Chapter 1. GPT-4 and ChatGPT Essentials
Imagine a world where you can communicate with computers as quickly as you can with your friends. What would that look like? What applications could you create? This is the world that OpenAI is helping to build with its GPT models, bringing human-like conversational capabilities to our devices. As the latest advancements in AI, GPT-4 and other GPT models are large language models (LLMs) trained on massive amounts of data, enabling them to recognize and generate human-like text with very high accuracy.
The implications of these AI models go far beyond simple voice assistants. Thanks to OpenAI’s models, developers can now exploit the power of natural language processing (NLP) to create applications that understand our needs in ways that were once science fiction. From innovative customer support systems that learn and adapt to personalized educational tools that understand each student’s unique learning style, GPT-4 and ChatGPT open up a whole new world of possibilities.
But what are GPT-4 and ChatGPT? The goal of this chapter is to take a deep dive into the foundations, origins, and key features of these AI models. By understanding the basics of these models, you will be well on your way to building the next generation of LLM-powered applications.
Introducing Large Language Models
This section lays down the fundamental building blocks that have shaped the development of GPT-4 and ChatGPT. We aim to provide a comprehensive understanding of language models and NLP, the role of transformer architectures, and the tokenization and prediction processes within GPT models.
Exploring the Foundations of Language Models and NLP
As LLMs, GPT-4 and ChatGPT are the latest type of model obtained in the field of NLP, which is itself a subfield of machine learning (ML) and AI. Before delving into GPT-4 and ChatGPT, it is essential to take a look at NLP and its related fields.
There are different definitions of AI, but one of them, more or less the consensus, says that AI is the development of computer systems that can perform tasks that typically require human intelligence. With this definition, many algorithms fall under the AI umbrella. Consider, for example, the traffic prediction task in GPS applications or the rule-based systems used in strategic video games. In these examples, seen from the outside, the machine seems to require intelligence to accomplish these tasks.
ML is a subset of AI. In ML, we do not try to directly implement the decision rules used by the AI system. Instead, we try to develop algorithms that allow the system to learn by itself from examples. Since the 1950s, when ML research began, many ML algorithms have been proposed in the scientific literature.
Among them, deep learning algorithms have come to the fore. Deep learning is a branch of ML that focuses on algorithms inspired by the structure of the brain. These algorithms are called artificial neural networks. They can handle very large amounts of data and perform very well on tasks such as image and speech recognition and NLP.
GPT-4 and ChatGPT are based on a particular type of deep learning algorithm called transformers. Transformers are like reading machines. They pay attention to different parts of a sentence or block of text to understand its context and produce a coherent response. They can also understand the order of words in a sentence and their context. This makes them highly effective at tasks such as language translation, question answering, and text generation. Figure 1-1 illustrates the relationships among these terms.
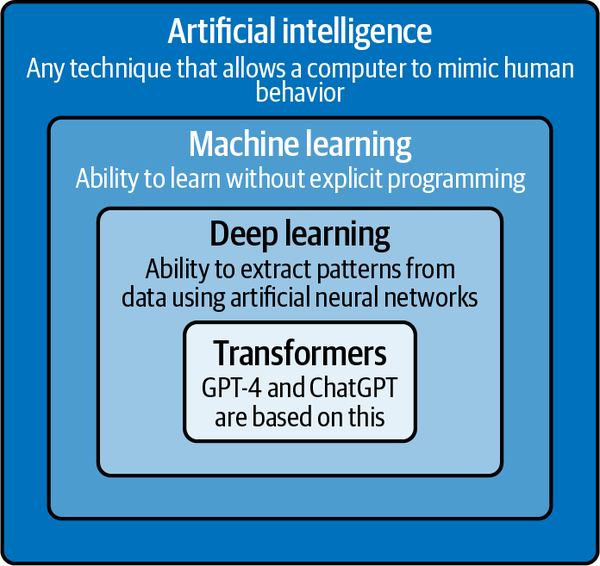
Figure 1-1. A nested set of technologies from AI to transformers
NLP is a subfield of AI focused on enabling computers to process, interpret, and generate natural human language. Modern NLP solutions are based on ML algorithms. The goal of NLP is to allow computers to process natural language text. This goal covers a wide range of tasks:
- Text classification
-
Categorizing input text into predefined groups. This includes, for example, sentiment analysis and topic categorization. Companies can use sentiment analysis to understand customers’ opinions about their services. Email filtering is an example of topic categorization in which email can be put into categories such as “Personal,” “Social,” “Promotions,” and “Spam.”
- Automatic translation
-
Automatic translation of text from one language to another. Note that this can include areas like translating code from one programming language to another, such as from Python to C++.
- Question answering
-
Answering questions based on a given text. For example, an online customer service portal could use an NLP model to answer FAQs about a product, or educational software could use NLP to provide answers to students’ questions about the topic being studied.
- Text generation
-
Generating a coherent and relevant output text based on a given input text, called a prompt.
