Chapter 1. Introduction
AI is no longer the realm of science fiction novels and dystopian Hollywood movies. It is fast becoming an integral part of people’s lives. Most of us interact with AI on a daily basis, oftentimes without even realizing it.
Current progress in AI has to a large extent been driven by advances in language modeling. LLMs (Large Language Models) represent one of the most significant technological advances in recent times, marking a new epoch in the world of tech. Similar inflection points in the past include the advent of the computer that ushered in the digital revolution, the birth of the Internet and the World Wide Web that connected the world together, and the emergence of the smartphone that reshaped human communication. The ongoing AI revolution is poised to make a similar transformative impact.
LLMs belong to a class of models termed as Generative AI. The distinguishing factor is the ability of these models to generate responses to user queries, called prompts. Generative AI encompasses models that generate images, videos, speech, music, and of course text. While there is an increasing focus on bringing all these modalities together into a single model, in this book we will stick to language and LLMs.
In this chapter, we will introduce language models and define what makes a language model large. We will go through a brief history of LLMs, contextualizing their place within the field of NLP (Natural Language Processing) and their evolution. We will highlight the impact LLMs are already having in the world and showcase key use cases, while discussing their strengths and limitations. We will also introduce LLM prompting and show how to interact with an LLM effectively, either through a user interface or through an API. Finally, we will end this chapter with a quick tutorial on building a Chat with my PDF chatbot prototype. We will then discuss the limitations of the prototype and the factors limiting its suitability for production use cases, thus setting the stage for the rest of the book.
Defining LLMs
A model is an approximation of a real world concept or phenomenon. A faithful model will be able to make predictions about the concept it is approximating. A language model approximates human language, and is built by training over a large body of text, thus imbuing it with various properties of language, including aspects of grammar (syntax) and meaning (semantics).
One way to train a language model is to teach it to predict the next token (this is equivalent to a word or a subword, but we will ignore this distinction for now) in a known text sequence. The model is trained over a large number of such sequences, and its parameters are updated iteratively such that it gets better at its predictions.
For example, consider the following text sequence appearing in a training dataset:
Afteraphysicalaltercationwiththepatronsofarestaurant,Alexwasfeelingextremelypleasedwithhimself.Hewalkedoutwithaswaggerandconfidencethatbetrayedhisinsecurities.Smilingfromeartoear,henoticedraindropsgrazinghisfaceandproceededtowalktowardsthehostel.
and the language model predicts the next word that comes after ‘…. and proceeded to walk towards the _’
There are a large number of valid continuations to this text sequence. It could be building or shelter, but it could also be embankment or catacomb. However, it is definitely not the or is, because that would break the rules of the English language. After training on a sufficiently large body of text, the model learns that neither the nor is are valid continuations. Thus, you can see how a simple task like learning to predict the next word in a text sequence can lead the model to learning the grammar of the language in its parameters, as well as even more complex skills.
Note
In practice, language models don’t exactly output a single word as the next token in a text sequence. They output a probability distribution over the entire vocabulary. (We will explore how this vocabulary is defined and constructed in Chapter 3). A well trained model will have high probabilities for valid continuations and very low probabilities for invalid continuations.
Figure 1-1 describes the model training process in a nutshell. The output of the model prediction is a probability distribution over the entire vocabulary of the language. This is compared to the original sequence, and the parameters of the model are updated according to an algorithm so that it makes better predictions in the future. This is repeated over a very large dataset. We will describe the model training process in detail in the next three chapters.
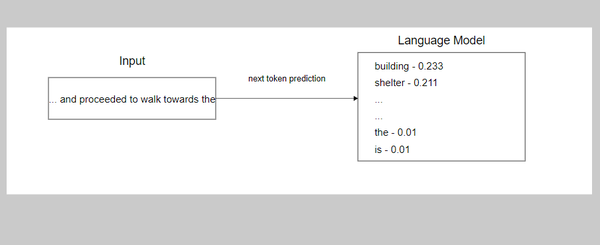
Figure 1-1. Model training using next token prediction
Is there a limit to what a model can learn from next token prediction alone? This is a very important question that determines how powerful LLMs can eventually be. There is plenty of disagreement in the research community, with some researchers arguing next token prediction is enough to achieve human level intelligence in models, and others pointing out the shortfalls of this paradigm. We will come back to this question throughout the book, and especially in Chapter 9, where we will discuss skills like reasoning.
Modern-day language models are based on neural networks. Several types of neural network architectures are used to train LLMs, the most prominent being the Transformer. We will learn more about neural networks, Transformers, and other architectures in detail in Chapter 4.
Language models can be trained to model not just human languages, but also programming languages like Python or Java. In fact, the Transformer architecture and the next token prediction objective can be applied to sequences that are not languages in the traditional sense at all, like representations of chess moves, DNA sequences, or airline schedules.
For example, Adam Karvonen trained Chess-GPT, a model trained only on chess games represented in PGN (Portable Game Notation) strings. PGN strings for chess look like ‘1. e4 d5 2. exd5 Qxd5…’ and so on. Even without providing the rules of the game explicitly, and just training the model to predict the next character in the PGN sequence, the model was able to learn the rules of the game including moves like castling, check, checkmate and even win chess games against experts. This shows the power of the next token prediction objective, and the Transformer architecture that forms the basis of the model. In Chapter 4, we will learn how to train our own Chess-GPT from scratch.
Another such example is the Geneformer, a model trained on millions of single-cell transcriptomes (representation of RNA molecules in a single cell) which can be used for making predictions in network biology, including disease progression, gene-dosage sensitivity, and finding therapeutic candidates.
