Capítulo 4. Codificación y evolución
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Todo cambia y nada permanece inmóvil.
Heráclito de Éfeso, citado por Platón en el Cratílico (360 a.C.)
Las aplicaciones cambian inevitablemente con el tiempo. Se añaden o modifican funciones a medida que se lanzan nuevos productos, se comprenden mejor las necesidades de los usuarios o cambian las circunstancias empresariales. Enel Capítulo 1 introdujimos la idea de la evolucionabilidad: debemos procurar construir sistemas que faciliten la adaptación al cambio (véase "Evolucionabilidad: facilitar el cambio").
En la mayoría de los casos, un cambio en las características de una aplicación también requiere un cambio en los datos que almacena: quizás haya que capturar un nuevo campo o tipo de registro, o quizás haya que presentar los datos existentes de una nueva forma.
Los modelos de datos que hemos analizado en el Capítulo 2 tienen distintas formas de afrontar ese cambio. Las bases de datos relacionales suelen asumir que todos los datos de la base de datos se ajustan a un esquema: aunque ese esquema puede cambiarse (mediante migraciones de esquema; es decir, declaraciones ALTER ), hay exactamente un esquema vigente en un momento dado. Por el contrario, las bases de datos de esquema en lectura ("sin esquema") no imponen un esquema, por lo que la base de datos puede contener una mezcla de formatos de datos antiguos y nuevos escritos en distintos momentos (véase "Flexibilidad del esquema en el modelo documental").
Cuando cambia un formato o esquema de datos, a menudo tiene que producirse el correspondiente cambio en el código de la aplicación (por ejemplo, añades un nuevo campo a un registro, y el código de la aplicación empieza a leer y escribir ese campo). Sin embargo, en una aplicación grande, los cambios de código a menudo no pueden producirse instantáneamente:
-
Con las aplicaciones del lado del servidor, tal vez quieras realizar una actualización continua (también conocida como implementación por etapas), desplegando la nueva versión en unos pocos nodos a la vez, comprobando si la nueva versión funciona correctamente, y abriéndote paso gradualmente por todos los nodos. Esto permite desplegar nuevas versiones sin tiempo de inactividad del servicio, y fomenta así lanzamientos más frecuentes y una mejor capacidad de evolución.
-
Con las aplicaciones del lado del cliente estás a merced del usuario, que puede no instalar la actualización durante algún tiempo.
Esto significa que en el sistema pueden coexistir al mismo tiempo versiones antiguas y nuevas del código, y formatos de datos antiguos y nuevos. Para que el sistema siga funcionando sin problemas, necesitamos mantener la compatibilidad en ambas direcciones:
- Compatibilidad con versiones anteriores
-
El código más reciente puede leer datos que fueron escritos por código más antiguo.
- Compatibilidad anticipada
-
El código antiguo puede leer datos que fueron escritos por código más reciente.
Normalmente, la compatibilidad hacia atrás no es difícil de conseguir: como autor del código más reciente, conoces el formato de los datos escritos por el código antiguo, y así puedes manejarlo explícitamente (si es necesario, simplemente manteniendo el código antiguo para leer los datos antiguos). La compatibilidad hacia adelante puede ser más complicada, porque requiere que el código antiguo ignore las adiciones hechas por una versión más reciente del código.
En este capítulo veremos varios formatos para codificar datos, como JSON, XML, Búferes de Protocolo, Thrift y Avro. En concreto, veremos cómo gestionan los cambios de esquema y cómo soportan los sistemas en los que deben coexistir datos y código antiguos y nuevos. Luego hablaremos de cómo se utilizan esos formatos para almacenar datos y para la comunicación: en servicios web, Transferencia de Estado Representacional (REST) y llamadas a procedimientos remotos (RPC), así como en sistemas de paso de mensajes como actores y colas de mensajes.
Formatos para codificar datos
Los programas suelen trabajar con datos en (al menos) dos representaciones diferentes:
-
En la memoria, los datos se guardan en objetos, structs, listas, matrices, tablas hash, árboles, etc. Estas estructuras de datos están optimizadas para un acceso y manipulación eficientes por parte de la CPU (normalmente mediante punteros).
-
Cuando quieres escribir datos en un archivo o enviarlos por la red, tienes que codificarlos como una especie de secuencia autocontenida de bytes (por ejemplo, un documento JSON). Puesto que un puntero no tendría sentido para ningún otro proceso, esta representación de secuencia de bytes tiene un aspecto bastante diferente de las estructuras de datos que se utilizan normalmente en memoria.i
Por tanto, necesitamos algún tipo de traducción entre ambas representaciones. La traducción de la representación en memoria a una secuencia de bytes se llama codificación (también conocida como serialización omarshalling), y la inversa se llama descodificación(parsing, deserialización,unmarshalling).ii
Choque terminológico
Lamentablemente,la serialización también se utiliza en el contexto de las transacciones (véase el Capítulo 7), con un significado completamente distinto. Para evitar sobrecargar la palabra, en este libro nos ceñiremos a codificación, aunque serialización sea quizás un término más común.
Como se trata de un problema tan común, hay una miríada de bibliotecas y formatos de codificación diferentes entre los que elegir. Hagamos un breve repaso.
Formatos específicos de idioma
Muchos lenguajes de programación incorporan soporte para codificar objetos en memoria en secuencias de bytes. Por ejemplo, Java tiene java.io.Serializable[1], Ruby tiene Marshal[2], Python tiene pickle[3], etc. También existen muchas bibliotecas de terceros, como Kryo para Java [4].
Estas bibliotecas de codificación son muy cómodas, porque permiten guardar y restaurar objetos en memoria con un mínimo de código adicional. Sin embargo, también tienen una serie de problemas profundos:
-
La codificación suele estar vinculada a un lenguaje de programación concreto, y leer los datos en otro lenguaje es muy difícil. Si almacenas o transmites datos en una codificación de este tipo, te estás comprometiendo con tu lenguaje de programación actual durante un tiempo potencialmente muy largo, e impidiendo la integración de tus sistemas con los de otras organizaciones (que pueden utilizar lenguajes diferentes).
-
Para restaurar los datos en los mismos tipos de objetos, el proceso de descodificación debe poder instanciar clases arbitrarias. Esto es con frecuencia una fuente de problemas de seguridad [5]: si un atacante consigue que tu aplicación descodifique una secuencia de bytes arbitraria, puede instanciar clases arbitrarias, lo que a su vez le permite a menudo hacer cosas terribles, como ejecutar remotamente código arbitrario [6,7].
-
El control de versiones de los datos suele ser una ocurrencia tardía en estas bibliotecas: como están pensadas para una codificación rápida y fácil de los datos, a menudo descuidan los inconvenientes problemas de la compatibilidad hacia delante y hacia atrás.
-
La eficiencia (el tiempo que tarda la CPU en codificar o descodificar, y el tamaño de la estructura codificada) también suele pensarse a posteriori. Por ejemplo, la serialización incorporada de Java es famosa por su mal rendimiento y su codificación hinchada [8].
Por estas razones, en general es mala idea utilizar la codificación incorporada de tu idioma para algo que no sea muy transitorio.
JSON, XML y variantes binarias
Pasando a las codificaciones estandarizadas que pueden escribir y leer muchos lenguajes de programación, JSON y XML son los contendientes obvios. Son ampliamente conocidos, ampliamente apoyados y casi tan ampliamente rechazados. A menudo se critica a XML por ser demasiado verboso e innecesariamente complicado [9]. La popularidad de JSON se debe principalmente a su soporte integrado en los navegadores web (por ser un subconjunto de JavaScript) y a su simplicidad en relación con XML. CSV es otro formato popular independiente del lenguaje, aunque menos potente.
JSON, XML y CSV son formatos textuales y, por tanto, algo legibles por los humanos (aunque la sintaxis es un tema popular de debate). Además de las cuestiones sintácticas superficiales, también tienen algunos problemas sutiles:
-
Hay mucha ambigüedad en torno a la codificación de los números. En XML y CSV, no puedes distinguir entre un número y una cadena que casualmente está formada por dígitos (salvo remitiéndote a un esquema externo). JSON distingue entre cadenas y números, pero no distingue entre enteros y números de coma flotante, y no especifica una precisión.
Esto es un problema cuando se trata de números grandes; por ejemplo, los números enteros mayores que253 no pueden representarse exactamente en un número de coma flotante de doble precisión IEEE 754, por lo que dichos números resultan inexactos cuando se analizan en un lenguaje que utiliza números de coma flotante (como JavaScript). Un ejemplo de números mayores que253 ocurre en Twitter, que utiliza un número de 64 bits para identificar cada tuit. El JSON devuelto por la API de Twitter incluye los ID de los tweets dos veces, una como número JSON y otra como cadena decimal, para evitar que las aplicaciones de JavaScript no analicen correctamente los números [10].
-
JSON y XML tienen un buen soporte para cadenas de caracteres Unicode (es decir, texto legible por humanos), pero no soportan cadenas binarias (secuencias de bytes sin una codificación de caracteres). Las cadenas binarias son una característica útil, por lo que la gente sortea esta limitación codificando los datos binarios como texto utilizando Base64. A continuación, se utiliza el esquema para indicar que el valor debe interpretarse como codificado en Base64. Esto funciona, pero es algo complicado y aumenta el tamaño de los datos en un 33%.
-
Existe soporte opcional de esquemas tanto para XML [11] como para JSON [12]. Estos lenguajes de esquemas son bastante potentes y, por tanto, bastante complicados de aprender e implementar. El uso de esquemas XML está bastante extendido, pero muchas herramientas basadas en JSON no se molestan en utilizar esquemas. Dado que la correcta interpretación de los datos (como números y cadenas binarias) depende de la información del esquema, las aplicaciones que no utilizan esquemas XML/JSON tienen que codificar la lógica de codificación/descodificación adecuada.
-
CSV no tiene ningún esquema, por lo que depende de la aplicación definir el significado de cada fila y columna. Si un cambio en la aplicación añade una nueva fila o columna, tienes que gestionar ese cambio manualmente. CSV también es un formato bastante vago (¿qué ocurre si un valor contiene una coma o un carácter de nueva línea?). Aunque sus reglas de escape se han especificado formalmente [13], no todos los analizadores sintácticos las implementan correctamente.
A pesar de estos defectos, JSON, XML y CSV son suficientemente buenos para muchos fines. Es probable que sigan siendo populares, especialmente como formatos de intercambio de datos (es decir, para enviar datos de una organización a otra). En estas situaciones, mientras la gente esté de acuerdo en cuál es el formato, a menudo no importa lo bonito o eficiente que sea el formato. La dificultad de conseguir que distintas organizaciones se pongan de acuerdo en algo pesa más que la mayoría de las demás preocupaciones.
Codificación binaria
Para los datos que sólo se utilizan internamente en tu organización, hay menos presión para utilizar un formato de codificación del mínimo común denominador. Por ejemplo, podrías elegir un formato más compacto o más rápido de analizar. Para un conjunto de datos pequeño, las ganancias son insignificantes, pero una vez que entras en los terabytes, la elección del formato de los datos puede tener un gran impacto.
JSON es menos verboso que XML, pero ambos siguen utilizando mucho espacio en comparación con los formatos binarios. Esta observación llevó al desarrollo de una profusión de codificaciones binarias para JSON (MessagePack, BSON, BJSON, UBJSON, BISON y Smile, por nombrar algunas) y para XML (WBXML y Fast Infoset, por ejemplo). Estos formatos se han adoptado en diversos nichos, pero ninguno de ellos está tan ampliamente adoptado como las versiones textuales de JSON y XML.
Algunos de estos formatos amplían el conjunto de tipos de datos (por ejemplo, distinguiendo entre números enteros y números de coma flotante, o añadiendo soporte para cadenas binarias), pero por lo demás mantienen sin cambios el modelo de datos JSON/XML. En concreto, como no prescriben un esquema, necesitan incluir todos los nombres de los campos objeto dentro de los datos codificados. Es decir, en una codificación binaria del documento JSON del Ejemplo 4-1, tendrán que incluir las cadenas userName, favoriteNumber y interests en algún lugar.
