Capítulo 4. Debes ser así de alto
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
La frase "Debes tener esta altura para montar" suele aparecer en las señales de los parques de atracciones y carnavales para informar a la gente del requisito de altura mínima para ciertas atracciones. Los carteles no están pensados para proteger la entrada, sino para garantizar la seguridad. Martin Fowler utilizó esta metáfora en su artículo sobre los requisitos previos para la arquitectura de microservicios. Del mismo modo, puedes pensar en este capítulo como la señal de "debes tener esta altura" que puede ayudarte a averiguar si es seguro para tu equipo subir al rapidísimo viaje de la implementación continua. En concreto, describiré una lista de prácticas centradas en la seguridad que los equipos deberían aplicar antes de pasar a una canalización totalmente automatizada.
Enviar cada commit a producción sin intervención manual tiene el potencial de romper cosas, por supuesto. Los defectos críticos que se cuelan por puertas de calidad inadecuadas pueden costar mucho dinero a las empresas y asustar a las partes interesadas para que vuelvan a complicar en exceso el proceso de publicación (y a imponer un control estricto de la producción). Por eso es nuestra responsabilidad como profesionales del software evaluar cuidadosamente si nuestros equipos están preparados, y si no lo están, situar la implementación continua en el contexto de un viaje mayor de madurez de la entrega continua. El objetivo de este viaje debe ser construir una base técnica y organizativa que permita a personas de todos los niveles de experiencia participar en un ciclo de vida de implementación de ritmo rápido.
El objetivo de este capítulo no es explicar cómo evitar los errores de los desarrolladores. Debemos aceptar que los desarrolladores son seres humanos que tendrán días malos y que se producirán errores. Debemos centrarnos en detectar los errores pronto y solucionarlos rápidamente, en lugar de intentar alcanzar la perfección absoluta del desarrollador, que es un estándar inalcanzable (e injusto). En lugar de eso, podemos esforzarnos por construir una red de seguridad de prácticas y automatización que haga que sea aceptable fallar y fácil recuperarse. Por eso hablaremos de herramientas de retroalimentación continua como la integración frecuente, las pruebas exhaustivas, el escaneo de código y la observabilidad. El dominio de estas prácticas centradas en la seguridad es por lo que deberíamos juzgar el rendimiento de nuestros equipos, en lugar del error ocasional.
Ahora que he expuesto este descargo de responsabilidad, veamos más de cerca las prácticas en sí. La mayoría de ellas son prácticas bien establecidas de entrega continua para las que sólo haremos un pequeño repaso, mientras que otras han surgido más recientemente y son especialmente relevantes para la implementación continua. Esta lista estará inevitablemente incompleta, y podrían aparecer nuevas técnicas innovadoras después de la publicación de este libro. No obstante, utilicémosla como punto de partida.
Equipos multifuncionales y autónomos
Equipos en silos suelen organizarse en torno a funciones o disciplinas específicas, como el desarrollo, las pruebas o el diseño. Un equipo multifuncional, por el contrario, está formado por miembros con diversas habilidades y debe incluir todas las funciones necesarias para entregar el producto en su conjunto (véase la Figura 4-1). Esto podría incluir conocimientos de infraestructura, frontend y backend, pero también pruebas, seguridad, diseño y gestión de proyectos.
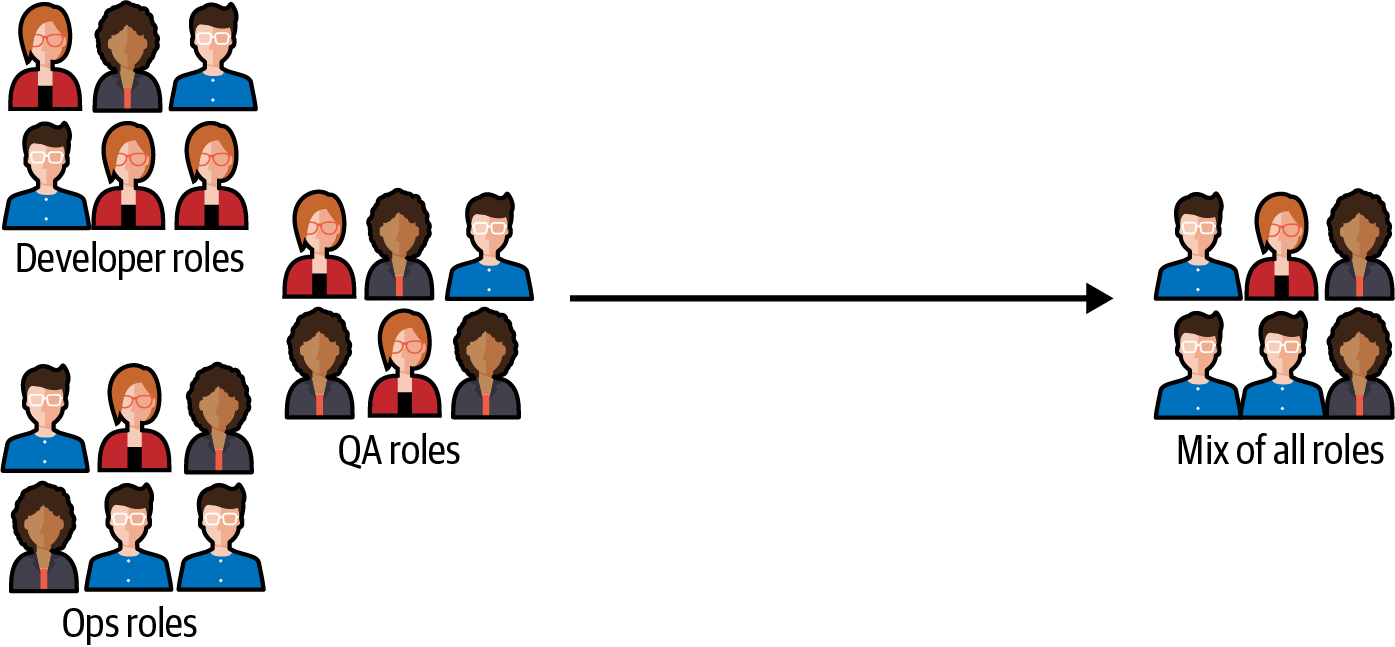
Figura 4-1. Equipos aislados (izquierda) frente a equipos interfuncionales (derecha)
Los equipos interfuncionales tienen varias ventajas en comparación con los equipos que están aislados, siendo las principales una colaboración más estrecha entre funciones, una mayor velocidad y menos fricciones organizativas. Cuando un equipo de producto es realmente interfuncional, también tiene varias cualidades que permiten la implementación continua de .
Toma rápida de decisiones
El mayor facilitador de la entrega rápida es que los equipos interfuncionales pueden actuar espontáneamente y ser flexibles, sin necesidad de implicar a otros en sus decisiones. Su proceso de toma de decisiones es autónomo, por lo que pueden adaptarse rápidamente a los requisitos cambiantes sin tener que traspasar los límites del equipo para aplicar un cambio.
Un equipo que despliega continuamente pequeños incrementos a producción necesita estar equipado para manejar el rápido ritmo de cambios que se produce con un bucle de retroalimentación muy corto. Con la implementación continua, se lanzan nuevas actualizaciones de código a los usuarios a diario, o incluso varias veces al día. Esto requiere un alto nivel de adaptabilidad en el que el equipo debe ser capaz de reaccionar rápidamente a los cambios de dirección y a las posibles correcciones.
Un equipo que depende del apoyo o la aprobación externos puede encontrarse rápidamente abrumando (o molestando) a sus colaboradores externos si empieza a realizar implementaciones muchas veces al día. Cuanto más consiga el equipo su objetivo de desplegar con frecuencia, más molestará a los colaboradores externos, que no es lo que desea el equipo .
Autonomía de ejecución
Un equipo verdaderamente interfuncional debe contener todas las habilidades de ingeniería necesarias para construir e implementar la aplicación. La implementación continua (o incluso la entrega continua) no funciona bien con equipos formados únicamente por el backend, el frontend o la infraestructura, porque la implementación a menudo puede hacer aflorar la compleja interdependencia entre todos estos componentes de software. Los cambios en una parte del sistema a menudo requieren cambios correspondientes en otra parte para poder desplegarse con seguridad, y viceversa. Y cuando los pequeños cambios se aplican individualmente a la producción, es esencial evitar los bloqueos constantes introducidos por los límites de los equipos, que harían que grandes cantidades de trabajo en curso se quedaran atascadas.
Las banderas de características y la expansión y contracción, por ejemplo, son técnicas de codificación especialmente comunes con la implementación continua, y requieren que los desarrolladores actualicen los sistemas de proveedores y consumidores en rápida sucesión para que puedan garantizar la estabilidad del entorno de producción. Si los equipos estuvieran divididos en silos en función de la pila tecnológica o de partes concretas del sistema, la coordinación de estos cambios sería difícil: los equipos tienen, naturalmente, diferentes cargas de trabajo con diferentes prioridades, y a menudo se quedarían esperando unos a otros en lugar de trabajar en las características.
En general, el equipo ideal que practica la implementación continua es el que contiene todas las funciones y habilidades técnicas necesarias para ocuparse de una parte vertical del negocio: un equipo de producto. Esto funciona especialmente bien en arquitecturas orientadas a microservicios, donde los productos están aislados entre sí tanto técnica como organizativamente.
Tener equipos interfuncionales no significa que todos los equipos deban tener el mismo aspecto, ni que ya no haya lugar para los equipos especializados. De hecho, en su libro Team Topologies1 Matthew Skelton y Manuel Pais reconocen cuatro categorías de equipos, algunos de los cuales son altamente especializados:
- Equipo alineado con la corriente
Como sugiere el nombre, un equipo alineado con la corriente está alineado con una corriente particular de trabajo (o dominio). Este tipo de equipo es responsable de aportar valor a los clientes rápidamente mediante nuevas funciones y mejoras orientadas al usuario.
- Equipo capacitador
Un equipo habilitador apoya a los equipos alineados con la corriente aportando conocimientos y herramientas especializados. Por ejemplo, puede ayudar a otros equipos a adoptar nuevas prácticas o tecnologías, o a resolver problemas complejos.
- Equipo de subsistema complicado
Este tipo de equipo trabaja en subsistemas complejos que requieren profundos conocimientos técnicos; por ejemplo, los que requieren experiencia en cálculo o matemáticas.
- Equipo de la plataforma
Un equipo de plataforma crea y mantiene un conjunto de productos y herramientas internos que otros equipos pueden utilizar para acelerar su trabajo, normalmente los que se pueden utilizar en forma de autoservicio.
Cada uno de estos equipos tendrá una especialización determinada, ya sea un dominio empresarial, una tecnología concreta o un tipo de problema complejo. Y todos ellos podrían mantener también sus propios productos, ya sean de cara al exterior o de cara al interior. Todos esos productos son candidatos potenciales a la implementación continua. Sin embargo, el requisito para practicar el despliegue continuo en esos productos es que, dentro de la especialización de ese equipo (sea cual sea), existan todas las capacidades necesarias para desarrollarlos e implementarlos. Esto significa plena autonomía y dominio de la pila de software elegida, de extremo a extremo.
Por ejemplo, en uno de los casos prácticos de este libro, Tom Vollerthun, de OTTO, describe con detalle cómo su empresa pasó de tener un equipo de control de calidad a permitir que los ingenieros de control de calidad fueran miembros de los equipos de producto. Éste fue un factor clave para la adopción de la implementación continua en OTTO, y te animo a que leas su caso práctico para comprender cómo lo consiguió la empresa .
Integración frecuente
Como comenté en los Capítulos 1 y 2, integrar el código con frecuencia es la columna vertebral de la integración continua, y también es una base para la entrega y la implementación continuas. En la práctica, significa añadir nuestros cambios de código a la rama principal compartida del equipo al menos una vez al día (o varias veces al día). La integración frecuente mantiene los deltas de cambio pequeños y manejables, que es un principio que resulta imperativo seguir cuando no hay verificación manual en un entorno de preproducción.