Therefore, I encourage you to think beyond the realm of human language when brainstorming novel use cases for language models. If you have a concept or phenomenon that can be encoded in a discrete sequence using a finite vocabulary (we will more formally define vocabulary in Chapter 3), then we can potentially train a useful model on it.
Note
Is there something special about the structure of language that makes it amenable to be modeled using the next token prediction objective? Or is the word ‘language’ in language models just a historical accident and any stream of tokens can be modeled using this paradigm? While this is still a topic of debate in the research community, directly modeling speech, video etc using this paradigm hasn’t been as effective, perhaps showing that the discrete nature of text and the structure provided by language, be it a human language like English, a programming language like Python, or a domain-specific code like DNA sequences is crucial to modeling success.
Around 2019, researchers realized that increasing the size of the language model predictably improved performance, with no saturation point in sight. This led to Kaplan et al.’s work on LLM scaling laws, which derives a mathematical formula describing the relationship between the amount of compute for training the model, the training dataset size, and the model size. Ever since then, companies and organizations have been training increasingly larger models.
There is no accepted convention on when a language model is deemed to be large. In fact, as the largest models get even larger, some models that would have been referred to as LLMs only a couple of years ago are now termed as SLMs (Small Language Model). In this book, we will remain generous and continue to refer to all language models over a billion parameters as large.
Another way in which a ‘large’ language model differs from smaller ones is the emergent capabilities that they possess. First hypothesized by Wei et al., emergent capabilities are those capabilities that are exhibited by larger models but not smaller ones.
According to this theory, for tasks that require these capabilities, the performance of smaller models is close to random. However, when the model size reaches a threshold, the performance suddenly starts to increase with size. Examples include multi-digit arithmetic operations, arithmetic and logical reasoning etc. This also suggests that certain capabilities that are completely absent in current models could be exhibited by future larger models.
These thresholds are not absolute, and as we see more advances in language modeling, data quality improvements etc, we can expect the thresholds to come down.
Note
Schaeffer et al. claim that the sudden jump in performance for certain tasks at a particular model size threshold is just an artifact of the evaluation metrics used to judge performance. This happens because many metrics do not assign partial credit and only reward fully solving the task, so model improvements might not be tracked. On the other hand, one could argue that for tasks like multi-step arithmetic, partially getting the answer right is just as useless as getting it completely wrong.
The question of what abilities are emergent is still being explored in the research community. In Chapter 5, we will discuss its implications for selecting the right model for our desired use case.
Warning
Unfortunately the phrase ‘emergent properties’ has multiple meanings in the literature. In some papers, the phrase is used to describe those capabilities that the model is not explicitly trained for. In this book, we will stick to Wei et al.’s definition.
To understand how current LLMs came to be, it is instructive to walk through a brief history of LLMs. As more historical details are out of scope for the book, we will provide links to external resources for further reading throughout the section.
A Brief History of LLMs
In order to present the history of LLMs, we need to start from the history of NLP (Natural Language Processing), the field that LLMs originated from. For a more detailed history of NLP, refer to Daniel Jurafsky’s seminal book on NLP.
Early years
The field traces its origins to the 1950s, driven by demand for machine translation, the task of automatically translating from one language to another. The early days were dominated by symbolic approaches; these were rule-based algorithms based on linguistic theories influenced by the works of linguists like Noam Chomsky.
In the mid-1960s, Joseph Weizenbaum released ELIZA, a chatbot program that applied pattern matching using regular expressions on the user’s input and selected response templates to generate an output. ELIZA consisted of several scripts, the most famous one being DOCTOR, that simulated a psychotherapist. This variant would respond by rephrasing the user’s input in the form of a question, similar to how a therapist would. The rephrasing was performed by filling in pre-defined templates with pattern matched words from the input.
As an example:
User:‘Iamnotfeelingwell’
ELIZA:‘Doyoubelieveitisnormaltobenotfeelingwell?’
You can try chatting with ELIZA online. Even in the era of ChatGPT, ELIZA can hold a somewhat convincing conversation, despite the fact that it is just rules-based.
Rule-based systems are brittle, hard to construct, and a maintenance nightmare. As the decades rolled by, the limitations of symbolic approaches became more and more evident, and the relative effectiveness of statistical approaches ensured that they became more commonplace. NLP researcher Frederik Jelinek famously quipped
Every time I fire a linguist, the performance of the speech recognizer goes up.
Frederik Jelinek
Machine learning based approaches became more widely used in the 1990s and 2000s. Traditional machine learning relied on human-driven feature engineering and feature selection, the process of identifying features that are predictive to solve a task. These features could be statistical like the average word length, or linguistic, like parts of speech.To learn more about traditional statistical NLP, I recommend reading Christopher Manning’s book.
The relevance of linguistics to modern day NLP application development is a point of debate. Many university courses on NLP have completely dropped content related to linguistics. Even though I don’t directly use linguistics in my work, I find that I rely on them more often than I expect to develop intuitions about model behavior and task decomposition. As such, I recommend Emily Bender’s books on syntax and semantics to understand the basics of this field.
The 2010s saw the advent of deep learning and its widespread impact on NLP. Deep learning is characterized by multi-layer neural network models that learn informative features by itself given raw input, thus removing the need for cumbersome feature engineering. Deep learning forms the foundation for modern NLP and LLMs. While a deeper treatment of the fundamentals of this subject is beyond the scope of this book, Appendix A provides a short primer to deep learning. To dig deeper into the principles of deep learning and neural networks, I recommend reading Goodfellow et al.’s book. For more hands-on deep learning training, I recommend Zhang et al.’s Dive into Deep Learning.