Ejemplo 4-1. Ejemplo de registro que codificaremos en varios formatos binarios en este capítulo
{"userName":"Martin","favoriteNumber":1337,"interests":["daydreaming","hacking"]}
Veamos un ejemplo de MessagePack, una codificación binaria para JSON. La Figura 4-1muestra la secuencia de bytes que obtienes si codificas el documento JSON del Ejemplo 4-1 con MessagePack [14]. Los primeros bytes son los siguientes
-
El primer byte,
0x83, indica que lo que sigue es un objeto (cuatro bits superiores =0x80) con tres campos (cuatro bits inferiores =0x03). (Por si te preguntas qué ocurre si un objeto tiene más de 15 campos, de modo que el número de campos no quepa en cuatro bits, entonces recibe un indicador de tipo diferente, y el número de campos se codifica en dos o cuatro bytes). -
El segundo byte,
0xa8, indica que lo que sigue es una cadena (cuatro bits superiores =0xa0) de ocho bytes de longitud (cuatro bits inferiores =0x08). -
Los ocho bytes siguientes son el nombre del campo
userNameen ASCII. Como la longitud se ha indicado anteriormente, no hace falta ningún marcador que nos indique dónde acaba la cadena (ni ningún escape). -
Los siete bytes siguientes codifican el valor de la cadena de seis letras
Martincon un prefijo0xa6, y así sucesivamente.
La codificación binaria tiene 66 bytes, que es sólo un poco menos que los 81 bytes que ocupa la codificación textual JSON (sin espacios en blanco). Todas las codificaciones binarias de JSON son similares en este aspecto. No está claro si una reducción de espacio tan pequeña (y quizás una aceleración en el análisis sintáctico) merece la pena por la pérdida de legibilidad humana.
En las secciones siguientes veremos cómo podemos hacerlo mucho mejor, y codificar el mismo registro en sólo 32 bytes.

Figura 4-1. Ejemplo de registro(Ejemplo 4-1) codificado mediante MessagePack.
Búferes de ahorro y protocolo
Apache Thrift [15] y Protocol Buffers (protobuf) [16] son bibliotecas de codificación binaria que se basan en el mismo principio. Protocol Buffers se desarrolló originalmente en Google, Thrift se desarrolló originalmente en Facebook, y ambas se hicieron de código abierto en 2007-08 [17].
Tanto Thrift como los búferes de protocolo requieren un esquema para cualquier dato que se codifique. Para codificar los datos del Ejemplo 4-1 en Thrift, describirías el esquema en el lenguaje de definición de interfaces (IDL) de Thrift de la siguiente manera:
structPerson{1:requiredstringuserName,2:optionali64favoriteNumber,3:optionallist<string>interests}
La definición del esquema equivalente para las memorias intermedias de protocolo es muy similar:
messagePerson{requiredstringuser_name=1;optionalint64favorite_number=2;repeatedstringinterests=3;}
Tanto Thrift como Protocol Buffers vienen con una herramienta de generación de código que toma una definición de esquema como las que se muestran aquí, y produce clases que implementan el esquema en varios lenguajes de programación [18]. El código de tu aplicación puede llamar a este código generado para codificar o descodificar registros del esquema.
¿Qué aspecto tienen los datos codificados con este esquema? Confusamente, Thrift tiene dos formatos diferentes de codificación binaria,iii llamados BinaryProtocol y CompactProtocol, respectivamente. Veamos primero el BinaryProtocol. Codificar el Ejemplo 4-1 en ese formato ocupa 59 bytes, como se muestra enla Figura 4-2 [19].
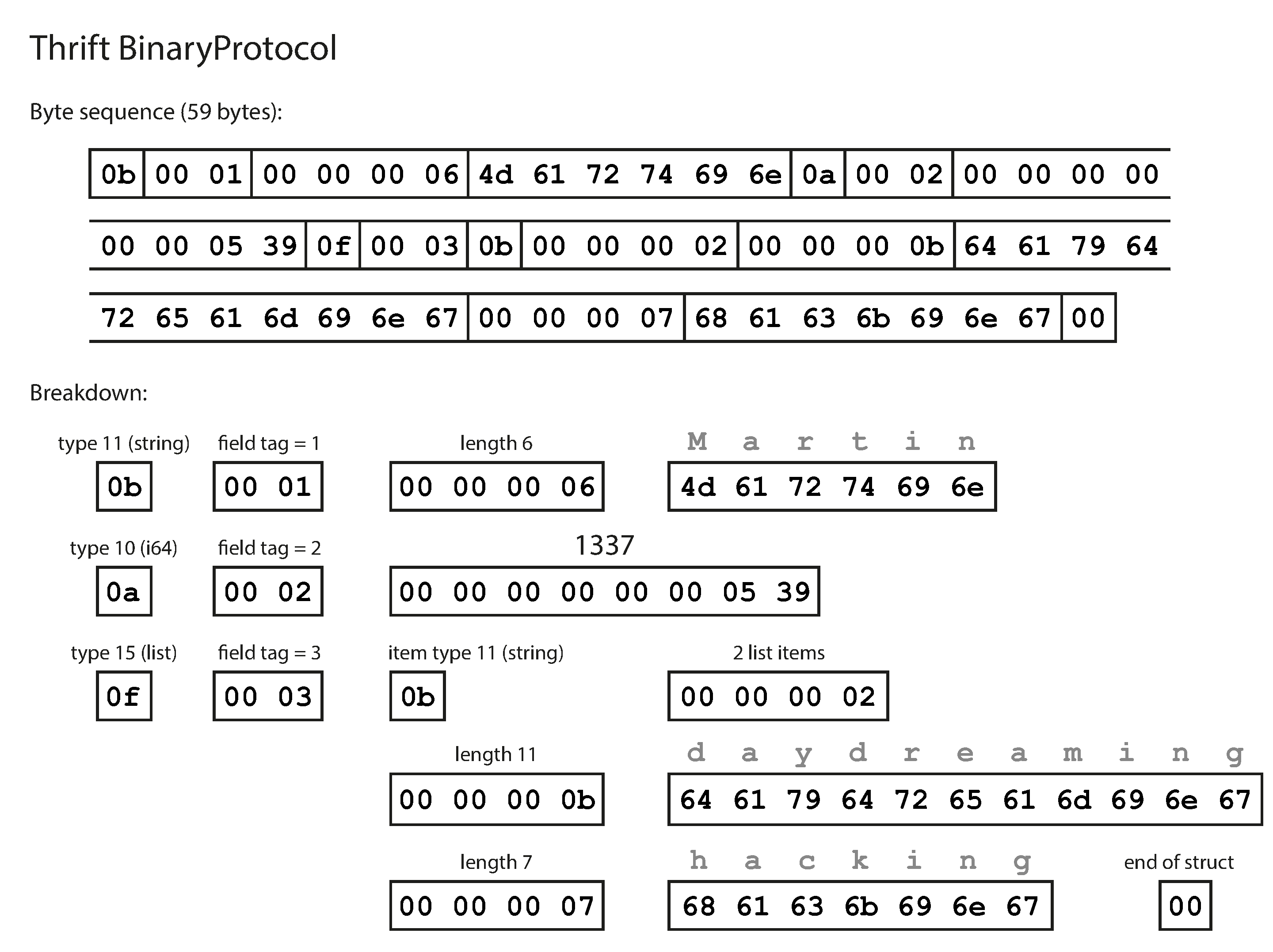
Figura 4-2. Ejemplo de registro codificado utilizando el Protocolo Binario de Thrift.
De forma similar a la Figura 4-1, cada campo tiene una anotación de tipo (para indicar si es una cadena, un entero, una lista, etc.) y, cuando es necesario, una indicación de longitud (longitud de una cadena, número de elementos de una lista). Las cadenas que aparecen en los datos ("Martin", "soñando despierto", "pirateando") también se codifican como ASCII (o mejor dicho, UTF-8), de forma similar a antes.
La gran diferencia respecto a la Figura 4-1 es que no hay nombres de campo (userName, favoriteNumber, interests). En su lugar, los datos codificados contienen etiquetas de campo, que son números (1, 2, y 3). Son los números que aparecen en la definición del esquema. Las etiquetas de campo son como alias para los campos: son una forma compacta de decir de qué campo estamos hablando, sin tener que deletrear el nombre del campo.
La codificación Thrift CompactProtocol es semánticamente equivalente a BinaryProtocol, pero como puedes ver en la Figura 4-3, empaqueta la misma información en sólo 34 bytes. En lugar de utilizar ocho bytes completos para el número 1337, se codifica en dos bytes, y el bit superior de cada byte se utiliza para indicar si aún quedan más bytes. Esto significa que los números entre -64 y 63 se codifican en un byte, los números entre -8192 y 8191 se codifican en dos bytes, etc. Los números más grandes utilizan más bytes.
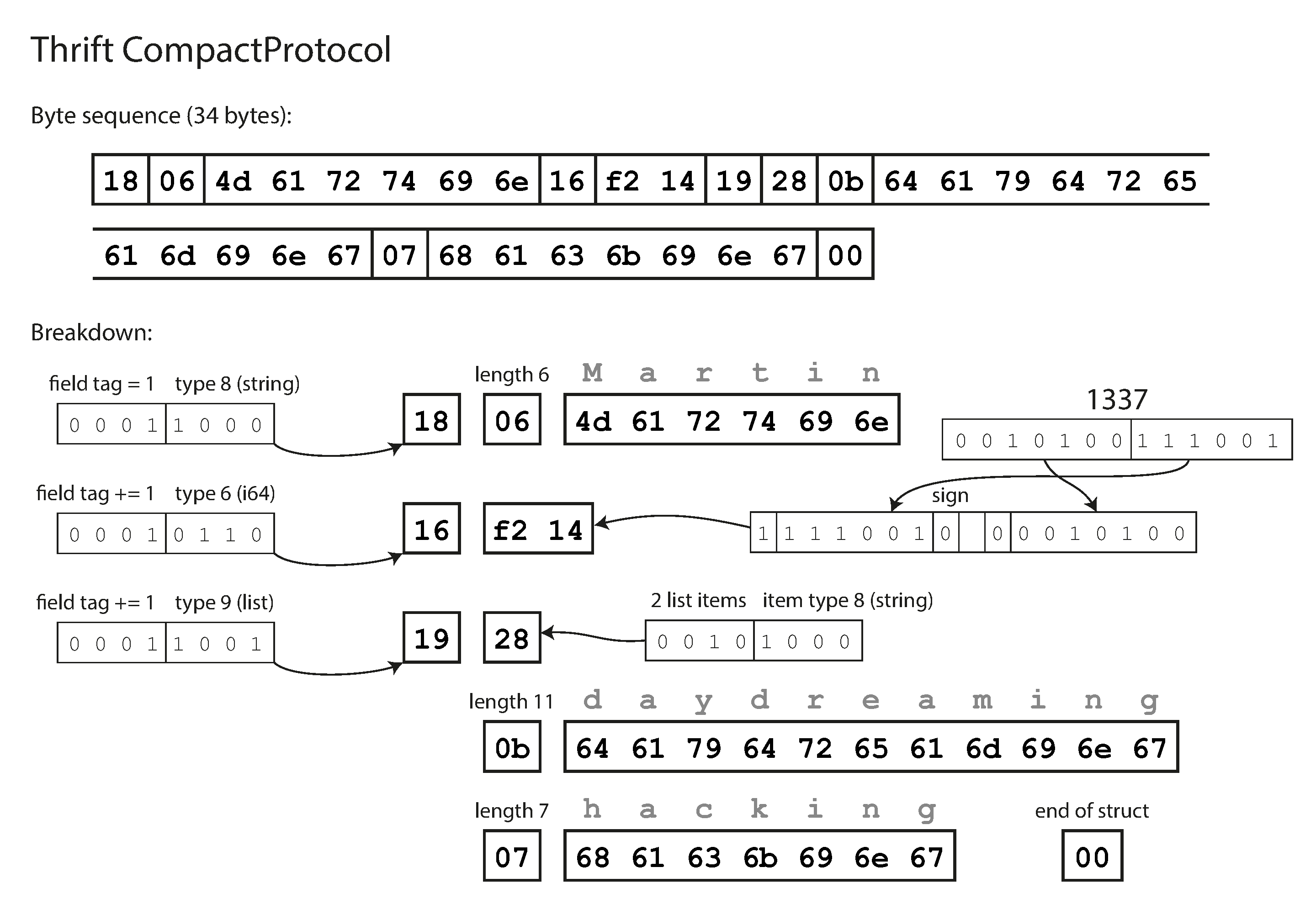
Figura 4-3. Ejemplo de registro codificado utilizando el CompactProtocolo de Thrift.
Por último, el Protocolo de Búferes (que sólo tiene un formato de codificación binaria) codifica los mismos datos que se muestran en la Figura 4-4. Realiza el empaquetado de bits de forma ligeramente distinta, pero por lo demás es muy similar al CompactProtocolo de Thrift. Los Búfers de Protocolo encajan el mismo registro en 33 bytes.
