Chapter 1. Introducing the Greenplum Database
There are many databases available. Why did the founders of Greenplum feel the need to create another? A brief history of the problem they solved, the company they built, and the product architecture will answer these questions.
Problems with the Traditional Data Warehouse
Sometime near the end of the twentieth century, there was a notion in the data community that the traditional relational data warehouse was floundering. As data volumes began to increase in size, the data warehouses of the time were beginning to run out of power and not scaling up in performance. Data loads were struggling to fit in their allotted time slots. More complicated analysis of the data was often pushed to analytic workstations, and the data transfer times were a significant fraction of the total analytic processing times. Furthermore, given the technology of the time, the analytics had to be run in-memory, and memory sizes were often only a fraction of the size of the data. This led to sampling the data, which can work well for some techniques but not for others, such as outlier detection. Ad hoc queries on the data presented performance challenges to the warehouse. The database community sought to provide responses to these challenges.
Responses to the Challenge
One alternative was NoSQL. Advocates of this position contended that SQL itself was not scalable and that performing analytics on large datasets required a new computing paradigm. Although the NoSQL advocates had successes in many use cases, they encountered some difficulties. There are many varieties of NoSQL databases, often with incompatible underlying models. Existing tools had years of experience in speaking to relational systems. There was a smaller community that understood NoSQL better than SQL, and analytics in this environment was still immature. The NoSQL movement morphed into a Not Only SQL movement, in which both paradigms were used when appropriate.
Another alternative was Hadoop. Originally a project to index the World Wide Web, Hadoop soon became a more general data analytics platform. MapReduce was its original programming model; this required developers to be skilled in Java and have a fairly good understanding of the underlying architecture to write performant code. Eventually, higher-level constructs emerged that allowed programmers to write code in Pig or even let analysts use HiveQL, SQL on top of Hadoop. However, SQL was never as complete or performant as a true relational system.
In recent years, Spark has emerged as an in-memory analytics platform. Its use is rapidly growing as the dramatic drop in price of memory modules makes it feasible to build large memory servers and clusters. Spark is particularly useful in iterative algorithms and large in-memory calculations, and its ecosystem is growing. Spark is still not as mature as older technologies, such as relational systems, and it has no native storage model.
Yet another response was the emergence of clustered relational systems, often called massively parallel processing (MPP) systems. The first entrant into this world was Teradata, in the mid- to late 1980s. In these systems, the relational data, traditionally housed in a single-system image, is dispersed into many systems. This model owes much to the scientific computing world, which discovered MPP before the relational world. The challenge faced by the MPP relational world was to make the parallel nature transparent to the user community so coding methods did not require change or sophisticated knowledge of the underlying cluster.
A Brief Greenplum History
Greenplum took the MPP approach to deal with the limitations of the traditional data warehouse. It was originally founded in 2003 by Scott Yara and Luke Lonergan as a merger of two companies, Didera and Metapa. Its purpose was to produce an analytic data warehouse with three major goals: rapid query response, rapid data loading, and rapid analytics by moving the analytics to the data.
It is important to note that Greenplum is an analytic data warehouse and not a transactional relational database. Although Greenplum does have the notion of a transaction, which is useful for extract, transform, and load (ETL) jobs, that’s not its purpose. It’s not designed for transactional purposes like ticket reservation systems, air traffic control, or the like. Successful Greenplum deployments include but are not limited to the following:
-
Fraud analytics
-
Financial risk management
-
Cybersecurity
-
Customer churn reduction
-
Predictive maintenance analytics
-
Manufacturing optimization
-
Smart cars and internet of things (IoT) analytics
-
Insurance claims reporting and pricing analytics
-
Health-care claim reporting and treatment evaluations
-
Student performance prediction and dropout prevention
-
Advertising effectiveness
-
Traditional data warehouses and business intelligence (BI)
From the beginning, Greenplum was based on PostgreSQL, the popular and widely used open source database. Greenplum kept in sync with PostgreSQL releases until it forked from the main PostgreSQL line at version 8.2.15.
The first version of this new company arrived in 2005, called Biz-Gres. In the same year, Greenplum and Sun Microsystems formed a partnership to build a 48-disk, 4-CPU, appliance-like product, following the success of the Netezza appliance. What distinguishes the two is that Netezza required special hardware, whereas all Greenplum products have always run on commodity servers, never requiring a special hardware boost.
