Kapitel 1. Was ist eBPF, und warum ist es wichtig?
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
eBPF ist eine revolutionäre Kernel-Technologie, die es Entwicklern ermöglicht, eigenen Code zu schreiben, der dynamisch in den Kernel geladen werden kann und so das Verhalten des Kernels verändert. (Keine Sorge, wenn du nicht genau weißt, was der Kernel ist - darauf kommen wir in diesem Kapitel noch zu sprechen).
Dies ermöglicht eine neue Generation von hochleistungsfähigen Netzwerk-, Beobachtungs- und Sicherheitswerkzeugen. Wenn du eine Anwendung mit diesen eBPF-basierten Werkzeugen instrumentieren willst, musst du die Anwendung dank eBPFs Blickwinkel im Kernel nicht verändern oder neu konfigurieren.
Mit eBPF kannst du u.a. folgende Dinge tun
-
Performance-Tracing für so ziemlich jeden Aspekt eines Systems
-
Leistungsstarke Netzwerke mit integrierter Transparenz
-
Erkennen und (optional) Verhindern bösartiger Aktivitäten
Machen wir eine kurze Reise durch die Geschichte des eBPF, beginnend mit dem Berkeley Packet Filter.
Die Wurzeln des eBPF: Der Berkeley Packet Filter
Was wir heute als "eBPF" bezeichnen, hat seine Wurzeln im BSD Packet Filter, der erstmals 1993 in einem Papier1 von Steven McCanne und Van Jacobson vom Lawrence Berkeley National Laboratory beschrieben. In diesem Papier wird eine Pseudomaschine beschrieben, die Filter ausführen kann, also Programme, die entscheiden, ob sie ein Netzwerkpaket annehmen oder ablehnen. Diese Programme wurden im BPF-Befehlssatz geschrieben, einem allgemeinen Satz von 32-Bit-Befehlen, der der Assemblersprache sehr ähnlich ist. Hier ist ein Beispiel, das direkt aus dem Papier stammt:
ldh [12] jeq #ETHERTYPE IP, L1, L2 L1: ret #TRUE L2: ret #0
Dieses winzige Stück Code filtert Pakete heraus, die keine Internet Protocol (IP) Pakete sind. Die Eingabe für diesen Filter ist ein Ethernet-Paket, und die erste Anweisung (ldh) lädt einen 2-Byte-Wert ab Byte 12 in dieses Paket. In der nächsten Anweisung (jeq) wird dieser Wert mit dem Wert verglichen, der ein IP-Paket darstellt. Wenn er übereinstimmt, springt die Ausführung zum Befehl L1 und das Paket wird akzeptiert, indem ein Wert ungleich Null zurückgegeben wird (hier als #TRUE bezeichnet). Stimmt der Wert nicht überein, ist das Paket kein IP-Paket und wird zurückgewiesen, indem 0 zurückgegeben wird.
Du kannst dir auch komplexere Filterprogramme vorstellen, die Entscheidungen auf der Grundlage anderer Aspekte des Pakets treffen (Beispiele findest du in dem Dokument). Wichtig ist, dass der Autor des Filters seine eigenen benutzerdefinierten Programme schreiben kann, die im Kernel ausgeführt werden, und das ist das Herzstück von eBPF.
BPF steht für "Berkeley Packet Filter" und wurde 1997 in der Kernel-Version 2.1.75 erstmals in Linux eingeführt,2 Dort wurde er im Dienstprogramm tcpdump verwendet, um die zu verfolgenden Pakete effizient zu erfassen.
Im Jahr 2012 wurde seccomp-bpf in Version 3.5 des Kernels eingeführt. Dies ermöglichte die Verwendung von BPF-Programmen, um Entscheidungen darüber zu treffen, ob User-Space-Anwendungen Systemaufrufe tätigen dürfen oder nicht. Wir werden das in Kapitel 10 genauer untersuchen. Dies war der erste Schritt in der Entwicklung der BPF von der Paketfilterung zu einer Allzweckplattform, wie wir sie heute kennen. Von diesem Zeitpunkt an machte das Wort Paketfilterim Namen weniger Sinn!
Vom BPF zum eBPF
Ab der Kernel-Version 3.18 im Jahr 2014 wurde die BPF zu dem weiterentwickelt, was wir "erweiterte BPF" oder "eBPF" nennen. Dies brachte mehrere wichtige Änderungen mit sich:
-
Der BPF-Befehlssatz wurde komplett überarbeitet, um auf 64-Bit-Maschinen effizienter zu sein, und der Interpreter wurde komplett neu geschrieben.
-
Es wurden eBPF-Maps eingeführt, also Datenstrukturen, auf die BPF-Programme und User-Space-Anwendungen zugreifen können, um Informationen gemeinsam zu nutzen. Du wirst in Kapitel 2 mehr über Maps erfahren.
-
Der Systemaufruf
bpf()wurde hinzugefügt, damit User-Space-Programme mit eBPF-Programmen im Kernel interagieren können. Du erfährst mehr über diesen Systemaufruf in Kapitel 4. -
Es wurden mehrere BPF-Hilfsfunktionen hinzugefügt. Ein paar Beispiele findest du in Kapitel 2 und weitere Details in Kapitel 6.