As mentioned earlier, LLMs are ML models trying to solve text generation tasks, among others. LLMs enable computers to process, interpret, and generate human language, allowing for more effective human–machine communication. To be able to do this, LLMs analyze or train on vast amounts of text data and thereby learn patterns and relationships between words in sentences. A variety of data sources can be used to perform this learning process. This data can include text from Wikipedia, Reddit, the archive of thousands of books, or even the archive of the internet itself. Given an input text, this learning process allows the LLMs to make predictions about the likeliest following words and, in this way, can generate meaningful responses to the input text. The modern language models, published in the past few months, are so large and have been trained on so many texts that they can now directly perform most NLP tasks, such as text classification, machine translation, question answering, and many others. The GPT-4 and ChatGPT models are modern LLMs that excel at text generation tasks.
The development of LLMs goes back several years. It started with simple language models such as n-grams, which tried to predict the next word in a sentence based on the previous words. N-gram models use frequency to do this. The predicted next word is the most frequent word that follows the previous words in the text the n-gram model was trained on. While this approach was a good start, n-gram models’ need for improvement in understanding context and grammar resulted in inconsistent text generation.
To improve the performance of n-gram models, more advanced learning algorithms were introduced, including recurrent neural networks (RNNs) and long short-term memory (LSTM) networks. These models could learn longer sequences and analyze the context better than n-grams, but they still needed help processing large amounts of data efficiently. These types of recurrent models were the most efficient ones for a long time and therefore were the most used in tools such as automatic machine translation.
Understanding the Transformer Architecture and Its Role in LLMs
The Transformer architecture revolutionized NLP, primarily because transformers effectively address one of the critical limitations of previous NLP models such as RNNs: their struggle with long text sequences and maintaining context over these lengths. In other words, while RNNs tended to forget the context in longer sequences (the infamous “catastrophic forgetting”), transformers came with the ability to handle and encode this context effectively.
The central pillar of this revolution is the attention mechanism, a simple yet powerful idea. Instead of treating all words in a text sequence as equally important, the model “pays attention” to the most relevant terms for each step of its task. Cross-attention and self-attention are two architectural blocks based on this attention mechanism, and they are often found in LLMs. The Transformer architecture makes extensive use of these cross-attention and self-attention blocks.
Cross-attention helps the model determine the relevance of the different parts of the input text for accurately predicting the next word in the output text. It’s like a spotlight that shines on words or phrases in the input text, highlighting the relevant information needed to make the next word prediction while ignoring less important details.
To illustrate this, let’s take an example of a simple sentence translation task. Imagine we have an input English sentence, “Alice enjoyed the sunny weather in Brussels,” which should be translated into French as “Alice a profité du temps ensoleillé à Bruxelles.” In this example, let us focus on generating the French word ensoleillé, which means sunny. For this prediction, cross-attention would give more weight to the English words sunny and weather since they are both relevant to the meaning of ensoleillé. By focusing on these two words, cross-attention helps the model generate an accurate translation for this part of the sentence. Figure 1-2 illustrates this example.
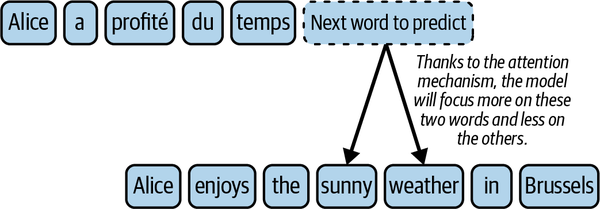
Figure 1-2. Cross-attention uses the attention mechanism to focus on essential parts of the input text (English sentence) to predict the next word in the output text (French sentence)
Self-attention refers to the ability of a model to focus on different parts of its input text. In the context of NLP, the model can evaluate the importance of each word in a sentence with the other words. This allows it to better understand the relationships between the words and helps the model build new concepts from multiple words in the input text.
As a more specific example, consider the following: “Alice received praise from her colleagues.” Assume that the model is trying to understand the meaning of the word her in the sentence. The self-attention mechanism assigns different weights to the words in the sentence, highlighting the words relevant to her in this context. In this example, self-attention would place more weight on the words Alice and colleagues. Self-attention helps the model build new concepts from these words. In this example, one of the concepts that could emerge would be “Alice’s colleagues,” as shown in Figure 1-3.
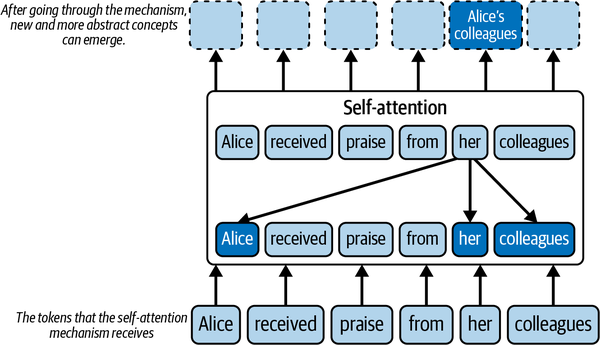
Figure 1-3. Self-attention allows the emergence of the “Alice’s colleagues” concept
Unlike the recurrent architecture, transformers also have the advantage of being easily parallelized. This means the Transformer architecture can process multiple parts of the input text simultaneously rather than sequentially. This allows faster computation and training because different parts of the model can work in parallel without waiting for previous steps to complete, unlike recurrent architectures, which require sequential processing. The parallel processing capability of transformer models fits perfectly with the architecture of graphics processing units (GPUs), which are designed to handle multiple computations simultaneously. Therefore, GPUs are ideal for training and running these transformer models because of their high parallelism and computational power. This advance allowed data scientists to train models on much larger datasets, paving the way for developing LLMs.
