Kapitel 1. Schema und Typen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Unter müssen wir zunächst definieren, welche Daten unsere Tabellen enthalten, wie diese Daten miteinander verknüpft sind und welche Beschränkungen für diese Daten gelten.
Unter benötigt SQLAlchemy eine Darstellung der Tabellen, die in der Datenbank vorhanden sein sollen, um den Zugriff auf die zugrunde liegende Datenbank zu ermöglichen. Das können wir auf drei Arten tun:
-
Benutzerdefinierte Objekte verwenden
Table -
Deklarative Klassen verwenden, die deine Tabellen repräsentieren
-
Sie aus der Datenbank ableiten
Dieses Kapitel konzentriert sich auf die erste Option, da dies der Ansatz ist, der in SQLAlchemy Core verwendet wird; die anderen beiden Optionen werden wir in späteren Kapiteln behandeln, nachdem wir die Grundlagen verstanden haben. Die Table Objekte enthalten eine Liste typisierter Spalten und ihrer Attribute, die mit einem gemeinsamen Metadaten-Container verbunden sind. Wir beginnen unsere Erkundung der Schemadefinitionen mit einem Blick auf die Typen, die für die Erstellung von Tabellen in SQLAlchemy verfügbar sind.
Typen
gibt es vier Kategorien von Typen, die wir in SQLAlchemy verwenden können:
-
Generische
-
SQL-Standard
-
Anbieterspezifisch
-
Benutzerdefiniert
SQLAlchemy definiert eine große Anzahl von generischen Typen, die von den tatsächlichen SQL-Typen, die von jeder Backend-Datenbank unterstützt werden, abstrahiert sind. Diese Typen sind alle im Modul sqlalchemy.types verfügbar, und der Einfachheit halber sind sie auch im Modul sqlalchemy verfügbar. Überlegen wir uns also, wie nützlich diese generischen Typen sind.
Der generische Typ Boolean verwendet in der Regel den SQL-Typ BOOLEAN und steht auf der Python-Seite für true oder false. Bei Backend-Datenbanken, die den Typ BOOLEAN nicht unterstützen, verwendet er jedoch auch SMALLINT. Dank SQLAlchemy bleibt dieses kleine Detail vor dir verborgen und du kannst dich darauf verlassen, dass alle Abfragen oder Anweisungen, die du erstellst, unabhängig vom verwendeten Datenbanktyp korrekt mit Feldern dieses Typs arbeiten. Du musst in deinem Python-Code nur mit true oder false umgehen. Diese Art von Verhalten macht die generischen Typen sehr mächtig und nützlich bei Datenbankübergängen oder geteilten Backend-Systemen, bei denen das Data Warehouse ein Datenbanktyp und die Transaktionsdatenbank ein anderer ist. Die generischen Typen und ihre zugehörigen Darstellungen in Python und SQL sind in Tabelle 1-1 zu sehen: .
| SQLAlchemy | Python | SQL |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Hinweis
Es ist wichtig, diese generischen Typen zu lernen, denn du wirst sie regelmäßig verwenden und definieren müssen.
Zusätzlich zu den in Tabelle 1-1 aufgelisteten generischen Typen stehen sowohl SQL-Standardtypen als auch herstellerspezifische Typen zur Verfügung. Sie werden häufig verwendet, wenn ein generischer Typ aufgrund seines Typs oder des in einem bestehenden Schema angegebenen spezifischen Typs nicht wie gewünscht im Datenbankschema funktioniert. Ein gutes Beispiel hierfür sind die Typen CHAR und NVARCHAR, die von der Verwendung des richtigen SQL-Typs anstelle des generischen Typs profitieren. Wenn wir mit einem Datenbankschema arbeiten, das vor der Verwendung von SQLAlchemy definiert wurde, sollten wir die Typen genau abgleichen. Es ist wichtig, daran zu denken, dass das Verhalten und die Verfügbarkeit von SQL-Standardtypen von Datenbank zu Datenbank unterschiedlich sein können. Die SQL-Standardtypen sind im Modul sqlalchemy.types verfügbar. Um sie von den generischen Typen zu unterscheiden, werden die Standardtypen in Großbuchstaben geschrieben.
