Kapitel 1. Der Imperativ der Datenqualität
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Im März 2022 migrierte Equifax seine Daten von lokalen Systemen auf eine neue Cloud-Infrastruktur - ein bekanntermaßen schwieriger Prozess. Dabei kam es zu einem Fehler, der sich auf die Berechnung der Kreditwürdigkeitswerte auswirkte. Etwa 12 % aller Kreditwürdigkeitsdaten des Unternehmens waren davon betroffen, und Hunderttausende von Menschen hatten am Ende einen um 25 oder mehr Punkte falschen Wert. In Unkenntnis des Fehlers änderten Kreditinstitute, die die Daten von Equifax nutzten, die Zinssätze, die sie ihren Kunden anboten, und lehnten sogar Kredit- und Hypothekenanträge ab, die eigentlich hätten genehmigt werden müssen.
Leider ist das nicht das einzige Problem mit der Datenqualität, das in letzter Zeit in den Nachrichten aufgetaucht ist:
-
Im Jahr 2020 gingen aufgrund eines Datenfehlers fast 16.000 positive COVID-19-Testergebnisse im Vereinigten Königreich verloren, was möglicherweise dazu führte, dass 50.000 Menschen nicht zur Selbstisolierung aufgefordert wurden.
-
Sogenannte "Fehltarife", die manchmal unbeabsichtigt um mehr als 90 % ermäßigt sind, haben die Fluggesellschaften gezwungen, entweder Geld zu verlieren oder ihren Ruf zu schädigen, indem sie diese "Fehltarife" nicht einhalten.
-
Facebook hat einer Gruppe von Sozialwissenschaftlern einen Datensatz zur Verfügung gestellt, in dem die Hälfte aller US-Nutzerinnen und -Nutzer nicht berücksichtigt wurde. Dies beeinträchtigt die Ergebnisse wissenschaftlicher Arbeiten, die den Einfluss sozialer Medien auf Wahlen und Demokratie untersuchen.
-
Die Videospielfirma Unity hat 110 Millionen Dollar mit ihrem KI-Werbesystem verloren, nachdem sie schlechte Trainingsdaten von einem Drittanbieter aufgenommen hatte.
Diese Nachrichten zeigen die Auswirkungen, die besonders schlechte Datenqualität habenkann - aberdas ist nicht das ganze Bild. Die überwiegende Mehrheit der Datenqualitätsprobleme wird nie entdeckt und vernichtet heimlich den Wert der Unternehmen, während du dies liest. Von denen, die entdeckt werden, werden nur wenige öffentlich bekannt gemacht.
Hier sind zwei Anekdoten, die du vielleicht nachvollziehen kannst, wenn du schon einmal in einem Datenteam gearbeitet hast:
-
Eines Tages zeigte eines der Produkt-Dashboards eines großen Technologieunternehmens einen plötzlichen Rückgang der Net Promoter Score (NPS)-Umfrageergebnisse an. Das bedeutete höchstwahrscheinlich, dass die Kunden über eine Produktänderung frustriert waren, und ließ bei allen im Unternehmen die Alarmglocken schrillen. Die Unternehmensleitung schaltete sich ein, und es wurde eine Task Force gebildet. Ingenieure und Analysten bewerteten jede Codeänderung des letzten Monats und durchkämmten alle Nutzerdaten, um herauszufinden, was die Ursache für die sinkenden Werte sein könnte.
Die Ursache wurde schließlich von den Datenwissenschaftlern, die die NPS-Daten analysierten, aufgedeckt . Bei ihrer Analyse entdeckten sie, dass alle Bewertungen von 9 oder 10 (von 10) in den letzten Ergebnissen nicht mehr vollständig auftauchten. Das führte zu einer Untersuchung durch das Technikteam, das herausfand, dass die NPS-Umfrage in einen Iframe eingebettet war, der die höchsten NPS-Antwortwerte abgeschnittenhatte - so dasses für einen Kunden physisch (oder sollten wir sagen: digital?) unmöglich war, 9 oder 10 zu wählen.
-
Ein Ride-Sharing-Unternehmen hatte ein ML-Modell entwickelt, um potenziell betrügerische neue Fahrerkonten zu erkennen und sie automatisch von der Anmeldung auszuschließen. Das Modell stützte sich auf die Kreditkartendaten Dritter. Das Modell erkannte unter anderem, dass die Wahrscheinlichkeit eines Betrugs höher war, wenn die Daten des Drittanbieters NULL waren; das war ein Zeichen dafür, dass die Person sich mit einer Karte anmeldete, die möglicherweise nicht legitim war.
Alles funktionierte gut, bis der Drittanbieter eines Tages ein Problem mit der Datenqualität hatte, das dazu führte, dass er viel häufiger als zuvor NULL Daten übermittelte. Niemand bemerkte den Fehler, und das Unternehmen nutzte weiterhin das ML-Modell, um Betrugsvorhersagen zu treffen. Dies führte dazu, dass vielen neuen Nutzern die Möglichkeit verweigert wurde, sich für die Dienste des Unternehmens anzumelden, da sie fälschlicherweise als betrügerische Konten eingestuft wurden.
Wir wetten, dass jeder Leser, der mit Daten arbeitet, ähnliche Erfahrungen gemacht hat. Wenn Daten richtig gemacht werden, entfalten sie einen unglaublichen Wert. Aber wenn du keine Qualitätssicherung für deine Daten hast, ist es, als würdest du versuchen, ein Restaurant mit Zutaten zu betreiben, die möglicherweise verunreinigt sind. Vielleicht hast du Glück und niemand wird krank - aber manchmal werden deine Kunden und dein Unternehmen darunter leiden, und du kannst darauf wetten, dass sie dein Essen nicht mehr auf dieselbe Weise betrachten werden. Eine Studie ergab, dass 91 % der IT-Entscheidungsträger/innen der Meinung sind, dass die Datenqualität in ihrem Unternehmen verbessert werden muss. 77 % gaben an, dass sie kein Vertrauen in die Geschäftsdaten ihres Unternehmens haben.
Gibt es eine Möglichkeit, das Vertrauen in Daten wiederherzustellen? Und kannst du sicherstellen, dass die Probleme, die wir gerade erwähnt haben, sofort erkannt und schnell behoben werden, bevor jemand anderes davon betroffen ist, auch (oder gerade) wenn du mit großen Mengen komplexer Daten arbeitest?
Wir glauben, dass die Antwort "Ja" lautet und die Lösung darin besteht, die Überwachung deiner Datenqualität mit maschinellem Lernen zu automatisieren. Dieses Buch hilft dir, die Möglichkeiten der automatisierten Überwachung der Datenqualität zu entdecken. Du erfährst, wie du eine Plattform implementierst, die hochwertige und vertrauenswürdige Daten für dein Unternehmen sicherstellt.
