Capítulo 4. El almacén de datos relacional
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
A mediados de la década de 2000, llevaba años utilizando bases de datos relacionales, pero nunca había estado expuesta a los almacenes de datos relacionales. Trabajaba como administrador de bases de datos (DBA) para una empresa que utilizaba un paquete de software de contabilidad para gestionar sus transacciones financieras. Los informes del paquete eran limitados y lentos, por lo que la empresa quería mejorar el rendimiento, crear cuadros de mando para dividir los datos y combinar sus datos financieros con los de una aplicación propia para comprender mejor el negocio.
Mi jefe contrató a una empresa de consultoría para construir una cosa llamada "almacén de datos relacional" y, en una decisión que cambió el curso de mi carrera, me pidió que le ayudara. Generamos cuadros de mando que ahorraron mucho tiempo a los usuarios finales y añadieron perspectivas empresariales que nunca antes habían tenido. Cuando vi la emoción en sus caras, supe que había encontrado mi nueva pasión. Cambié de carrera para centrarme en el almacenamiento de datos y nunca miré atrás.
¿Qué es un almacén de datos relacional?
Un almacén de datos relacional (RDW) es el lugar donde se almacenan y gestionan de forma centralizada grandes volúmenes de datos estructurados copiados de múltiples fuentes de datos para utilizarlos en la elaboración de informes históricos y de análisis de tendencias, de modo que tu empresa pueda tomar mejores decisiones empresariales. Se llama relacional porque se basa en el modelo relacional, un enfoque ampliamente utilizado para la representación y organización de datos para bases de datos. En el modelo relacional, los datos se organizan en tablas (también conocidas como relaciones, de ahí el nombre). Estas tablas constan de filas y columnas, donde cada fila representa una entidad (como un cliente o un producto) y cada columna representa un atributo de esa entidad (como el nombre, el precio o la cantidad). Se denomina almacén de datos porque recopila, almacena y gestiona volúmenes masivos de datos estructurados procedentes de diversas fuentes, como bases de datos transaccionales, sistemas de aplicaciones y fuentes de datos externas.
No todos los almacenes de datos se basan en el modelo relacional. Los almacenes dedatos no relacionales incluyen tipos como los almacenes de datos columnares, NoSQL y gráficos. Sin embargo, los almacenes de datos relacionales son mucho más populares y ampliamente adoptados, principalmente porque las bases de datos relacionales han sido el paradigma de gestión de datos dominante durante décadas. El modelo relacional es muy adecuado para los datos estructurados, que suelen encontrarse en las aplicaciones empresariales. También es popular debido al uso generalizado de SQL, que ha sido el lenguaje estándar para los almacenes de datos relacionales durante muchos años.
Un RDW actúa como repositorio central para muchas áreas temáticas y contiene la versión única de la verdad (SVOT). Concepto crítico en el almacenamiento de datos, la SVOT se refiere a la práctica de crear una visión unificada y coherente de los datos de una organización. Significa que todos los datos del almacén de datos se almacenan en un formato estandarizado y estructurado, y representan una versión única y exacta de la información. Esto garantiza que todos los usuarios tengan acceso a la misma información, eliminando cualquier discrepancia o incoherencia y suprimiendo los silos de datos. Esto mejora la toma de decisiones, la colaboración y la eficacia en toda la organización. También reduce el riesgo de errores y malentendidos que pueden surgir al trabajar con fuentes de datos dispares e incoherentes.
Imagina que no tienes un almacén de datos y estás generando informes directamente a partir de múltiples sistemas fuente, y quizá incluso de algunos archivos de Excel. Si el usuario de un informe cuestiona la exactitud de los datos, ¿qué puedes decirle? La "verdad" puede estar repartida en tantos sistemas fuente que es difícil rastrear de dónde proceden los datos. Además, algunos informes darán resultados diferentes para los mismos datos; por ejemplo, si dos informes utilizan una lógica compleja para extraer los datos de varias fuentes y la lógica se actualiza incorrectamente (o no se actualiza en absoluto). Tener todos los datos en una ubicación central significa que el almacén de datos es la única fuente de verdad; cualquier pregunta sobre los datos del informe puede ser respondida por el almacén de datos. Mantener un SVOT es esencial para las organizaciones que quieren aprovechar todo el potencial de sus datos.
Si un almacénde datos (DW) es utilizado por toda la empresa, suele denominarsealmacén de datos de empresa (EDW) . Se trata de una versión más completa y robusta de un almacén de datos, diseñada para dar soporte a las necesidades de toda la organización. Mientras que un DW estándar puede dar soporte a unas pocas unidades de negocio, con muchos DW en toda la organización, el EDW utiliza una gama más amplia de fuentes de datos y tipos de datos para dar soporte a todas las unidades de negocio. El EDW proporciona una visión única y unificada de todos los datos de la organización.
La Figura 4-1 ilustra una razón importante para tener un almacén de datos. El diagrama de la izquierda muestra lo difícil que es ejecutar un informe utilizando datos de varias aplicaciones cuando no se dispone de un almacén de datos. Cada departamento ejecuta un informe que recoge datos de todas las bases de datos asociadas a cada aplicación. Se ejecutan tantas consultas que es probable que tengas problemas de rendimiento y datos incorrectos. Es un caos. El diagrama de la derecha muestra que, con todos los datos de las aplicaciones copiados en el EDW, resulta muy fácil para cada departamento ejecutar un informe sin comprometer el rendimiento.
