Kapitel 1. Big Data - Jenseits des Rummels
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Ohne Big Data bist du blind und taub und stehst mitten auf einer Autobahn.
Geoffrey Moore
Wenn wir Arbeitsplatz-Bingo spielen würden, wäre die Wahrscheinlichkeit groß, dass du gewinnst, wenn du alle diese Begriffe ankreuzt, die du in den letzten drei Monaten in deinem Unternehmen gehört hast: digitale Transformation, Datenstrategie, transformative Erkenntnisse, Data Lake, Warehouse, Data Science, maschinelles Lernen und Intelligenz. Es ist mittlerweile allgemein bekannt, dass Daten eine wichtige Voraussetzung für den Erfolg von Unternehmen sind, und Unternehmen, die auf Daten und KI setzen, sind ihren Konkurrenten deutlich überlegen. Laut einer von Seagate gesponserten IDC-Studie wird die Menge der erfassten, gesammelten oder vervielfältigten Daten bis zum Jahr 2025 voraussichtlich auf 175 Zettabyte (ZB) anwachsen. Diese erfassten, gesammelten und vervielfältigten Daten werden als Global DataSphere bezeichnet. Diese Daten stammen aus drei Kategorien von Quellen:
- Der Kern
-
Traditionelle oder Cloud-basierte Rechenzentren
- Die Kante
-
Gehärtete Infrastruktur, wie z. B. Mobilfunkmasten
- Die Endpunkte
-
PCs, Tablets, Smartphones und Internet of Things (IoT)-Geräte
Die Studie prognostiziert außerdem, dass 49% dieser globalen Datensphäre bis zum Jahr 2025 in öffentlichen Cloud-Umgebungen angesiedelt sein werden.
Wenn du dich jemals gefragt hast: "Warum müssen diese Daten gespeichert werden? Wozu sind sie gut?", ist die Antwort ganz einfach. Stell dir all diese Daten wie Wortfetzen vor, die in verschiedenen Sprachen über den Globus verstreut sind und jeweils einen Informationsfetzen enthalten - wie Teile eines Puzzles. Wenn man sie sinnvoll zusammenfügt, entsteht eine Geschichte, die nicht nur Informationen liefert, sondern auch Unternehmen, Menschen und sogar die Welt verändern kann. Die meisten erfolgreichen Unternehmen nutzen bereits Daten, um die Wachstumstreiber für ihr Geschäft und die wahrgenommenen Kundenerfahrungen zu verstehen und die richtigen Maßnahmen zu ergreifen; die Betrachtung des "Trichters", d. h. der Kundenakquise, -akzeptanz, -bindung und -bindung, ist heute weitgehend die Sprache der Finanzierung von Produktinvestitionen. Diese Art der Datenverarbeitung und -analyse wird als Business Intelligence(BI) bezeichnet und als "Offline Insights" klassifiziert. Im Wesentlichen sind die Daten und die Erkenntnisse entscheidend für die Darstellung von Wachstumstrends, damit die Unternehmensleitung Maßnahmen ergreifen kann; dieser Arbeitsbereich ist jedoch von der Kerngeschäftslogik getrennt, mit der das Unternehmen selbst betrieben wird. Je ausgereifter die Datenplattform ist, desto mehr Anfragen erhalten wir von unseren Kunden, um mehr Szenarien in ihren Data Lakes zu testen, getreu dem Motto "Daten sind das neue Öl".
Unternehmen nutzen Daten, um die Wachstumstreiber für ihr Geschäft und die wahrgenommene Kundenerfahrung zu verstehen. Anhand der Daten können sie dann Ziele setzen und das Kundenerlebnis durch besseren Support und neue Funktionen verbessern. Sie können auch bessere Marketingstrategien entwickeln, um ihr Geschäft auszubauen und die Effizienz zu steigern, um die Kosten für die Entwicklung ihrer Produkte und Organisationen zu senken. Starbucks, der Coffee Shop, der rund um den Globus vertreten ist, nutzt Daten an allen möglichen Stellen, um sein Geschäft kontinuierlich zu messen und zu verbessern. Wie in diesem YouTube-Video erklärt, nutzt Starbucks die Daten seiner mobilen Anwendungen und setzt sie mit seinem Bestellsystem in Beziehung, um das Nutzungsverhalten seiner Kunden besser zu verstehen und gezielte Marketingkampagnen zu versenden. Starbucks verwendet Sensoren an seinen Kaffeemaschinen, die alle paar Sekunden Daten über den Gesundheitszustand der Maschinen liefern, und diese Daten werden analysiert, um die vorausschauende Wartung zu verbessern. Außerdem werden diese vernetzten Kaffeemaschinen genutzt, um Rezepte auf sie herunterzuladen, ohne dass ein Mensch eingreifen muss.
Während die Welt gerade lernt, mit der COVID-19-Pandemie umzugehen, nutzen Unternehmen Daten nicht nur, um ihr Geschäft umzugestalten, sondern auch, um die Gesundheit und Produktivität ihrer Organisationen zu messen, damit sich ihre Mitarbeiter/innen verbunden fühlen und Burnout minimieren können. Insgesamt werden Daten auch für Initiativen zur Rettung der Welt genutzt, wie z. B. das Projekt Zamba, das KI für die Erforschung und den Schutz von Wildtieren in den abgelegenen Dschungeln Afrikas einsetzt und das IoT und die Datenwissenschaft nutzt, um eine Kreislaufwirtschaft zur Förderung der ökologischen Nachhaltigkeit zu schaffen.
Was ist Big Data?
Alle bisher genannten Beispiele haben ein paar Dinge gemeinsam:
-
Diese Szenarien verdeutlichen, dass Daten auf vielfältige Weise erforscht und genutzt werden können, und wenn die Daten erzeugt werden, gibt es nicht wirklich eine klare Vorstellung von den Nutzungsmustern. Dies unterscheidet sich von traditionellen Online-Transaktionsverarbeitungs- (OLTP) und Online-Analytical-Processing-Systemen (OLAP), bei denen die Daten speziell für die Lösung bestimmter Geschäftsprobleme konzipiert und aufbereitet werden.
-
Daten können in allen möglichen Formen und Formaten vorliegen: Es kann sich um ein paar Bytes handeln, die von einem IoT-Sensor gesendet werden, um Daten aus den sozialen Medien, um Dateien aus LOB-Systemen und relationalen Datenbanken und manchmal sogar um Audio- und Videoinhalte.
-
Die Verarbeitungsszenarien von Big Data sind sehr unterschiedlich - egal ob es sich um Data Science, SQL-ähnliche Abfragen oder eine andere benutzerdefinierte Verarbeitung handelt.
-
Wie Studien zeigen, handelt es sich bei Big Data nicht nur um große Datenmengen, sondern sie können auch in verschiedenen Geschwindigkeiten ankommen: als ein großer Dump, wie z. B. Daten, die in Stapeln von relationalen Datenbanken aufgenommen werden, oder als kontinuierlicher Datenstrom, wie Clickstream- oder IoT-Daten.
