Kapitel 4. Der Systemaufruf bpf()
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Wie du in Kapitel 1 gesehen hast, stellen User-Space-Anwendungen, die wollen, dass der Kernel etwas für sie tut, Anfragen über die Systemaufruf-API. Wenn eine User-Space-Anwendung ein eBPF-Programm in den Kernel laden will, muss es also Systemaufrufe geben. Tatsächlich gibt es einen Systemaufruf namens bpf(), und in diesem Kapitel zeige ich dir, wie er zum Laden und zur Interaktion mit eBPF-Programmen und -Maps verwendet wird.
Es ist erwähnenswert, dass der eBPF-Code, der im Kernel läuft, keine Syscalls für den Zugriff auf Maps verwendet. Die Syscall-Schnittstelle wird nur von User-Space-Anwendungen verwendet. Stattdessen verwenden eBPF-Programme Hilfsfunktionen, um Maps zu lesen und zu schreiben; Beispiele dafür hast du bereits in den beiden vorherigen Kapiteln gesehen.
Wenn du später selbst eBPF-Programme schreibst, ist die Wahrscheinlichkeit groß, dass du diese bpf() Systemaufrufe nicht direkt selbst aufrufen wirst. Es gibt Bibliotheken, die ich später im Buch besprechen werde, die Abstraktionen auf höherer Ebene anbieten, um die Dinge zu vereinfachen. Allerdings entsprechen diese Abstraktionen in der Regel ziemlich direkt den zugrunde liegenden Syscall-Befehlen, die du in diesem Kapitel kennenlernst. Unabhängig davon, welche Bibliothek du verwendest, musst du die zugrundeliegenden Vorgänge - das Laden eines Programms, das Erstellen und Aufrufen von Maps usw. - beherrschen, die du in diesem Kapitel kennen lernst.
Bevor ich dir Beispiele für die Systemaufrufe von bpf() zeige, sollten wir uns ansehen, was in der Manpage von bpf() steht, nämlich dass bpf() verwendet wird, um "einen Befehl auf einer erweiterten BPF-Map oder einem Programm auszuführen". Sie sagt uns auch, dass die Signatur von bpf()wie folgt lautet:
intbpf(intcmd,unionbpf_attr*attr,unsignedintsize);
Das erste Argument von bpf(), cmd, gibt an, welcher Befehl ausgeführt werden soll. Der Syscall bpf() macht nicht nur eine Sache - es gibt viele verschiedene Befehle, die verwendet werden können, um eBPF-Programme und Maps zu manipulieren. Abbildung 4-1 zeigt einen Überblick über einige gängige Befehle, die der User Space Code verwenden kann, um eBPF-Programme zu laden, Maps zu erstellen, Programme an Ereignisse anzuhängen und auf die Schlüssel-Wert-Paare in einer Map zuzugreifen.
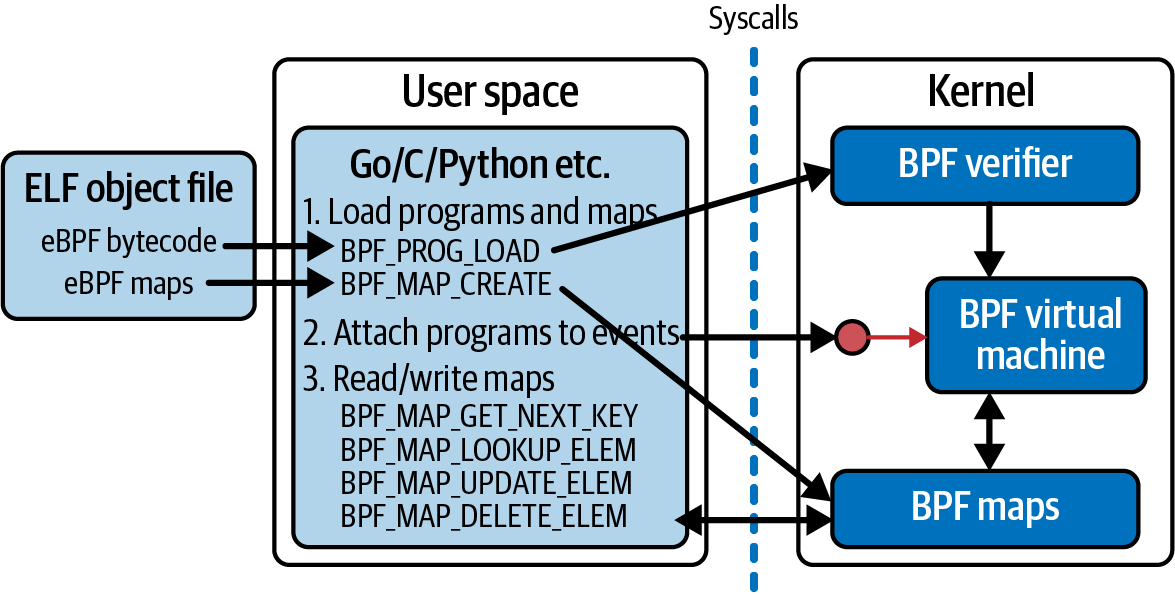
Abbildung 4-1. Ein Userspace-Programm interagiert mit eBPF-Programmen und Maps im Kernel über Syscalls
Das Argument attr für den Syscall bpf() enthält alle Daten, die zur Angabe der Parameter für den Befehl benötigt werden, und size gibt an, wie viele Bytes an Daten in attr enthalten sind.
Du hast strace bereits in Kapitel 1 kennengelernt, als ich damit gezeigt habe, wie User-Space-Code viele Anfragen über die Syscall-API stellt. In diesem Kapitel werde ich zeigen, wie der Syscall bpf() verwendet wird. Die Ausgabe von strace enthält die Argumente für jeden Syscall, aber damit die Beispielausgabe in diesem Kapitel nicht zu unübersichtlich wird, lasse ich viele Details der attr Argumente weg, sofern sie nicht besonders interessant sind.
Hinweis
Du findest den Code zusammen mit einer Anleitung zum Einrichten einer Umgebung, in der du ihn ausführen kannst, unter github.com/lizrice/learning-ebpf. Der Code für dieses Kapitel befindet sich im Verzeichnis chapter4.
Für dieses Beispiel verwende ich ein BCC-Programm namens hello-buffer-config.py, das auf den Beispielen in Kapitel 2 aufbaut. Wie das Beispiel hello-buffer.py sendet auch dieses Programm bei jeder Ausführung eine Nachricht an den Perf-Buffer, um Informationen über execve() syscall-Ereignisse vom Kernel an den User Space zu übermitteln. Neu in dieser Version ist, dass für jede Benutzerkennung unterschiedliche Nachrichten konfiguriert werden können.
Hier ist der eBPF-Quellcode:
structuser_msg_t{charmessage[12];};BPF_HASH(config,u32,structuser_msg_t);BPF_PERF_OUTPUT(output);structdata_t{intpid;intuid;charcommand[16];charmessage[12];};inthello(void*ctx){structdata_tdata={};structuser_msg_t*p;charmessage[12]="Hello World";data.pid=bpf_get_current_pid_tgid()>>32;data.uid=bpf_get_current_uid_gid()&0xFFFFFFFF;bpf_get_current_comm(&data.command,sizeof(data.command));p=config.lookup(&data.uid);if(p!=0){bpf_probe_read_kernel(&data.message,sizeof(data.message),p->message);}else{bpf_probe_read_kernel(&data.message,sizeof(data.message),message);}output.perf_submit(ctx,&data,sizeof(data));return0;}
- Diese Zeile zeigt an, dass es eine Strukturdefinition
user_msg_tgibt, die eine 12-stellige Nachricht enthält. 