Hochqualitative Daten sind das neue Gold
Es kommt mir vor, als wäre es erst gestern gewesen, dass Unternehmen damit zu kämpfen hatten, Daten aus isolierten Datenbanken zu erhalten. Apache Hadoop machte es möglich, fortgeschrittene Abfragen auf großen und komplexen Datensätzen durchzuführen (wenn man wusste, was man tat). Trotzdem waren die Daten in der jüngeren Vergangenheit in der Regel auf eine kleine Gruppe von Transaktionssystemen beschränkt - ein "ummauerter Garten" kritischer Ressourcen, die streng kontrolliert wurden und nur einen begrenzten Zugang hatten.
Innerhalb weniger Jahre haben Cloud-Data-Warehouses und Datenumwandlungstools die Art und Weise, wie wir mit Daten arbeiten, stark verändert. Heute wird jede Information, mit der ein Unternehmen in Berührung kommt, erfasst und gespeichert. Jeder Entscheidungsträger im Unternehmen kann entweder (a) ein interaktives Dashboard oder einen Bericht aufrufen, um Fragen mit Daten zu beantworten, oder (b) die Daten direkt abfragen. Systeme für maschinelles Lernen, die auf Daten aufbauen, unterstützen oder automatisieren Geschäftsentscheidungen und treiben neue Produkte voran.
"Wir glauben fest daran, dass die nächsten 10 Jahre das Jahrzehnt der Daten sein werden", schrieb die Silicon Valley Investmentfirma Andreessen Horowitz 2022. Die Medien bezeichnen Daten gerne als das neue Öl und das neue Gold. Wir sind der Meinung, dass diese Aussagen nur dann richtig sind , wenn die Daten selbst von hoher Qualität sind. Schlechte Daten sind schlimmer als gar keine Daten.
Um zu verstehen, warum das so ist, schauen wir uns einige der Trends rund um Daten an und warum Qualität in jedem Fall der entscheidende Faktor ist.
Datengetriebene Unternehmen sind die Disruptoren von heute
Häufig wird behauptet, dass die am schnellsten wachsenden und erfolgreichsten Unternehmen heute Softwarefirmen sind. Doch bei näherer Betrachtung sind es in Wirklichkeit Datenunternehmen.
Nimm Amazon. Das Unternehmen hat die größte Einzelhandelsplattform der Welt nicht nur mit erstklassigen Softwareentwicklern aufgebaut. Sie haben es geschafft, indem sie herausgefunden haben, wie sie Daten für personalisierte Empfehlungen, Echtzeitpreise und optimierte Logistik nutzen können. Um ein Beispiel aus einer anderen Branche zu nennen: Capital One ist eine der ersten US-Banken, die ihre Daten von lokalen Systemen in die Cloud verlagert hat. Durch die Nutzung von Daten zur Personalisierung des Marketings und für intelligentere Underwriting-Entscheidungen konnte sich die Bank abheben und ihr Wachstum beschleunigen.
Egal, ob es um Finanzdienstleistungen, Handel, digitale Medien oder das Gesundheitswesen geht, die Schnittstelle zwischen Daten und Software ist die Grenze des Wettbewerbs. Unternehmen können jedoch keine guten Entscheidungen treffen, geschweige denn eine Branche revolutionieren, wenn sie mit minderwertigen Daten arbeiten, denen ihre eigenen Mitarbeiter/innen nicht vertrauen. Es wäre ein Fehler, in neue Data-Science-, Machine-Learning- und generative KI-Projekte zu investieren, wenn die Grundlage für die Datenqualität mangelhaft ist.
Datenanalyse wird demokratisiert
In dem Bestreben, mit den Disruptoren Schritt zu halten - oder selbst einer zu werden - verlangen die Unternehmen von jedem Team, dass es datenorientierter arbeitet. Sie haben Analytik-Experten in die Funktionsbereiche (Marketing, Wachstum, Finanzen, Produktteams usw.) integriert, um die Nutzung von Daten für die Entscheidungsfindung zu verbessern: Können wir die Statistiken über die vergangenen Surf- und Kaufaktivitäten unserer Kunden auswerten, um maßgeschneiderte E-Mails zu schreiben? Können wir uns ansehen, wie unsere Power-User die neueste Funktion annehmen, um zu sehen, ob unsere Einführung erfolgreich war?
Es gibt inzwischen eine Vielzahl von Tools, mit denen Analysten - oder wirklich jeder in einem funktionsübergreifenden Team - die Antworten auf datenbezogene Fragen selbst finden können, ohne Code schreiben zu müssen. In Sekundenschnelle können sie ein Dashboard oder einen Bericht erstellen, für den ein Ingenieur vor nicht allzu langer Zeit noch einen Monat gebraucht hätte. Um diese Analyseanforderungen zu erfüllen, werden die Daten nicht mehr von einem kleinen, zentralisierten Team gepflegt oder stehen als konsolidierte Faktentabelle für das gesamte Unternehmen zur Verfügung. Stattdessen werden die Daten verstreut und von einer größeren Gruppe von Personen verwaltet, die näher an den Geschäftsbereichen sitzen.
Ohne qualitativ hochwertige Daten wird die Demokratisierung zu einem Albtraum für die Data Engineering Teams. Sie sind mit einem Rückstau an Fragen überfordert und immer auf der Hut vor der nächsten Feuerübung. Währenddessen wird der Rest der Organisation immer misstrauischer gegenüber den Daten, je mehr sie versuchen, mit ihnen zu arbeiten. Heuristiken und Vermutungen werden wieder zur Norm. Wenn das Vertrauen in die Daten nicht vorhanden ist, ist die Demokratisierung der Analytik letztlich Zeitverschwendung.
KI und maschinelles Lernen sind ein Unterscheidungsmerkmal
Viele Unternehmen haben KI/ML auf ihrer Roadmap, weil sie einen unglaublichen Wert in Form von personalisierten und automatisierten Interaktionen schaffen kann. Maschinelles Lernen (oder ML, das wir synonym zu KI verwenden) stützt sich auf fortschrittliche statistische Modelle zur Vorhersage der Zukunft auf der Grundlage historischer Signale in den Daten, die als Merkmale bezeichnet werden. Mit genügend Merkmalsdaten und den richtigen Modellierungstechniken kann KI jede häufige Interaktion mit einer Entität, die dem Unternehmen wichtig ist (Verbraucher, Inhalte, Transaktionen usw.), optimieren oder personalisieren.
