Chapter 13. Storytelling in Machine Learning
In Chapter 7, I argued that data scientists ought to become better storytellers. This holds true in general, but it takes on special importance with regard to machine learning (ML).
This chapter walks you through the main aspects of storytelling in ML, starting with feature engineering and finishing with the problem of interpretability.
A Holistic View of Storytelling in ML
Storytelling plays two related but distinct roles in ML (Figure 13-1). The better-known role is a salesperson, where you need to engage with an audience, possibly to gain or maintain stakeholder buy-in, a process that usually takes place after you’ve developed a model. The lesser-known role is a scientist, where you need to find hypotheses that will guide you throughout the process of developing the model.
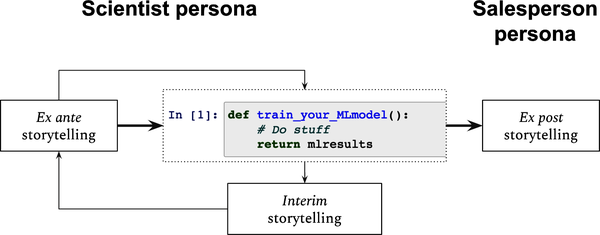
Figure 13-1. Storytelling in ML
Since the former takes place after you have developed your model, I call it ex post storytelling; your scientist persona is mostly invoked before (ex ante) and during (interim) the process of training the model.
Ex Ante and Interim Storytelling
Ex ante storytelling has four main steps: defining the problem, creating hypotheses, feature engineering, and training the model (Figure 13-2). While they usually flow in that direction, there’s a feedback loop between all of them, so it’s not uncommon that after you train a first model, ...
Get Data Science: The Hard Parts now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