Acumular miles de líneas cambiadas en nuestras máquinas de desarrollo o en una rama, sólo para enviarlas a producción todas a la vez, puede generar el caos y perturbar a los usuarios, a las partes interesadas y al resto del equipo. Por lo tanto, es fundamental que todos los miembros del equipo estén alineados en una etiqueta de commit de código que mantenga los cambios pequeños y los integre frecuentemente en main.
Un buen protocolo de confirmaciones con implementación continua también debe incluir herramientas para que el historial de versiones sea fácil de entender: aplastar las confirmaciones interdependientes, volver a basar con frecuencia para permitir fusiones rápidas, y mensajes de confirmación significativos con un identificador de tarea y coautores. Todas estas pequeñas acciones permiten al equipo mantener la claridad sobre qué cambios de código van unidos a qué implementación de producción.
Sin embargo, la principal herramienta para mejorar nuestra comprensión de lo que se implementa es, ante todo, la integración frecuente. Hay dos formas principales en que los equipos de software modernos lo consiguen: las ramas (muy) efímeras y el desarrollo basado en el tronco (TBD). Ambas son compatibles con una estrategia de implementación continua, aunque TBD es sin duda la favorita por su sencillez.
Ramas efímeras
Con las ramas de corta duración de , un desarrollador puede simplemente crear una nueva rama a partir de la principal, hacer sus cambios y luego enviar una solicitud pull (PR) para fusionar directamente los cambios cuando considere que su trabajo es lo suficientemente autónomo. Una vez que los cambios hayan sido revisados y aprobados, pueden fusionarse con la rama principal y pasar a producción. Esto ofrece un punto de control opcional para realizar revisiones del código. Es importante tener en cuenta que, para que una rama pueda llamarse "de vida corta", el desarrollo de una gran función normalmente debería durar más que la vida útil de una rama abierta, y los desarrolladores necesitarán fusionarse de nuevo con la principal varias veces durante el desarrollo. Por eso las ramas efímeras deben seguir utilizándose junto con otras técnicas para ocultar el trabajo en curso que no dependan del control de versiones, como los conmutadores de funciones.
No todas las ramas son iguales. Es importante recordar que las ramas de vida corta están pensadas para tareas pequeñas y específicas, y no deben utilizarse para esfuerzos de desarrollo a largo plazo ni para funciones completas. Lo ideal es que no duren más de un día. Las ramas de vida corta contrastan directamente con las ramas de características, por ejemplo, aunque ambas tengan el mismo aspecto en nuestros sistemas de control de versiones.
Ramas de corta duración frente a ramas de características
Las ramas de características de larga duración de son un antipatrón en la integración continua. Son típicas de flujos de trabajo de desarrollo como Gitflow, cuyo objetivo es segregar los cambios de iniciativas enteras hasta que estén listas para pasar a producción. Tales flujos de trabajo introducen un estrecho acoplamiento entre el proceso de publicación y la funcionalidad del sistema de control de versiones, y desalientan el uso de técnicas más modernas como las banderas de características.
Hay que reconocer que modelos como Gitflow funcionan notablemente bien para proyectos de código abierto en plataformas de colaboración como GitHub, donde los desarrolladores colaboran durante periodos más largos y la comunicación es asíncrona por naturaleza. Sin embargo, en un equipo cohesionado con canales de comunicación en tiempo real, las ramas de características largas aportan más sobrecarga que valor. De hecho, son activamente perjudiciales. Fomentan que el código se aleje significativamente de la producción y dejan que se acumule en grandes y dolorosos lotes que conducen a fusiones desordenadas y lanzamientos complicados.
Muchos equipos utilizan con éxito ramas de características efímeras con la implementación continua, pero esto requiere mucha disciplina y madurez de integración continua para no degenerar en ramas de características efímeras. Basta con que un desarrollador sucumba a la inercia y se olvide de integrar durante uno o dos días, para que una rama acumule suficientes cambios como para que ya no pueda llamarse "de corta duración".
Utilizar ramas como parte de la codificación diaria en el equipo facilita hacer lo incorrecto (acumular cambios accidentalmente), y dificulta hacer lo correcto (integrar conscientemente con frecuencia). Por eso, muchos equipos que buscan fomentar las buenas prácticas utilizan un paradigma diferente: el desarrollo basado en el tronco .
Desarrollo basado en troncos
TBD es una metodología en la que todos los desarrolladores trabajan en una única rama, normalmente conocida como tronco o principal. Este enfoque contrasta con otros modelos que se basan en ramas separadas, en los que los desarrolladores mantienen sus cambios alejados de la principal y los fusionan periódicamente.
En TBD, se anima a los desarrolladores a confirmar cambios pequeños e incrementales que mantengan el código base en verde y con capacidad de implementación en todo momento. Esto permite un bucle de retroalimentación aún más corto, ya que los cambios están disponibles para todos los demás desarrolladores en cuanto se confirman. Con la implementación continua, también estarán disponibles para los usuarios minutos después.
Otra ventaja clave de TBD es que reduce la complejidad del control de versiones del equipo. Con ramas de cualquier tipo, puede ser difícil seguir los cambios y fusionarlos de nuevo en la principal debido a conflictos y retrasos. Al trabajar en una única rama, los desarrolladores pueden evitar estos problemas y centrarse en construir cosas nuevas.
La TBD sigue siendo controvertida en algunas comunidades, pero muchos equipos la practican con éxito, incluidos la mayoría de aquellos con los que he tenido la suerte de trabajar. Esto es lo que los investigadores de DORA compartieron al respecto en 2018:
Nuestra investigación también descubrió que desarrollar fuera del tronco/máster, en lugar de en ramas de características de larga duración, se correlacionaba con un mayor rendimiento en la entrega. Los equipos que obtenían buenos resultados tenían menos de tres ramas activas en cualquier momento, sus ramas tenían una vida muy corta (menos de un día) antes de fusionarse con el tronco y nunca tenían periodos de "congelación del código" o de estabilización. Merece la pena volver a insistir en que estos resultados son independientes del tamaño del equipo, de la organización o del sector.
Incluso después de descubrir que las prácticas de desarrollo basadas en el tronco contribuyen a mejorar el rendimiento de la entrega de software, algunos desarrolladores acostumbrados al flujo de trabajo "GitHub Flow" siguen mostrándose escépticos. Este flujo de trabajo se basa en gran medida en el desarrollo con ramas y sólo se fusiona periódicamente con el tronco.2
A pesar de ello, el uso de TBD plantea algunos retos. El hecho de que todo el equipo se añada a la misma rama puede dificultar el trabajo simultáneo en varias tareas y la coordinación de actividades entre varios desarrolladores. Además, la carga de garantizar que los desarrolladores no se pisen unos a otros (o unas a otras líneas de código) debe abordarse durante la planificación del trabajo diario. Pero esto no es necesariamente negativo: cuando se trabaja con ramas, los desarrolladores siguen corriendo el riesgo de hacer cambios que se solapan; sólo que no se darían cuenta de estos cambios hasta el momento de la fusión, cuando el contexto está anquilosado y las líneas en disputa podrían haber divergido aún más significativamente. Se podría decir que la TBD ayuda a que los problemas de fusión salgan a la luz antes, cuando son más fáciles de solucionar.
Cuando se practica junto con la implementación continua, TBD significa que cada confirmación de código se implementará inmediatamente en producción. Esto supone la implementación más directa de un flujo continuo de cambios de una sola pieza. Como se explica en el Capítulo 1, este concepto de la fabricación ajustada es lo que hace que la implementación continua sea tan potente: elimina el despilfarro y el procesamiento por lotes del camino hacia la producción. Yo diría que, por esta razón, la combinación con TBD es la implementación más pura del despliegue continuo, aunque el uso de ramas de muy corta duración sigue siendo un buen compromiso cuando esto no es una opción.
En el estudio de caso sobre el banco digital N26 de la Parte V, puedes leer sobre una situación de este tipo: incapaces de hacer TBD debido a las limitaciones de la normativa, los ingenieros de N26 utilizan microbranchas y PR para proporcionar pruebas de revisión por pares y garantizar que no se realicen cambios arbitrarios en el sistema por parte de desarrolladores individuales. Sin embargo, acoplan este proceso con la programación en parejas y la programación en masa para que la revisión del código se produzca en directo y la integración en el main pueda acelerarse.
Esto nos lleva al siguiente tema: la revisión del código.
Revisiones frecuentes del código
Las revisiones del código son esenciales, ya que proporcionan un punto crucial de retroalimentación humana sobre el diseño, la corrección y la integridad del código. En la implementación continua, este canal humano de retroalimentación es también la única forma humana de retroalimentación en todo el camino hasta la producción. Esto hace que las revisiones del código sean especialmente significativas, ya que se convierten en la única herramienta que garantiza que cada línea de código sea comprobada por más de un par de ojos antes de la producción.
Por muy probada que esté una funcionalidad, si el desarrollador que la escribió ha entendido mal los requisitos, escribirá pruebas incorrectas que irán acompañadas de una implementación igualmente incorrecta. Por muchas herramientas elaboradas de escaneo de código que tengamos, sólo un humano puede detectar si el código respeta los requisitos funcionales y si respeta los acuerdos del equipo en cuanto a diseño y estructura. Hay muchos principios de diseño de código que van más allá de las triviales reglas de linting, y se han escrito libros y libros sobre ellos. Por ejemplo, el código debe estar bien dividido, su lectura no debe sorprender, debe pertenecer al nivel de abstracción adecuado y debe estar alineado conceptualmente con su arquitectura. Al fin y al cabo, si escribiéramos código sólo para que lo entendieran las máquinas y no otras personas, más nos valdría deshacernos de todos nuestros libros de diseño y lenguajes de programación altamente abstractos y volver a los antiguos espaguetis de ensamblaje con los que tenían que lidiar nuestras abuelas.3 nuestras abuelas.
Poner tanto énfasis en las revisiones del código puede parecer contradictorio con el resto de la mensajería de este libro hasta ahora. Como comentamos en el Capítulo 1, nos esforzamos por eliminar por completo los cuellos de botella manuales del camino hacia la producción. ¿No son las revisiones de código un ejemplo de cuello de botella manual en el que los cambios pueden acumularse y atascarse? ¿Y no acabamos de ver en la sección anterior las ventajas de la TBD sobre las ramas de características largas y los PR? ¿Cómo se supone que vamos a realizar revisiones del código sin PRs?
Solicitudes de extracción
Merece la pena mencionar en que, al mantener sus ramas pequeñas, muchos equipos también crean PR muy pequeños, que dan lugar a revisiones rápidas del código que no interrumpen tanto el flujo continuo de código a producción. En esos equipos, todos los desarrolladores deben estar muy comprometidos con el proceso de revisión del código, de modo que puedan minimizar el tiempo de espera de sus colegas que desean integrarse. Muchos ingenieros trabajan así, y consiguen mantener sus tiempos de espera razonablemente bajos y lograr un flujo de trabajo algo fluido.
Aun así, creo que podemos hacerlo incluso mejor.
Algo que he observado es que a lo largo de los años hemos llegado a asociar colectivamente la revisión de un RP abierto con el único momento y lugar para que se revise el código. Me gustaría cuestionar este concepto. Hay otra práctica en la caja de herramientas de la Programación eXtrema que ofrece una alternativa a los RP como motor de las revisiones de código: la programación por parejas.
Programación por parejas
La programación por parejas es una práctica muy antigua; casi tan antigua como la propia programación:
Betty Snyder y yo, desde el principio, fuimos una pareja. Y creo que los mejores programas y diseños se hacen por parejas, porque podéis criticaros mutuamente, y encontrar los errores del otro, y utilizar las mejores ideas.
Jean Bartik, uno de los primeros programadores4
La programación por parejas recobró popularidad en los primeros días de Agile, aunque parece haber pasado tristemente de moda, ya que muchas empresas se han olvidado de hacerla parte de su "transformación Agile". Pero a medida que prácticas como el TBD y la implementación continua se hacen cada vez más populares, merece la pena reevaluar la programación en parejas, ya que puede ofrecer más seguridad que las revisiones de código ordinarias mediante PR.
