Capítulo 4. Entrevista Técnica: Formación y evaluación de modelos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En este capítulo, trataremos en el proceso de entrenamiento del modelo de ML y las preguntas relacionadas con la entrevista. Para muchos profesionales, el entrenamiento del modelo es la parte más emocionante, y estoy de acuerdo: es muy satisfactorio ver cómo el modelo se vuelve cada vez más preciso a lo largo del proceso. Sin embargo, para empezar el entrenamiento de modelos de ML, el ajuste de hiperparámetros y la realización de experimentos con diversos algoritmos, necesitarás tener datos. En esencia, el aprendizaje automático consiste en dejar que los algoritmos encuentren patrones en los datos y luego hagan predicciones y tomen decisiones basadas en esos patrones. Disponer de datos útiles es la base del ML, y como dice el adagio del sector: "Basura dentro, basura fuera". Es decir, si los modelos de ML se entrenan con datos inútiles, el modelo y las inferencias resultantes también serán inútiles.
Empezaré con una visión general del procesamiento y la limpieza de datos, que transforma los datos brutos en un formato útil para los algoritmos de ML (y compatible con ellos). A continuación, repasaré la selección de algoritmos, como las compensaciones entre algoritmos de ML en diferentes escenarios, y cómo seleccionar en general el mejor para un problema determinado.
Después, cubriré el entrenamiento del modelo y el proceso de optimización de su rendimiento. Éste puede ser un proceso ambiguo y difícil, y aprenderás algunas buenas prácticas, como el ajuste de hiperparámetros y el seguimiento de experimentos, que pueden evitar que se pierdan los mejores resultados y garantizar que sean reproducibles. A este respecto, también repasaré cómo saber cuándo un algoritmo de ML es bueno, en un sentido práctico. Esto implica la evaluación del modelo y comparaciones con algunos modelos de referencia o heurísticas de referencia. La evaluación del modelo también puede ayudarte a determinar la eficacia del modelo con datos nuevos y desconocidos, y a descubrir si el modelo podría ajustarse en exceso, ajustarse por debajo o tener un rendimiento inferior en el mundo real.
Nota
Intento mencionar tantas técnicas habituales de entrevista de LD como me permite el espacio, pero hay muchas más bajo el sol. ¡Asegúrate de consultar los recursos enlazados para ampliar tu aprendizaje y preparación de la entrevista!
A lo largo de este capítulo, te daré consejos prácticos y ejemplos que te ayudarán a tener éxito en tus entrevistas de ML. Al final de este capítulo, deberías tener una sólida comprensión del proceso de limpieza de datos, preprocesamiento, entrenamiento de modelos y evaluación, y ser capaz de discutirlos bien en tus propias entrevistas.
Definir un problema de aprendizaje automático
En esta sección, proporciono una visión general de alto nivel sobre la definición de un problema de ML, incluyendo por qué y cómo esto aparece en las preguntas de las entrevistas.
Considera el siguiente escenario: tú, el candidato, estás recorriendo un proyecto de ML que has construido. El objetivo es predecir si un usuario hará clic en un correo electrónico promocional de los conciertos de un cantante concreto.1 Tu entrevistador se queda pensativo unos segundos después de tu resumen, y luego dice: "Parece que puedes utilizar el tiempo que un usuario escucha al artista A para determinar a quién se envían correos electrónicos promocionales de ese artista. Por ejemplo, si escuchan al artista A más de cinco horas a la semana, envía un correo electrónico si el artista A tiene un concierto en la zona del oyente. Dado que hay enfoques más sencillos que no utilizan el aprendizaje automático y consiguen lo mismo que tu modelo, ¿por qué elegiste el ML?".
Te congelas porque no habías pensado en esta cuestión. En aquel momento te parecía un proyecto divertido y autodirigido, y sólo querías aprender. No acabas de entender a qué quiere llegar el entrevistador con su pregunta. ¿A qué te dedicas?
Es importante comprender de antemano cómo puedes responder bien a estas preguntas. He aquí algunos ángulos posibles:
¿Pensaste primero en utilizar una línea de base basada en heurísticas (es decir, en reglas)? En situaciones aplicables, también puedes utilizar un modelo lo más simple posible, como un modelo de regresión logística, como línea de base. Entonces, el objetivo de tu modelo ML sería obtener mejores resultados que la línea de base.
En situaciones del mundo real, las nuevas iniciativas de ML no suelen lanzarse ni aprobarse a menos que exista un claro valor empresarial que justifique el tiempo y el esfuerzo de ingeniería. Por ejemplo, si los costes de implantar un sistema de ML para recomendar conciertos desde cero no superan los beneficios esperados, entonces es más fácil utilizar la heurística. El ahorro previsto en complejidades, trabajo manual o tiempo también es una razón para utilizar el ML en lugar de la heurística.
Pero no te preocupes: el entrevistador no está menospreciando tu proyecto, sino preguntando: "¿Por qué ML?". Esto es muy habitual en el mundo profesional del ML. Preguntar "¿por qué ML?" no significa "realmente no deberías haber utilizado ML". Es sólo el comienzo de una discusión, que los profesionales del ML tienen a menudo en su día a día. La forma en que respondas a esta pregunta, especialmente para los recién licenciados, puede ser una buena señal de si puedes hacer una buena transición para trabajar en ML en la industria.
Esto es lo que podrías decir que funcionaría en este escenario:
Sé sincero: "Para ser sincero, sólo quería aprender algunas técnicas nuevas de modelado con un proyecto paralelo, y como soy un gran usuario de Spotify, quería ver cómo podía emular su función de correo electrónico con ML".
Si estás hablando de un proyecto de trabajo: "En realidad, descubrí que la heurística funcionaba, pero sólo para los usuarios más medios. Por ejemplo, los usuarios pesados necesitan más tiempo de escucha para determinar sus artistas favoritos. Además, una vez que incluimos otros datos como gustos y añadir a listas de reproducción a la heurística, notamos una mayor respuesta al correo electrónico promocional. Así, la heurística se volvió demasiado complicada y difícil de escalar. Por eso empezamos a utilizar ML en su lugar, para que pudiera encontrar patrones en un mayor número de características."
Consejo
Ser honesto está bien. Como recién licenciada, una vez comencé uno de mis proyectos paralelos diciendo: "Esto es un clasificador de imágenes de Ariana Grande. Sólo quería hacer este proyecto por diversión, y no hay ninguna razón real por la que tuviera que ser Ariana Grande. Así es como lo hice...". Pero aun así conseguí que los entrevistadores me tomaran en serio, justificando el proyecto como una oportunidad para utilizar redes neuronales convolucionales.
Si estás haciendo tu propio proyecto paralelo y esperas utilizarlo para responder a preguntas de entrevistas, considera qué métodos heurísticos podrían lograr el objetivo que deseas. Más adelante, puedes utilizarlos como una simple línea de base para ver si el método ML es mejor. Esto te ayudará a destacar entre los demás candidatos. Trataré la selección y evaluación de modelos más adelante en este capítulo.
Preprocesamiento de datos e ingeniería de rasgos
En esta sección, resumiré las técnicas y escenarios habituales de preprocesamiento de datos e ingeniería de características de , así como las preguntas habituales de las entrevistas de ML que cubren este paso del ciclo de vida del ML. Para simplificar, supondré que los datos están disponibles para las preguntas de la entrevista de ML, aunque esto sea un reto común en los escenarios de la vida real. Empezaré con una introducción a la obtención de datos,2 el análisis exploratorio de datos (AED) y la ingeniería de características.
Consejo
Todas las funciones de datos y ML utilizarán el preprocesamiento de datos y el AED. Algunas de las técnicas de este capítulo son específicas para el ML, pero siguen siendo útiles para los analistas de datos o los ingenieros de datos.
Introducción a la Adquisición de Datos
La adquisición de datos, comúnmente denominada como adquisición de datos en el contexto del ML, puede implicar las siguientes opciones:
Acceso al trabajo, normalmente datos protegidos
Conjuntos de datos públicos, como los de Kaggle, oficinas de censos y similares
Web scraping (cuidado con las condiciones de algunos sitios)
Acceso académico, como formar parte de un laboratorio de investigación en tu universidad
Datos de compras a proveedores:
Algunos proveedores también ayudan a anotar y etiquetar datos, como Figure Eight y Scale AI.
Normalmente, tu lugar de trabajo o institución académica te ayudará a sufragar los gastos, ya que los precios suelen ser demasiado elevados para que merezcan la pena para proyectos paralelos individuales.