-
Der eBPF-Verifizierer wurde hinzugefügt, um sicherzustellen, dass eBPF-Programme sicher ausgeführt werden können. Dies wird in Kapitel 6 behandelt.
Damit war der Grundstein für eBPF gelegt, aber die Entwicklung kam nicht zur Ruhe! Seitdem hat sich eBPF erheblich weiterentwickelt.
Die Entwicklung von eBPF zu Produktionssystemen
Seit 2005 gab es im Linux-Kernel eine Funktion namens kprobes (Kernel Probes), die es ermöglichte, bei fast jeder Anweisung im Kernel-Code Traps zu setzen. Entwickler konnten Kernel-Module schreiben, die Funktionen zu Debugging- oder Leistungsmessungszwecken an kprobes anschlossen.3
Die Möglichkeit, eBPF-Programme an kprobes anzuhängen, wurde 2015 eingeführt und war der Startpunkt für eine Revolution in der Art und Weise, wie Tracing in Linux-Systemen durchgeführt wird. Gleichzeitig wurden Hooks in den Netzwerkstack des Kernels eingebaut, so dass eBPF-Programme mehr Aspekte der Netzwerkfunktionalität übernehmen können. In Kapitel 8 werden wir mehr darüber erfahren.
Im Jahr 2016 wurden eBPF-basierte Tools in Produktionssystemen eingesetzt. Brendan Greggs Arbeit am Tracing bei Netflix wurde in Infrastruktur- und Betriebskreisen weithin bekannt, ebenso wie seine Aussage, dass eBPF "Superkräfte zu Linux bringt". Im selben Jahr wurde das Cilium-Projekt angekündigt, das als erstes Netzwerkprojekt eBPF verwendet, um den gesamten Datenpfad in Containerumgebungen zu ersetzen.
Im folgenden Jahr machte Facebook (jetzt Meta) Katran zu einem Open-Source-Projekt. Katran, ein Layer-4-Load-Balancer, erfüllte den Bedarf von Facebook nach einer hoch skalierbaren und schnellen Lösung. Seit 2017 wird jedes einzelne Paket, das an Facebook.com gesendet wird, durch eBPF/XDP geleitet.4 Für mich persönlich war es das Jahr, das meine Begeisterung für die Möglichkeiten dieser Technologie entfachte, nachdem ich Thomas Grafs Vortragüber eBPF und das Cilium-Projekt auf der DockerCon in Austin, Texas, gesehen hatte.
Im Jahr 2018 wurde eBPF zu einem eigenen Subsystem im Linux-Kernel, für das Daniel Borkmann von Isovalent und Alexei Starovoitov von Meta verantwortlich sind (später kam Andrii Nakryiko, ebenfalls von Meta, hinzu). Im selben Jahr wurde das BPF Type Format (BTF) eingeführt, das eBPF-Programme viel portabler macht. Darauf gehen wir in Kapitel 5 ein.
Im Jahr 2020 wurde die LSM BPF eingeführt, mit der eBPF-Programme an die Linux Security Module (LSM)-Kernel-Schnittstelle angehängt werden können. Damit wurde ein dritter wichtiger Anwendungsfall für eBPF identifiziert: Es wurde klar, dass eBPF neben der Vernetzung und der Beobachtbarkeit auch eine großartige Plattform für Sicherheitswerkzeuge ist.
Im Laufe der Jahre sind die Fähigkeiten von eBPF dank der Arbeit von mehr als 300 Kernel-Entwicklern und vielen Mitwirkenden an den zugehörigen User-Space-Tools (wie bpftool, das wir in Kapitel 3 kennenlernen werden), Compilern und Programmiersprachenbibliotheken erheblich gewachsen. Früher waren Programme auf 4.096 Anweisungen beschränkt, aber diese Grenze ist auf 1 Million verifizierte Anweisungen angewachsen5 und ist durch die Unterstützung von Tail Calls und Funktionsaufrufen (die du in Kapitel 2 und 3 kennenlernen wirst) praktisch irrelevant geworden.
Hinweis
Wer könnte einen besseren Einblick in die Geschichte von eBPF geben als die Maintainer, die von Anfang an daran mitgearbeitet haben?
Alexei Starovoitov hielt einen faszinierenden Vortrag über die Geschichte der eBPF, ausgehend von ihren Wurzeln im Software-defined Networking (SDN). In seinem Vortrag geht er auf die Strategien ein, mit denen die frühen eBPF-Patches in den Kernel aufgenommen wurden, und verrät, dass der offizielle Geburtstag der eBPF der 26. September 2014 ist, an dem der erste Satz von Patches für den Verifier, den BPF-Systemaufruf und die Maps angenommen wurde.
Daniel Borkmann hat auch die Geschichte der BPF und ihre Entwicklung zur Unterstützung von Netzwerk- und Tracing-Funktionen diskutiert. Ich empfehle seinen Vortrag "eBPF und Kubernetes: Little Helper Minions for Scaling Microservices", der viele interessante Informationen enthält.
