Capítulo 1. Aplicaciones fiables, escalables y mantenibles
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Internet se hizo tan bien que la mayoría de la gente piensa que es un recurso natural como el océano Pacífico, y no algo creado por el hombre. ¿Cuándo fue la última vez que una tecnología de tal envergadura estuvo tan libre de errores?
Alan Kay, en entrevista con el Dr. Dobb's Journal (2012)

Hoy en día, muchas aplicaciones hacen un uso intensivo de datos, en contraposición a un uso intensivo de cálculo. La potencia bruta de la CPU rara vez es un factor limitante para estas aplicaciones: los mayores problemas suelen ser la cantidad de datos, su complejidad y la velocidad a la que cambian.
Una aplicación de uso intensivo de datos suele construirse a partir de bloques de construcción estándar que proporcionan una funcionalidad comúnmente necesaria. Por ejemplo, muchas aplicaciones necesitan
-
Almacenar datos para que ellos, u otra aplicación, puedan volver a encontrarlos más tarde(bases de datos)
-
Recordar el resultado de una operación costosa, para acelerar las lecturas(cachés)
-
Permitir a los usuarios buscar datos por palabra clave o filtrarlos de varias formas(índices de búsqueda)
-
Envía un mensaje a otro proceso, para que lo gestione de forma asíncrona(procesamiento de flujos).
-
Crujir periódicamente una gran cantidad de datos acumulados(procesamiento por lotes)
Si eso suena dolorosamente obvio, es sólo porque estos sistemas de datos son una abstracción tan exitosa: los utilizamos todo el tiempo sin pensar demasiado. Al crear una aplicación, la mayoría de los ingenieros ni soñarían con escribir un nuevo motor de almacenamiento de datos desde cero, porque las bases de datos son una herramienta perfectamente buena para el trabajo.
Pero la realidad no es tan sencilla. Hay muchos sistemas de bases de datos con características diferentes, porque las distintas aplicaciones tienen requisitos diferentes. Hay varios enfoques para el almacenamiento en caché, varias formas de construir índices de búsqueda, etc. Cuando construimos una aplicación, todavía tenemos que averiguar qué herramientas y qué enfoques son los más adecuados para la tarea que tenemos entre manos. Y puede ser difícil combinar herramientas cuando necesitas hacer algo que una sola herramienta no puede hacer por sí sola.
Este libro es un recorrido tanto por los principios como por los aspectos prácticos de los sistemas de datos, y por cómo puedes utilizarlos para crear aplicaciones intensivas en datos. Exploraremos qué tienen en común las distintas herramientas, qué las distingue y cómo consiguen sus características.
En este capítulo, empezaremos explorando los fundamentos de lo que intentamos conseguir: sistemas de datos fiables, escalables y mantenibles. Aclararemos qué significan esas cosas, esbozaremos algunas formas de pensar sobre ellas y repasaremos los fundamentos que necesitaremos en capítulos posteriores. En los capítulos siguientes continuaremos capa por capa, examinando las distintas decisiones de diseño que hay que tener en cuenta al trabajar en una aplicación intensiva en datos.
Pensar en sistemas de datos
Normalmente pensamos que las bases de datos, las colas, las cachés, etc. son categorías de herramientas muy diferentes. Aunque una base de datos y una cola de mensajes tienen cierta similitud superficial -ambas almacenan datos durante algún tiempo-, tienen patrones de acceso muy diferentes, lo que significa características de rendimiento distintas y, por tanto, implementaciones muy diferentes.
Entonces, ¿por qué debemos agruparlos todos bajo un término general como sistemas de datos?
En los últimos años han surgido muchas herramientas nuevas para el almacenamiento y procesamiento de datos. Están optimizadas para una variedad de casos de uso diferentes, y ya no encajan perfectamente en las categorías tradicionales [1]. Por ejemplo, hay almacenes de datos que también se utilizan como colas de mensajes (Redis), y hay colas de mensajes con garantías de durabilidad similares a las de las bases de datos (Apache Kafka). Los límites entre las categorías se están difuminando.
En segundo lugar, cada vez más aplicaciones tienen requisitos tan exigentes o amplios que una sola herramienta ya no puede satisfacer todas sus necesidades de procesamiento y almacenamiento de datos. En su lugar, el trabajo se divide en tareas que pueden realizarse eficazmente en una sola herramienta, y esas diferentes herramientas se unen mediante código de aplicación.
Por ejemplo, si tienes una capa de caché gestionada por la aplicación (utilizando Memcached o similar), o un servidor de búsqueda de texto completo (como Elasticsearch o Solr) separado de tu base de datos principal, normalmente es responsabilidad del código de la aplicación mantener esas cachés e índices sincronizados con la base de datos principal. La Figura 1-1 da una idea de cómo puede ser esto (entraremos en detalle en capítulos posteriores).
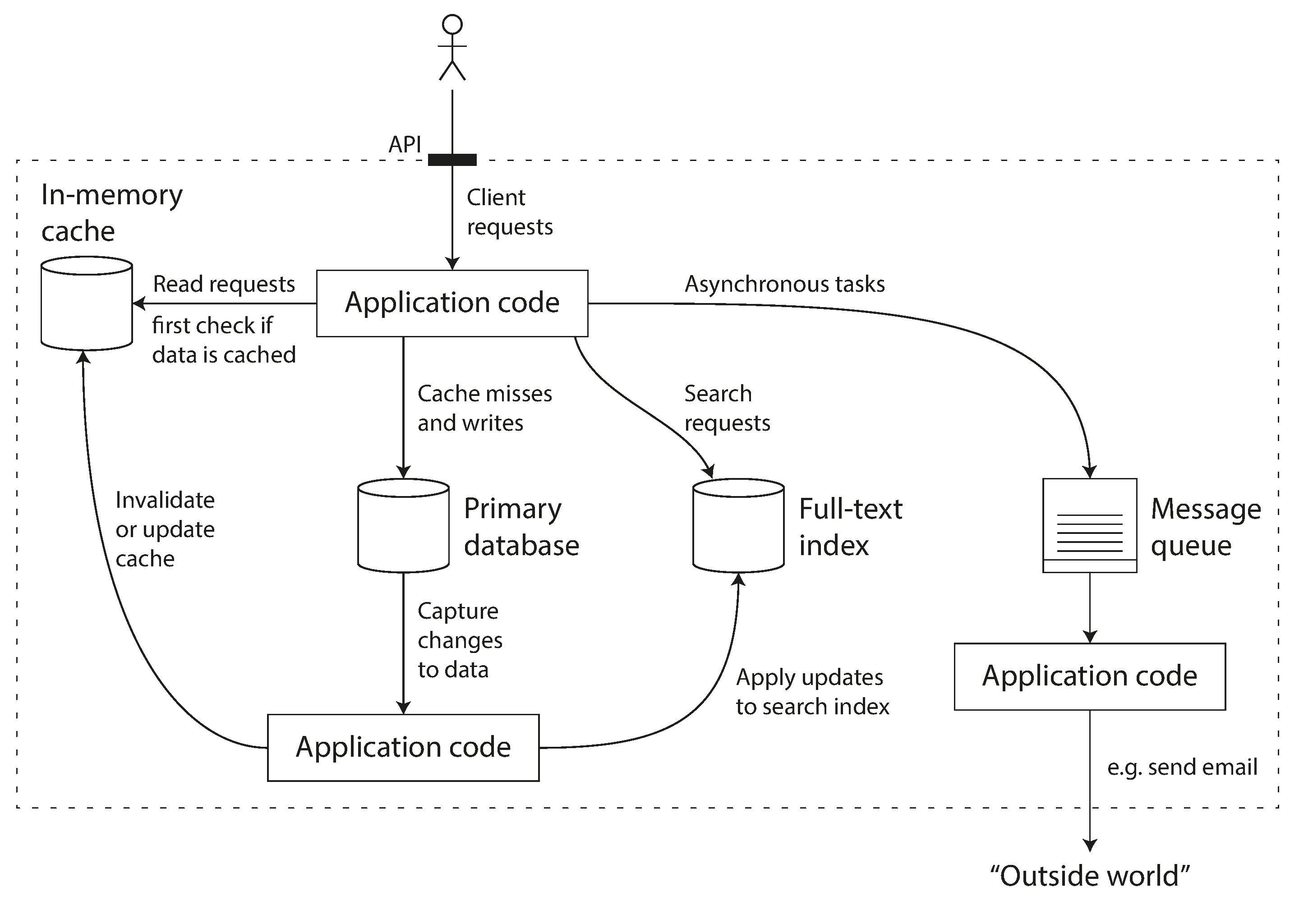
Figura 1-1. Una posible arquitectura para un sistema de datos que combine varios componentes.