2007 saw the first publicly known Greenplum product, version 3.0. Later releases added many new features, most notably mirroring and high availability (HA)—at a time when the underlying PostgreSQL could not provide any of these things.
In 2010, a consolidation began in the MPP database world. Many smaller companies were purchased by larger ones. EMC purchased Greenplum in July 2010, just after the release of Greenplum version 4.0. EMC packaged Greenplum into a hardware platform, the Data Computing Appliance (DCA). Although Greenplum began as a pure software play, with customers providing their own hardware platform, the DCA became the most popular platform.
2011 saw the release of the first paper describing Greenplum’s approach to in-database machine learning and analytics, MADlib. (MADlib is described in more detail in Chapter 6.) In 2012, EMC purchased Pivotal Labs, a well-established San Francisco–based company that specialized in application development incorporating pair programming, Agile methods, and involving the customer in the development process. This proved to be important not only for the future development process of Greenplum, but also for giving a name to Greenplum’s 2013 spinoff from EMC. The spinoff was called Pivotal Software and included assets from EMC as well as from VMware. These included the Java-centric Spring Framework, RabbitMQ, the Platform as a Service (PaaS) Cloud Foundry, and the in-memory data grid Apache Geode, available commercially as GemFire.
In 2015, Pivotal announced that it would adopt an open source strategy for its product set. Pivotal would donate much of the software to the Apache Foundation and the software then would be freely licensed under the Apache rules. However, it maintained a subscription-based enterprise version of the software, which it continues to sell and support.
The Pivotal data products now include the following:
-
Greenplum
-
Pivotal Postgres, a supported version of the open source PostgreSQL database
-
Pivotal GemFire, the open source version of Apache Geode
Officially, the open source version is known as the Greenplum Database and the commercial version is the Pivotal Greenplum Database. With the exception of some features that are proprietary and available only with the commercial edition, the products are the same.
By 2015, many customers were beginning to require open source. Greenplum’s adoption of an open source strategy saw Greenplum community contributions to the software as well as involvement of PostgreSQL contributors. Pivotal sees the move to open source as having several advantages:
-
Avoidance of vendor lock-in
-
Ability to attract talent in Greenplum development
-
Faster feature addition to Greenplum with community involvement
-
Greater ability to eventually merge Greenplum to the current PostgreSQL version
-
Meeting the demand of many customers for open source
There are several distinctions between the commercial Pivotal Greenplum and the open source Greenplum. Pivotal Greenplum offers the following:
-
24/7 premium support
-
Database installers and production-ready releases
-
GP Command Center—GUI management console
-
GP Workload Management—dynamic, rule-based resource management
-
GPText—Apache Solr–based text analytics
-
Greenplum-Kafka Integration
-
Greenplum Stream Server
-
gpcopyutility—to migrate data between Greenplum systems -
GemFire-Greenplum Connector—data transfer between Pivotal Greenplum and the Pivotal GemFire low-latency, in-memory data grid
-
QuickLZ compression
-
Open Database Connectivity (ODBC) and Object Linking and Embedding, Database (OLEDB) drivers for Pivotal Greenplum
Note
GPText is covered in Chapter 6; GP Command Center and GP Workload Management are discussed in Chapter 7; and Greenplum-Kafka Integration, Greenplum Stream Server Integration, and the GemFire-Greenplum Connector are discussed in Chapter 8.
2015 also saw the arrival of the Greenplum development organization’s use of an Agile development methodology; in 2016, there were 10 releases of Pivotal Greenplum, which included such features as the release of the GPORCA optimizer, a high-powered, highly parallel cost-based optimizer for big data. In addition, Greenplum added features like a more sophisticated Workload Manager to deal with issues of concurrency and runaway queries, and the adoption of a resilient connection pooling mechanism. The Agile release strategy allows Greenplum to quickly incorporate both customer requests as well as ecosystem features.
With the wider adoption of cloud-based systems in data warehousing, Greenplum added support for Amazon Simple Storage Service (Amazon S3) files for data as well as support for running Pivotal Greenplum in both Amazon Web Services (AWS) as well as Microsoft’s Azure and, recently, Google Cloud Platform (GCP). 2016 saw the addition of an improved Command Center monitoring and management tool and the release of the second-generation of native text analytics in Pivotal Greenplum. But perhaps most significant is Pivotal’s commitment to reintegrate Greenplum into more modern versions of PostgreSQL, eventually leading to PostgreSQL 9.x support. This is beneficial in many ways. Greenplum will acquire many of the features and performance improvements added to PostgreSQL in the past decade. In turn, Pivotal then can contribute back to the community.