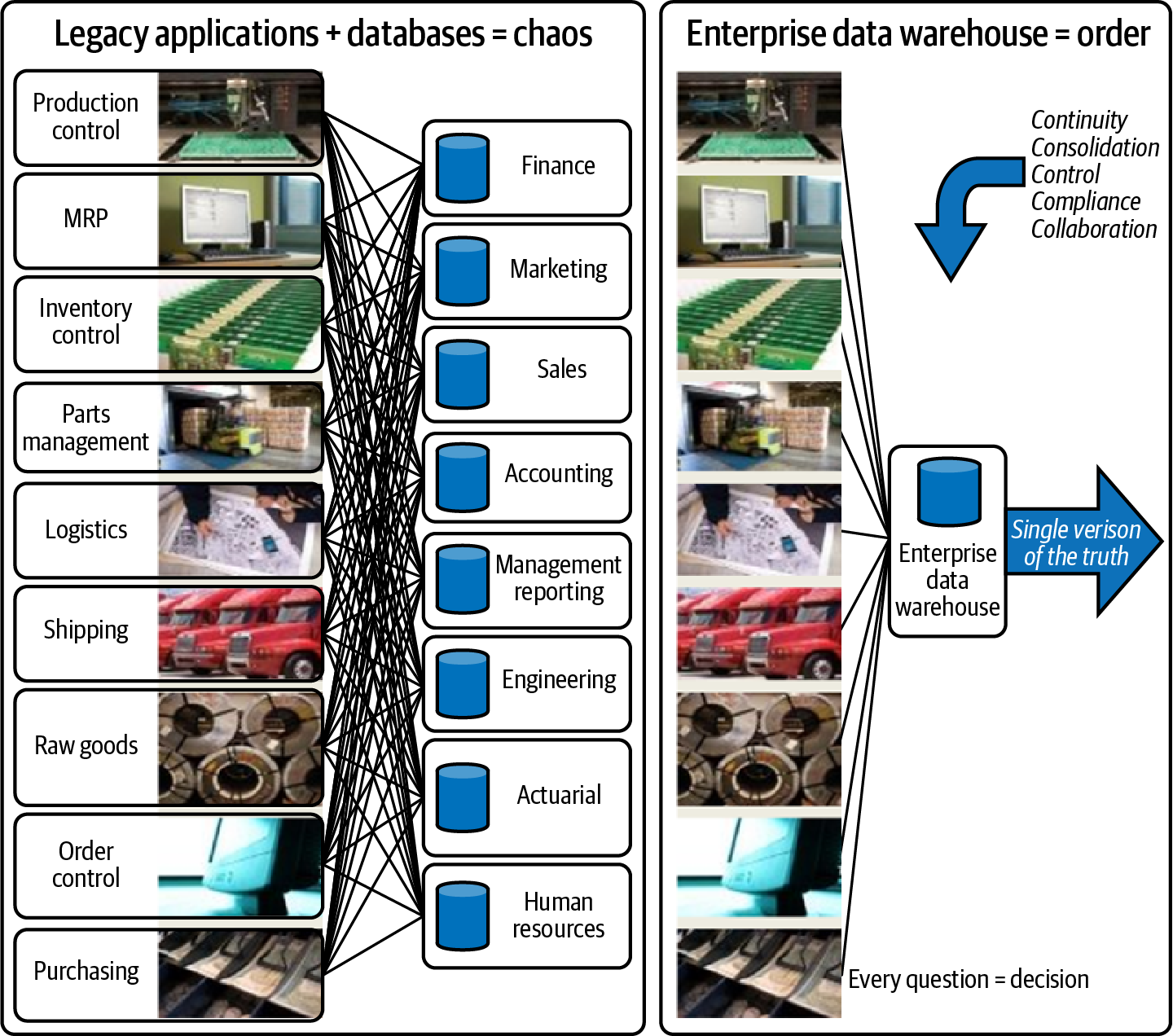
Figura 4-1. Antes y después de un almacén de datos empresarial
Normalmente, para construir un almacén de datos, crearás conductos de datos que realicen tres pasos, denominados extraer, transformar y cargar (ETL):
El pipeline extrae datos de los sistemas fuente, como bases de datos y archivos planos.
A continuación, los datos extraídos se transforman o manipulan para adaptarlos a los requisitos de los sistemas de destino (en este caso, para adaptarlos a un almacén de datos). Esto puede implicar limpiar, filtrar, agregar o combinar datos de múltiples fuentes.
Los datos transformados se cargan en el almacén de datos. Un DBA puede hacer que la base de datos y los nombres de los campos sean más significativos, facilitando y agilizando a los usuarios finales la creación de informes.