Dies sind einige der Merkmale von Big Data. Die Verarbeitung von Big Data bezieht sich auf eine Reihe von Werkzeugen und Technologien, die zum Speichern, Verwalten und Analysieren von Daten verwendet werden, ohne Einschränkungen oder Annahmen bezüglich der Quelle, des Formats oder der Größe der Daten zu machen.
Das Ziel der Big-Data-Verarbeitung ist es, eine große Menge an Daten mit unterschiedlicher Qualität zu analysieren und hochwertige Erkenntnisse zu gewinnen. Die Datenquellen, die wir zuvor gesehen haben, ob IoT-Sensoren oder Social-Media-Dumps, enthalten Signale, die für das Unternehmen wertvoll sind. Social Media Feeds enthalten zum Beispiel Indikatoren für die Stimmung der Kunden: ob sie ein Produkt geliebt und darüber getwittert haben oder ob es Probleme gab, über die sie sich beschwert haben. Diese Signale sind in einer großen Menge anderer Daten versteckt, was zu einer geringeren Wertdichte führt - du musst eine große Menge an Daten durchforsten, um eine kleine Menge an Signalen zu erhalten. In manchen Fällen ist es sogar möglich, dass du überhaupt keine Signale hast. Wie eine Nadel im Heuhaufen?
Außerdem sagt ein Signal für sich genommen vielleicht nicht viel aus, aber wenn du zwei schwache Signale kombinierst, erhältst du ein stärkeres Signal. Ein Beispiel: Sensordaten von Fahrzeugen geben Aufschluss darüber, wie oft die Bremsen benutzt oder das Gaspedal betätigt wird, Verkehrsdaten geben Aufschluss über das Verkehrsaufkommen und Autoverkaufsdaten geben Aufschluss darüber, wer welche Autos gekauft hat. Obwohl diese Datenquellen unterschiedlich sind, könnten die Versicherungsunternehmen die Sensordaten der Fahrzeuge und die Verkehrsmuster miteinander verknüpfen, um ein Profil der Sicherheit des Fahrers zu erstellen und so Fahrern mit einem sicheren Fahrprofil niedrigere Versicherungstarife anzubieten.
Wie in Abbildung 1-1 zu sehen ist, ermöglicht ein Big-Data-Verarbeitungssystem die Korrelation einer großen Datenmenge mit unterschiedlicher Wertdichte (die Wertdichte kann als Signal-Rausch-Verhältnis betrachtet werden), um Erkenntnisse mit definitiv hoher Wertdichte zu gewinnen. Diese Erkenntnisse haben das Potenzial, entscheidende Veränderungen bei Produkten, Prozessen und Organisationskulturen zu bewirken.
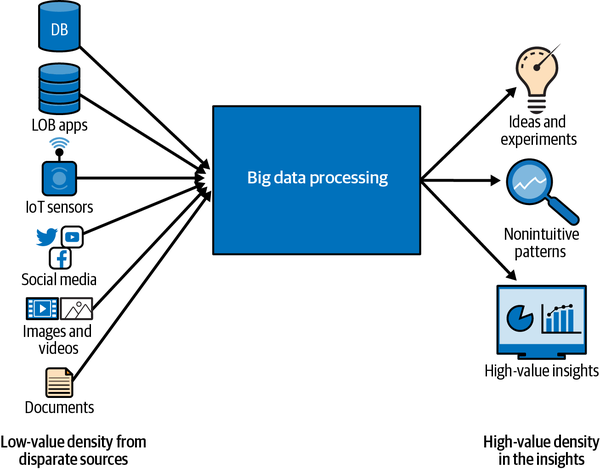
Abbildung 1-1. Überblick über die Big Data-Verarbeitung
Big Data wird normalerweise mit sechs Vs beschrieben. Spaß beiseite - vor ein paar Jahren haben wir Big Data mit nur drei Vs beschrieben: Volumen, Geschwindigkeitund Vielfalt. Inzwischen haben wir drei weitere Vs hinzugefügt: Wert, Wahrhaftigkeitund Variabilität. Das zeigt, wie viele neue Dimensionen in nur wenigen Jahren aufgetaucht sind. Wer weiß, vielleicht kommen bis zur Veröffentlichung dieses Buches noch weitere Vs hinzu! Werfen wir nun einen Blick auf die Vs:
- Band
-
Das ist der "große" Teil von Big Data, der sich auf die Größe der zu verarbeitenden Datensätze bezieht. Wenn Datenbanken oder Data Warehouses von Hyperscale sprechen, kann das Dutzende oder Hunderte von Terabytes (TB) und in seltenen Fällen Petabytes (PB) an Daten bedeuten. Hinzu kommen möglicherweise Tausende von Spalten in deinen Datensätzen, die eine weitere Dimension des Volumens darstellen. In der Welt der Big-Data-Verarbeitung sind PBs von Daten eher die Norm, und größere Data Lakes wachsen leicht auf Hunderte von PBs an, wenn immer mehr Szenarien auf dem Data Lake laufen. Dabei ist zu beachten, dass das Volumen bei Big Data ein Spektrum ist. Du brauchst ein System, das für TB Daten gut funktioniert und das genauso gut skalieren kann, wenn sich diese TB zu Hunderten von PBs anhäufen. So kann dein Unternehmen klein anfangen und mit dem Wachstum deines Unternehmens und deines Datenbestands mitwachsen.
- Geschwindigkeit
-
Die Daten im Big-Data-Ökosystem haben unterschiedliche "Geschwindigkeiten" in Bezug darauf, wie schnell sie erzeugt werden und wie schnell sie sich bewegen und verändern. Denk zum Beispiel an Trends in den sozialen Medien. Ein Video auf TikTok kann zwar viral gehen, aber ein paar Tage später ist es völlig irrelevant und macht Platz für den nächsten Trend. Genauso verhält es sich mit Gesundheitsdaten wie deinen täglichen Schritten: Während sie zu dem Zeitpunkt wichtig sind, um deine Aktivität zu messen, sind sie ein paar Tage später weniger aussagekräftig. In diesen Beispielen geht es um Millionen, manchmal sogar Milliarden von Ereignissen, die in großem Umfang generiert werden und die in nahezu Echtzeit verarbeitet werden müssen, sei es in Form von Echtzeitempfehlungen, welche Hashtags gerade angesagt sind oder wie weit du von deinem Tagesziel entfernt bist. Auf der anderen Seite gibt es Szenarien, in denen der Wert der Daten über einen langen Zeitraum bestehen bleibt. Zum Beispiel stützen sich Umsatzprognosen und Budgetplanung stark auf die Trends der vergangenen Jahre und nutzen Daten, die über die letzten Monate oder Jahre hinweg bestehen. Ein Big-Data-System, das beide Szenarien unterstützt - sowohl das Speichern großer Datenmengen in Stapeln als auch das kontinuierliche Streamen von Daten und deren Verarbeitung - gibt dir die Flexibilität, eine Vielzahl von Szenarien auf deinem Data Lake laufen zu lassen und Daten aus diesen verschiedenen Quellen miteinander zu verknüpfen, um Erkenntnisse zu gewinnen, die vorher nicht möglich gewesen wären. So kannst du zum Beispiel Verkäufe auf der Grundlage langfristiger Muster und schneller Trends aus den sozialen Medien mit demselben System vorhersagen.
