Chapter 4. Interface Design
Building data projects with large volumes of multistructured data is complex. In addition, there’s the potential complexity of integrating various components and technologies into a solution, supporting large numbers of concurrent users and different processing patterns, plus the need to be flexible in order to adapt to changing requirements and technologies.
So, how can we address these challenges when designing our systems? Well-designed interfaces can help build solutions that are maintainable, scalable, and resilient to change. In this chapter, we focus on what makes a good interface design, some nonfunctional considerations, and some common interface examples.
The Human Body
Before going into technology, let’s reflect on a system that’s far more complex than any we’re likely to ever build. This system also uses interfaces and very focused subsystems to reduce dependencies and adapt to changing conditions over time (although somewhat larger time spans than our systems will have to deal with). The system we’re referring to is the human body; if we think of it as a collection of high-level parts connected by interfaces, we can identify parallels to our own systems.
The Human Body Versus a Data Architecture
If we look at the main systems in the human body, we can begin to note some interesting parallels to a modern data architecture. Let’s take a look at some of these parallels, starting with the body’s peripheral nervous system and central nervous system.
Peripheral nervous system
The first major component we’re looking at is the network of information pipes that connect all the components in the body, allowing them to send and receive data with other components. This is our peripheral nervous system (PNS), the nerves that span our body and receive input from all of our senses. The PNS sends this input to our brain and sends commands out to other systems like muscles, instructing them to take actions. Think of this as the information superhighway of the body.
Distributed data systems have a number of similarities, with the clearest example being publish–subscribe (pub–sub) systems like Kafka. We talk more about pub–sub later in this chapter. For now, we can define pub–sub simply as a system that has publishers that publish data to a central broker, and subscribers that consume that data for further processing. If we look at Kafka in a data architecture, it will look something like Figure 4-1. In this example, Kafka is accepting information from external streams or sensors and sending to storage systems or near-real-time (NRT) processing systems where we can make decisions based on the data. These decisions then can travel back through Kafka and be sent to services that can take action based on commands generated from the decisions.
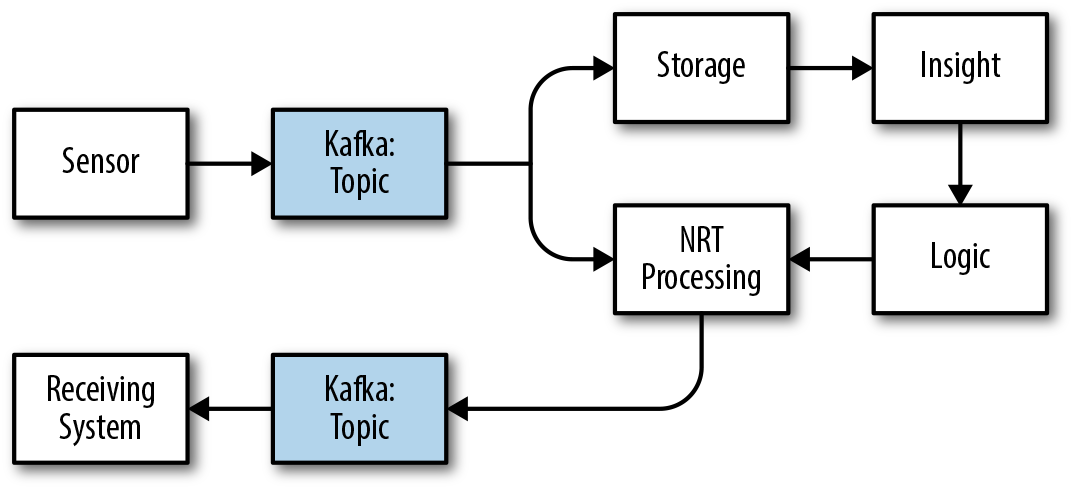
Figure 4-1. Data architecture compared to the PNS
Central nervous system
As shown in Figure 4-2, the central nervous system (CNS) is composed of the more purposeful parts of your nervous system like your brain and your spinal cord. These are systems that have more-complex jobs than just transporting information. These systems can be further broken down into subsystems that have specific functions; for example, the brain is composed of different lobes such as the occipital lobe, which provides visual processing functions; the frontal lobe, which controls a number of functions such as memory and language; and so on. These systems also control other systems in the body, such as muscles and the heart.
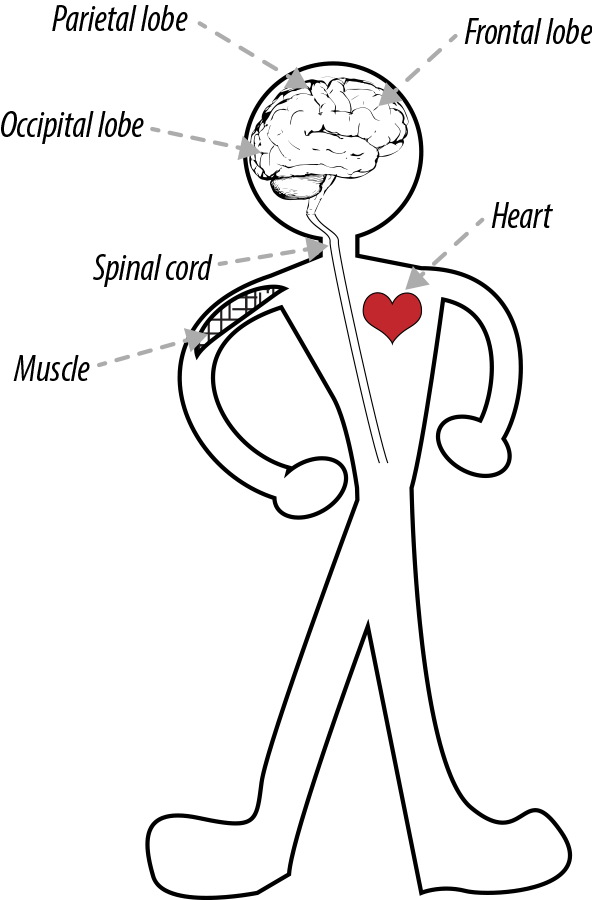
Figure 4-2. Central nervous system
If we relate this back to our big data architecture, the brain is the highlighted areas in Figure 4-3. Specifically, the brain represents the storage, NRT processing, insight, and logic components.