Qué no es un almacén de datos
Ahora que sabes lo que es un almacén de datos, vamos a aclarar su finalidad examinando las soluciones que no deberían considerarse un almacén de datos (aunque he visto a gente hacerlo muchas veces):
- Prefijo DW
Un almacén de datos no es una simple copia de una base de datos fuente de un sistema operativo con DW añadido al nombre del archivo. Por ejemplo, supongamos que copias una base de datos llamada Finanzas que contiene 50 tablas operativas y llamas a la copia DW_Finanzas, y luego utilizas esas 50 tablas para elaborar tus informes. Esto daría lugar a un almacén de datos diseñado para datos operativos, cuando en realidad lo necesitas diseñado para datos analíticos. Con los datos analíticos, tienes un mejor rendimiento de lectura y puedes crear modelos de datos para facilitar a los usuarios finales la elaboración de informes. (Te lo explicaré mejor en la siguiente sección).
- Opiniones con los sindicatos
Un almacén de datos no es una copia de múltiples tablas de varios sistemas fuente unidas en una vista SQL.( Launión se realiza mediante la sentencia SQL
UNION, que combina los resultados de dos o más sentenciasSELECTen un único conjunto de resultados). Por ejemplo, si copiaras datos de tres sistemas fuente que contienen clientes cada uno, acabarías con tres tablas en el almacén de datos llamadasCustomerSource1,CustomerSource2yCustomerSource3. Así que tendrías que crear una vista llamadaCustomerViewque fuera una sentenciaSELECTque uniera las tablasCustomerSource1,CustomerSource2, yCustomerSource3. Repetirías este proceso para otras tablas, como productos y pedidos.En su lugar, los datos de las tres tablas deben copiarse en una tabla del almacén de datos, lo que requiere el trabajo adicional de crear un modelo de datos que se ajuste a las tres tablas. Es probable que en este punto quieras utilizar la gestión de datos maestros (MDM), explicada en el Capítulo 6, para evitar duplicados y mejorar la accesibilidad y el rendimiento.
- Vertedero
Un almacén de datos no es un vertedero de tablas. Muchas veces, esta práctica surge cuando una empresa no tiene un DW y un usuario final quiere crear un informe a partir de un subconjunto de datos de un par de sistemas fuente. Para ayudarles rápidamente, una persona de TI crea un DW sin pensárselo mucho, copiando los datos de esos dos sistemas fuente en el DW. Entonces otros usuarios finales ven el beneficio que obtuvo el primer usuario final, y quieren datos adicionales de esos mismos sistemas fuente y de algunos otros para crear sus propios informes. Así que, una vez más, el informático copia rápidamente los datos solicitados en el DW. Este proceso se repite una y otra vez hasta que el DW se convierte en un revoltijo de bases de datos y tablas.
Muchos DW empiezan como soluciones puntuales para un par de usuarios, y luego se convierten en DW completos pero mal diseñados para toda la empresa. Hay una forma mejor.
En lugar de eso, cuando llegue esa primera solicitud de un usuario final, evalúa las necesidades de información de tu empresa. Averigua si la petición es realmente puntual o si debería ser el inicio de la construcción de un EDW. Si es así, es tu oportunidad de demostrar a los directivos por qué tu empresa necesita un DW. Si es así, insiste en que necesitas suficiente tiempo por adelantado para diseñar un DW que admita muchas fuentes de datos y usuarios finales. (Utiliza "¿Por qué utilizar un almacén de datos relacional?" para apoyar tu argumento).
El enfoque descendente
En un RDW, harás mucho trabajo previo para llevar los datos hasta el punto en que puedas utilizarlos para crear informes. Hacer todo este trabajo de antemano es una metodología de diseño e implementación denominada enfoque descendente. Este enfoque funciona bien para los informes de tipo histórico, en los que intentas determinar qué ocurrió(análisis descriptivo) y por qué ocurrió(análisis de diagnóstico). En el enfoque descendente, primero estableces la planificación general, el diseño y la arquitectura del almacén de datos, y luego desarrollas los componentes específicos. Este método subraya la importancia de definir una visión de toda la empresa y comprender los objetivos estratégicos y los requisitos de información de la organización antes de sumergirse en el desarrollo del almacén de datos.
El análisis descriptivo y el análisis de diagnóstico son dos tipos importantes de análisis de datos que se utilizan habitualmente en las empresas. El análisis descriptivo consiste en analizar los datos para describir acontecimientos pasados o actuales, a menudo mediante el uso de estadísticas resumidas o visualizaciones de datos. Este tipo de análisis se utiliza para comprender lo que ha ocurrido en el pasado y para identificar patrones o tendencias en los datos que puedan ayudar a tomar decisiones.
El análisis de diagnóstico se utiliza para investigar las causas de sucesos pasados, normalmente examinando las relaciones entre distintas variables o factores. Este tipo de análisis puede identificar las causas profundas de los problemas o diagnosticar cuestiones que pueden estar afectando al rendimiento empresarial.
Supongamos que una empresa quiere analizar los datos de ventas del año pasado. El análisis descriptivo consistiría en calcular estadísticas resumidas, como los ingresos totales por ventas, las ventas medias diarias y las ventas por categoría de producto, para entender lo que ocurrió. El análisis diagnóstico, en cambio, examinaría las relaciones entre factores (como las ventas y el gasto en marketing, o la estacionalidad y la demografía de los clientes) para comprender por qué las ventas fluctuaron a lo largo del año. Combinando ambos enfoques, las empresas pueden comprender mejor sus datos y tomar decisiones más informadas.