Benennen ist schwer
Die Anwendungen von eBPF gehen so weit über das Filtern von Paketen hinaus, dass das Akronym im Grunde bedeutungslos geworden ist und sich zu einem eigenständigen Begriff entwickelt hat. Und da die heute weit verbreiteten Linux-Kernel alle die "erweiterten" Teile unterstützen, werden die Begriffe eBPF und BPF weitgehend austauschbar verwendet. Im Kernel-Quellcode und bei der eBPF-Programmierung ist die gängige Terminologie BPF. Wie wir in Kapitel 4 sehen werden, lautet zum Beispiel der Systemaufruf für die Interaktion mit eBPF bpf(), Hilfsfunktionen beginnen mit bpf_ und die verschiedenen Arten von (e)BPF-Programmen werden mit Namen gekennzeichnet, die mit BPF_PROG_TYPE beginnen. Außerhalb der Kernel-Community scheint sich der Name "eBPF" durchgesetzt zu haben, zum Beispiel auf der Community-Seite ebpf.io und im Namen der eBPF Foundation.
Der Linux-Kernel
Um eBPF zu verstehen, musst du den Unterschied zwischen dem Kernel und dem User Space von Linux kennen. Das habe ich in meinem Bericht "Was ist eBPF?"6 behandelt, und ich habe einige der Inhalte für die nächsten Absätze angepasst.
Der Linux-Kernel ist die Softwareschicht zwischen deinen Anwendungen und der Hardware, auf der sie ausgeführt werden. Anwendungen laufen in einer unprivilegierten Schicht, dem so genannten User Space, der nicht direkt auf die Hardware zugreifen kann. Stattdessen stellt eine Anwendung über die Systemaufrufschnittstelle (syscall) Anfragen, um den Kernel zu bitten, in ihrem Namen zu handeln. Dieser Hardwarezugriff kann das Lesen und Schreiben von Dateien, das Senden und Empfangen von Netzwerkverkehr oder auch nur den Zugriff auf den Speicher umfassen. Der Kernel ist auch für die Koordinierung gleichzeitiger Prozesse zuständig, damit viele Anwendungen gleichzeitig laufen können. Dies wird in Abbildung 1-1 dargestellt.
Als Anwendungsentwickler nutzen wir die Systemaufrufschnittstelle in der Regel nicht direkt, weil uns Programmiersprachen High-Level-Abstraktionen und Standardbibliotheken zur Verfügung stellen, die einfachere Schnittstellen zum Programmieren sind. Daher sind sich viele Leute gar nicht bewusst, wie viel der Kernel tut, während unsere Programme laufen. Wenn du ein Gefühl dafür bekommen möchtest, wie oft der Kernel aufgerufen wird, kannst du das Dienstprogramm strace verwenden, um alle Systemaufrufe einer Anwendung anzuzeigen.
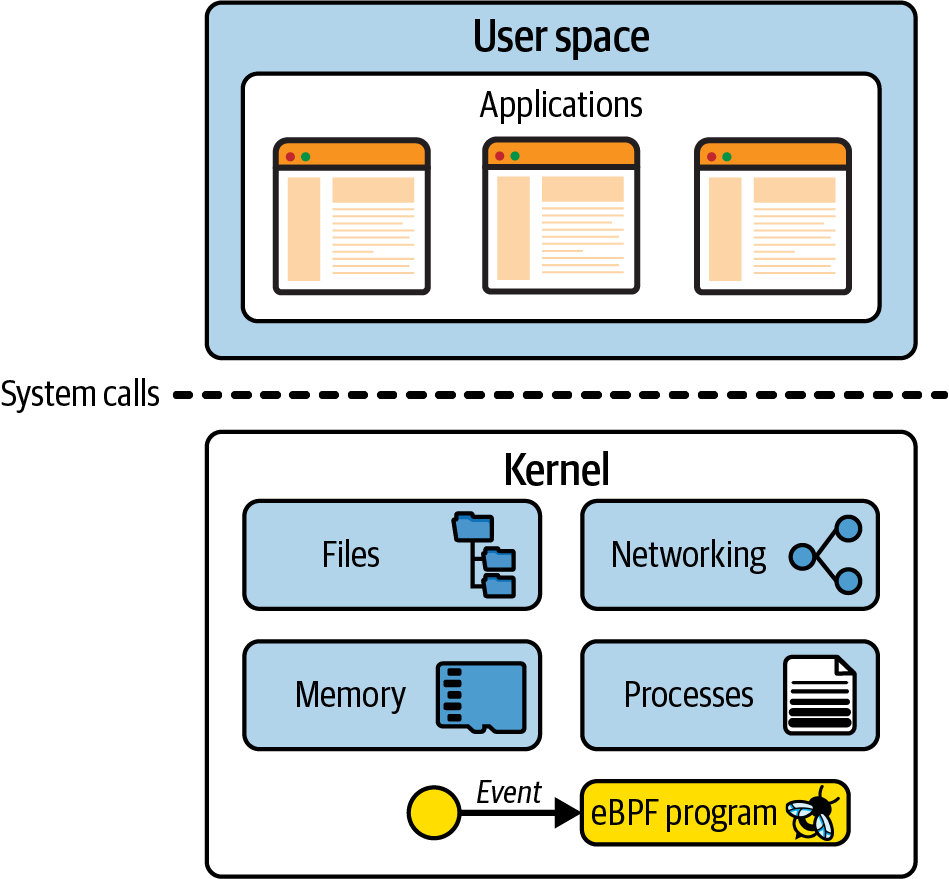
Abbildung 1-1. Anwendungen im Userspace verwenden die Syscall-Schnittstelle, um Anfragen an den Kernel zu stellen
Hier ist ein Beispiel, bei dem die Verwendung von cat, um das Wort "Hallo" auf dem Bildschirm auszugeben, mehr als 100 Systemaufrufe erfordert:
$ strace -c echo "hello" hello % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 24.62 0.001693 56 30 12 openat 17.49 0.001203 60 20 mmap 15.92 0.001095 57 19 newfstatat 15.66 0.001077 53 20 close 10.35 0.000712 712 1 execve 3.04 0.000209 52 4 mprotect 2.52 0.000173 57 3 read 2.33 0.000160 53 3 brk 2.09 0.000144 48 3 munmap 1.11 0.000076 76 1 write 0.96 0.000066 66 1 1 faccessat 0.76 0.000052 52 1 getrandom 0.68 0.000047 47 1 rseq 0.65 0.000045 45 1 set_robust_list 0.63 0.000043 43 1 prlimit64 0.61 0.000042 42 1 set_tid_address 0.58 0.000040 40 1 futex ------ ----------- ----------- --------- --------- ---------------- 100.00 0.006877 61 111 13 total
