Chapter 4. Scaling the Mesh: Self-Serve Data Infrastructure
Platform capabilities—provided through a central infrastructure team—enable many organizations to become more efficient and more scalable as a whole. Mature organizations often start their journey already having some form of platform infrastructure teams in place, whether this be teams responsible for existing data infrastructure around data warehouses or data lakes, or more generic infrastructure teams around cloud resource management. Often those teams already have a strong understanding about the pain points around central responsibility and can be strong partners for collaboration. It is important to understand, however, that changing toward a style of data-agnostic, self-serve data infrastructure usually requires bigger changes that again take time and resources. Do not expect your existing central infrastructure team to be the cure for all evil and enable the data mesh all by themselves while still taking care of their current responsibilities. In order to understand how infrastructure teams overloaded with central responsibility can escape their vicious circle, we first need to visualize the pain points of central infrastructure responsibility.
Pain Points of Central Data Responsibility
To fully grasp how demanding it can be to take on central responsibility for data and processes that require distributed domain knowledge, let us look at an example that is well known across many organizations at scale: granting access to data in a central data lake:
When building up a data lake in our company, we started by providing a central data pipeline for data ingestion, a distributed storage layer, and a distributed processing engine on top of it. After an initial testing phase, we started having real production data flowing in and we quickly realized the need to restrict the access for the sake of not sharing confidential data all across the company. We set up a process where anybody that needed access to data would file a request stating what data they needed access to, who it should be granted to, and what the reason was for the request. We would then check those requests for approval and execute the technical granting process if the request was legit. For the first couple months, this process was working quite fine. We had a good grasp of the data we were storing, and we understood the use case descriptions that were provided to request access. Yet slowly but surely the situation started to get out of hand. The number of requests started to increase, and it became more and more tedious to manually follow up on all of them. On top of this, the number of different datasets we stored was exploding, making it incredibly hard for us to understand all of them and judge if a certain request even made sense to begin with. It took until a year after the process was introduced for us to realize that our central infrastructure team became completely overwhelmed and paralyzed by a small process we introduced early as an easy fix to a problem at hand.
As expressed in the preceding example, it is common for teams responsible for central data-processing systems to be involved in the access-granting process as the last entity that executes the technical granting of access to requestors. In our case, however, the responsibility for the process as a whole was taken on by the central team. This included receiving all the requests, with all its details, from any aspiring data user in the company: what data the requester needs access to, who is part of the request, and what the use case is. At first glance, this sounds like a reasonable process, but it has some ingrained flaws:
- Decision making requires domain knowledge.
-
Judging if a provided use case description can suffice for an access approval requires an understanding of the use case itself, the requested data, and the security requirements around data sensitivity. This might work fine in a smaller company where a single team can still have an overview of all existing data use cases. With a growing number of datasets and use cases, this ultimately leads to one of two outcomes. Either the process becomes a bottleneck for the whole company, or the checking becomes superficial and no longer fulfills its original purpose.
- A manual centralized process does not scale.
-
Consider an ever-growing number of datasets, as well as an ever-growing number of users that want to access those. You quickly reach the point where parts of the central team will be doing nothing but answering access requests. Unless the company is willing to invest serious resources in maintaining a team with the sole responsibility to take care of such manual labor, one needs to rethink how to change the process itself to better scale for a data-driven organization.
This is only one of many examples that spark from central data teams taking on central responsibility that either requires distributed domain knowledge or heavy manual effort. The pattern across such cases is often very similar. It starts with a simple process that is set up quickly in small-scale environments but is eventually outgrown by an increasing number of data-driven use cases. Rather sooner than later you should take a step back and check if your setup still makes sense. What are the cases that still work perfectly fine? What are the cases that run the risk of being outscaled? What are the cases that already long breached that point? And, lastly, what can you do about it?
To understand how we can address these types of challenges, we will take a look at another example: the provisioning of compute resources for data processing.