Cuando combinas varias herramientas para prestar un servicio, la interfaz del servicio o la interfaz de programación de aplicaciones (API) suele ocultar esos detalles de implementación a los clientes. Ahora has creado esencialmente un nuevo sistema de datos de propósito especial a partir de componentes más pequeños de propósito general. Tu sistema de datos compuesto puede ofrecer ciertas garantías: por ejemplo, que la caché se invalidará o actualizará correctamente en las escrituras para que los clientes externos vean resultados coherentes. Ahora no eres sólo un desarrollador de aplicaciones, sino también un diseñador de sistemas de datos.
Si estás diseñando un sistema o servicio de datos, surgen muchas preguntas complicadas. ¿Cómo te aseguras de que los datos siguen siendo correctos y completos, incluso cuando las cosas van mal internamente? ¿Cómo proporcionas un buen rendimiento constante a los clientes, incluso cuando partes de tu sistema se degradan? ¿Cómo escalas para gestionar un aumento de la carga? ¿Qué aspecto tiene una buena API para el servicio?
Hay muchos factores que pueden influir en el diseño de un sistema de datos, como las habilidades y la experiencia de las personas implicadas, las dependencias de sistemas heredados, el plazo de entrega, la tolerancia de tu organización a distintos tipos de riesgo, las limitaciones normativas, etc. Esos factores dependen mucho de la situación.
En este libro, nos centramos en tres preocupaciones que son importantes en la mayoría de los sistemas de software:
- Fiabilidad
-
El sistema debe seguir funcionando correctamente (realizando la función correcta al nivel de rendimiento deseado) incluso ante la adversidad (fallos de hardware o software, e incluso errores humanos). Ver "Fiabilidad".
- Escalabilidad
-
A medida que el sistema crece (en volumen de datos, volumen de tráfico o complejidad), debe haber formas razonables de hacer frente a ese crecimiento. Ver "Escalabilidad".
- Mantenibilidad
-
Con el tiempo, muchas personas diferentes trabajarán en el sistema (ingeniería y operaciones, tanto manteniendo el comportamiento actual como adaptando el sistema a nuevos casos de uso), y todas ellas deberían poder trabajar en él de forma productiva. Véase "Mantenibilidad".
A menudo, estas palabras se pronuncian sin una comprensión clara de lo que significan. En aras de una ingeniería reflexiva, dedicaremos el resto de este capítulo a explorar formas de pensar sobre la fiabilidad, la escalabilidad y la mantenibilidad. Luego, en los capítulos siguientes, examinaremos diversas técnicas, arquitecturas y algoritmos que se utilizan para alcanzar esos objetivos.
Fiabilidad
Todo el mundo tiene una idea intuitiva de lo que significa que algo sea fiable o poco fiable. Para el software, las expectativas típicas incluyen:
-
La aplicación realiza la función que el usuario esperaba.
-
Puede tolerar que el usuario cometa errores o utilice el programa de forma inesperada.
-
Su rendimiento es suficientemente bueno para el caso de uso requerido, con la carga y el volumen de datos previstos.
-
El sistema impide cualquier acceso no autorizado y abuso.
Si todas esas cosas juntas significan "funcionar correctamente", entonces podemos entender la fiabilidad en el sentido aproximado de "seguir funcionando correctamente, incluso cuando las cosas van mal".
Las cosas que pueden ir mal se llaman fallos, y los sistemas que prevén los fallos y pueden hacerles frente se llaman tolerantes a fallos o resilientes. El primer término es ligeramente engañoso: sugiere que podríamos hacer un sistema tolerante a todos los tipos posibles de fallo, lo que en realidad no es factible. Si todo el planeta Tierra (y todos los servidores que hay en él) fuera tragado por un agujero negro, la tolerancia a ese fallo requeriría un alojamiento web en el espacio: buena suerte si se aprueba esa partida presupuestaria. Así que sólo tiene sentido hablar de tolerar determinados tiposde fallos.
Ten en cuenta que un fallo no es lo mismo que una avería [2]. Un fallo suele definirse como un componente del sistema que se desvía de sus especificaciones, mientras que un fallo es cuando el sistema en su conjunto deja de prestar el servicio requerido al usuario. Es imposible reducir a cero la probabilidad de un fallo, por lo que suele ser mejor diseñar mecanismos de tolerancia a fallos que impidan que los fallos provoquen fallos. En este libro cubrimos varias técnicas para construir sistemas fiables a partir de partes no fiables.
Contraintuitivamente, en tales sistemas tolerantes a fallos, puede tener sentido aumentar la tasa de fallos provocándolos deliberadamente; por ejemplo, matando aleatoriamente procesos individuales sin previo aviso. Muchos fallos críticos se deben en realidad a una mala gestión de errores [3]; al inducir fallos deliberadamente, te aseguras de que la maquinaria de tolerancia a fallos se ejercita y prueba continuamente, lo que puede aumentar tu confianza en que los fallos se gestionarán correctamente cuando se produzcan de forma natural. El Mono del Caos de Netflix [4] es un ejemplo de este enfoque.
Aunque generalmente preferimos tolerar los fallos a prevenirlos, hay casos en los que es mejor prevenir que curar (por ejemplo, porque no existe cura). Así ocurre, por ejemplo, en cuestiones de seguridad: si un atacante ha comprometido un sistema y ha accedido a datos sensibles, ese suceso no puede deshacerse. Sin embargo, este libro trata sobre todo de los tipos de fallos que se pueden curar, como se describe en los siguientes apartados.
Fallos de hardware
Cuando pensamos en las causas de fallo de un sistema, rápidamente nos vienen a la mente los fallos de hardware. Los discos duros se bloquean, la RAM se estropea, la red eléctrica sufre un apagón, alguien desenchufa el cable de red equivocado. Cualquiera que haya trabajado con grandes centros de datos puede decirte que estas cosas ocurren todo el tiempo cuando hay muchas máquinas.
Según los informes, los discos duros tienen un tiempo medio hasta el fallo (MTTF) de unos 10 a 50 años [5, 6]. Por tanto, en un clúster de almacenamiento con 10.000 discos, deberíamos esperar que muriera de media un disco al día.
Nuestra primera respuesta suele ser añadir redundancia a los componentes de hardware individuales para reducir la tasa de fallos del sistema. Los discos pueden instalarse en una configuración RAID, los servidores pueden tener fuentes de alimentación dobles y CPU intercambiables en caliente, y los centros de datos pueden tener baterías y generadores diésel para la energía de reserva. Cuando un componente muere, el componente redundante puede ocupar su lugar mientras se sustituye el componente averiado. Este enfoque no puede evitar por completo que los problemas de hardware provoquen fallos, pero se entiende bien y a menudo puede mantener una máquina en funcionamiento ininterrumpido durante años.
Hasta hace poco, la redundancia de componentes de hardware era suficiente para la mayoría de las aplicaciones, ya que hace que el fallo total de una sola máquina sea bastante raro. Mientras puedas restaurar una copia de seguridad en una máquina nueva con bastante rapidez, el tiempo de inactividad en caso de fallo no es catastrófico en la mayoría de las aplicaciones. Por tanto, la redundancia multimáquina sólo era necesaria para un pequeño número de aplicaciones para las que la alta disponibilidad era absolutamente esencial.
Sin embargo, a medida que han aumentado los volúmenes de datos y las demandas de computación de las aplicaciones, éstas han empezado a utilizar un mayor número de máquinas, lo que aumenta proporcionalmente la tasa de fallos de hardware. Además, en algunas plataformas en la nube, como Amazon Web Services (AWS), es bastante habitual que las instancias de máquinas virtuales dejen de estar disponibles sin previo aviso [7], ya que las plataformas están diseñadas para priorizar la flexibilidad y la elasticidadi sobre la fiabilidad de una sola máquina.
De ahí que se esté avanzando hacia sistemas que puedan tolerar la pérdida de máquinas enteras, utilizando técnicas de tolerancia a fallos de software con preferencia o además de la redundancia de hardware. Estos sistemas también tienen ventajas operativas: un sistema de servidor único requiere un tiempo de inactividad planificado si necesitas reiniciar la máquina (para aplicar parches de seguridad al sistema operativo, por ejemplo), mientras que un sistema que puede tolerar el fallo de una máquina puede parchearse de un nodo a la vez, sin tiempo de inactividad de todo el sistema (una actualización continua; véase el Capítulo 4).
Errores de software
Solemos pensar que los fallos de hardware son aleatorios e independientes entre sí: que falle el disco de una máquina no implica que vaya a fallar el disco de otra. Puede haber correlaciones débiles (por ejemplo, debidas a una causa común, como la temperatura del bastidor del servidor), pero por lo demás es improbable que un gran número de componentes de hardware fallen al mismo tiempo.
Otra clase de fallo es un error sistemático dentro del sistema [8]. Estos fallos son más difíciles de prever y, al estar correlacionados entre nodos, tienden a causar muchos más fallos en el sistema que los fallos de hardware no correlacionados [5]. Algunos ejemplos son:
-
Un fallo de software que hace que todas las instancias de un servidor de aplicaciones se bloqueen cuando se les da una mala entrada concreta. Por ejemplo, considera el segundo bisiesto del 30 de junio de 2012, que hizo que muchas aplicaciones se colgaran simultáneamente debido a un fallo en el kernel de Linux [9].