Die Datenqualität entscheidet über Erfolg oder Misserfolg von ML-Modellen. Du musst sicherstellen, dass du sowohl für das Training als auch für die Inferenz hochwertige Datensätze hast. Modelle sind recht gut, wenn die Daten, die sie in der Produktion sehen, mit der Verteilung der Daten übereinstimmen, auf denen sie trainiert wurden. Aber die Modelle schlagen kläglich fehl, wenn sie mit Daten konfrontiert werden, die weit außerhalb der Verteilung liegen, die sie zuvor gesehen haben. (Im Gegensatz zu Menschen, die eine höhere Intelligenz nutzen können, um von einem Bereich oder einer Verteilung auf einen anderen zu verallgemeinern und erhebliche Abweichungen von der Norm zu berücksichtigen).
Generative KI und Datenqualität
Wo wir gerade von Unterscheidungsmerkmalen sprechen: Was ist mit generativer KI? Diese Modelle funktionieren nicht wie herkömmliche ML. Anstatt Vorhersagen auf der Grundlage von Merkmalen zu treffen, die aus strukturierten Daten entwickelt wurden, nehmen sie unstrukturierte Rohdaten direkt auf - als ob man aus dem Feuerwehrschlauch trinken würde.
Ist Datenqualität noch relevant, wenn Unternehmen zunehmend auf generative KI angewiesen sind? Die Antwort ist ein klares Ja. Die Eingabeaufforderungen müssen strukturierte Daten aus dem Unternehmen enthalten (z. B. Kundeninformationen). Wenn du Teile deines Geschäfts mit diesen Modellen automatisierst, brauchst du Möglichkeiten, diese Automatisierung nachzuverfolgen und durch hochwertige Protokolle sicherzustellen, dass die Dinge wie erwartet funktionieren. Und selbst wenn die generative KI dem Hype gerecht wird oder ihn sogar übertrifft, müssen wir den Daten, die wir sammeln, zählen und analysieren, immer vertrauen können - wie Zeit und Geld.
Darüber hinaus wird es in den unstrukturierten Daten, mit denen Unternehmen diese generativen KI-Modelle füttern, immer noch Datenqualitätsprobleme geben. Diese sind mit herkömmlichen Ansätzen zur Überwachung der Datenqualität noch schwieriger zu finden und erfordern automatisierte ML oder KI, um sie zu identifizieren. Umso wichtiger sind die in diesem Buch behandelten Techniken als Grundlage, um sicherzustellen, dass neue generative KI-Anwendungen mit hochwertigen Daten arbeiten.
Unternehmen investieren in einen modernen Datenstack
Keine Zusammenfassung der heutigen Datentrends wäre vollständig ohne die Erwähnung des modernen Data Stack (auch wenn wir es kaum erwarten können, dass dieser Begriff aus der Mode kommt, um ganz ehrlich zu sein!) Heutzutage können die richtigen Software-as-a-Service (SaaS)-Anbieter das leisten, was vor 10 Jahren noch ein 100-köpfiges Team von Dateningenieuren in Vollzeit erledigt hätte. Unternehmen migrieren von der herkömmlichen Speicherung vor Ort zu Cloud-Systemen, mit denen sie mehr Daten als je zuvor nutzen können.
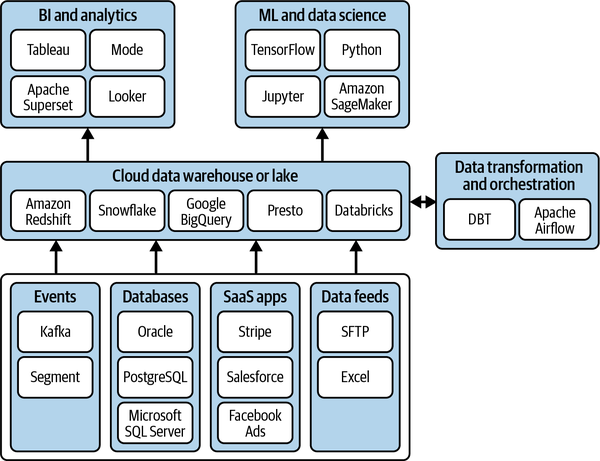
Abbildung 1-1. Der moderne Datenstapel.
Der moderne Datenstapel ist eine große Investition. Diese Investition wird untergraben, wenn Werkzeuge für die Datenqualität nicht berücksichtigt werden (wie in Abbildung 1-1). Vor allem, weil Migrationen eine wichtige Quelle für Datenqualitätsprobleme sein können, enden Unternehmen oft mit Daten, die sich nach dem Upgrade in einem schlechten Zustand befinden (siehe Abschnitt "Datenmigrationen"). Die Suche nach der Ursache von Problemen ist in einem brandneuen System, in dem sich alle erst einarbeiten müssen, noch schwieriger.
Mehr Daten, mehr Probleme
Im vorherigen Abschnitt haben wir die Trends erläutert, die dazu führen, dass Unternehmen mehr denn je auf hochwertige Daten angewiesen sind. Leider ist es schwieriger denn je, qualitativ hochwertige Daten zu erhalten. Es gibt mehr Komplexität, die sich schneller und mit weniger Leitplanken vollzieht. Das sind die zwei Seiten derselben Medaille: Fortschritt und Schmerz. In diesem Abschnitt werden wir einige der wichtigsten Faktoren für die Verschlechterung der Datenqualität untersuchen.
Eine Taxonomie der spezifischen Arten von Datenqualitätsproblemen, die auftreten können, findest du im Anhang A.
Probleme innerhalb der Datenfabrik
Traditionell war das Lagerhaus die Metapher der Wahl für die Funktionsweise von Datensystemen in einem Unternehmen, wobei der Schwerpunkt auf der Speicherung und dem Transport von Waren lag. Doch mit dem Aufkommen des modernen Data Stack und den neuen Methoden, mit denen Unternehmen mit Daten arbeiten, ist diese Metapher nicht mehr vollständig. Stattdessen gehen wir davon aus, dass Unternehmen heute eher eine Datenfabrik betreiben: eine komplexe Umgebung, die dazu dient, Rohstoffe in nützliche Produkte zu verwandeln.