Case Study: Centralized Compute Capabilities
Across many companies, the provisioning of compute resources for data processing is among the first capabilities to be put into the hands of central data infrastructure teams. Frequently, companies come from a setup where across multiple data teams a common story repeats over and over again until consciously disrupted. Let’s take a look at the following example:
I was hired as a data scientist to work on a new machine learning product for my new team. Upon joining the team, I was quickly introduced to our use case and to the data source we wanted to use to train a new model on. I worked with the data on my local machine and developed an algorithm that was fitting the given criteria quite well. I quickly realized, though, that productionizing my model was much more complicated than I originally thought. The full amount of data that needed to be processed to train our model was much bigger than what would fit on my local machine. While the team had some experience in working with the cloud, nobody ever had worked with a distributed data-processing engine before. It took us six weeks to set up a computation cluster and train the first model on the full production data. It took several hours to complete the run, but at least we made it work. Two weeks later, I was introduced to two fellow data scientists from different teams in our company and painfully realized that they went through the exact same journey when they joined.
When joining the team, instead of being able to fully focus on the problem domain, the person in the example had to spend the majority of their time setting up a computation cluster to be able to process the data they needed. Not only did this distract them from the job they were actually hired for, but it was also fully outside their area of expertise. It required a big learning curve to complete the task and, considering their summarizing statement, they completed the effort with mediocre results at best. Even worse, across their company, which seemed to be continuously looking for new use cases, multiple colleagues were following the same pattern and were reinventing the wheel.
Now that we discovered this repetitive scenario, how could we address the situation? The obvious choice is to instead put the compute infrastructure responsibility into the hands of a central data platform team. But there are many options on how to do so, and some options can lead you directly back into the traps of central infrastructure responsibility that were described in the previous section. To illustrate this point further, we will follow two scenarios and highlight the most important differences between the two.
In the first scenario, a central team is taking full responsibility for operating and maintaining the compute infrastructure, which is now offered to all decentralized data teams. They offer APIs for submitting jobs and allow teams to specify input and output locations for the data they are working with. This abstraction not only allows the decentralized teams to not care about the infrastructure itself anymore and leave it to the experts but even allows for resource optimization by running multitenant clusters that operate multiple jobs in parallel.
While the intentions behind the implemented model are pretty clear, it has some inherent flaws that lay underneath the surface. First, you need to develop a sophisticated data access model that understands who is allowed to see which data. Maintaining multitenant environments, even more so when abstracted away from the user, requires clearly defined rules and enforcement for data access. How do you guarantee that a team trying to access data that they should not have access to will get denied that access, while another team running on the same physical infrastructure is allowed to have that access? Second, while everything might work fine in the happy path, what happens if a job fails? How are job logs shared with the user—again, in a way that only they can see the logs for themselves? Are they even trained in how to read such logs? Does it require a central infrastructure engineer to babysit every team for every use case that is in development and again become the bottleneck? And for the worst-case scenario, what if a job failure is in fact caused by a cluster multitenancy issue, where one job influenced the execution of another?
The line of abstraction in the second scenario is drawn a bit lower than in the first. Again, you have clusters centrally operated and maintained by a data platform infrastructure team. However, instead of offering an API for job submission, you offer a template or an API for requesting a cluster. It contains all details necessary to be specified: What data do I need access to? Who is allowed to use the cluster? What should be the scale of my cluster? Do I need additional libraries to get the job done? Once the request is issued, the cluster creation is fully automated, and the requester will be provided the necessary information on how to use it. From that point on, they again have to use API calls to submit jobs to that specific cluster, but some key usability points change:
-
The cluster is running in isolation: no “noisy neighbor” can interrupt your work.
-
I am provided full access to the logs of my cluster—I am fully enabled to analyze any job execution errors by myself.
-
Data access is clearly defined on a cluster level and can be controlled and monitored on that entity.
As expressed in Figure 4-1, moving away from a fully decentralized responsibility of everyone needing to operate their own infrastructure does not necessarily mean full centralization. Giving all domain teams strong dependencies on the central infrastructure team would immediately make them the bottleneck. Rather, you need to strike a balance where the central team is offering a capability that takes away the biggest pain point (going from operating my own infrastructure to filling a template) yet still enabling the domain teams to take full ownership for the use cases they are working on. Yes, it requires more knowledge and responsibility on their side compared to the “all-central service” scenario, but in the end it is important to hit the trade-off between offloading decentralized teams and overloading central teams.