-
Un proceso fuera de control que utiliza algún recurso compartido: tiempo de CPU, memoria, espacio en disco o ancho de banda de red.
-
Un servicio del que depende el sistema que se ralentiza, deja de responder o empieza a devolver respuestas corruptas.
-
Fallos en cascada, en los que un pequeño fallo en un componente desencadena un fallo en otro componente, que a su vez desencadena más fallos [10].
Los errores que causan este tipo de fallos en el software suelen permanecer latentes durante mucho tiempo hasta que se desencadenan por una serie de circunstancias inusuales. En esas circunstancias, se revela que el software está haciendo algún tipo de suposición sobre su entorno, y aunque esa suposición suele ser cierta, finalmente deja de serlo por alguna razón [11].
No existe una solución rápida al problema de los fallos sistemáticos en el software. Muchas pequeñas cosas pueden ayudar: pensar cuidadosamente en las suposiciones e interacciones del sistema; realizar pruebas exhaustivas; aislar los procesos; permitir que los procesos fallen y se reinicien; medir, monitorear y analizar el comportamiento del sistema en producción. Si se espera que un sistema ofrezca alguna garantía (por ejemplo, en una cola de mensajes, que el número de mensajes entrantes sea igual al número de mensajes salientes), puede autocomprobarse constantemente mientras funciona y emitir una alerta si se encuentra una discrepancia [12].
Errores humanos
Los humanos diseñan y construyen sistemas de software, y los operadores que mantienen los sistemas en funcionamiento también son humanos. Incluso cuando tienen las mejores intenciones, se sabe que los humanos no son fiables. Por ejemplo, un estudio de grandes servicios de Internet descubrió que los errores de configuración de los operadores eran la causa principal de las interrupciones, mientras que los fallos de hardware (servidores o red) sólo intervenían en el 10-25% de las interrupciones [13].
¿Cómo conseguimos que nuestros sistemas sean fiables, a pesar de los humanos poco fiables? Los mejores sistemas combinan varios enfoques:
-
Diseña los sistemas de forma que se reduzcan al mínimo las posibilidades de error. Por ejemplo, las abstracciones, API e interfaces de administración bien diseñadas facilitan hacer "lo correcto" y desalientan hacer "lo incorrecto". Sin embargo, si las interfaces son demasiado restrictivas, la gente trabajará a su alrededor, anulando su beneficio, por lo que se trata de un equilibrio difícil de conseguir.
-
Desvincula los lugares donde las personas cometen más errores de los lugares donde pueden provocar fallos. En particular, proporciona entornos sandbox de no producción con todas las funciones, donde la gente pueda explorar y experimentar con seguridad, utilizando datos reales, sin afectar a usuarios reales.
-
Prueba a fondo en todos los niveles, desde las pruebas unitarias hasta las pruebas de integración de todo el sistema y las pruebas manuales [3]. Las pruebas automatizadas se utilizan ampliamente, se comprenden bien y son especialmente valiosas para cubrir casos aislados que rara vez surgen en el funcionamiento normal.
-
Permite una recuperación rápida y fácil de los errores humanos, para minimizar el impacto en caso de fallo. Por ejemplo, haz que sea rápido deshacer los cambios de configuración, despliega el nuevo código gradualmente (para que cualquier fallo inesperado afecte sólo a un pequeño subconjunto de usuarios), y proporciona herramientas para volver a calcular los datos (en caso de que resulte que el antiguo cálculo era incorrecto).
-
Establece un monitoreo detallado y claro, como métricas de rendimiento y tasas de error. En otras disciplinas de la ingeniería esto se denomina telemetría. (Una vez que un cohete ha abandonado el suelo, la telemetría es esencial para hacer un seguimiento de lo que está ocurriendo, y para comprender los fallos [14].) El monitoreo puede mostrarnos señales de alerta temprana y permitirnos comprobar si se está violando alguna suposición o restricción. Cuando se produce un problema, las métricas pueden ser inestimables para diagnosticarlo.
-
Implantar buenas prácticas de gestión y formación, un aspecto complejo e importante, y que va más allá del alcance de este libro.
¿Qué importancia tiene la fiabilidad?
La fiabilidad no es sólo para las centrales nucleares y el software de control del tráfico aéreo: también se espera que las aplicaciones más mundanas funcionen de forma fiable. Los fallos en las aplicaciones empresariales causan pérdida de productividad (y riesgos legales si las cifras se comunican incorrectamente), y las interrupciones de los sitios de comercio electrónico pueden tener enormes costes en términos de pérdida de ingresos y daños a la reputación.
Incluso en las aplicaciones "no críticas" tenemos una responsabilidad con nuestros usuarios. Piensa en un padre que almacena todas las fotos y vídeos de sus hijos en tu aplicación de fotos [15]. ¿Cómo se sentirían si esa base de datos se corrompiera de repente? ¿Sabrían cómo restaurarla a partir de una copia de seguridad?
Hay situaciones en las que podemos optar por sacrificar la fiabilidad para reducir el coste de desarrollo (por ejemplo, al desarrollar un producto prototipo para un mercado no probado) o el coste operativo (por ejemplo, para un servicio con un margen de beneficio muy estrecho), pero debemos ser muy conscientes de cuándo estamos recortando gastos.
Escalabilidad
Aunque un sistema funcione hoy de forma fiable, eso no significa que vaya a hacerlo necesariamente en el futuro. Un motivo habitual de degradación es el aumento de la carga: quizá el sistema haya pasado de 10.000 usuarios simultáneos a 100.000 usuarios simultáneos, o de 1 millón a 10 millones. Tal vez esté procesando volúmenes de datos mucho mayores que antes.
La escalabilidad es el término que utilizamos para describir la capacidad de un sistema para hacer frente a un aumento de la carga. Ten en cuenta, sin embargo, que no es una etiqueta unidimensional que podamos poner a un sistema: no tiene sentido decir "X es escalable" o "Y no es escalable". Más bien, hablar de escalabilidad significa plantearse preguntas como "Si el sistema crece de una manera determinada, ¿qué opciones tenemos para hacer frente al crecimiento?" y "¿Cómo podemos añadir recursos informáticos para manejar la carga adicional?".
Describir la carga
En primer lugar, tenemos que describir sucintamente la carga actual del sistema; sólo entonces podremos discutir cuestiones de crecimiento (¿qué ocurre si nuestra carga se duplica?). La carga puede describirse con unos pocos números que llamamos parámetros de carga. La mejor elección de parámetros depende de la arquitectura de tu sistema: pueden ser las peticiones por segundo a un servidor web, la relación entre lecturas y escrituras en una base de datos, el número de usuarios activos simultáneamente en una sala de chat, la tasa de aciertos en una memoria caché, o cualquier otra cosa. Quizás lo que te importe sea el caso medio, o quizás tu cuello de botella esté dominado por un pequeño número de casos extremos.
Para concretar esta idea, consideremos Twitter como ejemplo, utilizando datos publicados en noviembre de 2012 [16]. Dos de las principales operaciones de Twitter son:
- Publicar tweet
-
Un usuario puede publicar un nuevo mensaje a sus seguidores (4,6k peticiones/seg de media, más de 12k peticiones/seg en los picos).
- Inicio cronología
-
Un usuario puede ver los tweets publicados por las personas a las que sigue (300k peticiones/seg).
Simplemente manejar 12.000 escrituras por segundo (la tasa máxima de publicación de tweets) sería bastante fácil. Sin embargo, el reto de escalado de Twitter no se debe principalmente al volumen de tweets, sino alfan-outii-cada usuario sigue a mucha gente, y cada usuario es seguido por mucha gente. A grandes rasgos, hay dos formas de implementar estas dos operaciones:
-
Publicar un tuit simplemente inserta el nuevo tuit en una colección global de tuits. Cuando un usuario solicita su cronología de inicio, busca a todas las personas a las que sigue, encuentra todos los tweets de cada uno de esos usuarios y los fusiona (ordenados por tiempo). En una base de datos relacional como la dela Figura 1-2, podrías escribir una consulta como la siguiente
SELECTtweets.*,users.*FROMtweetsJOINusersONtweets.sender_id=users.idJOINfollowsONfollows.followee_id=users.idWHEREfollows.follower_id=current_user -
Mantén una caché para la línea de tiempo inicial de cada usuario, como un buzón de tweets para cada usuario destinatario (ver Figura 1-3). Cuando un usuario publica un tuit, busca a todas las personas que siguen a ese usuario, e inserta el nuevo tuit en cada una de sus cachés de línea temporal de origen. La petición de lectura de la línea temporal de inicio es entonces barata, porque su resultado se ha calculado con antelación.