Die herstellerspezifischen Typen sind genauso nützlich wie die SQL-Standardtypen; sie sind jedoch nur in bestimmten Backend-Datenbanken verfügbar. Welche Typen verfügbar sind, kannst du in der Dokumentation des gewählten Dialekts oder auf der Website von SQLALchemy nachlesen. Sie sind im Modul sqlalchemy.dialects verfügbar und es gibt Untermodule für jeden Datenbankdialekt. Auch hier sind die Typen in Großbuchstaben geschrieben, um sie von den generischen Typen zu unterscheiden. Vielleicht möchten wir die Vorteile des leistungsstarken JSON-Feldes von PostgreSQL nutzen, was wir mit der folgenden Anweisung tun können:
fromsqlalchemy.dialects.postgresqlimportJSON
Jetzt können wir JSON-Felder definieren, die wir später mit den vielen PostgreSQL-spezifischen JSON-Funktionen, wie z.B. array_to_json, innerhalb unserer Anwendung verwenden können.
Du kannst auch benutzerdefinierte Typen definieren, die bewirken, dass die Daten auf eine von dir gewählte Weise gespeichert werden. Ein Beispiel dafür wäre, dass dem Text in einer VARCHAR Spalte Zeichen vorangestellt werden, wenn er in den Datenbankdatensatz eingegeben wird, und dass sie entfernt werden, wenn das Feld aus dem Datensatz abgerufen wird. Das kann nützlich sein, wenn du mit Altdaten arbeitest, die noch von bestehenden Systemen verwendet werden, die diese Art der Voranstellung vornehmen, die in deiner neuen Anwendung nicht nützlich oder wichtig ist.
Nachdem wir nun die vier verschiedenen Typen kennengelernt haben, die wir zum Aufbau von Tabellen verwenden können, wollen wir uns ansehen, wie die Datenbankstruktur durch die Metadaten zusammengehalten wird.
Metadaten
Metadaten werden verwendet, um die Datenbankstruktur so zusammenzubinden, dass innerhalb von SQLAlchemy schnell auf sie zugegriffen werden kann. Es ist oft nützlich, sich die Metadaten als eine Art Katalog von Table Objekten mit optionalen Informationen über die Engine und die Verbindung vorzustellen. Auf diese Tabellen kann über ein Wörterbuch zugegriffen werden, MetaData.tables. Lesevorgänge sind thread-sicher, der Aufbau von Tabellen ist jedoch nicht vollständig thread-sicher. Die Metadaten müssen importiert und initialisiert werden, bevor Objekte mit ihnen verknüpft werden können. Initialisieren wir eine Instanz der MetaData Objekte, die wir in den restlichen Beispielen dieses Kapitels verwenden können, um unseren Informationskatalog zu speichern:
fromsqlalchemyimportMetaDatametadata=MetaData()
Sobald wir eine Möglichkeit haben, die Datenbankstruktur festzuhalten, können wir anfangen, Tabellen zu definieren.
Tische
Table Objekte werden in SQLAlchemy Core in einem mitgelieferten MetaData Objekt initialisiert, indem der Table Konstruktor mit dem Tabellennamen und den Metadaten aufgerufen wird; alle zusätzlichen Argumente werden als Spaltenobjekte angenommen. Es gibt auch einige zusätzliche Schlüsselwortargumente, die Funktionen ermöglichen, die wir später besprechen werden. Spaltenobjekte repräsentieren jedes Feld in der Tabelle. Die Spalten werden durch den Aufruf von Column mit einem Namen, einem Typ und Argumenten, die zusätzliche SQL-Konstrukte und Einschränkungen darstellen, erstellt. Im weiteren Verlauf dieses Kapitels werden wir eine Reihe von Tabellen erstellen, die wir in Teil I verwenden werden. In Beispiel 1-1 erstellen wir eine Tabelle, in der wir den Bestand an Keksen für unseren Online-Kekslieferdienst speichern können.