Crear datos sintéticos mediante simulaciones
Crear tus propios datos brutos, como tomar tus propias fotos, hacer crowdsourcing de datos o utilizar arte/diseños que tú mismo crees
Introducción al Análisis Exploratorio de Datos
Ahora que has adquirido los datos, es el momento de analizarlos. Tu objetivo principal con el AED es ver si los datos son suficientes como punto de partida o si necesitas más. Por lo tanto, intenta obtener una visión general de alto nivel de la distribución de los datos y encontrar cualquier defecto o rareza. Los defectos y rarezas pueden incluir demasiados valores perdidos, distribuciones de datos sesgadas o duplicados. El EDA también abarca los rasgos generales de cada característica, examinando las medias, las distribuciones, etc. Si encuentras defectos, hay formas de resolver los problemas más adelante, durante la limpieza de datos y la ingeniería de rasgos; lo importante durante el EDA es simplemente ser consciente de los posibles problemas.
Consejo
Para los profesionales del ML y los datos, es importante tener cierto conocimiento del dominio. En mis proyectos paralelos sobre precios de videojuegos, conocía bien la dinámica del sector y los comportamientos de los clientes, ya que yo mismo soy un ávido jugador. En el trabajo, necesito aprender sobre cada dominio para construir modelos ML útiles; por ejemplo, los clientes de las telecomunicaciones tienen comportamientos diferentes a los de la tecnología financiera.
Mi enfoque habitual es ejecutar ydata-profiling, antes conocido como pandas-profiling, y empezar a profundizar a partir del informe generado (en la Figura 4-1 se muestra un informe de ejemplo). Ten en cuenta que esto no es más que un punto de partida, y que será importante utilizar el conocimiento del dominio para detectar patrones o anomalías. Lo que puede ser un problema para algunos sectores y modelos, puede ser esperable en otros. Por ejemplo, en el caso de un problema de RecSys, es más habitual tener datos más dispersos que en un conjunto de datos de series temporales. No basta con mirar las estadísticas generadas. Además, algunos dominios tienen algoritmos que se ocupan de problemas comunes para ese dominio, y esos problemas son, por tanto, menos motivo de alarma.
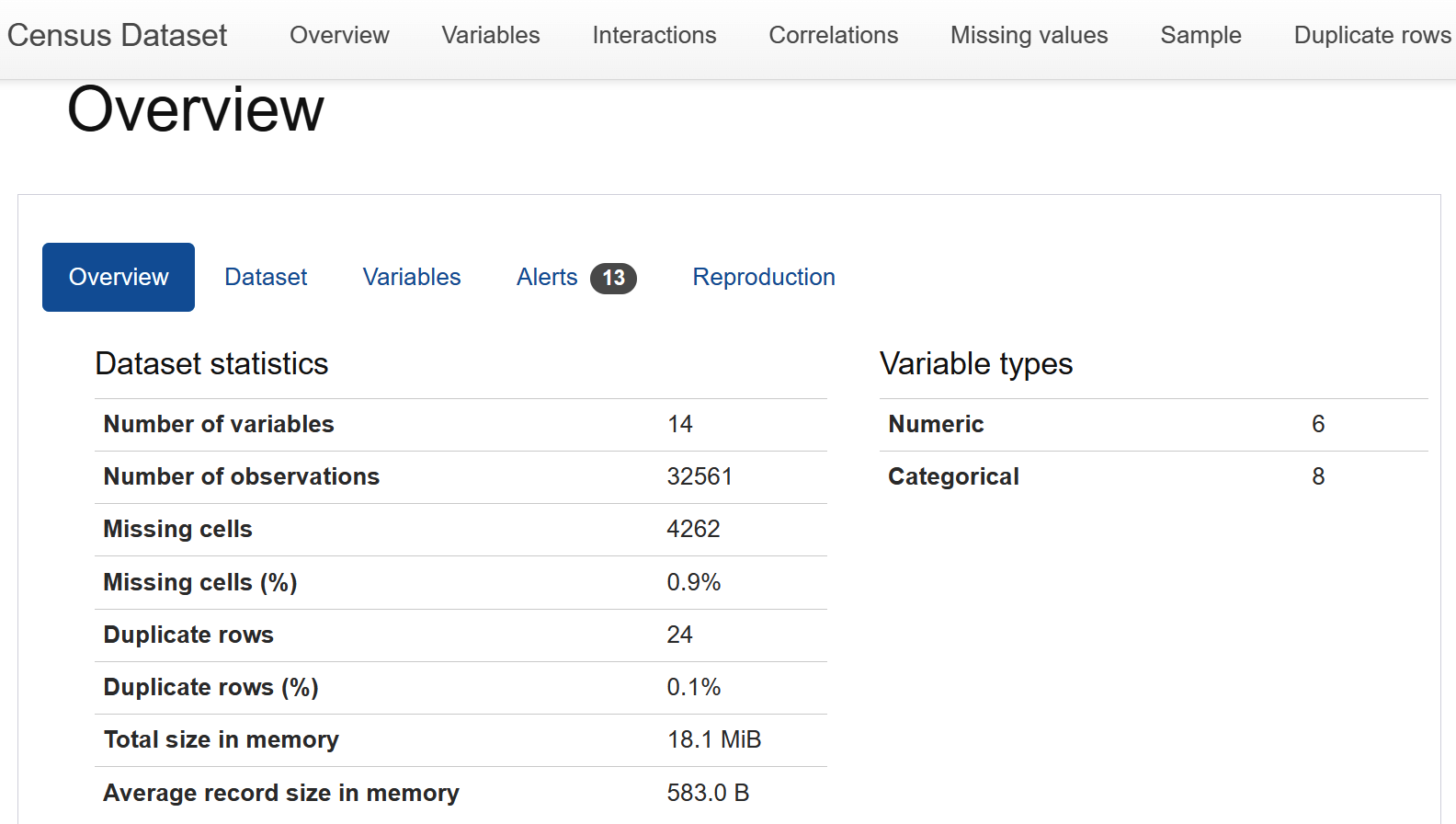
Figura 4-1. Captura de pantalla de ydata-profiling; fuente: documentación de ydata-profiling.
Más detalles sobre EDA están fuera del alcance de este libro, pero recomiendo a que lea Making Sense of Data de Glenn J. Myatt y Wayne P. Johnson (Wiley) para más información.
Después de algunas iteraciones, digamos que has completado el AED, llegando a un punto de decisión: los datos parecen suficientemente sólidos (por ahora) para continuar, o puede que necesites adquirir más datos u otro conjunto de datos primero; enjuaga y repite.
Consejo
Cuando los entrevistadores te preguntan qué harías al empezar con un problema de ML, esperan oírte mencionar el EDA en algún momento temprano del proceso, después de haber adquirido alguna(s) fuente(s) de datos. Es importante que demuestres que eres capaz de mirar críticamente los datos e incluso de encontrar fallos, no sólo de aceptar un conjunto de datos prelimpiado .
Introducción a la ingeniería de características
Después de explorar los datos, iterando hasta que haya un buen punto de partida para el entrenamiento del modelo, es el momento de la ingeniería de características. En ML, las características se refieren a las entradas de los modelos de ML. El objetivo es hacer modificaciones en el conjunto de datos para garantizar la compatibilidad con los modelos de ML, pero también para tratar cualquier fallo o carácter incompleto observado en los datos, como los valores omitidos. Los temas que trato aquí incluyen el tratamiento de los datos que faltan, el tratamiento de los datos duplicados, la normalización de los datos y el preprocesamiento de los datos.
Nota
Algunas de las técnicas se solapan con lo que comúnmente se denomina "limpieza de datos", que puede darse en más etapas del ciclo de vida del ML que la ingeniería de características, pero que es útil introducir aquí.
Tratamiento de datos perdidos con imputación
Hay técnicas de imputación comunes para tratar los datos que faltan que deberías poder mencionar en una entrevista, junto con sus pros y sus contras. Entre ellas se incluyen el relleno con el valor medio o la mediana y el uso de un modelo basado en árboles.
La Tabla 4-1 enumera algunas cosas que debes tener en cuenta al rellenar los valores que faltan.
| Técnica | Pros | Contras |
|---|---|---|
| Media/mediana/modo | Fácil de poner en práctica | Puede que no tenga en cuenta los valores atípicos en comparación con los métodos basados en árboles No son tan adecuados para variables categóricas |
| Modelos basados en árboles | Puede captar más patrones subyacentes Adecuado tanto para variables numéricas como categóricas |
Añade un nivel de complejidad durante el preprocesamiento de los datos Hay que volver a entrenar el modelo si cambia la distribución subyacente de los datos |
Tratamiento de datos duplicados
Hay casi un número infinito de formas en que las observaciones pueden duplicarse por accidente, por lo que éste es uno de los problemas que hay que descubrir al realizar EDA:
Los trabajos de ingestión de datos pueden ejecutarse dos veces debido a un error.
Al realizar algunas uniones complicadas, algunas filas podrían haberse duplicado involuntariamente y no haberse descubierto.