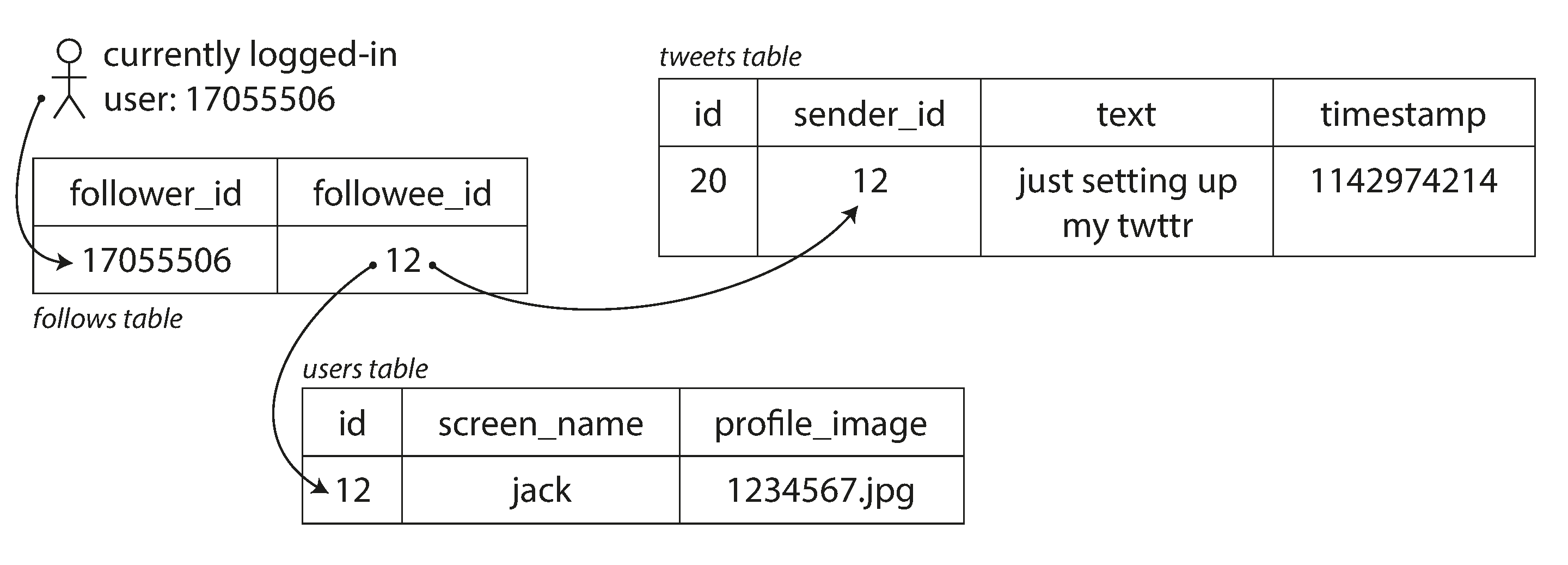
Figura 1-2. Esquema relacional simple para implementar una línea de tiempo de inicio de Twitter.
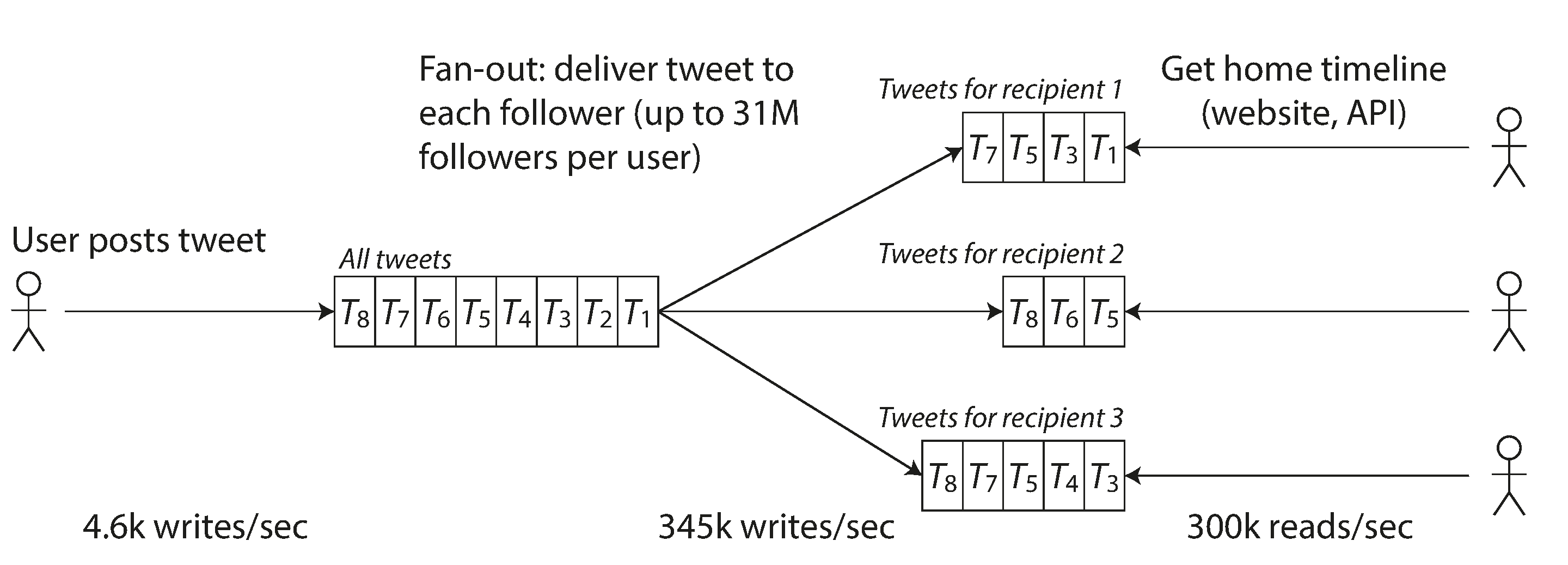
Figura 1-3. Canalización de datos de Twitter para enviar tweets a los seguidores, con parámetros de carga en noviembre de 2012 [16].
La primera versión de Twitter utilizaba el enfoque 1, pero los sistemas tenían dificultades para seguir el ritmo de la carga de consultas de la línea temporal de inicio, por lo que la empresa cambió al enfoque 2. Esto funciona mejor porque la tasa media de tweets publicados es casi dos órdenes de magnitud inferior a la tasa de lecturas de la cronología de inicio, por lo que en este caso es preferible hacer más trabajo en tiempo de escritura y menos en tiempo de lectura.
Sin embargo, el inconveniente del enfoque 2 es que publicar un tuit ahora requiere mucho trabajo extra. De media, un tuit se envía a unos 75 seguidores, por lo que 4,6k tuits por segundo se convierten en 345k escrituras por segundo en las cachés de la cronología de inicio. Pero esta media oculta el hecho de que el número de seguidores por usuario varía enormemente, y algunos usuarios tienen más de 30 millones de seguidores. Esto significa que un solo tuit puede dar lugar a más de 30 millones de escrituras en las cronologías de inicio. Hacerlo a tiempo -Twitter intenta enviar los tweets a los seguidores en cinco segundos- es un reto importante.
En el ejemplo de Twitter, la distribución de seguidores por usuario (quizá ponderada por la frecuencia con que esos usuarios tuitean) es un parámetro de carga clave para hablar de escalabilidad, ya que determina la carga de fan-out. Tu aplicación puede tener características muy diferentes, pero puedes aplicar principios similares para razonar sobre su carga.
El giro final de la anécdota de Twitter: ahora que el enfoque 2 está sólidamente implantado, Twitter está pasando a un híbrido de ambos enfoques. La mayoría de los tweets de los usuarios se siguen distribuyendo en las líneas de tiempo personales en el momento en que se publican, pero un pequeño número de usuarios con un gran número de seguidores (es decir, los famosos) quedan excluidos de esta distribución. Los tweets de los famosos a los que sigue un usuario se obtienen por separado y se combinan con la cronología personal del usuario cuando se leen, como en el enfoque 1. Este enfoque híbrido es capaz de ofrecer un rendimiento consistentemente bueno. Volveremos sobre este ejemplo en el Capítulo 12, cuando hayamos cubierto más aspectos técnicos.
Describir el rendimiento
Una vez que hayas descrito la carga de tu sistema, puedes investigar qué ocurre cuando aumenta la carga. Puedes verlo de dos formas:
-
Cuando aumentas un parámetro de carga y mantienes los recursos del sistema (CPU, memoria, ancho de banda de red, etc.) sin cambios, ¿cómo se ve afectado el rendimiento de tu sistema?
-
Cuando aumentas un parámetro de carga, ¿cuánto tienes que aumentar los recursos si quieres mantener invariable el rendimiento?
Ambas preguntas requieren cifras de rendimiento, así que veamos brevemente cómo describir el rendimiento de un sistema.
En un sistema de procesamiento por lotes como Hadoop, normalmente nos preocupamos por el rendimiento: elnúmero de registros que podemos procesar por segundo, o el tiempo total que se tarda en ejecutar un trabajo en un conjunto de datos de cierto tamaño.iii En los sistemas en línea, lo que suele ser más importante es eltiempo de respuestadel servicio, esdecir, el tiempo que transcurre entre que un cliente envía una solicitud y recibe una respuesta.