During the early years of deep learning, it was customary to construct a task-specific architecture to solve each task. Some of the types of neural network architectures used include multi-layer perceptrons, convolutional neural networks, recurrent neural networks, and recursive neural networks. To learn more about this era of NLP, I recommend reading Yoav Goldberg’s book on Neural NLP.
The modern LLM era
In 2017, the Transformer architecture was invented, quickly followed by the invention of efficient transfer learning techniques pioneered by Howard et al. among others and Transformer-based language models like BERT. These advances removed the need for constructing complex task-specific architectures. Instead, one could use the same Transformer model to train a variety of tasks. This new paradigm divided the training step into two stages: pre-training and fine-tuning. An initial large scale pre-training step initialized the Transformer model with general language capabilities. Subsequently, the pre-trained model could be trained on more concrete tasks, like information extraction or sentiment detection, using a process called fine-tuning. We will cover fine-tuning extensively throughout the book.
While academia and open-source collectives have made crucial and critical contributions to language modeling, large tech companies like OpenAI, Google, Meta, and Anthropic have taken the lead in training and releasing progressively larger LLMs. OpenAI in particular has played a pioneering role in advancing language modeling technology. The trajectory of the evolution of LLMs in the modern era can be traced through the advances ushered in by each version of the GPT (Generative Pre-trained Transformer) family of models trained by OpenAI.
-
GPT-1 - This version demonstrated unsupervised pre-training on large scale data, followed by task-specific supervised fine-tuning.
-
GPT-2 - This version was one of the first models to be trained on large-scale web data. This version also marked the rise of natural language prompting as a means to interact with a language model. It showed that pre-trained models could solve a variety of tasks zero-shot (solving a task without needing any examples) without any task-specific fine-tuning. We will discuss zero-shot and prompting in detail later in this chapter.
-
GPT-3 - Inspired by the scaling laws, this model is a hundred times larger than GPT-2 and popularized in-context/few-shot learning, where the model is fed with a few examples on how to solve a given task in the prompt, without needing to fine-tune the model. We will learn more about few-shot learning later in this chapter.
-
GPT-4 - A key aspect of this release is the alignment training used to make the model more controllable and adhere to the principles and values of the model trainer. We will learn about alignment training in Chapter 7.
-
o1 - This is a new family of models released by OpenAI, that focuses on improving its reasoning capabilities. This is one of the first models to focus on scaling inference-time computation. We will discuss more about inference-time computation in Chapter 9.
You might have noticed a trend here; through the years, the field has been experiencing a consolidation effect, with more and more parts of the NLP task pipeline being performed end-to-end, i.e. by a single model. Throughout this book, we will point out the consolidation effect where it is apparent, and discuss its implications for the future of LLMs.
A history of LLMs wouldn’t be complete without mentioning the impact of open source contributions to this field. Open source models, datasets, model architectures, and various developer libraries and tools have all had significant impacts on the development of this field. This book places a special importance on open-source, providing a thorough survey of the open-source LLM landscape and showcasing many open-source models and datasets.
Next, let’s explore how LLMs are being adopted and their impact on society.
The impact of LLMs
The tech world has long been susceptible to hype cycles, with exhilarating booms and depressing busts. More recently, we have witnessed the crypto/blockchain and Web3 booms, both of which are yet to live up to their promise. Is AI heading towards a similar fate? We have hard evidence that it is not.
At my company Hudson Labs, we analyzed discussions in the quarterly earnings calls of the 4000 largest publicly listed companies in the United States to track adoption of crypto, Web3, and AI in the enterprise.
We observed that 85 companies discussed Web3 in their earnings calls, with even fewer tangibly working on it. Crypto fared better, with 313 companies discussing it. Meanwhile, LLMs were discussed and adopted by 2,195 companies, meaning that at least 50% of America’s largest public companies are not only using LLMs to drive value, but it is also strategically so important to them as to merit discussion in their quarterly earnings call. Effective or not, LLM adoption in the enterprise is already a reality.
Figure 1-2 shows the number of companies discussing Web3 in their earnings calls over time. As you can see, the Web3 hype seems to be tapering off.
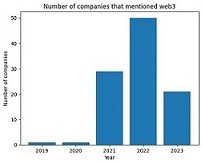
Figure 1-2. Companies that discussed Web3 in their earnings calls across time.
Similarly, Figure 1-3 shows the number of companies discussing crypto/blockchain in their earnings calls over time. As you can see, this is also a declining trend.
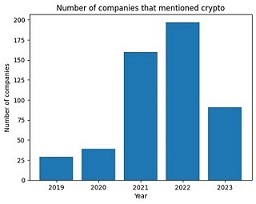
Figure 1-3. Companies that discussed crypto in their earnings calls across time.
Finally, let’s look at AI. As mentioned before, AI has reached amounts of adoption in the enterprise that no other recent technology trend has managed to in the recent past. The trend is only accelerating, as shown in Figure 1-4, which shows the number of companies at which AI was discussed during the earnings calls in just the first two months of the year. The sharp spike in 2024 shows that the trend is only growing.
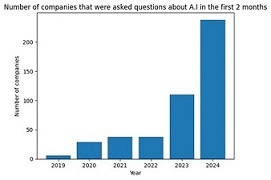
Figure 1-4. Companies that were asked questions about AI in their earnings calls during the first two months of the year
Note that these statistics only include Generative AI/LLM adoption and not data science/data analytics, whose adoption is even more ubiquitous in the enterprise. AI adoption is also not just limited to tech companies, with companies ranging from real estate companies to insurance firms joining in on the fun.