Da Anwendungen so stark auf den Kernel angewiesen sind, können wir viel darüber lernen, wie sich eine Anwendung verhält, wenn wir ihre Interaktionen mit dem Kernel beobachten können. Mit eBPF können wir den Kernel mit Instrumenten versehen, um diese Erkenntnisse zu gewinnen.
Wenn es dir zum Beispiel gelingt, den Systemaufruf zum Öffnen von Dateien abzufangen, kannst du genau sehen, auf welche Dateien eine Anwendung zugreift. Aber wie könntest du dieses Abfangen durchführen? Überlegen wir uns, was passieren würde, wenn wir den Kernel verändern und neuen Code hinzufügen würden, um eine Art Ausgabe zu erzeugen, wenn dieser Systemaufruf aufgerufen wird.
Hinzufügen neuer Funktionen zum Kernel
Der Linux-Kernel ist komplex und besteht zum Zeitpunkt der Erstellung dieses Artikels aus rund 30 Millionen Codezeilen.7 Änderungen an der Codebasis erfordern eine gewisse Vertrautheit mit dem bestehenden Code. Wenn du also nicht bereits ein Kernel-Entwickler bist, wird das wahrscheinlich eine Herausforderung sein.
Wenn du deine Änderungen in den Quellcode einbringen willst, stehst du außerdem vor einer Herausforderung, die nicht nur technischer Natur ist. Linux ist ein Allzweck-Betriebssystem, das in allen möglichen Umgebungen und unter allen Umständen eingesetzt wird. Wenn du also möchtest, dass deine Änderung Teil einer offiziellen Linux-Version wird, geht es nicht nur darum, einen funktionierenden Code zu schreiben. Der Code muss von der Gemeinschaft (und insbesondere von Linus Torvalds, dem Erfinder und Hauptentwickler von Linux) als eine Änderung akzeptiert werden, die dem Wohl aller dient. Das ist keine Selbstverständlichkeit - nur ein Drittel der eingereichten Kernel-Patches wird angenommen.8
Nehmen wir an, du hast einen guten technischen Ansatz gefunden, um den Systemaufruf zum Öffnen von Dateien abzufangen. Nach einigen Monaten Diskussion und harter Entwicklungsarbeit deinerseits, nehmen wir an, dass die Änderung im Kernel akzeptiert wird. Prima! Aber wie lange wird es dauern, bis sie auf allen Rechnern angekommen ist?
Alle zwei oder drei Monate gibt es eine neue Version des Linux-Kernels, aber selbst wenn eine Änderung in eine dieser Versionen aufgenommen wurde, ist sie noch lange nicht in den Produktionsumgebungen der meisten Menschen verfügbar. Das liegt daran, dass die meisten von uns nicht nur den Linux-Kernel direkt nutzen, sondern auch Linux-Distributionen wie Debian, Red Hat, Alpine und Ubuntu, die eine Version des Linux-Kernels mit verschiedenen anderen Komponenten zusammenfassen. Es kann gut sein, dass deine Lieblingsdistribution eine Kernelversion verwendet, die mehrere Jahre alt ist.
Viele Unternehmensanwender setzen zum Beispiel Red Hat Enterprise Linux (RHEL) ein. Zum Zeitpunkt der Erstellung dieses Artikels ist die aktuelle Version RHEL 8.5 vom November 2021 und verwendet die Version 4.18 des Linux-Kernels. Dieser Kernel wurde im August 2018 veröffentlicht.