Con la programación por parejas, todo el código de producción es desarrollado por una pareja de desarrolladores que comparten un teclado y una pantalla; virtuales en el caso del emparejamiento remoto. A medida que la pareja trabaja en una tarea, cambian los papeles entre teclear y razonar sobre el diseño del código. Como cada miembro de la pareja tiene que verbalizar sus suposiciones e ideas de diseño, debaten continuamente sobre la implementación y los requisitos, realizando así una revisión continua del código.
Un segundo par de ojos está en el código antes y durante el proceso de escritura, no sólo después. Esto puede ser más útil que una revisión en el momento del RP, porque ofrece una ventana de oportunidad mucho mayor (y más temprana) para enmendar errores de diseño o aclarar malentendidos sobre los requisitos. También evita la incomodidad social de solicitar grandes cambios después de que un colega haya trabajado mucho en un RP, que es una barrera más para la calidad del código (y, lamentablemente, una que he visto interponerse en el camino muchas veces).
La programación en parejas también puede acelerar la implementación de funciones y la resolución de errores, porque más de un cerebro está disponible para abordar los problemas a medida que surgen. También acelera la integración porque elimina el cuello de botella de tener que encontrar revisores disponibles, que podrían tener que cambiar de contexto para desbloquear a sus colegas. Debido a este proceso de revisión del código continuo y más participativo, el diseño final del código suele ser de mayor calidad y requiere menos reelaboración, lo que ahorra mucho tiempo.
La principal objeción a la programación por parejas suele ir en la línea de "¡se necesitan el doble de horas de trabajo para implementar lo mismo!". Pero creo que eso es inexacto en la mayoría de los casos, porque no tiene en cuenta todo el tiempo que ahorra. Incluso si esa objeción fuera exacta y realmente fuera mucho más caro tener un proceso de revisión continua del código, yo diría que sigue siendo una inversión que merece la pena considerar. Al fin y al cabo, estamos implementando cada commit en producción, y nuestro objetivo es mantener un alto nivel de seguridad frente al error humano en el proceso. La velocidad y la agilidad siempre requieren una inversión.
Personalmente, he utilizado la programación por parejas como herramienta de revisión del código en casi todos mis equipos, y la mayoría de los desarrolladores con los que trabajé la consideraron una gran ayuda para entregar productos, incorporar nuevos miembros al equipo y mantener un sentido compartido de propiedad del código .
Seguridad psicológica
Independientemente de que tu equipo utilice PR o programación por parejas, debes asegurarte de que las revisiones del código sean un proceso detallado y frecuente si piensas adoptar la implementación continua. Es responsabilidad de todos los miembros senior del equipo crear un espacio en el que todos los compañeros, especialmente los junior, se sientan capacitados para dar opiniones sinceras y hacer preguntas difíciles. La definición de "buen código" puede ser personal, pero eso no significa que no deba ser debatida y negociada por el equipo todos los días. Molestar brevemente los sentimientos de alguien nunca es agradable, pero es mejor que la alternativa: un círculo de empatía ruinosa en el que todos se dan palmaditas en la espalda a costa de la estabilidad del producto en producción.
Análisis de código automatizado
En hemos hablado de la importancia de que más de un par de ojos miren el código, pero eso no significa que no pueda automatizarse la detección de descuidos y errores comunes. Aquí es donde las herramientas de análisis de código pueden desempeñar un papel importante, mejorando también la seguridad de la implementación continua. Con la ayuda de la automatización, los desarrolladores y sus pares (o revisores de RP) pueden dejar de preocuparse por encontrar problemas de bajo nivel que podrían pasarse por alto fácilmente, y en su lugar pueden centrarse en el panorama general: por ejemplo, cómo encajan los cambios en la arquitectura existente, cómo deben liberarse y si satisfacen los requisitos.
Las herramientas de análisis estático de código pueden analizar el código sin ejecutarlo realmente, y suelen ser bastante rápidas, por lo que pueden integrarse como paso inicial del proceso para detectar errores comunes, o incluso en IDEs y ganchos de precompromiso. Pueden utilizarse para identificar todo tipo de problemas comunes, como fallos, vulnerabilidades de seguridad y problemas de utilización de recursos, así como para aplicar normas de codificación desde el principio.
Existen muchas herramientas de análisis de código de código abierto compatibles con una amplia variedad de lenguajes de programación. Puede que haya que hacer algunos ajustes y configuraciones iniciales, pero la mayoría de ellas son bastante sencillas de seguir utilizando después. Creo que, en la gran mayoría de los casos, las razones para incluirlas superan a las razones para no hacerlo.
En resumen, las herramientas de análisis estático de código son excelentes para evitar los fallos que se originan por falta de atención y errores comunes de programación. Sin embargo, hay dos funciones que quiero destacar especialmente como útiles en un escenario de implementación continua: el análisis de vulnerabilidades de seguridad y el análisis del rendimiento.
Algunos de los errores humanos con consecuencias más graves para las aplicaciones populares están relacionados con la seguridad y el rendimiento. También están entre los más difíciles de detectar, ya que las pruebas automatizadas suelen buscar regresiones en el comportamiento más que en las características interfuncionales del software. Como los desarrolladores trabajan en pequeños incrementos, es bastante fácil ser olvidadizo e introducir una fuga de recursos que sólo causará problemas en un entorno con mucha carga, como el de producción. Puede ser igualmente fácil olvidarse de desinfectar correctamente nuestras entradas en cada commit, abriendo el sistema a otro problema que sólo será evidente una vez que esté delante de usuarios desconocidos y que no confían en él. El análisis automatizado del código alivia esas preocupaciones y puede dar tranquilidad tanto a los desarrolladores como a las partes interesadas al considerar todo lo que podría ir mal con un flujo constante de cambios.
Automatización de pruebas
Como esto es el siglo XXI, no hace falta decir que la automatización de las pruebas es preferible a las pruebas manuales de regresión antes de cada implementación. Es más rápida, más eficaz, más coherente y más barata. Las pruebas automatizadas pueden ejecutarse rápida y repetidamente, sin necesidad de intervención humana, por lo que no están sujetas a errores o variaciones humanas como las pruebas manuales. Las pruebas de software de cada commit son el ejemplo de libro de texto de una tarea repetitiva y exacta que se adapta perfectamente a la paciencia infinita de un ordenador, y no tienen nada que hacer las manos humanas. La creatividad y la atención humanas deben reservarse para desafiar las suposiciones y empujar al sistema de formas inesperadas, no para verificar repetidamente las mismas características una y otra vez.
Automatizar las pruebas de regresión que solían ser manuales es algo que ya debería estar en lo alto de la lista de tareas pendientes de cualquier empresa, pero deberían tomárselo especialmente en serio los equipos que pretenden adoptar la implementación continua.
No deberíamos implementar continuamente código que no tenga una buena cobertura de pruebas. Como escribe Michael Feathers en Working Effectively with Legacy Code, el código sin pruebas es tan malo como el código heredado (y puede considerarse como tal):
Para mí, el código heredado es simplemente código sin pruebas. [...] El código sin pruebas es código malo. No importa lo bien escrito que esté; no importa lo bonito u orientado a objetos o lo bien encapsulado que esté. Con las pruebas, podemos cambiar el comportamiento de nuestro código de forma rápida y verificable. Sin ellas, realmente no sabemos si nuestro código está mejorando o empeorando.5
De hecho, no importa lo bonito que parezca nuestro código: sin una canalización respaldada por pruebas automatizadas exhaustivas, no podemos evitar que las regresiones se desplieguen a producción. Una cobertura de pruebas ausente o descuidada podría ser algo más tolerable con cambios que se detuvieran en preproducción para ser verificados manualmente, pero se convierte en una temeridad cuando la puerta a producción está abierta de par en par y no es posible ninguna verificación manual. Más adelante en su libro, Feathers continúa diciendo que hay dos formas de hacer cambios en un sistema de software: "Cubrir [con pruebas] y Modificar" o "Editar y Rezar". No hace falta decir que si utilizamos la implementación continua con el enfoque "Editar y rezar", vamos a tener que rezar mucho.
Una vez aclarado esto, podemos hablar de qué tipos de pruebas son necesarias. Al fin y al cabo, hay muchos tipos de pruebas automatizadas en la caja de herramientas de un desarrollador, y vienen con todo tipo de niveles de abstracción y granularidad: pruebas unitarias, pruebas de integración, pruebas de aceptación, pruebas de componentes, pruebas de regresión visual, pruebas de contratos, pruebas de viajes... sólo por nombrar algunas (no podría abarcarlas todas en esta sección, o se convertiría en su propio libro). Más allá de las pruebas unitarias, que en general se entienden bien, la terminología ha sido históricamente confusa en todo el sector, con definiciones contrapuestas para varios tipos de pruebas. Si encierras a dos desarrolladores en una habitación y les muestras el mismo código de prueba, probablemente obtendrás tres nombres diferentes para él.
Sin embargo, después de trabajar en unos cuantos equipos, empecé a darme cuenta de que la terminología no importa realmente, siempre que todo el equipo esté de acuerdo y se ciña a la misma definición. Cada miembro del equipo debe conocer los tipos de pruebas que se utilizan en su equipo, su nivel de abstracción, cuándo y dónde son apropiadas, y los límites de su sistema bajo prueba. El equipo debe actualizar periódicamente su estrategia de pruebas y renegociar qué cobertura es necesaria a medida que crece su producto.
Las capas de pruebas a utilizar variarán de una aplicación a otra y de una pila tecnológica a otra. Qué tipos de pruebas añadir, y cuántas, es una cuestión de opinión y puede ser exclusiva de cada equipo, pero creo que la regla general más útil es seguir el conocido modelo de la pirámide de pruebas.
El modelo piramidal de pruebas
La pirámide de pruebas es una metáfora visual que describe las distintas categorías de pruebas que deben realizarse en un sistema. Tiene forma piramidal porque la idea es que debe haber muchas pruebas de bajo nivel, como las pruebas unitarias, y muchas menos pruebas de alto nivel, como las pruebas de extremo a extremo. Las pruebas de la base de la pirámide pueden ser numerosas, ya que tienen una gran granularidad (clases o funciones individuales), se ejecutan muy rápidamente y son fáciles de escribir. Por otro lado, las pruebas de la parte superior de la pirámide son exhaustivas y valiosas, pero también se ejecutan mucho más lentamente y requieren configuraciones elaboradas, por lo que deberíamos utilizarlas sólo para validar el comportamiento más valioso del sistema y no todos sus detalles.
En la Figura 4-2, puedes ver algunos ejemplos del aspecto que podría tener una pirámide de pruebas para dos tipos diferentes de aplicaciones: una API REST y un frontend de aplicación de una página.