LLM usage in the enterprise
From the same analysis, we observed the key ways in which LLMs are used in the enterprise:
-
Employee Productivity: The primary means by which employee productivity has improved through LLM usage is with coding assistants like Github Copilot. LLMs are also widely used to help draft marketing and promotional text and automate marketing campaigns. In fact, the first major commercial success stories of LLMs were marketing startups like Jasper.ai and Copy.ai. Another key LLM-driven productivity enhancement is question answering assistants over a company’s extensive knowledge base drawn from heterogeneous data sources.
-
Report Generation: These include summarization tasks, completing mundane paperwork, and even drafting contracts. Examples of summarization tasks include summarizing financial reports, research papers, or even meeting minutes from audio or call transcripts.
-
Chatbots: LLM-driven chatbots are being increasingly deployed as customer service agents. They are also being used as an interface to a company’s documentation or product page.
-
Information Extraction and Sequence Tagging: Over the years, a large number of enterprises have developed complex NLP (Natural Language Processing) pipelines for language processing tasks. Many of these pipelines are being fully or partially replaced by an LLM. These pipelines are used to solve common NLP tasks like sentiment analysis, information extraction tasks like entity extraction and relation extraction, and sequence tagging tasks like named entity recognition. For a detailed list of NLP tasks and their description, see Fabio Chiusano’s blog
-
Translation: Translation tasks not only include translating text from one language to another, but also includes tasks where text is converted to a different form but in the same language, for example, converting informal text to formal text, abusive text to polite text and so on. Real-time translation apps like Erudite’s Instant Voice Translate promise to make language barrier driven embarrassing moments for tourists a thing of the past.
-
Workflows: LLMs are gradually being used to facilitate workflow automation, where a sequence of tasks can be performed by LLM-driven software systems, called agents. Agents can interact with their environment (search and retrieve data, run code, connect to other systems etc) and potentially operate autonomously. We will more formally define agents and explore how to build them in detail in Chapter 11.
Prompting
Now that we have our fundamentals in place, let’s begin learning how to effectively use LLMs.
The process by which you interact with an LLM is called prompting. Even though some companies attempt to anthropomorphise LLMs by giving them a name or a persona, it is good to always remember that when you are interacting with an LLM, you are prompting them and not chatting with them as you would with a human being. Remember that LLMs are next word predictors. This means that the text they generate is heavily dependent on the text they are fed, which includes the input (called the prompt) and the output tokens generated so far by the model. This is collectively called the context.
By feeding the LLM the right text in the context, you are priming it to generate the type of output you need. The ideal prompt would be the answer to this question - What would be the best prefix of N tokens that when fed to an LLM, will lead it to generate the correct answer with the highest probability?
As of the book’s writing, language models simply aren’t smart enough for you to prompt a model exactly the way you would speak to a human and expect best results. As language models get better over time, prompts can become more human-conversation-like. Those of you who have been around during the early days of search engines might recall that effectively using a search engine by entering the right form of queries was seen as a skill that is not trivial to acquire, but as search engines got better, search queries could become more free form.
When I started writing this book, I solicited opinions from the target readership on the topics they would like covered in this book. The most number of requests I received were on the topic of prompting, with practitioners wanting to understand how to effectively create prompts for their specific use cases.
Indeed, prompting is an important aspect of modern day LLMs. In fact, you will probably end up spending a significant amount of your time on any LLM-based project iterating on prompts, very inaccurately referred to as prompt engineering.
Tip
There have been attempts to automatically optimize prompts, like APO (Automatic Prompt Optimization) and AutoPrompt. We will discuss this further in Chapter 13.
It is important to manage one’s expectations on the effectiveness of prompt engineering. Prompts aren’t magical incantations that unlock hidden LLM capabilities. It is very unlikely that there are companies who have a significant advantage over others just by using a superior prompting technique unknown to others. On the flip side, not following basic prompting principles can severely hamper the performance of your LLM.
There are umpteen prompting tutorials available online. I recommend learningprompting.org’s prompting guide in particular. You do not need to know all the prompting techniques to become well-versed in prompting. Most of what you need to know about prompting can be learned in a couple of hours. What matters more is interacting with the LLMs you use frequently to observe their outputs and developing an intuition on their behavior.
If you have programming experience, I suggest viewing prompting through the lens of programming. In programming, instructions need to be explicit with no room for ambiguity. The challenge with prompting is that it is done in natural language, which is inherently ambiguous. Still, the best prompts state instructions as explicitly and as detailed as possible in a structured form, leaving very little room for ambiguity.We will learn more prompting nuances in Chapter 5 and Chapter 13.
Note
Here is a fun fact: language models are insensitive to word order. This property has been observed even in earlier models like BERT. For example, ask ChatGPT or your favorite LLM provider the question How do I tie my shoe laces? in jumbled form, say shoe tie my I how do laces? ChatGPT responds with Certainly! Here are step-by-step instructions on how to tie your shoelaces: … as if you asked a straight-forward question. In Chapter 4, we will see why this happens.
Next, let’s go through a few types of prompting modes:
Zero-shot prompting
This is the standard approach to prompting, where you provide the LLM with an instruction and optionally, some input text. The word zero-shot refers to the fact that there are no examples or demonstrations provided on how to solve the task.
Consider an example where your task is to assess the sentiment expressed in a restaurant review. To achieve this through zero-shot prompting, you can issue the following prompt:
“Classify the given passage according to its sentiment. The output can be one of Positive, Negative, Neutral. Passage: ‘The mashed potatoes took me back to my childhood school meals. I was so looking forward to having them again. NOT!’ Sentiment:”
A good zero-shot prompt will:
-
Provide the instruction in a precise and explicit manner.
-
Describe the output space or the range of acceptable outputs and output format. In this example, we mention the output should be one of three values.
-
Prime it to generate the correct text. By ending the prompt with Sentiment:, we are increasing the probability of the LLM generating the sentiment value as the next token.