- Das BCC-Makro
BPF_HASHwird verwendet, um eine Hashtabellen-Map namensconfigzu definieren. Sie enthält Werte des Typsuser_msg_t, die von Schlüsseln des Typsu32indiziert werden, was die richtige Größe für eine Benutzer-ID ist. (Wenn du die Typen für die Schlüssel und Werte nicht angibst, gibt BCC für beide den Typu64vor). 
- Die Ausgabe des Perf-Buffers wird genau so definiert wie in Kapitel 2. Du kannst beliebige Daten an einen Puffer übergeben, also musst du hier keine Datentypen angeben...

- ...obwohl das Programm in diesem Beispiel in der Praxis immer eine
data_tStruktur abgibt. Dies ist auch unverändert gegenüber dem Beispiel in Kapitel 2. 
- Der Rest des eBPF-Programms ist gegenüber der Version
hello(), die du zuvor gesehen hast, weitgehend unverändert. 
- Der einzige Unterschied besteht darin, dass der Code, nachdem er eine Hilfsfunktion verwendet hat, um die Benutzer-ID zu ermitteln, nach einem Eintrag in der Hash-Map
configmit dieser Benutzer-ID als Schlüssel sucht. Wenn es einen passenden Eintrag gibt, enthält der Wert eine Nachricht, die anstelle der Standardmeldung "Hello World" verwendet wird.
Der Python-Code hat zwei zusätzliche Zeilen:
b["config"][ct.c_int(0)]=ct.create_string_buffer(b"Hey root!")b["config"][ct.c_int(501)]=ct.create_string_buffer(b"Hi user 501!")
Diese definieren Nachrichten in der Hash-Tabelle config für die Benutzer-IDs 0 und 501, die dem Root-Benutzer und meiner Benutzer-ID auf dieser virtuellen Maschine entsprechen. Dieser Code verwendet das Python-Paket ctypes, um sicherzustellen, dass die Schlüssel und Werte dieselben Typen haben wie in der C-Definition von user_msg_t.
Hier ist eine illustrative Ausgabe dieses Beispiels, zusammen mit den Befehlen, die ich in einem zweiten Terminal ausgeführt habe, um sie zu erhalten:
Terminal 1 Terminal 2 $ ./hello-buffer-config.py 37926 501 bash Hi user 501! ls 37927 501 bash Hi user 501! sudo ls 37929 0 sudo Hey root! 37931 501 bash Hi user 501! sudo -u daemon ls 37933 1 sudo Hello World
Nachdem du nun eine Vorstellung davon bekommen hast, was dieses Programm macht, möchte ich dir die bpf() Systemaufrufe zeigen, die verwendet werden, wenn es läuft. Ich lasse es noch einmal mit strace laufen und gebe -e bpf an, um zu zeigen, dass ich nur an dem Systemaufruf bpf() interessiert bin:
$ strace -e bpf ./hello-buffer-config.py
Die Ausgabe, die du siehst, wenn du das selbst ausprobierst, zeigt mehrere Aufrufe dieses Syscalls. Bei jedem Aufruf siehst du den Befehl, der angibt, was der Syscall bpf() tun soll. In groben Zügen sieht das so aus:
bpf(BPF_BTF_LOAD, ...) = 3
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY…) = 4
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH...) = 5
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE,...prog_name="hello",...) = 6
bpf(BPF_MAP_UPDATE_ELEM, ...}
...
Gehen wir sie der Reihe nach durch. Weder du, der Leser, noch ich haben unendlich viel Geduld, also werde ich nicht jedes einzelne Argument für jeden einzelnen Aufruf diskutieren! Ich werde mich auf die Teile konzentrieren, von denen ich denke, dass sie wirklich helfen, die Geschichte zu erzählen, was passiert, wenn ein User-Space-Programm mit einem eBPF-Programm interagiert.
BTF-Daten laden
Der erste Aufruf von bpf(), den ich sehe, sieht so aus:
bpf(BPF_BTF_LOAD, {btf="\237\353\1\0...}, 128) = 3
In diesem Fall ist der Befehl, den du in der Ausgabe sehen kannst, BPF_BTF_LOAD. Dies ist nur einer von vielen gültigen Befehlen, die (zumindest zum Zeitpunkt der Erstellung dieses Artikels) im Kernel-Quellcode ausführlich dokumentiert sind.1
Wenn du einen relativ alten Linux-Kernel verwendest, kann es sein, dass du keinen Aufruf dieses Befehls siehst, da er sich auf BTF (BPF Type Format) bezieht.2 Mit BTF können eBPF-Programme über verschiedene Kernel-Versionen hinweg portiert werden, so dass du ein Programm auf einem Rechner kompilieren und auf einem anderen verwenden kannst, der vielleicht eine andere Kernel-Version und damit andere Datenstrukturen hat. Darauf werde ich in Kapitel 5 näher eingehen.
Dieser Aufruf an bpf() lädt einen Blob von BTF-Daten in den Kernel, und der Rückgabewert des Systemaufrufs bpf() (in meinem Beispiel3 ) ist ein Dateideskriptor, der auf diese Daten verweist.
Hinweis
Ein Dateideskriptor ist eine Kennung für eine geöffnete Datei (oder ein dateiähnliches Objekt). Wenn du eine Datei öffnest (mit dem Systemaufruf open() oder openat() ), ist der Rückgabewert ein Dateideskriptor, der dann als Argument an andere Systemaufrufe wie read() oder write() übergeben wird, um Operationen mit dieser Datei durchzuführen. In diesem Fall ist der Datenblock nicht wirklich eine Datei, aber er erhält einen Dateideskriptor als Identifikator, der für zukünftige Operationen, die sich auf ihn beziehen, verwendet werden kann.
Karten erstellen
Die nächste Seite bpf() erstellt die output perf buffer map:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, , key_size=4,
value_size=4, max_entries=4, ... map_name="output", ...}, 128) = 4
Aus dem Befehlsnamen BPF_MAP_CREATE kannst du wahrscheinlich schon erahnen, dass dieser Aufruf eine eBPF-Map erstellt. Du kannst sehen, dass der Typ dieser Map PERF_EVENT_ARRAY ist und sie output heißt. Die Schlüssel und Werte in dieser Perf Event Map sind 4 Byte lang. Außerdem gibt es eine Obergrenze von vier Schlüssel-Wert-Paaren, die in dieser Map gespeichert werden können, die durch das Feld max_entries definiert ist. Ich werde später in diesem Kapitel erklären, warum es vier Einträge in dieser Map gibt. Der Rückgabewert von 4 ist der Dateideskriptor für den User-Space-Code, der auf die Map output zugreift.
Der nächste bpf() Systemaufruf in der Ausgabe erstellt die config Karte:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=12,
max_entries=10240... map_name="config", ...btf_fd=3,...}, 128) = 5
Diese Map ist als Hash-Table-Map definiert, deren Schlüssel 4 Byte lang sind (das entspricht einer 32-Bit-Ganzzahl, die für eine Benutzer-ID verwendet werden kann) und deren Werte 12 Byte lang sind (das entspricht der Länge der Struktur msg_t ). Da ich die Größe der Tabelle nicht angegeben habe, wurde sie mit der BCC-Standardgröße von 10.240 Einträgen versehen.