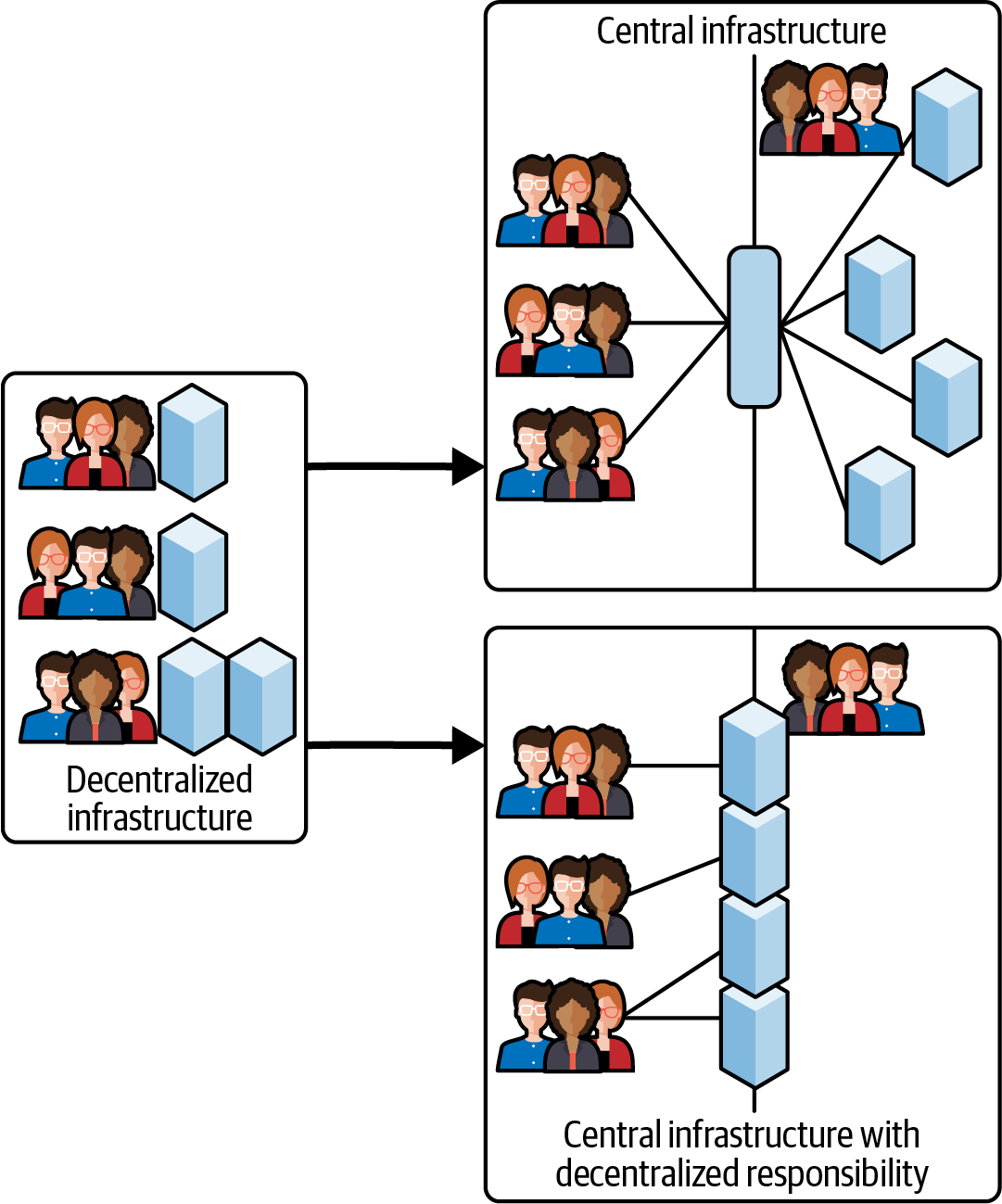
Figure 4-1. Decentralized versus central infrastructure
Data Infrastructure Capabilities
The introduced scenario of data compute infrastructure is only one example of a data platform capability. In a real company setup, such capabilities can evolve in many different directions, as expressed in Figure 4-2.