Beispiel 1-1. Instanziierung von Tabellenobjekten und Spalten
fromsqlalchemyimportTable,Column,Integer,Numeric,String,ForeignKeycookies=Table('cookies',metadata,Column('cookie_id',Integer(),primary_key=True),Column('cookie_name',String(50),index=True),Column('cookie_recipe_url',String(255)),Column('cookie_sku',String(55)),Column('quantity',Integer()),Column('unit_cost',Numeric(12,2)))
Beachte, wie wir diese Spalte als Primärschlüssel der Tabelle markiert haben. Mehr dazu in einer Sekunde.
Wir erstellen einen Index der Cookie-Namen, um die Abfragen in dieser Spalte zu beschleunigen.

Dies ist eine Spalte, die mehrere Argumente, Länge und Genauigkeit, benötigt, z.B. 11.2, was uns Zahlen mit bis zu 11 Stellen und zwei Nachkommastellen liefern würde.
Bevor wir uns näher mit Tabellen befassen, müssen wir ihre grundlegenden Bausteine verstehen: die Spalten.
Rubriken
Spalten definieren die Felder, die in unseren Tabellen vorhanden sind, und sie stellen das primäre Mittel dar, mit dem wir andere Beschränkungen durch ihre Schlüsselwortargumente definieren. Verschiedene Spaltentypen haben unterschiedliche Primärargumente. Spalten vom Typ String haben zum Beispiel die Länge als primäres Argument, während Zahlen mit einer Bruchkomponente die Genauigkeit und die Länge haben. Die meisten anderen Typen haben keine primären Argumente.
Hinweis
Manchmal wirst du Beispiele sehen, die nur String Spalten ohne eine Länge anzeigen, die das Hauptargument ist. Dieses Verhalten wird nicht allgemein unterstützt - MySQL und einige andere Datenbank-Backends lassen es zum Beispiel nicht zu.
Spalten können auch einige zusätzliche Schlüsselwortargumente haben, die ihr Verhalten noch weiter beeinflussen. Wir können Spalten als erforderlich kennzeichnen und/oder erzwingen, dass sie eindeutig sind. Wir können auch Standardwerte für den Anfang festlegen und die Werte ändern, wenn der Datensatz aktualisiert wird. Ein häufiger Anwendungsfall hierfür sind Felder, die angeben, wann ein Datensatz zu Protokollierungs- oder Prüfungszwecken erstellt oder aktualisiert wurde. Schauen wir uns diese Schlüsselwortargumente in Beispiel 1-2 in Aktion an.
Beispiel 1-2. Eine andere Tabelle mit mehr Spaltenoptionen
fromdatetimeimportdatetimefromsqlalchemyimportDateTimeusers=Table('users',metadata,Column('user_id',Integer(),primary_key=True),Column('username',String(15),nullable=False,unique=True),Column('email_address',String(255),nullable=False),Column('phone',String(20),nullable=False),Column('password',String(25),nullable=False),Column('created_on',DateTime(),default=datetime.now),Column('updated_on',DateTime(),default=datetime.now,onupdate=datetime.now))
Hier machen wir diese Spalte erforderlich (
nullable=False) und verlangen auch einen eindeutigen Wert.Die Standardeinstellung setzt diese Spalte auf die aktuelle Zeit, wenn kein Datum angegeben ist.
Wenn du hier
onupdateverwendest, wird diese Spalte jedes Mal auf die aktuelle Zeit zurückgesetzt, wenn ein Teil des Datensatzes aktualisiert wird.
Vorsicht
Du wirst feststellen, dass wir default und onupdate auf die Callable datetime.now gesetzt haben und nicht auf den Funktionsaufruf selbst, datetime.now(). Hätten wir den Funktionsaufruf selbst verwendet, wäre der Standardwert der Zeitpunkt, zu dem die Tabelle zum ersten Mal instanziiert wurde. Durch die Verwendung der Callable erhalten wir die Zeit, zu der jeder einzelne Datensatz instanziiert und aktualisiert wird.
Wir haben die Schlüsselwortargumente für Spalten verwendet, um Tabellenkonstrukte und Beschränkungen zu definieren. Es ist jedoch auch möglich, sie außerhalb eines Column Objekts zu deklarieren. Das ist wichtig, wenn du mit einer bestehenden Datenbank arbeitest, denn du musst SQLAlchemy das Schema, die Konstrukte und die Beschränkungen mitteilen, die in der Datenbank vorhanden sind. Wenn du zum Beispiel einen Index in der Datenbank hast, der nicht dem Standard-Indexbenennungsschema entspricht, das SQLAlchemy verwendet, musst du diesen Index manuell definieren. Die folgenden beiden Abschnitte zeigen dir, wie du genau das machst.