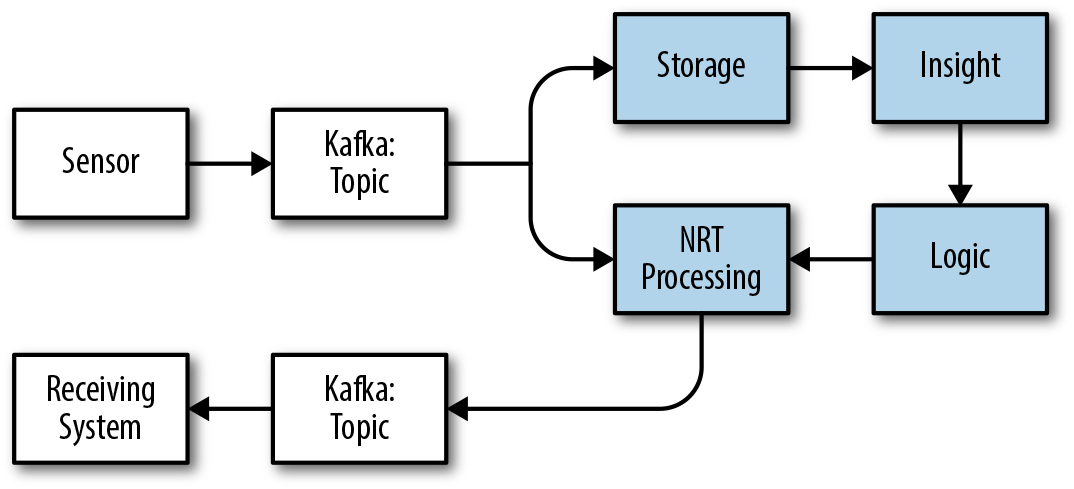
Figure 4-3. Data architecture compared to the PNS
Let’s take a minute and dig into each one of these systems and how they relate to the brain:
- Storage
-
Just as the brain has long-term and short-term memory, our data architecture has a number of data storage systems with different times to live (TTL). Additionally, our storage can be indexed in multiple ways, just as our brain uses different patterns to store and retrieve data.
- Insight
-
This can be compared to the reflective thought in our brains that processes input and applies analysis to drive decision-making processes. In data systems, this can be related to the analysis performed via tools like SQL and machine learning.
- Logic
-
Just as our brains arrive at decisions based on analysis of inputs and applying rules, our data systems will often have subsystems that serve the same functions.
- NRT processing
-
This can be related to the parts of the brain that react quickly to external stimuli and drive responses. There are even some actions that happen with so little thought we call them “muscle memory” actions. The more the logic is baked into the CNS, the faster the system can process responses to input. In our data systems, we can make a comparison to systems like stream-processing engines in which we can perform complex machine learning logic and make decisions with low-millisecond response times.
Senses
The input systems like eyes, skin, and ears help us gather information about the outside world. The actual perception of the world is done in the CNS, which leaves the sensory systems as decoupled systems focused only on information gathering. Additionally, these sensors use the PNS to distribute information.
In our data architectures, the equivalent to senses are anything that generates data. These could be agents on a node, systems that input application logs, or sensors in devices. In our diagram, these would be the sensors in the highlighted box shown in Figure 4-4 that feed information to our Kafka pipes.
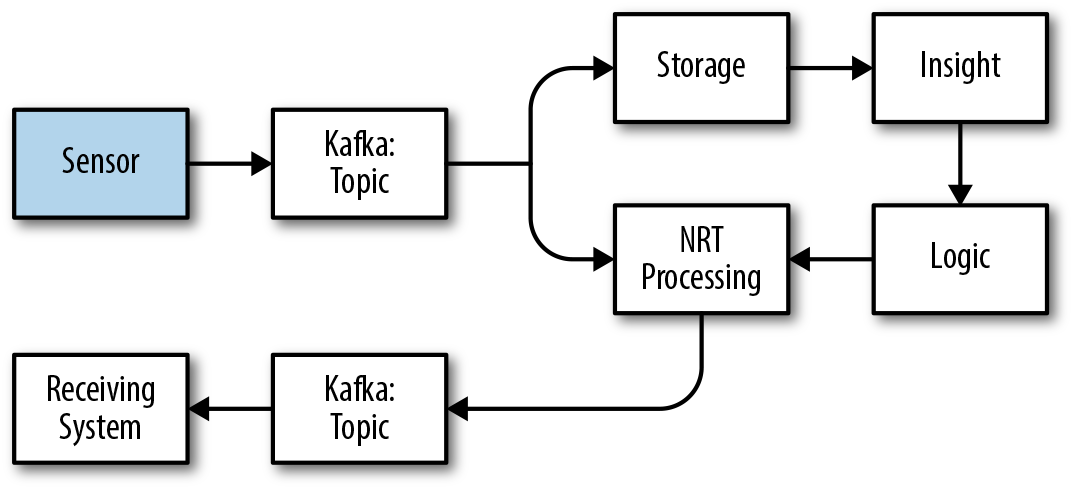
Figure 4-4. Data architecture compared to senses
Controllable systems
There are systems that can be controlled by communications sent through the PNS. Some of these systems are controlled through conscious thoughts and some via unconscious thoughts. These systems include muscles, heartbeats, and digestive functions.
In our data architecture, these are applications that process commands that are the outcome of data processing. A good example could be an application that customers interact with, and a command might be an instruction to lock down a person’s account because of fraud risk. In our diagram, controllable systems are those that receive inputs from Kafka pipes, as shown in the highlighted box in Figure 4-5.