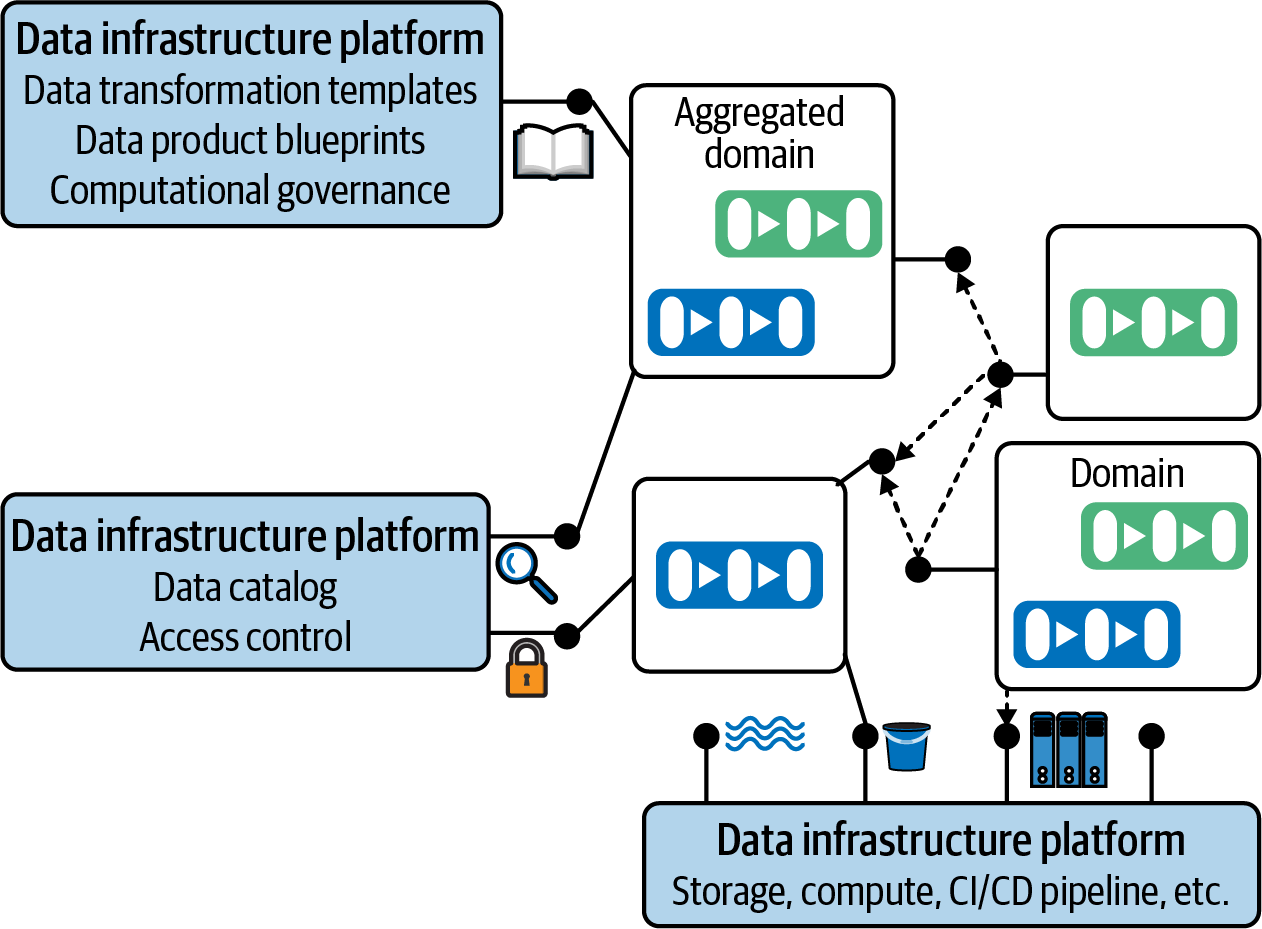
Figure 4-2. Data infrastructure platform capabilities
The foundation of the platform focuses on raw infrastructure topics like offering a company-wide event bus for data communication, a general data storage layer, a CI/CD pipeline, or the aforementioned compute infrastructure use case. It expands toward capabilities that allow defining processes around data, like data documentation and discoverability through a data catalog, or data access management. Finally, we are targeting advanced cases focusing on data practitioners’ productivity, like providing templates for the execution of data preparation use cases (e.g., format changes, cleaning of data), entire data product blueprints, or platform support for computational governance. Overall, the data infrastructure platform should drive—and should itself be driven by—open standards that allow for interoperability between data products and infrastructure tooling.
By now we should have many teams that have built successful and well-maintained data products. In addition to that, we have increased the efficiency and productivity of our data teams across the organization by providing them with a self-serve data infrastructure platform. We are in a strong position for working with data in our organization, and there is but one question that we still need to answer: how can we make our efforts last and set ourselves up for a successful path forward? How can we sustain the mesh?
Get Data Mesh in Practice now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