Anstelle von Stahl, Gummi und Elektronik nehmen wir Streaming-Datensätze, Replikate von Datenbanken, API-Extrakte von SaaS-Anwendungen und Rohdateien aus Datenfeeds auf. Die Fabrik ist auf einem Fundament gebaut, aber statt Zement sind es hier die Cloud Data Warehouses und Data Lakes, die das Fundament bilden. Die Maschinen, die in der Fabrik betrieben werden, sind in diesem Fall Extraktions-, Transformations- und Ladetools (ETL) wie Matillion und Fivetran, Orchestrierungsplattformen wie Apache Airflow und Transformationen in dbt, Apache Spark und SQL. Die Leute, die die Maschinen bedienen, sind die Data Engineers und Analytics Engineers des modernen Datenteams. Und die Produkte, die dabei entstehen, sind keine Konsum- oder Industriegüter, sondern kuratierte Datenprodukte, die die Entscheidungen von Geschäftsanwendern und Datenexperten, das Training und die Vorhersage von ML-Algorithmen und die direkten Feeds in andere Datensysteme unterstützen.
Die gleichen Dinge, die in einer physischen Fabrik schiefgehen können, können auch in einer Datenfabrik schiefgehen. Abbildung 1-2 gibt einen Überblick.
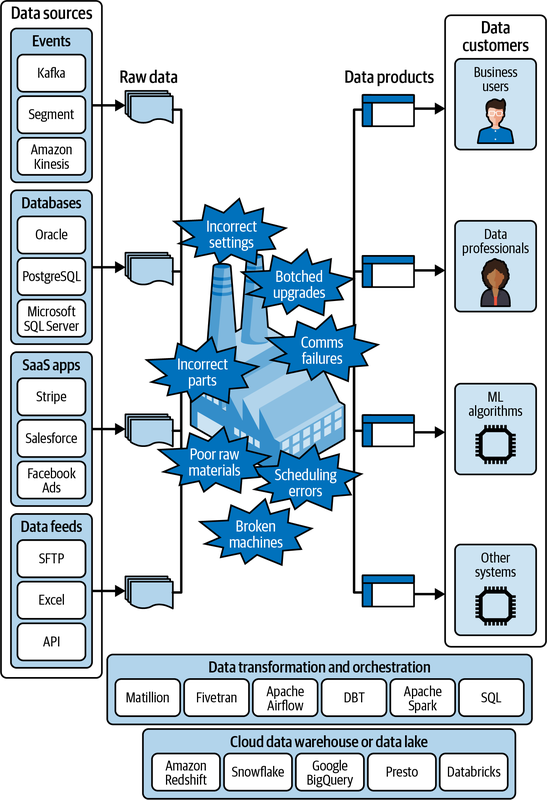
Abbildung 1-2. Die Datenfabrik und was in der Fabrikhalle schiefgehen kann.
- Kaputte Maschinen
Datenverarbeitungs- oder Orchestrierungstools können komplett ausfallen und den Datenfluss stoppen oder verschlechtern.
- Zeitplanungsprogramm Fehler
Datenverarbeitungsaufträge können in der falschen Reihenfolge oder mit der falschen Kadenz ausgeführt werden, was zu fehlenden Daten, falschen Berechnungen oder doppelten Daten führt.
- Schlechte Rohstoffe
Rohdaten, die in die Fabrik eingespeist werden, können aufgrund von vorgelagerten Problemen von schlechter Qualität sein, und die negativen Auswirkungen können sich auf das gesamte Lager ausbreiten.
- Falsche Teile
Fehler können in den SQL-, Spark- oder anderen Code, der die Daten verarbeitet und manipuliert, eingeschleust werden und ungültige Joins, Transformationen oder Aggregationen verursachen.
- Falsche Einstellungen
Ingenieuren können bei der Konfiguration komplexer Datenverarbeitungsaufträge Fehler unterlaufen, was zu einer Vielzahl von Problemen führen kann.
- Verpfuschte Upgrades
Der Versuch, Code, Anwendungsversionen oder ganze Subsysteme zu aktualisieren, kann zu subtilen, aber tiefgreifenden Unterschieden bei der Kodierung oder Transformation von Daten führen.
- Fehler in der Kommunikation
Gut gemeinte Änderungen, um neue Funktionen hinzuzufügen, können schlecht an die anderen betroffenen Teams kommuniziert werden, was zu Unstimmigkeiten in der Datenverarbeitungslogik führt und Qualitätsprobleme verursacht.
Probleme innerhalb der Datenfabrik sind oft die häufigsten Ursachen für Datenqualitätsprobleme, da sie sich direkt auf den Datenfluss und den Inhalt der Daten auswirken (und außerhalb einer Produktionsdatenumgebung sehr schwer zu testen sind).
Datenmigrationen
Datenmigrationen finden immer häufiger statt, da Unternehmen versuchen, mit der neuesten und besten Infrastruktur Schritt zu halten. Dazu gehört der Wechsel von einem lokalen Data Warehouse zu einem Cloud-Provider (z. B. Teradata zu Snowflake), von einem Cloud-Provider zu einem anderen (z. B. Amazon Web Services [AWS] zu Google Cloud Platform [GCP] oder umgekehrt), von einer Datenbank zu einer anderen (z. B. PostgreSQL zu AWS Aurora) oder von einer Datenbankversion zu einer anderen (z. B. Elasticsearch-Cluster-Migrationen).
Alle diese Migrationen sind anfällig für Probleme mit der Datenqualität. Werfen wir einen Blick auf die Migration von On-Premises Data Warehouses zu Cloud/SaaS-Providern. Viele Unternehmen haben sehr komplexe Datenpipelines, die aus Mainframe-Legacy-Systemen stammen, die in immer ältere On-Premise-Data-Warehouses übertragen wurden. Diese Altsysteme sind seit Jahrzehnten im Einsatz und haben im Laufe der Zeit eine enorme Komplexität aufgebaut, da neue Funktionen hinzugefügt wurden, Teams kamen und gingen und sich die Geschäftsanforderungen geändert haben.
Wenn Unternehmen dieses verworrene Geflecht aus Datenverarbeitung und -speicherung in die Cloud verlagern, versuchen sie, die Abläufe in ihrer On-Premise-Umgebung zu kopieren. Bei der Wiederherstellung der Datenströme in der Cloud können jedoch sehr subtile Probleme auftreten, die sich auf die Datenqualität auswirken.
Ein Unternehmen, mit dem wir zusammenarbeiten, erwähnte zum Beispiel, dass die Geburtsdaten seiner Kunden durch eine solche Migration stark verfälscht wurden (siehe Abbildung 1-3). In ihrem alten Mainframe wurden die Geburtsdaten als ganze Zahlen gespeichert, die von einem bestimmten Referenzdatum, wie dem 1. Januar 1900, abgeleitet waren. Beim Export wurden diese ganzen Zahlen dann im neuen Cloud-Warehouse in Datumsangaben umgewandelt. Das schien ganz einfach zu sein, bis auf die Tatsache, dass das Cloud Data Warehouse automatisch die Unix-Zeitstempel-Referenz von 1970 als Offset verwendete, was niemand wusste. Alle Geburtsdaten wurden weit in die Zukunft verschoben.