Algunos casos de perímetro pueden hacer que la fuente de datos proporcione datos duplicados.
... y así sucesivamente.
Si encuentras datos duplicados, puedes utilizar SQL o Python para deduplicar los datos, y asegurarte de que los registros se representan en un formato al que te resulte más fácil acceder y utilizar más adelante.
Normalizar los datos
Después de tratar los datos que faltan y los duplicados, los datos deben estar normalizados. Esto incluye tratar los valores atípicos, escalar las características y garantizar que los tipos y formatos de datos sean coherentes:
- Maneja los valores atípicos
Las técnicas para tratar los valores atípicos de incluyen eliminar los valores atípicos extremos del conjunto de datos, sustituirlos por valores menos extremos (lo que se conoce como winsorización) y transformaciones de escala logarítmica. Yo advertiría contra la eliminación de valores atípicos, ya que hacerlo depende realmente del conocimiento del dominio; en algunos dominios, hay consecuencias más graves; por ejemplo, eliminar datos de imágenes de coches de caballos de un conjunto de datos de entrenamiento de coches autoconducidos sólo porque no son un tipo común de vehículo podría hacer que el modelo no reconociera los coches de caballos en el mundo real. Por tanto, evalúa cuidadosamente las repercusiones antes de decidirte por una técnica concreta.
- Características de la escala
En los conjuntos de datos con múltiples características con valores numéricos, los algoritmos de ML pueden interpretar erróneamente que los valores más grandes tienen más impacto. Por ejemplo, una columna es el precio, que oscila entre 50 y 5.000 $, mientras que otra característica es la cantidad de veces que aparece un anuncio, que oscila entre 0 y 10 veces. Las dos características están en unidades diferentes, pero ambas son numéricas, por lo que es posible que la columna del precio se represente como de mayor magnitud de impacto. Algunos modelos, como los basados en el ascenso de gradiente, son más sensibles a la escala de las características. Por eso, es mejor escalar las características de modo que oscilen entre [-1, 1] o [0, 1].
Advertencia
Ten cuidado al escalar características. Es útil combinar distintas técnicas o utilizar lo que hayas encontrado al realizar el EDA. Por ejemplo, una característica puede tener valores atípicos extremos, como que la mayoría de ellos estén en el intervalo [0, 100], excepto una observación de 1000. Sin comprobarlo, podrías escalar los valores de las características basándote en el mínimo de 0 y el máximo de 1000. Esto puede hacer que se comprima la información contenida en las características.
- Coherencia de los tipos de datos
Una vez estaba trabajando en un modelo ML y obtuve resultados que no eran los que esperaba, y me llevó un tiempo depurarlos. Finalmente, identifiqué el problema: ¡una columna numérica estaba formateada como una cadena! Inspeccionar tus tipos de datos finales para asegurarte de que tendrán sentido una vez introducidos en tu modelo ML será útil antes de que sigas con el resto del proceso; considéralo una parte de la garantía de calidad (QA).
Consejo
Un entrevistador puede hacerte preguntas de seguimiento sobre cómo has manejado exactamente los valores atípicos, la escala de características o la coherencia del tipo de datos, así que asegúrate de repasar los fundamentos y las ventajas y desventajas de cada enfoque.
Preprocesamiento de datos
El preprocesamiento de los datos permitirá a que las características tengan sentido para el modelo ML en el contexto del tipo de algoritmo que estés utilizando. El preprocesamiento de datos estructurados puede incluir la codificación de un punto, la codificación de etiquetas, el binning, la selección de características, etc.
Consejo
Los datos no estructurados son "información que no está ordenada según un modelo o esquema de datos preestablecido y que, por tanto, no puede almacenarse en una base de datos relacional tradicional o RDBMS (sistema de gestión de bases de datos relacionales). El texto y los multimedia son dos tipos comunes de contenido no estructurado".3 Cuando te encuentres con datos no estructurados, el preprocesamiento puede ser diferente (pudiendo incluso transformar los datos para convertirlos en estructurados). A efectos ilustrativos, en este capítulo me centro en ejemplos de preprocesamiento de datos estructurados.
Codificación monocorde de datos categóricos
Puede que quieras representar datos categóricos como datos numéricos. Cada categoría se convierte en una característica, con 0 ó 1 representando el estado de esa característica en cada observación. Por ejemplo, imagina un conjunto de datos meteorológicos sencillo en el que sólo es posible que haga sol o esté nublado. Tendrías lo siguiente
- 1 de marzo
-
Tiempo: Soleado
Temperatura (Celsius): 27
- 2 de marzo
-
Tiempo: Soleado
Temperatura (Celsius): 25
- 3 de marzo
-
Tiempo: Nublado
Temperatura (Celsius): 20
Pero la función "Tiempo" puede codificarse de un solo golpe para tener funciones con todos los estados posibles del tiempo:
- 1 de marzo
-
Soleado: 1
Nublado: 0
- 2 de marzo
-
Soleado: 1
Nublado: 0
- 3 de marzo
-
Soleado: 0
Nublado: 1
A menudo se utiliza la codificación unívoca porque los números son más fáciles de entender para los algoritmos de ML; algunos algoritmos no tienen en cuenta los valores categóricos, pero esto ha mejorado con los años, ya que algunas implementaciones pueden tener en cuenta los valores categóricos y transformarlos entre bastidores.
Uno de los inconvenientes de la codificación de una sola vez es que, en el caso de rasgos originalmente con una cardinalidad alta (hay muchos valores únicos en ese rasgo), la codificación de una sola vez puede hacer que el recuento de rasgos aumente drásticamente, lo que puede resultar más caro computacionalmente.
Consejo
A veces, la falta de conocimiento del dominio o de comprensión de la lógica empresarial puede causar problemas en el preprocesamiento de datos. Un ejemplo es definir a los usuarios dados de baja como los que han cancelado un producto en los últimos siete días, pero el producto o la lógica empresarial en realidad cuenta a los usuarios dados de baja como los que se han ido en los últimos 60 días. (Si, por alguna razón, la lógica empresarial no funciona bien para ML, entonces podemos discutir un término medio).
Codificación de etiquetas
La codificación de etiquetas asigna las categorías a números, pero las mantiene en la misma característica. Por ejemplo, los tipos de tiempo pueden asignarse a números únicos, como se ilustra en la Figura 4-2.
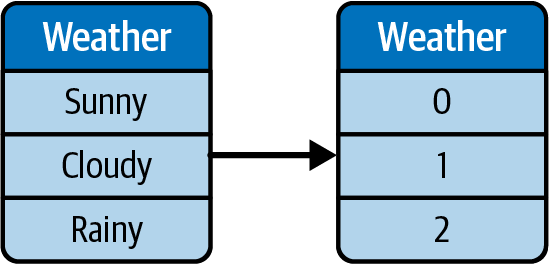
Figura 4-2. Ilustración de la codificación de etiquetas.
Uno de los inconvenientes de la codificación de etiquetas es que algunos algoritmos de ML pueden confundir la escala y los valores para significar una mayor magnitud de impacto. Siguiendo con nuestro ejemplo anterior, el Tiempo puede codificarse con etiquetas: Soleado se convierte en 0, y Nublado en 1. Pero para ML, esto podría confundir nublado como una magnitud mayor, ya que 1 es mayor que 0.
Afortunadamente, en muchos algoritmos de ML puedes utilizar clases incorporadas (por ejemplo, la clase LabelEncoder para que el algoritmo sepa entre bastidores que se trata sólo de una categorización y no necesariamente indicativa de magnitud.
Consejo
Por supuesto, si te olvidas de hacer saber al algoritmo que las características codificadas por etiquetas están, de hecho, codificadas por etiquetas, entonces el algoritmo de ML probablemente tratará esa característica como una característica numérica normal. Puedes ver cómo esto puede causar problemas si no lo abordas durante las preguntas de la entrevista.
Binning para valores numéricos
El binning puede reducir la cantidad de cardinalidad y ayudar a que los modelos generalicen más. Por ejemplo, si el conjunto de datos tiene un precio de 100 $, puede que no generalice la primera vez que vea 95 $, aunque en la aplicación concreta, 95 $ sea similar a 100 $. A modo de ilustración, puedes definir los perímetros de los contenedores como [15, 25, 35, 45, 55, 65, 75, 85, 99], lo que creará rangos de precios similares como "$15-$25", "$25-$35", "$35-$45", etc.
Una desventaja del binning es que introduce perímetros duros en los significados de los bins, de forma que una observación de 46$ se vería como completamente diferente del bin "35$- 45$", aunque pudiera seguir siendo similar.