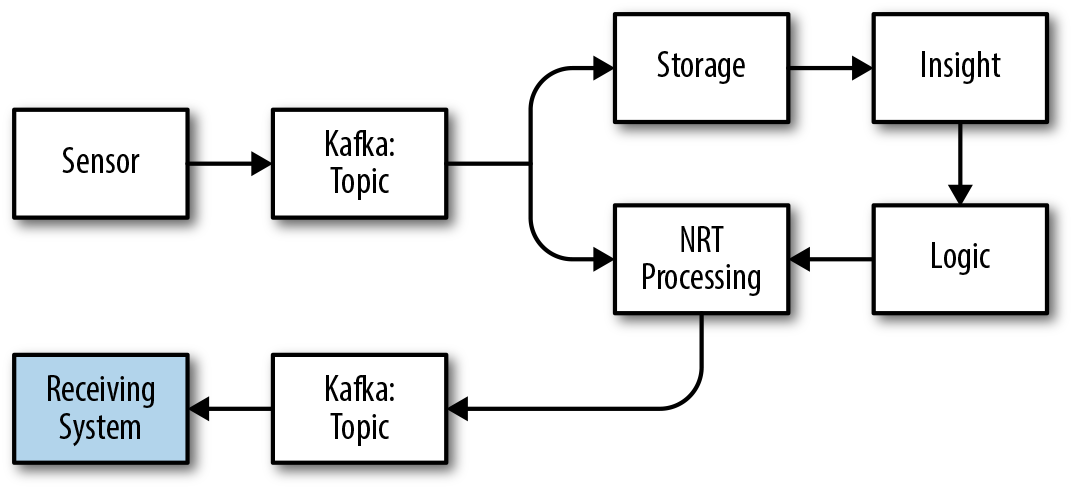
Figure 4-5. Data architecture compared to controllable systems
Human parts summary
Before we move on to more details of interface design, let’s reflect for a minute on the body-part example. The main point to understand is that we have different components that make up a larger system. These systems collect data, store it, process it, or react to it. With all this communication, it’s important that interfaces are clearly defined and agreed upon because the nature of these systems is that they are highly complex and operate independently. This means that they need to be decoupled in the correct ways. The same is true for complex data systems, so let’s talk in more detail about decoupling.
Decoupling
Decoupling is a common architectural pattern in designing complex systems—this allows components in a system to be independent by taking advantage of interfaces between systems. To draw a parallel with the human body, let’s consider the heart and the brain, as depicted in Figure 4-6. The brain is coupled (dependent) on the blood supplied by the heart, but not the heart itself. The heart could be replaced by a different “component”—for example, an artificial heart—without affecting the dependency that the brain has on blood flow. Thus the brain is coupled to the blood being pumped but not the system pumping the blood.
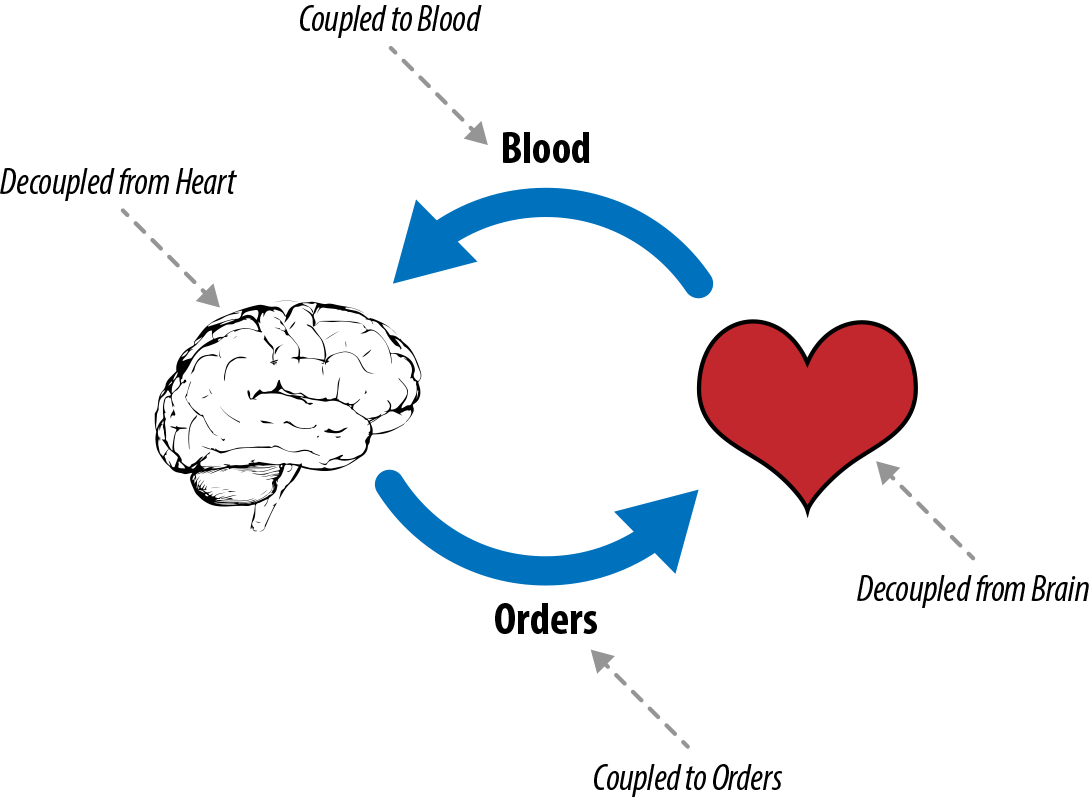
Figure 4-6. Decoupling in the human body
Decoupling applies itself throughout the human body, which is made up of trillions of cells and many subsystems. Subsystems in the body are commonly independent, with limited or no knowledge of the other components and how they work or what they are doing at any given moment; your heart knows nothing of your bladder, and your bladder is not concerned with the balancing sensors in the ear. The brain has a window of visibility into other systems but only through the messaging protocol that’s supported by the PNS. Even your brain is made up of parts that are decoupled from one another, each having its own regions and responsibilities.
Modern medicine is able to increasingly use our biology to do things like bypass broken spinal cords or send messages straight from implanted chips in the brain to robotic limbs or even real limbs reanimated through controlled electric stimulation. Experiments have given blind people limited sight by having a camera send signals back into the brain through an embedded chip.
In the example of the blind person given sight via a camera, the brain doesn’t know that the eyes have been replaced as the visual input system. The section of your brain that interprets visual information is interpreting the bits of information from the camera in a similar way as if it came from the eye.