Pivotal released Greenplum 5 in mid-2017. In Greenplum 5, the development team cleaned up many diversions from mainline PostgreSQL, focusing on where the MPP nature of Greenplum matters and where it doesn’t. In doing this, the code base is now considerably smaller and thus easier to manage and support.
It included features such as the following:
-
JSON support, which is of interest to those linking Greenplum and MongoDB and translating JSON into a relational format
-
XML enhancements such as an increased set of functions for importing XML data into Greenplum
-
PostgreSQL-based Analyze, which is an order of magnitude faster in generating table statistics
-
Enhanced vacuum performance
-
Lazy transactions IDs, which translate into fewer vacuum operations
-
Universally unique identifier (UUID) data type
-
Raster PostGIS
-
User-defined function (UDF) default parameters
What Is Massively Parallel Processing?
To best understand how MPP came to the analytic database world, it’s useful to begin with scientific computing.
Stymied by the amount of time required to do complex mathematical calculations, Seymour Cray introduced vectorized operations in the Cray-1 in the early 1970s. In this architecture, the CPU acts on all the elements of the vector simultaneously or in parallel, speeding the computation dramatically. As Cray computers became more expensive and budgets for science were static or shrinking, the scientific community expanded the notion of parallelism by dividing complex problems into small portions and dividing the work among a number of independent, small, inexpensive computers. This group of computers became known as a cluster. Tools to decompose complex problems were originally scarce and much expertise was required to be successful. The original attempts to extend the MPP architecture to data analytics were difficult. However, a number of small companies discovered that it was possible to start with standard SQL relational databases, distribute the data among the servers in the cluster, and transparently parallelize operations. Users could write SQL code without knowing the data distribution. Greenplum was one of the pioneers in this endeavor.
Here’s a small example of how MPP works. Suppose that there is a box of 1,200 business cards. The task is to scan all the cards and find the names of all those who work for Acme Widget. If a person can scan one card per second, it would take that one person 20 minutes to find all those people whose card says Acme Widget.
Let’s try it again, but this time distribute the cards into 10 equal piles of 120 cards each and recruit 10 people to scan the cards, each one scanning the cards in one pile. If they simultaneously scanned at the rate of 1 card per second, they would all finish in about 2 minutes. This cuts down the time required by a factor of 10.
This idea of data and workload distribution is at the heart of MPP database technology. In an MPP database, the data is distributed in chunks to all the nodes in the cluster. In the Greenplum database, these chunks of data and the processes that operate on them are known as segments. In an MPP database, as in the business card example, the amount of work distributed to each segment should be approximately the same to achieve optimal performance.
Of course, Greenplum is not the only MPP technology or even the only MPP database. Hadoop is a common MPP data storage and analytics tool. Spark also has an MPP architecture. Pivotal GemFire is an in-memory data-grid MPP architecture. These are all very different from Greenplum because they do not natively speak standard SQL.
The Greenplum Database Architecture
The Greenplum Database employs a shared-nothing architecture. This means that each server or node in the cluster has its own independent operating system (OS), memory, and storage infrastructure. Its name notwithstanding, in fact there is something shared and that is the network connection between the nodes that allows them to communicate and transfer data as necessary. Figure 1-1 illustrates the Greenplum Database architecture.