Selección de características
A veces, tu conjunto de datos tendrá características que están muy correlacionadas, es decir, hay colinealidad entre las características. Como ejemplo extremo, puedes tener la altura en centímetros pero también la altura en metros, que esencialmente capturan la misma información. Puede haber otras características que capten también una alta proporción de la misma información, y eliminarlas podría reducir accidentalmente el sobreajuste o mejorar la velocidad del modelo porque éste no necesita manejar tantas características. La reducción de la dimensionalidad es una técnica habitual para la selección de características; reduce la dimensionalidad de los datos conservando la información más importante .
También puedes utilizar tablas de importancia de características, como las que se proporcionan en XGBoost o CatBoost, y podar las características con la menor importancia, es decir, la menor contribución al modelo.
Ejemplos de Preguntas de Entrevista sobre Preprocesamiento de Datos e Ingeniería de Características
Ahora que ya he tratado algunos aspectos básicos del preprocesamiento de datos y la ingeniería de características, repasemos algunos ejemplos de preguntas de entrevista.
Pregunta de la entrevista 4-1: ¿Cuál es la diferencia entre ingeniería de rasgos y selección de rasgos?
- Ejemplo de respuesta
La ingeniería de características consiste en crear o transformar características a partir de datos brutos. Esto se hace para representar mejor los datos y hacerlos más adecuados para el ML en comparación con su formato bruto. Las técnicas más comunes incluyen el tratamiento de los datos que faltan, la estandarización de los formatos de datos, etc.
La selección de características consiste en reducir las características ML relevantes para simplificar el modelo y evitar el sobreajuste. Entre las técnicas habituales están el PCA (análisis de componentes principales) o el uso de la importancia de las características de los modelos basados en árboles para ver qué características aportan señales más útiles.
Pregunta de la entrevista 4-2: ¿Cómo evitas los problemas de fuga de datos mientras realizas el preprocesamiento de datos?
- Ejemplo de respuesta
Ser precavido con la formación, la validación y la división de los datos de prueba es una de las formas más comunes de evitar la fuga de datos. Sin embargo, las cosas no siempre son tan sencillas. Por ejemplo, en el caso de que la imputación de datos se realice con el valor medio de todas las observaciones de la característica, eso significa que el valor medio contiene información sobre todas las observaciones, no sólo sobre la división de entrenamiento. En ese caso, asegúrate de realizar la imputación de datos sólo con información sobre la división de entrenamiento, en la división de entrenamiento. Otros ejemplos de fuga de datos podrían ser las divisiones de series temporales; debemos tener cuidado de no barajar y dividir accidentalmente las series temporales de forma incorrecta (por ejemplo, utilizando mañana para predecir hoy en lugar de al revés).
Pregunta de la entrevista 4-3: ¿Cómo manejas una distribución de datos sesgada durante la ingeniería de características, suponiendo que la clase de datos minoritaria sea necesaria para el problema de aprendizaje automático?
- Ejemplo de respuesta
Las técnicas de muestreo,4 como sobremuestreo de las clases minoritarias de datos, podrían ayudar durante el preprocesamiento y la ingeniería de características (por ejemplo, utilizando técnicas como SMOTE). Es importante tener en cuenta que para el sobremuestreo, cualquier instancia duplicada o sintética debe generarse sólo a partir de los datos de entrenamiento, para evitar la fuga de datos con el conjunto de validación o prueba.
El proceso de formación de modelos
Ahora que tienes los datos listos para el ML, es hora de pasar al siguiente paso: el entrenamiento del modelo. Este proceso incluye los pasos de definir la tarea de ML, seleccionar los algoritmos de ML más adecuados para la tarea y entrenar realmente el modelo. En esta sección, también te proporcionaré preguntas y consejos habituales para las entrevistas, que te ayudarán a tener éxito.
El proceso de iteración en el entrenamiento de modelos
Al principio de un proyecto de ML, probablemente pensaste en cuál querías que fuera el resultado general, como "obtener la mayor precisión posible en una competición de Kaggle" o "utilizar estos datos para predecir los precios de venta de los videojuegos". Puede que también hayas empezado a investigar algunos algoritmos que sean buenos para la tarea, como las predicciones de series temporales. Determinar cuál será esa tarea final de ML es (a menudo) un proceso iterativo en el que puedes ir y venir de un paso a otro antes de dar con algo, como se ilustra en la Figura 4-3.
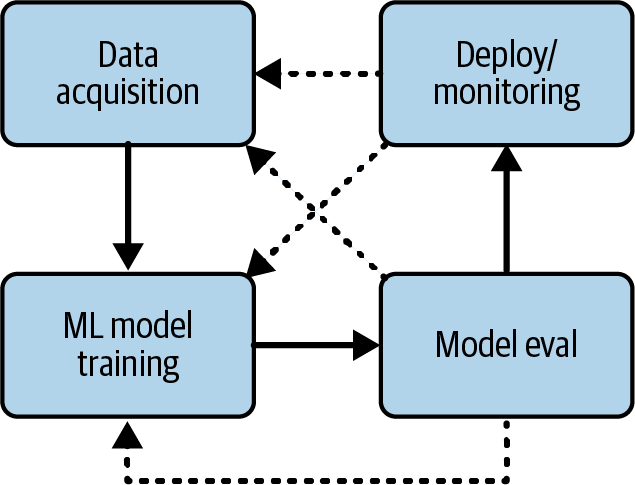
Figura 4-3. Ejemplo de proceso de iteración durante el entrenamiento ML.
Por ejemplo, veamos todos los pasos de un proyecto para predecir las ventas de videojuegos:
Define la tarea de ML, la selección del modelo. Puedes empezar con una idea: utilizar datos de series temporales con ARIMA (Media Móvil Integrada Autorregresiva), porque el problema parece sencillo: la predicción de precios suele utilizar datos de series temporales.
Adquisición de datos. Es posible que adquieras un conjunto de datos con datos de series temporales, es decir, que sólo tenga la hora, como una fecha o una marca de tiempo, y el precio. El precio futuro es la salida de las predicciones del modelo, y los precios históricos son las entradas.
Sin embargo, puedes encontrarte con una situación en la que utilizar ARIMA no parece funcionar, y solucionas el problema analizando los datos de origen más detenidamente. Resulta que estás combinando datos de los juegos de grandes empresas (también conocidos como juegos "AAA") con juegos más pequeños de estudios independientes (también conocidos como juegos "indie"). Los juegos AAA suelen tener grandes presupuestos para marketing y promoción, por lo que, de media, venden más que los juegos indie.
Define la tarea ML (otra vez). El siguiente paso es volver a evaluar la tarea ML. Después de pensarlo un poco, decides seguir prediciendo la serie temporal, con lo que la tarea ML sigue siendo la misma.
Adquisición de datos (otra vez). Esta vez, sin embargo, ya sabes qué debes hacer de forma diferente para que los resultados sean mejores. Así, adquieres más datos: si un juego es AAA o indie. Puede que incluso acabes etiquetándolo a mano.
Selección del modelo (otra vez). Ahora te das cuenta de que el modelo tiene que cambiar, ya que ARIMA no admite variables categóricas como las etiquetas "Indie" y "AAA". Así pues, buscas en Internet y encuentras otros algoritmos que pueden mezclar variables categóricas con variables numéricas, y pruebas con uno de ellos.
Sigue iterando los pasos anteriores hasta que sea suficientemente bueno. Podrías enjuagar y repetir si sigue sin funcionar bien, adquiriendo más tipos de características, probando diferentes modelos o haciendo ingeniería de características como la codificación de una sola vez. La tarea de ML también podría cambiar por el camino: en lugar de predecir las cifras exactas de ventas, podrías optar por predecir los intervalos, como las ventas (altas, medias, bajas), siendo las ventas altas las superiores a 50.000 unidades o algo que hayas definido mediante EDA.
Si has realizado un proyecto de principio a fin, conoces la naturaleza iterativa de los pasos descritos en esta sección. Te habrás dado cuenta de que, en este ejemplo, puedes ver claramente qué te llevó a volver a la adquisición de datos y qué te llevó después a volver a definir la tarea de ML. Siempre hay una razón, aunque la razón sea sólo ver si el nuevo enfoque funciona mejor que tu enfoque actual. Esto te proporcionará mucha información interesante para responder a las preguntas de tu entrevistador.
Los entrevistadores querrán asegurarse de lo siguiente:
Conoces las tareas de ML habituales en su campo.
Conoces los algoritmos habituales relacionados con dichas tareas.
Sabes cómo evaluar esos modelos.
Definir la tarea ML
En la sección anterior, has visto cómo los pasos desde la adquisición de datos hasta el entrenamiento del modelo son a menudo iterativos y que explicar la justificación de cada una de tus iteraciones te ayudará en tus respuestas a la entrevista.