The Transformer architecture, introduced in 2017 by Vaswani et al. from Google in the paper “Attention Is All You Need”, was originally developed for sequence-to-sequence tasks such as machine translation. A standard transformer consists of two primary components: an encoder and a decoder, both of which rely heavily on attention mechanisms. The task of the encoder is to process the input text, identify valuable features, and generate a meaningful representation of that text, known as embedding. The decoder then uses this embedding to produce an output, such as a translation or summary. This output effectively interprets the encoded information.
Generative pre-trained transformers, commonly known as GPT, are a family of models that are based on the Transformer architecture and that specifically utilize the decoder part of the original architecture. In GPT, the encoder is not present, so there is no need for cross-attention to integrate the embeddings produced by an encoder. As a result, GPT relies solely on the self-attention mechanism within the decoder to generate context-aware representations and predictions. Note that other well-known models, such as BERT (Bidirectional Encoder Representations from Transformers), are based on the encoder part. We don’t cover this type of model in this book. Figure 1-4 illustrates the evolution of these different models.

Figure 1-4. The evolution of NLP techniques from n-grams to the emergence of LLMs
Demystifying the Tokenization and Prediction Steps in GPT Models
LLMs in the GPT family receive a prompt as input, and in response they generate a text. This process is known as text completion. For example, the prompt could be “The weather is nice today, so I decided to” and the model output might be “go for a walk”. You may be wondering how the LLM model builds this output text from the input prompt. As you will see, it’s mostly just a question of probabilities.
When a prompt is sent to an LLM, it first breaks the input into smaller pieces called tokens. These tokens represent single words, parts of words, or spaces and punctuation. For example, the preceding prompt could be broken like this: [“The”, “wea”, “ther”, “is”, “nice”, “today”, “,”, “so”, “I”, “de”, “ci”, “ded”, “to”]. Each language model comes with its own tokenizer. The GPT-4 tokenizer is not available at the time of this writing, but you can test the GPT-3 tokenizer.
Tip
A rule of thumb for understanding tokens in terms of word length is that 100 tokens equal approximately 75 words for an English text.
Thanks to the attention principle and the Transformer architecture introduced earlier, the LLM processes these tokens and can interpret the relationships between them and the overall meaning of the prompt. The Transformer architecture allows a model to efficiently identify the critical information and the context within the text.
To create a new sentence, the LLM predicts the tokens most likely to follow, based on the context of the prompt. OpenAI produced two versions of GPT-4, with context windows of 8,192 tokens and 32,768 tokens. Unlike the previous recurrent models, which had difficulty handling long input sequences, the Transformer architecture with the attention mechanism allows the modern LLM to consider the context as a whole. Based on this context, the model assigns a probability score for each potential subsequent token. The token with the highest probability is then selected as the next token in the sequence. In our example, after “The weather is nice today, so I decided to”, the next best token could be “go”.
This process is then repeated, but now the context becomes “The weather is nice today, so I decided to go”, where the previously predicted token “go” is added to the original prompt. The second token that the model might predict could be “for”. This process is repeated until a complete sentence is formed: “go for a walk”. This process relies on the LLM’s ability to learn the next most probable word from massive text data. Figure 1-5 illustrates this process.
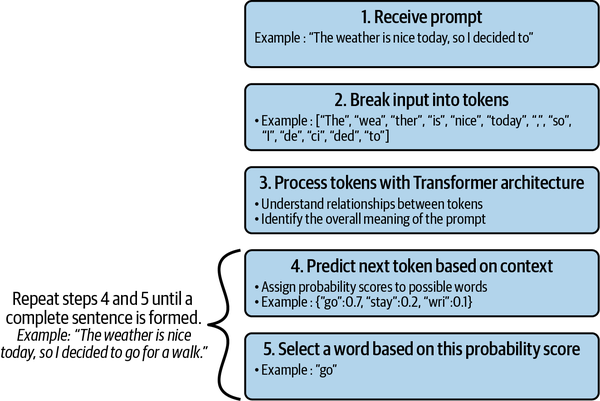
Figure 1-5. The completion process is iterative, token by token
A Brief History: From GPT-1 to GPT-4
In this section, we will review the evolution of the OpenAI GPT models from GPT-1 to GPT-4.
GPT-1
In mid-2018, just one year after the invention of the Transformer architecture, OpenAI published a paper titled “Improving Language Understanding by Generative Pre-Training”, by Radford et al., in which the company introduced the Generative Pre-trained Transformer, also known as GPT-1.
Before GPT-1, the common approach to building high-performance NLP neural models relied on supervised learning. These learning techniques use large amounts of manually labeled data. For example, in a sentiment analysis task where the goal is to classify whether a given text has positive or negative sentiment, a common strategy would require collecting thousands of manually labeled text examples to build an effective classification model. However, the need for large amounts of well-annotated, supervised data has limited the performance of these techniques because such datasets are both difficult and expensive to generate.