- Sorte
-
Wie wir in den ersten Vs gesehen haben, können Big-Data-Verarbeitungssysteme ein breites Spektrum an Szenarien abdecken. Der Schlüssel dazu ist die Unterstützung einer Vielzahl von Daten. Big-Data-Verarbeitungssysteme sind in der Lage, Daten zu verarbeiten, ohne Einschränkungen hinsichtlich der Größe, der Struktur oder der Quelle der Daten vorzunehmen. Sie bieten dir die Möglichkeit, mit strukturierten Daten (Datenbanktabellen, LOB-Systeme), die eine definierte tabellarische Struktur und starke Garantien haben, semistrukturierten Daten (Daten in flexibel definierten Strukturen wie CSV und JSON) und unstrukturierten Daten (Bilder, Social Media Feeds, Videos, Textdateien usw.) zu arbeiten. So kannst du Signale aus wertvollen Quellen (z. B. Versicherungs- oder Hypothekendokumente) erhalten, ohne Annahmen über das Datenformat treffen zu müssen.
Hinweis
Die meisten Data Warehouses versprechen eine Skalierbarkeit auf mehrere PB Daten und arbeiten mit unstrukturierten Daten, und sie verbessern unermüdlich die Unterstützung sowohl für größere Mengen als auch für eine größere Vielfalt. Es ist wichtig, sich daran zu erinnern, dass Data Warehouses nicht dafür ausgelegt sind, Dutzende oder Hunderte von PBs zu speichern und zu verarbeiten, zumindest nicht in der heutigen Form. Ein weiterer Aspekt sind die Kosten: Je nach Szenario kann es viel billiger sein, Daten im Data Lake zu speichern, als im Data Warehouse. Außerdem bieten Data Warehouses zwar Unterstützung für unstrukturierte Daten, aber ihr hochgradig optimierter Weg ist die Verarbeitung strukturierter Daten, die in einem proprietären, für das jeweilige Warehouse spezifischen Format vorliegen. Auch wenn die Grenzen zwischen Data Lakes und Data Warehouses immer mehr verschwimmen, ist es wichtig, diese ursprünglichen Wertvorstellungen bei der Auswahl der richtigen Architektur für deine Datenplattform im Hinterkopf zu behalten.
- Wahrhaftigkeit
-
Wahrhaftigkeit bezieht sich auf die Qualität und Herkunft von Big Data. Ein Big-Data-Analysesystem akzeptiert Daten ohne jegliche Annahmen über das Format oder die Quelle, was bedeutet, dass natürlich nicht alle Daten mit hochstrukturierten Erkenntnissen versorgt werden. Zum Beispiel könnte dein intelligenter Kühlschrank ein paar Bytes an Informationen über den Gesundheitszustand seines Geräts senden, und einige dieser Informationen könnten je nach Implementierung verloren gehen oder unvollkommen sein. Big-Data-Verarbeitungssysteme müssen eine Datenvorbereitungsphase einschließen, in der die Daten geprüft, bereinigt und aufbereitet werden, bevor komplexe Operationen durchgeführt werden.
- Variabilität
-
Ob es sich um die Größe, die Struktur, die Quelle oder die Qualität handelt, Variabilität ist das A und O bei Big-Data-Systemen. Jedes Verarbeitungssystem für Big Data muss variabel sein, damit es mit allen Arten von Daten arbeiten kann. Außerdem können die Verarbeitungssysteme die Struktur der gewünschten Daten bei Bedarf festlegen - das wird als Anwendung eines Schemas bei Bedarf bezeichnet. Wenn du zum Beispiel Taxidaten hast, die eine CSV-Datei mit Hunderten von Datenpunkten enthalten, könnte sich ein Verarbeitungssystem auf die Werte für Quelle und Ziel konzentrieren und den Rest ignorieren, während sich ein anderes auf die Fahreridentifikation und die Preisgestaltung konzentriert und den Rest ignoriert. Das ist die größte Stärke: Jedes System für sich enthält ein Teil des Puzzles, und wenn man sie alle zusammenbringt, erhält man Einblicke wie nie zuvor. Ich habe einmal mit einem Finanzdienstleistungsunternehmen zusammengearbeitet, das von verschiedenen Landkreisen Daten über Wohnungen und Grundstücke sammelte. Sie verarbeiteten diese Daten und fügten sie zusammen, um hervorragende Einblicke in die Grundstücks- und Hauswerte sowie in das Kaufverhalten je nach Region zu erhalten, die es ihnen ermöglichten, die Hypothekenzinsen entsprechend zu gestalten.
- Wert
-
Das wurde wahrscheinlich schon in den vorherigen Punkten unterstrichen, aber das wichtigste V, das hervorgehoben werden muss, ist der Wert der Daten in Big-Data-Systemen. Das Beste an Big-Data-Systemen ist, dass der Wert nicht nur einmalig ist. Die Daten werden in der Annahme gesammelt und gespeichert, dass sie für verschiedene Zielgruppen von Wert sind. Der Wert der Daten ändert sich auch im Laufe der Zeit, entweder wird er irrelevant, wenn sich Trends ändern, oder er zeigt Muster, die in der Vergangenheit vorherrschend waren. Nehmen wir das Beispiel der Verkaufsdaten. Verkaufsdaten werden für die Berechnung von Einnahmen und Steuern sowie für die Berechnung der Provisionen der Vertriebsmitarbeiter/innen verwendet. Außerdem kann eine Analyse der Verkaufstrends im Laufe der Zeit genutzt werden, um zukünftige Trends zu prognostizieren und Verkaufsziele festzulegen. Durch die Anwendung von maschinellen Lernverfahren auf Verkaufsdaten und deren Korrelation mit scheinbar nicht verwandten Daten, wie z. B. Trends in den sozialen Medien oder Wetterdaten, können eindeutige Trends im Verkauf vorhergesagt werden. Ein wichtiger Punkt, an den du dich erinnern solltest, ist, dass der Wert von Daten mit der Zeit abnehmen kann, je nachdem, welches Problem du zu lösen versuchst. Ein Beispiel: Ein Datensatz, der Wettermuster auf der ganzen Welt enthält, ist sehr wertvoll, wenn du analysierst, wie sich die Klimatrends im Laufe der Zeit verändern. Wenn du jedoch versuchst, die Verkaufszahlen für Regenschirme vorherzusagen, sind die Wetterdaten von vor fünf Jahren weniger relevant.
Abbildung 1-2 veranschaulicht diese Konzepte von Big Data.
