Part II. Getting Your Data
In this part of the book we start our journey along the dataviz toolchain (see Figure II-1), beginning with a couple of chapters on how to get your data if it hasn’t been provided for you.
In Chapter 5 we see how to get data off the Web, using Python’s requests library to grab web-based files and consume RESTful APIs. We also see how to use a couple of Python libraries that wrap more complex web APIs, namely Twitter (with Python’s Tweepy) and Google Docs. The chapter ends with an example of lightweight web scraping with the BeautifulSoup library.
In Chapter 6 we use Scrapy, Python’s industrial-strength web scraper, to get the Nobel Prize dataset we’ll be using for our web visualization. With this dirty dataset to hand, we’re ready for the next part of the book, Part III.
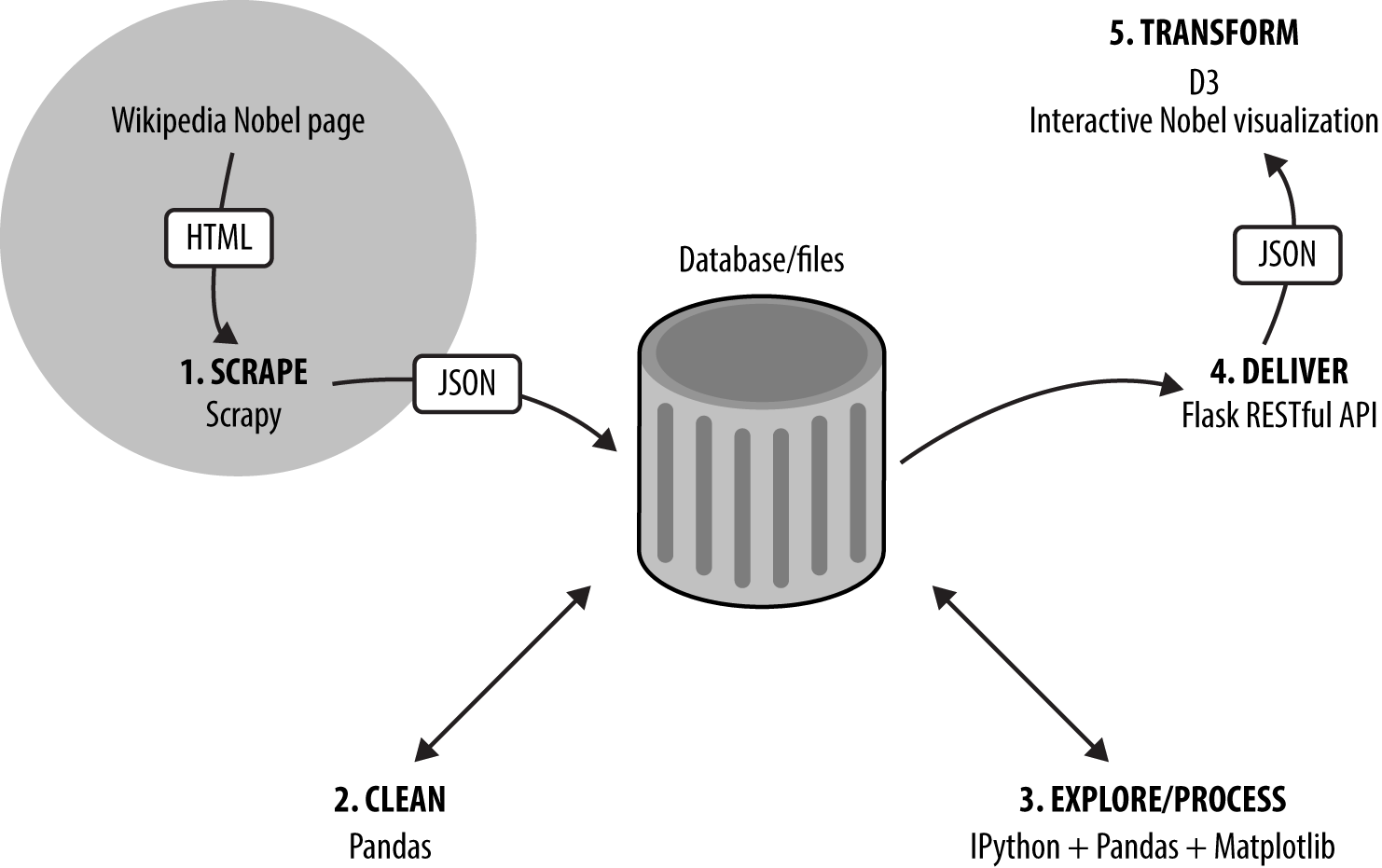
Figure II-1. Our dataviz toolchain: getting the data
Get Data Visualization with Python and JavaScript now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