In software architectures, this idea of decoupling systems through interface design is hugely important as a system grows and becomes increasingly complex. Good interface design will allow us to add, remove, and develop parts of our system without affecting the integrity of the system as a whole. When subsystems fail, we can bridge the gap and spin up new systems to replace them. And just like living organisms, decoupling in our architectures allows us to develop subsystems without disrupting the functioning of the entire system.
You can implement interface design in various ways: a distributed message system like Kafka, interfaces like Representational State Transfer (REST), public APIs, and message types like JSON, Avro, and Protobuffers.
To carry the parallels further, Kafka would be the transportation medium similar to the peripheral and central nervous systems, whereas JSON, Avro, and Protobuffers are the messages being sent through nerves. Figure 4-7 further illustrates this in a data system.

Figure 4-7. Decoupling with Kafka
Let’s walk through a couple of decoupling options with this Kafka architecture:
- Isolation
-
If system A stops working, it won’t break system B. System B will just wait until A comes back online. Also, a failure in system B doesn’t affect system A. This allows A and B to be tested independently from each other.
- Replay
-
If we have a failure in system B, we can use the interface and ability to replay from Kafka to try to re-create the problem. This is important not only for testing for failure, but also for validation that newer versions of system B react to the data as the old versions did.
- Extensible
-
This architecture allows us to add more systems that consume from topic Y1 without affecting system A1. This allows for architectures like that presented in Figure 4-8.
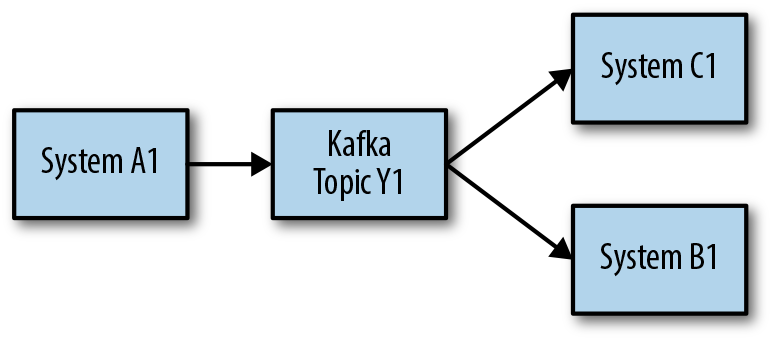
Figure 4-8. Extensibility with decoupled systems
Decoupling Considerations
As part of the work in creating artificial limbs, considerable research has gone into how the brain sends commands to other systems in the body; for example, instructing a hand to open or close. This process is illustrated in Figure 4-9. There was an idea before the research was done that maybe the brain sent detailed instructions to each muscle, but as scientists learned more, we now know that these commands sent from the brain are simply decoded near a specific system where more detailed actions are processed and executed. In the end, this process of sending messages to specific areas for decoding allows the brain to focus on more important things, whereas the individual systems can manage the details of executing commands. Over time these neural pathways can strengthen with repeated exposure to specific stimuli.
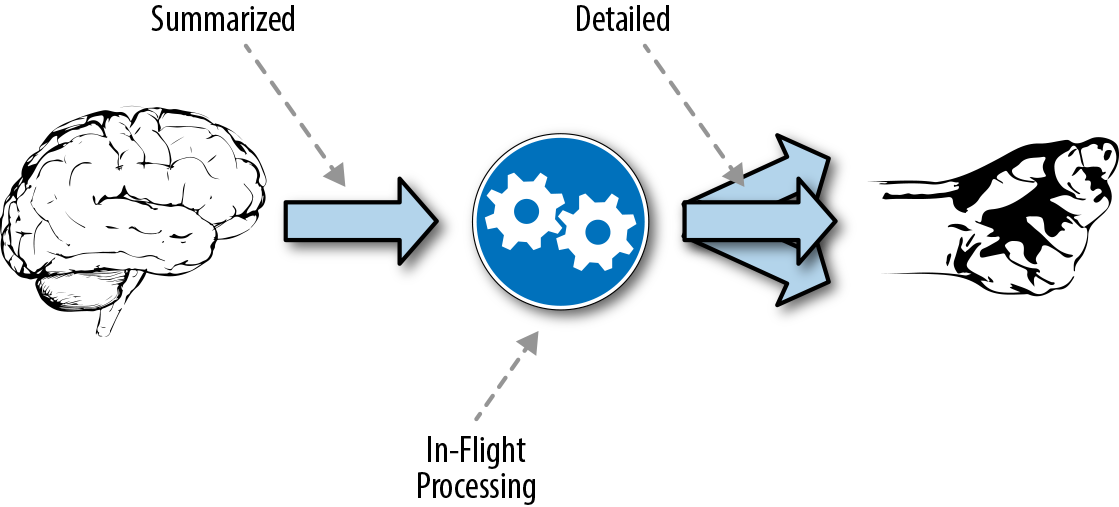
Figure 4-9. Decoupling in the human body
You can think of this concept as muscle memory. You will notice as you engage in repetitive actions such as sports or playing musical instruments that the practice leads to better performance and execution. Behind the scenes, you are optimizing operations and communications for certain instructions and building subroutines or models that execute the actions.
In the world of distributed data applications, we can see optimization and consolidation as the migration from ad hoc and batch processing to more real-time adaptive processing. Ad hoc and batch will always be present, but they should be there to get you closer to optimized processing. Just as with the body optimization allows you to do a task better, in the software architecture world, optimization can reduce SLAs, lead to better resource allocation, and facilitate more efficient processing. All of these can lead to better end-user experiences.
Specialization
The last area of the human body to consider is specialization. Consider the CNS and the brain specifically: the brain is made up of many subsystems, each with its unique region and responsibility. Some subsystems are for different types of storage, whereas some are for specific processing and access patterns.
Think about the storage systems in our brains. We have short-term memory, sensory memory, long-term memory, and implicit and explicit memory. Why so many memory types? The answer is there was an evolutionary benefit that each subsystem provided over having a generalized system. These various memory types most likely have different indexing strategies, flushing mechanisms, and aging-out/archiving processes. We find a parallel in software insomuch as we have different systems like relational databases, Lucene search engines, NoSQL stores, filesystems, block stores, distributed logs, and so forth that support different storage models and access patterns optimized for specific applications.