Wie die Karikatur in Abbildung 1-2 zeigt, dauert es buchstäblich Jahre, bis eine neue Funktion aus dem Ideenstadium in die Produktionsumgebung eines Linux-Kernels gelangt.9

Abbildung 1-2. Hinzufügen von Funktionen zum Kernel (Cartoon von Vadim Shchekoldin, Isovalent)
Kernel Module
Wenn du nicht jahrelang darauf warten willst, dass deine Änderungen in den Kernel aufgenommen werden, gibt es eine andere Möglichkeit. Der Linux-Kernel wurde so konzipiert, dass er Kernel-Module akzeptiert, die bei Bedarf geladen und entladen werden können. Wenn du das Verhalten des Kernels ändern oder erweitern möchtest, ist das Schreiben eines Moduls eine Möglichkeit, dies zu tun. Ein Kernelmodul kann unabhängig von der offiziellen Version des Linux-Kernels verbreitet werden und muss daher nicht in die Haupt-Codebasis aufgenommen werden.
Die größte Herausforderung dabei ist, dass es sich immer noch um eine vollständige Kernelprogrammierung handelt. Die Benutzer waren in der Vergangenheit sehr vorsichtig bei der Verwendung von Kernel-Modulen, und zwar aus einem einfachen Grund: Wenn der Kernel-Code abstürzt, wird der Rechner und alles, was darauf läuft, lahmgelegt. Wie kann ein Benutzer sicher sein, dass ein Kernelmodul sicher ist?
Sicher zu sein bedeutet nicht nur, nicht abzustürzen - der Benutzer möchte wissen, ob ein Kernelmodul aus Sicherheitssicht sicher ist. Enthält es Schwachstellen, die ein Angreifer ausnutzen könnte? Können wir den Autoren des Moduls vertrauen, dass sie keinen bösartigen Code einbauen? Da der Kernel privilegierter Code ist, hat er Zugriff auf alles auf dem Rechner, einschließlich aller Daten. Das gilt auch für Kernel-Module.
Die Sicherheit des Kernels ist ein wichtiger Grund, warum Linux-Distributionen so lange brauchen, um neue Versionen zu integrieren. Wenn andere Leute eine Kernelversion schon seit Monaten oder Jahren unter verschiedenen Bedingungen einsetzen, sollten die Probleme beseitigt worden sein. Die Betreuer der Distributionen können sich darauf verlassen, dass der Kernel, den sie an ihre Benutzer/Kunden ausliefern, gehärtetist , d.h. dasser sicher betrieben werden kann.
eBPF bietet einen ganz anderen Sicherheitsansatz: den eBPF-Verifizierer, der sicherstellt, dass ein eBPF-Programm nur dann geladen wird, wenn es sicher ausgeführt werden kann - es wird den Rechner nicht zum Absturz bringen oder in einer harten Schleife feststecken, und es wird nicht zulassen, dass Daten kompromittiert werden. Wir werden den Verifizierungsprozess in Kapitel 6 näher erläutern.
Dynamisches Laden von eBPF-Programmen
eBPF-Programme können dynamisch in den Kernel geladen und aus ihm entfernt werden. Sobald sie an ein Ereignis angehängt sind, werden sie durch dieses Ereignis ausgelöst, unabhängig davon, wodurch dieses Ereignis ausgelöst wurde. Wenn du zum Beispiel ein Programm an den Syscall zum Öffnen von Dateien anhängst, wird es immer dann ausgelöst, wenn ein Prozess versucht, eine Datei zu öffnen. Dabei spielt es keine Rolle, ob dieser Prozess bereits lief, als das Programm geladen wurde. Das ist ein enormer Vorteil im Vergleich zu einem Kernel-Upgrade, bei dem man den Rechner neu starten muss, um die neuen Funktionen zu nutzen.
Daraus ergibt sich eine der großen Stärken von Observability- oder Sicherheitstools, die eBPF nutzen: Sie haben sofort einen Überblick über alles, was auf dem Rechner passiert. In Umgebungen mit Containern bedeutet das, dass alle Prozesse, die in den Containern und auf dem Host-Rechner laufen, sichtbar sind. Auf die Konsequenzen für Cloud Native Deployments gehe ich später in diesem Kapitel ein.
Wie in Abbildung 1-3 dargestellt, kann man mit eBPF sehr schnell neue Kernel-Funktionen erstellen, ohne dass alle anderen Linux-Benutzer dieselben Änderungen akzeptieren müssen.

Abbildung 1-3. Hinzufügen von Kernel-Features mit eBPF (Cartoon von Vadim Shchekoldin, Isovalent)
Hohe Leistung der eBPF-Programme
eBPF-Programme sind ein sehr effizienter Weg, um eine Instrumentierung hinzuzufügen. Sobald das Programm geladen und JIT-kompiliert ist (was du in Kapitel 3 sehen wirst), läuft es als native Maschinenanweisungen auf der CPU. Außerdem muss nicht für jedes Ereignis zwischen Kernel- und Userspace gewechselt werden (was eine teure Operation ist).