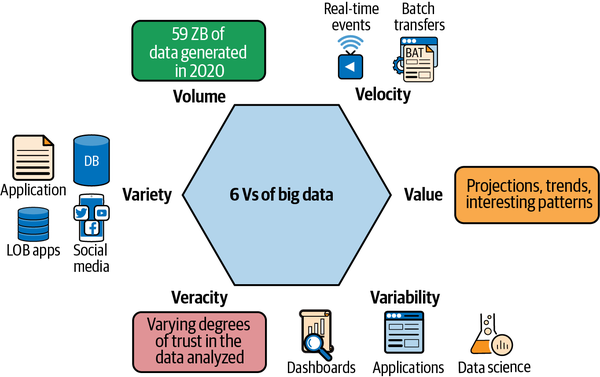
Abbildung 1-2. Die sechs Vs von Big Data
Elastische Dateninfrastruktur - die Herausforderung
Damit Unternehmen den Wert von Daten nutzen können, ist die Infrastruktur für die Speicherung, Verarbeitung und Analyse von Daten entscheidend, während sie gleichzeitig mit den wachsenden Anforderungen des Datenvolumens und der Formatvielfalt skaliert. Diese Infrastruktur muss nicht nur in der Lage sein, Daten in jedem Format, jeder Größe und jeder Form zu speichern, sondern auch, diese große Vielfalt an Daten aufzunehmen, zu verarbeiten und zu nutzen, um wertvolle Erkenntnisse zu gewinnen.
Außerdem muss diese Infrastruktur mit der Vermehrung der Daten und ihrer zunehmenden Vielfalt Schritt halten und elastisch skaliert werden können, wenn die Bedürfnisse der Organisationen und die Nachfrage nach Daten und Erkenntnissen steigen.
Grundlagen des Cloud Computing
Begriffe wie Cloud Computing und elastische Infrastruktur sind heute so allgegenwärtig, dass sie zu einem Teil unserer natürlichen Sprache geworden sind, genau wie "Frag Siri" oder "Hast du das gegoogelt?" Wir halten keine Sekunde inne, wenn wir diese Begriffe hören oder benutzen, aber was bedeuten sie und warum sind sie die größten Trendsetter für die Transformation? Schauen wir ein bisschen über den Tellerrand und lernen wir die Grundlagen des Cloud Computing kennen, bevor wir uns mit Cloud Data Lakes beschäftigen.
Cloud Computing ist ein großer Unterschied zu der Art und Weise, wie Unternehmen traditionell über IT-Ressourcen nachdachten. Beim traditionellen Ansatz hatten Unternehmen IT-Abteilungen, die Geräte oder Appliances kauften, um Software auszuführen. Bei diesen Geräten handelte es sich entweder um Laptops oder Desktops, die Entwicklern und Information Workern zur Verfügung gestellt wurden, oder um Rechenzentren, die von den IT-Abteilungen gewartet wurden und auf die der Rest des Unternehmens Zugriff hatte. Die IT-Abteilungen verfügten über Budgets für die Beschaffung von Hardware und kümmerten sich um den Support mit den Hardwareanbietern. Außerdem mussten sie Betriebsverfahren und entsprechende Arbeitskräfte bereitstellen, um die Betriebssysteme und Software, die auf dieser Hardware liefen, zu installieren und zu aktualisieren. Das warf einige Probleme auf: Die Geschäftskontinuität war durch Hardwareausfälle bedroht, die Softwareentwicklung und -nutzung wurde durch die begrenzten Ressourcen einer kleinen IT-Abteilung für die Installation und Aktualisierung blockiert, und vor allem gab es keine Möglichkeit, die Hardware zu skalieren, was das Wachstum des Unternehmens behinderte.
Terminologie des Cloud Computing
Einfach ausgedrückt bedeutet Cloud Computing ( ), dass deine IT-Abteilung Rechenressourcen über das Internet bereitstellt. Die Cloud-Computing-Ressourcen selbst gehören einem Cloud-Provider und werden von ihm betrieben und gewartet. Die Cloud ist nicht einheitlich - es gibt auch verschiedene Arten von Clouds:
- Öffentliche Wolke
-
Zu den Public Cloud-Providern gehören Microsoft Azure, Amazon Web Services (AWS) und Google Cloud Platform (GCP), um nur einige zu nennen. Die Public Cloud-Provider besitzen Rechenzentren, die Racks und Racks von Computern in Regionen auf der ganzen Welt beherbergen, und können Rechenressourcen von verschiedenen Organisationen die gleiche Infrastruktur nutzen, ein sogenanntes Multitenant-System. Die Public Cloud-Provider bieten Isolationsgarantien an, um sicherzustellen, dass zwar verschiedene Organisationen dieselbe Infrastruktur nutzen können, aber eine Organisation nicht auf die Ressourcen einer anderen zugreifen kann.
- Private Cloud
-
Anbieter wie VMware bieten private Clouds an, bei denen die Rechenressourcen in Rechenzentren vor Ort gehostet werden, die ausschließlich für eine Organisation bestimmt sind. Stell dir einen öffentlichen Cloud-Provider wie ein Einkaufszentrum vor, in dem Sandwich-Läden, Bäckereien, Zahnarztpraxen, Musikkurse und Friseursalons im selben Gebäude untergebracht werden können. Eine Private Cloud hingegen ist wie ein Schulgebäude, in dem das gesamte Gebäude nur für die Schule genutzt wird. Public Cloud-Provider bieten auch Private Cloud-Versionen ihrer Dienste an.
Dein Unternehmen kann mehr als einen Cloud-Provider nutzen, um seine Anforderungen zu erfüllen. Dies wird als Multicloud-Ansatz bezeichnet. Andererseits entscheiden sich manche Unternehmen für eine so genannte Hybrid-Cloud, bei der sie eine private Cloud auf einer lokalen Infrastruktur betreiben und einen Public-Cloud-Dienst nutzen, wobei ihre Ressourcen je nach Bedarf zwischen den beiden Umgebungen wechseln. Abbildung 1-3 veranschaulicht diese Konzepte.
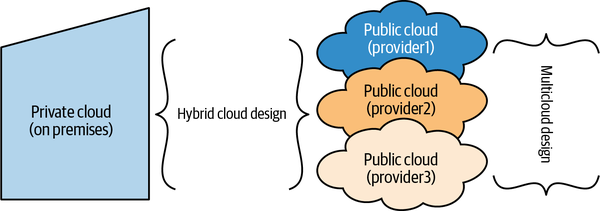
Abbildung 1-3. Cloud-Konzepte
Wir haben über Rechenressourcen gesprochen, aber was genau sind diese? Die Rechenressourcen in der Cloud gehören zu drei verschiedenen Kategorien:
- Infrastructure as a Service (IaaS)
-
Für jedes Angebot ( ) ist eine Basisinfrastruktur erforderlich, die aus Ressourcen für die Berechnung (Verarbeitung), Speicherung (Daten) und Vernetzung (Konnektivität) besteht. IaaS-Angebote beziehen sich auf virtualisierte Rechen-, Speicher- und Netzwerkressourcen, die du in der öffentlichen Cloud erstellen kannst, um deinen eigenen Dienst oder deine eigene Lösung unter Nutzung dieser Ressourcen aufzubauen.
- Platform as a Service (PaaS)
-
PaaS-Ressourcen sind im Wesentlichen Tools, die Anbieter anbieten und die Anwendungsentwickler nutzen können, um ihre eigenen Lösungen zu erstellen. Diese PaaS-Ressourcen können von den öffentlichen Cloud-Providern oder von Anbietern, die diese Tools exklusiv anbieten, bereitgestellt werden. Einige Beispiele für PaaS-Ressourcen sind betriebliche Datenbanken, die als Service angeboten werden, wie Azure Cosmos DB von Microsoft, Redshift von Amazon, MongoDB von Atlas oder das Data Warehouse von Snowflake, das diese als Service in allen öffentlichen Clouds aufbaut.