Para seleccionar el modelo ML, tienes que definir la tarea ML. Para averiguarlo, puedes preguntarte qué algoritmo utilizar y qué tarea(s) está(n) asociada(s) al algoritmo. Por ejemplo, ¿es clasificación o regresión?
No hay ningún método prescriptivo que te diga cuáles son los algoritmos correctos, pero en general querrás saberlo:
¿Tienes suficientes datos?
¿Predices una cantidad/valor numérico o una categoría/valor categórico?
¿Tienes datos etiquetados (es decir, conoces las etiquetas verdaderas)? Esto podría determinar si el aprendizaje supervisado o no supervisado es mejor para la tarea.
Las tareas pueden incluir regresión, clasificación, detección de anomalías, sistemas de recomendación, aprendizaje por refuerzo, procesamiento del lenguaje natural, IA generativa, etc., sobre las que ya has leído en el Capítulo 3. En la Figura 4-4 se ilustra una visión simplificada de la selección de la tarea de ML. Conocer el objetivo y los datos de que dispones (o piensas adquirir) puede ayudarte a seleccionar inicialmente las tareas. Por ejemplo, los distintos tipos de tareas de ML son más adecuados en función de los datos etiquetados de que se disponga o de si la variable objetivo es continua o categórica.
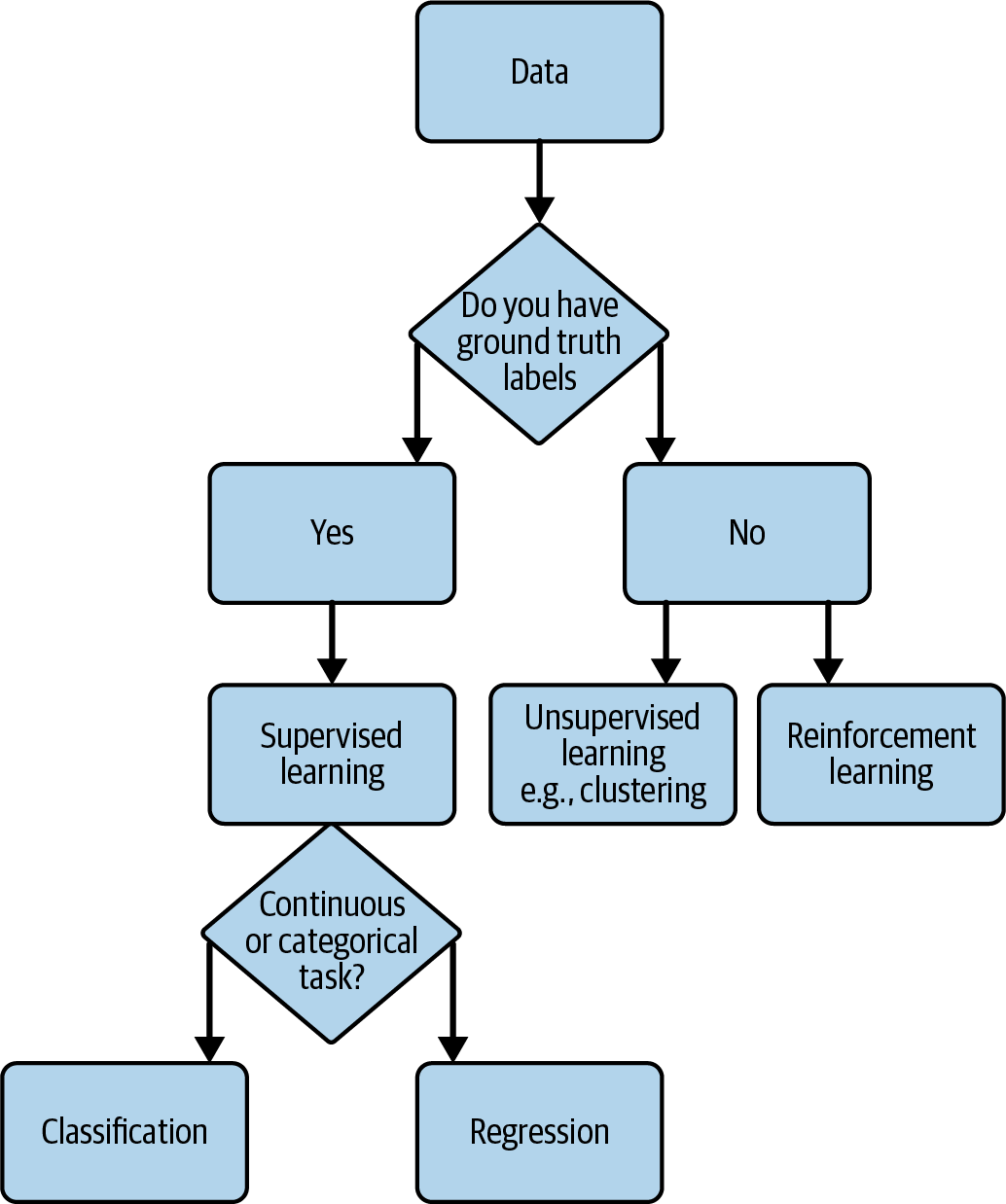
Figura 4-4. Diagrama de flujo simplificado de la selección de tareas de ML.
Visión general de la selección de modelos
Ahora que ya tienes una idea de la tarea de ML, pasemos a la selección del modelo. Recuerda que se trata de un proceso iterativo, por lo que no podrás decidirlo de una sola vez. Sin embargo, necesitas seleccionar un modelo (o unos cuantos) como punto de partida. En las entrevistas, te preguntarán por qué seleccionaste tal o cual algoritmo o modelo, y no bastará con que te guíes por tu instinto para responder con éxito. Como has visto en la Figura 4-4, ya tienes un punto de partida basado en la(s) tarea(s) de ML que has definido. Así que vamos a profundizar en algunos algoritmos y bibliotecas comunes (la mayoría en Python) que puedes utilizar para implementar la tarea.
Quiero hacer una aclaración rápida sobre terminología: cuando estás seleccionando un algoritmo inicialmente, eso no es técnicamente selección de modelo hasta que lo pruebas y comparas el rendimiento del modelo resultante. Este término suele utilizarse indistintamente, ya que inevitablemente querrás tomar la decisión final basándote en el rendimiento real del modelo. Como dice Jason Brownlee en Machine Learning Mastery: "La selección de modelos es un proceso que puede aplicarse tanto a distintos tipos de modelos (por ejemplo, regresión logística, SVM, KNN, etc.) como a modelos del mismo tipo configurados con distintos hiperparámetros de modelo (por ejemplo, distintos núcleos en una SVM)".5
He aquí algunos algoritmos y bibliotecas que pueden utilizarse como puntos de partida sencillos para cada tarea. Ten en cuenta que muchas bibliotecas son versátiles y pueden utilizarse para múltiples propósitos (por ejemplo, los árboles de decisión pueden utilizarse tanto para la clasificación como para la regresión), pero enumero algunos ejemplos simplificados para su comprensión:
- Clasificación
Los algoritmos incluyen árboles de decisión, bosques aleatorios y similares. Algunos ejemplos de bibliotecas Python para empezar son scikit-learn, CatBoost y LightGBM.
- Regresión
Los algoritmos incluyen la regresión logística, los árboles de decisión y similares. Algunos ejemplos de bibliotecas Python para empezar son scikit-learn y statsmodels.
- Agrupación (aprendizaje no supervisado)
Los algoritmos incluyen la agrupación de k-means, DBSCAN y similares. Un ejemplo de biblioteca Python para empezar es scikit-learn.
- Predicción de series temporales
Los algoritmos incluyen ARIMA, LSTM y similares. Algunos ejemplos de bibliotecas Python para empezar son statsmodels, Prophet, Keras/TensorFlow, etc.
- Sistemas de recomendación
Los algoritmos incluyen técnicas de factorización matricial como el filtrado colaborativo. Algunos ejemplos de bibliotecas y herramientas para empezar son MLlib de Spark o Amazon Personalize en AWS.
- Aprendizaje por refuerzo
Entre los algoritmos se incluyen el bandido de brazos múltiples, el aprendizaje Q y el gradiente de política. Algunas bibliotecas de ejemplo para empezar son Vowpal Wabbit, TorchRL (PyTorch) y TensorFlow-RL.
- Visión por ordenador
Las técnicas de aprendizaje profundo son puntos de partida habituales para las tareas de visión por ordenador. OpenCV es una importante biblioteca de visión por ordenador que también admite algunos modelos de ML. Los marcos de aprendizaje profundo más populares son TensorFlow, Keras, PyTorch y Caffe.