Das Papier von 201810 in dem der eXpress Data Path (XDP) beschrieben wird, enthält einige Beispiele für die Leistungsverbesserungen, die eBPF im Netzwerk ermöglicht. Zum Beispiel verbessert die Implementierung von Routing in XDP "die Leistung um den Faktor 2,5" im Vergleich zur regulären Linux-Kernel-Implementierung, und "XDP bietet einen Leistungsgewinn von 4,3x gegenüber IPVS" beim Lastausgleich.
Für die Nachverfolgung der Leistung und die Beobachtung der Sicherheit besteht ein weiterer Vorteil von eBPF darin, dass relevante Ereignisse innerhalb des Kernels gefiltert werden können, bevor die Kosten für das Senden an den Userspace anfallen. Bei der ursprünglichen BPF-Implementierung ging es schließlich darum, nur bestimmte Netzwerkpakete zu filtern. Heute können eBPF-Programme Informationen über alle möglichen Ereignisse in einem System sammeln und komplexe, angepasste programmatische Filter verwenden, um nur die relevanten Informationen an den Userspace zu senden.
eBPF in Cloud Native Umgebungen
Heutzutage entscheiden sich viele Unternehmen dafür, ihre Anwendungen nicht direkt auf Servern auszuführen. Stattdessen nutzen sie Cloud-native Ansätze: Container, Orchestratoren wie Kubernetes oder ECS oder serverlose Ansätze wie Lambda, Cloud Functions, Fargate und so weiter. Diese Ansätze nutzen alle die Automatisierung, um den Server auszuwählen, auf dem die einzelnen Workloads ausgeführt werden; bei Serverless wissen wir nicht einmal, auf welchem Server die einzelnen Workloads laufen.
Dennoch sind Server beteiligt, und auf jedem dieser Server (egal ob es sich um eine virtuelle Maschine oder einen Bare-Metal-Rechner handelt) läuft ein Kernel. Wenn Anwendungen in Containern auf demselben (virtuellen) Rechner laufen, teilen sie sich denselben Kernel. In einer Kubernetes-Umgebung bedeutet das, dass alle Container in allen Pods auf einem bestimmten Knoten denselben Kernel verwenden. Wenn wir diesen Kernel mit eBPF-Programmen instrumentieren, sind alle containerisierten Workloads auf diesem Knoten für diese eBPF-Programme sichtbar, wie in Abbildung 1-4 dargestellt.
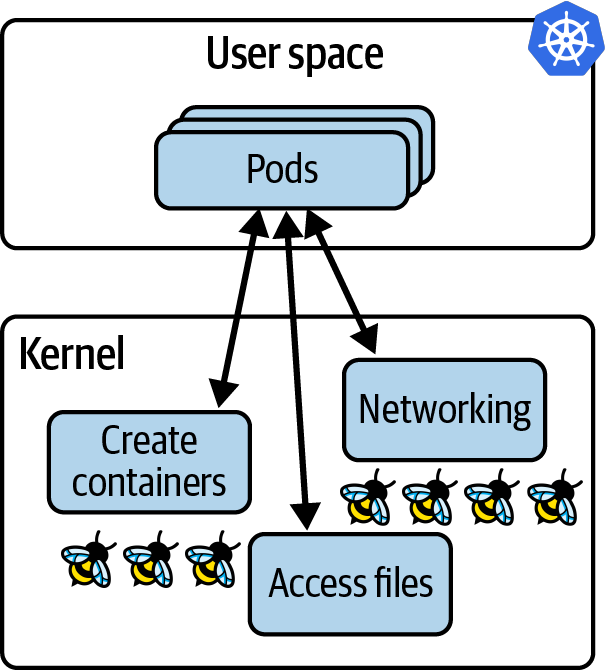
Abbildung 1-4. eBPF-Programme im Kernel haben Einblick in alle Anwendungen, die auf einem Kubernetes-Knoten laufen
Die Sichtbarkeit aller Prozesse auf dem Knoten in Kombination mit der Möglichkeit, eBPF-Programme dynamisch zu laden, verleiht uns die wahren Superkräfte des eBPF-basierten Toolings im Cloud Native Computing:
-
Wir müssen unsere Anwendungen nicht ändern, nicht einmal die Art und Weise, wie sie konfiguriert sind, um sie mit dem eBPF-Tooling zu instrumentieren.
-
Sobald es in den Kernel geladen und an ein Ereignis angehängt ist, kann ein eBPF-Programm damit beginnen, bereits existierende Anwendungsprozesse zu beobachten.