Latencia y tiempo de respuesta
Latencia y tiempo de respuesta suelen utilizarse como sinónimos, pero no son lo mismo. El tiempo de respuesta es lo que ve el cliente: además del tiempo real para procesar la solicitud (el tiempo de servicio), incluye los retrasos de la red y los retrasos de las colas. La latencia es la duración de la espera de una solicitud para ser atendida, durante la cual está latente, a la espera de ser atendida [17].
Aunque sólo hagas la misma petición una y otra vez, obtendrás un tiempo de respuesta ligeramente distinto en cada intento. En la práctica, en un sistema que gestiona diversas solicitudes, el tiempo de respuesta puede variar mucho. Por tanto, tenemos que pensar en el tiempo de respuesta no como un número único, sino como unadistribución de valores que puedes medir.
En la Figura 1-4, cada barra gris representa una solicitud a un servicio, y su altura muestra el tiempo que tardó esa solicitud. La mayoría de las solicitudes son razonablemente rápidas, pero hay casos atípicos que tardan mucho más. Tal vez las solicitudes lentas sean intrínsecamente más caras, por ejemplo, porque procesan más datos. Pero incluso en un escenario en el que pensarías que todas las solicitudes deberían tardar lo mismo, se producen variaciones: una latencia adicional aleatoria podría ser introducida por un cambio de contexto a un proceso en segundo plano, la pérdida de un paquete de red y la retransmisión TCP, una pausa en la recogida de basura, un fallo de página que obligue a una lectura desde el disco, vibraciones mecánicas en el bastidor del servidor [18], o muchas otras causas.
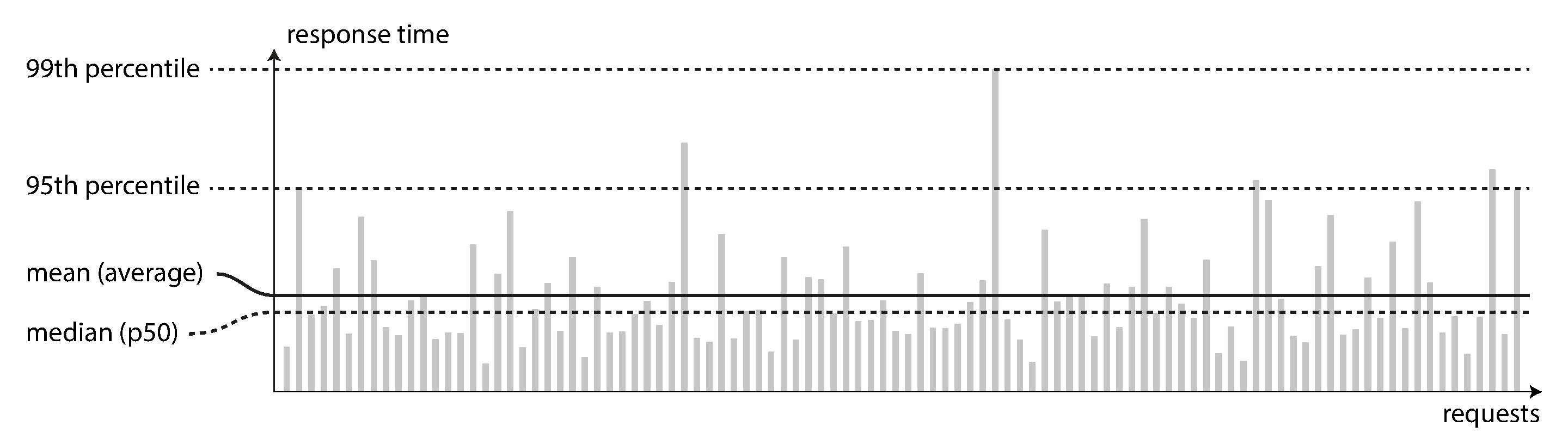
Figura 1-4. Ilustración de la media y los percentiles: tiempos de respuesta de una muestra de 100 peticiones a un servicio.
Es habitual que se informe del tiempo medio de respuesta de un servicio. (En sentido estricto, el término "media" no se refiere a ninguna fórmula concreta, pero en la práctica suele entenderse como lamedia aritmética: dados n valores, suma todos los valores y divídelos por n). Sin embargo, la media no es una métrica muy buena si quieres conocer tu tiempo de respuesta "típico", porque no te dice cuántos usuarios experimentaron realmente ese retraso.
Normalmente es mejor utilizar percentiles. Si tomas tu lista de tiempos de respuesta y la ordenas de más rápido a más lento, entonces la mediana es el punto medio: por ejemplo, si tu mediana de tiempo de respuesta es 200 ms, eso significa que la mitad de tus peticiones vuelven en menos de 200 ms, y la mitad de tus peticiones tardan más que eso.
Esto hace que la mediana sea una buena métrica si quieres saber cuánto tiempo suelen tener que esperar los usuarios: la mitad de las solicitudes de los usuarios se atienden en menos tiempo que la mediana del tiempo de respuesta, y la otra mitad tardan más que la mediana. La mediana también se conoce como percentil 50, y a veces se abrevia como p50. Ten en cuenta que la mediana se refiere a una única solicitud; si el usuario realiza varias solicitudes (en el transcurso de una sesión, o porque se incluyen varios recursos en una única página), la probabilidad de que al menos una de ellas sea más lenta que la mediana es mucho mayor que el 50%.
Para saber lo malos que son tus valores atípicos, puedes fijarte en los percentiles superiores: son habituales los percentiles 95,99 y 99,9 (abreviados p95, p99 y p999). Son los umbrales de tiempo de respuesta en los que el 95%, el 99% o el 99,9% de las solicitudes son más rápidas que ese umbral concreto. Por ejemplo, si el percentil 95 del tiempo de respuesta es de 1,5 segundos, significa que 95 de cada 100 solicitudes tardan menos de 1,5 segundos, y 5 de cada 100 solicitudes tardan 1,5 segundos o más. Esto se ilustra en la Figura 1-4.
Los percentiles altos de los tiempos de respuesta, también conocidos como latencias de cola, son importantes porque afectan directamente a la experiencia de los usuarios del servicio. Por ejemplo, Amazon describe los requisitos de tiempo de respuesta para los servicios internos en términos del percentil 99,9, aunque sólo afecte a 1 de cada 1.000 solicitudes. Esto se debe a que los clientes con las solicitudes más lentas suelen ser los que tienen más datos en sus cuentas porque han hecho muchas compras, es decir, son los clientes más valiosos [19]. Es importante mantener contentos a esos clientes asegurándose de que el sitio web sea rápido para ellos: Amazon también ha observado que un aumento de 100 ms en el tiempo de respuesta reduce las ventas en un 1% [20], y otros informan de que una ralentización de 1 segundo reduce una métrica de satisfacción del cliente en un 16% [21,22].
Por otra parte, optimizar el percentil 99,99 (la más lenta de cada 10.000 solicitudes) se consideró demasiado caro y que no aportaba suficientes beneficios para los fines de Amazon. Reducir los tiempos de respuesta en percentiles muy altos es difícil porque se ven fácilmente afectados por sucesos aleatorios fuera de tu control, y los beneficios son cada vez menores.
Por ejemplo, los percentiles se utilizan a menudo en los objetivos de nivel de servicio ( SLO) y en los acuerdos de nivel de servicio (SLA), contratos que definen el rendimiento y la disponibilidad esperados de un servicio. Un SLA puede establecer que se considera que el servicio está activo si tiene un tiempo de respuesta medio inferior a 200 ms y un percentil 99 inferior a 1 s (si el tiempo de respuesta es mayor, también podría estar inactivo), y se puede exigir que el servicio esté activo al menos el 99,9% del tiempo. Estas métricas fijan las expectativas de los clientes del servicio y les permiten exigir un reembolso si no se cumple el SLA.
Los retrasos en las colas suelen representar una gran parte del tiempo de respuesta en los percentiles altos. Como un servidor sólo puede procesar un pequeño número de cosas en paralelo (limitado, por ejemplo, por su número de núcleos de CPU), basta un pequeño número de peticiones lentas para retrasar el procesamiento de las peticiones siguientes, un efecto que a veces se conoce como bloqueo de cabecera. Incluso si esas peticiones posteriores se procesan rápidamente en el servidor, el cliente verá un tiempo de respuesta global lento debido al tiempo de espera para que se complete la petición anterior. Debido a este efecto, es importante medir los tiempos de respuesta en el lado del cliente.
Cuando se genera carga artificialmente para probar la escalabilidad de un sistema, el cliente que genera la carga necesita seguir enviando peticiones independientemente del tiempo de respuesta. Si el cliente espera a que se complete la solicitud anterior antes de enviar la siguiente, ese comportamiento tiene el efecto de mantener artificialmente las colas más cortas en la prueba de lo que serían en la realidad, lo que sesga las mediciones [23].