- Procesamiento del lenguaje natural
Todos los marcos de aprendizaje profundo mencionados anteriormente también pueden utilizarse para la PNL. Además, es habitual probar métodos basados en transformadores o encontrar algo en Hugging Face. Hoy en día, también es habitual utilizar la API OpenAI y modelos GPT. LangChain es una biblioteca de rápido crecimiento para flujos de trabajo de PNL. También está la recientemente lanzada Bard de Google.
Consejo
Si la tarea es de una de las familias de ML bien conocidas, también hay algoritmos bien conocidos específicos para esa tarea. Como siempre, la heurística que proporciono es sólo un punto de partida común, y puede que acabes probando otras técnicas versátiles, como los modelos basados en árboles o el ensamblaje.
Visión general del entrenamiento con modelos
Ahora que has pasado por los pasos de definir la tarea de ML y seleccionar un algoritmo, comenzarás el proceso de entrenamiento del modelo, que incluye el ajuste de hiperparámetros y el ajuste del optimizador o de la función de pérdida, si procede. El objetivo de este paso es ver cómo el modelo mejora cada vez más cambiando los parámetros del propio modelo. A veces, esto no funcionará, y tendrás que volver a las etapas anteriores para mejorar el modelo a través de los datos de entrada. Esta sección se centra en el ajuste del propio modelo, pero no de los datos.
En las entrevistas, es más interesante para el empleador escuchar cómo aumentaste el rendimiento de tu modelo, que simplemente que obtuviste un modelo de alto rendimiento. En algunos casos, incluso tener un modelo de bajo rendimiento al final puede demostrar tu idoneidad para el puesto si fuiste muy cuidadoso con tu proceso de entrenamiento ML, incluso cuando otros factores estaban fuera de tu control, como la adquisición de datos. En otros casos, tener un modelo de alta precisión no importa tanto al entrevistador si no lo has implementado; es habitual ver modelos que funcionan bien en la fase de entrenamiento y en la evaluación offline, pero que luego no lo hacen bien en producción o en escenarios reales.
Ajuste de hiperparámetros
Elajuste de hiperparámetros consiste en seleccionar en los hiperparámetros óptimos para el modelo mediante ajustes manuales, búsqueda en cuadrícula o incluso AutoML. Los hiperparámetros incluyen rasgos o arquitectura del propio modelo, como la tasa de aprendizaje, el tamaño del lote, el número de capas ocultas en una red neuronal, etc. Cada modelo específico puede tener sus propios parámetros, como el punto de cambio y la escala previa de estacionalidad en Prophet. El objetivo del ajuste de los hiperparámetros es, por ejemplo, ver si la tasa de aprendizaje es mayor o si el modelo convergerá más rápido y funcionará mejor.
Es importante disponer de un buen sistema de seguimiento de los experimentos de ajuste de hiperparámetros para que los experimentos puedan ser reproducibles. Imagínate el dolor que supondría ver una ejecución de un modelo que diera grandes resultados, pero como las modificaciones se hicieron directamente en el script, ¡perdiste los cambios exactos y no pudiste reproducir los buenos resultados! El seguimiento se tratará con más detalle en "Seguimiento de experimentos".
Funciones de pérdida ML
Las funciones de pérdida en ML miden la diferencia entre las salidas predichas del modelo y la verdad sobre el terreno. Un objetivo del modelo es minimizar la función de pérdida, ya que al hacerlo, el modelo está haciendo las predicciones más precisas según tu definición de precisión en el modelo. Ejemplos de funciones de pérdida ML son el error cuadrático medio (MSE) y el error absoluto medio (MAE).
Optimizadores ML
Los optimizadores son la forma en que se ajustan los parámetros del modelo ML para minimizar la función de pérdida. A veces, hay opciones para cambiar el optimizador; por ejemplo, PyTorch tiene 13 optimizadores comunes entre los que elegir. Adam y Adagrad son optimizadores populares, y es probable que los propios hiperparámetros del modelo se ajusten para mejorar el rendimiento. Esto podría ser una palanca adicional de la que tirar, dependiendo de la estructura de tu modelo y de las razones hipotéticas por las que tu optimizador actual no funciona.
Seguimiento de experimentos
Mientras realizas el ajuste de hiperparámetros, tendrás que llevar un registro del rendimiento de cada iteración del modelo. No podrás averiguar qué conjunto de parámetros funciona mejor si no tienes los registros de parámetros anteriores con los que comparar.
Es posible que una empresa con la que te entrevistes disponga de herramientas para el seguimiento de experimentos de ML. En general, no importa si tienes experiencia con la herramienta específica que utiliza la empresa, siempre que conozcas el seguimiento de experimentos. Yo he realizado el seguimiento de experimentos con Microsoft Excel antes, y también muchos otros profesionales. Sin embargo, cada vez es más habitual utilizar una plataforma centralizada de seguimiento de experimentos. Algunos ejemplos son MLflow, TensorBoard, Weights & Biases y Keras Tuner. Hay muchos más, como Kubeflow, DVC, Comet ML, etc. Para la entrevista, es muy poco probable que importe en cuáles tengas experiencia exactamente, siempre que seas consciente de que debes hacer un seguimiento de los resultados de algún modo en una ubicación centralizada.
Recurso adicional para la formación de modelos
Google tiene un sitio Google Machine Learning Education (gratuito en el momento de escribir esto) para quienes estén interesados en una visión más detallada; empieza con el Curso acelerado de aprendizaje automático (centrado en ML y TensorFlow y ejecutable en Google Colab).
Ejemplos de preguntas de entrevista sobre selección y formación de modelos
Ahora que hemos repasado las consideraciones habituales durante la formación de modelos, veamos algunos ejemplos de preguntas de entrevista.
Pregunta de la entrevista 4-4: ¿En qué situación utilizarías un algoritmo de aprendizaje por refuerzo en lugar de, por ejemplo, un método basado en árboles?
- Ejemplo de respuesta
Los algoritmos de RL son útiles cuando es importante aprender del ensayo y error y la secuencia de acciones es importante. La RL también es útil cuando el resultado puede retrasarse pero queremos que el agente RL mejore continuamente. Algunos ejemplos son los juegos, la robótica, los sistemas de recomendación, etc.
En cambio, los métodos basados en árboles, como los árboles de decisión o los bosques aleatorios, son útiles cuando el problema es estático y no secuencial. En otras palabras, no es tan útil tener en cuenta las recompensas retardadas o la toma de decisiones secuencial, y basta con un conjunto de datos estático (en el momento del entrenamiento).
Pregunta de la entrevista 4-5: ¿Cuáles son algunos de los errores más comunes que se cometen durante el entrenamiento de modelos, y cómo los evitarías?
- Ejemplo de respuesta
El sobreajuste es un problema común, cuando el modelo resultante capta información demasiado compleja en los datos de entrenamiento y no generaliza bien a las nuevas observaciones. Las técnicas de regularización6 para evitar el sobreajuste.
No ajustar los hiperparámetros comunes podría hacer que los modelos no funcionaran bien, ya que los hiperparámetros por defecto podrían (a menudo) no funcionar directamente como la mejor solución.
Sobredimensionar el problema también podría causar problemas durante el entrenamiento del modelo; a veces es mejor probar un modelo base sencillo antes de lanzarse directamente a modelos o combinaciones de modelos muy complejos.
Pregunta de la entrevista 4-6: ¿En qué escenario podrían ser útiles los modelos de conjunto?
- Ejemplo de respuesta
Cuando se trabaja con conjuntos de datos desequilibrados, en los que una clase supera significativamente a las demás, los métodos de conjunto pueden ayudar a mejorar la precisión de los resultados sobre las clases de datos minoritarias. Utilizando modelos de conjunto y combinando varios modelos, podemos evitar y reducir el sesgo del modelo hacia la clase de datos mayoritaria.
Evaluación del modelo
Ahora que estás entrenando tu modelo, es el momento de evaluarlo y determinar si debes seguir iterando sobre él o concluir que es suficientemente bueno. Como apunte, a menudo la métrica de negocio se decidirá y deberá decidirse antes de iniciar el modelado ML. Las métricas de negocio incluyen el aumento de la tasa de clics, la mejora de la tasa de conversión de los clientes o el logro de una mayor satisfacción medida por las encuestas a los clientes. Estas métricas no son las mismas que las métricas del modelo ML mencionadas en esta sección, sino que se utilizan para ver si el modelo funciona bien en el conjunto de datos de prueba después de haber sido entrenado en el conjunto de datos de entrenamiento y evaluado con el conjunto de datos de evaluación.
Los entrevistadores buscan conocimientos sobre formas habituales de evaluar modelos en este campo. Por ejemplo, las preguntas de la entrevista sobre series temporales pueden esperar que conozcas el error medio absoluto (MAE), el error cuadrático medio (RMSE) y métricas de evaluación similares, que formaron parte de una de mis entrevistas para un puesto en fintech. También es probable que hables de las compensaciones entre falsos positivos y falsos negativos, una gran parte de lo que me encontré cuando me entrevistaron para mi trabajo en el aprendizaje automático de seguridad. Otras expectativas comunes son conocer la compensación entre varianza y sesgo y cómo medirla, o la exactitud frente a la precisión y el recuerdo.
