The GRU is a variant of the LSTM and was introduced by K. Cho (for more information refer to: Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, by K. Cho, arXiv:1406.1078, 2014). It retains the LSTM's resistance to the vanishing gradient problem, but its internal structure is simpler, and therefore is faster to train, since fewer computations are needed to make updates to its hidden state. The gates for a GRU cell are illustrated in the following diagram:
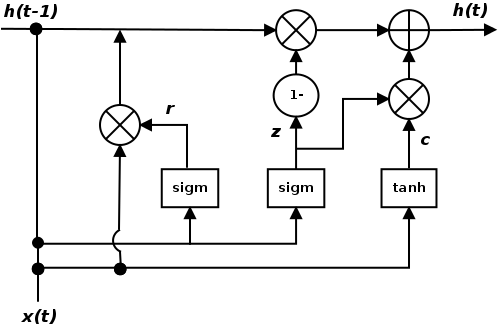
Instead of the input, forget, and output gates in the LSTM cell, the GRU cell has two gates, an update gate z, and ...