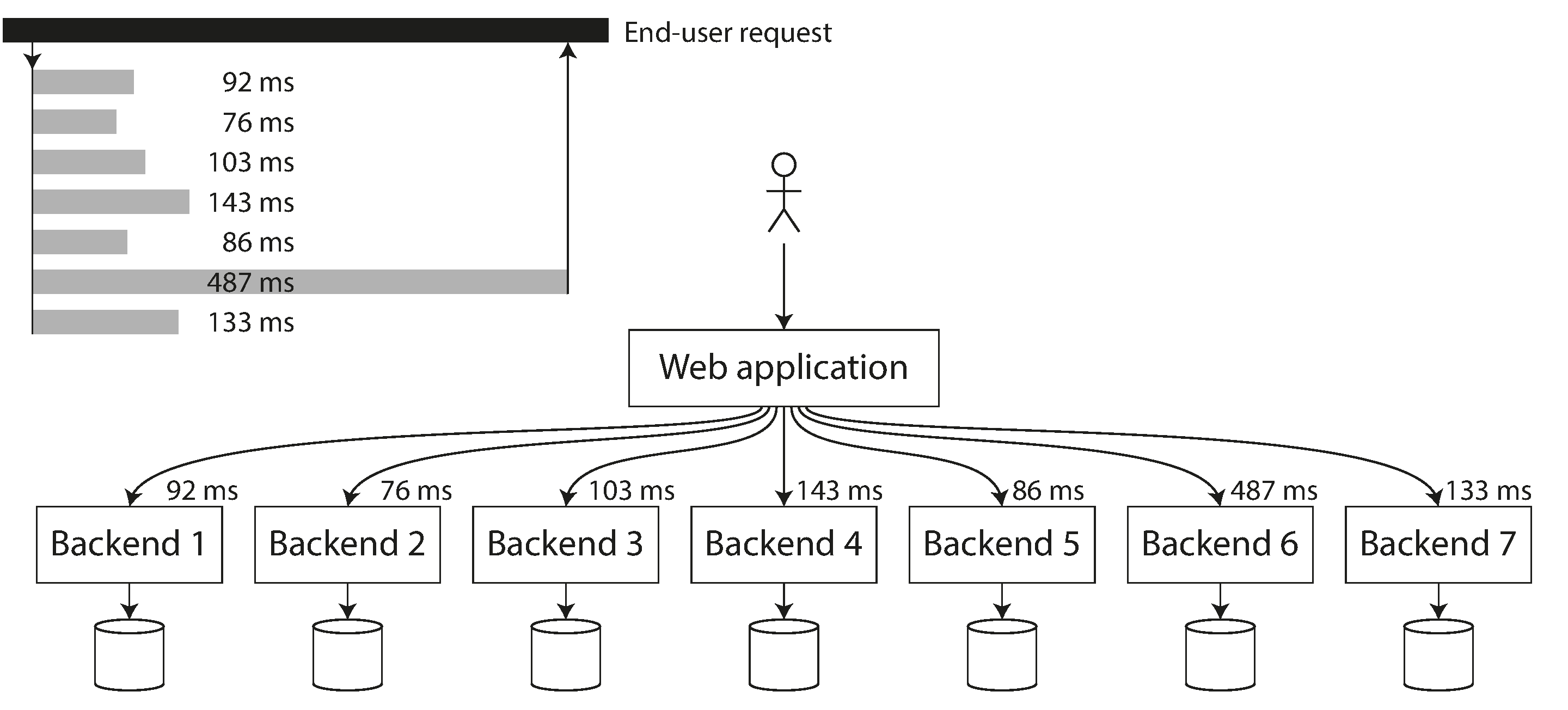
Figura 1-5. Cuando se necesitan varias llamadas al backend para servir una petición, basta una sola petición lenta del backend para ralentizar toda la petición del usuario final.
Enfoques para afrontar la carga
Ahora que hemos discutido los parámetros para describir la carga y las métricas para medir el rendimiento, podemos empezar a discutir la escalabilidad en serio: ¿cómo mantenemos un buen rendimiento incluso cuando nuestros parámetros de carga aumentan en cierta medida?
Es poco probable que una arquitectura adecuada para un nivel de carga pueda soportar 10 veces esa carga. Por tanto, si trabajas en un servicio de rápido crecimiento, es probable que tengas que replantearte tu arquitectura cada vez que aumente la carga en un orden de magnitud, o incluso más a menudo.
A menudo se habla de una dicotomía entre escalar hacia arriba(escalado vertical, pasar a una máquina más potente) y escalar hacia abajo(escalado horizontal, distribuir la carga entre varias máquinas más pequeñas). Distribuir la carga entre varias máquinas también se conoce como arquitectura de nada compartido. Un sistema que puede funcionar en una sola máquina suele ser más sencillo, pero las máquinas de gama alta pueden llegar a ser muy caras, por lo que las cargas de trabajo muy intensivas a menudo no pueden evitar el escalado. En realidad, las buenas arquitecturas suelen implicar una mezcla pragmática de enfoques: por ejemplo, utilizar varias máquinas bastante potentes puede seguir siendo más sencillo y barato que un gran número de pequeñas máquinas virtuales.
Algunos sistemas son elásticos, lo que significa que pueden añadir automáticamente recursos informáticos cuando detectan un aumento de la carga, mientras que otros sistemas se escalan manualmente (un humano analiza la capacidad y decide añadir más máquinas al sistema). Un sistema elástico puede ser útil si la carga es muy impredecible, pero los sistemas escalados manualmente son más sencillos y pueden tener menos sorpresas operativas (ver "Reequilibrar particiones").
Aunque distribuir servicios sin estado entre varias máquinas es bastante sencillo, llevar los sistemas de datos con estado de un único nodo a una configuración distribuida puede introducir mucha complejidad adicional. Por esta razón, hasta hace poco la sabiduría común era mantener tu base de datos en un único nodo (escalar hacia arriba) hasta que el coste de escalado o los requisitos de alta disponibilidad te obligaran a hacerla distribuida.
A medida que mejoren las herramientas y las abstracciones para los sistemas distribuidos, esta sabiduría común puede cambiar, al menos para algunos tipos de aplicaciones. Es concebible que los sistemas de datos distribuidos se conviertan en la norma en el futuro, incluso para casos de uso que no manejen grandes volúmenes de datos o tráfico. A lo largo de este libro trataremos muchos tipos de sistemas de datos distribuidos, y discutiremos cómo se comportan no sólo en términos de escalabilidad, sino también de facilidad de uso y mantenimiento.
La arquitectura de los sistemas que funcionan a gran escala suele ser muy específica de la aplicación: no existe una arquitectura escalable genérica, de talla única (conocida informalmente como salsa mágica de escalado). El problema puede ser el volumen de lecturas, el volumen de escrituras, el volumen de datos que hay que almacenar, la complejidad de los datos, los requisitos de tiempo de respuesta, los patrones de acceso, o (normalmente) alguna mezcla de todo esto más muchas otras cuestiones.
Por ejemplo, un sistema diseñado para gestionar 100.000 peticiones por segundo, cada una de 1 kB de tamaño, tiene un aspecto muy diferente de un sistema diseñado para 3 peticiones por minuto, cada una de 2 GB de tamaño, aunque los dos sistemas tengan el mismo rendimiento de datos.
Una arquitectura que se escala bien para una aplicación concreta se construye en torno a suposiciones sobre qué operaciones serán habituales y cuáles raras: los parámetros de carga. Si esas suposiciones resultan ser erróneas, el esfuerzo de ingeniería para el escalado es, en el mejor de los casos, baldío y, en el peor, contraproducente. En una empresa incipiente o en un producto no probado, suele ser más importante poder iterar rápidamente sobre las características del producto que escalarlo a una hipotética carga futura.
Aunque sean específicas para una aplicación concreta, las arquitecturas escalables suelen construirse a partir de bloques de construcción de uso general, dispuestos según patrones familiares. En este libro hablamos de esos bloques de construcción y patrones.
Mantenibilidad
Es bien sabido que la mayor parte del coste del software no está en su desarrollo inicial, sino en su mantenimiento continuo: corregir errores, mantener sus sistemas operativos, investigar fallos, adaptarlo a nuevas plataformas, modificarlo para nuevos casos de uso, pagar la deuda técnica y añadir nuevas funciones.
Sin embargo, por desgracia, a muchas personas que trabajan en sistemas de software les desagrada el mantenimiento de los llamados sistemasheredados: quizá implique arreglar los errores de otras personas, o trabajar con plataformas que ahora están anticuadas, o sistemas que se vieron obligados a hacer cosas para las que nunca fueron concebidos. Cada sistema heredado es desagradable a su manera, por lo que es difícil dar recomendaciones generales para tratar con ellos.