La Figura 4-2 muestra la arquitectura de un RDW típico. El ETL se utiliza para introducir datos de múltiples fuentes en el RDW, donde se pueden realizar informes y otros análisis.
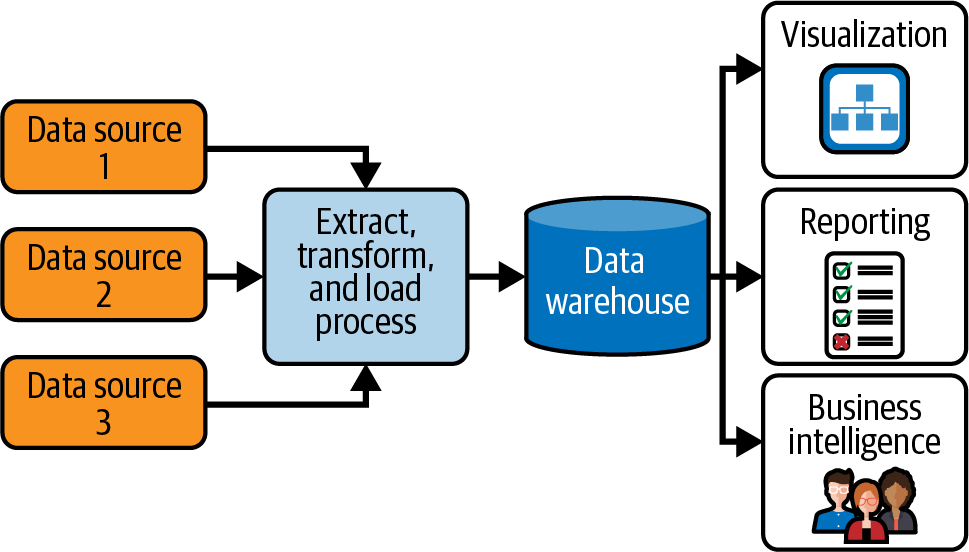
Figura 4-2. La arquitectura de un almacén de datos
El enfoque descendente suele implicar los siguientes pasos:
- 1. Formula algunas hipótesis por adelantado.
- Empieza con una comprensión clara de la estrategia corporativa. Después, asegúrate de saber qué preguntas quieres hacer a los datos.
- 2. Define los requisitos empresariales.
- Identificar las metas, objetivos e indicadores clave de rendimiento (KPI) de la organización. Recopila y analiza las necesidades de información de los distintos departamentos y usuarios. También puedes considerar este paso como la definición de tus necesidades de información.
- 3. Diseñar la arquitectura del almacén de datos.
- Basándote en los requisitos empresariales, crea una arquitectura de alto nivel para el almacén de datos, que incluya su estructura, los modelos de datos y los procesos de integración de datos. Éstos serán tus requisitos técnicos.
- 4. Desarrolla el modelo de datos.
- Diseña un modelo de datos detallado para el almacén de datos, teniendo en cuenta las relaciones entre las distintas entidades de datos y la granularidad de los datos.
- 5. Construye la arquitectura.
- Desarrolla las bases de datos, esquemas, tablas y campos adecuados para el almacén de datos. Éste es el enfoque descrito anteriormente, denominado esquema en escritura.
- 6. Desarrollar ETL.
- Desarrolla los procesos ETL para extraer datos de varios sistemas fuente, transformarlos al formato deseado y cargarlos en el almacén de datos.
- 7. Desarrollar e implementar herramientas y aplicaciones de BI.
- Implanta herramientas y aplicaciones de BI que permitan a los usuarios acceder a los datos almacenados en el almacén de datos, analizarlos e informar sobre ellos.
- 8. Prueba y perfecciona el almacén de datos.
- Realiza pruebas para garantizar la calidad, el rendimiento y la fiabilidad de los datos. Realiza los ajustes necesarios para optimizar el sistema.
- 9. Mantener y ampliar el almacén de datos.
- A medida que evolucionen las necesidades de la organización, actualiza y amplía el almacén de datos en consecuencia.
El enfoque descendente tiene algunas ventajas, como una visión global de las necesidades de datos de la organización, una mayor coherencia de los datos y una mejor gobernanza. Sin embargo, también puede consumir mucho tiempo y recursos, tardando más en aportar valor que el enfoque ascendente utilizado por el lago de datos, descrito en el Capítulo 5. La arquitectura moderna de almacén de datos, descrita en el Capítulo 10, combina los enfoques descendente y ascendente.
¿Por qué utilizar un almacén de datos relacional?
Tener un RDW facilita mucho la creación de cualquier tipo de solución de BI, ya que las soluciones de BI pueden extraer datos sólo del RDW sin tener que crear una lógica compleja para extraer datos de múltiples sistemas fuente. Además, no tendrán que limpiar o unir los datos porque el RDW ya lo habrá hecho. La solución de BI que se construya a partir del RDW podría ser un mercado de datos (que contiene un subconjunto de los datos del RDW para un grupo específico de personas, como se explica en el Capítulo 6), agregar datos para hacer consultas e informes más rápidos, e incluso ser utilizable dentro de Microsoft Excel. En resumen, con un RDW ya tienes una base sólida sobre la que construir.