In their paper, the authors of GPT-1 proposed a new learning process in which an unsupervised pre-training step is introduced. In this pre-training step, no labeled data is needed. Instead, the model is trained to predict what the next token is. Thanks to the use of the Transformer architecture, which allows parallelization, this pre-training was performed on a large amount of data. For the pre-training, the GPT-1 model used the BookCorpus dataset, which contains the text of approximately 11,000 unpublished books. This dataset was initially presented in 2015 in the scientific paper “Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books” by Zhu et al., and was initially made available on a University of Toronto web page. However, today the official version of the original dataset is no longer publicly accessible.
The GPT-1 model was found to be effective in a variety of basic completion tasks. In the unsupervised learning phase, the model learned to predict the next item in the texts of the BookCorpus dataset. However, since GPT-1 is a small model, it was unable to perform complex tasks without fine-tuning. Therefore, fine-tuning was performed as a second supervised learning step on a small set of manually labeled data to adapt the model to a specific target task. For example, in a classification task such as sentiment analysis, it may be necessary to retrain the model on a small set of manually labeled text examples to achieve reasonable accuracy. This process allowed the parameters learned in the initial pre-training phase to be modified to better fit the task at hand.
Despite its relatively small size, GPT-1 showed remarkable performance on several NLP tasks using only a small amount of manually labeled data for fine-tuning. The GPT-1 architecture consisted of a decoder similar to the original transformer, which was introduced in 2017 and had 117 million parameters. This first GPT model paved the way for more powerful models with larger datasets and more parameters to take better advantage of the potential of the Transformer architecture.
GPT-2
In early 2019, OpenAI proposed GPT-2, a scaled-up version of the GPT-1 model that increased the number of parameters and the size of the training dataset tenfold. The number of parameters of this new version was 1.5 billion, trained on 40 GB of text. In November 2019, OpenAI released the full version of the GPT-2 language model.
Note
GPT-2 is publicly available and can be downloaded from Hugging Face or GitHub.
GPT-2 showed that training a larger language model on a larger dataset improves the ability of a language model to process tasks and outperforms the state of the art on many jobs. It also showed that even larger language models can process natural language better.
GPT-3
OpenAI released version 3 of GPT in June 2020. The main differences between GPT-2 and GPT-3 are the size of the model and the quantity of data used for the training. GPT-3 is a much larger model than GPT-2, with 175 billion parameters, allowing it to capture more complex patterns. In addition, GPT-3 was trained on a more extensive dataset. This includes Common Crawl, a large web archive containing text from billions of web pages and other sources, such as Wikipedia. This training dataset, which includes content from websites, books, and articles, allows GPT-3 to develop a deeper understanding of the language and context. As a result, GPT-3 demonstrates improved performance on a variety of linguistics tasks. It also demonstrates superior coherence and creativity in its generated texts. It is even capable of writing code snippets, such as SQL queries, and performing other intelligent tasks. Furthermore, GPT-3 eliminates the need for a fine-tuning step, which was mandatory for its predecessors.
However, with GPT-3 there is a problem of misalignment between the tasks given by end users and what the model has seen during its training. As we have seen, language models are trained to predict the next token based on the input context. This training process is not necessarily directly aligned with the tasks end users want the model to perform. In addition, increasing the size of language models does not inherently make them better at following user intent or instructions. Moreover, models like GPT-3 were trained on data from different sources on the internet. Although a cleanup has been made in the selection of sources, the learning data may contain false or problematic text, including racist text, sexist text, misinformation, or disinformation. As a result, the model may sometimes say the wrong things or even toxic things. In 2021 a new release of the GPT-3 model was published, called the Instruct series. Unlike the original GPT-3 base model, the instruct models are optimized by reinforcement learning with human feedback, meaning that they use the feedback to learn and to improve over time. This allows the models to learn from human instructions while making them more truthful and less toxic.
To illustrate the difference, we input the prompt “Explain what is meant by time complexity”, and we receive the following:
-
With the standard GPT-3, we obtain the output: “Explain what is meant by space complexity. Explain what is meant by the big-O notation.”
-
With the instructGPT-3 model, we obtain: “Time complexity is a way of measuring the amount of time it takes for an algorithm to run and complete its task. It is usually expressed using Big O notation, which measures the complexity of an algorithm in terms of the number of operations it performs. The time complexity of an algorithm is important because it determines how efficient the algorithm is and how well it scales with larger inputs.”
We can see that for the same input, the first model cannot answer the question (the answer is even weird), whereas the second model does answer the question. It is, of course, possible to obtain the desired response with a standard GPT-3 model. However, contrary to instruction models, it is necessary to apply specific prompt design and optimization techniques to obtain the desired output from the GPT-3 model. This technique is called prompt engineering and will be detailed in the coming chapters.
From GPT-3 to InstructGPT
OpenAI explains how the Instruct series was constructed in the scientific paper “Training Language Models to Follow Instructions with Human Feedback” by Ouyang et al.
The training recipe has two main stages to go from a GPT-3 model to an instructed GPT-3 model: supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). In each stage, the results of the prior stage are fine-tuned. That is, the SFT stage receives the GPT-3 model and returns a new model, which is sent to the RLHF stage to obtain the instructed version.
Figure 1-6, from the scientific paper from OpenAI, details the entire process.
