Chapter 6. Theoretical Foundations of Distributed Deep Learning
This chapter introduces the key concepts and theoretical formulations of distributed deep learning (DDL), building on your learning from Part I of this book. You will revisit centralized and decentralized systems (described in the previous chapter) through the lens of DDL and explore the impact on the data flow and computation graphs when using these techniques. In this chapter, you will also learn about the different types of distributed learning and how to decide what type of DDL might be most suitable to scale out your training.
Distributed Deep Learning
Chapter 2 described the data flow during training, explaining the gradient computation flow, which involves the forward pass and backward pass, and the parameter update flow, which is guided by optimization techniques such as gradient descent. A pictorial presentation of these flows is shown in Figure 6-1. As shown in this figure, the gradient computation flow (indicated by the solid arrows) is local to the computation graphs, while the parameter update flow (indicated by the dashed arrows) closes the loop to complete the learning for each optimization step.
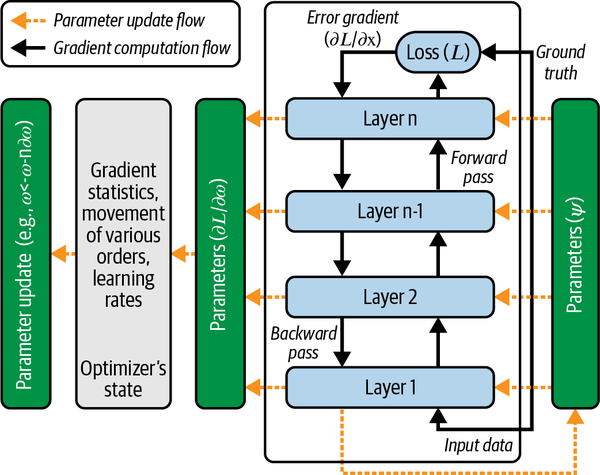
Figure 6-1. Revisiting the data flow in deep learning training
Within the framework of distributed systems, the data flow in training is distributed such that the independent processes execute the local gradient ...
Get Deep Learning at Scale now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