Im Gegensatz dazu steht das Sidecar-Modell, mit dem Funktionen wie Logging, Tracing, Sicherheit und Service-Mesh-Funktionen in Kubernetes-Anwendungen integriert werden können. Bei der Sidecar-Methode wird die Instrumentierung als Container ausgeführt, der in jeden Anwendungs-Pod "injiziert" wird. Dazu muss die YAML-Datei, die die Anwendungs-Pods definiert, geändert und die Definition des Sidecar-Containers hinzugefügt werden. Dieser Ansatz ist sicherlich bequemer, als die Instrumentierung in den Quellcode der Anwendung einzubauen (was wir vor dem Sidecar-Ansatz tun mussten, z. B. eine Logging-Bibliothek in unsere Anwendung einbinden und an den entsprechenden Stellen im Code Aufrufe in diese Bibliothek machen). Der Sidecar-Ansatz hat jedoch auch ein paar Nachteile:
-
Der Anwendungs-Pod muss neu gestartet werden, damit das Sidecar hinzugefügt werden kann.
-
Irgendetwas muss die YAML der Anwendung ändern. Das ist in der Regel ein automatischer Prozess, aber wenn etwas schief geht, wird das Sidecar nicht hinzugefügt, was bedeutet, dass der Pod nicht instrumentiert wird. Ein Deployment kann zum Beispiel mit einem Vermerk versehen werden, der besagt, dass ein Admission Controller die Sidecar-YAML zu den Pod-Spezifikationen für dieses Deployment hinzufügen soll. Wenn das Deployment jedoch nicht korrekt beschriftet ist, wird das Sidecar nicht hinzugefügt und ist daher für die Instrumentierung nicht sichtbar.
-
Wenn sich mehrere Container in einem Pod befinden, können sie zu unterschiedlichen Zeitpunkten ihre Bereitschaft erreichen, deren Reihenfolge nicht vorhersehbar ist. Die Startzeit eines Pods kann durch die Einbindung von Sidecars erheblich verlangsamt werden, oder schlimmer noch, es kann zu Race Conditions oder anderen Instabilitäten führen. In der Open Service Mesh-Dokumentation wird z. B. beschrieben, wie Anwendungscontainer darauf reagieren müssen, dass der gesamte Datenverkehr unterbrochen wird, bis der Envoy-Proxy-Container bereit ist.
-
Wenn Netzwerkfunktionen wie Service Mesh als Sidecar implementiert werden, bedeutet dies zwangsläufig, dass der gesamte Datenverkehr zum und vom Anwendungscontainer den Netzwerkstack im Kernel durchlaufen muss, um einen Netzwerk-Proxy-Container zu erreichen, was zu einer zusätzlichen Latenz führt; dies ist in Abbildung 1-5 dargestellt. Wir werden in Kapitel 9 über die Verbesserung der Netzwerkeffizienz mit eBPF sprechen.
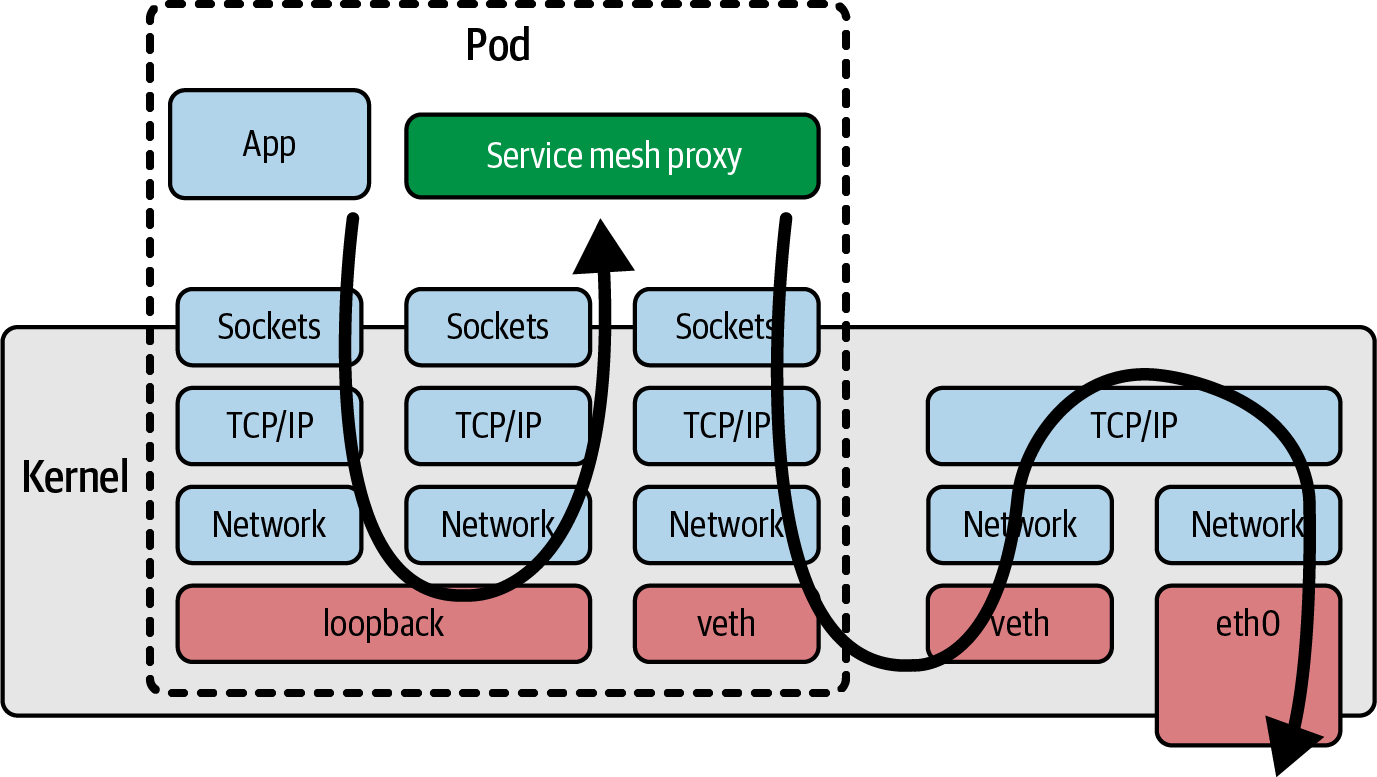
Abbildung 1-5. Pfad eines Netzwerkpakets mit einem Service-Mesh-Proxy-Sidecar-Container
All das sind Probleme, die dem Seitenwagenmodell innewohnen. Glücklicherweise haben wir jetzt, da eBPF als Plattform verfügbar ist, ein neues Modell, das diese Probleme vermeiden kann. Da eBPF-basierte Tools alles sehen können, was auf einer (virtuellen) Maschine passiert, ist es für Angreifer außerdem schwieriger, sie zu umgehen. Wenn es einem Angreifer zum Beispiel gelingt, eine Anwendung zum Schürfen von Kryptowährungen auf einem deiner Hosts zu