Veamos en detalle algunas de las principales ventajas que puedes obtener utilizando un RDW:
- Reduce el estrés del sistema de producción
Puede que hayas visto este problema antes: una llamada airada de un usuario final quejándose de que la inserción de pedidos a través de la aplicación de entrada de pedidos está tardando una eternidad. Lo investigas, y resulta que otro usuario final está ejecutando un informe a través de la aplicación de entrada de pedidos que está acaparando todos los recursos del servidor donde reside la aplicación. Esta situación es especialmente común cuando se permite a los usuarios finales crear consultas ad hoc y se les ocurre un SQL mal escrito.
Si copias la base de datos de la aplicación de entrada de pedidos en un DW y la optimizas, puedes hacer que todos los informes y consultas ad hoc vayan contra el DW y evitar por completo este problema, sobre todo si el usuario final necesita ejecutar un informe que vaya contra varias bases de datos de la aplicación.
- Optimizar para acceso de lectura
Las bases de datos de aplicaciones van a estar optimizadas para soportar todas las operaciones CRUD por igual, por lo que la lectura de datos no será todo lo rápida que podría ser. El almacén de datos, en cambio, es un sistema del tipo escribir una vez, leer muchas, lo que significa que se utilizará principalmente para la lectura de datos. Por tanto, puede optimizarse para el acceso de lectura, especialmente para los escaneos secuenciales de disco que consumen mucho tiempo y que suelen producirse cuando se ejecutan informes o consultas. Hay muchas técnicas de bases de datos que pueden utilizarse para acelerar el acceso de lectura en un DW, algunas en detrimento del acceso de escritura, que no nos preocupa.
- Integrar múltiples fuentes de datos
La capacidad de integrar muchas fuentes de datos para crear informes más útiles es una de las razones más importantes para crear un DW. Ubicar todos los datos en un solo lugar, en lugar de tenerlos dispersos en varias bases de datos, no sólo facilita la creación de informes, sino que mejora enormemente su rendimiento.
- Ejecuta informes históricos precisos
Sin un DW, los usuarios finales de las aplicaciones suelen ejecutar todos sus informes un día concreto de cada mes (normalmente el último). Luego los guardan en disco para tener copias a las que puedan recurrir en el futuro. Por ejemplo, el usuario quiere consultar un informe de hace unos meses que enumera las ventas de los clientes por estado. Sin embargo, un cliente se ha trasladado recientemente a otro estado. Si el usuario ejecuta un informe actual, mostraría incorrectamente las ventas de ese cliente en su nuevo estado en lugar de en su antiguo estado (ya que su registro en la base de datos se ha actualizado a su nuevo estado). Por lo tanto, el usuario debe consultar un informe antiguo guardado en lugar de ejecutar un informe actual.
Un DW puede encargarse de esto llevando la cuenta de cuándo se traslada un cliente (mediante el seguimiento del historial de ubicaciones del cliente con fechas de inicio y fin), así como de cualquier otro campo que sea necesario rastrear (por ejemplo, empleador o ingresos). Ahora el usuario puede ejecutar un informe hoy, pero pedirle que extraiga datos a partir de alguna fecha en el pasado, y el informe será preciso. Además, ya no es necesario guardar los archivos de los informes cada mes.
- Reestructurar y renombrar tablas
Muchas bases de datos de aplicaciones tienen nombres de tablas y campos muy difíciles de entender, especialmente los productos ERP y CRM más antiguos (piensa en nombres de tablas como
T116y nombres de campos comoRAP16). En el almacén de datos, puedes copiar los datos de esas tablas de origen en algo mucho más fácil de entender (por ejemplo,Customeren lugar deT116). También es probable que puedas crear un modelo de datos mejor para todas las tablas. Los usuarios finales podrán crear informes mucho más fácilmente cuando no tengan que traducir nombres crípticos de tablas y campos.- Protege contra las actualizaciones de las aplicaciones
Imagina que no tienes un DW y que, en su lugar, los usuarios crean informes contra una base de datos de la aplicación. Todo funciona bien y, de repente, muchos informes empiezan a dar errores. Resulta que la aplicación pasó por una actualización, instalando una nueva versión que renombró un montón de tablas y campos. Así que ahora debes revisar todos y cada uno de los informes, de entre cientos, y renombrar las tablas y campos modificados. Eso puede llevar meses, con el consiguiente disgusto de muchos usuarios finales. Incluso después de eso, los informes que se hayan omitido podrían seguir dando errores.
Un DW puede protegerte contra esto. Tras una actualización de la aplicación, sólo hay que actualizar el ETL que copia los datos de las bases de datos de la aplicación al DW, una tarea rápida. Los informes no tienen que modificarse. Los usuarios finales no verán ningún dato nuevo hasta que se arregle la ETL, pero sus informes no tendrán errores.
- Reduce los problemas de seguridad
Sin un DW, tu equipo tendría que dar a cada usuario final acceso de seguridad a cada base de datos de la aplicación que necesitara utilizar con fines informativos. Podrían ser docenas; el proceso de proporcionar acceso podría llevar semanas, y a veces aún podrían no tener acceso a todo lo que necesitan. Con un DW, cada usuario final sólo necesita acceso a las tablas adecuadas, y proporcionárselo es mucho más rápido y sencillo.