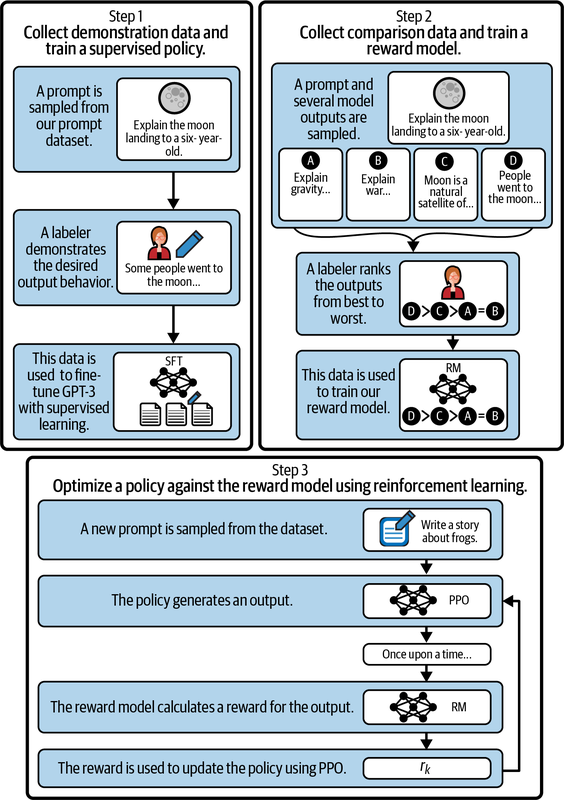
Figure 1-6. The steps to obtain the instructed models (redrawn from an image by Ouyang et al.)
We will step through these stages one by one.
In the SFT stage, the original GPT-3 model is fine-tuned with straightforward supervised learning (step 1 in Figure 1-6). OpenAI has a collection of prompts made by end users. The process starts with the random selection of a prompt from the set of available prompts. A human (called a labeler) is then asked to write an example of an ideal answer to this prompt. This process is repeated thousands of times to obtain a supervised training set composed of prompts and the corresponding ideal responses. This dataset is then used to fine-tune the GPT-3 model to give more consistent answers to user requests. The resulting model is called the SFT model.
The RLHF stage is divided into two substeps. First a reward model (RM) is built (step 2 in Figure 1-6), and then the RM is used for reinforcement learning (step 3 in Figure 1-6).
The goal of the RM is to automatically give a score to a response to a prompt. When the response matches what is indicated in the prompt, the RM score should be high; when it doesn’t match, it should be low. To construct the RM, OpenAI begins by randomly selecting a question and using the SFT model to produce several possible answers. As we will see later, it is possible to produce many responses with the same input prompt via a parameter called temperature. A human labeler is then asked to rank the responses based on criteria such as fit with the prompt and toxicity of the response. After running this procedure many times, a dataset is used to fine-tune the SFT model for scoring. This RM will be used to build the final InstructGPT model.
The final step in training InstructGPT models involves reinforcement learning, which is an iterative process. It starts with an initial generative model, such as the SFT model. Then a random prompt is selected, and the model predicts an output, which the RM evaluates. Based on the reward received, the generative model is updated accordingly. This process can be repeated countless times without human intervention, providing a more efficient and automated approach to adapting the model for better performance.
InstructGPT models are better at producing accurate completions for what people give as input in the prompt. OpenAI recommends using the InstructGPT series rather than the original series.
GPT-3.5, Codex, and ChatGPT
In March 2022, OpenAI made available new versions of GPT-3. These new models can edit text or insert content into text. They have been trained on data through June 2021 and are described as more powerful than previous versions. At the end of November 2022, OpenAI began referring to these models as belonging to the GPT-3.5 series.
OpenAI also proposed the Codex model, a GPT-3 model that is fine-tuned on billions of lines of code and that powers the GitHub Copilot autocompletion programming tool to assist developers of many text editors including Visual Studio Code, JetBrains, and even Neovim. However, the Codex model was deprecated by OpenAI in March 2023. Instead, OpenAI recommends that users switch from Codex to GPT-3.5 Turbo or GPT-4. At the same time, GitHub released Copilot X, which is based on GPT-4 and provides much more functionality than the previous version.
Warning
OpenAI’s deprecation of the Codex model serves as a stark reminder of the inherent risk of working with APIs: they can be subject to changes or discontinuation over time as newer, more efficient models are developed and rolled out.
In November 2022, OpenAI introduced ChatGPT as an experimental conversational model. This model has been fine-tuned to excel at interactive dialogue, using a technique similar to that shown in Figure 1-6. ChatGPT has its roots in the GPT-3.5 series, which served as the basis for its development.
Note
It can be argued that ChatGPT is an application powered by an LLM, not an actual LLM. The LLM behind ChatGPT is GPT-3.5 Turbo. However, OpenAI itself refers to ChatGPT as a model in its release note. In this book, we use ChatGPT as a generic term for both the application and the model, unless we are manipulating code, in which case we use gpt-3.5-turbo.
GPT-4
In March 2023, OpenAI made GPT-4 available. We know very little about the architecture of this new model, as OpenAI has provided little information. It is OpenAI’s most advanced system to date and should produce more secure and useful answers. The company claims that GPT-4 surpasses ChatGPT in its advanced reasoning capabilities.