installieren, wird er dir wahrscheinlich nicht den Gefallen tun, sie mit den Sidecars zu instrumentieren, die du für deine Anwendungs-Workloads verwendest. Wenn du dich auf ein Sidecar-basiertes Sicherheitstool verlässt, um zu verhindern, dass Apps unerwartete Netzwerkverbindungen herstellen, wird dieses Tool die Mining-App, die sich mit ihrem Mining-Pool verbindet, nicht erkennen, wenn das Sidecar nicht injiziert wurde. Im Gegensatz dazu kann die in eBPF implementierte Netzwerksicherheit den gesamten Datenverkehr auf dem Host-Rechner überwachen, so dass das Mining von Kryptowährungen leicht gestoppt werden könnte. Auf die Möglichkeit, Netzwerkpakete aus Sicherheitsgründen zu verwerfen, werden wir in Kapitel 8 zurückkommen.
Zusammenfassung
Ich hoffe, dieses Kapitel hat dir einen Einblick gegeben, warum eBPF als Plattform so mächtig ist. Sie ermöglicht es uns, das Verhalten des Kernels zu ändern und gibt uns die Flexibilität, maßgeschneiderte Tools oder angepasste Richtlinien zu erstellen. eBPF-basierte Tools können jedes Ereignis im gesamten Kernel und damit in allen Anwendungen, die auf einer (virtuellen) Maschine laufen, beobachten, unabhängig davon, ob sie in Containern laufen oder nicht. eBPF-Programme können auch dynamisch eingesetzt werden, so dass das Verhalten im laufenden Betrieb geändert werden kann.
Bis jetzt haben wir eBPF auf einer relativ konzeptionellen Ebene diskutiert. Im nächsten Kapitel werden wir konkreter werden und die Bestandteile einer eBPF-basierten Anwendung untersuchen.
1 "The BSD Packet Filter: A New Architecture for User-level Packet Capture" von Steven McCanne und Van Jacobson.
2 Diese und andere Details stammen aus Alexei Starovoitovs NetDev-Präsentation 2015, "BPF - in-kernel virtual machine".
3 Es gibt eine gute Beschreibung der Funktionsweise von kprobes in der Kernel-Dokumentation.
4 Diese wunderbare Tatsache stammt aus dem KubeCon 2020-Vortrag von Daniel Borkmann mit dem Titel "eBPF und Kubernetes: Kleine Helferlein für die Skalierung von Microservices".
5 Weitere Informationen über die Anweisungsgrenze und die "Komplexitätsgrenze" findest du unter https://oreil.ly/0iVer.
6 Auszug aus "Was ist eBPF?" von Liz Rice. Copyright © 2022 O'Reilly Media. Verwendung mit Genehmigung.
7 "Linux 5.12 Coming In At Around 28.8 Million Lines", Phoronix, März 2021.
8 Jiang Y, Adams B, German DM. 2013. "Wird mein Patch es schaffen? And How Fast?" (2013). Laut dieser Studie werden 33 % der Patches angenommen, und die meisten brauchen drei bis sechs Monate.
9 Zum Glück werden Sicherheits-Patches für bestehende Funktionen schneller zur Verfügung gestellt.
10 Høiland-Jørgensen T, Brouer JD, Borkmann D, et al. "The eXpress data path: fast programmable packet processing in the operating system kernel". Proceedings of the 14th International Conference on emerging Networking EXperiments and Technologies (CoNEXT '18). Association for Computing Machinery; 2018:54-66.
Get eBPF lernen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