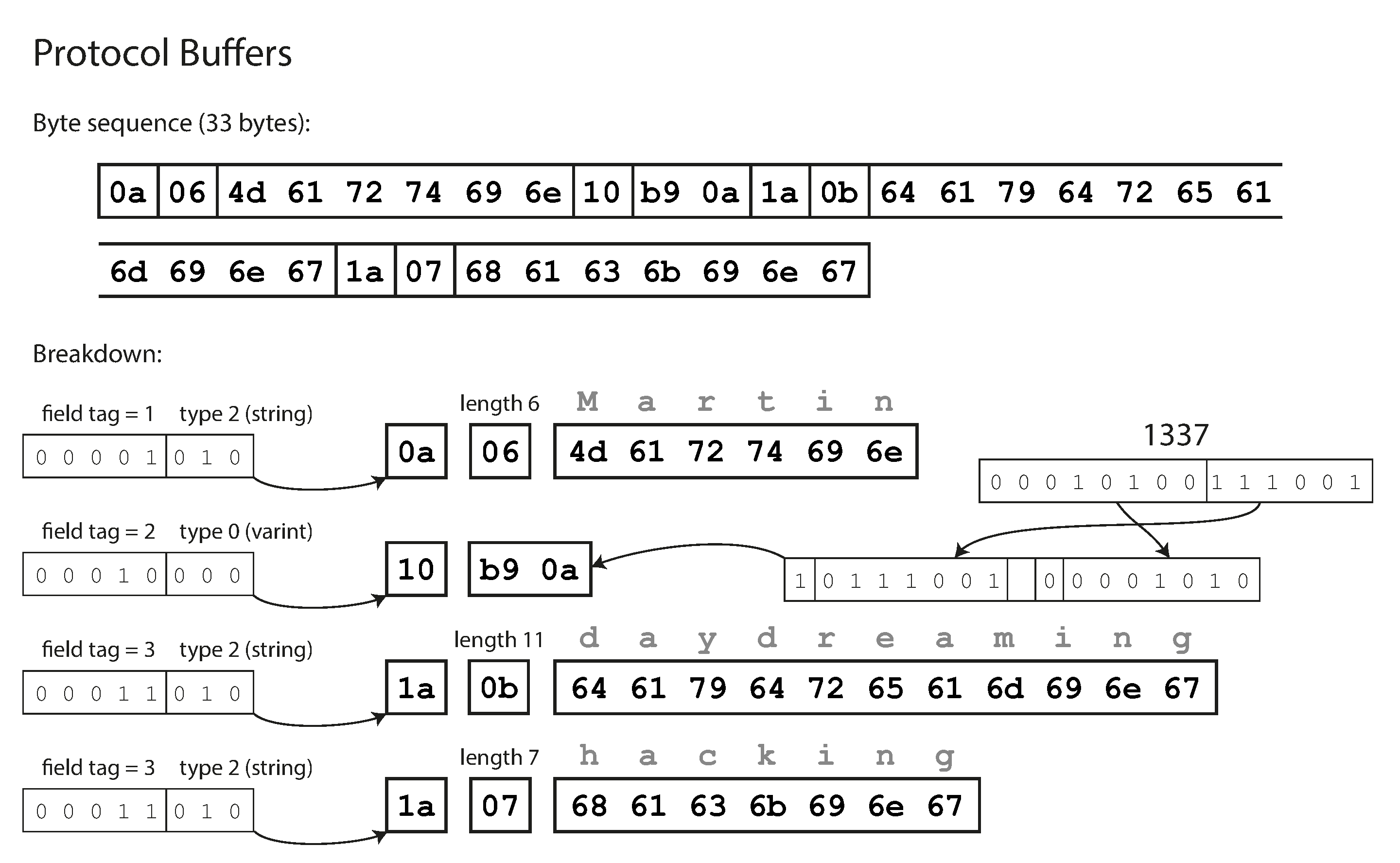
Figura 4-4. Ejemplo de registro codificado mediante búferes de protocolo.
Un detalle a tener en cuenta: en los esquemas mostrados anteriormente, cada campo estaba marcado como required o optional, pero esto no supone ninguna diferencia en cómo se codifica el campo (nada en los datos binarios indica si un campo era obligatorio). La diferencia es simplemente que required permite una comprobación en tiempo de ejecución que falla si el campo no está establecido, lo que puede ser útil para detectar errores.
Etiquetas de campo y evolución del esquema
Ya hemos dicho que los esquemas tienen que cambiar inevitablemente con el tiempo. A esto lo llamamos evolución del esquema. ¿Cómo gestionan Thrift y los búferes de protocolo los cambios de esquema manteniendo la compatibilidad hacia atrás y hacia delante?
Como puedes ver en los ejemplos, un registro codificado no es más que la concatenación de sus campos codificados. Cada campo se identifica por su número de etiqueta (los números 1, 2, 3 en los esquemas de muestra) y se anota con un tipo de dato (por ejemplo, cadena o entero). Si no se establece un valor de campo, simplemente se omite en el registro codificado. De esto se deduce que las etiquetas de campo son fundamentales para el significado de los datos codificados. Puedes cambiar el nombre de un campo en el esquema, ya que los datos codificados nunca hacen referencia a nombres de campo, pero no puedes cambiar la etiqueta de un campo, ya que eso invalidaría todos los datos codificados existentes .
Puedes añadir nuevos campos al esquema, siempre que des a cada campo un nuevo número de etiqueta. Si el código antiguo (que no conoce los nuevos números de etiqueta que has añadido) intenta leer datos escritos por el código nuevo, incluyendo un nuevo campo con un número de etiqueta que no reconoce, puede simplemente ignorar ese campo. La anotación datatype permite al analizador sintáctico determinar cuántos bytes debe omitir. Esto mantiene la compatibilidad con el futuro: el código antiguo puede leer los registros escritos por el código nuevo.
¿Qué pasa con la compatibilidad con versiones anteriores? Mientras cada campo tenga un número de etiqueta único, el código nuevo siempre podrá leer los datos antiguos, porque los números de etiqueta siguen teniendo el mismo significado. El único detalle es que si añades un nuevo campo, no puedes hacerlo obligatorio. Si añadieras un campo y lo hicieras obligatorio, esa comprobación fallaría si el código nuevo leyera los datos escritos por el código antiguo, porque el código antiguo no habrá escrito el nuevo campo que has añadido. Por tanto, para mantener la compatibilidad con versiones anteriores, todos los campos que añadas después de la implementación inicial del esquema deben ser opcionales o tener un valor por defecto.
Eliminar un campo es igual que añadirlo, pero con la compatibilidad inversa. Eso significa que sólo puedes eliminar un campo que sea opcional (un campo obligatorio nunca puede eliminarse), y que nunca puedes volver a utilizar el mismo número de etiqueta (porque aún puedes tener datos escritos en alguna parte que incluyan el antiguo número de etiqueta, y ese campo debe ser ignorado por el nuevo código).
Tipos de datos y evolución del esquema
¿Qué pasa si se cambia el tipo de datos de un campo? Puede ser posible -consulta la documentación para más detalles-, pero existe el riesgo de que los valores pierdan precisión o se trunquen. Por ejemplo, supongamos que cambias un entero de 32 bits por un entero de 64 bits. El código nuevo puede leer fácilmente los datos escritos por el código antiguo, porque el analizador sintáctico puede rellenar con ceros los bits que falten. Sin embargo, si el código antiguo lee los datos escritos por el código nuevo, el código antiguo sigue utilizando una variable de 32 bits para guardar el valor. Si el valor de 64 bits descodificado no cabe en 32 bits, se truncará.
Un detalle curioso de los búferes de protocolo es que no tienen un tipo de datos de lista o matriz, sino que tienen un marcador repeated para los campos (que es una tercera opción junto a required y optional). Como puedes ver en la Figura 4-4, la codificación de un campo repeated es exactamente lo que dice en la lata: la misma etiqueta de campo simplemente aparece varias veces en el registro. Esto tiene el bonito efecto de que está bien cambiar un campo optional (de un solo valor) por un campo repeated (de varios valores). El código nuevo que lee los datos antiguos ve una lista con cero o uno elementos (dependiendo de si el campo estaba presente); el código antiguo que lee los datos nuevos sólo ve el último elemento de la lista.
Thrift tiene un tipo de datos de lista dedicado, que se parametriza con el tipo de datos de los elementos de la lista. Esto no permite la misma evolución de monovalor a multivalor que los búferes de protocolo, pero tiene la ventaja de admitir listas anidadas.
Avro
Apache Avro [20] es otro formato de codificación binaria que es curiosamente diferente de Protocol Buffers y Thrift. Se inició en 2009 como un subproyecto de Hadoop, como resultado de que Thrift no se ajustaba bien a los casos de uso de Hadoop [21].
Avro también utiliza un esquema para especificar la estructura de los datos que se codifican. Tiene dos lenguajes de esquema: uno (Avro IDL) pensado para la edición humana, y otro (basado en JSON) que es más fácilmente legible por máquina.
Nuestro esquema de ejemplo, escrito en Avro IDL, podría tener este aspecto:
recordPerson{stringuserName;union{null,long}favoriteNumber=null;array<string>interests;}
La representación JSON equivalente de ese esquema es la siguiente:
{"type":"record","name":"Person","fields":[{"name":"userName","type":"string"},{"name":"favoriteNumber","type":["null","long"],"default":null},{"name":"interests","type":{"type":"array","items":"string"}}]}
En primer lugar, observa que no hay números de etiqueta en el esquema. Si codificamos nuestro registro de ejemplo(Ejemplo 4-1) utilizando este esquema, la codificación binaria Avro sólo tiene 32 bytes de longitud, la más compacta de todas las codificaciones que hemos visto. El desglose de la secuencia de bytes codificada se muestra en la Figura 4-5.
Si examinas la secuencia de bytes, verás que no hay nada que identifique los campos ni sus tipos de datos. La codificación consiste simplemente en valores concatenados. Una cadena es sólo un prefijo de longitud seguido de bytes UTF-8, pero no hay nada en los datos codificados que te indique que se trata de una cadena. Podría ser perfectamente un número entero, o algo totalmente distinto. Un entero se codifica utilizando una codificación de longitud variable (igual que el CompactProtocolo de Thrift).
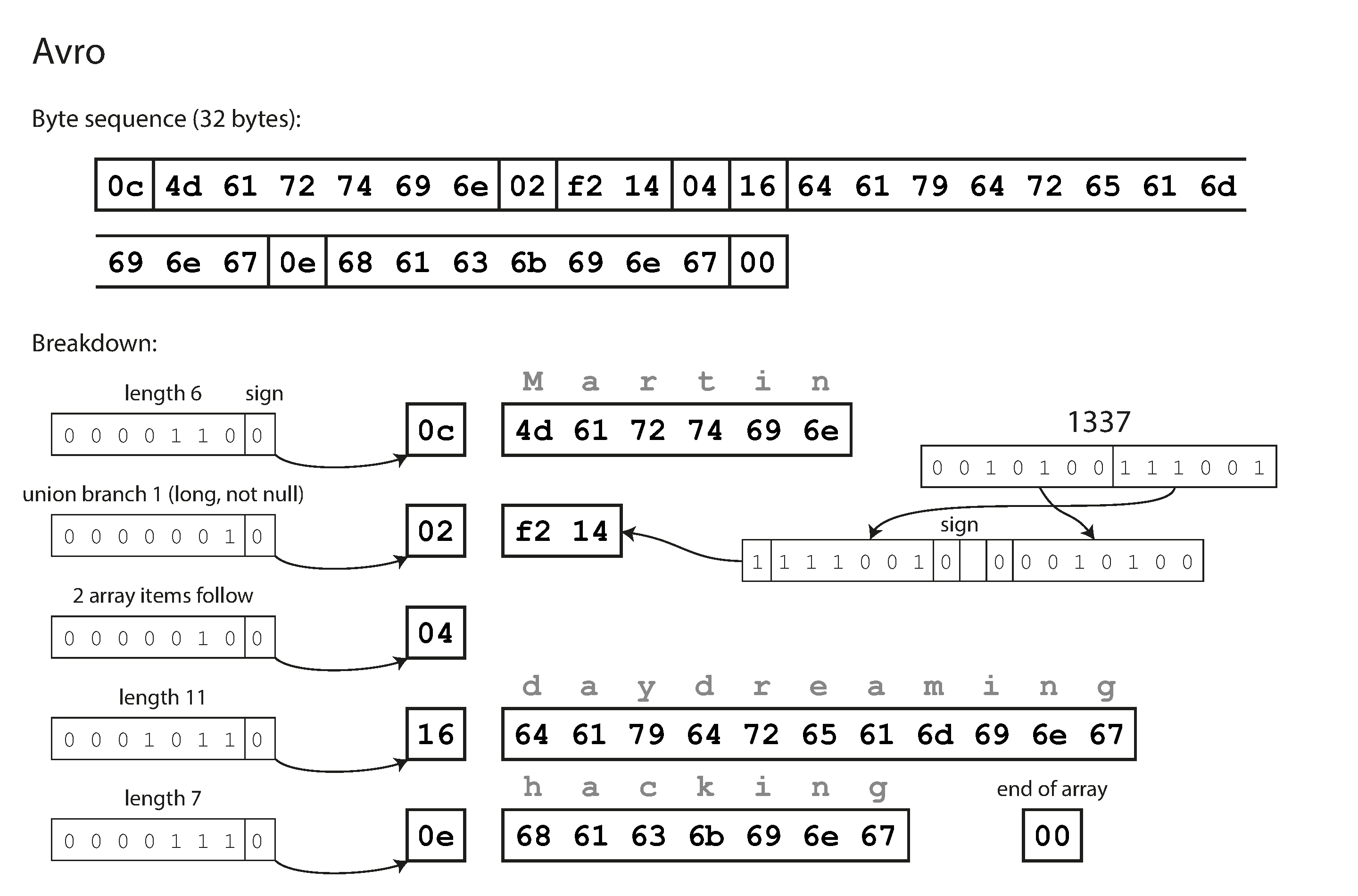
Figura 4-5. Ejemplo de registro codificado con Avro.