Wie bei vielen Problemen mit der Datenqualität traten die Auswirkungen später und im Stillen auf. Das Unternehmen hatte eine Marketing-Anwendung, die E-Mails an Kunden auf der Grundlage ihres Alters verschickte. Nachdem diese Anwendung auf das neue Cloud Data Warehouse verwiesen wurde, erhielten die Kunden keine E-Mails mehr, bis jemand das Problem bemerkte. (Marketingteams leiden oft sehr unter der schlechten Datenqualität. Eine Umfrage ergab, dass Marketingspezialisten 21 % ihres Gesamtbudgets für Datenprobleme verschwenden.)
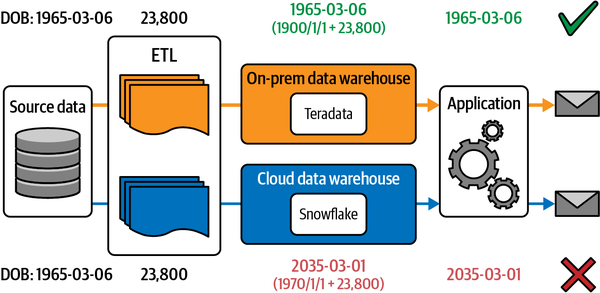
Abbildung 1-3. Wenn Daten, die in einem On-Prem-Data-Warehouse gespeichert sind, in ein Cloud-Data-Warehouse migriert werden, kann es zu Diskrepanzen kommen, wie in diesem Beispiel mit unterschiedlichen Bezugsdaten für die Berechnung des Geburtsdatums der Kunden.
Datenquellen von Drittanbietern
Die Nutzung von Daten Dritter - also Daten, die von außerhalb des Unternehmens stammen - ist einfacher und üblicher denn je. Um einige Beispiele zu nennen: Als Jeremy bei Instacart war, wurden unter anderem regelmäßig Daten von Dritten erhoben:
-
Wetterdaten für die Bedarfsprognose/-planung
-
Dienste von Drittanbietern für Karteninformationen für die Routenplanung
-
Produktkatalogdaten von Konsumgütern (CPG) zur Bereicherung des Such- und Einkaufserlebnisses der Nutzer
-
Daten zur Bewertung der Betrugsneigung zur Vermeidung von Rückbuchungen
-
Bestandsdaten des Einzelhändlers, um festzustellen, was sich zu einem bestimmten Zeitpunkt in den Regalen der einzelnen Filialen befindet
Häufig werden Fremddaten als Datenbeziehung zwischen zwei Partnern kodifiziert: Unternehmen A und Unternehmen B müssen zusammenarbeiten, um Kunde X zu bedienen oder Vorgang Y zu realisieren, und dafür müssen Daten ausgetauscht werden. Manchmal wird dies auch als Second-Party-Daten bezeichnet.
In anderen Fällen nutzt du öffentliche Daten oder Daten, die von einem Drittanbieter bereitgestellt werden, um sie in einer Eins-zu-Viel-Beziehung weiterzuverkaufen, oft um Entscheidungen über Einheiten (Kunden, Unternehmen, Standorte) zu treffen, über die du nur begrenzte Informationen hast. Wenn du die öffentlich zugänglichen Feeds im Online-Katalog Demyst durchsuchst, wirst du sehen, dass es möglich ist, mit nur wenigen Klicks umfassende Steuer-, Eigentums- und Unternehmensdaten zu nutzen.
Daten von Drittanbietern sind eine häufige Quelle für Probleme mit der Datenqualität. Das liegt nicht nur daran, dass die Anbieter Fehler machen, sondern auch daran, dass sie oft Änderungen vornehmen, z. B. an ihren APIs oder Datenformaten. Wenn du keinen klaren Datenvertrag hast, denken Dritte nicht unbedingt darüber nach, wie sich ihre Aktualisierungen auf deinen speziellen Anwendungsfall auswirken könnten, und sind auch nicht verpflichtet, dich darüber zu informieren oder Abhilfe zu schaffen.
Unternehmenswachstum und Wandel
Wir sind der Meinung, dass fast alle Daten zu Beginn von hoher Qualität sind. Wenn ein Produkt zum ersten Mal gebaut und mit Instrumenten ausgestattet wird, sind die Daten, die der Ingenieur, der es gebaut hat, über dieses Produkt erfasst, in der Regel sehr eng mit seiner Absicht und der Funktion des Produkts verbunden.
Aber Daten existieren nicht in einem Vakuum. In der realen Welt passt ein Unternehmen seine Produkte ständig an und verbessert sie, was sich wiederum auf die Daten auswirkt, die von diesen Produkten ausgegeben werden. Es ist wie beim zweiten Hauptsatz der Thermodynamik: Die Entropie der Daten wird mit der Zeit immer größer. Im Laufe der Zeit verschlechtert sich die Datenqualität durch die folgenden Faktoren:
- Neue Funktionen
Neue Funktionen erweitern oft den Umfang der Daten, die das System erfasst. Wenn es sich dabei um eine Änderung im Sinne von "zusätzliche Spalten hinzufügen" handelt, ist das Risiko für die Datenqualität nicht groß. In einigen Fällen können neue Funktionen jedoch bestehende Funktionen ersetzen, was einen plötzlichen Einfluss auf die vom System ausgegebenen Daten haben kann. In vielen Fällen können die neuen Funktionen die Form der Daten verändern. Die Granularität der Daten kann sich erhöhen, z. B. werden die Daten jetzt auf der Ebene eines Artikels und nicht mehr auf der Ebene des gesamten Produkts erfasst. Oder was vorher eine einzige Meldung war, wird in viele Meldungen aufgeteilt und umstrukturiert.
- Fehlerbehebungen
Laut dem CyLab Sustainable Computing Consortium der Carnegie Mellon University enthält eine kommerzielle Software durchschnittlich 20-30 Fehler pro 1.000 Codezeilen. Fehlerkorrekturen können die gleiche Wirkung haben wie neue Funktionen. Sie können auch die Datenqualität wirklich verbessern - aber wenn diese plötzliche Verbesserung als "Schock" für die Systeme kommt, die von den Daten abhängen, kann das negative Folgen haben (siehe Abschnitt "Datenschocks").