In real-world settings, your output format needs to be highly controllable, in order for it to fit in automated systems. We will discuss more techniques for ensuring controllability of outputs in Chapter 5.
Warning
Prompts are sensitive to model changes. You might painstakingly construct a prompt that seems to work well, but you might notice that the same prompt does not work for a different model. In fact, the same prompt might see degraded performance on the same API endpoint if the underlying model is updated in the meanwhile. We call this prompt drift. It is a good idea to version control prompts, and we will discuss tools to facilitate this in Chapter 5.
Few-shot prompting
In our example for zero-shot prompting, the LLM was able to solve the task without explaining it how to solve it. This is because the task is simple and clearly defined. In many cases, the tasks might be not so easy to describe in natural language. We can then add some examples in our prompt consisting of either outputs or input-output pairs. While this is called few-shot learning colloquially, the language model is not updated in any way through this prompting technique.
Here is an example for few-shot prompting:
‘A palindrome is a word that has the same letters when spelled left to right
or right to left.
Examples of words that are palindromes: kayak, civic, madam, radar
Examples of words that are not palindromes: kayla, civil, merge, moment
Answer the question with either Yes or No
Is the word rominmor a palindrome?
Answer:'
Chain-of-Thought prompting
If you are going to learn only one prompting technique, let that be chain-of-thought prompting, because it is one of the most impactful prompting techniques in existence.
As discussed earlier, the context of the LLM determines the next token predicted by it. Therefore, we need to optimize the content in the context (the user prompt + output tokens generated so far) to maximize the probability of the LLM generating the right future tokens. One way to do it is to prompt the LLM to think before generating. This elicits the LLM to generate the process to get to the answer instead of directly generating the answer. This might involve breaking the input task into subtasks and solving them one after the other.
When the LLM is eventually at the cusp of generating the answer, it can rely on a more relevant context that increases its probability of generating the right answer. We will call the initial text generated by the LLM as scratchpad text.
As an example, consider the following example:
'Solve the equation. 34 + 44 + 3 * 23 / 3 * 2. Think step by step.'After receiving the instruction Think step by step, the LLM then breaks down the problem and solves them individually.
Givenequation:34+44+3*23/3*2First,performmultiplicationanddivisionfromlefttoright:=34+44+(3*23/3*2)=34+44+(69/3*2)=34+44+(23*2)=34+44+46Now,performaddition:=78+46Finally,completetheaddition:=124So,thesolutiontotheequationis124.
Tip
Many LLMs these days solve tasks step-by-step without being explicitly prompted to. This is because they have been instruction-tuned to do so. We will learn more about instruction-tuning in Chapters 5 and 6. LLMs that have been instruction-tuned are easier to prompt.
In the case of LLMs accessible through a user interface, there might be a hidden prompt (called a system prompt) by the LLM provider that applies chain-of-thought prompting to relevant user prompts.
Should we add the ‘Think step-by-step’ chain-of-thought instruction for every prompt, like a cheat code to a game? Sprague et al. evaluated CoT prompting over a wide variety of tasks and found that chain-of-thought primarily helps with tasks that need mathematical or logical reasoning. Meanwhile for tasks involving common sense reasoning, they found that gains by CoT are limited. For knowledge based tasks, CoT might even hurt.
Note that arithmetic and logical reasoning could also be performed by delegating it to external tools like symbolic solvers and code interpreters. We will discuss this in detail in Chapter 11.
Warning
Using chain-of-thought prompting significantly increases the number of tokens generated by the model in order to solve a task, leading to higher costs.
Prompt chaining
Oftentimes, your tasks might need multiple steps and a large number of instructions. One way to go about this is by stuffing all the instructions into a single prompt. An alternative is to break down the task into multiple subtasks, and chain the prompts such that the output of one prompt determines the input to another. I have observed that prompt chaining consistently performs better than managing the entire task through a single prompt.
As an example, consider the task of extracting information from the text provided in the form and formatting the output in a structured manner. If there are missing or outlier values, then some special post processing rules are to be applied. In this case, it is good practice to split the task into two prompts, with the initial prompt performing the information extraction and the second prompt handling the post processing of the extracted information.
Adversarial Prompting
You might notice that for some queries, the LLM declines to execute your request. This is because it has been specifically trained to refuse certain kinds of requests (We will learn how to achieve this behavior in Chapter 7). This kind of training, which we will call alignment training, is imparted to the model to align it with the values and preferences of the entity developing the model.
For example, asking any decent LLM directly for instructions to build a bomb will result in a refusal. However, as of today, alignment training only provides a weak layer of security, as it can be bypassed by cleverly prompting the LLM, called adversarial prompting. Adversarial prompts can be generated either manually or using algorithms. These cleverly phrased prompts ‘trick’ the LLM into generating a response even if it was trained not to.
These clever prompting schemes are not just useful for illicit purposes. In many cases, the LLM simply does not respond the way you want it to, and clever prompting schemes might help. These clever prompting schemes range from asking the LLM to adopt a specific persona to outright emotional blackmail (‘If you don’t respond correctly to this query, many children will suffer!'). While there has been some work showing that adding emotion to a prompt may lead to better performance, there is no hard and sustained evidence that this is universally effective for a given model. Thus, I would not necessarily recommend using these in production applications.
Accessing LLMs through an API
You most likely have already interacted with an LLM through a chat interface like ChatGPT, Gemini, or Claude. Let’s now explore how to access them using the API. We will use the Open AIAPI as an example to access their GPT family of models. Most other proprietary models expose similar parameters through their API.