The same will go for our brain’s processing systems. Visual interpretation is very different from complex decision making. Like the brain, in software architecture there are different execution patterns and optimizations that are suited for different use cases: tools like SQL, Spark, Spark SQL, NoSQL APIs, search queries, and many, many more.
What Makes a Good Interface Design
After that abstract discussion about how certain components in the human body parallel those in software architecture, let’s examine what makes a good software interface design. You can consider interfaces to be the scaffolding of a large system—if you do it right, you can use your system for many years, changing it over time to meet the needs of many different use cases implemented by different technologies. If you do it wrong, it will be remembered as a poorly designed solution. Mastering interface design will be key to designing solid solutions.
The Contract
At the heart of a good interface definition is a contract between the implementers of the interface and the users of the interface. This contract must clearly define the inputs, outputs, and expected use and behavior of each function defined by the interface.
Whereas the functional specification is the core of an interface, secondary considerations are nonfunctional guarantees of the interface. In some cases we’ll want to define secondary considerations like expected availability, response times, throughput, and so on—in other words, the SLAs provided by the interface. We discuss these considerations later in the chapter.
The Abstraction
When defining an interface, note that we are building an abstraction over our system—users of the interface shouldn’t need to have visibility into the implementation of the system. This allows us to decouple our technology selections and concrete implementations from users of the system. Additionally, there are multiple options for how these interfaces are defined. Let’s look at a couple of these options.
Nonprogramming language interface
The most common example of a higher-level, nonprogramming language interface is a REST interface. Generally speaking, REST is a stateless client–server interface that is built on common standards such as HTTP and JSON.
REST allows for a simple way to provide an interface to a backend service and allows for making calls to that service without writing code—calls to the REST API can be made via a web browser or command line. This makes it easy to test calls and create simple clients to the service. It also makes it easy to create client interfaces in common programming languages such as Java, Python, and C++ in order to facilitate programmatic access to a service.
Generally, the inputs and outputs of a REST command are JSON, which is human readable (although some might argue with this), great for exploratory work, and well supported by common programming languages.
Code interface implementations
Although REST is a common and effective way to implement interfaces in a system, sometimes there are advantages to a more direct client layer implemented via a programming API. Consider a Kafka producer, which might involve partitioning, buffering, batching, and complex protocols. Although there is a Kafka REST interface, the Kafka API provides a richer and more performant interface to Kafka.
You should aim for your interface to be common around all the implementations you support. In addition, openness is important. If you are building a piece of code that is planned to be deployed in a product that you don’t own, it’s important to allow that team to have access to details of your implementation. This doesn’t necessarily need to be source code, but at a minimum this should include documentation, full interface definitions, and so on. In addition, by making the implementation open, you can get external help to flush out bugs, tune performance, and resolve issues.
Versioning
Versioning is important, particularly for interfaces heavily used by different applications. This includes backward compatibility. Note that backward compatibility is painful, requiring additional testing and planning, but it is important. There are a few ways to help counter this pain:
-
Make it easy to move to newer versions.
-
Change the API as infrequently as possible.
-
Be proactive about sharing information about deprecated calls and what’s supported and not supported in specific releases.
-
Strive to deliver regular release schedules. This will help your internal team determine when to deliver major functionality and facilitate the work of your interface’s consumers by providing predictable updates.
A great example of versioning gone wrong, and then right, is Kafka. In versions of Kafka before 0.10, if producers or consumers were on a different version than the brokers, bad things could happen. With the release of 0.10, clients would tell the Kafka broker which version they were on, and the broker would use that protocol for communication.
Barring a complete migration on every API change (which is not realistic at scale), a strong versioning solution should be designed up front, starting with the aforementioned recommendations.
Being Defensive
Although we’ve emphasized the need to create stable, user-friendly interfaces, it’s important to keep in mind that not all of the clients accessing your system are always friendly—either because of poorly implemented applications, maliciousness, or just problems in your design.
As a result, you must consider how others could use your interface to harm your system, and design safeguards for unexpected usage. Here are some common things to look for:
- Skew
-
If your system is a partitioned solution, skew can cause untold trouble for you—this is the case in which some partitions become much larger than other partitions. Look for skew and stop it before it causes disaster. Note that data skew is a potential problem that goes beyond the scope of this discussion, but it is still something to be mindful of when designing your interfaces.
- Load
-
A Denial-of-Service (DoS) attack, either inadvertent or malicious, can be disastrous for your system. Set up ways to look for load spikes and handle them.
- Odd input
-
If you make an input a string, assume that anything will be passed through. Think about past issues with SQL injection, or null values, or extremely large values. Make sure you validate all inputs to the system.
Documentation and Naming for Interfaces
Ideally, documentation for APIs is brief and to the point—good documentation should be concise and direct. If it takes a book to define your API, that could be a sign that your API is too complex. It should be the goal of any API or interface designer to create an interface so clear that documentation becomes unnecessary.
The documentation should focus on how this interface will behave, how to use the interface, and examples of use.
Important things to note in your documentation include the following:
-
What calls (functions) are provided by the interface.
-
Arguments to the calls defined by the interface, including formats, schemas, data types, and so on.
-
Outputs from calls, including detail on formats, schemas, data types, and so forth.
-
State requirements; for example, does the service maintain state or is this expected to be a stateless service?
-
Support and behavior in concurrent scenarios; for example, support for multiple requests.
-
Known failure cases/possible exceptions.
Similarly, naming of functions should be simple and explanatory. Ideally, the purpose of the function should be clear from the name and parameters.
Try to avoid putting technology solutions in the function name or definition. Think more of the function as being a verb. Let’s take a real-world example and relate that to our computer-world example.
Our example function will be the call goToLocation(locationId:String). In the real world, if we called goToLocation("Market"), we could implement this with walking, driving, bicycling, and so on. However, we don’t put any of that in the function name. All that the function and the users using the function need to know is the action (verb) the function is performing.
There’s a joke that naming is one of the most difficult things to do in software development. The best rule of thumb that we have found to reduce the time naming takes is to copy the style of a respected project in the same ecosystem. This provides two advantages:
-
It provides a guideline to follow.
-
It provides an external objective reference to back up your decisions.