Hinweis
Alle Befehle in "Schlüssel und Beschränkungen" und "Indizes" sind Teil des Table Konstruktors oder werden der Tabelle über spezielle Methoden hinzugefügt. Sie werden persistiert oder den Metadaten als eigenständige Anweisungen beigefügt.
Schlüssel und Beschränkungen
Schlüssel und Beschränkungen werden verwendet, um sicherzustellen, dass unsere Daten bestimmte Anforderungen erfüllen, bevor sie in der Datenbank gespeichert werden. Die Objekte, die Schlüssel und Einschränkungen repräsentieren, befinden sich im SQLAlchemy-Basismodul, und drei der gängigsten können wie folgt importiert werden:
fromsqlalchemyimportPrimaryKeyConstraint,UniqueConstraint,CheckConstraint
Der gebräuchlichste Schlüsseltyp ist der Primärschlüssel, der als eindeutiger Bezeichner für jeden Datensatz in einer Datenbanktabelle verwendet wird und dazu dient, eine korrekte Beziehung zwischen zwei zusammengehörigen Daten in verschiedenen Tabellen sicherzustellen. Wie du bereits in Beispiel 1-1 und Beispiel 1-2 gesehen hast, kann eine Spalte einfach mit dem Schlüsselwort primary_key zum Primärschlüssel gemacht werden. Du kannst auch zusammengesetzte Primärschlüssel definieren, indem du die Einstellung primary_key an True für mehrere Spalten zuweist. Der Schlüssel wird dann im Wesentlichen wie ein Tupel behandelt, in dem die als Schlüssel markierten Spalten in der Reihenfolge vorhanden sind, in der sie in der Tabelle definiert wurden. Primärschlüssel können auch nach den Spalten im Tabellenkonstruktor definiert werden, wie der folgende Ausschnitt zeigt. Du kannst mehrere durch Kommas getrennte Spalten hinzufügen, um einen zusammengesetzten Schlüssel zu erstellen. Wenn wir den Schlüssel explizit definieren wollten, wie in Beispiel 1-2 gezeigt, würde er so aussehen:
PrimaryKeyConstraint('user_id',name='user_pk')
Eine weitere gängige Einschränkung ist die eindeutige Einschränkung, mit der sichergestellt wird, dass keine zwei Werte in einem bestimmten Feld doppelt vorhanden sind. Für unseren Online-Cookie-Lieferservice möchten wir zum Beispiel sicherstellen, dass jeder Kunde einen eindeutigen Benutzernamen hat, um sich in unser System einzuloggen. Wir können den Spalten auch eindeutige Einschränkungen zuweisen, wie in der Spalte "Benutzername" gezeigt, oder wir können sie manuell definieren, wie hier gezeigt:
UniqueConstraint('username',name='uix_username')
Die in Beispiel 1-2 nicht gezeigte ist eine Prüfbeschränkung. Diese Art von Einschränkung wird verwendet, um sicherzustellen, dass die für eine Spalte gelieferten Daten mit einer Reihe von benutzerdefinierten Kriterien übereinstimmen. Im folgenden Beispiel stellen wir sicher, dass unit_cost niemals kleiner als 0,00 sein darf, weil jeder Keks in der Herstellung etwas kostet (erinnere dich an den Wirtschaftskurs 101: TINSTAAFC - es gibt keine kostenlosen Kekse!):
CheckConstraint('unit_cost >= 0.00',name='unit_cost_positive')
Zusätzlich zu den Schlüsseln und Beschränkungen möchten wir vielleicht auch die Suche nach bestimmten Feldern effizienter gestalten. Hier kommen die Indizes ins Spiel.