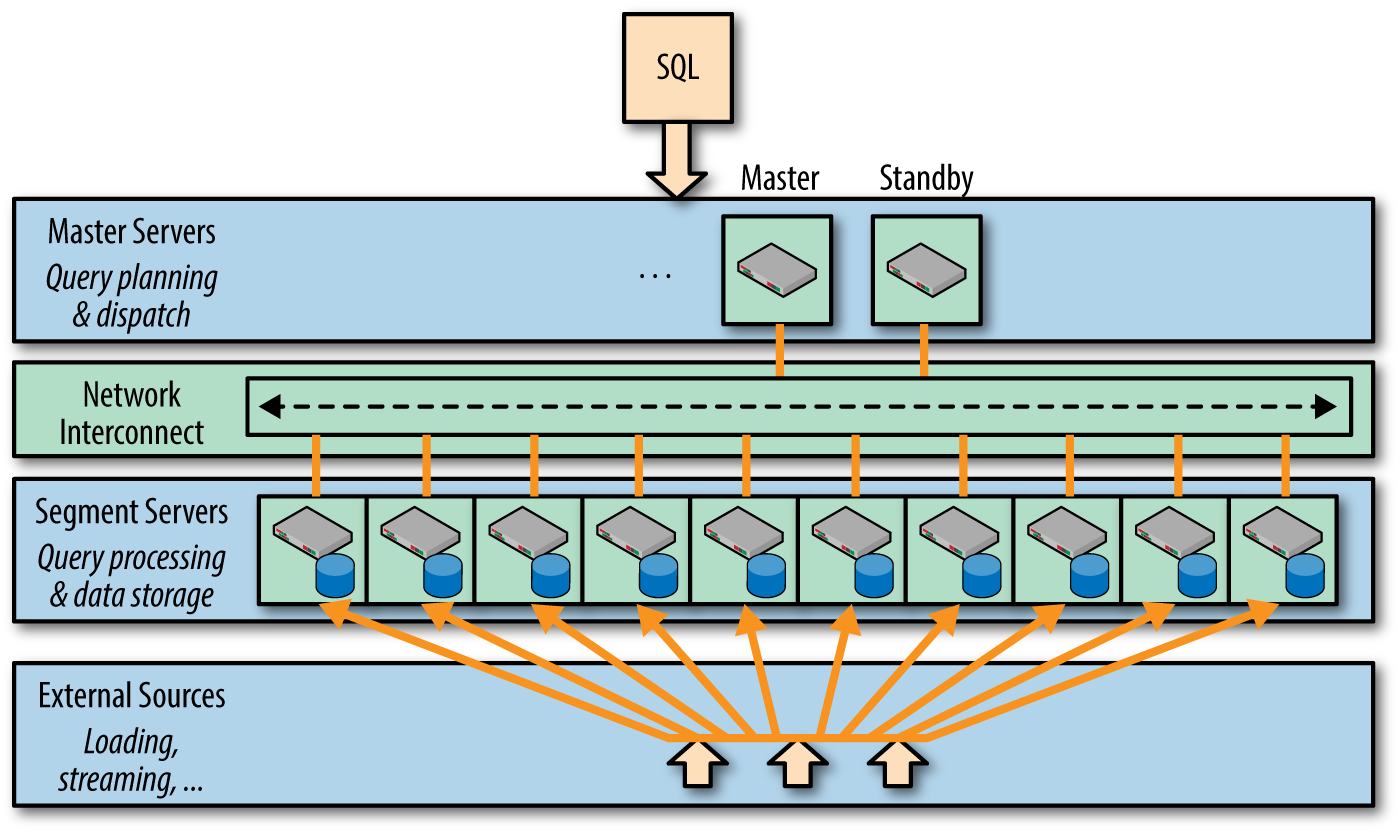
Figure 1-1. The Greenplum MPP architecture
Master and Standby Master
Greenplum users and database administrators (DBAs) connect to a master server, which houses the metadata for the entire system. This metadata is stored in a PostgreSQL database derivative. When the Greenplum instance on the master server receives a SQL statement, it parses it, examines the metadata repository, forms a plan to execute that statement, passes the plan to the workers, and awaits the result. In some circumstances, the master must perform some of the computation.
Only metadata is stored on the master. All the user data is stored on the segment servers, the worker nodes in the cluster. In addition to the master, all production systems should also have a standby server. The standby is a passive member of the cluster, whose job is to receive mirrored copies of changes made to the master’s metadata. In case of a master failure, the standby has a copy of the metadata, preventing the master from becoming a single point of failure.
Some Greenplum clusters use the standby as an ETL server because it has unused memory and CPU capacity. This might be satisfactory when the master is working, but in times of a failover to the standby, the standby now is doing the ETL work as well as the role of the master. This can become a choke point in the architecture.
Segments and Segment Hosts
Greenplum distributes user data into what are often known as shards, but are called segments in Greenplum. A segment host is the server on which the segments reside. Typically, there are several segments running on each segment server. In a Greenplum installation with eight segment servers, each might have six segments for a total of 48 segments. Every user table in Greenplum will have its data distributed in all 48 segments. (We go into more detail on distributing data in Chapter 4.) Unless directed by Greenplum support, users or DBAs should never connect to the segments themselves except through the master.