In the end, know that no matter how hard you try to design something, you will look back on it in a year or two and see things you wished you’d done better. It is just the nature of our world. Aiming for simple and repeatable is most likely your best bet.
Nonfunctional Considerations
As noted in the previous section, there are secondary, nonfunctional considerations to take into account when designing your interface. These include things like guarantees around availability of the system, response times of the system, and throughput. We’ll explore these considerations in this section.
Availability
All interfaces will specify a functional contract, but interfaces that define access to services or that interact with an external system might also need to specify the availability contracts. If the interface is defining the contract for a library that’s loaded locally to a program, defining availability would be irrelevant. However, if the interface is for an external service, providing a clear contract for when the service is available and the level of guarantee for service availability becomes much more important.
Think of this as the hours of business for a given service and the level of guarantee a customer has to which those hours are going to be committed. In a real-world example, we can compare the hours of a supermarket and a movie theater. Both will have hours of operation: suppose for the supermarket it is 6:00 A.M. to 10:00 P.M., and the movie theater is 10:00 A.M. to midnight.
Given these stated hours, we have some level of knowledge of which hours the supermarket and the movie theater will be open. However, things can happen that disrupt these expected hours; for example, during a heavy snowstorm the movie theater might shut down, whereas the supermarket remains open. In these cases, we can reasonably have an expectation that the supermarket holds itself to a higher guarantee level than the movie theater.
So, the takeaway here is that we need to provide two definitions of availability: the first is when the service will be available, and the second is the level of guarantee for those availability times.
You might be saying, “In the computer world, shouldn’t my services always be available?” Let’s look at examples of different availability levels:
- Scheduled maintenance windows
-
It’s common for a service to have a scheduled period during which the service is unavailable in order to allow for maintenance tasks to the service such as performing software upgrades, applying patches, and swapping out hardware.
- Only during specific hours
-
Some services may need to be available only within certain defined hours; for example, a service that’s expected to be accessed only during business hours. With the introduction of the cloud and the ability to start and stop services with a push of a button, it becomes practical (and economical) to provide availability for services only during these limited hours.
In addition to these expected availability windows, numerous things can disrupt availability such as hardware failures, network failures, and cloud outages. For these reasons, it’s impossible to promise 100% uptime during the documented availability windows, although there are ways to increase the level of confidence in the uptime percentage, including the following:
-
Utilizing components that are resilient to failure. Most of the systems discussed throughout this book as components in a big data application are designed for high availability and resistance to failure. For example, Kafka provides a data integration solution that’s designed to be scalable, replicated, and highly available. When deployed properly, Kafka provides a very resilient data integration layer. Similarly, other systems in the big data ecosystem can provide these types of resilience in other layers of our architectures, such as storage and processing.
-
Building redundancy into the system. Even the most resilient distributed system can fail, which is why having backup systems becomes crucial in mission-critical systems. This is a complex topic, and the mechanism to achieve redundancy will vary with different systems. Refer to vendor or project documentation for recommendations and details on how to deploy those systems in order to ensure you have the necessary levels of availability.
-
Using testing, including load testing and failure testing. We discuss this more in the section “Using Testing to Determine SLAs”.
Response-Time Guarantees
Like availability, response times are never perfect. Things like system failures, garbage collection, network latency, and more can affect response times of a service.
We should aim to give our users a tested and confirmed set of guarantees based on percentage of time; for example:
-
Response times of 10 milliseconds 95% of the time
-
Response times of 50 milliseconds 99% of the time
-
Response times of 1,000 milliseconds 99.99% of the time
Note that an advantage of using interfaces is that you can enhance the availability and response times of an implementation over time without disrupting clients using the system. It’s critical, though, that you have a testing framework in place to perform load testing of the system with every release to ensure adherence to your contracts.
Load Capacity
Load capacity defines how many requests can be handled in a given time period, and the limitations to scaling. Again, we don’t talk about how we provide these load guarantees in our contract; instead, we include a promise of what level of load capacity we will be offering. Just like availability and response time, we need to give detailed promises to our interface users. Here’s an example:
When under 100,000 requests a second:
-
Response times of 10 milliseconds 95% of the time
-
Response times of 50 milliseconds 99% of the time
-
Response times of 1,000 milliseconds 99.99% of the time
When between 100,000 and 200,000 requests a second:
-
Response times of 20 milliseconds 95% of the time
-
Response times of 100 milliseconds 99% of the time
-
Response times of 2,000 milliseconds 99.99% of the time
-
Not recommended beyond 200,000 requests a second
It’s recommended to keep these load definitions simple and, as appropriate, call out any specific limitations. As with availability and response times, you’ll have to load test on every release at a minimum and closely monitor activity in your production systems.
Using Testing to Determine SLAs
Regardless of your architecture and component selection, the only way to truly determine the guarantees that you can make around availability and response times is to test the system. You need to do this testing in the target deployment environment, using real-world data and under expected loads.
For example, if you claim in your interface that your system is safe from node failure, you should test random node failures on a regular basis in both your test and production systems. This type of testing in production might raise concerns—if so, this might reflect a lack of confidence in your system’s ability to recover, and in turn indicates a need to put more thought into your system’s failure recovery capabilities.
Without testing and simulating failure in a system, you know only in theory how it will handle failures. If your system is said to handle a node failure, no one should be paged at 3 A.M. when a node fails. Such failures need to be an expected occurrence, with self-healing mechanisms.
Common Interface Examples
Now that we have covered what makes a good interface design, let’s look at some common architectural patterns that are used in creating system interfaces.
Publish–Subscribe
The first pattern we’ll talk about is the common publish–subscribe (pub–sub) example, shown in Figure 4-10. In this implementation, we have components that publish messages to a central messaging system (broker), and components that subscribe to specific queues on the broker.