GPT-4o-mini and GPT-4o can be accessed through OpenAI’s Chat Completion API. Here is an example:
importosimportopenaiopenai.api_key=<INSERTYOURKEYHERE>output=openai.ChatCompletion.create(model="gpt-4o-mini",messages=[{"role":"system","content":"You are an expert storywriter."},{"role":"user","content":"Write me a short children's storyaboutadogandanelephantstoppingbeingfriendswitheachother."}])(output.choices[0].message)
Roles can be either system, user, assistant, or tool.
-
The system role is used to specify an overarching prompt.
-
The user role refers to user inputs
-
The assistant role refers to the model responses
-
The tool role is used to interact with external software tools.
We will discuss tools in more detail in Chapter 11.
Note
What is the difference between the system and user roles? Which instructions should go into the system prompt and which ones into the user prompt? System prompts are used for dictating the high-level overarching behavior of an LLM, like You are a financial expert well versed in writing formal reports. If you are allowing your users to directly interact with the LLM, then the system prompt can be used to provide your own instruction to the LLM along with the user request. In my experiments I have noticed that it doesn’t matter much if you place your instructions in the system prompt vs user prompt. What does matter is the length and number of instructions. LLMs typically can handle only a few instructions at a time. Instructions at the end or the beginning of the prompt are more likely to be adhered to.
Here are some of the parameters made available by Open AI:
n - This refers to the number of completions the model has to make for each input. As an example, if we used n=5 in the given example, it would generate five different children’s stories.
Tip
For tasks with high reliability requirements, I advise generating multiple completions; i.e. n>1 and then using a postprocessing function (which could involve an LLM call) to choose the best one. This is because the generated text is sampled from a probability distribution output by the LLM, and in some cases the answer might be wrong/bad just due to an unlucky token sampling. You might have to balance this process against your budget limitations.
stop and max_completion_tokens - These are used to limit the length of the generated output. stop allows you to specify end tokens which if generated, would stop the generation process. An example stop sequence is the newline token. If you ask the model to adhere to a particular output format, like a numbered list of sentences, then in order to stop generating after a particular number of sentences have been output, you can just provide the final number as a stop parameter.
presence_penalty and frequency_penalty - These are used to limit the repetitiveness of the generated output. By penalizing the probability for tokens that have already appeared in the output so far, we can ensure that the model isn’t being too repetitive. These parameters can be used while performing more creative tasks.
logit_bias - Using logit_bias, we can specify the tokens for which we would like to increase or decrease the probability of them being generated.
top_p and temperature - Both these parameters relate to decoding strategies. LLMs produce a distribution of token probabilities, and will sample from this distribution to generate the next token. There are many strategies to choose the next token to generate given the token probability distribution. We will discuss them in detail in Chapter 5 and Chapter 9. For now, just remember that a higher temperature setting results in more creative and diverse outputs, and a lower temperature setting results in more predictable outputs. This cheat sheet provides some recommended values for various use cases.
logprobs - This provides the most probable tokens for each output token along with their log probabilities. OpenAI limits this to the top 20 most probable tokens only. In Chapter 5, we will discuss how we can leverage logprobs information in various forms.
Strengths and limitations of LLMs
Developing an intuition on the strengths and limitations of LLMs is a crucial skill in being able to build useful LLM applications. Through the course of this book, and with ample hands-on practice, I hope you will be able to build that intuition. In general, LLMs are proficient at language tasks. You will almost never see them make spelling or grammar errors. They are also a vast improvement over previous techniques for understanding user instructions and intent. They also exhibit state-of-the-art performance on most NLP tasks like entity and relationship extraction and named entity recognition. They are also particularly strong at generating code, which is where LLMs have arguably found their greatest success through tools like Github Copilot.
Most LLM limitations boil down to the fact that they are just not intelligent enough. Even state-of-the-art models suffer from significant limitations in various forms of reasoning, including arithmetic reasoning, logical reasoning, and common sense reasoning. (We will define reasoning more formally in Chapter 9). LLMs are also unable to adhere to factuality, because of their lack of connection to the real world. Therefore, they tend to generate text that might be inconsistent with the facts and principles in the real world, which are colloquially termed as hallucinations. Hallucination is the bane of LLMs and one of the key reasons for hesitations in adopting them. In Chapter 9, we will engage in a deep dive into various methods to tackle hallucinations and address reasoning limitations.
Tons of LLM-generated articles are being generated every day and uploaded to the Web, and many of them make their way to the top of search engine results. For example, for a short while, for the query Can you melt eggs?, Google showed Yes, an egg can be melted, due to an AI-generated web page containing the incorrect answer. This kind of text is colloquially referred to as ‘AI slop’. Thus, there is a very strong incentive for search engines to accurately detect AI-generated text. Note that since LLMs are primarily trained on Web text, future LLMs can be contaminated by polluted text as well.
While LLMs are frequently used as an aid in creative tasks, they are nowhere near the level of professional authors. A fiction book authored by current LLMs is still unlikely to be a bestseller. LLM-generated text lacks the sheer ingenuity and the ability to evoke human emotions that human authors possess. Once you have read through enough LLM generated text, it is not that difficult to spot it.
Every LLM generates text with a distinct signature, some more apparent to humans than others. For example, you might have noticed that ChatGPT has a tendency to overuse certain words like delve, tapestry, bustling etc. ChatGPT also tends to generate sentences with an explanatory final clause, like He ate the entire pizza, indicating he was hungry. or The vampire sent a thousand text messages in a month, suggesting effective use of digital technologies. However, it is extremely hard to detect AI-generated text with 100% accuracy. Bad actors are also employing evasion techniques, for instance by asking another LLM to rephrase LLM-generated text so as to dilute the signature of the original LLM.