- Software as a Service (SaaS)
-
SaaS-Ressourcen bieten gebrauchsfertige Software-Dienste für ein Abonnement an. Du kannst sie überall nutzen, ohne sie auf deinen Computern installieren zu müssen, und obwohl du deine Entwickler/innen einsetzen kannst, um die Lösungen anzupassen, gibt es sofort einsetzbare Funktionen, die du sofort nutzen kannst. Einige Beispiele für SaaS-Dienste sind Microsoft 365, Netflix, Salesforce und Adobe Creative Cloud.
Nehmen wir an, du möchtest zum Abendessen eine Pizza essen. Wenn du IaaS nutzen würdest, würdest du Mehl, Hefe, Käse und Gemüse kaufen und deinen eigenen Teig machen, den Belag hinzufügen und deine Pizza backen. Um das richtig zu machen, musst du ein erfahrener Koch sein. Wenn du PaaS nutzen würdest, würdest du eine Pizza zum Mitnehmen kaufen und sie in den Ofen schieben. Du musst kein erfahrener Koch sein, aber du musst genug wissen, um einen Ofen zu bedienen und darauf zu achten, dass die Pizza nicht verbrennt. Wenn du SaaS nutzen würdest, würdest du die örtliche Pizzeria anrufen und dir die Pizza heiß nach Hause liefern lassen. Du musst keine Kochkenntnisse haben und kannst die Pizza sofort essen.
Das Wertangebot der Cloud
Eine der ersten Fragen, die ich immer wieder von Kunden und Unternehmen bekomme, die ihre ersten Schritte in die Cloud machen, ist, warum sie überhaupt in die Cloud wechseln sollten. Obwohl sich die Investition auf vielfältige Weise auszahlen kann, lässt sich der Nutzen in drei Hauptkategorien einteilen:
- Geringere TCO
-
Die Gesamtbetriebskosten (TCO) beziehen sich auf die Gesamtbetriebskosten der technischen Lösung, die du unterhältst, einschließlich der Kosten für das Rechenzentrum, die Software und die Gehälter der Mitarbeiter, die zur Verwaltung des Betriebs beschäftigt werden müssen. In fast allen Fällen, mit wenigen Ausnahmen, sind die Gesamtbetriebskosten für die Entwicklung von Lösungen in der Cloud deutlich niedriger als für Lösungen, die im eigenen Haus entwickelt und in deinem Rechenzentrum eingesetzt werden. Das liegt daran, dass du dich darauf konzentrieren kannst, Softwareteams einzustellen, die den Code für deine Geschäftslogik schreiben, während sich die Cloud-Provider um alle anderen Hardware- und Softwareanforderungen kümmern. Einige der Faktoren, die zu diesen niedrigeren Kosten beitragen, sind folgende:
- Kosten für Hardware
-
Die Cloud-Provider besitzen, bauen und unterstützen die Hardware-Ressourcen zu niedrigeren Kosten, als wenn du deine eigenen Rechenzentren bauen und betreiben, die Hardware warten und erneuern müsstest, wenn der Support ausläuft. Außerdem können Cloud-Provider dank des Fortschritts bei der Hardware viel schneller auf neuere Hardware zugreifen, als wenn du deine eigenen Rechenzentren bauen würdest.
- Kosten der Software
-
Neben dem Bau und der Wartung von Hardware besteht eine der wichtigsten Aufgaben einer IT-Organisation darin, Betriebssysteme zu unterstützen und zu implementieren und sie auf dem neuesten Stand zu halten. Normalerweise sind diese Aktualisierungen mit geplanten Ausfallzeiten verbunden, die auch für dein Unternehmen störend sein können. Die Cloud-Provider kümmern sich um diesen Zyklus, ohne deine IT-Abteilung zu belasten. In fast allen Fällen erfolgen diese Aktualisierungen auf abstrakte Weise, so dass du nicht von Ausfallzeiten betroffen bist.
- Bezahle für das, was du nutzt
-
Die meisten Cloud-Dienste arbeiten mit einem Abrechnungsmodell auf Abonnementbasis, d.h. du zahlst für das, was du nutzt. Wenn du Ressourcen hast, die nur für bestimmte Stunden am Tag oder bestimmte Tage in der Woche genutzt werden, zahlst du nur für diese Zeit, was viel günstiger ist, als wenn du die ganze Zeit Hardware hast, auch wenn du sie nicht nutzt.
- Elastische Skala
-
Die Ressourcen, die du für dein Unternehmen benötigst, sind sehr dynamisch und es gibt Zeiten, in denen du Ressourcen für geplante und ungeplante Nutzungssteigerungen bereitstellen musst. Wenn du deine Hardware wartest und betreibst, bist du an die Hardware gebunden, die du hast und die die Obergrenze für das Wachstum deines Unternehmens darstellt. Cloud-Ressourcen haben eine elastische Skalierung, und du kannst bei hohem Bedarf mit wenigen Klicks zusätzliche Ressourcen bereitstellen.
- Die Fähigkeit, mit Innovationen Schritt zu halten
-
Cloud-Provider sind ständig auf der Suche nach Innovationen und fügen ihrem Angebot neue Dienste und Technologien hinzu, je nachdem, was sie von zahlreichen Kunden erfahren. Die Nutzung modernster Dienste und Technologien hilft dir dabei, schneller Innovationen für deine Geschäftsszenarien zu entwickeln, als wenn du über eigene Entwickler verfügst, die vielleicht nicht über das nötige Wissen in der Branche verfügen.
Cloud Data Lake Architektur
Um zu verstehen, wie Cloud Data Lakes den wachsenden Datenanforderungen eines Unternehmens gerecht werden, müssen wir zunächst verstehen, wie die Datenverarbeitung und die Erkenntnisse vor einigen Jahrzehnten funktionierten. Unternehmen betrachteten Daten oft als etwas, das ein zu lösendes Geschäftsproblem ergänzte. Der Ansatz konzentrierte sich auf das Geschäftsproblem und umfasste die folgenden Schritte:
-
Identifiziere das zu lösende Problem.
-
Lege eine Struktur für die Daten fest, die zur Lösung des Problems beitragen kann.
-
Sammle oder generiere die Daten, die der Struktur entsprechen.
-
Speichere die Daten in einer OLTP-Datenbank, z. B. in Microsoft SQL Server.
-
Verwende eine weitere Reihe von Transformationen (Filter, Aggregationen usw.), um Daten in OLAP-Datenbanken zu speichern; auch hier werden SQL-Server verwendet.
-
Erstelle Dashboards und Abfragen aus diesen OLAP-Datenbanken, um dein Geschäftsproblem zu lösen.