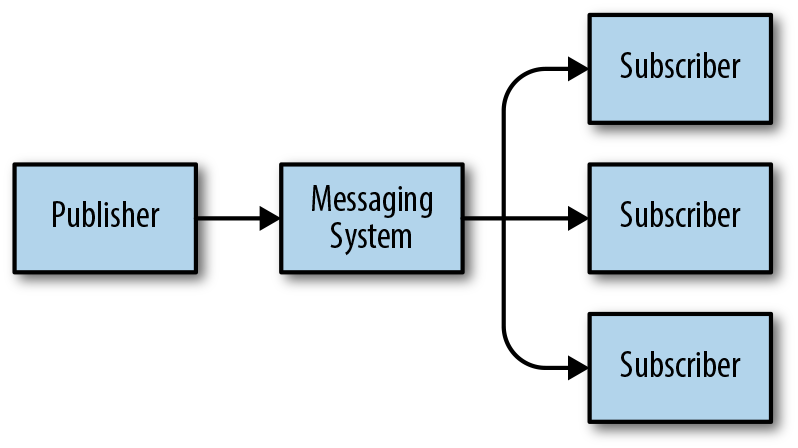
Figure 4-10. Pub–sub system
The central idea here is that the publisher on the left side need not care about anything going on with the subscribers on the right side. Publishers need to worry only about sending messages with content that matches what’s defined by the interface. These publishers don’t care who reads the messages or what those readers do with the messages.
In the context of application development, the pub–sub pattern allows components to be developed in isolation. Consider Figure 4-11. In this case, development on the subscribers is complete, but work on the publisher is still in progress. In this case, you can create a mock publisher, which allows development and testing to continue, avoiding disruption to the development schedule.
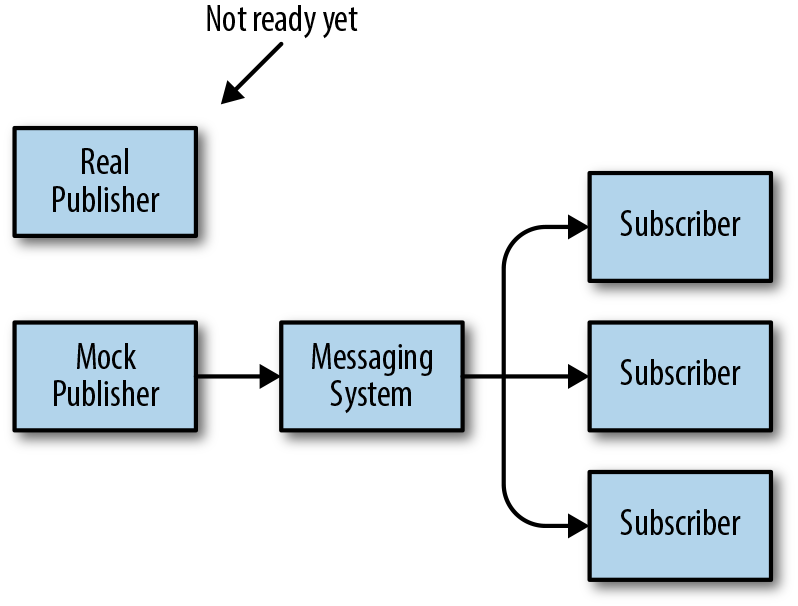
Figure 4-11. Decoupling with pub–sub systems
Enterprise Service Bus
Somewhat similar to the pub–sub model, but generally at a larger scale, is an Enterprise Service Bus (ESB) architecture. An ESB architecture will most likely have the following features:
- Transport layer
-
There is a requirement for a reliable, scalable pipe to accept messages and deliver them to one or more destination(s).
- Publishers
-
There are a number of systems that publish events to a network of topics on the message bus.
- Consumers
-
There are systems that listen to and consume messages.
- Workflow
-
There could be systems with workflow logic that can take an event and update state or determine what additional actions need to happen or whether additional events need to be fired.
- Asynchronous requests
-
There could also be a good deal of asynchronous request patterns used. We look at that pattern in the next subsection.
- Dashboards
-
There most likely is a dashboarding system that is in place that can monitor the state of the ESB and the state of all systems publishing to it.
ESBs were popular for a time in the earlier 2000s. However, there were issues around scale and coordination within an organization. It wasn’t until the success of Kafka and a centralized schema repository that the ESB concept made a comeback.
Request–Response Asynchronous Example
We’ve discussed the pub–sub model, which is a one-way interface, but what if we need to give responses back to requests? This will be the first example of a request–response interface, in this case an asynchronous model, versus a synchronous model that is discussed in the next section.
Before we begin looking at the example, let’s consider when an asynchronous request–response model is something we want to consider:
-
We want to request some information from a component.
-
We don’t have hard latency requirements on when the response should be returned to us.
-
Duplicate responses are acceptable.
-
We’re aware of resource requirements for this architecture; for example, memory requirements to persist maps of requests and message queues.
If this is a fit for your use case, an example architecture might look like that shown in Figure 4-12.
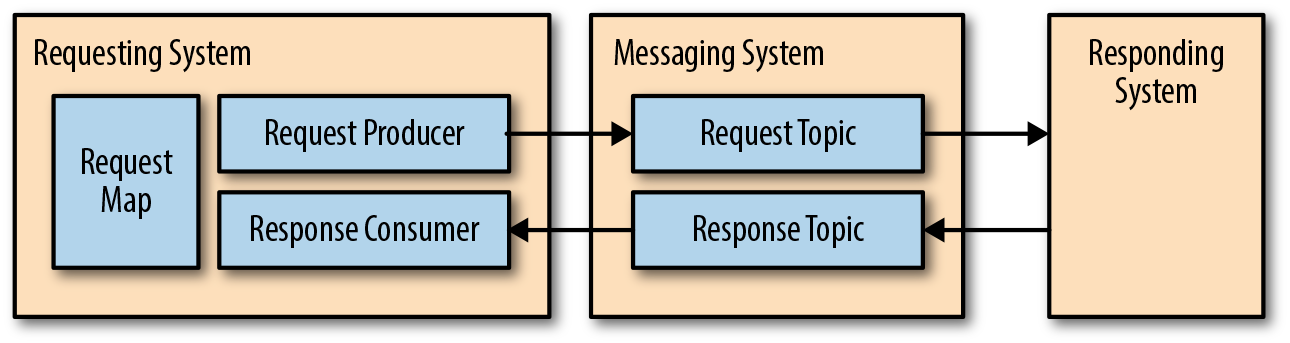
Figure 4-12. Asynchronous request–response architecture
Let’s look at some of the components in the diagram:
- Requesting system
-
This is simply the system that is making requests.