- Conservar datos históricos
Muchos sistemas de producción limitan la cantidad de datos históricos que conservan (por ejemplo, los datos de los últimos tres años). Lo hacen para ahorrar espacio y mejorar el rendimiento y, en algunos casos, para cumplir la normativa. Los datos antiguos suelen purgarse anual o mensualmente. Por otra parte, un DW puede almacenar todo el historial, por lo que nunca tendrás que preocuparte de ejecutar un informe para años más antiguos y no encontrar ningún dato.
- Gestión de datos maestros (MDM)
A medida que recopiles datos de múltiples sistemas fuente, muchas veces necesitarás utilizar MDM para eliminar registros duplicados de cosas como clientes, productos y activos. (Consulta el Capítulo 6 para una explicación más detallada de MDM.) El DW es el lugar perfecto para realizar MDM. Además, muchas de las herramientas MDM te permiten crear jerarquías (por ejemplo, Empresa → Departamento → Empleado), lo que añade más valor al dominio de los datos.
- Mejora la calidad de los datos tapando agujeros en los sistemas fuente
Te darás cuenta de que muchos de los datos que obtienes de los distintos sistemas fuente necesitan ser limpiados, a pesar de lo que digan los propietarios de las aplicaciones (les he oído decir "Nuestros datos están limpios" muchas veces, sólo para comprobar que estaban equivocados). Por ejemplo, una aplicación de entrada de pedidos puede requerir la fecha de nacimiento de un cliente, y si la persona que introduce los datos no conoce la fecha de nacimiento del cliente, podría introducir una fecha en el futuro o una fecha de hace más de 100 años sólo para poder completar el pedido. O puede que la aplicación no compruebe la exactitud de los dos dígitos introducidos para un código de estado. Siempre hay docenas de "agujeros" en el sistema fuente. No sólo puedes limpiar los datos en el DW, sino también notificar a las personas que mantienen las aplicaciones los agujeros de sus sistemas para que puedan solucionarlos. De este modo, ayudas a evitar la introducción de datos erróneos en el futuro.
- Eliminar la participación de TI en la creación de informes
Esto nos remite al BI de autoservicio mencionado en el Capítulo 3: construir un DW adecuado eliminará la necesidad de que el departamento de TI participe en la creación de informes y dejará esta tarea en manos del usuario final. Sin el cuello de botella de los limitados recursos de TI, los informes y cuadros de mando podrán crearse antes. Y los informáticos agradecerán poder trabajar en proyectos más interesantes que crear informes.
Inconvenientes de utilizar un almacén de datos relacional
Siempre hay compensaciones, y aquí tienes los inconvenientes que hay que tener en cuenta al construir un RDW:
- Complejidad
El diseño, la construcción y el mantenimiento de los DW pueden ser complejos y requerir mucho tiempo. Los conocimientos especializados y los recursos necesarios pueden aumentar los costes.
- Costes elevados
Implantar un DW puede ser caro, ya que requiere importantes inversiones en hardware, software y personal. El mantenimiento continuo y las actualizaciones también pueden aumentar el coste.
- Retos de la integración de datos
Integrar datos de varias fuentes puede ser un reto, ya que puede implicar tratar con diferentes formatos de datos, estructuras y problemas de calidad. Esto puede obligar a dedicar tiempo y esfuerzo a la limpieza y preprocesamiento de los datos. Además, algunos datos, como los datos en flujo de los dispositivos IoT, son demasiado difíciles de ingerir en un RDW, por lo que se pierden las perspectivas potenciales de esta información.
- Transformación de datos que consume tiempo
Para cargar los datos en un DW, puede ser necesario transformarlos para ajustarlos al modelo de datos del almacén. Este proceso puede llevar mucho tiempo, y los errores en la transformación de los datos pueden dar lugar a análisis inexactos.
- Latencia de los datos
Como los DW están diseñados para manejar grandes volúmenes de datos, pueden ser más lentos de procesar que otros tipos de bases de datos. Esto puede dar lugar a una latencia de datos, en la que los datos del almacén no están actualizados con los cambios más recientes de las bases de datos de origen.
- Ventana de mantenimiento
Con un RDW, normalmente necesitas una ventana de mantenimiento. Cargar y limpiar datos consume muchos recursos, y si los usuarios intentan ejecutar informes al mismo tiempo, experimentarán un rendimiento muy lento. Así que los usuarios deben estar bloqueados en el almacén mientras se realiza el mantenimiento, impidiendo el acceso 24 horas al día, 7 días a la semana. Si se produce algún problema durante la ventana de mantenimiento, como un trabajo ETL fallido, puede que tengas que ampliar la ventana de mantenimiento. Si los usuarios intentan ejecutar informes y siguen bloqueados, tendrás usuarios molestos que no podrán realizar su trabajo.
- Flexibilidad limitada
Los DW están diseñados para soportar tipos específicos de análisis, lo que puede limitar su flexibilidad para otros tipos de procesamiento o análisis de datos. Puede ser necesario integrar herramientas o sistemas adicionales con el almacén para satisfacer necesidades específicas.
- Cuestiones de seguridad y privacidad
Almacenar grandes cantidades de datos confidenciales en una ubicación centralizada puede aumentar el riesgo de violación de datos y de la privacidad, por lo que se necesitan fuertes medidas de seguridad.