Resumen de las métricas comunes de evaluación del ML
Aquí tienes algunas métricas comunes utilizadas para evaluar los modelos de ML. Las métricas que elijas dependerán de la tarea de ML.
Ten en cuenta que no definiré todos los términos en este libro, a riesgo de que se convierta en un libro de texto de estadística, pero definiré e ilustraré los más comunes. Se incluyen recursos adicionales si quieres comprender en profundidad el resto de las métricas.
Métricas de clasificación
Las métricas de clasificación se utilizan para medir el rendimiento de los modelos de clasificación. Como abreviatura, observa que TP = verdadero positivo, TN = verdadero negativo, FP = falso positivo y FN = falso negativo, como se ilustra en la Figura 4-5. Aquí tienes otros términos y valores que debes conocer:
Precisión = TP / (TP + FP) (como se ilustra en la Figura 4-6)
Recuerdo = TP / (TP + FN) (como se ilustra en la Figura 4-6)
Precisión = (TP + TN) / (TP + TN + FP + FN)
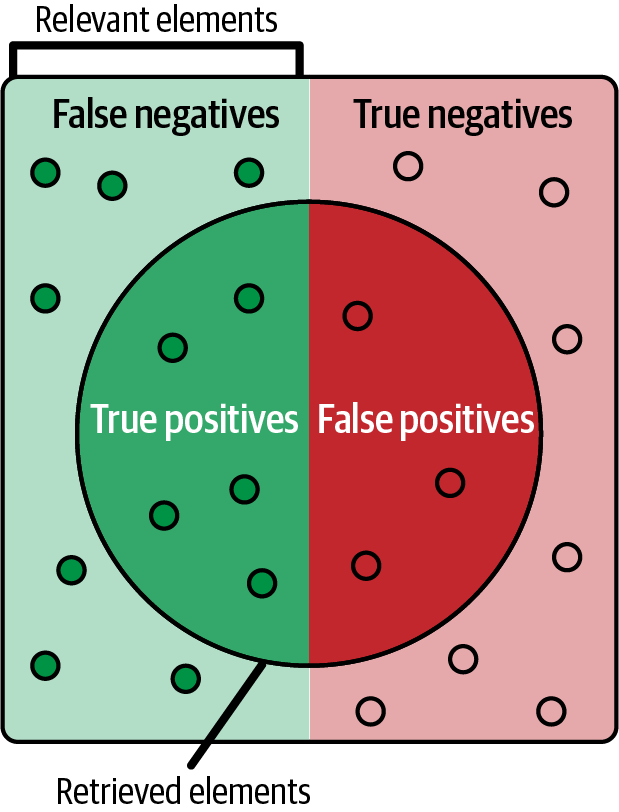
Figura 4-5. Ilustración de verdaderos positivos, falsos positivos, falsos negativos y verdaderos negativos; fuente: Walber, CC BY-SA 4.0, Wikimedia Commons.

Figura 4-6. Ilustración de la precisión frente a la recuperación.
Con estos términos, podemos construir varias evaluaciones:
- Matriz de confusión
Un resumen de los valores TP/TN/FP/FN en forma de matriz (como se ilustra en la Figura 4-7).
- Puntuación F1
Media armónica de precisión y recuperación.
- AUC (área bajo la curva ROC) y ROC (característica operativa del receptor)
La curva representa la tasa de verdaderos positivos frente a la tasa de falsos positivos con distintos umbrales.

Figura 4-7. Ejemplo de matriz de confusión.
Métricas de agrupación
Las métricas de agrupación se utilizan para medir el rendimiento de los modelos de agrupación. El uso de métricas de agrupación puede depender de si tienes o no etiquetas de verdad en el suelo. Aquí asumo que no las tienes, pero si las tienes, también se pueden utilizar las métricas de clasificación. Aquí tienes una lista de términos que debes conocer:
- Coeficiente de silueta
Mide la cohesión de un ítem con otros ítems de su cluster y la separación con ítems de otros clusters; oscila entre -1 y 1
- Índice Calinski-Harabasz
Una puntuación destinada a determinar la calidad de las agrupaciones; cuando la puntuación es más alta, significa que las agrupaciones son densas y están bien separadas
Métricas de clasificación
Las métricas de clasificación se utilizan para sistemas de recomendación o clasificación. He aquí algunos términos que debes conocer:
- Rango recíproco medio (MRR)
Mide la precisión de un sistema de clasificación en función de lo alto o bajo que aparezca el primer documento relevante
- Precisión en K
Calcula la proporción de elementos recomendados en la parte superior que son relevantes
- Ganancia acumulada descontada normalizada (GCDN)
Compara la importancia/rango que predijo el modelo ML con la relevancia real
Ahora que has decidido las métricas (y a veces querrás utilizar unas cuantas), tendrás que implementarlas con código. En las bibliotecas comunes de ML en Python, ya existen implementaciones de la mayoría de las métricas mencionadas, por lo que no tienes que implementarlas tú mismo desde cero. Las siguientes implementaciones de métricas son buenos puntos de partida:
Esta lista no es exhaustiva, así que echa un vistazo a la documentación de la biblioteca que estés utilizando. Si las implementaciones incorporadas no se ajustan a tus necesidades específicas por alguna razón, entonces puedes escribir algo personalizado. Si esto surge en la entrevista, es mejor que expliques por qué. Por ejemplo, si querías mezclar y combinar unas cuantas métricas diferentes de distintas bibliotecas, puede que tuvieras que escribir algo de código para conectarlas todas y agregarlas.
Compromisos en las métricas de evaluación
Para los entrevistadores, es importante que demuestres que puedes pensar críticamente sobre las métricas de evaluación del ML y las diversas compensaciones. Por ejemplo, utilizar sólo la precisión puede ocultar los defectos de un modelo con sus predicciones sobre una clase minoritaria (una categoría que tiene muy pocos puntos de datos en comparación con la clase mayoritaria) si el modelo es simplemente muy bueno con la predicción sobre la clase mayoritaria. En ese caso, sería bueno complementarlo con más métricas, como la puntuación F1. Sin embargo, a veces es necesario hacer explícitamente un compromiso.
Por ejemplo, en un modelo médico que predice el cáncer de pulmón a partir de imágenes de rayos X, los falsos negativos tendrán un impacto muy elevado. Por lo tanto, es deseable reducir los falsos negativos. Cuando se reducen los falsos negativos, aumenta la métrica de recuerdo (véase la definición en la sección anterior). Pero en algunas situaciones, en el camino hacia la reducción de los falsos negativos, el modelo puede haber aprendido accidentalmente a clasificar como positivos a más pacientes aunque no tengan cáncer de pulmón. En otras palabras, los falsos positivos han aumentado como resultado indirecto y han disminuido la precisión del modelo.
Por tanto, es importante decidir las compensaciones entre falsos positivos y falsos negativos; en algunos casos, el jugo puede merecer la pena, y a veces, puede que no. Será útil que puedas discutir este tipo de compensaciones cuando respondas a las preguntas de la entrevista.
Consejo
El entrevistador puede deducir de tus respuestas reflexivas que puedes pensar de forma crítica sobre los sesgos de los modelos y que puedes seleccionar modelos y métricas adecuados, lo que te convierte en un profesional del ML más eficaz.
Métodos adicionales para la evaluación offline
Utilizando las métricas del modelo que he descrito anteriormente, puedes medir la eficacia del modelo a la hora de predecir etiquetas no vistas anteriormente, en comparación con las etiquetas de la verdad básica que estaban ocultas al modelo. Es de esperar que hayas experimentado con algunos ajustes para llegar hasta aquí; incluso si tu primer modelo acabó siendo el de mejor rendimiento según las métricas, merece la pena ver qué es lo que no funciona. Puede que tu entrevistador también pregunte por ello.
Sin embargo, antes de implementar el modelo, es difícil confirmar que funcionará bien en vivo, en producción. En este caso, "en vivo" significa que está en el mundo, parecido a estar "en directo". La producción se refiere a sistemas de software que funcionan con entradas y salidas reales. Hay muchas razones por las que el modelo puede funcionar mal en producción a pesar de hacerlo bien en las métricas del modelo: la distribución de los datos en el mundo real a veces no se refleja en los datos de entrenamiento, y hay casos extremos y valores atípicos, etcétera.