Thus, plagiarism detection has become even more challenging. There have also been cases of students being unfairly accused of plagiarism due to inaccurate AI-text detectors. These trends are prompting universities worldwide to rethink the means through which students are evaluated, depending less on essays. Students are one of the heaviest users of LLM products, as showcased by a decline in ChatGPT usage numbers during summer months.
While words like ‘delve’ etc are known to be overused by LLMs, single-token frequencies should not be relied upon as a means of detecting LLM generated text. Having grown up in India learning Indian English, the word ‘delve’ appears in my vocabulary a lot more frequently than the average Westerner, and this can be found in my writing and publications well before the launch of ChatGPT. These nuances show that more robust techniques need to be developed to discover LLM generated text.
One promising approach uses syntactic templates. A syntactic template is a sequence of tokens having a particular order of POS tags, typically of length 5-8 tokens. Shaib et al. show that some of these templates appear in generated text even when decoding strategies aimed to increase token diversity are used. They show that these templates are learned during the early stages of the pre-training process.
An example template is: VBN IN JJ NNS: VBN (Past Participle Verb) + IN (Preposition) + JJ (Adjective) + NNS (Plural Noun)
Some phrases that follow this template include:
Engaged in complex tasks Trained in advanced techniques Entangled in deep emotions Immersed in vivid memories
Have you noticed any LLMs frequently using/over-using this template?
Building your first chatbot prototype
Next, let’s get into the weeds already and start building!
Over the last couple of years, a healthy ecosystem of libraries has propped up that has made experimenting and prototyping LLM applications so much easier. In fact, you can build a Chat with your PDF question answering chatbot in just around a hundred lines of code!
Let’s implement a simple application that allows the user to upload a PDF document, and provides a chat interface through which the user can ask questions about the content of the PDF and receive responses in a conversational manner.
The intended workflow for this application is as follows:
-
The user uploads a PDF of their choice through the user interface.
-
The application parses the PDF using a PDF parsing library and splits the extracted text into manageable chunks.
-
The chunks are converted into vector form, called embeddings.
-
When a user issues a query through the chat interface, the query is also converted into vector form.
-
The vector similarity between the query vector and each of the chunk vectors is calculated.
-
The text corresponding to the top-k most similar vectors are retrieved.
-
The retrieved text is fed along with the query and any other additional instructions to an LLM
-
The LLM uses the given information to generate an answer to the user query.
-
The response is displayed on the user interface. The user can now respond (clarification question, new question, gratitude etc.)
-
The entire conversation history is fed back to the LLM during each turn of the conversation.
Figure 1-5 shows how this workflow looks like.
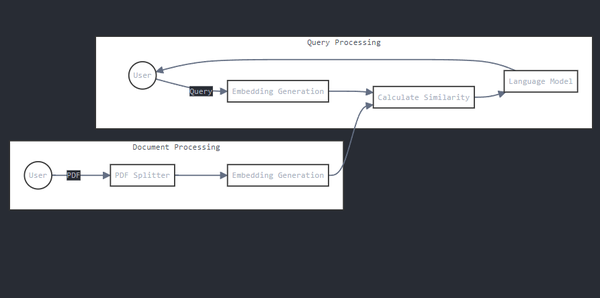
Figure 1-5. Workflow of a chatbot application
Let’s begin by installing the required libraries. For this set up, we are going to use:
-
LangChain: This very popular framework enables building LLM application pipelines.
-
Gradio: This library allows you to build LLM-driven user interfaces
-
Unstructured: This is a PDF parsing suite that supports a variety of methods for extracting text from PDFs.
-
Sentence-Transformers: This is a library facilitating embeddings generation from texts
-
Open AI: This API provides access to the GPT* family of models from Open AI.
Let’s import the required libraries and functions.
!pipinstallopenailangchaingradiounstructuredfromlangchain_community.document_loadersimportUnstructuredPDFLoaderfromlangchain_community.embeddingsimportHuggingFaceEmbeddingsfromlangchain_community.vectorstoresimportChromafromlangchain.chainsimportConversationalRetrievalChainfromlangchain.chat_modelsimportChatOpenAIimportgradioasgr
Next, let’s implement the PDF loading and parsing function. LangChain supports several PDF parsing libraries. PDF parsing can be performed in a variety of ways, including using LLMs. For this example, we will choose the Unstructured library.
loader=UnstructuredPDFLoader(input_file.name)data=loader.load()
The data variable contains the parsed PDF that has been split into paragraphs. We will refer to each paragraph as a chunk. Each chunk is now converted into its vector representation using an embedding model. LangChain supports a wide variety of embedding models. For this example, we will use the all-MiniLM-L6-V2 variant of sentence-transformer embeddings, available through the HuggingFace platform.
embeddings=HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
Now that we have loaded the embedding model, we can generate the vectors from the data and store them in a vector database. Several vector database integrations are available on LangChain. We will use Chroma for this example, as it is the simplest to use.
db=Chroma.from_documents(data,embeddings)
Now, the vector database is ready with the vectors! We can ask queries and get responses. For instance,
query = "How do I request a refund?" docs = db.similarity_search(query) print(docs[0].page_content)
This code retrieves the paragraph in the PDF whose vector is most similar to the vector representing the user query. Since vectors encode the meaning of the text, this means that the paragraph representing the similar vector has content similar to the content of the query.
Note that it is not guaranteed that the paragraph contains the answer to the query. Using embeddings, we can only get text that is similar to the query. The matched text need not contain the answer or even be relevant to answering the query.