Dieser bpf() Systemaufruf gibt auch einen Dateideskriptor zurück, 5, der verwendet wird, um in zukünftigen Systemaufrufen auf diese config Map zu verweisen.
Du kannst auch das Feld btf_fd=3 sehen, das dem Kernel mitteilt, dass er den BTF-Dateideskriptor 3 verwenden soll, der zuvor ermittelt wurde. Wie du in Kapitel 5 sehen wirst, beschreiben BTF-Informationen das Layout von Datenstrukturen. Wenn du diese Informationen in die Definition der Map aufnimmst, erhältst du Informationen über das Layout der Schlüssel- und Werttypen, die in dieser Map verwendet werden. Diese Informationen werden von Tools wie bpftool genutzt, um Map-Dumps aufzupolieren, damit sie für den Menschen lesbar sind - ein Beispiel dafür hast du in Kapitel 3 gesehen.
Ein Programm laden
Bis jetzt hast du gesehen, wie das Beispielprogramm Syscalls verwendet, um BTF-Daten in den Kernel zu laden und einige eBPF-Maps zu erstellen. Als Nächstes wird das eBPF-Programm mit dem folgenden Syscall bpf() in den Kernel geladen:
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=44,
insns=0xffffa836abe8, license="GPL", ... prog_name="hello", ...
expected_attach_type=BPF_CGROUP_INET_INGRESS, prog_btf_fd=3,...}, 128) = 6
Ein paar der Felder hier sind interessant:
Das Feld
prog_typebeschreibt den Programmtyp, der hier angibt, dass er mit einer kprobe verbunden werden soll. Mehr über Programmtypen erfährst du in Kapitel 7.Das Feld
insn_cntbedeutet "Anweisungsanzahl". Das ist die Anzahl der Bytecode-Anweisungen im Programm.Die Bytecode-Anweisungen, aus denen dieses eBPF-Programm besteht, befinden sich im Speicher an der Adresse, die im Feld
insnsangegeben ist.Dieses Programm wurde als GPL-lizensiert angegeben, damit es GPL-lizensierte BPF-Hilfsfunktionen verwenden kann.
Der Name des Programms ist
hello.expected_attach_typevonBPF_CGROUP_INET_INGRESSmag überraschen, denn das klingt nach etwas, das mit Ingress-Netzwerkverkehr zu tun hat, aber du weißt, dass dieses eBPF-Programm an eine kprobe angehängt werden wird. Tatsächlich wird das Feldexpected_attach_typenur für einige Programmtypen verwendet, undBPF_PROG_TYPE_KPROBEgehört nicht dazu.BPF_CGROUP_INET_INGRESSist zufällig der erste in der Liste der BPF-Anhangtypen,3 und hat daher den Wert0.Das Feld
prog_btf_fdteilt dem Kernel mit, welchen Blob der zuvor geladenen BTF-Daten er für dieses Programm verwenden soll. Der Wert3entspricht dem Dateideskriptor, der vom SyscallBPF_BTF_LOADzurückgegeben wurde (und es ist derselbe Blob von BTF-Daten, der für die Mapconfigverwendet wurde).
Wenn das Programm bei der Überprüfung fehlgeschlagen wäre (was ich in Kapitel 6 erläutern werde), hätte dieser Syscall einen negativen Wert zurückgegeben, aber hier siehst du, dass er den Dateideskriptor 6 zurückgegeben hat. Zusammenfassend lässt sich sagen, dass die Dateideskriptoren zu diesem Zeitpunkt die in Tabelle 4-1 angegebenen Bedeutungen haben.
| Datei-Deskriptor | Repräsentiert |
|---|---|
3 |
BTF-Daten |
4 |
output Perf-Buffer-Map |
5 |
config Hash Table Map |
6 |
hello eBPF-Programm |
Ändern einer Karte aus dem Userspace
Du hast bereits die Zeile im Quellcode des Python-Benutzerraums gesehen, die spezielle Meldungen konfiguriert, die für den Root-Benutzer mit der Benutzer-ID 0 und für den Benutzer mit der ID 501 angezeigt werden:
b["config"][ct.c_int(0)]=ct.create_string_buffer(b"Hey root!")b["config"][ct.c_int(501)]=ct.create_string_buffer(b"Hi user 501!")
Du kannst sehen, wie diese Einträge in der Map durch Syscalls wie diesen definiert werden:
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=5, key=0xffffa7842490, value=0xffffa7a2b410,
flags=BPF_ANY}, 128) = 0
Der Befehl BPF_MAP_UPDATE_ELEM aktualisiert das Schlüssel-Wert-Paar in einer Map. Das Flag BPF_ANY zeigt an, dass der Schlüssel in dieser Map erstellt werden soll, wenn er noch nicht existiert. Es gibt zwei dieser Aufrufe, die den zwei Einträgen entsprechen, die für zwei verschiedene Benutzer-IDs konfiguriert wurden.
Das Feld map_fd gibt an, mit welcher Map gearbeitet wird. Wie du siehst, ist es in diesem Fall 5, das ist der Wert des Dateideskriptors, der bei der Erstellung der Map config zurückgegeben wurde.
Dateideskriptoren werden vom Kernel für einen bestimmten Prozess zugewiesen, daher gilt dieser Wert von 5 nur für diesen bestimmten User-Space-Prozess, in dem das Python-Programm läuft. Allerdings können mehrere User-Space-Programme (und mehrere eBPF-Programme im Kernel) alle auf dieselbe Map zugreifen. Zwei User-Space-Programme, die auf dieselbe Map-Struktur im Kernel zugreifen, können sehr wohl unterschiedliche Dateideskriptorwerte erhalten; ebenso können zwei User-Space-Programme denselben Dateideskriptorwert für völlig unterschiedliche Maps haben.
Sowohl der Schlüssel als auch der Wert sind Zeiger, sodass du den numerischen Wert des Schlüssels oder des Wertes nicht aus dieser strace Ausgabe entnehmen kannst. Du könntest jedoch bpftool verwenden, um den Inhalt der Karte zu sehen, und würdest etwa Folgendes sehen:
$ bpftool map dump name config
[{
"key": 0,
"value": {
"message": "Hey root!"
}
},{
"key": 501,
"value": {
"message": "Hi user 501!"
}
}
]
Woher weiß bpftool, wie es diese Ausgabe formatieren soll? Woher weiß es zum Beispiel, dass der Wert eine Struktur mit einem Feld namens message ist, das eine Zeichenkette enthält? Die Antwort ist, dass es die Definitionen in den BTF-Informationen verwendet, die in dem Syscall BPF_MAP_CREATE enthalten sind, der diese Map definiert hat. Im nächsten Kapitel erfährst du mehr darüber, wie BTF diese Informationen weitergibt.
Du hast jetzt gesehen, wie der User Space mit dem Kernel interagiert, um Programme und Maps zu laden und die Informationen in einer Map zu aktualisieren. In der Abfolge der Syscalls, die du bis jetzt gesehen hast, wurde das Programm noch nicht mit einem Ereignis verknüpft. Dieser Schritt muss unbedingt erfolgen, sonst wird das Programm nie ausgelöst.