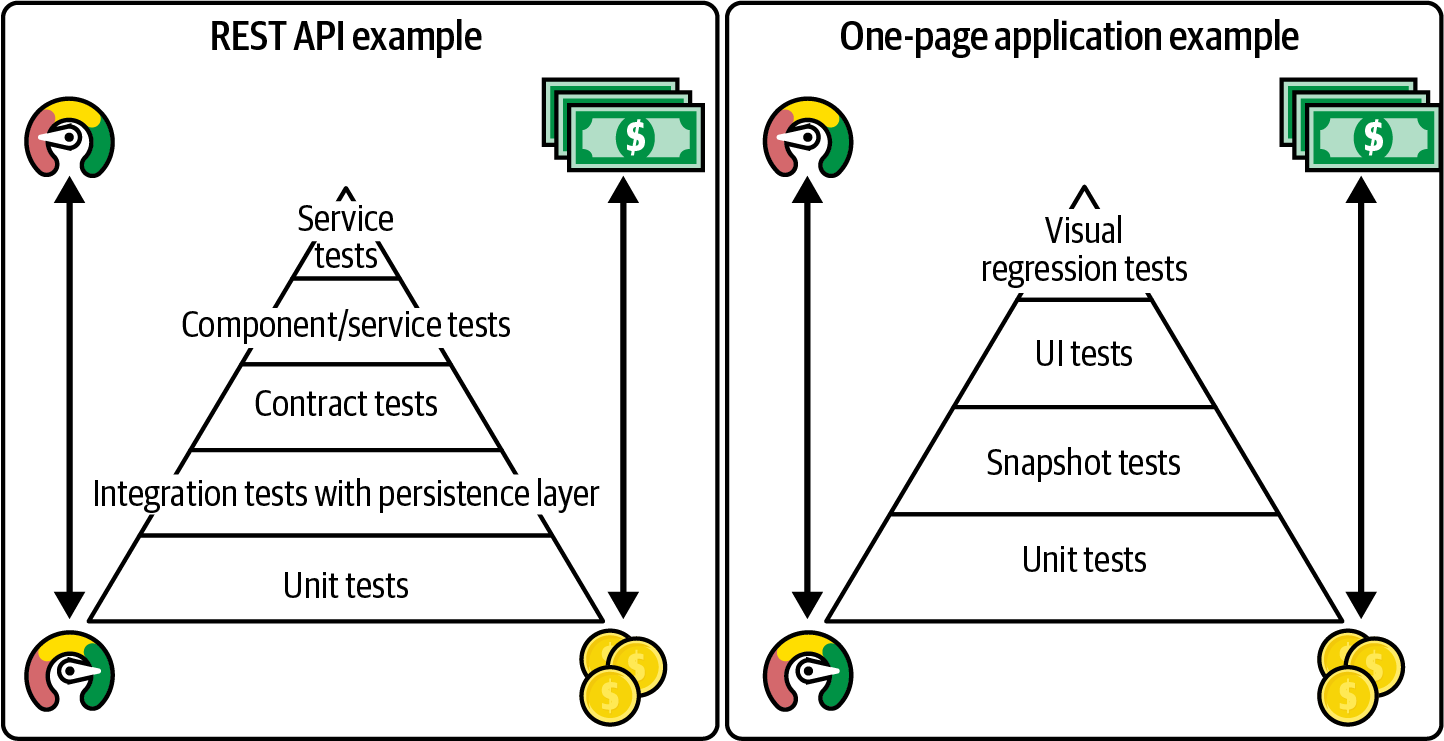
Figura 4-2. Dos ejemplos de pirámides de pruebas
En el pasado, sólo las pruebas unitarias de la base de la pirámide eran escritas durante la fase de implementación por los propios desarrolladores. La laboriosa tarea de escribir la cobertura de alto nivel se ha dejado históricamente en manos de los responsables del control de calidad como una optimización de la productividad del trabajo de pruebas manuales que habrían estado haciendo de todos modos. Esto solía ocurrir después de la fase de desarrollo.
Como comentamos en el Capítulo 2, este enfoque de la automatización de pruebas no es sostenible en los equipos modernos que utilizan la implementación continua. Cuando el código nunca se queda esperando en un repositorio de artefactos o en preproducción, se pierde la ventana de tiempo para añadir pruebas de alto nivel "más tarde". Por tanto, es imperativo que el equipo desplace las pruebas hacia la izquierda y que cada capa de la pirámide de pruebas se actualice durante la propia fase de desarrollo.
Trabajar con pruebas automatizadas en cada nivel de la pirámide de pruebas es algo que todo miembro del equipo que escriba código debe sentirse cómodo haciendo, independientemente de su antigüedad. Sólo cuando esto sea así, cada cambio podrá pasar a producción de forma segura, independientemente de quién lo haya producido. Con implementaciones de producción inmediatas, escribir buenas pruebas puede ser incluso más importante que escribir buen código.
El modelo del queso suizo
Otro buen modelo de cobertura de pruebas que puede complementar a la pirámide de pruebas clásica es el modelo del queso suizo. Este modelo fue propuesto por primera vez por James T. Reason, y aunque originalmente se aplicó a ámbitos como la seguridad aérea, la ingeniería y la sanidad, también es excelente para representar las pruebas de software.
En este modelo, todas las capas de la pirámide de pruebas pueden considerarse diferentes rebanadas de queso suizo. Los agujeros de cada rebanada representan distintas debilidades o falta de cobertura en las capas de pruebas. Un defecto puede pasar a través de una o dos capas, pero luego puede ser detectado por otra con una cobertura ligeramente diferente, como se muestra en la Figura 4-3. Los fallos que consiguen atravesar todas las lonchas de queso son los que los usuarios llegan a experimentar en producción.
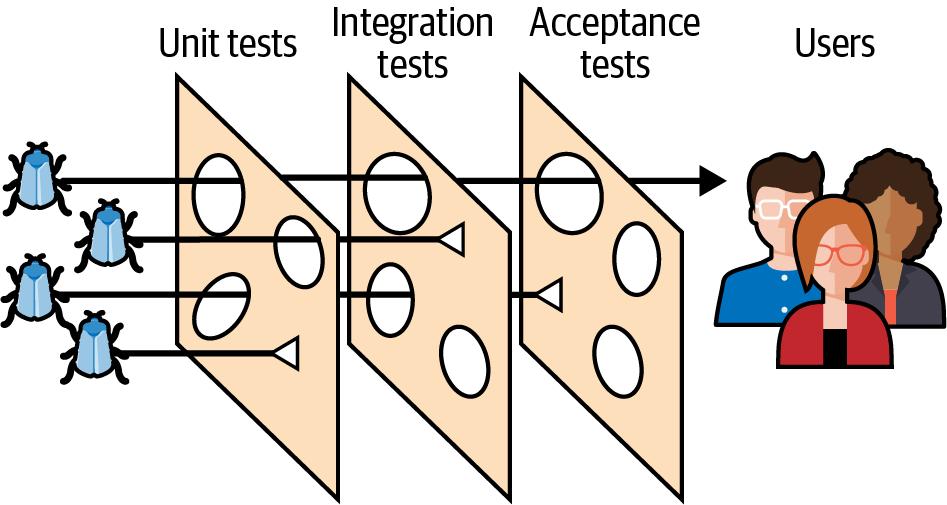
Figura 4-3. El modelo del queso suizo
Examinando las características de cada capa (por ejemplo, velocidad, escasez), podemos razonar sobre cuál es la cantidad adecuada de cobertura. Por ejemplo, las pruebas que son apropiadas para escribir en la primera capa, más detallada, podrían ser demasiado granulares para las capas más lentas y costosas, y además serían redundantes.
El modelo del queso suizo también puede ser útil para tomar decisiones sobre las áreas en las que hay un solapamiento inevitable entre las capas. Más solapamiento significa más protección en caso de que la cobertura se modifique incorrectamente en una de las otras capas, pero también significa un mayor coste de mantenimiento, ya que cambiar la funcionalidad requerirá actualizar más capas de pruebas.
Prueba primero
La Implementación continua requiere escribir pruebas durante la fase de implementación del código, pero eso en sí no es un concepto nuevo. Las pruebas unitarias llevan tiempo integradas en el ciclo de vida del desarrollo, especialmente con la introducción del principio de "primero las pruebas" y el desarrollo dirigido por pruebas (TDD). Puedes leer sobre TDD con mucha más profundidad en Test Driven Development: By Example,6 pero por ahora resumiré cómo funciona.
Como se muestra en la Figura 4-4, TDD consta de tres fases: escribir una prueba que falla, escribir la cantidad mínima de código necesaria para que esa prueba pase y, por último, refactorizar el código una vez protegido por la prueba.
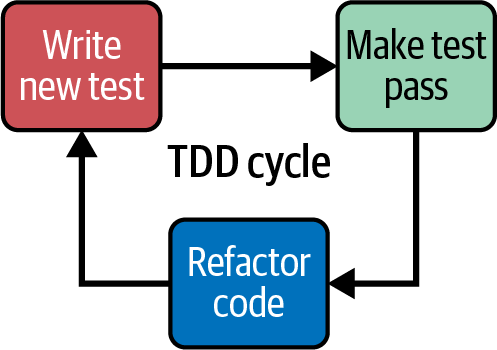
Figura 4-4. El ciclo de vida del TDD
Practicar TDD es otra de mis recomendaciones por defecto siempre que un equipo se plantea realizar Implementaciones automatizadas. El razonamiento es sencillo. Escribir las pruebas que fallan antes de escribir el código para ponerlas en verde es una forma fiable de asegurarse de que las pruebas se escriben realmente y la cobertura se mantiene firme. Esto puede parecer obvio debido a las normas que prohíben específicamente escribir cualquier código de producción sin una prueba correspondiente, pero hay otra ventaja más sutil en probar primero sobre probar después que actúa como una influencia positiva en la cobertura de las pruebas.
Al escribir las pruebas antes que el código, las pruebas actúan como el primer consumidor de la API del código. Esto obliga a los desarrolladores a pensar profundamente en los contratos de sus clases y funciones y en la forma en que interactúan entre sí, antes incluso de pensar en su implementación. Como resultado, el código que se escribe primero con pruebas es inherentemente comprobable y modular. Por otra parte, escribir las pruebas después de terminar la implementación no siempre funciona bien: un desarrollador puede encontrarse con que le cuesta inyectar los mocks necesarios o configurar el sistema para que se ejecute la prueba cuando no diseñó su código teniendo en cuenta la comprobabilidad. Puede que hayan producido un código muy denso, lo que da lugar a pruebas complicadas que necesitan realizar muchas aserciones o configuraciones. Esta dificultad añadida puede disuadir a los desarrolladores de escribir pruebas a posteriori, o puede llevar a no cubrir la funcionalidad tan a fondo como se necesita. Aunque pueda parecer contrario a la intuición, escribir pruebas primero es más fácil que escribirlas después.
Con la implementación continua, todo el trabajo en curso debe estar oculto bajo el patrón de expansión y contracción, de modo que podamos confirmarlo en cualquier momento siempre que se compile y supere las pruebas. Con la adición del bucle rápido de TDD, lo que sigue es que la base de código debería estar siempre, como mucho, a una prueba fallida de ser confirmable, y por tanto desplegable a producción.
De fuera a dentro
TDD es una práctica muy útil para diseñar software con las pruebas unitarias a la cabeza, pero sólo cubre la capa "unitaria" de la pirámide de pruebas, o el queso suizo. Puede que te preguntes, ¿dónde encajan las pruebas de nivel superior en este proceso?
Resulta que también es fácil incorporar pruebas de nivel superior en un flujo de trabajo que da prioridad a las pruebas. Este proceso se describió en Growing Object-Oriented Software, Guided by Tests:
Cuando estamos implementando una característica, empezamos escribiendo una prueba de aceptación, que ejercita la funcionalidad que queremos construir. Mientras falla, una prueba de aceptación demuestra que el sistema aún no implementa esa función; cuando la supera, hemos terminado. Cuando trabajamos en una función, utilizamos su prueba de aceptación para saber si realmente necesitamos el código que vamos a escribir: sólo escribimos el código que es directamente relevante. Por debajo de la prueba de aceptación, seguimos el ciclo de prueba/implementación/refactorización a nivel unitario para desarrollar la función.7
La Figura 4-5 ilustra el proceso.
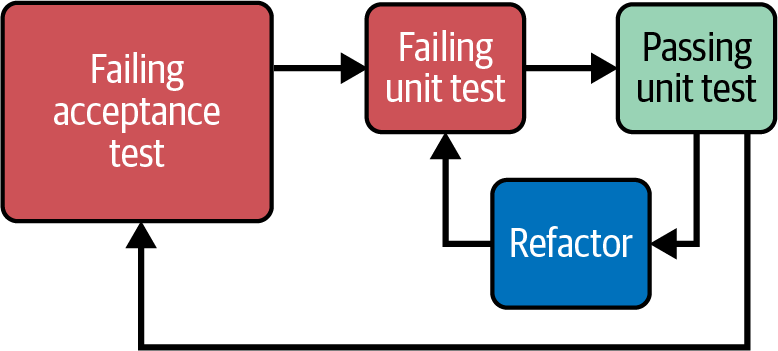
Figura 4-5. TDD fuera-dentro
Los fallos en las pruebas de alto nivel que se escriben antes de la implementación pueden servir de guía a los desarrolladores, proporcionándoles información sobre la integridad de su función y haciéndoles saber cuándo el código que han implementado es suficiente. Sin embargo, las pruebas de alto nivel pueden permanecer en rojo durante mucho tiempo, a veces mucho más del intervalo deseable entre confirmaciones de código. Está bien marcarlas como ignoradas antes de realizar un commit del trabajo en curso para que no fallen en el pipeline, volver a activarlas localmente, y comprobarlas sólo cuando estén en verde. Por supuesto, esto implica que el código incompleto esté bien oculto y no afecte a ninguna funcionalidad existente.