Para analizar los datos binarios, recorres los campos en el orden en que aparecen en el esquema y utilizas el esquema para saber el tipo de datos de cada campo. Esto significa que los datos binarios sólo pueden descodificarse correctamente si el código que lee los datos utiliza exactamente el mismo esquema que el código que escribió los datos. Cualquier desajuste en el esquema entre el lector y el escritor significaría datos descodificados incorrectamente.
Entonces, ¿cómo soporta Avro la evolución del esquema?
El esquema del escritor y el esquema del lector
Con Avro, cuando una aplicación quiere codificar unos datos (para escribirlos en un archivo o base de datos, para enviarlos por la red, etc.), los codifica utilizando cualquier versión del esquema que conozca; por ejemplo, ese esquema puede estar compilado en la aplicación. Esto se conoce comoesquema del escritor.
Cuando una aplicación quiere descodificar unos datos (leerlos de un archivo o de una base de datos, recibirlos de la red, etc.), está esperando que los datos estén en algún esquema, que se conoce como esquema del lector. Ese es el esquema en el que se basa el código de la aplicación: el código puede haberse generado a partir de ese esquema durante el proceso de creación de la aplicación.
La idea clave de Avro es que el esquema del escritor y el esquema del lector no tienen por qué ser iguales,sólo tienen que ser compatibles. Cuando se descodifican (leen) los datos, la biblioteca Avro resuelve las diferencias mirando el esquema del escritor y el esquema del lector uno al lado del otro y traduciendo los datos del esquema del escritor al esquema del lector. La especificación Avro [20] define exactamente cómo funciona esta resolución, y se ilustra en la Figura 4-6.
Por ejemplo, no hay problema si el esquema del escritor y el esquema del lector tienen sus campos en un orden diferente, porque la resolución del esquema hace coincidir los campos por nombre de campo. Si el código que lee los datos encuentra un campo que aparece en el esquema del escritor pero no en el del lector, se ignora. Si el código que lee los datos espera algún campo, pero el esquema del escritor no contiene un campo con ese nombre, se rellena con un valor por defecto declarado en el esquema del lector.
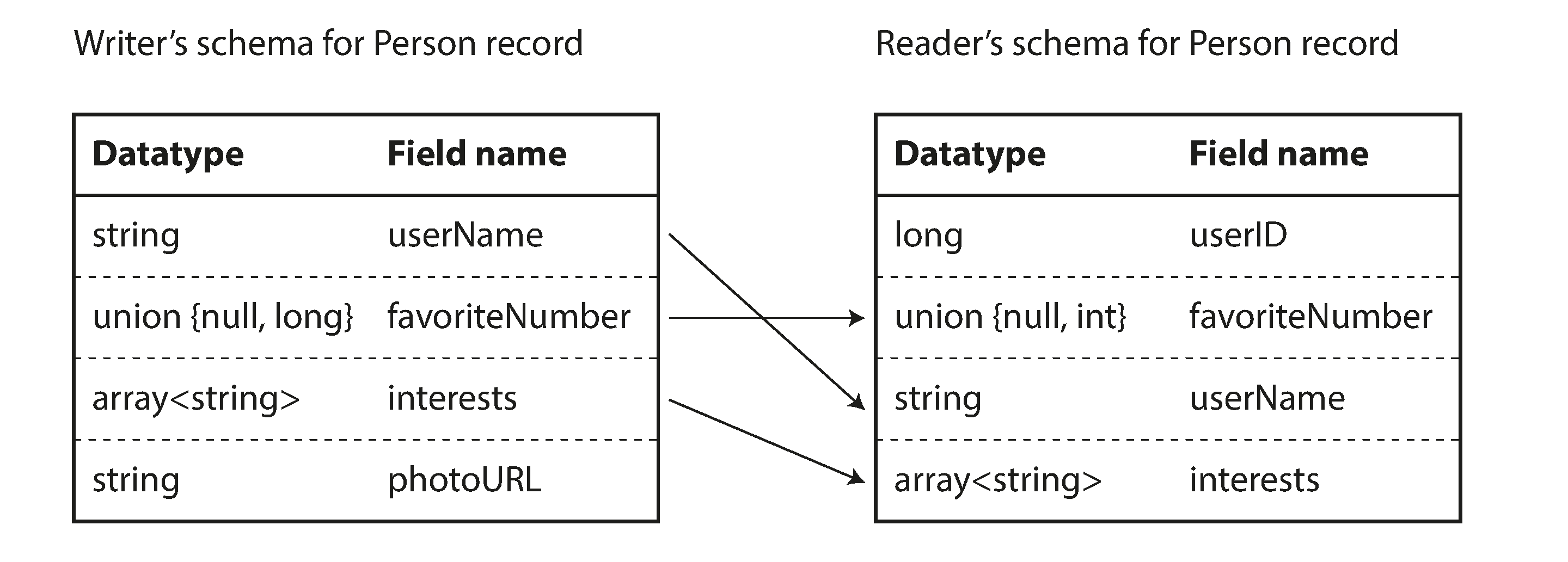
Figura 4-6. Un lector Avro resuelve las diferencias entre el esquema del escritor y el esquema del lector.
Reglas de evolución del esquema
Con Avro, la compatibilidad hacia adelante significa que puedes tener una nueva versión del esquema como escritor y una versión antigua del esquema como lector. Por el contrario, la compatibilidad hacia atrás significa que puedes tener una nueva versión del esquema como lector y una versión antigua como escritor.
Para mantener la compatibilidad, sólo puedes añadir o eliminar un campo que tenga un valor por defecto. (El campofavoriteNumber de nuestro esquema Avro tiene un valor por defecto de null.) Por ejemplo, supongamos que añades un campo con un valor por defecto, de modo que este nuevo campo existe en el nuevo esquema pero no en el antiguo. Cuando un lector que utilice el nuevo esquema lea un registro escrito con el esquema antiguo, el valor por defecto se rellenará para el campo que falta.
Si añadieras un campo que no tiene valor por defecto, los nuevos lectores no podrían leer los datos escritos por los antiguos escritores, por lo que romperías la compatibilidad hacia atrás. Si eliminas un campo que no tiene valor por defecto, los lectores antiguos no podrán leer los datos escritos por los nuevos escritores, por lo que se romperá la compatibilidad hacia adelante.
En algunos lenguajes de programación, null es un valor por defecto aceptable para cualquier variable, pero no es así en Avro: si quieres permitir que un campo sea nulo, tienes que utilizar un tipo de unión. Por ejemplo,union { null, long, string } field; indica que field puede ser un número, o una cadena, o nulo. Sólo puedes utilizar null como valor por defecto si es una de las ramas de la unión.iv Esto es un poco más verboso que tener todo anulable por defecto, pero ayuda a evitar errores al ser explícito sobre lo que puede y no puede ser nulo [22].
En consecuencia, Avro no tiene marcadores optional y required del mismo modo que Protocol Buffers y Thrift (en su lugar tiene tipos de unión y valores por defecto).
Cambiar el tipo de datos de un campo es posible, siempre que Avro pueda convertir el tipo. Cambiar el nombre de un campo es posible, pero un poco complicado: el esquema del lector puede contener alias para los nombres de campo, de modo que puede comparar los nombres de campo del esquema de un escritor antiguo con los alias. Esto significa que cambiar el nombre de un campo es compatible hacia atrás, pero no hacia adelante. Del mismo modo, añadir una rama a un tipo de unión es compatible hacia atrás pero no hacia adelante.
Pero, ¿cuál es el esquema del escritor?
Hay una cuestión importante que hemos pasado por alto hasta ahora: ¿cómo sabe el lector el esquema del escritor con el que se codificó un dato concreto? No podemos incluir todo el esquema con cada registro, porque probablemente el esquema sería mucho mayor que los datos codificados, lo que haría inútil todo el ahorro de espacio de la codificación binaria.
La respuesta depende del contexto en el que se utilice Avro. Por poner algunos ejemplos:
- Archivo grande con muchos registros
-
Un uso habitual de Avro -especialmente en el contexto de Hadoop- es para almacenar un gran archivo que contenga millones de registros, todos codificados con el mismo esquema. (Trataremos este tipo de situación en el Capítulo 10.) En este caso, el escritor de ese archivo puede limitarse a incluir el esquema del escritor una sola vez al principio del archivo. Avro especifica un formato de archivo (archivos contenedores de objetos) para hacer esto.
- Base de datos con registros escritos individualmente
-
En una base de datos, distintos registros pueden escribirse en distintos momentos utilizando esquemas de escritor diferentes: no puedes dar por supuesto que todos los registros tendrán el mismo esquema. La solución más sencilla es incluir un número de versión al principio de cada registro codificado, y mantener una lista de versiones del esquema en tu base de datos. Un lector puede obtener un registro, extraer el número de versión y, a continuación, obtener de la base de datos el esquema del escritor para ese número de versión. Utilizando el esquema de ese escritor, puede descodificar el resto del registro. (Espresso [23] funciona así, por ejemplo.)
- Enviar registros a través de una conexión de red
-
Cuando dos procesos se comunican a través de una conexión de red bidireccional, pueden negociar la versión del esquema al establecer la conexión y utilizar ese esquema durante toda la conexión. El protocolo Avro RPC (ver "Flujo de datos a través de servicios: REST y RPC") funciona así.
Una base de datos de versiones de esquemas es útil en cualquier caso, ya que actúa como documentación y te da la oportunidad de comprobar la compatibilidad de los esquemas [24]. Como número de versión, podrías utilizar un simple número entero incremental, o podrías utilizar un hash del esquema.
Esquemas generados dinámicamente
Una ventaja del enfoque de Avro, en comparación con los Búferes de Protocolo y Thrift, es que el esquema no contiene ningún número de etiqueta. Pero, ¿por qué es esto importante? ¿Qué problema hay en mantener un par de números en el esquema?
La diferencia es que Avro es más amigable con los esquemas generados dinámicamente. Por ejemplo, supongamos que tienes una base de datos relacional cuyo contenido quieres volcar a un archivo, y quieres utilizar un formato binario para evitar los problemas antes mencionados con los formatos textuales (JSON, CSV, XML). Si utilizas Avro, puedes generar con bastante facilidad un esquema Avro (en la representación JSON que vimos antes) a partir del esquema relacional y codificar el contenido de la base de datos utilizando ese esquema, volcándolo todo en un archivo contenedor de objetos Avro [25]. Generas un esquema de registro para cada tabla de la base de datos, y cada columna se convierte en un campo de ese registro. El nombre de la columna en la base de datos se corresponde con el nombre del campo en Avro.