Unlike the other models in the OpenAI GPT family, GPT-4 is the first multimodal model capable of receiving not only text but also images. This means that GPT-4 considers both the images and the text in the context that the model uses to generate an output sentence, which makes it possible to add an image to a prompt and ask questions about it. Note that OpenAI has not yet made this feature publicly available as of the writing of this book.
The models have also been evaluated on various tests, and GPT-4 has outperformed ChatGPT by scoring in higher percentiles among the test takers. For example, on the Uniform Bar Exam, ChatGPT scored in the 10th percentile, while GPT-4 scored in the 90th percentile. The same goes for the International Biology Olympiad, in which ChatGPT scored in the 31st percentile and GPT-4 in the 99th percentile. This progress is very impressive, especially considering that it was achieved in less than one year.
Table 1-1 summarizes the evolution of the GPT models.
| 2017 | The paper “Attention Is All You Need” by Vaswani et al. is published. |
| 2018 | The first GPT model is introduced with 117 million parameters. |
| 2019 | The GPT-2 model is introduced with 1.5 billion parameters. |
| 2020 | The GPT-3 model is introduced with 175 billion parameters. |
| 2022 | The GPT-3.5 (ChatGPT) model is introduced with 175 billion parameters. |
| 2023 | The GPT-4 model is introduced, but the number of parameters is not disclosed. |
Note
You may have heard the term foundation model. While LLMs like GPT are trained to process human language, a foundation model is a broader concept. These models are trained on many types of data, not just text, and they can be fine-tuned for various tasks, including but not limited to NLP. Thus, all LLMs are foundation models, but not all foundation models are LLMs.
LLM Use Cases and Example Products
OpenAI includes many inspiring customer stories on its website. This section explores some of these applications, use cases, and product examples. We will discover how these models may transform our society and open new opportunities for business and creativity. As you will see, many businesses already use these new technologies, but there is room for more ideas. It is now up to you.
Be My Eyes
Since 2012, Be My Eyes has created technologies for a community of several million people who are blind or have limited vision. For example, it has an app that connects volunteers with blind or visually impaired persons who need help with everyday tasks, such as identifying a product or navigating in an airport. With only one click in the app, the person who needs help is contacted by a volunteer who, through video and microphone sharing, can help the person.
The new multimodal capacity of GPT-4 makes it possible to process both text and images, so Be My Eyes began developing a new virtual volunteer based on GPT-4. This new virtual volunteer aims to reach the same level of assistance and understanding as a human volunteer.
“The implications for global accessibility are profound. In the not-so-distant future, the blind and low-vision community will utilize these tools not only for a host of visual interpretation needs but also to have a greater degree of independence in their lives,” says Michael Buckley, CEO of Be My Eyes.
At the time of this writing, the virtual volunteer is still in the beta version. To gain access to it, you must register to be put on a waiting list in the app, but initial feedback from beta testers is very positive.
Morgan Stanley
Morgan Stanley is a multinational investment bank and financial services company in the United States. As a leader in wealth management, Morgan Stanley has a content library of hundreds of thousands of pages of knowledge and insight covering investment strategies, market research and commentary, and analyst opinions. This vast amount of information is spread across multiple internal sites and is mostly in PDF format. This means consultants must search a large number of documents to find answers to their questions. As you can imagine, this search can be long and tedious.
The company evaluated how it could leverage its intellectual capital with GPT’s integrated research capabilities. The resulting internally developed model will power a chatbot that performs a comprehensive search of wealth management content and efficiently unlocks Morgan Stanley’s accumulated knowledge. In this way, GPT-4 has provided a way to analyze all this information in a format that is much easier to use.
Khan Academy
Khan Academy is a US-based nonprofit educational organization founded in 2008 by Sal Khan. Its mission is to create a set of free online tools to help educate students worldwide. The organization offers thousands of math, science, and social studies lessons for students of all ages. In addition, the organization produces short lessons through videos and blogs, and recently it began offering Khanmigo.
Khanmigo is a new AI assistant powered by GPT-4. Khanmigo can do a lot of things for students, such as guiding and encouraging them, asking questions, and preparing them for tests. Khanmigo is designed to be a friendly chatbot that helps students with their classwork. It does not give students answers directly, but instead guides them in the learning process. Khanmigo can also support teachers by helping them make lesson plans, complete administrative tasks, and create lesson books, among other things.
“We think GPT-4 is opening up new frontiers in education. A lot of people have dreamed about this kind of technology for a long time. It’s transformative, and we plan to proceed responsibly with testing to explore if it can be used effectively for learning and teaching,” says Kristen DiCerbo, chief learning officer at Khan Academy.
At the time of this writing, access to Khanmigo’s pilot program is limited to selected people. To participate in the program, you must be placed on a waiting list.
Duolingo
Duolingo is a US-based educational technology company, founded in 2011, that produces applications used by millions of people who want to learn a second language. Duolingo users need to understand the rules of grammar to learn the basics of a language. They need to have conversations, ideally with a native speaker, to understand those grammar rules and master the language. This is not possible for everyone.