We will depend on the LLM to distinguish between irrelevant and relevant context. We provide the LLM with the query and the retrieved text and ask it to answer the query given the provided information. This workflow can be implemented using a chain in LangChain.
conversational_chain=ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.1),retriever=pdfsearch.as_retriever(search_kwargs={"k":3}))
We use the ConversationalRetrievalChain, which supports the following workflow:
-
Takes the previous conversational history if it exists, and the current response/query from the user and creates a standalone question.
-
Uses a chosen retrieval method to retrieve top-k most similar chunks to the question
-
Takes the retrieved chunks, the conversational history, the current user/response query, instructions and feeds it to the LLM. The LLM generates the answer.
We can call the chain and append the result to the chat history as thus:
output=conversational_chain({'question':query,'chat_history':conversational_history})conversational_history+=[(query,output['answer'])]
Our chatbot is ready. Let’s wrap it up by connecting it with a user interface. We will use Gradio, a light-weight Python framework for building LLM-driven user interfaces.
withgr.Blocks()asapp:withgr.Row():chatbot=gr.Chatbot(value=[],elem_id='qa_chatbot').style(height=500)withgr.Row():withgr.Column(scale=0.80):textbox=gr.Textbox(placeholder="Enter text").style(container=False)withgr.Column(scale=0.10):upload_button=gr.UploadButton("Upload a PDF",file_types=[".pdf"]).style()
We need some more code for writing the event handlers that wait for user events. Refer to the full code on the book’s Github repo.
Finally, we initialize the application.
if __name__ == "__main__":
app.launch()[source,python]
Our chatbot application is ready!
From prototype to production
Is building LLM applications that easy? Unfortunately not. We have built a prototype, and a decent one at that. In fact, for many non-critical use cases, the performance of this application might even be sufficient. However, a large number of use cases demand accuracy and reliability guarantees that this application is not able to meet. This book aims to address the gap between prototype and production.
In the prototype tutorial, we treated LLMs as a black box. But if you are building serious applications using LLMs, it is important to understand what happens under the hood, even if you might never train an LLM yourself. Therefore, in Chapters 2, 3, and 4, we will walk through each of the ingredients that go into making an LLM and show how they are trained. Developing a strong understanding of what LLMs are made of and how they are trained will come in handy while debugging failure modes.
In the tutorial, we used a proprietary LLM from OpenAI, without putting much thought into whether it is the optimal LLM to use for the application. Today, there are hundreds or even thousands of LLMs available for commercial use. In Chapter 5, we will explore the LLM landscape, covering both open source and proprietary models, the relevant dimensions along which models differ, and how to choose the right model that satisfies the criteria for a given use case. For example, one of the criteria for our PDF chatbot might be to operate within a severe budgetary restriction. We will learn how to evaluate LLMs and assess their limitations and capabilities with respect to a given use case, develop custom evaluation metrics and benchmark datasets, and understand the pitfalls involved in both automated evaluation and human evaluation.
What if the PDFs we intend to upload to the PDF chatbot belong to a specialized domain which the LLM doesn’t seem to be adept at? What if the LLM is unable to follow the instructions mentioned in user queries? We might need to update the parameters of the model by fine-tuning it over data from the specialized domain. In Chapter 6, we will introduce model fine-tuning, understand the scenarios in which it might be useful, and demonstrate how to construct a fine-tuning dataset.
It is possible that standard fine-tuning might not be suitable for our purposes. Maybe it is too expensive, or ineffective. In Chapter 7, we will learn about techniques like parameter-efficient fine-tuning that update only a small subset of the parameters of the model. We will also explore reinforcement learning based methods, especially in the context of alignment training that aims to make the model more controllable.
We may notice that our chatbot is hallucinating, or that it is facing difficulty answering questions because of faulty reasoning. In Chapter 8, we will discuss methods for enhancing reasoning capabilities, including various inference-time compute techniques.
A production-grade PDF chatbot will need to satisfy a lot of non-functional requirements, including minimizing latency (the time the user needs to wait for the model response), and cost. In Chapter 9, we will discuss various techniques for inference optimization, including caching, distillation, and quantization.
In the tutorial, we showed a rudimentary method to parse, chunk, and embed documents. But during usage, we might notice that the vector similarity might be ineffective and often returns irrelevant document chunks. Or that the retrieved chunks do not contain all the information within them to answer the query. In Chapter 10, we will explore embeddings in more detail, and learn how to fine-tune our own embeddings. We will also show how to more effectively chunk our data.
We might want to extend the functionality of our chatbot by connecting the LLM to code interpreters, databases, APIs etc. We might also want the chatbot to answer complex queries that need to be broken down into multiple steps. In Chapter 11, we will explore how to interface LLMs with external tools and data sources and enable LLMs to break down tasks, make autonomous decisions, and interface with their environment.
The PDF chatbot follows a paradigm called RAG (Retrieval Augmented Generation). RAG refers to systems where LLMs are connected to external data sources, like the PDFs uploaded by users in our chatbot use case. In Chapter 12, we will define a comprehensive RAG pipeline and learn how to architect robust RAG systems.
Finally, in Chapter 13 we will discuss design patterns and programming paradigms for developing LLM applications, and explore the scaffolding software that needs to be built around these applications to develop robust and reliable systems, including guardrails and verification modules.
These topics and more will be covered in the rest of the book. I am excited to go along this journey with you, hopefully providing you with the tools, techniques, and intuition to develop production-grade LLM applications!
Summary
In this chapter, we introduced language models, provided a brief history, and discussed the impact they are already having on the world. We showed how to effectively interact with the model, by introducing various prompting techniques. We also gave a high level overview of the strengths and limitations of language models. We showed how easy it is to build prototype applications and highlighted the challenges involved in taking it to production. In the next chapter, we will begin our journey into the world of LLMs by introducing the ingredients that go into making an LLM.
Get Designing Large Language Model Applications now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