A single Greenplum segment server runs multiple segments. Thus, all other things being equal, it will run faster than a single-instance database running on the same server. That said, you should never use a single-instance Greenplum installation for a business-critical process because it provides no HA or failover in case of hardware, software, or storage error.
Private Interconnect
The master must communicate with the segments and the segments must communicate with one another. They do this on a private User Datagram Protocol (UDP) network that is distinct from the public network on which users connect to the master. This is critical. Were the segments to communicate on the public network, user downloads and other heavy loads would greatly affect Greenplum performance. The private network is critical. Greenplum requires a 10 Gb network and strongly urges using 10 Gb switches for redundancy.
Other than the master, the standby, and the segment servers, some other servers might be plumbed into the private interconnect network. Greenplum will use these to do fast parallel data loading and unloading. We discuss this topic in Chapter 5.
Mirror Segments
In addition to the redundancy provided by the standby master, Greenplum strongly urges the creation of mirror segments. These are segments that maintain a copy of the data on a primary segment, the one that actually does the work. Should either a primary segment or the host housing a primary segment fail, the mirrored segment contains all of the data on the primary segment. Of course, the primary and its mirror must reside on different segment hosts. When a segment fails, the system automatically fails-over from the primary to the mirrored segment, but operations in flight fail and must be restarted. DBAs can run a process to recover the failed segment to synchronize it with the current state of the databases.
Additional Resources
This book is but the first step in learning about Greenplum. There are many other information sources available to you.
Greenplum Documentation
The Greenplum documentation will answer many questions that both new and experienced users have. You can download this up-to-date information, free of charge, from the Greenplum documentation site.
There is also a wealth of information about Greenplum available on the Pivotal website.
Latest Documentation
When you see a Greenplum documentation page URL that includes the word “latest,” this refers to the latest Greenplum release. That web page can also get you to documentation for all supported releases.
Greenplum Best Practices Guide
If you’re implementing Greenplum, you should read the Best Practices guide. As this book should make clear, there are a number of things to consider to make good use of the power of the Greenplum Database. If you’re accustomed to single-node databases, you are likely to miss some of the important issues that this document helps explain. No one should build or manage a production cluster without reading it and following its suggestions.
Greenplum Cluster Concepts Guide
For a discussion on building Greenplum clusters, the Greenplum Cluster Concepts Guide (PDF) is invaluable for understanding cluster issues that pertain to appliances, cloud-based Greenplum, or customer-built commodity clusters.
PivotalGuru (Formerly Greenplum Guru)
Pivotal’s Jon Roberts has a PivotalGuru website that discusses issues and techniques that many Greenplum users find valuable. Although Jon is a long-time Pivotal employee, the content on PivotalGuru is his own and is not supported by Pivotal.
Pivotal Greenplum Blogs
Members of the Greenplum engineering, field services, and data science groups blog about Greenplum, providing insights and use cases not found in many other locations. These tend to be more technical in nature.
Greenplum YouTube Channel
The Greenplum YouTube channel has informative content on a variety of technical topics. Most of the videos are general and will be helpful to those without prior experience with Greenplum. Others, such as the discussion on the Pivotal Query Optimizer, go into considerable depth.
In addition to this material, there are some interesting discussions about the history of Greenplum that warrant examination:
Greenplum Knowledge Base
Some topics in the knowledge base can get a bit esoteric. Probably not a place to start, this resource is more suited to experienced users. The Pivotal Greenplum Knowledge Base houses general questions, their answers, and some detailed discussions on deeper topics.
Greenplum.org
As part of the Greenplum open source initiative, Pivotal formed two Google groups tasked with facilitating discussion about Greenplum. The first group deals with user questions about Greenplum. Pivotal data personnel monitor the group and provide answers in a timely fashion. The second group is a conversation vehicle for the Greenplum development community. (To view these, you need to be a member of the Google groups gpdb-dev and gpdb-users.) In the spirit of transparency, Pivotal invites interested parties to listen in and learn about the development process and potentially contribute.
There are two mailing lists that provide insight into the current and future state of the Greenplum database: gpdb-users@greenplum.org, on issues arising from the Greenplum user community; and gpdb-dev@greenplum.org, on detailed internal topics mostly for the Greenplum developers.
Other Sources
Internet searches on Greenplum return many hits. It’s wise to remember that not everything on the internet is accurate. In particular, as Greenplum evolves over time, comments made in years past might no longer reflect the current state of things.
Get Data Warehousing with Greenplum, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