Ahora, si el esquema de la base de datos cambia (por ejemplo, a una tabla se le añade una columna y se le quita otra), sólo tienes que generar un nuevo esquema Avro a partir del esquema actualizado de la base de datos y exportar los datos en el nuevo esquema Avro. El proceso de exportación de datos no necesita prestar ninguna atención al cambio de esquema: simplemente puede realizar la conversión de esquema cada vez que se ejecute. Cualquiera que lea los nuevos archivos de datos verá que los campos del registro han cambiado, pero como los campos se identifican por su nombre, el esquema actualizado del escritor puede seguir coincidiendo con el antiguo esquema del lector.
En cambio, si utilizaras Thrift o Protocol Buffers para este fin, las etiquetas de campo probablemente tendrían que asignarse a mano: cada vez que cambiara el esquema de la base de datos, un administrador tendría que actualizar manualmente la correspondencia entre los nombres de las columnas de la base de datos y las etiquetas de campo. (Podría ser posible automatizarlo, pero el generador de esquemas tendría que tener mucho cuidado de no asignar etiquetas de campo utilizadas previamente). Este tipo de esquema generado dinámicamente simplemente no era un objetivo de diseño de Thrift o Protocol Buffers, mientras que sí lo era para Avro.
Generación de código y lenguajes tipados dinámicamente
Thrift y Protocol Buffers se basan en la generación de código: una vez definido un esquema, puedes generar código que implemente ese esquema en un lenguaje de programación de tu elección. Esto es útil en lenguajes tipados estáticamente, como Java, C++ o C#, porque permite utilizar estructuras eficientes en memoria para los datos descodificados, y permite la comprobación de tipos y el autocompletado en los IDE al escribir programas que acceden a las estructuras de datos.
En los lenguajes de programación tipados dinámicamente, como JavaScript, Ruby o Python, no tiene mucho sentido generar código, ya que no hay verificador de tipos en tiempo de compilación que satisfacer. La generación de código suele estar mal vista en estos lenguajes, ya que de otro modo evitan un paso de compilación explícito. Además, en el caso de un esquema generado dinámicamente (como un esquema Avro generado a partir de una tabla de base de datos), la generación de código es un obstáculo innecesario para llegar a los datos.
Avro proporciona una generación de código opcional para los lenguajes de programación tipados estáticamente, pero puede utilizarse igual de bien sin ninguna generación de código. Si tienes un archivo contenedor de objetos (que incorpora el esquema del escritor), puedes simplemente abrirlo utilizando la biblioteca Avro y mirar los datos del mismo modo que podrías mirar un archivo JSON. El archivo se autodescribe, ya que incluye todos los metadatos necesarios.
Esta propiedad es especialmente útil en conjunción con lenguajes de procesamiento de datos de tipado dinámico como Apache Pig [26]. En Pig, puedes simplemente abrir unos archivos Avro, empezar a analizarlos y escribir conjuntos de datos derivados en archivos de salida en formato Avro sin pensar siquiera en esquemas.
Los méritos de los esquemas
Como hemos visto, tanto Protocol Buffers como Thrift y Avro utilizan un esquema para describir un formato de codificación binario. Sus lenguajes de esquema son mucho más sencillos que XML Schema o JSON Schema, que admiten reglas de validación mucho más detalladas (por ejemplo, "el valor de cadena de este campo debe coincidir con esta expresión regular" o "el valor entero de este campo debe estar comprendido entre 0 y 100"). Dado que los búferes de protocolo, Thrift y Avro son más sencillos de implementar y más sencillos de utilizar, han crecido hasta admitir una gama bastante amplia de lenguajes de programación.
Las ideas en las que se basan estas codificaciones no son en absoluto nuevas. Por ejemplo, tienen mucho en común con ASN.1, un lenguaje de definición de esquemas que se estandarizó por primera vez en 1984 [27]. Se utilizó para definir varios protocolos de red, y su codificación binaria (DER) aún se utiliza para codificar certificados SSL (X.509), por ejemplo [28]. ASN.1 admite la evolución de esquemas mediante números de etiqueta, de forma similar a Protocol Buffers y Thrift [29]. Sin embargo, también es muy complejo y está mal documentado, por lo que ASN.1probablemente no sea una buena elección para nuevas aplicaciones.
Muchos sistemas de datos también implementan algún tipo de codificación binaria propia para sus datos. Por ejemplo, la mayoría de las bases de datos relacionales tienen un protocolo de red a través del cual puedes enviar consultas a la base de datos y obtener respuestas. Esos protocolos suelen ser específicos de una base de datos concreta, y el proveedor de la base de datos proporciona un controlador (por ejemplo, mediante las API ODBC o JDBC) que descodifica las respuestas del protocolo de red de la base de datos en estructuras de datos en memoria.
Así, podemos ver que, aunque los formatos de datos textuales como JSON, XML y CSV están muy extendidos, las codificaciones binarias basadas en esquemas también son una opción viable. Tienen una serie de buenas propiedades:
-
Pueden ser mucho más compactos que las distintas variantes de "JSON binario", ya que pueden omitir los nombres de los campos de los datos codificados.
-
El esquema es una valiosa forma de documentación, y como el esquema es necesario para la descodificación, puedes estar seguro de que está actualizado (mientras que la documentación mantenida manualmente puede divergir fácilmente de la realidad).
-
Mantener una base de datos de esquemas te permite comprobar la compatibilidad hacia delante y hacia atrás de los cambios de esquema, antes de implementar nada.
-
Para los usuarios de lenguajes de programación tipados estáticamente, la capacidad de generar código a partir del esquema es útil, ya que permite la comprobación de tipos en tiempo de compilación.
En resumen, la evolución del esquema permite el mismo tipo de flexibilidad que ofrecen las bases de datos JSON de esquema/esquema en lectura (véase "Flexibilidad del esquema en el modelo de documento"), al tiempo que proporciona mejores garantías sobre tus datos y mejores herramientas.
Modos de flujo de datos
Al principio de este capítulo dijimos que siempre que quieras enviar algún dato a otro proceso con el que no compartas memoria -por ejemplo, siempre que quieras enviar datos a través de la red o escribirlos en un archivo- necesitas codificarlo como una secuencia de bytes. A continuación, hablamos de una serie de codificaciones diferentes para hacerlo.
Hemos hablado de la compatibilidad hacia delante y hacia atrás, que son importantes para la evolucionabilidad (facilitar el cambio permitiendo actualizar distintas partes del sistema de forma independiente, y no tener que cambiarlo todo a la vez). La compatibilidad es una relación entre un proceso que codifica los datos y otro proceso que los descodifica.
Es una idea bastante abstracta: hay muchas formas en que los datos pueden fluir de un proceso a otro. ¿Quién codifica los datos y quién los descodifica? En el resto de este capítulo exploraremos algunas de las formas más habituales de flujo de datos entre procesos:
-
A través de bases de datos (ver "Flujo de datos a través de bases de datos")
-
Mediante llamadas a servicios (consulta "Flujo de datos a través de servicios: REST y RPC")
-
Mediante el paso asíncrono de mensajes (ver "Flujo de datos con paso de mensajes")
Flujo de datos a través de bases de datos
En una base de datos, el proceso que escribe en la base de datos codifica los datos, y el proceso que lee de la base de datos los descodifica. Puede haber un único proceso que acceda a la base de datos, en cuyo caso el lector es simplemente una versión posterior del mismo proceso; en ese caso, puedes pensar que almacenar algo en la base de datos es como enviar un mensaje a tu yo futuro.
La retrocompatibilidad es claramente necesaria aquí; de lo contrario, tu yo futuro no podrá descodificar lo que escribiste anteriormente.
En general, es habitual que varios procesos diferentes accedan a una base de datos al mismo tiempo. Esos procesos pueden ser varias aplicaciones o servicios diferentes, o pueden ser simplemente varias instancias del mismo servicio (que se ejecutan en paralelo por escalabilidad o tolerancia a fallos). En cualquier caso, en un entorno en el que la aplicación está cambiando, es probable que algunos procesos que acceden a la base de datos estén ejecutando código más reciente y otros código más antiguo; por ejemplo, porque se está implantando una nueva versión en una actualización continua, de modo que algunas instancias se han actualizado mientras que otras aún no.
Esto significa que un valor de la base de datos puede ser escrito por una versión más reciente del código, y leído posteriormente por una versión más antigua del código que aún se esté ejecutando. Por tanto, la compatibilidad hacia adelante también suele ser necesaria para las bases de datos.
Sin embargo, hay un inconveniente adicional. Supongamos que añades un campo al esquema de un registro, y el código más reciente escribe un valor para ese nuevo campo en la base de datos. Posteriormente, una versión más antigua del código (que aún no conoce el nuevo campo) lee el registro, lo actualiza y lo vuelve a escribir. En esta situación, el comportamiento deseable suele ser que el código antiguo mantenga intacto el nuevo campo, aunque no haya podido ser interpretado.
Los formatos de codificación comentados anteriormente admiten esa conservación de campos desconocidos, pero a veces hay que tener cuidado a nivel de aplicación, como se ilustra en la Figura 4-7. Por ejemplo, si descodificas un valor de la base de datos en objetos modelo en la aplicación, y más tarde vuelves a codificar esos objetos modelo, el campo desconocido podría perderse en ese proceso de traducción. Resolver esto no es un problema difícil; sólo tienes que ser consciente de ello.
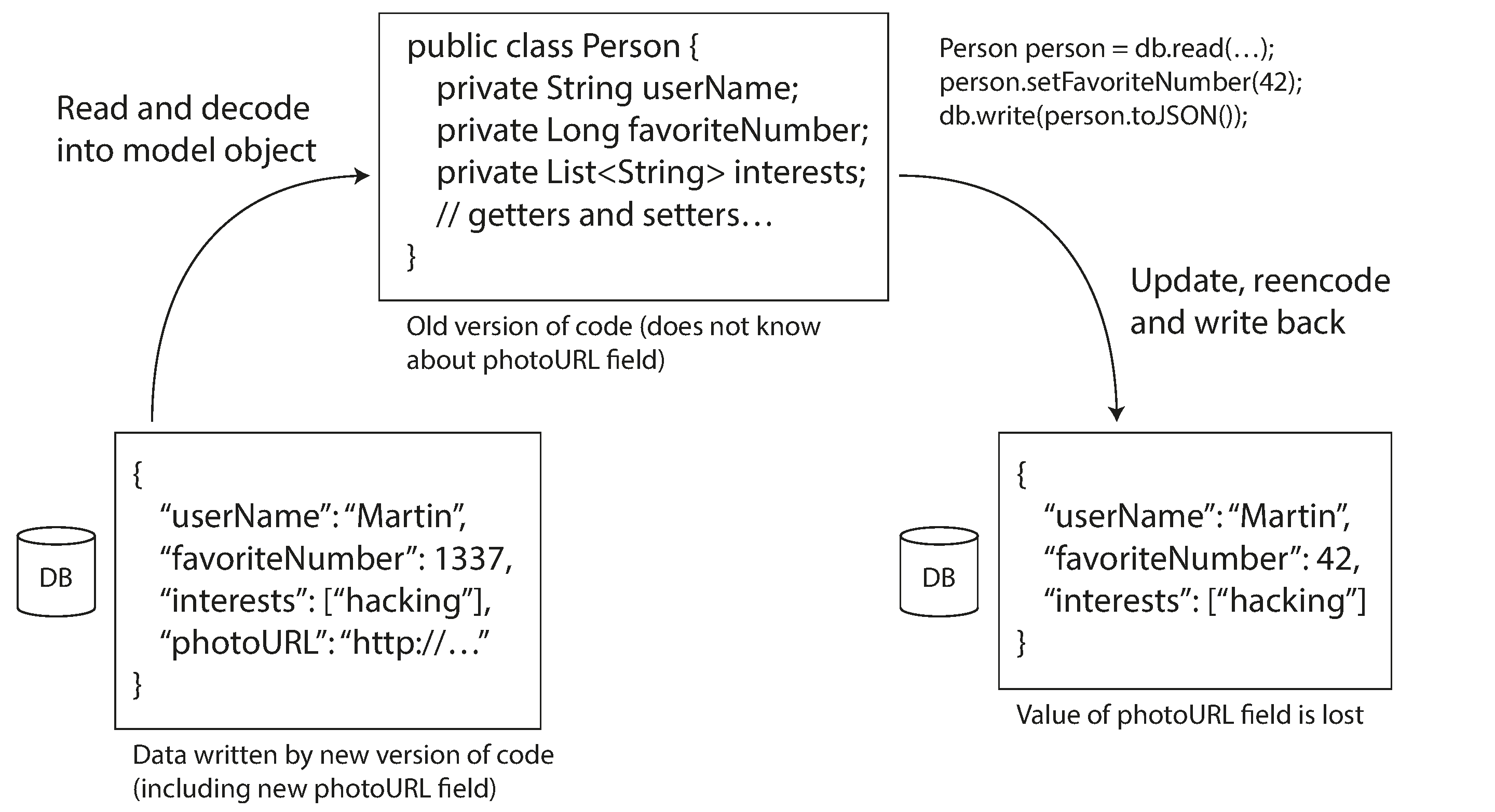
Figura 4-7. Cuando una versión antigua de la aplicación actualiza datos escritos previamente por una versión más reciente de la aplicación, pueden perderse datos si no tienes cuidado.
