Teil II. Deine Daten erhalten
In diesem Teil des Buches beginnen wir unsere Reise entlang der Dataviz-Toolchain (siehe Abbildung II-1), beginnend mit ein paar Kapiteln darüber, wie du deine Daten bekommst, wenn sie dir nicht zur Verfügung gestellt wurden.
In Kapitel 5 sehen wir, wie man Daten aus dem Internet abruft, indem man die Python-Bibliothek Requests verwendet, um webbasierte Dateien zu erfassen und RESTful-APIs zu nutzen. Außerdem sehen wir, wie wir einige Python-Bibliotheken nutzen, die komplexere Web-APIs verpacken, nämlich Twitter (mit Pythons Tweepy) und Google Docs. Das Kapitel endet mit einem Beispiel für leichtgewichtiges Web-Scraping mit der Beautiful Soup-Bibliothek.
In Kapitel 6 verwenden wir Scrapy, den industrietauglichen Web Scraper von Python, um den Nobelpreis-Datensatz zu erhalten, den wir für unsere Webvisualisierung verwenden werden. Mit diesem schmutzigen Datensatz in der Hand sind wir bereit für den nächsten Teil des Buches, Teil III.
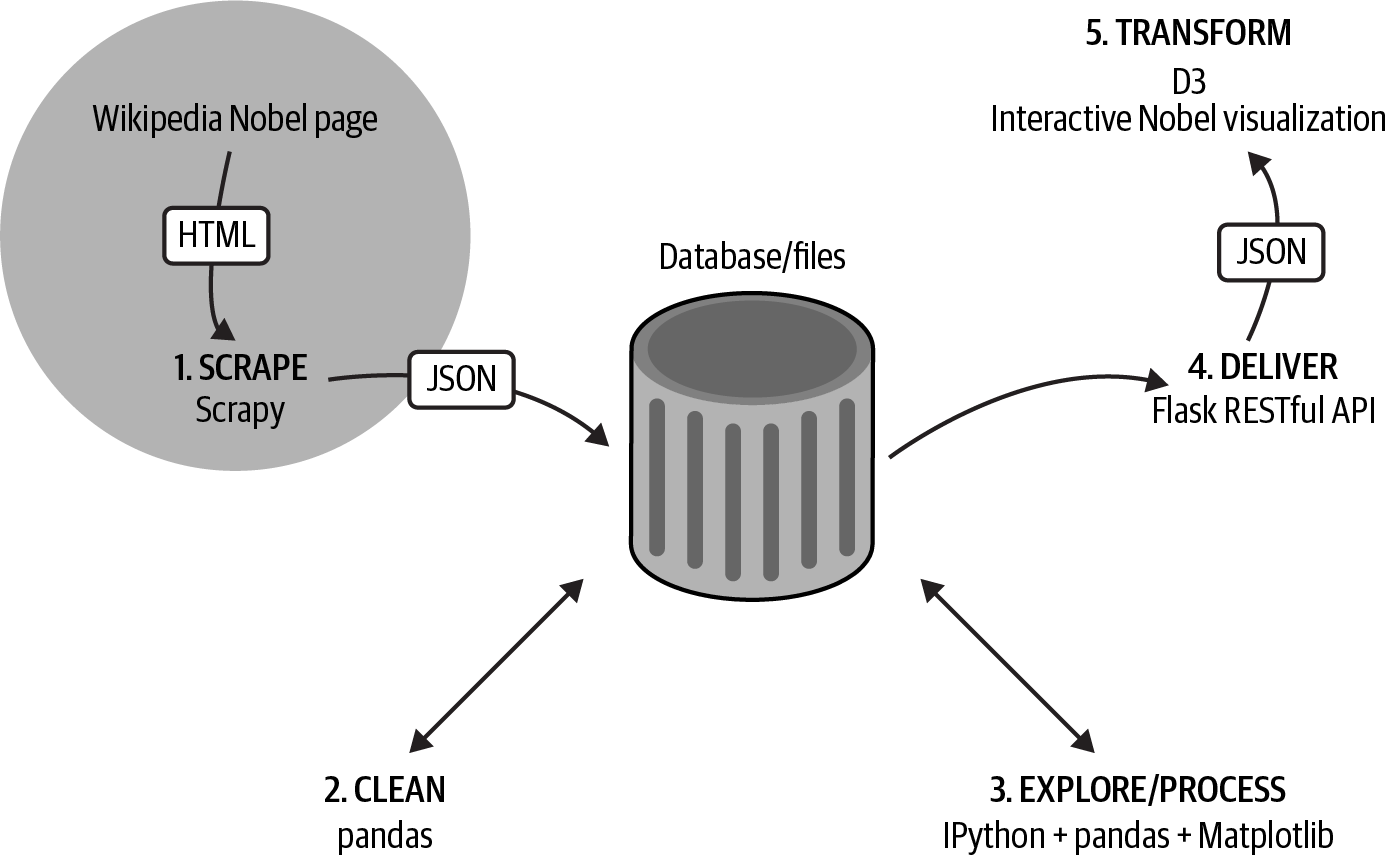
Abbildung II-1. Unsere Dataviz-Toolchain: Beschaffung der Daten
Tipp
Den Code für diesen Teil des Buches findest du im GitHub Repo des Buches.
Get Datenvisualisierung mit Python und JavaScript, 2. now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