- Refactors
Refactoring findet statt, wenn Teams die Struktur des Codes oder der Systeme hinter einer Anwendung verbessern wollen, ohne die Funktionalität zu verändern. Refactoring birgt jedoch oft das Risiko unbeabsichtigter Änderungen - vor allem bei Dingen wie der Datenerfassung, die im Anwendungscode nicht zuverlässig getestet werden können.
- Optimierungen
Häufig werden Änderungen vorgenommen, um die Geschwindigkeit oder Effizienz einer Anwendung zu verbessern. In vielen Fällen kann die Art der Datenerfassung ein Leistungsproblem darstellen, und Änderungen können sich auf die Zuverlässigkeit, die zeitliche Granularität oder die Einzigartigkeit der vom System ausgegebenen Daten auswirken.
- Neue Teams
Neue Teams übernehmen oft eine Altanwendung und wissen nur bedingt, wie diese mit anderen Systemen interagiert oder wie die von ihr erzeugten Daten genutzt werden. Wenn sie Änderungen an ihrem Produkt vornehmen, kann es passieren, dass sie unbeabsichtigt mit den bestehenden Erwartungen anderer Teams brechen und dadurch Probleme mit der Datenqualität verursachen.
- Ausfälle
Zusätzlich zu den absichtlichen Änderungen kommt es bei vielen Systemen zu Ausfällen, bei denen sie nicht mehr oder nur noch in eingeschränktem Maße funktionieren. Die Datenerfassung geht während dieser Ausfälle oft komplett verloren. Das ist oft kein Problem für die Datenqualität an sich, denn die fehlenden Daten spiegeln die mangelnde Aktivität aufgrund des Ausfalls wider. In vielen Fällen kann sich der Ausfall jedoch auf die übermittelten Daten auswirken, ohne den Dienst selbst zu beeinträchtigen, was ein Problem der Datenqualität darstellt.
Exogene Faktoren
Wenn du Daten nutzt, um Entscheidungen zu treffen oder Produkte zu entwickeln, wird es immer Faktoren geben, die sich auf die Daten auswirken, die außerhalb deiner Kontrolle liegen, wie z. B. das Verhalten der Nutzer/innen, globale Ereignisse, Aktionen der Wettbewerber/innen, Lieferanten und Marktkräfte. Dabei handelt es sich zwar nicht um Probleme mit der Datenqualität an sich, aber sie sehen oft aus wie Probleme mit der Datenqualität und müssen auch so behandelt werden.
In einigen Branchen treffen Unternehmen zum Beispiel automatisierte Entscheidungen auf der Grundlage von Echtzeitdaten über die Aktivitäten der Konkurrenz. E-Commerce-Unternehmen überwachen die Preisdaten ihrer Konkurrenten und passen daraufhin ihre Preise fast sofort an. Fluggesellschaften machen dasselbe. Wenn ein Konkurrent sein Verhalten auf plötzliche, drastische Weise ändert, wird das Unternehmen sofort das Gleiche tun - und am Ende eine große Veränderung in seinen Daten feststellen. Es ist wichtig, dass die Unternehmen über diese Veränderungen informiert werden, denn sie sind nicht immer erwünscht oder beabsichtigt.
Jede Diskussion über exogene Faktoren wäre nachlässig, wenn sie nicht die COVID-19-Pandemie erwähnen würde. Jeder musste die Anfangsmonate von COVID-19 bei der Analyse des Nutzerverhaltens als Sonderfall behandeln. Abbildung 1-4 zeigt zum Beispiel, wie sich die Daten über die Anzahl der protokollierten Meilen für Taxifahrten in Chicago im März 2020 dramatisch verändert haben.
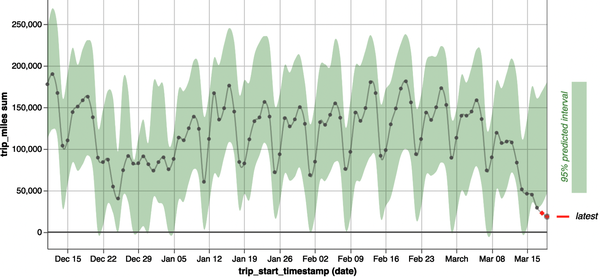
Abbildung 1-4. Die durchschnittliche Länge einer Taxifahrt in Chicago ist im März 2020 stark gesunken. Die Taxidaten sind öffentlich zugänglich auf der Website der Stadt Chicago. Sieh dir dieses Bild in voller Größe an unter https://oreil.ly/adqm_1_4.
Während der COVID-19 mussten die Modelle für maschinelles Lernen schnell auf neue Daten umgestellt werden, da ihre auf historischen Trends basierenden Annahmen nicht mehr zutrafen. In einem bekannten Fall konnte sich das Modell von Zillow zur Vorhersage von Immobilienpreisen, das einen neuen Geschäftszweig, Zillow Offers, antrieb, nicht schnell genug anpassen. Der automatisierte Dienst zahlte zu viel für Häuser, die er auf dem sich verändernden Markt nicht mehr verkaufen konnte, und leider musste Zillow daraufhin fast ein Viertel seiner Belegschaft entlassen.
Teams befinden sich in der Regel in einer von zwei Situationen, was externe Faktoren angeht:
-
In manchen Fällen, wie z.B. bei COVID-19, sind die externen Veränderungen so dramatisch, dass du deine Entscheidungsprozesse auf den Prüfstand stellen und deine ML-Modelle möglicherweise neu trainieren musst. Das ist fast so wie bei einem Datenqualitätsproblem - es ist eine Veränderung, über die du sofort informiert werden willst, damit du den Schaden begrenzen kannst.
-
In anderen Fällen haben externe Faktoren einen subtileren Einfluss, z. B. ein Problem in der Lieferkette, das sich auf die Bearbeitungszeiten deiner Aufträge auswirkt. Du musst den Kontext dieser Veränderungen schnell verstehen und Probleme mit der Datenqualität ausschließen, die oft wie echte externe Trends aussehen können.
Warum wir eine Überwachung der Datenqualität brauchen
Angesichts der zunehmenden Bedeutung hochwertiger Daten und der Tatsache, dass Probleme mit der Datenqualität häufiger denn je auftreten, bist du vielleicht schon davon überzeugt, dass die Verbesserung der Datenqualität wichtig ist. Aber wie solltest du über eine solche Initiative denken? Ist es eine einmalige Maßnahme, bei der du deine Daten über einen Zeitraum von mehreren Monaten oder Quartalen auf Vordermann bringst und die Dinge von da an reibungslos laufen lässt?