Ich warne dich: Verschiedene Arten von eBPF-Programmen werden auf unterschiedliche Weise mit verschiedenen Ereignissen verknüpft! Später in diesem Kapitel zeige ich dir die Syscalls, die in diesem Beispiel verwendet werden, um sich an das Ereignis kprobe anzuhängen, und in diesem Fall geht es nicht um bpf(). Im Gegensatz dazu zeige ich dir in den Übungen am Ende dieses Kapitels ein anderes Beispiel, bei dem ein bpf() Syscall verwendet wird, um ein Programm an ein Raw Tracepoint Event anzuhängen.
Bevor wir zu diesen Details kommen, möchte ich darauf eingehen, was passiert, wenn du das Programm beendest. Du wirst feststellen, dass das Programm und die Karten automatisch entladen werden, weil der Kernel sie mit Hilfe von Referenzzählungen verfolgt.
BPF-Programm und Kartenreferenzen
Du weißt, dass das Laden eines BPF-Programms in den Kernel mit dem Syscall bpf() einen Dateideskriptor zurückgibt. Innerhalb des Kernels ist dieser Dateideskriptor eine Referenz auf das Programm. Der User-Space-Prozess, der den Syscall ausgeführt hat, besitzt diesen Dateideskriptor. Wenn dieser Prozess beendet wird, wird der Dateideskriptor freigegeben und die Anzahl der Verweise auf das Programm wird verringert. Wenn es keine Verweise mehr auf ein BPF-Programm gibt, entfernt der Kernel das Programm.
Eine zusätzliche Referenz wird erstellt, wenn du ein Programm an das Dateisystem anheftest.
Pinning
Du hast Pinning bereits in Kapitel 3 mit dem folgenden Befehl in Aktion gesehen:
bpftool prog load hello.bpf.o /sys/fs/bpf/hello
Hinweis
Diese angehefteten Objekte sind keine echten Dateien, die auf der Festplatte gespeichert sind. Sie werden in einem Pseudo-Dateisystem erstellt, das sich wie ein normales plattenbasiertes Dateisystem mit Verzeichnissen und Dateien verhält. Sie werden jedoch im Speicher gehalten, was bedeutet, dass sie bei einem Neustart des Systems nicht an ihrem Platz bleiben.
Wenn bpftool dir erlauben würde, das Programm zu laden, ohne es anzuheften, wäre das sinnlos, denn der Dateideskriptor wird freigegeben, wenn bpftool beendet wird, und wenn es keine Verweise gibt, wird das Programm gelöscht, so dass nichts Nützliches erreicht worden wäre. Das Anheften an das Dateisystem bedeutet jedoch, dass es einen zusätzlichen Verweis auf das Programm gibt, so dass das Programm auch nach Beendigung des Befehls geladen bleibt.
Der Referenzzähler wird auch erhöht, wenn ein BPF-Programm mit einem Hook verbunden wird, der es auslöst. Das Verhalten dieser Referenzzähler hängt vom Typ des BPF-Programms ab. Du wirst in Kapitel 7 mehr über diese Programmtypen erfahren, aber es gibt einige, die sich auf die Nachverfolgung beziehen (wie kprobes und tracepoints) und immer mit einem User-Space-Prozess verbunden sind; für diese Arten von eBPF-Programmen wird der Referenzzähler des Kernels dekrementiert, wenn der Prozess beendet wird. Programme, die innerhalb des Netzwerkstapels oder der cgroups (kurz für "control groups") angehängt sind, sind nicht mit einem User-Space-Prozess verbunden und bleiben daher auch dann bestehen, wenn das User-Space-Programm, das sie lädt, beendet wird. Du hast bereits ein Beispiel dafür gesehen, als du ein XDP-Programm mit dem Befehl ip link geladen hast:
ip link set dev eth0 xdp obj hello.bpf.o sec xdp
Der Befehl ip ist abgeschlossen, und es gibt keine Definition eines angehefteten Ortes, aber trotzdem zeigt dir bpftool, dass das XDP-Programm im Kernel geladen ist:
$ bpftool prog list
…
1255: xdp name hello tag 9d0e949f89f1a82c gpl
loaded_at 2022-11-01T19:21:14+0000 uid 0
xlated 48B jited 108B memlock 4096B map_ids 612
Die Anzahl der Verweise für dieses Programm ist ungleich Null, da die Verbindung zum XDP-Hook auch nach Abschluss des ip link -Befehls bestehen bleibt.
eBPF-Maps haben auch Referenzzähler und werden aufgeräumt, wenn ihr Referenzzähler auf Null sinkt. Jedes eBPF-Programm, das eine Map benutzt, erhöht den Zähler, ebenso wie jeder Dateideskriptor, den User-Space-Programme für die Map halten könnten.
Es ist möglich, dass der Quellcode eines eBPF-Programms eine Map definiert, auf die das Programm eigentlich nicht verweist. Angenommen, du möchtest einige Metadaten über ein Programm speichern; du könntest sie als globale Variable definieren, und wie du im vorherigen Kapitel gesehen hast, werden diese Informationen in einer Map gespeichert. Wenn das eBPF-Programm nichts mit dieser Map macht, gibt es nicht automatisch eine Referenzzählung vom Programm zur Map. Es gibt einen BPF(BPF_PROG_BIND_MAP) Syscall, der eine Map mit einem Programm verknüpft, damit die Map nicht gelöscht wird, sobald das User-Space-Loader-Programm beendet wird und keine Dateideskriptor-Referenz auf die Map mehr hat.
Karten können auch an das Dateisystem angeheftet werden, und User-Space-Programme können auf die Karte zugreifen, wenn sie den Pfad zur Karte kennen.
Hinweis
Alexei Starovoitov hat in seinem Blogbeitrag "Lifetime of BPF Objects" eine gute Beschreibung der BPF-Referenzzähler und Dateideskriptoren geschrieben .
Eine weitere Möglichkeit, einen Verweis auf ein BPF-Programm zu erstellen, ist ein BPF-Link.
BPF Links
BPF-Links bilden eine Abstraktionsebene zwischen einem eBPF-Programm und dem Ereignis, an das es angehängt ist. Ein BPF-Link selbst kann an das Dateisystem angeheftet werden, wodurch ein zusätzlicher Verweis auf das Programm entsteht. Das bedeutet, dass der User-Space-Prozess, der das Programm in den Kernel geladen hat, beendet werden kann und das Programm geladen bleibt. Der Dateideskriptor für das User-Space-Ladeprogramm wird freigegeben, wodurch die Anzahl der Verweise auf das Programm sinkt, aber die Anzahl der Verweise ist aufgrund des BPF-Links ungleich Null.
Du wirst Gelegenheit haben, BPF-Links in Aktion zu sehen, wenn du die Übungen am Ende dieses Kapitels machst. Kommen wir nun zurück zu der Abfolge der bpf() Syscalls, die von hello-buffer-config.py verwendet werden.
Zusätzliche Syscalls, die an eBPF beteiligt sind
Um es noch einmal zusammenzufassen: Bisher hast du bpf() Syscalls gesehen, die dem Kernel die BTF-Daten, das Programm und die Maps sowie die Map-Daten hinzufügen. Das nächste, was die Ausgabe von strace zeigt, betrifft die Einrichtung des Perf-Buffers.