Indizes
Indizes werden verwendet, um die Suche nach Feldwerten zu beschleunigen. In Beispiel 1-1 haben wir einen Index für die Spalte cookie_name erstellt, weil wir wissen, dass wir oft nach dieser Spalte suchen werden. Wenn Indizes wie in diesem Beispiel erstellt werden, hast du einen Index namens ix_cookies_cookie_name. Wir können einen Index auch mit einer expliziten Konstruktionsart definieren. Mehrere Spalten können durch ein Komma voneinander getrennt werden. Du kannst auch ein Schlüsselwortargument von unique=True hinzufügen, damit der Index auch eindeutig ist. Wenn du Indizes explizit erstellst, werden sie nach den Spalten an den Table Konstruktor übergeben. Um den in Beispiel 1-1 erstellten Index zu imitieren, können wir ihn explizit erstellen, wie hier gezeigt:
fromsqlalchemyimportIndexIndex('ix_cookies_cookie_name','cookie_name')
Wir können auch funktionale Indizes erstellen, die sich je nach verwendeter Backend-Datenbank ein wenig unterscheiden. So kannst du einen Index für Situationen erstellen, in denen du häufig Abfragen auf der Grundlage eines ungewöhnlichen Kontexts durchführen musst. Was wäre zum Beispiel, wenn wir nach der SKU eines Kekses und seinem Namen als verbundenes Element suchen wollen, z. B. SKU0001 Chocolate Chip? Wir könnten einen Index wie diesen definieren, um diese Suche zu optimieren:
Index('ix_test',mytable.c.cookie_sku,mytable.c.cookie_name))
Jetzt ist es an der Zeit, in den wichtigsten Teil der relationalen Datenbanken einzutauchen: Tabellenbeziehungen und wie man sie definiert.
Beziehungen und ForeignKeyConstraints
Jetzt wir eine Tabelle mit Spalten mit den richtigen Beschränkungen und Indizes haben, schauen wir uns an, wie wir Beziehungen zwischen den Tabellen erstellen. Wir brauchen eine Möglichkeit, Bestellungen zu verfolgen, einschließlich der Einzelposten, die für jeden Keks und die bestellte Menge stehen. In Abbildung 1-1 siehst du, wie diese Tabellen miteinander verknüpft sind.
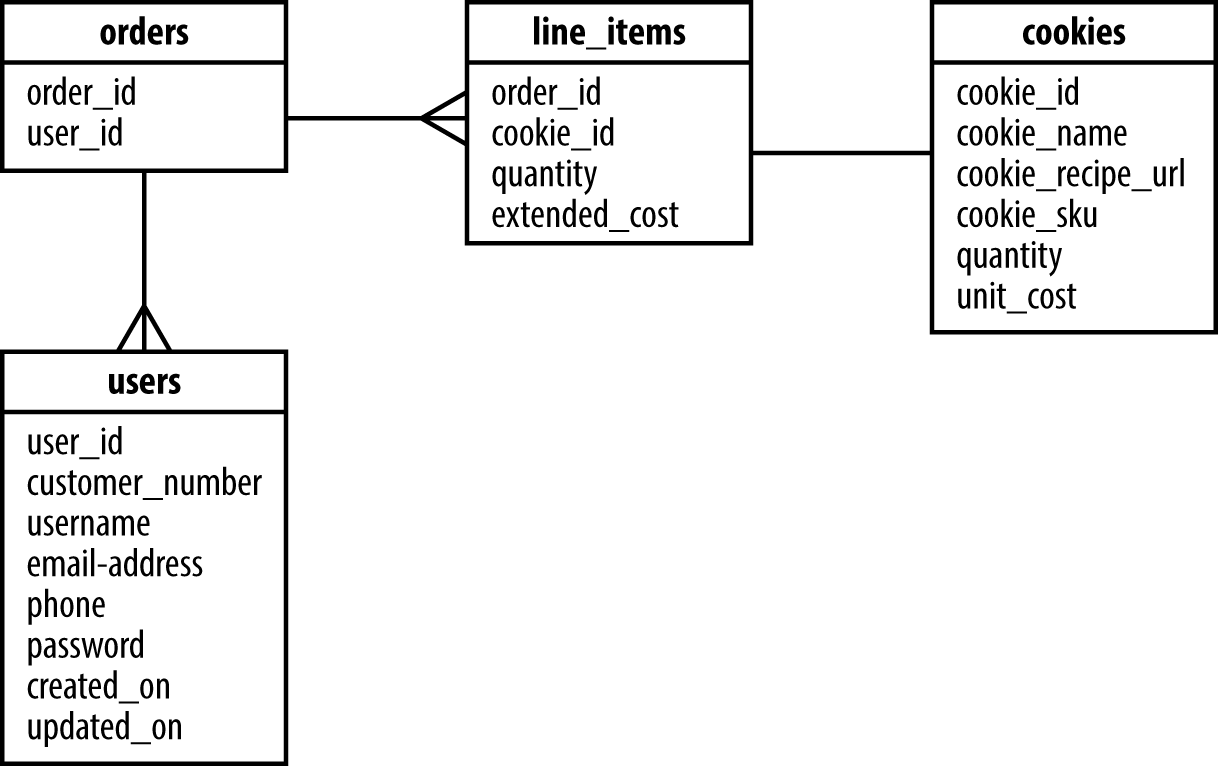
Abbildung 1-1. Visualisierung der Beziehung
