Capítulo 11. Procesamiento de flujos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Un sistema complejo que funciona resulta invariablemente haber evolucionado a partir de un sistema simple que funciona. La proposición inversa también parece ser cierta: Un sistema complejo diseñado desde cero nunca funciona y no se puede hacer que funcione.
John Gall, Sistemática (1975)
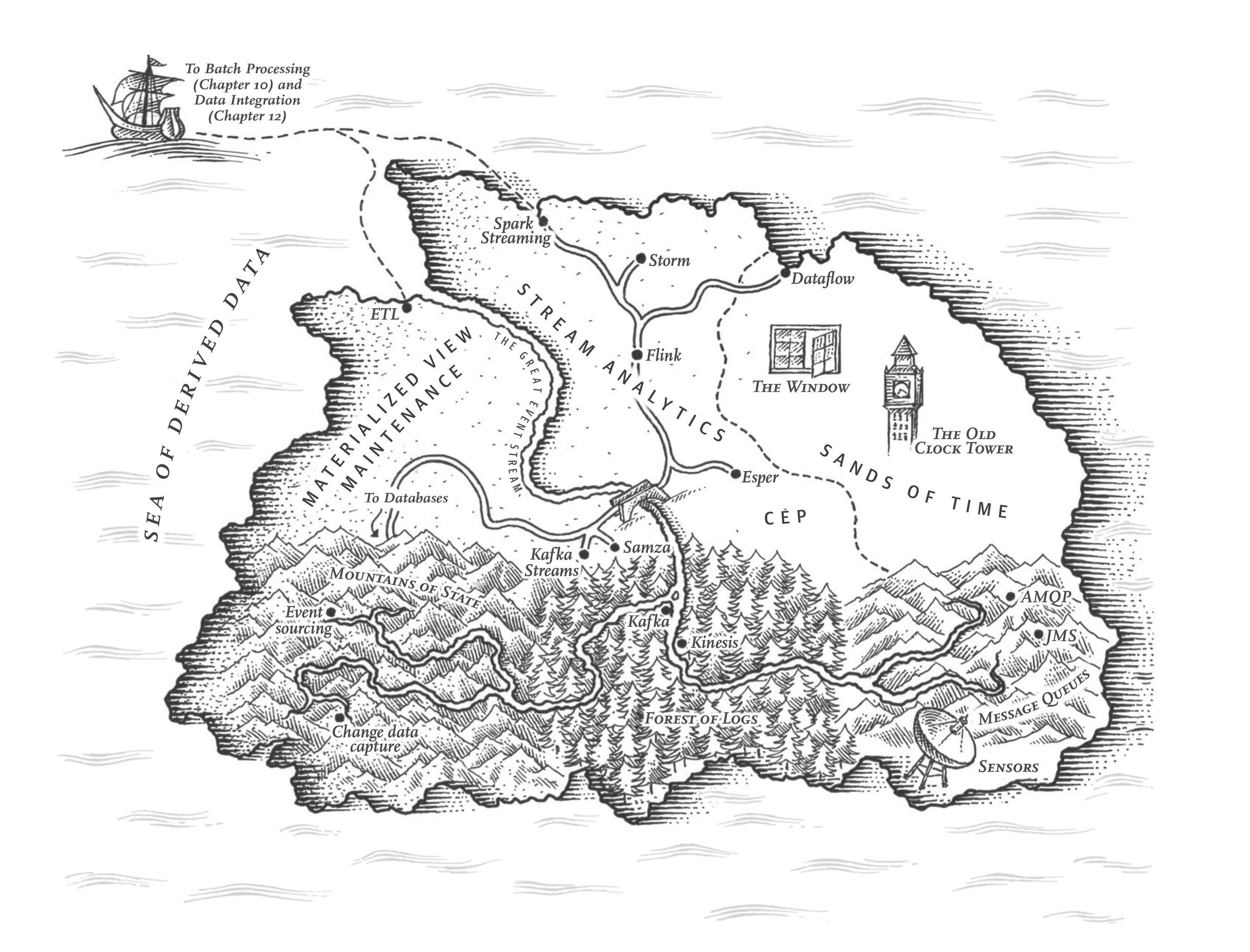
En el Capítulo 10 hablamos del procesamiento por lotes: técnicas que leen un conjunto de archivos como entrada y producen un nuevo conjunto de archivos de salida. La salida es una forma de datos derivados; es decir, un conjunto de datos que puede volver a crearse ejecutando de nuevo el proceso por lotes si es necesario. Hemos visto cómo esta idea sencilla pero poderosa puede utilizarse para crear índices de búsqueda, sistemas de recomendación, análisis y mucho más.
Sin embargo, a lo largo del Capítulo 10 se ha mantenido un gran supuesto: que la entrada esté acotada -es decir, que tenga un tamaño conocido y finito- para que el proceso por lotes sepa cuándo ha terminado de leer su entrada. Por ejemplo, la operación de ordenación que es fundamental en MapReduce debe leer toda su entrada antes de poder empezar a producir la salida: puede ocurrir que el último registro de entrada sea el que tenga la clave más baja y, por tanto, tenga que ser ...
Get Diseño de aplicaciones intensivas en datos now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