En mi experiencia, utilizar una combinación de los principios de "primero las pruebas" y "fuera dentro" cuando trabajábamos con la implementación continua fue una parte importante de lo que permitió a nuestros equipos sentirse seguros de la cobertura de pruebas de nuestra aplicación. Cada nueva línea de código que añadíamos dejaba tras de sí un rastro de pruebas unitarias y de alto nivel. Del mismo modo, cada fallo que arreglábamos se probaba primero mediante una prueba automatizada fallida que podíamos hacer verde y que evitaría que el fallo volviera a aparecer. Este enfoque estaba haciendo que nuestra red de seguridad para las regresiones fuera cada vez más sólida a medida que nuestros productos evolucionaban.
¿Y el legado?
No todos los equipos de pueden permitirse el lujo de trabajar con bases de código nuevas en las que puedan aumentar progresivamente la cobertura de las pruebas a medida que desarrollan el código. Además, es difícil decidir si una aplicación heredada o heredada puede funcionar bien con la implementación continua y, en caso afirmativo, en qué momento. Además, confiar sólo en TDD para añadir cobertura de forma oportunista puede no ser suficiente, ya que algunas áreas heredadas del código pueden permanecer intactas durante mucho tiempo o ser difíciles de refactorizar. En situaciones como éstas, a menudo es necesario trabajar en la cobertura de las pruebas por adelantado para que el sistema pueda modificarse con seguridad. Cuando el código de la aplicación está muy enmarañado, incluso hacer aperturas para añadir pruebas puede afectar a áreas no relacionadas que aún no se han cubierto.
Mi regla general aquí es implementar primero un conjunto de pruebas de alto nivel, que pueda hurgar y pinchar en el sistema desde fuera y tratarlo como una caja negra, en lugar de intentar desentrañar el código para añadir pruebas a nivel unitario. Esto debería bastar para verificar que cualquier funcionalidad crítica para el negocio está bien protegida y te permite refactorizar algunas aperturas más adelante.
Un conjunto de pruebas de este tipo puede crearse aunque no entendamos necesariamente todas las características del sistema, que pueden estar enterradas bajo una montaña de código enrevesado que es el resultado de años y años de cambios en los requisitos. Con el enfoque que Michael Feathers describe como "pruebas de caracterización", podemos utilizar las propias pruebas para hurgar en el sistema y cuestionar nuestras suposiciones sobre su funcionamiento.
Con las pruebas de caracterización, podemos escribir pruebas que desencadenen un comportamiento con la entrada que queremos probar, pero luego hacer afirmaciones "ficticias" que sabemos que fallarán, como afirmar contra valores nulos. El mensaje de fallo revelará el resultado real de la operación, lo que nos permitirá volver atrás y modificar nuestra prueba para ponerla en verde. Entonces podremos pasar a la siguiente prueba, hasta que hayamos agotado todos los tipos de entrada que pensamos que el sistema podría recibir en el mundo real. Este proceso deja tras de sí una especificación ejecutable de lo que hace actualmente el sistema de producción, y puede protegerlo de cambios involuntarios más adelante (incluso cuando su comportamiento pueda ser contraintuitivo).
Las pruebas de caracterización pueden ser útiles para preparar una aplicación heredada, si no para una implementación continua, al menos para una refactorización segura y para añadir funciones.
Implementaciones sin tiempo de inactividad
Quizás uno de los elementos más obvios de esta lista, pero que merece la pena mencionar por si acaso, son las Implementaciones de tiempo de inactividad cero. Las Implementaciones sin tiempo de inactividad son un requisito previo para los equipos que desean realizar implementaciones muy a menudo. Definitivamente, no queremos que nuestros usuarios vean un mensaje de ventana de mantenimiento varias veces al día, que es lo que ocurre si simplemente desmontamos nuestra infraestructura y la reconstruimos con la nueva versión, como se muestra en la Figura 4-6.
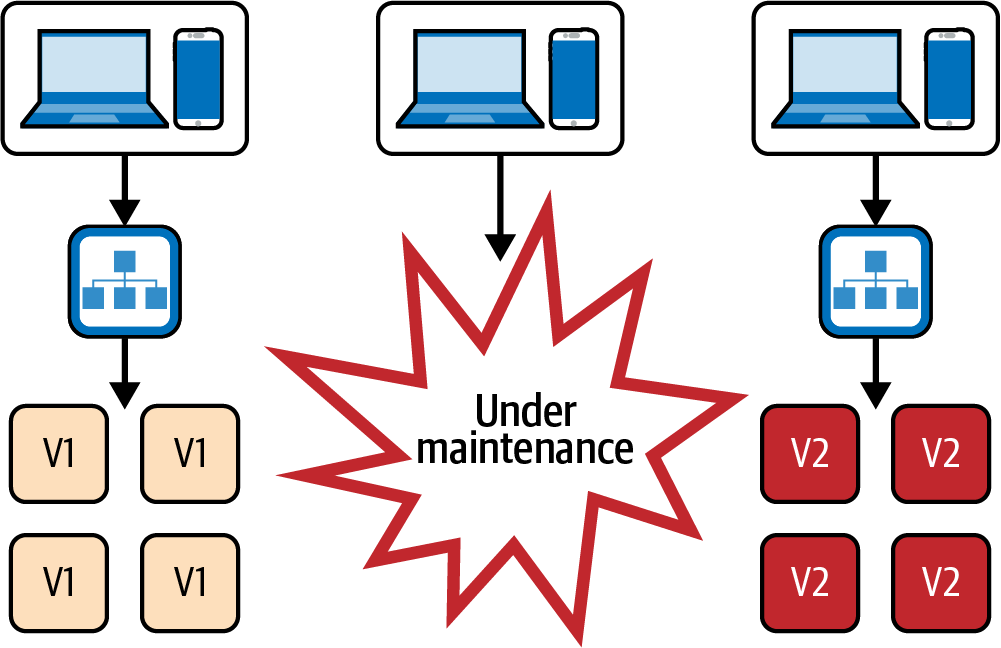
Figura 4-6. Implementación con tiempo de inactividad
Existen varias técnicas para evitar una ventana de implementación y conseguir un tiempo de inactividad cero, las más conocidas son las implementaciones azul/verde y las implementaciones continuas.
Implementaciones azul/verde
Implementación azul/verde es una técnica que se basa en utilizar dos entornos de producción idénticos, denominados respectivamente "azul" y "verde". Durante una implementación, la nueva versión de la aplicación se despliega inicialmente en el entorno azul. Una vez que se ha comprobado que el entorno azul funciona como se espera y está listo para entrar en funcionamiento, se redirige el tráfico entrante y la nueva versión entra en funcionamiento. Tanto la pila azul como la verde están en funcionamiento durante la implementación, y el punto de entrada de tráfico simplemente cambia entre las dos; véase la Figura 4-7.
Cada empresa puede implantar una configuración azul/verde de forma un poco diferente. La mayoría crea un nuevo entorno justo antes de la implementación, mientras que otras dejan ambos entornos siempre en funcionamiento para mayor seguridad, sobre todo para poder volver atrás en cualquier momento (aunque la doble infraestructura puede resultar bastante cara). Qué pila se denomina "azul" y cuál "verde" también puede variar. En algunos casos tienen nombres fijos, mientras que en otros se intercambian en el momento de la implementación. Sin embargo, los detalles de implementación no importan para nuestros fines, y podemos referirnos simplemente a la implementación azul/verde como cualquier configuración que alterne entre flotas idénticas de servidores de producción.
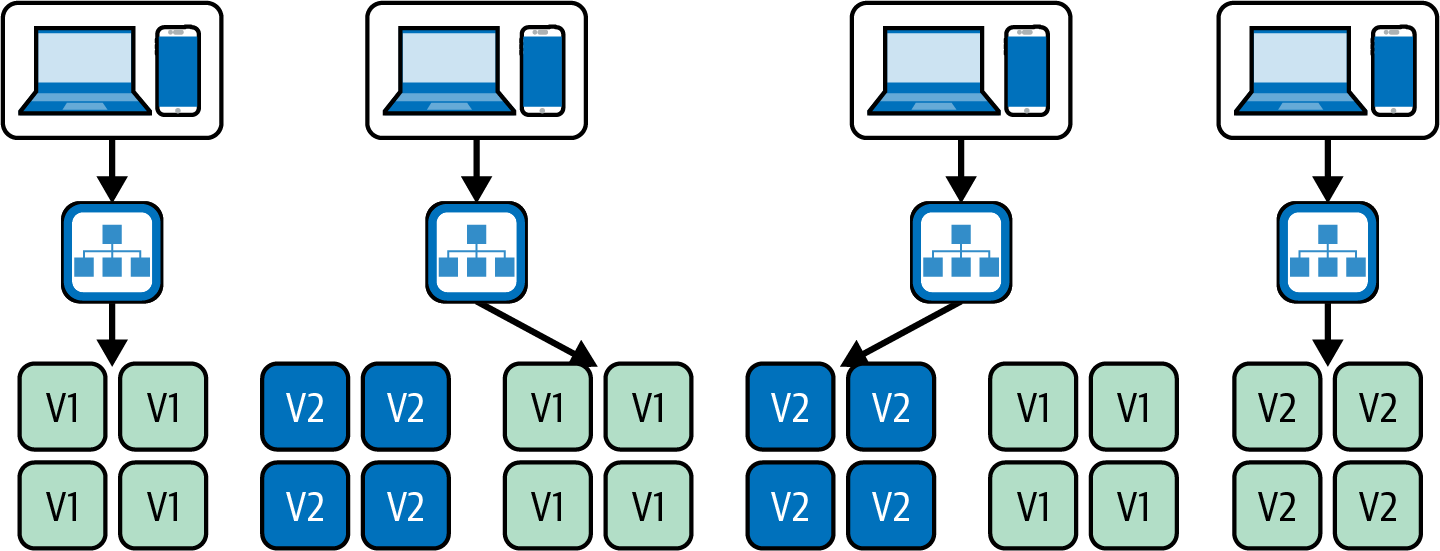
Figura 4-7. Implementación azul/verde
Una ventaja de la implementación azul/verde es que permite una rápida reversión en caso de problema con la nueva versión de la aplicación. Si hay problemas con el entorno verde, el tráfico puede ser simplemente redirigido de nuevo al entorno azul, minimizando el tiempo de inactividad y reduciendo al mínimo el impacto en los usuarios.
Una implementación azul/verde se basa en mantener dos versiones diferentes de la aplicación en funcionamiento, al menos durante una pequeña ventana de solapamiento. Esto garantiza que siempre habrá al menos una versión en ejecución de la aplicación disponible para servir al tráfico, lo que elimina la brecha del tiempo de inactividad.
Sin embargo, es importante señalar que este solapamiento causa cierta sobrecarga a los desarrolladores. Al realizar un cambio, necesitan mantener el código base de cada nueva versión N de la aplicación siempre capaz de ejecutarse junto a la versión N - 1. Esto es especialmente cierto si queremos mantener realmente la capacidad de retroceder.
Mantener la compatibilidad N - 1 significa que los desarrolladores deben tener especial cuidado, por ejemplo, al aplicar evoluciones del esquema de la base de datos, cambiar el contrato entre el backend y el frontend, o cambiar el contrato con cualquier otro componente externo de .
Implementaciones continuas
Implementaciones sucesivas (o actualizaciones sucesivas) es una técnica para implementar actualizaciones en el clúster de aplicaciones sustituyendo las instancias actuales por instancias nuevas que contengan la última versión. A medida que las nuevas instancias estén en buen estado, las antiguas se pueden ir eliminando gradualmente, como se muestra en la Figura 4-8. Esta técnica se utiliza habitualmente en configuraciones en las que la aplicación se ejecuta en un clúster de contenedores, como ECS o Kubernetes.