Eine Möglichkeit, eine Beziehung zu implementieren, wird in Beispiel 1-3 in der Tabelle line_items in der Spalte order_id gezeigt; dies führt zu einer ForeignKeyConstraint, um die Beziehung zwischen den beiden Tabellen zu definieren. In diesem Fall können viele Einzelposten für eine einzige Bestellung vorhanden sein. Wenn du jedoch tiefer in die Tabelle line_items einsteigst, wirst du sehen, dass wir auch eine Beziehung mit der Tabelle cookies über die Spalte cookie_id haben ForeignKey. Das liegt daran, dass line_items eigentlich eine Assoziationstabelle ist, die zusätzliche Daten zwischen Bestellungen und Cookies enthält. Assoziationstabellen werden verwendet, um Many-to-Many-Beziehungen zwischen zwei anderen Tabellen zu ermöglichen. Ein einzelnes ForeignKey in einer Tabelle ist normalerweise ein Zeichen für eine Eins-zu-Viel-Beziehung; wenn es jedoch mehrere ForeignKey Beziehungen in einer Tabelle gibt, ist die Wahrscheinlichkeit groß, dass es sich um eine Assoziationstabelle handelt.
Beispiel 1-3. Weitere Tabellen mit Beziehungen
fromsqlalchemyimportForeignKeyorders=Table('orders',metadata,Column('order_id',Integer(),primary_key=True),Column('user_id',ForeignKey('users.user_id')),Column('shipped',Boolean(),default=False))line_items=Table('line_items',metadata,Column('line_items_id',Integer(),primary_key=True),Column('order_id',ForeignKey('orders.order_id')),Column('cookie_id',ForeignKey('cookies.cookie_id')),Column('quantity',Integer()),Column('extended_cost',Numeric(12,2)))
Beachte, dass wir eine Zeichenkette anstelle eines tatsächlichen Verweises auf die Spalte verwendet haben.
Durch die Verwendung von Strings anstelle einer echten Spalte können wir die Tabellendefinitionen auf mehrere Module aufteilen und/oder müssen uns nicht um die Reihenfolge kümmern, in der unsere Tabellen geladen werden. Das liegt daran, dass SQLAlchemy den String nur dann in einen Tabellennamen und eine Spalte auflöst, wenn das erste Mal darauf zugegriffen wird. Wenn wir harte Referenzen wie cookies.c.cookie_id in unseren ForeignKey Definitionen verwenden, wird diese Auflösung während der Modulinitialisierung durchgeführt und könnte je nach Reihenfolge, in der die Tabellen geladen werden, fehlschlagen.