Diese Art von Ansatz ist bei Software oft sinnvoll, bei Daten jedoch viel weniger. Der Code ist heute derselbe wie morgen, es sei denn, er wird absichtlich aktualisiert. Du kannst ihn in einer kontrollierten QA-Umgebung testen und auch Unit-Tests durchführen, die nur einen Teil des Systems isolieren. Wenn deine Tests bestanden sind, bist du im Grunde fertig.
Daten hingegen sind chaotisch und verändern sich ständig. Sie hängen von externen Faktoren ab, die du nicht kontrollieren kannst, z. B. wie die Nutzer/innen in Echtzeit mit deinem Produkt interagieren. Deshalb kannst du sie nur in der Produktion ganzheitlich testen. Deine Tests müssen in der Lage sein, das ganze Rauschen - und es gibt eine Menge Rauschen - aus dem echten Datenqualitätssignal herauszufiltern.
Während Softwarefehler durch automatisierte Tests und Nutzerfeedback oft schnell entdeckt und behoben werden, sind wir der festen Überzeugung, dass die große Mehrheit der Datenqualitätsprobleme nie entdeckt wird. Weil den Teams die richtigen Überwachungs-Tools für Daten fehlen, passieren Probleme im Stillen und bleiben unbemerkt.
Erschwerend kommt hinzu, dass die Kosten für die Behebung eines Datenqualitätsproblems dramatisch ansteigen, je mehr Zeit seit dem Auftreten des Problems verstrichen ist.
-
Die Zahl der möglichen Veränderungen, die das Problem verursacht haben könnten, steigt linear mit der Länge des Zeitraums, den du auswertest.
-
Je länger eine Änderung zurückliegt, desto weniger weiß das Team, warum sie vorgenommen wurde oder welche Auswirkungen sie haben könnte.
-
Die Kosten für die "Behebung" des Problems (einschließlich des Backfillings der Daten) steigen mit der Zeit, die seit dem Auftreten des Problems vergangen ist.
-
Probleme, die über einen längeren Zeitraum bestehen, werden für andere nachgelagerte Systeme zum "normalen Verhalten", so dass die Behebung dieser Probleme zu neuen Vorfällen führen kann.
Wenn ein Vorfall eingeführt und dann später behoben wird, hat er zwei verschiedene Arten von Auswirkungen. Wir nennen sie "Datennarben" und "Datenschocks".
Daten-Narben
Wenn ein Vorfall passiert, hinterlässt er eine Narbe in den Daten, es sei denn, die Daten werden mühsam repariert (was oft unmöglich oder teuer ist). Wir haben diesen Begriff zum ersten Mal von Daniele Perito, Chief Data Officer und Mitbegründer von Faire, gehört. Eine Narbe ist ein Zeitraum für einen bestimmten Datensatz, in dem eine Untergruppe von Datensätzen ungültig oder anomal ist und von allen Systemen, die in Zukunft mit diesen Datensätzen arbeiten, nicht mehr als vertrauenswürdig angesehen werden kann.
Datennarben wirken sich auf ML-Modelle aus, da diese Modelle sich anpassen müssen, um unterschiedliche Beziehungen in den Daten während des Zeitraums der Narbe zu lernen. Das schwächt ihre Leistung und schränkt ihre Fähigkeit ein, aus allen Daten zu lernen, die während der Narbe erfasst wurden. Außerdem wird dadurch der Glaube des Modells an die Wichtigkeit der von der Narbe betroffenen Merkmale geschwächt - das Modell wird diese Eingaben untergewichten, weil es fälschlicherweise glaubt, dass sie im Datensatz weniger häufig vorkommen. Selbst wenn es dir gelingt, die Narbe in der Vergangenheit zu reparieren, kann es leicht zu einem so genannten Datenleck in nachgelagerten ML-Anwendungen kommen, indem du versehentlich einige Informationen über den aktuellen Zustand in deine Korrektur einbeziehst. Das führt dazu, dass das Modell in Offline-Evaluierungen sehr gut funktioniert (da es Zugang zu "zeitgereisten" Informationen aus der Zukunft hat), aber in der Produktion (wo es diese Informationen nicht mehr hat) unregelmäßig arbeitet.
Datennarben haben auch große Auswirkungen auf zukünftige Analysen oder Data Science-Arbeiten, die mit diesem Datensatz durchgeführt werden. Sie können zu komplexeren Datenpipelines führen, die schwieriger zu schreiben und zu pflegen sind, da die Datennutzer viele Ausnahmen behandeln müssen, um durch die Narbe verursachte Verzerrungen zu vermeiden. Diese Ausnahmen müssen möglicherweise in allen Berichten oder Visualisierungen, die Daten aus der Zeit der Narbe enthalten, berücksichtigt werden, was den kognitiven Aufwand für alle erhöht, die versuchen, die Daten zu interpretieren oder Entscheidungen auf ihrer Grundlage zu treffen. Oder Narben müssen ganz aus dem Datensatz entfernt werden, was zu einer "Datenamnesie" für diesen Zeitraum führt, was sich auf Trendanalysen oder zeitbasierte Vergleiche auswirken kann (z. B. was war unser Ergebnis im Vergleich zum Vorjahr für diese Statistik?).
Datenschocks
Neben dem Vernarbungseffekt gibt es auch Auswirkungen in der Produktion, die sowohl dann auftreten, wenn das Datenqualitätsproblem eingeführt wurde , als auch dann, wenn das Datenproblem behoben ist. Das nennen wir einen Datenqualitätsschock, der auch die KI/ML und die Entscheidungsfindung beeinflussen kann.
Wenn das Datenqualitätsproblem zum ersten Mal auftritt, werden alle ML-Modelle, die aus den Daten abgeleitete Merkmale verwenden, plötzlich mit Daten konfrontiert, die sich völlig von denen unterscheiden, auf denen sie trainiert wurden. Das führt dazu, dass sie von den neuen Daten "geschockt" werden und Vorhersagen treffen, die für die von dem Datenqualitätsproblem betroffenen Beobachtungen oft sehr ungenau sind. Dieser Schock hält so lange an, bis die Modelle mit neuen Daten neu trainiert werden, was bei einem kontinuierlichen Bereitstellungsmodell oft automatisch geschieht.
Wenn dann die Datenqualität korrigiert wird, führt dies zu einem weiteren Schock für das Modell (es sei denn, die Daten werden historisch repariert, was oft nicht möglich ist). Der Schock durch die Korrektur kann oft genauso schlimm sein wie der ursprüngliche Schock durch die Einführung des Datenqualitätsproblems!