Hinweis
Der Rest dieses Kapitels geht relativ tief in die Syscall-Sequenzen ein, die bei der Verwendung von Perf-Puffern, Ring-Puffern, K-Probes und Map-Iterationen eine Rolle spielen. Nicht alle eBPF-Programme müssen diese Dinge tun. Wenn du es also eilig hast oder es dir zu detailliert ist, kannst du gerne zur Kapitelzusammenfassung übergehen. Ich werde nicht beleidigt sein!
Initialisierung des Leistungspuffers
Du hast die bpf(BPF_MAP_UPDATE_ELEM) Aufrufe gesehen, die Einträge in die config Karte hinzufügen. Als nächstes zeigt die Ausgabe einige Aufrufe, die wie folgt aussehen:
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0xffffa7842490, value=0xffffa7a2b410,
flags=BPF_ANY}, 128) = 0
Diese sehen den Aufrufen, die die config Map-Einträge definiert haben, sehr ähnlich, außer dass in diesem Fall der Dateideskriptor der Map 4 ist, der die output Perf Buffer Map darstellt.
Wie zuvor sind der Schlüssel und der Wert Zeiger, sodass du den numerischen Wert des Schlüssels oder des Wertes nicht aus dieser strace Ausgabe entnehmen kannst. Ich sehe, dass dieser Syscall viermal mit identischen Werten für alle Parameter wiederholt wird, obwohl es keine Möglichkeit gibt, herauszufinden, ob sich die Werte, die die Zeiger enthalten, zwischen den einzelnen Aufrufen geändert haben. Ein Blick auf diese BPF_MAP_UPDATE_ELEM bpf() Aufrufe lässt einige Fragen darüber offen, wie der Puffer eingerichtet und verwendet wird:
Warum gibt es vier Aufrufe von
BPF_MAP_UPDATE_ELEM? Hängt das damit zusammen, dass die Karteoutputmit maximal vier Einträgen erstellt wurde?Nach diesen vier Instanzen von
BPF_MAP_UPDATE_ELEMerscheinen keine weiterenbpf()Syscalls in derstraceAusgabe. Das mag etwas seltsam erscheinen, denn die Map ist dazu da, dass das eBPF-Programm jedes Mal, wenn es ausgelöst wird, Daten schreiben kann, und du hast gesehen, dass der User-Space-Code Daten anzeigt. Diese Daten werden eindeutig nicht mitbpf()Syscalls aus der Map geholt. Wie werden sie also beschafft?
Du hast auch noch keinen Hinweis darauf gesehen, wie das eBPF-Programm mit dem kprobe-Ereignis verbunden wird, das es auslöst. Um eine Erklärung für all diese Bedenken zu bekommen, muss strace noch ein paar weitere Syscalls anzeigen, wenn das Beispiel ausgeführt wird, etwa so:
$ strace -e bpf,perf_event_open,ioctl,ppoll ./hello-buffer-config.py
Der Kürze halber werde ich die Aufrufe von ioctl() ignorieren, die nicht speziell mit der eBPF-Funktionalität dieses Beispiels zu tun haben.
Anhängen an Kprobe Events
Du hast gesehen, dass der Dateideskriptor 6 zugewiesen wurde, um das eBPF-Programm Hallo zu repräsentieren, sobald es in den Kernel geladen wurde. Um das eBPF-Programm an ein Ereignis anzuhängen, brauchst du auch einen Dateideskriptor, der dieses Ereignis repräsentiert. Die folgende Zeile aus der Ausgabe von strace zeigt die Erstellung des Dateideskriptors für die execve() kprobe:
perf_event_open({type=0x6 /* PERF_TYPE_??? */, ...},...) = 7
Laut der Manpage für den Syscall perf_event_open() wird damit "ein Dateideskriptor erstellt, der die Messung von Leistungsinformationen ermöglicht." Aus der Ausgabe kannst du ersehen, dass strace nicht weiß, wie der Parameter type mit dem Wert 6 zu interpretieren ist, aber wenn du die Manpage genauer untersuchst, wird beschrieben, wie Linux dynamische Typen von Performance Measurement Unit unterstützt:
...gibt es ein Unterverzeichnis pro PMU-Instanz unter /sys/bus/event_source/devices. In jedem Unterverzeichnis gibt es eine Typdatei, deren Inhalt eine ganze Zahl ist, die im Typfeld verwendet werden kann.
Wenn du in diesem Verzeichnis nachschaust, findest du eine kprobe/type-Datei:
$ cat /sys/bus/event_source/devices/kprobe/type 6
Daran kannst du sehen, dass der Aufruf von perf_event_open() den Wert 6 hat, um anzuzeigen, dass es sich um ein Perf-Ereignis vom Typ kprobe handelt.
Leider gibt strace keine Details aus, die eindeutig zeigen würden, dass die kprobe an den Syscall execve() angehängt ist, aber ich hoffe, dass es genug Beweise gibt, um dich davon zu überzeugen, dass der zurückgegebene Dateideskriptor genau das darstellt.
Der Rückgabewert von perf_event_open() ist 7, und das steht für den Dateideskriptor für das Perf-Ereignis der kprobe, und du weißt, dass der Dateideskriptor 6 das Programm hello eBPF darstellt. In der Manpage für perf_event_open() wird auch erklärt, wie du ioctl() verwendest, um die Verbindung zwischen den beiden Programmen herzustellen:
PERF_EVENT_IOC_SET_BPF[...] ermöglicht es, ein Berkeley Packet Filter (BPF) Programm an ein bestehendes kprobe Tracepoint Event anzuhängen. Das Argument ist ein BPF-Programmdateideskriptor, der durch einen vorherigenbpf(2)Systemaufruf erstellt wurde.
Das erklärt den folgenden ioctl() Syscall, den du in der strace Ausgabe siehst, mit Argumenten, die sich auf die beiden Dateideskriptoren beziehen:
ioctl(7, PERF_EVENT_IOC_SET_BPF, 6) = 0
Es gibt auch einen weiteren ioctl() Aufruf, der das Ereignis kprobe aktiviert:
ioctl(7, PERF_EVENT_IOC_ENABLE, 0) = 0
Damit sollte das eBPF-Programm immer dann ausgelöst werden, wenn execve() auf diesem Rechner ausgeführt wird.
Einrichten und Ablesen von Perf Events
Ich habe bereits erwähnt, dass ich vier Aufrufe an bpf(BPF_MAP_UPDATE_ELEM) im Zusammenhang mit dem Output Perf Buffer sehe. Mit den zusätzlichen Syscalls, die getrackt werden, zeigt die Ausgabe von strace vier Sequenzen, wie diese:
perf_event_open({type=PERF_TYPE_SOFTWARE, size=0 /* PERF_ATTR_SIZE_??? */,
config=PERF_COUNT_SW_BPF_OUTPUT, ...}, -1, X, -1, PERF_FLAG_FD_CLOEXEC) = Y
ioctl(Y, PERF_EVENT_IOC_ENABLE, 0) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0xffffa7842490, value=0xffffa7a2b410,
flags=BPF_ANY}, 128) = 0
Ich habe X verwendet, um anzugeben, wo die Ausgabe die Werte 0, 1, 2 und 3 in den vier Instanzen dieses Aufrufs anzeigt. In der Manpage für den Syscall perf_event_open() siehst du, dass dies das Feld cpu ist und das Feld davor pid oder die Prozess-ID. Aus der Manpage:
pid == -1 und cpu >= 0
Damit werden alle Prozesse/Threads auf der angegebenen CPU gemessen.