Valores diferentes escritos en momentos diferentes
Por lo general, una base de datos permite actualizar cualquier valor en cualquier momento. Esto significa que dentro de una misma base de datos puedes tener algunos valores que se escribieron hace cinco milisegundos y otros que se escribieron hace cinco años.
Cuando despliegas una nueva versión de tu aplicación (de una aplicación del lado del servidor, al menos), puedes sustituir por completo la versión antigua por la nueva en pocos minutos. No ocurre lo mismo con el contenido de las bases de datos: los datos de hace cinco años seguirán ahí, en la codificación original, a menos que los hayas reescrito explícitamente desde entonces. Esta observación se resume a veces como los datos sobreviven al código.
Reescribir(migrar) los datos a un nuevo esquema es ciertamente posible, pero es algo caro de hacer en un gran conjunto de datos, por lo que la mayoría de las bases de datos lo evitan si es posible. La mayoría de las bases de datos relacionales permiten cambios sencillos en el esquema, como añadir una nueva columna con un valor por defecto null, sin reescribir los datos existentes.v Cuando se lee una fila antigua, la base de datos rellena nulls para cualquier columna que falte de los datos codificados en el disco.La base de datos de documentos de LinkedIn, Espresso, utiliza Avro para el almacenamiento, lo que le permite utilizar las reglas de evolución del esquema de Avro [23].
Así, la evolución del esquema permite que toda la base de datos aparezca como si estuviera codificada con un único esquema, aunque el almacenamiento subyacente pueda contener registros codificados con varias versiones históricas del esquema.
Almacenamiento de archivos
Puede que de vez en cuando tomes una instantánea de tu base de datos, por ejemplo con fines de copia de seguridad o para cargarla en un almacén de datos (ver "Almacén de datos"). En este caso, el volcado de datos se codificará normalmente utilizando el esquema más reciente, aunque la codificación original en la base de datos fuente contuviera una mezcla de versiones de esquemas de distintas épocas. Puesto que vas a copiar los datos de todos modos, es mejor que codifiques la copia de los datos de forma coherente.
Como el volcado de datos se escribe de una sola vez y a partir de ahí es inmutable, los formatos como los archivos contenedores de objetos Avro son una buena opción. También es una buena oportunidad para codificar los datos en un formato orientado a columnas que facilite el análisis, como Parquet (consulta "Compresión de columnas").
En el capítulo 10 hablaremos más sobre el uso de datos en el almacenamiento de archivos.
Flujo de datos a través de servicios: REST y RPC
Cuando tienes procesos que necesitan comunicarse a través de una red, hay algunas formas diferentes de organizar esa comunicación. La disposición más común es tener dos roles: clientes yservidores. Los servidores exponen una API a través de la red, y los clientes pueden conectarse a los servidores para hacer peticiones a esa API. La API expuesta por el servidor se conoce como servicio.
La web funciona así: los clientes (navegadores web) hacen peticiones a los servidores web, haciendo peticiones GET para descargar HTML, CSS, JavaScript, imágenes, etc., y haciendo peticiones POST para enviar datos al servidor. La API consiste en un conjunto estandarizado de protocolos y formatos de datos (HTTP, URL, SSL/TLS, HTML, etc.). Dado que los navegadores web, los servidores web y los autores de sitios web están de acuerdo en su mayoría con estas normas, puedes utilizar cualquier navegador web para acceder a cualquier sitio web (¡al menos en teoría!).
Los navegadores web no son el único tipo de cliente. Por ejemplo, una aplicación nativa que se ejecute en un dispositivo móvil o en un ordenador de sobremesa también puede hacer solicitudes de red a un servidor, y una aplicación JavaScript del lado del cliente que se ejecute dentro de un navegador web puede utilizar XMLHttpRequest para convertirse en un cliente HTTP (esta técnica se conoce como Ajax [30]). En este caso, la respuesta del servidor no suele ser HTML para mostrar a un humano, sino datos en una codificación que sea conveniente para su posterior procesamiento por el código de la aplicación del lado del cliente (como JSON). Aunque se utilice HTTP como protocolo de transporte, la API que se implemente encima es específica de la aplicación, y el cliente y el servidor tienen que ponerse de acuerdo sobre los detalles de esa API.
Además, un servidor puede ser a su vez cliente de otro servicio (por ejemplo, el servidor típico de una aplicación web actúa como cliente de una base de datos). Este enfoque se utiliza a menudo para descomponer una aplicación grande en servicios más pequeños por área de funcionalidad, de forma que un servicio hace una petición a otro cuando necesita alguna funcionalidad o datos de ese otro servicio. Esta forma de construir aplicaciones se ha denominado tradicionalmente arquitectura orientada a servicios (SOA), más recientemente refinada y rebautizada como arquitectura de microservicios[31,32].
En cierto modo, los servicios son similares a las bases de datos: normalmente permiten a los clientes enviar y consultar datos. Sin embargo, mientras que las bases de datos permiten consultas arbitrarias utilizando los lenguajes de consulta que comentamos enel Capítulo 2, los servicios exponen una API específica de la aplicación que sólo permite entradas y salidas predeterminadas por la lógica empresarial (código de aplicación) del servicio [33]. Esta restricción proporciona cierto grado de encapsulamiento: los servicios pueden imponer restricciones de grano fino sobre lo que los clientes pueden y no pueden hacer.
Un objetivo clave del diseño de una arquitectura orientada a servicios/microservicios es facilitar el cambio y el mantenimiento de la aplicación haciendo que los servicios se puedan implementar y evolucionar de forma independiente. Por ejemplo, cada servicio debería ser propiedad de un equipo, y ese equipo debería poder lanzar nuevas versiones del servicio con frecuencia, sin tener que coordinarse con otros equipos. En otras palabras, debemos esperar que se ejecuten al mismo tiempo versiones antiguas y nuevas de servidores y clientes, por lo que la codificación de datos utilizada por servidores y clientes debe ser compatible entre versiones de la API del servicio, precisamente de lo que hemos estado hablando en este capítulo.
Servicios web
Cuando se utiliza HTTP como protocolo subyacente para hablar con el servicio, se denomina servicio web. Quizá sea un nombre un poco inapropiado, porque los servicios web no sólo se utilizan en la web, sino en varios contextos diferentes. Por ejemplo:
-
Una aplicación cliente que se ejecuta en el dispositivo de un usuario (por ejemplo, una aplicación nativa en un dispositivo móvil, o una aplicación web JavaScript que utiliza Ajax) que realiza solicitudes a un servicio a través de HTTP. Estas peticiones suelen realizarse a través de la red pública de Internet.
-
Un servicio que realiza peticiones a otro servicio propiedad de la misma organización, a menudo ubicado en el mismo centro de datos, como parte de una arquitectura orientada a servicios/microservicios. (El software que soporta este tipo de casos de uso a veces se denomina middleware).
-
Un servicio hace peticiones a un servicio de otra organización, normalmente a través de Internet. Se utiliza para el intercambio de datos entre los sistemas backend de distintas organizaciones. Esta categoría incluye las API públicas proporcionadas por servicios en línea, como los sistemas de procesamiento de tarjetas de crédito, o OAuth para el acceso compartido a los datos de los usuarios.
Hay dos enfoques populares de los servicios web: REST y SOAP. Son casi diametralmente opuestos en cuanto a filosofía, y a menudo objeto de acalorados debates entre sus respectivos defensores.vi
REST no es un protocolo, sino más bien una filosofía de diseño que se basa en los principios de HTTP [34, 35]. Hace hincapié en formatos de datos sencillos, utilizando URL para identificar recursos y empleando características de HTTP para el control de caché, la autenticación y la negociación del tipo de contenido. REST ha ido ganando popularidad frente a SOAP, al menos en el contexto de la integración de servicios entre organizaciones [36], y a menudo se asocia con los microservicios [31]. Una API diseñada según los principios de REST se denomina RESTful.
Por el contrario, SOAP es un protocolo basado en XML para realizar solicitudes de API de red.vii Aunque se suele utilizar sobre HTTP, pretende ser independiente de HTTP y evita utilizar la mayoría de sus características. En su lugar, viene acompañado de una extensa y compleja multitud de normas relacionadas (el marco de servicios web, conocido como WS-*) que añaden diversas características [37].
La API de un servicio web SOAP se describe mediante un lenguaje basado en XML llamado Lenguaje de Descripción de Servicios Web, o WSDL. El WSDL permite generar código para que un cliente pueda acceder a un servicio remoto utilizando clases y llamadas a métodos locales (que se codifican en mensajes XML y son descodificados de nuevo por el framework). Esto es útil en los lenguajes de programación de tipado estático, pero no tanto en los de tipado dinámico (consulta "Generación de código y lenguajes de tipado dinámico").
Como WSDL no está diseñado para ser legible por humanos, y como los mensajes SOAP son a menudo demasiado complejos para construirlos manualmente, los usuarios de SOAP dependen en gran medida del soporte de herramientas, la generación de código y los IDE [38]. Para los usuarios de lenguajes de programación que no son compatibles con los proveedores de SOAP, la integración con los servicios SOAP es difícil.
Aunque SOAP y sus diversas extensiones están ostensiblemente estandarizadas, la interoperabilidad entre las implementaciones de distintos proveedores suele causar problemas [39]. Por todas estas razones, aunque SOAP se sigue utilizando en muchas grandes empresas, ha caído en desgracia en la mayoría de las empresas más pequeñas.
Las API RESTful tienden a favorecer enfoques más sencillos, que suelen implicar menos generación de código y herramientas automatizadas. Se puede utilizar un formato de definición como OpenAPI, también conocido como Swagger [40], para describir las API RESTful y producir documentación.
Los problemas de las llamadas a procedimientos remotos (RPC)
Los servicios web no son más que la última encarnación de una larga serie de tecnologías para realizar solicitudes API a través de una red, muchas de las cuales recibieron mucha publicidad pero tienen graves problemas. Los Enterprise JavaBeans (EJB) y la Invocación Remota de Métodos (RMI) de Java se limitan a Java. El Modelo de Objetos de Componentes Distribuidos (DCOM) se limita a las plataformas Microsoft. La arquitectura CORBA (Common Object Request Broker Architecture) es excesivamente compleja y no ofrece compatibilidad hacia atrás ni hacia delante [41].
Todos ellos se basan en la idea de llamada a procedimiento remoto (RPC), que existe desde los años 70 [42]. El modelo RPC intenta que una petición a un servicio de red remoto parezca lo mismo que llamar a una función o método de tu lenguaje de programación, dentro del mismo proceso (esta abstracción se denomina transparencia de localización). Aunque el RPC parece cómodo al principio, el enfoque es fundamentalmente defectuoso [43,44]. Una solicitud de red es muy diferente de una llamada a una función local:
-
Una llamada a una función local es predecible y tiene éxito o falla, dependiendo sólo de los parámetros que están bajo tu control. Una petición de red es impredecible: la petición o la respuesta pueden perderse debido a un problema de red, o la máquina remota puede ser lenta o no estar disponible, y tales problemas están totalmente fuera de tu control. Los problemas de red son habituales, por lo que tienes que anticiparte a ellos, por ejemplo, reintentando una petición fallida.
-
Una llamada a una función local devuelve un resultado, lanza una excepción o no vuelve nunca (porque entra en un bucle infinito o el proceso se bloquea). Una petición de red tiene otro resultado posible: puede volver sin resultado, debido a un tiempo de espera. En ese caso, sencillamente no sabes qué ha ocurrido: si no recibes una respuesta del servicio remoto, no tienes forma de saber si la solicitud se ha realizado o no. (Trataremos este tema con más detalle en el Capítulo 8).
-
Si reintentas una petición de red fallida, podría ocurrir que la petición anterior realmente se realizara, y sólo se perdiera la respuesta.En ese caso, reintentar hará que la acción se realice varias veces, a menos que incorpores un mecanismo de deduplicación(idempotencia) en el protocolo. Las llamadas a funciones locales no tienen este problema. (Hablaremos de la idempotencia con más detalle en el Capítulo 11).