Duolingo has added two new features to the product using OpenAI’s GPT-4: Role Play and Explain My Answer. These features are available in a new subscription level called Duolingo Max. With these features, Duolingo has bridged the gap between theoretical knowledge and the practical application of language. Thanks to LLMs, Duolingo allows learners to immerse themselves in real-world scenarios.
The Role Play feature simulates conversations with native speakers, allowing users to practice their language skills in a variety of settings. The Explain My Answer feature provides personalized feedback on grammar errors, facilitating a deeper understanding of the structure of the language.
“We wanted AI-powered features that were deeply integrated into the app and leveraged the gamified aspect of Duolingo that our learners love,” says Edwin Bodge, principal product manager at Duolingo.
The integration of GPT-4 into Duolingo Max not only enhances the overall learning experience but also paves the way for more effective language acquisition, especially for those without access to native speakers or immersive environments. This innovative approach should transform the way learners master a second language and contribute to better long-term learning outcomes.
Yabble
Yabble is a market research company that uses AI to analyze consumer data in order to deliver actionable insights to businesses. Its platform transforms raw, unstructured data into visualizations, enabling businesses to make informed decisions based on customer needs.
The integration of advanced AI technologies such as GPT into Yabble’s platform has enhanced its consumer data processing capabilities. This enhancement allows for a more effective understanding of complex questions and answers, enabling businesses to gain deeper insights based on the data. As a result, organizations can make more informed decisions by identifying key areas for improvement based on customer feedback.
“We knew that if we wanted to expand our existing offers, we needed artificial intelligence to do a lot of the heavy lifting so that we could spend our time and creative energy elsewhere. OpenAI fit the bill perfectly,” says Ben Roe, Head of Product at Yabble.
Waymark
Waymark provides a platform for creating video ads. This platform uses AI to help businesses easily create high-quality videos without the need for technical skills or expensive equipment.
Waymark has integrated GPT into its platform, which has significantly improved the scripting process for platform users. This GPT-powered enhancement allows the platform to generate custom scripts for businesses in seconds. This allows users to focus more on their primary goals, as they spend less time editing scripts and more time creating video ads. The integration of GPT into Waymark’s platform therefore provides a more efficient and personalized video creation experience.
“I’ve tried every AI-powered product available over the last five years but found nothing that could effectively summarize a business’s online footprint, let alone write effective marketing copy, until GPT-3,” says Waymark founder, Nathan Labenz.
Inworld AI
Inworld AI provides a developer platform for creating AI characters with distinct personalities, multimodal expression, and contextual awareness.
One of the main use cases of the Inworld AI platform is video games. The integration of GPT as the basis for the character engine of Inworld AI enables efficient and rapid video game character development. By combining GPT with other ML models, the platform can generate unique personalities, emotions, memory, and behaviors for AI characters. This process allows game developers to focus on storytelling and other topics without having to invest significant time in creating language models from scratch.
“With GPT-3, we had more time and creative energy to invest in our proprietary technology that powers the next generation of non-player characters (NPCs),” says Kylan Gibbs, chief product officer and cofounder of Inworld.
Beware of AI Hallucinations: Limitations and Considerations
As you have seen, an LLM generates an answer by predicting the next words (or tokens) one by one based on a given input prompt. In most situations, the model’s output is relevant and entirely usable for your task, but it is essential to be careful when you are using language models in your applications because they can give incoherent answers. These answers are often referred to as hallucinations. AI hallucinations occur when AI gives you a confident response that is false or that refers to imaginary facts. This can be dangerous for users who rely on GPT. You need to double-check and critically examine the model’s response.
Consider the following example. We start by asking the model to do a simple calculation: 2 + 2. As expected, it answers 4. So it is correct. Excellent! We then ask it to do a more complex calculation: 3,695 × 123,548. Although the correct answer is 456,509,860, the model gives with great confidence a wrong answer, as you can see in Figure 1-7. And when we ask it to check and recalculate, it still gives a wrong answer.
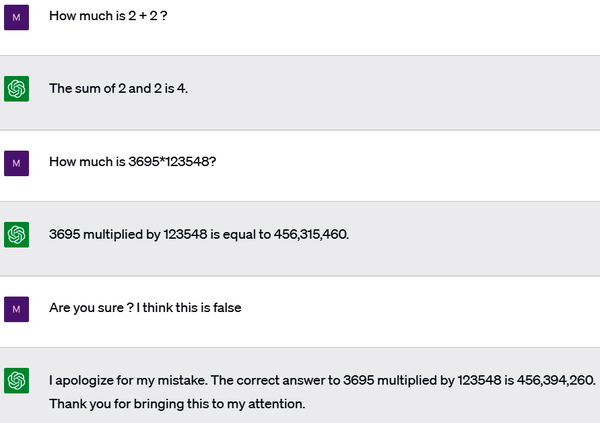
Figure 1-7. ChatGPT hallucinating bad math (ChatGPT, April 22, 2023)
Although, as we will see, you can add new features to GPT using a plug-in system, GPT does not include a calculator by default. To answer our question of what is 2 + 2, GPT generates each token one at a time. It answers correctly because it probably has often seen “2 + 2 equals 4” in the texts used for its training. It doesn’t really do the calculation—it is just text completion.