Die Tatsache, dass diese Sequenz viermal vorkommt, entspricht der Tatsache, dass es in meinem Laptop vier CPU-Kerne gibt. Das ist endlich die Erklärung dafür, warum es vier Einträge in der "Output"-Perf-Buffer-Map gibt: Es gibt einen für jeden CPU-Kern. Das erklärt auch den Teil "Array" im Namen des Map-Typs BPF_MAP_TYPE_PERF_EVENT_ARRAY, da die Map nicht nur einen Perf Ring Buffer darstellt, sondern ein Array von Puffern, einen für jeden Kern.
Wenn du eBPF-Programme schreibst, brauchst du dich nicht um Details wie die Anzahl der Kerne zu kümmern, da dies von einer der eBPF-Bibliotheken, die in Kapitel 10 besprochen werden, für dich erledigt wird, aber ich denke, es ist ein interessanter Aspekt der Syscalls, die du siehst, wenn du strace für dieses Programm verwendest.
Die perf_event_open() Aufrufe geben jeweils einen Dateideskriptor zurück, den ich als Y dargestellt habe; diese haben die Werte 8, 9, 10 und 11. Die ioctl() Syscalls aktivieren die Perf-Ausgabe für jeden dieser Dateideskriptoren. Die BPF_MAP_UPDATE_ELEM bpf() Syscalls setzen den Map-Eintrag so, dass er auf den Perf-Ringpuffer für jeden CPU-Kern zeigt, um anzuzeigen, wo er Daten senden kann.
Der User-Space-Code kann dann ppoll() für alle vier Deskriptoren des Ausgabestroms verwenden, um die Datenausgabe zu erhalten, unabhängig davon, in welchem Kern das eBPF-Programm Hallo für ein bestimmtes execve() kprobe-Ereignis läuft. Hier ist der Syscall zu ppoll():
ppoll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN}, {fd=10, events=POLLIN},
{fd=11, events=POLLIN}], 4, NULL, NULL, 0) = 1 ([{fd=8, revents=POLLIN}])
Wie du sehen wirst, wenn du das Beispielprogramm selbst ausführst, blockieren diese ppoll() Aufrufe so lange, bis es etwas aus einem der Dateideskriptoren zu lesen gibt. Der Rückgabewert wird erst dann auf den Bildschirm geschrieben, wenn etwas den Aufruf execve() auslöst, der das eBPF-Programm dazu veranlasst, die Daten zu schreiben, die der Userspace mit diesem ppoll() Aufruf abruft.
In Kapitel 2 habe ich erwähnt, dass BPF-Ringpuffer jetzt gegenüber Perf-Puffern bevorzugt werden, wenn du einen Kernel der Version 5.8 oder höher hast.4 Schauen wir uns eine modifizierte Version desselben Beispielcodes an, die einen Ringpuffer verwendet.
Ringpuffer
Wie in der Kernel-Dokumentation erläutert, werden Ringpuffer den Perf-Puffern vorgezogen, zum einen aus Leistungsgründen, zum anderen aber auch, um sicherzustellen, dass die Reihenfolge der Daten erhalten bleibt, auch wenn die Daten von verschiedenen CPU-Kernen übermittelt werden. Es gibt nur einen Puffer, der von allen Kernen genutzt wird.
Es sind nicht viele Änderungen nötig, um hello-buffer-config.py so zu konvertieren, dass sie einen Ringpuffer verwendet. Im zugehörigen GitHub Repo findest du dieses Beispiel als chapter4/hello-ring-buffer-config.py. Tabelle 4-2 zeigt die Unterschiede.
| hello-buffer-config.py | hello-ring-buffer-config.py |
|---|---|
BPF_PERF_OUTPUT(output); |
BPF_RINGBUF_OUTPUT(output, 1); |
output.perf_submit(ctx, &data, sizeof(data)); |
output.ringbuf_output(&data, sizeof(data), 0); |
b["output"]. |
b["output"]. |
b.perf_buffer_poll() |
b.ring_buffer_poll() |
Da sich diese Änderungen nur auf den Puffer output beziehen, bleiben die Syscalls zum Laden des Programms und der config Map sowie zum Anhängen des Programms an das kprobe-Ereignis erwartungsgemäß unverändert.
Der bpf() Syscall, der die output Ringpufferkarte erstellt, sieht wie folgt aus:
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_RINGBUF, key_size=0, value_size=0,
max_entries=4096, ... map_name="output", ...}, 128) = 4
Der größte Unterschied in der Ausgabe von strace besteht darin, dass es keine Anzeichen für die vier verschiedenen Systemaufrufe perf_event_open(), ioctl() und bpf(BPF_MAP_UPDATE_ELEM) gibt, die du beim Einrichten eines Perf-Buffers beobachtet hast. Bei einem Ringpuffer gibt es nur einen Dateideskriptor, der von allen CPU-Kernen gemeinsam genutzt wird.
Zum Zeitpunkt der Erstellung dieses Artikels verwendet BCC den ppoll Mechanismus, den ich zuvor für Perf-Buffer gezeigt habe, aber er verwendet den neueren epoll Mechanismus, um auf Daten aus dem Ringpuffer zu warten. Nutzen wir dies als Gelegenheit, den Unterschied zwischen ppoll und epoll zu verstehen.
Im Perf-Buffer-Beispiel habe ich gezeigt, wie hello-buffer-config.py einen ppoll() Syscall erzeugt, etwa so:
ppoll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN}, {fd=10, events=POLLIN},
{fd=11, events=POLLIN}], 4, NULL, NULL, 0) = 1 ([{fd=8, revents=POLLIN}])
Beachte, dass dabei die Dateideskriptoren 8, 9, 10 und 11 übergeben werden, aus denen der User-Space-Prozess Daten abrufen möchte. Jedes Mal, wenn dieses Polling-Ereignis Daten zurückliefert, muss ein weiterer Aufruf an ppoll() erfolgen, um denselben Satz von Dateideskriptoren erneut einzurichten. Bei der Verwendung von epoll wird der Dateideskriptorensatz in einem Kernelobjekt verwaltet.
Du kannst dies in der folgenden Abfolge von epoll-bezogenen Systemaufrufen sehen, die gemacht werden, wenn hello-ring-buffer-config.py den Zugriff auf den output Ringpuffer einrichtet.
Zuerst bittet das User-Space-Programm darum, eine neue epoll Instanz im Kernel zu erstellen:
epoll_create1(EPOLL_CLOEXEC) = 8
Dies gibt den Dateideskriptor 8 zurück. Dann erfolgt ein Aufruf an epoll_ctl(), der dem Kernel mitteilt, dass er den Dateideskriptor 4 (den output Puffer) zu der Menge der Dateideskriptoren in dieser epoll Instanz hinzufügen soll:
epoll_ctl(8, EPOLL_CTL_ADD, 4, {events=EPOLLIN, data={u32=0, u64=0}}) = 0
Das User-Space-Programm verwendet epoll_pwait(), um zu warten, bis Daten im Ringpuffer verfügbar sind. Dieser Aufruf kehrt nur zurück, wenn Daten verfügbar sind:
epoll_pwait(8, [{events=EPOLLIN, data={u32=0, u64=0}}], 1, -1, NULL, 8) = 1
Wenn du einen Code schreibst, der ein Framework wie BCC (oder libbpf oder eine der anderen Bibliotheken, die ich später in diesem Buch beschreibe) verwendet, musst du diese grundlegenden Details darüber, wie deine User-Space-Anwendung Informationen vom Kernel über Perf oder Ringbuffer erhält, natürlich nicht kennen. Ich hoffe, du fandest es interessant, einen Blick unter die Haube zu werfen und zu sehen, wie diese Dinge funktionieren.