Poblar un almacén de datos
Como las tablas de origen que se introducen en un almacén de datos cambian con el tiempo, el DW tiene que reflejar esos cambios. Esto parece bastante sencillo, pero hay que tomar muchas decisiones: con qué frecuencia extraer (o tirar) los datos, qué método de extracción utilizar, cómo extraer físicamente los datos y cómo determinar qué datos han cambiado desde la última extracción. Discutiré brevemente cada una de ellas.
Con qué frecuencia extraer los datos
La frecuencia con la que necesitas actualizar el DW depende en gran medida de la frecuencia con la que se actualizan los sistemas fuente y de la puntualidad con la que el usuario final necesita los informes. A menudo, los usuarios finales no quieren ver los datos del día actual, sino que prefieren obtener todos los datos hasta el final del día anterior. En este caso, puedes ejecutar tus trabajos para extraer los datos de los sistemas fuente mediante herramientas ETL cada noche, después de que las bases de datos del sistema fuente hayan terminado de actualizarse, creando una ventana de mantenimiento nocturno para realizar toda la transferencia de datos. Si los usuarios finales necesitan actualizaciones durante el día, entonces será necesaria una extracción más frecuente, digamos cada hora.
Una cosa a tener en cuenta es el tamaño de los datos de cada extracción. Si es muy grande, actualizar el DW puede llevar demasiado tiempo, por lo que quizá quieras dividir la actualización en trozos más pequeños y hacer extracciones y actualizaciones más frecuentes (por ejemplo, cada hora en lugar de cada día). Además, puede llevar demasiado tiempo transferir grandes cantidades de datos desde los sistemas fuente al almacén de datos, sobre todo si los datos fuente están en local y no tienes una gran canalización desde el sistema fuente a Internet. Ésta es otra razón por la que tal vez quieras pasar de una gran transferencia nocturna a transferencias más pequeñas cada hora durante el día.
Métodos de extracción
Existen dos métodos para extraer datos de los sistemas fuente. Veamos cada uno de ellos:
- Extracción total
En una extracción completa, todos los datos se extraen por completo de una o varias tablas del sistema fuente. Esto funciona mejor con tablas pequeñas. Como esta extracción refleja todos los datos disponibles actualmente en el sistema fuente, no es necesario hacer un seguimiento de los cambios, lo que hace que este método sea muy fácil de construir. Los datos de origen se proporcionan tal cual, y no necesitas ninguna información adicional (por ejemplo, marcas de tiempo).
- Extracción incremental
En la extracción incremental, estás extrayendo sólo los datos que han cambiado desde un momento determinado (como la última extracción o el final de un periodo fiscal) en lugar de toda la tabla. Esto funciona mejor con tablas grandes, y sólo funciona cuando es posible identificar toda la información modificada (lo que se explica más adelante).
Con la mayoría de los sistemas fuente, utilizarás una combinación de estos dos métodos.
Tanto si haces una extracción completa como incremental, hay dos formas de extraer los datos: online y offline.
En la extracción en línea, el proceso de extracción puede conectarse directamente al sistema fuente para acceder a las tablas de origen, o puede conectarse a un sistema intermedio que almacene los cambios en los datos de forma preconfigurada (por ejemplo, en registros de transacciones o tablas de cambios).
Sin embargo, no siempre se dispone de acceso directo al sistema fuente. En tales casos, los datos se organizan fuera del sistema fuente original y se crean mediante una rutina de extracción procedente del sistema fuente (por ejemplo, un mainframe realiza una rutina de extracción en una tabla y deposita los datos en una carpeta de un sistema de archivos). Los datos extraídos suelen depositarse en un archivo plano con un formato definido y genérico (por ejemplo, CSV o JSON).
Cómo determinar qué datos han cambiado desde la última extracción
Por desgracia, para muchos sistemas fuente puede resultar difícil identificar los datos modificados recientemente y realizar una extracción incremental. A continuación se presentan varias técnicas para identificar los datos modificados recientemente y realizar una extracción incremental de los sistemas fuente. Estas técnicas pueden funcionar junto con los métodos de extracción de datos comentados. Algunas técnicas se basan en las características de los sistemas fuente; otras pueden requerir modificaciones en los sistemas fuente. Los propietarios del sistema fuente deben evaluar cuidadosamente cualquier técnica antes de aplicarla:
- Marcas de tiempo
Las marcas de tiempo son la opción preferible y la más fácil de aplicar. Las tablas de algunos sistemas operativos tienen columnas de marca de tiempo con la hora y la fecha en que se modificó por última vez una fila determinada, lo que facilita la identificación de los datos más recientes. En las bases de datos relacionales, la columna de fecha y hora suele tener el tipo de datos
timestampodatetime, junto con un nombre de columna comoTimestampoLast Modified. La aplicación fuente rellenará entonces esta columna. Si no es así, puedes configurar la base de datos relacional para que indique por defecto la fecha actual cuando se guarde el registro, o puedes añadir activadores de base de datos para que rellenen la columna.- Captura de datos de cambios
La mayoría de las bases de datos relacionales admiten la captura de datos de cambios (CDC), que registra los
INSERTs,UPDATEs yDELETEs aplicados a las tablas de la base de datos y pone a disposición un registro de lo que ha cambiado, dónde y cuándo, basado en el registro de transacciones de la base de datos relacional. Si necesitas un almacenamiento de datos casi en tiempo real, en el que puedas ver reflejados los cambios del sistema fuente en el almacén de datos en pocos segundos, la CDC puede ser la tecnología facilitadora clave.- Partición
Algunos sistemas fuente utilizan la partición por rango, en la que las tablas fuente se particionan a lo largo de una clave de fecha, lo que facilita la identificación de nuevos datos. Por ejemplo, si estás extrayendo de una tabla de pedidos particionada por días, es fácil identificar los datos del día actual o del anterior.