Du kannst auch eine ForeignKeyConstraint explizit definieren, was nützlich sein kann, wenn du versuchst, ein bestehendes Datenbankschema abzugleichen, damit es mit SQLAlchemy verwendet werden kann. Das funktioniert genauso wie bei der Erstellung von Schlüsseln, Constraints und Indizes, um Namensschemata usw. abzugleichen. Du musst die ForeignKeyConstraint aus dem Modul sqlalchemy importieren, bevor du sie in deiner Tabellendefinition definierst. Der folgende Code zeigt, wie du die ForeignKeyConstraint für das Feld order_id zwischen der Tabelle line_items und orders erstellst:
ForeignKeyConstraint(['order_id'],['orders.order_id'])
Bis zu diesem Punkt haben wir die Tabellen so definiert, dass SQLAlchemy sie verstehen kann. Wenn deine Datenbank bereits existiert und das Schema bereits erstellt ist, kannst du mit dem Schreiben von Abfragen beginnen. Wenn du jedoch ein komplettes Schema erstellen oder eine Tabelle hinzufügen möchtest, musst du wissen, wie du diese in der Datenbank für eine dauerhafte Speicherung aufbewahren kannst.
Persistieren der Tische
Alle unserer Tabellen und zusätzlichen Schemadefinitionen sind mit einer Instanz von metadata verbunden. Um das Schema in die Datenbank zu übertragen, müssen wir lediglich die create_all() Methode auf unserer metadata Instanz mit der Engine aufzurufen, wo sie diese Tabellen erstellen soll:
metadata.create_all(engine)
Standardmäßig versucht create_all nicht, Tabellen neu zu erstellen, die bereits in der Datenbank vorhanden sind, und es ist sicher, es mehrmals auszuführen. Es ist klüger, ein Datenbankmigrationstool wie Alembic zu verwenden, um Änderungen an bestehenden Tabellen oder zusätzlichen Schemata vorzunehmen, als zu versuchen, Änderungen direkt in deinem Anwendungscode zu kodieren (wir werden das in Kapitel 11 genauer untersuchen). Nachdem wir nun die Tabellen in der Datenbank persistiert haben, sehen wir uns Beispiel 1-4 an, das den vollständigen Code für die Tabellen zeigt, an denen wir in diesem Kapitel gearbeitet haben.
Beispiel 1-4. Vollständiges In-Memory SQLite Codebeispiel
fromdatetimeimportdatetimefromsqlalchemyimport(MetaData,Table,Column,Integer,Numeric,String,DateTime,ForeignKey,create_engine)metadata=MetaData()cookies=Table('cookies',metadata,Column('cookie_id',Integer(),primary_key=True),Column('cookie_name',String(50),index=True),Column('cookie_recipe_url',String(255)),Column('cookie_sku',String(55)),Column('quantity',Integer()),Column('unit_cost',Numeric(12,2)))users=Table('users',metadata,Column('user_id',Integer(),primary_key=True),Column('customer_number',Integer(),autoincrement=True),Column('username',String(15),nullable=False,unique=True),Column('email_address',String(255),nullable=False),Column('phone',String(20),nullable=False),Column('password',String(25),nullable=False),Column('created_on',DateTime(),default=datetime.now),Column('updated_on',DateTime(),default=datetime.now,onupdate=datetime.now))orders=Table('orders',metadata,Column('order_id',Integer(),primary_key=True),Column('user_id',ForeignKey('users.user_id')))line_items=Table('line_items',metadata,Column('line_items_id',Integer(),primary_key=True),Column('order_id',ForeignKey('orders.order_id')),Column('cookie_id',ForeignKey('cookies.cookie_id')),Column('quantity',Integer()),Column('extended_cost',Numeric(12,2)))engine=create_engine('sqlite:///:memory:')metadata.create_all(engine)
In diesem Kapitel haben wir uns angesehen, wie Metadaten von SQLAlchemy als Katalog verwendet werden, um Tabellenschemata und andere Daten zu speichern. Wir können auch eine Tabelle mit mehreren Spalten und Beschränkungen definieren. Wir haben uns die Arten von Constraints angeschaut und wie man sie explizit außerhalb eines Spaltenobjekts konstruiert, um sie an ein bestehendes Schema oder Namensschema anzupassen. Dann haben wir uns damit beschäftigt, wie man Standardwerte und onupdate Werte für Audits festlegt. Schließlich wissen wir jetzt, wie wir unser Schema in der Datenbank persistieren oder speichern können, um es wieder zu verwenden. Im nächsten Schritt lernen wir, wie wir mit Hilfe der SQL Expression Language mit den Daten in unserem Schema arbeiten können.
Get Essential SQLAlchemy, 2. Auflage now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