Es kann aber durchaus vorkommen, dass du Code schreibst, der aus dem Userspace auf eine Map zugreift, und es könnte hilfreich sein, ein Beispiel dafür zu sehen, wie das geht. Weiter oben in diesem Kapitel habe ich bpftool benutzt, um den Inhalt der Map config zu untersuchen. Da es sich um ein Dienstprogramm handelt, das im Userspace läuft, verwenden wir strace, um zu sehen, welche Systemaufrufe es tätigt, um diese Informationen zu erhalten.
Informationen von einer Karte ablesen
Der folgende Befehl zeigt einen Auszug der bpf() Syscalls, die bpftool beim Lesen des Inhalts der config Map macht:
$ strace -e bpf bpftool map dump name config
Wie du sehen wirst, besteht die Sequenz aus zwei Hauptschritten:
Gehe alle Karten durch und suche nach allen Karten mit dem Namen
config.Wenn eine übereinstimmende Karte gefunden wird, wird durch alle Elemente in dieser Karte iteriert.
Eine Karte finden
Die Ausgabe beginnt mit einer wiederholten Abfolge von ähnlichen Aufrufen, da bpftool alle Maps auf der Suche nach einer Map mit dem Namen config durchläuft:
bpf(BPF_MAP_GET_NEXT_ID, {start_id=0,...}, 12) = 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=48...}, 12) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3, ...}}, 16) = 0
bpf(BPF_MAP_GET_NEXT_ID, {start_id=48, ...}, 12) = 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=116, ...}, 12) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3...}}, 16) = 0
BPF_MAP_GET_NEXT_IDerhält die ID der nächsten Karte nach dem in angegebenen Wert.start_idBPF_MAP_GET_FD_BY_IDgibt den Dateideskriptor für die angegebene Map-ID zurück.BPF_OBJ_GET_INFO_BY_FDruft Informationen über das Objekt (in diesem Fall die Karte) ab, auf das der Dateideskriptor verweist. Zu diesen Informationen gehört auch der Name, damit überprüfen kann, ob es sich um die gesuchte Karte handelt.bpftool- Die Abfolge wiederholt sich, um die ID der nächsten Karte nach der in Schritt 1 zu erhalten.
Für jede in den Kernel geladene Map gibt es eine Gruppe dieser drei Syscalls und du solltest auch sehen, dass die Werte für start_id und map_id mit den IDs dieser Maps übereinstimmen. Das wiederholte Muster endet, wenn es keine weiteren Maps mehr zu betrachten gibt, was dazu führt, dass BPF_MAP_GET_NEXT_ID einen Wert von ENOENT zurückgibt, etwa so:
bpf(BPF_MAP_GET_NEXT_ID, {start_id=133,...}, 12) = -1 ENOENT (No such file or
directory)
Wenn eine passende Map gefunden wurde, hält bpftool ihren Dateideskriptor fest, damit sie die Elemente aus dieser Map lesen kann.
Kartenelemente lesen
Zu diesem Zeitpunkt hat bpftool einen Dateideskriptor, der auf die Karte(n) verweist, aus denen er lesen will. Schauen wir uns die Syscall-Sequenz zum Lesen dieser Informationen an:
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL,
next_key=0xaaaaf7a63960}, 24) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0xaaaaf7a63960,
value=0xaaaaf7a63980, flags=BPF_ANY}, 32) = 0
[{
"key": 0,
"value": {
"message": "Hey root!"
}
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0xaaaaf7a63960,
next_key=0xaaaaf7a63960}, 24) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0xaaaaf7a63960,
value=0xaaaaf7a63980, flags=BPF_ANY}, 32) = 0
},{
"key": 501,
"value": {
"message": "Hi user 501!"
}
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0xaaaaf7a63960,
next_key=0xaaaaf7a63960}, 24) = -1 ENOENT (No such file or directory)
}
]
+++ exited with 0 +++
- Zuerst muss die Anwendung einen gültigen Schlüssel finden, der in der Karte vorhanden ist. Dies geschieht mit der
BPF_MAP_GET_NEXT_KEYVariante desbpf()Systemaufrufs. Das Argumentkeyist ein Zeiger auf einen Schlüssel und der Syscall gibt den nächsten gültigen Schlüssel nach diesem zurück. Wenn du einen NULL-Zeiger übergibst, fordert die Anwendung den ersten gültigen Schlüssel in der Map an. Der Kernel schreibt den Schlüssel an die Stelle, die durch den Zeigernext_keyangegeben wird. - Bei einem Schlüssel fordert die Anwendung den zugehörigen Wert an, der in den durch
valueangegebenen Speicherplatz geschrieben wird. - Zu diesem Zeitpunkt hat
bpftoolden Inhalt des ersten Schlüssel-Wert-Paares und schreibt diese Information auf den Bildschirm. - Hier geht
bpftoolzum nächsten Schlüssel in der Map über, ruft seinen Wert ab und gibt dieses Schlüssel-Wert-Paar auf dem Bildschirm aus. - Der nächste Aufruf von
BPF_MAP_GET_NEXT_KEYgibtENOENTzurück, um anzuzeigen, dass es keine weiteren Einträge in der Karte gibt. - Hier schließt
bpftooldie Ausgabe auf dem Bildschirm ab und beendet sich.
Beachte, dass hier bpftool der Dateideskriptor 3 zugewiesen wurde, um der Map config zu entsprechen. Das ist die gleiche Map, auf die sich hello-buffer-config.py mit dem Dateideskriptor 4 bezieht. Wie ich bereits erwähnt habe, sind Dateideskriptoren prozessspezifisch.
Diese Analyse des Verhaltens von bpftool zeigt, wie ein User-Space-Programm durch die verfügbaren Maps und durch die in einer Map gespeicherten Schlüssel-Wert-Paare iterieren kann.
Zusammenfassung
In diesem Kapitel hast du gesehen, wie User-Space-Code den Syscall bpf() verwendet, um eBPF-Programme und -Maps zu laden. Du hast gesehen, wie Programme und Maps mit den Befehlen BPF_PROG_LOAD und BPF_MAP_CREATE erstellt werden.
Du hast gelernt, dass der Kernel die Anzahl der Verweise auf eBPF-Programme und -Maps verfolgt und sie freigibt, wenn die Anzahl der Verweise auf Null sinkt. Du hast auch die Konzepte des Pinning von BPF-Objekten in einem Dateisystem und die Verwendung von BPF-Links zur Erstellung zusätzlicher Referenzen kennengelernt.
Du hast gesehen, wie BPF_MAP_UPDATE_ELEM verwendet wird, um Einträge in einer Map aus dem Userspace zu erstellen. Es gibt ähnliche Befehle -BPF_MAP_LOOKUP_ELEM und BPF_MAP_DELETE_ELEM- zum Abrufen und Löschen von Werten aus einer Map. Außerdem gibt es den Befehl BPF_MAP_GET_NEXT_KEY, um den nächsten Schlüssel in einer Map zu finden. Mit diesem Befehl kannst du alle gültigen Einträge durchgehen.