- Activadores de bases de datos
Puedes añadir un activador para
INSERT,UPDATE, yDELETEen una única tabla y hacer que esos activadores escriban la información sobre el cambio de registro en una "tabla de cambios". Esto es similar a la captura de datos de cambios, así que utiliza CDC si tu producto de base de datos lo admite; si no, utiliza disparadores.MERGEdeclaraciónLa opción menos preferible es hacer una extracción completa del sistema de origen a un área de preparación en el DW, y luego comparar esta tabla con una extracción completa anterior del sistema de origen utilizando una sentencia
MERGEpara identificar los datos modificados. Tendrás que comparar todos los campos de origen con todos los campos de destino (o utilizar una función hash). Es probable que este enfoque no tenga un impacto significativo en el sistema de origen, pero puede suponer una carga considerable para el DW, sobre todo si los volúmenes de datos son grandes. Esta opción suele ser el último recurso si no hay otras opciones posibles.
Se ha exagerado mucho la muerte del almacén de datos relacional
Hacia principios de la década de 2010, la gente de TI empezó a preguntarse si el almacén de datos relacional ya no era necesario, preguntando: "¿Ha muerto el almacén de datos relacional?". Muchos lo entendieron como una pregunta sobre si las empresas seguían necesitando los DW. Y los necesitan, como se señala en este capítulo. Pero la pregunta se refiere realmente a la arquitectura del almacén de datos: ¿puedes utilizar sólo un lago de datos, o deberías utilizar tanto un lago de datos como un RDW?
Cuando aparecieron por primera vez los lagos de datos, se basaban en la tecnología Apache Hadoop, y fueron sobre todo los vendedores de Hadoop los que declararon muerto el RDW. "Pon todos tus datos en el lago de datos y deshazte de tu RDW", aconsejaban. Como se menciona en el Capítulo 2, todos los proyectos que lo intentaron fracasaron.
Durante muchos años, había pensado que los RDW siempre serían necesarios porque todos los lagos de datos se basaban en Hadoop y tenían demasiadas limitaciones. Pero cuando aparecieron soluciones como Delta lake (ver Capítulo 12) y los lagos de datos empezaron a utilizar productos mejores y más fáciles de usar que Hadoop (ver Capítulo 16), empecé a ver algunos casos de uso en los que una solución podía funcionar sin un RDW. Ese tipo de solución es una arquitectura de lago de datos, que se tratará en el Capítulo 12.
Sin embargo, sigue habiendo muchos casos de uso en los que se necesita un RDW. Y aunque las tecnologías de los lagos de datos seguirán mejorando, lo que reducirá o eliminará las preocupaciones por eludir un RDW (véase el Capítulo 12), nunca eliminaremos por completo los RDW. Creo que hay tres razones para ello. En primer lugar, sigue siendo más difícil informar desde un lago de datos que desde un DW. Segundo, los RDW siguen satisfaciendo las necesidades de información de los usuarios y aportando valor. En tercer lugar, mucha gente utiliza, depende y confía en los DW y no quiere sustituirlos por lagos de datos.
Los lagos de datos ofrecen una rica fuente de datos para los científicos de datos y los consumidores de datos de autoservicio ("usuarios avanzados"), y satisfacen bien las necesidades de la analítica y el big data. Pero no todos los trabajadores de datos e información quieren convertirse en usuarios avanzados. La mayoría sigue necesitando datos relacionales bien integrados, sistemáticamente depurados y de fácil acceso, que incluyan un registro histórico que recoja cómo han evolucionado o progresado las cosas durante un periodo de tiempo. Estas personas están mejor atendidas con un almacén de datos.
Resumen
Este capítulo trata de la primera solución tecnológica ampliamente utilizada para centralizar datos de múltiples fuentes y elaborar informes sobre ellos: el almacén relacional de datos. El RDW revolucionó la forma en que las empresas y organizaciones gestionan sus datos al proporcionar un repositorio centralizado para el almacenamiento y la recuperación de datos, permitiendo una gestión y un análisis de datos más eficientes. Con la capacidad de almacenar y organizar los datos de forma estructurada, los RDW permiten a los usuarios generar consultas e informes complejos de forma rápida y sencilla, proporcionando información valiosa y apoyando la toma de decisiones críticas.
Hoy en día, el almacén de datos relacional sigue siendo un componente fundamental de muchas arquitecturas de datos y puede verse en una amplia gama de sectores, desde las finanzas y la sanidad hasta el comercio minorista y la fabricación. En el siguiente capítulo se analiza la próxima tecnología que se convertirá en un factor importante para centralizar los datos e informar sobre ellos: el lago de datos.
Get Descifrar las arquitecturas de datos now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