Wenn ein Unternehmen zum Beispiel seine Verkäufe verstehen wollte, entwickelte es eine Anwendung, in die die Vertriebsmitarbeiter ihre Leads, Kunden und Aufträge zusammen mit den Verkaufsdaten eingeben konnten. Diese Anwendung wurde von einer oder mehreren operativen Datenbanken unterstützt. Es konnte eine Datenbank geben, in der die Kundendaten gespeichert wurden, eine andere, in der die Mitarbeiterdaten für die Vertriebsmitarbeiter gespeichert wurden, und eine dritte, in der die Verkaufsdaten gespeichert wurden, die sowohl auf die Kunden- als auch auf die Mitarbeiterdatenbank verwiesen. Die On-Premises-Datenbank (auch "On Prem" genannt) besteht aus drei Schichten (siehe Abbildung 1-4):
- Unternehmensdatenlager
-
Dies ist die Komponente, in der die Daten gespeichert werden. Sie enthält eine Datenbankkomponente zur Speicherung der Daten und eine Metadatenkomponente zur Beschreibung der in der Datenbank gespeicherten Daten.
- Data Marts
-
Data Marts sind ein Segment des Enterprise Data Warehouse, das geschäfts- oder themenorientierte Datenbanken enthält, die Daten für die Anwendung bereithalten. Die Daten im Data Warehouse durchlaufen eine weitere Reihe von Transformationen, um in den Data Marts gespeichert zu werden.
- Verbrauchsschicht/Business Intelligence (BI)
-
Dies besteht aus den verschiedenen Visualisierungs- und Abfragetools, die von BI-Analysten verwendet werden, um die Daten in den Data Marts (oder dem Warehouse) abzufragen, um Erkenntnisse zu gewinnen.
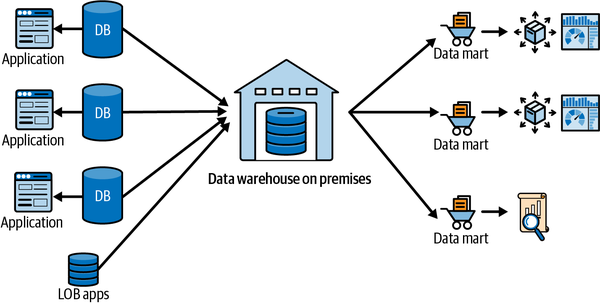
Abbildung 1-4. Traditionelles On-Premises-Data-Warehouse
Einschränkungen von lokalen Data-Warehouse-Lösungen
Auch wenn dies gut funktioniert, um Einblicke in das Geschäft zu erhalten, gibt es ein paar wichtige Einschränkungen bei dieser Architektur:
- Hochgradig strukturierte Daten
-
Diese Architektur setzt voraus, dass die Daten von in jeder Phase hoch strukturiert sind. Wie wir in den vorherigen Beispielen gesehen haben, ist diese Annahme nicht mehr realistisch. Die Daten können aus jeder beliebigen Quelle stammen, z. B. von IoT-Sensoren, Social-Media-Feeds und Video-/Audiodateien, und sie können jedes beliebige Format haben (JSON, CSV, PNG - fülle diese Liste mit allen dir bekannten Formaten). In den meisten Fällen kann eine strenge Struktur nicht erzwungen werden.
- Siloisierte Datenspeicher
-
Mehrere Kopien der gleichen Daten werden in Datenspeichern gespeichert, die für bestimmte Zwecke spezialisiert sind. Dies erweist sich als Nachteil, da die Speicherung dieser Kopien derselben Daten mit hohen Kosten verbunden ist und das Hin- und Herkopieren von Daten sowohl teuer als auch fehleranfällig ist, was zu inkonsistenten Datenversionen in mehreren Datenspeichern führt, während die Daten kopiert werden.
- Hardware-Bereitstellung für Spitzenauslastung
-
Lokale Data Warehouses erfordern, dass Unternehmen die für den Betrieb dieser Dienste erforderliche Hardware installieren und warten. Wenn du mit Nachfrageschüben rechnest (z.B. wenn du das Geschäftsjahr abschließt oder über die Feiertage mehr Umsatz erwartest), musst du für diese Spitzenauslastung vorausplanen und die Hardware kaufen, auch wenn das bedeutet, dass ein Teil deiner Hardware für den Rest der Zeit nicht ausgelastet ist. Das erhöht deine TCO. Beachte, dass dies vor allem eine Einschränkung in Bezug auf On-Premises-Hardware ist und kein Unterschied zwischen Data Warehouse- und Data Lake-Architektur.
Was ist eine Cloud Data Lake Architektur?
Wie wir in "Was ist Big Data?" gesehen haben , gehen die Big-Data-Szenarien weit über die Grenzen herkömmlicher Unternehmens-Data-Warehouses hinaus. Cloud-Data-Lake-Architekturen sind darauf ausgelegt, genau diese Probleme zu lösen, denn sie wurden entwickelt, um den Anforderungen des explosionsartigen Wachstums von Daten und deren Quellen gerecht zu werden, ohne Annahmen über die Quelle, die Formate, die Größe oder die Qualität der Daten zu treffen. Im Gegensatz zum problemorientierten Ansatz herkömmlicher Data Warehouses verfolgen Cloud Data Lakes einen datenorientierten Ansatz. In einer Cloud-Data-Lake-Architektur werden alle Daten als nützlich erachtet - entweder sofort oder zur Deckung eines zukünftigen Bedarfs. Der erste Schritt in einer Cloud-Data-Lake-Architektur besteht darin, die Daten in ihrem rohen, natürlichen Zustand aufzunehmen, ohne Einschränkungen hinsichtlich der Quelle, der Größe oder des Formats der Daten. Diese Daten werden in einem Cloud Data Lake gespeichert, einem Speichersystem, das hoch skalierbar ist und alle Arten von Daten speichern kann. Diese Rohdaten haben eine unterschiedliche Qualität und einen unterschiedlichen Wert und müssen weiterverarbeitet werden, um wertvolle Erkenntnisse zu gewinnen.
Wie in Abbildung 1-5 dargestellt, arbeiten die Verarbeitungssysteme in einem Cloud Data Lake mit den Daten, die im Data Lake gespeichert sind, und ermöglichen dem Datenentwickler, ein Schema nach Bedarf zu definieren, d.h. die Daten zum Zeitpunkt der Verarbeitung zu beschreiben. Diese Verarbeitungssysteme verarbeiten dann die unstrukturierten Daten mit geringem Wert, um hochwertige Daten zu erzeugen, die oft strukturiert sind und aussagekräftige Erkenntnisse enthalten. Diese hochwertigen, strukturierten Daten werden dann entweder in ein unternehmensweites Data Warehouse geladen oder direkt aus dem Data Lake konsumiert. Wenn dir all diese Konzepte hochkomplex erscheinen, mach dir keine Sorgen - wir werden in den Kapiteln 2 und3 sehr ausführlich auf diese Verarbeitung eingehen.