In Analyse-/Berichtsfällen äußern sich diese Schocks oft in Form von Kennzahlen oder Analysen, die plötzlich unerwartete Veränderungen aufweisen. Wenn diese Veränderungen beobachtet werden, werden sie oft fälschlicherweise für reale Veränderungen gehalten (der Zweck dieser Berichte ist es ja, die Realität widerzuspiegeln), sodass Abläufe geändert oder andere Entscheidungen getroffen werden, um auf das Datenqualitätsproblem zu reagieren, als ob es real wäre. Das Gleiche kann auch in umgekehrter Richtung passieren, wenn die Korrektur veröffentlicht wird.
Je länger das Datenqualitätsproblem nicht behoben wird, desto tiefer ist die Narbe und desto größer ist der Schock, wenn es behoben wird.
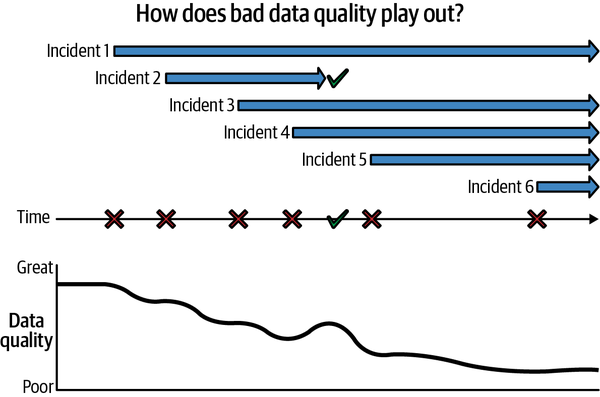
Abbildung 1-5. Wie sich Vorfälle häufen und die Datenqualität und das Vertrauen mit der Zeit untergraben. Jeder Balken ist eine Datennarbe, die der Vorfall hinterlassen hat. Jedes X (das markiert, wann der Vorfall zum ersten Mal auftrat) ist ein Datenschock. Das Häkchen (wenn Vorfall 2 behoben wurde) ist ebenfalls ein Datenschock.
Wenn man zulässt, dass sich die Narben und Schocks immer weiter anhäufen, führt das dazu, dass die objektive Qualität der Daten mit der Zeit immer mehr abnimmt. Abbildung 1-5 zeigt, wie sich Vorfälle häufen, so dass jeder davon überzeugt ist, dass die Datenqualität niedrig und die Daten selbst nicht vertrauenswürdig sind. Und so schwer es auch ist, Daten wieder aufzufüllen, so schwer ist es auch, Vertrauen wieder herzustellen.
Deshalb ist ein Umdenken in den Unternehmen erforderlich, wenn es um die Bekämpfung schlechter Datenqualität geht. Es sollte kein einmaliges Projekt sein, um die Datenqualität für eine bestimmte Datenquelle zu verbessern. Vielmehr muss es sich um eine Initiative zur kontinuierlichen Überwachung der Datenqualität handeln, bei der Datenqualitätsprobleme sofort erkannt und so schnell wie möglich behoben werden.
Ohne Überwachung der Datenqualität bleiben Probleme so lange unentdeckt, bis ein Geschäftsnutzer, ein Datenexperte oder ein Kunde des ML-Algorithmus oder anderer Systeme sie bemerkt. Der Betrieb einer Datenfabrik auf diese Weise ist vergleichbar mit einer Fabrik, die Konsumgüter ohne Qualitätskontrolle herstellt.
Die Überwachung der Datenqualität automatisieren: Die neue Grenze
Datenexperten erleben heute aufregende, geradezu erstaunliche Veränderungen in diesem Bereich. Ob es sich um Investitionen in generative KI, die Demokratisierung von Analysen im gesamten Unternehmen oder die Migration von einer alten Datenbank in die Cloud handelt, fast jedes Unternehmen ist dabei, etwas Neues mit Daten zu machen, was es noch nie zuvor getan hat.
Für die meisten Unternehmen ist daher jetzt der beste Zeitpunkt, in Datenqualität zu investieren. Mit der zunehmenden Nutzung von Daten steigen auch die Risiken und negativen Auswirkungen von Datenqualitätsproblemen. Datenqualität ist etwas, das ständig überwacht und sorgfältig gepflegt werden muss, indem Probleme behoben werden, sobald sie auftreten.
Eine wirksame Überwachung der Datenqualität ist keine leichte Aufgabe - vor allem, wenn es sich um Tausende von Tabellen und Milliarden von Datensätzen handelt, wie es in großen Unternehmen üblich ist. Es liegt zwar auf der Hand, dass es nicht funktioniert, wenn Menschen deine Daten manuell überprüfen, aber es funktioniert auch nicht, wenn du alte Lösungen wie das Schreiben von Tests für deine Daten und das Verfolgen von Schlüsselkennzahlen verwendest. Vielleicht möchtest du dies für deine wichtigsten Tabellen tun, aber es für dein gesamtes Data Warehouse zu implementieren, ist einfach nicht machbar.
In diesem Buch stellen wir dir das Konzept der automatisierten Überwachung der Datenqualität mit unüberwachtem ML vor. Dies ist eine neue Technik mit vielen Vorteilen. Sie erfordert kaum manuelle Einstellungen und lässt sich problemlos auf dein Data Warehouse übertragen. Mit der richtigen Implementierung lernt sie automatisch die geeigneten Schwellenwerte dafür, ob eine Datenänderung groß genug ist, um ein Qualitätsproblem zu signalisieren. Sie kann eine breite Palette von Problemen aufdecken, einschließlich unbekannter Unbekannter, für die noch nie jemand einen Test geschrieben hat.
Der Einsatz von ML bringt seine eigenen Herausforderungen mit sich. Die Erstellung des Modells ist an sich schon eine komplizierte Aufgabe, aber du musst auch sicherstellen, dass es mit einer Vielzahl von realen Daten funktioniert, ohne zu über- oder unteralarmieren. Du musst Benachrichtigungen einrichten, die deinem Team helfen, Probleme effektiv einzuteilen, sowie Integrationen mit deinem Daten-Toolkit, die die Datenqualität in den Mittelpunkt deines Unternehmens rücken. Und du brauchst einen Plan, wie du deine Überwachungsplattform langfristig einsetzen und verwalten kannst.
Keine Sorge - wir sind hier, um dir mit Ratschlägen und Tools zur Seite zu stehen, die du auf deinem Weg brauchst. Wir glauben, dass die Automatisierung der Datenqualitätsüberwachung mit ML genauso aufregend ist wie jede andere Dateninnovation der letzten Jahre und einer der wichtigsten Durchbrüche in der modernen Datenverarbeitung ist. Wir hoffen, dass du uns am Ende dieses Buches zustimmst.
Get Die Überwachung der Datenqualität automatisieren now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