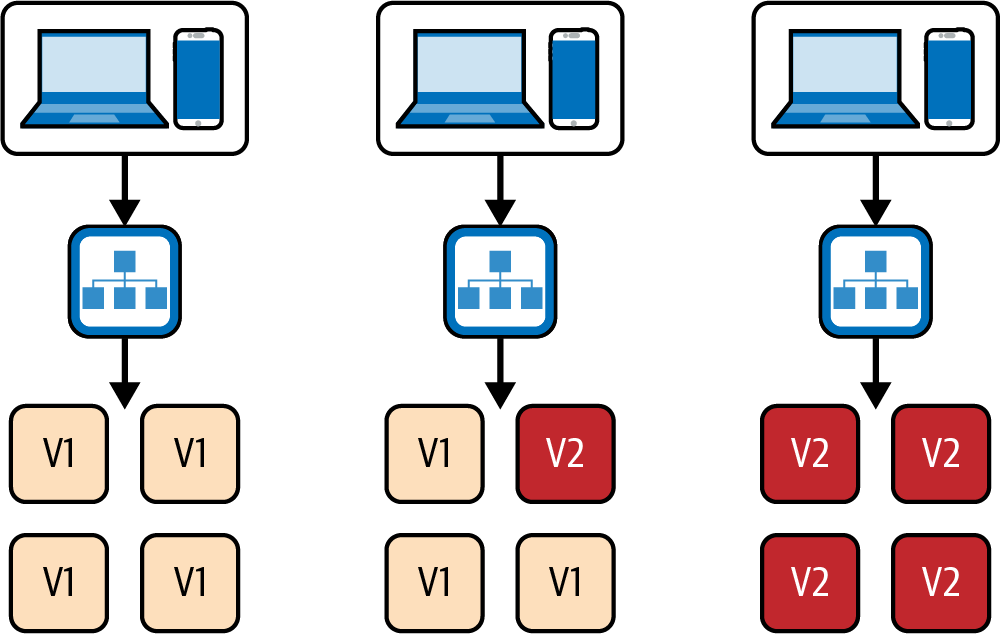
Figura 4-8. Una actualización continua
Este enfoque es menos costoso que la implementación azul/verde, ya que sólo necesita una pila en ejecución de la infraestructura de producción. Se utiliza más comúnmente con implementaciones basadas en contenedores, aunque también puede hacerse con máquinas virtuales anticuadas.
Al igual que las implementaciones azul/verde, este enfoque también sufre el problema de compatibilidad N - 1: durante un breve periodo de tiempo, coexistirán instancias de la nueva versión con la antigua, por lo que es importante asegurarse de que el contrato con cualquier sistema externo siga siendo compatible con ambas versiones.
Implementaciones canarias
Antes de que empecemos a describir las Implementaciones canarias en, merece la pena mencionar que se trata de un área en la que la terminología puede resultar confusa: a veces se hace referencia a las Implementaciones canarias como Lanzamientos canarios y viceversa. Los despliegues y las implementaciones son eventos distintos, especialmente en el caso de la implementación continua, en la que los equipos desacoplan habitualmente las implementaciones y las implementaciones mediante cambios de funciones (como expliqué en el Capítulo 3). En esta sección, hablaré sólo de implementaciones canarias, lo que significa desplegar nuevas instancias con la versión más reciente del código y la configuración. Hablaremos de " lanzamientoscanarios" en el Capítulo 12, donde te mostraré cómo realizar despliegues progresivos de una función visible (idealmente en tiempo de ejecución y mediante el uso de una bandera de función que no requiera una nueva implementación).
Una implementación canaria puede considerarse un incremento de las implementaciones de tiempo de inactividad cero. Su objetivo va más allá de proporcionar un tiempo de inactividad cero: también permite validar la nueva versión de la aplicación con un subconjunto de tráfico antes de desplegar la actualización a todos los usuarios; véase la Figura 4-9.
Esto se consigue desplegando un subconjunto de instancias con la nueva versión (el canario), y luego condicionando el despliegue al resto de la infraestructura al rendimiento de la nueva versión. Esta comparación se automatiza recogiendo métricas tanto de la versión nueva como de la antigua y comparándolas entre sí. Esta capacidad la ofrecen herramientas como Spinnaker.
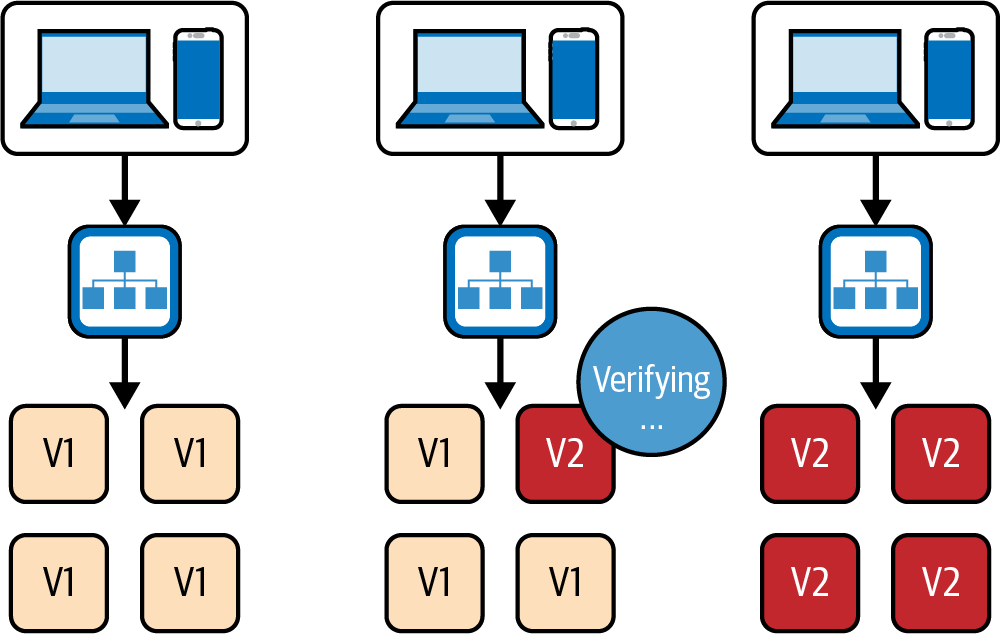
Figura 4-9. Una implementación canaria
Esta estrategia proporciona información más precisa que una simple implementación rodante o azul/verde, en la que las comprobaciones automatizadas suelen consistir en una simple comprobación de estado o una prueba de humo. Una implementación canaria puede detectar cosas mucho más interesantes, como una diferencia significativa en la tasa de errores de la aplicación o problemas de rendimiento.
Las Implementaciones Canarias automatizadas en torno a las métricas de la aplicación pueden ser una herramienta extremadamente potente para comprobar que las nuevas versiones del código no tienen un impacto imprevisto en la producción. Este tipo de retroalimentación exhaustiva y extensa puede ser un requisito previo en las grandes empresas que quieren adoptar la implementación continua, pero temen el impacto en el rendimiento u otros requisitos críticos interfuncionales.
Sin embargo, las Implementaciones canarias pueden tener algunos inconvenientes importantes. Pueden ser bastante complicados de configurar, y requieren que las métricas en las que se basan sean significativas y estables. Además, recopilar los datos necesarios para que un análisis estadístico arroje resultados precisos puede llevar mucho tiempo, ralentizando el proceso de implementación y creando un cuello de botella.
Teniendo en cuenta estos problemas, yo consideraría que las Implementaciones canarias no son "imprescindibles" para la implementación continua en la mayoría de las organizaciones pequeñas y medianas. Personalmente, he utilizado estrategias de implementación más sencillas en todos los equipos en los que practicamos la implementación continua. No sentíamos la necesidad de sofisticadas implementaciones canarias, ya que nuestra cobertura de pruebas, la activación de funciones y la observabilidad y las alarmas eran lo suficientemente completas como para mantenernos a salvo.
Dicho esto, la Implementación canaria es sin duda una técnica interesante que puede tranquilizar a las partes interesadas cuando las nuevas implementaciones se consideran de alto riesgo, y me entusiasma ver cómo evolucionan y las adoptan cada vez más empresas de.
Estrategias de implementación y pasos manuales
En cabe señalar que algunos equipos realizan pasos manuales dentro de las Implementaciones azules/verdes o rodantes como herramienta de control de calidad y/o de lanzamiento de características, por ejemplo, realizando sólo una implementación parcial en producción y ejecutando después algunos pasos de verificación manual antes de completarla.
Este tipo de flujo de trabajo encaja razonablemente bien con la entrega continua, pero no es compatible con la implementación continua. Cuando el ritmo de commits que llegan a producción es mucho mayor, añadir la intervención humana en medio de las Implementaciones crea torpemente una enorme cola de cambios que hay que ordenar. La intervención manual también hace que la nueva versión de la aplicación en producción se comporte como una preproducción: las propias Implementaciones se convierten en un punto de cola en el que se espera a que finalicen las pruebas o la experimentación antes del paso "final definitivo" de la implementación. Las Implementaciones parciales con actividad manual a su alrededor siguen siendo una puerta de entrada a la producción.
Yo desaconsejaría este enfoque, y creo que los indicadores de características en tiempo de ejecución y las pruebas automatizadas son mucho más adecuados para verificar los cambios sin acoplar las implementaciones al control de calidad y a la experimentación del producto.
Ejemplo de antipatrón: Azul/verde como herramienta de control de calidad
En me he encontrado con equipos que recurren a implementaciones manuales azul/verde para probar nuevas versiones en el entorno azul. Esto implica acceder al entorno temporal en una URL privada y realizar pruebas de regresión para asegurarse de que todo funciona como se espera. Sólo cuando el equipo haya determinado que la nueva versión tiene buen aspecto, pasará al entorno verde. Sin embargo, este proceso debe automatizarse si el equipo quiere pasar a la implementación continua, quizá sustituyéndolo por pruebas de regresión automatizadas en entornos inferiores, pruebas de humo automatizadas o implementaciones canarias.
Ejemplo de antipatrón: Implementaciones parciales como herramienta de liberación canaria
Del mismo modo, los equipos de pueden tener la tentación de controlar manualmente las Implementaciones rodantes como una forma de prueba A/B para validar nuevas funciones. Incluyen la nueva función en la siguiente versión de la aplicación, pero sólo la despliegan en unas pocas instancias. Si la función funciona bien con el subconjunto de tráfico expuesto, los interesados decidirán desplegarla al resto de la infraestructura.
Como ya he dicho, este tipo de despliegue manual y parcial de los cambios no es compatible con las implementaciones continuas en producción. La implementación debe estar totalmente automatizada, y el proceso de pruebas A/B de cara al usuario debe sustituirse por indicadores de función. El uso de las banderas de función de para obtener información de los usuarios permite un control más preciso sobre qué usuarios deben ver la función que una implementación parcial. Por ejemplo, permiten seleccionar un subconjunto de usuarios por porcentaje de tráfico o incluso por región, en lugar de un número arbitrario de solicitudes que llegan a instancias específicas. Y lo que es más importante, si una función no funciona bien, no hay necesidad de revertirla, y la espera de los comentarios de los usuarios no retrasará torpemente el despliegue de otros cambios de código.
Recomendaría a cualquier equipo que esté pensando en pasar a la implementación continua que sustituya los pasos de la implementación manual por una combinación de indicadores de características y pruebas automatizadas antes de abrir la puerta a la producción. En una cadena de despliegue continuo, la implementación en producción debe ser siempre totalmente automatizada.
Observabilidad y monitoreo
Por muy sofisticadas que sean tus estrategias de revisión del código, pruebas e implementación en , aún pueden surgir problemas de producción. A veces esto puede ocurrir mucho tiempo después de la última implementación, ya que las condiciones necesarias para que surjan los problemas pueden aparecer aleatoriamente.
Por eso es fundamental que los desarrolladores puedan obtener información de calidad sobre el estado de la producción, y que la información sea muy visible en radiadores de información disponibles para todo el equipo.