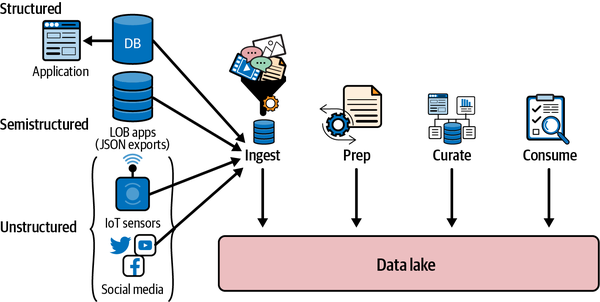
Abbildung 1-5. Cloud Data Lake Architektur
Vorteile einer Cloud Data Lake Architektur
Die Cloud-Data-Lake-Architektur überwindet die Grenzen der traditionellen Data-Warehouse-Architekturen auf folgende Weise:
- Keine Einschränkungen für die Daten
-
Wie wir gesehen haben, besteht eine Data-Lake-Architektur aus Tools, die alle Arten von Daten aufnehmen, speichern und verarbeiten können, ohne dass es Einschränkungen hinsichtlich der Quelle, Größe oder Struktur der Daten gibt. Außerdem sind diese Systeme so konzipiert, dass sie mit Daten arbeiten können, die mit beliebiger Geschwindigkeit in den Data Lake einfließen: Echtzeitdaten, die kontinuierlich ausgegeben werden, sowie Datenmengen, die nach einem bestimmten Zeitplan in Stapeln aufgenommen werden. Außerdem ist die Speicherung im Data Lake extrem kostengünstig, so dass wir alle Daten standardmäßig speichern können, ohne uns um die Rechnungen zu kümmern. Erinnere dich daran, dass du früher zweimal nachdenken musstest, bevor du mit den alten Filmrollen-Kameras Fotos gemacht hast.
- Eine einzige Speicherung ohne Silos
-
Beachte, dass in einer Cloud-Data-Lake-Architektur deine Daten im selben Speicher verarbeitet werden, sodass du keine speziellen Datenspeicher für spezielle Zwecke mehr brauchst. Das senkt nicht nur deine Kosten, sondern vermeidet auch Fehler, die beim Hin- und Herschieben von Daten zwischen verschiedenen Speichern entstehen.
- Flexibilität bei der Ausführung verschiedener Berechnungen auf demselben Datenspeicher
-
Wie du siehst, entkoppelt eine Cloud-Data-Lake-Architektur von Natur aus Compute und Speicherung. Während die Speicherebene als No-Silos-Repository dient, kannst du eine Vielzahl von Datenverarbeitungsprogrammen auf derselben Speicherebene ausführen. So kannst du zum Beispiel dieselbe Ebene der Speicherung nutzen, um Data-Warehouse-ähnliche BI-Abfragen, fortschrittliches maschinelles Lernen und Data-Science-Berechnungen oder sogar maßgeschneiderte, domänenspezifische Berechnungen durchzuführen, wie z. B. High-Performance-Computing für die Medienverarbeitung oder die Analyse seismischer Daten.
- Bezahle für das, was du nutzt
-
Cloud-Dienste und -Tools sind so konzipiert, dass sie sich bei Bedarf elastisch vergrößern und verkleinern lassen, und du kannst Verarbeitungssysteme nach Bedarf erstellen und löschen. Das bedeutet, dass du diese Systeme bei Nachfrageschüben in der Urlaubszeit oder beim Haushaltsabschluss hochfahren kannst, ohne sie für den Rest des Jahres zu benötigen. Das senkt die Gesamtbetriebskosten drastisch.
- Unabhängige Skalierung von Datenverarbeitung und Speicherung
-
In einer Cloud-Data-Lake-Architektur sind Rechenleistung und Speicherung verschiedene Arten von Ressourcen, die unabhängig voneinander skaliert werden können, so dass du deine Ressourcen je nach Bedarf skalieren kannst. Speichersysteme in der Cloud sind sehr günstig und ermöglichen es dir, große Datenmengen zu speichern, ohne die Bank zu sprengen. Rechenressourcen sind in der Regel teurer als die Speicherung, können aber bei Bedarf gestartet oder gestoppt werden und bieten so eine wirtschaftliche Skalierung.
Hinweis
Technisch gesehen ist es möglich, die Rechenleistung und die Speicherung auch in einer Apache Hadoop-Architektur vor Ort unabhängig voneinander zu skalieren. Dies erfordert jedoch eine sorgfältige Auswahl von Hardware, die speziell für die Berechnung und Speicherung optimiert ist und über eine optimale Netzwerkanbindung verfügt. Genau das bieten Cloud-Provider mit ihren Cloud-Infrastrukturdiensten an. Nur wenige Unternehmen verfügen über diese Art von Fachwissen und entscheiden sich ausdrücklich dafür, ihre Dienste vor Ort zu betreiben.
Diese Flexibilität bei der Verarbeitung aller Arten von Daten auf kosteneffiziente Weise hilft Unternehmen, den Wert von Daten zu erkennen und sie in wertvolle Erkenntnisse umzuwandeln.
Definiere deine Cloud Data Lake-Reise
Ich habe mit Hunderten von Kunden über ihre Big-Data-Analytics-Szenarien gesprochen und ihnen bei Teilen ihrer Cloud-Data-Lake-Reise geholfen. Diese Kunden haben unterschiedliche Motivationen und Probleme zu lösen: Einige Kunden sind neu in der Cloud und wollen ihre ersten Schritte mit Data Lakes machen, andere haben einen Data Lake in der Cloud implementiert, der einige grundlegende Szenarien unterstützt, und sind sich nicht sicher, was sie als Nächstes tun sollen, einige sind Cloud-Native-Kunden, die direkt mit Data Lakes als Teil ihrer Anwendungsarchitekturen beginnen wollen, und wieder andere haben bereits eine ausgereifte Implementierung ihrer Data Lakes in der Cloud und wollen die Macht der Daten nutzen, um die nächste Stufe der Differenzierung im Vergleich zu ihren Kollegen und Konkurrenten anzubieten. Wenn ich meine Erkenntnisse aus all diesen Gesprächen zusammenfassen müsste, würde das im Wesentlichen auf zwei Dinge hinauslaufen:
-
Unabhängig von deinem Cloud-Reifegrad solltest du deinen Data Lake für die Zukunft deines Unternehmens planen.
-
Entscheide dich bei der Umsetzung für das, was du sofort brauchst!
Du denkst vielleicht, dass das zu offensichtlich und zu allgemein klingt. Im weiteren Verlauf des Buches wirst du jedoch feststellen, dass der Rahmen und die Anleitungen, die ich für die Gestaltung und Optimierung von Cloud Data Lakes vorschreibe, davon ausgehen, dass du dich ständig mit diesen beiden Fragen auseinandersetzt:
-
Was ist das Geschäftsproblem, das die Entscheidungen im Data Lake bestimmt?
-
Wenn ich dieses Problem gelöst habe, was kann ich dann noch tun, um mein Unternehmen mit dem Data Lake zu differenzieren?
