestro debate sobre la ejecución de bases de datos en Kubernetes. En el próximo capítulo, profundizaremos en la gestión de operaciones de bases de datos en Kubernetes utilizando el patrón operador.
Get Gestión de datos nativos de la nube en Kubernetes now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