-
Cada vez que llamas a una función local, normalmente tarda más o menos el mismo tiempo en ejecutarse. Una solicitud de red es mucho más lenta que una llamada a una función, y su latencia también es muy variable: en los buenos momentos puede completarse en menos de un milisegundo, pero cuando la red está congestionada o el servicio remoto está sobrecargado puede tardar muchos segundos en hacer exactamente lo mismo.
-
Cuando llamas a una función local, puedes pasarle eficientemente referencias (punteros) a objetos de la memoria local. Cuando haces una petición de red, todos esos parámetros deben codificarse en una secuencia de bytes que pueda enviarse por la red. Eso está bien si los parámetros son primitivos como números o cadenas, pero rápidamente se vuelve problemático con objetos más grandes.
-
El cliente y el servicio pueden estar implementados en lenguajes de programación diferentes, por lo que el marco RPC debe traducir los tipos de datos de un lenguaje a otro. Esto puede acabar feo, ya que no todos los lenguajes tienen los mismos tipos -recuerda los problemas de JavaScript con los números mayores que253, por ejemplo (ver "JSON, XML y variantes binarias"). Este problema no existe en un único proceso escrito en un único lenguaje.
Todos estos factores significan que no tiene sentido intentar que un servicio remoto se parezca demasiado a un objeto local en tu lenguaje de programación, porque es algo fundamentalmente distinto. Parte del atractivo de REST es que no trata de ocultar el hecho de que es un protocolo de red (aunque esto no parece impedir que la gente construya bibliotecas RPC sobre REST).
Orientaciones actuales para el EPR
A pesar de todos estos problemas, la RPC no va a desaparecer. Se han construido varios marcos RPC sobre todas las codificaciones mencionadas en este capítulo: por ejemplo, Thrift y Avro vienen con soporte RPC incluido, gRPC es una implementación RPC que utiliza Protocol Buffers, Finagle también utiliza Thrift, y Rest.li utiliza JSON sobre HTTP.
Esta nueva generación de marcos RPC es más explícita sobre el hecho de que una solicitud remota es diferente de una llamada a una función local. Por ejemplo, Finagle y Rest.li utilizan futuros(promesas) para encapsular acciones asíncronas que pueden fallar. Los futuros también simplifican las situaciones en las que necesitas hacer peticiones a varios servicios en paralelo, y combinar sus resultados [45]. gRPC admite secuencias, en las que una llamada consiste no sólo en una petición y una respuesta, sino en una serie de peticiones y respuestas a lo largo del tiempo [46].
Algunos de estos marcos también proporcionan descubrimiento de servicios,es decir, permiten que un cliente averigüe en qué dirección IP y número de puerto puede encontrar un servicio concreto. Volveremos sobre este tema en "Enrutamiento de peticiones".
Los protocolos RPC personalizados con un formato de codificación binario pueden conseguir un mejor rendimiento que algo genérico como JSON sobre REST. Sin embargo, una API RESTful tiene otras ventajas significativas: es buena para la experimentación y la depuración (puedes simplemente hacer peticiones a ella utilizando un navegador web o la herramienta de línea de comandos curl, sin necesidad de generar código o instalar software), es compatible con todos los lenguajes de programación y plataformas principales, y hay un vasto ecosistema de herramientas disponibles (servidores, cachés, equilibradores de carga, proxies, cortafuegos, herramientas de monitoreo y depuración, herramientas de prueba, etc.).
Por estas razones, REST parece ser el estilo predominante para las API públicas. Los marcos RPC se centran principalmente en las peticiones entre servicios pertenecientes a la misma organización, normalmente dentro del mismo centro de datos.
Codificación y evolución de datos para RPC
Para la evolucionabilidad, es importante que los clientes y servidores RPC puedan cambiarse e implementarse independientemente. En comparación con los datos que fluyen a través de bases de datos (como se describe en la última sección), podemos hacer una suposición simplificadora en el caso del flujo de datos a través de servicios: es razonable suponer que todos los servidores se actualizarán primero, y todos los clientes después. Así, sólo necesitas compatibilidad hacia atrás en las peticiones, y hacia adelante en las respuestas.
Las propiedades de compatibilidad hacia atrás y hacia delante de un esquema RPC se heredan de la codificación que utilice:
-
Thrift, gRPC (búferes de protocolo) y Avro RPC pueden evolucionar según las reglas de compatibilidad del formato de codificación respectivo.
-
En SOAP, las peticiones y respuestas se especifican con esquemas XML. Éstos pueden evolucionar, pero existen algunos escollos sutiles [47].
-
Las API RESTful suelen utilizar JSON (sin un esquema formalmente especificado) para las respuestas, y JSON o parámetros de solicitud codificados por URI/formulario para las solicitudes. Añadir parámetros de solicitud opcionales y añadir nuevos campos a los objetos de respuesta suelen considerarse cambios que mantienen la compatibilidad.
La compatibilidad de los servicios se ve dificultada por el hecho de que el RPC se utiliza a menudo para la comunicación a través de los límites de la organización, por lo que el proveedor de un servicio no suele tener control sobre sus clientes y no puede obligarles a actualizarse. Por tanto, la compatibilidad debe mantenerse durante mucho tiempo, quizá indefinidamente. Si es necesario un cambio que rompa la compatibilidad, el proveedor de servicios suele acabar manteniendo varias versiones de la API del servicio, una al lado de la otra.
No hay acuerdo sobre cómo debe funcionar el versionado de la API (es decir, cómo puede indicar un cliente qué versión de la API quiere utilizar [48]). Para las API RESTful, los enfoques habituales son utilizar un número de versión en la URL o en la cabecera HTTP Accept. Para los servicios que utilizan claves de API para identificar a un cliente concreto, otra opción es almacenar la versión de API solicitada por un cliente en el servidor y permitir que esta selección de versión se actualice a través de una interfaz administrativa independiente [49].
Flujo de datos de paso de mensajes
Hemos estado estudiando las distintas formas en que los datos codificados fluyen de un proceso a otro. Hasta ahora, hemos hablado de REST y RPC (en los que un proceso envía una solicitud a través de la red a otro proceso y espera una respuesta lo antes posible), y de bases de datos (en las que un proceso escribe datos codificados, y otro proceso los vuelve a leer en algún momento futuro).
En esta última sección, examinaremos brevemente los sistemas asíncronos de paso de mensajes, que están a medio camino entre el RPC y las bases de datos. Se parecen al RPC en que la solicitud de un cliente (normalmente llamada mensaje) se entrega a otro proceso con baja latencia. Se parecen a las bases de datos en que el mensaje no se envía a través de una conexión de red directa, sino que pasa por un intermediario llamado corredor de mensajes (también llamado cola de mensajes o middleware orientado a mensajes), que almacena el mensaje temporalmente.
Utilizar un intermediario de mensajes tiene varias ventajas en comparación con el RPC directo:
-
Puede actuar como un búfer si el destinatario no está disponible o está sobrecargado, y mejorar así la fiabilidad del sistema.
-
Puede volver a entregar automáticamente mensajes a un proceso que se ha bloqueado, y evitar así que se pierdan mensajes.
-
Evita que el remitente tenga que conocer la dirección IP y el número de puerto del destinatario (lo que resulta especialmente útil en una implementación en la nube, donde las máquinas virtuales suelen ir y venir).
-
Permite enviar un mensaje a varios destinatarios.
-
Desvincula lógicamente al emisor del destinatario (el emisor sólo publica mensajes y no le importa quién los consume).
Sin embargo, una diferencia con respecto a RPC es que la comunicación por paso de mensajes suele ser unidireccional: un emisor normalmente no espera recibir una respuesta a sus mensajes. Es posible que un proceso envíe una respuesta, pero normalmente se haría en un canal aparte. Este patrón de comunicación esasíncrono: el emisor no espera a que se entregue el mensaje, sino que simplemente lo envía y luego se olvida de él.
Corredores de mensajes
En el pasado, el panorama de los intermediarios de mensajes estaba dominado por el software empresarial comercial de empresas como TIBCO, IBM WebSphere y webMethods. Más recientemente, se han popularizado implementaciones de código abierto como RabbitMQ, ActiveMQ, HornetQ, NATS y Apache Kafka. Las compararemos con más detalle en el Capítulo 11.
La semántica detallada de la entrega varía según la implementación y la configuración, pero en general, los intermediarios de mensajes se utilizan de la siguiente manera: un proceso envía un mensaje a una cola o tema con nombre, y el intermediario se asegura de que el mensaje se entrega a uno o más consumidores o suscriptores de esa cola o tema. Puede haber muchos productores y muchos consumidores en el mismo tema.
Un tema sólo proporciona un flujo de datos unidireccional. Sin embargo, un consumidor puede a su vez publicar mensajes en otro tema (para poder encadenarlos, como veremos en el Capítulo 11), o en una cola de respuesta que sea consumida por el emisor del mensaje original (permitiendo un flujo de datos petición/respuesta, similar al RPC).
Los intermediarios de mensajes no suelen imponer ningún modelo de datos concreto: un mensaje es sólo una secuencia de bytes con algunos metadatos, por lo que puedes utilizar cualquier formato de codificación. Si la codificación es compatible hacia adelante y hacia atrás, tendrás la máxima flexibilidad para cambiar los editores y consumidores de forma independiente e implementarlos en cualquier orden.
Si un consumidor vuelve a publicar mensajes en otro tema, puede que tengas que tener cuidado de conservar los campos desconocidos, para evitar el problema descrito anteriormente en el contexto de las bases de datos(Figura 4-7).
Marcos de actores distribuidos
El modelo de actor es un modelo de programación para la concurrencia en un único proceso. En lugar de tratar directamente con hilos (y los problemas asociados de condiciones de carrera, bloqueo y punto muerto), la lógica se encapsula en actores. Cada actor suele representar a un cliente o entidad, puede tener algún estado local (que no se comparte con ningún otro actor), y se comunica con otros actores enviando y recibiendo mensajes asíncronos. La entrega de mensajes no está garantizada: en determinadas situaciones de error, los mensajes se perderán. Como cada actor sólo procesa un mensaje a la vez, no necesita preocuparse por los hilos, y cada actor puede ser programado independientemente por el marco.
En los marcos de actores distribuidos, este modelo de programación se utiliza para escalar una aplicación a través de múltiples nodos. Se utiliza el mismo mecanismo de paso de mensajes, independientemente de que el emisor y el receptor estén en el mismo nodo o en nodos diferentes. Si están en nodos diferentes, el mensaje se codifica de forma transparente en una secuencia de bytes, se envía por la red y se descodifica en el otro lado.
La transparencia de localización funciona mejor en el modelo de actor que en RPC, porque el modelo de actor ya asume que los mensajes pueden perderse, incluso dentro de un mismo proceso. Aunque es probable que la latencia en la red sea mayor que dentro del mismo proceso, hay menos desajuste fundamental entre la comunicación local y la remota cuando se utiliza el modelo de actor.
Un marco de trabajo de actor distribuido integra esencialmente un corredor de mensajes y el modelo de programación de actores en un único marco de trabajo. Sin embargo, si quieres realizar actualizaciones continuas de tu aplicación basada en actores, tendrás que preocuparte de la compatibilidad hacia delante y hacia atrás, ya que los mensajes pueden enviarse desde un nodo que ejecute la nueva versión a otro que ejecute la antigua, y viceversa.
Tres marcos populares de actores distribuidos manejan la codificación de mensajes de la siguiente manera:
-
Akka utiliza por defecto la serialización incorporada de Java, que no proporciona compatibilidad hacia adelante ni hacia atrás. Sin embargo, puedes sustituirla por algo como los búferes de protocolo, y así ganar la capacidad de hacer actualizaciones progresivas [50].
-
Orleans admite actualizaciones continuas mediante su propio mecanismo de versiones. Permite definir nuevos métodos de actor (es decir, nuevos tipos de mensajes entrantes que un actor puede procesar) manteniendo la compatibilidad con versiones anteriores, siempre que no se modifiquen los métodos existentes [51,52].
-
En Erlang OTP es sorprendentemente difícil hacer cambios en los esquemas de los registros (a pesar de que el sistema tiene muchas características diseñadas para la alta disponibilidad); las actualizaciones continuas son posibles, pero deben planificarse cuidadosamente [53]. Un nuevo tipo de datos experimental
maps(una estructura similar a JSON, introducida en Erlang R17 en 2014) puede facilitar esto en el futuro [54].