La observabilidad se refiere a la capacidad de monitorizar y comprender el comportamiento del sistema implementado examinando sus resultados, como registros, métricas y trazas. Representa la capacidad fundamental de formular nuevas preguntas sobre el sistema en funcionamiento, ofreciendo una forma exploratoria de comprenderlo. También permite a los equipos identificar y diagnosticar problemas, así como obtener información sobre cómo funciona (o falla) el sistema en diferentes condiciones.
Si tienes dudas sobre lo que debes monitorizar, al menos en el aspecto técnico, Google proporciona un excelente punto de partida en su libro SRE, que describe cuatro señales de oro:
Latencia, o tiempo que tarda el sistema en atender una solicitud.
Tráfico, una medida de cuánta demanda (por ejemplo, solicitudes HTTP, mensajes entrantes, transacciones por segundo) se está ejerciendo sobre el sistema.
Errores, o la tasa de errores, especialmente en comparación con el tráfico global.
Saturación, o qué parte de la "capacidad" de tu sistema se está utilizando. Esto podría traducirse en uso de memoria y CPU, instancias actuales frente a tu límite de escalado, o llenado del disco duro.
Por el lado del frontend, también deberías vigilar la evolución de las siguientes métricas de Core Web Vital a lo largo del tiempo:
- Pintura de mayor contenido (LCP)
Este es una medida del momento en que se renderiza el elemento más grande de la página, que es un indicador de la velocidad de carga global percibida por el usuario.
- Desplazamiento de disposición acumulado (CLS)
-
Cuando un elemento de cambia de posición de un fotograma a otro, se trata de un desplazamiento de diseño. Los cambios de diseño deben reducirse al mínimo, ya que pueden alterar la experiencia del usuario de muchas maneras.
- Interacción con la siguiente pintura (INP)
Se trata de una medida de la latencia de todas las interacciones de clic, toque y teclado con una página y, en particular, del intervalo más largo. Es una indicación de la capacidad de respuesta percibida de la página.
Además de las métricas puramente técnicas, el equipo debe asegurarse de recopilar también datos de métricas relevantes para el negocio que reflejen el dominio de la aplicación; por ejemplo, el número de búsquedas realizadas, las tasas de conversión, las tasas de clics y las tasas de rebote.
La generación de resultados, como registros, métricas y trazas, debe integrarse en cada incremento de funcionalidad que se añada al sistema, por dos razones: para obtener visibilidad ya en la primera implementación, y porque añadirla a posteriori puede requerir un rediseño del código, con el consiguiente derroche de trabajo.
Toda esta información puede resultar fácilmente abrumadora y ruidosa para los desarrolladores, por lo que también es importante que las señales más cruciales se condensen en cuadros de mando fáciles de leer en , cuyos ejemplos se muestran en las Figuras 4-10 y 4-11. Un desarrollador familiarizado con el sistema no debería necesitar más que un vistazo para determinar si funciona con normalidad. Si se detectan problemas, debería disponerse de información más detallada, como registros y trazas individuales, para buscarlos con fines de depuración en espacios separados.
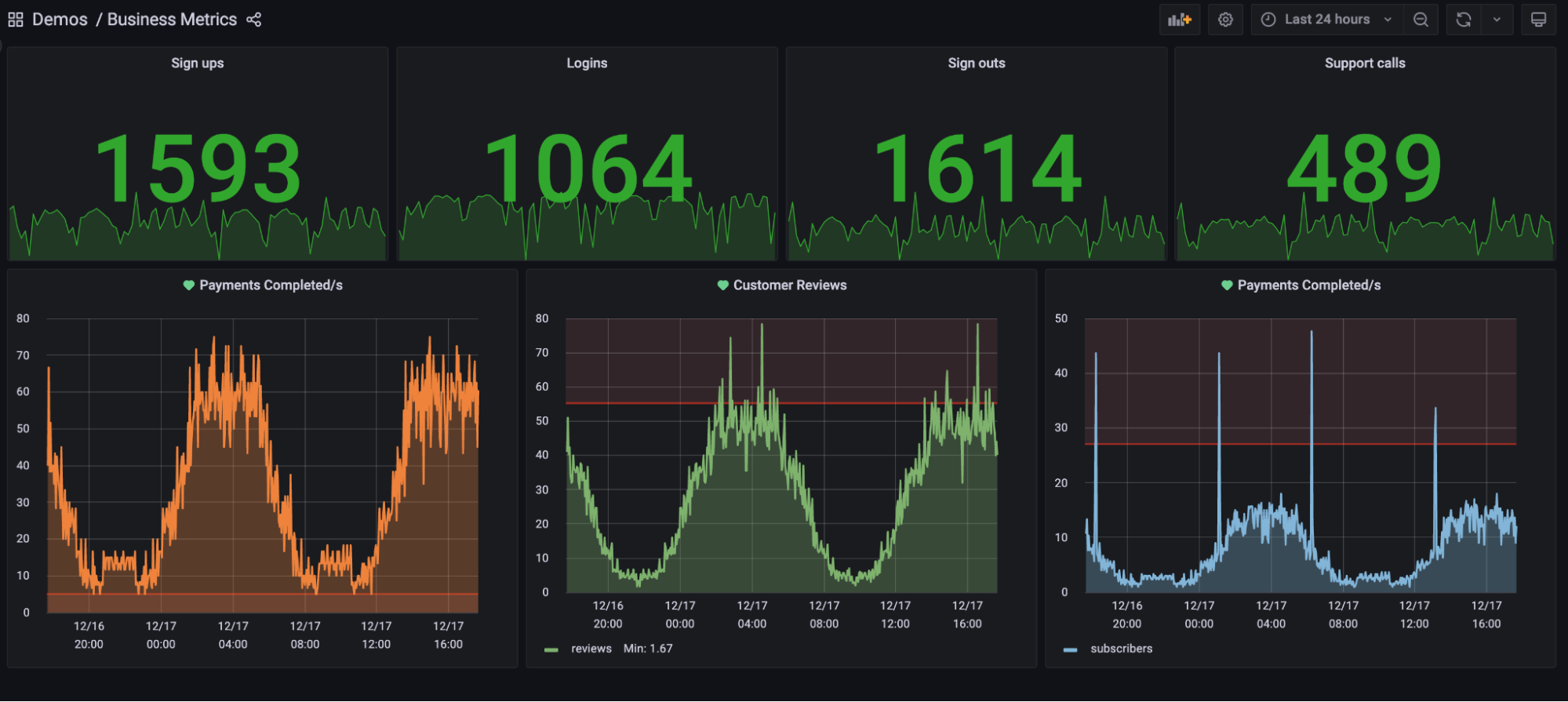
Figura 4-10. Un ejemplo de cuadro de mando con métricas empresariales
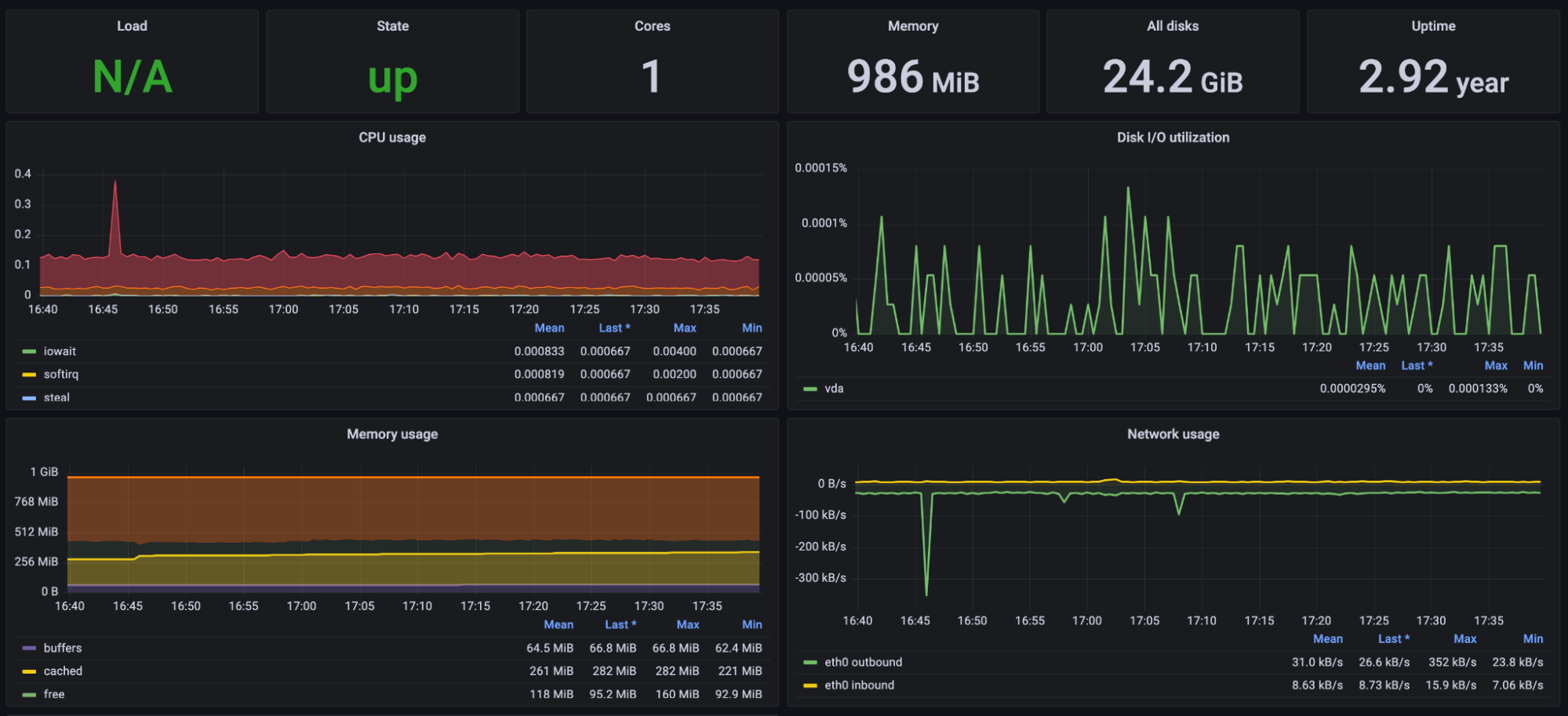
Figura 4-11. Un ejemplo de panel de control con métricas técnicas
Se está produciendo mucha innovación en el espacio de la observabilidad, con herramientas como Datadog, Splunk, Prometheus, Grafana y NewRelic proliferando y viendo cada vez más adopción en los últimos años.
Alertas
Mantener un ojo en los paneles de control durante el trabajo diario es crucial con la implementación continua, pero no se puede esperar que los desarrolladores mantengan los ojos pegados a su pestaña de Datadog el 100% del tiempo. Por eso los desarrolladores deben ser notificados de las anomalías de forma proactiva, aunque hagan todo lo posible por prestar atención a las herramientas de monitoreo. Esto puede conseguirse mediante el uso de alertas.
La mayoría de las herramientas de observabilidad ofrecen alertas que avisan a los desarrolladores a través de diversos canales -notificaciones de Slack, SMS, llamadas telefónicas, palomas mensajeras, etc.- cuando determinadas métricas empiezan a comportarse de forma extraña. Esto es imprescindible con implementaciones frecuentes.
Las alertas pueden basarse en distintos factores, como el rendimiento del sistema, los patrones de uso o la aparición de mensajes de registro o errores específicos. Configurándolas en función de indicadores clave, los equipos pueden recibir notificaciones de los problemas en cuanto se producen, lo que les permite tomar medidas proactivas para solucionar el problema antes de que se convierta en crítico.
Información frente a ruido
Muchas alertas y monitores de pueden resultar abrumadores si no se configuran adecuadamente. Cuando hay demasiados monitores, o cuando las alertas saltan constantemente porque son defectuosas, los desarrolladores pueden aprender rápidamente a no prestarles atención y perder el interés, ignorando potencialmente problemas críticos.