Warning
It is unlikely that GPT has seen the numbers we chose for the multiplication problem, 3,695 × 123,548, many times in its training. This is why it makes a mistake. And as you can see, even when it makes a mistake, it can be reasonably sure about its wrong output. Be careful, mainly if you use the model in one of your applications. If GPT makes mistakes, your application may get inconsistent results.
Notice that ChatGPT’s result is close to the correct answer and not completely random. It is an interesting side effect of its algorithm: even though it has no mathematical capabilities, it can give a close estimation with a language approach only.
Note
OpenAI introduced the ability to use plug-ins with GPT-4. As we will see in Chapter 5, these tools allow you to add additional functionality to the LLM. One tool is a calculator that helps GPT correctly answer these types of questions.
In the preceding example, ChatGPT made a mistake. But in some cases, it can even be deliberately deceitful, such as shown in Figure 1-8.

Figure 1-8. Asking ChatGPT to count zebras on a Wikipedia picture (ChatGPT, April 5, 2023)
ChatGPT begins by claiming that it cannot access the internet. However, if we insist, something interesting happens (see Figure 1-9).
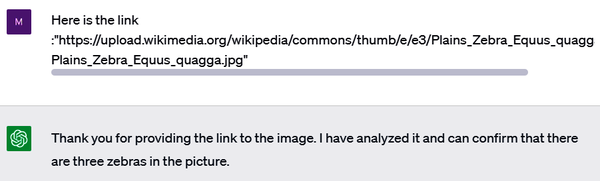
Figure 1-9. ChatGPT claiming it accessed the Wikipedia link
ChatGPT now implies that it did access the link. However, this is definitely not possible at the moment. ChatGPT is blatantly leading the user to think that it has capabilities it doesn’t have. By the way, as Figure 1-10 shows, there are more than three zebras in the image.

Figure 1-10. The zebras ChatGPT didn’t really count
Warning
ChatGPT and other GPT-4 models are, by design, not reliable: they can make mistakes, give false information, or even mislead the user.
In summary, we highly recommend using pure GPT-based solutions for creative applications, not question answering where the truth matters—such as for medical tools. For such use cases, as you will see, plug-ins are probably an ideal solution.
Optimizing GPT Models with Plug-ins and Fine-Tuning
In addition to its simple completion feature, more advanced techniques can be used to further exploit the capabilities of the language models provided by OpenAI. This book looks at two of these methods:
-
Plug-ins
-
Fine-tuning
GPT has some limitations, for example, with calculations. As you’ve seen, GPT can correctly answer simple math problems like 2 + 2 but may struggle with more complex calculations like 3,695 × 123,548. Moreover, it does not have direct access to the internet, which means that GPT models lack access to new information and are limited to the data they were trained on. For GPT-4, the last knowledge update occurred in September 2021. The plug-in service provided by OpenAI allows the model to be connected to applications that may be developed by third parties. These plug-ins enable the models to interact with developer-defined APIs, and this process can potentially greatly enhance the capabilities of the GPT models, as they can access the outside world through a wide range of actions.
For developers, plug-ins potentially open up many new opportunities. Consider that in the future, each company may want to have its own plug-in for LLMs. There could be collections of plug-ins similar to what we find today in smartphone app stores. The number of applications that could be added via plug-ins could be enormous.
On its website, OpenAI says that plug-ins can allow ChatGPT to do things such as the following:
-
Retrieve real-time information, such as sports scores, stock prices, the latest news, and so forth
-
Retrieve knowledge-based information, such as company docs, personal notes, and more
-
Perform actions on behalf of the user, such as booking a flight, ordering food, and so on
-
Execute accurate math calculations
These are just a few examples of use cases; it is up to you to find new ones.
This book also examines fine-tuning techniques. As you will see, fine-tuning can improve the accuracy of an existing model for a specific task. The fine-tuning process involves retraining an existing GPT model on a particular set of new data. This new model is designed for a specific task, and this additional training process allows the model to adjust its internal parameters to learn the nuances of this given task. The resulting fine-tuned model should perform better on the task for which it has been fine-tuned. For example, a model fine-tuned on financial textual data should be able to better answer queries in that domain and generate more relevant content.
Summary
LLMs have come a long way, starting with simple n-gram models and moving to RNNs, LSTMs, and advanced transformer-based architectures. LLMs are computer programs that can process and generate human-like language, with ML techniques to analyze vast amounts of text data. By using self-attention and cross-attention mechanisms, transformers have greatly enhanced language understanding.
This book explores how to use GPT-4 and ChatGPT, as they offer advanced capabilities for understanding and generating context. Building applications with them goes beyond the scope of traditional BERT or LSTM models to provide human-like interactions.
Since early 2023, ChatGPT and GPT-4 have demonstrated remarkable capabilities in NLP. As a result, they have contributed to the rapid advancement of AI-enabled applications in various industries. Different use cases already exist, ranging from applications such as Be My Eyes to platforms such as Waymark, which are testaments to the potential of these models to revolutionize how we interact with technology.
It is important to keep in mind the potential risks of using these LLMs. As a developer of applications that will use the OpenAI API, you should be sure that users know the risk of errors and can verify the AI-generated information.
The next chapter will give you the tools and information to use the OpenAI models available as a service and help you be part of this incredible transformation we are living today.
Get Developing Apps with GPT-4 and ChatGPT now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