Resumen
En este capítulo hemos visto varias formas de convertir estructuras de datos en bytes en la red o bytes en disco. Hemos visto cómo los detalles de estas codificaciones afectan no sólo a su eficacia, sino, lo que es más importante, a la arquitectura de las aplicaciones y a tus opciones para hacerlas evolucionar.
En particular, muchos servicios necesitan admitir actualizaciones continuas, en las que una nueva versión de un servicio se despliega gradualmente en unos pocos nodos cada vez, en lugar de desplegarse en todos los nodos simultáneamente. Las actualizaciones continuas permiten lanzar nuevas versiones de un servicio sin tiempo de inactividad (fomentando así los pequeños lanzamientos frecuentes en lugar de los grandes lanzamientos poco frecuentes) y hacen que las implementaciones sean menos arriesgadas (permitiendo detectar lanzamientos defectuosos y revertirlos antes de que afecten a un gran número de usuarios). Estas propiedades son enormemente beneficiosas para la evolucionabilidad, es decir, la facilidad para realizar cambios en una aplicación.
Durante las actualizaciones continuas, o por otras razones, debemos suponer que diferentes nodos están ejecutando versiones distintas del código de nuestra aplicación. Por tanto, es importante que todos los datos que circulen por el sistema estén codificados de forma que ofrezcan compatibilidad hacia atrás (el código nuevo puede leer los datos antiguos) y hacia adelante (el código antiguo puede leer los datos nuevos).
Hemos hablado de varios formatos de codificación de datos y de sus propiedades de compatibilidad:
-
Las codificaciones específicas de un lenguaje de programación se limitan a un único lenguaje de programación y a menudo no proporcionan compatibilidad hacia delante y hacia atrás.
-
Los formatos textuales como JSON, XML y CSV están muy extendidos, y su compatibilidad depende de cómo los utilices. Tienen lenguajes de esquema opcionales, que a veces son útiles y a veces un obstáculo. Estos formatos son algo vagos en cuanto a los tipos de datos, por lo que tienes que tener cuidado con cosas como los números y las cadenas binarias.
-
Los formatos binarios basados en esquemas, como Thrift, Protocol Buffers y Avro, permiten una codificación compacta y eficaz con una semántica de compatibilidad hacia delante y hacia atrás claramente definida. Los esquemas pueden ser útiles para la documentación y la generación de código en lenguajes tipados estáticamente. Sin embargo, estos formatos tienen el inconveniente de que hay que descodificar los datos antes de que sean legibles para el ser humano.
También discutimos varios modos de flujo de datos, ilustrando diferentes escenarios en los que las codificaciones de datos son importantes:
-
Bases de datos, donde el proceso que escribe en la base de datos codifica los datos y el proceso que lee de la base de datos los descodifica
-
API RPC y REST, donde el cliente codifica una petición, el servidor descodifica la petición y codifica una respuesta, y el cliente finalmente descodifica la respuesta.
-
Paso asíncrono de mensajes (mediante intermediarios o actores de mensajes), en el que los nodos se comunican enviándose mensajes codificados por el emisor y descodificados por el receptor.
Podemos concluir que, con un poco de cuidado, la compatibilidad hacia atrás/hacia delante y las actualizaciones continuas son bastante factibles. Que la evolución de tu aplicación sea rápida y tus Implementaciones frecuentes.
Notas a pie de página
i A excepción de algunos casos especiales, como ciertos archivos mapeados en memoria o cuando se opera directamente sobre datos comprimidos (como se describe en"Compresión de columnas").
ii Ten en cuenta que la codificaciónno tiene nada que ver con la encriptación. En este libro no hablamos de encriptación.
iii En realidad, tiene tres -BinaryProtocol, CompactProtocol y DenseProtocol-, aunque DenseProtocol sólo es compatible con la implementación de C++, por lo que no cuenta como lenguaje cruzado [18]. Además de éstos, también tiene dos formatos de codificación diferentes basados en JSON [19]. ¡Qué divertido!
iv Para ser precisos, el valor por defecto debe ser del tipo de la primera rama de la unión, aunque ésta es una limitación específica de Avro, no una característica general de los tipos de unión.
v Excepto MySQL, que a menudo reescribe una tabla entera aunque no sea estrictamente necesario, como se menciona en"Flexibilidad del esquema en el modelo documental".
vi Incluso dentro de cada campo hay muchas discusiones. Por ejemplo, HATEOAS(hipermedia como motor del estado de la aplicación), provoca a menudo discusiones [35].
vii A pesar de la similitud de siglas, SOAP no es un requisito para SOA. SOAP es una tecnología concreta, mientras que SOA es un enfoque general para construir sistemas.
Referencias
[1] "Especificación de serialización de objetos Java", docs.oracle.com, 2010.
[2] "Documentación de la API de Ruby 2.2.0", ruby-doc.org, Dic 2014.
[3] "Manual de referencia de la biblioteca estándar de Python 3.4.3", docs.python.org, febrero de 2015.
[4] "EsotericSoftware/kryo",github.com, octubre de 2014.
[5] "CWE-502: Deserialización de datos no fiables", Enumeración de Debilidades Comunes, cwe.mitre.org, 30 de julio de 2014.
[6] Steve Breen: "¿Qué tienen en común WebLogic, WebSphere, JBoss, Jenkins, OpenNMS y tu aplicación? Esta vulnerabilidad", foxglovesecurity.com, 6 de noviembre de 2015.
[7] Patrick McKenzie: "What the Rails Security Issue Means for Your Startup," kalzumeus.com, 31 de enero de 2013.
[8] Eishay Smith: "jvm-serializers wiki",github.com, noviembre de 2014.
[9] "XML es una mala copia de las expresiones S", c2.com wiki.
[10] Matt Harris: "Snowflake: An Update and Some Very Important Information", correo electrónico a la lista de correo Twitter Development Talk, 19 de octubre de 2010.
[11] Shudi (Sandy) Gao, C. M. Sperberg-McQueen y Henry S. Thompson: "XML Schema 1.1", Recomendación del W3C, mayo de 2001.
[12] Francis Galiegue, Kris Zyp y Gary Court: "Esquema JSON", IETF Internet-Draft, febrero de 2013.
[13] Yakov Shafranovich: "RFC 4180: Formato común y tipo MIME para archivos de valores separados por comas (CSV)", octubre de 2005.
[14] "Especificación de MessagePack", msgpack.org.
[15] Mark Slee, Aditya Agarwal y Marc Kwiatkowski: "Thrift: Scalable Cross-Language Services Implementation", informe técnico de Facebook, abril de 2007.
[16] "Guía del desarrollador de búferes de protocolo", Google, Inc, developers.google.com.
[17] Igor Anishchenko: "Thrift vs Buffers de protocolo vs Avro - Comparación sesgada", slideshare.net, 17 de septiembre de 2012.
[18] "Una matriz de las características que admite cada biblioteca de lenguaje individual",wiki.apache.org.
[19] Martin Kleppmann: "Evolución de esquemas en Avro, búferes de protocolo y Thrift", martin.kleppmann.com, 5 de diciembre de 2012.
[20] "Documentación de Apache Avro 1.7.7", avro.apache.org, julio de 2014.
[21] Doug Cutting, Chad Walters, Jim Kellerman, et al.: "[PROPUESTA] Nuevo Subproyecto: Avro", hilo de correo electrónico en la lista de correo hadoop-general,mail-archives.apache.org, abril de 2009.
[22] Tony Hoare: "Referencias nulas: El error del billón de dólares", en la QCon de Londres, marzo de 2009.
[23] Aditya Auradkar y Tom Quiggle: "Introducing Espresso-LinkedIn's Hot New Distributed Document Store", engineering.linkedin.com, 21 de enero de 2015.
[24] Jay Kreps: "Putting Apache Kafka to Use: A Practical Guide to Building a Stream Data Platform (Part 2)", blog.confluent.io, 25 de febrero de 2015.
[25] Gwen Shapira: "El problema de gestionar esquemas", radar.oreilly.com, 4 de noviembre de 2014.
[26] "Documentación de Apache Pig 0.14.0", pig.apache.org, noviembre de 2014.
[27] John Larmouth:ASN.1 Completo. Morgan Kaufmann, 1999. ISBN: 978-0-122-33435-1
[28] Russell Housley, Warwick Ford, Tim Polk y David Solo: "RFC 2459: Internet X.509 Public Key Infrastructure: Certificate and CRL Profile", IETF Network Working Group, Standards Track, enero de 1999.
[29] Lev Walkin: "Pregunta: Extensibilidad y eliminación de campos", lionet.info, 21 de septiembre de 2010.
[30] Jesse James Garrett: "Ajax: Un nuevo enfoque para las aplicaciones web", adaptivepath.com, 18 de febrero de 2005.
[31] Sam Newman: Building Microservices. O'Reilly Media, 2015. ISBN: 978-1-491-95035-7
[32] Chris Richardson: "Microservicios: Decomposing Applications for Deployability and Scalability", infoq.com, 25 de mayo de 2014.
[33] Pat Helland: "Datos en el exterior frente a datos en el interior", en la 2ª Conferencia Bienal sobre Investigación en Sistemas de Datos Innovadores (CIDR), enero de 2005.
[34] Roy Thomas Fielding: "Architectural Styles and the Design of Network-Based Software Architectures", tesis doctoral, Universidad de California, Irvine, 2000.
[35] Roy Thomas Fielding: "Las API REST deben estar orientadas al hipertexto", roy.gbiv.com, 20 de octubre de 2008.
[36] "REST en paz, SOAP", royal.pingdom.com, 15 de octubre de 2010.
[37] "Web Services Standards as of Q1 2007," innoq.com, febrero de 2007.
[38] Pete Lacey: "La S significa Simple", harmful.cat-v.org, 15 de noviembre de 2006.
[39] Stefan Tilkov: "Entrevista: Pete Lacey Critica los Servicios Web", infoq.com, 12 de diciembre de 2006.
[40] "OpenAPI Specification (fka Swagger RESTful API Documentation Specification) Version 2.0,"swagger.io, 8 de septiembre de 2014.
[41] Michi Henning: "Auge y caída de CORBA",Communications of the ACM, volumen 51, número 8, páginas 52-57, agosto de 2008.doi:10.1145/1378704.1378718
[42] Andrew D. Birrell y Bruce Jay Nelson: "Implementing Remote Procedure Calls", ACM Transactions on Computer Systems (TOCS), volumen 2, número 1, páginas 39-59, febrero de 1984.doi:10.1145/2080.357392
[43] Jim Waldo, Geoff Wyant, Ann Wollrath y Sam Kendall: "A Note on Distributed Computing", Sun Microsystems Laboratories, Inc., Informe técnico TR-94-29, noviembre de 1994.
[44] Steve Vinoski: "Convenience over Correctness", IEEE Internet Computing, volumen 12, número 4, páginas 89-92, julio de 2008.doi:10.1109/MIC.2008.75
[45] Marius Eriksen: "Tu servidor como función", enel 7º Taller sobre Lenguajes de Programación y Sistemas Operativos (PLOS), noviembre de 2013.doi:10.1145/2525528.2525538
[46] "Conceptos de gRPC", Fundación Linux, grpc.io.
[47] Aditya Narayan e Irina Singh: "Designing and Versioning Compatible Web Services", ibm.com, 28 de marzo de 2007.
[48] Troy Hunt: "Your API Versioning Is Wrong, Which Is Why I Decided to Do It 3 Different Wrong Ways," troyhunt.com, 10 de febrero de 2014.
[49] "Actualizaciones de la API", Stripe, Inc. abril de 2015.
[50] Jonas Bonér: "Upgrade in an Akka Cluster", correo electrónico a la lista de correo akka-user, grokbase.com, 28 de agosto de 2013.
[51] Philip A. Bernstein, Sergey Bykov, Alan Geller y otros: "Orleans: Distributed Virtual Actors for Programmability and Scalability", Informe técnico de Microsoft Research MSR-TR-2014-41, marzo de 2014.
[52] "Documentación de Microsoft Project Orleans", Microsoft Research, dotnet.github.io, 2017.
[53] David Mercer, Sean Hinde, Yinso Chen y Richard A O'Keefe: "beginner: Updating Data Structures", hilo de correo electrónico en la lista de correo erlang-questions, erlang.com, 29 de octubre de 2007.
[54] Fred Hebert: "Posdata: Mapas", learnyousomeerlang.com, 9 de abril de 2014.
Get Diseño de aplicaciones intensivas en datos now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