Las alertas deben ser pocas y significativas, en lugar de ruidosas y redundantes. Por ejemplo, en el aspecto técnico puede que sólo quieras alertar sobre unas pocas métricas clave, como picos de errores de aplicación, latencia fuera de control o insuficientes instancias sanas. Pero no desprecies las métricas orientadas al negocio. La ausencia repentina de ciertos tipos de solicitudes, por ejemplo, puede indicar que los usuarios tienen problemas para completar un flujo concreto (por ejemplo, la última confirmación ha vuelto invisible el botón de pago).
Algunos equipos crean nuevas alertas para cualquier métrica nueva, y mantienen los umbrales bajos para que la alerta se dispare más a menudo. Esto puede parecer un enfoque exhaustivo, pero no es útil. Las alertas que gritan lobo pueden ser incluso peores que no tener alertas en absoluto. No tener alertas al menos mantiene al equipo atento, ya que es consciente de que hay un vacío de información, mientras que las malas alertas ofrecen una falsa sensación de seguridad en virtud de su existencia, a pesar de ser ignoradas la mayor parte del tiempo.
La mala información es peor que la falta de información. Por eso, un equipo que trabaje con implementación continua debe acostumbrarse a refactorizar su observabilidad y sus alertas con la misma atención que reserva a su código de aplicación, sus pruebas automatizadas y su pipeline.
El equipo de Datadog proporciona una buena heurística en su blog sobre lo que constituyen alertas "significativas", y ayuda a separar estas alertas del ruido -alertar sobre síntomas en lugar de causas-, que también se trata en el libro de SRE de Google:
Las páginas [como en "avisar a alguien"] son extremadamente eficaces para transmitir información, pero pueden ser bastante perjudiciales si se utilizan en exceso, o si están vinculadas a alertas mal diseñadas. En general, una página es el tipo de alerta más apropiado cuando el sistema del que eres responsable deja de hacer un trabajo útil con un rendimiento, latencia o tasas de error aceptables. Ése es el tipo de problemas que quieres conocer de inmediato.
El hecho de que tu sistema haya dejado de hacer un trabajo útil es un síntoma, es decir, es una manifestación de un problema que puede tener varias causas diferentes. Por ejemplo: si tu sitio web ha estado respondiendo muy lentamente durante los últimos tres minutos, eso es un síntoma. Entre las posibles causas se encuentran la alta latencia de la base de datos, el fallo de los servidores de aplicaciones, la caída de Memcached, la alta carga, etc. Siempre que sea posible, construye tus páginas en función de los síntomas y no de las causas. [...]
La búsqueda de síntomas muestra problemas reales, a menudo de cara al usuario, en lugar de problemas hipotéticos o internos. Contrasta la paginación de un síntoma, como la lentitud de respuesta de un sitio web, con la paginación de las causas potenciales del síntoma, como la elevada carga de tus servidores web. Tus usuarios no sabrán ni les importará la carga de los servidores si el sitio web sigue respondiendo con rapidez, y a tus ingenieros les molestará que se les moleste por algo que sólo se nota internamente y que puede volver a niveles normales sin intervención.8
Confianza de las partes interesadas
En este capítulo de , hemos hablado mucho de los requisitos técnicos previos para trabajar con seguridad en la implementación continua. Creo que es necesario cerrar el capítulo con una reflexión sobre el impacto del factor humano.
Abrir la puerta de producción a todos los commits es un ejercicio de confianza entre los interesados y su equipo. Como desarrolladores que trabajamos a diario en el sistema, conocemos a fondo todas las medidas de seguridad que ponemos en marcha para evitar que ocurran Bad Things™ en la producción. Con la implementación continua, somos nosotros quienes mantenemos el control de las puertas de calidad: al fin y al cabo, estamos implementando y configurando la automatización que actuará en nuestro nombre. Pero nuestras partes interesadas no pueden decir lo mismo. Todo lo que pueden ver, desde su perspectiva, es una pérdida de su oportunidad de aportar información y bloquear cambios peligrosos antes de que sea demasiado tarde. No tienen visibilidad de la meticulosidad de las capas y capas de automatización que hacen innecesaria su aprobación, y tienen que confiar en nuestra palabra de ingenieros. De hecho, les estamos pidiendo que renuncien a su único poder sobre el camino hacia la producción. Ante esta gran petición, debemos esforzarnos por ser empáticos con cualquier preocupación que nos planteen. Aunque hayamos hecho un trabajo excelente al implantar una base técnica perfecta, la cultural podría seguir siendo la más complicada después de todo.
Sin embargo, la implementación continua es un trabajo de equipo, y es necesario que las partes interesadas estén de acuerdo para sacar el máximo partido de esta práctica. La confianza de las partes interesadas también les hará más pacientes con los posibles problemas iniciales mientras el equipo se acostumbra a esta nueva forma de trabajar. Así que hablemos de cómo entusiasmarles (en lugar de asustarles) con las Implementaciones automatizadas.
¿Cómo convencer al jefe?
Como consultor, he tenido que hacer mi buena parte de trabajo de convencimiento en los equipos en los que estábamos cerca de la implementación continua, pero aún no habíamos llegado a ella. Según mi experiencia, este convencimiento se hace mejor cuando queda poco por hacer.
Ninguna de las prácticas tratadas en este capítulo es necesaria exclusivamente para la implementación continua: cada una de ellas puede implementarse de forma independiente y constituye una inversión más que justificable por sí sola. Sin duda, mejorarán la calidad de la aplicación incluso con una puerta manual a la producción todavía en funcionamiento.
Por lo tanto, animaría a mis colegas ingenieros a ponerlas en práctica independientemente de si la implementación continua es el objetivo final, ya que conducirán a una implementación más sólida de la entrega continua.
Una vez que el equipo haya alcanzado un gran nivel de madurez en la entrega continua, las minuciosas pruebas manuales de cada detalle empezarán a parecer redundantes en lugar de necesarias. Cuando el equipo haya llegado a ese punto, mi experiencia me dice que incluso las partes interesadas aprenderán a encontrar molestas las pruebas manuales. Es entonces cuando resulta más fácil sugerir ir un paso más allá sin provocar reacciones fuertes. En ese momento, la sugerencia puede incluso ser bien recibida, ya que su única consecuencia será la eliminación de trabajo redundante.
Según mi experiencia, este enfoque no sólo elimina la mayor parte de la "negociación" de estas conversaciones, sino que también ayuda al equipo a asegurarse de que está realmente preparado, ya que ha evaluado hasta qué punto sigue confiando en la mirada humana por encima de la automatización. Tu jefe podría incluso apreciar que la preparación para la implementación continua es un objetivo claro y concreto que el equipo puede adoptar para guiar su mejora continua.
Esto plantea la pregunta: "Entonces, ¿cómo sabemos cuándo estamos preparados?".
Como verás en los casos prácticos de la Parte V, algunas empresas audaces como AutoScout24 toman la decisión de adoptar la implementación continua desde el primer día, en cuanto pasan a un ecosistema de producción moderno con microservicios, banderas de características, etc. Sin embargo, si tu empresa es un poco más indecisa, la siguiente sección puede darte algunos consejos útiles.
¿Cuándo estaremos preparados?
Hemos cubierto aquí un montón de prácticas, y podría ser tentador pensar que cada una de ellas tiene que estar chapada en oro hasta la perfección antes de considerar siquiera la eliminación de los pasos humanos de nuestras tuberías. Me gustaría disuadir a mis lectores de esa línea de pensamiento. Como comentamos en el Capítulo 2, una de las ventajas de la implementación continua es que, una vez activada, pone a prueba todas y cada una de las puertas de la calidad. A medida que el código pasa a producción cada vez más a menudo, cualquier laguna en nuestros procesos saldrá a la luz rápidamente, y el equipo podrá abordarla a medida que surja. Si esperamos a que nuestras redes de seguridad sean absolutamente perfectas, puede que nunca lleguemos a dar el salto. Hacer lo doloroso antes y más a menudo permite que las prácticas se perfeccionen de forma natural.
Si es el momento adecuado o no, es una pregunta difícil y, en última instancia, una que cada equipo debe responder en función de las circunstancias en las que se encuentre. Por eso responderé a esta pregunta con otra pregunta -varias, de hecho-. Estas son algunas cosas que te sugiero que consideres para que puedas llegar a tus propias conclusiones:
¿Conoce mi equipo todas las prácticas tratadas en este capítulo?
-
¿Hemos aplicado cada una de las prácticas de este capítulo? En caso afirmativo, ¿con qué grado de sofisticación? Y si no, ¿tenemos una buena razón para no necesitarla?
Para cada práctica que hemos implantado, ¿cada miembro del equipo trabaja con ella con confianza en lugar de ignorarla o eludirla?
Si mañana implementáramos la implementación continua, ¿qué tipo de defecto de código me preocuparía más (por ejemplo, impacto en el rendimiento, vulnerabilidad de seguridad, regresión en una función específica)? ¿Qué tipo de defecto preocuparía más a mis interlocutores? ¿La protección contra ellos es hoy manual o automatizada?
Si mañana implementamos la implementación continua, ¿hay alguna señal concreta del sistema de producción a la que debería prestar especial atención? ¿Tenemos métricas de fácil acceso que nos den visibilidad de ello hoy? Si hay una degradación, ¿tenemos ya alertas para esa señal?
¿Existe un número significativo de defectos que actualmente sólo se detectan comprobando los cambios manualmente? En caso afirmativo, ¿qué tienen en común? ¿Qué tipo de automatización sería necesaria para detectarlos antes?
Dadas nuestras prácticas técnicas, ¿la puerta manual a la producción se siente hoy como un salvavidas, o se siente redundante y como un inconveniente? ¿Todos los miembros del equipo sienten lo mismo? ¿Nuestras partes interesadas sienten lo mismo?
Éstas son sólo algunas de las preguntas que me gusta plantearme cuando evalúo si la implementación continua es la opción adecuada en un momento determinado. Incluso para quienes no tengan previsto implantarlo en breve, el proceso de encontrar las respuestas a estas preguntas puede conducir a una comprensión más profunda de la estrategia de calidad del equipo y de la solidez de su sistema .
Resumen
En este capítulo hemos hablado de algunas de las prácticas que nuestros equipos deben implantar antes de pasar a la implementación continua. Algunos requisitos son culturales y organizativos, como la confianza de las partes interesadas y los equipos multifuncionales y autónomos con el hábito de la integración frecuente y las revisiones del código. La mayoría de los demás requisitos son técnicos: implementaciones sin tiempo de inactividad, una canalización con varias capas de pruebas automatizadas, observabilidad y alertas.
No se trata de inversiones valiosas sólo para la implementación continua. Más bien, son buenas prácticas que se sostienen por sí solas. Esto significa que pueden aplicarse como mejoras aisladas y seguir dando grandes resultados para el ciclo de vida de entrega de software del equipo. La decisión de pasar a la implementación continua puede tomarse (o anularse) más adelante sin pérdida alguna.
Esta base de prácticas puede garantizar que la eliminación de la puerta final a la producción sea lo menos dolorosa posible.
1 Matthew Skelton y Manuel Pais, Team Topologies: Organizing Business and Technology Teams for Fast Flow (Portland, OR: IT Revolution Press, 2019).
2 Nicole Forsgren y otros, Accelerate: Building and Scaling High Performing Technology Organizations (Portland, OR: IT Revolution Press, 2018), p. 91.
3 Aunque no sea muy conocido, la programación solía ser un trabajo desempeñado por mujeres. De hecho, los primeros programadores de principios del siglo XIX eran mujeres. Para saber más, visita https://oreil.ly/cQb11.
4 "Jean Bartik, los programadores de ENIAC", Museo de Historia de la Informática, 2011, vídeo, https://oreil.ly/4S38P.
5 Michael Feathers, Working Effectively with Legacy Code (Boston: Pearson, 2004), p. 16.
6 Kent Beck, Desarrollo dirigido por pruebas: By Example (Boston: Addison-Wesley, 2002).
7 Steve Freeman y Nat Pryce, Growing Object-Oriented Software, Guided by Tests (Boston: Addison-Wesley, 2009), p. 7.
8 Alexis Lê-Quôc, "Monitoreo 101: Alertar sobre lo que importa", Datadog, 2016, https://oreil.ly/M3Wzn.
Get Despliegue continuo now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