Sin embargo, podemos y debemos diseñar el software de forma que, con suerte, minimice el dolor durante el mantenimiento, y así evitar crear nosotros mismos software heredado. Para ello, prestaremos especial atención a tres principios de diseño de sistemas de software:
- Operatividad
-
Facilita a los equipos de operaciones el buen funcionamiento del sistema.
- Simplicidad
-
Facilita a los nuevos ingenieros la comprensión del sistema, eliminando toda la complejidad posible del mismo. (Ten en cuenta que esto no es lo mismo que simplicidad de la interfaz de usuario).
- Evolucionabilidad
-
Facilita a los ingenieros la introducción de cambios en el sistema en el futuro, adaptándolo a casos de uso imprevistos a medida que cambian los requisitos. También se conoce como extensibilidad, modificabilidad oplasticidad.
Como antes con la fiabilidad y la escalabilidad, no hay soluciones fáciles para conseguir estos objetivos, sino que intentaremos pensar en sistemas teniendo en cuenta la operabilidad, la sencillez y la evolucionabilidad.
Operabilidad: Facilitar la vida a las operaciones
Se ha sugerido que "las buenas operaciones a menudo pueden sortear las limitaciones de un software malo (o incompleto), pero un buen software no puede funcionar de forma fiable con malas operaciones" [12]. Aunque algunos aspectos de las operaciones pueden y deben automatizarse, sigue correspondiendo a los humanos establecer esa automatización en primer lugar y asegurarse de que funciona correctamente.
Los equipos de operaciones son vitales para que un sistema de software funcione sin problemas. Un buen equipo de operaciones suele ser responsable de lo siguiente, y más [29]:
-
Monitorear la salud del sistema y restablecer rápidamente el servicio si entra en mal estado.
-
Localizar la causa de los problemas, como fallos del sistema o rendimiento degradado
-
Mantener actualizados el software y las plataformas, incluidos los parches de seguridad
-
Controlar cómo los distintos sistemas se afectan mutuamente, de modo que pueda evitarse un cambio problemático antes de que cause daños.
-
Anticiparse a los problemas futuros y resolverlos antes de que se produzcan (por ejemplo, planificación de la capacidad).
-
Establecimiento de buenas prácticas y herramientas para la implementación, gestión de la configuración, etc.
-
Realizar tareas de mantenimiento complejas, como trasladar una aplicación de una plataforma a otra
-
Mantener la seguridad del sistema a medida que se realizan cambios en la configuración
-
Definir procesos que hagan predecibles las operaciones y ayuden a mantener estable el entorno de producción
-
Preservar el conocimiento de la organización sobre el sistema, incluso cuando las personas van y vienen.
Una buena operatividad significa facilitar las tareas rutinarias, permitiendo al equipo de operaciones centrar sus esfuerzos en actividades de alto valor. Los sistemas de datos pueden hacer varias cosas para facilitar las tareas rutinarias, entre ellas
-
Proporcionar visibilidad del comportamiento en tiempo de ejecución y de las partes internas del sistema, con un buen monitoreo
-
Proporcionar un buen soporte para la automatización y la integración con herramientas estándar
-
Evitar la dependencia de máquinas individuales (permitiendo que las máquinas se desconecten para su mantenimiento mientras el sistema en su conjunto sigue funcionando sin interrupciones).
-
Proporcionar una buena documentación y un modelo operativo fácil de entender ("Si hago X, ocurrirá Y").
-
Proporcionar un buen comportamiento por defecto, pero también dar a los administradores la libertad de anular los valores por defecto cuando sea necesario
-
Autoreparación cuando proceda, pero también dando a los administradores control manual sobre el estado del sistema cuando sea necesario
-
Mostrar un comportamiento predecible, minimizando las sorpresas
Simplicidad: Gestionar la complejidad
Los pequeños proyectos de software pueden tener un código deliciosamente sencillo y expresivo, pero a medida que los proyectos se hacen más grandes, a menudo se vuelven muy complejos y difíciles de entender. Esta complejidad ralentiza a todos los que necesitan trabajar en el sistema, aumentando aún más el coste de mantenimiento. Un proyecto de software sumido en la complejidad se describe a veces como una gran bola de barro[30].
Hay varios síntomas posibles de complejidad: explosión del espacio de estados, acoplamiento estrecho de módulos, dependencias enmarañadas, nomenclatura y terminología incoherentes, hacks destinados a resolver problemas de rendimiento, encasillamiento especial para solucionar problemas en otros lugares, y muchos más. Ya se ha hablado mucho de este tema [31,32,33].
Cuando la complejidad dificulta el mantenimiento, a menudo se sobrepasan los presupuestos y los calendarios. En el software complejo, también hay un mayor riesgo de introducir errores al hacer un cambio: cuando el sistema es más difícil de entender y razonar para los desarrolladores, es más fácil que se pasen por alto suposiciones ocultas, consecuencias imprevistas e interacciones inesperadas. Por el contrario, reducir la complejidad mejora enormemente la capacidad de mantenimiento del software, por lo que la simplicidad debería ser un objetivo clave de los sistemas que construimos.
Simplificar un sistema no significa necesariamente reducir su funcionalidad; también puede significar eliminar la complejidad accidental. Moseley y Marks [32] definen la complejidad como accidental si no es inherente al problema que resuelve el software (tal y como lo ven los usuarios), sino que surge únicamente de la implementación.
Una de las mejores herramientas que tenemos para eliminar la complejidad accidental es la abstracción. Una buena abstracción puede ocultar una gran cantidad de detalles de implementación tras una fachada limpia y sencilla de entender. Una buena abstracción también puede utilizarse para una amplia gama de aplicaciones diferentes. Esta reutilización no sólo es más eficiente que reimplementar una cosa similar varias veces, sino que también conduce a un software de mayor calidad, ya que las mejoras de calidad en el componente abstraído benefician a todas las aplicaciones que lo utilizan.
Por ejemplo, los lenguajes de programación de alto nivel son abstracciones que ocultan el código máquina, los registros de la CPU y las llamadas al sistema. SQL es una abstracción que oculta complejas estructuras de datos en disco y en memoria, peticiones concurrentes de otros clientes e incoherencias tras fallos. Por supuesto, al programar en un lenguaje de alto nivel, seguimos utilizando código máquina; sólo que no lo utilizamosdirectamente, porque la abstracción del lenguaje de programación nos evita tener que pensar en él.
Sin embargo, encontrar buenas abstracciones es muy difícil. En el campo de los sistemas distribuidos, aunque hay muchos algoritmos buenos, está mucho menos claro cómo deberíamos empaquetarlos en abstracciones que nos ayuden a mantener la complejidad del sistema en un nivel manejable.
A lo largo de este libro, mantendremos los ojos abiertos para encontrar buenas abstracciones que nos permitan extraer partes de un gran sistema en componentes bien definidos y reutilizables.
Evolucionabilidad: Facilitar el cambio
Es muy poco probable que los requisitos de tu sistema permanezcan inalterados para siempre. Es mucho más probable que estén en constante cambio: te enteras de nuevos datos, surgen casos de uso antes imprevistos, cambian las prioridades empresariales, los usuarios solicitan nuevas funciones, las nuevas plataformas sustituyen a las antiguas, cambian los requisitos legales o normativos, el crecimiento del sistema obliga a cambios arquitectónicos, etc.
En cuanto a los procesos organizativos, los patrones de trabajo Ágiles proporcionan un marco para adaptarse al cambio. La comunidad Ágil también ha desarrollado herramientas y patrones técnicos útiles para desarrollar software en un entorno que cambia con frecuencia, como el desarrollo basado en pruebas (TDD) y la refactorización.
La mayoría de los debates sobre estas técnicas ágiles se centran en una escala local bastante pequeña (un par de archivos de código fuente dentro de la misma aplicación). En este libro, buscamos formas de aumentar la agilidad a nivel de un sistema de datos mayor, quizás formado por varias aplicaciones o servicios diferentes con características distintas. Por ejemplo, ¿cómo "refactorizarías" la arquitectura de Twitter para ensamblar líneas de tiempo domésticas ("Describir la carga") del enfoque 1 al enfoque 2?
La facilidad con la que puedes modificar un sistema de datos, y adaptarlo a los requisitos cambiantes, está estrechamente relacionada con su simplicidad y sus abstracciones: los sistemas sencillos y fáciles de entender suelen ser más fáciles de modificar que los complejos. Pero como se trata de una idea tan importante, utilizaremos una palabra diferente para referirnos a la agilidad a nivel de sistema de datos: evolucionabilidad[34].
Resumen
En este capítulo, hemos explorado algunas formas fundamentales de pensar sobre las aplicaciones intensivas en datos. Estos principios nos guiarán a lo largo del resto del libro, donde nos sumergiremos en profundos detalles técnicos.
Una aplicación tiene que cumplir varios requisitos para ser útil. Hay requisitos funcionales (lo que debe hacer, como permitir que los datos se almacenen, recuperen, busquen y procesen de diversas formas), y algunos requisitos no funcionales (propiedades generales como seguridad, fiabilidad, conformidad, escalabilidad, compatibilidad y mantenibilidad). En este capítulo hemos tratado en detalle la fiabilidad, la escalabilidad y la mantenibilidad.