Du hast Beispiele für User-Space-Programme gesehen, die perf_event_open() und ioctl() zum Anhängen von eBPF-Programmen an kprobe-Ereignisse verwenden. Bei anderen Arten von eBPF-Programmen kann die Attachment-Methode sehr unterschiedlich sein, und einige von ihnen verwenden sogar den Systemaufruf bpf(). So gibt es zum Beispiel den Systemaufruf bpf(BPF_PROG_ATTACH), der zum Anhängen von cgroup-Programmen verwendet werden kann, sowie und bpf(BPF_RAW_TRACEPOINT_OPEN) für Raw Tracepoints (siehe Übung 5 am Ende dieses Kapitels).
Ich habe auch gezeigt, wie du BPF_MAP_GET_NEXT_ID, BPF_MAP_GET_FD_BY_ID und BPF_OBJ_GET_INFO_BY_FD verwenden kannst, um Karten- (und andere) Objekte zu finden, die vom Kernel gehalten werden.
Es gibt noch einige andere bpf() Befehle, die ich in diesem Kapitel nicht behandelt habe, aber was du hier gesehen hast, reicht aus, um einen guten Überblick zu bekommen.
Du hast auch gesehen, wie BTF-Daten in den Kernel geladen werden, und ich habe erwähnt, dass bpftool diese Informationen nutzt, um das Format von Datenstrukturen zu verstehen, damit es sie gut ausgeben kann. Ich habe noch nicht erklärt, wie BTF-Daten aussehen und wie sie verwendet werden, um eBPF-Programme zwischen verschiedenen Kernel-Versionen portabel zu machen. Das kommt im nächsten Kapitel dran.
Übungen
Hier sind ein paar Dinge, die du ausprobieren kannst, wenn du den bpf() syscall weiter erforschen möchtest:
Überprüfe, ob das Feld
insn_cnteinesBPF_PROG_LOADSystemaufrufs mit der Anzahl der Anweisungen übereinstimmt, die ausgegeben werden, wenn du den übersetzten eBPF-Bytecode für dieses Programm mitbpftoolausgibst. (Dies ist auf der Manpage für denbpf()Systemaufruf dokumentiert.)Führe zwei Instanzen des Beispielprogramms aus, so dass es zwei Maps mit dem Namen
configgibt. Wenn dubpftool map dump name configausführst, enthält die Ausgabe Informationen über die beiden verschiedenen Maps und deren Inhalt. Führe das Programm unterstraceaus und verfolge die Verwendung der verschiedenen Dateideskriptoren anhand der Syscall-Ausgabe. Kannst du erkennen, wo er Informationen über eine Map abruft und wo er die darin gespeicherten Schlüssel-Wert-Paare abruft?Verwende
bpftool map update, um die Karteconfigzu ändern, während eines der Beispielprogramme läuft. Mitsudo -u usernamekannst du überprüfen, ob diese Konfigurationsänderungen vom eBPF-Programm übernommen werden.Während hello-buffer-config.py läuft, verwende
bpftool, um das Programm an das BPF-Dateisystem zu binden, etwa so:bpftool prog pin name hello /sys/fs/bpf/hi
Beende das laufende Programm und überprüfe mit
bpftool prog list, ob das Programm hello noch im Kernel geladen ist. Du kannst den Link auflösen, indem du den Pin mitrm /sys/fs/bpf/hientfernst.Das Anhängen an einen rohen Tracepoint ist auf der Syscall-Ebene wesentlich einfacher als das Anhängen an eine kprobe, da es einfach einen
bpf()Syscall beinhaltet. Versuche, hello-buffer-config.py so zu konvertieren, dass sie an den Raw Tracepoint fürsys_enteranhängt, indem du das BCC-MakroRAW_TRACEPOINT_PROBEverwendest (wenn du die Übungen in Kapitel 2 gemacht hast, hast du bereits ein passendes Programm, das du verwenden kannst). Du musst das Programm nicht explizit in den Python-Code einbinden, da BCC das für dich übernimmt. Wenn du das Programm unterstraceausführst, solltest du einen ähnlichen Syscall sehen wie diesen:bpf(BPF_RAW_TRACEPOINT_OPEN, {raw_tracepoint={name="sys_enter", prog_fd=6}}, 128) = 7Der Tracepoint im Kernel hat den Namen
sys_enter, und das eBPF-Programm mit dem Dateideskriptor6wird an ihn angehängt. Von nun an wird das eBPF-Programm immer dann ausgelöst, wenn die Ausführung im Kernel diesen Tracepoint erreicht.Führe die Anwendung opensnoop aus dem BCC libbpf-Toolset aus. Dieses Tool richtet einige BPF-Links ein, die du mit
bpftoolsehen kannst, etwa so:$ bpftool link list 116: perf_event prog 1849 bpf_cookie 0 pids opensnoop(17711) 117: perf_event prog 1851 bpf_cookie 0 pids opensnoop(17711)Bestätige, dass die Programm-IDs (1849 und 1851 in meinem Beispiel) mit der Ausgabe der geladenen eBPF-Programme übereinstimmen:
$ bpftool prog list ... 1849: tracepoint name tracepoint__syscalls__sys_enter_openat tag 8ee3432dcd98ffc3 gpl run_time_ns 95875 run_cnt 121 loaded_at 2023-01-08T15:49:54+0000 uid 0 xlated 240B jited 264B memlock 4096B map_ids 571,568 btf_id 710 pids opensnoop(17711) 1851: tracepoint name tracepoint__syscalls__sys_exit_openat tag 387291c2fb839ac6 gpl run_time_ns 8515669 run_cnt 120 loaded_at 2023-01-08T15:49:54+0000 uid 0 xlated 696B jited 744B memlock 4096B map_ids 568,571,569 btf_id 710 pids opensnoop(17711)Während opensnoop läuft, versuche, einen dieser Links mit
bpftool link pin id 116 /sys/fs/bpf/mylinkzu pinnen (mit einer der Link-IDs, die du in der Ausgabe vonbpftool link listsiehst). Du solltest sehen, dass auch nach dem Beenden von opensnoop sowohl der Link als auch das entsprechende Programm im Kernel geladen bleiben.Wenn du zu dem Beispielcode in Kapitel 5 übergehst, findest du eine Version von hello-buffer-config.py, die mit der libbpf-Bibliothek geschrieben wurde. Diese Bibliothek stellt automatisch einen BPF-Link zu dem Programm her, das sie in den Kernel lädt. Verwende
strace, um diebpf()Systemaufrufe zu sehen, die es macht, undbpf(BPF_LINK_CREATE)Systemaufrufe.
1 Wenn du alle BPF-Befehle sehen willst, findest du sie in der Header-Datei linux/bpf.h.
2 BTF wurde mit dem Kernel 5.1 eingeführt, ist aber in einigen Linux-Distributionen zurückportiert worden, wie du in dieser Diskussion sehen kannst.
3 Diese sind im bpf_attach_type enumerator in linux/bpf.h definiert.
4 Zur Erinnerung: Weitere Informationen über den Unterschied findest du in Andrii Nakryikos Blogbeitrag "BPF Ringpuffer".
Get eBPF lernen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