- Request map
-
This is a data structure that maintains the list of requests that have been submitted and are awaiting a response. The request map will consume memory for every outstanding request, which means that there’s a limit to the number of outstanding requests that can be stored based on memory constraints.
- Request producer
-
This is the component that sends requests along with a key (for use in indexing the request map) to the messaging system.
- Request topic
-
This is a dedicated queue for the requests being sent out. This topic can be shared with other requests, but note that it would be wise to balance the use of this topic with throughput and response times. Also, any request in this topic should be going to the same responding system.
- Responding system
-
This is a system that takes a given request and returns an answer. Ideally, this system has no state itself but can work with stateful systems.
- Response topic
-
This is the queue for response messages. The important thing to note is the number of requesting systems assigned to a given response topic. The more requesting systems assigned to a given response topic, the more responses will have to be dropped by a specific requesting system because it doesn’t need the responses intended for other requesting systems.
- Response consumer
-
This is the consumer that is listening to the response topic and will be using the request map to link responses back to the original thread that requested the information. If the request is not in the request map, that response has already been processed or the response was meant for another requesting system but used the same response topic.
The big advantage with this type of interface design is that it allows us to decouple the processing of the request from the response and gives the responder flexibility in terms of time constraints to return results back to the requester.
This is normally a good solution for requests that take a long time (many seconds to hours) to process. However, this doesn’t mean that you can’t use it for more real-time solutions. Suppose that you use Kafka as the queue along with some basic processing before returning a response. In this case, you could be looking at a couple to tens of milliseconds of latency round-trip, depending on the system being queried.
Request–Response Synchronous Example
The last interface design we explore is a request–response interaction that is synchronous and has a tight SLA for response times. In this model, we don’t need any queues; instead, we need only old-fashioned web servers. In this model, shown in Figure 4-13, we have the requesting system that sends a request and then simply waits for the answering system to return a reply. As you can see, this request and response happens in a single transaction, which can provide advantages in terms of response guarantees, reduction of latency, and removing the need to consider the possibility of duplicate responses.
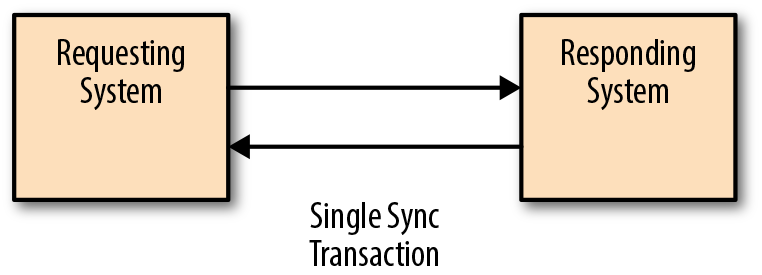
Figure 4-13. Synchronous request–response architecture
This can present challenges in terms of scaling because network bandwidth, hardware resources, and so on could affect response times and the number of requests that can be processed. This also presents challenges for the cases in which the answering system is unavailable. If we are worried about web servers going down or load, we can support multiple systems that are behind a load balancer with a virtual IP address, as shown in Figure 4-14. This is basically the architecture that supports many web applications.
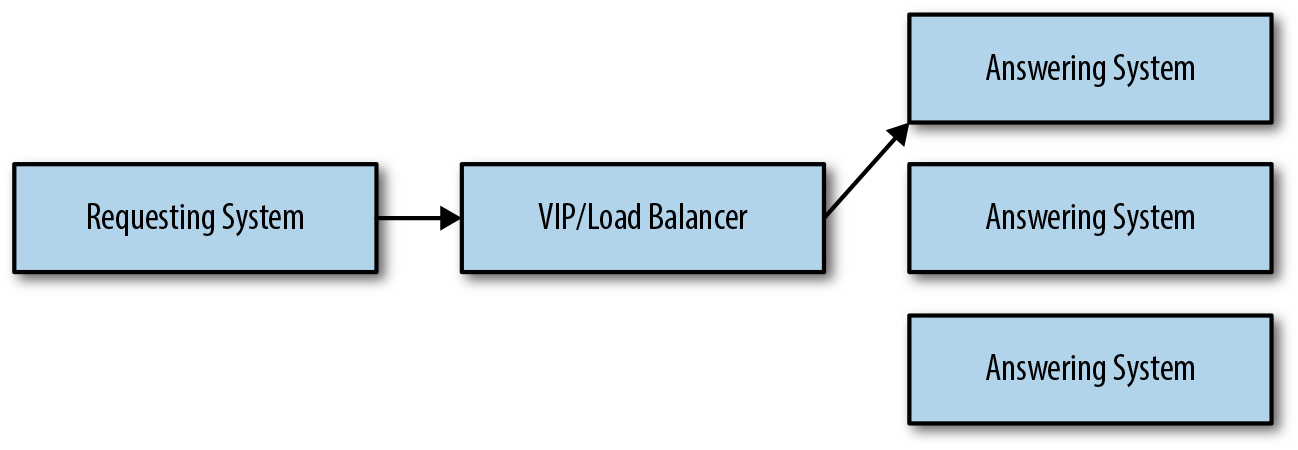
Figure 4-14. Scaling synchronous request–response architectures
Summary
Just like the human body, scalable and maintainable software architectures rely on interfaces and abstractions. Well-designed abstractions allow us to decouple concrete implementation decisions from overall architectures. This decoupling facilitates the development process by allowing us to create mock implementations of services and shields us from implementation changes within systems.
There are a number of ways in which we can implement our interfaces, such as standard APIs, REST interfaces, and publish–subscribe systems. The choice of how to design your interface should be influenced by your architecture and requirements; for example, if your system is a straightforward Java application, defining Java APIs might be sufficient. Alternatively, if you need to allow for access from multiple languages or external hosts, a REST interface becomes a more likely solution.
In addition to the functional interface design, you also need to be mindful of nonfunctional requirements. These considerations include defining the availability of services that implement the interface, and response times and throughput for the services.
Finally, there are several architectural models to consider when creating system interfaces, including publish–subscribe systems, and synchronous and asynchronous request–response systems.
Get Foundations for Architecting Data Solutions now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