Fiabilidad significa hacer que los sistemas funcionen correctamente, incluso cuando se producen fallos. Los fallos pueden estar en el hardware (normalmente aleatorios y no correlacionados), en el software (los fallos suelen ser sistemáticos y difíciles de tratar) y en los humanos (que inevitablemente cometen errores de vez en cuando). Las técnicas de tolerancia a los fallos pueden ocultar ciertos tipos de fallos al usuario final.
La escalabilidad significa disponer de estrategias para mantener un buen rendimiento, incluso cuando aumenta la carga. Para hablar de escalabilidad, primero necesitamos formas de describir cuantitativamente la carga y el rendimiento. Hemos visto brevemente las líneas de tiempo de inicio de Twitter como ejemplo de descripción de la carga, y los percentiles del tiempo de respuesta como forma de medir el rendimiento. En un sistema escalable, puedes añadir capacidad de procesamiento para seguir siendo fiable bajo una carga elevada.
La mantenibilidad tiene muchas facetas, pero en esencia se trata de hacer la vida mejor a los equipos de ingeniería y operaciones que necesitan trabajar con el sistema. Unas buenas abstracciones pueden ayudar a reducir la complejidad y hacer que el sistema sea más fácil de modificar y adaptar a nuevos casos de uso. Una buena operabilidad significa tener una buena visibilidad de la salud del sistema y disponer de formas eficaces de gestionarlo.
Desgraciadamente, no existe una solución fácil para hacer que las aplicaciones sean fiables, escalables o mantenibles. Sin embargo, hay ciertos patrones y técnicas que siguen reapareciendo en distintos tipos de aplicaciones. En los próximos capítulos veremos algunos ejemplos de sistemas de datos y analizaremos cómo funcionan para alcanzar esos objetivos.
Más adelante, en la Parte III del libro, veremos patrones para sistemas formados por varios componentes que trabajan juntos, como el de la Figura 1-1.
Notas a pie de página
i Definido en "Enfoques para afrontar la carga".
ii Término tomado de la ingeniería electrónica, que describe el número de entradas de una puerta lógica que están conectadas a la salida de otra puerta. La salida debe suministrar suficiente corriente para controlar todas las entradas conectadas. En los sistemas de procesamiento de transacciones, lo utilizamos para describir el número de peticiones a otros servicios que tenemos que hacer para atender una petición entrante.
iii En un mundo ideal, el tiempo de ejecución de un trabajo por lotes es el tamaño del conjunto de datos dividido por el rendimiento. En la práctica, el tiempo de ejecución suele ser mayor, debido a la desviación (los datos no se reparten uniformemente entre los procesos de los trabajadores) y a la necesidad de esperar a que finalice la tarea más lenta.
Referencias
[1] Michael Stonebraker y Uğur Çetintemel:"'One Size Fits All': An Idea Whose Time Has Come and Gone", en la 21ª Conferencia Internacional sobre Ingeniería de Datos (ICDE), abril de 2005.
[2] Walter L. Heimerdinger y Charles B. Weinstock: "A Conceptual Framework for System Fault Tolerance", Informe técnico CMU/SEI-92-TR-033, Instituto de Ingeniería de Software, Universidad Carnegie Mellon, octubre de 1992.
[3] Ding Yuan, Yu Luo, Xin Zhuang y otros: "Las pruebas sencillas pueden evitar la mayoría de los fallos críticos: An Analysis of Production Failures in Distributed Data-Intensive Systems", en el 11º Simposio USENIX sobre Diseño e Implementación de Sistemas Operativos (OSDI), octubre de 2014.
[4] Yury Izrailevsky y Ariel Tseitlin: "El Ejército Simio de Netflix",netflixtechblog.com, 19 de julio de 2011.
[5] Daniel Ford, François Labelle, Florentina I. Popovici y otros: "Availability in Globally Distributed Storage Systems", en 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI), octubre de 2010.
[6] Brian Beach: "Hard Drive Reliability Update - Sep 2014," backblaze.com, 23 de septiembre de 2014.
[7] Laurie Voss: "AWS: Lo bueno, lo malo y lo feo", blog.awe.sm, 18 de diciembre de 2012.
[8] Haryadi S. Gunawi, Mingzhe Hao, Tanakorn Leesatapornwongsa y otros: "¿Qué bichos viven en la nube?", en el 5º Simposio ACM sobre Computación en la Nube (SoCC), noviembre de 2014.doi:10.1145/2670979.2670986
[9] Nelson Minar: "Leap Second Crashes Half the Internet", somebits.com, 3 de julio de 2012.
[10] Amazon Web Services: "Summary of the Amazon EC2 and Amazon RDS Service Disruption in the US East Region," aws.amazon.com, 29 de abril de 2011.
[11] Richard I. Cook: "Cómo fallan los sistemas complejos", Laboratorio de Tecnologías Cognitivas, abril de 2000.
[12] Jay Kreps: "Getting Real About Distributed System Reliability", blog.empathybox.com, 19 de marzo de 2012.
[13] David Oppenheimer, Archana Ganapathi y David A. Patterson: "Why Do Internet Services Fail, and What Can Be Done About It?", en el 4º Simposio USENIX sobre Tecnologías y Sistemas de Internet (USITS), marzo de 2003.
[14] Nathan Marz: "Principios de ingeniería de software, Parte 1", nathanmarz.com, 2 de abril de 2013.
[15] Michael Jurewitz: "El impacto humano de los bichos",jury.me, 15 de marzo de 2013.
[16] Raffi Krikorian: "Timelines at Scale", en la QCon de San Francisco, noviembre de 2012.
[17] Martin Fowler:Patrones de arquitectura de aplicaciones empresariales. Addison Wesley, 2002. ISBN: 978-0-321-12742-6
[18] Kelly Sommers: "Después de tanto dar vueltas, ¿qué causó una latencia de disco de 500 ms incluso cuando sustituimos el servidor físico?" twitter.com, 13 de noviembre de 2014.
[19] Giuseppe DeCandia, Deniz Hastorun, Madan Jampani y otros: "Dynamo: Amazon's Highly Available Key-Value Store", en el 21º Simposio ACM sobre Principios de Sistemas Operativos (SOSP), octubre de 2007.
[20] Greg Linden: "Hacer que los datos sean útiles", diapositivas de la presentación en la clase de Minería de Datos de la Universidad de Stanford (CS345), diciembre de 2006.
[21] Tammy Everts: "El coste real del tiempo lento frente al tiempo de inactividad", slideshare.net, 5 de noviembre de 2014.
[22] Jake Brutlag: "La velocidad importa",ai.googleblog.com, 23 de junio de 2009.
[23] Tyler Treat: "Todo lo que sabes sobre la latencia es erróneo", bravenewgeek.com, 12 de diciembre de 2015.
[24] Jeffrey Dean y Luiz André Barroso: "La cola a escala",Communications of the ACM, volumen 56, número 2, páginas 74-80, febrero de 2013.doi:10.1145/2408776.2408794
[25] Graham Cormode, Vladislav Shkapenyuk, Divesh Srivastava y Bojian Xu: "Forward Decay: A Practical Time Decay Model for Streaming Systems", en la 25ª Conferencia Internacional del IEEE sobre Ingeniería de Datos (ICDE), marzo de 2009.
[26] Ted Dunning y Otmar Ertl: "Computing Extremely Accurate Quantiles Using t-Digests", github.com, marzo de 2014.
[27] Gil Tene: "HdrHistograma", hdrhistogram.org.
[28] Baron Schwartz: "Por qué los percentiles no funcionan como crees", solarwinds.com, 18 de noviembre de 2016.
[29] James Hamilton: "On Designing and Deploying Internet-Scale Services", en la 21ª Conferencia de Administración de Sistemas de Grandes Instalaciones (LISA), noviembre de 2007.
[30] Brian Foote y Joseph Yoder: "Big Ball of Mud", enla 4ª Conferencia sobre Lenguajes Patrón de Programas (PLoP), septiembre de 1997.
[31] Frederick P Brooks: "No Silver Bullet - Essence and Accident in Software Engineering", en The Mythical Man-Month, Anniversary edition, Addison-Wesley, 1995. ISBN: 978-0-201-83595-3
[32] Ben Moseley y Peter Marks: "Out of the Tar Pit", en BCS Software Practice Advancement (SPA), 2006.
[33] Rich Hickey: "Simple Made Easy", en Strange Loop, septiembre de 2011.
[34] Hongyu Pei Breivold, Ivica Crnkovic y Peter J. Eriksson: "Analyzing Software Evolvability", en la 32.ª Conferencia Internacional Anual del IEEE sobre Software Informático y Aplicaciones(COMPSAC), julio de 2008.doi:10.1109/COMPSAC.2008.50
Get Diseño de aplicaciones intensivas en datos now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