Lass mich dir ein konkretes Beispiel geben. Ein häufiges Szenario, das Kunden dazu veranlasst, einen Cloud Data Lake zu implementieren, ist die Tatsache, dass ihre lokale Hardware, die ihren Hadoop-Cluster unterstützt, kurz vor dem Ende ihrer Lebensdauer steht. Dieser Hadoop-Cluster wird hauptsächlich von den Datenplattform- und BI-Teams genutzt, um Dashboards und Cubes mit Daten zu erstellen, die von den lokalen transaktionalen Speichersystemen eingespeist werden. Das Unternehmen muss sich entscheiden, ob es weitere Hardware kaufen und die lokale Hardware weiterhin warten soll oder ob es in den Cloud Data Lake investieren will, von dem alle reden, weil er elastische Skalierung, niedrigere Betriebskosten, eine größere Anzahl von Funktionen und Diensten und all die anderen Vorzüge verspricht, die wir im vorherigen Abschnitt gesehen haben. Wenn sich diese Kunden für einen Wechsel in die Cloud entscheiden, müssen sie die tickende Uhr beachten, wenn ihre Hardware das Ende ihrer Lebensdauer erreicht. Dieser Ansatz ist völlig in Ordnung, vor allem, wenn man bedenkt, dass es sich um Produktionssysteme handelt, die eine wichtige Geschäftsfunktion erfüllen. Drei Dinge werden diesen Kunden jedoch schnell klar:
-
Es kostet viel Mühe, ihre Umsetzung überhaupt anzuheben und zu verschieben.
-
Wenn sie den Wert der Cloud erkennen und weitere Szenarien hinzufügen wollen, werden sie durch ihre Designentscheidungen eingeschränkt, wie z. B. Sicherheitsmodelle, Datenorganisation usw., die ursprünglich von einem Satz von BI-Szenarien ausgingen, die auf dem Data Lake laufen.
-
In manchen Fällen sind Lift-and-Shift-Architekturen teurer, sowohl was die Kosten als auch die Wartung angeht, und machen den ursprünglichen Zweck zunichte.
Das ist doch überraschend, oder? Diese Überraschungen rühren in erster Linie von den Unterschieden in den Architekturen von On-Premises- und Cloud-Systemen her. In einem lokalen Hadoop-Cluster sind Rechen- und Speicherkapazitäten eng miteinander verknüpft, während in der Cloud eine Objektspeicher-/Data-Lake-Speicherebene (z. B. Amazon S3, Azure Data Lake Store (ADLS) und Google Cloud Storage (GCS)) und eine Vielzahl von Rechenoptionen als IaaS (Bereitstellung von VMs und Ausführung eigener Software) oder PaaS (z. B. Azure HDInsight, Amazon EMR usw.) zur Verfügung stehen, wie in Abbildung 1-6 dargestellt. In der Cloud ist deine Data-Lake-Lösung im Wesentlichen eine Struktur, die du aus Legosteinen baust, die IaaS-, PaaS- oder SaaS-Angebote sein können.
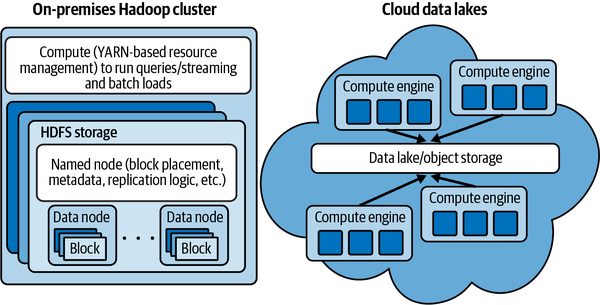
Abbildung 1-6. On-Premises- versus Cloud-Architekturen
Wir haben bereits die Vorteile entkoppelter Rechen- und Speicherarchitekturen in Bezug auf unabhängige Skalierung und geringere Kosten gesehen. In der Cloud Data Lake-Implementierung kommunizieren die Rechensysteme mit den Speichersystemen beispielsweise über die Netzwerksysteme und nicht über lokale Verbindungen. Wenn du dies nicht optimierst, werden sowohl deine Kosten als auch deine Leistung beeinträchtigt. Sobald du deine Data-Lake-Implementierung für deine primären BI-Szenarien abgeschlossen hast, kannst du den Wert deines Data Lakes steigern, indem du weitere Szenarien aktivierst, unterschiedliche Datensätze einbeziehst oder mehr explorative Data-Science-Analysen mit den Daten in deinem Data Lake durchführst. Gleichzeitig musst du sicherstellen, dass bei einer explorativen Data-Science-Analyse nicht versehentlich die Datensätze gelöscht werden, die für das Dashboard benötigt werden, das dein Vertriebsleiter jeden Morgen sehen möchte. Du musst sicherstellen, dass deine Datenorganisation und Sicherheitsmodelle diese Isolierung und Zugriffskontrolle gewährleisten.
Wenn du diese erstaunlichen Möglichkeiten mit der ursprünglichen Motivation für den Umzug in die Cloud in Verbindung bringst, nämlich dass deine On-Premises-Server das Ende ihrer Lebensdauer erreicht haben, musst du einen Plan formulieren, der dir hilft, deine Zeitvorgaben einzuhalten und dich für den Erfolg in der Cloud zu rüsten. Der Umzug in den Cloud Data Lake hat zwei Ziele:
-
Herunterfahren deiner Systeme vor Ort
-
So wirst du in der Cloud erfolgreich
Die meisten Kunden konzentrieren sich am Ende nur auf das erste Ziel und treiben sich selbst in große technische Schulden, bevor sie ihre Anwendungen umgestalten müssen. Wenn du über eine Cloud-Data-Lake-Architektur nachdenkst, stelle sicher, dass du die folgenden Ziele im Blick hast:
-
Migriere deinen Data Lake in die Cloud.
-
Modernisiere deinen Data Lake, um ihn an die Cloud-Architektur anzupassen.
Diese beiden Ziele gehen Hand in Hand, wenn es darum geht, eine Architektur zu finden, die dem wachsenden Umfang und den Anforderungen deines Unternehmens gerecht wird.
Um zu verstehen, wie du diese beiden Ziele erreichen kannst, musst du wissen, was die Cloud-Architektur ist, welche Überlegungen bei der Implementierung angestellt werden müssen und wie du deinen Data Lake hinsichtlich Skalierung und Leistung optimieren kannst. Auf diese Fragen gehen wir in den Kapiteln2-4 ausführlich ein. Wir werden uns auch darauf konzentrieren, einen Rahmen zu schaffen, der dir hilft, die verschiedenen Aspekte deiner Reise zum Cloud Data Lake zu berücksichtigen.
Zusammenfassung
In diesem Kapitel haben wir zunächst über den Wertbeitrag von Daten und die transformativen Erkenntnisse gesprochen, die Unternehmen umkrempeln können. Außerdem haben wir ein grundlegendes Verständnis für Cloud Computing und die Unterschiede zwischen einem traditionellen Data Warehouse und einer Cloud Data Lake-Architektur entwickelt. Schließlich haben wir uns angesehen, was Big Data, die Cloud und Data Lakes sind. Angesichts des Unterschieds zwischen On-Premises- und Cloud-Architekturen betonten wir, wie wichtig es ist, bei der Entwicklung eines Cloud Data Lakes eine neue Denkweise einzunehmen, die wiederum eine neue Architektur definiert. Diese Änderung der Denkweise möchte ich dir ans Herz legen, wenn wir uns in den nächsten Kapiteln mit den Details von Cloud-Data-Lake-Architekturen und ihren Implementierungsüberlegungen beschäftigen.
Get Der Cloud Data Lake now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