Hoy en día, muchos empresarios buscan experiencia para comprender cómo pueden comportarse los modelos en la producción. Esto es diferente de una perspectiva escolar o académica, porque con insumos reales, los modelos que se comporten mal causarán pérdidas reales a una empresa. Por ejemplo, un mal modelo de detección de fraudes podría costar millones a un banco. Un sistema de recomendación que siga mostrando contenido irrelevante o inapropiado puede hacer que los clientes pierdan la confianza en una empresa. En algunos casos, la empresa podría ser demandada. A tus entrevistadores les interesará saber si eres consciente de ello y si has reflexionado sobre cómo prevenir este tipo de situaciones.
Por otra parte, es muy gratificante trabajar en ML sabiendo que, si el modelo tiene éxito, ¡podría formar parte de la prevención de pérdidas millonarias por fraude o podría estar trabajando entre bastidores de tu aplicación de streaming de música favorita!
Puedes seguir evaluando los modelos antes de ponerlos en producción y calibrar si son realmente robustos y pueden generalizarse a nuevos datos. Entre los métodos para hacerlo se incluyen:
- Pruebas de perturbación7
Introduce algo de ruido o transforma los datos de prueba. Por ejemplo, en el caso de las imágenes, comprueba si añadir aleatoriamente algunos píxeles hace que el modelo sea incapaz de predecir el resultado correcto.
- Pruebas de invarianza
Comprueba si un modelo ML funciona de forma coherente en diferentes condiciones. Por ejemplo, eliminar o cambiar ciertas entradas no debería provocar cambios drásticos en la salida. Si eliminas una característica por completo y el modelo hace predicciones diferentes, entonces deberías plantearte investigar esa característica. Esto es especialmente importante si esa característica es, o está relacionada con, información sensible, como la raza o los datos demográficos.
- Evaluación por cortes
Comprueba el rendimiento de tu modelo en varias porciones, o subgrupos, de la división de prueba. Por ejemplo, puede que tu modelo funcione bien en general en métricas como la precisión y la F1, pero cuando investigas, su rendimiento es bajo en personas mayores de 35 años y menores de 15 años. Esto será importante investigarlo e iterarlo, sobre todo si has pasado por alto algunos grupos durante el entrenamiento.
Para más información sobre estas técnicas de evaluación, consulta Designing Machine Learning Systems de Chip Huyen (O'Reilly).
Versionado de modelos
El objetivo de la evaluación de modelos es ver si un modelo funciona lo suficientemente bien, o si funciona mejor que la línea de base u otro modelo ML. Después de cada entrenamiento del modelo, tendrás varios artefactos del modelo, como la definición del modelo, los parámetros del modelo, la instantánea de los datos, etc. Cuando quieras elegir el modelo que ha funcionado bien, es más cómodo si los artefactos del modelo de salida se pueden recuperar fácilmente. Disponer de versiones del modelo es más cómodo que ejecutar todo el proceso de entrenamiento del modelo para regenerar los artefactos del modelo, aunque conozcas los hiperparámetros concretos que dieron lugar a dicho modelo.
Las herramientas utilizadas para el seguimiento de experimentos (enumeradas en "Seguimiento de experimentos" más arriba en este capítulo) a menudo también admiten el versionado de modelos.
Ejemplos de preguntas de entrevista sobre la evaluación de modelos
Ahora que hemos repasado las técnicas y consideraciones habituales para la evaluación de modelos, veamos algunos ejemplos de preguntas de entrevista.
Pregunta de la entrevista 4-7: ¿Qué es la métrica ROC y cuándo es útil?
- Ejemplo de respuesta
La curva ROC (receiver operating characteristic) puede utilizarse para evaluar un modelo de clasificación binaria. La curva traza la tasa de verdaderos positivos frente a la tasa de falsos positivos en varios umbrales -siendo el umbral la probabilidad entre 0 y 1, por encima de la cual se considera que la predicción es de esa clase-. Por ejemplo, si el umbral se fija en 0,6, las predicciones probabilísticas del modelo que estén por encima de 0,6 de probabilidad de ser la clase 1 se etiquetarán como clase 1.
Utilizar el ROC puede ayudarnos a determinar la compensación entre la tasa de verdaderos positivos y la tasa de falsos positivos con distintos umbrales, y así podremos decidir cuál es el umbral óptimo que debemos utilizar.
Pregunta de la entrevista 4-8: ¿Cuál es la diferencia entre precisión y memoria; cuándo utilizarías una sobre la otra en una tarea de clasificación?
- Ejemplo de respuesta
La precisión mide la exactitud del modelo a la hora de hacer predicciones correctas (calidad), y la recuperación mide la exactitud del modelo en términos de cuántos elementos relevantes se predicen correctamente (cantidad). Matemáticamente, la precisión es TP / (TP + FP), mientras que la recuperación es TP / (TP + FN).
La precisión puede ser más importante que la recuperación cuando es más crítico reducir los FP y mantenerlos bajos. Un ejemplo es la detección de malware o de spam por correo electrónico, donde demasiados falsos positivos pueden provocar la desconfianza del usuario. Los FP en la detección de spam de correo electrónico pueden mover correos electrónicos comerciales legítimos a la carpeta de spam, causando retrasos y pérdidas de negocio.
Por otra parte, el recuerdo puede ser más importante que la precisión en predicciones de alto riesgo, como los diagnósticos médicos. Aumentar el recuerdo significa que hay menos falsos negativos, aunque eso cause potencialmente algunos FP accidentales. En esta situación, es más prioritario minimizar las posibilidades de pasar por alto casos verdaderos.
Pregunta de la entrevista 4-9: ¿Qué es la NDCG (ganancia acumulada descontada normalizada), explicada a alto nivel? ¿Para qué tipo de tarea de ML se utiliza?
- Ejemplo de respuesta
El NDCG se utiliza para medir la calidad de las tareas de clasificación, como los sistemas de recomendación, la recuperación de información y los motores/aplicaciones de búsqueda. Compara la importancia/rango que predijo el modelo ML con la relevancia real. Si las predicciones del modelo difieren mucho de la relevancia real (o ideal), como mostrar en la parte superior de un sitio web de compras productos que no interesan al cliente, la puntuación será más baja. La NDCG se calcula mediante la suma de las puntuaciones de relevancia previstas (DCG, o ganancia acumulada descontada) dividida por la IDCG (ganancia acumulada descontada ideal). A continuación, se normaliza para que el resultado esté entre 0 y 1.
Resumen
En este capítulo, he recorrido una visión general del proceso de modelado y entrenamiento de ML y cómo cada paso se relaciona con la entrevista de ML. En primer lugar, definiste la tarea de ML y adquiriste los datos adecuados. A continuación, seleccionaste el modelo basándote en qué algoritmos eran adecuados para la tarea como punto de partida. También seleccionaste un modelo de referencia, empezando con algo sencillo con lo que comparar cualquier otro modelo de ML, como un método basado en la heurística o un modelo lo más sencillo posible, como la regresión logística.
En todos estos pasos, es importante señalar en una entrevista cómo iteraste en el proceso para mejorar el modelo, lo que incluso podría implicar volver a un paso anterior, como la adquisición de datos. Al responder a las preguntas de la entrevista sobre tu experiencia con el entrenamiento de modelos ML en tus propios proyectos, ya sean escolares, personales o de trabajo, es esencial que hables de las compensaciones a las que te enfrentaste y de las razones por las que pensaste que una determinada técnica sería útil.
No basta con tener un modelo muy preciso (medido en el conjunto de pruebas), ya que hoy en día a los empleadores les importa mucho que el candidato a ML esté expuesto a cómo podrían comportarse los modelos en producción. Si estás solicitando un puesto de ML que construye los conductos y la infraestructura de producción, entonces es aún más importante. Por último, has repasado cómo evaluar los modelos de ML y seleccionar el mejor.
En el próximo capítulo, hablaré del siguiente componente principal de las entrevistas técnicas de ML: la codificación.
1 Supongamos que para este proyecto existe algún conjunto de datos público que se adapta bien a este problema.
2 Ten en cuenta cualquier problema de licencias, derechos de autor y privacidad.
3 "Datos no estructurados", MongoDB, consultado el 24 de octubre de 2023, https://oreil.ly/3DqzA.
4 Las técnicas de muestreo se tratan en el Capítulo 3.
5 Jason Brownlee, "A Gentle Introduction to Model Selection for Machine Learning", Machine Learning Mastery (blog), 26 de septiembre de 2019, https://oreil.ly/2ylZa.
6 Mencionado en el Capítulo 3.
7 Esta terminología se utiliza en el libro de Chip Huyen Designing Machine Learning Systems (O'Reilly), y yo utilizo los mismos términos en esta sección por comodidad, ya que no parece existir una terminología unificada, sino más bien una agrupación de alto nivel.
Get Entrevistas sobre aprendizaje automático now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

